基于LSTM的文本多分类任务
概述:
LSTM(Long Short-Term Memory,长短时记忆)模型是一种特殊的循环神经网络(RNN)架构,由Hochreiter和Schmidhuber于1997年提出。LSTM被设计来解决标准RNN在处理序列数据时遇到的长期依赖问题,即难以学习时间序列中相隔较远的事件之间的关联。
LSTM模型的核心是它的细胞(cell)状态和三个控制门结构:遗忘门(forget gate)、输入门(input gate)和输出门(output gate)。
以下是对LSTM模型关键组成部分的简述:
细胞状态(Cell State):细胞状态是LSTM的核心,它贯穿于整个LSTM单元,可以传输信息到网络的遥远部分。细胞状态可以看作是信息流动的“高速公路”,它允许信息在序列的不同部分之间长期传递。
遗忘门(Forget Gate):遗忘门决定了哪些信息应该从细胞状态中丢弃。它通过一个称为sigmoid的激活函数查看上一个隐藏状态(( h_{t-1} ))和当前输入(( x_t )),并输出一个介于0到1之间的数值给每个在细胞状态中的数字。1表示“完全保留这个信息”,而0表示“完全丢弃这个信息”。
输入门(Input Gate):输入门负责更新细胞状态。首先,一个sigmoid函数决定哪些值我们将要更新,然后一个tanh函数创建一个新的候选值向量,( \tilde{C}_t ),它可以被加到状态中。在遗忘门忘记旧状态的信息后,我们将这个候选值与sigmoid门的输出相乘,决定实际要更新的状态部分。
输出门(Output Gate):最后,我们需要决定输出值。输出值是基于细胞状态的,但会是一个过滤后的版本。首先,我们运行一个sigmoid函数来决定细胞状态的哪些部分将输出。然后,我们将细胞状态通过tanh(得到一个介于-1到1之间的值)并乘以sigmoid门的输出,以决定最终的输出。
代码案例
数据采用推特上对于新冠病毒的评级
代码详情如下
加载数据与依赖
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from wordcloud import WordCloud
import re
from nltk.corpus import stopwords #模块包含了英语和其他语言的停用词列表。停用词是指在语言中非常常见的单词,#加载数据
os.chdir('E:\python code\文本分类')train_Data = pd.read_excel('Corona_NLP_train.xlsx')
test_Data = pd.read_excel('Corona_NLP_test.xlsx')#train_data = pd.read_csv(train_path, encoding="ISO-8859-1")
数据处理
"""
----------------------------------------------------------------------------
################### 数据处理 ###################
----------------------------------------------------------------------------
"""
print(train_Data.head())
print(train_Data.columns)
print(train_Data['Sentiment'].value_counts())
print(train_Data.shape)
print(test_Data.shape)
print(train_Data.info())#查看详情
for i in range(3):print(i)print(train_Data['OriginalTweet'][i].lower())#lower 转小写train_Data['OriginalTweet'] = train_Data['OriginalTweet'].astype(str)train_Data=train_Data.dropna(subset=['Location'])
test_Data=test_Data.dropna(subset=['Location'])#调整标签
def change_sen(sentiment):if sentiment == "Extremely Positive":return 'positive'elif sentiment == "Extremely Negative":return 'negative'elif sentiment == "Positive":return 'positive'elif sentiment == "Negative":return 'negative'else:return 'netural'train_Data['Sentiment'] = train_Data['Sentiment'].apply(lambda x: change_sen(x))
test_Data['Sentiment'] = test_Data['Sentiment'].apply(lambda x: change_sen(x))EDA
----------------------------------------------------------------------------
################### EDA ###################
----------------------------------------------------------------------------
"""# 筛选前20的地区
top_20 = train_Data['Location'].value_counts().head(20)# 标记颜色
colors = ['#FF6347', '#FF7F50', '#FFD700', '#ADFF2F', '#00CED1', '#8A2BE2', '#A52A2A', '#5F9EA0', '#D2691E', '#FF1493', '#00BFFF', '#696969', '#008080', '#FFD700', '#9ACD32', '#FF4500', '#2E8B57', '#8B0000', '#B8860B', '#B0E0E6']# 构建柱形图
top_20.plot(kind='bar', color=colors, rot=45, figsize=(12, 6))# Add title and labels
plt.title("Top 20 Tweet Locations by Frequency")
plt.ylabel('Frequency')
plt.xlabel('Location')
plt.show()# 查看标签的分布
plt.figure(figsize=(8, 6))
sns.countplot(x='Sentiment', data=train_Data, color='#422e9e')
plt.title("Sentiment Distribution")
plt.xlabel("Sentiment")
plt.ylabel("Count")
plt.show()#查看内容的分布
#isinstance() 是一个内置函数,用来检查一个对象是否是一个特定类或继承自该类的实例。
text = ' '.join(tweet for tweet in train_Data['OriginalTweet'] if isinstance(tweet,str))Wordcloud = WordCloud(width=800 , height= 400,background_color='white').generate(text)plt.figure(figsize=(10,5))
plt.imshow(Wordcloud,interpolation='bilinear')
plt.axis('off')
plt.show()#查看文本的平均长度
text_len = [len(i) for i in train_Data['OriginalTweet']]
# 绘制箱型图
plt.boxplot(text_len) # 设置vert=False让箱型图水平显示
plt.title('Boxplot of String Lengths')
plt.xlabel('Length of Strings')
plt.xticks([]) # 不显示x轴的刻度
plt.show()# 绘制柱形图
sns.histplot(text_len, bins=30, kde=True, color="#eb4034")
plt.title("Tweet Length Distribution")
plt.show()前20地区的分布

类别分布

中间出现的词汇频率

特征工程
"""
----------------------------------------------------------------------------
################### 特征工程 ###################
----------------------------------------------------------------------------
"""
X = train_Data['OriginalTweet'].copy()y = train_Data['Sentiment'].copy()def data_cleaner(tweet):# 删除 http#sub 是re模块中的一个函数,用于替换字符串中符合正则表达式的部分。#\S+ 匹配一个或多个非空白字符# 删除 http 开头的连续的字符直到第一个空格tweet = re.sub(r'http\S+', ' ', tweet)#test = re.sub(r'http\S+', ' ', 'http:www.baidu.com test')#print(test)# 去除<>#.*? 是一个非贪婪匹配,.匹配除了换行符之外的任何单个字符,* 表示“零个或多个”的意思,? 使得.*变成非贪婪模式,意味着它会匹配尽可能少的字符。#*? 无线的匹配,如果精确的匹配加 .tweet = re.sub(r'<.*?>',' ', tweet)#test = re.sub(r'--*?', ' ', '<a---> test')#print(test)# 删除数字#\d 匹配任何数字字符(0-9)#+ 表示匹配前面的字符(在这里是\d)一次或多次。tweet = re.sub(r'\d+',' ', tweet)#test = re.sub(r'\d+',' ', '<a-123--> test')#print(test)# 删除一些和字符组合在一起的脏数据 # tweet = re.sub(r'#\w+',' ', tweet)#test = re.sub(r'#\w+',' ', 'Hello #world, this --s a #test tweet')#print(test)# 删除和字母组合在一起的脏数据 @tweet = re.sub(r'@\w+',' ', tweet)#添加停止测tweet = tweet.split()tweet = " ".join([word for word in tweet if not word in stop_words])return tweetstop_words = stopwords.words('english')
#调整字符
X_cleaned = X.apply(data_cleaner)
#查看数据
X_cleaned.head()
token 转化
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences# 加载token
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_cleaned)#转换
X = tokenizer.texts_to_sequences(X_cleaned)# 向量表
vocab_size = len(tokenizer.word_index) + 1
print(f"向量表: {vocab_size}")# 查看赌赢数据的详情
print(f"\nSentence:\n{X_cleaned[6]}")
print(f"\nAfter tokenizing:\n{X[6]}")#对数据长度和截断和填充 默认最大长度 ,从尾部填充
# X_padded = pad_sequences(X, maxlen=5, padding='post')
X = pad_sequences(X, padding='post')
print(f"\nAfter padding:\n{X[6]}")调整标签
"""
----------------------------------------------------------------------------
################### 调整标签 ###################
----------------------------------------------------------------------------
"""text = {"netural":0, "positive":1,"negative":2}
train_Data['Sentiment'] = train_Data['Sentiment'].map(text)y.replace(text, inplace=True)print(y.shape)模型训练
import tensorflow as tf
from tensorflow.keras import layers as L
from tensorflow.keras.losses import SparseCategoricalCrossentropy #适用于稀疏标签数据的交叉熵损失函数# Hyperparameters
EPOCHS = 10
BATCH_SIZE = 32
embedding_dim = 16
units = 256# Define the model
model = tf.keras.Sequential([# 用于将输入的整数序列转换为密集的向量表示。vocab_size应该被替换为词汇表的大小。L.Embedding(vocab_size, embedding_dim), #一个双向的LSTM层,它能够处理序列数据并且提供前向和后向的上下文信息。#units是LSTM层中单元的数量。return_sequences=True表示LSTM层的每个时间步都会返回一个输出,#这在后面接GlobalMaxPool1D层时是必需的L.Bidirectional(L.LSTM(units, return_sequences=True)),#全局最大池化层,它会沿着时间维度对序列进行最大值池化,从而减少输出的维度。L.GlobalMaxPool1D(),L.Dropout(0.4),#层:一个全连接层,这里用于实现非线性变换,activation="relu"指定了Rectified Linear Unit激活函数。L.Dense(64, activation="relu"),L.Dropout(0.4),L.Dense(3) #最后输出3个结果
])# Compile the model
model.compile(#定义损失函数损失函数是SparseCategoricalCrossentropy,它适用于整数标签的稀疏分类问题#并且设置from_logits=True表示输入的是未经激活的logitsloss=SparseCategoricalCrossentropy(from_logits=True),optimizer='adam',metrics=['accuracy']
)# 清除之前的TensorFlow会话,释放资源,并确保后续的模型训练不受之前会话的影响。
tf.keras.backend.clear_session()history = model.fit(X, y, epochs=EPOCHS, validation_split=0.12, batch_size=BATCH_SIZE)结果如下:
Epoch 1/10
896/896 [] - 78s 82ms/step - loss: 0.7185 - accuracy: 0.6824 - val_loss: 0.4261 - val_accuracy: 0.8526
Epoch 2/10
896/896 [] - 57s 64ms/step - loss: 0.3591 - accuracy: 0.8832 - val_loss: 0.3745 - val_accuracy: 0.8741
Epoch 3/10
896/896 [] - 68s 76ms/step - loss: 0.2382 - accuracy: 0.9257 - val_loss: 0.4173 - val_accuracy: 0.8677
Epoch 4/10
896/896 [] - 73s 81ms/step - loss: 0.1755 - accuracy: 0.9465 - val_loss: 0.4795 - val_accuracy: 0.8529
Epoch 5/10
896/896 [] - 73s 82ms/step - loss: 0.1394 - accuracy: 0.9556 - val_loss: 0.5664 - val_accuracy: 0.8450
Epoch 6/10
896/896 [] - 79s 88ms/step - loss: 0.1119 - accuracy: 0.9642 - val_loss: 0.6328 - val_accuracy: 0.8401
Epoch 7/10
896/896 [] - 58s 64ms/step - loss: 0.0923 - accuracy: 0.9699 - val_loss: 0.7140 - val_accuracy: 0.8281
Epoch 8/10
896/896 [] - 80s 89ms/step - loss: 0.0731 - accuracy: 0.9760 - val_loss: 0.7973 - val_accuracy: 0.8191
Epoch 9/10
896/896 [] - 74s 83ms/step - loss: 0.0566 - accuracy: 0.9822 - val_loss: 0.9219 - val_accuracy: 0.8133
Epoch 10/10
896/896 [] - 52s 58ms/step - loss: 0.0472 - accuracy: 0.9851 - val_loss: 1.0420 - val_accuracy: 0.8140
模型验证
"""
----------------------------------------------------------------------------
################### 模型验证 ###################
----------------------------------------------------------------------------
"""plt.figure(figsize=(10, 6))
plt.plot(history.history['accuracy'], label='Training Accuracy', color='blue')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy', color='orange')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()#测试处理
X_test = test_Data['OriginalTweet'].copy()
y_test = test_Data['Sentiment'].copy()X_test = X_test.apply(data_cleaner)X_test = tokenizer.texts_to_sequences(X_test)X_test = pad_sequences(X_test, padding='post')y_test.replace(text, inplace=True)loss, acc = model.evaluate(X_test,y_test,verbose=0)
print('测试集损失: {}'.format(loss))
print('测试集准确率: {}'.format(acc))pred = model.predict(X_test).argmax(axis=1)
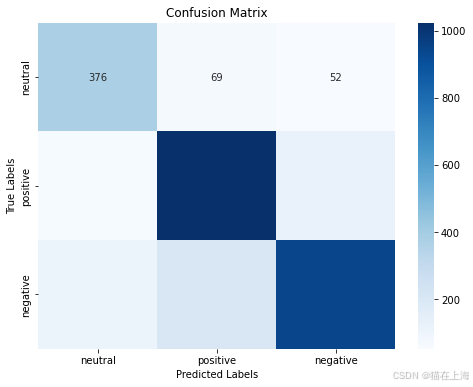
#混淆矩阵
print("Unique values in y_test:", y_test.unique())
print("Unique values in pred:", np.unique(pred))pred = pred.astype(int)from sklearn.metrics import confusion_matrix
conf = confusion_matrix(y_test, pred)labels = ['neutral', 'positive', 'negative']
cm = pd.DataFrame(conf, index=labels, columns=labels)import matplotlib.pyplot as plt
import seaborn as snsplt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix')
plt.show()
相关文章:

基于LSTM的文本多分类任务
概述: LSTM(Long Short-Term Memory,长短时记忆)模型是一种特殊的循环神经网络(RNN)架构,由Hochreiter和Schmidhuber于1997年提出。LSTM被设计来解决标准RNN在处理序列数据时遇到的长期依赖问题…...

Git忽略文件
在Git中,你可以通过修改 .gitignore 文件来忽略整个文件夹。以下是具体步骤: 打开或创建 .gitignore 文件 确保你的项目根目录下有一个 .gitignore 文件。如果没有,创建一个: touch .gitignore 在 .gitignore 文件中添加要忽略…...

Spring的事务管理
tx标签用于配置事务管理用于声明和配置事务的相关属性 transaction-manager指定一个事务管理器的引用,用于管理事务的生命周期。propagation指定事务的传播属性,决定了在嵌套事务中如何处理事务。isolation指定事务的隔离级别,用于控制事务之…...

java int值可以直接赋值给char类型 详解
在 Java 中,int 值可以直接赋值给 char 类型,但有一定的限制和机制。以下是详细的解释: 1. Java 中的 char 和 int 类型关系 char 的本质 char 是一个 16 位无符号整数类型,用于表示 Unicode 字符。范围为 0 到 65535࿰…...

淘宝商品数据获取:Python爬虫技术的应用与实践
引言 随着电子商务的蓬勃发展,淘宝作为中国最大的电商平台之一,拥有海量的商品数据。这些数据对于市场分析、消费者行为研究、商品推荐系统等领域具有极高的价值。然而,如何高效、合法地从淘宝平台获取这些数据,成为了一个技术挑…...

【力扣】389.找不同
问题描述 思路解析 只有小写字母,这种设计参数小的,直接桶排序我最开始的想法是使用两个不同的数组,分别存入他们单个字符转换后的值,然后比较是否相同。也确实通过了 看了题解后,发现可以优化,首先因为t相…...
)
何时在 SQL 中使用 CHAR、VARCHAR 和 VARCHAR(MAX)
在管理数据库表时,考虑 CHAR、VARCHAR 和 VARCHAR(MAX) 是必不可少的。此外,使用正确的工具(例如dbForge Studio for SQL Server) ,与数据库相关的任务都会变得更加容易。它是针对 SQL Server 专业人员的强大的一体化解…...

pnpm安装electron出现postinstall$ node install.js报错
pnpm install --registryhttp://registry.npm.taobao.org安装依赖包的时候出现了postinstall$ node install.js报错 找到install.js 找到downloadArtifact方法,添加如下代码 mirrorOptions:{mirror:"http://npmmirror.com/mirrors/electron/"}http://n…...

如何从 Hugging Face 数据集中随机采样数据并保存为新的 Arrow 文件
如何从 Hugging Face 数据集中随机采样数据并保存为新的 Arrow 文件 在使用 Hugging Face 的数据集进行模型训练时,有时我们并不需要整个数据集,尤其是当数据集非常大时。为了节省存储空间和提高训练效率,我们可以从数据集中随机采样一部分数…...
)
Rook入门:打造云原生Ceph存储的全面学习路径(上)
文章目录 一.Rook简介二.Rook与Ceph架构2.1 Rook结构体系2.2 Rook包含组件2.3 Rook与kubernetes结合的架构图如下2.4 ceph特点2.5 ceph架构2.6 ceph组件 三.Rook部署Ceph集群3.1 部署条件3.2 获取rook最新版本3.3 rook资源文件目录结构3.4 部署Rook/CRD/Ceph集群3.5 查看rook部…...

AWS账号提额
Lightsail提额 控制台右上角,用户名点开,选择Service Quotas 在导航栏中AWS服务中找到lightsail点进去 在搜索框搜索instance找到相应的实例类型申请配额 4.根据自己的需求选择要提额的地区 5.根据需求来提升配额数量,提升小额配额等大约1小时生效 Ligh…...
)
计算机网络(三)
一个IP包,其数据长度为4900字节,通过一个MTU为1220字节的网络时,路由器的分片情况如何?请用图表的形式表示出路由器分片情况。 已知 IP 包的数据长度为 4900 字节,IP 首部长度通常为 20 字节,所以整个 IP …...

去哪儿Android面试题及参考答案
TCP 的三次握手与四次挥手过程是什么? TCP(Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层通信协议 ,三次握手和四次挥手是其建立连接和断开连接的重要过程。 三次握手过程 第一次握手:客户端向服务器发送一个 SYN(同步序列号)包,其中包…...

探索温度计的数字化设计:一个可视化温度数据的Web图表案例
随着科技的发展,数据可视化在各个领域中的应用越来越广泛。在温度监控和展示方面,传统的温度计已逐渐被数字化温度计所取代。本文将介绍一个使用Echarts库创建的温度计Web图表,该图表通过动态数据可视化展示了温度值,并通过渐变色…...
)
JS API事件监听(绑定)
事件监听 语法 元素对象.addEventListener(事件监听,要执行的函数) 事件监听三要素 事件源:那个dom元素被事件触发了,要获取dom元素 事件类型:用说明方式触发,比如鼠标单击click、鼠标经过mouseover等 事件调用的函数&#x…...

【k8s】kube-state-metrics 和 metrics-server
kube-state-metrics 和 metrics-server 是 Kubernetes 生态系统中两个重要的监控组件,但它们的功能和用途有所不同。下面是对这两个组件的详细介绍: kube-state-metrics 功能: kube-state-metrics 是一个简单的服务,它监听 Kub…...

Linux设置开启启动脚本
1.问题 每次启动虚拟机需要手动启动网络,不然没有enss33选项 需要启动 /mnt/hgfs/dft_shared/init_env/initaial_env.sh 文件 2.解决方案 2.1 修改/etc/rc.d/rc.local 文件 /etc/rc.d/rc.local 文件会在 Linux 系统各项服务都启动完毕之后再被运行。所以你想要…...
)
数据结构-图(一)
文章目录 图一、图的基本概念(一)图的定义(二)有向图与无向图(三)顶点的度、入度与出度(四)路径、回路与连通图 二、图的存储及基本操作(一)邻接矩阵…...

SQL面试题——抖音SQL面试题 最近一笔有效订单
最近一笔有效订单 题目背景如下,现有订单表order,包含订单ID,订单时间,下单用户,当前订单是否有效 +---------+----------------------+----------+-----------+ | ord_id | ord_time | user_id | is_valid | +---------+----------------------+--------…...

【人工智能基础05】决策树模型
文章目录 一. 基础内容1. 决策树基本原理1.1. 定义1.2. 表示成条件概率 2. 决策树的训练算法2.1. 划分选择的算法信息增益(ID3 算法)信息增益比(C4.5 算法)基尼指数(CART 算法)举例说明:计算各个…...

远程桌面协助控制软件 RustDesk v1.3.3 多语言中文版
RustDesk 是一款开源的远程桌面软件,支持多平台操作,包括Windows、macOS、Linux、iOS、Android和Web。它提供端到端加密和基于角色的访问控制,确保安全性和隐私保护。使用简单,无需复杂配置,通过输入ID和密码即可快速连…...

git的学习笔记
一,git的安装 mac电脑的安装 xcode-select --install windows安装,用指令麻烦一些 随便找个视频观看看教程,去官网下载就可以了。 centos安装 sudo yum install git -y ubuntu安装 sudo apt-get install git -y 查看git安装的版本 git --ver…...

【目标检测】YOLO:深度挖掘YOLO的性能指标。
YOLO 性能指标 1、物体检测指标2、性能评估指标详解2.1 平均精度(mAP)2.2 每秒帧数(FPS)2.3 交并比(IoU)2.4 混淆矩阵(Confusion Matrix)2.5 F1-Score2.6 PR曲线(Precisi…...

第一届帕鲁杯”应急响应“解析-上部分
这个帕鲁杯是一个模拟真实生产场景的应急响应题目,这个具有拓扑网络结构,考察综合能力以及对各个系统的应急响应 网络拓扑结构图如下 相关的资产情况如下 mysql01:10.66.1.10mysql02:10.66.1.11PC01:10.66.1.12PC02…...

前端http,ws拉流播放视频
可以在西瓜播放器官网APi调试拉取的视频流是否可以播放 类似http拉流地址为:http://localhost:8866/live?urlrtsp://admin:admin123192.168.11.50:554/cam/realmonitor?channel1&subtype01 <!DOCTYPE html> <html><head><meta charset…...

揭开广告引擎的神秘面纱:如何在0.1秒内精准匹配用户需求?
目录 一、广告系统与广告引擎介绍 (一)广告系统与广告粗分 (二)广告引擎在广告系统中的重要性分析 二、广告引擎整体架构和工作过程 (一)一般概述 (二)核心功能架构图 三、标…...
)
【2024】使用Docker搭建redis sentinel哨兵模式集群全流程(包含部署、测试、错误点指正以及直接部署)
目录💻 前言**Docker Compose介绍**最终实现效果 一、搭建集群1、创建文件结构2、创建redis节点3、验证节点4、创建sentinel哨兵5、验证Sentinel功能 二、spring连接1、添加依赖2、添加配置3、启动测试 三、直接部署流程1、拉取配置2、修改端口创建 前言 本篇文章主…...

Spring WebFlux与Spring MVC
Spring WebFlux 是对 Spring Boot 项目中传统 Spring MVC 部分的一种替代选择,主要是为了解决现代 Web 应用在高并发和低延迟场景下的性能瓶颈。 1.WebFlux 是对 Spring MVC 的替代 架构替代: Spring MVC 使用的是基于 Servlet 规范的阻塞式模型…...

江协科技最新OLED保姆级移植hal库
江协科技最新OLED移植到hal库保姆级步骤 源码工程存档 工程和源码下载(密码 1i8y) 原因 江协科技的开源OLED封装的非常完美, 可以满足我们日常的大部分开发, 如果可以用在hal库 ,将是如虎添翼, 为我们开发调试又增加一个新的瑞士军刀, 所以我们接下来手把手的去官网移植源码…...
)
Vue框架开发一个简单的购物车(Vue.js)
让我们利用所学知识来开发一个简单的购物车 (记得暴露属性和方法!!!) 首先来看一下最基本的一个html框架 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"&…...

探索嵌入式硬件设计:揭秘智能设备的心脏
目录 引言 嵌入式系统简介 嵌入式硬件设计的组成部分 设计流程 微控制器选择 原理图设计 PCB布局 编程与调试 系统集成与测试 深入理解微控制器 存储器管理 输入/输出接口 通信接口 电源管理 硬件抽象层(HAL) 操作系统(OS&am…...

逆向攻防世界CTF系列42-reverse_re3
逆向攻防世界CTF系列42-reverse_re3 参考:CTF-reverse-reverse_re3(全网最详细wp,超4000字有效解析)_ctfreverse题目-CSDN博客 64位无壳 _int64 __fastcall main(__int64 a1, char **a2, char **a3) {int v4; // [rsp4h] [rbp-…...

AIGC时代 | 如何从零开始学网页设计及3D编程
文章目录 一、网页设计入门1. 基础知识2. 学习平台与资源3. 示例代码:简单的HTMLCSSJavaScript网页 二、3D编程入门1. 基础知识2. 学习平台与资源3. 示例代码:简单的Unity 3D游戏 《编程真好玩:从零开始学网页设计及3D编程》内容简介作者简介…...

EMall实践DDD模拟电商系统总结
目录 一、事件风暴 二、系统用例 三、领域上下文 四、架构设计 (一)六边形架构 (二)系统分层 五、系统实现 (一)项目结构 (二)提交订单功能实现 (三࿰…...

基于多VSG独立微网的多目标二次控制MATLAB仿真模型
“电气仔推送”获得资料(专享优惠) 模型简介 本文将一致性算法引入微电网的二次频率和电压控制,自适应调节功率参考值和补偿电压,同时实现频率电压恢复、有功 无功功率的比例均分以及功率振荡抑制,提高系统的暂态和稳…...
之微服务信息自动抓取:namespaceName、deploymentName等全解析)
自动化运维(k8s)之微服务信息自动抓取:namespaceName、deploymentName等全解析
前言:公司云原生k8s二开工程师发了一串通用性命令用来查询以下数值,我想着能不能将这命令写成一个自动化脚本。 起初设计的 版本一:开头加一条环境变量,执行脚本后,提示输入:需要查询的命名空间,…...

nginx 代理 web service 提供 soap + xml 服务
nginx 代理 web service 提供 soap xml 服务 最关键的配置: # Nginx默认反向后的端口为80,因此存在被代理后的端口为80的问题,这就导致访问出错。主要原因在Nginx的配置文件的host配置时没有设置响应的端口。Host配置只有host,没有对应的p…...

深入理解 MongoDB:一款灵活高效的 NoSQL 数据库
在现代应用程序开发中,数据存储技术已经从传统的关系型数据库(RDBMS)扩展到多样化的 NoSQL 数据库。MongoDB 作为一款广泛使用的文档型数据库,以其灵活性、高性能和易用性成为开发者的首选之一。本篇博文将从 MongoDB 的核心概念、…...

vue3 + vite + antdv 项目中自定义图标
前言: 去iconfont-阿里巴巴矢量图标库 下载自己需要的icon图标,下载格式为svg;项目中在存放静态资源的文件夹下 assets 创建一个存放svg格式的图片的文件夹。 步骤: 1、安装vite-plugin-svg-icons npm i vite-plugin-svg-icons …...

PDF版地形图矢量出现的问题
项目描述:已建风电场道路测绘项目,收集到的数据为PDF版本的地形图,图上标注了项目竣工时期的现状,之后项目对施工区域进行了复垦恢复地貌,现阶段需要准确的知道实际复垦修复之后的道路及其它临时用地的面积 解决方法&…...

JavaScript 高级教程:异步编程、面向对象与性能优化
在前两篇教程中,我们学习了 JavaScript 的基础和进阶内容。这篇文章将带领你进入更深层次,学习 JavaScript 的异步编程模型、面向对象编程(OOP),以及性能优化的技巧。这些内容对于构建复杂、流畅的前端应用至关重要。 …...

有一个已经排好序的数组。现输入一个数,要求按原来的规律将它插入数组中。-多语言
目录 C 语言实现 Python 实现 Java 实现 Js 实现 题目:有一个已经排好序的数组。现输入一个数,要求按原来的规律将它插入数组中。 程序分析:首先判断此数是否大于最后一个数,然后再考虑插入中间的数的情况,插入后此元素之后的数,依次后移…...

OCR实现微信截图改名
pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple/ ──(Sat,Nov30)─┘ pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install paddleo…...

c++stl模板总结
stl 总结stl模板vectordequelistforward_liststl集合类set&unorder_setmap&unorder_map 自适应容器栈和队列stackqueuepriority_queue 总结stl模板 vector 1.初始化 vector具有多个重载的构造函数,可以在实例化vector时指定他开始时应该包含的元素个数以…...
系统评估)
文本生成类(机器翻译)系统评估
在机器翻译任务中常用评价指标:BLEU、ROGUE、METEOR、PPL。 这些指标的缺点:只能反应模型输出是否类似于测试文本。 BLUE(Bilingual Evaluation Understudy):是用于评估模型生成的句子(candidate)和实际句子(referen…...

Harmony NEXT-越过相机读写权限上传图片至项目云存储中
问题成因 在制作用户注册登录界面时想要实现用户头像上传共能,查询API文档,发现有picker和PhotoAccessHelper两个包可以选择使用,但是在使用PhotoAccessHelper包拉起相册并读入所选的照片后将该照片传入云存储中产生报错,需要相册…...

C++算法练习-day53——17.电话号码的字母组合
题目来源:. - 力扣(LeetCode) 题目思路分析 题目要求我们将一个数字字符串(每个数字对应一组字母,如2对应abc,3对应def等)转换成所有可能的字母组合。这是一个典型的组合生成问题,…...

计算机网络性能
任何一个系统都可以或需要不同的指标来度量系统的优劣、状态或特性。计算机网络是综合计算机技术与通信技术的复杂系统,可以通过许多指标对一个计算机网络的整体或局部、全面或部分、静态或动态等不同方面的性能进行度量与评价 1、传输时延 当一个分组在输出链路发…...

MAC卸载Vmware Fusion后无法再安装解决方案
MAC卸载Vmware Fusion后无法再安装解决方案 执行脚本 sudo rm -rf /Library/Application Support/VMware/VMware Fusion sudo rm -rf /Library/Application Support/VMware/Usbarb.rules sudo rm -rf /Library/Application Support/VMware Fusion sudo rm -rf /Library/Prefe…...

windows 服务器角色
windows 服务器角色 Active Directory Rights Management Services Active Directory RightsManagement Services (AD RS)帮助保护信息,防止未授权使用。AD RMS 将建立用户标识,并为授权用户提供受保护信息的许可证。 ServicesActive Directory 联合身…...