大模型高质量rag构建:A Cheat Sheet and Some Recipes For Building Advanced RAG
原文:A Cheat Sheet and Some Recipes For Building Advanced RAG — LlamaIndex - Build Knowledge Assistants over your Enterprise DataLlamaIndex is a simple, flexible framework for building knowledge assistants using LLMs connected to your enterprise data.![]() https://www.llamaindex.ai/blog/a-cheat-sheet-and-some-recipes-for-building-advanced-rag-803a9d94c41b
https://www.llamaindex.ai/blog/a-cheat-sheet-and-some-recipes-for-building-advanced-rag-803a9d94c41b
一、TL;DR
- 给出了典型的基础rag并定义了2条rag是成功的要求
- 基于2条rag的成功要求给出了构建高级rag的相关技术,包括块大小优化、结构化外部知识、信息压缩、结果重排等
- 对上述所有的方法,给出了LlamaIndex的demo代码和相关的其他参考链接
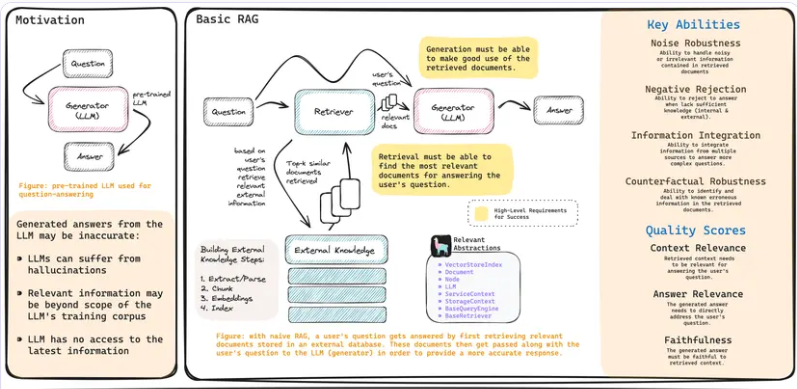

二、基础RAG
如今所定义的主流RAG(检索增强型生成)涉及从外部知识数据库中检索文档,并将这些文档连同用户的查询一起传递给大型语言模型(LLM),以生成回答。换句话说,RAG包含检索组件、外部知识数据库和生成组件。
LlamaIndex基础RAG配方:
from llama_index import SimpleDirectoryReader, VectorStoreIndex# load data
documents = SimpleDirectoryReader(input_dir="...").load_data()# build VectorStoreIndex that takes care of chunking documents
# and encoding chunks to embeddings for future retrieval
index = VectorStoreIndex.from_documents(documents=documents)# The QueryEngine class is equipped with the generator
# and facilitates the retrieval and generation steps
query_engine = index.as_query_engine()# Use your Default RAG
response = query_engine.query("A user's query")三、RAG的成功要求
为了使一个RAG系统被认为是成功的(即能够为用户提供有用且相关的答案),实际上只有两个高级要求:
- 检索必须能够找到与用户查询最相关的文档(能够找到)。
- 生成必须能够充分利用检索到的文档来充分回答用户查询(充分找到)。
四、高级RAG
构建高级RAG实际上就是应用更复杂的技术和策略(针对检索或生成组件),以确保这些要求最终得以满足。此外,我们可以将一种复杂的技术归类为:要么是独立(或多或少)于另一个要求来解决这两个高级成功要求中的一个,要么是同时解决这两个要求。
4.1 检索的高级技术必须能够找到与用户查询最相关的文档
下面,我们简要描述一些更复杂的技术,以帮助实现第一个成功要求。
4.1.1 块大小优化
由于LLM(大型语言模型)受到上下文长度的限制,在构建外部知识库时,有必要将文档分割成块。块过大或过小都会给生成组件带来问题,导致回答不准确
LlamaIndex Chunk Size Optimization Recipe:
from llama_index import ServiceContext
from llama_index.param_tuner.base import ParamTuner, RunResult
from llama_index.evaluation import SemanticSimilarityEvaluator, BatchEvalRunner### Recipe
### Perform hyperparameter tuning as in traditional ML via grid-search
### 1. Define an objective function that ranks different parameter combos
### 2. Build ParamTuner object
### 3. Execute hyperparameter tuning with ParamTuner.tune()# 1. Define objective function
def objective_function(params_dict):chunk_size = params_dict["chunk_size"]docs = params_dict["docs"]top_k = params_dict["top_k"]eval_qs = params_dict["eval_qs"]ref_response_strs = params_dict["ref_response_strs"]# build RAG pipelineindex = _build_index(chunk_size, docs) # helper function not shown herequery_engine = index.as_query_engine(similarity_top_k=top_k)# perform inference with RAG pipeline on a provided questions `eval_qs`pred_response_objs = get_responses(eval_qs, query_engine, show_progress=True)# perform evaluations of predictions by comparing them to reference# responses `ref_response_strs`evaluator = SemanticSimilarityEvaluator(...)eval_batch_runner = BatchEvalRunner({"semantic_similarity": evaluator}, workers=2, show_progress=True)eval_results = eval_batch_runner.evaluate_responses(eval_qs, responses=pred_response_objs, reference=ref_response_strs)# get semantic similarity metricmean_score = np.array([r.score for r in eval_results["semantic_similarity"]]).mean()return RunResult(score=mean_score, params=params_dict)# 2. Build ParamTuner object
param_dict = {"chunk_size": [256, 512, 1024]} # params/values to search over
fixed_param_dict = { # fixed hyperparams"top_k": 2,"docs": docs,"eval_qs": eval_qs[:10],"ref_response_strs": ref_response_strs[:10],
}
param_tuner = ParamTuner(param_fn=objective_function,param_dict=param_dict,fixed_param_dict=fixed_param_dict,show_progress=True,
)# 3. Execute hyperparameter search
results = param_tuner.tune()
best_result = results.best_run_result
best_chunk_size = results.best_run_result.params["chunk_size"]4.1.2 结构化外部知识
在复杂场景中,可能需要构建比基础向量索引更具结构化的外部知识,以便在处理合理分离的外部知识源时,允许进行递归检索或路由检索:
LlamaIndex Recursive Retrieval Recipe:
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.schema import IndexNode### Recipe
### Build a recursive retriever that retrieves using small chunks
### but passes associated larger chunks to the generation stage# load data
documents = SimpleDirectoryReader(input_file="some_data_path/llama2.pdf"
).load_data()# build parent chunks via NodeParser
node_parser = SentenceSplitter(chunk_size=1024)
base_nodes = node_parser.get_nodes_from_documents(documents)# define smaller child chunks
sub_chunk_sizes = [256, 512]
sub_node_parsers = [SentenceSplitter(chunk_size=c, chunk_overlap=20) for c in sub_chunk_sizes
]
all_nodes = []
for base_node in base_nodes:for n in sub_node_parsers:sub_nodes = n.get_nodes_from_documents([base_node])sub_inodes = [IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes]all_nodes.extend(sub_inodes)# also add original node to nodeoriginal_node = IndexNode.from_text_node(base_node, base_node.node_id)all_nodes.append(original_node)# define a VectorStoreIndex with all of the nodes
vector_index_chunk = VectorStoreIndex(all_nodes, service_context=service_context
)
vector_retriever_chunk = vector_index_chunk.as_retriever(similarity_top_k=2)# build RecursiveRetriever
all_nodes_dict = {n.node_id: n for n in all_nodes}
retriever_chunk = RecursiveRetriever("vector",retriever_dict={"vector": vector_retriever_chunk},node_dict=all_nodes_dict,verbose=True,
)# build RetrieverQueryEngine using recursive_retriever
query_engine_chunk = RetrieverQueryEngine.from_args(retriever_chunk, service_context=service_context
)# perform inference with advanced RAG (i.e. query engine)
response = query_engine_chunk.query("Can you tell me about the key concepts for safety finetuning"
)4.1.3 其他有用的链接
我们有一些指南展示了在复杂情况下确保准确检索的其他高级技术的应用。以下是一些精选链接:
- Building External Knowledge using Knowledge Graphs
- Performing Mixed Retrieval with Auto Retrievers
- Building Fusion Retrievers
- Fine-tuning Embedding Models used in Retrieval
- Transforming Query Embeddings (HyDE)
4.2 生成的高级技术必须能够充分利用检索到的文档
与前一节类似,我们提供了一些此类复杂技术的例子,这些技术可以被描述为确保检索到的文档与生成器的大型语言模型(LLM)很好地对齐。
4.2.1 信息压缩:
大型语言模型(LLM)不仅受到上下文长度的限制,而且如果检索到的文档携带过多的噪声(即无关信息),还可能导致回答质量下降。
LlamaIndex:
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import LongLLMLinguaPostprocessor### Recipe
### Define a Postprocessor object, here LongLLMLinguaPostprocessor
### Build QueryEngine that uses this Postprocessor on retrieved docs# Define Postprocessor
node_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder},
)# Define VectorStoreIndex
documents = SimpleDirectoryReader(input_dir="...").load_data()
index = VectorStoreIndex.from_documents(documents)# Define QueryEngine
retriever = index.as_retriever(similarity_top_k=2)
retriever_query_engine = RetrieverQueryEngine.from_args(retriever, node_postprocessors=[node_postprocessor]
)# Used your advanced RAG
response = retriever_query_engine.query("A user query")4.2.2 结果重排:
LLM(大型语言模型)存在所谓的“迷失在中间”现象,即LLM会重点关注提示的两端。鉴于此,在将检索到的文档传递给生成组件之前,重新对它们进行排序是有益的。
LlamaIndex结果重排以提升生成效果的方法:
import os
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.postprocessor.cohere_rerank import CohereRerank
from llama_index.postprocessor import LongLLMLinguaPostprocessor### Recipe
### Define a Postprocessor object, here CohereRerank
### Build QueryEngine that uses this Postprocessor on retrieved docs# Build CohereRerank post retrieval processor
api_key = os.environ["COHERE_API_KEY"]
cohere_rerank = CohereRerank(api_key=api_key, top_n=2)# Build QueryEngine (RAG) using the post processor
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
index = VectorStoreIndex.from_documents(documents=documents)
query_engine = index.as_query_engine(similarity_top_k=10,node_postprocessors=[cohere_rerank],
)# Use your advanced RAG
response = query_engine.query("What did Sam Altman do in this essay?"
)4.3 同时满足检索和生成成功要求的高级技术
在本小节中,我们考虑一些复杂的办法,这些办法利用检索和生成的协同作用,以实现更好的检索效果以及更准确地回答用户查询的生成结果。
4.3.1 生成器增强型检索:
这些技术利用LLM(大型语言模型)的固有推理能力,在执行检索之前对用户查询进行优化,以便更准确地表明需要什么内容才能提供有用的回答。
LlamaIndex生成器增强型检索:
from llama_index.llms import OpenAI
from llama_index.query_engine import FLAREInstructQueryEngine
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,ServiceContext,
)
### Recipe
### Build a FLAREInstructQueryEngine which has the generator LLM play
### a more active role in retrieval by prompting it to elicit retrieval
### instructions on what it needs to answer the user query.# Build FLAREInstructQueryEngine
documents = SimpleDirectoryReader("./data/paul_graham").load_data()
index = VectorStoreIndex.from_documents(documents)
index_query_engine = index.as_query_engine(similarity_top_k=2)
service_context = ServiceContext.from_defaults(llm=OpenAI(model="gpt-4"))
flare_query_engine = FLAREInstructQueryEngine(query_engine=index_query_engine,service_context=service_context,max_iterations=7,verbose=True,
)# Use your advanced RAG
response = flare_query_engine.query("Can you tell me about the author's trajectory in the startup world?"
)4.3.2 迭代式检索-生成型RAG:
-
在某些复杂情况下,可能需要多步推理才能为用户查询提供有用且相关的答案。
from llama_index.query_engine import RetryQueryEngine
from llama_index.evaluation import RelevancyEvaluator### Recipe
### Build a RetryQueryEngine which performs retrieval-generation cycles
### until it either achieves a passing evaluation or a max number of
### cycles has been reached# Build RetryQueryEngine
documents = SimpleDirectoryReader("./data/paul_graham").load_data()
index = VectorStoreIndex.from_documents(documents)
base_query_engine = index.as_query_engine()
query_response_evaluator = RelevancyEvaluator() # evaluator to critique # retrieval-generation cycles
retry_query_engine = RetryQueryEngine(base_query_engine, query_response_evaluator
)# Use your advanced rag
retry_response = retry_query_engine.query("A user query")五、RAG的评估方面
评估RAG系统当然是至关重要的。在他们的综述论文中,高云帆等人在附带的RAG备忘单的右上角部分指出了7个评估方面。LlamaIndex库包含几个评估抽象以及与RAGAs的集成,以帮助构建者通过这些评估方面的视角,了解他们的RAG系统在多大程度上达到了成功要求。下面,我们列出了一些精选的评估笔记本指南。
- Answer Relevancy and Context Relevancy
- Faithfulness
- Retrieval Evaluation
- Batch Evaluations with BatchEvalRunner
你现在能够构建高级RAG了
在阅读了这篇博客文章之后,我们希望你感觉更有能力、更有信心去应用这些复杂的技术来构建高级RAG系统了!
相关文章:

大模型高质量rag构建:A Cheat Sheet and Some Recipes For Building Advanced RAG
原文:A Cheat Sheet and Some Recipes For Building Advanced RAG — LlamaIndex - Build Knowledge Assistants over your Enterprise DataLlamaIndex is a simple, flexible framework for building knowledge assistants using LLMs connected to your enterpris…...

LeetCode 78.子集
问题描述 给定一个不含重复元素的整数数组 nums,返回其所有可能的子集(幂集)。 示例 输入: nums [1,2,3] 输出: [ [], [1], [1,2], [1,2,3], [1,3], [2], [2,3], [3] ]解法:回溯算法 回溯是一种 暴力…...
)
变量(Variable)
免责声明 如有异议请在评论区友好交流,或者私信 内容纯属个人见解,仅供学习参考 如若从事非法行业请勿食用 如有雷同纯属巧合 版权问题请直接联系本人进行删改 前言 提示:从小学解方程变量x,到中学阶段函数自变量x因变量y&…...

【STM32】最后一刷-江科大Flash闪存-学习笔记
FLASH简介 STM32F1系列的FLASH包含程序存储器、系统存储器和选项字节三个部分,通过闪存存储器接口(外设)可以对程序存储器和选项字节进行擦除和编程,(系统存储器用于存储原厂写入的BootLoader程序,用于串口…...

Dify 深度集成 MCP实现灾害应急响应
一、架构设计 1.1 分层架构 #mermaid-svg-5dVNjmixTX17cCfg {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-5dVNjmixTX17cCfg .error-icon{fill:#552222;}#mermaid-svg-5dVNjmixTX17cCfg .error-text{fill:#552222…...

2025 年上半年软考信息系统项目管理师备考计划
2025 年上半年软考信息系统项目管理师备考计划 2025 年上半年软考信息系统项目管理师考试时间为 5 月 24 日 - 27 日,从现在开始备考,需合理规划,高效学习。以下为详细备考计划: 一、基础学习阶段(现在 - 4 月上…...

Scikit-learn使用指南
1. Scikit-learn 简介 定义: Scikit-learn(简称 sklearn)是基于 Python 的开源机器学习库,提供了一系列算法和工具,用于数据挖掘、数据预处理、分类、回归、聚类、模型评估等任务。特点: 基于 NumPy、SciP…...

学习大模型需要具备哪些技术、知识和基础
数学基础 概率论与数理统计:用于理解模型中的不确定性、概率分布,以及进行数据的统计分析、评估模型的性能等。例如,通过概率分布来描述模型预测结果的可信度,利用统计方法对数据进行抽样、估计模型的参数等。线性代数࿱…...
)
十五届蓝桥杯省赛Java B组(持续更新..)
目录 十五届蓝桥杯省赛Java B组第一题:报数第二题:类斐波那契数第三题:分布式队列第四题:食堂第五题:最优分组第六题:星际旅行第七题:LITS游戏第八题:拼十字 十五届蓝桥杯省赛Java B…...

Flink SQL Client bug ---datagen connector
原始sql语句如下 CREATE TABLE test_source (event_time TIMESTAMP(3), -- 事件时间(精确到毫秒)click INT, -- 随机数值字段WATERMARK FOR event_time AS event_time - INTERVAL 5 SECOND WITH (connector datagen, …...

股指期货的多头套期保值是什么意思?
多头套期保值,又叫“买入套期保值”,听起来很复杂,其实很简单。它的核心就是“提前锁定价格,防止未来价格上涨”。 举个例子,假设你是一家工厂的老板,过几个月要买一批原材料。现在原材料的价格是100元/吨…...

hadoop集群配置-scp命令
scp 命令用于在不同主机之间复制文件或目录,在Hadoop集群配置中常用于将配置文件或相关资源分发到各个节点。以下是 scp 命令的基本用法和在Hadoop集群配置中的示例: 基本语法 scp [-r] [源文件或目录] [目标用户目标主机:目标路径] - -r :…...

Redis 源码硬核解析系列专题 - 结语:从源码看Redis的设计哲学
1. 引言 通过前七篇的源码解析,我们从Redis的整体架构、核心数据结构、事件驱动模型,到内存管理、持久化、主从复制与集群模式,逐步揭开了Redis高性能与简洁性的秘密。本篇将总结这些技术细节,提炼Redis的设计哲学,并探讨如何将源码学习成果应用到实际开发中。 2. Redis的…...

解决QSharedPointer栈变量的崩溃问题
目录 参考崩溃代码现象 解决 参考 QSharedPointer的陷阱 qt中的共享指针,QSharedPointer类 崩溃 代码 #include <QtCore/QCoreApplication> #include <QDebug> #include <QSharedPointer>class MyClass { public:void doSomething() {qDebug…...

Lambda 表达式是什么以及如何使用
目录 📌 Kotlin 的 Lambda 表达式详解 🎯 什么是 Lambda 表达式? 🔥 1. Lambda 表达式的基本语法 ✅ 示例 1:Lambda 基本写法 ✅ 示例 2:使用 it 关键字(单参数简化) ✅ 示例 3…...

C++自定义迭代器
实现自己的迭代器 最近在写数据结构,使用类模板实现,碰到了一些问题,其中有一个就是遍历的问题,查阅资料最后实现了自己的迭代器,让我实现的数据结构能像STL一样进行for循环遍历。 类的构成 #include <stdexcept…...

PWA 中的 Service Worker:如何实现应用离线功能
前言 在当今快速发展的互联网时代,Progressive Web App (PWA) 正在逐步成为现代 Web 开发的主流选择。PWA 将 Web 应用和原生应用的最佳特性相结合,提供了丰富的用户体验。而在 PWA 的众多技术中,Service Worker 无疑是其核心组件之一。 作…...

dockerfile制作镜像
1.docker pull centos:centos7 2.dockerfile内容 FROM centos:centos7 #指定镜像维护的作者和邮箱 MAINTAINER csdn< **********qq.com #设置环境变量mypath ENV MYPATH /usr/local #设置进入容器的默认目录是/usr/local WORKDIR $MYPATH # 下载并替换 CentOS 镜像源 RUN …...
DevSecOps概述)
网络空间安全(46)DevSecOps概述
一、定义与核心理念 DevSecOps是“开发(Development)、安全(Security)和运营(Operations)”的结合,它将安全实践融入软件开发生命周期的每个阶段,从需求、设计、开发、测试到部署和运…...

LeetCode 211
实现支持通配符的字典树(Trie):解决单词匹配问题 一、问题描述 我们需要设计一个数据结构,支持以下功能: 添加新单词搜索字符串是否与任何已添加的单词匹配,其中搜索字符串可能包含通配符 .(…...

Docker Compose 启动jar包项目
参考文章安装Docker和Docker Compose 点击跳转 配置 创建一个文件夹存放项目例如mydata mkdir /mydata上传jar包 假设我的jar包名称为goudan.jar 编写dockerfile文件 vim app-dockerfile按键盘上的i进行编辑 # 使用jdk8 FROM openjdk:8-jre# 设置时区 上海 ENV TZAsia/Sh…...

利用deepseek直接调用其他文生图网站生成图片
这次deepseek输入中文后,其实翻译英文后,是可以丢到比如pollinations.这个网站,来生成图片,用法如下: 你是一个图像生成助手,请根据我的简单描述,想象并详细描述一幅完整的画面。 然后将你的详…...

远程装个Jupyter-AI协作笔记本,Jupyter容器镜像版本怎么选?安装部署教程
通过Docker下载Jupyter镜像部署,输入jupyter会发现 有几个版本,不知道怎么选?这几个版本有什么差别? 常见版本有: jupyter/base-notebookjupyter/minimal-notebookjupyter/scipy-notebookjupyter/datascience-notebo…...

11. 盛最多水的容器
leetcode Hot 100系列 文章目录 一、核心操作二、外层配合操作三、核心模式代码总结 一、核心操作 最左右两边逐步往中间走,每次在左右中选取小的一个或–记录最大面积 提示:小白个人理解,如有错误敬请谅解! 二、外层配合操作…...

Selenium Web自动化如何快速又准确的定位元素路径,强调一遍是元素路径
如果文章对你有用,请给个赞! 匹配的ChromeDriver和浏览器版本是更好完成自动化的基础,可以从这里去下载驱动程序: 最全ChromeDriver下载含win linux mac 最新版本134.0.6998.165 持续更新..._chromedriver 134-CSDN博客 如果你问…...

Kotlin 基础语法解析
详细的 Kotlin 基础语法解析,结合概念说明和实用场景: --- ### **一、变量与常量** #### **1. 变量类型** - **val**(不可变变量):声明后不可重新赋值,类似 Java 的 final。 kotlin val name "Kotl…...

html 列表循环滚动,动态初始化字段数据
html <div class"layui-row"><div class"layui-col-md4"><div class"boxall"><div class"alltitle">超时菜品排行</div><div class"marquee-container"><div class"scroll-…...

【大模型基础_毛玉仁】5.4 定位编辑法:ROME
目录 5.4 定位编辑法:ROME5.4.1 知识存储位置1)因果跟踪实验2)阻断实验 5.4.2 知识存储机制5.4.3 精准知识编辑1)确定键向量2)优化值向量3)插入知识 5.4 定位编辑法:ROME 定位编辑:…...

Using SAP an introduction for beginners and business users
Using SAP an introduction for beginners and business users...

Android学习总结之RecyclerView补充篇
在 Android 开发中,列表数据更新的性能一直是关键痛点。传统的 notifyDataSetChanged() 会触发全量刷新,导致不必要的界面重绘。而 DiffUtil 作为 Android 提供的高效差异计算工具,能精准识别数据变化,实现局部更新,成…...

mapbox基础,使用geojson加载cluster聚合图层
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:mapbox 从入门到精通 文章目录 一、🍀前言1.1 ☘️mapboxgl.Map 地图对象1.2 ☘️mapboxgl.Map style属性1.3 ☘️circle点图层样式二、🍀使用geojson加…...

函数:static和extern
0.前言 在正式开始之前先说作用域和生命周期 作用域: 作用域有分为局部变量和全局变量 局部变量:一个变量仅在其中一段代码内起作用 全局变量:所有的代码都可以使用这个变量 生命周期: 生命周期是一个代码从运行开始到结束…...

【QT】练习1
1、设计一个颜色选择器,可以输入RGB的颜色值,点击确认,可以把主界面的背景颜色改成设置的颜色 修改背景颜色:setStyleSheet(“background-color 红绿蓝颜色值”); // mainwindow.cpp #include "mainwindow.h" #include…...

GreenPlum学习
简介 Greenplum是一个面向数据仓库应用的关系型数据库,因为有良好的体系结构,所以在数据存储、高并发、高可用、线性扩展、反应速度、易用性和性价比等方面有非常明显的优势。Greenplum是一种基于PostgreSQL的分布式数据库,其采用sharednothi…...
)
张量-pytroch基础(2)
张量-pytroch网站-笔记 张量是一种特殊的数据结构,跟数组(array)和矩阵(matrix)非常相似。 张量和 NumPy 中的 ndarray 很像,不过张量可以在 GPU 或其他硬件加速器上运行。 事实上,张量和 Nu…...

Linux多线程编程的艺术:封装线程、锁、条件变量和信号量的工程实践
目录 📌这篇博客能带给你什么? 🔥为什么需要封装这些组件? 一、线程封装 框架设计 构造与析构 1.线程创建 2.线程分离 3.线程取消 4.线程等待 二、锁封装 框架设计 构造与析构 1.加锁 2.解锁 3.RAII模式 三、条件…...
)
2025年智慧能源与控制工程国际学术会议(SECE 2025)
官网:www.ic-sece.com 简介 2025年智慧能源与控制工程国际学术会议(SECE 2025)将于2025年4月18日线上会议形式召开,这是一个集中探讨全球智慧能源和控制工程领域创新和挑战的国际学术平台。旨在汇集全球领域内的学者、研究人员、…...

Android 16开发实战指南|锁屏交互+Vulkan优化全解析
一、环境搭建与项目初始化 1. 安装Android Studio Ladybug 下载地址:Android Studio官网关键配置: # 安装后立即更新SDK SDK Manager → SDK Platforms → 安装Android 16 (Preview) SDK Manager → SDK Tools → 更新Android SDK Build-Tools至34.0.0 # 通过命令行安装SDK组…...
 用法详解)
sscanf() 用法详解
sscanf() 是 scanf() 的变体,它用于从字符串中提取格式化数据,常用于解析输入字符串。 1️⃣ sscanf() 语法 int sscanf(const char *str, const char *format, ...); str:要解析的字符串(必须是 const char*,可以用…...

0基础入门scrapy 框架,获取豆瓣top250存入mysql
一、基础教程 创建项目命令 scrapy startproject mySpider --项目名称 创建爬虫文件 scrapy genspider itcast "itcast.cn" --自动生成 itcast.py 文件 爬虫名称 爬虫网址 运行爬虫 scrapy crawl baidu(爬虫名) 使用终端运行太麻烦了,而且…...
)
Linux常见操作命令(2)
(一)复制和移动 复制和移动都分为文件和文件夹,具体的命令是cp和mv。 1.复制文件(复制的文件要是已创建) 格式:cp 源文件 目标文件。 示例:把filel.txt复制一份得到file2.txt。 那么对应的命令就是&#x…...

谷歌将 Android OS 完全转变为 “内部开发”
2025 年 3 月 27 日,据 Android Authority 报道,谷歌证实将从下周开始完全在内部分支机构闭门开发安卓操作系统。相关信息如下: 背景:多年来,谷歌同时维护着两大安卓主要分支,一是面向公众开放的 “安卓开源…...

移动端六大语言速记:第2部分 - 控制结构
移动端六大语言速记:第2部分 - 控制结构 本文继续对比Java、Kotlin、Flutter(Dart)、Python、ArkTS和Swift这六种移动端开发语言的控制结构,帮助开发者快速掌握各语言的语法差异。 2. 控制结构 2.1 条件语句 各语言条件语句的语法对比: …...

【 Vue 2 中的 Mixins 模式】
Vue 2 中的 Mixins 模式 在 Vue 2 里,mixins 是一种灵活的复用代码的方式,它能让你在多个组件间共享代码。借助 mixins,你可以把一些通用的选项(像 data、methods、computed 等)封装到一个对象里,然后在多…...
)
STM32F103_LL库+寄存器学习笔记13 - 梳理外设CAN与如何发送CAN报文(串行发送)
导言 CAN总线因其高速稳定的数据传输与卓越抗干扰性能,在汽车、机器人及工业自动化中被广泛应用。它采用分布式网络结构,实现多节点间实时通信,确保各控制模块精准协同。在汽车领域,CAN总线连接发动机、制动、车身系统,…...

DataPlatter:利用最少成本数据提升机器人操控的泛化能力
25年3月来自中科院计算所的论文“DataPlatter: Boosting Robotic Manipulation Generalization with Minimal Costly Data”。 视觉-语言-动作 (VLA) 模型在具身人工智能中的应用日益广泛,这加剧对多样化操作演示的需求。然而,数据收集的高成本往往导致…...

受控组件和非受控组件的区别
在 React 中,受控组件(Controlled Components) 和 非受控组件(Uncontrolled Components) 是处理表单元素的两种不同方式,它们的核心区别在于 数据管理的方式 和 与 React 的交互模式。 受控组件…...

Mhand Pro 多节点动作捕捉手套:一副手套多场景应用
随着动作捕捉技术的发展,动捕手套的出现为虚拟现实交互、VR游戏开发、机器臂/灵巧手遥操作等方面带来了更加便捷可行的方案。 广州虚拟动力作为一家在动作捕捉领域深耕多年的公司,基于传感器技术而研发的多节点惯性动作捕捉手套,兼具VR交互与…...

Kafka消息丢失全解析!原因、预防与解决方案
作为一名高并发系统开发工程师,在使用消息中间件的过程中,无法避免遇到系统中消息丢失的问题,而Kafka作为主流的消息队列系统,消息丢失问题尤为常见。 在这篇文章中,将深入浅出地分析Kafka消息丢失的各种情况…...
BERT与Transformer到底选哪个-上部
一、先理清「技术家谱」:BERT和Transformer是啥关系? 就像「包子」和「面食」的关系——BERT是「Transformer家族」的「明星成员」,而GPT、Qwen、DeepSeek这些大模型则是「Transformer家族」的「超级后辈」。 1.1 BERT:Transfor…...