构建大语言模型应用:数据准备(第二部分)
本专栏通过检索增强生成(RAG)应用的视角来学习大语言模型(LLM)。
本系列文章
- 简介
- 数据准备(本文)
- 句子转换器
- 向量数据库
- 搜索与检索
- 大语言模型
- 开源检索增强生成
- 评估
- 大语言模型服务
- 高级检索增强生成 RAG

如上图所示,是检索增强生成(RAG)的数据准备流程
在上一篇文章中,我们深入探讨了检索增强生成(RAG)流程,全面了解了它的各个组成部分。
任何机器学习应用的初始阶段都需要进行数据准备。这包括建立数据摄取流程以及对数据进行预处理,使其与推理流程兼容。
在本文中,我们将把注意力转向检索增强生成(RAG)的数据准备方面。目标是有效地组织和构建数据结构,确保在我们的应用程序中能够以最佳性能找到答案。
下面让我们深入了解细节。
1. 步骤一:数据摄取
构建一个用户友好的聊天机器人,始于明智的数据选择。这篇博客将探讨如何为成功的语言模型(LLM)应用有效地收集、管理和清理数据。
- 明智选择:确定数据源,从门户网站到应用程序编程接口(API),并设置一个推送机制,以便为你的大语言模型应用持续更新数据。
- 数据治理至关重要:预先实施数据治理政策。对文档来源进行审核和编目,编辑掉敏感数据,并为上下文训练奠定基础。
- 质量检查:评估数据的多样性、规模和噪声水平。质量较低的数据集会使回复质量下降,因此需要一个早期分类机制。
- 保持领先:即使在快节奏的大语言模型开发中,也要坚持数据治理。这可以降低风险,并确保可扩展、稳健的数据提取。
- 实时清理:从诸如Slack这样的平台获取数据?实时过滤掉噪声、拼写错误和敏感内容,以打造一个干净、有效的大语言模型应用。
2. 步骤二:数据清洗
我们文件的每一页都会转换为一个文档对象,并且有两个基本组成部分:页面内容(page_content)和元数据(metadata)。
页面内容展示了直接从文档页面提取的文本内容。
元数据是一组至关重要的附加详细信息,比如文档的来源(它所源自的文件)、页码、文件类型以及其他信息要点。元数据在发挥其作用并生成有深刻见解的答案时,会记录它所利用的特定来源。

更多内容:Data Loading
为了实现这一点,我们利用强大的工具,如数据加载器(Data Loaders),这些工具由像LangChain和Llamaindex这样的开源库提供。这些库支持各种格式,从PDF和CSV到HTML、Markdown,甚至是数据库。
!pip install pypdf
!pip install langchain
# 对于PDF文件,我们需要从langchain框架中导入PyPDFLoader
from langchain_community.document_loaders import PyPDFLoader# 对于CSV文件,我们需要导入csv_loader
# 对于Doc文件,我们需要导入UnstructuredWordDocumentLoader
# 对于文本文档,我们需要导入TextLoaderfilePath = "/content/A_miniature_version_of_the_course_can_be_found_here__1701743458.pdf"
loader = PyPDFLoader(filePath)
# 加载文档
pages = loader.load_and_split()
print(pages[0].page_content)
这种方法的一个优点是可以通过页码来检索文档。
3. 步骤三:分块

3.1. 为什么要分块?
在应用程序领域中,关键在于你如何处理数据——无论是Markdown文件、PDF文件还是其他文本文件。想象一下:你有一个庞大的PDF文件,并且你渴望就其内容提出问题。问题在于,传统的将整个文档和你的问题一股脑抛给模型的方法并不管用。为什么呢?嗯,让我们来谈谈模型上下文窗口的局限性。
以GPT-3.5 及其类似模型为例。可以把上下文窗口想象成窥视文档的一个窗口,通常只限于一页或几页的内容。那么,一次性共享整个文档呢?不太现实。但是别担心!
诀窍在于对数据进行分块。将其分解为易于处理的部分,只将最相关的分块发送给模型。这样,你就不会让模型不堪重负,并且能够获得你渴望的精确见解。
通过将我们的结构化文档分解为可管理的分块,我们使大语言模型能够以无与伦比的效率处理信息。不再受页面限制的约束,这种方法确保关键细节不会在处理过程中丢失。
3.2. 分块前的考虑因素
- 文档的结构和长度:
- 长文档:书籍、学术文章等。
- 短文档:社交媒体帖子、客户评论等。
- 嵌入模型:分块大小决定了应该使用哪种嵌入模型。
- 预期查询:应用场景是什么?
3.3. 分块大小
- 小块大小:例如:单个句子 → 生成时的上下文信息较少。
- 大块大小:例如:整页、多个段落、整个文档。在这种情况下,分块涵盖更多信息,这可以通过更多的上下文来提高生成的有效性。
3.3.1. 选择分块大小
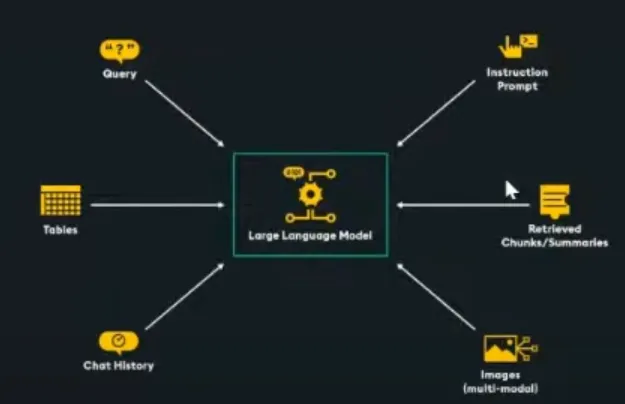
- 大语言模型上下文窗口:对可以输入到大语言模型的数据量有限制。
- 前K个检索到的分块:假设大语言模型有一个10,000个Token的上下文窗口大小,我们为给定的用户查询预留大约1000个Token,为指令提示和聊天记录预留2000个Token,那么只剩下7000个Token用于其他任何信息。假设我们打算将K = 10,即前10个分块传递给大语言模型,这意味着我们将剩余的7000个Token除以总共10个分块,那么每个分块的最大大小约为700个Token。
- 分块大小范围:下一步是选择一系列可能的分块大小进行测试。如前所述,选择应考虑内容的性质(例如,短消息或长篇文档)、你将使用的嵌入模型及其能力(例如,标记限制)。目标是在保留上下文和保持准确性之间找到平衡。首先探索各种分块大小,包括较小的分块(例如,128或256个Token)以捕获更精细的语义信息,以及较大的分块(例如,512或1024个Token)以保留更多上下文。
- 评估每个分块大小的性能:要测试各种分块大小,你可以使用多个索引,或者使用具有多个命名空间的单个索引。使用具有代表性的数据集,为你想要测试的分块大小创建嵌入,并将它们保存在你的索引(或多个索引)中。然后,你可以运行一系列查询,通过这些查询评估质量,并比较各种分块大小的性能。这很可能是一个迭代过程,你针对不同的查询测试不同的分块大小,直到你能够确定适合你的内容和预期查询的性能最佳的分块大小。
高上下文长度的限制:由于Transformer模型的自注意力机制,高上下文长度可能会导致时间和内存呈二次方增加。
在LlamaIndex发布的这个例子中,你可以从下面的表格中看到,随着分块大小的增加,平均响应时间会有小幅上升。有趣的是,平均忠实度似乎在分块大小为1024时达到峰值,而平均相关性随着分块大小的增加持续提高,也在分块大小为1024时达到峰值。这表明分块大小为1024可能在响应时间和回复质量(以忠实度和相关性衡量)之间达到最佳平衡。

3.4. 分块方法
有不同的分块方法,并且每种方法可能适用于不同的情况。通过研究每种方法的优缺点,我们的目标是确定应用它们的合适场景。
3.4.1. 固定大小分块
我们决定每个分块中的标记数量,并可选择添加重叠部分以确保效果。为什么要重叠呢?是为了确保语义上下文的丰富性在各个分块之间保持完整。
为什么选择固定大小呢?在大多数情况下,这是最佳选择。它不仅计算成本低,节省处理能力,而且使用起来也很方便。无需复杂的自然语言处理库,只需用固定大小的分块优雅地分解你的数据即可。
以下是使用LangChain进行固定大小分块的示例:
text = "..." # 你的文本
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator = "\n\n",chunk_size = 256,chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
3.4.2. “上下文感知”分块
这些是一组利用我们正在分块的内容的特性,并对其应用更复杂分块的方法。以下是一些示例:
3.4.2.1. 句子分割
正如我们之前提到的,许多模型针对嵌入句子级别的内容进行了优化。自然地,我们会使用句子分块,并且有几种方法和工具可用于实现这一点,包括:
- 简单分割:最直接的方法是按句号(“.”)和换行符分割句子。虽然这可能快速且简单,但这种方法不会考虑所有可能的边界情况。这是一个非常简单的示例:
text = "..." # 你的文本
docs = text.split(".")
- NLTK:自然语言工具包(NLTK)是一个流行的用于处理人类语言数据的Python库。它提供了一个句子标记器,可以将文本分割成句子,有助于创建更有意义的分块。例如,要将NLTK与LangChain一起使用,可以执行以下操作:
text = "..." # 你的文本
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
docs = text_splitter.split_text(text)
- spaCy:spaCy是另一个用于自然语言处理任务的强大Python库。它提供了一种复杂的句子分割功能,可以有效地将文本分割成单独的句子,从而在生成的分块中更好地保留上下文。例如,要将spaCy与LangChain一起使用,可以执行以下操作:
text = "..." # 你的文本
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpaCyTextSplitter()
docs = text_splitter.split_text(text)
3.4.2.2. 递归分块
来认识一下我们的秘密武器:LangChain的RecursiveCharacterTextSplitter。这个多功能工具可以根据选定的字符优雅地分割文本,同时保留语义上下文。想想双换行符、单换行符和空格——它就像把信息雕琢成易于理解的、有意义的部分。
它是如何工作的呢?很简单。只需传入文档并指定所需的分块长度(假设为1000个单词)。你甚至可以微调分块之间的重叠部分。
以下是如何使用LangChain进行递归分块的示例:
text = "..." # 你的文本
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(# 设置一个非常小的分块大小,仅用于演示。chunk_size = 256,chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
3.4.2.3. 特殊分块
Markdown和LaTeX是你可能会遇到的两种结构化和格式化内容的示例。在这些情况下,你可以使用特殊的分块方法,在分块过程中保留内容的原始结构。
- Markdown:Markdown是一种常用于格式化文本的轻量级标记语言。通过识别Markdown语法(例如,标题、列表和代码块),你可以根据其结构和层次结构智能地分割内容,从而得到语义更连贯的分块。例如:
from langchain.text_splitter import MarkdownTextSplitter
markdown_text = "..."
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])
- LaTeX:LaTeX是一种常用于学术论文和技术文档的文档准备系统和标记语言。通过解析LaTeX命令和环境,你可以创建尊重内容逻辑组织(例如,章节、子章节和方程式)的分块,从而得到更准确和上下文相关的结果。例如:
from langchain.text_splitter import LatexTextSplitter
latex_text = "..."
latex_splitter = LatexTextSplitter(chunk_size=100, chunk_overlap=0)
docs = latex_splitter.create_documents([latex_text])
3.5. 多模态分块

- 从文档中提取表格和图像:使用LayoutPDFReader、Unstructured等工具。提取的表格和图像可以用标题、描述和摘要等元数据进行标记。
- 多模态方法:
- 文本嵌入:总结图像和表格。
- 多模态嵌入:使用可以处理原始图像的嵌入模型。
4. 步骤四:Tokenization 标记化

最常用标记化方法总结
标记化包括将短语、句子、段落或整个文本文档分割成更小的单元,例如单个单词或术语。在本文中,我们将了解主要的标记化方法以及它们目前的应用场景。我建议你也查看一下Hugging Face制作的这个标记器总结,以获取更深入的指南。
4.1. 词级标记化 Word-Level Tokenization
词级标记化包括将文本分割成单词单元。为了正确地进行标记化,需要考虑一些注意事项。
- 空格和标点符号标记化:
将文本分割成较小的块比看起来要难,并且有多种方法可以做到这一点。例如,让我们看一下下面的句子:
“Don't you like science? We sure do.”
对这段文本进行标记化的一种简单方法是按空格分割,这将得到:
["Don't", "you", "like", "science?", "We", "sure", "do."]
如果我们看一下标记“science?”和“do.”,我们会注意到标点符号与单词“science”和“do”连在一起,这并不理想。我们应该考虑标点符号,这样模型就不必学习一个单词及其后面可能出现的每个标点符号的不同表示形式,否则模型必须学习的表示形式数量会激增。
考虑标点符号后,对我们的文本进行标记化将得到:
["Don", "'", "t", "you", "like", "science", "?", "We", "sure", "do", "."]
- 基于规则的标记化:
前面的标记化方法比单纯基于空格的标记化要好一些。然而,我们可以进一步改进标记化处理“Don't”这个单词的方式。“Don't”代表“do not”,所以用类似于["Do", "n't"]这样的方式进行标记化会更好。其他一些特定规则可以进一步改进标记化效果。
然而,根据我们应用于文本标记化的规则不同,对于相同的文本会生成不同的标记化输出。因此,只有当你向预训练模型输入的内容是使用与训练数据标记化相同的规则进行标记化时,预训练模型才能正常运行。
- 词级标记化的问题:
词级标记化对于大规模文本语料库可能会导致问题,因为它会生成非常大的词汇表。例如,Transformer XL语言模型使用空格和标点符号标记化,导致词汇表大小达到267,000。
由于词汇表如此之大,模型的输入和输出层有一个巨大的嵌入矩阵,这增加了内存和时间复杂度。作为参考,Transformer模型的词汇表大小很少会超过50,000。
4.2. 字符级标记化 Character-Level Tokenization
那么,如果词级标记化不可行,为什么不直接对字符进行标记化呢?
尽管字符级标记化会极大地降低内存和时间复杂度,但它会使模型更难学习到有意义的输入表示。例如,学习字母“t”的一个有意义且与上下文无关的表示,要比学习单词“today”的与上下文无关的表示难得多。
因此,字符级标记化往往会导致性能下降。为了兼顾两者的优点,Transformer模型通常会使用一种介于词级和字符级标记化之间的混合方法,称为子词标记化。
4.3. 子词标记化 Subword Tokenization
子词标记化算法基于这样一个原则:常用词不应被分割成更小的子词,而罕见词则应被分解为有意义的子词。
例如,“annoyingly”可能被认为是一个罕见词,可以分解为“annoying”和“ly”。“annoying”和“ly”作为独立的子词出现的频率会更高,同时,“annoyingly”的意思通过“annoying”和“ly”的组合含义得以保留。
除了使模型的词汇表大小合理之外,子词标记化还能让模型学习到有意义的、与上下文无关的表示。此外,子词标记化可用于处理模型从未见过的单词,方法是将它们分解为已知的子词。
现在让我们来看看几种不同的子词标记化方法。
字节对编码(Byte-Pair Encoding: BPE)
字节对编码(BPE)依赖于一个预标记器,该预标记器将训练数据分割成单词(例如像GPT-2和RoBERTa中使用的基于空格的标记化方法)。
在预标记化之后,BPE创建一个基础词汇表,该词汇表由语料库中唯一单词集合中出现的所有符号组成,并学习合并规则,以便从基础词汇表中的两个符号形成一个新符号。这个过程会不断迭代,直到词汇表达到所需的大小。
词块(WordPiece)
用于BERT、DistilBERT和ELECTRA的词块方法与BPE非常相似。WordPiece首先将词汇表初始化为包含训练数据中出现的每个字符,然后逐步学习一定数量的合并规则。与BPE不同的是,WordPiece不会选择最频繁出现的符号对,而是选择一旦添加到词汇表中就能使训练数据出现概率最大化的那个符号对。
直观地说,WordPiece与BPE略有不同,因为它会评估合并两个符号所带来的损失,以确保这样做是值得的。
一元语法(Unigram)
与BPE或WordPiece不同,一元语法(Unigram)将其基础词汇表初始化为大量的符号,然后逐步削减每个符号,以获得一个较小的词汇表。例如,基础词汇表可以对应于所有预标记化的单词和最常见的子字符串。Unigram通常与SentencePiece一起使用。
句子片段(SentencePiece)
到目前为止描述的所有标记化算法都有一个相同的问题:它们都假定输入文本使用空格来分隔单词。然而,并非所有语言都使用空格来分隔单词。
为了从根本上解决这个问题,SentencePiece将输入视为一个原始输入流,因此将空格也包含在要使用的字符集合中。然后,它使用BPE或Unigram算法来构建合适的词汇表。
使用SentencePiece的模型示例包括ALBERT、XLNet、MarianMT和T5。
OpenAI标记化可视化:https://platform.openai.com/tokenizer
结论
在这篇博客中,我们探讨了检索增强生成(RAG)应用程序的数据准备过程,强调了为实现最佳性能进行高效的数据结构化。它涵盖了将原始数据转换为结构化文档、创建相关的数据块,以及子词标记化等标记化方法。我们强调了选择合适数据块大小的重要性,以及对每种标记化方法的考量因素。这篇文章为根据特定应用需求定制数据准备工作提供了深刻见解。
鸣谢
在这篇博客文章中,我们汇集了来自各种来源的信息,包括研究论文、技术博客、官方文档等。每个来源都在相应的图片下方进行了适当的标注,并提供了来源链接。
以下是参考列表:
- https://dataroots.io/blog/aiden-data-ingestion
- https://www.pinecone.io/learn/chunking-strategies/
- https://www.youtube.com/watch?v=uhVMFZjUOJI&t=1209s
- https://medium.com/nlplanet/two-minutes-nlp-a-taxonomy-of-tokenization-methods-60e330aacad3
- https://medium.com/@vipra_singh/building-llm-applications-data-preparation-part-2-b7306d224245
相关文章:
)
构建大语言模型应用:数据准备(第二部分)
本专栏通过检索增强生成(RAG)应用的视角来学习大语言模型(LLM)。 本系列文章 简介数据准备(本文)句子转换器向量数据库搜索与检索大语言模型开源检索增强生成评估大语言模型服务高级检索增强生成 RAG 如上…...

mac m 芯片 动态切换 jdk 版本jdk8.jdk11.jdk17
下载 jdk 版本. 默认安装路径在. /Library/Java/JavaVirtualMachines配置环境变量 # 动态获取所有 JDK 路径 export JAVA_8_HOME$(/usr/libexec/java_home -v 1.8) export JAVA_11_HOME$(/usr/libexec/java_home -v 11) export JAVA_17_HOME$(/usr/libexec/java_home -v 17)#…...

如何通过python将视频转换为字符视频
请欣赏另类的老鼠舞 字符老鼠舞 与原版对比 对比 实现过程 1. 安装库 pip install numpy pip install Pillow pip install opencv-python pip install moviepy 2. 读取视频帧并转换为灰度图 import cv2def make_video(input_video_path, output_video_path):video_cap cv2…...
组)
如何高效备考蓝桥杯(c/c++)组
以下是针对蓝桥杯C/C组的高效备考策略,结合你的当前基础(C语法简单算法题),分阶段提升竞赛能力,重点突破高频考点: 一、蓝桥杯C/C组核心考点梳理 根据历年真题,重点考察以下内容(按…...

两数之和-力扣
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 你可以按任意顺序返回答案。 示例 1…...

react撤销和恢复
创建一个历史记录栈past,和一个撤销过的栈future,,在每次操作store的时候,将当前的store的数据,存入历史记录栈past中,, 如果是撤销操作,,就从这个历史栈中取最后面那个数…...

华为机试—密码验证合格程序
题目 你需要书写一个程序验证给定的密码是否合格。 合格的密码要求: 长度超过 8 位必须包含大写字母、小写字母、数字、特殊字符中的至少三种不能分割出两个独立的、长度大于 2 的连续子串,使得这两个子串完全相同;更具体地,如果…...

分布式ID生成器:雪花算法原理与应用解析
在互联网分布式系统中,生成全局唯一的ID是一个核心问题。传统的数据库自增ID、UUID虽然各有优缺点,但在高并发、分库分表场景下往往无法满足需求。美团Leaf分布式ID生成器便是为了解决这些问题而诞生的,其核心实现便是基于Snowflakeÿ…...

搭建Flutter开发环境 - MacOs
一、配置Flutter SDK 1.1 到官网下载Flutter SDK 打开Flutter中文社区网址,往下滚动,找到下载并安装Flutter,选择适合自己电脑的安装包进行下载。下载完毕后,解压放到你想要放置的目录下,我放到了 User/账户/develop…...
】Dart访问控制)
【Flutter学习(1)】Dart访问控制
疑问代码片段: class _MyHomePageState extends State<MyHomePage> {int _counter 0;void _incrementCounter() {setState(() {_counter;});} }对Flutter初始文件里下划线的疑问 为什么这里的类和申明的计数器都要在前面加一个下划线? 在 Dart 中…...

Day50 单词规律
给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。 这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。 class Solution {public boolean wordPattern(String p…...

HTTP和HTTPS区别
一:工作原理 HTTP 超文本传输协议。 一种应用层协议,用于在客户端(如浏览器)和服务器之间传输超文本数据(如HTML、图片)。 明文传输,无加密。 HTTPS 安全的超文本传输协议。 是HTTP的加密…...

拥抱AI变革机遇,联易融自研供应链金融垂直领域大模型“蜂联 AI”
2025年3月25日,中国领先的供应链金融科技解决方案服务商联易融科技集团(09959.HK,以下简称“联易融”)发布2024年业绩公告。2024年公司总收入及收益达10.3亿元,同比增长19%;受益于产品结构优化与运营效率改…...

常用数据库
模式的定义于删除 1.定义模式 CREATE SCHEMA [ <模式名> ] AUTHORIZATION < 用户名 >;要创建模式,调用该命令的用户必须拥有数据库管理员权限,或者获得了DBA授权 eg:为用户WANG定义一个模式S-C-SC CREATE SCHEMA "S-C-SC" AUT…...

Hive UDF开发实战:构建高性能JSON生成器
目录 一、背景与需求场景 二、开发环境准备 2.1 基础工具栈 2.2 Maven依赖配置 三、核心代码实现...
——利用Multisim软件实现3线-8线译码器)
数字电子技术基础(三十六)——利用Multisim软件实现3线-8线译码器
目录 1 手动方式实现3线-8线译码器 2 使用字选择器实现3线-8线译码器 现在尝试利用Multisim软件来实现3线-8线译码器。本实验目的是验证74LS138的基本功能,简单来说就是“N中选1”。 实验设计: (1)使能信号:时&am…...

解析 HTML 网站架构规范
2025/3/28 向全栈工程师迈进! 一、网页基本的组成部分 网页的外观多种多样,但是除了全屏视频或游戏,或艺术作品页面,或只是结构不当的页面以外,都倾向于使用类似的标准组件。 1.1页眉 通常横跨于整个页面顶部有一…...
处理音频数据的输出的函数)
小智机器人关键函数解析,Application::OutputAudio()处理音频数据的输出的函数
以下是对 Application::OutputAudio() 函数的详细解释: 源码: void Application::OutputAudio() { // 扬声器的输出auto now std::chrono::steady_clock::now();auto codec Board::GetInstance().GetAudioCodec();const int max_silence_seconds 10;…...
)
基于javaweb的SpringBoot驾校预约学习系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

《边缘计算风云录:FPGA与MCU的算力之争》
点击下面图片带您领略全新的嵌入式学习路线 🔥爆款热榜 88万阅读 1.6万收藏 文章目录 **第一章:边城烽烟——数据洪流压境****第二章:寒铁剑匣——FPGA的千机变****第三章:枯木禅杖——MCU的至简道****第四章:双生契…...

3.3 元组
元组(tuple): 1.元组的定义: -通过 tuple() !!!元组中的元素不能发生改变!!! #测试元组的定义 # - 定义空元组 tuple1 ()print(tu…...

PyTorch版本过低导致属性错误-Linux服务器
问题 在 Jupyter Lab 中配置 Python 环境(如 PyTorch 或其他库)通常涉及以下几个步骤: 1. 检查当前 Jupyter Lab 的内核环境 运行以下命令查看当前可用的内核: !jupyter kernelspec list或者 jupyter kernelspec list这会显示 …...

一文解读DeepSeek大模型在政府工作中具体的场景应用
引言 本文以政务内部管理的视角,介绍DeepSeek大模型在政务数字化在转型中的提质增效应用!政务本是一个复杂的系统,对外要提供公共服务,对内有严格的安全管理要求。DeepSeek大模型在政务系统中的应用,对外提升服务水平&…...

场馆预约小程序的设计与实现
摘 要 时代在进步,人们对日常生活质量的要求不再受限于衣食住行。现代人不仅想要一个健康的身体,还想拥有一身宛如黄金比例的身材。但是人们平常除了上下班和上下学的时间,其余空余时间寥寥无几,所以我们需要用体育场馆预约来节省…...

【C++】string
个人主页:NiKo C专栏:C程序设计 目录 一、标准库中的string类 二、string的遍历 三、string容量 四、string修改 一、标准库中的string类 1、string类 C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,…...

在 RK3588 多线程推理 YOLO 时,同时开启硬件解码和 RGA 加速的性能分析
一、前言 本文是基于RK3588的YOLO多线程推理多级硬件加速引擎框架设计项目的延申与拓展,单独分析所提出的方案4的性能和加速原理,即同时开启 RKmpp 硬件视频解码和 RGA 硬件图像缩放、旋转。 二、实验结果回顾 在项目的总览篇中,给出了该方案…...

sqli-labs靶场 less 8
文章目录 sqli-labs靶场less 8 布尔盲注 sqli-labs靶场 每道题都从以下模板讲解,并且每个步骤都有图片,清晰明了,便于复盘。 sql注入的基本步骤 注入点注入类型 字符型:判断闭合方式 (‘、"、’、“”…...

3.2 列表的常见函数
1.列表的常用函数 -如何查看一个不认识的内容 -help() -查看官方帮助文档 -dir() -查看内部函数 -随机数语句 import randomranom.randint(0,101) 随机生成0-100内的数字 list1 [1,2,3,4,5]list2 list([1,2,3,4,5,])list2 list("wang…...

Apache Doris 高频问题排查指南:从报错到性能优化
一、部署与配置问题 1. FE启动失败:Address already in use ERROR: fe.journal.Catalog constructor exception. port9010 is already used. 原因:端口被占用或残留进程未释放 解决: # 查找占用进程 lsof -i :9010 # 终止残留进程 kill…...

Hadoop/Spark 生态
Hadoop/Spark 生态是大数据处理的核心技术体系,专为解决海量数据的存储、计算和分析问题而设计。以下从底层原理到核心组件详细讲解,帮助你快速建立知识框架! 一、为什么需要 Hadoop/Spark? 传统单机瓶颈: 数据量超…...
——算术运算类指令)
51单片机的五类指令(二)——算术运算类指令
目录 一、加法指令 (一)不带进位加法指令(ADD) (二)带进位加法指令(ADDC) (三)加 1 指令(INC) (四)十进制…...

uniapp选择文件使用formData格式提交数据
1. Vue实现 在vue项目中,我们有个文件,和一些其他字段数据需要提交的时候,我们都是使用axios 设置请求头中的Content-Type: multipart/form-data,然后new FormData的方式来进行提交。方式如下: const sendRequest = () => {const formData = new FormData()formData…...

mac Python多版本第三方库的安装路径
终端查看python版本是 3.12,但是pycharm使用的python版本是 3.9 终端正常安装包以后,pycharm都可以正常使用,但是将 pycharm的python换成 3.12 版本,之前安装的库都没有了 通过终端查看安装库的位置,确实是安装到py…...

第 26 场 蓝桥月赛 部分题解
第 26 场 蓝桥月赛 2.灯笼猜谜3.元宵分配4.摆放汤圆5.元宵交友(运行超时 通过90%) 2.灯笼猜谜 分析:以当前位置为视角,要想移动的距离尽可能的少,按顺序猜谜语,给你一个区间,有三种情况…...

【Vue3知识】Vue3集成富文本编辑器TinyMCE
Vue3集成富文本编辑器TinyMce 集成一、安装依赖二、基础集成示例1. 组件封装:RichEditor.vue 三、关键配置说明1. **API Key 配置**2. **图片上传处理**3. **多语言支持** 四、完整本地化部署步骤(无 API Key)五、在父组件中使用六、常见问题…...

pod生命周期
1.init容器:做主容器运行前需要做的准备条件 2.探针 通俗易懂就是检测容器是否正常运行工作 启动探针startupProbe:检测应用是否完成启动 ,如果启动则禁用其他探测 直到成功为止,探测失败则杀死容器,容器服从重启策略…...

Oracle数据库数据编程SQL<3.3 PL/SQL 游标>
游标(Cursor)是Oracle数据库中用于处理查询结果集的重要机制,它允许开发者逐行处理SQL语句返回的数据。 目录 一、游标基本概念 1. 游标定义 2. 游标分类 二、静态游标 (一)显式游标 【一】不带参数,普通的显示游标 1. 显式…...

OLLAMA 未授权访问-漏洞挖掘
1.漏洞描述 Ollama存在未授权访问漏洞。由于Ollama默认未设置身份验证和访问控制功能,未经授权的攻击者可在远程条件下调用Ollama服务接口,执行包括但不限于敏感模型资产窃取、虚假信息投喂、模型计算资源滥用和拒绝服务、系统配置篡改和扩大利用等恶意…...

多线程—线程安全集合类与死锁
上篇文章: 多线程—JUChttps://blog.csdn.net/sniper_fandc/article/details/146713322?fromshareblogdetail&sharetypeblogdetail&sharerId146713322&sharereferPC&sharesourcesniper_fandc&sharefromfrom_link 目录 1 线程安全的集合类 …...
)
【鸿蒙5.0】鸿蒙登录界面 web嵌入(隐私页面加载)
在鸿蒙应用中嵌入 Web 页面并加载隐私页面,可借助 WebView 组件来实现。以下是一个完整示例,展示如何在鸿蒙 ArkTS 里嵌入 Web 页面并加载隐私政策页面。 在 HarmonyOS 应用开发中,如果你希望嵌入一个网页,并且特别关注隐私页面加…...

C++轻量HeaderOnly的JSON库
文章目录 1 nlohmann/json库说明2 nlohmann/json特点3 nlohmann/json库的使用方法3.1 引入头文件3.2 解析JSON字符串3.3 访问JSON数据3.4 生成JSON对象3.5 修改JSON数据3.6 将JSON写入文件3.7 遍历JSON对象 4 代码示例4.1 定义JSON数值类型4.2 从STL容器转换到json4.3 string序…...

打包python文件生成exe
下载PyInstaller 官网 pip install pyinstaller验证是否安装成功 pyinstaller --version打包 pyinstaller "C:\Documents and Settings\project\myscript.py"会生成.spec,build,dist三项,其中build,dist为文件夹,dist是最后的可执行文件&a…...
)
Nginx — Nginx安装证书模块(配置HTTPS和TCPS)
一、安装和编译证书模块 [rootmaster nginx]# wget https://nginx.org/download/nginx-1.25.3.tar.gz [rootmaster nginx]# tar -zxvf nginx-1.25.3.tar.gz [rootmaster nginx]# cd nginx-1.25.3 [rootmaster nginx]# ./configure --prefix/usr/local/nginx --with-http_stub_…...
)
《Mycat核心技术》第21章:高可用负载均衡集群的实现(HAProxy + Keepalived + Mycat)
作者:冰河 星球:http://m6z.cn/6aeFbs 博客:https://binghe.gitcode.host 文章汇总:https://binghe.gitcode.host/md/all/all.html 星球项目地址:https://binghe.gitcode.host/md/zsxq/introduce.html 沉淀,…...

Dynamic WallPaper-壁纸动态-Mac电脑-4K超高清
Dynamic WallPaper-壁纸动态-Mac电脑-4K超高清 文章目录 Dynamic WallPaper-壁纸动态-Mac电脑-4K超高清一、介绍二、效果三、下载 一、介绍 Dynamic Wallpaper for mac版,是一款4K超高清动态壁纸软件,告别单调的静态壁纸,拥抱活泼的动态壁纸…...

MySQL8.4 NDB Cluster 集群配置安装
文章目录 前置条件安装步骤环境准备下载 安装 RPM 包安装 NDB 组件与常见错误配置节点启用节点配置启动 MySQL 集群验证集群状态 关于 ndb_mgm集群管理备份与恢复集群配置管理日志相关 MySQL NDB Cluster 是一个分布式数据库解决方案,提供高可用性、数据分片和自动故…...

多线程开发中List的使用
由于ArrayList在多线程高并发情况下是不安全的,因此要慎用,那么此时如果涉及到集合操作,应该怎么选: 方案一:Vector: 特点:通过给所有方法都用 synchronized 修饰从而保证线程安全, 缺点&…...

Html 页面图标的展示列表
Html 页面中经常需要使用网页图标,这些图标的样式和名称都不容易记住。常用的网页图标展示页面链接记录如下: Material Design Icons 图标库 - FontAwesome 字体图标中文Icon...

Vue实现动态路由的后端控制
在传统开发后台管理系统时,都会涉及权限控制这一功能需求 即:根据不同登录的角色账号来使用该账号拥有的功能,也就是说系统左边的菜单栏不是固定不变的。 首先是基础路由配置带有component的。 const allRoutes [// 基础路由{path: /,name…...

AI训练中的专有名词大白话版
AI训练中的专有名词大白话版 1. 数据集(Dataset) 👉 人话:AI的“练习题题库”,包含一堆带答案的题目(比如猫狗照片标签)。 🔹 例子: 训练集(练习…...