java数据结构-哈希表
什么是哈希表
最理想的搜索方法 , 即就是在查找某元素时 , 不进行任何比较的操作 , 一次直接查找到需要搜索的元素 , 可以达到这种要求的方法就是哈希表.哈希表就是通过构造一种存储结构 , 通过某种函数使元素存储的位置与其关键码位形成一 一映射的关系 , 这样在查找元素的时候就可以很快找到目标元素
哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
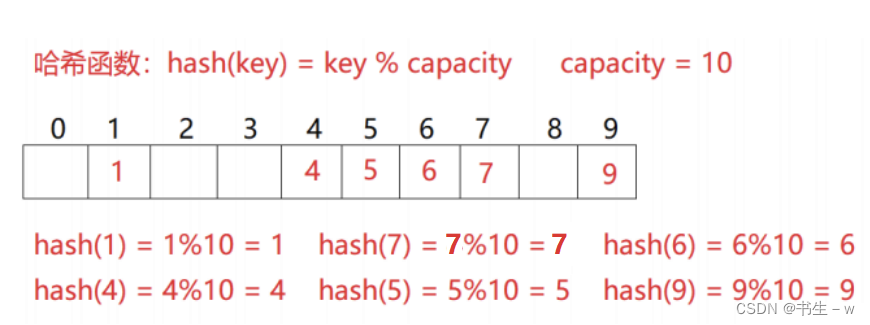
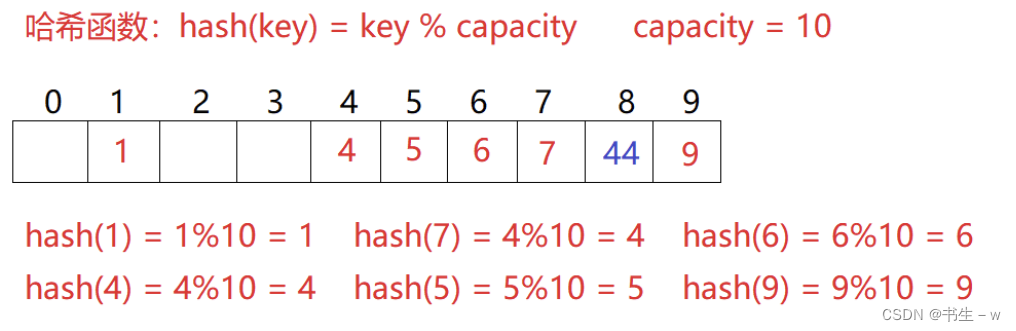
存在一个数组集合 {1,7,6,4,5,9}.
哈希函数设置为:hash(key) = key % capacity;
capacity 为存储元素底层空间总的大小。
如图所示: 这样存储数据更加便于查找
采取上面的方法,确实能避免多次关键码的比较,搜索的效率也提高的,但是问题来了,拿上述图的情况来举例子的话,我接着还要插入一个元素 14,该怎么办呢?
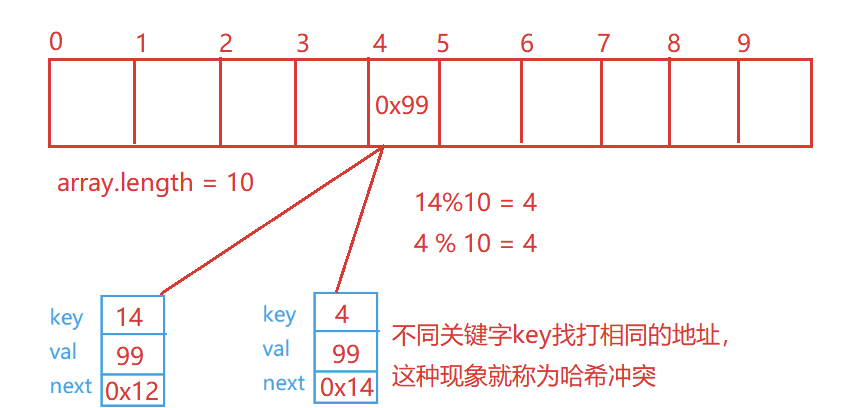
这个就是我们本章的重点,哈希冲突,4%10 = 4;14%10 = 4,此时发生了哈希冲突。
什么是哈希冲突
哈希冲突的概念
首先我们得知道,哈希冲突是必然的,无论怎么插入,插入多少都无法杜绝,哪怕就插入两个元素4,14都发生了哈希冲突,我们能做的就是尽量避免哈希冲突的发生。
这也就是我们哈希表这种结构存在的问题。
哈希冲突的概念:两个不同关键字key通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
降低哈希冲突的发生的概率
两种解决方法
1.设计好的哈希函数;2.降低负载因子
哈希函数设计原则:
-
哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间。
-
哈希函数计算出来的地址能均匀分布在整个空间中。
-
哈希函数应该比较简单。
常用的两种哈希函数
1. 直接定制法
取关键字的某个线性函数为散列地址: Hash ( Key ) = A*Key + B
优点:简单、均匀。
缺点:需要事先知道关 键字的分布情况 使用场景:适合查找比较小且连续的情况。
2. 除留余数法
设散列表中允许的 地址数为 m ,取一个不大于 m ,但最接近或者等于 m 的质数 p 作为除数,按照哈希函数: Hash(key) = key% p(p<=m), 将关键码转换成哈希地址
降低负载因子
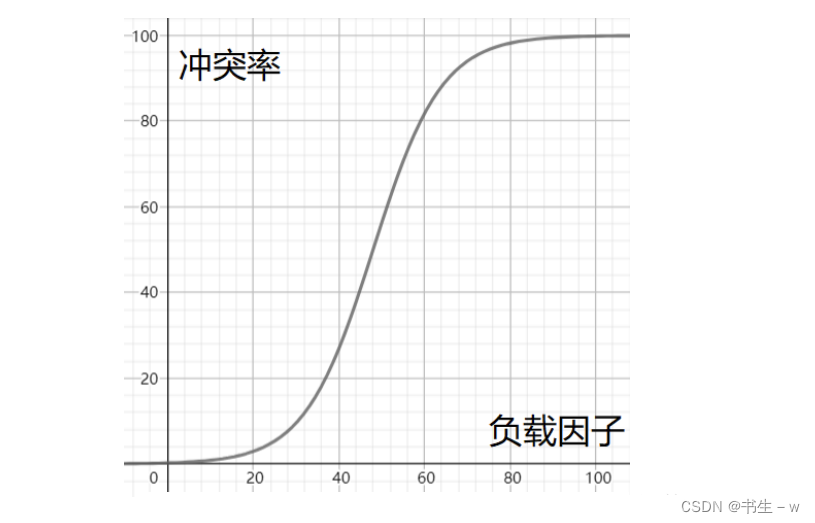
从图中我们可以直到要想降低冲突的概率,只能减小负载因子,而负载因子又取决于数组的长度。
公式: 负载因子 = 哈希表中元素的个数 / 数组的长度
因为哈希表中的已有的元素个数是不可变的,所以我们只能通过增大数组长度来降低负载因子。
当冲突发生时如何解决哈希冲突
解决哈希冲突 两种常见的方法是: 闭散列 和 开散列
闭散列
闭散列:有两种(线性探测法&&二次探测法)
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以 把 key 存放到冲突位置中的 “ 下一个 ” 空位置中去。
线性探测
①什么是线性探测:
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
②线性探测的相关操作:
当插入操作时,通过哈希函数获取待插入元素在哈希表中的位置 ;如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到 ;下一个空位置,插入新元素
简而言之就是寻找下一个空的地方
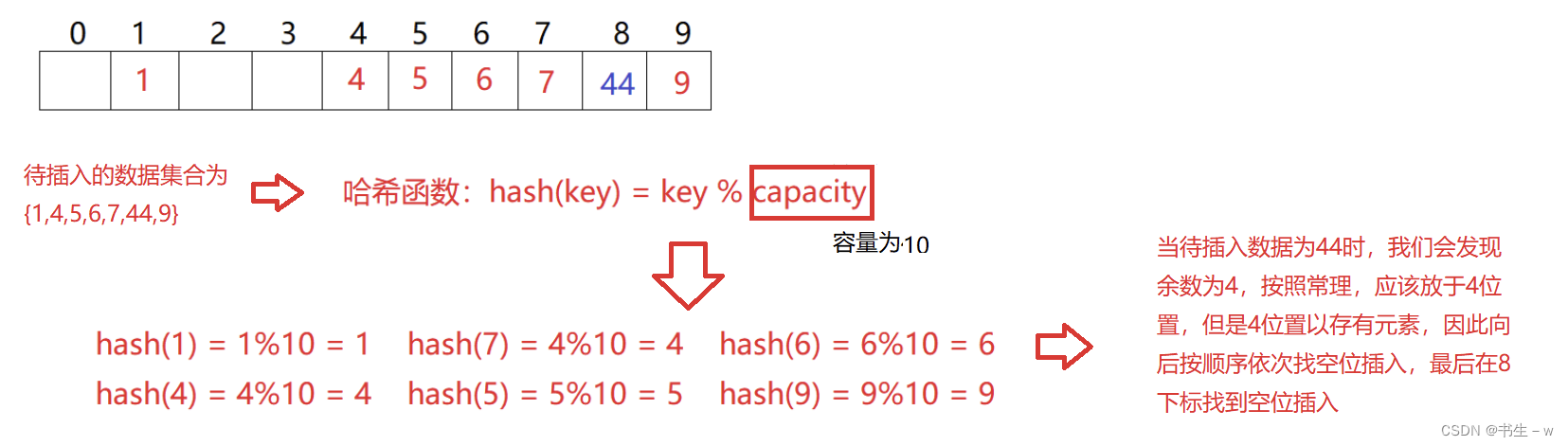
③弊端:(可能会导致冲突元素均被放在一起)
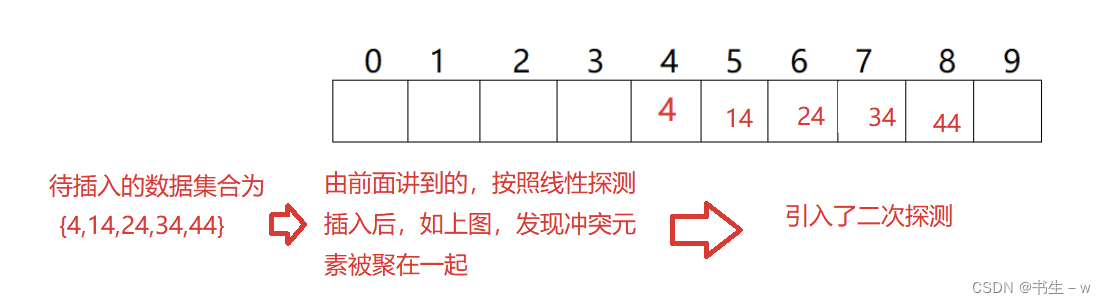
二次探测
①如何进行二次探测:
利用这个公式进入插入。其中:i = 1,2,3…,Hi是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
对于上述线性探测中的问题如果要插入44,产生冲突,使用解决后的情况为:
②重要结论:
当表的长度为质数且表装载因子 a 不超过 0.5 时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情 况,但在插入时必须确保表的装载因子a 不超过 0.5 ,如果超出必须考虑增容。
因此:闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
开散列
开散列:它的叫法有很多,也叫做哈希桶/链地址法/拉链法
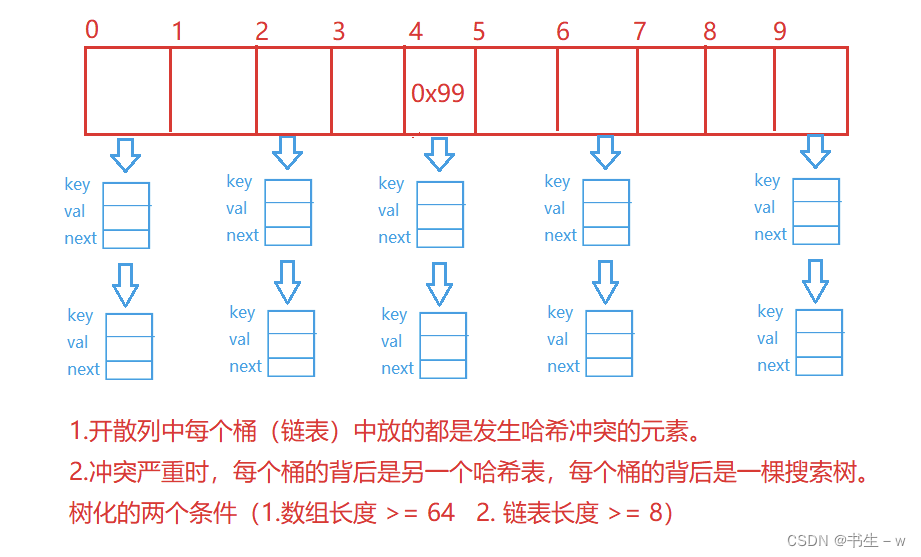
①什么是哈希桶???
开散列法又叫链地址法 ( 开链法 ) , 首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。 开散列,可以认为是把一个在大集合中的搜索问题转化为在小集合中做搜索了。 参照下图:
②哈希桶如何进行存储???(链式存储法).
③若遇到负载因子过大,要扩容,那么存入的数据又该怎么进行处理???(链表中的每一个数要进行重新哈希),以下为二倍扩容后的图
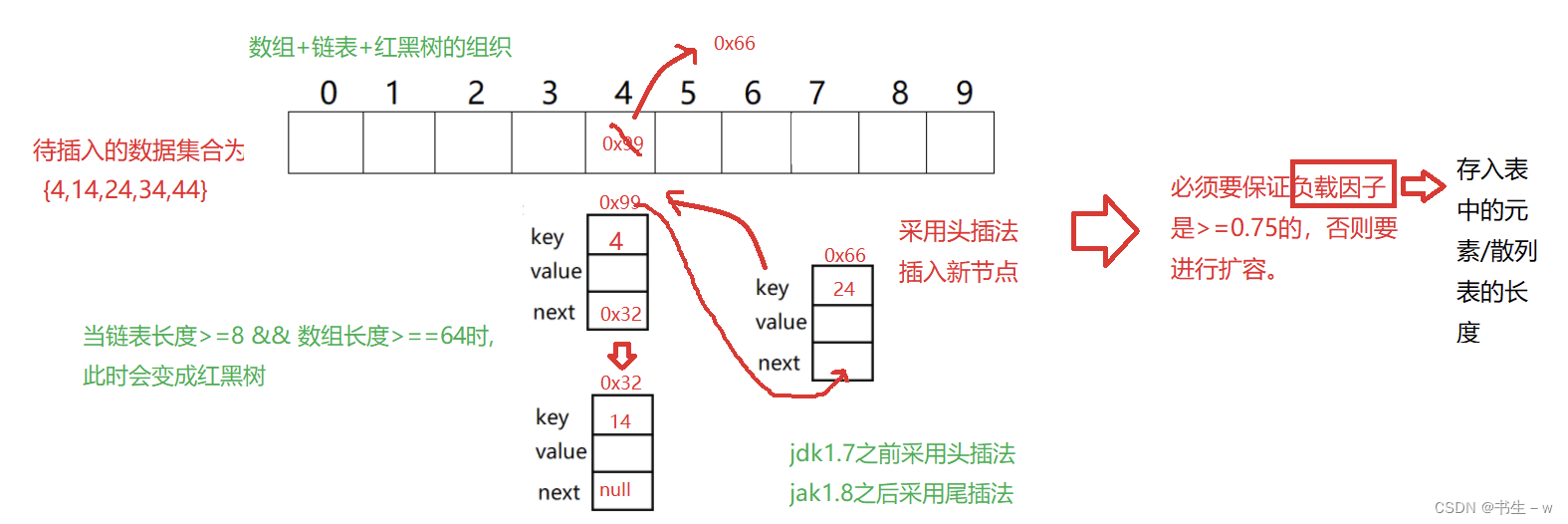

实现一个哈希表
public class HashBuck {static class Node {public int key;public int val;public Node next;public Node(int key,int val) {this.key = key;this.val = val;}}public Node[] array;public int usedSize;public static final double DEFAULT_LOAD_FACTOR = 0.75;public HashBuck() {this.array = new Node[10];}/*** put函数* @param key* @param val*/public void put(int key,int val) {//1、找到Key所在的位置int index = key % this.array.length;//2、遍历这个下标的链表,看是不是有相同的key。有 要更新val值的Node cur = array[index];while (cur != null) {if(cur.key == key) {cur.val = val;//更新val值return;}cur = cur.next;}//3、没有这个key这个元素,头插法Node node = new Node(key, val);node.next = array[index];array[index] = node;this.usedSize++;//4、插入元素成功之后,检查当前散列表的负载因子if(loadFactor() >= DEFAULT_LOAD_FACTOR) {resize();//}}//扩容private void resize() {Node[] newArray = new Node[array.length*2];for (int i = 0; i < array.length; i++) {Node cur = array[i];while (cur != null) {int index = cur.key % newArray.length;//获取新的下标 11//就是把cur这个节点,以头插/尾插的形式 插入到新的数组对应下标的链表当中Node curNext = cur.next;cur.next = newArray[index];//先绑定后面newArray[index] = cur;//绑定前面cur = curNext;}}array = newArray;}private double loadFactor() {return 1.0*usedSize/array.length;}/*** 根据key获取val值* @param key* @return*/public int get(int key) {//1、找到Key所在的位置int index = key % this.array.length;//2、遍历这个下标的链表,看是不是有相同的key。有 要更新val值的Node cur = array[index];while (cur != null) {if(cur.key == key) {return cur.val;}cur = cur.next;}return -1;}说明:以上的代码只是简单的实现了两个重要的函数:插数据和取数据
并且只是简单的实现,底层的树化并没有实现。
问题--》
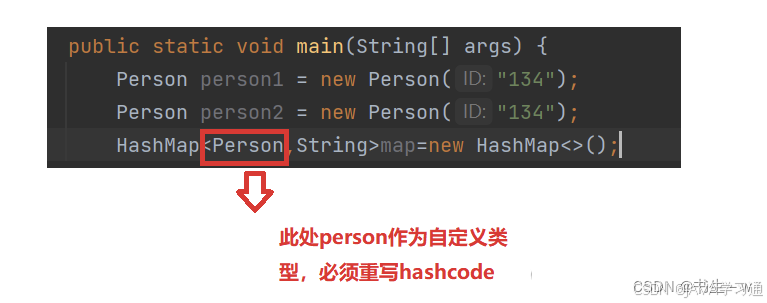
问题一:以上代码的key是整形,所以找地址的时候,可以直接用 key % array.length,如果我的key是一个引用类型呢???,我怎么找地址???
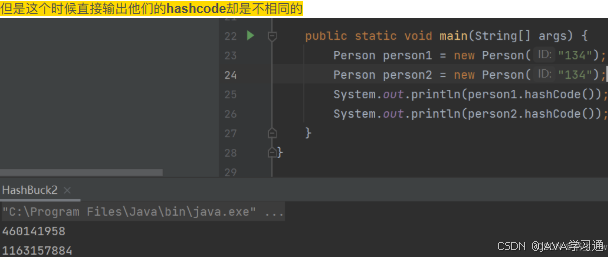
下面这段代码,两者的 id 都一样,运行结果却不一样,这就和我们刚刚的相同的key发生冲突就不一致了
class Person {public String id;public Person(String id) {this.id = id;}@Overridepublic String toString() {return "Person{" +"id=" + id +'}';}
}
public class Test {public static void main(String[] args) {Person person1 = new Person("134");Person person2 = new Person("134");System.out.println(person1.hashCode());System.out.println(person2.hashCode());}
}
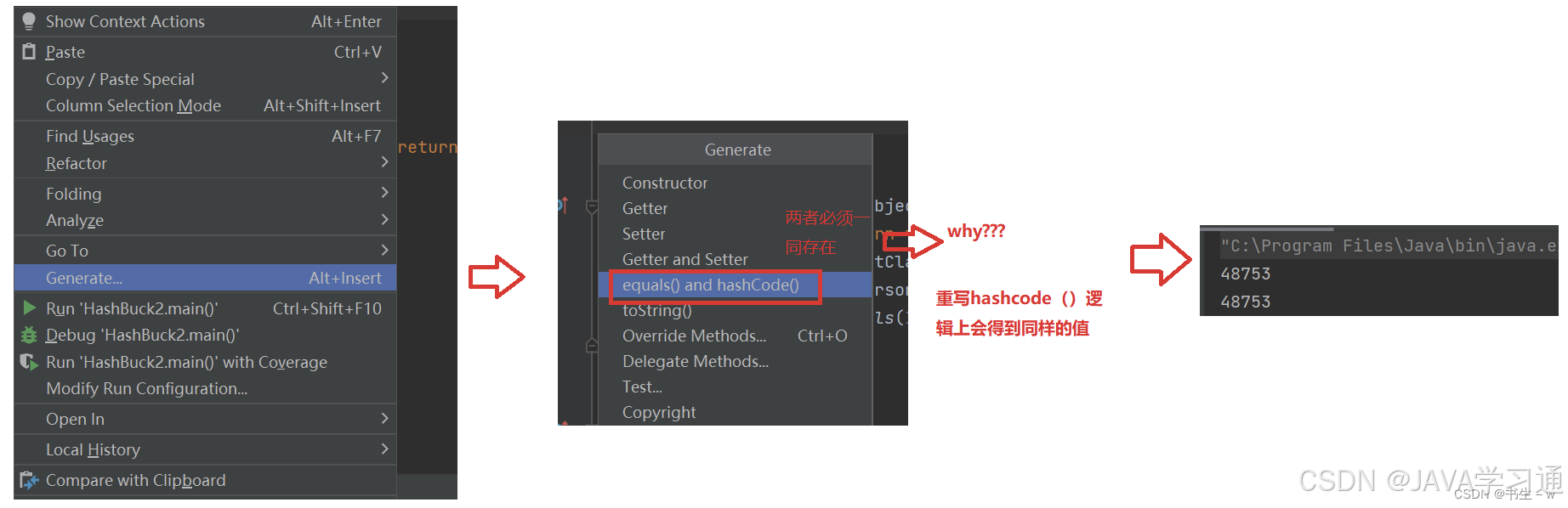
重写hashCode()方法
class Person {public String id;public Person(String id) {this.id = id;}@Overridepublic String toString() {return "Person{" +"id=" + id +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return id == person.id;}@Overridepublic int hashCode() {return Objects.hash(id);}
}
public class Test {public static void main(String[] args) {Person person1 = new Person("134");Person person2 = new Person("134");System.out.println(person1.hashCode());System.out.println(person2.hashCode());}
}1.为什么引用类型就要谈到 hashCode() ??
在引用类型中,比较对象的相等性通常需要使用 equals() 方法。但是在某些情况下,我们需要将对象用作集合(如 HashSet、HashMap)的键或进行哈希表操作时,还需要使用 hashCode() 方法。
在 Java 中,对象的哈希码(hash code)在哈希表等数据结构中用于确定对象的存储位置。哈希表通过使用对象的哈希码来快速查找和操作元素,以实现高效的插入、查找和删除操作。因此,为了在哈希表中正确地处理对象,我们需要重写 hashCode() 方法。
在哈希表中,首先会根据对象的哈希码计算出存储位置(存储桶),然后再使用 equals() 方法来进一步比较键的相等性。如果不重写 hashCode() 方法,不同的对象即使内容相等,它们的哈希码可能不同,导致在哈希表中无法正确地查找或比较它们。
2.按道理来说,学号相同的两个对象应该是同一个人,为什么重写 hashCode(),返回对象的哈希代码值才会一样,不重写为什么会导致最终在数组中寻找的地址不相同??因为底层的hashCode()是Object类的方法,底层是由C/C++代码写的,我们是看不到,但是因为它是根据对象的存储位置来返回的哈希代码值,这里就可以解释了,person1和person2本质上就是两个不同的对象,在内存中存储的地址也不同,所以最终返回的哈希代码值必然是不相同的,哈希代码值不同,那么在数组中根据 hash % array.length 寻找的地址也就不相同。而重写 hashCode() 方法之后,咱们根据 Person 中的成员变量 id 来返回对应的哈希代码值,这就相当于当一个对象,多次调用,那么返回的哈希代码值就必然相同。
所以我们的哈希表的实现就可以相应的改写成这样:
public class HashBuck<K,V> {static class Node<K,V> {public K key;public V val;public Node<K,V> next;public Node(K key,V val) {this.key = key;this.val = val;}}//往期泛型博客有具体讲到数组为什么这样写public Node<K,V>[] array = (Node<K,V>[]) new Node[10];public int usedSize;public static final double DEFAULT_LOAD_FACTOR = 0.75;public void put(K key, V val) {Node<K,V> node = new Node<>(key,val);int hash = key.hashCode();int index = hash % array.length;Node<K,V> cur = array[index];while(cur != null) {if(cur.key.equals(key)) {cur.val = val;return;}cur = cur.next;}//头插node.next = array[index];array[index] = node;this.usedSize++;if(loadFactor() >= DEFAULT_LOAD_FACTOR) {reSize();}}private double loadFactor() {return this.usedSize * 1.0 / array.length;}private void reSize() {Node<K,V>[] newArray = (Node<K, V>[]) new Node[2 * array.length];for (int i = 0; i < array.length; i++) {Node<K,V> cur = array[i];while (cur != null) {Node<K,V> curNext = cur.next;int hash = cur.key.hashCode();int index = hash % newArray.length;cur.next = newArray[index];newArray[index] = cur;cur = cur.next;}}array = newArray;}public V get(K key) {int hash = key.hashCode();int index = hash % array.length;Node<K,V> cur = array[index];while(cur != null) {if(cur.key == key) {return cur.val;}cur = cur.next;}return null;}
}性能分析
虽然哈希表一直在和冲突做斗争,但在实际使用过程中,我们认为哈希表的冲突率是不高的,冲突个数是可控的,也就是每个桶中的链表的长度是一个常数,所以,通常意义下,我们认为哈希表的插入 / 删除 / 查找时间复杂度是 O(1)
面试问题一:hashCode()和equals() 在HashMap中的作用分别是什么???
1. hashCode() 方法用于确定对象在哈希表中的存储位置。HashMap 使用哈希码来计算键的存储位置,以便在查找、插入和删除元素时能够快速定位到对应的存储桶(bucket)。每个键对象的 hashCode() 方法返回的哈希码将被用作该键在哈希表中的索引。
2. equals() 方法用于检查两个键对象是否相等。当两个键的哈希码相同时,HashMap 会使用 equals() 方法来进一步比较键的内容是否相等。这是为了解决哈希冲突的情况,当不同的键具有相同的哈希码时,需要通过 equals() 方法进行确切的比较来确定它们是否相等。
具体来说,当我们向 HashMap 中插入键值对时,它会根据键的哈希码找到对应的存储桶,并在该存储桶中进行查找或插入操作。在这个过程中,会使用键对象的 hashCode() 方法来计算哈希码,并使用 equals() 方法来检查键的相等性。
在使用自定义类作为键时,我们通常需要重写 hashCode() 和 equals() 方法,以确保它们的正确性和一致性。重写 hashCode() 方法是为了根据对象的属性计算哈希码,以便在哈希表中能够正确定位到存储位置。而重写 equals() 方法是为了根据对象的属性比较相等性,以确保在哈希表中进行查找、插入和删除操作时的正确性。
总结而言,hashCode() 方法在 HashMap 中用于确定键的存储位置,而 equals() 方法用于检查键的相等性。这两个方法在 HashMap 中共同工作,确保正确的键查找和存储。hashCode():用来找元素在数组中的位置;
equals():用来比较数组下链表中的每个元素的 key 与我的 key 是否相同。
equals也一样,如果不重写,上面的person1和person2的比较结果必然是不相同。
hashCode()和equals()就好比查字典,比如要查美丽,肯定要先查美字在多少页--hashCode(),然后它的组词有美景,美女,美丽,equals()就能找到美丽。答案肯定是不一定,一定。
同一个地址下链表中的key不一定一样,就好比数组长度为10,4和14找到的都是4下标。
而equals一样,hashCode就一定一样,4和4肯定都在4下标。
所以这时候再回过头来看HashMap数据的打印时,就能明白HashMap和HashSet为什么无序了,它本身就不是一个顺序结构,至于TreeMap和TreeSet为啥有序,这就和我们之前学过的优先级队列是一个道理了。(整形的key,输出时,自然而然就排好序了,如果key是引用类型,则需要实现Comparable接口,或者传比较器)
相关文章:

java数据结构-哈希表
什么是哈希表 最理想的搜索方法 , 即就是在查找某元素时 , 不进行任何比较的操作 , 一次直接查找到需要搜索的元素 , 可以达到这种要求的方法就是哈希表. 哈希表就是通过构造一种存储结构 , 通过某种函数使元素存储的位置与其关键码位形成一 一映射的关系 , 这样在查找元素的时…...
X64向量指令访问地址未对齐引起SIGSEGV)
Linux错误(6)X64向量指令访问地址未对齐引起SIGSEGV
Linux错误(6)X64向量指令访问地址未对齐引起SIGSEGV Author: Once Day Date: 2025年4月4日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 全系列文章可参考专栏: Linux实…...

SpringBoot配置文件多环境开发
目录 一、设置临时属性的几种方法 1.启动jar包时,设置临时属性 2.idea配置临时属性 3.启动类中创建数组指定临时属性 二、多环境开发 1.包含模式 2.分组模式 三、配置文件的优先级 1.bootstrap 文件优先: 2.特定配置文件优先 3.文件夹位置优…...

解锁健康密码:拥抱活力养生生活
在追求高品质生活的今天,健康养生成为了人们关注的焦点。它不仅关乎当下的生活质量,更是对未来的有力投资。 合理的饮食是健康养生的基石。一日三餐,应遵循 “五谷为养,五果为助,五畜为益,五菜为充” 的原则…...

手动将ModelScope的模型下载到本地
一、ModelScope 介绍 ModelScope 官网地址: https://www.modelscope.cn/home 模型库地址:https://www.modelscope.cn/models 文档中心:https://www.modelscope.cn/docs/home ModelScope旨在打造下一代开源的模型即服务共享平台,为…...

【Git】“warning: LF will be replaced by CRLF”的解决办法
一、原因分析 不同操作系统的换行符标准不同: • Windows:使用 CRLF(\r\n)表示换行; • Linux/Mac:使用 LF(\n)表示换行 Git 检测到本地文件的换行符与仓库设置或目标平台不兼容时…...

Linux常用基础命令应用
目录 一、文件与目录管理 1. 基础导航与查看 2. 文件操作核心命令 二、文本处理与日志分析 1. 查看与过滤 2. 组合命令与管道 三、系统管理与权限控制 1. 进程与资源监控 2. 权限与用户管理 四、网络与远程操作 1. …...

C++11可变参数模板单例模式
单例模式 该示例代码采用C11标准,解决以下问题: 通过类模板函数实现不同类型单例;单例类构造函数支持不同的个数;消除代码重复 示例代码 .h文件如下: //C11Singleton.h文件 #pragma oncetemplate <typename T&…...

JVM 有哪些垃圾回收器
垃圾收集算法 标记-复制算法(Copying): 将可用内存按容量划分为两个区域,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面, 然后再把已使用过的内存空间一次清理掉。 标记-清除算法(Mark-Sweep): 算法分为“标记” 和“清除”两个…...
的奥秘:从LLMChain到RouterChain)
6. 链式结构(Chain)的奥秘:从LLMChain到RouterChain
引言:从“单兵作战”到“流水线革命” 2023年某电商平台客服系统因处理复杂咨询需手动串联多个AI模块,平均响应时间长达12秒。引入LangChain链式架构后,工单处理速度提升8倍,错误率下降45%。本文将深入解析链式编程范式ÿ…...

TypeScript语言的操作系统原理
TypeScript语言的操作系统原理 引言 操作系统是计算机系统中最重要的组成部分之一,它为应用程序提供了一个运行环境,并管理着计算机硬件和软件资源。随着编程语言的发展,特别是TypeScript的流行,许多开发者开始探索将这种强类型…...

时间序列入门
时间序列入门 第一章 时间序列概述1.1 时间序列简介1.1.1 时间序列定义1.1.2 时间序列分量1.1.3 时间序列分类 第二章 时间序列绘图2.1 单变量时序绘制2.2 多变量时序绘制 第一章 时间序列概述 1.1 时间序列简介 1.1.1 时间序列定义 在进行时间序列之前,需要学习…...

VirtualBox安装FnOS
1.下载FnOS镜像 下载网址: https://www.fnnas.com/2.创建虚拟机 虚拟机配置如图所示(注意操作系统类型和网卡配置) (注意启动顺序) 3.启动虚拟机 网卡类型选择桥接的Virtual Adapter 如果没有IP地址或者IP地址无法…...

函数栈帧的创建与销毁
函数栈帧的创建与销毁 函数栈帧简介认识寄存器解析函数栈帧的创建与销毁 函数栈帧简介 我们在编程的过程中经常会听见函数栈帧这个词汇,那到底什么是函数栈帧呢?接下来就为大家解答一下,我们都知道,一个函数的创建是需要去开辟空…...

Scheme语言的算法
Scheme语言的算法探索 引言 Scheme是一种以表达式为基础的编程语言,属于Lisp家族,因其简洁、灵活的语法而受到广泛关注。Scheme不仅适合教学,还被用于实际应用开发和研究。本文将深入探讨Scheme语言的算法,包括其基本特性、常用…...

[C++面试] new、delete相关面试点
一、入门 1、说说new与malloc的基本用途 int* p1 (int*)malloc(sizeof(int)); // C风格 int* p2 new int(10); // C风格,初始化为10 new 是 C 中的运算符,用于在堆上动态分配内存并调用对象的构造函数,会自动计算所需内存…...
洛谷 P10268 符卡对决 题解)
(回滚莫队)洛谷 P10268 符卡对决 题解
居然还没调出来?感觉是数据类型的问题,真是吓人。先把思路写一下吧。 题意 灵梦一共有 n n n 张符卡,每张卡都有一个能力值,对于第 i i i 张卡,它的能力值为 a i a_i ai,现在她想从中选出两张符卡并…...
)
C语言复习笔记--指针(3)
接上篇文章C语言复习笔记--指针(2)-CSDN博客我们继续进行指针的复习. 二级指针 指针变量也是变量,是变量就有地址,那指针变量的地址取出来后要存在在什么变量中呢?这就是⼆级指针. ⼆级指针的运算见下: 指针数组 指针数组概念 既然要联系数组和指针就涉…...

Fastjson 处理 JSON 生成与解析指南
Fastjson 是阿里巴巴开源的高性能 JSON 库,适用于 Java 对象的序列化(生成 JSON)和反序列化(解析 JSON)。以下是详细使用指南: 1. 添加依赖 <dependency><groupId>com.alibaba</groupId>…...

深度学习数据集划分比例多少合适
在机器学习和深度学习中,测试集的划分比例需要根据数据量、任务类型和领域需求灵活调整。 1. 常规划分比例 通用场景 训练集 : 验证集 : 测试集 60% : 20% : 20% 适用于大多数中等规模数据集(如数万到数十万样本),平衡了训练数…...

查询当前用户的购物车和清空购物车
业务需求: 在小程序用户端购物车页面能查到当前用户的所有菜品或者套餐 代码实现 controller层 GetMapping("/list")public Result<List<ShoppingCart>> list(){List<ShoppingCart> list shoppingCartService.shopShoppingCart();r…...

大模型如何引爆餐饮与电商行业变革
大模型如何引爆餐饮与电商行业变革? 一、时代背景:大模型重构产业逻辑的底层动力 1. 技术跃迁催生效率革命 2025年,大模型技术迎来"普惠临界点"。李开复在中关村论坛指出,大模型推理成本每年降低10倍,使得…...

【MySQL】01.MySQL环境安装
注意:在MYSQL的安装与卸载中,需要使用root用户进行。 一、卸载不必要的环境 • 查看是否有运行的服务 [rootVM-24-10-centos etc]# ps axj |grep mysql1 22030 22029 22029 ? -1 Sl 27 0:00 /usr/sbin/mysqld --daemonize --pid-fi…...

java 匿名内部类 和 Lambda 表达式
java 匿名内部类 和 Lambda 表达式 一、匿名内部类1.1说明1.2 匿名内部类的作用1.3 特点1.4 接口的正常使用情况(抽象类同理)1.5 通过局部内部类使用接口(抽象类同理)1.6 通过匿名内部类使用接口(抽象类同理࿰…...

Linux系统调用编程
进程和线程 进程是操作系统资源分配的基本单位,拥有独立的地址空间、内存、文件描述符等资源,进程间相互隔离。每个进程由程序代码、数据段和进程控制块(PCB)组成,PCB记录了进程状态、资源分配等信息。 线程是…...

Redis 数据类型详解
Redis 数据类型详解 Redis 是一个高性能的键值存储系统,支持多种数据类型,每种类型都有其特定的使用场景和操作命令。以下是 Redis 主要数据类型的详细介绍: 一、基本数据类型 1. String(字符串) 特点:…...

orangepi zero烧录及SSH联网
下载对应版本的armbian镜像 armbian的默认用户root,默认密码:1234 下载烧录工具win32diskimager https://sourceforge.net/projects/win32diskimager/files/Archive/ 插入16G以上TF卡,使用win32diskimager烧录armbian镜像 烧录完毕后用l…...

七均线策略思路
一种基于移动平均线的交易策略,具体如下: 1. 移动平均线计算: 计算了六个不同周期的收盘价移动平均值,分别为MA5、MA10、MA20、MA30、MA40和MA60。 2. 买入条件(BK): 当满足以下所有条件时执行买…...

【python脚本】基于pyautogui的python脚本
一、什么是自动化 自动化是指使用技术手段模拟人工,执行重复性任务。准确率100%,高于人工。 自动化应用场景: 自动化测试自动化运维自动化办公自动化游戏 二、pyautogui的使用 先使用 pip install pyautogui 指令安装这个第三方库 2.1 …...

人工智能时代人才培养的变革路径:模式创新、能力重塑与认证赋能
在科技日新月异的今天,人工智能(AI)已成为推动社会进步与经济发展的核心力量。从自动驾驶到医疗诊断,从金融分析到教育创新,AI的触角已延伸至人类生活的每一个角落。这一变革不仅重塑了产业格局,更对人才培养提出了前所未有的挑战与机遇。在人工智能时代,如何培养适应未…...

xpath定位
一、路径符号核心区别(表格速查) 符号名称作用范围典型使用场景性能影响/单斜杠./ 相对路径直接子级, /绝对路劲-根路径精确层级定位高效//双斜杠//当前元素下开始查找,可以跨嵌套层模糊层级/跨嵌套定位较低效 一、XPath基础定位类型&#…...
深度解析)
Python列表(List)深度解析
列表(List)是Python中最基础且强大的数据结构之一,但它的底层实现和特性远比表面看起来复杂。本文将深入探讨列表的各个方面。 1. 列表基础特性 1.1 可变序列类型 lst [1, 2, 3] lst[1] 20 # 可变性1.2 异构容器 mixed [1, "hello", 3.14, [1, 2]…...

Mybatis---入门
1. 什么是MyBatis? MyBatis是⼀款优秀的 持久层 框架,⽤于简化JDBC的开发。 MyBatis本是 Apache的⼀个开源项⽬iBatis,2010年这个项⽬由apache迁移到了google code,并且改名为MyBatis 。2013年11⽉迁移到Github. 官⽹:MyBa…...

FPGA--HDLBits网站练习
目录 用状态机编写一个 LED流水灯代码 CPLD和FPGA芯片 CPLD(复杂可编程逻辑器件) FPGA(现场可编程门阵列) Verilog练习 基本 向量 用状态机编写一个 LED流水灯代码 往期作业已完成,博客地址: FPGA…...

《Linux内存管理:实验驱动的深度探索》【附录】【实验环境搭建 4】【Qemu 如何模拟numa架构】
我们在学习 linux 内核时,会涉及到很多 numa 的知识,那我们该如何在 qemu 中模拟这种情况,来配合我们的学习呢? 我们该如何模拟 如下的 numa 架构 Qemu 模拟 NUMA 架构 -M virt,gic-version3,virtualizationon,typevirt \ -cp…...

如何分析 jstat 统计来定位 GC?
全文目录: 开篇语前言摘要概述jstat 的核心命令与参数详解基本命令格式示例 jstat 输出解读主要字段含义 典型 GC 问题分析案例案例 1:年轻代 GC 过于频繁案例 2:老年代发生频繁 Full GC案例 3:元空间(Metaspace&#…...

Day51 | 3. 无重复字符的最长子串、12. 整数转罗马数字、49. 字母异位词分组、73. 矩阵置零
3. 无重复字符的最长子串 题目链接:3. 无重复字符的最长子串 - 力扣(LeetCode) 题目难度:中等 代码: class Solution {public int lengthOfLongestSubstring(String s) {Set<Character> setnew HashSet<&…...

【Linux系统编程】进程概念,进程状态
目录 一,操作系统(Operator System) 1-1概念 1-2设计操作系统的目的 1-3核心功能 1-4系统调用和库函数概念 二,进程(Process) 2-1进程概念与基本操作 2-2task_struct结构体内容 2-3查看进程 2-4通…...

第二十八章:Python可视化图表扩展-和弦图、旭日图、六边形箱图、桑基图和主题流图
一、引言 在数据可视化领域,除了常见的折线图、柱状图和散点图,还有一些高级图表类型可以帮助我们更直观地展示复杂数据关系。本文将介绍五种扩展图表:和弦图、旭日图、六边形箱图、桑基图和主题流图。这些图表在展示数据关系、层次结构和流量…...

深入理解C++引用:从基础到现代编程实践
一、引用的本质与基本特性 1.1 引用定义 引用是为现有变量创建的别名,通过&符号声明。其核心特点: 必须初始化且不能重新绑定 与被引用变量共享内存地址 无独立存储空间(编译器实现) 类型必须严格匹配 int value 42; in…...

OpenVLA-OFT——微调VLA的三大关键设计:支持动作分块的并行解码、连续动作表示以及L1回归目标
前言 25年3.26日,这是一个值得纪念的日子,这一天,我司「七月在线」的定位正式升级为了:具身智能的场景落地与定制开发商 ,后续则从定制开发 逐步过渡到 标准产品化 比如25年q2起,在定制开发之外࿰…...

linux3 mkdir rmdir rm cp touch ls -d /*/
Linux 系统的初始目录结构遵循 FHS(Filesystem Hierarchy Standard,文件系统层次标准),定义了每个目录的核心功能和存储内容。以下是 Linux 系统初始安装后的主要目录及其作用: 1. 核心系统目录 目录用途典型内容示例…...

TDengine 中的视图
简介 从 v3.2.1.0 开始,TDengine 企业版提供视图功能,便于用户简化操作,提升用户间的分享能力。 视图(View)本质上是一个存储在数据库中的查询语句。视图(非物化视图)本身不包含数据ÿ…...

算法设计学习9
实验目的及要求: 通过排序算法的实验,旨在深化学生对不同排序算法原理和性能的理解,培养其分析和比较算法效率的能力。通过实际编程,学生将掌握排序算法的实现方法,了解不同算法的优劣,并通过性能测试验证其…...

PGSQL 对象创建函数生成工具
文章目录 代码结果 代码 <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>PGSQL 函数生成器</tit…...

企业安全——FIPs
0x00 前言 先来看一道题目。这道题目涉及到的就是道德规范和互联网相关内容,本文会对相关内容进行描述和整理。 正确答案是:D 注意FIPs的主要目的是为了限制,也就是针对数据的守则。 0x01 RFC 1087 1989年1月 互联网架构委员会 IAB 发布了…...
——XBridge20240424攻击)
历年跨链合约恶意交易详解(二)——XBridge20240424攻击
漏洞合约函数 /*** dev token owner can list the pair of their token with their corresponding chain id* param baseToken struct that contains token address and its corresponding chain id* param correspondingToken struct that contains token address and its cor…...
)
《AI大模型开发笔记》MCP快速入门实战(一)
目录 1. MCP入门介绍 2. Function calling技术回顾 3. 大模型Agent开发技术体系回顾 二、 MCP客户端Client开发流程 1. uv工具入门使用指南 1.1 uv入门介绍 1.2 uv安装流程 1.3 uv的基本用法介绍 2.MCP极简客户端搭建流程 2.1 创建 MCP 客户端项目 2.2 创建MCP客户端…...

01背包问题:详细解释为什么重量维度必须从大到小遍历。
01背包 问题描述 题目链接:https://www.lanqiao.cn/problems/1174/learning/?page1&first_category_id1&problem_id1174 特点:每件物品只能拿或者不拿。 解法1 设置状态:dp[i][j]指的是前i件物品重量为j的最大价值。 第i件物品…...

Nginx配置伪静态,URL重写
Nginx配置伪静态,URL重写 [ Nginx ] 在Nginx低版本中,是不支持PATHINFO的,但是可以通过在Nginx.conf中配置转发规则实现: location / { // …..省略部分代码if (!-e $request_filename) {rewrite ^(.*)$ /index.php?s/$1 l…...