书生大模型实战营第4期——3.3 LMDeploy 量化部署实践
文章目录
- 1 基础任务
- 2 配置LMDeploy环境
- 2.1 环境搭建
- 2.2 模型配置
- 2.3 LMDeploy验证启动模型文件
- 3 LMDeploy与InternLM2.5
- 3.1 LMDeploy API部署InternLM2.5
- 3.1.1 启动API服务器
- 3.1.2 以命令行形式连接API服务器
- 3.1.3 以Gradio网页形式连接API服务器
- 3.2 LMDeploy Lite
- 3.2.1 设置最大kv cache缓存大小
- 3.2.2 设置在线 kv cache int4/int8 量化
- 3.2.3 W4A16 模型量化和部署
- 3.2.4 W4A16 量化+ KV cache+KV cache 量化
- 4 LMDeploy与InternVL2
- 4.1 LMDeploy Lite
- 4.1.1 W4A16 模型量化和部署
- 4.1.2 W4A16 量化+ KV cache+KV cache 量化
- 4.2 LMDeploy API部署InternVL2
- 5 LMDeploy之FastAPI与Function call
- 5.1 API开发
- 5.2 Function call
1 基础任务
- 使用结合W4A16量化与kv cache量化的internlm2_5-1_8b-chat模型封装本地API并与大模型进行一次对话。
- 使用Function call功能让大模型完成一次简单的"加"与"乘"函数调用
2 配置LMDeploy环境
2.1 环境搭建
新建或选择Cuda12.2-conda镜像A100*30%或50%开发机。
创建一个名为lmdeploy的conda环境,python版本为3.10,创建成功后激活环境并安装0.5.3版本的lmdeploy及相关包。
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
pip install timm==1.0.8 openai==1.40.3 lmdeploy[all]==0.5.3pip install datasets==2.19.22.2 模型配置
为方便文件管理,我们需要一个存放模型的目录,本教程统一放置在/root/models/目录。
运行以下命令,创建文件夹并设置开发机共享目录的软链接。
mkdir /root/models
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2_5-7b-chat /root/models
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2_5-1_8b-chat /root/models
ln -s /root/share/new_models/OpenGVLab/InternVL2-26B /root/models此时,我们可以看到/root/models中会出现internlm2_5-7b-chat、internlm2_5-1_8b-chat和InternVL2-26B文件夹。
教程使用internlm2_5-7b-chat和InternVL2-26B作为演示。由于上述模型量化会消耗大量时间(约8h),量化作业请使用internlm2_5-1_8b-chat模型完成。
2.3 LMDeploy验证启动模型文件
在量化工作正式开始前,我们还需要验证一下获取的模型文件能否正常工作,以免竹篮打水一场空。
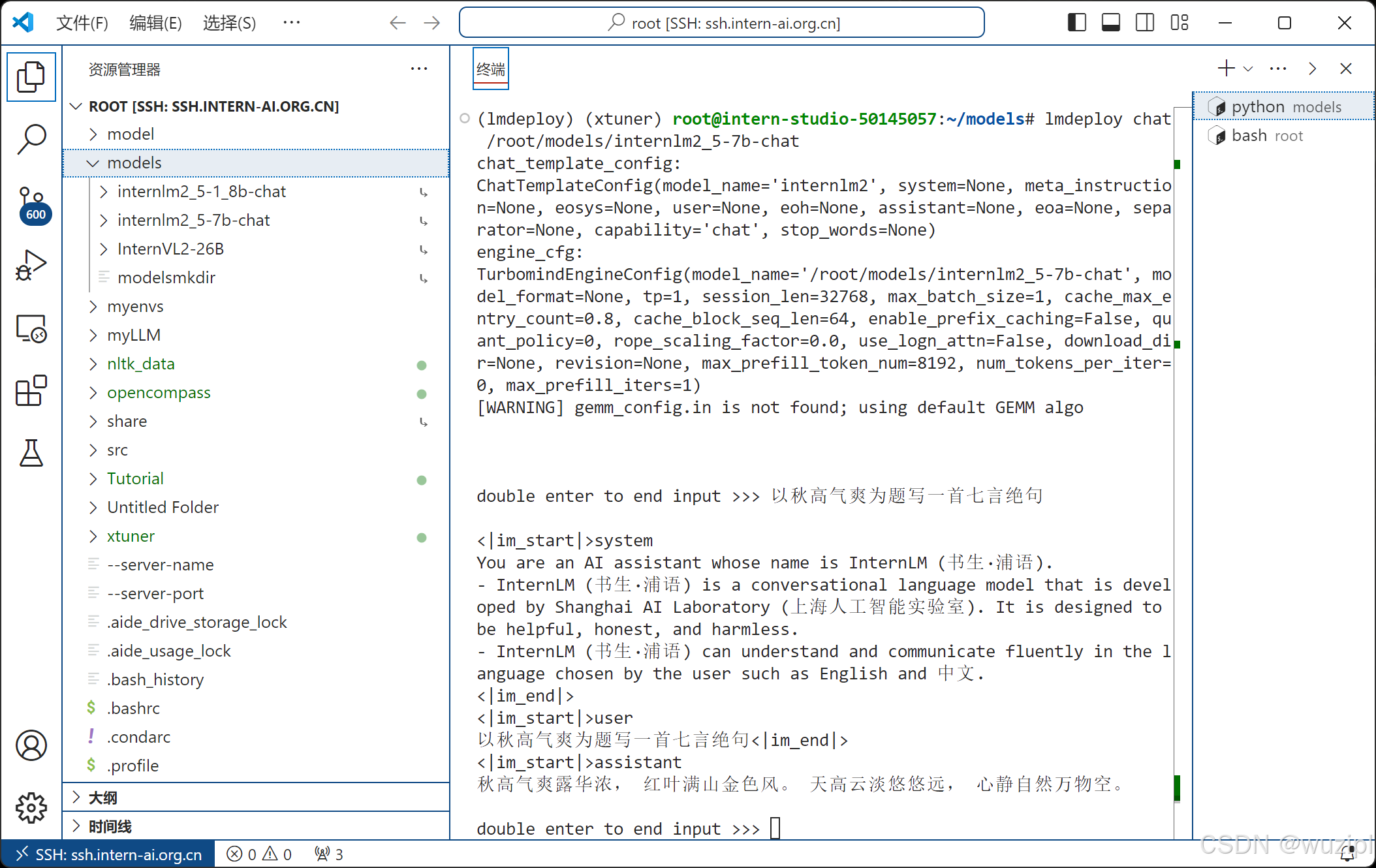
让我们进入创建好的conda环境并启动InternLM2_5-7b-chat!
conda activate lmdeploy
lmdeploy chat /root/models/internlm2_5-7b-chat稍待片刻,启动成功,此时,我们可以在CLI(“命令行界面” Command Line Interface的缩写)中和InternLM2.5尽情对话了,注意输入内容完成后需要按两次回车才能够执行,以下为示例。
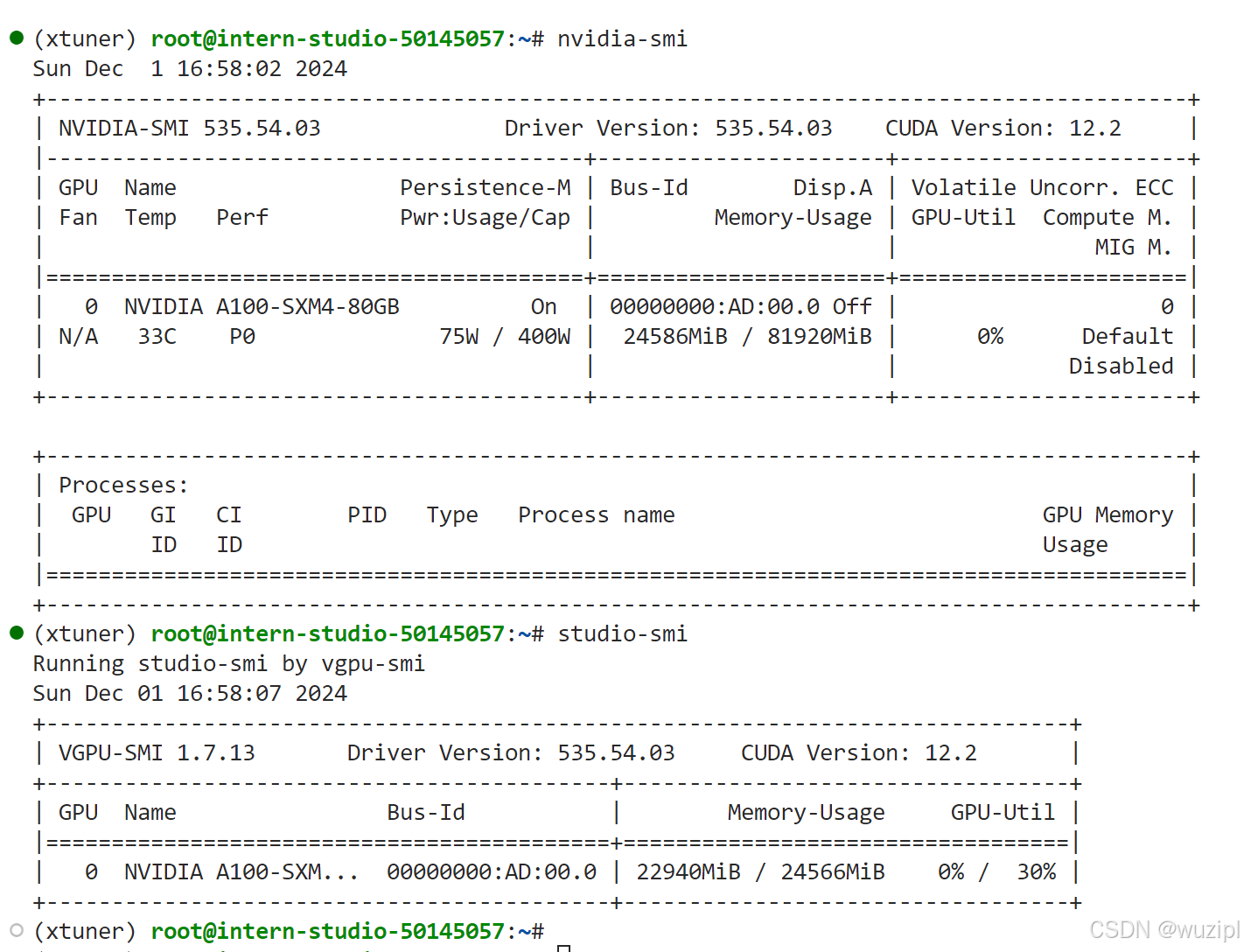
如果想要实现显存资源的监控,我们也可以新开一个终端输入如下两条指令的任意一条,查看命令输入时的显存占用情况。
nvidia-smi
studio-smi 注释:实验室提供的环境为虚拟化的显存,nvidia-smi是NVIDIA GPU驱动程序的一部分,用于显示NVIDIA GPU的当前状态,故当前环境只能看80GB单卡 A100 显存使用情况,无法观测虚拟化后30%或50%A100等的显存情况。针对于此,实验室提供了studio-smi 命令工具,能够观测到虚拟化后的显存使用情况。
如果是在开发机上,可以直接查看右上角指标仪表板:

3 LMDeploy与InternLM2.5
3.1 LMDeploy API部署InternLM2.5
以上我们直接在本地部署InternLM2.5。而在实际应用中,我们有时会将大模型封装为API接口服务,供客户端访问。
3.1.1 启动API服务器
首先让我们进入创建好的conda环境,并通下命令启动API服务器,部署InternLM2.5模型:
conda activate lmdeploy
lmdeploy serve api_server \/root/models/internlm2_5-7b-chat \--model-format hf \--quant-policy 0 \--server-name 0.0.0.0 \--server-port 23333 \--tp 1命令解释:
- lmdeploy serve api_server:这个命令用于启动API服务器。
- /root/models/internlm2_5-7b-chat:这是模型的路径。
- –model-format hf:这个参数指定了模型的格式。hf代表“Hugging Face”格式。
- –quant-policy 0:这个参数指定了量化策略。
- –server-name 0.0.0.0:这个参数指定了服务器的名称。在这里,0.0.0.0是一个特殊的IP地址,它表示所有网络接口。
- –server-port 23333:这个参数指定了服务器的端口号。在这里,23333是服务器将监听的端口号。
- –tp 1:这个参数表示并行数量(GPU数量)。
稍待片刻,终端显示如下。

如果使用的VSCode,可以直接点击http://0.0.0.0:23333打开页面。
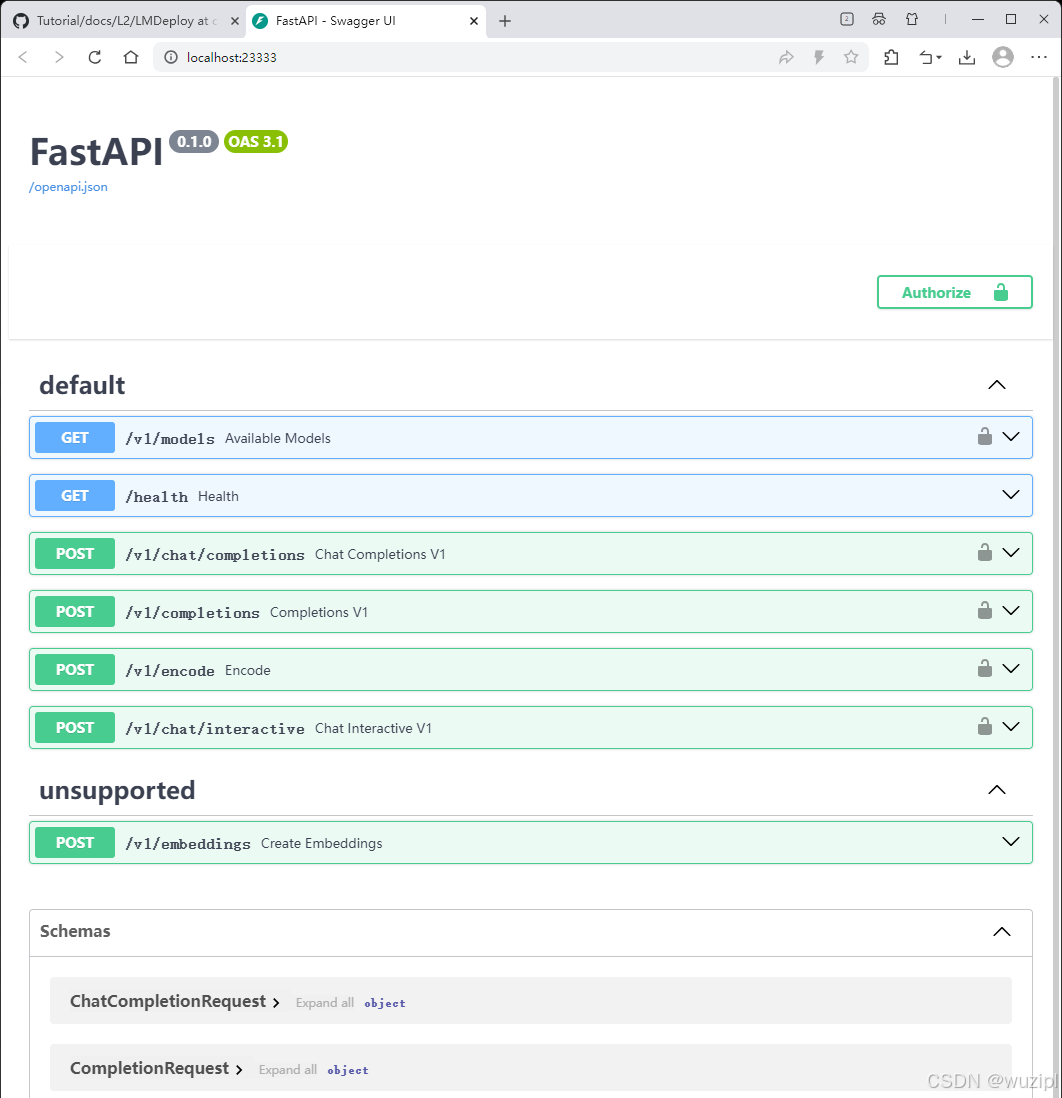
如果是在开发机上运行命令的,本地需要做一下ssh转发才能直接访问。
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 你的ssh端口号然后打开浏览器,访问http://127.0.0.1:23333看到上图界面即代表部署成功。
3.1.2 以命令行形式连接API服务器
关闭http://127.0.0.1:23333网页,但保持终端和本地窗口不动,按箭头操作新建一个终端。
运行如下命令,激活conda环境并启动命令行客户端。
conda activate lmdeploy
lmdeploy serve api_client http://localhost:23333稍待片刻,等出现double enter to end input >>>的输入提示即启动成功,此时便可以随意与InternLM2.5对话,同样是两下回车确定,输入exit退出。

3.1.3 以Gradio网页形式连接API服务器
保持第一个终端不动,在新建终端中输入exit退出。
输入以下命令,使用Gradio作为前端,启动网页。
lmdeploy serve gradio http://localhost:23333 \--server-name 0.0.0.0 \--server-port 6006稍待片刻,如果是在VSCode中运行的,将跳出模型交互页面。
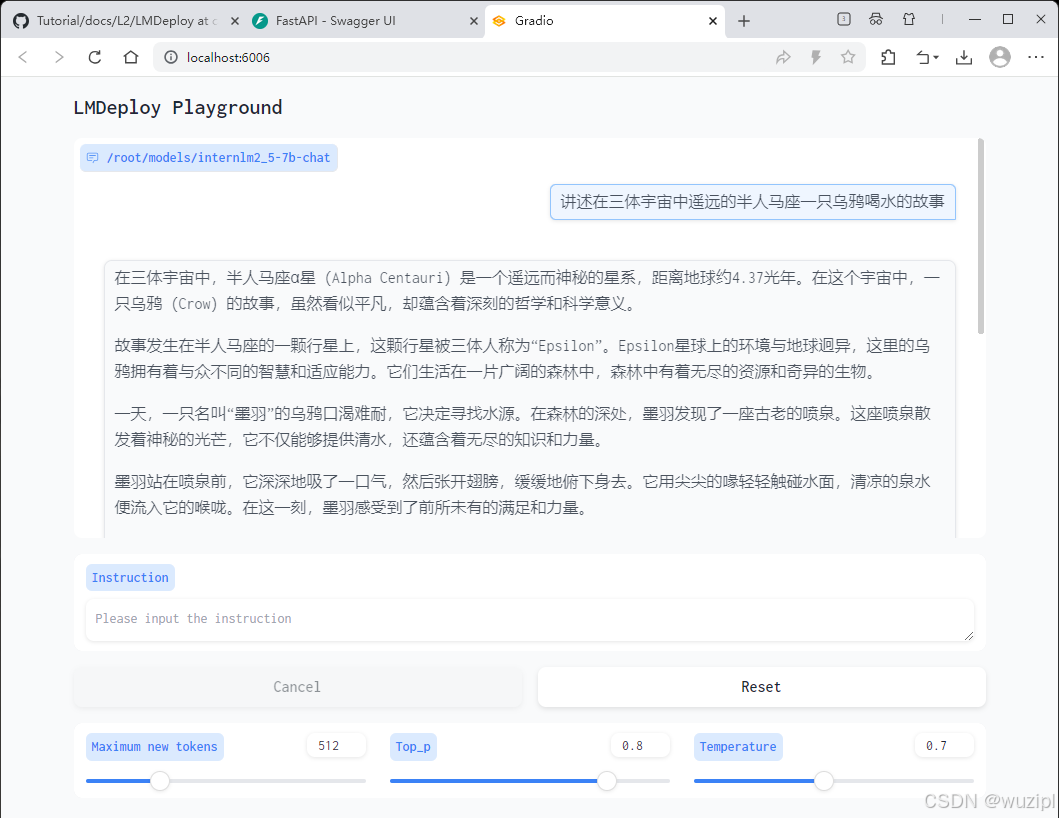
如果是在远程开发机上运行的,本次需要重新ssh转发。
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p <你的ssh端口号>打开浏览器,访问地址http://127.0.0.1:6006,然后就可以与模型尽情对话了。
3.2 LMDeploy Lite
随着模型变得越来越大,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。LMDeploy 提供了权重量化和 k/v cache两种策略。
3.2.1 设置最大kv cache缓存大小
kv cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,kv cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,kv cache全部存储于显存,以加快访存速度。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、kv cache占用的显存,以及中间运算结果占用的显存。LMDeploy的kv cache管理器可以通过设置–cache-max-entry-count参数,控制kv缓存占用剩余显存的最大比例。默认的比例为0.8。
首先我们先来回顾一下InternLM2.5正常运行时占用显存。

占用了36GB,那么试一试执行以下命令,再来观看占用显存情况。
lmdeploy chat /root/models/internlm2_5-7b-chat --cache-max-entry-count 0.4稍待片刻,观测显存占用情况,可以看到减少了约10GB的显存。

3.2.2 设置在线 kv cache int4/int8 量化
自 v0.4.0 起,LMDeploy 支持在线 kv cache int4/int8 量化,量化方式为 per-head per-token 的非对称量化。此外,通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 和cache-max-entry-count参数。目前,LMDeploy 规定 quant_policy=4 表示 kv int4 量化,quant_policy=8 表示 kv int8 量化。
我们通过2.1 LMDeploy API部署InternLM2.5的实践为例,输入以下指令,启动API服务器。
lmdeploy serve api_server \/root/models/internlm2_5-7b-chat \--model-format hf \--quant-policy 4 \--cache-max-entry-count 0.4\--server-name 0.0.0.0 \--server-port 23333 \--tp 1稍待片刻,显示如下即代表服务启动成功。
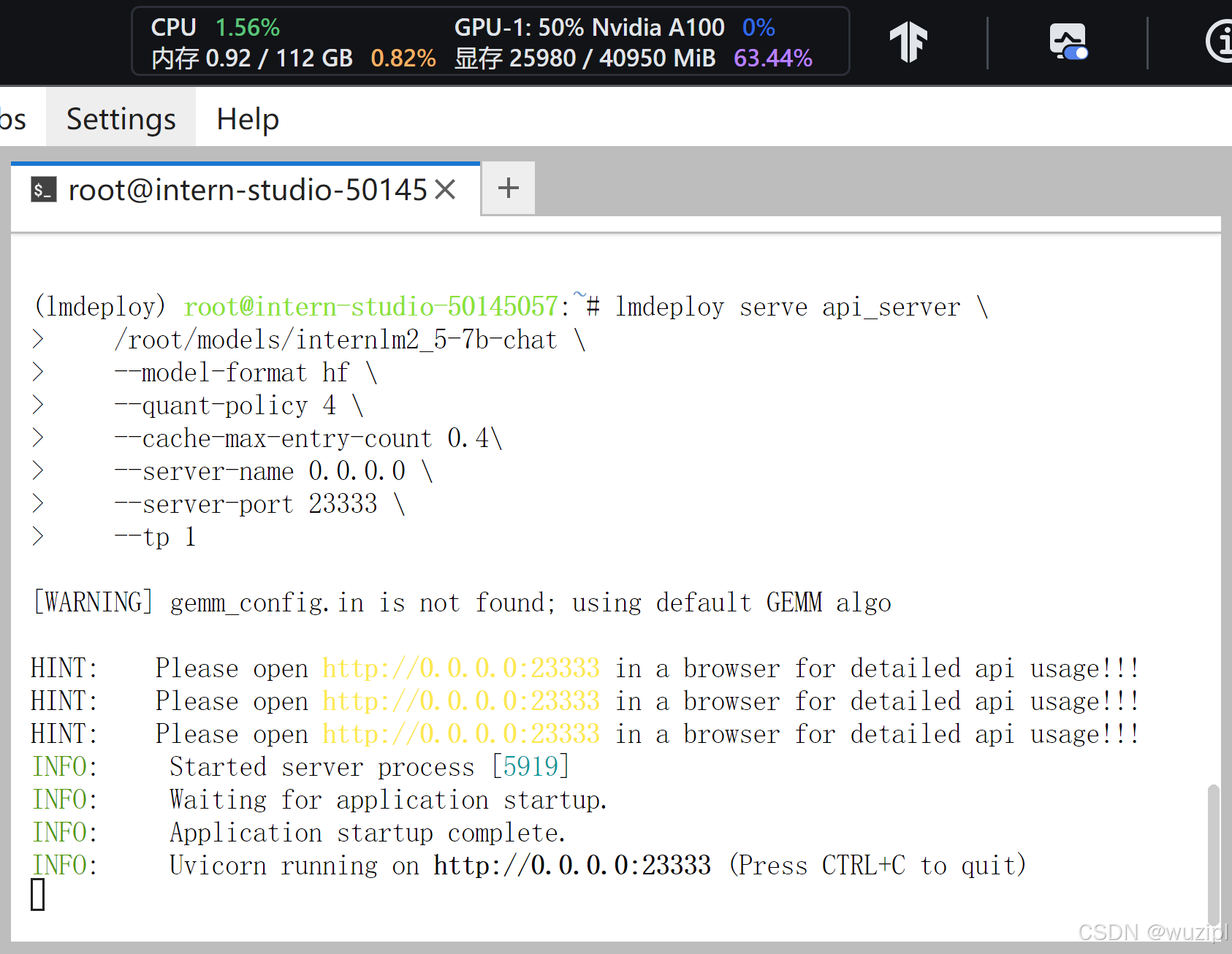
想要和此时的模型对话的话可以回顾3.1.2 以命令行形式连接API服务器或者3.1.3 以Gradio网页形式连接API服务器的内容自行对话,步骤完全一致,本章主要观测显存状态。
可以看到此时显存占用约19GB,相较于2.3 LMDeploy验证启动模型文件直接启动模型的显存占用情况(23GB)减少了4GB的占用。此时4GB显存的减少逻辑与2.2.1 设置最大kv cache缓存大小中4GB显存的减少一致,均因设置kv cache占用参数cache-max-entry-count至0.4而减少了4GB显存占用。
那么本节中19GB的显存占用与2.2.1 设置最大kv cache缓存大小中19GB的显存占用区别何在呢?
由于都使用BF16精度下的internlm2.5 7B模型,故剩余显存均为10GB,且 cache-max-entry-count 均为0.4,这意味着LMDeploy将分配40%的剩余显存用于kv cache,即10GB*0.4=4GB。但quant-policy 设置为4时,意味着使用int4精度进行量化。因此,LMDeploy将会使用int4精度提前开辟4GB的kv cache。
相比使用BF16精度的kv cache,int4的Cache可以在相同4GB的显存下只需要4位来存储一个数值,而BF16需要16位。这意味着int4的Cache可以存储的元素数量是BF16的四倍。
3.2.3 W4A16 模型量化和部署
准确说,模型量化是一种优化技术,旨在减少机器学习模型的大小并提高其推理速度。量化通过将模型的权重和激活从高精度(如16位浮点数)转换为低精度(如8位整数、4位整数、甚至二值网络)来实现。
那么标题中的W4A16又是什么意思呢?
- W4:这通常表示权重量化为4位整数(int4)。这意味着模型中的权重参数将从它们原始的浮点表示(例如FP32、BF16或FP16,Internlm2.5精度为BF16)转换为4位的整数表示。这样做可以显著减少模型的大小。
- A16:这表示激活(或输入/输出)仍然保持在16位浮点数(例如FP16或BF16)。激活是在神经网络中传播的数据,通常在每层运算之后产生。
因此,W4A16的量化配置意味着:
- 权重被量化为4位整数。
- 激活保持为16位浮点数。
让我们回到LMDeploy,在最新的版本中,LMDeploy使用的是AWQ算法,能够实现模型的4bit权重量化。输入以下指令,执行量化工作。(不建议运行,在InternStudio上运行需要8小时)
lmdeploy lite auto_awq \/root/models/internlm2_5-7b-chat \--calib-dataset 'ptb' \--calib-samples 128 \--calib-seqlen 2048 \--w-bits 4 \--w-group-size 128 \--batch-size 1 \--search-scale False \--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit完成作业时请使用1.8B模型进行量化:(建议运行以下命令)
lmdeploy lite auto_awq \/root/models/internlm2_5-1_8b-chat \--calib-dataset 'ptb' \--calib-samples 128 \--calib-seqlen 2048 \--w-bits 4 \--w-group-size 128 \--batch-size 1 \--search-scale False \--work-dir /root/models/internlm2_5-1_8b-chat-w4a16-4bit命令解释:
- lmdeploy lite auto_awq: lite这是LMDeploy的命令,用于启动量化过程,而auto_awq代表自动权重量化(auto-weight-quantization)。
- /root/models/internlm2_5-7b-chat: 模型文件的路径。
- –calib-dataset ‘ptb’: 这个参数指定了一个校准数据集,这里使用的是’ptb’(Penn Treebank,一个常用的语言模型数据集)。
- –calib-samples 128: 这指定了用于校准的样本数量—128个样本
- –calib-seqlen 2048: 这指定了校准过程中使用的序列长度—2048
- –w-bits 4: 这表示权重(weights)的位数将被量化为4位。
- –work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit: 这是工作目录的路径,用于存储量化后的模型和中间结果。
等终端输出如下时,说明正在推理中,稍待片刻。
等待推理完成,便可以直接在你设置的目标文件夹看到对应的模型文件。
那么推理后的模型和原本的模型区别在哪里呢?最明显的两点是模型文件大小以及占据显存大小。
我们可以输入如下指令查看在当前目录中显示所有子目录的大小。
cd /root/models/
du -sh *输出结果如下。(其余文件夹都是以软链接的形式存在的,不占用空间,故显示为0)

那么原模型大小呢?输入以下指令查看。
cd /root/share/new_models/Shanghai_AI_Laboratory/
du -sh *终端输出结果如下。
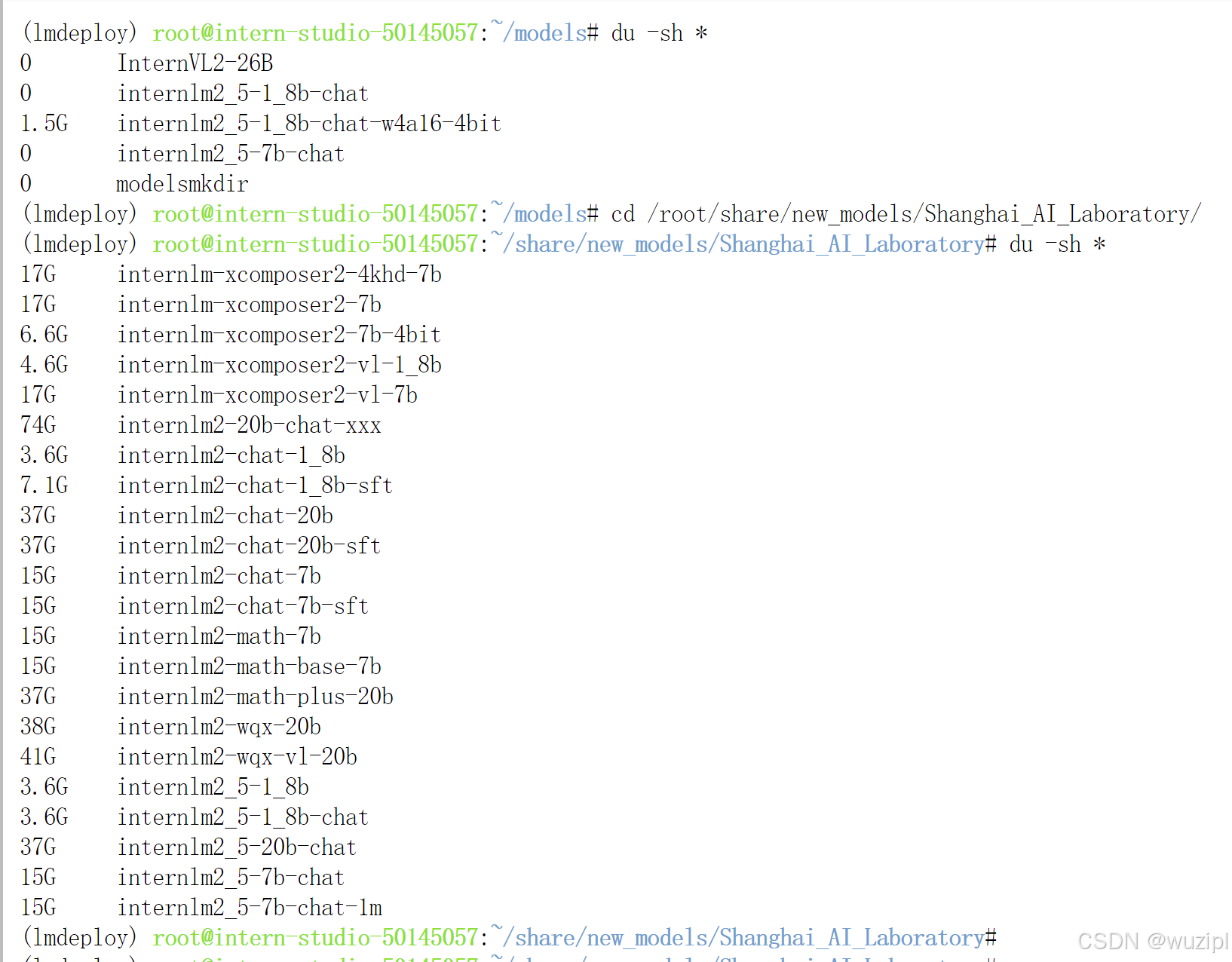
一经对比即可发觉,1.5G对3.6G,瘦身很多。
那么显存占用情况对比呢?输入以下指令启动量化后的模型。
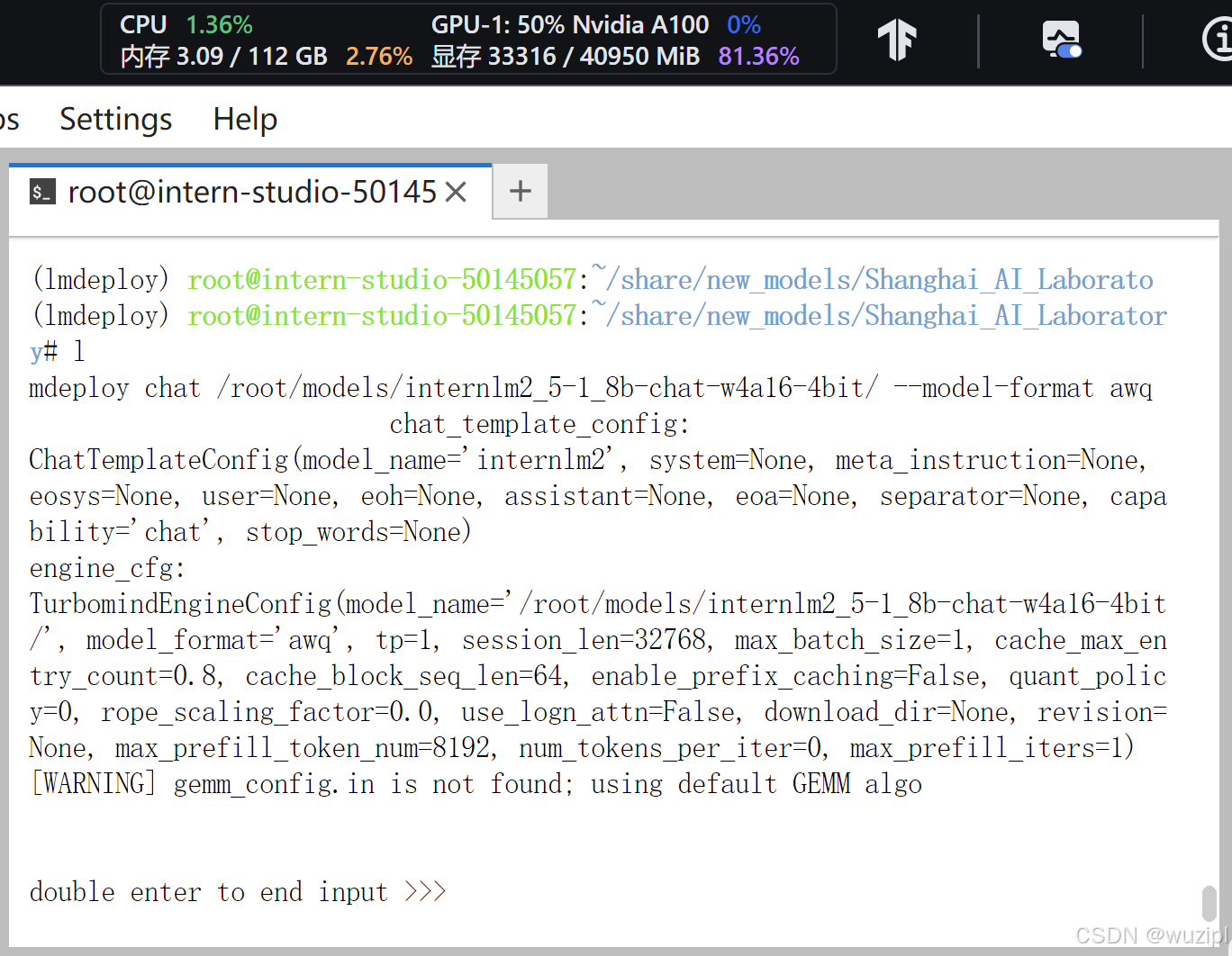
lmdeploy chat /root/models/internlm2_5-7b-chat-w4a16-4bit/ --model-format awq稍待片刻,我们直接观测右上角的显存占用33.3GB。
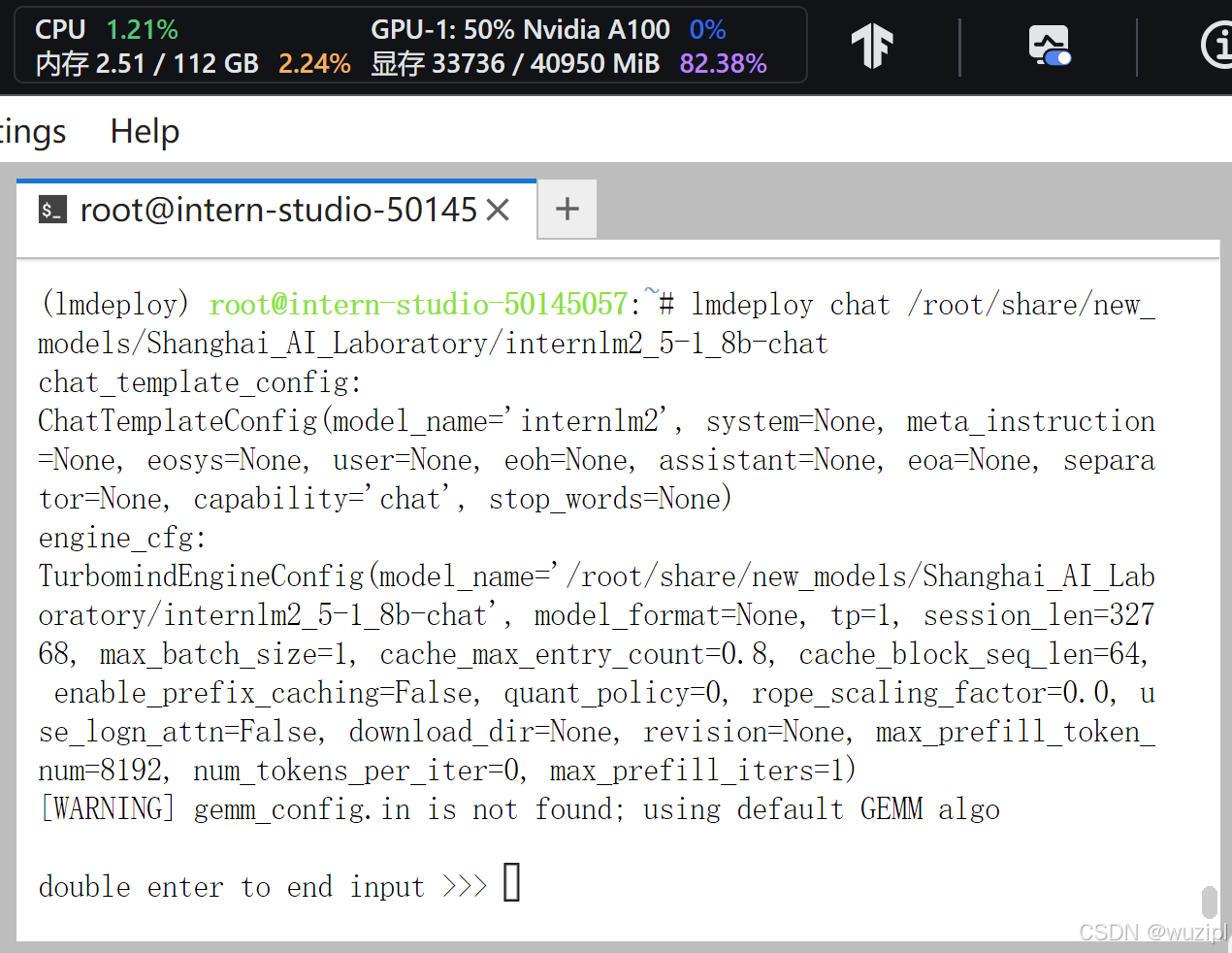
再来看运行未量化的internlm2_5-1_8b-chat模型情况,占用显存33.7GB。量化后模型体积明显变小,但运行占用显存变化不大。
3.2.4 W4A16 量化+ KV cache+KV cache 量化
我知道你们肯定有人在想,介绍了那么多方法,能不能全都要?当然可以!
输入以下指令,让我们同时启用量化后的模型、设定kv cache占用和kv cache int4量化。
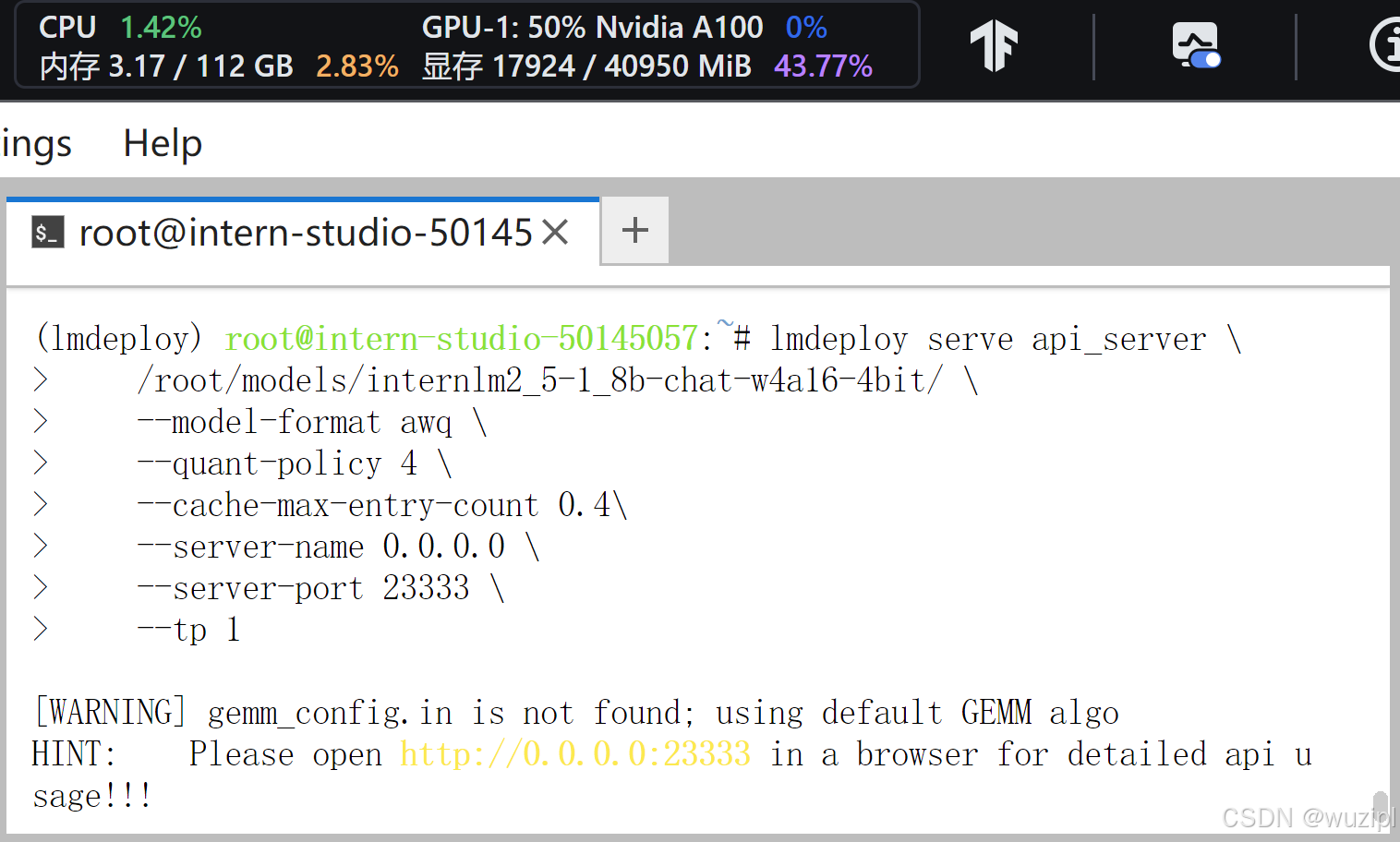
lmdeploy serve api_server \/root/models/internlm2_5-7b-chat-w4a16-4bit/ \--model-format awq \--quant-policy 4 \--cache-max-entry-count 0.4\--server-name 0.0.0.0 \--server-port 23333 \--tp 1此时显存占用18GB,比上面33GB大幅度降低。
4 LMDeploy与InternVL2
4.1 LMDeploy Lite
InternVL2-26B需要约70+GB显存,但是为了让我们能够在30%A100上运行,需要先进行量化操作,这也是量化本身的意义所在——即降低模型部署成本。
InternVL2-26B模型量化过程与InternLM2.5基本一致,但耗时比较长,本章将方法列述,未进行实际运行和截图。
4.1.1 W4A16 模型量化和部署
进入conda环境,并输入以下指令,执行模型的量化工作。(本步骤耗时较长,请耐心等待)
conda activate lmdeploy
lmdeploy lite auto_awq \/root/models/InternVL2-26B \--calib-dataset 'ptb' \--calib-samples 128 \--calib-seqlen 2048 \--w-bits 4 \--w-group-size 128 \--batch-size 1 \--search-scale False \--work-dir /root/models/InternVL2-26B-w4a16-4bit等待推理完成,便可以在左侧/models内直接看到对应的模型文件。
4.1.2 W4A16 量化+ KV cache+KV cache 量化
输入以下指令,让我们启用量化后的模型。
lmdeploy serve api_server \/root/models/InternVL2-26B-w4a16-4bit \--model-format awq \--quant-policy 4 \--cache-max-entry-count 0.1\--server-name 0.0.0.0 \--server-port 23333 \--tp 1启动后观测显存占用情况,比量化前大幅度降低,可以使用一张30%A100部署了。
根据InternVL2介绍,InternVL2 26B是由一个6B的ViT、一个100M的MLP以及一个19.86B的internlm组成的。如果推理图片,pytorch会占用额外的激活显存,需要开启50%A100进行图片推理。
4.2 LMDeploy API部署InternVL2
具体封装操作与之前大同小异,仅仅在数个指令细节上作调整,故本章节大部分操作与3.1 LMDeploy API部署InternLM2.5中几近完全一样,同学们可自行"依葫芦画瓢",以下教程仅做参考。
通过以下命令启动API服务器,部署InternVL2模型:
lmdeploy serve api_server \/root/models/InternVL2-26B-w4a16-4bit/ \--model-format awq \--quant-policy 4 \--cache-max-entry-count 0.1 \--server-name 0.0.0.0 \--server-port 23333 \--tp 1其余步骤与 “3.1.1 启动API服务器” 剩余内容一致。命令行形式、Gradio网页形式连接操作与 “3.1.2 以命令行形式连接API服务器” 和 “3.1.3 以Gradio网页形式连接API服务器” 步骤流程、指令完全一致,不再赘述。
5 LMDeploy之FastAPI与Function call
之前在3.1.1 启动API服务器与4.2 LMDeploy API部署InternVL2均是借助FastAPI封装一个API出来让LMDeploy自行进行访问,在这一章节中我们将依托于LMDeploy封装出来的API进行更加灵活更具DIY的开发。
5.1 API开发
与之前一样,让我们进入创建好的conda环境并输入指令启动API服务器。
conda activate lmdeploy
lmdeploy serve api_server \/root/models/internlm2_5-7b-chat-w4a16-4bit \--model-format awq \--cache-max-entry-count 0.4 \--quant-policy 4 \--server-name 0.0.0.0 \--server-port 23333 \--tp 1完成作业时请使用以下命令:
conda activate lmdeploy
lmdeploy serve api_server \/root/models/internlm2_5-1_8b-chat-w4a16-4bit \--model-format awq \--cache-max-entry-count 0.4 \--quant-policy 4 \--server-name 0.0.0.0 \--server-port 23333 \--tp 1
保持终端窗口不动,按箭头操作新建一个终端。
在新建终端中输入如下指令,新建internlm2_5.py。
touch /root/internlm2_5.py此时我们可以在左侧的File Broswer中看到internlm2_5.py文件,双击打开。
将以下内容复制粘贴进internlm2_5.py。
# 导入openai模块中的OpenAI类,这个类用于与OpenAI API进行交互
from openai import OpenAI# 创建一个OpenAI的客户端实例,需要传入API密钥和API的基础URL
client = OpenAI(api_key='YOUR_API_KEY', # 替换为你的OpenAI API密钥,由于我们使用的本地API,无需密钥,任意填写即可base_url="http://localhost:23333/v1" # 指定API的基础URL,这里使用了本地地址和端口
)# 调用client.models.list()方法获取所有可用的模型,并选择第一个模型的ID
# models.list()返回一个模型列表,每个模型都有一个id属性
model_name = client.models.list().data[0].id# 使用client.chat.completions.create()方法创建一个聊天补全请求
# 这个方法需要传入多个参数来指定请求的细节
response = client.chat.completions.create(model=model_name, # 指定要使用的模型IDmessages=[ # 定义消息列表,列表中的每个字典代表一个消息{"role": "system", "content": "你是一个友好的小助手,负责解决问题."}, # 系统消息,定义助手的行为{"role": "user", "content": "帮我讲述一个关于狐狸和西瓜的小故事"}, # 用户消息,询问时间管理的建议],temperature=0.8, # 控制生成文本的随机性,值越高生成的文本越随机top_p=0.8 # 控制生成文本的多样性,值越高生成的文本越多样
)# 打印出API的响应结果
print(response.choices[0].message.content)按Ctrl+S键保存(Mac用户按Command+S)。
现在让我们在新建终端输入以下指令激活环境并运行python代码。
conda activate lmdeploy
python /root/internlm2_5.py终端会输出如下结果。
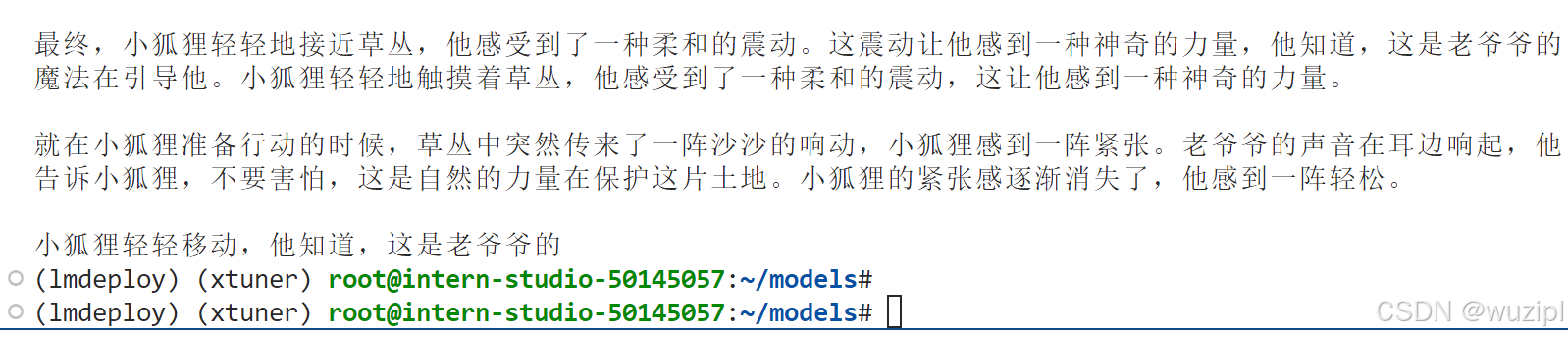
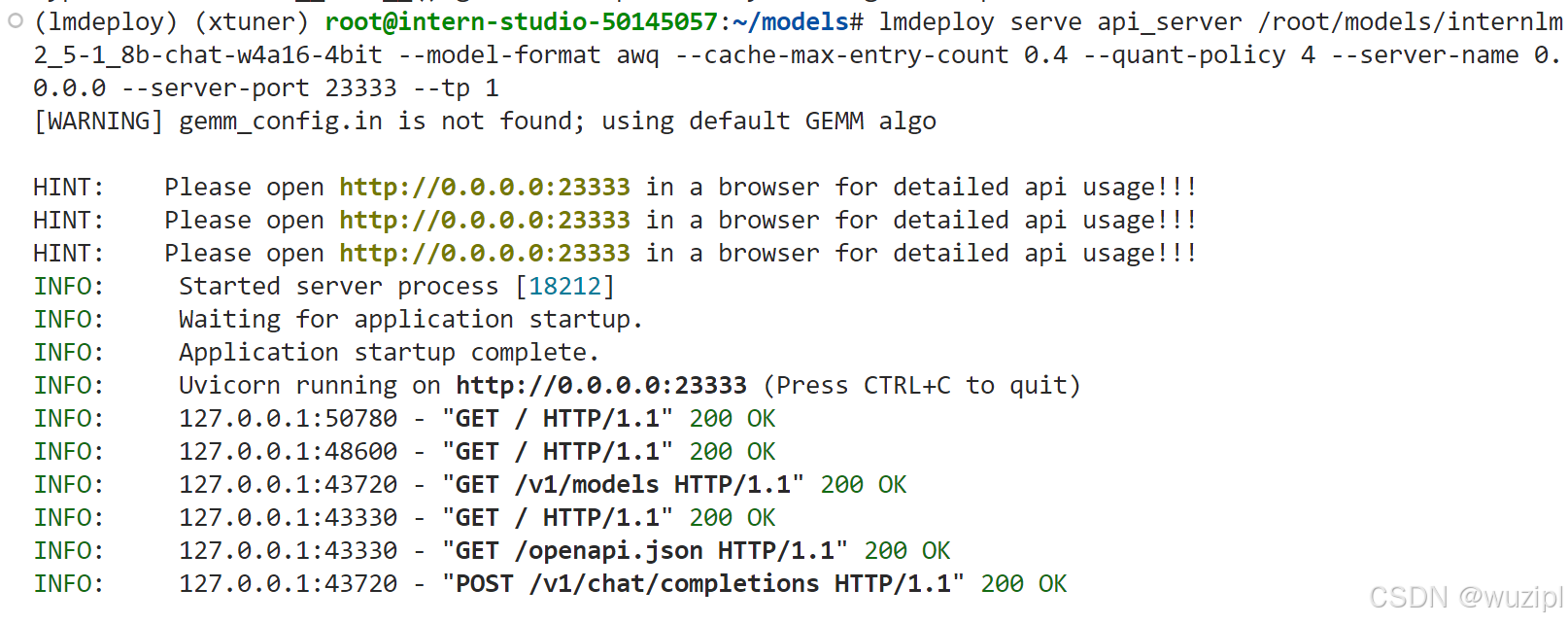
此时代表我们成功地使用本地API与大模型进行了一次对话,如果切回第一个终端窗口,会看到如下信息,这代表其成功的完成了一次用户问题GET与输出POST。
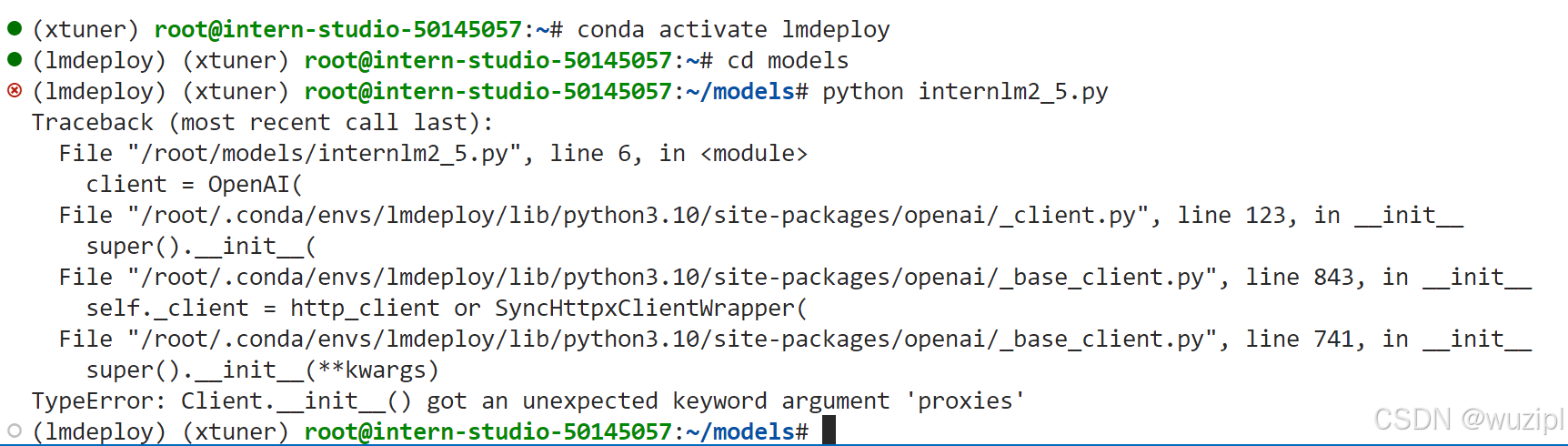
另外,在开始运行internlm2_5.py的时候,是报错的(错误信息如下图),后来运行 pip install --upgrade openai 更新了openai库后修复。
5.2 Function call
关于Function call,即函数调用功能,它允许开发者在调用模型时,详细说明函数的作用,并使模型能够智能地根据用户的提问来输入参数并执行函数。完成调用后,模型会将函数的输出结果作为回答用户问题的依据。
首先让我们进入创建好的conda环境并启动API服务器。
conda activate lmdeploy
lmdeploy serve api_server \/root/models/internlm2_5-7b-chat \--model-format hf \--quant-policy 0 \--server-name 0.0.0.0 \--server-port 23333 \--tp 1目前LMDeploy在0.5.3版本中支持了对InternLM2, InternLM2.5和llama3.1这三个模型,故我们选用InternLM2.5 封装API。
让我们使用一个简单的例子作为演示。输入如下指令,新建internlm2_5_func.py。
touch /root/internlm2_5_func.py双击打开,并将以下内容复制粘贴进internlm2_5_func.py。
from openai import OpenAIdef add(a: int, b: int):return a + bdef mul(a: int, b: int):return a * btools = [{'type': 'function','function': {'name': 'add','description': 'Compute the sum of two numbers','parameters': {'type': 'object','properties': {'a': {'type': 'int','description': 'A number',},'b': {'type': 'int','description': 'A number',},},'required': ['a', 'b'],},}
}, {'type': 'function','function': {'name': 'mul','description': 'Calculate the product of two numbers','parameters': {'type': 'object','properties': {'a': {'type': 'int','description': 'A number',},'b': {'type': 'int','description': 'A number',},},'required': ['a', 'b'],},}
}]
messages = [{'role': 'user', 'content': 'Compute (3+5)*2'}]client = OpenAI(api_key='18077', base_url='http://localhost:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(model=model_name,messages=messages,temperature=0.8,top_p=0.8,stream=False,tools=tools)
print(response)
func1_name = response.choices[0].message.tool_calls[0].function.name
func1_args = response.choices[0].message.tool_calls[0].function.arguments
func1_out = eval(f'{func1_name}(**{func1_args})')
print(func1_out)messages.append({'role': 'assistant','content': response.choices[0].message.content
})
messages.append({'role': 'environment','content': f'3+5={func1_out}','name': 'plugin'
})
response = client.chat.completions.create(model=model_name,messages=messages,temperature=0.8,top_p=0.8,stream=False,tools=tools)
print(response)
func2_name = response.choices[0].message.tool_calls[0].function.name
func2_args = response.choices[0].message.tool_calls[0].function.arguments
func2_out = eval(f'{func2_name}(**{func2_args})')
print(func2_out)按Ctrl+S键保存(Mac用户按Command+S)。
现在让我们输入以下指令运行python代码。
python /root/internlm2_5_func.py稍待片刻终端输出如下。

我们可以看出InternLM2.5将输入’Compute (3+5)*2’根据提供的function拆分成了"加"和"乘"两步,第一步调用function add实现加,再于第二步调用function mul实现乘,再最终输出结果16。
相关文章:

书生大模型实战营第4期——3.3 LMDeploy 量化部署实践
文章目录 1 基础任务2 配置LMDeploy环境2.1 环境搭建2.2 模型配置2.3 LMDeploy验证启动模型文件 3 LMDeploy与InternLM2.53.1 LMDeploy API部署InternLM2.53.1.1 启动API服务器3.1.2 以命令行形式连接API服务器3.1.3 以Gradio网页形式连接API服务器 3.2 LMDeploy Lite3.2.1 设置…...

11.28深度学习_bp算法
七、BP算法 多层神经网络的学习能力比单层网络强得多。想要训练多层网络,需要更强大的学习算法。误差反向传播算法(Back Propagation)是其中最杰出的代表,它是目前最成功的神经网络学习算法。现实任务使用神经网络时,…...

U盘文件夹变打不开的文件:深度解析、恢复策略与预防之道
一、U盘文件夹变打不开的文件现象解析 在日常使用U盘的过程中,我们时常会遇到这样的困扰:原本存储有序、可以轻松访问的文件夹,突然之间变成了无法打开的文件。这些文件通常以未知图标或乱码形式显示,双击或右键尝试打开时&#…...

软件工程中的需求分析流程详解
一、需求分析的定义 需求分析(Requirements Analysis)是指在软件开发过程中,通过与用户、相关人员的沟通与讨论,全面理解和确定软件需求的过程。需求分析的最终目标是清晰、准确地定义软件系统应具备的功能、性能、用户界面、约束…...
_kaic)
springboot369高校教师教研信息填报系统(论文+源码)_kaic
毕 业 设 计(论 文) 题目:高校教师教研信息填报系统的设计与实现 摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,…...

Docker Buildx 与 CNB 多平台构建实践
一、Docker Buildx 功能介绍 docker buildx 是 Docker 提供的一个增强版构建工具,支持更强大的构建功能,特别是在构建多平台镜像和高效处理复杂 Docker 镜像方面。 1.1 主要功能 多平台构建支持 使用 docker buildx,可以在单台设备上构建…...

VBA字典与数组第二十一讲:文本转换为数组函数Split
《VBA数组与字典方案》教程(10144533)是我推出的第三套教程,目前已经是第二版修订了。这套教程定位于中级,字典是VBA的精华,我要求学员必学。7.1.3.9教程和手册掌握后,可以解决大多数工作中遇到的实际问题。…...
)
开源项目 - 人脸关键点检测 facial landmark 人脸关键点 (98个关键点)
开源项目 - 人脸关键点检测 facial landmark 人脸关键点 (98个关键点) 示例: 助力快速掌握数据集的信息和使用方式。 数据可以如此美好!...

【Postgres_Python】使用python脚本批量导出PG数据库
示例代码说明: 有多个数据库需要导出为.sql格式,数据库名与sql文件名一致,读取的数据库名需要根据文件名进行拼接 import psycopg2 import subprocess import os folder_path D:/HQ/chongqing_20241112 # 获取文件夹下所有文件和文件夹的名称 filename…...
无窗口系统下搭建 OpenGL ES + Qt 开发环境,并绘制旋转金字塔)
嵌入式Linux(SOC带GPU树莓派)无窗口系统下搭建 OpenGL ES + Qt 开发环境,并绘制旋转金字塔
树莓派无窗口系统下搭建 OpenGL ES Qt 开发环境,并绘制旋转金字塔 1. 安装 OpenGL ES 开发环境 运行以下命令安装所需的 OpenGL ES 开发工具和库: sudo apt install cmake mesa-utils libegl1-mesa-dev libgles2-mesa-dev libdrm-dev libgbm-dev2. 安…...

MySQL事物
目录 何谓事物? 何谓数据库事务? 并发事务带来了哪些问题? 脏读(Dirty read) 丢失修改(Lostto modify) 不可重复读(Unrepeatable read) 幻读(Phantom read) 不可重复读和幻读有什么区别? 并发事务的控制方式有哪些? SQL 标准定义了哪些事务隔离级别?…...

在 CentOS 上安装 Docker:构建容器化环境全攻略
一、引言 在当今的软件开发与运维领域,Docker 无疑是一颗璀璨的明星。它以轻量级虚拟化的卓越特性,为应用程序的打包、分发和管理开辟了崭新的高效便捷之路。无论是开发环境的快速搭建,还是生产环境的稳定部署,Docker 都展现出了…...

基于Spring Boot的宠物咖啡馆平台的设计与实现
私信我获取源码和万字论文,制作不易,感谢点赞支持。 基于Spring Boot的宠物咖啡馆平台的设计与实现 摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了基于Spring Boot的宠物咖啡馆平台的设…...

JAVAWeb之javascript学习
1.js引入方式 1. 内嵌式:在head中,通过一对script标签引入JS代码;cript代码放置位置有一定的随意性,一般放在head标签中;2.引入外部js文件 在head中,通过一对script标签引入外部JS代码;注意&…...
的TCP通讯(操作记录))
电脑与优傲协作机器人(实体)的TCP通讯(操作记录)
目录 一、UR通信端口 二、电脑(客户端)连接协作机器人(服务端) 1.设置网络方法 2.检查设置 3.示教器切换远程控制(注) 4.客户端与协作机器人建立连接 5.连接测试 三、电脑(服务端&#…...

C++初阶——动态内存管理
目录 1、C/C内存区域划分 2、C动态内存管理:malloc/calloc/realloc/free 3、C动态内存管理:new/delete 3.1 new/delete内置类型 3.2 new/delete自定义类型 4、operator new与operator delete函数 5、new和delete的实现原理 5.1 内置类型 5.2 自定…...
)
Python 【图像分类】之 PyTorch 进行猫狗分类功能的实现(Swanlab训练可视化/ Gradio 实现猫狗分类 Demo)
Python 【图像分类】之 PyTorch 进行猫狗分类功能的实现(Swanlab训练可视化/ Gradio 实现猫狗分类 Demo) 目录 Python 【图像分类】之 PyTorch 进行猫狗分类功能的实现(Swanlab训练可视化/ Gradio 实现猫狗分类 Demo) 一、简单介绍 二、PyTorch 三、CNN 1、神经网络 2、卷…...

Attention显存统计与分析
Attention显存估计 简单的Attention函数 import torch import torch.nn as nn import einops class Attention(nn.Module):def __init__(self, dim, num_heads8, qkv_biasFalse, qk_scaleNone, attn_drop0., proj_drop0.):super().__init__()self.num_heads num_headshead_d…...

java反射
反射 Java 反射是 Java 提供的一种强大特性,它允许程序在运行时动态地获取类的信息,并操作类的属性和方法。这为编写灵活、可扩展的 Java 应用程序提供了强有力的支持 获取Class对象 package ref;public class Person {private String name ;private …...

Spring Boot入门
1、Spring Boot是什么 Spring Boot 帮我们简单、快速地创建一个独立的、生产级别的 Spring 应用(说明:Spring Boot底层是Spring) 大多数 Spring Boot 应用只需要编写少量配置即可快速整合 Spring 平台以及第三方技术 特性: 快速…...

Spring Web:深度解析与实战应用
概述 大家好,欢迎来到今天的技术分享。我是你们的老朋友,今天,我们要深入探讨的是Spring Web模块,这个模块为Java Web应用程序提供了全面的支持,不仅具备基本的面向Web的综合特性,还能与常见框架如Struts2无…...

学习日志019--初识PyQt
使用pyqt创建一个登录界面 from PyQt6.QtCore import Qt # 引入pyqt6包 from PyQt6.QtGui import QIcon, QMovie from PyQt6.QtWidgets import QApplication, QWidget, QPushButton, QLabel, QLineEdit import sysclass MyWidget(QWidget):# 构造函数,继承父类的构造…...
入门趣谈(五))
Swift 宏(Macro)入门趣谈(五)
概述 苹果在去年 WWDC 23 中就为 Swift 语言新增了“其利断金”的重要小伙伴 Swift 宏(Swift Macro)。为此,苹果特地用 2 段视频(入门和进阶)颇为隆重的介绍了它。 那么到底 Swift 宏是什么?有什么用&…...

Linux 35.6 + JetPack v5.1.4@DeepStream安装
Linux 35.6 JetPack v5.1.4DeepStream安装 1. 源由2. 步骤Step 1 安装Jetpack 5.1.4 L4T 35.6Step 2 安装依赖组件Step 3 安装librdkafkaStep 4 安装 DeepStream SDKStep 5 测试 deepstream-appStep 6 运行 deepstream-app 3. 总结3.1 版本问题3.2 二进制help 4. 参考资料 1. …...

C++基础:list的底层实现
文章目录 1.基本结构2.迭代器的实现2.1 尾插的实现2.2 迭代器的实现 3.打印函数(模版复用实例化)4.任意位置的插入删除1. 插入2. 删除 5.析构与拷贝构造5.1 析构函数5.2 拷贝构造5.3 赋值重载 1.基本结构 与vector和string不同list需要: 一个类来放入数据和指针也就是节点 一…...
Spring中@Transactional注解与事务传播机制
文章目录 事务传播机制事务失效的场景 事务传播机制 事务的传播特性指的是 当一个事务方法调用另一个事务方法时,事务方法应该如何执行。 事务传播行为类型外部不存在事务外部存在事务使用方式REQUIRED(默认)开启新的事务融合到外部事务中Transactional(propagati…...

实验七 用 MATLAB 设计 FIR 数字滤波器
实验目的 加深对窗函数法设计 FIR 数字滤波器的基本原理的理解。 学习用 Matlab 语言的窗函数法编写设计 FIR 数字滤波器的程序。 了解 Matlab 语言有关窗函数法设计 FIR 数字滤波器的常用函数用法。 掌握 FIR 滤波器的快速卷积实现原理。 不同滤波器的设计方法具有不同的优…...

Linux - selinux
七、selinux 1、说明 SELinux是Security-Enhanced Linux的缩写,意思是安全强化的linux。 SELinux是对程序、文件等权限设置依据的一个内核模块。由于启动网络服务的也是程序,因此刚好也 是能够控制网络服务能否访问系统资源的一道关卡。 传统的文件权…...

【STL】C++ vector类模板
文章目录 基本概念vector的使用定义和初始化构造函数赋值操作容量和大小插入和删除数据存取 互换容器vector的迭代器vector储存自定义数据类型 基本概念 vector是类型相同的对象的容器,vector的大小可以变化,可以向数组中增加元素。因此,vec…...
)
物联网——WatchDog(监听器)
看门狗简介 独立看门狗框图 看门狗原理:定时器溢出,产生系统复位信号;若定时‘喂狗’则不产生系统复位信号 定时中断基本结构(对比) IWDG键寄存器 独立看门狗超时时间 WWDG(窗口看门狗) WWDG特性 WWDG超时时间 由于…...

从零开始写游戏之斗地主-网络通信
在确定了数据结构后,原本是打算直接开始写斗地主的游戏运行逻辑的。但是突然想到我本地写出来之后,也测试不了啊,所以还是先写通信模块了。 基本框架 在Java语言中搞网络通信,那么就得请出Netty这个老演员了。 主要分为两个端&…...

【智能控制】实验,基于MATLAB的模糊推理系统设计,模糊控制系统设计
关注作者了解更多 我的其他CSDN专栏 过程控制系统 工程测试技术 虚拟仪器技术 可编程控制器 工业现场总线 数字图像处理 智能控制 传感器技术 嵌入式系统 复变函数与积分变换 单片机原理 线性代数 大学物理 热工与工程流体力学 数字信号处理 光电融合集成电路…...

Vega Editor 基于 Web 的图形编辑器
Vega Editor 是一个强大的基于 Web 的图形编辑器,专为 Vega 和 Vega-Lite 可视化语法设计。它提供了一个交互式的环境,用户可以在其中编写、预览和分享他们的 Vega 和 Vega-Lite 可视化作品。Vega 和 Vega-Lite 是用于声明性可视化的开源语法,…...

SQL 中SET @variable的使用
在 SQL 中,SET variable 用于声明和赋值用户定义的变量。具体来说, 符号用于表示一个局部变量,可以在 SQL 语句中存储和使用。它通常在存储过程、函数或简单的 SQL 查询中使用。 1. 声明并赋值给变量 你可以使用 SET 语句给一个变量赋值。例…...

基于 Vite 封装工具库实践
项目背景:公司在多个项目中频繁使用相同的工具函数。为了避免每次开发新项目时都重复复制代码,决定通过 Vite 封装一个时间函数组件库。该库将被发布到 Verdaccio 供团队其他项目使用。 项目介绍 本项目封装了一个时间函数工具库,使用 Momen…...
)
Oracle DataGuard 主备正常切换 (Switchover)
前言 众所周知,DataGuard 的切换分为两种情况: 系统正常情况下的切换:这种方式称为 switchover,是无损切换,不会丢失数据。灾难情况下的切换:这种情况下一般主库已经启动不起来了,称为 failov…...

[Redis#13] cpp-redis接口 | set | hash |zset
目录 Set 1. Sadd 和 Smembers 2. Sismember 3. Scard 4. Spop 5. Sinter 6. Sinter store Hash 1. Hset 和 Hget 2. Hexists 3. Hdel 4. Hkeys 和 Hvals 5. Hmget 和 Hmset Zset 1. Zadd 和 Zrange 2. Zcard 3. Zrem 4. Zscore cpp-redis 的学习 主要关注于…...

青海摇摇了3天,技术退步明显.......
最近快手上的青海摇招聘活动非常火热,我已经在思考是否备战张诗尧的秋招活动。开个玩笑正片开始: 先说一下自己的情况,大专生,20年通过校招进入杭州某软件公司,干了接近4年的功能测试,今年年初,…...

Flask+Minio实现断点续传技术教程
什么是MinIO MinIO是一个高性能的分布式对象存储服务,与Amazon S3 API兼容。它允许用户存储和检索任意规模的数据,非常适合于使用S3 API的应用程序。MinIO支持多租户存储,提供高可用性、高扩展性、强一致性和数据持久性。它还可以作为软件定义…...

Java中Logger定义的三种方式
在 Java 项目中,日志记录是开发中的一个重要部分,用于跟踪系统运行状态、排查问题以及记录重要事件。在定义日志记录器时,经常会遇到一些写法上的选择,比如 Logger 的作用域、是否使用静态变量,以及如何命名变量。本篇…...

模型压缩技术
目录 模型压缩技术 权重剪枝: 量化技术: 知识蒸馏: 低秩分解: 一、权重剪枝 二、量化技术 三、知识蒸馏 四、低秩分解 模型压缩技术 权重剪枝: 描述:通过删除模型中不重要的权重来减少参数数量和计算量。举例说明:假设我们有一个神经网络模型,其中某些神经元的…...

面试题整理
1 spring使用中有哪些设计模式 工厂模式-beanFactory,代理模式-aop,单例模式-每个bean默认都是单例的,原型模式-当将bean的作用域改为prototype时每次获取bean时使用了原型模式创建对象,责任链模式-dispatchServle查找url对应的处理器映射器时使用了,观察者模式-spring的…...

Linux
1、显示系统中所有进程 ps -ef运行效果: [rootredhat-9 ~]# ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 19:01 ? 00:00:01 /usr/lib/systemd/systemd rhgb --switched-r root 2 0 0…...

力扣_2389. 和有限的最长子序列
力扣_2389. 和有限的最长子序列 给你一个长度为 n 的整数数组 nums ,和一个长度为 m 的整数数组 queries 。 返回一个长度为 m 的数组 answer ,其中 answer[i] 是 nums 中 元素之和小于等于 queries[i] 的 子序列 的 最大 长度 。 子序列 是由一个数组…...

UI设计从入门到进阶,全能实战课
课程内容: ├── 【宣导片】从入门到进阶!你的第一门UI必修课!.mp4 ├── 第0课:UI知识体系梳理 学习路径.mp4 ├── 第1课:IOS设计规范——基础规范与切图.mp4 ├── 第2课:IOS新趋势解析——模块规范与设计原则(上).mp4…...
)
Formality:等价性检查的流程与模式(Guide、Setup、Preverify、Match与Verify)
相关阅读 Formalityhttps://blog.csdn.net/weixin_45791458/category_12841971.html?spm1001.2014.3001.5482 等价性检查的流程 图1概述了使用Formality进行等效性检查的具体步骤。 图1 等价性检查流程 启动Formality(Start Formality) 要启动Formality,请…...
)
【Linux】————(日志、线程池及死锁问题)
作者主页: 作者主页 本篇博客专栏:Linux 创作时间 :2024年11月29日 日志 关于日志,首先我们来说一下日志的作用, 作用: 问题追踪:通过日志不仅仅包括我们程序的一些bug,也可以在…...

【自动化】配置信息抽取
公共基本信息配置文件抽取 公共基本信息比如卖家、买家、管理员,验证码等基本信息,再比如数据库、redis、各个服务的域名,这些目前是写死在代码之中的,为了能够更好的维护他们,我们将他们放入配置文件进行管理 公共的…...

Python毕业设计选题:基于django+vue的校园影院售票系统
开发语言:Python框架:djangoPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 管理员登录 管理员功能界面 用户管理 影院信息管理 电影类型管理 电影信息管理 系统…...

Docker化部署Flask:轻量级Web应用的快速部署方案
Flask是一个用Python编写的轻量级Web应用框架,以其简洁性和灵活性而受到开发者的喜爱。Docker作为一种流行的容器化技术,为应用的部署和管理提供了极大的便利。本文将探讨Flask的优点、Docker部署的好处,并详细介绍如何将Flask应用Docker化部…...