【Block总结】自适应矩形卷积,即插即用|CVPR2025
论文信息
- 标题: Adaptive Rectangular Convolution for Remote Sensing Pansharpening
- 年份: 2025年
- 会议: CVPR
- 论文地址: arXiv
- 代码地址: GitHub
- 任务: 遥感图像融合(Pansharpening)
创新点
本论文提出了一种新颖的自适应矩形卷积模块(ARConv),其主要创新点包括:
- 自适应卷积核设计: ARConv能够根据图像中不同物体的大小自适应地调整卷积核的高度和宽度,克服了传统卷积核在形状和采样点数量上的固定限制。
- 动态采样点调整: 根据学习到的卷积核特征,动态调整采样点的数量,以有效捕捉不同尺度的特征。
- ARNet架构: 基于U-net架构,提出ARNet网络,利用ARConv模块在不同深度自适应地提取特征,生成高分辨率多光谱图像。
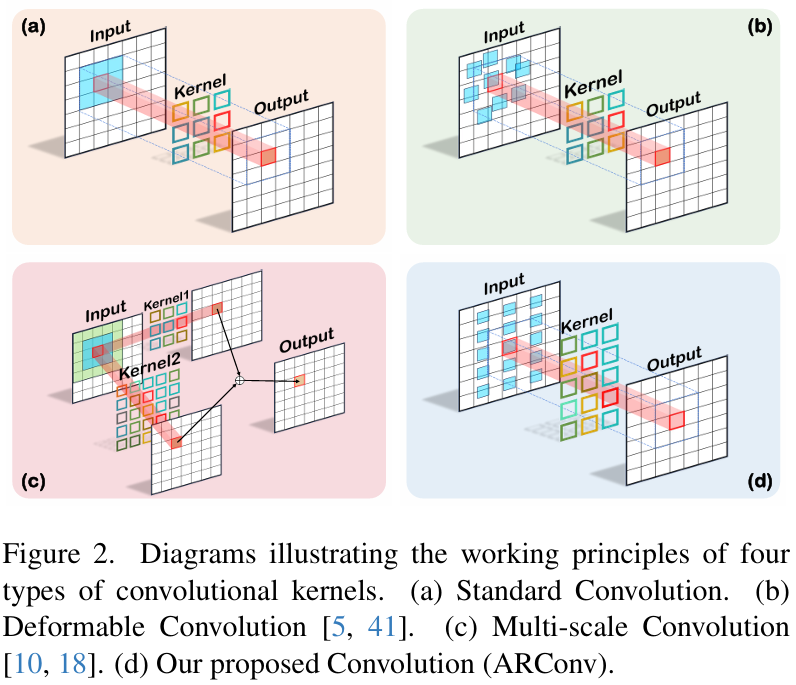
方法
论文中提出的ARConv模块的工作流程如下:
- 卷积核高度和宽度学习: 通过两个子网络分别预测卷积核的高度和宽度特征图。每个子网络由共享特征提取器和高度/宽度学习器组成,最后通过Sigmoid函数和调制因子约束高度和宽度的范围。
- 采样点数量选择: 根据高度和宽度特征图的均值水平,确定卷积核在垂直和水平方向上的采样点数量,并选择奇数个采样点以避免过多参数。
- 生成采样图: 利用标准卷积的采样网格和ARConv的偏移矩阵,结合插值方法,生成最终的采样图。
- 卷积实现: 对采样图进行卷积操作,并引入仿射变换以增强空间适应性。
ARNet网络结构基于U-net架构,将标准卷积层替换为ARConv模块,通过下采样和上采样步骤,结合ARConv在不同深度自适应地提取特征,最终将学习到的细节注入到低分辨率多光谱图像中,生成高分辨率多光谱图像。
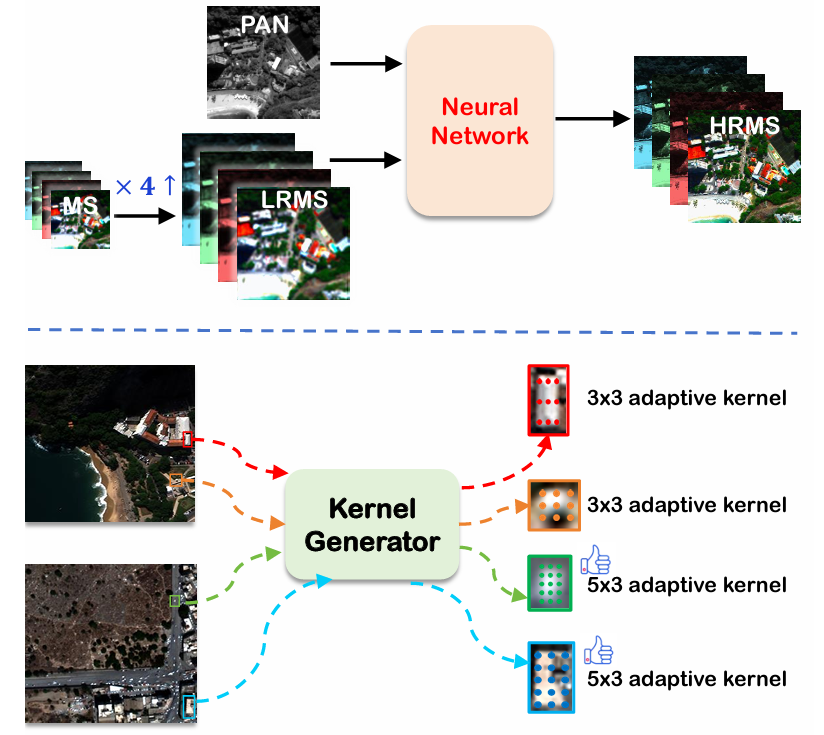
效果
在多个数据集(如WorldView3、QuickBird和GaoFen-2)上进行了广泛评估,使用的评估指标包括SAM、ERGAS、Q8、Dλ、Ds和HQNR。实验结果表明:
- 性能提升: ARConv在提升融合性能方面优于以往技术,尤其在不同卷积核高度和宽度学习范围的影响实验中,ARNet的性能表现出先提升后下降的趋势,表明适当的卷积核范围对性能至关重要。
- 消融实验: 通过移除ARConv中的不同模块,验证了各模块的有效性,结果显示移除任一模块都会导致性能下降,尤其在未采用仿射变换时,性能急剧下降,说明仿射变换对增强空间适应性至关重要。
- 通用性验证: 将ARConv集成到其他融合网络(如FusionNet、LAGNet、CANNet)中,显著提升了这些网络的性能,证明了ARConv的通用性和有效性。
总结
本论文提出的自适应矩形卷积(ARConv)通过自适应学习卷积核的高度和宽度,并根据学习到的尺度动态调整采样点数量,为遥感图像融合任务提供了一种新颖有效的解决方案。ARNet在多个数据集上表现出色,且可视化研究表明卷积核能够根据物体大小和形状有效调整其高度和宽度,充分验证了该方法的有效性和创新性。
代码
import torch
import torch.nn as nnclass ARConv(nn.Module):def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, l_max=9, w_max=9, flag=False, modulation=True):super(ARConv, self).__init__()self.lmax = l_maxself.wmax = w_maxself.inc = incself.outc = outcself.kernel_size = kernel_sizeself.padding = paddingself.stride = strideself.zero_padding = nn.ZeroPad2d(padding)self.flag = flagself.modulation = modulationself.i_list = [33, 35, 53, 37, 73, 55, 57, 75, 77]self.convs = nn.ModuleList([nn.Conv2d(inc, outc, kernel_size=(i // 10, i % 10), stride=(i // 10, i % 10), padding=0)for i in self.i_list])self.m_conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=3, padding=1, stride=stride),nn.LeakyReLU(),nn.Dropout2d(0.3),nn.Conv2d(outc, outc, kernel_size=3, padding=1, stride=stride),nn.LeakyReLU(),nn.Dropout2d(0.3),nn.Conv2d(outc, outc, kernel_size=3, padding=1, stride=stride),nn.Tanh())self.b_conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=3, padding=1, stride=stride),nn.LeakyReLU(),nn.Dropout2d(0.3),nn.Conv2d(outc, outc, kernel_size=3, padding=1, stride=stride),nn.LeakyReLU(),nn.Dropout2d(0.3),nn.Conv2d(outc, outc, kernel_size=3, padding=1, stride=stride))self.p_conv = nn.Sequential(nn.Conv2d(inc, inc, kernel_size=3, padding=1, stride=stride),nn.BatchNorm2d(inc),nn.LeakyReLU(),nn.Dropout2d(0),nn.Conv2d(inc, inc, kernel_size=3, padding=1, stride=stride),nn.BatchNorm2d(inc),nn.LeakyReLU(),)self.l_conv = nn.Sequential(nn.Conv2d(inc, 1, kernel_size=3, padding=1, stride=stride),nn.BatchNorm2d(1),nn.LeakyReLU(),nn.Dropout2d(0),nn.Conv2d(1, 1, 1),nn.BatchNorm2d(1),nn.Sigmoid())self.w_conv = nn.Sequential(nn.Conv2d(inc, 1, kernel_size=3, padding=1, stride=stride),nn.BatchNorm2d(1),nn.LeakyReLU(),nn.Dropout2d(0),nn.Conv2d(1, 1, 1),nn.BatchNorm2d(1),nn.Sigmoid())self.dropout1 = nn.Dropout(0.3)self.dropout2 = nn.Dropout2d(0.3)self.hook_handles = []self.hook_handles.append(self.m_conv[0].register_full_backward_hook(self._set_lr))self.hook_handles.append(self.m_conv[1].register_full_backward_hook(self._set_lr))self.hook_handles.append(self.b_conv[0].register_full_backward_hook(self._set_lr))self.hook_handles.append(self.b_conv[1].register_full_backward_hook(self._set_lr))self.hook_handles.append(self.p_conv[0].register_full_backward_hook(self._set_lr))self.hook_handles.append(self.p_conv[1].register_full_backward_hook(self._set_lr))self.hook_handles.append(self.l_conv[0].register_full_backward_hook(self._set_lr))self.hook_handles.append(self.l_conv[1].register_full_backward_hook(self._set_lr))self.hook_handles.append(self.w_conv[0].register_full_backward_hook(self._set_lr))self.hook_handles.append(self.w_conv[1].register_full_backward_hook(self._set_lr))self.reserved_NXY = nn.Parameter(torch.tensor([3, 3], dtype=torch.int32), requires_grad=False)@staticmethoddef _set_lr(module, grad_input, grad_output):grad_input = tuple(g * 0.1 if g is not None else None for g in grad_input)grad_output = tuple(g * 0.1 if g is not None else None for g in grad_output)return grad_inputdef remove_hooks(self):for handle in self.hook_handles:handle.remove() # 移除钩子函数self.hook_handles.clear() # 清空句柄列表def forward(self, x, epoch, hw_range):assert isinstance(hw_range, list) and len(hw_range) == 2, "hw_range should be a list with 2 elements, represent the range of h w"scale = hw_range[1] // 9if hw_range[0] == 1 and hw_range[1] == 3:scale = 1m = self.m_conv(x)bias = self.b_conv(x)offset = self.p_conv(x * 100)l = self.l_conv(offset) * (hw_range[1] - 1) + 1 # b, 1, h, ww = self.w_conv(offset) * (hw_range[1] - 1) + 1 # b, 1, h, wif epoch <= 100:mean_l = l.mean(dim=0).mean(dim=1).mean(dim=1)mean_w = w.mean(dim=0).mean(dim=1).mean(dim=1)N_X = int(mean_l // scale)N_Y = int(mean_w // scale)def phi(x):if x % 2 == 0:x -= 1return xN_X, N_Y = phi(N_X), phi(N_Y)N_X, N_Y = max(N_X, 3), max(N_Y, 3)N_X, N_Y = min(N_X, 7), min(N_Y, 7)if epoch == 100:self.reserved_NXY = self.reserved_NXY = nn.Parameter(torch.tensor([N_X, N_Y], dtype=torch.int32, device=x.device),requires_grad=False)else:N_X = self.reserved_NXY[0]N_Y = self.reserved_NXY[1]N = N_X * N_Y# print(N_X, N_Y)l = l.repeat([1, N, 1, 1])w = w.repeat([1, N, 1, 1])offset = torch.cat((l, w), dim=1)dtype = offset.data.type()if self.padding:x = self.zero_padding(x)p = self._get_p(offset, dtype, N_X, N_Y) # (b, 2*N, h, w)p = p.contiguous().permute(0, 2, 3, 1) # (b, h, w, 2*N)q_lt = p.detach().floor()q_rb = q_lt + 1q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1),torch.clamp(q_lt[..., N:], 0, x.size(3) - 1),],dim=-1,).long()q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1),torch.clamp(q_rb[..., N:], 0, x.size(3) - 1),],dim=-1,).long()q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)# clip pp = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1),torch.clamp(p[..., N:], 0, x.size(3) - 1),],dim=-1,)# bilinear kernel (b, h, w, N)g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))# (b, c, h, w, N)x_q_lt = self._get_x_q(x, q_lt, N)x_q_rb = self._get_x_q(x, q_rb, N)x_q_lb = self._get_x_q(x, q_lb, N)x_q_rt = self._get_x_q(x, q_rt, N)# (b, c, h, w, N)x_offset = (g_lt.unsqueeze(dim=1) * x_q_lt+ g_rb.unsqueeze(dim=1) * x_q_rb+ g_lb.unsqueeze(dim=1) * x_q_lb+ g_rt.unsqueeze(dim=1) * x_q_rt)x_offset = self._reshape_x_offset(x_offset, N_X, N_Y)x_offset = self.dropout2(x_offset)x_offset = self.convs[self.i_list.index(N_X * 10 + N_Y)](x_offset)out = x_offset * m + biasreturn outdef _get_p_n(self, N, dtype, n_x, n_y):p_n_x, p_n_y = torch.meshgrid(torch.arange(-(n_x - 1) // 2, (n_x - 1) // 2 + 1),torch.arange(-(n_y - 1) // 2, (n_y - 1) // 2 + 1),)p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)return p_ndef _get_p_0(self, h, w, N, dtype):p_0_x, p_0_y = torch.meshgrid(torch.arange(1, h * self.stride + 1, self.stride),torch.arange(1, w * self.stride + 1, self.stride),)p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)return p_0def _get_p(self, offset, dtype, n_x, n_y):N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)L, W = offset.split([N, N], dim=1)L = L / n_xW = W / n_yoffsett = torch.cat([L, W], dim=1)p_n = self._get_p_n(N, dtype, n_x, n_y)p_n = p_n.repeat([1, 1, h, w])p_0 = self._get_p_0(h, w, N, dtype)p = p_0 + offsett * p_nreturn pdef _get_x_q(self, x, q, N):b, h, w, _ = q.size()padded_w = x.size(3)c = x.size(1)x = x.contiguous().view(b, c, -1)index = q[..., :N] * padded_w + q[..., N:]index = (index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1))x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)return x_offset@staticmethoddef _reshape_x_offset(x_offset, n_x, n_y):b, c, h, w, N = x_offset.size()x_offset = torch.cat([x_offset[..., s:s + n_y].contiguous().view(b, c, h, w * n_y) for s in range(0, N, n_y)],dim=-1)x_offset = x_offset.contiguous().view(b, c, h * n_x, w * n_y)return x_offsetif __name__ == "__main__":# 定义输入张量大小(Batch、Channel、Height、Wight)B, C, H, W = 16, 512, 40, 40input_tensor = torch.randn(B,C,H,W) # 随机生成输入张量dim=C# 创建 ARConv 实例block = ARConv(inc=dim,outc=dim)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")sablock = block.to(device)print(sablock)input_tensor = input_tensor.to(device)# 执行前向传播output = sablock(input_tensor,50,[0,18])# 打印输入和输出的形状print(f"Input: {input_tensor.shape}")print(f"Output: {output.shape}")
代码详解
1. 核心结构解析
1.1 初始化部分 (__init__)
-
多尺度卷积层 (
self.convs):- 包含9种不同尺寸的卷积核(如3x3,5x5等),通过i_list中的两位数编码(十位和个位分别表示高度和宽度的尺寸)。
- 例如,i=33对应kernel_size=(3,3),stride=(3,3)。
-
调制网络 (
m_conv):- 由三个卷积层组成,输出通过Tanh激活,生成调制因子m,用于调整特征权重。
-
偏置网络 (
b_conv):- 生成偏置项bias,与调制后的特征相加。
-
位置偏移网络 (
p_conv):- 生成基础偏移量,输入被放大100倍以增强位置敏感性。
-
长宽预测网络 (
l_conv,w_conv):- 预测每个位置的长宽偏移量l和w,通过Sigmoid映射到[0,1]后缩放至指定范围。
-
梯度调整钩子:
- 注册反向传播钩子,将特定层的梯度缩小到0.1倍,稳定训练过程。
1.2 前向传播 (forward)
-
动态核尺寸选择:
- 根据当前训练轮数(epoch)动态确定N_X和N_Y(卷积核分块数)。
- 前100轮计算平均偏移确定分块数,之后固定。确保核尺寸为奇数(phi函数处理)。
-
可变形采样:
- 使用预测的偏移量生成采样网格§,通过双线性插值获取变形后的特征(x_offset)。
-
多尺度卷积处理:
- 根据N_X和N_Y选择对应的卷积层处理变形后的特征,结合调制因子和偏置输出最终特征。
2. 关键机制
- 动态核适应: 根据输入特征动态调整卷积核的分布区域,增强模型对不同尺度特征的捕捉能力。
- 可变形卷积: 通过预测的偏移量实现非规则采样,突破传统卷积的固定几何结构限制。
- 梯度控制: 使用自定义梯度缩放策略(0.1倍),防止调制网络训练不稳定。
3. 数据流动示例
输入尺寸: (16,512,40,40)
输出尺寸: (16,512,40,40)
处理过程:
- 偏移预测网络生成40x40网格的偏移量
- 双线性插值生成变形特征图
- 根据动态选择的核尺寸(如3x3)进行分块卷积
- 调制网络调整特征权重,偏置网络添加位置偏置
4. 潜在优化点
- 核尺寸选择策略: 当前基于平均偏移的启发式方法可能不够鲁棒,可探索可学习的自动选择机制。
- 计算效率: 多尺度卷积组的并行计算可能带来内存压力,可考虑动态生成卷积参数。
- 梯度控制: 固定0.1倍的梯度缩放可能不够灵活,可尝试自适应梯度裁剪。
5. 应用场景建议
该模块特别适用于以下场景:
- 细粒度视觉识别(如医学图像分析)
- 不规则形状目标检测
- 多尺度特征融合层
- 视频动作识别中的时空特征建模
# 典型使用示例
class ARNet(nn.Module):def __init__(self):super().__init__()self.conv1 = ARConv(512, 512)def forward(self, x, epoch):# 假设hw_range根据网络深度动态调整hw = [0, 18] if epoch < 50 else [9, 27] return self.conv1(x, epoch, hw)# 训练时需传入当前epoch
for epoch in range(100):output = model(input, epoch=epoch, hw_range=[0,18])
相关文章:

【Block总结】自适应矩形卷积,即插即用|CVPR2025
论文信息 标题: Adaptive Rectangular Convolution for Remote Sensing Pansharpening年份: 2025年会议: CVPR论文地址: arXiv代码地址: GitHub任务: 遥感图像融合(Pansharpening) 创新点 本论文提出了一种新颖的自适应矩形卷积模块(ARCon…...

第2课:JSX语法与组件基础
第2课:JSX语法与组件基础 学习目标 深入理解JSX语法掌握组件的基本结构和用法学习使用Props传递数据掌握React中的样式添加方法创建任务卡片组件 一、JSX语法深入 1. 什么是JSX? JSX是JavaScript XML的缩写,它允许我们在JavaScript中编写…...

DevOps与Docker的关系
DevOps 与 Docker 是相辅相成的关系。DevOps 是一种强调开发(Development)与运维(Operations)之间协作的文化、实践和工具链,而 Docker 是一种容器化技术,为 DevOps 的实现提供了高效的技术支撑。 Docker …...

嵌入式AI简介
嵌入式AI是一种将人工智能算法部署在终端设备中运行的技术,使智能硬件能够在本地实时完成感知、交互和决策功能,无需依赖云端计算。以下是其核心要点: 一、核心特点 1. 本地化处理:数据在设备端直接处理,无需联网&a…...

多GPU训练
写在前面 限于财力不足,本机上只有一个 GPU 可供使用,因此这部分的代码只能够稍作了解,能够使用的 GPU 也只有一个。 多 GPU 的数据并行:有几张卡,对一个小批量数据,有几张卡就分成几块,每个 …...
:JVM运行时数据区与方法区详解)
JVM虚拟机篇(三):JVM运行时数据区与方法区详解
JVM虚拟机篇(三):JVM运行时数据区与方法区详解 JVM虚拟机篇(三):JVM运行时数据区与方法区详解一、引言二、JVM运行时数据区2.1 概述2.2 各部分的作用与交互2.2.1 堆与其他区域的关系2.2.2 方法区与其他区域…...

Rust学习日记:编写一个Python扩展
参考https://segmentfault.com/a/1190000044555330 命令行创建一个新的Rust项目cargo new --lib rust_python_ext 配置Cargo.toml [package] name "rust_python_ext" version "0.1.0" edition "2024"[lib] name "rust_python_ext"…...

Pod的调度
在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某些节点上&…...

系统思考:思考的快与慢
在做重大决策之前,什么原因一定要补充碳水化合物?人类的大脑其实有两套运作模式:系统1:自动驾驶模式,依赖直觉,反应快但易出错;系统2:手动驾驶模式,理性严谨,…...
)
[ 计算机网络 ] | HTTP协议(一)
目录 前置知识: URL URL的URLENCODE和URLDECODE HTTP协议的宏观格式 如何保证报文是完整的?怎么做序列,反序列化的? 前置知识: URL 我们把数据给别人,别人把数据给我们,不是在做IO嘛~&am…...

大模型快速 ASGI 服务器uvicorn
基础概念类 1. 什么是 Uvicorn,它的作用是什么? 答案:Uvicorn 是一个基于 Python 的快速 ASGI(异步服务器网关接口)服务器。它的主要作用是作为 Web 应用程序的服务器,负责接收客户端的请求,并…...

android studio 基础
1.android Module not specified 今天做一个实验时出现:Android Studio Run/Debug configuration error: Module not specified,要想解决这个问题: 1、打开根目录的 settings.gradle,删除 include :exampleapp 2、在 Android Stu…...
零食商品加数据清洗、销量、店铺及词云数据分析_源码及相关说明文档;售后可私博主)
python爬虫爬取淘宝热销(热门)零食商品加数据清洗、销量、店铺及词云数据分析_源码及相关说明文档;售后可私博主
TOC 如有侵权,联系删除 一、环境说明 使用前必须检查以下环境 (1)python编译环境 (2)python脚本执行所需要的库,具体看代码(main.py)import导入的部分库 (3)确保电脑可…...

Android /proc/meminfo解释
高通8295设备 msmnile_gvmq:/proc # cat meminfo MemTotal: 16433968 kB MemFree: 7709832 kB…...

VScode 玩 MCP的server
vscode 1.99版本刚支持MCP server,我就测试了一下 翻到一个gitte的MCP sever 我本身是Mac版本1.99居然没更新agent,所以我就直接用1.100版本的vscode inside了来掩饰一下了 点击setting,然后你要edit一下这个json配置文件 主要修改的其实是…...

详解 MySQL 索引的最左前缀匹配原则
MySQL 的最左前缀匹配原则主要是针对复合索引(也称为联合索引)而言的。其核心思想是:只有查询条件中包含索引最左侧(第一列)开始的连续一段列,才能让 MySQL 有效地利用该索引。 一、 复合索引的结构 复合…...

ROS Master多设备连接
Bash Shell Shell是位于用户与操作系统内核之间的桥梁,当用户在终端敲入命令后,这些输入首先会进入内核中的tty子系统,TTY子系统负责捕获并处理终端的输入输出流,确保数据正确无误的在终端和系统内核之中。Shell在此过程不仅仅是…...

【Mysql】数据库备份与恢复
一、备份类型 物理备份:直接对数据库的数据文件、日志文件、索引文件进行备份 逻辑备份:对数据库对象(库、表)以SQL语句的形式导出进行备份 二、备份工具 1、使用tar、gzip等方式压缩打包数据库文件(完全备份、物理冷…...

Java HttpURLConnection修仙指南:从萌新到HTTP请求大能的渡劫手册
一、筑基篇:初识HttpURLConnection 1.1 基础开光(创建连接) URL url new URL("https://api.example.com/data"); HttpURLConnection conn (HttpURLConnection) url.openConnection(); // 注意!此处可能抛出Malforme…...

python 重要易忘 语言基础
Collections 1、Counter 计数器 counter:计数器 类似字典 统计可迭代对象中元素的出现次数, Counter({b: 3, c: 2, a: 1, d: 1}) 相当于字典{b: 3, c: 2, a: 1, d: 1} a.items() 取键值对 对应为dict_items([(a, 1), (b, 3), (c, 2), (d, 1)]) 也可以是 list(a.items…...

【新能源汽车研发测试数据深度分析:从传感器到智能决策的硬核方法论】
摘要: 本文系统性解构新能源汽车(NEV)研发测试中的数据采集、处理及分析全链条,覆盖传感器融合、大数据清洗、AI算法优化等核心技术,并引入行业顶级案例(如特斯拉Autopilot验证、宁德时代BMS算法迭代&#…...

GD32H759IMT6 Cortex-M7 OpenHarmony轻量系统移植——接管中断修改为不接管
笔者在去年利用国庆时间,将Cortex-M7 的国产厂商兆易创新GD32H459移植OpenHarmony轻量系统,但是适配不太完善——只能选择liteos-m接管中断。这样导致使用中断非常麻烦。于是笔者最近将接管中断模式修改为不接管,这样可以方便的使用gd32提供的…...

MySQL基础学习笔记
学习笔记 1. 基础小知识1.1 数据库分类1.2 下载安装、变量配置过程(略)1.3 连接命令1.4 连接mysql服务端的软件选择1.4.1 要求不高的话,选择有很多1.4.2 适合做企业级管理的工具(适合团队协作)1.4.3 总结 1.5 编程语言…...

[Linux]进程状态、僵尸进程处理回收、进程优先级 + 图例展示
目录 一、进程状态 1.一般操作系统学科的进程状态 二、Linux操作系统的进程状态 运行状态(R) 睡眠状态(S) 深度睡眠状态(D) 暂停状态(T) 追踪暂停状态&#x…...

2022 年 6 月青少年软编等考 C 语言七级真题解析
目录 T1. 有多少种二叉树思路分析T2. 城堡问题T3. 快速堆猪思路分析T4. 重建二叉树思路分析T1. 有多少种二叉树 题目链接:SOJ D1189 输入 n ( 1 < n < 13 ) n\ (1<n<13) n (1<n<13),求 n n n 个结点的二叉树有多少种形态? 思路分析 此题考查 C a…...

flutter修改 Container 中的 Text 和 Image 的样式
在Flutter中,Container 是一个常用的布局组件,它可以包含子组件(如文本、图片等),并允许你通过设置各种属性来自定义样式。如果你需要修改 Container 中的 Text 和 Image 的样式,可以通过以下方式实现。 1.…...

零基础入门unity游戏开发——动画篇】Animation动画窗口,创建编辑动画
考虑到每个人基础可能不一样,且并不是所有人都有同时做2D、3D开发的需求,所以我把 【零基础入门unity游戏开发】 分为成了C#篇、unity通用篇、unity3D篇、unity2D篇。 【C#篇】:主要讲解C#的基础语法,包括变量、数据类型、运算符、…...

【设计模式】命令模式
简介 假设你有一个智能家居遥控器,上面有多个按钮,每个按钮对应不同的设备操作(如开灯、关灯、调空调温度)。 命令模式的解决方案是: 将每个操作(如“开灯”)封装成一个独立的命令对象&#x…...

Python作业3 字符田字格绘制
字符田字格绘制:编写程序,用字符方式打印输出一个简单的田字格,要求采用函数方式,以田字格宽度为参数,能够根据参数绘制任意大小的田字格。 def draw(n):line 3 * n 1for i in range(1, line 1):if i % 3 1:print(n * " —— —— ", end"&quo…...
)
文章记单词 | 第23篇(六级)
一,单词释义 occupy /ˈɒkjupaɪ/v. 占用,占领,使忙碌thermal /ˈθɜːml/adj. 热的,热量的,保暖的;n. 热气流persistent /pəˈsɪstənt/adj. 执着的,坚持不懈的,持续存在的wee…...

【算法】滑动窗口
什么是滑动窗口算法? 滑动窗口算法本质上就是双指针的一种情况,当两个指针进行移动的方向是同一个方向,并且这两个指针并不会向后回退,一直是往一个方向进行移动的。这也就是滑动窗口的使用场景。 滑动窗口算法的一般步骤 进窗…...

可视化工具
在PyTorch中,可视化工具对于模型调试、性能分析和结果解释至关重要。以下是常用的可视化工具及其应用场景: 1. 训练过程监控 TensorBoard (PyTorch官方集成) 用途:跟踪训练指标(损失、准确率)、可视化模型结构、分析…...

hashtable遍历的方法有哪些
在 Java 中,遍历 Hashtable(或其现代替代品 HashMap)有多种方式,以下是 6 种常用方法的详细说明和代码示例: 1. 使用 keySet() 增强 for 循环 Hashtable<String, Integer> table new Hashtable<>(); // …...

LeetCode --- 443周赛
题目列表 Q1. 到达每个位置的最小费用 Q2. 子字符串连接后的最长回文串 I Q3. 子字符串连接后的最长回文串 II Q4. 使 K 个子数组内元素相等的最少操作数 一、到达每个位置的最小费用 题目要求返回从队尾到达任意位置的最小费用,规则:如果下标 i i i …...

从零构建大语言模型全栈开发指南:附录与资源-3.面试与进阶-200道大模型面试真题与职业发展路线图-基础理论篇50题
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 附录与资源-3. 面试与进阶:200道大模型面试真题与职业发展路线图一、大模型面试真题分类与解析1. 基础理论篇(50+题精选)2. 进阶实战篇(50+题精选)3. 应用场景篇(70题精选)二、职业发展路线图1. …...

使用Android Studio开发基于Java+xml的安卓app之环境搭建
以下是使用Android Studio搭建基于Java和XML的Android应用开发环境的详细步骤: 一、系统要求 操作系统:Windows 7/8/10/11(64位)内存:建议8GB及以上磁盘空间:至少5GB空闲(建议预留10GB以上&…...

GD32H759IMT6 Cortex-M7 OpenHarmony轻量系统移植——4.1版本升级到5.0.3
笔者在去年利用国庆时间,将Cortex-M7 的国产厂商兆易创新GD32H459移植OpenHarmony轻量系统,但是适配不太完善——只能选择liteos-m接管中断。这样导致使用中断非常麻烦。于是笔者最近将接管中断模式修改为不接管,这样可以方便的使用gd32提供的…...

学习汇编随手记
学习汇编随手记 前言 本笔记是关于王爽汇编的笔记,覆盖不全,到了内中断就完结了,听从学长建议,我跑去学xv6了,x86告辞。 1. 寄存器 1.1 寄存器初步 (A,B,C,D)X是通用寄存器,通常存放一般性数据&#x…...

打造高效英文单词记忆系统:基于Python的实现与分析
在当今全球化的世界中,掌握一门外语已成为必不可少的技能。对于许多学习者来说,记忆大量的英文单词是一个漫长而艰难的过程。为了提高学习效率,我们开发了一个基于Python的英文单词记忆系统。这个系统结合了数据管理、复习计划、学习统计和测试练习等多个模块,旨在为用户提…...
)
【漫话机器学习系列】182.噪声修正线性单元(Noisy ReLU)
噪声修正线性单元(Noisy ReLU)详解 1. 引言 在深度学习中,修正线性单元(ReLU, Rectified Linear Unit) 是一种常见的激活函数,具有计算简单、梯度稳定等优点。然而,ReLU 也有一些缺点…...

连续数据离散化与逆离散化策略
数学语言描述: 在区间[a,b]中有一组符合某分布的数据: 1.求相同区间中另一组符合同样分布的数据与这组数据的均方误差 2.求区间中点与数据的均方误差 3.求在区间中均匀分布的一组数据与这组数据的均方误差 一:同分布数据随机映射 假设在…...

《安富莱嵌入式周报》第352期:手持开源终端,基于参数阵列的定向扬声器,炫酷ASCII播放器,PCB电阻箱,支持1Ω到500KΩ,Pebble智能手表代码重构
周报汇总地址:嵌入式周报 - uCOS & uCGUI & emWin & embOS & TouchGFX & ThreadX - 硬汉嵌入式论坛 - Powered by Discuz! 视频版 https://www.bilibili.com/video/BV1DEf3YiEqE/ 《安富莱嵌入式周报》第352期:手持开源终端&#x…...

游戏引擎学习第205天
回顾 我们今天要实现的是一些实体浏览功能,原本是昨天就计划好的,但因为渲染上的一些问题耽搁了一些时间。 实际上,我们遇到的并不是一个真正的bug,尽管我们花了大约40分钟才搞清楚,最终发现它只是渲染方式的一个正常…...
)
Boost库搜索引擎项目(版本1)
Boost库搜索引擎 项目开源地址 Github:https://github.com/H0308/BoostSearchingEngine Gitee:https://gitee.com/EPSDA/BoostSearchingEngine 版本声明 当前为最初版本,后续会根据其他内容对当前项目进行修改,具体见后续版本…...

复古千禧Y2风格霓虹发光酸性镀铬金属短片音乐视频文字标题动画AE/PR模板
踏入时光机,重温 21 世纪初大胆、未来主义和超光彩的美学!这是一个动态的 After Effects 模板,旨在重现千禧年的标志性视觉效果——铬反射、霓虹灯发光、闪亮的金属和流畅的动态图形。无论您是在制作时尚宣传片、怀旧音乐视频还是时尚的社交媒…...

如何高效使用 Ubuntu 中文官方网站
Ubuntu 中文官方网站 一、快速导航与核心模块 首页焦点区 顶部菜单栏:快速访问「下载」「文档」「支持」「商店」等核心功能。轮播图区:展示最新版本(如 Ubuntu 24.04 LTS)和特色功能(如 Ubuntu Pro 订阅服务)。搜索框:支持中文关键词搜索(如 "边缘计算"),…...
)
简单多状态dp问题 + 总结(一)
文章目录 按摩师题解代码 打家劫舍II题解代码 删除并获得点数题解代码 粉刷房子题解代码 按摩师 题目链接 题解 1. 细节处理:题目是有没有客人的时候,所有n等于零时返回零 2. 状态表示:到达i位置时的最长预约时长 3. 状态转移方程…...

2022 CCF CSP-S2.假期计划
题目 4732. 假期计划 算法标签: 搜索, 枚举, 贪心 思路 最多转车 k k k次等价于路线长度小于等于 k 1 k 1 k1, 经过的点没有限制, 注意到点的数量 2500 2500 2500, 因此 n 2 n ^ 2 n2的时间复杂度是可以考虑的, 边的数量 10000 10000 10000, n m n \times m nm时间复杂…...
 | 零基础入门STM32第九十三步)
STM32低功耗模式详解:睡眠、停机、待机模式原理与实践(下) | 零基础入门STM32第九十三步
主题内容教学目的/扩展视频低功耗模式什么是低功耗,模式介绍,切换方法。为电池设备开发做准备。 师从洋桃电子,杜洋老师 📑文章目录 一、低功耗模式基本工作原理1.1 功耗层级对比1.2 工作流程 二、睡眠模式实践2.1 测试程序解析2.…...

【Docker】在Orin Nano上使用Docker
1、安装Docker 1)使用 SDKManager 烧写系统时,选择NVIDIA Container Runtime,将会安装Docker, 并将 NVIDIA GPU 暴露给容器中的应用程序,这样可以在Docker中使用GPU等NVIDIA的特性。 2)使用命令安装 添加源 distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \…...