Elasticsearch笔记
官网
https://www.elastic.co/docs
简介
Elasticsearch 是一个分布式、开源的搜索引擎,专门用于处理大规模的数据搜索和分析。它基于 Apache Lucene 构建,具有实时搜索、分布式计算和高可扩展性,广泛用于 全文检索、日志分析、监控数据分析 等场景。
Elasticsearch 生态
- Elasticsearch:核心搜索引擎,负责存储、索引和搜索数据
- Kibana:可视化平台,用于查询、分析和展示Elasticsearch 中的数据。
- Logstash:数据处理管道,负责数据收集、过滤、增强和传输到 Elasticsearch。
- Beats:轻量级的数据传输工具,收集和发送数据到 Logstash 或 Elasticsearch。
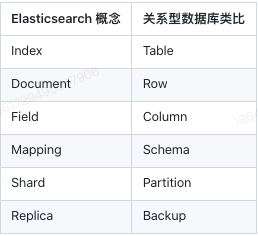
核心概念
-
索引(Index):类似于关系型数据库中的表,索引是数据存储和搜索的 基本单位。每个索引可以存储多条文档数据。
-
文档(Document):索引中的每条记录,类似于数据库中的行。文档以 JSON 格式存储。
-
字段(Field):文档中的每个键值对,类似于数据库中的列。
-
映射(Mapping):用于定义 Elasticsearch 索引中文档字段的数据类型及其处理方式,类似于关系型数据库中的 Schema 表结构,帮助控制字段的存储、索引和查询行为。
-
集群(Cluster):多个节点组成的群集,用于存储数据并提供搜索功能。集群中的每个节点都可以处理数据。
-
分片(Shard):为了实现横向扩展,ES 将索引拆分成多个分片,每个分片可以分布在不同节点上。
-
副本(Replica):分片的复制品,用于提高可用性和容错性。
全文索引
分词
Elasticsearch 的分词器会将输入文本拆解成独立的词条tokens,方便进行索引和搜索。分词的具体过程包括以下几步:
1.字符过滤:去除特殊字符、HTML 标签或进行其他文本清理。
2.分词:根据指定的分词器(analyzer),将文本按规则拆分成一个个词条。例如,英文可以按空格拆分,中文使用专门的分词器处理。
3.词汇过滤:对分词结果进行过滤,如去掉停用词(常见但无意义的词,如 “the”、“is” 等)或进行词形归并(如将动词变为原形)。
倒排索引
倒排索引与传统正排索引相反,通过词项到文档的映射实现快速检索。例如,正排索引类似书籍目录(文档→内容),而倒排索引类似索引页(关键词→页码)
- 分词与规范化:文档内容经分词器(如IK分词器)拆分为词项,去除停用词并进行规范化处理(如小写转换、词干提取) 例如,中文“生存还是死亡”分词为“生存”“死亡”,并记录其文档ID、位置等信息。
- 存储结构:倒排索引由**单词词典(Term Dictionary)和倒排列表(Posting List)**组成。词典存储词项及指向倒排列表的指针,倒排列表记录包含该词项的文档ID、词频(TF)、位置(POS)等信息
打分规则
打分规则(_Score)是用于衡量每个文档与查询条件的匹配度的评分机制。搜索结果的默认排序方式是按相关性得分(_score)从高到低。Elasticsearch 使用 BM25 算法 来计算每个文档的得分,它是基于词频、反向文档频率、文档长度等因素来评估文档和查询的相关性。
打分主要因素:
- 词频(TF, Term Frequency):查询词在文档中出现的次数,出现次数越多,得分越高。
- 反向文档频率(IDF, Inverse Document Frequency):查询词在所有文档中出现的频率。词在越少的文档中出现,IDF 值越高,得分越高。
- 文档长度:较短的文档往往被认为更相关,因为查询词在短文档中占的比例更大。
查询语法
DSL 查询(Domain Specific Language)
一种基于 JSON 的查询语言,它是 Elasticsearch 中最常用的查询方式。
{"query": {"match": {"message": "Elasticsearch 是强大的"}}
}这个查询会对 message 进行分词,并查找包含 “Elasticsearch” 和 “强大” 词条的文档。
EQL( Event Query Language)
是一种用于检测和检索时间序列 事件 的查询语言,常用于日志和安全监控场景。
process where process.name == "malware.exe"SQL 查询
Elasticsearch 提供了类似于传统数据库的 SQL 查询语法,允许用户以 SQL 的形式查询 Elasticsearch 中的数据。
SELECT name, age FROM users WHERE age > 30 ORDER BY age DESC查询条件
match
用于全文检索,将查询字符串进行分词并匹配文档中对应的字段。适用于全文检索,分词后匹配文档内容。
{ "match": { "content": "你好" } }
term
精确匹配查询,不进行分词。通常用于结构化数据的精确匹配,如数字、日期、关键词等。适用于字段的精确匹配,如状态、ID、布尔值等。
{ "term": { "status": "active" } }
terms
匹配多个值中的任意一个,相当于多个 term 查询的组合。适用于多值匹配的场景。
{ "terms": { "status": ["active", "pending"] } }
range
范围查询,常用于数字、日期字段,支持大于、小于、区间等查询。适用于数值或日期的范围查询。
{ "range": { "age": { "gte": 18, "lte": 30 } } }
wildcard
通配符查询,支持 * 和 ?,前者匹配任意字符,后者匹配单个字符。适用于部分匹配的查询,如模糊搜索。
{ "wildcard": { "name": "鱼*" } }
bool
组合查询,通过 must、should、must_not 等组合多个查询条件。适用于复杂的多条件查询,可以灵活组合。
{ "bool": { "must": [
{ "term": { "status": "active" } },
{ "range": { "age": { "gte": 18 } } } ] } }
其他查询条件查看官网
数据同步
数据流向:mysql->ES
数据同步一般有 2 个过程:全量同步(首次)+ 增量同步(新数据)
1.定时任务
比如 1 分钟 1 次,找到 MySQL 中过去几分钟内(至少是定时周期的 2 倍)发生改变的数据,然后更新到 ES。
2.双写
写数据的时候,必须也去写 ES;更新删除数据库同理。
可以通过事务保证数据一致性,使用事务时,要先保证 MySQL 写成功,因为如果 ES 写入失败了,不会触发回滚,但是可以通过定时任务 + 日志 + 告警进行检测和修复。
3.Logstash 数据同步管道
一般要配合 消息队列 + beats 采集器
4.监听 MySQL Binlog
有任何数据变更时都能够实时监听到,并且同步到 Elasticsearch。一般不需要自己监听,可以使用现成的技术,比如 Canal 。
Canal 的核心原理:数据库每次修改时,会修改 binlog 文件,只要监听该文件的修改,就能第一时间得到消息并处理
环境搭建
1.安装Elasticsearch
查看是否兼容:文档
安装参考官方文档
Windows解压安装:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/zip-windows.html
其他系统安装:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/targz.html
进入es目录:.\bin\elasticsearch.bat
2.安装Kibana
只要是同一套技术,所有版本必须一致!
参考官方文档
安装Kibana
进入目录执行
.\bin\kibana.bat
访问 http://localhost:5601/即可
实战(两种方法)
1.引入依赖
<!-- elasticsearch-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>2.修改配置
spring:elasticsearch:uris: http://xxx:9200username: elasticpassword: coder_swag3.测试
@SpringBootTest
public class ElasticsearchRestTemplateTest {@Autowiredprivate ElasticsearchRestTemplate elasticsearchRestTemplate;private final String INDEX_NAME = "test_index";// Index (Create) a document@Testpublic void indexDocument() {Map<String, Object> doc = new HashMap<>();doc.put("title", "Elasticsearch Introduction");doc.put("content", "Learn Elasticsearch basics and advanced usage.");doc.put("tags", "elasticsearch,search");doc.put("answer", "Yes");doc.put("userId", 1L);doc.put("editTime", "2023-09-01 10:00:00");doc.put("createTime", "2023-09-01 09:00:00");doc.put("updateTime", "2023-09-01 09:10:00");doc.put("isDelete", false);IndexQuery indexQuery = new IndexQueryBuilder().withId("1").withObject(doc).build();String documentId = elasticsearchRestTemplate.index(indexQuery, IndexCoordinates.of(INDEX_NAME));assertThat(documentId).isNotNull();}// Get (Retrieve) a document by ID@Testpublic void getDocument() {String documentId = "1"; // Replace with the actual ID of an indexed documentMap<String, Object> document = elasticsearchRestTemplate.get(documentId, Map.class, IndexCoordinates.of(INDEX_NAME));assertThat(document).isNotNull();assertThat(document.get("title")).isEqualTo("Elasticsearch Introduction");}// Update a document@Testpublic void updateDocument() {String documentId = "1"; // Replace with the actual ID of an indexed documentMap<String, Object> updates = new HashMap<>();updates.put("title", "Updated Elasticsearch Title");updates.put("updateTime", "2023-09-01 10:30:00");UpdateQuery updateQuery = UpdateQuery.builder(documentId).withDocument(Document.from(updates)).build();elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of(INDEX_NAME));Map<String, Object> updatedDocument = elasticsearchRestTemplate.get(documentId, Map.class, IndexCoordinates.of(INDEX_NAME));assertThat(updatedDocument.get("title")).isEqualTo("Updated Elasticsearch Title");}// Delete a document@Testpublic void deleteDocument() {String documentId = "1"; // Replace with the actual ID of an indexed documentString result = elasticsearchRestTemplate.delete(documentId, IndexCoordinates.of(INDEX_NAME));assertThat(result).isNotNull();}// Delete the entire index@Testpublic void deleteIndex() {IndexOperations indexOps = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(INDEX_NAME));boolean deleted = indexOps.delete();assertThat(deleted).isTrue();}
}4.通过kibana查看
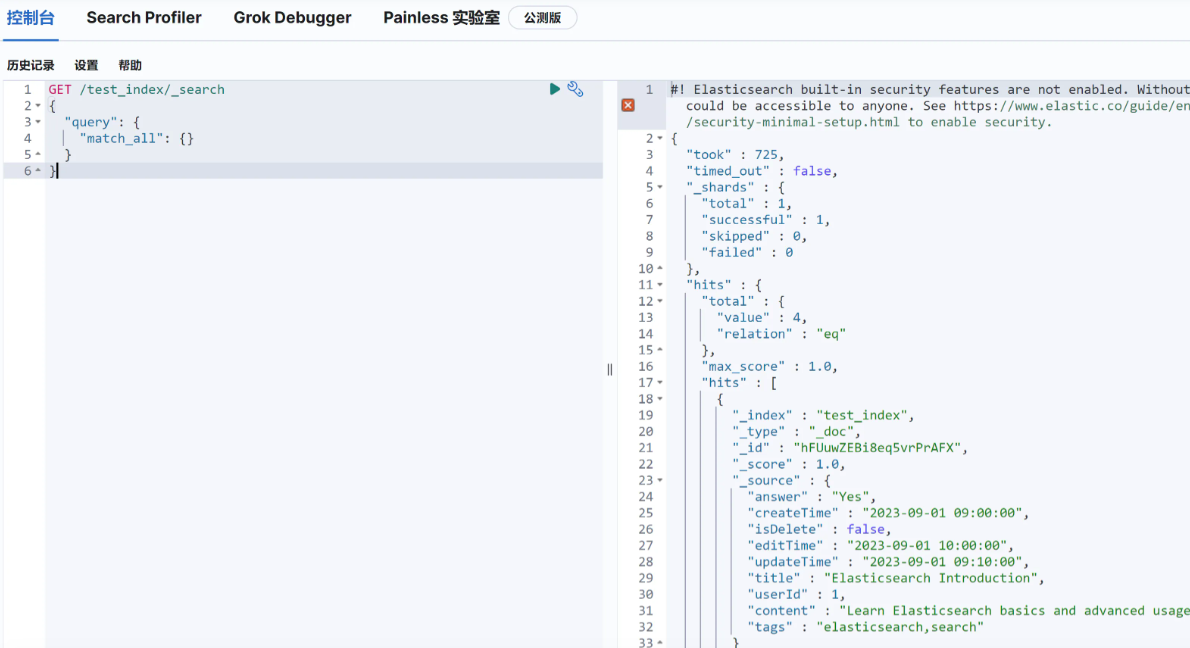
上述代码都是用 Map 来传递数据。记得之前使用 MyBatis 操作数据库的时候,都要定义一个数据库实体类,然后把参数传给这个实体类的对象就可以了,会更方便和规范。
没错,Spring Data Elasticsearch 也是支持这种标准 Dao 层开发方式的
5.编写 ES Dao 层
5.1 定义实体类
@Document(indexName = "question")
@Data
public class QuestionEsDTO implements Serializable {private static final String DATE_TIME_PATTERN = "yyyy-MM-dd HH:mm:ss";/*** id*/@Idprivate Long id;/*** 标题*/private String title;/*** 内容*/private String content;/*** 答案*/private String answer;/*** 标签列表*/private List<String> tags;/*** 创建用户 id*/private Long userId;/*** 创建时间*/@Field(type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)private Date createTime;/*** 更新时间*/@Field(type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)private Date updateTime;/*** 是否删除*/private Integer isDelete;private static final long serialVersionUID = 1L;/*** 对象转包装类** @param question* @return*/public static QuestionEsDTO objToDto(Question question) {if (question == null) {return null;}QuestionEsDTO questionEsDTO = new QuestionEsDTO();BeanUtils.copyProperties(question, questionEsDTO);String tagsStr = question.getTags();if (StringUtils.isNotBlank(tagsStr)) {questionEsDTO.setTags(JSONUtil.toList(tagsStr, String.class));}return questionEsDTO;}/*** 包装类转对象** @param questionEsDTO* @return*/public static Question dtoToObj(QuestionEsDTO questionEsDTO) {if (questionEsDTO == null) {return null;}Question question = new Question();BeanUtils.copyProperties(questionEsDTO, question);List<String> tagList = questionEsDTO.getTags();if (CollUtil.isNotEmpty(tagList)) {question.setTags(JSONUtil.toJsonStr(tagList));}return question;}
}5.2定义 Dao 层
在 esdao 包中统一存放对 Elasticsearch 的操作,只需要继承 ElasticsearchRepository 类即可,该类集成大量的CRUD操作。
/*** 题目 ES 操作*/
public interface QuestionEsDao extends ElasticsearchRepository<QuestionEsDTO, Long> {/*** 根据用户 id 查询* @param userId* @return*///而且还支持根据方法名自动映射为查询操作,比如在 QuestionEsDao 中定义下列方法,就会自动根据 userId 查询数据。
List<QuestionEsDTO> findByUserId(Long userId);}6.向ES全量写入数据
可以通过实现 CommandLineRunner 接口定义单次任务
// todo 取消注释开启任务
@Component
@Slf4j
public class FullSyncQuestionToEs implements CommandLineRunner {@Resourceprivate QuestionService questionService;@Resourceprivate QuestionEsDao questionEsDao;@Overridepublic void run(String... args) {// 全量获取题目(数据量不大的情况下使用)List<Question> questionList = questionService.list();if (CollUtil.isEmpty(questionList)) {return;}// 转为 ES 实体类List<QuestionEsDTO> questionEsDTOList = questionList.stream().map(QuestionEsDTO::objToDto).collect(Collectors.toList());// 分页批量插入到 ESfinal int pageSize = 500;int total = questionEsDTOList.size();log.info("FullSyncQuestionToEs start, total {}", total);for (int i = 0; i < total; i += pageSize) {// 注意同步的数据下标不能超过总数据量int end = Math.min(i + pageSize, total);log.info("sync from {} to {}", i, end);questionEsDao.saveAll(questionEsDTOList.subList(i, end));}log.info("FullSyncQuestionToEs end, total {}", total);}
}7.数据同步
根据之前的方案设计,通过定时任务进行增量同步,每分钟同步过去 5 分钟内数据库发生修改的题目数据。
7.1编写查询某个时间后更新的所有题目的方法
public interface QuestionMapper extends BaseMapper<Question> {/*** 查询题目列表(包括已被删除的数据)*/@Select("select * from question where updateTime >= #{minUpdateTime}")List<Question> listQuestionWithDelete(Date minUpdateTime);
}7.2 编写增量同步到 ES 的定时任务
// todo 取消注释开启任务
//@Component
@Slf4j
public class IncSyncQuestionToEs {@Resourceprivate QuestionMapper questionMapper;@Resourceprivate QuestionEsDao questionEsDao;/*** 每分钟执行一次*/@Scheduled(fixedRate = 60 * 1000)public void run() {// 查询近 5 分钟内的数据long FIVE_MINUTES = 5 * 60 * 1000L;Date fiveMinutesAgoDate = new Date(new Date().getTime() - FIVE_MINUTES);List<Question> questionList = questionMapper.listQuestionWithDelete(fiveMinutesAgoDate);if (CollUtil.isEmpty(questionList)) {log.info("no inc question");return;}List<QuestionEsDTO> questionEsDTOList = questionList.stream().map(QuestionEsDTO::objToDto).collect(Collectors.toList());final int pageSize = 500;int total = questionEsDTOList.size();log.info("IncSyncQuestionToEs start, total {}", total);for (int i = 0; i < total; i += pageSize) {int end = Math.min(i + pageSize, total);log.info("sync from {} to {}", i, end);questionEsDao.saveAll(questionEsDTOList.subList(i, end));}log.info("IncSyncQuestionToEs end, total {}", total);}
}相关文章:

Elasticsearch笔记
官网 https://www.elastic.co/docs 简介 Elasticsearch 是一个分布式、开源的搜索引擎,专门用于处理大规模的数据搜索和分析。它基于 Apache Lucene 构建,具有实时搜索、分布式计算和高可扩展性,广泛用于 全文检索、日志分析、监控数据分析…...
)
在Windows下使用Docker部署Nacos注册中心(基于MySQL容器)
需要两个容器Nacos容器和MySQL容器,MySQL容器专注数据存储,Nacos容器专注服务发现/配置管理 准备工作 确保已安装Docker Desktop for Windows确保已启用WSL 2(推荐)或Hyper-V确保Docker服务正在运行 部署步骤 1. 拉取所需镜像 # 拉取MySQL镜像(这里…...
:革新未来治理的下一站)
去中心化自治组织(DAO):革新未来治理的下一站
去中心化自治组织(DAO):革新未来治理的下一站 引言 去中心化自治组织(DAO)的诞生,像是互联网时代的一道新曙光。它打破了传统组织的等级壁垒,以去中心化和智能合约为核心,让社区成员能够直接参与决策并共享收益。从NFT社区到投资基金,DAO的应用场景正以前所未有的速…...

ideal自动生成类图的方法
在 IntelliJ IDEA 中,“**在项目资源管理器中选择以下类**” 是指通过 **项目资源管理器(Project Tool Window)** 找到并选中你需要生成类图的类文件(如 .java 文件),然后通过右键菜单或快捷键操作生成类图…...

爬虫获取1688关键字搜索接口的实战指南
在当今电商行业竞争激烈的环境下,数据的重要性不言而喻。1688作为国内领先的B2B电商平台,拥有海量的商品信息,这些数据对于商家的市场分析、选品决策、价格策略制定等都有着重要的价值。本文将详细介绍如何通过爬虫技术获取1688关键字搜索接口…...

视频设备轨迹回放平台EasyCVR渡口码头智能监控系统方案,确保港口安全稳定运行
一、背景 近年来,随着水上交通运输业的快速发展,辖区内渡口码头数量持续增加,船舶运营规模不断扩大,各类船舶活动频繁,给水上交通安全监管带来了巨大挑战。近期发生的多起村民使用无证木船捕鱼导致的伤亡事故…...
)
使用 Sales_data 类实现交易合并(三十)
1. Sales_data 类定义 假设 Sales_data 类定义在头文件 Sales_data.h 中,其基本定义如下: // Sales_data.h #ifndef SALES_DATA_H #define SALES_DATA_H#include <string>struct Sales_data {std::string bookNo; // ISBN 编号unsigned uni…...

电力系统惯量及其作用解析
电力系统中的惯量是指由同步发电机的旋转质量提供的惯性,用于抵抗系统频率变化的能力。其核心作用及要点如下: 1. 物理基础 转动惯量:同步发电机的转子具有质量,其转动惯量()决定了转子抵抗转速变化的能力…...
用来高效搜索高维向量的最近邻)
HNSW(Hierarchical Navigable Small World,分层可导航小世界)用来高效搜索高维向量的最近邻
HNSW(Hierarchical Navigable Small World,分层可导航小世界)是一种用于 高效最近邻搜索(ANN, Approximate Nearest Neighbors) 的索引结构,专门用于在 高维向量(比如文本、图像、音频的嵌入向量…...
)
STM32 CAN学习(一)
CAN总线应用最多的是汽车领域。 CAN(Controller Area Network)控制器 局域 网 局域网:把几台电脑连接到一台路由器上,这几台电脑就可以进行通讯了。 控制器在汽车中的专业术语叫做ECU(Electronic Control Unit&…...

高效内存位操作:如何用C++实现数据块交换的性能飞跃?
「性能优化就像考古,每一层都有惊喜」—— 某匿名C工程师 文章目录 问题场景:当内存操作成为性能瓶颈性能深潜:揭开内存操作的面纱内存访问的三重代价原始方案的性能缺陷 性能突破:从编译器视角重构代码方案一:指针魔法…...

Spring Boot向Vue发送消息通过WebSocket实现通信
后端实现步骤 添加Spring Boot WebSocket依赖配置WebSocket端点和消息代理创建控制器,使用SimpMessagingTemplate发送消息 前端实现步骤 安装sockjs-client和stompjs库封装WebSocket连接工具类在Vue组件中建立连接,订阅主题 详细实现步骤 后端&…...

USB转串口数据抓包--Bus hound
Bus Hound是一款强大的总线分析工具。 Bus Hound 支持哪些设备 ? 所有的 IDE , SCSI , USB 和 1394 设备都得到支持,包括磁盘驱动器,鼠 标、扫描仪,网络摄像头,等等。只要是枚举成以上所列的总线类型的…...
)
Android 使用CameraX实现预览、拍照、录制视频(Java版)
Android 官方关于相机的介绍如下: https://developer.android.google.cn/media/camera/get-started-with-camera?hlzh_cn 一、开始使用 Android 相机 Android相机一般包含前置摄像头和后置摄像头,使用相机可以开发一系列激动人心的应用,例…...

【已解决】Javascript setMonth跨月问题;2025-03-31 setMonth后变成 2025-05-01
文章目录 bug重现解决方法:用第三方插件来实现(不推荐原生代码来实现)。项目中用的有dayjs。若要自己实现,参考 AI给出方案: bug重现 今天(2025-04-01)遇到的一个问题。原代码逻辑大概是这样的…...

DeepSeek技术架构解析:MLA多头潜在注意力
一、前言 我们上一篇已经讲了 DeepSeek技术架构解析:MoE混合专家模型 这一篇我们来说一说DeepSeek的创新之一:MLA多头潜在注意力。 MLA主要通过优化KV-cache来减少显存占用,从而提升推理性能。我们知道这个结论之前,老周带大家…...

02.02、返回倒数第 k 个节点
02.02、[简单] 返回倒数第 k 个节点 1、题目描述 实现一种算法,找出单向链表中倒数第 k 个节点。返回该节点的值。 2、题解思路 本题的关键在于使用双指针法,通过两个指针(fast 和 slow),让 fast 指针比 slow 指针…...
C++版——day2)
剑指Offer(数据结构与算法面试题精讲)C++版——day2
剑指Offer(数据结构与算法面试题精讲)C++版——day2 题目一:只出现一次的数据题目二:单词长度的最大乘积题目三:排序数组中的两个数字之和题目一:只出现一次的数据 一种很简单的思路是,使用数组存储出现过的元素,比如如果0出现过,那么arr[0]=1,但是有个问题,题目中没…...

nginx的自动跳转https
mkdir /usr/local/nginx/certs/ 创建一个目录 然后用openssl生成证书 编辑nginx的配置文件 自动跳转成功 做一个优化,如果访问的时候后面加了其他的uri也一起自动跳转了...
)
正则表达式(Regular Expression,简称 Regex)
一、5w2h(七问法)分析正则表达式 是的,5W2H 完全可以应用于研究 正则表达式(Regular Expressions)。通过回答 5W2H 的七个问题,我们可以全面理解正则表达式的定义、用途、使用方法、适用场景等,…...

Windows下在IntelliJ IDEA 使用 Git 拉取、提交脚本出现换行符问题
文章目录 背景问题拉取代码时提交代码时 问题原因解决方案1.全局配置 Git 的换行符处理策略2.在 IntelliJ IDEA 中配置换行符3.使用 .gitattributes 文件 背景 在 Windows 系统下使用 IntelliJ IDEA 进行 Git 操作(如拉取和提交脚本)时,经常…...
)
Python 实现的运筹优化系统代码详解(整数规划问题)
一、引言 在数学建模的广袤领域里,整数规划问题占据着极为重要的地位。它广泛应用于工业生产、资源分配、项目管理等诸多实际场景,旨在寻求在一系列约束条件下,使目标函数达到最优(最大或最小)且决策变量取整数值的解决…...

conda安装python 遇到 pip is configured with locations that require TLS/SSL问题本质解决方案
以前写了一篇文章,不过不是专门为了解决这个问题的,但是不能访问pip install 不能安装来自https 协议的包问题几乎每次都出现,之前解决方案只是治标不治本 https://blog.csdn.net/wangsenling/article/details/130194456https…...

嘿嘿,好久不见
2025年4月2日,6~22℃,一般 遇见的事:参加了曲靖的事业单位D类考试。 感受到的情绪:考场一半的人都没有到位,这路上你到了可能都会受到眷顾。 反思:这路上很难,总有人会提前放弃,不…...

virsh 的工作原理
virsh是用于管理虚拟化环境中的客户机和Hypervisor的命令行工具。它基于libvirt管理API构建,与virt-manager等工具类似,都是通过调用libvirt API来实现虚拟化的管理。virsh是完全在命令行文本模式下运行的用户态工具,因此它是系统管理员通过脚…...

Qt实现HTTP GET/POST/PUT/DELETE请求
引言 在现代应用程序开发中,HTTP请求是与服务器交互的核心方式。Qt作为跨平台的C框架,提供了强大的网络模块(QNetworkAccessManager),支持GET、POST、PUT、DELETE等HTTP方法。本文将手把手教你如何用Qt实现这些请求&a…...
05-01-自考数据结构(20331)树与二叉树大题总结)
(041)05-01-自考数据结构(20331)树与二叉树大题总结
实际考试中,计算题约占40%,推理题约占30%,算法设计题约占30%。建议重点练习遍历序列相关的递归分治解法, 知识拓扑 知识点介绍 一、计算题类型与解法 1. 结点数量计算 题型示例: 已知一棵完全二叉树的第6层有8个叶子结点,求该二叉树最多有多少个结点? 解法步骤: 完…...
-- 第三部分:JS宏编程语言开发基础)
WPS JS宏编程教程(从基础到进阶)-- 第三部分:JS宏编程语言开发基础
第三部分:JS宏编程语言开发基础 @[TOC](第三部分:JS宏编程语言开发基础)**第三部分:JS宏编程语言开发基础**1. 变量与数据类型**变量声明:三种方式****示例代码****数据类型判断****实战:动态处理单元格类型**2. 运算符全解析**算术运算符****易错点:字符串拼接 vs 数值相…...

迈向云原生:理想汽车 OLAP 引擎变革之路
在如今数据驱动的时代,高效的分析引擎对企业至关重要。理想汽车作为智能电动汽车的领军企业,面临着海量数据分析的挑战。本文将展开介绍理想汽车 OLAP 引擎从存算一体向云原生架构演进的变革历程,以及在此过程中面临的挑战,以及是…...

Spark,HDFS客户端操作
hadoop客户端环境准备 找到资料包路径下的Windows依赖文件夹,拷贝hadoop-3.1.0到非中文路径(比如d:\hadoop-3.1.0) ① 打开环境变量 ② 在下方系统变量中新建HADOOP_HOME环境变量,值就是保存hadoop的目录。 效果如下: ③ 配置Path…...

QuecPython 的 VScode 环境搭建和使用教程
为方便开发者使用 VSCode 开发 QuecPython,QuecPython 团队特推出了名为 QuecPython 的 VSCode 插件。 插件目前支持的功能有: 固件烧录REPL 命令交互代码补全文件传输文件系统目录树运行指定脚本文件 目前支持所有QUecPython系列模组。 插件安装 点…...

Linux Vim 编辑器的使用
Vim 编辑器的使用 一、安装及介绍二、基础操作三、高级功能四、配置与插件 一、安装及介绍 Vim是一款强大且高度可定制的文本编辑器,相当于 Windows 中的记事本。具备命令、插入、底行等多种模式。它可通过简单的键盘命令实现高效的文本编辑、查找替换、分屏操作等…...

Java 基础-28- 多态 — 多态下的类型转换问题
在 Java 中,多态(Polymorphism)是面向对象编程的核心概念之一。多态允许不同类型的对象通过相同的方法接口进行操作,而实际调用的行为取决于对象的实际类型。虽然多态提供了极大的灵活性,但在多态的使用过程中…...

机器学习中的自监督学习概述与实现过程
概述 机器学习中有四种主要学习方式: 监督式学习 (Supervised Learning):这种学习方式通过使用带有标签的数据集进行训练,目的是使机器能够学习到数据之间的关联性,并能够对新的、未见过的数据做出预测或分类。应用领域包括语音识…...

AI Agent开发大全第十四课-零售智能导购智能体的RAG开发理论部分
开篇 经过前面的一些课程,我们手上已经积累了各种LLM的API调用、向量库的建立和使用、embedding算法的意义和基本使用。 这已经为我们具备了开发一个基本的问答类RAG的开发必需要素了。下面我们会来讲一个基本问答类场景的RAG,零售中的“智能导购”场景。 智能导购 大家先…...

Git相关笔记1 - 本地文件上传远程仓库
Git相关笔记 目录 Git相关笔记Git上传相关文件第一步创建一个仓库:第二步本地创建空文件夹:第三步开始在gitbush上传文件:解决外网网络连接的问题:中文文件的编码问题:参考资料 Git上传相关文件 第一步创建一个仓库&a…...

机器学习算法
目录 行向量与列向量 信息论 Logistic回归 支持向量机SVM 核函数: 决策树 Decision Tree CART决策树 ID3 决策树 C4.5 决策树 决策树的过拟合问题 回归树 ***仅做复习需要,若侵权请及时联系我 行向量与列向量 行向量:是一个横…...

学习记录706@微信小程序+springboot项目 真机测试 WebSocket错误: {errMsg: Invalid HTTP status.}连接不上
我微信小程序springboot项目 真机测试 websocket 总是报错 WebSocket错误: {errMsg: Invalid HTTP status.},总是连接不上,但是开发者工具测试就没有问题。 最后解决方案是编码token,之前是没有编码直接拼接的,原因不详。 consol…...

SSH服务
一、准备 #请说明以下服务对应的端口号或者端口对应的服务 ssh 22 telnet 23 http 80 https 443 ftp 20 21 RDP 3389 mysql 3306 redis 6379 zabbix 10050 10051 elasticsear…...

GitHub上免费学习工具的精选汇总
以下是GitHub上免费学习工具的精选汇总,涵盖编程语言、开发框架、数据科学、面试准备等多个方向,结合工具的功能特点、社区活跃度及适用场景进行分类推荐: 一、编程语言与开发框架 Web Developer Roadmap 简介:为开发者提供全栈学…...

2025.4.1总结
今天看了一部网上很火的记录片《God,my brother》,中文名为《上帝不如我兄弟》,简述的是一个自媒体博主杜克遇到孟加拉一哥(车夫),最终一哥在杜克的帮助下,成功实现阶级跨越,而杜克也因此成为百…...

MySQL日志管理
目录 查询日志 慢查询日志 错误日志 二进制日志 其他功能 查询日志 查询日志用来记录所有查询语句的信息,由于开启此日志会占用大量内存,所以一般不会开启 查看查询日志是否开启 开启查询日志 慢查询日志 用于性能的调优,查看执行速度超…...

vscode中的【粘滞滚动】的基本概念和作用,关闭了以后如何开启
1、粘滞滚动的基本概念和作用 VSCode中的“粘滞”功能主要是指编辑器在滚动时的一种特殊效果,使得编辑器在滚动到某个位置时会“粘”在那里,而不是平滑滚动到底部或顶部。 粘滞滚动的基本概念和作用 粘滞滚动功能可以让用户在滚动时更直观地看到当前…...

我用Axure画了一个富文本编辑器,还带交互
最近尝试用Axure RP复刻了一个富文本编辑器,不仅完整还原了工具栏的各类功能,还通过交互设计实现了接近真实编辑器操作体验。整个设计过程聚焦功能还原与交互流畅性,最终成果令人惊喜。 编辑器采用经典的三区布局:顶部工具栏集成了…...
)
Mysql之Redo log(Red log of MySQL)
Mysql之Redo log 数据库事务的4个特性之一的持久性是数据库保证数据一致性的关键,mysql为了确保事务在系统崩溃后也能恢复,引入了redo log 重做日志这一机制。 什么是redo log 持久性指的是一旦事务提交数据就要永久的保存到数据库中,不能…...

Spring Cloud ReactorServiceInstanceLoadBalancer 自定义负载均衡
自定义负载均衡类 import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.springframework.beans.factory.ObjectProvider; import org.springframework.cloud.client.ServiceInstance; import org.springframework.cloud.client…...

汽车诊断开发入门以及OBD检测
一、OBD 概述 定义:OBD 即 On - Board Diagnostics,车载自动诊断系统。它能实时监测车辆各项系统和部件状态,以此帮助诊断故障并预警。设计初衷与发展:最初设计目的是控制汽车尾气排放,确保符合环境标准。随着技术进步…...

高速PCB设计过孔不添乱,乐趣少一半
高速先生成员--姜杰 高速先生最近写了不少介绍高速信号仿真的文章(文章链接汇总,看这篇就够了《聊聊100G信号的仿真》)。雷豹逐一研读后感觉获益匪浅,甚至一度觉得自己强的可怕,不过,在得知即将负责一个11…...

人工智能在医疗领域的前沿应用与挑战
在当今数字化时代,人工智能(AI)技术正以前所未有的速度改变着我们的生活,其中医疗领域无疑是受益最为显著的行业之一。从疾病诊断、治疗方案制定到患者护理,AI的应用不仅提高了医疗服务的效率和质量,还为医…...

怎么实现实时无延迟的体育电竞动画直播
要实现真正的实时无延迟动画直播,需要考虑以下几个关键方面: 一、技术方案选择 1.WebRTC技术 点对点(P2P)传输协议,延迟可低至100-500ms 适用于互动性强的应用场景 开源且被主流浏览器支持 2.低延迟HLS/CMAF 可将延迟控制在1-3秒 兼容…...