机器学习中的自监督学习概述与实现过程
概述
机器学习中有四种主要学习方式:
-
监督式学习 (Supervised Learning):这种学习方式通过使用带有标签的数据集进行训练,目的是使机器能够学习到数据之间的关联性,并能够对新的、未见过的数据做出预测或分类。应用领域包括语音识别、图像识别、医学诊断等。监督学习通常需要大量的标注数据,因此获取和维护这些数据集可能非常昂贵和耗时。
-
非监督式学习 (Unsupervised Learning):非监督式学习使用未标注的数据,通过算法来发现数据中的结构和模式。这种学习方式适合于市场细分、社交网络分析、异常检测等任务。自监督学习 (Self-Supervised Learning) 是非监督学习的一种,它通过从数据本身生成伪标签来训练模型。
-
半监督式学习 (Semi-Supervised Learning):这种学习方式结合了监督学习和非监督学习的特点,使用少量的标记数据和大量的未标记数据。这种方法特别适用于标签获取成本较高,但未标记数据容易获得的情况。例如,“Noisy Student”是一种半监督学习方法,通过自我训练和模型蒸馏的方式,利用未标记数据来提高模型性能。
-
强化学习 (Reinforcement Learning):强化学习是一种让机器通过与环境的交互来学习最优行为策略的方法。它通常涉及到一个智能体(agent)在一定的策略下,通过尝试和错误来最大化累积奖励。强化学习在游戏、机器人控制和推荐系统等领域有广泛应用。
每种学习方式都有其特定的应用场景和优缺点,研究人员会根据实际问题和数据的可用性来选择最合适的方法。

由于数据标注的成本较高或特定领域的数据难以获得,因此研究的方向逐渐关注于无监督学习。而本文要介绍的自监督学习就是属于无监督学习的一种,它通过挖掘大量无标签数据本身的信息,人为地制造标签(预文本),这样一来就可以使用监督式学习的方式进行训练,正如其名称所示,通过自己来监督自己。目的是希望模型能够学习到数据中的通用表征,并应用至不同的下游任务里。
训练步骤会分为两部分,首先用这些未标记数据训练一个初步的模型产生出一种通用的表征,接着再根据下游任务使用少量的有标签数据进行微调(这边只需要少量有标签数据是因为模型在第一部分时就已经将参数训练得差不多了)。

自监督学习主要分为五种:生成方法(Generative methods)、预测方法(Predictive methods)、对比方法(Contrastive methods)、引导方法(Booststrapping methods)、额外正则化方法(Simply Extra Regularization methods)。
一、生成方法(Generative methods)
通过训练模型在像素空间的重建能力,可以获得对图像理解的语义信息。换句话说,就是先将图像上的某些像素进行遮蔽(mask),让模型能够还原回原来的图像内容。
例如,图像修复(Image Inpainting)的方法,使用的是基于自编码器(AutoEncoder)的模型——上下文编码器(Context Encoders),根据图像缺失部分的周围环境生成出合理的假设。这种方法通过学习图像中存在的模式,并利用这些模式来填充缺失或损坏的区域,从而达到恢复图像的目的。
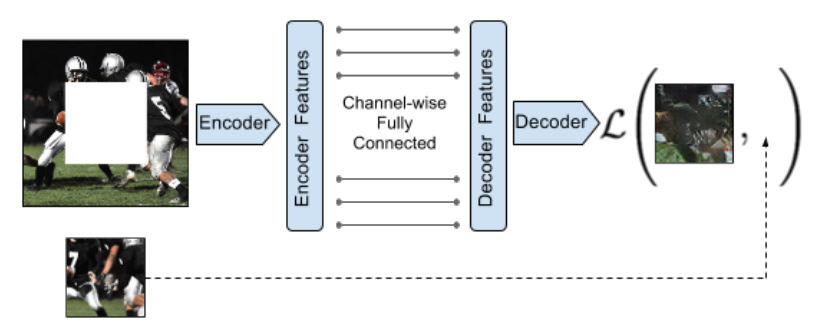
也可以利用自然语言处理(NLP)模型,如BERT和GPT,来执行类似的图像处理任务。首先,将图像转换为一维数据再输入到模型中。下图(a)展示了使用GPT进行训练的方法,该方法是利用图像中的一部分像素来预测下一部分像素;下图(b)则是使用BERT,方法是在一维图像数据中遮蔽(mask)一些像素,让模型预测这些被遮蔽的像素。然后,这些模型就可以应用到下游任务中。更多详细信息可以参考Image GPT官方网站。

二、预测方法(Predictive methods)
由于模型仅基于像素生成高级表示是一项较为困难的任务,并且计算成本也很高,因此研究者们希望采用其他不涉及图像重建的方法。预测性方法(Predictive methods)不需要重建图像,而是通过对图像进行各种变换,然后让模型恢复原状。
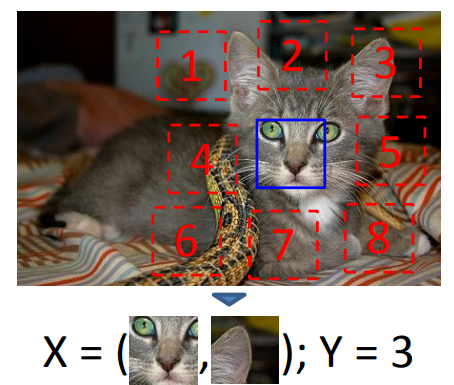
其中较为著名的一篇论文是ICCV 2015年的《Unsupervised Visual Representation Learning by Context Prediction》(无监督视觉表示学习通过上下文预测),该论文通过在图像中选取两个区域(patch),并利用其中一个区域预测另一个区域的相对位置。
这种方法的核心思想是利用图像内部的空间上下文信息来训练一个丰富的视觉表示。具体来说,给定一个大型的未标记图像集合,论文中的方法从每张图像中提取随机的图像块对,并训练一个卷积神经网络来预测第二个图像块相对于第一个图像块的位置。这项任务的挑战在于,模型需要能够识别物体及其部分,以便理解它们之间的相对空间位置。研究表明,通过这种方式学习到的特征表示能够捕捉图像间的视觉相似性,例如,这种方法可以从Pascal VOC 2011检测数据集中无监督地发现物体,如猫、人甚至鸟类。
此外,论文还展示了学习到的卷积网络可以在RCNN框架中使用,并且与随机初始化的卷积网络相比,提供了显著的性能提升,在使用Pascal提供的训练集注释的算法中达到了最先进的性能水平。
论文 Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles 提出了一种无监督学习方法,用于学习图像表示,其核心思想是通过解决“拼图”问题来训练模型。这种方法与之前提到的利用图像中选定的 patch 的方法有相似之处,但具体实施上存在一些差异。
在这篇 ECCV 2016 的论文中,不是简单地选择两个或几个 patch,而是一次性选择图像中的九个 patch。这些 patch 被随机地从原始图像中裁剪出来,然后以某种顺序排列,形成所谓的“拼图”。接着,模型的任务是识别这些 patch 的组成分布,并预测它们正确的顺序,以便能够重建原始图像的布局。
这个过程可以视为一种自监督学习任务,因为模型的训练目标是基于图像本身的固有结构,而不是依赖于外部的标注信息。通过这种方式,模型被训练来识别图像中的对象部分以及它们的空间排列。这种方法的优势在于,它能够学习到关于对象的语义信息,并且能够捕捉到对象部分之间的空间关系。
论文中提出的“拼图”方法,通过强制模型解决拼图问题,学习到的特征表示能够很好地迁移到其他视觉任务中,如对象检测和分类。实验结果表明,这种方法学习到的特征在多个迁移学习基准测试中超越了当时的最先进方法。


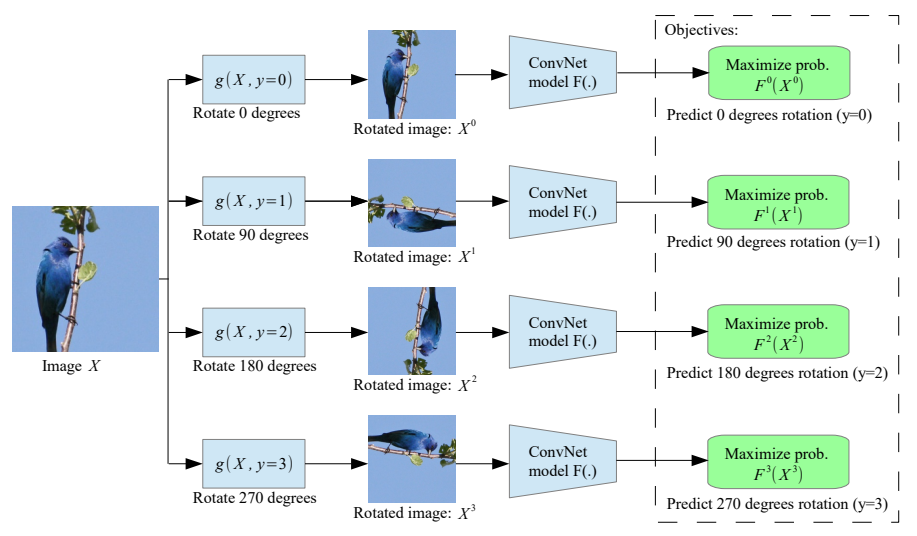
这篇论文《Unsupervised Representation Learning by Predicting Image Rotations》确实是ICLR 2018的一篇会议论文,作者是Spyros Gidaris, Praveer Singh, Nikos Komodakis,他们来自University Paris-Est, LIGM Ecole des Ponts ParisTech。这篇论文提出了一种新颖的无监督表示学习方法,通过训练卷积神经网络(ConvNets)来识别输入图像所应用的2D旋转变换。
这种方法的核心思想是,如果一个模型能够识别出图像被旋转了多少度,那么它必须首先学习到图像中对象的概念,比如它们在图像中的位置、类型和姿态。具体来说,该方法将图像旋转四次,即0°、90°、180°和270°,然后训练ConvNets来识别这四种旋转中的一种。尽管这个任务看起来非常简单,但论文中通过实验表明,它实际上为语义特征学习提供了一个非常强大的监督信号。
论文中提到,这种方法在多个无监督特征学习基准测试中进行了全面评估,并在所有测试中展示了最先进的性能。例如,在PASCAL VOC 2007检测任务中,使用这种方法无监督预训练的AlexNet模型达到了54.4%的mAP(平均精度均值),仅比有监督情况下低2.4个百分点。当将无监督学习到的特征迁移到其他任务,如ImageNet分类、PASCAL分类、PASCAL分割和CIFAR-10分类时,也获得了类似的显著结果。
此外,论文还提供了代码和模型的GitHub链接:https://github.com/gidariss/FeatureLearningRotNet,供有兴趣的研究者进一步研究和使用。
最后则是使用聚类(Cluster)的方式结合CNN,并进行端到端(end to end)的训练,在ImageNet分类和其他迁移学习任务上都获得了很好的结果。
这边讨论两篇相关论文,首先是ECCV 2018的Deep Clustering for Unsupervised Learning of Visual Features,使用k-means对大量未标记的数据进行训练得到伪标签(Pseudo-labels),再用监督学习的方式去学习。

第二篇是ICLR 2020的Self-labelling via simultaneous clustering and representation learning,在该篇论文中加入了约束(constraint)——所有样本预测的标签分布要尽可能地平均分配,因为聚类算法得到的伪标签不一定是正确的,可能会产生某个类别占了大多数的情况。

三、对比方法(Contrastive methods)
对比学习(Contrastive Learning)目前在自监督学习中最为广泛运用,其概念为相同类别的图像间的相似度越高越好(即距离尽可能地近),不同类别的图像相似度越低越好(即距离尽可能地远),模型架构主要是使用孪生网络(Siamese Network)。
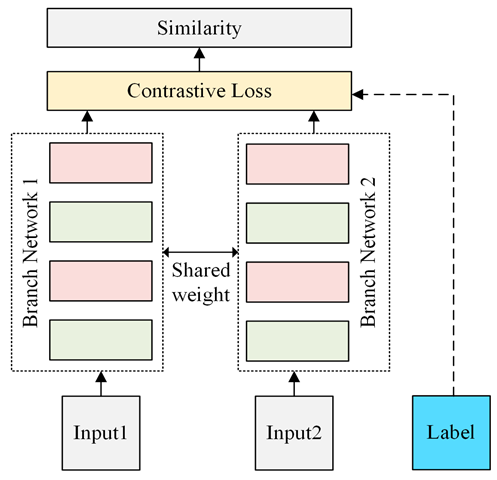
孪生网络(Siamese Network)
但我们的数据并没有标签,该怎么区分哪些图像是相同类别呢?因此我们先对图像做各种数据增强(data augmentation)后,再让模型去预测经过数据增强后的图像与原图之间的相似度,该结果要越高越好,同时对其他图的预测则是越低越好。

source
代表作有FAIR提出的MoCov1、MoCov2、MoCov3,Google Brain提出的SimCLRv1、SimCLRv2,这边仅介绍MoCov1及SimCLRv1,若想了解更详细的内容可参考其论文和以下我觉得写得很好的文章:
- 大概是全网最详细的何恺明团队顶作MoCo系列解读!(上)
- 大概是全网最详细的何恺明团队顶作MoCo系列解读…(完结篇)
- MoCo 三部曲
- Self-Supervised Learning 超详细解读(二):SimCLR系列
3.1 MoCov1
主要贡献为提出字典队列(Dictionary as a queue)、动量编码器(Momentum Encoder)、打乱批量归一化(Shuffling BN)
从过往的实验结果中可知,使用更多的负样本(negative samples)来训练能得到更好的结果,但负样本的数量与批量大小(batch size)成正比,而批量大小越大需要越多的运算成本,因此没办法使用太大的批量大小。为了解决难以运用大量负样本的问题,采用了字典队列(Dictionary as a queue)的方式,就是将原本的记忆库(memory bank,用于保存所有数据的表征)改成队列的形式来储存。
字典队列的做法为每个训练周期(epoch)会将一个批量的表征加入队列(enqueue),并移除保存最久的一个批量的表征(dequeue),这样一来这个队列字典的总数不会随着训练周期而变大,不会占用太多的内存及运算成本。
动量编码器(Momentum Encoder)是指下图 © 中关键编码器(key encoder)的参数θ_k的更新方式改为查询编码器(query encoder)参数θ_q的移动平均,目的是为了让队列字典中的数据保持一致性,公式如下
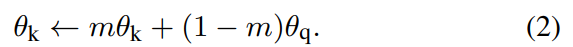
在提出动量编码器之前的参数更新是使用下图 (b) 的更新方法,对于样本x_q做数据增强得到正样本、从记忆库中抽取出k个作为负样本后,再去计算对比损失(Contrastive loss)并更新θ_q和这些负样本的键值(key value,即k值),这边并不会去做关键编码器参数θ_k的反向传播。这样的做法会导致某些键值在很多次迭代后才被采样并更新,但查询编码器每次都会更新,以至于抽取出的样本与当前的查询编码器没有一致性。
打乱批量归一化(Shuffling BN)是针对数据泄露(Data Leakage)的解决方法,因为模型能通过每个批量间计算的平均值和方差找到一些信息而导致数据泄露的现象。因此在训练前会先将样本的顺序打乱,提取特征后再恢复原本的顺序。

3.2 SimCLRv1
主要贡献为提出数据增强组合(Data augmentation combination)的想法、增加投影头(Projection head)、归一化温度缩放交叉熵损失函数(NT-Xent loss function)
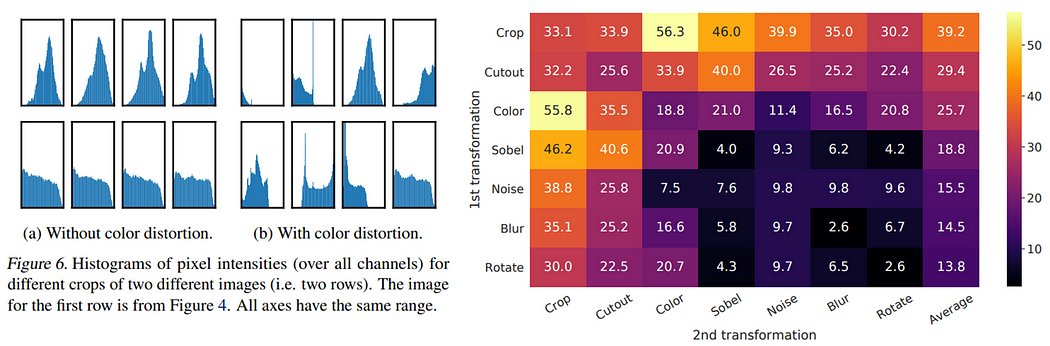
其思路非常简单,首先抽取一些图像组成一个批量,将批量里的图像做不同的数据增强,其中包括随机裁剪(random crop)、颜色失真(color distortion)、高斯模糊(Gaussian blur),接着进行对比学习(Contrastive Learning),即区分是否为相同的图像。
对于数据增强,论文提到只单纯用随机裁剪没有太大效果,需要结合颜色失真,这是因为随机裁剪后的图像与原图像在像素值的分布差异不大(下图左)。同时也实验了使用两种数据增强组合的结果会更好(下图右)。
SimCLRv1的整体流程如下图所示,由编码器(Encoder)得到的表征会再经过投影头(Projection head)映射到较低维的空间中,得到新的表征z_i、z_j。该投影头是一个两层的多层感知机(MLP),只在自监督学习训练时使用,其作用为去除编码器中数据增强后的信息,仅关注于原始数据的信息。
当要在下游任务上进行微调(Fine-tune)时就不会使用到投影头,会另外接一层非线性分类器(Non-Linear Classifier)。

source
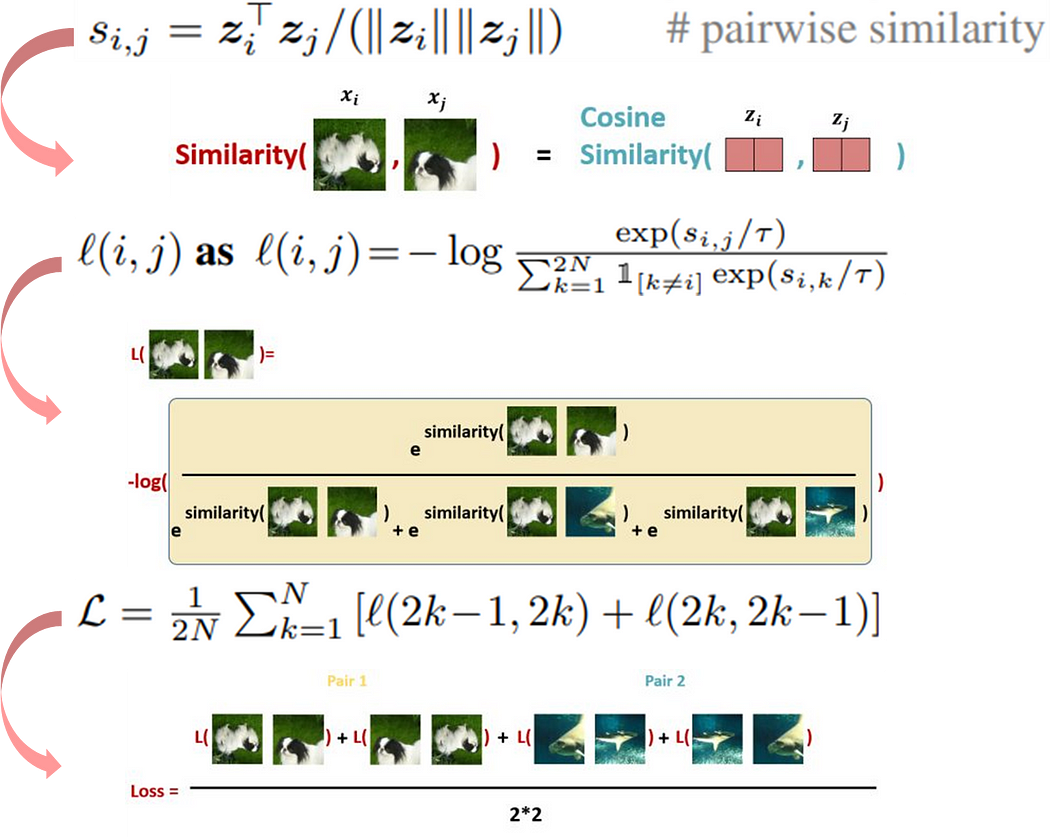
归一化温度缩放交叉熵损失函数(NT-Xent loss function)的计算方式分为三个步骤:
- 计算一组正样本对(pair)间的相似度,并且每一个批量中的所有正样本对都要计算(每次只计算一个批量是为了降低运算量)。
- 计算正样本对的相似度概率,分子为正样本对的相似度、分母为所有正样本对和负样本对的相似度之和。值得注意的是对于同一个正样本对需要交换顺序再计算一次。公式中的N表示为一个批量所拥有的图像张数,经过数据增强后会有2N张图像。
- 将每一个批量中的所有正样本对计算出来的损失加总取平均。
source1, source2
四、 引导方法(Booststrapping methods)
由于对比方法需要选取负样本,且其数据特性不能太简单,也不能太难,因此如何选择负样本是一个困难的问题。
负样本的主要贡献在于避免发生模型坍塌(model collapse)的现象,若训练数据只有正样本,模型会倾向于得到平凡解(trivial solution)。这句话的意思是指不论输入什么样的图像,模型的两个分支皆输出一模一样的表征以得到最高的相似度。
那有没有办法是不使用负样本的呢?以下来介绍两篇相关论文:BYOL、SimSiam。
4.1 BYOL(Bootstrap your own latent)
主要贡献为新增预测器(predictor)、使用指数移动平均(exponential moving average)、批量归一化(batch normalization)、L2损失(L2 loss)
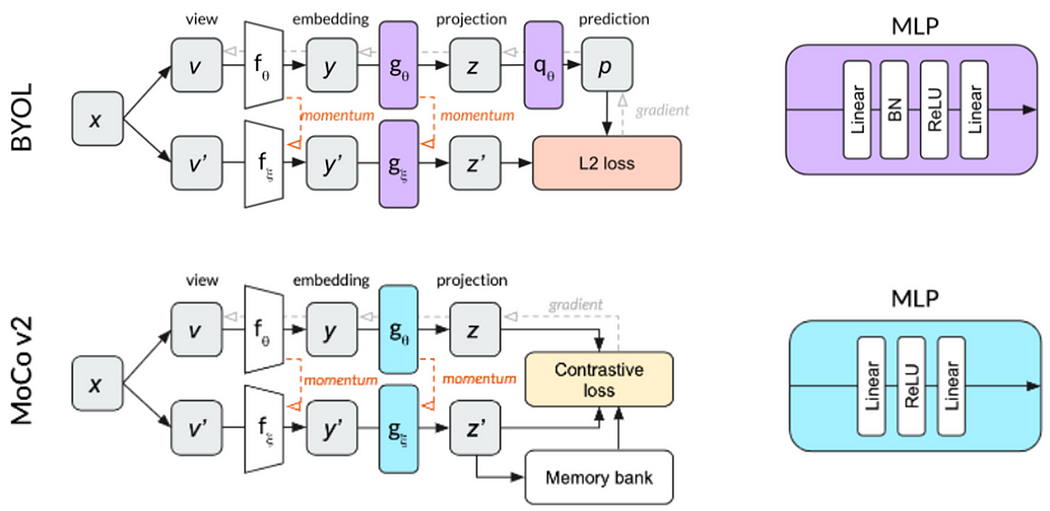
BYOL的模型架构与MoCov2类似,MoCov2是基于MoCov1融合SimCLRv1的做法,加入投影头(Projection head)以及更多的数据增强(增加了模糊增强,blur augmentation)。
整体流程如下:
- 先将图像x做两种不同的数据增强t, t′,分别送入不同的分支,其中一个分支称为在线分支(online,该分支多加了预测层),另一个称为目标分支(target)。
- 各自经过视图(得到数据增强后的结果v, v′)、表征(经过编码器f_θ, f_ξ得到表征y_θ, y′_ξ)、投影(经过投影头g_θ, g_ξ映射到较低维的空间)。
- 在在线分支会再经过一层预测(为一个两层的MLP),接着与目标分支的输出z′_ξ计算损失。BYOL的损失函数使用L2损失(下式1),另外也跟SimCLRv1一样会交换顺序再计算一次(下式2)。
- 与MoCo相同,损失只会反向传播给在线分支(下式3),而目标分支的参数是由在线分支参数θ的指数移动平均(下式4)的方式来更新,下图中的sg指停止梯度传播(stop-gradient)。
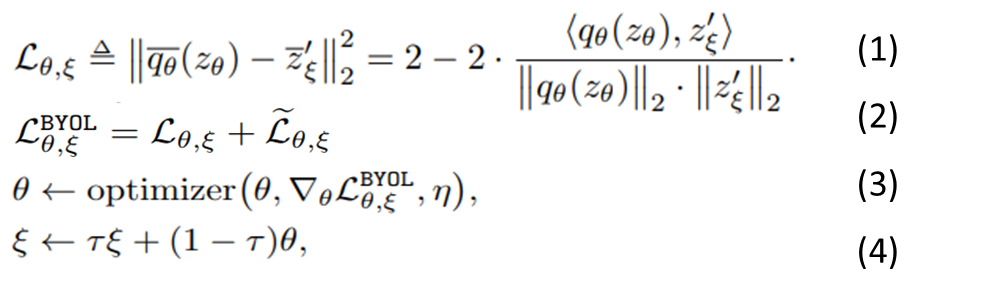
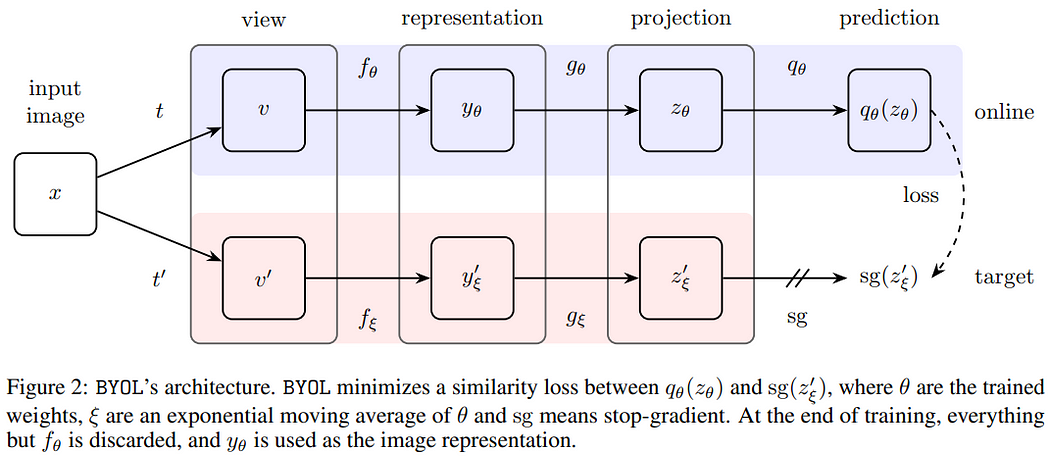
这样的设计方式能防止模型坍塌的关键在于新增预测器和停止梯度传播并使用指数移动平均来更新目标分支,让两个分支的架构及参数不完全相同,模型较难往平凡解的方向走。
除此之外,还有一个大功臣——在投影头中加入了批量归一化。看下图BYOL和MoCov2的比较,BYOL的投影头、预测器都使用相同的MLP架构,而MLP中多新增了批量归一化。
在Understanding Self-Supervised and Contrastive Learning with “Bootstrap Your Own Latent” (BYOL)一文中实验了各种批量归一化的消融研究(ablation study),发现若不使用批量归一化就相当于随机的结果,并猜测使用批量归一化是一种隐性的对比学习。意思是指这样的操作就是将批量中的每个图像与批量的图像平均做比较,而批量中的其他图像为当前图像的负样本。
source
基于这个观点,原文作者发表了一篇研究BYOL works even without batch statistics来解释。作者认为批量归一化之所以有效是因为能让模型有合适的初始化参数,以至于使得训练更稳定,并实验使用组归一化(Group normalization)和权重标准化(weight standardization)也能有相同效果。

4.2 SimSiam(Simple Siamese)
主要贡献为使结构更加简洁,不需要使用负样本对(negative sample pairs)、大批量(large batches)、动量编码器(momentum encoders)
SimSiam由FAIR提出,其模型架构与BYOL非常相似,去除了使用指数移动平均的更新方式,直接使用孪生网络(Siamese network),即两分支的编码器f共享参数,如下图和伪代码可以看出整体结构更简洁。
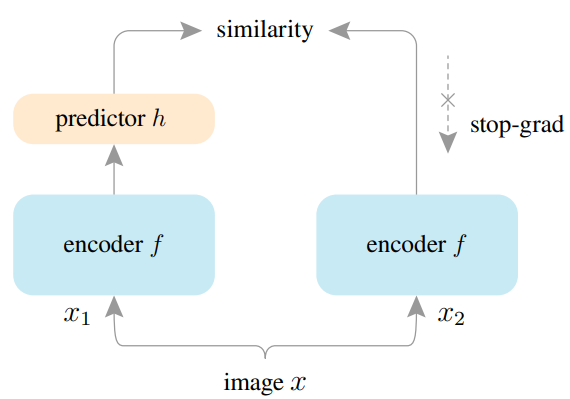
架构图

作者做了一系列的消融研究来分析让模型免于坍塌的原因,例如:有无使用停止梯度传播(stop-gradient)、预测器(Predictor)、批量大小(64~4096)、批量归一化(Batch Normalization)、相似性函数(Similarity Function)、分支结构对称与否(Symmetrization/Asymmetrization/Asymmetrization 2x),大多不可避免影响准确度,除了拿掉停止梯度传播或预测器之外,其他操作并不会造成模型坍塌的现象。
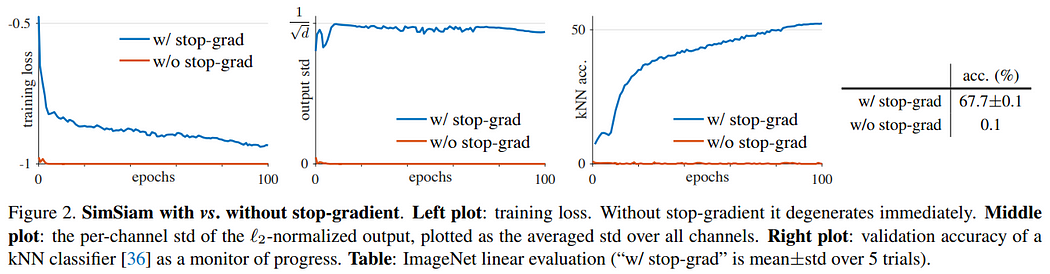
作者认为最关键的原因在于停止梯度传播,相当于引入了额外的变量,让SimSiam的实现类似于期望最大化(Expectation-Maximization, EM)算法,并针对这个假设做实验来验证。
在该假设下的损失函数(下式5)中F_θ为编码器f、τ为数据增强、η为引入的额外变量(下标x是指图像x,这边可以将η_x想象成是停止梯度传播分支的表征),接着针对该损失函数进行优化(下式6),期望能最小化两分支编码器输出的距离的期望值。
首先固定η求解θ(下式7),再固定θ去求解η(下式8),反复迭代进行训练,目标是得到下式11的结果(将η_x代入至下式5、6,并找出最佳参数θ)。由于η_x是图像x的表征,因此可写成如下式9的样子,下式10是指使用不同的数据增强。

五、简单额外正则化方法(Simply Extra Regularization methods)
除了引导方法外,简单额外正则化方法也能够在不使用负样本的情况下,取得优秀的结果。概念为从表征本身挖掘更多的信息去学习,在训练过程中加上一些正则化,让正样本经过数据增强后的两个表征间越相似越好。
以下来介绍两篇相关论文:SwAV、Barlow Twins。
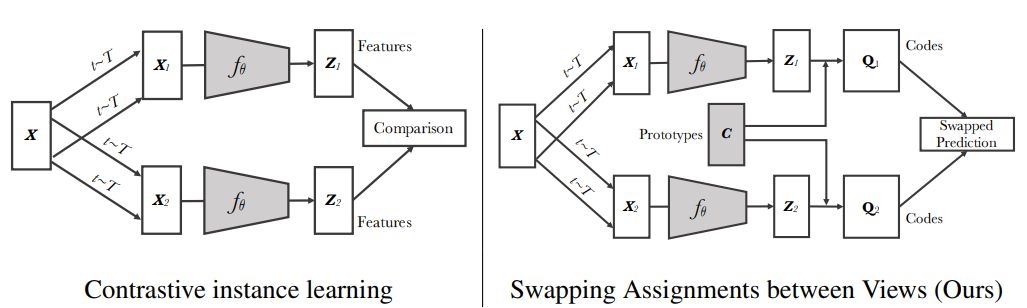
5.1 SwAV(Swapping Assignments between Views)
主要贡献为提出原型(Prototypes)、多裁剪策略(Multi-crop strategy)
在对比学习的基础上结合聚类(clustering),不直接比较表征,而是比较不同视角(View)下的聚类结果(clustering assignments),并且该结果可以互相交换预测(Swapping)。
两者的差异如下图,在SwAV的做法中会将表征z_i与原型C做内积后再进行softmax,计算出相似程度得到代码Q,接着交叉预测不同视角的代码,其中原型为聚类中心。
损失函数定义为交叉预测结果之和
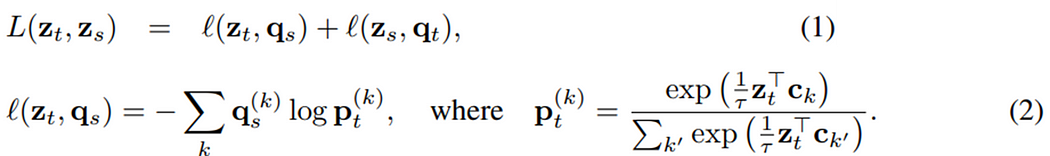
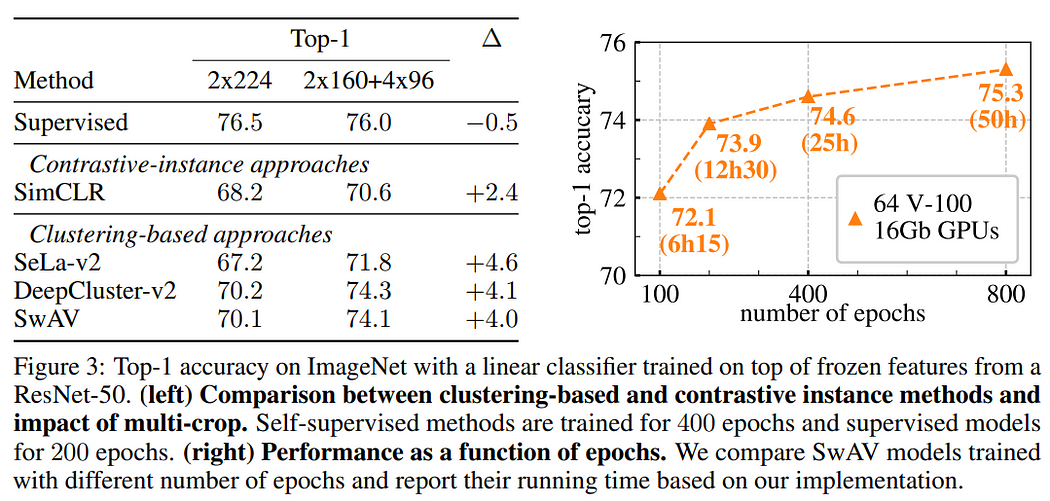
此外,提出了新的数据增强方法——多裁剪(Multi-crop),由2个较大的裁剪和V个较小的裁剪组成(例如:2个160分辨率+4个96分辨率),能够学习更局部的特征、提升正样本的数量,也不会增加计算量。由下图的实验结果可得知采用多裁剪能增加4%的准确率,而且不只是在SwAV有效,对于其他的自监督学习(SSL)方法也有很大的帮助。
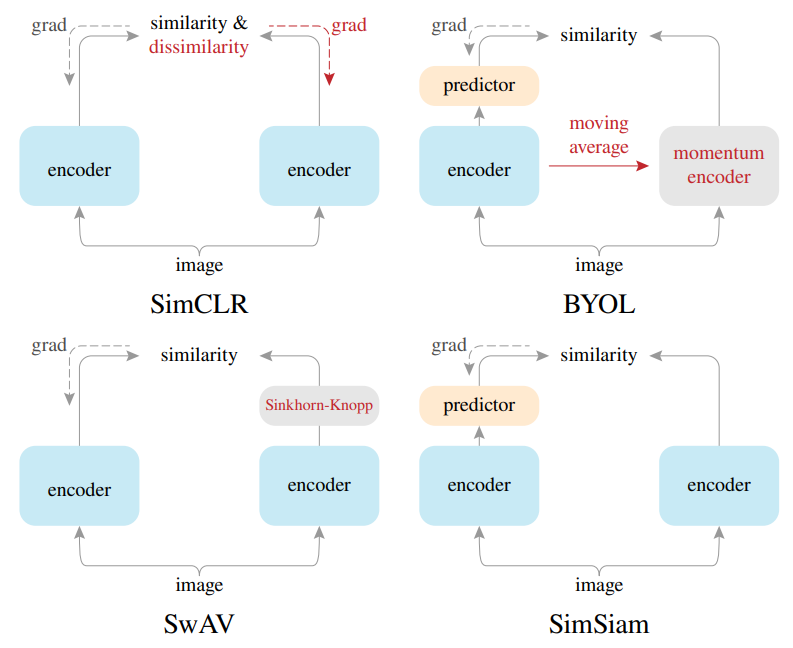
以下是各个孪生架构的比较图,可以看出这些模型的结构都非常相似。
5.2 Barlow Twins
主要贡献为提出交叉相关矩阵(cross-correlation matrix)
前半部与对比学习相同,后半部则是对批量中的所有图像提取的表征(即下图的嵌入向量Embeddings)去计算交叉相关矩阵,并期望该矩阵近似单位矩阵(identity matrix),也就是对角线上的值为1,其余的值为0。如此一来,可以表示为相同样本在不同数据增强下所得到的表征非常相近,而不同样本则会越远。
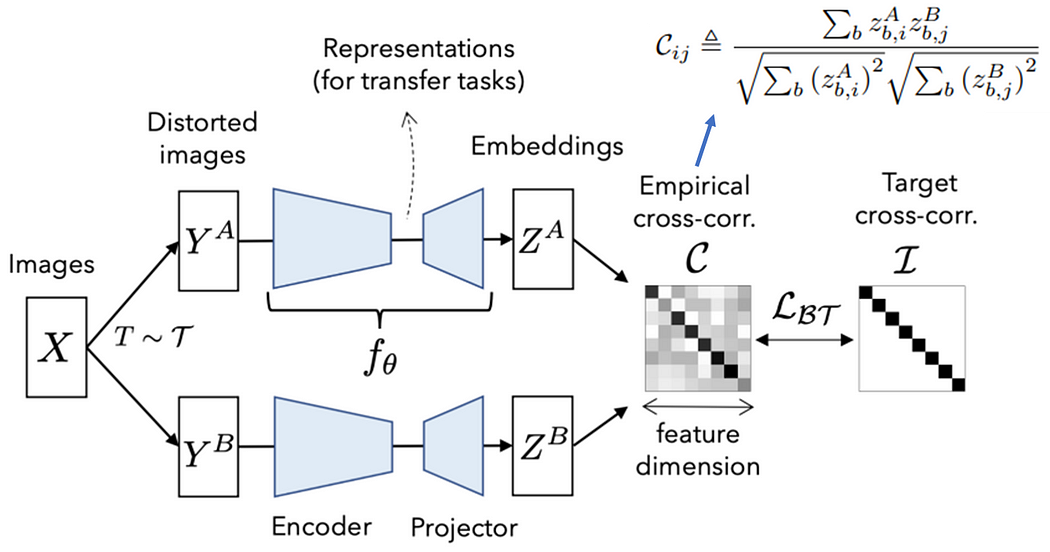
损失函数定义如下:
- 不变性项(invariance term)为让对角线上的元素尽可能地为1
- 冗余减少项(redundancy reduction term)为让不在对角线上的元素尽可能地为0
- λ用于调节这两项的权衡(trade-off)
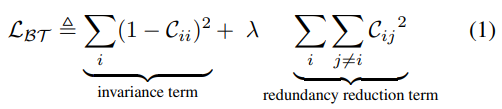
相关文章:

机器学习中的自监督学习概述与实现过程
概述 机器学习中有四种主要学习方式: 监督式学习 (Supervised Learning):这种学习方式通过使用带有标签的数据集进行训练,目的是使机器能够学习到数据之间的关联性,并能够对新的、未见过的数据做出预测或分类。应用领域包括语音识…...

AI Agent开发大全第十四课-零售智能导购智能体的RAG开发理论部分
开篇 经过前面的一些课程,我们手上已经积累了各种LLM的API调用、向量库的建立和使用、embedding算法的意义和基本使用。 这已经为我们具备了开发一个基本的问答类RAG的开发必需要素了。下面我们会来讲一个基本问答类场景的RAG,零售中的“智能导购”场景。 智能导购 大家先…...

Git相关笔记1 - 本地文件上传远程仓库
Git相关笔记 目录 Git相关笔记Git上传相关文件第一步创建一个仓库:第二步本地创建空文件夹:第三步开始在gitbush上传文件:解决外网网络连接的问题:中文文件的编码问题:参考资料 Git上传相关文件 第一步创建一个仓库&a…...

机器学习算法
目录 行向量与列向量 信息论 Logistic回归 支持向量机SVM 核函数: 决策树 Decision Tree CART决策树 ID3 决策树 C4.5 决策树 决策树的过拟合问题 回归树 ***仅做复习需要,若侵权请及时联系我 行向量与列向量 行向量:是一个横…...

学习记录706@微信小程序+springboot项目 真机测试 WebSocket错误: {errMsg: Invalid HTTP status.}连接不上
我微信小程序springboot项目 真机测试 websocket 总是报错 WebSocket错误: {errMsg: Invalid HTTP status.},总是连接不上,但是开发者工具测试就没有问题。 最后解决方案是编码token,之前是没有编码直接拼接的,原因不详。 consol…...

SSH服务
一、准备 #请说明以下服务对应的端口号或者端口对应的服务 ssh 22 telnet 23 http 80 https 443 ftp 20 21 RDP 3389 mysql 3306 redis 6379 zabbix 10050 10051 elasticsear…...

GitHub上免费学习工具的精选汇总
以下是GitHub上免费学习工具的精选汇总,涵盖编程语言、开发框架、数据科学、面试准备等多个方向,结合工具的功能特点、社区活跃度及适用场景进行分类推荐: 一、编程语言与开发框架 Web Developer Roadmap 简介:为开发者提供全栈学…...

2025.4.1总结
今天看了一部网上很火的记录片《God,my brother》,中文名为《上帝不如我兄弟》,简述的是一个自媒体博主杜克遇到孟加拉一哥(车夫),最终一哥在杜克的帮助下,成功实现阶级跨越,而杜克也因此成为百…...

MySQL日志管理
目录 查询日志 慢查询日志 错误日志 二进制日志 其他功能 查询日志 查询日志用来记录所有查询语句的信息,由于开启此日志会占用大量内存,所以一般不会开启 查看查询日志是否开启 开启查询日志 慢查询日志 用于性能的调优,查看执行速度超…...

vscode中的【粘滞滚动】的基本概念和作用,关闭了以后如何开启
1、粘滞滚动的基本概念和作用 VSCode中的“粘滞”功能主要是指编辑器在滚动时的一种特殊效果,使得编辑器在滚动到某个位置时会“粘”在那里,而不是平滑滚动到底部或顶部。 粘滞滚动的基本概念和作用 粘滞滚动功能可以让用户在滚动时更直观地看到当前…...

我用Axure画了一个富文本编辑器,还带交互
最近尝试用Axure RP复刻了一个富文本编辑器,不仅完整还原了工具栏的各类功能,还通过交互设计实现了接近真实编辑器操作体验。整个设计过程聚焦功能还原与交互流畅性,最终成果令人惊喜。 编辑器采用经典的三区布局:顶部工具栏集成了…...
)
Mysql之Redo log(Red log of MySQL)
Mysql之Redo log 数据库事务的4个特性之一的持久性是数据库保证数据一致性的关键,mysql为了确保事务在系统崩溃后也能恢复,引入了redo log 重做日志这一机制。 什么是redo log 持久性指的是一旦事务提交数据就要永久的保存到数据库中,不能…...

Spring Cloud ReactorServiceInstanceLoadBalancer 自定义负载均衡
自定义负载均衡类 import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.springframework.beans.factory.ObjectProvider; import org.springframework.cloud.client.ServiceInstance; import org.springframework.cloud.client…...

汽车诊断开发入门以及OBD检测
一、OBD 概述 定义:OBD 即 On - Board Diagnostics,车载自动诊断系统。它能实时监测车辆各项系统和部件状态,以此帮助诊断故障并预警。设计初衷与发展:最初设计目的是控制汽车尾气排放,确保符合环境标准。随着技术进步…...

高速PCB设计过孔不添乱,乐趣少一半
高速先生成员--姜杰 高速先生最近写了不少介绍高速信号仿真的文章(文章链接汇总,看这篇就够了《聊聊100G信号的仿真》)。雷豹逐一研读后感觉获益匪浅,甚至一度觉得自己强的可怕,不过,在得知即将负责一个11…...

人工智能在医疗领域的前沿应用与挑战
在当今数字化时代,人工智能(AI)技术正以前所未有的速度改变着我们的生活,其中医疗领域无疑是受益最为显著的行业之一。从疾病诊断、治疗方案制定到患者护理,AI的应用不仅提高了医疗服务的效率和质量,还为医…...

怎么实现实时无延迟的体育电竞动画直播
要实现真正的实时无延迟动画直播,需要考虑以下几个关键方面: 一、技术方案选择 1.WebRTC技术 点对点(P2P)传输协议,延迟可低至100-500ms 适用于互动性强的应用场景 开源且被主流浏览器支持 2.低延迟HLS/CMAF 可将延迟控制在1-3秒 兼容…...

VLAN、QinQ、VXLAN的区别
1、技术本质与封装方式 技术OSI层级封装原理标识位长度拓展性VLAN数据链路层L2在以太网帧头插入802.1Q Tag(单层VLAN标签)12位(4094个)有限,仅支持单一网络域内隔离QinQ数据链路层L2在原始VLAN标签外再封装一层802.1Q…...

使用大语言模型进行Python图表可视化
Python使用matplotlib进行可视化一直有2个问题,一是代码繁琐,二是默认模板比较丑。因此发展出seaborn等在matplotlib上二次开发,以更少的代码进行画图的和美化的库,但是这也带来了定制化不足的问题。在大模型时代,这个…...
安装ubuntu22.04)
Mac电脑(M芯片)安装ubuntu22.04
一、下载VMware虚拟机 VMware官网下载VMware Fusion 二、下载ubuntu镜像 M系列的Mac电脑要下载arm架构的镜像 方法一:官网下载 方法二:清华源下载 清华源镜像 点击获取下载链接 选择Ubuntu,下载22.04.5(arm64,Server) 三、创建虚拟机 …...
与逻辑卷管理)
【linux】管理磁盘——RAID10(含备份)与逻辑卷管理
RAID概念 当今CPU性能每年可提升30%-50%但硬盘仅提升7%硬盘在服务器中需要持续、频繁、大量的I/O操作,故障机率较大,则需要对硬盘进行技术改造,提 升读写性能、可靠性1988年,加利福尼亚大学伯克利分校首次提出并定义了RAID技术概…...

Day3 蓝桥杯省赛冲刺精炼刷题 —— 排序算法与贪心思维
一、0实现插入排序 - 蓝桥云课 算法代码: #include <stdio.h>const int N 10000; // 定义数组的最大大小int arr[N 10], temp[N 10]; // arr为待排序的数组,temp为辅助数组// 合并操作:将两个已经排好序的子数组合并为一个有序数…...

查看iphone手机的使用记录-克魔实战
如何查看 iOS 设备近期的详细使用数据 在日常使用手机时,了解设备的运行状态和各项硬件的使用情况可以帮助分析耗电情况、优化应用使用方式。iOS 设备提供了一些数据记录,能够显示应用的启动和关闭时间、后台运行情况,以及应用在使用过程中调…...

Tcp——客户端服务器
Tcp——客户端服务器 目录 一、基本概念 二、代码 2.1 ser服务器 2.2 cil客户端 一、基本概念 TCP(传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。在TCP/IP模型中,TCP位于IP层之上,应用层之下&#x…...

《HarmonyOS Next开发进阶:打造功能完备的Todo应用华章》
章节 6:日期选择器与日期处理 目标 学习如何使用DatePicker组件。理解日期格式化和日期计算。 内容 日期选择器基础 使用DatePicker组件。处理日期选择事件。 日期格式化 格式化日期为友好的文本。 日期计算 判断日期是否过期或即将到期。 代码示例 Entry Com…...

化学方程式配平 第33次CCF-CSP计算机软件能力认证
很经典的大模拟题目 但是还不算难 大模拟题最需要注意的就是细节 写代码一定要考虑全面 并且要细心多debug 多打断点STL库的熟练使用 istringstream真的处理字符串非常好用 注意解耦合思想 这样改代码debug更加清晰 https://www.acwing.com/problem/content/5724/ #includ…...

数据结构【链表】
链表 1.单链表1.1概念与结构1.1.1结点1.1.2链表的性质1.1.3链表的打印 1.2实现单链表1.3链表的分类 2.双向链表2.1概念与结构2.2实现双链表 3.顺序表与链表的分析 1.单链表 1.1概念与结构 概念:链表是⼀种物理存储结构上非连续、非顺序的存储结构,数据…...

AIP-210 Unicode
编号210原文链接AIP-210: Unicode状态批准创建日期2018-06-28更新日期2018-06-28 API在处理(解释、限制长度、计费)字符串值和字符串编码时,应当保持一致,范围从理解上的歧义(如域“限制为1024个字符”)到…...
技术的多种工作模式)
WiFi(无线局域网)技术的多种工作模式
WiFi(无线局域网)技术支持多种工作模式,以满足不同的网络需求和应用场景。以下是主要的WiFi工作模式及其详细说明: 1. 基础设施模式(Infrastructure Mode) [无线接入点 (AP)]/ | \ [客户端…...

游戏引擎学习第198天
回顾并为今天的内容设定 今天我们有一些代码需要处理。昨天我们进行了一些调试界面的整合工作,之前我们做了一些临时的、粗糙的操作,将一些东西读进来并放到调试界面中。今天,我们并不打算进行大规模的工作,更多的是对之前的代码…...

git命令简陋版本
git push git pull 临时仓库暂存区 ##############创建提交################ git init #创建git地址 git config --global user.name "***YQ1007" git config --global user.email "***gmail.com" git remote…...

MySQL 进阶 面经级
会用数据库,找大厂工作是远远不够的。 本人2025美团暑期AI面试好几个MySQL场景问题不会答,已脏面评。遂在此整理学习! 文章目录 美团AI面1.数据库分片sharding的概念,它有什么优势和挑战?优势Sharding 挑战 2. 分库分表的常见策…...

JavaScript数组Array的使用:添加、删除、排序、遍历、互转
1、数组的概述 数组是存储于一个连续空间且具有相同数据类型的元素集合。可以把数组看作一张单行表格,该表格的每一个单元格都可以存储一个数据,而且各单元格中存储的数据类型可以不同。这些单元格被称为数组元素,每个数组元素都有一个索引号,通过索引号可以方便地引用数组…...
Vue Transition组件类名+TailwindCSS
#本文教学结合TailwindCSS实现一个Transition动画的例子# 举例代码: <transition enter-active-class"transition-all duration-300 ease-out"enter-from-class"opacity-0 translate-y-[-10px]"enter-to-class"opacity-100 translate-…...

蓝桥杯备赛:动态规划入门
写题的时候我发现:除了输入输出、循环、条件等基本语句一类的题目之外,我就什么都不会了,题目根本写不下去。 需要学:动态规划、哈希表、二分法、贪心算法等基本算法 现在什么都不会,对这些东西也是一点都不会懂&…...

【VSCode SSH 连接远程服务器】:身份验证时,出现 key: invalid format 的问题
从其它电脑上把私钥文件复制后,出现格式错误 很有可能是复制的时候引入了乱码 很有可能是复制的时候引入了乱码 因此直接从其它电脑上把私钥文件复制到新设备上即可!(不直接复制私钥的内容) 亲测有效。...

git和VScode
游戏存档保存的是游戏的进度 git保存的是代码的进度 Vscode和git 要正常的使用git首先要设置姓名和邮箱 要配合gitee(也可以是其他平台,以gitee举例)使用,首先创造一个gitee账号,复制邮箱和用户名 在VScode中找到…...

c语言数据结构——八大排序算法实现
文章目录 八大排序算法排序算法种类选择排序类堆排序算法思路时间复杂度和空间复杂度 选择排序算法思路算法优化时间复杂度和空间复杂度 插入排序类插入排序算法思路时间复杂度和空间复杂度 希尔排序算法思路时间复杂度和空间复杂度 非比较排序类计数排序时间复杂度和空间复杂度…...
:异常)
Python入门(5):异常
目录 1 异常处理基础概念 1.1 什么是异常? 1.2 异常与错误的区别 2 异常处理基础 2.1 常见内置异常类型 2.2 try-except 基本结构 2.3 捕获多个异常 2.4 抛出异常 2.4.1 使用raise语句 2.4.2 自定义异常类 3 高级异常处理技巧 3.1 不要过度捕…...
——边缘检测)
OpenCv(五)——边缘检测
目录 边缘检测 一、sobel算子边缘检测 (1)原理 1、X轴方向的边缘检测 2、Y轴方向的边缘检测 (2)sobel算子参数 (3)X轴方向边缘检测代码演示 1、显示圆的图像 2、x方向上的边缘检测…...

论文笔记:Instruction-Tuning Llama-3-8B Excels in City-Scale MobilityPrediction
2024 Sigspatial Hummob Workshop 第2/3名 提出了 Llama-3-8B-Mob——一个基于 Llama-3-8B的指令微调版本,专为长期、多城市人类移动预测而设计。 1 问题定义 2 方法 将轨迹预测问题重构为一个带有指令的问答任务 通过 GPT-3.5 和 4 进行实验,发现虽然…...

基础框架系列分享:一个通用的Excel报表生成管理框架
由于我们系统经常要生成大量的Excel报表(Word,PDF报表也有,另行分享),最初始他们的方案是,设计一个表,和Excel完全对应,然后读表,把数据填进去,这显然是非常不…...

Linux安装Ubuntu24.04系统 并安装配置Nvidia 4090 显卡驱动
目录标题 方式一、离线安装一、检查确认系统的版本首先在终端输入下载注意:注意, 后面带notebook的是笔记本的驱动,不要下载错了点击view点击下载二、安装我选择的是 NVIDIA Proprietary.安装完成之后,再次检查补充步骤三:禁用默认nouveau显卡驱动,后重启系统补充步骤四:…...

Deepdiff的使用实战记录
使用场景:在做数据库迁移 或 底层代码重构优化,用于对比新旧代码的接口层返回数据对比 1.模拟在新改造的接口上新加了字段is_ok,且时间戳字段精度变成毫秒,img字段域名变更,能准确对比。 api_old {"ret":…...

C语言:多线程
多线程概述 定义 多线程是指在一个程序中可以同时运行多个不同的执行路径(线程),这些线程可以并发或并行执行。并发是指多个线程在宏观上同时执行,但在微观上可能是交替执行的;并行则是指多个线程真正地同时执行&…...
——进程调度)
Linux(25)——进程调度
目录 一、Linux 进程调度: 二、进程优先级: 1、普通调度策略: 2、完全公平调度程序: 三、nice 值: 1、nice 值范围: 2、nice 值修改权限: (1)降低: …...

SAP CO88根据标准价格拆分增量错误解决
CO88事务码可能出现如下错误,错误消息号 MLCCS015。出现该错误,表示成本组件分解出现了问题,参照 MLCCS015 错误的帮助文档: 其实这里已经说明了原因和解决方法,但不是很具体。note 632752 - Use of the program MLCCS…...

spring boot 整合redis
1.在pom文件中添加spring-boot-starter-data-redis依赖启动器 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency> 2.编写三个实体类 RedisHash("p…...
)
游戏被外挂攻破?金融数据遭篡改?AI反作弊系统实战方案(代码+详细步骤)
一、背景与需求分析 随着游戏行业与金融领域的数字化进程加速,作弊行为(如游戏外挂、金融数据篡改)日益复杂化。传统基于规则的防御手段已难以应对新型攻击,而AI技术通过动态行为分析、异常检测等能力,为安全领域提供了革命性解决方案。本文以游戏反作弊系统和金融数据安…...

【JavaWeb】前端基础
JavaWeb 前端三大件:HTML(主要用于网页主体结构的搭建),CSS(页面美化),JavaScript(主要用于页面元素的动态代理) 1. HTML 1.1 html概述 HTML:Hyper Text …...