Bert论文解析
文章目录
- BERT:用于语言理解的深度双向转换器的预训练
- 一、摘要
- 三、BERT
- 介绍BERT及其详细实现
- 答疑:为什么没有标注的数据可以用来预训练模型?
- 1. 掩码语言模型(Masked Language Model, MLM)
- 2. 下一句预测(Next Sentence Prediction, NSP)
- 3. 预训练数据与目标
- 4. 为什么未标记数据能用于预训练?
- 5. 补充说明
- 模型架构
- 输入输出表示
- 3.1 预训练BERT
- 3.2 微调BERT
- 总结:BERT的突出贡献
- 1. 解决了传统语言模型的「单向上下文限制」问题
- 2. 解决了NLP任务的「任务特定架构依赖」问题
- 3. 缓解了「长距离依赖」和「语义消歧」问题
- 4. 降低了「高质量标注数据依赖」问题
- 5. 统一了NLP的「迁移学习范式」
- 实际应用中的效果举例
- 局限性与后续改进
- 总结
BERT:用于语言理解的深度双向转换器的预训练
论文:https://arxiv.org/abs/1810.04805
一、摘要
引入一种新的语言表示模型BERT,它源于Transformers的双向编码器表示。Bidirectional Encoder Representations from Transformers。
BERT的原理简述——便捷性
BERT旨在通过联合调节所有层中的左右上下文,从未标记文本中预训练深度双向表示。因此,只需一个额外的输出层即可对预训练的BERT模型进行微调,为各种任务(例如问答和语言推理)创建最先进的模型,而无需对特定任务的架构进行实质性修改。
BERT的效果
BERT在概念上简单,在经验上强大,它在11个自然语言处理任务上获得了新的最先进的结果,包括将GLUE得分提高到80.5%(7.7%的绝对改善),MultiNLI准确度达到86.7%(绝对改善4.6%),SQuAD v1.1问答测试F1为93.2(绝对改善1.5分),SQuAD v2.0测试F1为83.1(绝对改善5.1分)。
三、BERT
介绍BERT及其详细实现
BERT框架分为两个步骤:预训练和微调。
- 预训练阶段,模型在不同的预训练任务中对未标记的数据进行训练;
- 对于微调,BERT模型首先使用预训练的参数进行初始化,并且所有参数都使用来自下游任务的标记数据进行微调。每个下游任务具有单独的微调模型;
图1中的问答示例将作为本节的运行示例。
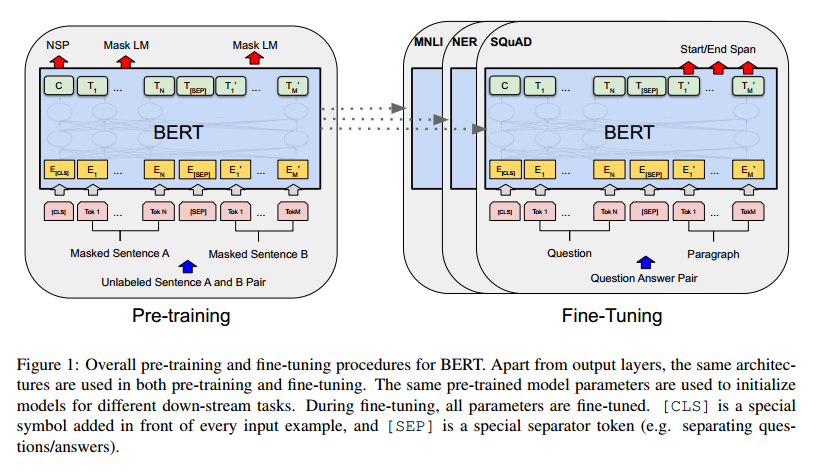
图一:BERT的总体预训练和微调过程。除了输出层,预训练和微调都使用相同的架构。相同的预训练模型参数用于初始化不同下游任务的模型。在微调期间,所有参数都进行微调。[CLS]是在每个输入示例前面添加的特殊符号,而[SEP]是一个特殊的分隔符标记(例如分隔问题/答案)。
答疑:为什么没有标注的数据可以用来预训练模型?
BERT的预训练阶段确实是在未标记的数据上进行的,但它通过设计自监督学习(Self-supervised Learning) 任务,从无标签数据中自动生成监督信号。具体来说,BERT通过以下两个预训练任务来学习语言表示:(后面论文中有详情)
1. 掩码语言模型(Masked Language Model, MLM)
- 核心思想:随机遮盖输入文本中的部分单词(通常比例为15%),让模型预测被遮盖的单词。
- 具体步骤:
- 输入文本中的部分单词会被替换为
[MASK]标记(如:"The cat sat on the [MASK].")。 - 模型需要根据上下文预测被遮盖的原始单词(如预测
[MASK]位置应为"mat")。
- 输入文本中的部分单词会被替换为
- 改进细节:
- 为了缓解预训练(有
[MASK])和微调(无[MASK])的不一致性,BERT在遮盖时采用以下策略:- 80%的概率替换为
[MASK]。 - 10%的概率替换为随机单词。
- 10%的概率保留原单词。
- 80%的概率替换为
- 模型通过交叉熵损失函数优化预测结果。
- 为了缓解预训练(有
2. 下一句预测(Next Sentence Prediction, NSP)
- 核心思想:判断两个句子是否是连续的上下文关系,学习句子级别的语义关联。
- 具体步骤:
- 输入一对句子
A和B,其中:- 50%的概率
B是A的真实下一句(正例)。 - 50%的概率
B是随机采样的其他句子(负例)。
- 50%的概率
- 模型需要预测
B是否是A的下一句(二分类任务)。
- 输入一对句子
- 示例:
- 正例:
("[CLS] The cat sat on the mat. [SEP] It was very cozy. [SEP]")→ 标签IsNext。 - 负例:
("[CLS] The cat sat on the mat. [SEP] The sky is blue. [SEP]")→ 标签NotNext。
- 正例:
3. 预训练数据与目标
- 数据来源:大规模无标注文本(如Wikipedia、BookCorpus)。
- 训练目标:同时优化MLM(单词级别)和NSP(句子级别)的损失函数,使模型学会:
- 双向上下文表示(通过MLM)。
- 句子间逻辑关系(通过NSP)。
4. 为什么未标记数据能用于预训练?
- 自监督的巧妙设计:通过破坏输入数据(如遮盖单词或打乱句子)并让模型修复,无需人工标注即可生成监督信号。
- 通用表征学习:模型从海量文本中学习通用的语言规律(如语法、语义、常识),为下游任务提供良好的初始化参数。
5. 补充说明
- BERT的预训练需要极大的计算资源(TPU/GPU集群),因此通常直接使用已预训练好的模型进行微调。
- 后续研究(如RoBERTa)发现NSP任务并非必要,仅MLM也能取得良好效果,但BERT的原始设计包含两者。
回到论文
通过这两个任务,BERT能够从未标记数据中学习丰富的语言表示,进而通过微调适配各种下游任务(如文本分类、问答等)。
BERT的一个显著特点是其跨不同任务的统一架构。预训练架构和最终下游架构之间的差异最小。
模型架构
模型架构时基于Transformer的,但是是双向的。
模型架构 BERT的模型架构是一个多层双向Transformer编码器,基于Vaswani的Transformer(2017)(就是著名的那篇"Attention all you need")实现,并在tensor2tensor库中发布。由于Transformer的使用已经变得普遍,我们的实现与原始几乎相同,我们将省略模型架构的详尽背景描述,并请读者参考Vaswani等人(2017)以及优秀的指导。
在这项工作中,我们将层数(即Transformer块)表示为L,隐藏大小表示为H,自注意头的数量表示为A。我们主要报告两种模型大小的结果:BERT-BASE(L=12,H=768,A=12,总参数=110M)和BERT-LARGE(L=24,H=1024,A=16,总参数= 340M)。
为了进行比较,我们选择了BERT-BASE与OpenAI GPT具有相同的模型大小。然而,重要的是,BERT Transformer使用双向自注意,而GPT Transformer使用约束自注意,其中每个令牌只能关注其左侧的上下文。
输入输出表示
WordPiece嵌入:基于子词的分词方法,但它在合并子词对时使用最大化似然估计(MLE),即基于语言模型的概率建模
输入嵌入分为:标记嵌入(标识每个子词),分割嵌入(标识句子),位置嵌入(标识位置)
输入/输出表示 为了使BERT处理各种下游任务,我们的输入表示能够在一个令牌序列中明确地表示单个句子和一对句子(例如,问题,答案)。在整个工作中,“句子”可以是连续文本的任意跨度,而不是实际的语言句子。“序列”是指BERT的输入令牌序列,它可以是单个句子或两个句子组合在一起。
我们使用WordPiece嵌入(Wu et al,2016),具有30000个标记词汇表。每个序列的第一个标记总是一个特殊的分类标记([CLS])。与此标记对应的最终隐藏状态用作分类任务的聚合序列表示。句子对被打包在一起成为单个序列。我们以两种方式区分句子。首先,我们用一个特殊的标记([SEP])将它们分开。2其次,我们向每个标记添加一个学习的嵌入,指示它是属于句子A还是句子B。3如图1所示,我们将输入嵌入表示为E,将特殊[CLS]标记的最终隐藏向量表示为 C ∈ R H C \in R^H C∈RH,将第i个输入标记的最终隐藏向量表示为 T i ∈ R H T_i \in R^H Ti∈RH。
对于一个给定的token,它的输入表示是通过对相应的token、segment和position嵌入求和来构造的。

图二:BERT输入表示。输入嵌入是标记嵌入、分割嵌入和位置嵌入的总和。
3.1 预训练BERT
与Peters等人(2018 a)和拉德福等人不同(2018),我们不使用传统的从左到右或从右到左的语言模型来预训练BERT。相反,我们使用本节中描述的两个无监督任务来预训练BERT。该步骤在图1的左侧部分中呈现。
任务#1:Masked LM 直觉上,我们有理由相信,深度双向模型比从左到右模型或从左到右和从右到左模型的浅层连接更强大。不幸的是,标准的条件语言模型只能从左到右或从右到左训练,因为双向条件会让每个单词间接地“看到自己”,并且该模型可以在多层上下文中简单地预测目标词。
为了训练深度双向表征,我们简单地随机屏蔽一定比例的输入标记,然后预测那些被屏蔽的标记词。我们将这个过程称为“屏蔽LM”(MLM),尽管在文献中它通常被称为完形填空任务(Taylor,1953)。在这种情况下,对应于掩码标记的最终隐藏向量被馈送到词汇表上的输出softmax中,在我们所有的实验中,我们随机屏蔽每个序列中所有WordPiece标记的15%。与去噪自动编码器(Vincent et al,2008)相比,我们只预测被屏蔽的单词,而不是重建整个输入。
实际上就是用完型填空的方式,来进行预训练。
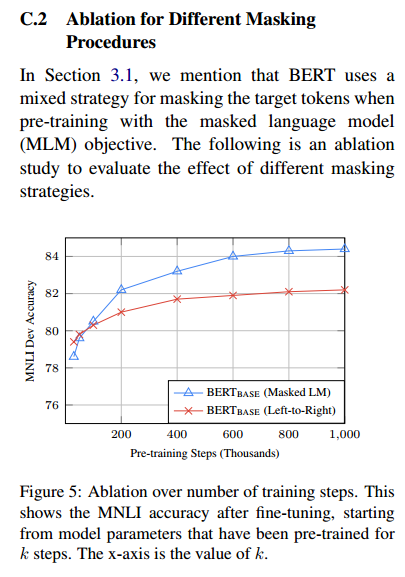
虽然这允许我们获得双向预训练模型,但缺点是我们在预训练和微调之间产生了不匹配,因为[MASK]令牌在微调期间不会出现。为了缓解这一点,我们并不总是用实际的[MASK] token替换“masked”单词。训练数据生成器随机选择15%的token位置进行预测。如果第i个token被选中,我们用(1)80%用[MASK] token(2)10%的时间用随机token(3)10%的时间用未改变的第i个token。然后,Ti将用于预测具有交叉熵损失的原始token。我们在附录C.2中比较了这个过程的变化。
任务#2:下一句预测(NSP) 许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都是基于理解两个句子之间的关系,而语言建模并不能直接捕捉到这一点。为了训练一个理解句子关系的模型,我们对一个二值化的下一句预测任务进行了预训练,这个任务可以从任何单语语料库中简单地生成。具体来说,当为每个预训练示例选择句子A和B时,50%的时间B是A之后的实际下一个句子(标记为IsNext),并且50%的时间它是来自语料库的随机句子(标记为NotNext)。如图1所示,C用于下一句预测(NSP)。尽管简单,我们在第5.1节中证明,针对这一任务的预训练对QA和NLI都非常有益。
NSP任务与Jernite et al(2017)和Logeswaran and Lee(2018)中使用的表征学习目标密切相关。然而,在之前的工作中,只有句子嵌入被转移到下游任务,BERT将所有参数转移到初始化最终任务模型参数。
训练了哪些语料
预训练数据预训练过程在很大程度上遵循现有的语言模型预训练文献。对于预训练语料库,我们使用BooksCorpus(8亿单词)(Zhu et al,2015)和英文维基百科(25亿单词)。对于维基百科,我们只提取文本段落,而忽略列表,表格和标题。为了提取长的连续序列,使用文档级语料库而不是像十亿字基准(Chelba et al,2013)那样的混洗的文本级语料库是至关重要的。
3.2 微调BERT
微调是直接的,因为Transformer中的自我注意机制允许BERT通过交换适当的输入和输出来建模许多下游任务-无论它们涉及单个文本还是文本对。对于涉及文本对的应用程序,一个常见的模式是在应用双向交叉注意之前独立编码文本对,例如Parikh et al(2016); Seo et al(2017). BERT使用自注意机制来统一这两个阶段,因为使用自注意编码串联文本对有效地包括两个句子之间的双向交叉注意。
对于每个任务,我们只需将特定于任务的输入和输出插入BERT,并端到端地微调所有参数。在输入端,来自预训练的句子A和句子B类似于(1)释义中的句子对,(2)蕴涵中的假设-前提对,(3)问答中的问题-段落对,以及(4)一个堕落的文本- 在输出端,标记表示被馈送到输出层中用于标记级任务,例如序列标记或问题回答,并且[CLS]表示被馈送到输出层中用于分类,例如蕴涵或情感分析。
与预训练相比,微调相对简单。从完全相同的预训练模型开始,本文中的所有结果最多可以在单个Cloud TPU上复现1小时,或者在GPU上几个小时。我们在第4节的相应小节中描述了特定于任务的详细信息。更多详细信息可以在附录A.5中找到。

总结:BERT的突出贡献
BERT(Bidirectional Encoder Representations from Transformers)是自然语言处理(NLP)领域的里程碑式模型,它通过预训练-微调范式解决了多个核心问题,显著提升了各类NLP任务的性能。以下是BERT主要解决的问题及其贡献:
1. 解决了传统语言模型的「单向上下文限制」问题
- 传统方法的缺陷:
- 在BERT之前,主流语言模型(如GPT、ELMo)要么是单向的(从左到右或从右到左),要么是浅层双向的(如ELMo通过拼接左右向LSTM的结果)。
- 单向模型无法同时利用单词的完整上下文信息(例如,预测单词"bank"时,无法同时考虑左右侧的上下文:“river bank” vs. “bank account”)。
- BERT的解决方案:
- 通过Masked Language Model (MLM) 预训练任务,强制模型基于双向上下文预测被遮盖的单词,真正实现了深度双向编码。
- 效果:模型能更准确地理解词语的语义(如一词多义)和句法结构。
2. 解决了NLP任务的「任务特定架构依赖」问题
- 传统方法的缺陷:
- 不同NLP任务(如文本分类、问答、命名实体识别)需要设计不同的模型架构,且通常需要大量任务特定的标注数据。
- BERT的解决方案:
- 通过统一的预训练-微调框架,使用相同的预训练模型结构适配多种下游任务,仅需在预训练模型基础上添加轻量级的任务相关输出层(如分类头)。
- 效果:
- 减少了对任务特定架构设计的依赖。
- 在小样本场景下表现更好(预训练模型已学习通用语言知识)。
3. 缓解了「长距离依赖」和「语义消歧」问题
- 传统方法的缺陷:
- 基于RNN的模型难以捕捉长距离依赖(梯度消失/爆炸)。
- 词向量(如Word2Vec)是静态的,无法根据上下文调整词义(如"apple"在水果和公司场景下的不同含义)。
- BERT的解决方案:
- 基于Transformer的自注意力机制,直接建模任意距离的单词关系。
- 生成动态上下文词向量(同一单词在不同句子中的表示不同)。
- 效果:显著提升了对复杂语境的理解能力(如指代消解、语义角色标注)。
4. 降低了「高质量标注数据依赖」问题
- 传统方法的缺陷:
- 监督学习需要大量人工标注数据,成本高昂。
- BERT的解决方案:
- 通过自监督学习(MLM和NSP)从无标注文本中预训练,仅需在下游任务微调时使用少量标注数据。
- 效果:在低资源任务(如小语种、垂直领域)中仍能表现良好。
5. 统一了NLP的「迁移学习范式」
- 传统方法的缺陷:
- 迁移学习在计算机视觉(CV)中已成熟(如ImageNet预训练),但NLP领域缺乏通用方案。
- BERT的解决方案:
- 提供了一种可扩展的预训练框架,后续模型(如RoBERTa、ALBERT)均基于此范式改进。
- 效果:推动NLP进入「预训练大模型」时代,成为工业界和学术界的基础工具。
实际应用中的效果举例
| 任务类型 | BERT的改进 |
|---|---|
| 文本分类(如情感分析) | 准确率提升5-10%以上(如GLUE基准) |
| 问答系统(如SQuAD) | F1分数首次超过人类基线(从85.8%提升到93.2%) |
| 命名实体识别(NER) | 实体边界和类型识别更精准 |
| 机器翻译 | 作为编码器提升低资源语言翻译质量 |
局限性与后续改进
尽管BERT解决了上述问题,但仍存在一些不足,后续研究在此基础上优化:
- 计算资源需求高 → 模型压缩技术(如DistilBERT)。
- NSP任务效果有限 → RoBERTa移除NSP,仅用MLM。
- 长文本处理弱 → Transformer-XH、Longformer改进位置编码。
总结
BERT的核心贡献是通过双向Transformer和自监督预训练,统一了NLP任务的表示学习框架,解决了语义理解、迁移学习和架构碎片化等关键问题,成为现代NLP的基础技术。
相关文章:

Bert论文解析
文章目录 BERT:用于语言理解的深度双向转换器的预训练一、摘要三、BERT介绍BERT及其详细实现答疑:为什么没有标注的数据可以用来预训练模型?1. 掩码语言模型(Masked Language Model, MLM)2. 下一句预测(Nex…...
详解)
【数学】勒让德定理(legendres-formula)详解
勒让德定理(Legendre’s Formula)详解 这段代码使用的数学原理是勒让德定理,它是计算质数p在n!的质因数分解中指数的核心方法。 一、定理内容 对于任意质数p和正整数n,p在n!的质因数分解中的指数(即n!能被p整除的最…...

时空联合规划算法
本文主要讲解时空时空联合规划算法。 文章目录 前言一、时空联合规划基本概念1.1 EM Planner算法求解过程1.2 时空联合规划算法求解过程二、基于搜索的规划方法2.1 构建三维时空联合规划地图2.2 基于Hybrid A*的时空联合规划二、基于迭代搜索的规划方法2.1 这段时间更新中2.2 这…...

如何在idea中新建一个项目
Java通常展现的方式就是项目,但是在不熟悉idea的情况下,我们应该如何创建一个项目呢? 第一步:点击File-->New-->Project 第二步:选择 Empty Project 第三步:点击File-->找到Project Structure--&…...
适配器模式)
设计模式简述(十三)适配器模式
适配器模式 描述基本使用使用关于适配器关联不兼容类的方式如果原有抽象层是抽象类若原有抽象是接口使用 描述 适配器模式常用于系统已经上限稳定运行,但现有需求需要将两个不匹配的类放到一起工作时使用。 也就是说这是一个迭代阶段使用的模式。 这种模式&#x…...

功耗日志抓取需求
最近罗列了一些功耗分析需要的常见日志: 测试功耗前: adb shell dumpsys batterystats --reset adb shell dumpsys batterystats --enable full-wake-history 测试功耗后,使用脚本导出如下功耗日志: 脚本 chmod x collect_logs.s…...
装饰器模式)
设计模式简述(十一)装饰器模式
装饰器模式 描述基本使用使用 描述 装饰器模式是一种功能型模式 用于动态增强对象的功能 这么一说感觉上和代理模式有些类似 抽象装饰器 要实现原有业务接口,并注入原有业务对象 至于对原有业务对象的调用,可以采用private业务对象 实现业务接口方法的…...

MongoDB基础知识
MongoDB基础知识 目录 基础篇 一、MongoDB入门指南(零基础必读)二、MongoDB简介三、MongoDB安装与配置四、MongoDB基本操作五、MongoDB查询操作 进阶篇 六、MongoDB索引七、MongoDB聚合操作八、MongoDB数据模型九、MongoDB安全十、MongoDB备份恢复十一…...
:入门、架构及基本概念)
Kubernetes详细教程(一):入门、架构及基本概念
Kubernetes(常简称为K8s)是一个开源的平台,用于自动化部署、扩展和管理容器化应用程序。 官方文档:https://kubernetes.io/zh-cn/docs/concepts/overview/components/ 一、入门 (一)Kubernetes是什么&am…...

架构思维:限流技术深度解析
文章目录 Pre业务场景熔断 VS 限流4大限流算法固定时间窗口计数滑动时间窗口计数漏桶令牌桶 方案实现使用令牌桶还是漏桶模式?在 Nginx 中实现限流还是在网关层中实现限流?使用分布式限流还是单机限流?使用哪个开源技术? 限流方案…...

批量改CAD图层颜色——CAD c#二次开发
一个文件夹下大量图纸(几百甚至几千个文件)需要改图层颜色时,可采用插件实现,效果如下: 转换前: 转换后: 使用方式如下:netload加载此dll插件,输入xx运行。 附部分代码如…...

vue猜词游戏
说明:我希望用vue实现猜词游戏 Vue Wordle 游戏规则总结 核心规则 单词选择 目标单词从预设词库(DEFAULT_WORDS)中随机选取,均为5字母单词(如apple、zebra等)。 输入要求 长度限制:必须…...

SQL ②-库操作 | 数据类型
这里是Themberfue SQL语法 数据库术语 DATABASE:数据库,保存有组织的数据的容器(通常是一个文件或一组文件)。TABLE:表,某种特定类型数据的结构化清单。SCHEMA:模式,关于数据库和表…...

云轴科技ZStack CTO王为@中国GenAI大会:AI原生实践重构AI Infra新范式
4月1-2日,2025中国生成式AI大会(GenAICon 2025)在北京举办,该会议已成为国内AI领域最具影响力的产业峰会之一。来自学术界与产业界的50位嘉宾围绕GenAI应用、大模型、AI智能体、具身智能、DeepSeek R1与推理模型等话题,…...

处理甘特图启动依赖报错。
处理甘特图启动报错 一、修改甘特图下载地址1.1 配置修改1.2 修改地址(https://registry.npmmirror.com) 二、安装依赖1.1 安装sass-loader1.2 适配安装dhtmlx-gantt 一、修改甘特图下载地址 1.1 配置修改 npm config get registry1.2 修改地址(https://registry.npmmirror.c…...

JSX、支持HTML标签、Ref的使用、虚拟DOM的使用
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...

leetcode376-摆动序列
leetcode 376 思路 变量定义: prediff:记录上一次相邻元素的差值。用于判断当前差值与上一个差值的关系curdiff:记录当前相邻元素的差值result:记录当前的摆动序列的长度,初始化为 1,因为至少一个元素就…...
 --- 中的多协议与漏洞利用技术(杂项知识点 重点) 持续更新)
内网渗透(杂项集合) --- 中的多协议与漏洞利用技术(杂项知识点 重点) 持续更新
目录 1. NetBIOS 名称的网络协议在局域网中内网渗透中起到什么作用 2. 使用 UDP 端口耗尽技术强制所有 DNS 查找失败,这个技术如何应用在局域网内网渗透测试中 3. 在本地创建一个 HTTP 服务来伪造 WPAD 服务器 什么是 WPAD 服务器?这个服务器是干嘛的…...

14-产品经理-维护计划
产品经理的另一个职责是制定计划。古人云,凡事预则立,不预则废。 产品需要做规划,才能有轻重缓急,才能正确的做事。因此对于产品经理而言,计划是必需的。 对于产品经理自己而言,发布计划可以帮助他规划产…...

12-产品经理-维护模块
需求模块是帮助产品经理进行需求的分类和维护。 1. 维护模块 在具体产品的“研发需求”页面左侧,点击“维护模块”。也可以在具体产品的“设置”-“模块”下进行维护。 点击保存后,返回模块页面。还可以点击“子模块”对已有模块进行子模块的维护。 点击…...

解析HiveQL的ALTER TABLE ADD/REPLACE COLUMNS语句
阅读以下ALTER TABLE的ADD/REPLACE COLUMNS语句的语法,用C#编写解析函数,一个一个字符解析,所有关键字不区分大小写,一个或多个空格、Tab和换行的组合都可以是关键词之间的分隔,表名和字段名可能包含空格和Tab…...

MySQL-SQL-DML语句、INSER添加数据、UPDATE更新数据、DELETE删除数据
一. DML 1. DML的英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。 2. 添加数据(INSERT);修改数据(UPDATE);删除数据(DELETE) 二. DML-INSER添加数据 -- DML insert -- 指定字段添加数…...

学透Spring Boot — 017. 处理静态文件
这是我的《学透Spring Boot》专栏的第17篇文章,了解更多内容请移步我的专栏: Postnull CSDN 学透 Spring Boot 目录 静态文件 静态文件的默认位置 通过配置文件配置路径 通过代码配置路径 静态文件的自动配置 总结 静态文件 以前的传统MVC的项目…...

Linux进程间通信——共享内存
1.概念 共享内存(Shared Memory)就是允许多个进程访问同一个内存空间,是在多个进程之间共享和传递数据最高效的方式。操作系统将不同进程之间共享内存安排为同一段物理内存,进程可以将共享内存连接到它们自己的地址空间中&#x…...

如何在大型项目中组织和管理 Vue 3 Hooks?
众所周知,Vue Hooks(通常指 Composition API 中的功能)是 Vue 3 引入的一种代码组织方式,用于更灵活地组合和复用逻辑。但是在项目中大量使用这种写法该如何更好的搭建结构呢?以下是可供参考实践的案例。 一、Hooks 组织原则 单一职责每个 Hook 应专注于完成单一功能,避…...

前后端开发的未来趋势
随着技术的不断进步,前后端开发模式也在不断演变。未来,微服务架构、Serverless、前后端融合(GraphQL、BFF)等趋势将深刻影响开发方式,使应用更高效、灵活、可扩展。 1. 微服务架构与 Serverless 1.1 微服务架构(Microservices Architecture) 微服务是一种软件架构模式…...

产品经理课程
原型工具 一、土耳其机器人 这个说法来源于 1770 年出现的一个骗局,一个叫沃尔夫冈冯肯佩伦(Wolfgang von Kempelen)的人为了取悦奥地利女皇玛丽娅特蕾莎(Maria Theresia),“制造”了一个会下国际象棋的机…...

【开源宝藏】30天学会CSS - DAY12 第十二课 从左向右填充的文字标题动画
用伪元素搞定文字填充动效:一行 JS 不写,效果炸裂 你是否曾经在设计页面标题时,觉得纯文字太寡淡?或者想做一个有动感的文字特效,但又不想引入 JS 甚至 SVG? 在这篇文章中,我们将通过 一段不到…...

Nginx 负载均衡案例配置
负载均衡案例 基于 docker 进行 案例测试 1、创建三个 Nginx 实例 创建目录结构 为每个 Nginx 实例创建单独的目录,用于存储 HTML 文件和配置文件 mkdir -p data/nginx1/html mkdir -p data/nginx2/html mkdir -p data/nginx3/html添加自定义 HTML 文件 在每个…...

Golang系列 - 内存对齐
Golang系列-内存对齐 常见类型header的size大小内存对齐空结构体类型参考 摘要: 本文将围绕内存对齐展开, 包括字符串、数组、切片等类型header的size大小、内存对齐、空结构体类型的对齐等等内容. 关键词: Golang, 内存对齐, 字符串, 数组, 切片 常见类型header的size大小 首…...

nginx中的limit_req 和 limit_conn
在 Nginx 中,limit_req 和 limit_conn 是两个用于限制客户端请求的指令,它们分别用于限制请求速率和并发连接数。 limit_req limit_req 用于限制请求速率,防止客户端发送过多请求影响服务器性能。它通过 limit_req_zone 指令定义一个共享内存…...

Python Cookbook-5.4 根据对应值将键或索引排序
任务 需要统计不同元素出现的次数,并且根据它们的出现次数安排它们的顺序——比如,你想制作一个柱状图。 解决方案 柱状图,如果不考虑它在图形图像上的含义,实际上是基于各种不同元素(用Python的列表或字典很容易处理)出现的次…...

U535982 J-A 小梦的AB交换
U535982 J-A 小梦的AB交换 - 洛谷 题目描述 小梦有一个长度为 2⋅n 的 AB 串 s,即 s 中只包含 "A" 和 "B" 两种字符,且其中恰好有 n 个 "A" 和 n 个 "B"。 他可以对 s 执行以下操作: 选择 i,j (…...

2025高频面试算法总结篇【排序】
文章目录 直接刷题链接直达把数组排成最小的数删除有序数组中的重复项求两个排序数组的中位数求一个循环递增数组的最小值数组中的逆序对如何找到一个无序数组的中位数链表排序从一大段文本中找出TOP K 的高频词汇 直接刷题链接直达 把一个数组排成最大的数 剑指 Offer 45. 把…...

计算机视觉基础4——特征点及其描述子
一、特征点检测 (一)特征点定义 图像中具有独特局部性质的点。 (二)特征点性质 具有局部性(对遮挡和混乱场景鲁棒)、数量足够多(一幅图像可产生成百上千个)、独特性(…...

React 初学者进阶指南:从环境搭建到部署上线
概览 环境搭建 核心概念 TodoList 实战 部署上线 一、快速搭建 React 开发环境 1. 选型:Vite 或 Create React App Vite:轻量、热更新速度快、可定制度高,适合追求更高效率的开发者。Create React App (CRA):社区支持全面,文档丰富,适合初学者上手。我使用的是Vite 提示…...

docker加docker compose实现软件快速安装启动
docker 下载镜像官网页面:https://hub.docker.com/ docker是什么? 加速应用构建、分享、运行 docker命令 镜像操作 容器操作 docker ps:查看运行中的容器 docker ps -a: 查看所有容器,包括停止的 除了docker run和docker exec两个命令其余执…...

使用人工智能大模型腾讯元宝,如何免费快速做工作总结?
今天我们学习使用人工智能大模型腾讯元宝,如何免费快速做工作总结? 手把手学习视频地址:https://edu.csdn.net/learn/40402/666429 第一步在腾讯元宝对话框中输入如何协助老师做工作总结,通过提问,我们了解了老师做工…...

【小兔鲜】day03 Home模块与一级分类
【小兔鲜】day03 Home模块与一级分类 1. Home-整体结构搭建和分类实现1.1 页面结构 2. Home-banner轮播图功能实现 1. Home-整体结构搭建和分类实现 1.1 页面结构 分类实现 2. Home-banner轮播图功能实现 轮播图实现 在HomeBanner.vue中写出轮播图的结构 在apis目录下新建h…...

c++使用gstreamer录屏+声音
说明: c使用gstreamer完成录制电脑桌面的功能 我希望用gstreamer录屏,默认10秒,自动保存录屏文件到本地 这里是不带声音的版本,仅录屏, step1:C:\Users\wangrusheng\source\repos\CMakeProject1\CMakeProject1\CMakeL…...

PowerToys:Windows高效工具集
Microsoft PowerToys 是微软官方推出的 免费开源效率工具集,专为 Windows 系统设计,通过模块化功能解决高频操作痛点,提升用户生产力。支持 Windows 10/11 系统,覆盖开发者、设计师及普通办公场景。 一、核心功能亮点 高…...

pulsar中的延迟队列使用详解
Apache Pulsar的延迟队列支持任意时间精度的延迟消息投递,适用于金融交易、定时提醒等高时效性场景。其核心设计通过堆外内存索引队列与持久化分片存储实现,兼顾灵活性与可扩展性。以下从实现原理、使用方式、优化策略及挑战展开解析: 一、核…...

import torch 失败
1. 使用 PyTorch 官方 Conda 频道安装 运行以下命令(根据你的 CUDA 版本选择): # CPU 版本 conda install pytorch torchvision torchaudio cpuonly -c pytorch# CUDA 11.8 版本 conda install pytorch torchvision torchaudio pytorch-cud…...

什么是异步?
什么是异步? 异步是一个术语,用于描述不需要同时行动或协调就能独立运行的流程。这一概念在技术和计算领域尤为重要,它允许系统的不同部分按自己的节奏运行,而无需等待同步信号或事件。在区块链技术中,异步是指网络中…...

Llama 4 家族:原生多模态 AI 创新新时代的开启
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

情感语音的“开源先锋”!网易开源
语音合成技术近年来取得了显著进步,特别是在语音克隆、语音助手、配音服务和有声读物等领域。然而,如何让合成的语音更具情感,更贴近人类的真实表达,一直是这一领域的重要研究方向。今天,我们将为大家介绍一款由网易有…...

消息队列基础概念及选型,常见解决方案包括消息可靠性、消息有序、消息堆积、重复消费、事务消息
前言 是时候总结下消息队列相关知识点啦!我搓搓搓搓 本文包括消息队列基础概念介绍,常见解决方案包括消息可靠性、消息有序、消息堆积、重复消费、事务消息 参考资料: Kafka常见问题总结 | JavaGuide RocketMQ常见问题总结 | JavaGuide …...

子类是否能继承
继承 父类: 子 类 构造方法 非私有 不能继承 私有(private)不能继承 成员变量 非私有 能继承 私有&…...
)
计算机系统--- BIOS(基本输入输出系统)
一、BIOS的定义与核心定位 BIOS(Basic Input/Output System)是计算机启动时运行的底层固件,存储在主板的ROM芯片中。它是连接硬件与操作系统的桥梁,负责初始化硬件、加载启动程序,并提供基础配置界面。其核心目标是&a…...

Ollama 与 llama.cpp 深度对比
Ollama 与 llama.cpp 深度对比 1. 定位与架构 维度llama.cppOllama核心定位Meta LLaMA 的 C 推理框架,专注底层优化基于 llama.cpp 的高层封装工具,提供一站式服务技术栈纯 C 实现,支持量化/内存管理/硬件指令集优化(AVX/NEON/M…...