Muduo网络库实现 [十五] - HttpContext模块
目录
设计思路
类的设计
解码过程
模块的实现
私有接口
请求函数
解析函数
公有接口
疑惑点
设计思路
记录每一次请求处理的进度,便于下一次处理。
上下文模块是Http协议模块中最重要的一个模块,他需要记录每一次请求处理的进度,需要保存一个HttpRequest对象,后续关于这个连接的http的处理的信息全部都是在这个上下文中保存。
那既然是记录,肯定就要让它知道当前是在哪个进度了,所以我们就用状态码去表示
//处理状态
enum HttpRecvStatu{RECV_ERR, //接收错误RECV_LINE, //接收请求行RECV_HEAD, //接收头部RECV_BODY, //接收正文RECV_OVER //接收完毕
};注意:这些枚举值通常表示当前正在处理的状态,而不是已经完成的状态。
同时,由于收到的http请求报文可能是会出错的,而出错的话,我们是不会将这个报文进行业务的处理的,而是直接返回一个请求错误的状态码的报文,那么我们的上下文当中不可避免的还需要保存一个变量用来保存状态码。
还需要有一个 HttpRequest 对象来存储从客户端请求中解析出的各种信息。
具体来说,HttpRequest 对象通常会存储以下请求要素:
- 请求方法 (Method):如 GET、POST、PUT、DELETE 等
- 请求的 URL 路径
- HTTP 版本 (如 HTTP/1.1)
- 请求头 (Headers):如 Content-Type、User-Agent、Cookie 等
- 请求参数 (如 URL 中的查询参数)
- 请求体 (Body):POST 请求中包含的数据
- 其他请求相关的元数据
类的设计
既然它需要那么多状态,那说明它肯定是要处理这些状态的,也就是需要处理请求行,处理头部,处理正文,处理错误。那这些报文从哪里来呢?肯定是需要从缓冲区接收过来的,当然接收过来之后,我们还需要把缓冲区的数据的请求行段,请求头部段,请求正文段,分离出来,以便后续我们使用。接下来我们先看一个解码的过程,来加深理解一下流程
解码过程
假设我们收到了以下 HTTP 请求:
GET /my%20documents/report.pdf?search=machine+learning&year=2023 HTTP/1.1第一步:解析请求行
正则表达式匹配结果:
- matches[1] = "GET"(请求方法)
- matches[2] = "/my%20documents/report.pdf"(路径部分)
- matches[3] = "search=machine+learning&year=2023"(查询字符串部分)
- matches[4] = "HTTP/1.1"(HTTP版本)
第二步:解码路径部分
我们对 matches[2] 使用 UrlDecode(matches[2], false) 进行解码:
- 参数 false 表示不将加号(+)转换为空格
- 将 %20 解码为空格字符
- 输入:"/my%20documents/report.pdf"
- 输出:"/my documents/report.pdf"
第三步:处理查询字符串
- 首先拆分查询字符串(matches[3]):
- 输入:"search=machine+learning&year=2023"
- 使用
&作为分隔符拆分 - 结果:["search=machine+learning", "year=2023"]
- 对每个参数进行处理: 对于第一个参数 "search=machine+learning":
- 找到等号(=)位置:pos = 6
- 提取键:str.substr(0, pos) = "search"
- 提取值:str.substr(pos + 1) = "machine+learning"
- 对键进行解码:UrlDecode("search", true) = "search"(无需解码)
- 对值进行解码:UrlDecode("machine+learning", true) = "machine learning" (注意这里使用 true 参数,将加号转换为空格)
- 将键值对保存到请求对象:_request.setParam("search", "machine learning")
- 找到等号(=)位置:pos = 4
- 提取键:str.substr(0, pos) = "year"
- 提取值:str.substr(pos + 1) = "2023"
- 对键进行解码:UrlDecode("year", true) = "year"(无需解码)
- 对值进行解码:UrlDecode("2023", true) = "2023"(无需解码)
- 将键值对保存到请求对象:_request.setParam("year", "2023")
结果
请求对象中现在包含以下数据:
- 路径: "/my documents/report.pdf"
- 查询参数:
- "search" -> "machine learning"
- "year" -> "2023"
所以我们的类声明如下
#define MAX_LINE 8192 // HTTP请求行最大长度// HTTP请求解析上下文类
class HttpContext
{
private:HttpParseStatu _parse_status; // 当前解析状态int _status_code; // 状态码HttpRequest _request; // 存储解析出的HTTP请求信息private:bool RecvLine(Buffer *buf); // 接收请求行bool RecvHead(Buffer* buf); // 接收请求头部bool RecvBody(); // 接收请求正文bool ParseLine(const string &line); // 解析请求行bool ParsesHead(string &line); // 解析请求头部public:HttpContext(); // 构造函数void ReSet(); // 重置解析状态int StatusCode(); // 获取HTTP状态码HttpParseStatu ParseStatus(); // 获取当前解析状态HttpRequest& Request(); // 获取解析完成的HTTP请求void RecvHttpRequest(Buffer *buf); // 接收处理HTTP请求数据
};模块的实现
对于私有模块,也就是接收缓冲区的数据,然后把请求行,请求头部,请求正文获取到并且解析出来,然后放入到HttpRequest中存储,以供应用层进行调用
私有接口
请求函数
对于请求函数,基本上就是大差不差,先判断状态是否匹配,然后获取缓冲区数据的一行数据,进行判断是否是完整的数据,然后判断异常,异常有两种,第一种是没有拿到请求数据(请求行,请求头部,请求正文),但是缓冲区的数据已经超过最大值了,但还不是完整的数据,这说明数据是错的,那么我们就不处理,直接修改状态成错误,设置错误状态码就行了。第二种就是拿到了请求数据,但是数据也是巨大,这个时候我们也是不处理,修改状态为错误。设置错误状态码。如果合法了就开始解析请求数据,然后更新数据。这里解析请求数据是不一样的,等会重点讲解析的函数
bool RecvLine(Buffer *buf) // 接收请求行{if (_parse_status != RECV_HTTP_LINE){return false;}string line = buf->GetLineAndPop(); // 根据 HTTP 协议规范,HTTP 请求的结构是固定的,第一行必须是请求行if (line.size() == 0) // 说明出问题了,去缓冲区找问题{if (buf->ReadAbleSize() > MAX_LINE) // 说明此时缓冲区有数据,但是数据太大了还没有结束{_parse_status = RECV_HTTP_ERR;_status_code = 414; // URI TOO LONGreturn false;}// 否则就说明缓冲区的请求行太少,还没发完,再等等return true;}if (line.size() > MAX_LINE) // 说明虽然拿到了请求行,但是肯定是错误的,请求行的数据哪能那么多{_parse_status = RECV_HTTP_ERR;_status_code = 414; // URI TOO LONGreturn false;}//走到这就说明请求行合法了,开始处理bool ret = ParseLine(line);if(ret == false){return false;}//请求行状态结束,更新下一个状态_parse_status = RECV_HTTP_HEAD;return true;}bool RecvHead(Buffer* buf) // 接收请求报头{if (_parse_status != RECV_HTTP_HEAD) //进行判断是否是请求报头的状态了{return false;}//走到这就说明第一行的请求行已经被取走了,现在缓冲区的第一行就是请求报头了while(1)//因为报头的格式每行都是xxxx\n\r,一直到空格行才算结束{string line = buf->GetLineAndPop();if (line.size() == 0) // 说明出问题了,去缓冲区找问题{if (buf->ReadAbleSize() > MAX_LINE) // 说明此时缓冲区有数据,但是数据太大了还没有结束{_parse_status = RECV_HTTP_ERR;_status_code = 414; // URI TOO LONGreturn false;}// 否则就说明缓冲区的请求行太少,还没发完,再等等return true;}if (line.size() > MAX_LINE) // 说明虽然拿到了请求行,但是肯定是错误的,请求行的数据哪能那么多{_parse_status = RECV_HTTP_ERR;_status_code = 414; // URI TOO LONGreturn false;}//走到这就说明拿到了正常的数据if(line == "\n" || line == "\r\n") //如果这一行是报头的结束标志就要退出循环{break;}int ret = ParsesHead(line); //因为每一行都不一样,所以每取一行就要进行保存if(ret == false){return false;}}_parse_status = RECV_HTTP_BODY;return true;}bool RecvBody() // 接收请求正文{if(_parse_status != RECV_HTTP_BODY){return false;}size_t content_size = _request.GetLength(); //这也是固定格式,就是正文中会有一行是表示正文长度的if(content_size == 0) //因为正文可能有也可能没有{_parse_status = RECV_HTTP_OVER;return true;}//因为正文可能会很长int real_size = content_size - _request._body.size();//如果缓冲区数据充足if(buf->ReadAbleSize() >= real_size){_request._body.append(buf->ReadPos(), real_size);buf->MoveReadIndex(real_size);_parse_status = RECV_HTTP_OVER;return true;}//如果缓冲区数据不够,先全拿出,但是不能设置状态_request._body.append(buf->ReadPos(), buf->ReadAbleSize());buf->MoveReadIndex(buf->ReadAbleSize());return true;}对于请求报头来说,因为每行都是xxx: yyyyy\r\n;的格式,但是内容是不同的,所以我们要处理一行就解析一行,不然等你读取完你再处理,你xxx对应的值是yyyy,不还是要把每行再分离出来吗?所以就需要一个循环,取一行就解析一行。一直到读取到空格行,也就是结束的标志。然后把状态更新一下
对于请求正文来说,也有一些不同,因为一般情况下,正文的数据会非常的多,一次性会处理不完,处理不完怎么办呢,那么我们就读取一点拿过来一点,然后记录下这个读取长度。在请求头部中,会有个记录请求正文长度的,我们获取到这个长度之后,然后减去这个已经存储的长度,就是剩余我们还需要的长度,然后下次再进行判断,如果缓冲区的数据大于了还需要的长度,就说明已经有充足的数据了,然后就直接把剩余的数据追加到之前的数据后面就可以了,接着更新状态
解析函数
首先,我们最先从缓冲区获取的数据也就是请求行数据,那肯定最先用的就是解析请求行函数了
解析请求行的时候我们使用的正则表达式是这个:
(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?在这个正则表达式的匹配结果中,如果我们的url中没有携带参数,那么参数部分的匹配结果就是一个空串,他也是在matches里面的,这一点我们不需要关心,因为后续我们解析参数的时候会将这种情况给他处理了。
然后我们用 bool ret = regex_match(line, matches, e); 去把获取到的数据放在maches中,然后通过matches[1],[2],[...]放到我们定义的HttpRequest对象中存储起来。
query 变量存储的是从HTTP请求URL中提取的查询字符串(query string)部分。
具体来说,当HTTP请求有如下形式时:
GET /path/to/resource?name=value&another=data HTTP/1.1
query 变量会存储 name=value&another=data 这部分内容。
在正则表达式匹配中,matches[3] 对应的是第三个捕获组 (?:\\?(.*))? 中的 (.*) 部分,也就是问号 ? 后面的所有内容,直到空格之前。
之后的代码会进一步处理这个查询字符串:
- 使用
&分隔符将查询字符串分割成多个键值对 - 对每个键值对,查找
=的位置来分离键和值 - 对键和值进行URL解码(处理百分号编码和特殊字符)
- 将解码后的键值对存储到请求对象中
最后就是
- 从已经找到的每个查询字符串部分(如"name=value")中,使用等号("=")的位置将字符串分割成两部分
string key = Util::UrlDecode(str.substr(0, pos),true);- 提取等号前面的部分作为键(key)
- 使用
str.substr(0, pos)获取从字符串开始到等号位置的子字符串 - 然后用
Util::UrlDecode进行URL解码,true参数表示将加号(+)转换为空格
string val = Util::UrlDecode(str.substr(pos+1),true);- 提取等号后面的部分作为值(value)
- 使用
str.substr(pos+1)获取从等号后一个位置到结尾的子字符串 - 同样进行URL解码,
true参数表示将加号转换为空格
_requset.SetParam(key,val);- 将解码后的键值对添加到HTTP请求对象中
- 这样应用程序就可以通过HTTP请求对象访问这些查询参数
bool ParseLine(const string &line) // 解析请求行{smatch matches;std::regex e("(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?");bool ret = regex_match(line, matches, e);if(ret == false){_parse_status = RECV_HTTP_ERR;_status_code = 400; // BAD REQUESTreturn false;}//存储请求的方法,资源路径,协议版本_request._method = matches[1];_request._path = Util::UrlDecode(matches[2],false); //资源路径需要解码,但是只有查询字符串才要空格转加号_request._version = matches[4];string query = matches[3];//分三步:1.分割&前后的内容放入vector中 2.循环查找=的位置,分割=前后的内容,前面是key,后面是val 3.存储kvvector<string> query_array;Util::Spilt<query, "&", &query_array>;for(auto &str : query_array){size_t pos = str.find("=");if(pos == string::npos) //这个是固定格式,如果没有找到=就说明是错误的{_parse_status = RECV_HTTP_ERR;_status_code = 400; // BAD REQUESTreturn false;}string key = Util::UrlDecode(str.substr(0, pos),true);string val = Util::UrlDecode(str.substr(pos+1),true);_requset.SetParam(key,val);}return true;}接下来就是解析报头了,先把每行中的最后\n\r给删掉,然后去找每行的固定格式: 找到之后更新状态就行了
bool ParsesHead(string &line) // 解析请求报头{//先删除末尾无用字符if(line.back() == "\n"){line.pop_back();}if(line.back() == "\n"){line.pop_back();}size_t pos = line.find(": "); //这个也是固定格式if(pos == string::npos){_parse_status = RECV_HTTP_ERR;_status_code = 400; // BAD REQUESTreturn false;}}为什么会没有解析正文这个函数呢?
- 灵活性考虑 - HTTP请求正文有多种格式(JSON、XML、表单数据、二进制数据等),不同应用需要不同的解析方式。如果在库中内置特定的解析方法,可能会限制库的通用性。
- 分离关注点 - 这符合"关注点分离"的软件设计原则,网络库负责网络通信和基本协议解析,应用层代码负责特定业务逻辑和数据格式解析。
- 避免依赖膨胀 - 如果实现各种正文格式的解析,可能需要引入额外的依赖库(如JSON解析库),这会使muduo库变得臃肿。
- 性能考虑 - 通用的解析方法可能无法满足特定应用的性能需求,让用户自行实现可以针对特定场景进行优化。
在实际使用中,muduo的这种设计让开发者可以根据自己的需求选择适合的请求正文解析方式,比如对于JSON格式可以使用rapidjson,对于表单数据可以自行实现解析逻辑等。这提供了更大的灵活性,也符合C++库的设计理念。
公有接口
HttpContext() - 构造函数,初始化解析状态为接收请求行(RECV_HTTP_LINE),状态码为200(成功)。
void ReSet() - 重置函数,将状态恢复到初始状态: 重置状态码为200
重置解析状态为接收请求行
清空请求对象
int StatusCode() - 返回当前HTTP状态码。
HttpParseStatu ParseStatus() - 返回当前的解析状态(如接收请求行、接收头部等)。
HttpRequest& Request() - 返回已解析的HTTP请求对象的引用,供上层访问。
void RecvHttpRequest(Buffer *buf) - 核心解析函数,根据当前解析状态调用相应的处理函数: 如果是接收请求行状态,调用RecvLine
如果是接收头部状态,调用RecvHead
如果是接收正文状态,调用RecvBody
HttpContext():_parse_status(RECV_HTTP_LINE),_status_code(200){}void ReSet(){_status_code(200);_parse_status(RECV_HTTP_LINE);_request.Reset();}//返回状态码int StatusCode(){return _status_code;}//返回解析状态HttpParseStatu ParseStatus(){return _parse_status;}//返回已经解析并处理的请求信息HttpRequest& Request(){return _request;}void RecvHttpRequest(Buffer *buf){switch (_parse_status){case RECV_HTTP_LINE:RecvLine(buf);case RECV_HTTP_HEAD:RecvHead(buf);case RECV_HTTP_BODY:RecvBody(buf);default:break;}}疑惑点
读取请求的接口,为什么不要break?
- 提高解析效率 - 允许在一次函数调用中尽可能多地解析数据。例如,如果缓冲区中同时包含了请求行和请求头部的数据,这种设计可以一次性处理完所有可用数据,而不必等待下一次调用。
- 状态机连续处理 - HTTP解析是一个状态机过程,当一个状态处理完成后,如果有更多数据可以处理,应该立即进入下一个状态进行处理。
- 最大化缓冲区利用 - 充分利用每次
RecvHttpRequest调用处理尽可能多的数据,减少处理延迟。
解析和接收两个意思一样吗?
接收(Receiving):
- 指的是从网络中获取原始数据(字节流)的过程
- 属于网络 I/O 操作,涉及到套接字读取
- 关注的是"如何获取数据"
- 例如:从 TCP 连接读取字节流到缓冲区
解析(Parsing):
- 指的是将已接收的原始数据转换为结构化信息的过程
- 属于数据处理操作,涉及到语法分析
- 关注的是"如何理解数据"
- 例如:将 HTTP 原始报文分解为请求行、头部字段、请求体等
在 HTTP 服务器的工作流程中:
- 首先接收原始的 HTTP 请求报文(字节流)
- 然后解析这些字节流,提取出各种 HTTP 请求组件
- 最后基于解析结果进行业务处理
为什么需要设置单个接收函数,比如接收请求行,接收请求报头,难道不能设置一个函数用于接收整个报文吗?

为什么要解析呢 它既然接收成功了不就说明是一个完整的吗?
解析就好比翻译,你收到了一封外国友人的信,他是用他们国家的语言写的,你虽然有一个完整的信,但是你读不懂内容,所以就需要翻译信的内容了
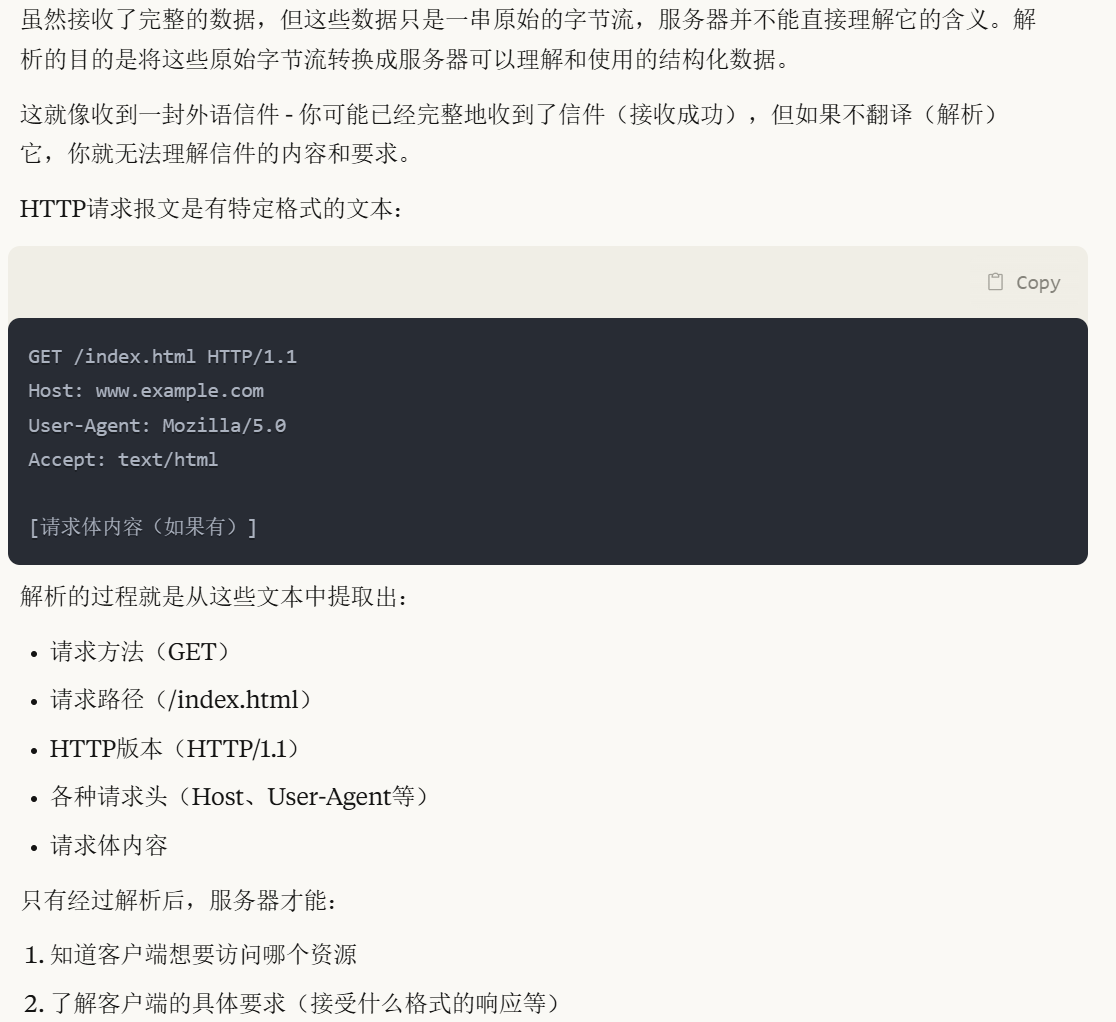
std::regex e("(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?"); 这个是什么?

_request._path = Util::UrlDecode(matches[2],false); //资源路径需要解码,但是只有查询字符串才要空格转加号

相关文章:

Muduo网络库实现 [十五] - HttpContext模块
目录 设计思路 类的设计 解码过程 模块的实现 私有接口 请求函数 解析函数 公有接口 疑惑点 设计思路 记录每一次请求处理的进度,便于下一次处理。 上下文模块是Http协议模块中最重要的一个模块,他需要记录每一次请求处理的进度,需…...

构建自己的私有 Git 服务器:基于 Gitea 的轻量化部署实战指南
对于个人开发者、小型团队乃至企业来说,将项目代码托管在 GitHub、Gitee 等公共平台虽然方便,但也存在一定的隐私与可控性问题。 搭建一套私有 Git 代码仓库系统,可以实现对源码的完全控制,同时不依赖任何第三方平台,…...

【计科】计算机科学与技术,从离散数学到软件工程,从理学/抽象/科学到工学/具体/技术
【计科】计算机科学与技术,从离散数学到软件工程,从理学/抽象/科学到工学/具体/技术 文章目录 1、发展史与桥梁(离散数学 -> 算法/数据结构 -> 软件工程)2、离散数学(数理逻辑-命题/谓词/集合/函数/关系 -> 代…...

架构与大数据-RabbitMQ和Kafka的技术实现异同及落地场景上的异同
RabbitMQ与Kafka技术实现及场景对比 一、技术实现异同 对比维度RabbitMQKafka核心协议/模型基于 AMQP 协议,支持点对点、发布/订阅、Topic Exchange 等多种消息模式,支持灵活的路由规则基于 发布-订阅模型,…...

工程画图-UML类图 组合和聚合
组合VS聚合 组合&聚合浅层理解 组合似组装,电脑组装,少装一个CPU行不?不行,没CPU哪还是电脑啊。用实心菱形表示。 而聚合似起义,聚是一团火,散是满天星。就像公司和员工,少你一个照常运转…...
:用 Go 写一个 RESTful API 服务!)
Go语言-初学者日记(七):用 Go 写一个 RESTful API 服务!
👷 实践是最好的学习方式!这一篇我们将用 Go Gin 框架从零开始开发一个用户管理 API 服务。你将学到: 如何初始化项目并引入依赖如何组织目录结构如何用 Gin 实现 RESTful 接口如何通过 curl 测试 API进阶功能拓展建议 🧰 一、项…...

数据结构:手工创建表达式树的方法
1. 表达式树 表达式树(Binary Expression Tree)是一类特殊的二叉树,用以表示表达式,如图 7.6.1 所示,是一棵表示了 a b * c d * (e f) 的表达式树。 图 7.6.1 表达式树示例 表达式树有如下特点: 操作数…...

自定义类型:联合和枚举
文章目录 前言一、联合体类型的声明1.1 联合体类型的声明1.2 联合体的特点1.3 相同成员的结构体和联合体对比1.4 联合体大小的计算1.5 联合体的一个练习 二、枚举类型的声明2.1 枚举类型的声明2.2 枚举类型的优点2.3 枚举类型的使用1. 用于 switch 语句2. 作为函数参数 总结 前…...

注意力机制
实现了Bahdanau式加法注意力的核心计算逻辑。以下是三个线性层设计的完整技术解析: 一、数学公式推导 注意力分数计算流程: s c o r e ( h d e c , h e n c ) v T ⋅ tanh ( W 1 ⋅ h e n c W 2 ⋅ h d e c ) score(h_{dec}, h_{enc}) v^T \cdot …...
)
OrangePi5Plus开发板不能正确识别USB 3.0 设备 (绿联HUB和Camera)
1、先插好上电(可正确识别) 2、上电开机后插,报错如下,只能检测到USB2.0--480M,识别不到USB3.0-5Gbps,重新插拔也不行 Apr 4 21:30:00 orangepi5plus kernel: [ 423.575966] usb 5-1: reset high-speed…...

KubeVirt虚拟化管理架构
目录 一. KubeVirt简介 1.1 KubeVirt的价值 1.2 KubeVirt架构 1.3 KubeVirt组件 1.4 KubeVirt流程管理 KubeVirt实战 2.1 Kubevirt安装 2.1.1节点规划 2.1.2 环境准备 2.1.3 安装KubeVirt 2.1.4 安装CDI 2.1.5 安装virtctl命令工具 2.1.6 生成官方虚拟机 2.1.7 进…...

游戏引擎学习第202天
调试器:启用“跳转到定义/声明”功能 开始了一个完整游戏的开发过程,并分享了一些实用技巧。首先,讨论了如何在 Visual Studio 中使用“跳转到定义”和“跳转到声明”功能,但当前的项目并未启用这些功能,因为缺少浏览…...

sqlalchemy查询json
第一种:字段op是json格式: {"uid": "cxb123456789","role": 2,"op_start_time": 1743513707504,"op_end_time": 1743513707504,"op_start_id": "op_001","op_end_id"…...

2024第十五届蓝桥杯大赛软件赛省赛C/C++ 大学 B 组
记录刷题的过程、感悟、题解。 希望能帮到,那些与我一同前行的,来自远方的朋友😉 大纲: 1、握手问题-(解析)-简单组合问题(别人叫她 鸽巢定理)😇,感觉叫高级了…...

Linux系统之wc命令的基本使用
Linux系统之wc命令的基本使用 一、命令简介二、基本语法格式三、核心功能选项四、典型使用案例4.1 创建示例文件4.2 基础统计操作4.3 组合选项使用4.4 管道流处理 五、高级应用技巧4.1 递归统计代码行数4.2 统计CSV文件数据量4.3 监控日志增长速率4.4 字符与字节差异说明 七、命…...

SQL Server 2022 脏读问题排查与思考
总结sqlserver的使用,总是会回想起很多开发过程当中加班努(拼)力(命)的场景,今天,就把之前一个由于数据库脏读到这的OA系统员工请假流程状态不一致问题和解决思路分享一下。 业务场景描述 由于…...

Linux系统时间
1. Linux系统时间 jiffies是linux内核中的一个全局变量,用来记录以内核的节拍时间为单位时间长度的一个数值。 jiffies变量开机时有一个基准值,然后内核每过一个节拍时间jiffies就会加1。 一个时间节拍的时间取决于操作系统的配置,Linux系统一…...

【Windows批处理】命令入门详解
Windows 批处理(Batch Script)是一种用于在 Windows 操作系统上自动执行命令的脚本语言。它基于 Windows 命令提示符(cmd.exe)并使用 .bat 或 .cmd 文件格式。 一、批处理基础 1. 创建批处理文件 批处理脚本本质上是一组按顺序执…...

fpga系列 HDL:ModelSim 条件断点调试 modelsim支持的tcl语言
条件断点调试配置流程: 触发动作用tcl语言描述,modelsim支持的tcl语言见:https://home.engineering.iastate.edu/~zzhang/courses/cpre581-f08/resources/modelsim_quickguide.pdf 运行效果:...

Linux: network: 两台直连的主机业务不通
前提环境,有一个产品的设定是两个主机之间必须是拿网线直连。但是设备管理者可能误将设置配错,不是直连。 最近遇到一个问题,说一个主机发的包,没有到对端,一开始怀疑设定的bond设备的问题,检查了bond的设置状态,发现没有问题,就感觉非常的奇怪。后来就开始怀疑两个主机…...

虚拟地址空间布局架构
一、内存管理架构 1.Linux内核整体架构以及子系统 内存管理子系统架构分为用户空间、内核空间及硬件部分 3 个层面: 用户空间:应用程序使用malloc()申请内存资源,通过free()释放内存资源。内核空间:内核是操作系统的一部分&…...
节点的配置)
在VMware下Hadoop分布式集群环境的配置--基于Yarn模式的一个Master节点、两个Slaver(Worker)节点的配置
你遇到的大部分ubuntu中配置hadoop的问题这里都有解决方法!!!(近10000字) 概要 在Docker虚拟容器环境下,进行Hadoop-3.2.2分布式集群环境的配置与安装,完成基于Yarn模式的一个Master节点、两个…...

go day 01
go day 01 配置go环境 install go on D:\huang\lang\go\D:\huang\lang\go\bin\go xxx.go # D:\huang\lang\go\bin 设置到环境变量go go version# 创建任意一个目录,创建三个文件夹 # D:\huang\lang\goProject bin、pkg、src # 创建三个系统环境变量 GOROOT GOPATH GOBIN # GOR…...
RestAPI 毛子(Tags))
(二)RestAPI 毛子(Tags)
文章目录 项目地址一、给Habit添加Tags1.1 创建Tags1. 创建一个新的HabitTags实体2. 设置Habit和Tags的关系3. 设置HabitTag表4. 在HabitConfiguration里配置5. 将表添加到EFCore里6. 迁移数据 1.2 给Habit增加/修改标签1. 创建UpsertHabitTagsDto2. 创建查询HabitWithTagsDto3…...

Elasticsearch:使用机器学习生成筛选器和分类标签
作者:来自 Elastic Andre Luiz 探索使用机器学习模型与传统硬编码方法在搜索体验中自动创建筛选器和分类标签的优缺点 筛选器和分类标签是用来优化搜索结果的机制,帮助用户更快速地找到相关内容或产品。在传统方法中,规则是手动定义的。例如…...

Python接口自动化测试之UnitTest详解
↵ 基本概念 UnitTest单元测试框架是受到JUnit的启发,与其他语言中的主流单元测试框架有着相似的风格。其支持测试自动化,配置共享和关机代码测试。支持将测试样例聚合到测试集中,并将测试与报告框架独立。 它分为四个部分test fixture、Te…...

《概率论与数理统计》期末复习笔记_上
目录 第1章 随机事件与概率 1.1 随机事件 1.2 事件的关系与运算 1.3 概率的定义与性质 1.4 古典概型_重点 1.5 几何概型 1.6 条件概率与乘法公式 1.7 全概率公式与贝叶斯公式_重点 1.8 事件的独立性_重点 1.9 伯努利概型_重难点 第2章 随机变量及其分布 2.1 随机变…...

工程师 - Doxygen介绍
Code Documentation. Automated. Free, open source, cross-platform. Version 1.12.0 is now available! Release date: 7 August 2024 官方网址: Doxygen homepage 文档: Doxygen: Overview Github网址: https://github.com/doxygen/…...

开源且完全没有审核限制的大型语言模型的概述
开源且完全没有审核限制的大型语言模型的概述 关键要点 研究表明,存在多个开源的大型语言模型(LLM)完全没有审核限制,适合开放对话。包括基于 Llama、Mixtral、Phi-2 和 StableLM 的模型,参数范围从 2.78 亿到 4050 亿…...

Qt QTableView QAbstractTableModel实现复选框+代理实现单元格编辑
话不多说,直接看代码 一、Model 1、QTableModel_Test.h #pragma once#include <QAbstractTableModel> #include <QObject> #include <QModelIndex>class QTableModel_Test : public QAbstractTableModel {Q_OBJECT public:QTableModel_Test(Q…...

2025.3.19
1、用vim编辑/etc/hosts文件,将本机和第二个虚拟机的ip地址和主机名写入该文件,然后ping 两个主机的主机名能否ping通; (1)在第一个虚拟机编辑/etc/hosts: 首先使用hostname、hostnamectl、hostname -f指令查看主机名…...
是蓝牙低功耗(Bluetooth Low Energy,简称BLE)协议栈中的一个核心协议)
GATT(Generic Attribute Profile)是蓝牙低功耗(Bluetooth Low Energy,简称BLE)协议栈中的一个核心协议
蓝牙的 GATT(Generic Attribute Profile) 是蓝牙低功耗(Bluetooth Low Energy,简称BLE)协议栈中的一个核心协议,用于定义设备如何通过蓝牙进行数据传输和交互。GATT 是基于 ATT(Attribute Proto…...

打造下一代智能体验:交互型 AI 的崛起与实践
在人工智能技术不断飞跃的今天,我们正迎来一个从"一问一答"向"多轮交互、智能反馈"转变的新时代——交互型 AI(Interactive AI)。 什么是交互型 AI? 交互型 AI 指的是具备多轮对话能力、状态记忆、工具调用…...

关于uint8_t、uint16_t、uint32_t、uint64_t的区别与分析
一、类型定义与字节大小 uint8_t、uint16_t、uint32_t、uint64_t 是 C/C 中定义的无符号整数类型,通过 typedef 对基础类型起别名实现。位宽(bit)和字节数严格固定: uint8_t:8 位,占用 1 字节ÿ…...

19685 握手问题
19685 握手问题 ⭐️难度:简单 🌟考点:2024、省赛、数学 📖 📚 package test ;import java.util.Scanner; public class Main {public static void main(String[] args) {Scanner scanner new Scanner(System.in);…...

react redux的学习,单个reducer
redux系列文章目录 一 什么redux? redux是一个专门用于做状态管理的JS库(不是react插件库)。它可以用在react, angular, vue等项目中, 但基本与react配合使用。集中式管理react应用中多个组件共享的状 简单来说,就是存储页面的状态值的一个库…...

CCF GESP C++编程 二级认证真题 2025年3月
C 二级 2025 年 03 月 CCF GESP C编程 二级认证真题 题号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 答案 D C A A D A D A C B C D B C C 1 单选题 第 1 题 2025年春节有两件轰动全球的事件,一个是DeepSeek横空出世,另一个是贺岁片《哪吒2》票房惊人&#…...

Lua函数与表+Lua子文件加载与元表
Lua函数相关示例代码 --脚本型语言,不能先调用,再定义,因为代码是从上往下执行的 --第一种声明函数 function func1()print("这是func1") end--先定义,再调用,没有问题 func1() -------------------------…...

Linux systemd 服务全面详解
一、systemd 是什么? systemd 是 Linux 系统的现代初始化系统(init)和服务管理器,替代传统的 SysVinit 和 Upstart。它不仅是系统启动的“总指挥”,还统一管理服务、日志、设备挂载、定时任务等。 核心作用 服务管理…...

Linux系统调用编程
目录 1.Linux下进程和线程进程线程区别查看进程pid终止进程pid 2.Linux虚拟内存管理与stm32内存映射设计目标与架构差异地址空间管理机制对比内存使用与性能特性 3.Linux系统调用函数fork()wait()exec() 4.树莓派环境下练习创建账号1创建用户账号2.配置用户权限3.查看用户 登录…...

AWS Langfuse AI用Bedrock模型使用完全教程
AWS Langfuse AI使用完全教程 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 AWS Langfuse AI使用完全教程Langfuse是什么?准备工作创建Langfuse账户1.创建LLM应用程序启用Bedrock…...

【Docker项目实战】使用Docker部署MediaCMS内容管理系统
【Docker项目实战】使用Docker部署MediaCMS内容管理系统 前言一、MediaCMS介绍1.1 MediaCMS 简介1.2 主要特点1.3 使用场景二、本次实践规划2.1 本地环境规划2.2 本次实践介绍三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本四、下载Med…...
)
OpenHarmony子系统开发 - DFX(一)
OpenHarmony子系统开发 - DFX(一) 一、DFX概述 简介 在OpenHarmony中,DFX(Design for X)是为了提升质量属性的软件设计,目前包含的内容主要有:DFR(Design for Reliability,可靠性)…...

深入解析:使用Python爬取Bilibili视频
深入解析:使用Python爬取Bilibili视频 引言 Bilibili,作为中国领先的年轻人文化社区,拥有海量的视频资源。对于想要下载Bilibili视频的用户来说,手动下载不仅费时费力,而且效率低下。本文将介绍如何使用Python编写一…...

详解数据结构线性表 c++实现
线性表 线性表是一种非常基础且重要的数据结构,它是具有相同数据类型的 n(n≥0)个数据元素的有限序列。这里的 “有限” 意味着元素的数量是确定的,“序列” 则表示元素之间存在着顺序关系。 顺序表 顺序表是线性表的一种顺序存…...

Prolog语言的网络协议栈
Prolog语言的网络协议栈 引言 网络协议栈是现代计算机网络的重要组成部分,它负责在网络中的各个节点之间以标准化的方式传输数据。在这一体系中,不同层次的协议相互协作,以实现从物理传输到应用层数据处理的功能。Prolog是一种以符号逻辑为…...
)
音视频基础(音频常用概念)
文章目录 **1. 比特率(Bitrate)****概念****影响****音频比特率****视频比特率** **2. 码率(Bitrate)****3. 帧(Frame)****概念****视频帧****音频帧** **4. 帧长(Frame Length)****…...

洛谷题单3-P5725 【深基4.习8】求三角形-python-流程图重构
题目描述 模仿例题,打印出不同方向的正方形,然后打印三角形矩阵。中间有个空行。 输入格式 输入矩阵的规模,不超过 9 9 9。 输出格式 输出矩形和正方形 输入输出样例 输入 4输出 01020304 05060708 09101112 13141516010203040506 …...

【数据结构】邻接表 vs 邻接矩阵:5大核心优势解析与稀疏图存储优化指南
邻接表法 导读一、邻接矩阵的不足邻接表二、存储结构三、算法评价3.1 时间复杂度3.2 空间复杂度 四、邻接表特点4.1 特点解读特点3特点4特点5 结语 导读 大家好,很高兴又和大家见面啦!!! 图作为一种复杂的数据结构,其…...

编程能力的跃迁时刻:技术革命与认知重构的交响曲
在软件开发领域,从业者常将"一万小时定律"视为能力增长的圭臬,但真正的能力跃迁往往发生在特定技术范式转换的临界点。当开发者首次理解递归算法的本质,当面向对象编程替代过程式思维,当自动化工具链重塑开发流程,这些认知地震时刻往往成为技术生涯的分水岭。 …...