大模型学习四:DeepSeek Janus-Pro 多模态理解和生成模型 本地部署指南(折腾版)
一、说明简介
DeepSeek Janus-Pro是一款先进的多模态理解和生成模型,旨在实现高质量的文本-图像生成与多模态理解。它是由DeepSeek团队研发的,是之前Janus模型的升级版,能够同时处理文本和图像,即可以理解图片内容,也能生成图像。
技术特点
- 双路径视觉编码设计:Janus-Pro采用双路径视觉编码设计,理解路径使用SigLIP-L编码器提取图像的高层语义特征,适用于问答、分类等任务;生成路径采用VQ tokenizer将图像转换为离散token序列,关注细节纹理,支持文本到图像生成。
- 统一Transformer架构:两种任务的特征序列通过统一的Transformer处理,实现知识融合与任务协同,同时简化模型结构1。
- 多模态对齐:使用真实文生图数据替代ImageNet,提升训练效率与生成质量。
- 扩展训练数据:新增图像字幕、表格图表等复杂场景数据,增强模型泛化能力。
性能表现
在MMBench基准测试中,Janus-Pro得分79.2,超越LLaVA、MetaMorph等模型;在GenEval测试中得分0.80,优于DALL-E 3(0.67)和Stable Diffusion 3(0.74),尤其在细节与审美质量上表现突出。
应用场景
Janus-Pro可以精准识别地标(如杭州西湖三潭印月)并解析文化内涵,生成符合复杂指令的图像(如特定风格插画或场景设计)。此外,它还能对图片进行描述、识别地标景点、识别图像中的文字,并对图片中的知识进行介绍。
Janus Github主页: https://github.com/deepseek-ai/Janus
二、 Janus 模型运行硬件要求
| 任务类型 | Janus-Pro-1B | Janus-Pro-7B |
| 图像识别 | 5G( 3060) | 15G(4080) |
| 图片生成 | 14G(4080) | 40G( 3090/4090*2) |
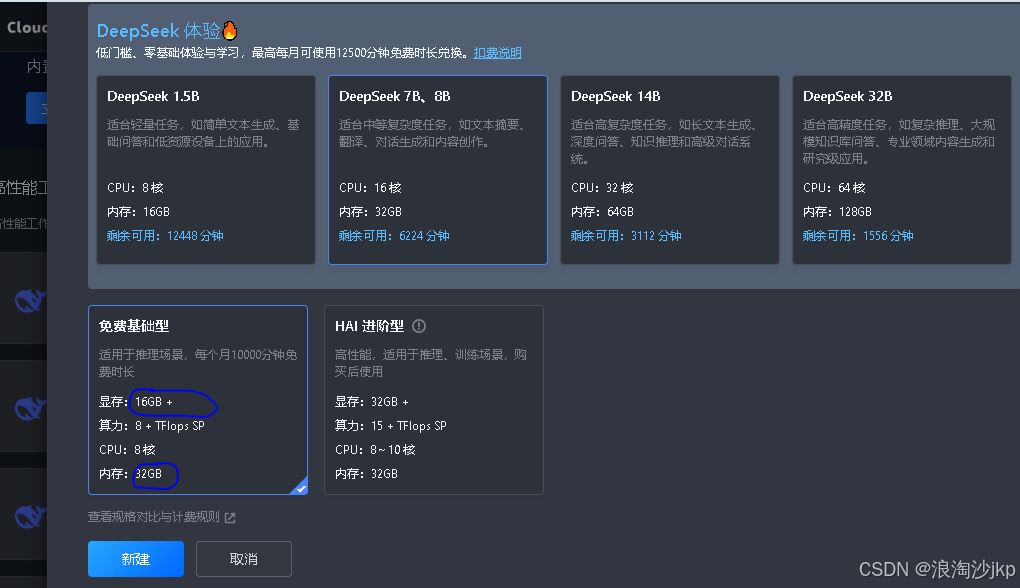
本文采用的系统是 下图免费基础型,只能图像识别7b模型,图片生成1b模型,据说1B模型效果不好,好在我们只是学习过程,好坏暂时不论
三、 janus模型下载和项目部署
1、下载源码
cd /workplace
git clone https://github.com/deepseek-ai/Janus.git
#难道关税大战,github也要干掉了,有点怀疑啊,慢的要死,我是直接上传,clone不成功
cd Janus(base) root@VM-0-80-ubuntu:/workspace# cd Janus
(base) root@VM-0-80-ubuntu:/workspace/Janus# ls
LICENSE-CODE generation_inference.py janus_pro_tech_report.pdf
LICENSE-MODEL images pyproject.toml
Makefile inference.py requirements.txt
README.md interactivechat.py
demo janus
2、安装虚拟环境和依赖
conda create -n janus python=3.10
conda init
source ~/.bashrc
conda activate janus
cd /workspace/Janus
# 注意后面的点
pip install -e .
pip install flash-attn#安装jupyter
conda install ipykernel
conda install ipywidgets
python -m ipykernel install --user --name janus --display-name "Python (janus)"选择janus环境
3、下载预训练模型
这里我们考虑在项目主目录下创建models文件夹,用于保存Janus-Pro-1B和7B模型权重。考虑到国 内网络环境,这里推荐直接在Modelscope上进行模型权重下载。
Janus-Pro-1B模型权重: 魔搭社区 Janus-Pro-7B模型权重: 魔搭社区
- 安装modelscope
pip install modelscope- 创建模型文件夹
mkdir -p Janus-Pro-1B
mkdir -p Janus-Pro-7B-
下载Janus-Pro-1B模型权重
# 下载1B模型
modelscope download --model deepseek-ai/Janus-Pro-1B --local_dir ./Janus-Pro-1B-
下载Janus-Pro-7B模型权重
# 下载7B模型
modelscope download --model deepseek-ai/Janus-Pro-7B --local_dir ./Janus-Pro-7B四、Jannus本地调用流程
1、Janus-Pro-7B模型
/workspace/Janus/Janus-Pro-7B.ipynb
创建Janus-Pro-7B.ipynb
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images# specify the path to the model
model_path = "./Janus-Pro-7B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizervl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()conversation = [{"role": "User","content": "<image_placeholder>\nConvert the formula into latex code.","images": ["images/equation.png"],},{"role": "Assistant", "content": ""},
]# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)# # run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)# # run the model to get the response
outputs = vl_gpt.language_model.generate(inputs_embeds=inputs_embeds,attention_mask=prepare_inputs.attention_mask,pad_token_id=tokenizer.eos_token_id,bos_token_id=tokenizer.bos_token_id,eos_token_id=tokenizer.eos_token_id,max_new_tokens=512,do_sample=False,use_cache=True,
)answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)结论:我的环境16G显存+32G内存跑不动,精度已经设置为 float16
2、Janus-Pro-1B模型
识别图片
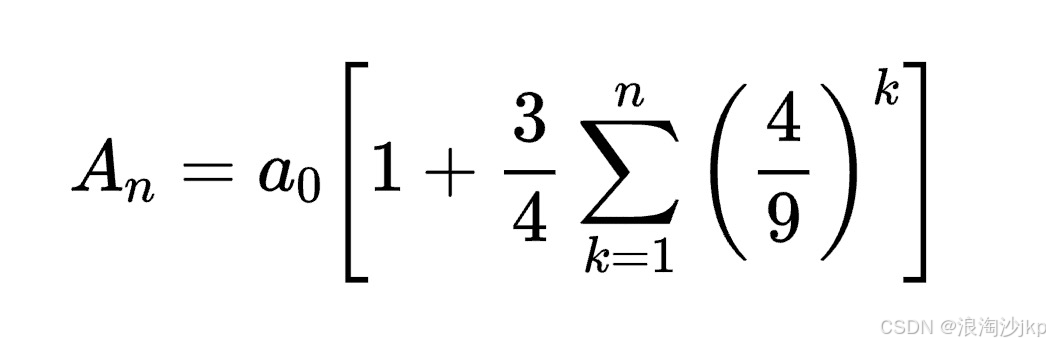
/workspace/Janus/Janus-Pro-1B.ipynb
创建Janus-Pro-1B.ipynb
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images# specify the path to the model
model_path = "./Janus-Pro-1B"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizervl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()conversation = [{"role": "User","content": "<image_placeholder>\nConvert the formula into latex code.","images": ["images/doge.png"],},{"role": "Assistant", "content": ""},
]# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)# # run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)# # run the model to get the response
outputs = vl_gpt.language_model.generate(inputs_embeds=inputs_embeds,attention_mask=prepare_inputs.attention_mask,pad_token_id=tokenizer.eos_token_id,bos_token_id=tokenizer.bos_token_id,eos_token_id=tokenizer.eos_token_id,max_new_tokens=512,do_sample=False,use_cache=True,
)answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)Python version is above 3.10, patching the collections module.
/root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/models/auto/image_processing_auto.py:602: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead warnings.warn(
/root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/models/auto/image_processing_auto.py:602: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead warnings.warn( Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
/root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/models/auto/image_processing_auto.py:602: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead warnings.warn( Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`. You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
/root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/models/auto/image_processing_auto.py:602: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead warnings.warn( Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`. You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message. Some kwargs in processor config are unused and will not have any effect: add_special_token, image_tag, sft_format, num_image_tokens, mask_prompt, ignore_id.
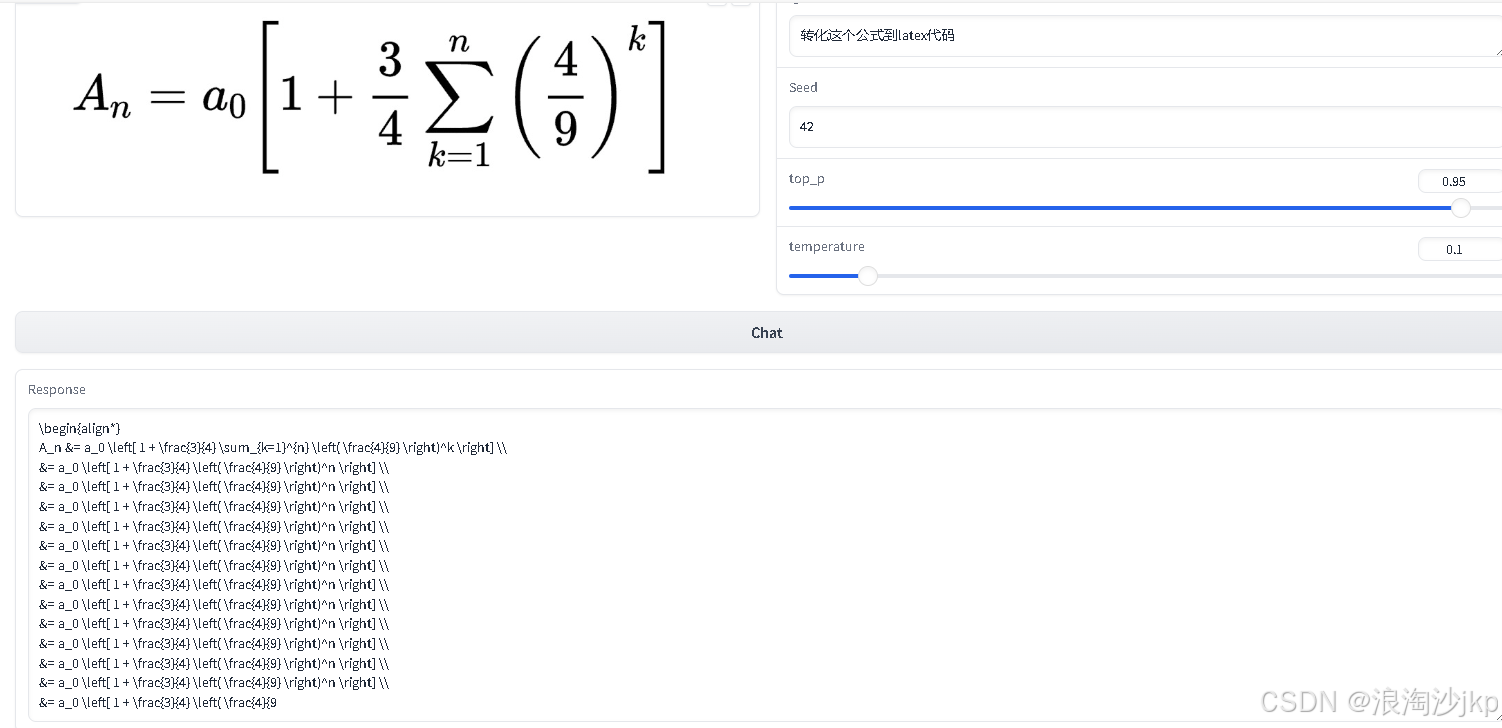
You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. User: <image_placeholder> Convert the formula into latex code. Assistant: \begin{equation} A_n = a_0 \begin{bmatrix} 1 & + \frac{3}{4} \sum_{k=1}^{n} \begin{bmatrix} 4 & \\ 9 & \end{bmatrix}^k \end{bmatrix} \end{equation} The LaTeX code for the given formula is: \begin{equation} A_n = a_0 \begin{bmatrix} 1 & + \frac{3}{4} \sum_{k=1}^{n} \begin{bmatrix} 4 & \\ 9 & \end{bmatrix}^k \end{bmatrix} \end{equation}
识别图片,代码改为该图片
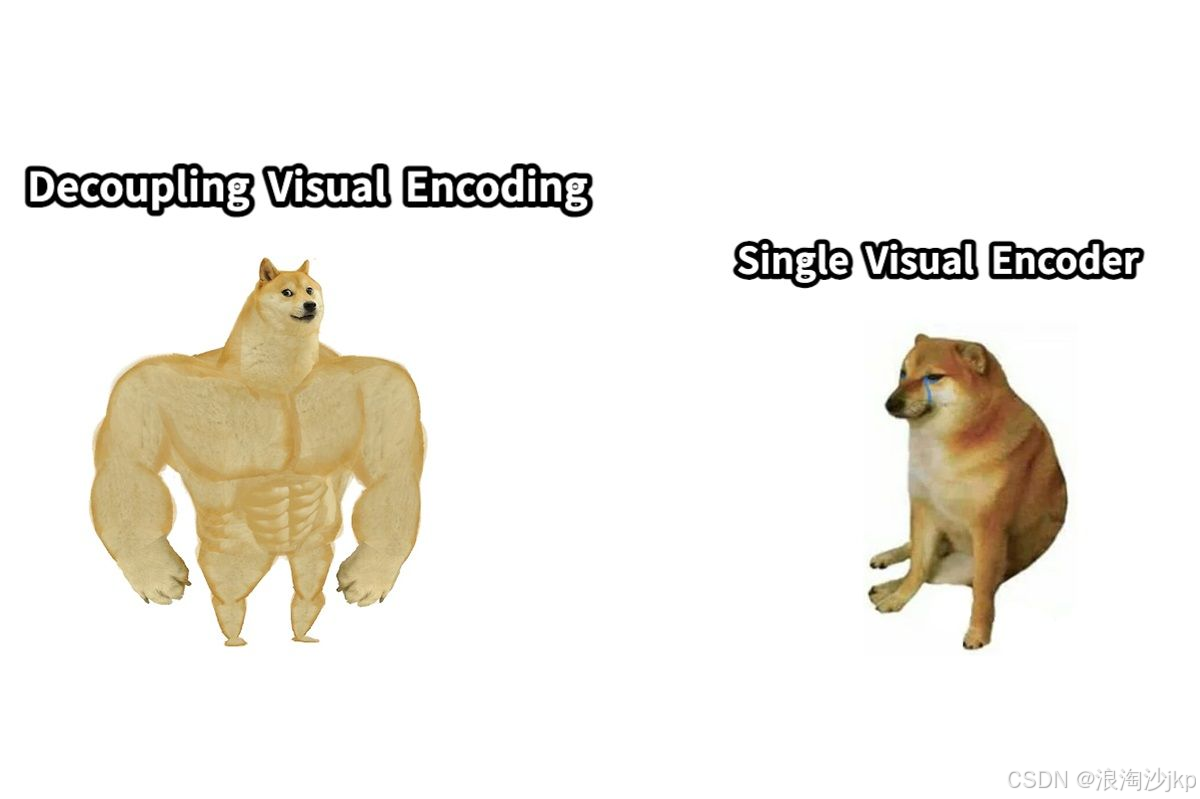
Some kwargs in processor config are unused and will not have any effect: add_special_token, image_tag, sft_format, num_image_tokens, mask_prompt, ignore_id.
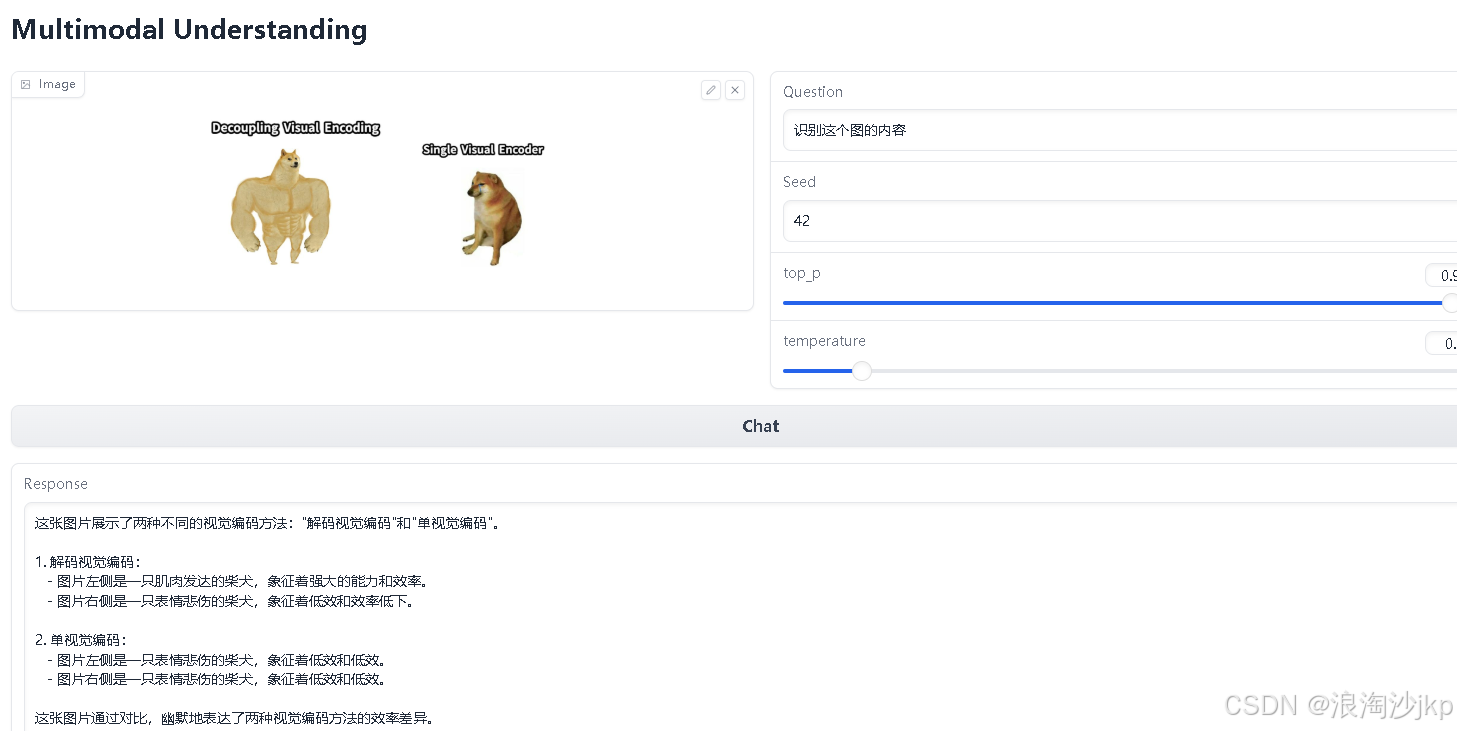
You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. User: <image_placeholder> Convert the formula into latex code. Assistant: Sure, I can help you with that. Here's the formula in LaTeX code: \[ \text{Decoupling Visual Encoding} = \text{A} \times \text{B} \] Where: - \( A \) is the number of features in the visual representation. - \( B \) is the number of features in the textual representation. This formula represents the relationship between visual and textual features in visual encoding.
(janus) root@VM-0-80-ubuntu:/workspace/Janus# nvidia-smi
Fri Apr 4 10:26:39 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:09.0 Off | 0 |
| N/A 50C P0 29W / 70W | 7866MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
为什么比网上用得都多啊,显存啊显存
五、Janus-Pro-7B-8bit模型
没有玩7B心有不甘,从魔塔社区下载了Janus-Pro-7B-8bit模型
1、下载模型
# 下载模型
modelscope download --model yh123556/Janus-Pro-7B-8bit --local_dir ./Janus-Pro-7B-8bitDownloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▊| 4.63G/4.64G [15:16<00:02, 4.87MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.63G/4.64G [15:16<00:02, 4.26MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.63G/4.64G [15:16<00:01, 4.87MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.63G/4.64G [15:17<00:01, 4.89MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.63G/4.64G [15:17<00:01, 5.38MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.63G/4.64G [15:17<00:01, 5.72MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.63G/4.64G [15:17<00:01, 4.56MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.63G/4.64G [15:17<00:00, 5.04MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.63G/4.64G [15:17<00:00, 5.55MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.64G/4.64G [15:18<00:00, 5.95MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|█████████████████████████████████████████████████████▉| 4.64G/4.64G [15:18<00:00, 5.46MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|██████████████████████████████████████████████████████| 4.64G/4.64G [15:18<00:00, 5.42MB/s]
Processing 11 items: 100%|███████████████████████████████████████████████████████████████████████████████████| 11.0/11.0 [15:18<00:00, 83.5s/it
2、编码
/workspace/Janus/Janus-Pro-1B.ipynb
创建Janus-Pro-1B.ipynb
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_imagestorch.cuda.empty_cache()# specify the path to the model
model_path = "./Janus-Pro-7B-8bit"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizervl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True, load_in_8bit=True
)
vl_gpt = vl_gpt.eval()conversation = [{"role": "User","content": "<image_placeholder>\nConvert the formula into latex code.","images": ["images/doge.png"],},{"role": "Assistant", "content": ""},
]# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device,dtype=torch.float16)
# # run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)# # run the model to get the response
outputs = vl_gpt.language_model.generate(inputs_embeds=inputs_embeds,attention_mask=prepare_inputs.attention_mask,pad_token_id=tokenizer.eos_token_id,bos_token_id=tokenizer.bos_token_id,eos_token_id=tokenizer.eos_token_id,max_new_tokens=512,do_sample=False,use_cache=True,
)answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)错误出现
ImportError: Using `bitsandbytes` 8-bit quantization requires the latest version of bitsandbytes: `pip install -U bitsandbytes`
解决错误
pip install -U bitsandbytes运行结果
Python version is above 3.10, patching the collections module.
/root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/models/auto/image_processing_auto.py:602: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead warnings.warn(
/root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/models/auto/image_processing_auto.py:602: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead warnings.warn( Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
/root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/models/auto/image_processing_auto.py:602: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead warnings.warn( Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`. Some kwargs in processor config are unused and will not have any effect: num_image_tokens, add_special_token, image_tag, sft_format, ignore_id, mask_prompt.
/root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/models/auto/image_processing_auto.py:602: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead warnings.warn( Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`. Some kwargs in processor config are unused and will not have any effect: num_image_tokens, add_special_token, image_tag, sft_format, ignore_id, mask_prompt. The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead.
/root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/models/auto/image_processing_auto.py:602: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead warnings.warn( Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`. Some kwargs in processor config are unused and will not have any effect: num_image_tokens, add_special_token, image_tag, sft_format, ignore_id, mask_prompt. The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead. /root/miniforge3/envs/janus/lib/python3.10/site-packages/transformers/quantizers/auto.py:212: UserWarning: You passed `quantization_config` or equivalent parameters to `from_pretrained` but the model you're loading already has a `quantization_config` attribute. The `quantization_config` from the model will be used. warnings.warn(warning_msg) `low_cpu_mem_usage` was None, now default to True since model is quantized.
Loading checkpoint shards: 100%
2/2 [00:09<00:00, 4.48s/it]
You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. User: <image_placeholder> Convert the formula into latex code. Assistant: Here is the LaTeX code for the given image: ```latex \begin{figure}[h] \centering \includegraphics[width=0.5\textwidth]{image.png} \caption{Decoupling Visual Encoding and Single Visual Encoder} \label{fig:decoupling} \end{figure} ``` This code will generate a figure with the same layout as the provided image.
六、Gradio 前端UI界面调用方法
1、安装环境
conda create -n janus python=3.9
conda init
source ~/.bashrc
conda activate janus
cd /workspace/Janus
# 注意后面的点
pip install -e .[gradio]
pip install flash-attn modelscopepip install -U bitsandbytes# 下载模型
modelscope download --model yh123556/Janus-Pro-7B-8bit --local_dir ./Janus-Pro-7B-8bit2、构建app_januspro-7b-8bit.py文件且运行
修改:
model_path = "./Janus-Pro-7B-8bit"vl_gpt = AutoModelForCausalLM.from_pretrained(model_path,language_config=language_config,trust_remote_code=True,load_in_8bit=True)
#全部注释
#if torch.cuda.is_available():
# vl_gpt = vl_gpt.to(torch.bfloat16).cuda()
#else:
# vl_gpt = vl_gpt.to(torch.float16) prepare_inputs = vl_chat_processor(conversations=conversation, images=pil_images, force_batchify=True).to(cuda_device, dtype=torch.float16 if torch.cuda.is_available() else torch.float16)全部代码
import gradio as gr
import torch
from transformers import AutoConfig, AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images
from PIL import Imageimport numpy as np
import os
import time
# import spaces # Import spaces for ZeroGPU compatibility# Load model and processor
model_path = "./Janus-Pro-7B-8bit"
config = AutoConfig.from_pretrained(model_path)
language_config = config.language_config
language_config._attn_implementation = 'eager'
vl_gpt = AutoModelForCausalLM.from_pretrained(model_path,language_config=language_config,trust_remote_code=True,load_in_8bit=True)
#if torch.cuda.is_available():# vl_gpt = vl_gpt.to(torch.bfloat16).cuda()
# vl_gpt = vl_gpt.to(torch.float16).cuda()
#else:
# vl_gpt = vl_gpt.to(torch.float16)vl_chat_processor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
cuda_device = 'cuda' if torch.cuda.is_available() else 'cpu'@torch.inference_mode()
# @spaces.GPU(duration=120)
# Multimodal Understanding function
def multimodal_understanding(image, question, seed, top_p, temperature):# Clear CUDA cache before generatingtorch.cuda.empty_cache()# set seedtorch.manual_seed(seed)np.random.seed(seed)torch.cuda.manual_seed(seed)conversation = [{"role": "<|User|>","content": f"<image_placeholder>\n{question}","images": [image],},{"role": "<|Assistant|>", "content": ""},]pil_images = [Image.fromarray(image)]prepare_inputs = vl_chat_processor(conversations=conversation, images=pil_images, force_batchify=True).to(cuda_device, dtype=torch.float16 if torch.cuda.is_available() else torch.float16)inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)outputs = vl_gpt.language_model.generate(inputs_embeds=inputs_embeds,attention_mask=prepare_inputs.attention_mask,pad_token_id=tokenizer.eos_token_id,bos_token_id=tokenizer.bos_token_id,eos_token_id=tokenizer.eos_token_id,max_new_tokens=512,do_sample=False if temperature == 0 else True,use_cache=True,temperature=temperature,top_p=top_p,)answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)return answerdef generate(input_ids,width,height,temperature: float = 1,parallel_size: int = 5,cfg_weight: float = 5,image_token_num_per_image: int = 576,patch_size: int = 16):# Clear CUDA cache before generatingtorch.cuda.empty_cache()tokens = torch.zeros((parallel_size * 2, len(input_ids)), dtype=torch.int).to(cuda_device)for i in range(parallel_size * 2):tokens[i, :] = input_idsif i % 2 != 0:tokens[i, 1:-1] = vl_chat_processor.pad_idinputs_embeds = vl_gpt.language_model.get_input_embeddings()(tokens)generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).to(cuda_device)pkv = Nonefor i in range(image_token_num_per_image):with torch.no_grad():outputs = vl_gpt.language_model.model(inputs_embeds=inputs_embeds,use_cache=True,past_key_values=pkv)pkv = outputs.past_key_valueshidden_states = outputs.last_hidden_statelogits = vl_gpt.gen_head(hidden_states[:, -1, :])logit_cond = logits[0::2, :]logit_uncond = logits[1::2, :]logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)probs = torch.softmax(logits / temperature, dim=-1)next_token = torch.multinomial(probs, num_samples=1)generated_tokens[:, i] = next_token.squeeze(dim=-1)next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)img_embeds = vl_gpt.prepare_gen_img_embeds(next_token)inputs_embeds = img_embeds.unsqueeze(dim=1)patches = vl_gpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int),shape=[parallel_size, 8, width // patch_size, height // patch_size])return generated_tokens.to(dtype=torch.int), patchesdef unpack(dec, width, height, parallel_size=5):dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)dec = np.clip((dec + 1) / 2 * 255, 0, 255)visual_img = np.zeros((parallel_size, width, height, 3), dtype=np.uint8)visual_img[:, :, :] = decreturn visual_img@torch.inference_mode()
# @spaces.GPU(duration=120) # Specify a duration to avoid timeout
def generate_image(prompt,seed=None,guidance=5,t2i_temperature=1.0):# Clear CUDA cache and avoid tracking gradientstorch.cuda.empty_cache()# Set the seed for reproducible resultsif seed is not None:torch.manual_seed(seed)torch.cuda.manual_seed(seed)np.random.seed(seed)width = 384height = 384parallel_size = 5with torch.no_grad():messages = [{'role': '<|User|>', 'content': prompt},{'role': '<|Assistant|>', 'content': ''}]text = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(conversations=messages,sft_format=vl_chat_processor.sft_format,system_prompt='')text = text + vl_chat_processor.image_start_taginput_ids = torch.LongTensor(tokenizer.encode(text))output, patches = generate(input_ids,width // 16 * 16,height // 16 * 16,cfg_weight=guidance,parallel_size=parallel_size,temperature=t2i_temperature)images = unpack(patches,width // 16 * 16,height // 16 * 16,parallel_size=parallel_size)return [Image.fromarray(images[i]).resize((768, 768), Image.LANCZOS) for i in range(parallel_size)]# Gradio interface
with gr.Blocks() as deepseek:gr.Markdown(value="# Multimodal Understanding")with gr.Row():image_input = gr.Image()with gr.Column():question_input = gr.Textbox(label="Question")und_seed_input = gr.Number(label="Seed", precision=0, value=42)top_p = gr.Slider(minimum=0, maximum=1, value=0.95, step=0.05, label="top_p")temperature = gr.Slider(minimum=0, maximum=1, value=0.1, step=0.05, label="temperature")understanding_button = gr.Button("Chat")understanding_output = gr.Textbox(label="Response")examples_inpainting = gr.Examples(label="Multimodal Understanding examples",examples=[["explain this meme","images/doge.png",],["Convert the formula into latex code.","images/equation.png",],],inputs=[question_input, image_input],)gr.Markdown(value="# Text-to-Image Generation")with gr.Row():cfg_weight_input = gr.Slider(minimum=1, maximum=10, value=5, step=0.5, label="CFG Weight")t2i_temperature = gr.Slider(minimum=0, maximum=1, value=1.0, step=0.05, label="temperature")prompt_input = gr.Textbox(label="Prompt. (Prompt in more detail can help produce better images!)")seed_input = gr.Number(label="Seed (Optional)", precision=0, value=12345)generation_button = gr.Button("Generate Images")image_output = gr.Gallery(label="Generated Images", columns=2, rows=2, height=300)examples_t2i = gr.Examples(label="Text to image generation examples.",examples=["Master shifu racoon wearing drip attire as a street gangster.","The face of a beautiful girl","Astronaut in a jungle, cold color palette, muted colors, detailed, 8k","A glass of red wine on a reflective surface.","A cute and adorable baby fox with big brown eyes, autumn leaves in the background enchanting,immortal,fluffy, shiny mane,Petals,fairyism,unreal engine 5 and Octane Render,highly detailed, photorealistic, cinematic, natural colors.","The image features an intricately designed eye set against a circular backdrop adorned with ornate swirl patterns that evoke both realism and surrealism. At the center of attention is a strikingly vivid blue iris surrounded by delicate veins radiating outward from the pupil to create depth and intensity. The eyelashes are long and dark, casting subtle shadows on the skin around them which appears smooth yet slightly textured as if aged or weathered over time.\n\nAbove the eye, there's a stone-like structure resembling part of classical architecture, adding layers of mystery and timeless elegance to the composition. This architectural element contrasts sharply but harmoniously with the organic curves surrounding it. Below the eye lies another decorative motif reminiscent of baroque artistry, further enhancing the overall sense of eternity encapsulated within each meticulously crafted detail. \n\nOverall, the atmosphere exudes a mysterious aura intertwined seamlessly with elements suggesting timelessness, achieved through the juxtaposition of realistic textures and surreal artistic flourishes. Each component\u2014from the intricate designs framing the eye to the ancient-looking stone piece above\u2014contributes uniquely towards creating a visually captivating tableau imbued with enigmatic allure.",],inputs=prompt_input,)understanding_button.click(multimodal_understanding,inputs=[image_input, question_input, und_seed_input, top_p, temperature],outputs=understanding_output)generation_button.click(fn=generate_image,inputs=[prompt_input, seed_input, cfg_weight_input, t2i_temperature],outputs=image_output)deepseek.launch(share=True,server_name="0.0.0.0")
#deepseek.queue(concurrency_count=1, max_size=10).launch(server_name="0.0.0.0", server_port=37906, root_path="/path")
运行,并配置这个是外网穿透
运行之前
下载地址:https://download.csdn.net/download/jiangkp/90567145
mv frpc_linux_amd64_v0.2 /root/miniforge3/envs/janus/lib/python3.9/site-packages/gradio
chmod +x /root/miniforge3/envs/janus/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2然后运行
python demo/app_januspro-7b-8bit.py
Running on local URL: http://0.0.0.0:7860
Running on public URL: https://d35019aaf88c9b8c69.gradio.live
图片识别
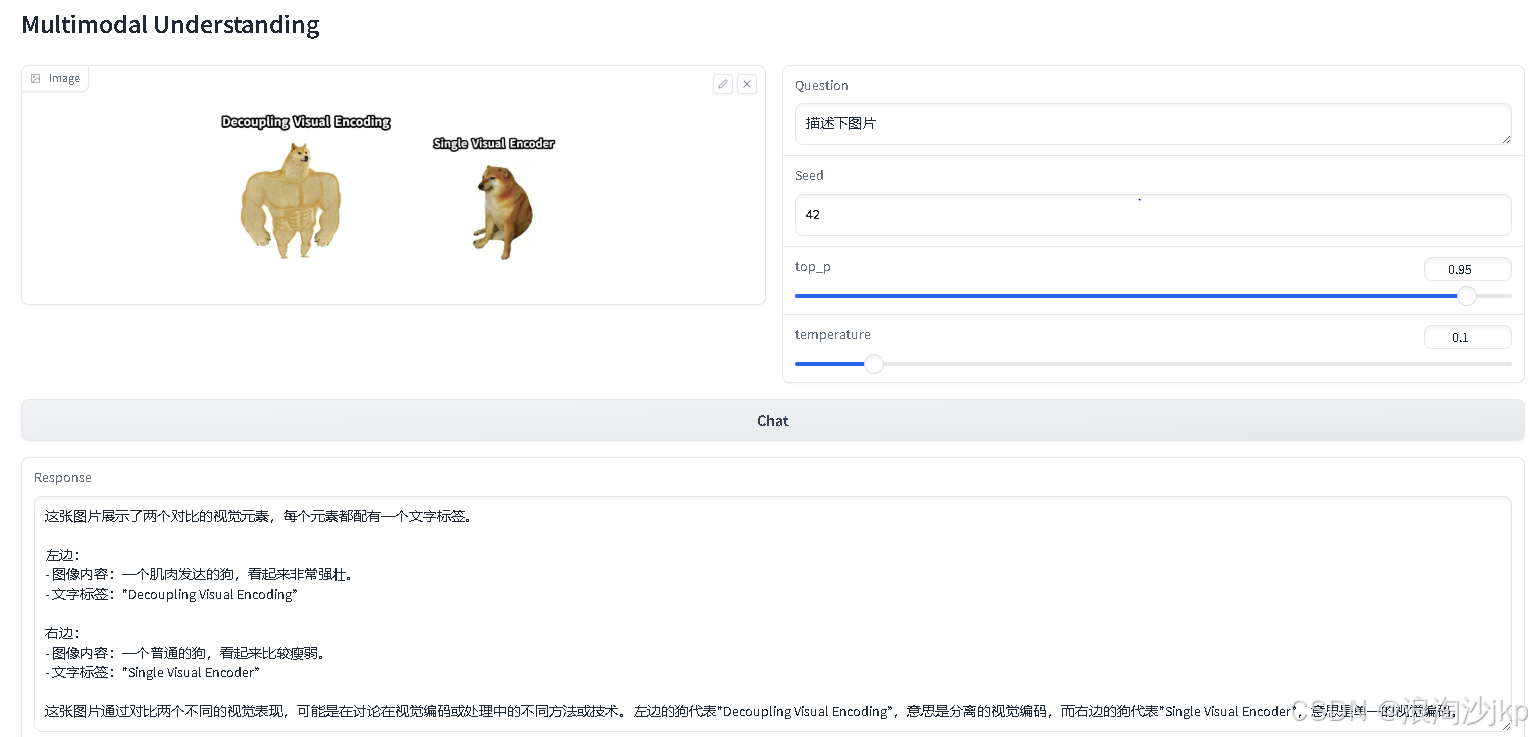
文生图

主要还是穷,溢出了吧
改为1B的
3、下载1B模型
modelscope download --model deepseek-ai/Janus-Pro-1B --local_dir ./Janus-Pro-1B4、构建app_januspro-1b.py并运行
/workspace/Janus/demo/app_januspro-1b.py
在下载代码原来文件app_januspro.py上修改就可以了,不是我们改过的文件
model_path = "/workspace/Janus/Janus-Pro-1B"
运行之前,前面改过,就不用改了,这个是外网穿透
下载地址:https://download.csdn.net/download/jiangkp/90567145
mv frpc_linux_amd64_v0.2 /root/miniforge3/envs/janus/lib/python3.9/site-packages/gradio
chmod +x /root/miniforge3/envs/janus/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2然后运行
python demo/app_januspro-1b.py图文识别
文生图:

再来一张,这是1B,能出来就不错了喔
女孩呢?不识别中文吧
相关文章:
)
大模型学习四:DeepSeek Janus-Pro 多模态理解和生成模型 本地部署指南(折腾版)
一、说明简介 DeepSeek Janus-Pro是一款先进的多模态理解和生成模型,旨在实现高质量的文本-图像生成与多模态理解。它是由DeepSeek团队研发的,是之前Janus模型的升级版,能够同时处理文本和图像,即可以理解图片内容,…...

《AI大模型应知应会100篇》第3篇:大模型的能力边界:它能做什么,不能做什么
第3篇:大模型的能力边界:它能做什么,不能做什么 摘要 在人工智能飞速发展的今天,大语言模型(LLM)已经成为许多领域的核心技术。然而,尽管它们展现出了惊人的能力,但也有明显的局限性…...
)
MySQL 面试知识点详解(索引、存储引擎、事务与隔离级别、MVCC、锁机制、优化)
一、索引基础概念 1 索引是什么? 定义:索引是帮助MySQL高效获取数据的有序数据结构,类似书籍的目录。核心作用:减少磁盘I/O次数,提升查询速度(以空间换时间)。 2 索引的优缺点 优点缺点加速…...

JS API
const变量优先 即对象、数组等引用类型数据可以用const声明 API作用和分类 DOM (ducument object model) 操作网页内容即HTML标签的 树状模型 HTML中标签 JS中对象 最大对象 document 其次大 html 以此类推 获取DOM对象 CSS 中 使用选择器 JS 中 选多个 时代的眼泪 修…...

hackmyvm-Principle
近况: 很难受、 也很累。 但是庆幸靶机很好 正值清明时节 清明时节雨纷纷 🌧️,路上行人欲断魂 😢。 靶机地址 信息收集 主机发现 端口扫描 80端口仅仅是一个nginx 的欢迎界面而已 robots.txt的内容 hi.html的内容 hackme不存在 investigat…...

小刚说C语言刷题——第14讲 逻辑运算符
当我们需要将一个表达式取反,或者要判断两个表达式组成的大的表达式的结果时,要用到逻辑运算符。 1.逻辑运算符的分类 (1)逻辑非(!) !a,当a为真时,!a为假。当a为假时,!a为真。 例…...

池化技术的深度解析与实践指南【大模型总结】
池化技术的深度解析与实践指南 池化技术作为计算机系统中的核心优化手段,通过资源复用和预分配机制显著提升系统性能。本文将从原理、实现到最佳实践,全方位剖析池化技术的核心要点,并结合实际案例说明其应用场景与调优策略。 一、池化技术的…...
,源码可白嫖!)
基于Java的区域化智慧养老系统(源码+lw+部署文档+讲解),源码可白嫖!
摘 要 时代在飞速进步,每个行业都在努力发展现在先进技术,通过这些先进的技术来提高自己的水平和优势,区域化智慧养老系统当然不能排除在外。区域化智慧养老系统是在实际应用和软件工程的开发原理之上,运用Java语言、JSP技术以及…...
真题解析 中国电子学会全国青少年软件编程等级考试)
2025年3月 Scratch 图形化(一级)真题解析 中国电子学会全国青少年软件编程等级考试
2025.03 Scratch图形化编程等级考试一级真题试卷 一、选择题 第 1 题 气球初始位置如下图所示,scratch运行下列程序,气球会朝哪个方向移动?( ) A.水平向右 B.垂直向下 C.水平向左 D.垂直向上 答案:…...

Docker 命令简写配置
alias dpsdocker ps --format "table {{.ID}}\t{{.Image}}\t{{.Ports}}\t{{.Status}}\t{{.Names}}" 配置好后,需要输入: source ~/.bashrc 后生效...

linux signal up/down/down_interruptiable\down_uninterruptiable使用
在Linux内核中,down, down_interruptible, down_killable, 和 up 是用于操作信号量(semap hores)的函数,它们用于进程同步和互斥。以下是对这些函数的简要说明。 1,down(&sem): 这个函数用于获取信号量。如果信号…...

【嵌入式-stm32电位器控制以及旋转编码器控制LED亮暗】
嵌入式-stm32电位器控制LED亮暗 任务1代码1Key.cKey.hTimer.cTimer.hPWM.cPWM.hmain.c 实验现象1任务2代码2Key.cKey.hmain.c 实验现象2问题与解决总结 源码框架取自江协科技,在此基础上做扩展开发。 任务1 本文主要介绍利用stm32f103C8T6实现电位器控制PWM的占空比…...

Mysql 中 ACID 背后的原理
在 MySQL 中,ACID 是事务处理的核心原则,用于保证数据库在执行事务时的可靠性、数据一致性和稳定性。ACID 是四个关键特性的首字母缩写,分别是:Atomicity(原子性)、Consistency(一致性ÿ…...

【算法】简单数论
模运算 a m o d b a − ⌊ a / b ⌋ b a\ mod \ b a - \lfloor a / b \rfloor \times b a mod ba−⌊a/b⌋b n m o d p n \ mod\ p n mod p得到的结果的正负至于被除数 n n n有关 模运算的性质: ( a b ) m o d m ( ( a m o d m ) ( b m o d m ) ) m o d m …...

mybatis慢sql无所遁形
痛点问题: 扫描项目的慢sql 并提出优化建议 开源项目地址:gitee:mybatis-sql-optimizer-spring-boot-starter: 这个starter可以帮助开发者在开发阶段发现SQL性能问题,并提供优化建议,从而提高应用程序的数据库访问效…...

MCP有哪些比较好的资源?
MCP(Model Context Protocol)是一种由Anthropic公司推出的开放协议,旨在为AI模型与开发环境之间提供统一的上下文交互接口。目前,围绕MCP协议的资源非常丰富,以下是一些比较好的MCP资源推荐: Smithery Smit…...

Nginx功能及应用全解:从负载均衡到反向代理的全面剖析
Nginx作为一款开源的高性能HTTP服务器和反向代理服务器,凭借其高效的资源利用率和灵活的配置方式,已成为互联网领域中最受欢迎的Web服务器之一。无论是作为HTTP服务器、负载均衡器,还是作为反向代理和缓存服务器,Nginx的多种功能广…...

FreeRTOS/任务创建和删除的API函数
任务的创建和删除本质就是调用FreeRTOS的API函数 API函数描述xTaskCreate()动态方式创建任务xTaskCreateStatic()静态方式创建任务vTaskDelete()删除任务 动态创建任务 任务的任务控制块以及任务的占空间所需的内存,均由FreeRTOS从FreeRTOS管理的堆中分配 静态创建…...

【jvm】GC评估指标
目录 1. 说明2. 吞吐量(Throughput)3. 暂停时间(Pause Time)4. 内存占用(Footprint)5. 频率(Frequency)6. 对象晋升率(Promotion Rate)7. 内存分配速率&#…...
和数据加载器(DataLoader)-pytroch学习3)
数据集(Dataset)和数据加载器(DataLoader)-pytroch学习3
pytorch网站学习 处理数据样本的代码往往会变得很乱、难以维护;理想情况下,我们希望把数据部分的代码和模型训练部分分开写,这样更容易阅读、也更好维护。 简单说:数据和模型最好“分工明确”,不要写在一起。 PyTor…...

影响RTOS实时性的因素有哪些?
目录 1、任务调度延迟 2、中断处理延迟 3、系统负载 4、任务优先级反转 5、时钟精度 6、内存管理 影响RTOS实时性的因素主要包括任务调度延迟、中断处理延迟、系统负载、任务优先级反转、时钟精度、内存管理等。 1、任务调度延迟 任务调度器是RTOS的核心,当…...

二叉树 递归
本篇基于b站灵茶山艾府的课上例题与课后作业。 104. 二叉树的最大深度 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出&…...

ZLMediaKit 源码分析——[5] ZLToolKit 中EventPoller之延时任务处理
系列文章目录 第一篇 基于SRS 的 WebRTC 环境搭建 第二篇 基于SRS 实现RTSP接入与WebRTC播放 第三篇 centos下基于ZLMediaKit 的WebRTC 环境搭建 第四篇 WebRTC学习一:获取音频和视频设备 第五篇 WebRTC学习二:WebRTC音视频数据采集 第六篇 WebRTC学习三…...

【51单片机】2-6【I/O口】电动车简易防盗报警器实现
1.硬件 51最小系统继电器模块震动传感器模块433M无线收发模块 2.软件 #include "reg52.h" #include<intrins.h> #define J_ON 1 #define J_OFF 0sbit switcher P1^0;//继电器 sbit D0_ON P1^1;//433M无线收发模块 sbit D1_OFF P1^2; sbit vibrate …...
)
windows下载安装远程桌面工具RealVNC-Server教程(RealVNC_E4_6_1版带注册码)
文章目录 前言一、下载安装包二、安装步骤三、使用VNC-Viewer客户端远程连接,输入ip地址,密码完成连接 前言 在现代工作和生活中,远程控制软件为我们带来了极大的便利。RealVNC - Server 是一款功能强大的远程控制服务器软件,通过…...

C语言的操作系统
C语言的操作系统 引言 操作系统是一种系统软件,它管理计算机硬件和软件资源,并为计算机程序提供公共服务。在现代计算机科学中,操作系统是不可或缺的组成部分,而C语言则是实现高效操作系统的主要编程语言之一。本文将探讨C语言在…...

selectdb修改表副本
如果想修改doris(也就是selectdb数据库)表的副本数需要首先确定是否分区表,当前没有数据字典得知哪个表是分区的,只能先show partitions看结果 首先,副本数不应该大于be节点数 其次,修改期间最好不要跑业务…...

leetcode数组-有序数组的平方
题目 题目链接:https://leetcode.cn/problems/squares-of-a-sorted-array/ 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 输入:nums [-4,-1,0,3,10] 输出ÿ…...

【python中级】关于Cython 的源代码pyx的说明
【python中级】关于Cython 的源代码pyx的说明 1.背景2.编译3.语法1.背景 Cython 是一个编程语言和工具链,用于将 Python 代码(或类 Python 的代码)编译成 C 语言,再进一步生成高性能的 Python 扩展模块(.so 或 .pyd 文件)。 在 Python 中,.pyx 文件是 Cython 的源代码文…...

开放最短路径优先 - OSPF【LSA详细】
目录 LSA的头部结构 LSA类型 LSA数据包 LSA的主要作用是传递路由信息。 LSA的头部结构 共占20个字节,不同类型的LSA头部字段部分都是相同的。 链路状态老化时间(Link-State Age) 2个字节。指示该条LSA的老化时间,即它存在了多长时间,单位…...

PyTorch:解锁AI新时代的钥匙
揭开PyTorch面纱 对于许多刚开始接触人工智能领域的朋友来说,PyTorch这个名字或许既熟悉又陌生。熟悉在于它频繁出现在各类技术论坛和新闻报道中;而陌生则源于对这样一个强大工具背后运作机制的好奇。简单来说,PyTorch是一个开源库ÿ…...

欧几里得算法求最大公约数、最小公倍数
这段代码就是不断用较小数和余数来更新 a 和 b,直到余数变为 0,最后返回的 a 就是最大公约数。 #include <iostream> using namespace std;//最大公约数 int gcd(int a, int b){//这个循环表示只要 b 不是 0,就继续进行。//因为当 b …...
)
QEMU源码全解析 —— 块设备虚拟化(14)
接前一篇文章:QEMU源码全解析 —— 块设备虚拟化(13) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM源码解析与应用》 —— 李强,机械工业出版社 特此致谢! 上一回开始解析VirtioDeviceClass的realize函数virtio_blk_device_realize(),再来回…...

深入理解AOP:面向切面编程的核心概念与实战应用
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...

3500 阶乘求和
3500 阶乘求和 ⭐️难度:中等 🌟考点:2023、思维、省赛 📖 📚 import java.util.Scanner;public class Main {public static void main(String[] args) {long sum 0;for(int i1;i<50;i) { // 之后取模都相等su…...

正则入门到精通
一、正则表达式入门 正则表达式本质上是一串字符序列,用于定义一个文本模式。通过这个模式,我们可以指定要匹配的文本特征。例如,如果你想匹配一个以 “abc” 开头的字符串,正则表达式可以写作 “^abc”,其中 …...

Mysql 行级锁在什么样的情况下会升级为表级锁?
在 MySQL 中,行级锁通常由 InnoDB 存储引擎使用,因为它支持高并发和细粒度的锁定。通常情况下,InnoDB 在执行诸如 UPDATE、DELETE 或 SELECT FOR UPDATE 等操作时,会为被修改的数据行加锁(行级锁)。但是&am…...

docker部署kkfileview
拉取 KKFileView 镜像 docker pull keking/kkfileview或指定版本 docker pull keking/kkfileview:4.1.0运行 KKFileView 容器 docker run -d \--name kkfileview \-p 8012:8012 \--restart always \keking/kkfileview-d:后台运行 -p 8012:8012:将容器…...

优选算法的妙思之流:分治——快排专题
专栏:算法的魔法世界 个人主页:手握风云 目录 一、快速排序 二、例题讲解 2.1. 颜色分类 2.2. 排序数组 2.3. 数组中的第K个最大元素 2.4. 库存管理 III 一、快速排序 分治,简单理解为“分而治之”,将一个大问题划分为若干个…...

蓝桥杯嵌入式第15届真题-个人理解+解析
个人吐槽 #因为最近蓝桥杯快要开始了,我舍不得米白费了,所以就认真刷刷模拟题,但是我感觉真题会更好,所以就看了一下上届的真题。不过它是真的长,我看着就头晕,但是还是把几个模块认真分析了一下就还是很容…...

数据库系统概述 | 第二章课后习题答案
本文为数据库系统概论(第五版)【高等教育出版社】部分课后答案 如有错误,望指正 👻 习题 👻 答案...

深入解析CPU主要参数:选购与性能评估指南
引言 中央处理器(CPU)作为计算机的"大脑",其性能直接决定了整机的运算能力和响应速度。无论是组装新电脑、升级旧系统还是选购笔记本电脑,理解CPU的关键参数都至关重要。本文将从技术角度全面解析CPU的各项主要参数&am…...

Lettuce与Springboot集成使用
一、Lettuce核心优势与Spring Boot集成背景 Lettuce特性 基于Netty的非阻塞I/O模型,支持同步/异步/响应式编程线程安全:共享单连接实现多线程并发操作,性能衰减低原生支持Redis集群、哨兵、主从架构,自动重连机制保障高可用Spring…...

【Kafka基础】ZooKeeper在Kafka中的核心作用:分布式系统中枢神经系统
在分布式系统的世界里,协调和管理多个节点间的状态是一项复杂而关键的任务。Apache Kafka作为一款高性能的分布式消息系统,其设计哲学是"专为单一目的而优化"——即高效处理消息流。为了实现这一目标,Kafka选择将集群协调管理的重任…...

专业的情商测评工具:EQ-i在线测评系统
专业的情商测评工具:EQ-i在线测评系统 基于巴昂情商量表的专业情商评估工具,帮助您更好地了解自己的情商水平。 什么是EQ-i? EQ-i(Emotional Quotient Inventory)是由Reuven Bar-On开发的情商量表,是国际上…...

Ubuntu安装Podman教程
1、先修改apt源为阿里源加速 备份原文件: sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup 修改源配置: vim sources.list删除里面全部内容后,粘贴阿里源: deb http://mirrors.aliyun.com/ubuntu/ focal main re…...

7.训练篇5-毕设
使用23w张数据集-vit-打算30轮-内存崩了-改为batch_size 8 我准备用23w张数据集,太大了,这个用不了,所以 是否保留 .stack() 加载所有图片?情况建议✅ 小数据集(<2w张,图像小)想加快速度可…...

java数据结构-哈希表
什么是哈希表 最理想的搜索方法 , 即就是在查找某元素时 , 不进行任何比较的操作 , 一次直接查找到需要搜索的元素 , 可以达到这种要求的方法就是哈希表. 哈希表就是通过构造一种存储结构 , 通过某种函数使元素存储的位置与其关键码位形成一 一映射的关系 , 这样在查找元素的时…...
X64向量指令访问地址未对齐引起SIGSEGV)
Linux错误(6)X64向量指令访问地址未对齐引起SIGSEGV
Linux错误(6)X64向量指令访问地址未对齐引起SIGSEGV Author: Once Day Date: 2025年4月4日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 全系列文章可参考专栏: Linux实…...

SpringBoot配置文件多环境开发
目录 一、设置临时属性的几种方法 1.启动jar包时,设置临时属性 2.idea配置临时属性 3.启动类中创建数组指定临时属性 二、多环境开发 1.包含模式 2.分组模式 三、配置文件的优先级 1.bootstrap 文件优先: 2.特定配置文件优先 3.文件夹位置优…...