RDMA驱动学习(三)- cq的创建
用户通过ibv_create_cq接口创建完成队列,函数原型和常见用法如下,本节以该用法为例看下cq的创建过程。
struct ibv_cq *ibv_create_cq(struct ibv_context *context, int cqe,void *cq_context,struct ibv_comp_channel *channel,int comp_vector);
cq = ibv_create_cq(ctx, ncqe, NULL, NULL, 0);
用户态
ncqe为cq队列的容量,cqe_sz是cqe的大小,默认64B;mlx5_alloc_cq_buf就是通过posix_memalign分配cq队列的内存,记录到cq->buf_a。
static struct ibv_cq_ex *create_cq(struct ibv_context *context,const struct ibv_cq_init_attr_ex *cq_attr,int cq_alloc_flags,struct mlx5dv_cq_init_attr *mlx5cq_attr)
{...ncqe = align_queue_size(cq_attr->cqe + 1);cqe_sz = get_cqe_size(mlx5cq_attr);mlx5_alloc_cq_buf(to_mctx(context), cq, &cq->buf_a, ncqe, cqe_sz);cq->dbrec = mlx5_alloc_dbrec(to_mctx(context), cq->parent_domain,&cq->custom_db);...
}
然后通过mlx5_alloc_dbrec分配dbr,dbr位于物理内存,大小为8B,同时对齐到8B,记录了软件poll到了什么位置,即ci,以及cq的状态信息,dbr地址会被记录到cqc中,当用户执行poll_cq之后会更新dbr,后续会具体介绍。
__be32 *mlx5_alloc_dbrec(struct mlx5_context *context, struct ibv_pd *pd,bool *custom_alloc)
{ struct mlx5_db_page *page;__be32 *db = NULL;int i, j;...
default_alloc:pthread_mutex_lock(&context->dbr_map_mutex);page = list_top(&context->dbr_available_pages, struct mlx5_db_page,available);if (page)goto found;page = __add_page(context);if (!page)goto out;found:...return db;
}分配dbr的时候首先尝试去空闲链表中获取,如果拿不到则执行__add_page,开始时空闲链表为空,因此执行__add_page。
static struct mlx5_db_page *__add_page(struct mlx5_context *context)
{ struct mlx5_db_page *page;int ps = to_mdev(context->ibv_ctx.context.device)->page_size;int pp;int i;int nlong;int ret;pp = ps / context->cache_line_size; nlong = (pp + 8 * sizeof(long) - 1) / (8 * sizeof(long));page = malloc(sizeof *page + nlong * sizeof(long));if (!page) return NULL;if (mlx5_is_extern_alloc(context))ret = mlx5_alloc_buf_extern(context, &page->buf, ps);elseret = mlx5_alloc_buf(&page->buf, ps, ps);if (ret) {free(page);return NULL;}page->num_db = pp;page->use_cnt = 0;for (i = 0; i < nlong; ++i)page->free[i] = ~0;cl_qmap_insert(&context->dbr_map, (uintptr_t) page->buf.buf,&page->cl_map);list_add(&context->dbr_available_pages, &page->available);return page;
}struct mlx5_db_page {cl_map_item_t cl_map;struct list_node available;struct mlx5_buf buf;int num_db;int use_cnt;unsigned long free[0];
}; ps为page size,mlx5一次性分配一个物理页用于存储多个dbr,用结构体mlx5_db_page page描述。通过mlx5_alloc_buf分配了大小为ps的内存,即一个物理页,地址记录到page中buf。这里为了防止false sharing,将dbr地址对齐到了cache_line_size,因此一个物理页能存储dbr的数量pp为page大小除以cacheline大小,pp记录到page的num_db,page中use_cnt初始化为0,表示这个page中还没有dbr被占用。page中free数组相当于一个bitmap,记录了这个page中dbr的空闲情况,nlong表示为了记录num_db个dbr需要几个long,即最少需要几个long才能有num_db个bit,free数组初始化为全1,表示所有dbr都为空闲。mlx通过树和链表的方式管理每一个mlx5_db_page,因此将page插入到dbr_available_pages链表head,链表节点为list_node available,将page插入到dbr_map,树节点为cl_map_item_t cl_map。
然后再回到mlx5_alloc_dbrec的逻辑
__be32 *mlx5_alloc_dbrec(struct mlx5_context *context, struct ibv_pd *pd,bool *custom_alloc)
{ ...++page->use_cnt;if (page->use_cnt == page->num_db)list_del(&page->available);for (i = 0; !page->free[i]; ++i)/* nothing */;j = ffsl(page->free[i]);--j;page->free[i] &= ~(1UL << j); db = page->buf.buf + (i * 8 * sizeof(long) + j) * context->cache_line_size;out:pthread_mutex_unlock(&context->dbr_map_mutex);return db;
}
首先增加use_cnt,表示又占用了一个dbr,如果use_cnt等于num_db,表示这个page已经满了,因此从空闲链表中删除。遍历free数组,找到第一个不为一的long,说明这个long里有空闲的dbr,然后通过ffsl找到free[i]中第一个为1的位置 j,然后将free[i]的第 j 位改为0,表示占用了,然后索引对应的dbr,因为一个long能存8 * sizeof(long)个dbr,因此这次分配的索引就是(i * 8 * sizeof(long) + j),最后将这个地址记录到db。
然后回到create_cq逻辑。
static struct ibv_cq_ex *create_cq(struct ibv_context *context,const struct ibv_cq_init_attr_ex *cq_attr,int cq_alloc_flags,struct mlx5dv_cq_init_attr *mlx5cq_attr)
{...cq->dbrec[MLX5_CQ_SET_CI] = 0; cq->dbrec[MLX5_CQ_ARM_DB] = 0; cq->arm_sn = 0; cq->cqe_sz = cqe_sz;cq->flags = cq_alloc_flags;cmd_drv->buf_addr = (uintptr_t) cq->buf_a.buf;cmd_drv->db_addr = (uintptr_t) cq->dbrec;cmd_drv->cqe_size = cqe_sz;{struct ibv_cq_init_attr_ex cq_attr_ex = *cq_attr;cq_attr_ex.cqe = ncqe - 1;ret = ibv_cmd_create_cq_ex(context, &cq_attr_ex, &cq->verbs_cq,&cmd_ex.ibv_cmd, sizeof(cmd_ex),&resp_ex.ibv_resp, sizeof(resp_ex),CREATE_CQ_CMD_FLAGS_TS_IGNORED_EX);}...
}
初始化dbrec和cq,然后将buf地址,dbrec地址,cqe_sz记录到cmd_drv,然后执行ibv_cmd_create_cq_ex,进入到了内核态。
内核态
dma映射
int mlx5_ib_create_cq(struct ib_cq *ibcq, const struct ib_cq_init_attr *attr,struct ib_udata *udata)
{if (udata) {err = create_cq_user(dev, udata, cq, entries, &cqb, &cqe_size,&index, &inlen);...}
}
进入内核态后执行mlx5_ib_create_cq,由于是用户态的create_cq,因此执行create_cq_user,cqb类型为mlx5_ifc_create_cq_in_bits,即第二章中介绍的create_cq的cmd,会在create_cq_user创建。
static int create_cq_user(struct mlx5_ib_dev *dev, struct ib_udata *udata,struct mlx5_ib_cq *cq, int entries, u32 **cqb,int *cqe_size, int *index, int *inlen)
{struct mlx5_ib_create_cq ucmd = {};*cqe_size = ucmd.cqe_size;cq->buf.umem = ib_umem_get_peer(udata, ucmd.buf_addr,entries * ucmd.cqe_size,IB_ACCESS_LOCAL_WRITE, 0);...
}
entries为cq容量,cqe_size为cqe大小,然后执行ib_umem_get_peer,因为用户态中的buf_addr或者dbr的地址均为虚拟地址,用户态软件使用虚拟地址访问cq,但是硬件需要使用总线地址访问cq,所以ib_umem_get_peer作用就是将虚拟地址连续的addr转为总线地址。
struct ib_umem *ib_umem_get_peer(struct ib_udata *udata, unsigned long addr, size_t size, int access, unsigned long peer_mem_flags)
{return __ib_umem_get(udata, addr, size, access, IB_PEER_MEM_ALLOW | peer_mem_flags);
}
首先分配ib_umem umem,相关信息都会记录到umem里。
struct ib_umem *__ib_umem_get(struct ib_udata *udata,unsigned long addr, size_t size, int access,unsigned long peer_mem_flags)
{struct ib_umem *umem;struct page **page_list;unsigned long dma_attr = 0;struct mm_struct *mm;unsigned long npages;int ret;struct scatterlist *sg = NULL;unsigned int gup_flags = FOLL_WRITE;unsigned long dma_attrs = 0;...umem = kzalloc(sizeof(*umem), GFP_KERNEL);if (!umem)return ERR_PTR(-ENOMEM);umem->context = context;umem->length = size;umem->address = addr;...
}
然后分配page_list,page_list用于保存接下来通过get_user_pages返回的物理页,ib_umem_num_pages计算得到npages,表示这段内存一共占用了多少个物理页。然后创建sg_table,用于保存离散的物理页集合,sg被赋值为sg_table的scatterlist sgl。
{page_list = (struct page **) __get_free_page(GFP_KERNEL);if (!page_list) {ret = -ENOMEM;goto umem_kfree;}npages = ib_umem_num_pages(umem);...cur_base = addr & PAGE_MASK;ret = sg_alloc_table(&umem->sg_head, npages, GFP_KERNEL);sg = umem->sg_head.sgl;...
}
接下来开始通过get_user_pages获取入参addr这个虚拟地址对应的物理页集合,get_user_pages通过每个页的虚拟地址找vma,找到之后通过follow_page_mask获取对应的物理页,如果没有分配物理页就分配,并且pin住保证不会交换,因为page_list大小为一个物理页,所以这里一次性最多传进去的page数为PAGE_SIZE / sizeof (struct page *)。
{while (npages) {cond_resched();down_read(&mm->mmap_sem);ret = get_user_pages_longterm(cur_base,min_t(unsigned long, npages,PAGE_SIZE / sizeof (struct page *)),gup_flags, page_list, NULL);if (ret < 0) {pr_debug("%s: failed to get user pages, nr_pages=%lu, flags=%u\n", __func__,min_t(unsigned long, npages,PAGE_SIZE / sizeof(struct page *)),gup_flags);up_read(&mm->mmap_sem);goto umem_release;}cur_base += ret * PAGE_SIZE;npages -= ret;sg = ib_umem_add_sg_table(sg, page_list, ret,dma_get_max_seg_size(context->device->dma_device),&umem->sg_nents);up_read(&mm->mmap_sem);}}
然后开始将返回的ret个物理页通过ib_umem_add_sg_table加入到sg_table中,因为第一次调用的时候sg里还没有保存page,所以可以通过sg_page判断是否是第一次调用。对于非第一次的调用这里会尝试合并本次操作的page到当前的sg里,通过page_to_pfn(sg_page(sg))可以拿到当前sg里物理页的pfn,然后加上sg的物理页数就得到了sg保存的连续物理页后的第一个物理页的pfn,如果和page_list[0]的pfn相等,说明是连续的,可以合并,通过设置update_cur_sg表示可以将page_list合并到当前sg。
static struct scatterlist *ib_umem_add_sg_table(struct scatterlist *sg,struct page **page_list,unsigned long npages,unsigned int max_seg_sz,int *nents)
{unsigned long first_pfn;unsigned long i = 0;bool update_cur_sg = false;bool first = !sg_page(sg);if (!first && (page_to_pfn(sg_page(sg)) + (sg->length >> PAGE_SHIFT) ==page_to_pfn(page_list[0])))update_cur_sg = true;...
}
然后开始循环添加page_list的页面到sg_table,拿到这次循环要处理的第一个page即first_page和他的pfn即first_pfn,然后从i往后看接下来有多少个物理页是连续的,len表示连续的page数量,如果可以合并到当前sg,那么直接更新sg的长度信息,然后continue。如果不能合并且不是第一次执行,那么就需要通过sg_next切换到下一个sg并更新,最后返回当前处理的sg。
static struct scatterlist *ib_umem_add_sg_table(struct scatterlist *sg,struct page **page_list,unsigned long npages,unsigned int max_seg_sz,int *nents)
{while (i != npages) {unsigned long len;struct page *first_page = page_list[i];first_pfn = page_to_pfn(first_page); */for (len = 0; i != npages &&first_pfn + len == page_to_pfn(page_list[i]) &&len < (max_seg_sz >> PAGE_SHIFT);len++)i++;/* Squash N contiguous pages from page_list into current sge */if (update_cur_sg) {if ((max_seg_sz - sg->length) >= (len << PAGE_SHIFT)) {sg_set_page(sg, sg_page(sg),sg->length + (len << PAGE_SHIFT),0);update_cur_sg = false;continue;}update_cur_sg = false;}/* Squash N contiguous pages into next sge or first sge */if (!first)sg = sg_next(sg);(*nents)++;sg_set_page(sg, first_page, len << PAGE_SHIFT, 0);first = false;}return sg;
}
最后通过sg_mark_end标记当前sg为最后一个sg,如果access属性有IB_ACCESS_RELAXED_ORDERING,那么dma_attr需要设置上DMA_ATTR_WEAK_ORDERING,表示读写可以乱序。最后通过ib_dma_map_sg_attrs将sg_table的物理页执行dma映射,实际用的就是dma_map_sg_attrs。
struct ib_umem *__ib_umem_get(struct ib_udata *udata,unsigned long addr, size_t size, int access,unsigned long peer_mem_flags)
{...sg_mark_end(sg);if (access & IB_ACCESS_RELAXED_ORDERING)dma_attr |= DMA_ATTR_WEAK_ORDERING;umem->nmap = ib_dma_map_sg_attrs(context->device,umem->sg_head.sgl,umem->sg_nents,DMA_BIDIRECTIONAL, dma_attrs); ...
}
这里就完成了对cq buf的dma映射,回到create_cq_user的逻辑:
page_size = mlx5_umem_find_best_cq_quantized_pgoff(cq->buf.umem, cqc, log_page_size, MLX5_ADAPTER_PAGE_SHIFT,page_offset, 64, &page_offset_quantized);if (!page_size) {err = -EINVAL;goto err_umem;} err = mlx5_ib_db_map_user(context, udata, ucmd.db_addr, &cq->db);if (err)goto err_umem;ncont = ib_umem_num_dma_blocks(cq->buf.umem, page_size);网卡支持多种大小的页大小,mlx5_umem_find_best_cq_quantized_pgoff就是计算出最合适的页大小,返回给pag_size,page_offset_quantized为buffer首地址相对于页的偏移,假设这里返回的还是4K,ib_umem_num_dma_blocks计算cq buff一共占用了多少个物理页。
然后执行mlx5_ib_db_map_user完成对dbr的dma映射。
int mlx5_ib_db_map_user(struct mlx5_ib_ucontext *context,struct ib_udata *udata, unsigned long virt,struct mlx5_db *db)
{ struct mlx5_ib_user_db_page *page;int err = 0;mutex_lock(&context->db_page_mutex);list_for_each_entry(page, &context->db_page_list, list)if ((current->mm == page->mm) &&(page->user_virt == (virt & PAGE_MASK)))goto found;page = kmalloc(sizeof(*page), GFP_KERNEL);if (!page) {err = -ENOMEM;goto out;}page->user_virt = (virt & PAGE_MASK);page->refcnt = 0;page->umem =ib_umem_get_peer(udata, virt & PAGE_MASK,PAGE_SIZE, 0, 0);if (IS_ERR(page->umem)) {err = PTR_ERR(page->umem);kfree(page);goto out;}mmgrab(current->mm);page->mm = current->mm;list_add(&page->list, &context->db_page_list);found:db->dma = sg_dma_address(page->umem->sg_head.sgl) + (virt & ~PAGE_MASK);db->u.user_page = page;++page->refcnt;out:mutex_unlock(&context->db_page_mutex);return err;
}用户态分配dbr的时候会一次性分配一个page以容纳多个dbr,因此这里核心逻辑就是判断当前dbr所在的页是否已经执行过dma映射,执行过dma映射的页会保存在db_page_list链表中,所以这里先遍历链表里所有的mlx5_ib_user_db_page,如果发现和当前要映射的page是同一个进程,并且虚拟地址相等,就说明已经映射过,那直接通过umem中的sg_table拿到首地址加上偏移就得到了dma地址;如果没有找到,说明是第一次映射,将ib_umem_get_peer完成映射,将信息保存到page的umem,然后将当前page加入到db_page_list。
cmd初始化
然后开始初始化mailbox机制中的输入,即mlx5_ifc_create_cq_in_bits,如下所示,其中cq context entry即cqc,pas为cq buff对应的物理页集合。
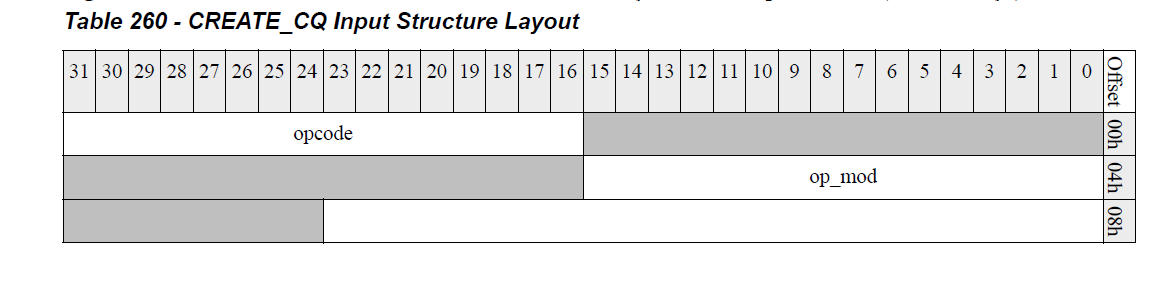

void mlx5_ib_populate_pas(struct ib_umem *umem, size_t page_size, __be64 *pas,u64 access_flags)
{struct ib_block_iter biter;rdma_umem_for_each_dma_block (umem, &biter, page_size) {*pas = cpu_to_be64(rdma_block_iter_dma_address(&biter) |access_flags);pas++;}
}
然后执行mlx5_ib_populate_pas,这里会将sg_table记录的物理内存即cq buff按照page_size大小记录到pas数组。
首先创建一个ib_block_iter,初始化设置__sg为scatterlist,__sg_nents 为nents,即sg_table里的成员个数。
#define rdma_umem_for_each_dma_block(umem, biter, pgsz) \for (__rdma_umem_block_iter_start(biter, umem, pgsz); \__rdma_block_iter_next(biter);)static inline void __rdma_umem_block_iter_start(struct ib_block_iter *biter,struct ib_umem *umem,unsigned long pgsz)
{__rdma_block_iter_start(biter, umem->sg_head.sgl, umem->nmap, pgsz);
}void __rdma_block_iter_start(struct ib_block_iter *biter,struct scatterlist *sglist, unsigned int nents,unsigned long pgsz)
{memset(biter, 0, sizeof(struct ib_block_iter));biter->__sg = sglist;biter->__sg_nents = nents;/* Driver provides best block size to use */biter->__pg_bit = __fls(pgsz);
}struct ib_block_iter {/* internal states */struct scatterlist *__sg; /* sg holding the current aligned block */dma_addr_t __dma_addr; /* unaligned DMA address of this block */unsigned int __sg_nents; /* number of SG entries */unsigned int __sg_advance; /* number of bytes to advance in sg in next step */unsigned int __pg_bit; /* alignment of current block */
};
然后通过__rdma_block_iter_next遍历sg_table,biter的dma_addr设置为当前scatterlist的dma地址,__sg_advance表示在当前entry中的偏移,第一次为0,所以biter第一次的__dma_addr就是第一个entry的dma地址,将dma地址记录到pas第一项,然后开始移动到下一个物理页,即将__sg_advance加上物理页大小,如果__sg_advance大于当前entry对应的物理内存长度,那么通过sg_next移动到scatterlist的下一个entry,直到遍历完成所有entry,就将所有物理页记录到了pas。
bool __rdma_block_iter_next(struct ib_block_iter *biter)
{unsigned int block_offset;if (!biter->__sg_nents || !biter->__sg)return false;biter->__dma_addr = sg_dma_address(biter->__sg) + biter->__sg_advance;block_offset = biter->__dma_addr & (BIT_ULL(biter->__pg_bit) - 1);biter->__sg_advance += BIT_ULL(biter->__pg_bit) - block_offset;if (biter->__sg_advance >= sg_dma_len(biter->__sg)) {biter->__sg_advance = 0;biter->__sg = sg_next(biter->__sg);biter->__sg_nents--;}return true;
}
static int create_cq_user(struct mlx5_ib_dev *dev, struct ib_udata *udata,struct mlx5_ib_cq *cq, int entries, u32 **cqb,int *cqe_size, int *index, int *inlen)
{...cqc = MLX5_ADDR_OF(create_cq_in, *cqb, cq_context);MLX5_SET(cqc, cqc, log_page_size,order_base_2(page_size) - MLX5_ADAPTER_PAGE_SHIFT);MLX5_SET(cqc, cqc, page_offset, page_offset_quantized);...
}
然后开始设置mlx5_ifc_create_cq_in_bits的cqc,cqc的格式如下所示,log_page_size表示以log表示的物理页大小;page_offset表示cq buff首地址相对物理页的偏移,对于cq这个值必须为0。
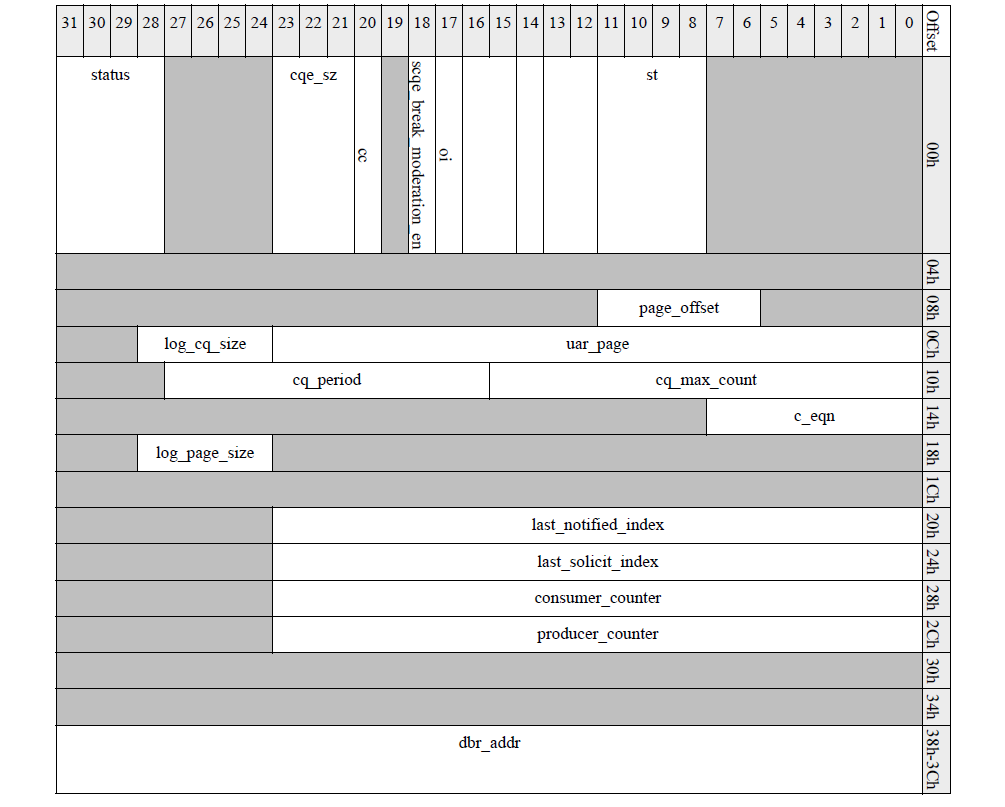
cmd执行
然后回到create_cq的逻辑
int mlx5_ib_create_cq(struct ib_cq *ibcq, const struct ib_cq_init_attr *attr,struct ib_udata *udata)
{...cqc = MLX5_ADDR_OF(create_cq_in, cqb, cq_context);MLX5_SET(cqc, cqc, cqe_sz,cqe_sz_to_mlx_sz(cqe_size,cq->private_flags &MLX5_IB_CQ_PR_FLAGS_CQE_128_PAD));MLX5_SET(cqc, cqc, log_cq_size, ilog2(entries));MLX5_SET(cqc, cqc, uar_page, index);MLX5_SET(cqc, cqc, c_eqn_or_apu_element, eqn);MLX5_SET64(cqc, cqc, dbr_addr, cq->db.dma);if (cq->create_flags & IB_UVERBS_CQ_FLAGS_IGNORE_OVERRUN)MLX5_SET(cqc, cqc, oi, 1);err = mlx5_core_create_cq(dev->mdev, &cq->mcq, cqb, inlen, out, sizeof(out));...
}
设置好cqc之后执行mlx5_core_create_cq,会执行到mlx5_create_cq
int mlx5_create_cq(struct mlx5_core_dev *dev, struct mlx5_core_cq *cq,u32 *in, int inlen, u32 *out, int outlen)
{int eqn = MLX5_GET(cqc, MLX5_ADDR_OF(create_cq_in, in, cq_context),c_eqn_or_apu_element);u32 din[MLX5_ST_SZ_DW(destroy_cq_in)] = {};struct mlx5_eq_comp *eq;int err;eq = mlx5_eqn2comp_eq(dev, eqn);if (IS_ERR(eq))return PTR_ERR(eq);memset(out, 0, outlen);MLX5_SET(create_cq_in, in, opcode, MLX5_CMD_OP_CREATE_CQ);err = mlx5_cmd_do(dev, in, inlen, out, outlen);if (err)return err;cq->cqn = MLX5_GET(create_cq_out, out, cqn);cq->cons_index = 0;cq->arm_sn = 0;cq->eq = eq; cq->uid = MLX5_GET(create_cq_in, in, uid);refcount_set(&cq->refcount, 1); init_completion(&cq->free);...
}
就是执行mlx5_cmd_do,通过第二章介绍的mailbox机制将cmd下发给硬件执行,执行完成后将结果通过out返回,得到cqn记录到cq,到这里cq的创建就完成了。
相关文章:
- cq的创建)
RDMA驱动学习(三)- cq的创建
用户通过ibv_create_cq接口创建完成队列,函数原型和常见用法如下,本节以该用法为例看下cq的创建过程。 struct ibv_cq *ibv_create_cq(struct ibv_context *context, int cqe,void *cq_context,struct ibv_comp_channel *channel,int comp_vector); cq …...

Python-使用类和实例-Sun-Mon
9.2.1 Car类 class Car():"""概述车辆信息"""def __init__(self,make,model,year):"""初始化参数"""self.makemakeself.modelmodelself.yearyear //__init__方法会把依据Car类创建的实例传入的实参的值ÿ…...

【MIT-OS6.S081笔记0.5】xv6 gdb调试环境搭建
补充一下xv6 gdb调试环境的搭建,我这里装的是最新的15.2的gdb的版本。我下载的是下面的第二个xz后缀的文件: 配置最详细的步骤可以参考下面的文章: [MIT 6.S081] Lab 0: 实验配置, 调试及测试 这里记录一下踩过的一些报错: 文…...

vmware虚拟机移植
最近发现虚拟机的系统非常适合移植,接下来看一下具体的过程 复制vmdk 第一个重要的文件是保存vmdk,如果磁盘使用的是多个文件则最好进行合并一下(用着用着会发现vmdk文件特别大,这是正常的,不要想着能压缩了…...

最大子数组和
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组 是数组中的一个连续部分。 示例 1: 输入:nums [-2,1,-3,4,-1,2,1,-5,4] 输出ÿ…...

活着就好20241202
亲爱的朋友们,大家早上好!今天是2024年12月2日,第49周的第一天,也是十二月的第二天,农历甲辰[龙]年十月三十。在这个全新月份的开始、阳光初升的清晨,愿第一缕阳光悄悄探进你的房间,带给你满满的…...
)
Scala的练习题(成绩计算)
//1.迭代器,跳过第一个元素 //2.把字符串转成数字 //3.如何判断一个正整数是否可以被三整除? (123) % 3 0 import wyyyy.Studentimport scala.collection.mutable.ListBuffer import scala.io.Sourcecase class Student(name: St…...

Docker中配置Mysql主从备份
Mysql配置主从备份 一、Docker中实现跨服务器主从备份二、配置步骤1.配置主库2.配置从库3.遇到问题3.其它使用到的命令 一、Docker中实现跨服务器主从备份 在 Docker 中配置 MySQL 主从备份主要通过 MySQL 主从复制实现 二、配置步骤 1.配置主库 # 进入mysql主库容器 docke…...
)
分布式通用计算——MapReduce(重点在shuffle 阶段)
图片均来源于B站:哈喽鹏程 面向批处理的分布式计算框架——MapReduce 1、Mapreduce 起源2、适用场景3、MapReduce 词频统计原理 1、Mapreduce 起源 2、适用场景 3、MapReduce 词频统计原理 map 阶段到reduce阶段,通过hash取模来实现reduce 。比如&…...
模式说明)
VMware三种网络模式(桥接、NAT模式、仅主机)模式说明
VMware三种网络模式(桥接、NAT模式、仅主机)模式说明 VMware 提供了三种主要的网络连接模式:桥接模式(Bridged Mode)、NAT模式(Network Address Translation Mode)和仅主机模式(Hos…...

实习冲刺第三十八天
236.二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大࿰…...
详解(一))
[Linux] 信号(singal)详解(一)
标题:[Linux] 信号(singal)详解 水墨不写bug (图片来源于网络) 目录 一、认识信号 1、认识信号 2、信号特点 3、基本概念 二、信号的产生(5种方式) 三、信号的保存 正文开始: 一、认识信号 1、认识信…...
)
【设计模式系列】备忘录模式(十九)
目录 一、什么是备忘录模式 二、备忘录模式的角色 三、备忘录模式的典型应用场景 四、备忘录模式在Calendar中的应用 一、什么是备忘录模式 备忘录模式(Memento Pattern)是一种行为型设计模式,它允许在不暴露对象内部状态的情况下保存和恢…...

书生大模型实战营第4期——3.3 LMDeploy 量化部署实践
文章目录 1 基础任务2 配置LMDeploy环境2.1 环境搭建2.2 模型配置2.3 LMDeploy验证启动模型文件 3 LMDeploy与InternLM2.53.1 LMDeploy API部署InternLM2.53.1.1 启动API服务器3.1.2 以命令行形式连接API服务器3.1.3 以Gradio网页形式连接API服务器 3.2 LMDeploy Lite3.2.1 设置…...

11.28深度学习_bp算法
七、BP算法 多层神经网络的学习能力比单层网络强得多。想要训练多层网络,需要更强大的学习算法。误差反向传播算法(Back Propagation)是其中最杰出的代表,它是目前最成功的神经网络学习算法。现实任务使用神经网络时,…...

U盘文件夹变打不开的文件:深度解析、恢复策略与预防之道
一、U盘文件夹变打不开的文件现象解析 在日常使用U盘的过程中,我们时常会遇到这样的困扰:原本存储有序、可以轻松访问的文件夹,突然之间变成了无法打开的文件。这些文件通常以未知图标或乱码形式显示,双击或右键尝试打开时&#…...

软件工程中的需求分析流程详解
一、需求分析的定义 需求分析(Requirements Analysis)是指在软件开发过程中,通过与用户、相关人员的沟通与讨论,全面理解和确定软件需求的过程。需求分析的最终目标是清晰、准确地定义软件系统应具备的功能、性能、用户界面、约束…...
_kaic)
springboot369高校教师教研信息填报系统(论文+源码)_kaic
毕 业 设 计(论 文) 题目:高校教师教研信息填报系统的设计与实现 摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,…...

Docker Buildx 与 CNB 多平台构建实践
一、Docker Buildx 功能介绍 docker buildx 是 Docker 提供的一个增强版构建工具,支持更强大的构建功能,特别是在构建多平台镜像和高效处理复杂 Docker 镜像方面。 1.1 主要功能 多平台构建支持 使用 docker buildx,可以在单台设备上构建…...

VBA字典与数组第二十一讲:文本转换为数组函数Split
《VBA数组与字典方案》教程(10144533)是我推出的第三套教程,目前已经是第二版修订了。这套教程定位于中级,字典是VBA的精华,我要求学员必学。7.1.3.9教程和手册掌握后,可以解决大多数工作中遇到的实际问题。…...
)
开源项目 - 人脸关键点检测 facial landmark 人脸关键点 (98个关键点)
开源项目 - 人脸关键点检测 facial landmark 人脸关键点 (98个关键点) 示例: 助力快速掌握数据集的信息和使用方式。 数据可以如此美好!...

【Postgres_Python】使用python脚本批量导出PG数据库
示例代码说明: 有多个数据库需要导出为.sql格式,数据库名与sql文件名一致,读取的数据库名需要根据文件名进行拼接 import psycopg2 import subprocess import os folder_path D:/HQ/chongqing_20241112 # 获取文件夹下所有文件和文件夹的名称 filename…...
无窗口系统下搭建 OpenGL ES + Qt 开发环境,并绘制旋转金字塔)
嵌入式Linux(SOC带GPU树莓派)无窗口系统下搭建 OpenGL ES + Qt 开发环境,并绘制旋转金字塔
树莓派无窗口系统下搭建 OpenGL ES Qt 开发环境,并绘制旋转金字塔 1. 安装 OpenGL ES 开发环境 运行以下命令安装所需的 OpenGL ES 开发工具和库: sudo apt install cmake mesa-utils libegl1-mesa-dev libgles2-mesa-dev libdrm-dev libgbm-dev2. 安…...

MySQL事物
目录 何谓事物? 何谓数据库事务? 并发事务带来了哪些问题? 脏读(Dirty read) 丢失修改(Lostto modify) 不可重复读(Unrepeatable read) 幻读(Phantom read) 不可重复读和幻读有什么区别? 并发事务的控制方式有哪些? SQL 标准定义了哪些事务隔离级别?…...

在 CentOS 上安装 Docker:构建容器化环境全攻略
一、引言 在当今的软件开发与运维领域,Docker 无疑是一颗璀璨的明星。它以轻量级虚拟化的卓越特性,为应用程序的打包、分发和管理开辟了崭新的高效便捷之路。无论是开发环境的快速搭建,还是生产环境的稳定部署,Docker 都展现出了…...

基于Spring Boot的宠物咖啡馆平台的设计与实现
私信我获取源码和万字论文,制作不易,感谢点赞支持。 基于Spring Boot的宠物咖啡馆平台的设计与实现 摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了基于Spring Boot的宠物咖啡馆平台的设…...

JAVAWeb之javascript学习
1.js引入方式 1. 内嵌式:在head中,通过一对script标签引入JS代码;cript代码放置位置有一定的随意性,一般放在head标签中;2.引入外部js文件 在head中,通过一对script标签引入外部JS代码;注意&…...
的TCP通讯(操作记录))
电脑与优傲协作机器人(实体)的TCP通讯(操作记录)
目录 一、UR通信端口 二、电脑(客户端)连接协作机器人(服务端) 1.设置网络方法 2.检查设置 3.示教器切换远程控制(注) 4.客户端与协作机器人建立连接 5.连接测试 三、电脑(服务端&#…...

C++初阶——动态内存管理
目录 1、C/C内存区域划分 2、C动态内存管理:malloc/calloc/realloc/free 3、C动态内存管理:new/delete 3.1 new/delete内置类型 3.2 new/delete自定义类型 4、operator new与operator delete函数 5、new和delete的实现原理 5.1 内置类型 5.2 自定…...
)
Python 【图像分类】之 PyTorch 进行猫狗分类功能的实现(Swanlab训练可视化/ Gradio 实现猫狗分类 Demo)
Python 【图像分类】之 PyTorch 进行猫狗分类功能的实现(Swanlab训练可视化/ Gradio 实现猫狗分类 Demo) 目录 Python 【图像分类】之 PyTorch 进行猫狗分类功能的实现(Swanlab训练可视化/ Gradio 实现猫狗分类 Demo) 一、简单介绍 二、PyTorch 三、CNN 1、神经网络 2、卷…...

Attention显存统计与分析
Attention显存估计 简单的Attention函数 import torch import torch.nn as nn import einops class Attention(nn.Module):def __init__(self, dim, num_heads8, qkv_biasFalse, qk_scaleNone, attn_drop0., proj_drop0.):super().__init__()self.num_heads num_headshead_d…...

java反射
反射 Java 反射是 Java 提供的一种强大特性,它允许程序在运行时动态地获取类的信息,并操作类的属性和方法。这为编写灵活、可扩展的 Java 应用程序提供了强有力的支持 获取Class对象 package ref;public class Person {private String name ;private …...

Spring Boot入门
1、Spring Boot是什么 Spring Boot 帮我们简单、快速地创建一个独立的、生产级别的 Spring 应用(说明:Spring Boot底层是Spring) 大多数 Spring Boot 应用只需要编写少量配置即可快速整合 Spring 平台以及第三方技术 特性: 快速…...

Spring Web:深度解析与实战应用
概述 大家好,欢迎来到今天的技术分享。我是你们的老朋友,今天,我们要深入探讨的是Spring Web模块,这个模块为Java Web应用程序提供了全面的支持,不仅具备基本的面向Web的综合特性,还能与常见框架如Struts2无…...

学习日志019--初识PyQt
使用pyqt创建一个登录界面 from PyQt6.QtCore import Qt # 引入pyqt6包 from PyQt6.QtGui import QIcon, QMovie from PyQt6.QtWidgets import QApplication, QWidget, QPushButton, QLabel, QLineEdit import sysclass MyWidget(QWidget):# 构造函数,继承父类的构造…...
入门趣谈(五))
Swift 宏(Macro)入门趣谈(五)
概述 苹果在去年 WWDC 23 中就为 Swift 语言新增了“其利断金”的重要小伙伴 Swift 宏(Swift Macro)。为此,苹果特地用 2 段视频(入门和进阶)颇为隆重的介绍了它。 那么到底 Swift 宏是什么?有什么用&…...

Linux 35.6 + JetPack v5.1.4@DeepStream安装
Linux 35.6 JetPack v5.1.4DeepStream安装 1. 源由2. 步骤Step 1 安装Jetpack 5.1.4 L4T 35.6Step 2 安装依赖组件Step 3 安装librdkafkaStep 4 安装 DeepStream SDKStep 5 测试 deepstream-appStep 6 运行 deepstream-app 3. 总结3.1 版本问题3.2 二进制help 4. 参考资料 1. …...

C++基础:list的底层实现
文章目录 1.基本结构2.迭代器的实现2.1 尾插的实现2.2 迭代器的实现 3.打印函数(模版复用实例化)4.任意位置的插入删除1. 插入2. 删除 5.析构与拷贝构造5.1 析构函数5.2 拷贝构造5.3 赋值重载 1.基本结构 与vector和string不同list需要: 一个类来放入数据和指针也就是节点 一…...
Spring中@Transactional注解与事务传播机制
文章目录 事务传播机制事务失效的场景 事务传播机制 事务的传播特性指的是 当一个事务方法调用另一个事务方法时,事务方法应该如何执行。 事务传播行为类型外部不存在事务外部存在事务使用方式REQUIRED(默认)开启新的事务融合到外部事务中Transactional(propagati…...

实验七 用 MATLAB 设计 FIR 数字滤波器
实验目的 加深对窗函数法设计 FIR 数字滤波器的基本原理的理解。 学习用 Matlab 语言的窗函数法编写设计 FIR 数字滤波器的程序。 了解 Matlab 语言有关窗函数法设计 FIR 数字滤波器的常用函数用法。 掌握 FIR 滤波器的快速卷积实现原理。 不同滤波器的设计方法具有不同的优…...

Linux - selinux
七、selinux 1、说明 SELinux是Security-Enhanced Linux的缩写,意思是安全强化的linux。 SELinux是对程序、文件等权限设置依据的一个内核模块。由于启动网络服务的也是程序,因此刚好也 是能够控制网络服务能否访问系统资源的一道关卡。 传统的文件权…...

【STL】C++ vector类模板
文章目录 基本概念vector的使用定义和初始化构造函数赋值操作容量和大小插入和删除数据存取 互换容器vector的迭代器vector储存自定义数据类型 基本概念 vector是类型相同的对象的容器,vector的大小可以变化,可以向数组中增加元素。因此,vec…...
)
物联网——WatchDog(监听器)
看门狗简介 独立看门狗框图 看门狗原理:定时器溢出,产生系统复位信号;若定时‘喂狗’则不产生系统复位信号 定时中断基本结构(对比) IWDG键寄存器 独立看门狗超时时间 WWDG(窗口看门狗) WWDG特性 WWDG超时时间 由于…...

从零开始写游戏之斗地主-网络通信
在确定了数据结构后,原本是打算直接开始写斗地主的游戏运行逻辑的。但是突然想到我本地写出来之后,也测试不了啊,所以还是先写通信模块了。 基本框架 在Java语言中搞网络通信,那么就得请出Netty这个老演员了。 主要分为两个端&…...

【智能控制】实验,基于MATLAB的模糊推理系统设计,模糊控制系统设计
关注作者了解更多 我的其他CSDN专栏 过程控制系统 工程测试技术 虚拟仪器技术 可编程控制器 工业现场总线 数字图像处理 智能控制 传感器技术 嵌入式系统 复变函数与积分变换 单片机原理 线性代数 大学物理 热工与工程流体力学 数字信号处理 光电融合集成电路…...

Vega Editor 基于 Web 的图形编辑器
Vega Editor 是一个强大的基于 Web 的图形编辑器,专为 Vega 和 Vega-Lite 可视化语法设计。它提供了一个交互式的环境,用户可以在其中编写、预览和分享他们的 Vega 和 Vega-Lite 可视化作品。Vega 和 Vega-Lite 是用于声明性可视化的开源语法,…...

SQL 中SET @variable的使用
在 SQL 中,SET variable 用于声明和赋值用户定义的变量。具体来说, 符号用于表示一个局部变量,可以在 SQL 语句中存储和使用。它通常在存储过程、函数或简单的 SQL 查询中使用。 1. 声明并赋值给变量 你可以使用 SET 语句给一个变量赋值。例…...

基于 Vite 封装工具库实践
项目背景:公司在多个项目中频繁使用相同的工具函数。为了避免每次开发新项目时都重复复制代码,决定通过 Vite 封装一个时间函数组件库。该库将被发布到 Verdaccio 供团队其他项目使用。 项目介绍 本项目封装了一个时间函数工具库,使用 Momen…...
)
Oracle DataGuard 主备正常切换 (Switchover)
前言 众所周知,DataGuard 的切换分为两种情况: 系统正常情况下的切换:这种方式称为 switchover,是无损切换,不会丢失数据。灾难情况下的切换:这种情况下一般主库已经启动不起来了,称为 failov…...

[Redis#13] cpp-redis接口 | set | hash |zset
目录 Set 1. Sadd 和 Smembers 2. Sismember 3. Scard 4. Spop 5. Sinter 6. Sinter store Hash 1. Hset 和 Hget 2. Hexists 3. Hdel 4. Hkeys 和 Hvals 5. Hmget 和 Hmset Zset 1. Zadd 和 Zrange 2. Zcard 3. Zrem 4. Zscore cpp-redis 的学习 主要关注于…...