课程6. 决策树
课程6. 决策树
- 决策树
- 直觉
- 模型结构
- 几何解释
- 决策树的构建
- ID3算法
- 信息内容标准
- 使用决策树处理差距
- 推广到回归问题
- 分支标准与经典损失函数的关系
- 过度拟合和欠拟合
- 欠拟合
- 过拟合
- 优点和缺点
- 案例
- 随机生成数据集分类
- IRIS 数据集
- 解决回归问题的一个简短例子
决策树
今天我们继续探索一类可以同时解决分类问题和回归问题的新型机器学习算法。
我们已经研究了度量和线性算法,今天我们将研究最具代表性的算法类型之一——决策树。
直觉
通常,在解决各种机器学习问题时,人们必须根据给定问题的顺序答案做出决策。让我们看一个出现类似问题的真实例子。
医生预约
此类任务的一个典型例子是对各种疾病的医学诊断。当病人来找医生抱怨咳嗽时,医生会检查他并回答以下问题:
- 您咳嗽多长时间了?
- 有温度吗?
- 你的鼻子是否堵塞?
- 肺和支气管的声音如何?
- 病人的心率是多少?
- 年龄、是否存在荧光透视照片、其他因素?
根据这些问题的答案,医生为患者做出诊断。
请注意,您只需向医生询问少数问题,而不是所有可能的问题,并且您不需要重新阅读整本医学参考书。您对医生每个问题的回答都会缩小可能的判决数量,直到只剩下一个,而且这个过程很快(5-6 个问题)。
这是决策树结构中嵌入的逻辑。
模型结构
决策树就是所谓的图,即由边连接的一些顶点的序列。您可以将决策树想象为学校计算机科学课上学习的流程图的类似物。

所有树节点都分为叶和内部。根据以下原理,树的工作简化为沿着这些顶点沿边的顺序移动。
由其特征描述向量表示的对象被输入到树的输入。在原始对象的每个内部节点处,都会计算某些表达式的值,该表达式可以取两个值之一 - True 或 False。根据这个值,我们转到树的左边或右边的分支,直到最终到达某个叶节点。每个叶节点包含一些答案,我们将其接受为原始对象分类的结果。稍后我们将考虑对回归问题的推广。
定义谓词 β β β 是一个对于某个对象 x x x 来说可以为真或为假的表达式。
注意:一般来说,谓词的概念比本讲座中给出的概念要广泛一些。通过谓词,我们将理解形式函数
β ( x ⃗ ) = [ ( − 1 ) j ⋅ x i > a ] β(\vec{x}) = [ (-1)^j \cdot x_i > a ] β(x)=[(−1)j⋅xi>a]
也就是说,简单地回答这个问题:特征描述向量的第 i 个坐标是否大于(小于)某个预设数字 a?
正式地,该算法可以描述如下。
令 v 0 v_0 v0为决策树的初始顶点, v v v为当前顶点。那么决策树的决策算法如下所示:
- v = v 0 v=v_0 v=v0
- 当顶点 v v v 是内部时:
- 如果顶点 v v v 处的谓词(函数) β v \beta_v βv 的值等于 1,那么我们继续考虑位于当前顶点右下方的顶点;
- 否则,我们考虑左下顶点。
- 当我们到达一个叶节点时,我们返回与该节点对应的 c v c_v cv类。
请注意,与线性方法不同,在我们的例子中,不需要首先考虑二元分类的问题;我们可以立即讨论多类分类问题的一般情况。
几何解释
让我们考虑二维的情况,即只有 2 个特征的情况。在这种情况下,决策树算法的操作是透明的:决策树识别平面上属于某一类或另一类的区域。

事实上,对于这张图片,决策树的结构将是这样的:
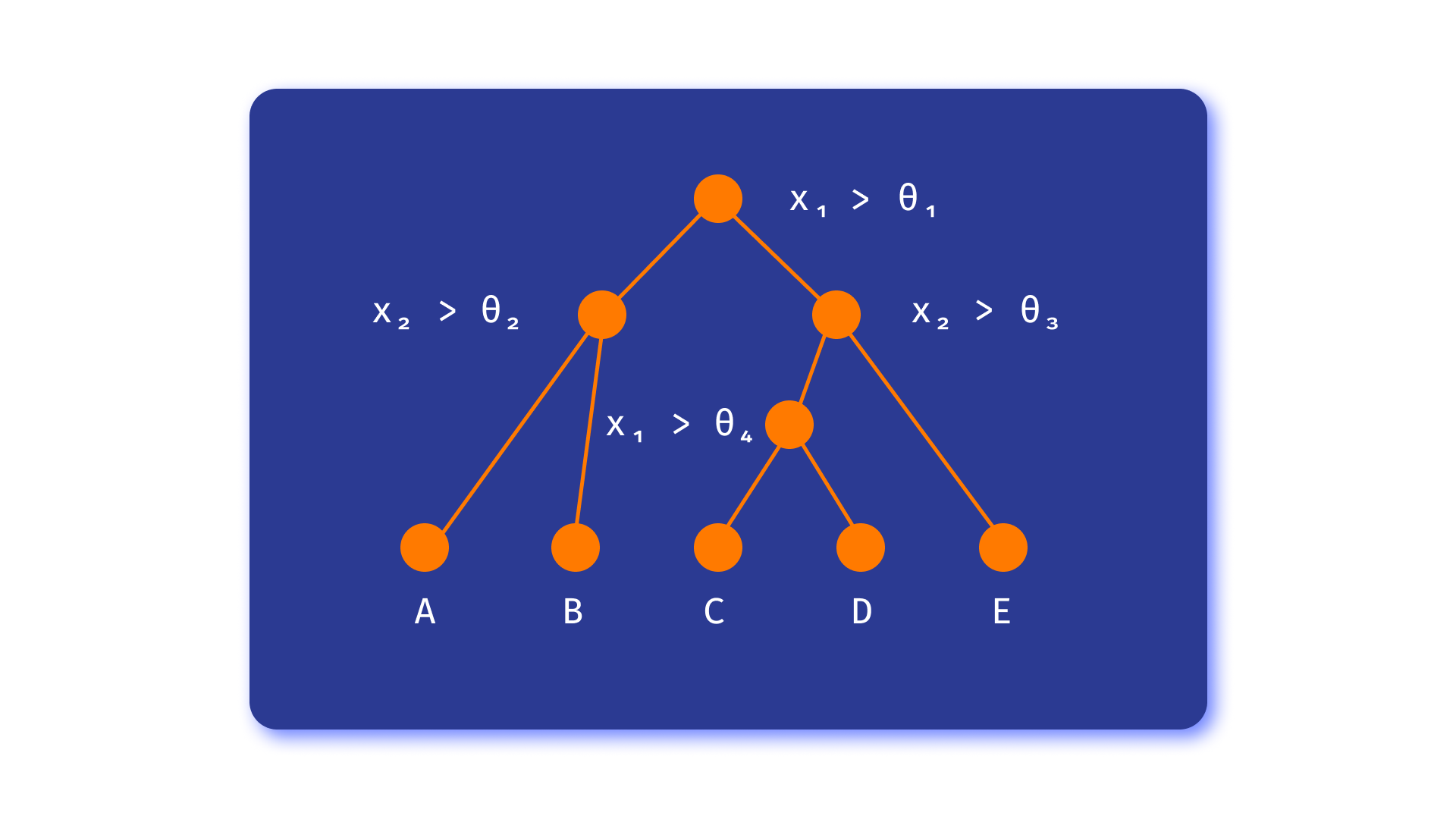
决策树的构建
一旦树被构建出来,我们就弄清楚了决策树算法是如何工作的。但目前还不完全清楚,如何在手头有标记样本的情况下,为其标记构建最佳决策树。让我们以众多决策树算法之一作为示例来看一下这个问题。
一般来说,决策树的构建归结为以下内容:
a) 选择内部顶点和叶顶点的数量。
b) 选择叶节点的布局。
c) 在内部节点处选择谓词序列。
通常,树是通过将原始样本连续分割成两部分来构建的,使得每个子样本的分割质量都是最好的(我们稍后会阐明这意味着什么)。这种顺序分区定义了构建决策树的所有 3 个点。
现在听起来这很抽象。让我们考虑一下这种算法的一个具体例子。
ID3算法
这个算法说明了决策树构建的基本思想。如今,更多有趣的修改已经面世。但我们会考虑基本选择。
该算法可归结为以下一系列操作:
- 在输入处,我们接收从特征描述空间 X 中获取的对象对样本和来自一组类别的响应:U = { ( x , y ) ∣ x ∈ X , y ∈ { 1... N } (x,y) | x \in X, y \in \{1 ... N\} (x,y)∣x∈X,y∈{1...N}} (此处 N 是可能的类别的数量)。
- 如果样本中的所有对象都属于同一类 c:
返回类 c 的叶节点。
- 否则:
- 让我们找到一个谓词(即取值 True 或 False 的表达式)β,借助它我们可以将原始样本最好地分成两部分。
我们将根据一定的规则构建最佳划分,我们称之为信息含量准则。这是某个函数 H ( β , U ) H(β, U) H(β,U),给定一个子样本,它将告诉我们分割的效果有多好。
- 根据谓词 β 将样本分为两部分: U 0 = { x ∈ U : β ( x ) = F a l s e } U_0 = \{x \in U: β(x) = False\} U0={x∈U:β(x)=False} 和 U 1 = { x ∈ U : β ( x ) = T r u e } U_1 = \{x \in U: β(x) = True\} U1={x∈U:β(x)=True}
- 如果其中一个子样本为空,则
将多数类的叶节点返回给 U。
- 创建一个新的具有谓词β的内部节点。
- 通过调用 LearnID3( U 0 U_0 U0) 和 LearnID3( U 1 U_1 U1) 来构建左子树和右子树。

信息内容标准
如前所述,要构建决策树,必须定义一些信息内容标准来评估目标变量在谓词集对象之间的分布质量。也就是说,信息含量标准的值越高,谓词的选择就越准确。
作为一个例子,我们可以考虑基尼标准:
I ( β , X ) = ∣ { ( x i , x j ) : y i = y j , β ( x i ) = β ( x j ) } ∣ I(β, X)=|\{(x_i, x_j): y_i=y_j, β(x_i)=β(x_j)\}| I(β,X)=∣{(xi,xj):yi=yj,β(xi)=β(xj)}∣
第二个例子是V. I. Donskoy的类似D标准:
I ( β , X ) = ∣ { ( x i , x j ) : y i ≠ y j , β ( x i ) ≠ β ( x j ) } ∣ I(β, X)=|\{(x_i, x_j): y_i \neq y_j, β(x_i) \neq β(x_j)\}| I(β,X)=∣{(xi,xj):yi=yj,β(xi)=β(xj)}∣
基尼标准计算根据谓词 β 划分而最终落入同一分支的对象中,有多少个对象实际上应该最终落入同一分支。
相反,顿斯科伊标准计算的是属于不同分支的对象中有多少属于不同的类别。
这些标准相似但并不等同。
注意:
需要注意的是,LearnID3程序中的经典标准是第三个标准——熵标准。它评估分区的信息属性。我们不考虑它,因为要这样做我们必须深入研究信息论,首先讨论概率论的基本原理。然而,所提出的标准给出了选择谓词的可能方法的想法,我们认为这对于这些模型的正确和高质量工作来说已经足够了。
停止标准:
如果我们将 LearnID3 过程一直延续到最后,我们将得到一个过度拟合的结构。因此,让我们考虑一些提前终止该程序的标准。
以下规则可被视为停止标准的示例:
- 树的大小限制(最大深度、叶节点数、节点总数)。
- 叶节点中对象数量的限制。
- 如果所有对象都属于同一类,则停止算法。
使用决策树处理差距
决策树有一个显著的特性:
他们可以处理存在空白的数据。这个属性背后的想法非常简单。
假设我们遇到一个在第 i 个坐标上有间隙的物体,也就是说,我们不知道 x i x_i xi的值是多少。
假设在叶节点 V 处,我们需要计算形式为 β v = [ x i > a ] \beta_v = [x_i > a] βv=[xi>a](或 [ x i < a ] [x_i < a] [xi<a])的谓词 β v β_v βv 的值,其中 a 是某个数字。谓词的值无法计算,也就是说,我们不知道应该将对象 x 发送到树的右边分支还是左边。
然后我们将做出如下决定:
在树的训练阶段,在每个节点上,我们会计算将随机选择的对象发送到左边或右边的概率(也就是说,我们会计算从训练样本中将多少个对象发送到左边,多少个对象发送到右边,然后将两者都除以样本中的对象数量)。
在模型测试阶段,我们确定我们的对象最有可能落入哪个分支。根据在训练阶段形成的概率评估,我们做出适当的决定。
尽管无法计算某些谓词的值,算法仍继续运行。

推广到回归问题
使用以下技巧可以构建回归问题的泛化:我们将一些预测值放在叶节点中,而不是类标签中。将来,决策树的算法与分类的情况非常相似:我们在叶节点之间分配对象,并且在训练过程中计算落入每个叶节点的对象的标签的平均值。测试阶段的预测将正是这个平均值。
在回归的情况下,使用其他分支标准。之前研究的标准并不适用,因为现在对象类的概念根本没有定义。在这方面,定义了其他分支标准,例如基于最小化对象标签的方差、与中位数的绝对偏差等的分支标准。
分支标准与经典损失函数的关系
树的分支标准具有与线性算法的损失函数类似的含义。
例如,假设我们树的目标是最小化每个叶子的均方误差。也就是说,如果 Y Y Y 是属于某个叶子的对象的标签集合,则 c c c 是该叶子的预测。然后我们可以定义损失函数如下:
L ( y i , c ) = ( y i − c ) 2 L(y_i, c) = (y_i - c)^2 L(yi,c)=(yi−c)2
那么本表中整个集合的损失估计为:
Q ( X , Y , c ) = 1 N ∑ i = 1 N ( y i − c ) 2 → min c Q(X, Y, c) = \frac{1}{N}\sum\limits_{i=1}^N(y_i - c)^2 → \min\limits_c Q(X,Y,c)=N1i=1∑N(yi−c)2→cmin
在这种情况下,最佳 c c c 将是,很容易看出, c = ∑ i = 1 N y i N c = \frac{\sum\limits_{i=1}^Ny_i}{N} c=Ni=1∑Nyi
然后:
Q ∗ ( X , Y ) = 1 N ∑ i = 1 N ( y i − y ˉ ) 2 Q^*(X, Y) = \frac{1}{N}\sum\limits_{i=1}^N(y_i - \bar{y})^2 Q∗(X,Y)=N1i=1∑N(yi−yˉ)2
其中 y ˉ \bar{y} yˉ 是 y i y_i yi 的平均值。也就是说, Q ∗ Q^* Q∗ 表示我们想要最小化的每个叶子中的样本方差的估计值。也就是说,最小化 Q ∗ Q^* Q∗ 是我们的分支标准。
类似地,我们可以得出这样的结论:例如,最小化一张纸上的标签与中值的绝对偏差的标准对应于另一个流行的损失函数:
L ( y i , c ) = ∣ y i − c ∣ L(y_i,c) = |y_i - c| L(yi,c)=∣yi−c∣
过度拟合和欠拟合
让我们稍微离题一下,讨论一下训练所有 ML 模型时的两个非常重要的问题。
这些常见的问题被称为过度拟合和欠拟合。它们的名字已经十分充分地描述了它们的本质,但我们将详细探讨它们出现的原因。
欠拟合
欠拟合是指模型由于某种原因无法概括数据中的模式并学习必要的依赖关系的情况。
训练不足的问题可能有两个常见原因:
- 模型根本没有足够的时间学习。这里,时间被理解为梯度下降的步数。这同样适用于错误设置的超参数,例如学习率(参见第 3 讲)
- 从技术上讲,该模型无法学习对其而言过于复杂的依赖关系。换句话说,该模型缺乏容量。让我们举一个这种情况的例子。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snssns.set_theme()x = np.linspace(-1, 1, 100)
y = np.polyval([2, 1, 0.3, -1], x) + np.random.randn(x.shape[0]) * 0.2
plt.figure(figsize=(15,8))
plt.scatter(x,y)
输出:

在这种情况下,需要对三次多项式的行为进行建模。如果我们尝试建立线性回归会发生什么?
from sklearn.linear_model import LinearRegressionLR = LinearRegression().fit(x.reshape(-1, 1), y)
preds = LR.predict(x.reshape(-1, 1))plt.figure(figsize=(15,8))
plt.scatter(x, y)
plt.plot(x, preds, c="g")
输出:

显然逻辑回归无法应对这项任务。关键在于,该模型根本缺乏模拟过于复杂关系的参数。这是训练不足情况的一个可能例子。
欠拟合问题的解决方案通常非常简单。选择具有更多参数的更复杂模型,或者增加训练迭代次数就足够了。
如果在给定的例子中,我们增加模型参数的数量,用三次多项式回归代替线性回归,我们将轻松地以足够高的精度解决问题。
coef = np.polyfit(x, y, 3)
preds = np.polyval(coef, x)plt.figure(figsize=(15,8))
plt.scatter(x, y)
plt.plot(x, preds, c="g")
输出:

过拟合
过度拟合的问题比欠拟合的问题更加复杂,也更具挑战性。
欠拟合是由于所选模型的复杂性不够,而过度拟合则是由于过于复杂。与我们的预期相反,过于复杂的模型也无法学习数据中所需的依赖关系。更准确地说,它将以很大的概率学习数据中纯属偶然出现的、对我们的任务来说并不自然的依赖关系。
过度拟合问题的另一个常见原因是数据不足。事实上,在某些情况下,可以通过降低模型的复杂性来弥补数据的不足。我们希望使模型变得更加复杂,这总是导致我们需要增加用于训练的数据集。
让我们举几个例子:
示例 1:
想象一下你正在教一个来自很远国家的外国人玩“抛硬币”游戏。您希望他了解游戏的基本要点:一枚硬币有两种状态(“正面”和“反面”),它们以相等(或几乎相等)的概率随机出现。
你开始向外国人演示一系列实验,抛硬币并向他宣布结果。
假设你抛硬币三次然后停下来。生活经验表明,本案中三次老鹰落地的结果完全是真实的。我们假设发生了这样的事情,并且外国人听说硬币三次都出现了正面。如果你现在问他如何理解这个游戏的规则,会发生什么?
当然,外国人会告诉你,这个游戏很愚蠢,其全部目的就是观看正面出现。
这是外国人的错觉,是由于缺乏数据而导致的过度训练的结果。
示例 2:
当我们讨论欠拟合时,我们尝试用一个过于简单的模型来建模三次多项式,即线性回归。她这项任务完成得很糟糕。常识告诉我们,二次多项式不太可能很好地完成这项任务,因为原始数据是使用三次多项式依赖关系建模的。这就是为什么三次多项式已经很好地模拟了这个样本。如果我们以四次多项式作为模型会怎么样?还有 5 吗?也许 30 度?毕竟,它们每个都可以对低阶依赖关系进行建模,也就是说,理论上,30 次多项式应该可以像 3 次多项式一样完成这项任务,甚至可能做得更好。
让我们检查一下这是否属实。
x = np.linspace(-1, 1, 20)
y = np.polyval([2, 1, 0.3, -1], x) + np.random.randn(x.shape[0]) * 0.5
plt.figure(figsize=(15, 8))
plt.scatter(x, y, alpha=0.7)plt.title('Test data')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.tight_layout()plt.show()
输出:

# 使用 np.polyfit 查找所需次数的多项式依赖关系
coef_3 = np.polyfit(x, y, 3)
coef_30 = np.polyfit(x, y, 30)
preds_3 = np.polyval(coef_3, x)
preds_30 = np.polyval(coef_30, x)# 让我们显示得到的结果
plt.figure(figsize=(15,8))
plt.scatter(x, y);
plt.plot(x, preds_3, c="g");
plt.plot(x, preds_30, c="r");
输出:

似乎有些不对劲。当然,30 次多项式可以应对向它提出的具体点的近似值,但它似乎没有学到真正的依赖关系,而是学到了受一些随机因素影响的依赖关系。
为了了解他所做的一切是否正确,我们必须向他提供一些他尚未学到的新例子。这样的例子被称为测试样本。
让我们从相同的分布中生成一个测试样本,并检查这个多项式在测试中的表现如何。
x_test = np.linspace(-0.6, 0.6, 100)
y_test = np.polyval([2, 1, 0.3, -1], x_test) + np.random.randn(x_test.shape[0]) * 0.5preds_test_3 = np.polyval(coef_3, x_test)
preds_test_30 = np.polyval(coef_30, x_test)plt.figure(figsize=(15,8))
plt.scatter(x_test, y_test)
plt.plot(x_test, preds_test_3, c="g")
plt.plot(x_test, preds_test_30, c="r")
输出:

显然,三次多项式的表现要好得多。这可以通过测量回归质量指标来确认。
from sklearn.metrics import mean_absolute_error as msemse_3_train = mse(y, preds_3)
mse_30_train = mse(y, preds_30)
mse_3_test = mse(y_test, preds_test_3)
mse_30_test = mse(y_test, preds_test_30)
mse_3_train
mse_30_train
mse_3_test
mse_30_test
输出:
0.36941090138029803
8.354371916485804e-11
0.5550770938313432
0.9459880708945329
注意:训练样本上的30次多项式的误差几乎为零。这是因为训练样本中只有 20 个点。总是可以选择一个 30 次的多项式,使得它穿过任意 20 个点集的所有点。但在测试样本上,他的成绩几乎比测试样本上的结果差2倍。
给定的方法是追踪过度拟合的主要方法之一。
优点和缺点
优点:
- 它们很容易解释。在商业中,这往往成为关键。更复杂的算法(我们将在后面讨论)类似于“黑匣子”,并且不清楚它们究竟根据什么原理做出决策。决策树可以轻松地实现可视化:您几乎总是可以回答为什么针对给定对象获得给定预测的问题。
- 它们适用于分类和回归 - 在这种情况下,树叶将包含数字,而不是类值。
- 相当快。
- 不需要对数据进行严格的预处理:树对特征的规模不敏感,并且能够抵抗多重共线性(回归模型的解释变量(因素)之间存在线性关系)。
- 可以处理数字和分类特征。
- 可以处理数据缺口,尽管从代码角度支持这一点相当困难
缺点:
- 它们过度拟合,模型过多地调整参数(分支分裂)以适应训练样本。在火车上它能运行得很好,但在新数据上则不行。 需要修剪树枝(剪枝)或设置树叶元素的最小数量或树的最大深度,以防止过度拟合。
- 树对输入数据中的噪声非常敏感,训练集稍有变化,整个模型就会发生巨大变化
- 不稳定。数据中的微小变化可能会显著改变最终的决策树。这个问题可以通过使用决策树集合来解决(如下所述)。
- 模型只能进行内插,但不能进行外推(森林和树木增强也是如此)。也就是说,决策树对位于平行六面体之外的特征空间中的物体做出恒定的预测,该预测覆盖训练样本中的所有物体。
- 决策树构建的划分边界有其自身的局限性(由垂直于某些坐标轴的超平面组成)。通常你可以得到一个非常简单的问题的一个非常复杂的解决方案。
案例
随机生成数据集分类
以该数据集为例,我们将看到在使用决策树解决分类问题时,决策域在分类问题中是什么样的。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme()# 将点添加到第一类的平面
np.seed = 10
train_data = np.random.normal(size=(50, 2))
train_data = np.r_[train_data, np.random.normal(size=(50, 2), loc=0.5, scale=2)]
train_labels = np.zeros(100)# 添加第二个类别的点
train_data = np.r_[train_data, np.random.normal(size=(100, 2), loc=4, scale=2)]
train_labels = np.r_[train_labels, np.ones(100)]
plt.rcParams["figure.figsize"] = (14, 10)
plt.scatter(train_data[:, 0],train_data[:, 1],c=train_labels,s=100,cmap="autumn",edgecolors="black",linewidth=1.5,
)
输出:

from sklearn.tree import DecisionTreeClassifier# 让我们编写一个辅助函数,它将返回一个网格以供进一步渲染
def get_grid(data):x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1return np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))clf_tree = DecisionTreeClassifier(criterion="gini", max_depth=30, random_state=17)# 树的训练
clf_tree.fit(train_data, train_labels)# 分割面
xx, yy = get_grid(train_data)
predicted = clf_tree.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.pcolormesh(xx, yy, predicted, cmap="Blues")
plt.scatter(train_data[:, 0],train_data[:, 1],c=train_labels,s=100,cmap="autumn",edgecolors="black",linewidth=1.5,
);
输出:

clf_tree = DecisionTreeClassifier(criterion="gini", max_depth=3, random_state=17)# 树的训练
clf_tree.fit(train_data, train_labels)# 分割面
xx, yy = get_grid(train_data)
predicted = clf_tree.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.pcolormesh(xx, yy, predicted, cmap="Blues")
plt.scatter(train_data[:, 0],train_data[:, 1],c=train_labels,s=100,cmap="autumn",edgecolors="black",linewidth=1.5,
);
输出:

clf_tree = DecisionTreeClassifier(criterion="entropy", max_depth=30, random_state=17)# 树的训练
clf_tree.fit(train_data, train_labels)# 分割面
xx, yy = get_grid(train_data)
predicted = clf_tree.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.pcolormesh(xx, yy, predicted, cmap="Blues")
plt.scatter(train_data[:, 0],train_data[:, 1],c=train_labels,s=100,cmap="autumn",edgecolors="black",linewidth=1.5,
);
输出:

IRIS 数据集
现在让我们转向我们已经喜爱的 Fisher 鸢尾花数据集。让我们看一下投影到二维特征子空间的决策域。
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import linear_model
from sklearn import metrics
iris = datasets.load_iris()
iris.feature_names
输出:
[‘sepal length (cm)’,
‘sepal width (cm)’,
‘petal length (cm)’,
‘petal width (cm)’]
目标变量是鸢尾花的品种:
- 0 - Setosa
- 1 - Versicolor
- 2 - Virginica
问题:找到花瓣的大小(长度/宽度)和鸢尾花品种之间的关系。
df = pd.DataFrame(iris.data)
df.columns = iris.feature_names
df["target"] = iris.target
df["name"] = df.target.apply(lambda x: iris.target_names[x])
df
输出:

sns.pairplot(df[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)', 'name']], hue = 'name')
输出:

import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier# 设置参数
n_classes = 3
plot_colors = "ryb"
plot_step = 0.02
plt.figure(figsize=(20, 12))
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3]]):# 选择当前的特征对X = iris.data[:, pair]y = iris.target# 训练模型clf = DecisionTreeClassifier(max_depth=40).fit(X, y)# 让我们画出类别边界plt.subplot(2, 3, pairidx + 1)x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step), np.arange(y_min, y_max, plot_step))plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)cs = plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu)plt.xlabel(iris.feature_names[pair[0]])plt.ylabel(iris.feature_names[pair[1]])# 预览for i, color in zip(range(n_classes), plot_colors):idx = np.where(y == i)plt.scatter(X[idx, 0],X[idx, 1],c=color,label=iris.target_names[i],cmap=plt.cm.RdYlBu,edgecolor="black",s=15,)plt.suptitle("Class boundary according to the constructed algorithm")
plt.legend(loc="lower right", borderpad=0, handletextpad=0)
输出:
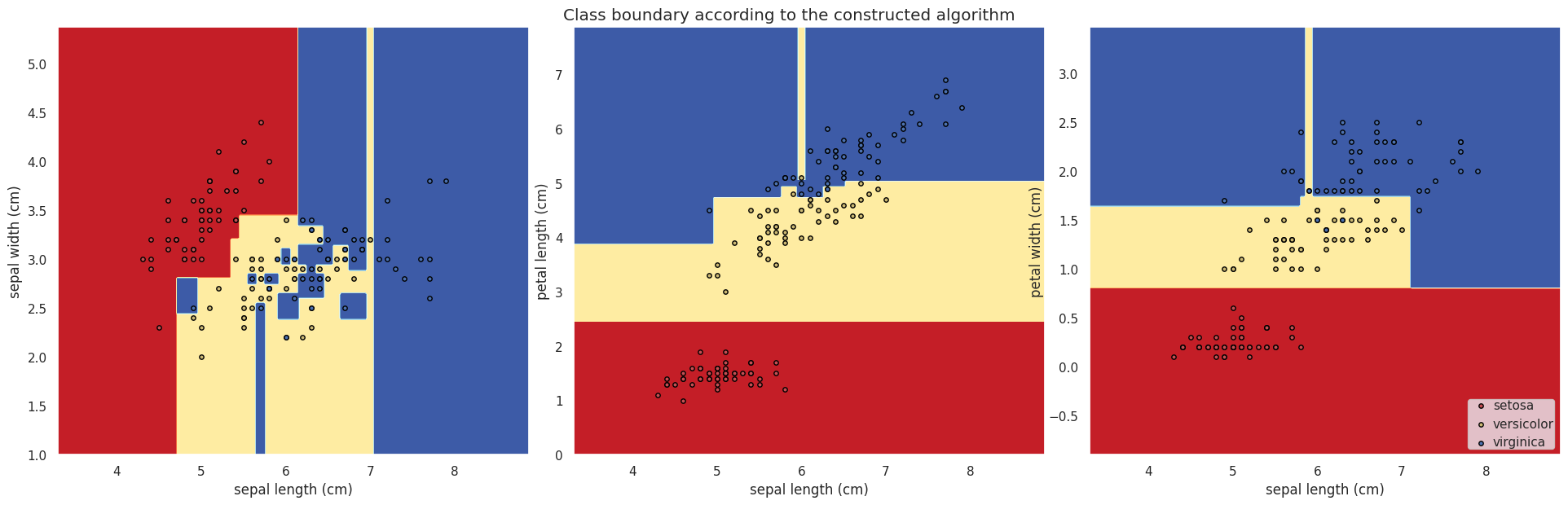
解决回归问题的一个简短例子
最后,我们将给出一个使用决策树解决回归问题的例子。
让我们尝试应用决策树来预测加州公寓的价格(流行的加州住房数据集)。
让我们选择决策树深度的最佳限制(参数max_depth)。该参数用于避免模型过度拟合。
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing
import tqdm
from tqdm.auto import tqdmX, y = fetch_california_housing(return_X_y=True)
X_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)scores = []
train_scores = []
for max_d in tqdm(range(2, 100)):reg = DecisionTreeRegressor(max_depth=max_d)reg.fit(X_train, y_train)test_score = reg.score(x_test, y_test)train_scores.append(reg.score(X_train, y_train))scores.append(test_score)
from matplotlib import pyplot as pltplt.plot(list(range(2, 100)), scores)
plt.plot(list(range(2, 100)), train_scores)
输出:

max(scores)
输出:
0.699358110826223
import numpy as np
np.argmax(scores)
输出:np.int64(6)
因此,通过将树深度限制为 2+ 找到的值来实现最佳指标
相关文章:

课程6. 决策树
课程6. 决策树 决策树直觉模型结构几何解释决策树的构建ID3算法信息内容标准使用决策树处理差距推广到回归问题分支标准与经典损失函数的关系 过度拟合和欠拟合欠拟合过拟合 优点和缺点案例随机生成数据集分类IRIS 数据集解决回归问题的一个简短例子 决策树 今天我们继续探索一…...

【UE5.3.2】初学1:适合初学者的入门路线图和建议
3D人物的动作制作 大神分析:3D人物的动作制作通常可以分为以下几个步骤: 角色绑定(Rigging):将3D人物模型绑定到一个骨骼结构上,使得模型能够进行动画控制。 动画制作(Animation):通过控制骨骼结构,制作出人物的各种动作,例如走路、跳跃、打斗等。 动画编辑(Ani…...
内核 API)
OpenCV 图形API(4)内核 API
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 G-API 背后的核心理念是可移植性——使用 G-API 构建的流水线必须是可移植的(或者至少具备可移植的能力)。这意味着&…...

pom.xml与.yml,java配置参数传递
pom.xml与 .yml java配置参数传递 在Java项目中,通过 pom.xml 和 .yml 文件(如 application.yml)传递变量通常涉及 构建时(Maven)和 运行时(Spring Boot)两个阶段的配置。以下是具体的实现方法&…...
_21)
LeetCode算法题(Go语言实现)_21
题目 给你一个整数数组 arr,如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。 一、代码实现 func uniqueOccurrences(arr []int) bool {freq : make(map[int]int)// 统计每个数字的出现次数for _, num : range arr {freq[n…...

Docker部署前后端分离项目
镜像下载 在有网络的电脑下载镜像(Windows):依次在CMD命令台执行以下代码 docker pull node:20docker pull openjdk:22-jdkdocker pull mysql:8.0docker pull nginx:1.27 删除镜像代码: docker rmi node:latest 查看镜像列表…...
)
Linux系统安装MySQL 8.0完整指南(新手友好版)
MySQL作为最流行的开源关系型数据库之一,广泛应用于各种开发和生产环境。本教程将详细介绍在Linux系统上安装MySQL 8.0的全过程,包括卸载旧版本、安装新版本、基础配置和远程连接设置,特别适合Linux新手学习使用。 一、卸载旧版MySQL&#x…...

第二次作业
#创建表,把id设为主键 mysql> create table test02(-> id int primary key, #----主键约束-> name varchar(50)-> ); Query OK, 0 rows affected (0.02 sec) #插入数据测试 mysql> insert into test02 values(1,"成都"); Query OK, 1 r…...

AI大模型下传统 Spring Java工程开发的演进和变化方向
1. 背景和动因 传统Spring开发优势:Spring生态以稳定、模块化、依赖注入(DI)等特性著称,长期支撑企业级应用开发,具备高扩展性和可维护性。AI大模型崛起:近几年,LLM(如GPT-4、LLaMA…...

周学习总结
这周继续学习了Java的知识点,还写了考查递归、递推与贪心的算法题。 算法小结 递归与递推一般是观察观察题干,分析题目的规律,可能还会用到分治算法,推导出一个合理的表达式,再使用函数递归来进行求解。 贪心在求解时…...

19.思科路由器:OSPF协议引入直连路由的实验研究
思科路由器:OSPF协议引入直连路由的实验研究 一、实验拓扑二、基本配置2.1、sw1的配置2.2、开启交换机三层功能三、ospf的配置3.1、R1的配置3.2、R2的配置3.3、重启ospf进程四、引入直连路由五、验证结果随着互联网技术的不断发展,路由器作为网络互联的关键设备,其性能与稳定…...
)
Zcanpro搭配USBCANFD-200U在新能源汽车研发测试中的应用指南(周立功/致远电子)
——国产工具链的崛起与智能汽车测试新范式 引言:新能源汽车测试的国产化突围 随着新能源汽车智能化、网联化程度的提升,研发测试面临三大核心挑战:多协议融合(CAN FD/LIN/以太网)、高实时性数据交互需求、复杂工况下…...

JSON的基础知识
文章目录 前言json协议的基本格式json 数组类型 的语法规则json协议报文的实例json常见的一些格式错误在gd32中使用cjson库小结 前言 json协议在互联网应用,物联网应用中都会用到。所谓工欲善其事必先利其器,我们需要学习了解json协议的具体格式…...
学习笔记)
week2|机器学习(吴恩达)学习笔记
一、多维特征 1.1、什么是多维特征? 1)在我们的原始估计房价的版本中,我们只有一个变量: x x x 来预估 y y y 2)但是现在假设你也知道其他的参数变量,那么我们就可以引入多个参数来提高预测 y y y的准确…...
GRU 门控循环单元(上集),详细结构说明)
各类神经网络学习:(七)GRU 门控循环单元(上集),详细结构说明
上一篇下一篇LSTM(下集)GRU(下集) GRU(门控循环单元) 它其实是 R N N RNN RNN 和 L S T M LSTM LSTM 的折中版,有关 R N N RNN RNN 和 L S T M LSTM LSTM 请参考往期博客。 实际应用要比 …...
实现双人视频/音频通话功能(附完整的项目代码))
uniapp利用第三方(阿里云)实现双人视频/音频通话功能(附完整的项目代码)
要在UniApp中利用阿里云实现双人视频/音频通话功能,你需要使用阿里云的实时音视频服务(RTC)。以下是一个基本的实现步骤和示例代码。 基本的操作步骤 注册阿里云账号并开通RTC服务: 访问阿里云官网,注册账号并开通RTC服务。 获取AppID和AppKey: 在RTC控制台创建应用,…...

wsl2的centos7安装jdk17、maven
JDK安装 查询系统中的jdk rpm -qa | grep java按照查询的结果,删除对应版本 yum -y remove java-1.7.0-openjdk*检查是否删除 java -version 下载JDK17 JDK17,下载之后存到wsl目录下(看你自己)然后一键安装 sudo rpm -ivh jd…...

Android 单例模式全解析:从基础实现到最佳实践
单例模式(Singleton Pattern)是软件开发中常用的设计模式,其核心是确保一个类在全局范围内只有一个实例,并提供全局访问点。在 Android 开发中,单例模式常用于管理全局资源(如网络管理器、数据库助手、配置…...

Redis GEO
Redis GEO 引言 Redis GEO是Redis数据库中的一种高级功能,允许用户存储地理位置信息并执行基于地理空间查询的操作。本文将详细介绍Redis GEO的基本概念、使用方法以及在实际应用中的优势。 基本概念 GEO编码 GEO编码是指将地理位置信息(如经纬度&a…...

vulnhub-serile靶机通关攻略
下载地址:https://www.vulnhub.com/entry/serial-1,349/ 靶机安装特殊,附带安装参考文章:https://zhuanlan.zhihu.com/p/113887109 扫描IP地址 arp-scan -l扫描端口 nmap -p- 192.168.112.141访问80端口 线索指向cookie cookie是base64编…...

SAP-ABAP:OData 协议深度解析:架构、实践与最佳应用
OData 协议深度解析:架构、实践与最佳应用 一、协议基础与核心特性 协议定义与目标 定位:基于REST的开放数据协议,标准化数据访问接口,由OASIS组织维护,最新版本为OData v4.01。设计哲学:通过统一资源标识符(URI)和HTTP方法抽象数据操作,降低异构系统集成复杂度。核心…...
)
408 计算机网络 知识点记忆(3)
前言 本文基于王道考研课程与湖科大计算机网络课程教学内容,系统梳理核心知识记忆点和框架,既为个人复习沉淀思考,亦希望能与同行者互助共进。(PS:后续将持续迭代优化细节) 往期内容 408 计算机网络 知识…...

java学习笔记10——集合框架
枚举类的使用 Collection接口继承树 Map接口继承树 Collection 接口方法 总结: 集合框架概述 1.内存层面需要针对于多个数据进行存储。此时,可以考虑的容器有:数组、集合类2.数组存储多个数据方面的特点:> 数组一旦初始化,其长度就是确定的…...

埃文科技企业AI大模型一体机——昇腾体系+DeepSeek+RAG一站式解决方案
面对企业级市场海量数据资产与复杂业务场景深度耦合的刚需,埃文科技重磅推出基于华为昇腾算力DeepSeek大模型的企业一体机产品,提供DeepSeek多版本大模型一体机选择,为企业提供本地昇腾算力DeepSeek大模型RAG知识库的一体化解决方案ÿ…...

蓝桥杯---BFS解决FloofFill算法1---图像渲染
文章目录 1.算法简介2.题目概述3.算法原理4.代码分析 1.算法简介 这个算法是关于我们的floodfill的相关的问题,这个算法其实从名字就可以看出来:洪水灌溉,其实这个算法的过程就和他的名字非常相似,下面的这个图就生动的展示了这个…...

个人博客网站从搭建到上线教程
步骤1:设计个人网站 设计个人博客网站的风格样式,可以在各个模板网站上多浏览浏览,以便有更多设计网站风格样式的经验。 设计个人博客网站的内容,你希望你的网站包含哪些内容如你的个人基本信息介绍、你想分享的项目、你想分享的技术文档等等。 步骤2:选择开发技术栈 因…...

【FreeRTOS】裸机开发与操作系统区别
🔎【博主简介】🔎 🏅CSDN博客专家 🏅2021年博客之星物联网与嵌入式开发TOP5 🏅2022年博客之星物联网与嵌入式开发TOP4 🏅2021年2022年C站百大博主 🏅华为云开发…...

力扣每日一题:2712——使所有字符相等的最小成本
使所有字符相等的最小成本 题目示例示例1示例2 题解这些话乍一看可能看不懂,但是多读两遍就明白了。很神奇的解法,像魔术一样。 题目 给你一个下标从 0 开始、长度为 n 的二进制字符串 s ,你可以对其执行两种操作: 选中一个下标…...
——网络原理——IP数据报结构IP协议解析(简述))
Java EE(17)——网络原理——IP数据报结构IP协议解析(简述)
一.IP数据报结构 (1)版本:指明协议的版本,IPv4就是4,IPv6就是6 (2)首部长度:单位是4字节,表示IP报头的长度范围是20~60字节 (3)8位区分服务:实际上只有4位TOS有效,分别是最小延时,最…...
Pycharm运行时报“Empty suite”,可能是忽略了这个问题
问题:使用Pycharm运行testcases目录下的.py文件,报“Empty suite”,没有找到测试项。 排查过python解释器、pytest框架安装等等,依然报这个错,依然没找到,最后终端运行: pytest test_demo.py&a…...

Linux快速安装docker和docker-componse步骤
在 CentOS 7 上安装 Docker 和 Docker Compose 的步骤如下: 1. 安装 Docker 1.1. 更新系统 首先,确保你的系统是最新版本: sudo yum update -y1.2. 安装必要的包 安装 yum-utils,这是管理 YUM 源的工具: sudo yu…...

OP2177运算放大器:高性能模拟信号处理的关键元件
在现代电子系统中,模拟信号处理至关重要,运算放大器作为模拟电路的核心部件,其性能优劣直接影响系统的整体表现。OP2177 是一款具有卓越性能的运算放大器,在众多领域有着广泛应用。以下将结合相关资料,对 OP2177 进行全…...

paddle ocr
paddle ocr paddle ocr笔记准备工作referenceto onnx文本检测文本检测文字识别 paddle ocr笔记 准备工作 下载字典ppocr_keys_v1.txt,下标从1开始模型转换 reference paddlepaddle to onnx 下载模型,或者直接使用python跑一下并且把本地模型拿过来…...
下都能正确解析)
通过动态获取项目的上下文路径来确保请求的 URL 兼容两种启动方式(IDEA 启动和 Tomcat 部署)下都能正确解析
背景 因为在不同的启动环境下,获取上下文路径的方式需要有所调整。在 IDEA 中运行时,路径是基于当前页面的 URL(如 index.html),而在 Tomcat 部署时,它是基于项目上下文路径(如 ssm-project&am…...

Spring Boot 整合 ElasticJob 分布式任务调度教程
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Spring Boot 整合 ElasticJob 分布式任务调度教程 一、ElasticJob 简介 ElasticJob 是当当网开源的分布式任务调度解决方案,支持: …...
)
Django项目之订单管理part6(message组件和组合搜索组件)
一.前言 我们前面讲的差不多了,接着上节课讲,今天要来做一个撤单要求,我们可以用ajax请求,但是我这里介绍最后一个知识点,message组件,但是我会把两种方式都讲出来的,讲完这个就开始讲我们最重…...

[MySql] 多表关系, 多表查询
一. 多表关系 1.1 一对多 例如: 员工 - 部门表 (一个部门可以有多个员工) 并且在多的一方增加一个字段关联一的一方的主键. 外键约束: 物理外键 (使用 foreign key 定义外键关联另一张表的主键) 缺点: 影响增删改效率; 仅用于单节点, 不适用与集群; 易引发死锁, 性能低; …...

Open GL ES ->GLSurfaceView在正交投影下的图片旋转、缩放、位移
XML文件 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:o…...

一文详解QT环境搭建:Windows使用CLion配置QT开发环境
在当今的软件开发领域,跨平台应用的需求日益增长,Qt作为一款流行的C图形用户界面库,因其强大的功能和易用性而备受开发者青睐。与此同时,CLion作为一款专为C/C打造的强大IDE,提供了丰富的特性和高效的编码体验。本文将…...

MSTP和链路聚合
MSTP 802.1S --- MSTP --- 多生成树协议 --- 就是在RSTP基础上,再针对链路利用率低问题进行优化,可以和RSTP以及STP向下兼容。 实例 --- Instance --- 可以理解为一个V LAN或者多个VALN的集合。一个交换网络可以针对一个实例创建一棵树,起到…...
:ls)
每天学一个 Linux 命令(8):ls
大家好,欢迎来到《每天掌握一个Linux命令》系列。在这个系列中,我们将逐步学习并熟练掌握Linux命令,今天,我们要学习的命令是ls。 01 什么是ls命令 在Linux系统中,ls命令是“list”的缩写,其英文全称为“list directory contents”,即“列出目录内容”。该命令非常实用…...

交换机、路由器、VLAN、单臂路由、三层交换、STP
华为模拟安装 1.依次安装wincap 2.wireshark 3.virtual box 4.ensp 一、设置 1.virtual box设置 2.计算机防火墙允许以上程序 3.eNSP设置 路由器:AR2240 交换机:S5700、CE12800 防火墙USG6000V 交换机 一、交换机工作原理 1、回顾 二层交换机…...

算法 | 2024最新算法:斑翠鸟优化算法原理,公式,应用,算法改进研究综述,matlab代码
基于斑翠鸟优化算法的原理、应用及改进研究综述 一、算法原理 斑翠鸟优化算法(Pied Kingfisher Optimizer, PKO)是2024年由Bouaouda等人提出的一种新型仿生智能优化算法,其灵感来源于斑翠鸟的捕食行为与共生关系。算法通过模拟斑翠鸟的栖息悬停、潜水捕鱼及与其他生物的共生…...
(pipe、管道四种场景))
六十天Linux从0到项目搭建(第二十二天)(pipe、管道四种场景)
1 关于 pipe 系统调用的解析 int pipe(int pipefd[2]) 是 Unix/Linux 系统中用于创建匿名管道的系统调用。以下是关于管道特点的详细解释: 输出型参数 pipefd[2] 是输出型参数,调用成功后: pipefd[0] 存放管道的读取端文件描述符 pipefd[1…...

数据安全与网络安全——问答复习
目录 1、请简要分析勒索软件攻击的原理,并给出技术防护⽅案。 勒索软件攻击原理: 技术防护⽅案 2、举例数据安全问题 数据泄露 数据篡改 数据丢失 3、如何应对数据安全问题 技术层⾯ 管理层⾯ 4、软件漏洞 产⽣原因: 缓冲区溢出漏洞: 注⼊漏…...

ESP-01模块连接手机热点问题及解决方法
在使用ESP-01模块连接手机热点时,可能会遇到一些问题。本文将详细介绍如何解决这些问题,并分享最终通过将WiFi切换到2.4GHz成功解决问题的经验。 一、问题描述 在尝试使用ESP-01模块连接手机热点时,遇到了连接失败的问题。以下是操作过程中…...

go中锁的入门到进阶使用
Go 并发编程:从入门到精通的锁机制 引言:为什么需要锁? Go 语言以其天生支持并发的特性深受开发者喜爱,但并发带来的问题也不容小觑,比如数据竞争、并发安全等。如果多个 Goroutine 访问同一个变量,没有做…...

JS判断对象是否为空的方法
在 JavaScript 中,判断一个对象是否为空对象(即没有自身可枚举属性),可以通过以下方法实现: 方法 1:使用 Object.keys() javascript function isEmptyObject(obj) {// 确保是普通对象(排除 n…...

idea导入tomcat的jar
概述 对于老项目,未使用 Maven/Gradle 管理依赖的,在需要编译 Servlet/JSP 代码时,需要手动添加 Tomcat JAR 依赖(如 servlet-api.jar)方能进行编绎。 步骤: 1、找到 Tomcat 的 JAR 文件 进入 Tomcat 安…...

Linux 下安装和使用 Jupyter Notebook
Jupyter Notebook / Lab 是 Python 开发和数据分析中不可或缺的工具。为了避免环境污染,推荐使用虚拟环境方式安装并启动它。本教程将教你如何: 安装 Python、pip、venv使用虚拟环境安装 Jupyter汉化安装实用插件设置登录密码启动并远程访问编写一个一键…...