Dust3r、Mast3r、Fast3r
目录
一.Dust3r
1.简述
2.PointMap与ConfidenceMap
3.模型结构
4.损失函数
5.全局对齐
二.Mast3r
1.简述
2.MASt3R matching
3.MASt3R sfm
匹配与标准点图
BA优化
三.Fast3r
1.简述
2.模型结构
3.损失函数
三维重建是计算机视觉中的一个高层任务,包含了很多底层的计算机视觉技术。传统的三维重建,如SFM(structure from motion),就像是一个系列的pipeline工程,包含了关键点提取、本质矩阵计算、三角化、相机位姿估计、稀疏重建、稠密重建等。
一.Dust3r
1.简述
传统的三维重建将任务拆解为了多个子问题,作者认为这样的设定,存在几个问题:
- 前一个子任务会把误差累进到后一个子任务中,比如匹配的误差就不可避免会给三角化带来影响
- 后一个子任务的信息很难前馈到前一个子任务中,比如相机估计出来的位姿能够用于重建,但重建后的结果却很难前馈到估计位姿过程中去
而DUSt3R则完全不划分任何子任务,输入两张图像就直接通过网络模型来端到端地计算3D点云。
DUSt3R(Dense Unconstrained Stereo 3D Reconstruction),在非标定、不含位姿信息的图像上进行稠密三维重建。如下图,相比传统方法,DUSt3R从非约束的图像集合中直接恢复出对应的相机坐标系下面的三维点位置信息。然后在三维点信息基础上进行相机标定、深度估计、相机位姿估计、稠密三维重建等。DUSt3R利用数据驱动的方式,采用神经网络的方法,直接从2D图像对中估计3D点云信息,从而跳过了传统三维重建方法中的提取特征点、特征点匹配、点云三角化等步骤。使得整个三维重建pipeline变得简洁,仅仅包含了3D点云估计、全局对齐两个步骤。

从2D图像直接估计出3D点云信息,这让重建技术有了新的角度。传统的SFM,会先去构建图像和图像的2D对应关系,然后三角化获得空间点云,然后利用其他图像和已知图像的2D-2D匹配关系,转化为2D-3D匹配关系,使用PnP的方式进行求解。而现在,我们直接拥有了2D图像对应的3D点云信息(相机坐标系下面),剩下的问题就是如何让这些在各自相机坐标系下面的3D点云形成一个完整的场景表达。这就是Global Alignment需要完成的事情。
2.PointMap与ConfidenceMap
先来看一下DUSt3R的输出格式,对于H*W*3的RGB图像而言,最终会输出一个H*W*3的PointMap和一个H*W的ConfidenceMap。其中ConfidenceMap非常好理解,就是每个像素对应的PointMap的置信度,一共有H*W个像素,所以ConfidenceMap的维度是H*W。
而PointMap则是每个RGB图像的像素点对应的三维空间坐标,因为每个空间点是三维坐标,一共有H*W个像素,所以PointMap的维度是H*W*3。
PointMap的物理含义是,从光心与对应像素的组成的射线,遇到的最近的空间结构在相机坐标系中的坐标。但需要注意,这实际上隐含了所有被相机观测的物体都是不透明物体这一假设。如下图,在存在透明/半透明结构时,这时最近的3D点应该是半透玻璃,但实际上因为被半透玻璃遮蔽的物体有更显著的特征,因为基于PointMap大概率无法很好的重建出这类结构。

3.模型结构

USt3R的功能是从2D图像中恢复出相机坐标系下面的三维点。其输入是两张图像,采用的是孪生网络结构。首先,两张图像分别经过参数共享的ViT encoder,然后分别经过transformer decoder(利用cross attention来进行特征交互),随后利用各自的head分别输出点云和置信度。针对图像1分支,输出包括了图像相同大小的置信度特征和图像大小的点云![]() ,其坐标是在图像1代表的camera的相机坐标系。而图像2分支,输出包括了图像相同大小的置信度特征和图像大小的点云
,其坐标是在图像1代表的camera的相机坐标系。而图像2分支,输出包括了图像相同大小的置信度特征和图像大小的点云 ![]() ,其坐标同样是图像1代表的camera的相机坐标系。
,其坐标同样是图像1代表的camera的相机坐标系。
DUSt3R输出的点云是从2D图像中获取的,因为单目相机的深度是不具有唯一性的,因此从两张图像中恢复出来的3D点云是不具备尺度信息的,也就是![]() 不具备实际的物理尺寸。
不具备实际的物理尺寸。
简单来说,输入的两张图像I1、I2会用同一个ViT模型进行编码得到对应的F1、F2,然后基于transformer和cross-attention来融合两帧的信息进行解码,最后把所有解码器的输出用DPT head来融合并输出最终每一帧图像的PointMap与ConfidenceMap。(代码里的head有linear和dpt两种,先用linear进行低分辨率训练,然后dpt在更高分辨率上训练从而节省时间)

简要模型概览
4.损失函数
损失函数由两部分组成,第一部分是3D点空间距离,第二部分是置信度。
3D点距离损失
DUSt3R的损失函数包含两个部分,一个是置信度得分,一个预测点云和真值点云在欧式空间的距离。这里值得一提的是真值点云的获取。因为真值点云是在相机坐标下面,因此当我们有图像对应的深度图和相机的内参以后,我们可以采用公式![]() 获取,其中 i,j 是图像像素坐标值。而为了获取到图像2在camera1的像素坐标系下的点云真值,则需要借助camera1和camera2的位姿信息。也就是利用公式
获取,其中 i,j 是图像像素坐标值。而为了获取到图像2在camera1的像素坐标系下的点云真值,则需要借助camera1和camera2的位姿信息。也就是利用公式![]() 来获取,其中 Pm,Pn 都是世界坐标系到相机坐标系的变换矩阵, h 是普通坐标转化为齐次坐标。因此,在构建训练集的时候,我们就需要获得图像对应的相机内参、以及相机位姿信息,方便构建图像对应的相机坐标系下的点云和在其他相机坐标系下的点云。
来获取,其中 Pm,Pn 都是世界坐标系到相机坐标系的变换矩阵, h 是普通坐标转化为齐次坐标。因此,在构建训练集的时候,我们就需要获得图像对应的相机内参、以及相机位姿信息,方便构建图像对应的相机坐标系下的点云和在其他相机坐标系下的点云。
假设第j张图像(只有两张图,所以j=1或2)的第i个像素在基准坐标系对应的真实空间点为![]() ,而预测出来的为
,而预测出来的为![]() ,那么计算3D回归损失:
,那么计算3D回归损失:

其中![]() 是归一化因子,表示3D点到原点的平均距离。上述loss只衡量了PointMap的3D点与真实3D点之间的误差,但网络还会输出一个ConfidenceMap,还需要把置信度融合进loss里:
是归一化因子,表示3D点到原点的平均距离。上述loss只衡量了PointMap的3D点与真实3D点之间的误差,但网络还会输出一个ConfidenceMap,还需要把置信度融合进loss里:

训练损失函数
下图是网络的输出结果,从左往右依次是原图、深度图、置信图、重建结果。

网络输出结果
5.全局对齐
输入了一个图像集合,两两图像能够构建出很多图像对,利用上面的DUSt3R网络,能够获得对应的置信度和点云,通过置信度信息,能够剔除那些两张图像重合度不够的图像对。
全局对齐的目标就是将所有的预测点云都统一到一个坐标系下面。因为网络一次输出的一对点云是在同一个相机坐标系下面,因此全局对齐部分需要去估计 N 个相机位姿和 N 个尺度因子, N 表示图像对的对数。通过优化公式可以看出,优化的目标是让每个点云转化到世界坐标系中的点云具有一致性,也就是欧式距离最小。
利用全局对齐获得了世界坐标系下面的点云,进一步,通过公式![]() 可以估计出相机的位姿、内参、深度图等信息。其中
可以估计出相机的位姿、内参、深度图等信息。其中
![]() 表示第 n 张图上的第 i,j 像素点对应的点云(世界坐标系下面)。以下是重建结果图:从左往右依次是原图、深度图、置信图、重建结果。
表示第 n 张图上的第 i,j 像素点对应的点云(世界坐标系下面)。以下是重建结果图:从左往右依次是原图、深度图、置信图、重建结果。
作者指出,相比于传统的BA(Bundle Adjustment)利用重投影,在2D图像上进行误差优化,本文的全局对齐是在3D空间中进行优化的,采用了标准的梯度下降法,能够快速地收敛。
二.Mast3r
1.简述
MASt3R是对DUSt3R的改进,MASt3R其实分为了两篇文章,一篇是MASt3R matching,基于DUSt3R的网络主体结构,多了一些模块用于两帧之间的匹配;还有一篇是MASt3R sfm,这篇是基于MASt3R matching做的一个用于多图sfm。因为MASt3R sfm是基于MASt3R matching的网络结构并用到了里面一些NN算法,所以我们先来看MASt3R matching。
2.MASt3R matching
matching的网络结构跟DUSt3R基本保持一致,蓝色的部分是新增的模块。比较明显的是新增了一个head用来提取local feature,然后是多了两个最邻近匹配模块用来构建匹配。

对于H*W*3的输入图像而言,最终除了会输出一个H*W*3的PointMap和一个H*W的ConfidenceMap外,还会为每个像素生成一个长度为d的特征,也就是H*W*3的LocalFeature,也就是用神经网络来提取特征。剩余的网络部分与DUSt3R保持一致。
关于loss部分,MASt3R matching对DUStER的![]() 做了一点小改动,然后新增了匹配loss。
做了一点小改动,然后新增了匹配loss。
具体而言,MASt3R matching取消了不同的深度正则化项,直接用gt的平均深度![]()

然后因为新增了一个用于匹配的head输出,而希望每个像素点最多和另一张图的一个像素点匹配,作者将这部分描述为infoNCE loss,假设gt的匹配点为![]() ,并记
,并记![]() 的输出:
的输出:

有了上述模型与Loss就可以训练了,但是网络的输出还需要经过一些处理,才能得到需要的匹配关系。注意,网络只输出了PointMap和每个像素的LocalFeature,而期望得到的是两个图像之间的像素点级别的匹配,匹配相关的部分就是图中新增的NN模块。
作者在匹配时设计了一个新算法,先对两个图像对应的特征点进行降采样,先得到图像1的特征点对于图像2的正向NN匹配,在从已经匹配上的图像2特征点反向NN匹配到图像1,能够形成闭环的NN匹配关系便成为最终的匹配。一次迭代同时包含正向和反向NN匹配,通过这样就能快速收敛。

到这matching还没结束,还有一步优化,因为之前不是降采样了嘛,降采样之后的最邻近不一定是真的最邻近,所以还要回到原分辨率的图像上去,重新分块再来一遍匹配(无论是分块还是降采样肯定都比直接全局NN快得多)。这样就得到了最终的匹配关系。

3.MASt3R sfm
看总览下pipeline:

虽然看起来MASt3R sfm直接在pipeline里集成了多帧输入,但是因为网络从DUSt3R一脉相承仍然只能一次处理两张图像,只是MASt3R sfm确实在多帧输入的处理方式上存在很多改进,效果也确实好很多。
MASt3R sfm是基于MASt3R matching的网络结构来开展的,MASt3R sfm只用了MASt3R matching里encoder的输出作为tokenFeature(注意不是head输出的LocalFeature),而不需要像素级别的匹配关系。
MASt3R sfm也是像DUSt3R那样,先基于重叠视角构建一个Graph,具体做法如下:
- 根据encoder输出的tokenFeature,使用最远点采样算法(farthest point sampling, FPS)来选出N个关键帧(或控制帧,理解成聚类算法的中心点一样东西),然后把这N个关键帧两两相连,构成
条边
- 剩余的普通帧连接到最近的关键帧上,然后还会通过NN算法连接到最近的k个普通帧上去
在上述过程中计算特征的距离完全是基于tokenFeature,对tokenFeature白化(feature whitening)后计算二进制距离来实现的。而由于一个图像不止一个特征,所以会采用ASMK算法计算相似度来描述两张图像重叠视野,也就是用ASMK相似度来描述两张图像是否接近。
这里使用encoder输出而不是head的输出作为feature的好处是显而易见的:encoder的输入只要一张图像,所以每张图像都过一遍encoder就行了,而encoder又是不可缺少的步骤,相当于提取特征没有开销。
也就是构建pair时用encoder输出作为tokenFeature,而后续的匹配和优化则使用head输出的LocalFeature。
匹配与标准点图
通过上述共视图计算两两pair的PointMap、ConfidenceMap和LocalFeature后,会首先使用MASt3R matching中提到NN算法来匹配一个pair中的2D-3D点(分别得到![]()
![]() ,其中
,其中![]() 表示一个pair中第i张到第j张图的2D-3D匹配点对)。
表示一个pair中第i张到第j张图的2D-3D匹配点对)。
但是从构建共视图中就可以看出来,同一张图像肯定不止参与一个pair的运算,这样相当于一张图像同时有好几个PointMap,每个PointMap都可能有一定误差,而且一对多这样子也不方便后面计算,所以作者将一张图像的所有PointMap合成为一个Canonical PointMap(姑且翻译成标准点图),其实就是PointMap对于置信度的加权平均(这里![]() 表示每个pair,
表示每个pair,![]() 是对应的置信度):
是对应的置信度):

BA优化
回想一下,我们期望得到的输出是3D点云,使用Canonical PointMap作为点云可以吗?显然不可以,首先多帧之间的Canonical PointMap不一定对齐,其次每帧估计出来的Canonical PointMap也不一定准确(比如不满足针孔相机模型,所有2D-3D连线不一定能过光心)。
在DUSt3R里是仅对共视图的连接关系进行多帧优化,相对而言确实比较粗糙。而在MASt3R里,首先会先固定Canonical PointMap来优化出一个尽可能满足针孔相机模型约束的焦距,从而恢复出一个比较接近的相机内参矩阵,这个优化仅涉及自身的Canonical PointMap,所以跟pair什么的没关系,如果图片是不同相机拍的也可以为每个相机做单独的优化:

然后来优化Canonical PointMap对于像素的重投影误差,这会同时优化相机内参K和共视图中pair连接的相对位姿(外参),这是使用3D点误差来优化的。这里的
![]()
是把3D点投影到2D点映射,![]()

这里的c指的是pair中的匹配像素,qc是匹配置信度,可以由MASt3R对应的置信度加权得到。注意这个优化是把所有匹配作为内点来优化对应的Sim3变换,但是实际上不可能所有的匹配都是内点,所以作者又引入了一个用置信度加权的重投影误差优化来尽量消除外点影响,这里的ρ(⋅)是一个鲁棒核函数:
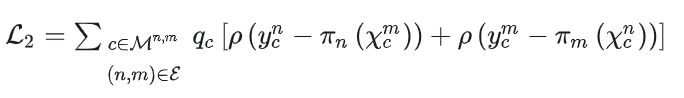

三.Fast3r
1.简述
DUSt3R通过将成对重建问题转化为点图的回归问题能够直接从RGB图像中预测三维结构。这代表了三维重建领域的一次根本性转变,因为端到端可学习的解决方案不仅减少了流程中误差的累积,还显著简化了操作。
然而, DUSt3R的根本是重建两幅图像输入的场景。为了处理多于两幅图像,DUSt3R需要计算O(N²)对点图并执行全局对齐优化过程。这一过程计算成本高昂,随着图像数量的增加,其扩展性较差。 例如,在A100 GPU上仅处理48个视角就可能导致内存溢出(OOM)。另外,两两重建这一过程限制了模型的上下文信息,既影响了训练期间的学习效果,也限制了推理阶段的最终精度。从这个意义上说,DUSt3R与传统SfM和MVS方法一样,面临着成对处理的瓶颈问题。
Fast3R是一种新型的多视图重建框架,旨在克服上面提到的局限性。 FAST3R在Dust3R的基础上,利用Transformer-based架构并行处理多个图像,允许在单个前向传递中重建N个图像。通过消除对顺序或成对处理的需要,每个帧可以在重建期间同时关注输入集中的所有其他帧,从而显著减少错误累积 并且Fast3R推理的时间也大大减少。总的来说,Fast3R是一种基于Transformer的多视角点图估计模型,无需全局后处理,在速度、计算开销和可扩展性方面实现了显著提升。模型性能随着视角数量的增加而提升。
2.模型结构
如图,输入N个无序无pose的RGB图像![]() ,Fast3R预测对应的pointmap
,Fast3R预测对应的pointmap![]() (
(![]() )以及confidence map
)以及confidence map
![]() 来重建场景,不过这里的
来重建场景,不过这里的 ![]() 有两类,一种是全局pointmap
有两类,一种是全局pointmap ![]() ,另一种是局部pointmap
,另一种是局部pointmap ![]() ,confidence map也一样,全局置信图
,confidence map也一样,全局置信图 ![]() ,局部置信图
,局部置信图 ![]() ,比如,在MASt3R中,
,比如,在MASt3R中, ![]() 是在视角1的坐标系下,
是在视角1的坐标系下, ![]() 就是当前相机坐标系:
就是当前相机坐标系:

Fast3R的结构设计来源于DUSt3R,包括三部分:image encoding, fusion transformer,
and pointmap decoding,并且处理图片的方式是 并行 的。
(1)Image encoder
与DUST3R一样,对于任意的图片 ![]() ,encoder部分使用CroCo ViT里面的
,encoder部分使用CroCo ViT里面的 ![]() ,即分成patch提取特征,最后得到
,即分成patch提取特征,最后得到 ![]() ,其中
,其中 ![]() ,记作:
,记作:
![]()
然后,在fusion transformer之前,往patch 特征H里面添加一维的索引嵌入(image index positional embeddings),索引嵌入帮助融合Transformer确定哪些补丁来自同一图像,并且是识别 ![]() 的机制,而
的机制,而 ![]() 定义了全局坐标系。使模型能够从原本排列不变的标记集中隐式地联合推理所有图像的相机pose。
定义了全局坐标系。使模型能够从原本排列不变的标记集中隐式地联合推理所有图像的相机pose。
(2)Fusion transformer
Fast3R 主要的计算在Fusion transformer过程中,我们使用的是与ViTB或 BERT类似的12层transformer,还可以按照比例放大,在此过程中,直接执行all-to-all的自注意力,这样,Fast3R获得了包含整个数据集的场景信息。
(3)pointmap decoding
Fast3R的位置编码细节也很讲究,这个细节大家感兴趣可以仔细看看,可以达到训练20张图,推理1000张图的效果。最后,使用DPT-Large的decoder得到点图 ![]() 以及置信图
以及置信图 ![]() ,下面简单介绍一下DPT-L。
,下面简单介绍一下DPT-L。
DPT探讨了如何将视觉Transformer应用于密集预测任务(如语义分割、深度估计等)。通过引入层次化特征提取、多尺度特征融合以及专门的密集预测头,改进了ViT架构,使其能够有效处理高分辨率输入并生成像素级预测。

3.损失函数
Fast3R的预测 ![]() 与GT的loss是DUST3R的一个广义版本,即归一化 3D 逐点回归损失的置信加权:
与GT的loss是DUST3R的一个广义版本,即归一化 3D 逐点回归损失的置信加权:
![]()
首先,我们回顾DUST3R的点图loss:

在此基础上,使用confidence-ajusted loss:

我们的直觉是置信度加权有助于模型处理标签噪声。与DUST3R类似,我们在真实世界的扫描数据上进行训练,这些数据通常包含底层点图标签中的系统性误差。例如,在真实激光扫描中,玻璃或薄结构通常无法正确重建,而相机配准中的误差会导致图像与点图标签之间的错位。
参考链接:
Dust3r:
https://zhuanlan.zhihu.com/p/686078541
https://zhuanlan.zhihu.com/p/28169401009
Mast3r:
MASt3R-CSDN博客
https://zhuanlan.zhihu.com/p/17982445115
Fast3r:
【论文笔记】Fast3R:前向并行muti-view重建方法-CSDN博客
相关文章:

Dust3r、Mast3r、Fast3r
目录 一.Dust3r 1.简述 2.PointMap与ConfidenceMap 3.模型结构 4.损失函数 5.全局对齐 二.Mast3r 1.简述 2.MASt3R matching 3.MASt3R sfm 匹配与标准点图 BA优化 三.Fast3r 1.简述 2.模型结构 3.损失函数 三维重建是计算机视觉中的一个高层任务,包…...

HTML5 Web SQL 数据库学习笔记
HTML5 的 Web SQL 数据库曾是一种用于在浏览器客户端存储数据的技术,但目前已被废弃。尽管如此,了解其基本概念和操作方法仍具有一定的学习价值。以下是关于 Web SQL 数据库的学习笔记。 一、Web SQL 数据库概述 1.1 状态与替代方案 Web SQL API 已被…...

Plastiform复制胶泥:高精度表面复制与测量的高效工具
在工业制造和质量检测领域,表面复制和测量是确保产品质量的关键环节。Plastiform复制胶泥作为一种创新材料,凭借其出色的性能和多样化的应用,为用户提供了可靠的解决方案。它能够快速捕捉复杂表面的细节,确保测量结果的准确性&…...

安装 `torch-sparse` 和 `torch-cluster`
✅ 安装 torch-sparse 和 torch-cluster 请直接运行下面这条 一行命令 来装 PyG 剩余依赖(适配我已装好的 PyTorch 2.5.1cpu): pip install torch-sparse torch-cluster -f https://data.pyg.org/whl/torch-2.5.1cpu.html✅ 或者自己去官网…...

Linux之基础知识
目录 一、环境准备 1.1、常规登录 1.2、免密登录 二、Linux基本指令 2.1、ls命令 2.2、pwd命令 2.3、cd命令 2.4、touch命令 2.5、mkdir命令 2.6、rmdir和rm命令 2.7man命令 2.8、cp命令 2.9、mv命令 2.10、cat命令 2.11、echo命令 2.11.1、Ctrl r 快捷键 2…...

[mlr3] Bootstrap与交叉验证k-fold cross validation
五折交叉验证因其无放回分层抽样和重复验证机制,成为超参数调优的首选; 而Bootstrap因有放回抽样的重复性和验证集的不稳定性,主要服务于参数估计(置信区间的计算)而非调优。 实际应用中,可结合两者优势&am…...

自动化构建攻略:Jenkins + Gitee 实现 Spring Boot 项目自动化构建
Jenkins Gitee 实现 Spring Boot 项目自动化构建 环境准备安装配置jdk安装配置maven安装git安装配置Jenkins 测试构建测试自动化触发 环境准备 云服务器环境: 系统版本:Ubuntu 24.04 64位ecs规格:4核(vCPU)8 GiB公网带宽:10Mbi…...

Python 中的不可变数据类型的解析
# Python 中的不可变数据类型的解析 在 Python 的世界里,数据类型扮演着至关重要的角色。根据数据是否可以在创建后被修改,Python 数据类型可分为可变和不可变两类。本文将聚焦于不可变数据类型,详细介绍它们的特点,并结合具体实例…...

【Kafka】分布式消息队列的核心奥秘
文章目录 一、Kafka 的基石概念主题(Topic)分区(Partition)生产者(Producer)消费者(Consumer) 二、Kafka 的架构探秘Broker 集群副本机制 三、Kafka 的卓越特性高…...

基于Promise链式调用的多层级请求性能优化
代码优化-循环嵌套关联请求 1. 背景 在实际开发中,我们经常会遇到需要嵌套关联请求的场景,比如: 获取项目列表获取项目详情获取项目进度 2. 问题 在这种场景下,我们可能会遇到以下问题: 串行请求瀑布流ÿ…...

RuoYi基础学习
1 若依搭建 前后端分离版本:RuoYi-Vue利用SpringBoot作为后端开发框架,与Vue.js结合,实现了前后端分离的开发模式。这种架构有助于提高开发效率,前后端可以独立开发和部署,更适合现代化的Web应用开发。 RuoYi-Vue3&a…...

解决关于原生gmssl无法直接输出sm2私钥明文的问题
解决关于原生gmssl无法直接输出sm2私钥明文的问题 问题描述解决方法解决方法一解决方法二 问题描述 通过gmssl生成sm2公私钥对时,输出的是加密的sm2私钥,无法获取到SM2私钥明文。 解决方法 解决方法一 手动解密: 解决方法二 修改源码&…...

AT24Cxx移植第三方库到裸机中使用
简介 MCU : STM32F103C8T6 库: HAL库裸机开发 EEPROM : AT24C02, 256Byte容量,I2C接口 电路图 AT24C02 电路图 电路图引用 逻辑直接读写 // 写入数据到 EEPROM HAL_StatusTypeDef EEPROM_WriteByte(uint16_t MemAddress, uint8_t Data) {// 发送数据uint8_t …...

【落羽的落羽 C++】内存区域、C++的内存管理
文章目录 一、内存区域二、C的内存管理1. new和delete2. new和delete的特点3. 实现的原理 一、内存区域 C语言和C中,我们常把计算机的内存分为不同的区域,有各自不同的功能: 栈区:存放函数的局部变量、参数、返回地址等。堆区&a…...
)
星际旅行(去年蓝桥杯省赛b组-第7题)
题目链接: 蓝桥账户中心 朋友分享给我一道题,我刚开始其实先用dfs写,但是直接就超时了(很大的一部分原因是截图中没有数据范围) #include<bits/stdc.h> using namespace std; const int MAXN 1e97; vector<int> graph[MAXN]; bool visite…...

转发和重定向的区别详解
转发(Forward)和重定向(Redirect)是 Web 开发中两种常用的请求处理方式,主要用于将客户端请求从一个资源转移到另一个资源。它们在实现机制、行为表现和应用场景上有显著区别,以下是对两者的详细解析&#…...

HarmonyOS NEXT——【鸿蒙相册图片以及文件上传Picker封装】
1、鸿蒙系统文件/图片上传base64: 鸿蒙应用需要上传图片或者文件时,由于更高的安全性与更严谨的访问权限,通常无法直接从系统相册或文件管理中直接上传,因此我们可以通过picker对象去拉起相册访问的能力,引导用户选择…...

Java中文件copy的5种方式
Java中文件copy的5种方式 传统字节流缓冲流jdk7 Files.copy通道(零拷贝)内存映射对比 传统字节流 缓冲流 jdk7 Files.copy 通道(零拷贝) 内存映射 对比...

Nacos Client 模块的作用是什么?是如何与 Server 端通信的?
Nacos Client 模块是 Nacos 架构中的重要组成部分,它负责与 Nacos Server 端进行交互,实现服务注册、服务发现、配置管理等核心功能。 可以将 Nacos Client 理解为 Nacos 提供给应用程序使用的 SDK。 Nacos Client 模块的主要作用: 服务注册 (Service R…...

c中的变量命名规则
在 C 中,变量命名需要遵循一定的规则和约定,以确保代码的可读性和合法性。以下是 C 变量命名的详细规则: 1. 基本规则 字母开头:变量名必须以字母(a-z 或 A-Z)或下划线(_)开头&…...
详解)
DDR(Double Data Rate)详解
一、DDR的定义与核心特性 DDR(双倍数据率同步动态随机存取存储器) 是一种 基于时钟上升沿和下降沿传输数据的高速内存技术,广泛应用于计算机、嵌入式系统、移动设备等领域。其核心特性包括: 双倍数据率:每个时钟周期传…...

aocache:AOCache 新增功能深度解析:从性能监控到灵活配置的全方位升级
最近对aocache 进行了重要升级,最新版本0.6.0增加了几项新功能:性能分析日志,AOCache性能分析工具,切入点自定义配置,全局配置,本文详细说明这几项目新功能的作用和使用方式。 一、性能分析日志 需求背景…...
-引入IK solver控制机器人)
IsaacLab最新2025教程(7)-引入IK solver控制机器人
机器人控制可以直接给定关节角进行驱动实现功能,完成任务,但是关节角不是很直观而且做teleoperation或者是结合VLA模型时候,用eef pose会更符合直觉一些,isaacsim用的是LulaKinematics,因为IsaacLab现在是ETHZ的团队在…...

【测试】每日3道面试题 3/30
每日更新,建议关注收藏点赞。 白盒测试逻辑覆盖标准?哪种覆盖标准覆盖率最高? 5种。语句覆盖、分支/判定覆盖、条件覆盖、条件组合覆盖【覆盖率最高,所有可能条件组合都验证】、路径覆盖【理论上最高,但实际很难实现】…...

矩阵中对角线的遍历问题【C++】
1,按对角线进行矩阵排序 题目链接:3446. 按对角线进行矩阵排序 - 力扣(LeetCode) 【题目描述】 对于一个m*n的矩阵grid,要求对该矩阵进行 变换,使得变换后的矩阵满足: 主对角线右上的所有对角…...

自动化与智能化的认知差异
从认知心理学的角度对自动化和智能化进行了区分,我们可以从同化、顺应、平衡、图式方面来理解:一、自动化与图式及同化(1)图式是认知心理学中的一个重要概念,指个体对世界的知觉经验和理解方式,是个体过去经…...

leetcode 2360 图中最长的环 题解
题面 给定一个有向图,每个点出度最大为一,现在问你图中最长的环的长度是多少,如果没有环输出 -1, 1 ≤ n ≤ 1 0 5 1 \le n \le 10^5 1≤n≤105。 题面 解题思路 我们直接说结论,我们从任意一个点出发,用…...

鸿蒙UI开发
鸿蒙UI开发 本文旨在分享一些鸿蒙UI布局开发上的一些建议,特别是对屏幕宽高比发生变化时的应对思路和好的实践。 折叠屏适配 一般情况(自适应布局/响应式布局) 1.自适应布局 1.1自适应拉伸 左右组件定宽 TypeScript //左右定宽 Row() { …...

华宇TAS应用中间件与晓窗科技智慧校园管理一体化平台完成兼容互认证
近日,华宇TAS应用中间件与安徽晓窗教育科技有限公司(以下简称晓窗科技)的智慧校园管理一体化平台V1.0完成兼容性认证。经双方联合测试,两款产品在稳定性、安全性以及性能等方面表现优异,可以满足政企客户对于数据安全以…...

Java——数组
一、数组是? 数组就是一个容器,用于存储一批同种类型的数据。 数组变量名中存储的是数组在内存中的地址,数组是一种引用数据类型。 二、静态初始化数组 (一)定义 即定义数组的时候直接给数组赋值。 (…...

MySQL排序详解
MySQL支持两种方式排序filesort和indexindex是指扫描索引本身完成排序,index效率高filesort是指通过内存或者排序文件完成排序,filesort效率低 order by满足两种情况时会使用index排序 order by语句使用索引最左列where条件字段和order by字段组合满足索…...

【python实战】-- 选择解压汇总mode进行数据汇总20250329更新
系列文章目录 文章目录 系列文章目录前言一、功能列表二、程序如下:总结 前言 一、功能列表 该模板用于多功能数据汇总处理: 1、用于解压压缩包,输入指定路径,即可解压多级压缩文件; 2、镜筒反射率、LAB文件汇总&…...

Java 程序员面试题:从基础到高阶的深度解析
引言 Java 作为全球最流行的编程语言之一,其面试题不仅考察候选人的编程能力,更关注对底层原理和架构设计的理解。本文将系统梳理 Java 面试中的高频考点,结合代码示例与原理分析,助您从容应对技术面试。 一、Java 基础语法与核…...
:带验证码的用户登录)
JSP(实验):带验证码的用户登录
[实验目的] 1.掌握应用request对象获取表单提交的数据。 2.掌握解决获取表单提交数据产生中文乱码的问题。 3.掌握使用response对象进行定时跳转功能。 4.掌握使用session对象完成登录和注销功能。 [实验要求] 设计带验证码…...
)
【安全运营】关于攻击面管理相关概念的梳理(二)
CYNC(持续可见性和网络控制) CYNC(Continuous Visibility and Network Control)即“持续可见性和网络控制”,是一个与网络安全和IT运营管理相关的概念。它强调的是在一个组织的数字环境中,确保对所有资产、…...

【Linux篇】进程入门指南:操作系统中的第一步
步入进程世界:初学者必懂的操作系统概念 一. 冯诺依曼体系结构1.1 背景与历史1.2 组成部分1.3 意义 二. 进程2.1 进程概念2.1.1 PCB(进程控制块) 2.2 查看进程2.2.1 使用系统文件查看2.2.2 使⽤top和ps这些⽤⼾级⼯具来获取2.2.3 通过系统调用…...
)
Linux进程状态补充(10)
文章目录 前言一、阻塞二、挂起三、运行R四、休眠D五、四个重要概念总结 前言 上篇内容大家看的云里雾里,这实在是正常不过,因为例如 写实拷贝 等一些概念的深层原理我还没有讲解,大家不用紧张,我们继续往下学习就行!&…...
、STM32F1xx_DFP、 ST-Link、STM32CubeMX】)
STM32_HAL开发环境搭建【Keil(MDK-ARM)、STM32F1xx_DFP、 ST-Link、STM32CubeMX】
安装Keil(MDK-ARM)【集成开发环境IDE】 我们会在Keil(MDK-ARM)上去编写代码、编译代码、烧写代码、调试代码。 Keil(MDK-ARM)的安装方法: 教学视频的第02分03秒开始看。 安装过程中请修改一下下面两个路径,避免占用C盘空间。 Core就是Keil(MDK-ARM)的…...

全自动数字网络机器人:重塑未来的无形引擎 ——从金融量化到万物互联,为何必须“ALL IN”?
全自动数字网络机器人:重塑未来的无形引擎 ——从金融量化到万物互联,为何必须“ALL IN”? (2025年3月29日) “未来十年,代码将比石油更具价值。” —— DeepSeek创始人梁文锋 一、数据洪流与AI进化&#…...

每日一题之修建灌木
问题描述 爱丽丝要完成一项修剪灌木的工作。 有 N 棵灌木整齐的从左到右排成一排。爱丽丝在每天傍晩会修剪一棵灌 木, 让灌木的高度变为 0 厘米。爱丽丝修剪灌木的顺序是从最左侧的灌木开始, 每天向右修剪一棵灌木。当修剪了最右侧的灌木后, 她会调转方向, 下一天开 始向左修…...

智能仪表板DevExpress Dashboard v24.2新版亮点:支持.NET 9
使用DevExpress BI Dashboard,再选择合适的UI元素(图表、数据透视表、数据卡、计量器、地图和网格),删除相应参数、值和序列的数据字段,就可以轻松地为执行主管和商业用户创建有洞察力、信息丰富的、跨平台和设备的决策…...

ubuntu下终端打不开的排查思路和解决方法
问题现象描述:ubuntu开机后系统桌面显示正常,其他图形化的app也都能打开无异常,唯独只有terminal终端打不开,无论是鼠标点击终端软件,还是ctrlaltt,还是altF2后输入gnome-terminal后按回车,这三…...

鸿蒙项目源码-天气预报app-原创!原创!原创!
鸿蒙天气预报项目源码包运行成功含文档ArkTS语言。 我半个月写的原创作品,请尊重原创。 原创作品,盗版必究!!!! 原创作品,盗版必究!!!! 原创作品…...
)
Turtle事件处理(键盘与鼠标交互)
Turtle 提供了 事件驱动编程,允许我们使用 键盘 和 鼠标 控制 Turtle,从而实现交互式绘图。例如,我们可以让 Turtle 响应 按键、鼠标点击 和 拖动 事件,使其根据用户的输入进行移动、旋转或绘制图形。 1. 事件机制概述 Turtle 的事件处理主要依赖 turtle.Screen() 提供的 …...

算法基础——模拟
目录 1 多项式输出 2.蛇形方阵 3.字符串的展开 模拟,顾名思义,就是题⽬让你做什么你就做什么,考察的是将思路转化成代码的代码能⼒。这类题⼀般较为简单,属于竞赛⾥⾯的签到题(但是,万事⽆绝对ÿ…...
和联想(Lenovo)作为全球两大电脑品牌,并不是简单的“拼接电脑”)
惠普(HP)和联想(Lenovo)作为全球两大电脑品牌,并不是简单的“拼接电脑”
惠普(HP)和联想(Lenovo)作为全球两大电脑品牌,并不是简单的“拼接电脑”,它们都有自己的核心技术、专利设计和生态体系。以下是它们“自己的”核心部分: 1. 关键自研技术 品牌自研技术/专利说明…...

一些练习 C 语言的小游戏
一些练习 C 语言的小游戏 — 1. 猜数字游戏 描述:程序随机生成一个数字,玩家需要猜测这个数字,并根据提示(太高或太低)调整猜测,直到猜中为止。 功能点: 随机数生成 (rand() 函数)。循环和…...

曲线拟合 | Matlab基于贝叶斯多项式的曲线拟合
效果一览 代码功能 代码功能简述 目标:实现贝叶斯多项式曲线拟合,动态展示随着数据点逐步增加,模型后验分布的更新过程。 核心步骤: 数据生成:在区间[0,1]生成带噪声的正弦曲线作为训练数据。 参数设置:…...
)
Python 序列构成的数组(对序列使用+和_)
对序列使用和* Python 程序员会默认序列是支持 和 * 操作的。通常 号两侧的序列由 相同类型的数据所构成,在拼接的过程中,两个被操作的序列都不会被 修改,Python 会新建一个包含同样类型数据的序列来作为拼接的结果。 如果想要把一个序列…...

洛谷题单1-P5703 【深基2.例5】苹果采购-python-流程图重构
题目描述 现在需要采购一些苹果,每名同学都可以分到固定数量的苹果,并且已经知道了同学的数量,请问需要采购多少个苹果? 输入格式 输入两个不超过 1 0 9 10^9 109 正整数,分别表示每人分到的数量和同学的人数。 输…...