Python数据结构与算法-基础预热篇
目录
语言基础
1.内置函数
1.1math库
1.2collections
1.2.1Counter:计数器
1.2.2deque双端对列
1.2.3defaultdict有默认值的字典
1.3heapq堆(完全二叉树)
1.4functool
1.5itertools
1.5.1无限迭代器
1.5.2有限迭代器
1.5.3排列组合迭代器
2.序列变量相关
2.1enumerate(iterable, start=0)
2.2filter(function, iterable)
2.3format(value[, format_spec])
2.4len(s)
2.5list([iterable])
2.6map(function, iterable, ...)
2.7reversed(seq)
2.8slice(stop)
2.9slice(start, stop, step)
2.10sorted(iterable, *, key=None, reverse=False)
2.11tuple([iterable])
2.12zip(*iterables)
3.进制转换
3.1bin(x)
3.2hex(x)
3.3oct(x)
4.常用函数
4.1数学操作函数
4.2序列和集合操作
4.3类型转换和判断
4.4其他常用
语言基础
1.内置函数
1.1math库

1.1.1math.e:
返回欧拉数(Euler's number),大约等于 2.71828。
1.1.2math.inf:
返回正无穷大浮点数(Infinity)。
1.1.3math.nan:
返回一个浮点值 NaN(Not a Number),表示不是一个数字。
1.1.4math.pi:
π,一般指圆周率,大约等于 3.14159。
1.1.5math.tau:
数学常数 τ(tau),大约等于 6.283185,精确到可用精度。Tau 是一个圆周常数,等于 2π,即圆的周长与半径之比。
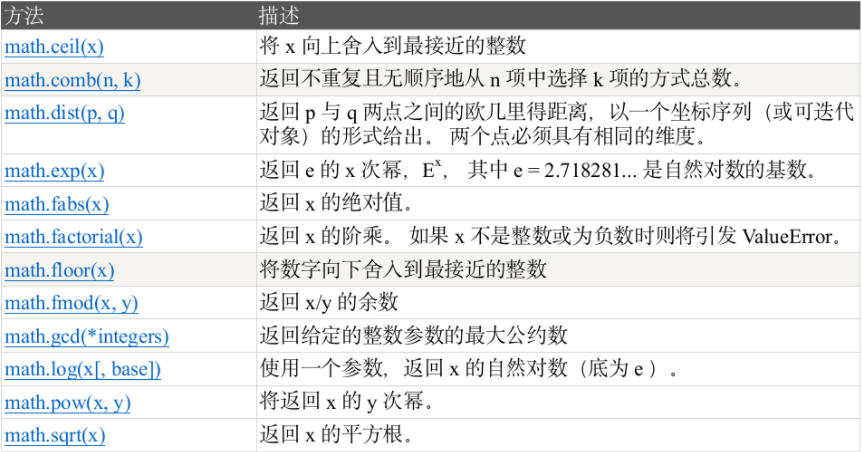
1.1.6math.ceil(x):
将 x 向上舍入到最接近的整数。
1.1.7math.comb(n, k):
返回不重复且无顺序地从 n 项中选择 k 项的方式总数,即组合数。
1.1.8math.dist(p, q):
返回 p 与 q 两点之间的欧几里得距离,以一个坐标序列(或可迭代对象)的形式给出。两个点必须具有相同的维度。
1.1.9math.exp(x):
返回 e 的 x 次幂,其中 e ≈ 2.71828... 是自然对数的基数。
1.1.10math.fabs(x):
返回 x 的绝对值。
1.1.11math.factorial(x):
返回 x 的阶乘。如果 x 不是整数或为负数时则将引发 ValueError。
1.1.12math.floor(x):
将数字向下舍入到最接近的整数。
1.1.13math.fmod(x, y):
返回 x/y 的余数。
1.1.14math.gcd(*integers):
返回给定的整数参数的最大公约数。
1.1.15math.log([x, base]):
使用一个参数,返回 x 的自然对数(底为 e)。如果提供第二个参数 base,则返回以 base 为底的对数。
1.1.16math.pow(x, y):
将返回 x 的 y 次幂。
1.1.17math.sqrt(x):
返回 x 的平方根。

1.1.18math.cos(x):
返回 x 弧度的余弦值。
1.1.19math.sin(x):
返回 x 弧度的正弦值。
1.1.20math.tan(x):
返回 x 弧度的正切值。
1.1.21math.acos(x):
返回 x 的反余弦值,结果范围在 0 到 π 之间。
1.1.22math.asin(x):
返回 x 的反正弦值,结果范围在 -π/2 到 π/2 之间。
1.1.23math.atan(x):
返回 x 的反正切值,结果范围在 -π/2 到 π/2 之间。
1.1.24math.cosh(x):
返回 x 的双曲余弦值。
1.1.25math.degrees(x):
将角度 x 从弧度转换为度数。
1.1.26math.radians(x):
将角度 x 从度数转换为弧度。
1.1.27math.sinh(x):
返回 x 的双曲正弦值。
1.1.28math.cosh(x):
再次列出,应该是重复,返回 x 的双曲余弦值。
1.1.29math.tanh(x):
返回 x 的双曲正切值。
1.2collections
1.2.1Counter:计数器
调用
from collections import Counter
most_common(k):筛选并返回出现频率最高的 k 个元素及其计数。
from collections import Counter
c = Counter(['apple', 'orange', 'apple', 'pear', 'orange', 'banana'])
print(c.most_common(2)) # 输出出现频率最高的两个元素
elements():返回一个迭代器,迭代器中的每个元素会根据其在数据结构中出现的次数重复对应次数。
for element in c.elements():
print(element)
clear():清空数据结构中的所有元素。
c.clear()
字典功能:Counter 对象继承自字典,因此可以使用字典的大部分方法,如 keys(), values(), items(), get() 等。
print(c.keys()) # 输出所有元素
print(c.values()) # 输出所有计数
print(c.items()) # 输出元素及其计数的元组列表
数学运算:Counter 对象支持加法、减法、交集、并集等数学运算。
c1 = Counter(['apple', 'orange'])
c2 = Counter(['orange', 'banana'])
print(c1 + c2) # 并集
print(c1 - c2) # 差集
1.2.2deque双端对列

调用
from collections import deque
append(x):添加元素 x 到双端队列的右端。
# 创建一个空的双端队列
d = deque()# 添加元素到右端
d.append(1)
d.append(2)
d.append(3)
print(list(d)) # 输出: [1, 2, 3]
appendleft(x):添加元素 x 到双端队列的左端。
# 添加元素到左端
d.appendleft(0)
d.appendleft(-1)
d.appendleft(-2)
print(list(d)) # 输出: [-2, -1, 0, 1, 2, 3]
pop():移除并返回双端队列最右侧的一个元素。
# 移除并返回最右侧的元素
print(d.pop()) # 输出: 3
print(list(d)) # 输出: [-2, -1, 0, 1, 2]
popleft():移除并返回双端队列最左侧的一个元素。
# 移除并返回最左侧的元素
print(d.popleft()) # 输出: -2
print(list(d)) # 输出: [-1, 0, 1, 2]
insert(i, x):在位置 i 插入元素 x。
# 在位置 i 插入元素 x
d.insert(2, 1.5)
print(list(d)) # 输出: [-1, 0, 1.5, 1, 2]
extend(iterable):扩展双端队列的右侧,通过添加 iterable 参数中的元素。
# 扩展双端队列的右侧
d.extend([4, 5, 6])
print(list(d)) # 输出: [-1, 0, 1.5, 1, 2, 4, 5, 6]
extendleft(iterable):扩展双端队列的左侧,通过添加 iterable 参数中的元素。注意,左添加时,在结果中 iterable 参数中的顺序将被反过来添加。
# 扩展双端队列的左侧,注意添加的顺序会被反转
d.extendleft([7, 8, 9])
print(list(d)) # 输出: [9, 8, 7, -1, 0, 1.5, 1, 2, 4, 5, 6]
remove(value):移除找到的第一个值为 value 的元素。
# 移除找到的第一个值为 value 的元素
d.remove(1.5)
print(list(d)) # 输出: [9, 8, 7, -1, 0, 1, 2, 4, 5, 6]
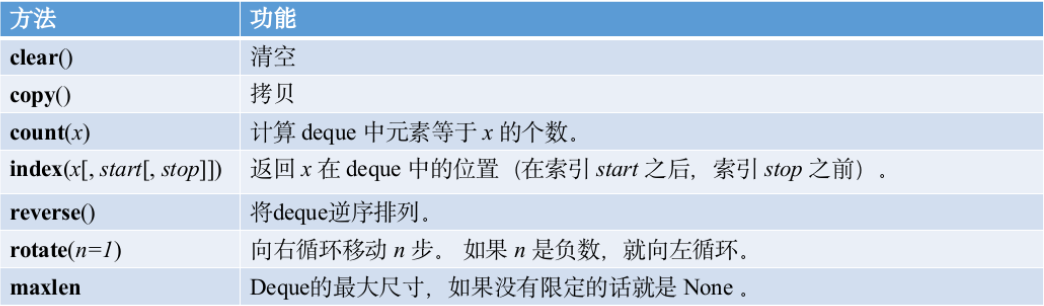
调用
from collections import deque
clear():清空双端队列中的所有元素。
# 创建一个双端队列
d = deque([1, 2, 3, 4, 5])# 清空双端队列中的所有元素
d.clear()
print(list(d)) # 输出: []
copy():返回双端队列的一个拷贝。拷贝的内容赋值给一个新的对象存储在内存中。
# 创建一个双端队列并返回其拷贝
d = deque([1, 2, 3, 4, 5])
d_copy = d.copy()
print(list(d))
print(list(d_copy)) # 输出与原始双端队列相同
count(x):计算双端队列中元素等于 x 的个数。
# 计算双端队列中元素等于 x 的个数
d = deque([1, 2, 2, 3, 2, 4])
count_of_2 = d.count(2)
print(count_of_2) # 输出: 3
index(x[, start[, stop]]):返回 x 在双端队列中的位置(在索引 start 之后,索引 stop 之前)。如果元素不存在,则抛出 ValueError。
# 返回 x 在双端队列中的位置
index_of_3 = d.index(3)
print(index_of_3) # 输出: 2index_of_null = d.index(7)
print(index_of_null) # 输出: ...ValueError:...
reverse():将双端队列中的元素逆序排列。
# 将双端队列中的元素逆序排列
d.reverse()
print(list(d)) # 输出: [4, 2, 3, 2, 2, 1]
rotate(n):向右循环移动 n 步。如果 n 是负数,就向左循环。例如,d.rotate(1) 会将 d 的最后一个元素移动到第一个位置,其他元素相应地向右移动。
# 向右循环移动 n 步
d.rotate(1)
print(list(d)) # 输出: [2, 4, 2, 3, 2, 1]# 向左循环移动 n 步
d.rotate(-1)
print(list(d)) # 输出: [1, 2, 4, 2, 3, 2]
maxlen:双端队列的最大尺寸,如果没有限定的话就是 None,表示双端队列可以无限增长。
# 设置双端队列的最大尺寸
d = deque(maxlen=3)
d.extend([1, 2, 3])
print(list(d)) # 输出: [1, 2, 3]d.append(4)
print(list(d)) # 输出: [2, 3, 4],因为限制了队列长度,1被移除了(最左边的先出队列,符合队列的基本性质)
1.2.3defaultdict有默认值的字典
普通的字典(dict对象),查询的key不存在时,会报错。
在字典中获取一个键(key)有两种方法:
使用 get 方法
使用 [] 操作符
使用普通的字典(dict)时,如果引用的键不存在,就会抛出 KeyError。
from collections import defaultdict# 创建一个默认值为整数0的defaultdict
d = defaultdict(int)
# x元素是不存在d中的
print(d['x']) # 输出: 0,因为int()默认值为0# 创建一个默认值为空列表的defaultdict
d = defaultdict(list)
print(d['x']) # 输出: [], 因为list()默认值为空列表# 创建一个默认值为空集的defaultdict
d = defaultdict(set)
print(d['x']) # 输出: set(), 因为set()默认值为空集# 创建一个默认值为空字典的defaultdict
d = defaultdict(dict)
print(d['x']) # 输出: {}, 因为dict()默认值为空字典
如果希望在键不存在时返回一个默认值,可以使用 defaultdict。
1.3heapq堆(完全二叉树)
堆(Heap)是一种特殊的完全二叉树数据结构,满足以下特性:
1.完全二叉树:堆是一棵完全二叉树,即除最后一层外,其他层的节点都被元素填满,且最后一层的节点尽可能地从左到右排列。
2.堆序性质:在最大堆中,每个节点的值都大于或等于其子节点的值;在最小堆中,每个节点的值都小于或等于其子节点的值。
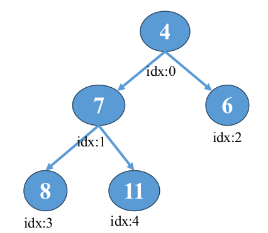
堆通常通过数组来实现,因为完全二叉树可以高效地映射到数组中。
在数组表示中,假设根节点存储在数组的第一个位置(索引为0),对于任意一个节点,其父节点和子节点的位置可以通过以下公式计算:
父节点索引:parent(i) = (i - 1) // 2
左子节点索引:left(i) = 2 * i + 1
右子节点索引:right(i) = 2 * i + 2
堆的常见操作包括:
1.插入元素:将新元素添加到堆中,并通过上浮操作(sift up)维护堆的性质。
2.删除堆顶元素:移除堆顶元素(最大堆的最大值或最小堆的最小值),并通过下沉操作(sift down)重新平衡堆。
3.构建堆:将无序数组转换为堆结构,常用的方法是从最后一个非叶子节点开始,依次对每个节点进行下沉操作。
eg:
使用list表示一个堆
1.将无序List转换成最小堆:
heapq.heapify(a)
2.最小堆a中添加元素x:
heapq.heappush(a, x)
3.弹出并返回最小元素:
heapq.heappop(a)
4.弹出并返回最小元素,同时添加元素x:
heapq.heapreplace(a, x)
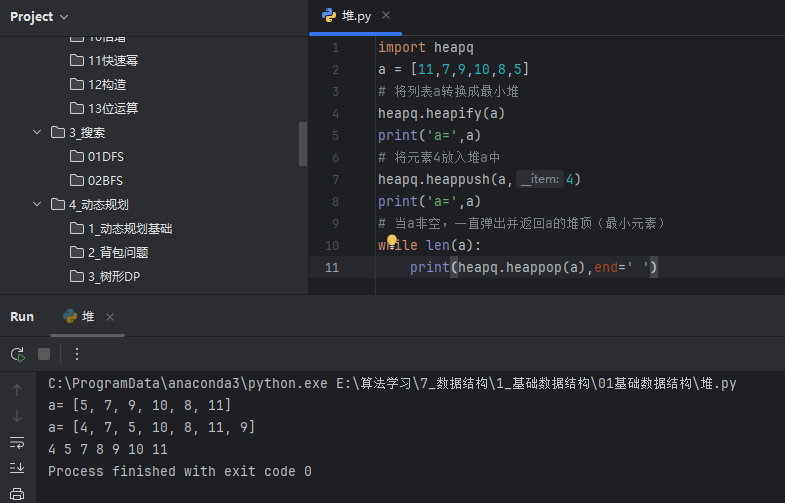
import heapq
a = [11,7,9,10,8,5]
# 将列表a转换成最小堆
heapq.heapify(a)
print('a=',a)
# 将元素4放入堆a中
heapq.heappush(a,4)
print('a=',a)
# 当a非空,一直弹出并返回a的堆顶(最小元素)
while len(a):print(heapq.heappop(a),end=' ')
1.4functool
functools 模块用于高阶函数,即参数或返回值为其他函数的函数。
partial 函数用于“冻结”某些函数的参数或关键字参数,然后返回一个新函数。
partial 函数的使用:
functools.partial(func, *args, **keywords),其中:func 是需要被扩展的函数。
*args 是需要被固定的位置参数。
**keywords 是需要被固定的关键字参数。
from functools import partial# 定义一个函数,接受任意数量的位置参数和关键字参数
def add(*args, **kwargs):# 打印位置参数for n in args:print(n)# 打印关键字参数for k, v in kwargs.items():print('s:s' % (k, v))# 普通调用
add(1, 2, 3, v1=10, v2=20)
"""
1
2
3
v1:10
v2:20
"""# 使用 partial 创建偏函数
add_partial = partial(add, 10, k1=10, k2=20)
add_partial(1, 2, 3, k3=20)
"""
1
2
3
10
k1:10
k2:20
k3:20
"""
偏函数在函数式编程中的主要用途:
固定参数:创建预设参数的新函数,便于重复调用。
提高可读性:减少重复参数设置,使代码更清晰。
函数重用:通过定制通用函数行为,避免定义多个相似函数。
延迟计算:在调用时才计算结果,适用于昂贵或条件触发的计算。
柯里化:将多参数函数转换为单参数函数,增强灵活性。
装饰器:为函数添加额外行为,如日志记录或性能监控。
高阶函数:简化高阶函数的使用,使其更易于理解和应用。
参数默认值:在默认值可能变化时,模拟默认参数行为。
1.5itertools
1.5.1无限迭代器
生成长度为无限的迭代器:
调用
import itertools
count(start=0, step=1):
count 函数创建一个迭代器,从 start 值开始,每次增加 step 值。默认 start 是 0,step 是 1。
这个迭代器会无限地生成连续的整数。
# 使用 count 函数
counter = itertools.count(10, 5) # 从 10 开始,每次增加 5
for i in itertools.islice(counter, 5): # 使用 islice 来限制迭代次数,避免无限循环
print(i)
cycle(iterable):
cycle 函数创建一个迭代器,它会循环遍历 iterable 中的所有元素。当元素遍历完成后,迭代器会从头开始再次遍历,形成一个无限循环。
# 使用 cycle 函数
cyclic = itertools.cycle([1, 2, 3])
for i in itertools.islice(cyclic, 10): # 同样使用 islice 来限制迭代次数
print(i)
repeat(object[, times]):
repeat 函数创建一个迭代器,如果没有指定 times 参数,它会无限循环遍历 object。
如果指定了 times 参数,迭代器会遍历 object 指定的次数。
# 使用 repeat 函数
repeated = itertools.repeat('hello', 5) # 重复 'hello' 5 次
for i in repeated:
print(i)
1.5.2有限迭代器
from itertools import accumulate
accumulate(iterable[, func]):
accumulate 函数创建一个迭代器,返回基于 iterable 中的元素的累积汇总值。
如果没有提供 func 参数,默认执行加法操作,即返回元素的累积和。
如果提供了 func 参数,将使用这个双目(两个参数的)函数来计算累积结果。
示例:
accumulate([1,2,3,4,5]) 将返回 [1, 3, 6, 10, 15],这是元素的累积和。
accumulate([1,2,3,4,5], max) 将返回 [1, 2, 3, 4, 5],因为 max 函数在累积过程中总是返回当前最大值。
accumulate([1,2,3,4,5], operator.mul) 将返回 [1, 2, 6, 24, 120],因为 operator.mul 函数执行乘法操作。
import operator# 使用 accumulate 函数
print(list(itertools.accumulate([1, 2, 3, 4, 5]))) # 输出: [1, 3, 6, 10, 15]
print(list(itertools.accumulate([1, 2, 3, 4, 5], max))) # 输出: [1, 2, 3, 4, 5]
print(list(itertools.accumulate([1, 2, 3, 4, 5], operator.mul))) # 输出: [1, 2, 6, 24, 120]
chain(*iterables):
chain 函数用于合并多个迭代器。将所有提供的迭代器中的元素串联起来,形成一个单一的迭代器。
示例:
chain('ABC', 'DEF') 将返回一个迭代器,该迭代器生成 'ABCDEF',即两个字符串的串联。
# 使用 chain 函数
print(''.join(itertools.chain('ABC', 'DEF'))) # 输出: ABCDEF
accumulate 函数返回的是一个迭代器,如果要返回一个列表,可以使用 list() 函数来转换。同样,chain 函数也返回一个迭代器,如果要返回一个字符串,可以使用 ''.join() 来转换
1.5.3排列组合迭代器
product(*iterables, repeat=1):
product 函数用于计算可迭代对象的笛卡儿积
*iterables 表示多个可迭代对象,它们的笛卡儿积将被计算
repeat 参数表示这些可迭代序列重复的次数
import itertools# product 示例:计算笛卡儿积
print(list(itertools.product([1, 2, 3], [4, 5, 6])))
# 输出: [(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)]# product 示例:重复同一个可迭代对象
print(list(itertools.product('ab', repeat=2)))
# 输出: [('a', 'a'), ('a', 'b'), ('b', 'a'), ('b', 'b')]
permutations(iterable, r=None):
permutations 函数用于生成可迭代对象中元素的所有可能排列
如果 r 未指定或为 None,则默认为 iterable 的长度,即生成所有元素的排列
如果指定了 r,则生成长度为 r 的排列
# permutations 示例:生成所有排列
print(list(itertools.permutations('ABCD', 2)))
# 输出: [('A', 'B'), ('A', 'C'), ('A', 'D'), ('B', 'A'), ('B', 'C'), ('B', 'D'), ('C', 'A'), ('C', 'B'), ('C', 'D'), ('D', 'A'), ('D', 'B'), ('D', 'C')]# permutations 示例:生成所有元素的排列(r=None 或者不指定)
print(list(itertools.permutations([1, 2, 3, 4])))
# 输出: [(1, 2, 3, 4), (1, 2, 4, 3), (1, 3, 2, 4), ...]
combinations(iterable, r):
combinations 函数用于生成可迭代对象中元素的所有可能组合
r 参数指定了组合的长度
# combinations 示例:生成所有组合
print(list(itertools.combinations('ABCD', 2)))
# 输出: [('A', 'B'), ('A', 'C'), ('A', 'D'), ('B', 'C'), ('B', 'D'), ('C', 'D')]# combinations 示例:生成长度为3的组合
print(list(itertools.combinations([1, 2, 3, 4, 5], 3)))
# 输出: [(1, 2, 3), (1, 2, 4), (1, 2, 5), (1, 3, 4), (1, 3, 5), (1, 4, 5), (2, 3, 4), (2, 3, 5), (2, 4, 5), (3, 4, 5)]
2.序列变量相关

2.1enumerate(iterable, start=0)
返回一个枚举对象,其中包含计数(从 start 开始,默认为 0)和通过迭代 iterable 获得的值。
# enumerate 示例
for index, value in enumerate(['a', 'b', 'c'], start=1):print(f"{index}: {value}")
2.2filter(function, iterable)
从 iterable 中筛选出使 function 返回 True 的元素,构成一个新的迭代器。
# filter 示例
numbers = [1, 2, 3, 4, 5]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers)
2.3format(value[, format_spec])
将 value 转换为 format_spec 指定格式的字符串表示。
# format 示例
print(format(3.14159, '.2f')) # 格式化为两位小数
2.4len(s)
返回对象 s 的长度,即元素个数。
# len 示例
my_list = [1, 2, 3, 4, 5]
print(len(my_list))
2.5list([iterable])
将 iterable 转换为列表,或者如果未提供参数,则创建一个空列表。
# list 示例
my_iterable = (x for x in range(5))
my_list = list(my_iterable)
print(my_list)
2.6map(function, iterable, ...)
对 iterable 中的每一项应用 function 函数,并返回结果的迭代器。
# map 示例
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x**2, numbers))
print(squared_numbers)
2.7reversed(seq)
返回一个反向迭代器,用于遍历 seq。
# reversed 示例
my_list = [1, 2, 3, 4, 5]
reversed_list = list(reversed(my_list))
print(reversed_list)

2.8slice(stop)
返回一个 slice 对象,用于获取序列的切片。
# slice 示例
my_list = [1, 2, 3, 4, 5]
sliced_list = my_list[1:4:2] # 从索引1开始到索引4,步长为2
print(sliced_list)
2.9slice(start, stop, step)
返回一个 slice 对象,用于获取序列的切片,可以指定起始索引、结束索引和步长。
my_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]# 使用 slice 获取切片
# slice(start, stop, step)
# 从索引 2 开始到索引 7 结束,步长为 2
sliced_list = my_list[slice(2, 7, 2)]
print(sliced_list) # 输出: [2, 4, 6]
2.10sorted(iterable, *, key=None, reverse=False)
将 iterable 中的元素排序并返回一个新的列表。
# sorted 示例
my_list = [3, 1, 4, 1, 5, 9, 2]
sorted_list = sorted(my_list, key=lambda x: -x) # 降序排序
print(sorted_list)
2.11tuple([iterable])
将 iterable 转换为元组,或者如果未提供参数,则创建一个空元组。
# tuple 示例
my_iterable = [1, 2, 3]
my_tuple = tuple(my_iterable)
print(my_tuple)
2.12zip(*iterables)
创建一个聚合了来自每个 iterable 对象中元素的迭代器,元素是元组形式。
# zip 示例
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
zipped = list(zip(list1, list2))
print(zipped)
3.进制转换

3.1bin(x)
将一个整数 x 转换为一个前缀为 '0b' 的二进制字符串。
# bin 示例:转换为二进制字符串
number = 10
bin_str = bin(number)
print(number) # 输出: 0b1010
3.2hex(x)
将一个整数 x 转换为一个前缀为 '0x' 的小写十六进制字符串。
# hex 示例:转换为十六进制字符串
number = 255
hex_str = hex(number)
print(number) # 输出: 0xff
3.3oct(x)
将一个整数 x 转换为一个前缀为 '0o' 的八进制字符串。
# oct 示例:转换为八进制字符串
number = 63
oct_str = oct(number)
print(number) # 输出: 0o77
4.常用函数
4.1数学操作函数

4.2序列和集合操作

4.3类型转换和判断

4.4其他常用

相关文章:

Python数据结构与算法-基础预热篇
目录 语言基础 1.内置函数 1.1math库 1.2collections 1.2.1Counter:计数器 1.2.2deque双端对列 1.2.3defaultdict有默认值的字典 1.3heapq堆(完全二叉树) 1.4functool 1.5itertools 1.5.1无限迭代器 1.5.2有限迭代器 1.5.3排列组合迭代器 2.序…...

构建可扩展、可靠的网络抓取、监控和自动化应用程序的终极指南
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 无论您是企业主、营销人员还是软件开发人员,您都很有可能在某个时候使用过 Web 自动化工具。每个人都希望更聪明地工作…...

【蓝桥杯】重点冲刺
【最高优先级】必考核心算法(占分60%以上) 动态规划(DP) 🌟🌟🌟 背包问题:01背包、完全背包(必须掌握空间优化的一维写法) 线性DP:最长上升子序列(LIS)、最长公共子序列(LCS) 路径问题:网格路径计数(含障碍物)、最小路径和 经典模型:打家劫舍、股票买卖问…...

质量工程师的2025:从“找bug“到“造质量“的职业进化
想象一下,2025年的某天:阅读原文 早晨,AI测试助手已经自动运行了夜间回归测试,并将可疑问题标记出来 你喝着咖啡,通过质量数据看板分析系统健康度 下午的会议上,你正用业务语言向产品经理解释:…...

2025年CNG 汽车加气站操作工题目分享
CNG 汽车加气站操作工题目分享: 单选题 1、CNG 加气站中,加气机的加气软管应( )进行检查。 A. 每天 B. 每周 C. 每月 D. 每季度 答案:A 解析:加气软管是加气操作中频繁使用的部件,每天检…...

【QT5 多线程示例】线程池
线程池 【C并发编程】(九)线程池 QThreadPool 和 QRunnable 是 Qt 提供的线程池管理机制。QRunnable 是一个任务抽象类;定义任务逻辑需要继承QRunnable 并实现 run() 方法。QThreadPool 负责管理线程,并将 QRunnable 任务分配到…...

飞致云荣获“Alibaba Cloud Linux最佳AI镜像服务商”称号
2025年3月24日,阿里云云市场联合龙蜥社区发布“2024年度Alibaba Cloud Linux最佳AI镜像服务商”评选结果。 经过主办方的严格考量,飞致云(即杭州飞致云信息科技有限公司)凭借旗下MaxKB开源知识库问答系统、1Panel开源面板、Halo开…...

FAST-LIVO2 Fast, Direct LiDAR-Inertial-Visual Odometry论文阅读
FAST-LIVO2 Fast, Direct LiDAR-Inertial-Visual Odometry论文阅读 论文下载论文翻译FAST-LIVO2: 快速、直接的LiDAR-惯性-视觉里程计摘要I 引言II 相关工作_直接方法__LiDAR-视觉(-惯性)SLAM_ III 系统概述IV 具有顺序状态更新的误差状态迭代卡尔曼滤波…...

kubesphere 终端shell连不上的问题
使用nginx代理kubesphere控制台会出现容器的终端shell连不上的问题 下面是一个样例配置可以解决这个问题: 注意修改为你的ip地址: upstream k8s { ip_hash; server masterip1:30880; server masterip2:30880; server masterip3:30880; } nginx.conf #…...

无人机,雷达定点飞行时,位置发散,位置很飘,原因分析
参考: 无人车传感器 IMU与GPS数据融合进行定位机制_gps imu 组合定位原始数-CSDN博客 我的无人机使用雷达定位,位置模式很飘 雷达的更新频率也是10HZ, 而px飞控的频率是100HZ,没有对两者之间的频率差异做出处理 所以才导致无人…...
)
外星人入侵(python设计小游戏)
这个游戏简而言之就是操作一个飞机对前方的飞船进行射击,和一款很久之前的游戏很像,这里是超级低配版那个游戏,先来看看效果图: 由于设计的是全屏的,所以电脑不能截图。。。。 下面的就是你操控的飞船,上面…...

Stereolabs ZED Box Mini:NVIDIA Orin™驱动,双GMSL2输入,智能机器视觉AI新选择”
Stereolabs近日推出了ZED Box Mini,这是一款专为视觉AI设计的紧凑型迷你电脑(ECU)。该产品搭载了NVIDIA Orin™系列处理器,具备强大的AI视觉处理能力,适用于机器人、智能基础设施和工业应用等多种场景。ZED Box Mini以…...

IP协议的介绍
网络层的主要功能是在复杂的网络环境中确定一个合适的路径.网络层的协议主要是IP协议.IP协议头格式如下: 1.4位版本号:指定IP协议的版本,常用的是IPV4,对于IPV4来说,这里的值就是4. 2.4位头部长度,单位也是4个字节,4bit表示的最大数字是15,因此IP头部的最大长度就是60字节 3.…...
)
【入门初级篇】布局类组件的使用(2)
【入门初级篇】布局类组件的使用(2) 视频要点 (1)2分栏场景介绍与实操演示 (2)3分栏场景介绍与实操演示 点击访问myBuilder产品运营平台 CSDN站内资源下载myBuilder 交流请加微信:MyBuilder8…...

高并发金融系统,“可观测-可追溯-可回滚“的闭环审计体系
一句话总结 在高并发金融系统中,审计方案设计需平衡"观测粒度"与"系统损耗",通过双AOP实现非侵入式采集,三表机制保障操作原子性,最终形成"可观测-可追溯-可回滚"的闭环体系。 业务痛点与需求 在…...
Spring Webflux)
(九)Spring Webflux
底层基于Netty实现的Web容器与请求/响应处理机制 参照:Spring WebFlux :: Spring Frameworkhttps://docs.spring.io/spring-framework/reference/6.0/web/webflux.html 一、组件对比 API功能 Servlet-阻塞式Web WebFlux-响应式Web 前端控制器 DispatcherServl…...

如何在Webpack中配置别名路径?
如何在Webpack中配置别名路径? 文章目录 如何在Webpack中配置别名路径?1. 引言2. 配置别名路径的基本原理3. 如何配置别名路径3.1 基本配置3.2 结合Babel与TypeScript3.2.1 Babel配置3.2.2 TypeScript配置 3.3 适用场景与最佳实践 4. 调试与常见问题4.1 …...

office_word中使用宏以及DeepSeek
前言 Word中可以利用DeepSeek来生成各种宏,从而生成我们需要各种数据和图表,这样可以大大减少我们手工的操作。 1、Office的版本 采用的是微软的office2016,如下图: 2、新建一个Word文档 3、开启开发工具 这样菜单中的“开发工具…...

利用GitHub Pages快速部署前端框架静态网页
文章目录 前言GitHub Pages 来部署前端框架(Vue 3 Vite)项目1、配置 GitHub Pages 部署2、将项目推送到 GitHub3、部署到 GitHub Pages4、访问部署页面5、修改代码后的更新部署顺序 前言 可以先参考: 使用 GitHub Pages 快速部署静态网页: …...

前端性能优化思路_场景题
20 万人同时在直播间打赏,前端优化需要考虑高并发、性能优化、流畅体验等问题,涉及 WebSocket 处理、消息去抖、虚拟列表优化、动画优化、CDN 加速 等多个方面。 WebSocket 高并发优化 (1)使用 WebSocket 替代轮询 轮询…...

45 55跳跃游戏解题记录
先是55跳跃游戏,暴力解法会怎样?会超出时间限制,而且有很多细节要注意: func canJump(nums []int) bool {// 处理空数组情况,当nums只剩一个元素时,nums[i:]导致越界。if len(nums) 0 {return false}// 如…...

一个简单的用C#实现的分布式雪花ID算法
雪花ID是一个依赖时间戳根据算法生成的一个Int64的数字ID,一般用来做主键或者订单号等。以下是一个用C#写的雪花ID的简单实现方法 using System; using System.Collections.Concurrent; using System.Diagnostics;public class SnowflakeIdGenerator {// 配置常量p…...

16个气象数据可视化网站整理分享
好的!以下是关于“16个气象数据可视化网站整理分享”的软文: 16个气象数据可视化网站整理分享 气象数据可视化已成为现代气象研究、决策支持以及公众天气服务的重要组成部分。从天气预报到气候变化监测,全球许多气象数据可视化平台为专业人士…...

一周学会Flask3 Python Web开发-SQLAlchemy数据迁移migrate
锋哥原创的Flask3 Python Web开发 Flask3视频教程: 2025版 Flask3 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 模型类(表)不是一成不变的,当你添加了新的模型类,或是在模型类中添加了新的字段,甚至是修改…...
现代C++的关键性概念: 如何利用多维数组的指针安全地遍历所有元素)
[原创](Modern C++)现代C++的关键性概念: 如何利用多维数组的指针安全地遍历所有元素
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、C …...

本地化智能运维助手:基于 LangChain 数据增强 和 DeepSeek-R1 的K8s运维文档检索与问答系统 Demo
写在前面 博文内容为基于 LangChain 数据增强 和 Ollams 本地部署 DeepSeek-R1实现 K8s运维文档检索与问答系统 Demo通过 Demo 对 LEDVR 工作流, 语义检索有基本认知理解不足小伙伴帮忙指正 😃,生活加油 我看远山,远山悲悯 持续分享技术干货…...

中间件框架漏洞攻略
中间件(英语:Middleware)是提供系统软件和应⽤软件之间连接的软件,以便于软件各部件之间的沟通。 中间件处在操作系统和更⾼⼀级应⽤程序之间。他充当的功能是:将应⽤程序运⾏环境与操作系统隔离,从⽽实…...

在 Ubuntu 上安装 Docker 的完整指南
1. 卸载旧版本(如有) 在安装新版本前,建议先卸载旧版本: sudo apt remove docker docker-engine docker.io containerd runc 2. 安装依赖包 更新软件包索引并安装必要的依赖: sudo apt update sudo apt install -y ca-certificates curl gnupg lsb-release 3. 添加 Do…...

Another Redis Desktop Manager下载安装使用
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Another Redis Desktop Manager下载安装使用…...

GitLab 中文版17.10正式发布,27项重点功能解读【一】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

mysql慢查询日志
在 MySQL 中,慢查询日志(Slow Query Log)用于记录执行时间超过指定阈值的 SQL 语句。通过分析慢查询日志,可以优化数据库性能。以下是查看和配置 MySQL 慢查询日志的详细步骤: 1. 检查慢查询日志是否已启用 登录 MySQ…...

unity 截图并且展现在UI中
using UnityEngine; using UnityEngine.UI; using System.IO; using System.Collections.Generic; using System; using System.Collections;public class ScreenshotManager : MonoBehaviour {[Header("UI 设置")]public RawImage latestScreenshotDisplay; // 显示…...
)
Linux上位机开发实践(MPP平台的核心构成)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 芯片行业是一个赢者通吃的行业。也就是说细分领域的前两名,相比较后来者而言,拥有很多无可比拟的优势。以安防市场的soc来说…...

Hosts文件与DNS的关系:原理、应用场景与安全风险
目录 引言 Hosts文件与DNS的基本概念 2.1 什么是Hosts文件? 2.2 什么是DNS? Hosts文件与DNS的关系 Hosts文件的应用场景 4.1 本地开发与测试 4.2 屏蔽广告与恶意网站 4.3 绕过DNS污染或劫持 Hosts文件的优势 5.1 解析速度快 5.2 不受DNS缓存影…...

Stable Diffusion vue本地api接口对接,模型切换, ai功能集成开源项目 ollama-chat-ui-vue
1.开启Stable Diffusion的api服务 编辑webui-user.bat 添加 –api 开启api服务,然后保存启动就可以了 2.api 文档地址 http://127.0.0.1:7860/docs3. 文生图 接口 地址 /sdapi/v1/txt2img //post 请求入参 {enable_hr: false, // 开启高清hrdenoising_stre…...

【含文档+源码】基于SpringBoot的过滤协同算法之网上服装商城设计与实现
项目介绍 本课程演示的是一款 基于SpringBoot的过滤协同算法之网上服装商城设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署…...
)
优化 Docker 构建之方法(Methods for Optimizing Docker Construction)
优化 Docker 构建之方法 优化 Docker 构建不仅是为了提高效率,它还是降低部署成本、确保安全性和保持跨环境一致性的有效方法。每个层、依赖项和配置选择都会影响镜像的大小、安全性和可维护性。大型镜像部署速度较慢且消耗更多资源,这会增加成本&#…...

谈谈空间复杂度考量,特别是递归调用栈空间消耗?
空间复杂度考量是算法设计的核心要素之一,递归调用栈的消耗问题在前端领域尤为突出。 以下结合真实开发场景进行深度解析: 一、递归调用栈的典型问题 1. 深层次DOM遍历的陷阱 // 危险操作:递归遍历未知层级的DOM树 function countDOMNode…...

四川省汽车加气站操作工备考题库及答案分享
1.按压力容器的设计压力分为( )个压力等级。 A. 三 B. 四 C. 五 D. 六 答案:B。解析:按压力容器的设计压力分为低压、中压、高压、超高压四个压力等级。 2.缓冲罐的安装位置在天然气压缩机( )。 A. 出口处 …...

《探秘SQL的BETWEEN:解锁数据范围查询的深度奥秘》
在数据的广袤宇宙中,结构化查询语言(SQL)宛如一座精密的导航系统,引导我们穿越数据的浩瀚星河,精准定位所需信息。其中,BETWEEN作为SQL的关键工具之一,以其独特的能力,在数据的海洋里…...

AppArmor 使用说明
目录 一:AppArmor 功能介绍二:AppArmor 配置介绍1、AppArmor 配置文件存放路径2、AppArmor 配置文件命名规则 三: AppArmor 工作模式1、AppArmor 两种工作模式2、查看当前进程的工作模式3、给指定进程切换工作模式4、重新加载配置文件生效 四…...

Linux的一些常见指令
一、ls指令 语法: ls (选项) 功能: ls可以查看当前目录下的所有文件和目录。 常用选项: -a:列出目录下的所有文件,包括以点(.)开头的隐含文件 。-d:将目录像文件一样显示,不显示其下的文件。…...

MATLAB中getfield函数用法
目录 语法 说明 示例 访问标量结构体的字段 嵌套结构体的字段 结构体数组元素的字段 嵌套结构体数组的索引 字段的元素 getfield函数的功能是结构体数组字段。 语法 value getfield(S,field) value getfield(S,field1,...,fieldN) value getfield(S,idx,field1,..…...

算法 | 河马优化算法原理,公式,应用,算法改进及研究综述,matlab代码
以下是关于河马优化算法(Hippopotamus Optimization Algorithm, HO)的完整综述,包含原理、公式、应用场景、改进方向及可直接运行的 Matlab 完整代码。一、算法原理 河马优化算法(HO)由Amiri等人于2024年提出,是受河马群体行为启发的元启发式算法,其核心基于以下三阶段行…...

Oracle到MySQL实时数据互通:透明网关跨库查询终极方案
技术架构概述 节点类型IP示例Oracle数据库172.18.0.11透明网关节点192.168.5.20MySQL数据库10.10.8.100 提示:透明网关支持部署在Oracle服务器实现集中式管理 一、MySQL环境准备 1. ODBC驱动部署 从MySQL官网获取对应版本的ODBC驱动: # 企业版推荐使…...

BAPLIE船图文件:EDI 核心字段与应用场景解析
BAPLIE(Bay Plan/Stowage Plan Occupied and Empty Locations Message)作为EDIFACT国际报文标准(D96A版本)的核心成员,是集装箱海运领域实现船舶配载数字化的关键工具。其通过结构化数据精确描述集装箱在船舶上的物理位…...

C#中获取字节数据的高字节和低字节
字节顺序(Endianness): 1.小端序(Little-Endian):低字节在前(x86架构) 2.大端序(Big-Endian):高字节在前(网络字节序) 特性小端序(Little-Endian)大端序(B…...
(7))
26考研——查找_树形查找_二叉排序树(BST)(7)
408答疑 文章目录 三、树形查找二叉排序树(BST)二叉排序树中结点值之间的关系二叉树形查找二叉排序树的查找过程示例 向二叉排序树中插入结点插入过程示例 构造二叉排序树的过程构造示例 二叉排序树中删除结点的操作情况一:被删除结点是叶结点…...
图像拼接模块的用于创建权重图函数createWeightMap())
OpenCV图像拼接(5)图像拼接模块的用于创建权重图函数createWeightMap()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::detail::createWeightMap 是 OpenCV 库中用于图像拼接模块的一个函数,主要用于创建权重图。这个权重图在图像拼接过程中扮演着重…...

【Unity】 鼠标拖动物体移动速度跟不上鼠标,会掉落
错误示范: 一开始把移动的代码写到update里去了,发现物体老是掉(总之移动非常不流畅,体验感很差) void Update(){Ray ray Camera.main.ScreenPointToRay(Input.mousePosition);if (Physics.Raycast(ray, out RaycastHit hit, M…...