Kafka消息丢失全解析!原因、预防与解决方案
作为一名高并发系统开发工程师,在使用消息中间件的过程中,无法避免遇到系统中消息丢失的问题,而Kafka作为主流的消息队列系统,消息丢失问题尤为常见。
在这篇文章中,将深入浅出地分析Kafka消息丢失的各种情况,并提供真实且实用的解决方案。
一、Kafka基础知识
Kafka是什么?
Kafka是一个分布式的流处理平台,被广泛用于构建实时数据管道和流式应用。它具有高吞吐量、可靠性、可扩展性的特点,已成为大数据生态系统中不可或缺的组件。
Kafka的核心概念

在上面的架构图中,Kafka的几个重要组件包括:
- Broker - Kafka服务器,负责接收、存储消息
- Producer - 生产者,负责发送消息到Kafka
- Consumer - 消费者,负责从Kafka获取消息并处理
- Topic - 主题,Kafka消息的逻辑分类
- Partition - 分区,每个Topic可以有多个分区,分布在不同Broker上
- Zookeeper - 管理Kafka集群元数据和协调
二、Kafka消息丢失的情况分析
Kafka虽然以高可靠性著称,但在三个环节仍可能发生消息丢失:
- 生产者端:消息发送失败或确认机制配置不当
- Broker端:服务器宕机或磁盘故障
- 消费者端:提交偏移量后处理消息失败
1. 生产者端消息丢失
生产者端消息丢失通常发生在以下情况:

生产者端丢失原因分析
-
Fire and Forget(发后即忘)模式
- 当使用acks=0配置时,生产者不等待服务器的确认就认为消息发送成功
- 如果网络出现问题或Broker宕机,消息会丢失但生产者不会感知
-
异步发送未处理回调
- 使用异步发送时,如果回调中未正确处理发送失败的情况
- 消息发送失败但程序继续执行,导致消息丢失
-
重试次数不足
- 当网络抖动或Broker临时不可用,默认重试次数不足可能导致消息丢失
2. Broker端消息丢失
Broker端的消息丢失主要与以下因素有关:

Broker端丢失原因分析
-
副本因子(replication.factor)设置过低
- 当副本因子为1时,表示数据只存在于一个Broker上
- 如果该Broker宕机,数据将完全丢失
-
最小同步副本(min.insync.replicas)配置不当
- 如果配置为1,则只要Leader副本确认就会返回ack
- 如果在数据同步到follower前Leader宕机,数据会丢失
-
允许非同步副本选举为Leader
- 默认配置unclean.leader.election.enable=false
- 如果设置为true,可能选举落后的副本作为新Leader,导致数据丢失
3. 消费者端消息丢失
消费者端丢失主要发生在以下情况:
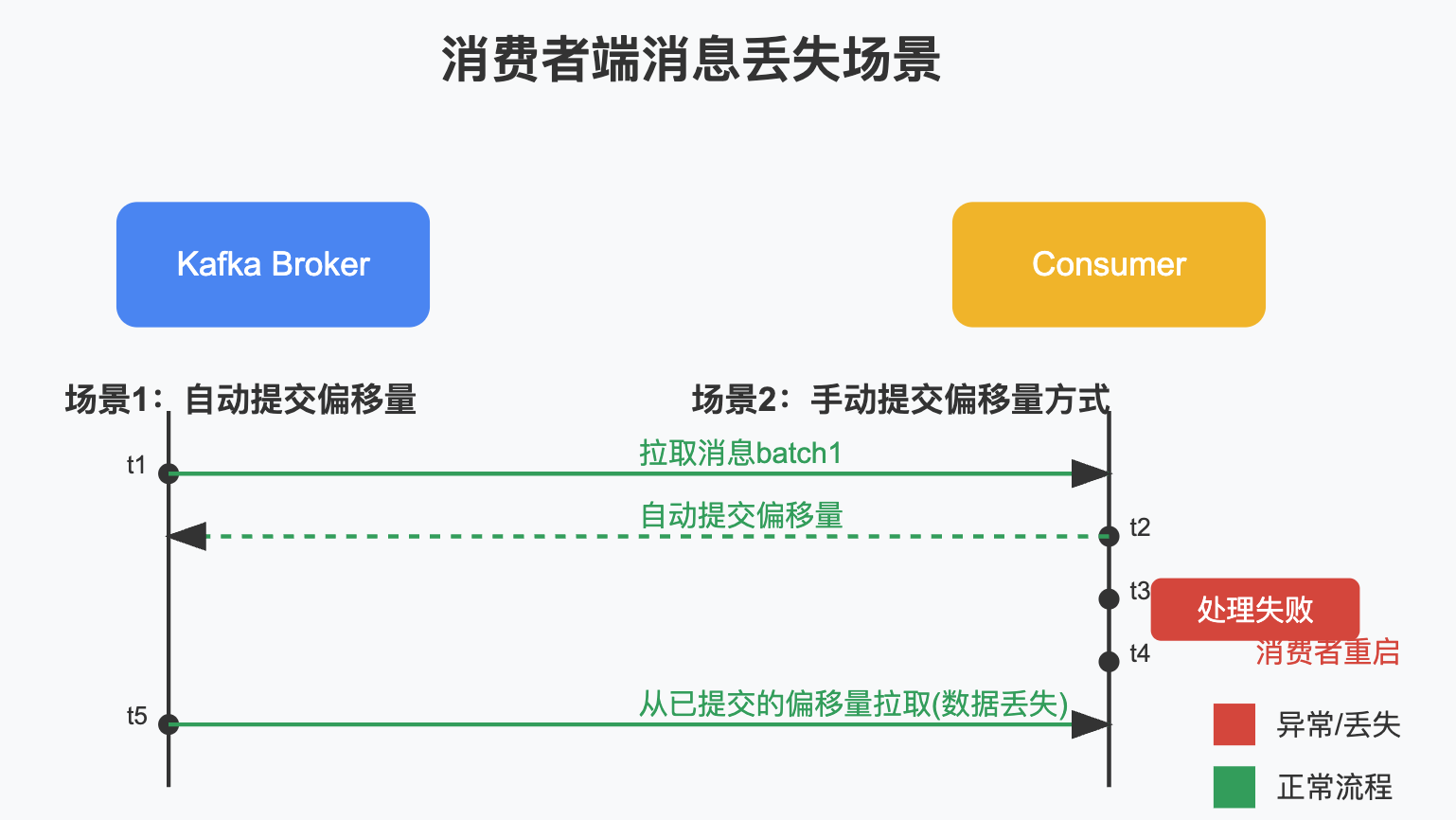
消费者端丢失原因分析
-
自动提交偏移量
- 默认情况下,消费者会自动提交偏移量(enable.auto.commit=true)
- 如果提交了偏移量但处理消息过程中失败,重启后会从已提交的偏移量开始消费,导致消息丢失
-
先提交偏移量再处理消息
- 如果手动提交偏移量时,在消息处理完成前就提交
- 处理过程中出现异常,消息实际未处理成功但偏移量已提交
三、如何防止Kafka消息丢失
现在让我们来看看如何在各环节防止消息丢失。
1. 生产者端防止消息丢失
// 1. 生产者配置示例
Properties props = new Properties();
// 设置broker集群地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "broker1:9092,broker2:9092,broker3:9092");
// 设置key/value序列化器
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 设置确认机制为all,所有ISR副本都确认才算成功
props.put(ProducerConfig.ACKS_CONFIG, "all");
// 设置重试次数
props.put(ProducerConfig.RETRIES_CONFIG, 10);
// 设置重试间隔
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
// 幂等性,避免消息重复
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 设置拦截器(可选)
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, "com.example.kafka.MyProducerInterceptor");// 创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 2. 同步发送示例
try {ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");// 同步发送,等待服务器确认RecordMetadata metadata = producer.send(record).get();System.out.println("Message sent successfully to partition " + metadata.partition() + " offset " + metadata.offset());
} catch (Exception e) {// 处理发送异常System.err.println("Error sending message: " + e.getMessage());// 可以进行重试或其他补偿措施
}// 3. 异步发送示例(带回调处理)
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception != null) {// 发送失败,进行错误处理System.err.println("Failed to send message: " + exception.getMessage());// 可以将消息保存到本地,稍后重试saveToLocalStorage(record);} else {// 发送成功System.out.println("Message sent successfully to partition " + metadata.partition() + " offset " + metadata.offset());}}
});// 关闭生产者
producer.close();
关键配置:
- acks=all:确保消息被所有同步副本(ISR)接收才视为成功
- retries:设置足够的重试次数,避免因网络抖动导致的发送失败
- enable.idempotence=true:启用幂等性,避免消息重复
- 使用同步发送或正确处理异步回调:捕获并处理发送异常
最佳实践:
- 使用带回调的异步发送提高性能,同时确保在回调中正确处理异常
- 对关键业务消息,可使用本地消息表或事务消息
- 实现自定义拦截器来记录发送失败的消息
2. Broker端防止消息丢失
# broker端配置示例 (server.properties)############################# 副本配置 #############################
# 设置Topic默认副本数为3
default.replication.factor=3# 设置最小同步副本数
min.insync.replicas=2# 禁止非同步副本成为Leader(默认值为false)
unclean.leader.election.enable=false############################# 数据可靠性配置 #############################
# 设置数据刷盘策略,有以下选项:
# 0: 由操作系统控制,性能最好但风险最高
# 1: 每秒刷盘一次,平衡性能和可靠性
# -1: 每次写入都刷盘,可靠性最高但性能最差
log.flush.interval.messages=1000
log.flush.interval.ms=1000# 指定分区在内存中的保留时间,默认为-1(不受限制)
log.retention.ms=604800000 # 7天############################# Topic默认配置 #############################
# 创建topic时的默认分区数
num.partitions=3############################# 其他重要配置 #############################
# 控制器failover超时时间,大型集群可适当增加此值
controller.socket.timeout.ms=30000# Topic创建命令示例(针对特别重要的Topic单独配置)
bin/kafka-topics.sh --create --bootstrap-server broker1:9092 --topic important-topic \--partitions 6 --replication-factor 3 \--config min.insync.replicas=2 \--config flush.messages=1 \--config retention.ms=1209600000
关键配置:
- replication.factor=3:设置足够的副本数,通常为3
- min.insync.replicas=2:要求至少2个副本同步成功才认为写入成功
- unclean.leader.election.enable=false:禁止未同步的副本成为leader
- log.flush.interval.ms:控制数据刷盘频率,权衡性能和可靠性
最佳实践:
- 至少3个Broker的集群,保证高可用性
- 对重要Topic增加副本因子,提高可靠性
- 定期监控ISR副本数量,确保副本健康
- 合理配置刷盘策略,避免因服务器宕机导致数据丢失
3. 消费者端防止消息丢失
// 1. 消费者配置示例
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "broker1:9092,broker2:9092,broker3:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-consumer-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 关闭自动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
// 如果使用自动提交,设置较大的提交间隔
// props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);// 从最早的偏移量开始消费(可选,首次消费时使用)
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));// 2. 手动确认 - 先处理消息再提交偏移量
try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));if (!records.isEmpty()) {// 处理消息批次processRecords(records);// 成功处理后再提交偏移量consumer.commitSync();}}
} catch (Exception e) {// 处理异常
} finally {consumer.close();
}// 3. 更精细的偏移量控制 - 按分区提交偏移量
try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));// 按分区处理记录Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();for (TopicPartition partition : records.partitions()) {List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);for (ConsumerRecord<String, String> record : partitionRecords) {// 处理单条消息processRecord(record);}// 获取该分区最后一条记录的偏移量long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();// 存储该分区的偏移量currentOffsets.put(partition, new OffsetAndMetadata(lastOffset + 1));}// 提交处理完的分区偏移量if (!currentOffsets.isEmpty()) {consumer.commitSync(currentOffsets);}}
} catch (Exception e) {// 处理异常
} finally {consumer.close();
}// 4. 处理消息的事务方式
private void processRecordsWithTransaction(ConsumerRecords<String, String> records) {// 开启数据库事务Connection conn = null;try {conn = dataSource.getConnection();conn.setAutoCommit(false);// 处理消息并执行数据库操作for (ConsumerRecord<String, String> record : records) {processRecordInTransaction(conn, record);}// 提交数据库事务conn.commit();// 提交Kafka偏移量consumer.commitSync();} catch (Exception e) {// 回滚数据库事务if (conn != null) {try {conn.rollback();} catch (SQLException ex) {ex.printStackTrace();}}throw new RuntimeException("Failed to process records", e);} finally {// 关闭连接if (conn != null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}
}
关键配置与策略:
- 关闭自动提交偏移量(enable.auto.commit=false):手动控制偏移量提交
- 先处理消息再提交偏移量:确保消息处理成功后再提交
- 按分区提交偏移量:更精细的控制,提高并发处理能力
- 使用事务处理:将数据库操作和偏移量提交放在同一事务中
最佳实践:
- 保证消息处理的幂等性,处理潜在的重复消费
- 实现消费失败重试机制,例如把失败消息放入"死信队列"
- 根据业务需求,考虑将重要消息持久化到本地
- 监控消费延迟,及时发现消费异常
四、深入理解Kafka可靠性机制
1. 生产者可靠性原理

生产者工作原理
-
消息累加器(RecordAccumulator):生产者并不是每条消息都立即发送,而是会缓存到一个消息累加器中,等到达一定条件后批量发送
-
消息累加器触发条件:
- batch.size:当累积的数据量达到设定值
- linger.ms:当数据累积时间达到设定值
-
Sender线程:单独的线程负责将消息批次从累加器中取出并发送到对应的Broker
-
确认机制(acks):
- acks=0:不等待确认
- acks=1:只等待Leader副本确认
- acks=all:等待所有ISR副本确认
2. Broker数据可靠性原理

Broker副本机制
-
ISR(In-Sync Replicas):与Leader保持同步的副本集合,只有ISR中的副本才能被选为新Leader
-
HW(High Watermark):消费者能看到的最高偏移量,ISR中所有副本都复制了的位置
- HW之前的消息对消费者可见
- 只有写入HW之前的消息才被认为是"已提交"的消息
-
LEO(Log End Offset):每个副本的日志末端位置
- Leader副本LEO > HW:表示有新消息写入但未同步完成
- Follower副本LEO < Leader LEO:表示副本正在追赶Leader
-
数据同步流程:
- Leader接收消息后追加到本地日志
- Follower通过fetch请求从Leader拉取消息
- Leader更新HW(取所有ISR副本LEO的最小值)
- 当acks=all时,只有消息被所有ISR副本同步后才返回成功
3. 消费者可靠性原理

消费者偏移量管理
-
偏移量(Offset)概念:
- 每条消息在分区中的唯一标识
- 消费者通过记录消费偏移量来追踪消费进度
-
偏移量存储:
- 0.9版本之前:存储在ZooKeeper中
- 0.9版本之后:存储在名为__consumer_offsets的内部Topic中
-
提交偏移量的方式:
- 自动提交:enable.auto.commit=true,按固定时间间隔自动提交
- 同步手动提交:commitSync(),阻塞直到提交成功
- 异步手动提交:commitAsync(),不阻塞,通过回调获取结果
-
消息处理与偏移量提交顺序:
- 先消费后提交:可能重复消费,但不会丢失
- 先提交后消费:可能丢失消息,但不会重复
-
消费者再均衡:
- 消费者加入/离开群组时触发再均衡
- 再均衡过程中,分区所有权会转移,需要正确处理偏移量提交
- 通过ConsumerRebalanceListener接口可以处理再均衡事件
五、扩展话题,Kafka消息保证语义
1. 消息传递语义

Kafka支持三种消息传递语义:
-
At Most Once (最多一次)
- 消息可能丢失,但绝不重复
- 性能最好,可靠性最低
- 适用场景:日志收集、指标监控等允许少量数据丢失的场景
-
At Least Once (至少一次)
- 消息不会丢失,但可能重复
- 性能较好,可靠性较高
- 适用场景:大多数业务场景,需要确保消费端实现幂等性
-
Exactly Once (恰好一次)
- 消息既不丢失也不重复
- 需要Kafka 0.11+版本支持
- 通过生产者幂等性和事务特性实现
- 适用场景:金融交易、计费系统等对数据精确性要求高的场景
2. 实现Exactly Once语义
Kafka 0.11版本后引入了事务支持,可以实现真正的Exactly Once语义:
// 1. 生产者端实现Exactly Once (使用事务API)
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "broker1:9092,broker2:9092,broker3:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 启用幂等性
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 设置事务ID (必须唯一)
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transactional-id");
// 设置事务超时时间
props.put(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 60000); // 60秒KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 初始化事务
producer.initTransactions();try {// 开始事务producer.beginTransaction();// 在事务中发送消息for (int i = 0; i < 10; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key-" + i, "value-" + i);producer.send(record);}// 提交事务producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {// 这些异常无法恢复,需要关闭生产者producer.close();
} catch (KafkaException e) {// 其他异常可以中止事务producer.abortTransaction();
} finally {producer.close();
}// 2. 消费者端实现Exactly Once
Properties consumerProps = new Properties();
consumerProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "broker1:9092,broker2:9092,broker3:9092");
consumerProps.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group-id");
consumerProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumerProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 设置隔离级别,只读取已提交的消息
consumerProps.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
// 关闭自动提交
consumerProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Arrays.asList("my-topic"));// 3. 消费-处理-生产模式 (消费者端读取+生产者端写入,事务性处理)
Properties processorProps = new Properties();
// ... 设置基础配置同上 ...// 设置事务ID
processorProps.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-processor-transactional-id");
// 启用幂等性
processorProps.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);KafkaProducer<String, String> processorProducer = new KafkaProducer<>(processorProps);
processorProducer.initTransactions();try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));if (!records.isEmpty()) {// 存储当前消费的偏移量Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();for (ConsumerRecord<String, String> record : records) {TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(record.offset() + 1);offsets.put(topicPartition, offsetAndMetadata);}// 开始事务processorProducer.beginTransaction();try {// 处理消息并产生新消息for (ConsumerRecord<String, String> record : records) {// 业务处理String processedValue = processRecord(record.value());// 发送处理后的消息ProducerRecord<String, String> outputRecord = new ProducerRecord<>("output-topic", record.key(), processedValue);processorProducer.send(outputRecord);}// 在同一事务中提交消费者偏移量processorProducer.sendOffsetsToTransaction(offsets, consumer.groupMetadata());// 提交事务processorProducer.commitTransaction();} catch (Exception e) {// 发生异常,中止事务processorProducer.abortTransaction();throw e;}}}
} finally {processorProducer.close();consumer.close();
}// 简单的消息处理方法
private static String processRecord(String input) {// 实际的业务处理逻辑return "processed-" + input;
}
事务API关键点:
-
Transactional ID
- 每个生产者需要指定一个唯一的事务ID
- 事务ID可以跨会话保持事务状态,实现故障恢复
-
事务的基本操作
- initTransactions():初始化事务环境
- beginTransaction():开始一个新事务
- commitTransaction():提交事务
- abortTransaction():中止事务
-
消费-处理-生产场景
- 在同一个事务中可以将消费者偏移量与生产者发送的消息绑定
- 通过sendOffsetsToTransaction()方法实现
-
消费者隔离级别
- 通常设置为read_committed,只读取已提交的事务消息
- 避免读取到可能会被中止的事务消息
六、Kafka消息丢失的监控与告警
为了及时发现消息丢失问题,建立健全的监控系统至关重要。
1. 关键监控指标
-
生产者端
- errors-per-second:错误率
- record-error-rate:消息错误率
- record-retry-rate:消息重试率
-
Broker端
- UnderReplicatedPartitions:副本同步不足的分区数
- OfflinePartitionsCount:离线分区数
- ISRShrink/ISRExpand:ISR收缩/扩大事件
-
消费者端
- records-lag:消费延迟(表示有多少消息未消费)
- records-lag-max:最大消费延迟
- records-lag-avg:平均消费延迟
2. 监控系统搭建
常用监控组合:
- Kafka内置JMX监控 + Prometheus + Grafana
- Kafka Manager/CMAK + 自定义告警
- Confluent Control Center(商业版)
七、面试热点问题
1. Kafka如何保证消息不丢失?
生产者端:
- 使用acks=all确保所有副本接收消息
- 配置足够的重试次数
- 实现异步发送的错误回调处理
- 必要时使用事务API
Broker端:
- 配置合理的副本因子(至少3)
- 设置min.insync.replicas >= 2
- 禁用unclean.leader.election
- 合理配置数据持久化策略
消费者端:
- 关闭自动提交或增加自动提交间隔
- 使用手动提交,并在处理成功后提交
- 实现消息处理的幂等性
2. Kafka的消息传递语义有哪些?各适用于什么场景?
- At Most Once:适用于允许少量数据丢失的场景,如日志收集
- At Least Once:适用于大多数业务场景,要求实现消费端幂等性
- Exactly Once:适用于金融、计费等对数据精确性要求高的场景
3. Kafka如何实现Exactly Once语义?
实现Exactly Once需要从两方面保证:
- 生产者到Broker:使用幂等性生产者(enable.idempotence=true)和事务API
- Broker到消费者:设置消费者隔离级别为read_committed,只读取已提交的事务消息
- 端到端:通过事务机制将消费者偏移量提交和生产者发送消息绑定在同一事务中
关键实现技术:
- 生产者PID(Producer ID)和序列号实现幂等性
- 事务协调者(Transaction Coordinator)管理事务状态
- 控制消息(Control Messages)标记事务边界
4. 如何处理Kafka的消息积压问题?
- 定位原因:确定是生产速度过快还是消费速度过慢
- 提高消费能力:
- 增加消费者数量(需要增加分区数支持)
- 优化消费者处理逻辑,减少单条消息处理时间
- 提高消费者批量处理能力(max.poll.records)
- 临时措施:
- 启动独立消费者组进行"追赶"处理
- 对非关键消息实现"丢弃策略"
- 消息间隔采样消费
5. Kafka的LEO和HW是什么?与消息丢失有什么关系?
LEO (Log End Offset):分区中最后一条消息的偏移量+1,表示下一条待写入消息的偏移量。
HW (High Watermark):所有ISR副本都已复制的最高偏移量,只有HW之前的消息对消费者可见。
与消息丢失的关系:
- 只有HW之前的消息才被认为已提交,对消费者可见
- Leader宕机时,新选举的Leader将截断日志到HW位置,HW之后的消息会丢失
- min.insync.replicas设置过小可能导致消息在HW提交前丢失
6. 在Kafka系统中,消息重复和消息丢失哪个更容易处理?为什么?
消息重复通常比消息丢失更容易处理:
-
重复处理:可以通过设计幂等性操作解决重复问题
- 使用唯一ID去重
- 依赖数据库唯一约束
- 使用业务状态机
-
消息丢失:一旦丢失,数据可能无法恢复
- 需要从源头重新生成数据
- 可能需要进行数据修复和业务补偿
- 有时无法确定哪些数据丢失了
所以在设计系统时,通常宁可接受重复也不接受丢失。
总结
Kafka消息丢失是生产环境中常见的问题,但通过正确的配置和设计可以有效避免。
对于不同的业务场景,我们需要根据数据可靠性要求和性能需求,选择合适的解决方案。
- 对于一般业务,At Least Once语义加上消费端幂等设计是最佳选择
- 对于金融、支付等核心业务,应考虑使用Exactly Once语义
- 对于日志、监控等非关键业务,可以使用At Most Once语义以获得更好的性能
最后,建立完善的监控系统,及时发现并处理潜在的消息丢失问题,是保障Kafka系统稳定运行的重要保障。
Kafka不丢失消息的配置就像我们日常生活中的"安全带+安全气囊+ABS"组合,层层保护,共同确保消息传输的安全可靠。只有理解了原理,我们才能更加胸有成竹地应对各种挑战。
相关文章:

Kafka消息丢失全解析!原因、预防与解决方案
作为一名高并发系统开发工程师,在使用消息中间件的过程中,无法避免遇到系统中消息丢失的问题,而Kafka作为主流的消息队列系统,消息丢失问题尤为常见。 在这篇文章中,将深入浅出地分析Kafka消息丢失的各种情况…...
BERT与Transformer到底选哪个-上部
一、先理清「技术家谱」:BERT和Transformer是啥关系? 就像「包子」和「面食」的关系——BERT是「Transformer家族」的「明星成员」,而GPT、Qwen、DeepSeek这些大模型则是「Transformer家族」的「超级后辈」。 1.1 BERT:Transfor…...

【Unity】记录TMPro使用过程踩的一些坑
1、打包到webgl无法输入中文,编辑器模式可以,但是webgl不行,试过网上的脚本,还是不行 解决方法:暂时没找到 2、针对字体asset是中文时,overflow的效果模式处理奇怪,它会出现除了overflow模式以…...

数据处理的两种范式:深入解析OLTP与OLAP系统
目录 前言1. OLTP:业务运作的基石1.1 OLTP的核心定义与价值1.2 OLTP的技术架构特点1.3 OLTP的典型应用场景 2. OLAP:决策支持的大脑2.1 OLAP的基本概念与作用2.2 OLAP的技术实现方式2.3 OLAP的应用实践 3. OLTP与OLAP的对比与融合3.1 核心差异的深度解析…...

本地飞牛NAS快速部署WordPress个人网站并一键上线公网远程访问
文章目录 前言1. Docker下载源设置2. Docker下载WordPress3. Docker部署Mysql数据库4. WordPress 参数设置5. 飞牛云安装Cpolar工具6. 固定Cpolar公网地址7. 修改WordPress配置文件8. 公网域名访问WordPress 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗…...

windows环境下的cmake使用
创建一个目录testcmake 进入目录 创建一个文件main.cpp : #include <iostream> using namespace std; int main(){cout<<"what is going on?"<<endl;return 0; }再创建一个cmakelists.txt set(CMAKE_CXX_STANDARD 20) add_executable(test2 mai…...
(续~))
多线程(多线程案例)(续~)
目录 一、单例模式 1. 饿汉模式 2. 懒汉模式 二、阻塞队列 1. 阻塞队列是什么 2. 生产者消费者模型 3. 标准库中的阻塞队列 4. 自实现阻塞队列 三、定时器 1. 定时器是什么 2. 标准库中的定时器 欢迎观看我滴上一篇关于 多线程的博客呀,直达地址…...

同步SVPWM调制策略的初步学习记录
最近项目需要用到一些同步调制SVPWM相关的内容(现在的我基本都是项目驱动了),因此对该内容进行一定的学习。 1 同步SVPWM调制的背景 我们熟知的一些知识是:SVPWM(空间矢量脉宽调制)是一种用于逆变器的调制…...

权重参数矩阵
目录 1. 权重参数矩阵的定义与作用 2. 权重矩阵的初始化与训练 3. 权重矩阵的解读与分析 (1) 可视化权重分布 (2) 统计指标分析 4. 权重矩阵的常见问题与优化 (1) 过拟合与欠拟合 (2) 梯度问题 (3) 权重对称性问题 5. 实际应用示例 案例1:全连接网络中的…...

堆叠虚拟化
各厂商叫法不同:思科 VSS 锐捷 VSU 华为 Stack 华三 IRF 虚拟化为一台设备进行管理,从而实现高可靠性。当任意交换机故障时,都能实现设备、链路切换,保护客户业务稳定运行 传统的园区网高可靠性技术出现故障时切换时间很难做到毫…...

3.31-4 性能面试题
面试题 1、性能问题的六个特征: (1)、持续缓慢: (2)、随着时间推进越来越慢、 (3)、随着负载增加越来越慢、 (4)、零星挂起或异常错误、 (5…...
)
2025年最新自动化/控制保研夏令营预推免面试真题分享(东南/浙大/华科清华)
笔者来2021级本科自动化专业,以下部分将介绍我在夏令营以及预推免期间发生经历和问题 东南大学自动化学院 东南大学: 东南大学面试有一个十分明显的特点,就是极其注重专业课,基本上就是在面试的时候电脑上会有几个文件夹&#x…...

freecad手动装插件 add on
python工作台输入 FreeCAD.ConfigGet("UserAppData") 在返回的地址上新建文件夹:Mod #like /home/chen/snap/freecad/common 进入Mod #like /home/chen/snap/freecad/common/Mod git clone 你要的项目 #like git clone https://github.com/looooo/f…...

mysql 主从搭建步骤
主库: 开启log-bin参数,log-bin 参数修改需要重启服务器 --You can change the server_id value dynamically by issuing a statement like this:SET GLOBAL server_id 2;--to enable binary logging using a log file name prefix of mysql-bin, and c…...

从AI大模型到MCP中台:构建下一代智能服务的核心架构
从AI大模型到MCP中台:构建下一代智能服务的核心架构 引言:AI大模型带来的服务重构革命 在ChatGPT掀起全球AI热潮的今天,大模型展现出的惊人能力正在重塑整个软件服务架构。但鲜为人知的是,真正决定AI服务成败的不仅是模型本身&a…...

31天Python入门——第18天:面向对象三大特性·封装继承多态
你好,我是安然无虞。 文章目录 面向对象三大特性1. 封装2. 继承3. 多态4. 抽象基类5. 补充练习 面向对象三大特性 面向对象编程(Object-Oriented Programming, 简称OOP)有三大特性, 分别是封装、继承和多态.这些特性是面向对象编程的基础, …...

css_z-index属性
z-index 工作原理及层叠上下文(Stacking Context) 在 CSS 中,z-index 主要用于控制元素的堆叠顺序,决定哪些元素显示在上层,哪些元素在下层。它的工作原理涉及 层叠上下文(Stacking Context)&a…...

ros2--xacro
什么是xacro 在ROS 2中,Xacro(XML Macros)是一种基于XML的宏语言,专门用于简化URDF(Unified Robot Description Format)文件的编写。它通过宏定义、变量替换和代码复用等功能,让机器人模型的描…...

Nordic 新一代无线 SoC nRF54L系列介绍
目录 概述 1 nRF54L系列特点 1.1 内存 1.2 芯片封装 2 增强的多协议支持 3 其他特性 4 nRF54L系列MCU特性 4.1 多协议无线电 4.2 安全性 4.3 存储空间 4.4 工作参数 4.5 调试接口 4.6 外设 概述 全新 nRF54L 系列的所有三款器件均将 2.4 GHz 无线电和 MCU 功能 (包括…...

力扣HOT100之矩阵:240. 搜索二维矩阵 II
这道题直接暴力AC的,虽然也能过,但是耗时太长了。 class Solution { public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int edge min(matrix.size(), matrix[0].size()) - 1; //先在edge * edge的矩阵中搜索for…...

一个判断A股交易状态的python脚本
最近在做股票数据相关的项目,需要用到判断某一天某个时刻A股的状态,比如休市,收盘,交易中等,发动脑筋想了一下,这个其实还是比较简单的,这里我把实现方法分享给大家。 思路 当天是否休市 对于某…...

为什么package.json里的npm和npm -v版本不一致?
这个情况出现是因为package.json里的 npm 版本和系统实际使用的 npm 版本是两个不同的概念。让我来解释一下: 原因解释 全局 npm vs 项目依赖: npm -v显示的是系统全局安装的 npm 版本(位于/usr/bin/npm或类似路径)package.jso…...

Rust 有问有答之 use 关键字
use 是什么# use 是 Rust 编程语言的关键字。using 是 编程语言 C# 的关键字。 关键字是预定义的保留标识符,对编译器有特殊意义。 using 关键字有三个主要用途: using 语句定义一个范围,在此范围的末尾将释放对象。 using 指令为命名空间创…...

[skip]CBAM
论文题目:CBAM: Convolutional Block Attention Module 中文题目:CBAM: 注意力卷积模块 0摘要 我们提出了卷积块注意力模块(CBAM),一个简单而有效的前馈卷积神经网络注意力模块。给定一个中间特征图,我们的模块沿着两个独立的维度(通道和空间)顺序推断注意力图,然后…...
)
突破反爬困境:SDK开发,浏览器模块(七)
声明 本文所讨论的内容及技术均纯属学术交流与技术研究目的,旨在探讨和总结互联网数据流动、前后端技术架构及安全防御中的技术演进。文中提及的各类技术手段和策略均仅供技术人员在合法与合规的前提下进行研究、学习与防御测试之用。 作者不支持亦不鼓励任何未经授…...
:使用属性表(Property Sheet)实现自动化Qt编译流程)
在MFC中使用Qt(四):使用属性表(Property Sheet)实现自动化Qt编译流程
前言 首先回顾下前面文章介绍的: 在MFC中使用Qt(一):玩腻了MFC,试试在MFC中使用Qt!(手动配置编译Qt) 在MFC中使用Qt(二):实现Qt文件的自动编译流…...

相机镜头景深
文章目录 定义影响因素实际应用特殊情况 参考:B站优致谱视觉 定义 景深是指在摄影机镜头或其他成像器前沿着能够取得清晰图像的成像器轴线所测定的物体距离范围。简单来说,就是在一张照片中,从前景到背景,能够保持清晰锐利的区域…...

HTML实现图片上添加水印的工具
HTML实现图片上添加水印的工具 本文介绍两种实现方式:图片上添加文字水印和图片上添加图片水印。部分源码参照自网络。 一、图片上添加文字水印 先看效果图: 源码如下: <!DOCTYPE html> <html lang"zh"> <head&…...

mysql JSON_ARRAYAGG联合JSON_OBJECT使用
父表数据(表名:class) idname1一年级2二年级3三年级 子表数据(表名:students) idnameclassId11张三112李四113小明3 sql查询(推荐使用方法一) 方法一 (使用IFNull判断子表数据是否…...

VMware虚拟机 ubuntu22.04无法与共享粘贴板和拖拽文件的解决方案
VMware虚拟机 ubuntu22.04无法与共享粘贴板和拖拉文件的解决方案 卸载VMware tools安装open-vm-tools还无法拖拽文件 卸载VMware tools 确保卸载完vmware-tools # 进入vmware-tools安装目录/bin sudo vmware-uninstall-tools.pl sudo rm -rf /usr/lib/vmware-tools sudo apt-…...

C++STL---<functional>
C标准库中的 <functional> 库是一个强大的工具集,它提供了用于处理函数对象、函数绑定、函数包装等功能的设施,极大地增强了代码的灵活性和可复用性。 1. 函数对象(Functors) 函数对象,也被称作仿函数…...
 的实现与协议栈交互源码解析)
【Android】BluetoothSocket.connect () 的实现与协议栈交互源码解析
本文以 Android 蓝牙框架中的BluetoothSocket.connect()方法为切入点,深入剖析 Android 设备与远程蓝牙设备建立连接的全流程。从 Java 层的 API 调用出发,逐步追踪至 JNI 层的接口转发,最终进入 Buedroid 协议栈(RFCOMM/L2CAP 层),揭示蓝牙连接的核心机制。重点解析了权…...
——简单多状态)
算法导论(动态规划)——简单多状态
算法思路(17.16) 状态表示: 在处理线性动态规划问题时,我们可以通过“经验 题目要求”来定义状态表示。通常有两种选择: 以某个位置为结尾的情况;以某个位置为起点的情况。 本题中,我们选择更常…...
学习介绍及其高阶应用,金融风险分析)
主成分分析(PCA)学习介绍及其高阶应用,金融风险分析
前言 主成分分析(Principal Component Analysis, PCA)是统计学中一种重要的降维技术。它通过寻找数据中各特征之间的线性关系,来降低数据的维度,同时保留数据中的主要信息。PCA在机器学习、信号处理、图像处理等领域广泛应用&…...

利用 SSRF 和 Redis 未授权访问进行内网渗透
目录 环境搭建 编辑 发现内网存活主机 编辑 扫描内网端口 编辑 利用 Redis 未授权访问进行 Webshell 写入 步骤1:生成 payload 方式1:使用python生成 payload 方式二:使用 Gopher 工具 步骤 2:写入 Webshell…...

计算机网络和因特网
目录 1、什么是Internet? 1.1定义 1.2具体构成描述 2、什么是协议? 2.1 服务描述 2.2 网络协议 3、网络边缘 3.1 定义与组成 3.2 模式 3.3服务 4、接入网、物理媒介 4.1、宽带有线接入网技术 4.2、宽带无线接入网技术 5、网络核心…...

1.oracle修改配置文件
1.找到oracle的安装路径 D:\app\baozi\product\11.2.0\dbhome_1\NETWORK\ADMIN ,修改下面的两个文件。如果提示没有权限,可以先把这两个文件复制到桌面,修改完后,在复制回来。 2.查看自己电脑的主机名, 右击 - 此电脑 …...

算法篇-------------双指针法
温馨提示:由于c语言在编程上更有优势,更加简洁,本文代码均为c代码,其他语言也可以 做,思想是不变的! 1.应用场景 涉及到对数组的操作的题目,可以考虑双指针方法解决 2.基…...

Java关于包和final
什么是包? 包就是文件夹。用来管理等各种不同功能的java类,方便后期代码维护 包名的规则:公司域名反写包的作用,需要全部英文小写,见名知意。例如:com.pdsu.domain package com.pdsu.demain;public class…...

2025年华为HCIP题库分享
1101、 【拖拽题】OPSF邻接关系建立的过程中需要使用不同的报文,那么请分别将以下各个状态和该状态使用的报文联系起来。 答题格式为:11 22 33 43 正确答案:【12】【21】【24】【33】 解析: 建立邻居关系 RouterA的一个连接到广…...

49. 字母异位词分组
leetcode Hot 100系列 文章目录 一、核心操作二、外层配合操作三、核心模式代码总结 一、核心操作 先把每一个词都排序,拍完之后相同的就是字母异位词使用map,排序完的作为key,一个string数组作为value对于每一个词,排完序之后将…...
)
python 语法篇(一)
目录 1 正则匹配注意点11.1 正则匹配字符串写法1.2 创建re函数(1)re.search()--搜索第一个匹配项(2)re.match() - 从字符串开头匹配(3)re.findall() - 返回所有匹配项的列表(4)re.fi…...

机器学习ML极简指南
机器学习是现代AI的核心,从推荐系统到自动驾驶,无处不在。但每个智能应用背后,都离不开那些奠基性的模型。本文用最简练的方式拆解核心机器学习模型,助你面试时对答如流,稳如老G。 线性回归 线性回归试图通过"最…...
步骤,http和https协议)
爬虫:网络请求(通信)步骤,http和https协议
电脑(浏览器):www.baidu.com——url DNS服务器:IP地址标注服务器——1.1.38 DNS服务器返回IP地址给浏览器 浏览器拿到IP地址去访问服务器,返回响应 服务器返回给响应数据:html/css/js/jpg... html:文本 cs…...

【杂谈】-大型语言模型对具身人工智能发展的推动与挑战
大型语言模型对具身人工智能发展的推动与挑战 文章目录 大型语言模型对具身人工智能发展的推动与挑战1. 具身人工智能(Embodied AI)的内涵解析2. 大型语言模型的功能与作用3. 最新发展趋势4. 面临的挑战与考量因素5. 总结与展望 多年来,研发能…...

解决Beats Solo Buds 无法自动切换音频到耳机的问题
一、核心问题定位 现象矛盾点: Beats 耳机能连接但需手动切换音频 AirPods 可自动切换 → 排除 iOS 系统级故障 问题可能源于 Beats 固件兼容性 或 音频路由逻辑冲突 关键差异: 设备 芯片类型 自动切换协议支持 固件更新方式 AirPods 二代 H1芯片 原…...

MySQL基本查询
一.create 1.1 单行数据 全列插入 1.2 多行数据 指定列插入 1.3插入否则更新 1.4替换 二.Retrieve 2.1.SELECT列 2.1.1全列查询 2.1.2指定列查询 2.1.3查询字段为表达式 2.1.4 为查询结果指定别名 2.1.5结果去重 2.2WHERE 条件 2.2.1比较运算符 2.2.3逻辑运算符…...

面基:为什么不推荐用UUID作为主键
推荐回答结构: 技术理论层面分析 实际项目中的教训 优化改进过程 总结提炼认知 阐述回答 在阐述回答时,你可以从 UUID 本身特性带来的问题,以及在实际工作中遇到的具体场景和优化过程等方面展开,下面从这一思路,给…...

oracle 常用函数的应用
在使用开发中会经常遇到数据类型转换、显示系统时间等情况,需要使用函数来实现。通过函数来实现业务需求会非常的省事便捷,函数可以用在适当的dml语句和查询语句中。 Oracle 数据库中主要使用两种类型的函数: (1)单行函数:对每一个…...

ubuntu的ubuntu--vg-ubuntu--lv磁盘扩容
在我们安装ubuntu时,如果选择的是自动分区,就会按照逻辑卷的形式来分区,并且只分配100G其余的并不会被分配,这对我们大多数情况来说都是不合理的,所以,如何扩充呢 下面以一个小的案例来说明如何扩充 问题…...