Python----机器学习(线性回归:反向传播和梯度下降)
一、前向传播与反向传播的区别
前向传播是在参数固定后,向公式中传入参数,进行预测的一个过程。当参 数值选择的不恰当时,会导致最后的预测值不符合我们的预期,于是我们就 需要重新修改参数值。
在前向传播实验中时,我们都是通过手动修改w值来使直线能更好的拟合散点。
反向传播是在前向传播后进行的,它是对参数进行更新的一个过程,反向传 播的过程中参数会根据某些规律修改从而改变损失函数的值。
二、损失函数
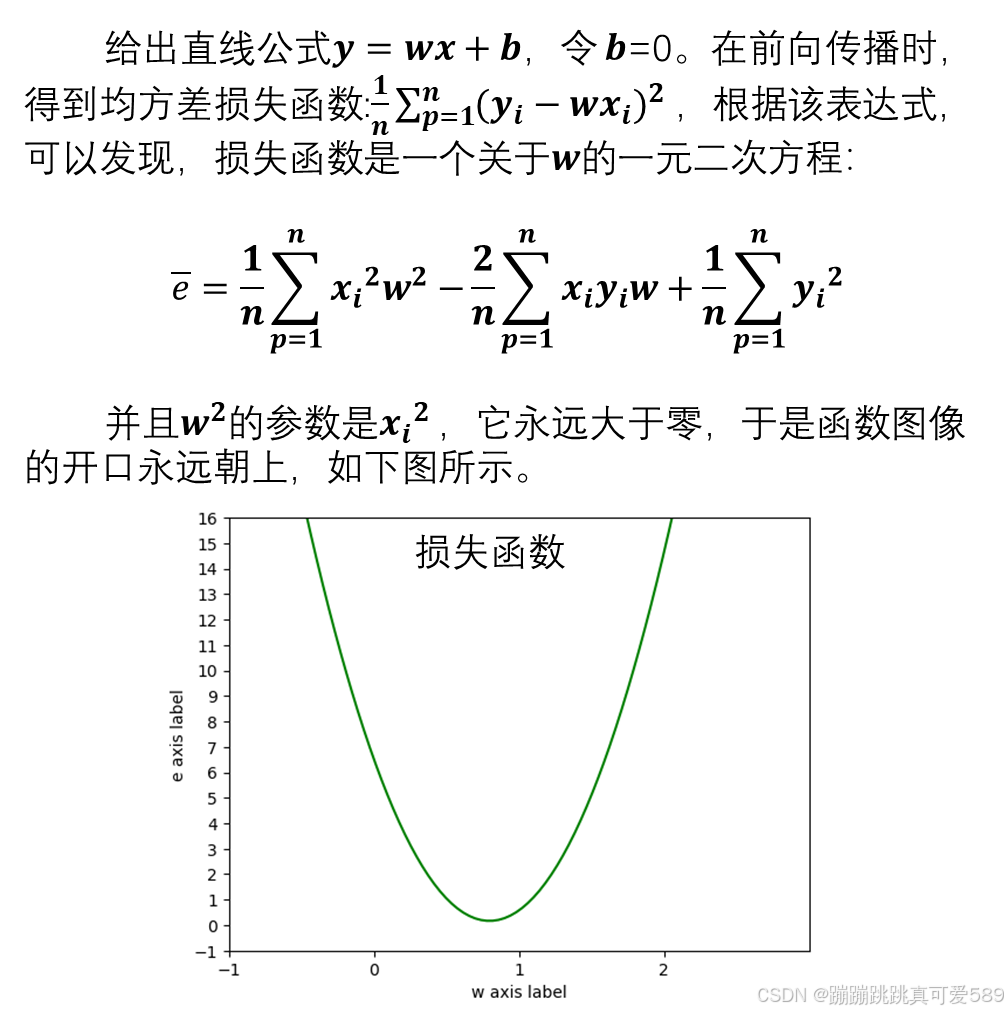
三、梯度下降
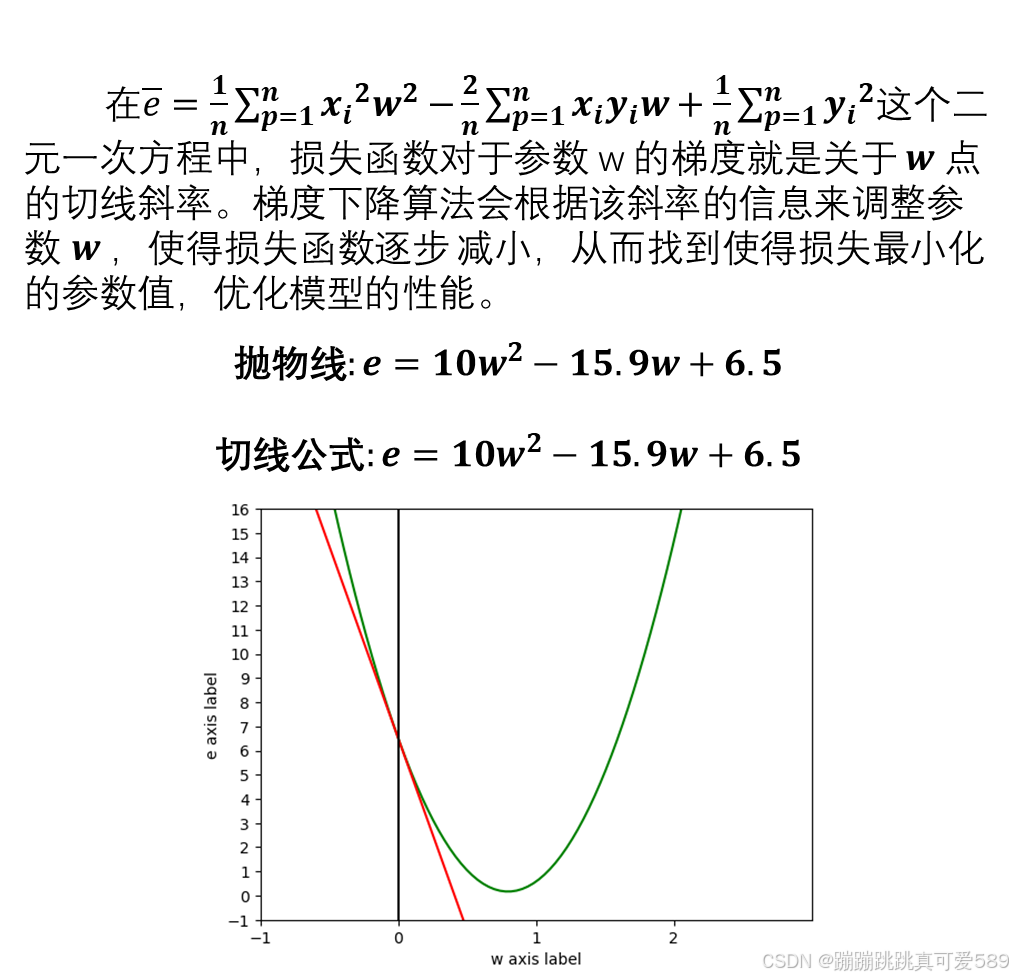
在机器学习中,对于很多监督学习模型,需要对原始的模型构建损失函数 J,接下来便是通过优化算法对损失函数J进行优化,最小化损失函数,以便寻找到最优的参数theta.
于是,基于搜索的梯度下降法就产生了。
梯度下降法的含义是通过当前点的梯度(偏导数)的反方向寻找到新的迭代点,并从当前点移动到新的迭代点继续寻找新的迭代点,直到找到最优解。
假设你在一个陌生的山地上,你想找到一个谷底,那么肯定是想沿着向下的坡行走,如果想尽快的走到 谷底,那么肯定是要沿着最陡峭的坡下山。每走一步,都找到这里位置最陡峭的下坡走下一步,这就是 梯度下降。
在这个比喻中,梯度就像是山上的坡度,告诉我们在当前位置上地势变化最快的方向。为了尽快走向谷 底,我们需要沿着最陡峭的坡向下行走,而梯度下降算法正是这样的方法。
每走一步,我们都找到当前位置最陡峭的下坡方向,然后朝着该方向迈进一小步。这样,我们就在梯度 的指引下逐步向着谷底走去,直到到达谷底(局部或全局最优点)。
在机器学习中,梯度表示损失函数对于模型参数的偏导数。具体来说,对于每个可训练参数,梯度告诉 我们在当前参数值下,沿着每个参数方向变化时,损失函数的变化率。通过计算损失函数对参数的梯 度,梯度下降算法能够根据梯度的信息来调整参数,朝着减少损失的方向更新模型,从而逐步优化模 型,使得模型性能更好。
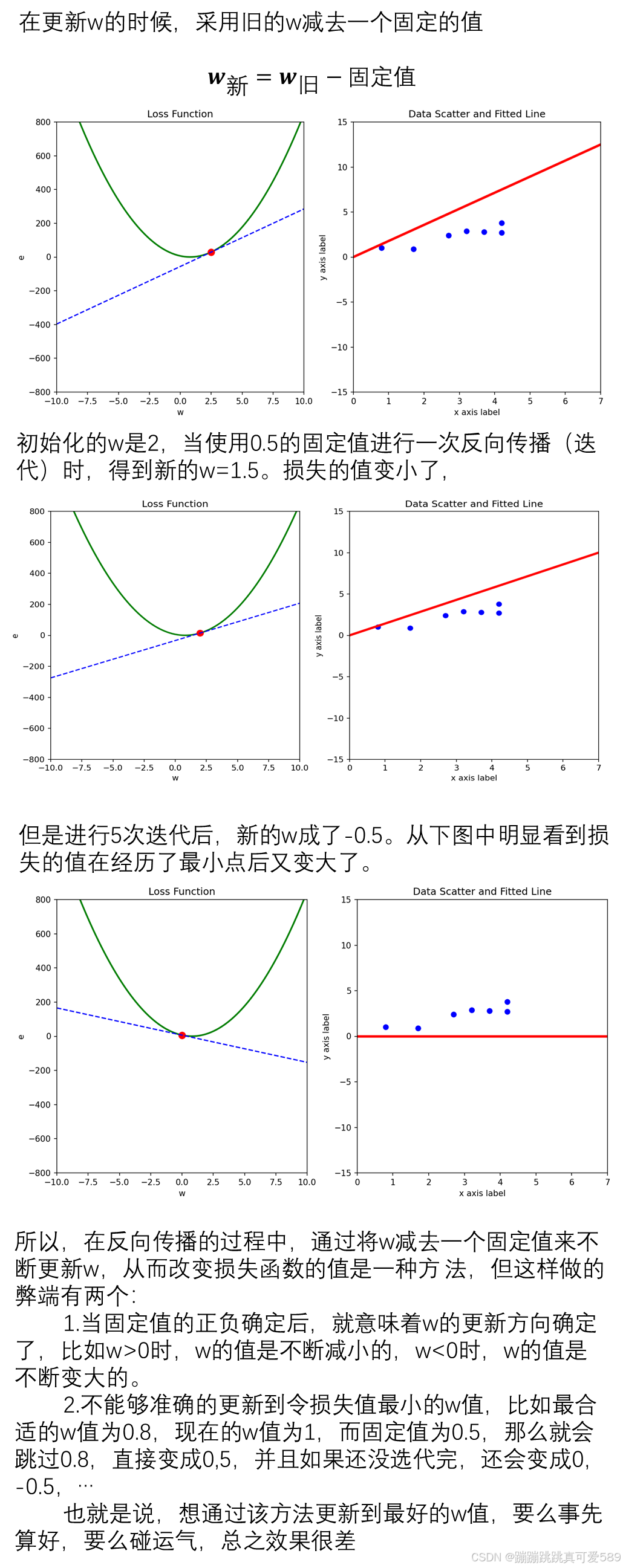
3.1、固定值法
3.2、小固定值
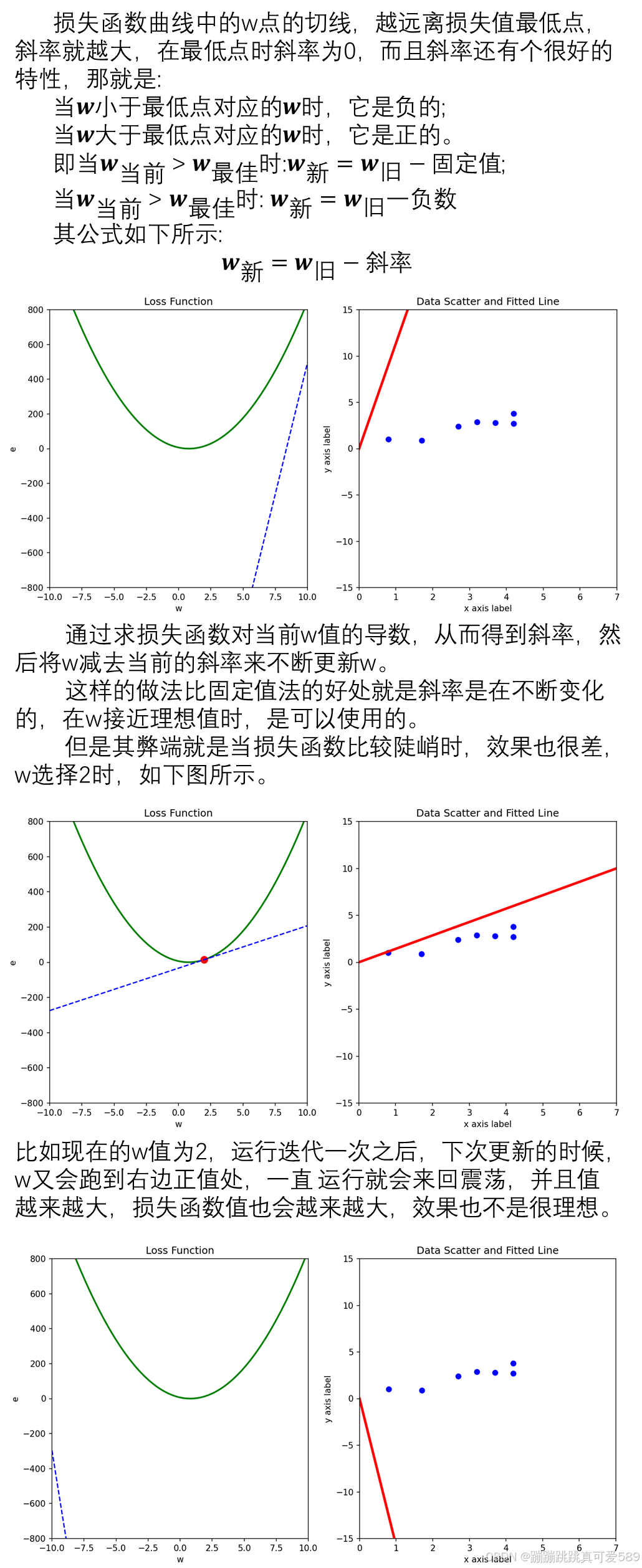
3.3、小固定值*斜率法
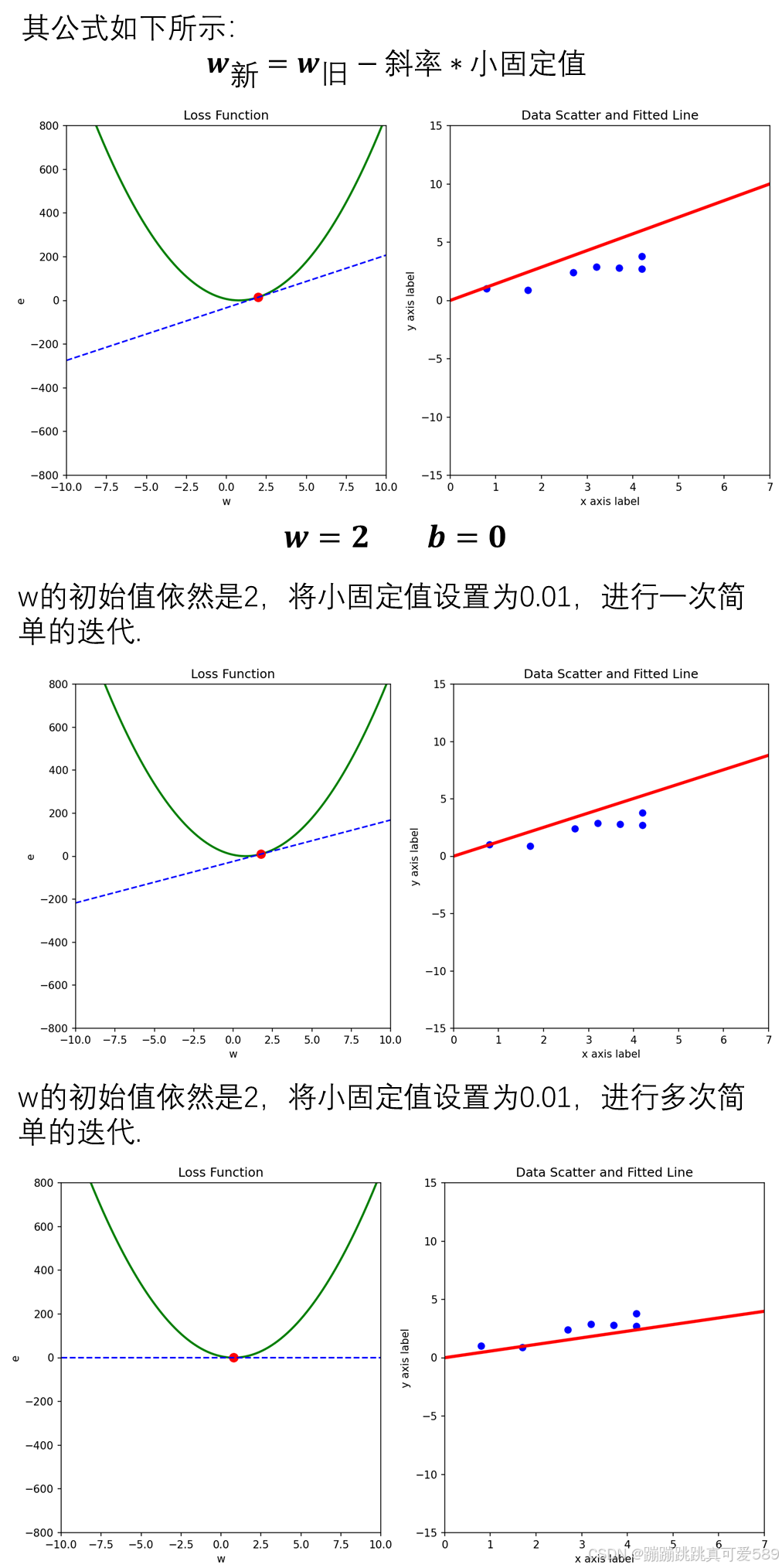
斜率法的优点是其更新的方向明确,就是梯度的方向,但是当斜率值过大时,会不受控制。于是为了解 决斜率法的弊端,就提出了上面对斜率值的大小进行限制的方法,通过一个小固定值*斜率,使w每次更 新的幅度不会太大,从而保证能够使w能向正确的方向更新。
在第三个式子中,小固定值被称为学习率,通过改变学习率的值能调整w的更新速度,而整个式子就叫 做梯度下降(Gradient Descent,GD),是一种优化函数,作用是降低损失。 于是,我们可以在输入一套参数后,令模型在反向传播的过程中通过梯度下降的方式来更新参数,使损 失函数值变小,从而使其能够更加准确的描述植物的环境温度与其生长高度的关系。
3.4、学习率和梯度下降
在机器学习中,学习率是一个超参数,用于控制权重更新的速度。通常来说,学习率越大,参数更新就 越快,模型就越快学习,但如果学习率过大,模型可能会不稳定,甚至无法收敛到最优解。因此,确定 一个合适的学习率是非常重要的。
梯度下降是机器学习中一种常用的优化算法。它的基本思想是在训练过程中通过不断调整参数,使损失 函数(代表模型预测结果与真实结果之间的差距)达到最小值。为了实现这一目标,梯度下降算法会计 算损失函数的梯度(带方向的斜率),然后根据梯度的方向更新权重,使损失函数不断减小。
对于一个模型来说,我们可以计算每一个权重对损失函数的影响程度,然后根据损失函数的梯度来更新 这些权重。一般来说,如果梯度是负的,那么我们就需要增加权重的值,反之,如果梯度是正的,我们 就需要减小权重的值。通过不断重复这一过程,我们就可以找到一组使损失函数最小的权重值,从而训 练出一个优秀的模型。
四、设计思路
模块导入
import numpy as np
import matplotlib.pyplot as plt数据聚集输入
data = np.array([[0.8,1.0],[1.7,0.9],[2.7,2.4],[3.2,2.9],[3.7,2.8],[4.2,3.8],[4.2,2.7]])
#将特征和标签(需要拟合的目标)分离
x_data=data[:,0]
y_data=data[:,1]
前向计算
w_old=2
w_new=0
b=0
y_hat=w_old*x_data+b
#学习率
learning=0.01单点误差
e=y_data-y_hat均方误差(损失函数)
e_=(np.mean((y_data-y_hat)**2))图像绘制
批量梯度下降法
w_new=w_old-0.5随机梯度下降法
w_new=w_old*K小批量梯度下降法
w_new=w_old-K*learning
fig=plt.figure(figsize=(10,5))
ax1=fig.add_subplot(1,2,1)
ax2=fig.add_subplot(1,2,2)for i in range(5):ax1.cla()ax2.cla()#k=1/n(2*w)*x**2-1/n(xy)K=2*w_old*np.mean(x_data**2)-2*np.mean(x_data*y_data)y_hat = w_new * x_data + be_=np.mean(y_hat-y_data)**2w_values = np.linspace(-10, 10, 200) # w 取值范围e_values = [np.mean(y_data - (w_value * x_data + b)) ** 2 for w_value in w_values]ax1.set_xlim(-10, 10)ax1.set_ylim(-800, 800)ax1.set_xlabel("w")ax1.set_ylabel("e")ax1.set_title("Loss Function")ax1.plot(w_values, e_values, color='g', linewidth=2) # 绘制损失函数曲线ax1.plot(w_old, e_, marker='o', markersize=8, color='r') # 标记当前 w 值对应的损失# 计算切线斜率和截距tangent_point = np.mean((y_data - (w_old * x_data + b)) ** 2) # 在 w_old 处对应的损失tangent_slope = -2 * np.mean(x_data * y_data) + 2 * w_old * np.mean(x_data ** 2) # 切线的斜率为损失函数在 w_old 处的导数tangent_intercept = tangent_point - tangent_slope * w_old # 切线的截距# 绘制切线tangent_line = tangent_slope * w_values + tangent_interceptax1.plot(w_values, tangent_line, color='b', linestyle='--') # 绘制切线# 右侧子图:散点和拟合直线ax2.set_xlim(0, 7)ax2.set_ylim(-15, 15)ax2.set_xlabel("x axis label")ax2.set_ylabel("y axis label")ax2.scatter(x_data, y_data, color='b') # 绘制训练数据散点图y_lower_lr = w_old * 0 + by_upper_lr = w_old * 5 + bax2.plot([0, 7], [y_lower_lr, y_upper_lr], color='r', linewidth=3) # 绘制线性回归直线ax2.set_title("Data Scatter and Fitted Line")# 批量梯度下降法# w_new=w_old-0.5# # 随机梯度下降法# w_new=w_old*K# # 小批量梯度下降法w_new=w_old-K*learningw_old = w_newplt.pause(1)
plt.show()完整代码
import numpy as np # 导入 NumPy 库用于数值计算
import matplotlib.pyplot as plt # 导入 Matplotlib 库用于数据可视化 # 1. 数据聚集输入
data = np.array( # 定义一个包含 x 和 y 数据点的 NumPy 数组 [ [0.8, 1.0], [1.7, 0.9], [2.7, 2.4], [3.2, 2.9], [3.7, 2.8], [4.2, 3.8], [4.2, 2.7] ])
# 将特征和标签(需要拟合的目标)分离
x_data = data[:, 0] # 提取 x 数据作为特征
y_data = data[:, 1] # 提取 y 数据作为标签 # 2. 前向计算 y = w * x + b
w_old = 2 # 初始化旧的权重(斜率)
w_new = 0 # 初始化新的权重
b = 0 # 初始化偏置(截距)
y_hat = w_old * x_data + b # 计算预测值 # 学习率
learning = 0.01 # 定义学习率,用于更新权重 # 3. 单点误差
e = y_data - y_hat # 计算每个数据点的误差(真实值与预测值之差) # 4. 均方误差(损失函数)
e_ = (np.mean((y_data - y_hat) ** 2)) # 计算均方误差(MSE) # 5. 图像绘制
fig = plt.figure(figsize=(10, 5)) # 创建一个图形对象,设置图形尺寸
ax1 = fig.add_subplot(1, 2, 1) # 左侧子图
ax2 = fig.add_subplot(1, 2, 2) # 右侧子图 # 进行多次迭代以展示梯度下降过程
for i in range(5): ax1.cla() # 清除左侧子图内容 ax2.cla() # 清除右侧子图内容 # 计算梯度 K(损失函数的导数) K = 2 * w_old * np.mean(x_data ** 2) - 2 * np.mean(x_data * y_data) # K 为损失函数对 w 的导数 y_hat = w_new * x_data + b # 更新预测值 e_ = np.mean(y_hat - y_data) ** 2 # 计算当前 w_new 的均方误差(损失) w_values = np.linspace(-10, 10, 200) # 创建一个从 -10 到 10 的权重值数组 e_values = [np.mean(y_data - (w_value * x_data + b)) ** 2 for w_value in w_values] # 计算不同 w 值对应的均方误差 # 图像装饰 ax1.set_xlim(-10, 10) # 设置 x 轴范围 ax1.set_ylim(-800, 800) # 设置 y 轴范围 ax1.set_xlabel("w") # x 轴标签 ax1.set_ylabel("e") # y 轴标签 ax1.set_title("Loss Function") # 子图标题 ax1.plot(w_values, e_values, color='g', linewidth=2) # 绘制损失函数曲线 ax1.plot(w_old, e_, marker='o', markersize=8, color='r') # 标记当前 w 值对应的损失 # 计算切线的斜率和截距 tangent_point = np.mean((y_data - (w_old * x_data + b)) ** 2) # 在 w_old 处的损失值 tangent_slope = -2 * np.mean(x_data * y_data) + 2 * w_old * np.mean(x_data ** 2) # 切线的斜率 tangent_intercept = tangent_point - tangent_slope * w_old # 切线的截距 # 绘制切线 tangent_line = tangent_slope * w_values + tangent_intercept # 计算切线方程 ax1.plot(w_values, tangent_line, color='b', linestyle='--') # 绘制切线 # 右侧子图:散点和拟合直线 ax2.set_xlim(0, 7) # 设置 x 轴范围 ax2.set_ylim(-15, 15) # 设置 y 轴范围 ax2.set_xlabel("x axis label") # x 轴标签 ax2.set_ylabel("y axis label") # y 轴标签 ax2.scatter(x_data, y_data, color='b') # 绘制训练数据散点图 y_lower_lr = w_old * 0 + b # 拟合线在 x=0 时的 y 值 y_upper_lr = w_old * 5 + b # 拟合线在 x=5 时的 y 值 ax2.plot([0, 7], [y_lower_lr, y_upper_lr], color='r', linewidth=3) # 绘制线性回归直线 ax2.set_title("Data Scatter and Fitted Line") # 子图标题 # 批量梯度下降法 # w_new = w_old - 0.5 # 随机梯度下降法 # w_new = w_old * K # 小批量梯度下降法 w_new = w_old - K * learning # 更新权重,使用计算得出的 K 和学习率 w_old = w_new # 将新的权重传递给 w_old plt.pause(1) # 暂停 1 秒以展示动画效果
plt.show() # 展示绘图结果 相关文章:
)
Python----机器学习(线性回归:反向传播和梯度下降)
一、前向传播与反向传播的区别 前向传播是在参数固定后,向公式中传入参数,进行预测的一个过程。当参 数值选择的不恰当时,会导致最后的预测值不符合我们的预期,于是我们就 需要重新修改参数值。 在前向传播实验中时,我…...

如何平衡元器件成本与性能
要平衡元器件成本与性能,企业应当明确设计需求和目标、优化元器件选型策略、建立成本性能评估体系、推进标准化设计、加强供应链管理。其中,优化元器件选型策略尤其关键,它直接关系到产品的成本、性能与生命周期。在选型时,工程师…...

java项目分享-分布式电商项目附软件链接
今天来分享一下github上最热门的开源电商项目安装部署,star 12.2k,自行安装部署历时两天,看了这篇文章快的话半天搞定!该踩的坑都踩完了,软件也打包好了就差喂嘴里。 项目简介 mall-swarm是一套微服务商城系统…...

低代码框架
在数字化转型浪潮中,软件开发的效率与成本成为企业关注的焦点。低代码框架应运而生,以其独特的开发模式,打破了传统软件开发的壁垒,为企业和开发者带来了全新的解决方案。那么,究竟什么是低代码框架呢? …...

Git Reset 命令详解与实用示例
文章目录 Git Reset 命令详解与实用示例git reset 主要选项git reset 示例1. 撤销最近一次提交(但保留更改)2. 撤销最近一次提交,并清除暂存区3. 彻底撤销提交,并丢弃所有更改4. 回退到特定的提交5. 取消暂存的文件 git reset 与 …...
)
多层内网渗透测试虚拟仿真实验环境(Tomcat、ladon64、frp、Weblogic、权限维持、SSH Server Wrapper后门)
在线环境:https://www.yijinglab.com/ 拓扑图 信息收集 IP地址扫描 确定目标IP为10.1.1.121 全端口扫描 访问靶机8080端口,发现目标是一个Tomcat服务,版本...

<贪心算法>
前言:在主包还没有接触算法的时候,就常听人提起“贪心”,当时是layman,根本不知道说的是什么,以为很难呢,但去了解一下,发现也不过如此嘛(bushi),还以为是什么高级东西呢…...
并训练Fashion-MNIST)
使用PyTorch实现GoogleNet(Inception)并训练Fashion-MNIST
GoogleNet(又称Inception v1)是2014年ILSVRC冠军模型,其核心创新是Inception模块,通过并行多尺度卷积提升特征提取能力。本文将展示如何用PyTorch实现GoogleNet,并在Fashion-MNIST数据集上进行训练。 1. 环境准备 im…...

KingbaseES物理备份还原之备份还原
此篇续接上一篇<<KingbaseES物理备份还原之物理备份>>,上一篇写物理备份相关操作,此篇写备份还原的具体操作步骤. KingbaseES版本:V009R004C011B003 一.执行最新物理备份还原 --停止数据库服务,并创建物理备份还原测试目录 [V9R4C11B3192-168-198-198 V8]$ sys_ct…...
之ForwardAdd(标准版))
Unity Standard Shader 解析(二)之ForwardAdd(标准版)
一、ForwardAdd // Additive forward pass (one light per pass)Pass{Name "FORWARD_DELTA"Tags { "LightMode" "ForwardAdd" }Blend [_SrcBlend] OneFog { Color (0,0,0,0) } // in additive pass fog should be blackZWrite OffZTest LEqual…...

.NET 使用 WMQ 连接Queue 发送 message 实例
1. 首先得下载客户端,没有客户端无法发送message. 安装好之后长这样 我装的是7.5 安装目录如下 tools/dotnet 目录中有演示的demo 2. .Net 连接MQ必须引用bin目录中的 amqmdnet.dll 因为他是创建Queuemanager 的核心库, 项目中引用using IBM.WMQ; 才…...

设计模式之单例模式
视频链接: 设计模式|狂神说 单例模式是什么? 单例模式是确保一个类在整个应用程序中只有一个实例,并提供一个全局方法访问这个实例。 单例模式分为饿汉式和懒汉式。 饿汉式单例 饿汉式顾名思义就是,程序一启动就创建这个单例bea…...

从入门到入土,SQLServer 2022慢查询问题总结
列为,由于公司原因,作者接触了一个SQLServer 2022作为数据存储到项目,可能是上一任的哥们儿离开的时候带有情绪,所以现在项目的主要问题就是,所有功能都实现了,但是就是慢,列表页3s打底,客户很生气,经过几周摸爬滚打,作以下总结,作为自己的成长记录。 一、索引问题…...

大语言模型在端到端智驾中的应用
大语言模型在端到端智驾中的应用 双系统端到端 小鹏:AI天玑系统—神经网络XNet规控大模型XPlanner大语言模型XBrain 商汤绝影:DriveAGI 理想:端到端VLM VLA端到端 Waymo:EMMA OPENEMMA Wayve:LINGO-2...
——基于miniQMT的量化交易回测系统开发实记)
【深度学习量化交易19】行情数据获取方式比测(1)——基于miniQMT的量化交易回测系统开发实记
我是Mr.看海,我在尝试用信号处理的知识积累和思考方式做量化交易,应用深度学习和AI实现股票自动交易,目的是实现财务自由~ 目前我正在开发基于miniQMT的量化交易系统——看海量化交易系统。 经常使用MiniQMT的朋友都知道,xtquant的…...

《网络管理》实践环节03:snmp服务器上对网络设备和服务器进行初步监控
兰生幽谷,不为莫服而不芳; 君子行义,不为莫知而止休。 应用拓扑图 3.0准备工作 所有Linux服务器上(服务器和Agent端)安装下列工具 yum -y install net-snmp net-snmp-utils 保证所有的HCL网络设备和服务器相互间能…...

linux操作系统
1.linux进程管理 操作系统都有进程的概念 查看和关闭程序 2.关闭进程 3,查看计算机硬件信息 4.定时任务...

Python基础语法 - 判断语句
Python基础语法 - 判断语句 1. if语句 if 条件:# 条件为True时执行的代码示例 age 18 if age > 18:print("您已成年")2. if-else语句 if 条件:# 条件为True时执行的代码 else:# 条件为False时执行的代码示例 age 16 if age > 18:print("您已成年&q…...

c++柔性数组、友元、类模版
目录 1、柔性数组: 2、友元函数: 3、静态成员 注意事项 面试题:c/c static的作用? C语言: C: 为什么可以创建出 objx 4、对象与对象之间的关系 5、类模版 1、柔性数组: #define _CRT_SECURE_NO_WARNINGS #…...

电子技术基础
目录 一、整体概述 二、知识点梳理及考点分析 (一)半导体器件 (二)基本放大电路 (三)功率放大电路 (四)集成运算放大器 (五)直流稳压电源 ࿰…...

解码大模型时代算力基座的隐形引擎
在千亿参数大模型竞速的今天,算力军备竞赛已进入白热化阶段。当我们聚焦GPU集群的运算峰值时,一个关键命题正在浮出水面:支撑大模型全生命周期的存力基座,正在成为制约AI进化的关键变量。绿算技术将深入解剖大模型训练与推理场景中…...

【NetCore】ControllerBase:ASP.NET Core 中的基石类
ControllerBase:ASP.NET Core 中的基石类 一、什么是 ControllerBase?二、ControllerBase 的主要功能三、ControllerBase 的常用属性四、ControllerBase 的常用方法2. 模型绑定与验证3. 依赖注入五、ControllerBase 与 Controller 的区别六、实际开发中的最佳实践七、总结在 …...

人工智能之数学基础:矩阵分解之LU分解
本文重点 LU分解是线性代数中一种重要的矩阵分解方法,它将一个方阵分解为一个下三角矩阵(L)和一个上三角矩阵(U)的乘积。这种分解方法在数值线性代数中有着广泛的应用,特别是在求解线性方程组、计算矩阵的行列式、求逆矩阵等方面。 LU分解的基本概念 设A是一个nn的方阵…...
面向对象--封装(5)静态成员及静态构造函数和静态类 以及和常量的区别)
C#核心学习(六)面向对象--封装(5)静态成员及静态构造函数和静态类 以及和常量的区别
目录 一、什么是静态的?什么是常量? 1. 静态(Static) 2. 常量(const) 二、类中的静态成员有什么用? 1. 共享数据 2. 工具方法与全局配置 3. 单例模式 三、静态类和静态成…...

去中心化稳定币机制解析与产品策略建议
去中心化稳定币机制解析与产品策略建议(以Maker/DAI为例) 一、核心机制对比:法币抵押型 vs. 加密货币抵押型 法币抵押型(如USDT) 技术逻辑:1:1美元储备托管于中心化机构(如银行)&…...

构造超小程序
文章目录 构造超小程序1 编译器-大小优化2 编译器-移除 C 异常3 链接器-移除所有依赖库4 移除所有函数依赖_RTC_InitBase() _RTC_Shutdown()__security_cookie __security_check_cookie()__chkstk() 5 链接器-移除清单文件6 链接器-移除调试信息7 链接器-关闭随机基址8 移除异常…...

JSONP跨域访问漏洞
一、漏洞一:利用回调GetCookie <?php$conn new mysqli(127.0.0.1,root,root,learn) or die("数据库连接不成功"); $conn->set_charset(utf8); $sql "select articleid,author,viewcount,creattime from learn3 where articleid < 5"; $result…...

数据结构优化DP总结
单调栈:Codeforces Round 622 (Div. 2) C2. Skyscrapers (hard version) 简单来讲就是最后需要呈现出一个单峰数组,使得总高度最高。 最开始想到暴力枚举每一个元素都充当最高的“单峰”,但是这里的 n 过大,这样枚举肯定会TLE。 …...
(序列化和反序列化、TCP协议、会话和守护进程))
Linux网络相关概念和重要知识(4)(序列化和反序列化、TCP协议、会话和守护进程)
目录 1.序列化和反序列化 (1)为什么需要序列化 (2)序列化方案 ①json ②json序列化代码模板 ③json反序列化代码模板 ④将自定义方案和json结合 2.TCP协议(传输控制协议) (1)…...

[MySQL初阶]MySQL数据库基础
MySQL数据库基础 1. 数据库基础1.1 什么是数据库1.2 主流数据库2. 数据库的基本使用2.1 连接服务器2.2 使用案例2.3 数据逻辑存储3. MySQL架构与分类3.1 MySQL架构3.2 SQL分类4. 存储引擎4.1 存储引擎基本概念4.2 存储引擎基本操作1. 数据库基础 1.1 什么是数据库 存储数据用…...

【mysql 的安装及使用】
MySQL 9.0 一、下载MySQL[MySQL 9.0 下载] [(https://dev.mysql.com/downloads/mysql/)选择自定义,选择合适安装路径二、检查安装情况配置环境变量打开命令行查看版本创建数据库在MySQL中,可以使用create database语句来创建数据库。以下是创建一个名为my_db的数据库的示例:…...

d202542
一、142.环形链表I 142. 环形链表 II - 力扣(LeetCode) 用set统计一下 如果再次出现那么就环的第一个return返回就行 public ListNode detectCycle(ListNode head) {Set<ListNode> set new HashSet<>();ListNode cur head;while(cur ! …...

vscode代码片段的设置与使用
在 Visual Studio Code (VS Code) 中,可以通过自定义**代码片段(Snippets)**快速插入常用代码模板。以下是详细设置步骤: 步骤 1:打开代码片段设置 按下快捷键 Ctrl Shift P(Windows/Linux)或…...

3D 地图渲染-区域纹理图添加
引入-初始化地图(关键代码) // 初始化页面引入高德 webapi -- index.html 文件 <script src https://webapi.amap.com/maps?v2.0&key您申请的key值></script>// 添加地图容器 <div idcontainer ></div>// 地图初始化应该…...

spring-security原理与应用系列:HttpSecurity.filters
目录 AnyRequestMatcher WebSecurityConfig HttpSecurity AbstractInterceptUrlConfigurer AbstractAuthenticationProcessingFilter 类图 在前面的文章《spring-security原理与应用系列:securityFilterChainBuilders》中,我们遗留了一个问题&…...

每日总结4.2
蓝桥杯刷题: 1. 方格分割(dfs,选中心点,开始上下左右遍历,达到边界时数量加一) #include <bits/stdc.h> using namespace std; bool vis[10][10]; int mp[10][10]; int ans0; int dx[4]{1,0,0,-1}; int dy[4]{…...
:分布式存储 Leader 设计)
架构师面试(二十五):分布式存储 Leader 设计
问题 在非常多的分布式存储系统中,如:Zookeeper、Etcd、Kafka等,往往会存在一个 【Leader】 角色,并由该角色负责数据的写入,这样设计最主要的原因是什么呢? A. 唯一负责数据写入的 Leader 角色可以避免并…...

mycat --分片规则--
文章目录 MyCat分片规则详解1. rule1 (基于id的func1算法)2. sharding-by-date (按日期分片)3. rule2 (基于user_id的func1算法)4. sharding-by-intfile (基于枚举值分片)5. auto-sharding-long (长整型范围分片)6. mod-long (取模分片)7. sharding-by-murmur (MurmurHash分片)…...

系统分析师备考启动
以考促学:软件高级系统分析师。 一、考试目的: 1、练习三遍读书法、快速阅读、番茄工作法、第一性原理、思维导图等学习方法和学习工具的使用。 2、掌握知识、编织知识网、顺便拿证。 二、组织形式: 小组统一安排学习内容,每…...

轻量级搜索接口技术解析:快速实现关键词检索的Java/Python实践
Hi,你好! 轻量级搜索接口技术解析:快速实现关键词检索的Java/Python实践 接口特性与适用场景 本接口适用于需要快速集成搜索能力的开发场景,支持通过关键词获取结构化搜索结果。典型应用场景包括: 垂直领域信息检索…...

防爆风扇选型指南:根据风量风压匹配应用场景
在化工、石油、煤矿等存在易燃易爆气体或粉尘的危险环境中,通风设备的安全性能至关重要,防爆风扇成为保障生产环境安全与空气流通的关键装备。正确选型是确保其发挥最佳效能的前提,而根据风量风压匹配应用场景则是选型的核心要点。 风量&am…...

Laravel 中使用 JWT 作用户登录,身份认证
什么是JWT: JWT 全名 JSON Web Token,是一种开放标准 (RFC 7519)。 用于在网络应用环境间安全地传输信息作为 JSON 对象。 它是一种轻量级的认证和授权机制,特别适合分布式系统的身份验证。 核心特点 紧凑格式:体积小&#x…...

Git安装
1、 下载Git https://git-scm.com/ 2、 双击【Git-2.44.0-64-bit.exe】安装: 2-1、 选择自定义安装目录:F:\software\Git 2-2、 一直点击next,直到安装成功。 2-3、 在git项目文件夹,右键出现Git GUI Here和Git Bash Here就说明成…...

bit与byte的区别与联系?
李升伟 整理 byte 和 bit 是计算机中常用的数据单位,它们的主要区别和联系如下: 1. 定义 bit(比特):计算机中最小的数据单位,表示一个二进制位,值为0或1。 byte(字节)…...
:Cookie映射与移动设备ID映射解析)
程序化广告行业(51/89):Cookie映射与移动设备ID映射解析
程序化广告行业(51/89):Cookie映射与移动设备ID映射解析 在当今数字化营销的浪潮中,程序化广告已经成为企业精准触达目标客户的重要手段。作为一名对程序化广告充满兴趣的学习者,我希望通过这篇博客和大家一起深入探索…...

从吉卜力漫画到艺术创造:GPT-4o多种风格绘图Prompt大全
在3月底,GPT-4o掀起了一阵吉卜力绘图浪潮,大家纷纷输入一张图片,让4o模型进行风格化迁移,其中吉卜力风格的漫画在社交媒体上最为火热。在大家争议4o的训练数据是否侵权和4o背后的技术原理的时候,我们先来玩一玩&#x…...

48. 旋转图像
leetcode Hot 100系列 文章目录 一、核心操作二、外层配合操作三、核心模式代码总结 一、核心操作 先上下翻转再沿着对角线翻转 提示:小白个人理解,如有错误敬请谅解! 二、外层配合操作 三、核心模式代码 代码如下: class S…...

【Linux篇】自主Shell命令行解释器
📌 个人主页: 孙同学_ 🔧 文章专栏:Liunx 💡 关注我,分享经验,助你少走弯路! 文章目录 1. 获取用户名的接口2. 等待用户输入接口3. 将上述代码进行面向对象式的封装4. 命令行解析5.…...

leetcode 2873. 有序三元组中的最大值 I
欢迎关注更多精彩 关注我,学习常用算法与数据结构,一题多解,降维打击。 文章目录 题目描述题目剖析&信息挖掘解题思路方法一 暴力枚举法思路注意复杂度代码实现 方法二 公式拆分动态规划思路注意复杂度代码实现 题目描述 [2873] 有序三元…...

深度学习 Deep Learning 第14章 自编码器
深度学习 Deep Learning 第14章 自编码器 内容概要 本章深入探讨了自编码器(Autoencoders),这是一种用于特征学习和降维的神经网络架构。自编码器通过编码器和解码器两个部分,将输入数据映射到一个内部表示(编码&…...