【Weaviate】数据库:向量存储与搜索的新纪元

🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、什么是Weaviate
2、Weaviate 能做什么?
3、Weaviate 和传统数据库的区别
二、Weaviate数据库概述
1、Weaviate的起源
2、Weaviate 诞生的背景
3、为什么叫 "Weaviate"?
4、Weaviate核心功能
5、主要特性
三、架构解析
1、存储层(Storage Layer)
2、索引层(Indexing Layer)
3、查询层(Query Layer)
4、API 层(API & Integration Layer)
四、工作原理
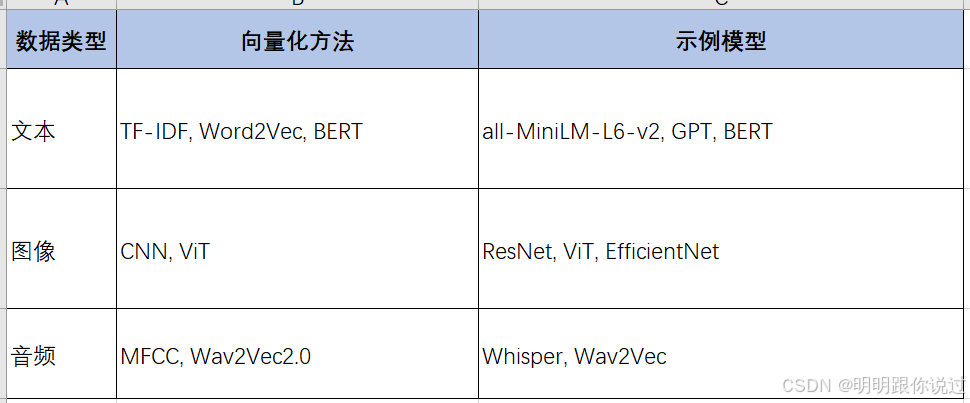
1、数据向量化过程
1.1、文本向量化
1.2、图像向量化
1.3、音频向量化
2、向量索引与搜索机制
2.1、什么是向量索引?
2.2、向量搜索的核心步骤
3、查询处理与结果返回流程
3.1、接收查询请求(API 层)
3.2、向量搜索(索引层)
3.3、数据匹配与筛选(存储层)
3.4、返回结果(查询层 & API 层)
一、引言
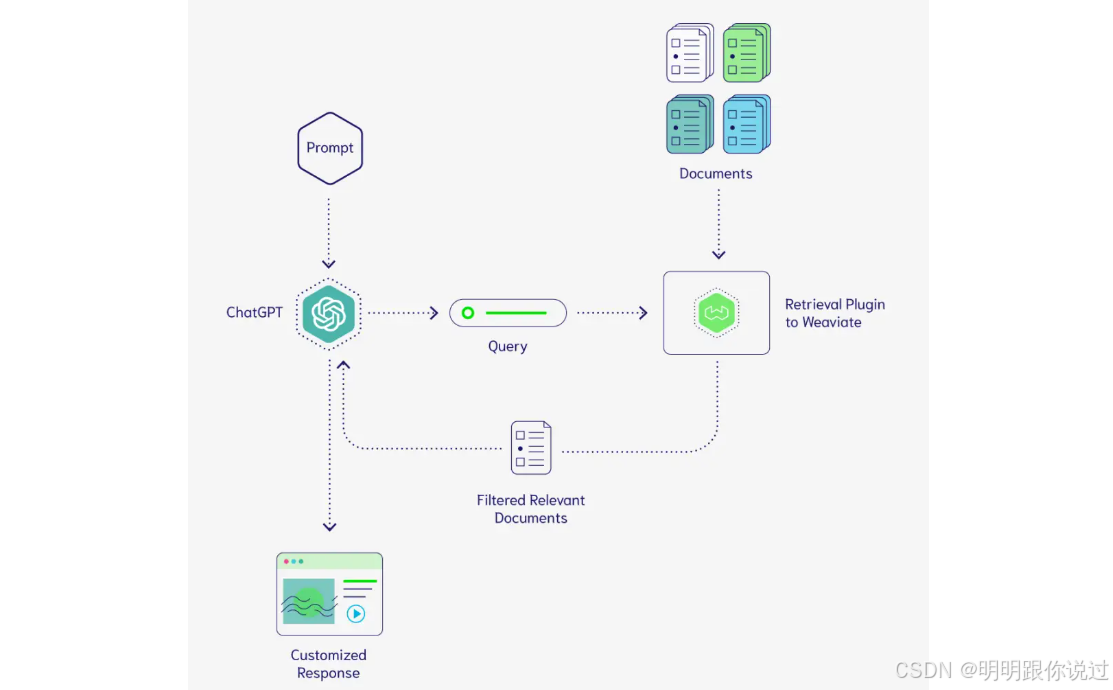
1、什么是Weaviate
Weaviate 是一个向量数据库,它的主要作用是存储和搜索文本、图片、音频等数据的向量表示。
想象你有一个大图书馆📚,但里面的书没有分类、没有索引,想找某一本书只能一本一本翻,效率非常低。Weaviate 就像一个超级智能图书管理员,它会把每本书的内容转换成数字(向量),然后存起来,想要搜索时,输入一句话,它就能迅速找到最相似的内容!💡

2、Weaviate 能做什么?
1️⃣ 智能搜索:
- 🔍 你输入 "一部关于人工智能的科幻电影",它能立刻找到《黑客帝国》《她》等类似的电影。
- 📨 你输入 "中奖"、"免费" 之类的词,它能检索到相关的垃圾短信。
2️⃣ 语义匹配:
- Weaviate 不仅能匹配完全一样的文本,还能理解意思相近的内容。
- 比如,你搜索 "如何提高编程能力",它能找到 "提升代码技能的 10 个方法" 之类的文章。
3️⃣ 多模态数据(不仅限于文本):
- 图片:你上传一张猫的照片,它能找到数据库里所有相似的猫照片。
- 音频:你放一段音乐,它能找到类似风格的歌曲。
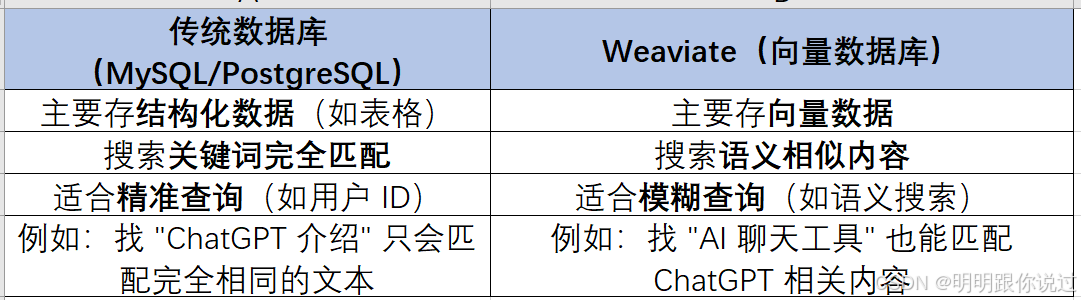
3、Weaviate 和传统数据库的区别
二、Weaviate数据库概述
1、Weaviate的起源
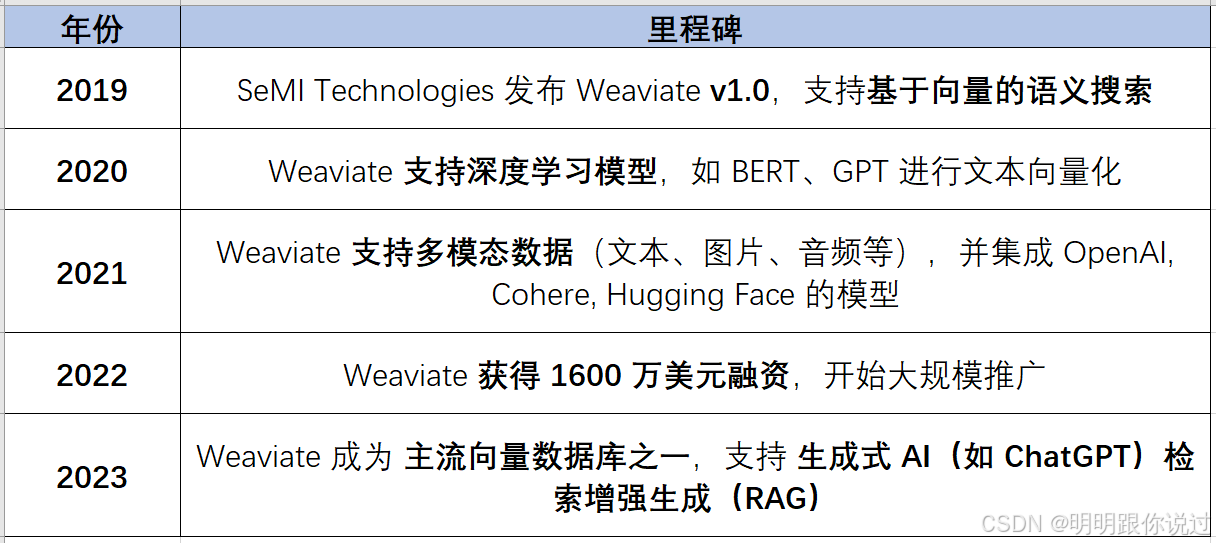
Weaviate 是由荷兰公司 SeMI Technologies 开发的一个开源向量数据库,最早发布于 2019 年。它的诞生源于一个核心问题:如何让 AI 更高效地存储和搜索大规模的非结构化数据(文本、图片、音频等)?
2、Weaviate 诞生的背景
在 2010 年代,机器学习和自然语言处理(NLP) 迅速发展,特别是BERT、GPT 等大规模预训练模型的出现,让 AI 在语义理解方面更强大。但问题是:
- 传统数据库(如 MySQL、PostgreSQL)只能存结构化数据,对 AI 处理的文本、图片等非结构化数据支持很差。
- 关键词搜索(如 Elasticsearch)无法理解语义,比如:
- 我们搜索 "AI 机器人",但数据库里只有 "人工智能助手",普通搜索引擎不会认为它们是一样的。
- 向量化搜索(基于神经网络的语义搜索)能解决这个问题,但当时没有高效、易用的向量数据库。
为了解决这个问题,SeMI Technologies 在 2019 年发布了 Weaviate,它是一种专门为 AI 设计的数据库,可以存储、索引和搜索向量化数据。
3、为什么叫 "Weaviate"?
Weaviate 这个名字来源于 “Weave(编织)+ Vi(可视化)+ Ate(智能)” 的组合,寓意:
- Weave(编织):像一张智能网络一样,把数据和 AI 连接起来。
- Vi(可视化):它不仅能存储数据,还能支持数据可视化、语义搜索等功能。
- Ate(智能):Weaviate 结合 AI 和机器学习,帮助用户更智能地搜索和管理数据。
4、Weaviate核心功能
✅ 1. 向量存储(Vector Storage)
- Weaviate 支持存储文本、图片、音频、视频等数据的向量化表示。
- 可以使用预训练模型(如 OpenAI, Hugging Face, Cohere, SBERT)自动向量化数据,也支持自定义向量。
- 适用于语义搜索、推荐系统、异常检测等 AI 应用。
✅ 2. 语义搜索(Semantic Search)
- 基于向量相似性(最近邻搜索, ANN),比传统数据库的关键词搜索更智能。
- 查询方式:
- 语义搜索("找到与这个文本最相似的内容")
- Hybrid Search(结合传统关键词 + 向量搜索)
- 跨模态搜索(同时支持文本、图片等)
- 适用于智能问答、客户支持、知识管理等场景。
✅ 3. 可扩展的存储与检索
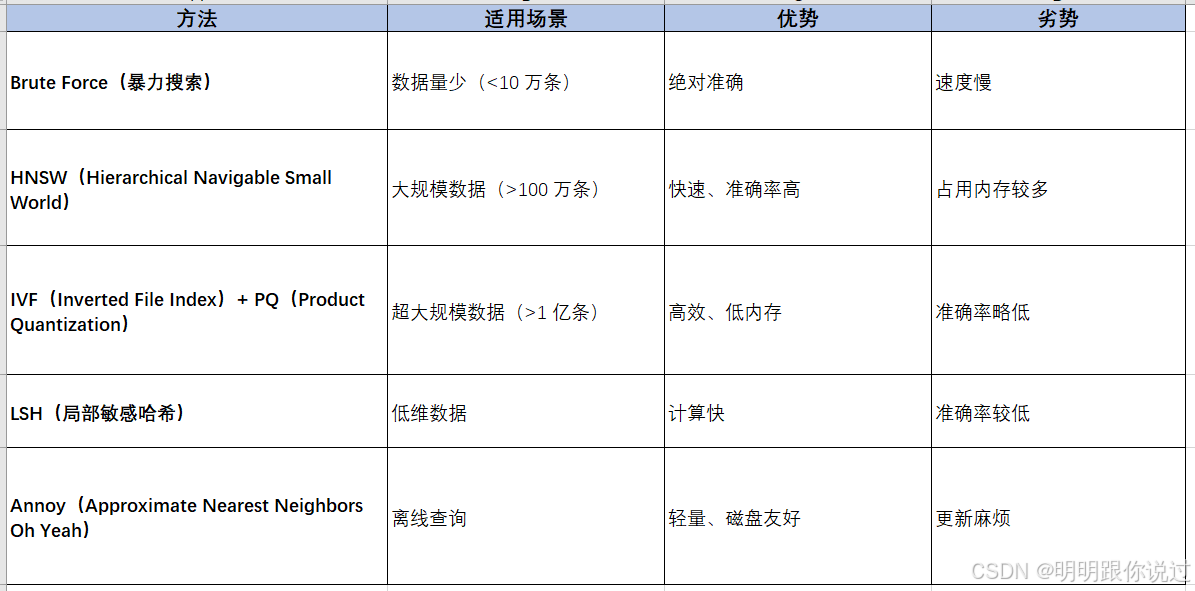
- Weaviate 支持亿级数据存储,并且可以分布式部署,适用于大规模 AI 应用。
- HNSW(Hierarchical Navigable Small World)索引算法,提供高效的向量检索,比 brute-force 计算快很多。
- GraphQL & REST API 查询,简单易用。
✅ 4. 自动模式(Schema-Free 或 Schema-Based)
- Schema-Free:可以直接存储 JSON 数据,无需预定义模式,适合灵活的 AI 数据存储。
- Schema-Based:支持定义数据结构,适用于严格的企业级应用。
✅ 5. 多模态数据支持
- Weaviate 不仅能存文本,还能存储和搜索图片、音频、视频的向量化表示。
- 适用于跨模态搜索(Multimodal Search),比如:
- 上传一张图片,搜索相似的文本描述。
- 用语音输入查询,找到相关的文档或图片。
5、主要特性
🔹 1. 轻量级 & 易部署
- 单机部署(Docker / Kubernetes)💻
- 云端版本(Weaviate Cloud) ☁️
- 可扩展集群(分布式架构) 🏗️
🔹 2. 开源 & 高性能
- 完全开源(Apache 2.0 许可证),无需付费
- 使用 HNSW(Hierarchical Navigable Small World) 提供超快的向量检索(适用于海量数据)
🔹 3. 多种 API 兼容
- RESTful API
- GraphQL
- Python & Go SDK
- 支持 LangChain / LlamaIndex
🔹 4. 与 LLM(大语言模型)无缝集成
- 支持 OpenAI, Hugging Face, Cohere 的模型,自动向量化数据
- 适用于RAG(检索增强生成),让 ChatGPT 能查询自己的知识库
三、架构解析
1、存储层(Storage Layer)
🔹 作用:负责存储原始数据(文档、文本、图片、元数据等)和向量数据。
🔹 组件:
- 对象存储(Object Storage):
- Weaviate 可以存储 JSON 格式的对象,支持结构化和非结构化数据。
- 数据存储方式类似 NoSQL,每个对象可带有元数据字段。
- 向量存储(Vector Storage):
- Weaviate 默认使用 SQLite / LMDB 进行数据持久化。
- 也支持连接 外部对象存储(S3、MinIO)。
- 多模态支持(Multimodal Storage):
- 存储文本、图片、音频、视频等数据,并支持向量化。
✅ 特点:
- 支持结构化和非结构化数据
- 可持久化存储到磁盘
- 支持外部对象存储(S3/MinIO)
- 可搭配 MySQL / PostgreSQL 进行扩展

2、索引层(Indexing Layer)
🔹 作用:负责高效索引管理,加速向量搜索。
🔹 核心技术:
✅ 1. HNSW(Hierarchical Navigable Small World)索引
- HNSW 是 Weaviate 默认的向量索引,提供近似最近邻搜索(ANN)。
- 比传统 brute-force(暴力搜索)快 10~100 倍。
- 适用于大规模数据集(可扩展至亿级数据)。
✅ 2. 关键词索引(Lexical Indexing)
- Weaviate 结合了传统倒排索引(类似 Elasticsearch)和向量索引。
- 支持 Hybrid Search(关键词 + 向量搜索结合)。
✅ 3. 多模态索引
- 可以索引文本、图片、音频、视频的向量,适用于跨模态检索。
✅ 特点:
- HNSW 提供高效向量检索
- 支持 Hybrid Search(关键词 + 向量检索)
- 支持跨模态索引
- 支持自定义索引字段
3、查询层(Query Layer)
🔹 作用:负责接收查询请求、执行检索、返回匹配结果。
🔹 主要查询方式:
✅ 1. 语义搜索(Semantic Search)
- 基于向量相似度,支持 最近邻搜索(k-NN / ANN)。
- 适用于AI 问答、智能推荐、语义搜索等场景。
✅ 2. Hybrid Search(混合搜索)
- 结合 关键词搜索(Lexical Search)+ 向量搜索(Vector Search)。
- 适用于需要匹配关键词 & 语义的查询(例如企业搜索)。
✅ 3. 过滤搜索(Filter & Faceted Search)
- Weaviate 支持按属性筛选数据(类似 SQL 的
WHERE条件)。 - 可以在向量搜索的基础上再筛选(Metadata Filtering)。
✅ 特点:
- 支持 GraphQL 查询
- 支持 REST API 查询
- 支持向量搜索、关键词搜索、混合搜索
- 支持按属性筛选(Filter)
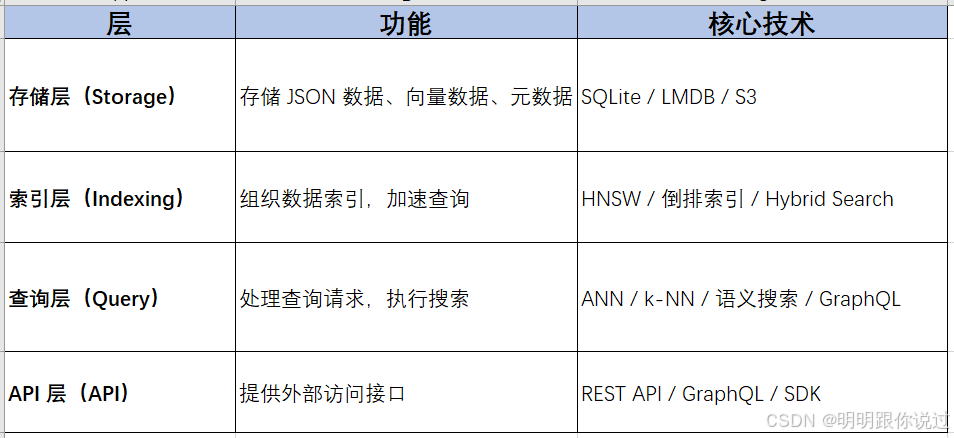
4、API 层(API & Integration Layer)
🔹 作用:提供REST API / GraphQL API 供外部应用访问。
🔹 主要 API:
✅ 1. REST API
- 适用于标准 HTTP 请求。
- 允许存储、查询、删除数据。
✅ 2. GraphQL API
- Weaviate 原生支持 GraphQL,可用于复杂查询。
- 适用于AI 搜索、知识库管理等应用。
✅ 3. SDK & 生态集成
- 官方 SDK:
- Python
- Go
- JavaScript
- LLM & AI 框架集成:
- LangChain(RAG 应用)
- LlamaIndex(索引管理)
- Hugging Face / OpenAI API(自动向量化)
- Stable Diffusion / CLIP(多模态搜索)
四、工作原理
1、数据向量化过程
数据向量化就是把文本、图片、音频等信息转换成计算机可以理解的“数字表示”,也就是 “向量”(一个包含一串数字的列表)。这些向量可以用来计算相似性、分类、搜索等操作。
1.1、文本向量化
👉 为什么要向量化?
计算机不能直接理解“你好”或“hello”,但可以理解 数字,所以我们要把文字转换成向量。
👉 向量化的方式
- 词袋模型(Bag of Words, BoW):统计每个单词出现的次数,但不考虑语序。例如:
- "猫 喜欢 鱼" →
[1, 1, 1, 0, 0] - "狗 不 喜欢 鱼" →
[0, 1, 1, 1, 1]
- "猫 喜欢 鱼" →
- TF-IDF(词频-逆文档频率):不仅统计词频,还考虑词的重要性。
- Word2Vec / FastText / GloVe:把每个单词变成一个固定长度的向量,比如
你好 → [0.2, 0.5, -0.1, ...]。 - Transformer 模型(BERT、GPT、Sentence-BERT):对整句话进行编码,得到一个上下文相关的向量,比如
这是一条短信 → [0.3, -0.2, 0.8, ...]。
1.2、图像向量化
👉 为什么要向量化?
计算机不能直接理解“猫”或“狗”的图片,它只能看到像素值(RGB 颜色值),所以要把图片转换成固定大小的向量,方便分类和搜索。
👉 向量化的方式
- 传统方法(SIFT、HOG、SURF):手工提取特征,如边缘、形状等。
- 深度学习(CNN:卷积神经网络):使用 ResNet、EfficientNet、ViT 等模型,把整个图片编码成一个高维向量。
1.3、音频向量化
👉 为什么要向量化?
计算机只能处理数字信号,所以要把音频转换成数字向量,方便进行语音识别、音频分类等任务。
👉 向量化的方式
- MFCC(梅尔频率倒谱系数):提取音频的频谱特征,常用于语音识别。
- VGGish / Wav2Vec2.0 / Whisper:使用深度学习模型,将音频转换成向量。
2、向量索引与搜索机制
2.1、什么是向量索引?
想象你有 100 万条短信或图片的向量,每个向量有 768 维(比如 BERT 生成的文本向量)。如果想找到 与某条新短信最相似的短信,直接遍历 100 万条数据进行计算会 非常慢。
💡 向量索引的作用:
- 把所有向量 组织成一种高效的数据结构,加快搜索速度。
- 让查找相似向量的过程 尽量少计算,提高查询效率。
向量索引就像 高速公路的收费站,帮你快速找到正确的路,而不是盲目遍历所有可能的路径。
2.2、向量搜索的核心步骤
1️⃣ 数据向量化 📌
- 文本 → 用 BERT、Word2Vec 把文本转成 768 维向量。
- 图片 → 用 ResNet/Vision Transformer 把图片转成 2048 维向量。
- 音频 → 用 Wav2Vec2.0 把语音转成 512 维向量。
2️⃣ 建立索引 🏗️
- 选择合适的索引算法,比如 HNSW 或 IVF-PQ。
- 把向量存入索引结构,组织成 高效的查找方式。
3️⃣ 执行搜索 🔍
- 计算 新向量 和 索引中的向量 的相似度(比如余弦相似度、欧几里得距离)。
- 返回 最相似的K个向量(KNN 搜索)。
4️⃣ 排序与筛选 🎯
- 可以结合元数据(比如消息时间、类别等)进一步筛选搜索结果。
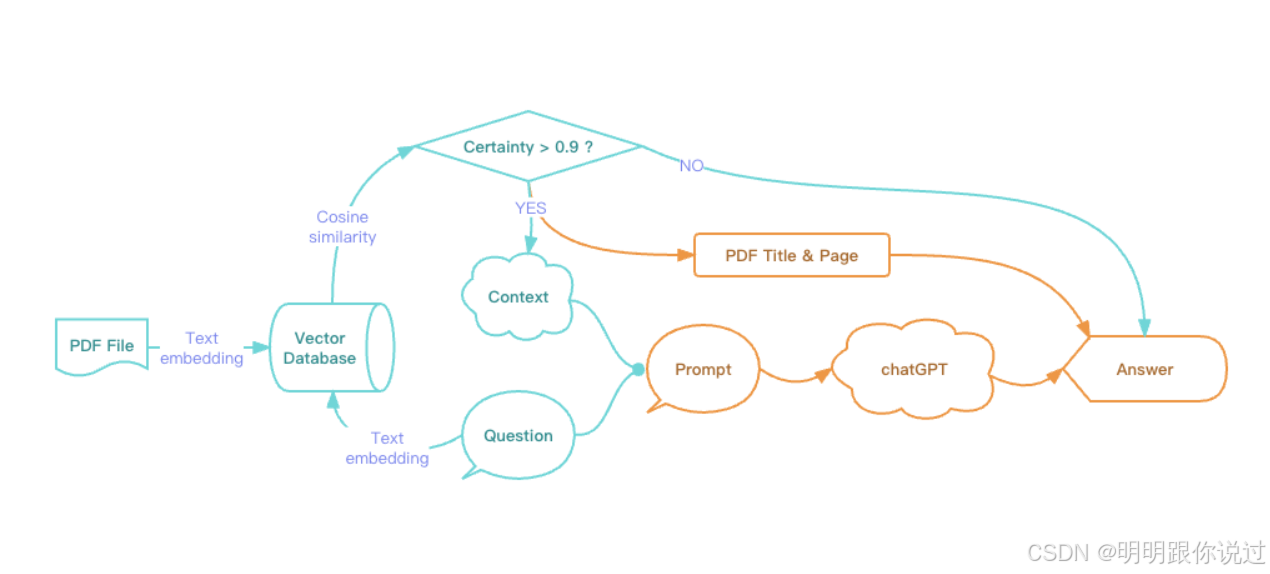
3、查询处理与结果返回流程
在 Weaviate 或任何向量数据库中,查询处理和结果返回的流程 主要包含 4 大阶段:
- 接收查询请求(API 层)
- 向量搜索(索引层)
- 数据匹配与筛选(存储层)
- 返回结果(查询层 & API 层)
3.1、接收查询请求(API 层)
- 用户通过 REST API 或 GraphQL 查询 Weaviate,发送查询请求。
- 查询的类型可以是:
- 相似性搜索(Nearest Neighbor Search, NNS)
- 带过滤条件的查询(Metadata Filtering)
- 全文搜索(Lexical Search)

3.2、向量搜索(索引层)
📌 核心目标:从百万级数据中 高效查找最相似的向量!
关键步骤:
- 文本向量化:
- Weaviate 内置 text2vec-transformers 模块,先将输入的文本转换为 向量(比如 768 维 BERT 向量)。
- 索引搜索(HNSW):
- 在 HNSW(Hierarchical Navigable Small World)索引 中快速定位 最接近的 K 个向量(Top-K 查询)。
- 相似度计算:
- 计算查询向量与索引向量的 余弦相似度(Cosine Similarity) 或 欧几里得距离(L2)。
- 初步筛选结果:
- 选出相似度 最高的 K 条短信,进入下一步数据匹配。
3.3、数据匹配与筛选(存储层)
🔹 从匹配的向量中,提取完整的数据(如原始文本、标签等)
- 查询的结果是最相似的向量 ID,但 Weaviate 还需要返回对应的原始数据。
- Weaviate 存储层 负责 检索元数据,如短信内容、是否垃圾短信(Spam / Ham)。
- 可能会应用 额外的过滤条件(例如,只获取 2024 年后的短信)。
3.4、返回结果(查询层 & API 层)
🔹 最终 Weaviate 返回 JSON 结果,供前端或 AI 模型使用
完整的查询流程
1️⃣ 用户发送查询 → 通过 REST API 或 GraphQL 提交查询请求(nearText、where 过滤等)。
2️⃣ Weaviate 解析查询 → 调用 text2vec-transformers 模块,把查询转成 向量表示。
3️⃣ 执行索引搜索 → HNSW 向量索引 进行 最近邻搜索(KNN),找到相似的向量。
4️⃣ 数据匹配 & 过滤 → 查询存储层,获取完整的短信内容和元数据。
5️⃣ 返回查询结果 → 结果通过 JSON 格式 返回给用户或前端应用。
💡 这个过程适用于 Weaviate,也适用于 FAISS、Milvus、Pinecone 等向量数据库的查询逻辑! 🚀
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
相关文章:

【Weaviate】数据库:向量存储与搜索的新纪元
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Weaviate 2、Weaviate 能做什么? …...

机器学习之激活函数
什么是激活函数 激活函数是神经网络的关键组件,作用于神经元输出。神经元汇总输入并计算净输入值,激活函数将其非线性变换,生成神经元最终输出,该输出作为后续神经元输入在网络中传播。 为什么需要激活函数 引入非线性 无激活…...
)
ACWing:178. 第K短路 (A*算法)
178. 第K短路 - AcWing题库 ac代码: #include<iostream> #include<cstring> #include<queue> using namespace std; const int N1010; const int M20020; struct node{int d,end,d1;bool operator <(const node &x)const{return d>x.d…...
)
Windows 图形显示驱动开发-WDDM 3.0功能- 硬件翻转队列(一)
WDDM 3.0 之前的翻转队列模型 许多新式显示控制器支持对按顺序显示的多个帧排队的能力。 从 WDDM 2.1 开始,OS 支持将在下一个 VSync 中显示的多个未完成的翻转覆盖请求。 显示微型端口驱动程序 (KMD) 通过 DXGK_DRIVERCAPS 中的 MaxQueuedMultiPlaneOverlayFlipVS…...

本地仓库设置
将代码仓库初始化为远程仓库,主要涉及在服务器上搭建 Git 服务,并将本地代码推送到服务器上。以下是详细的步骤: 1. 选择服务器 首先,你需要一台服务器作为代码托管的远程仓库。服务器可以是本地服务器、云服务器,甚…...

openEuler系统迁移 Docker 数据目录到 /home,解决Docker 临时文件占用大问题
根据错误信息 write /var/lib/docker/tmp/...: no space left on device,问题的根源是 根分区(/)的磁盘空间不足,而非 /home 分区的问题。以下是详细解释和解决方案: 问题原因分析 Docker 临时文件占用根分区空间&…...

LoRA有哪些 参数高效微调方法?
LoRA有哪些 参数高效微调方法? 目录 LoRA有哪些 参数高效微调方法?一、**Fisher 信息矩阵(FIM)近似方差**公式原理LoRA 应用示例二、**动态梯度方差(指数加权移动平均)**公式原理LoRA 代码示例三、**分层梯度方差(结构稀疏性)**公式原理案例:文本分类任务四、**局部方…...

【Xinference rerank】学习如何在Xinference中使用重新排序模型
xinferance 官方网站 给定一个查询和一系列文档,Rerank 会根据与查询的语义相关性从最相关到最不相关对文档进行重新排序。在 Xinference 中,可以通过 Rerank 端点调用 Rerank 模型来对一系列文档进行排序。 from xinference.client import Clientclie…...

pyqt 上传文件或者文件夹打包压缩文件并添加密码并将密码和目标文件信息保存在json文件
一、完整代码实现 import sys import os import json import pyzipper from datetime import datetime from PyQt5.QtWidgets import (QApplication, QWidget, QVBoxLayout, QHBoxLayout,QPushButton, QLineEdit, QLabel, QFileDialog,QMessageBox, QProgressBar) from PyQt5.…...
)
Java 大视界 -- Java 大数据机器学习模型的对抗攻击与防御技术研究(137)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

中间件漏洞之weblogic
目录 weblogic简介弱口令后台getshell漏洞利用修复建议 CVE-2017-10271xmldecoder反序列化漏洞漏洞利用修复建议 CVE-2018-2894任意文件上传漏洞利用修复建议 CVE-2014-4210 weblogic ssrf漏洞利用修复建议 CVE-2020-14882&14883漏洞利用修复建议 CVE-2018-2628漏洞利用修复…...

centos 安装pip时报错 Cannot find a valid baseurl for repo: centos-sclo-rh/x86_64
centos 安装pip时报错 [rootindex-es app-ai]# yum update Loaded plugins: fastestmirror Repository centos-sclo-rh is listed more than once in the configuration Determining fastest mirrors Could not retrieve mirrorlist http://mirrorlist.centos.org?archx86_64…...
:扩散模型)
Pika 技术浅析(三):扩散模型
扩散模型(Diffusion Models)是近年来在生成模型领域中取得显著进展的一种方法,尤其在图像和视频生成任务中表现出色。Pika在其视频生成过程中采用了扩散模型,通过前向扩散过程和逆向扩散过程,实现了从噪声生成高质量视频的功能。 1. 基本原理 1.1 扩散模型的核心思想 扩…...
)
【HarmonyOS Next之旅】DevEco Studio使用指南(三)
目录 1 -> 一体化工程迁移 1.1 -> 自动迁移 1.2 -> 手动迁移 1.2.1 -> API 10及以上历史工程迁移 1.2.2 -> API 9历史工程迁移 1 -> 一体化工程迁移 DevEco Studio从 NEXT Developer Beta1版本开始,提供开箱即用的开发体验,将SD…...
--架构设计指南)
Node.js系列(1)--架构设计指南
Node.js架构设计指南 🏗️ 引言 Node.js作为一个高性能的JavaScript运行时环境,其架构设计对于构建可扩展的服务端应用至关重要。本文将深入探讨Node.js的架构设计原则、最佳实践和实现方案。 架构概述 Node.js架构主要包括以下方面: 事…...

Pytorch学习笔记
1.gather选择函数的用法 PyTorch入门笔记-gather选择函数 2.max函数的用法 Pytorch的max()与min()函数...

JAVA | 聚焦 String 的常见用法与底层内存原理
*个人主页 文章专栏 《赛博算命之梅花易数的JAVA实现》* 文章目录 *[个人主页](https://blog.csdn.net/2401_87533975?spm1011.2124.3001.5343)文章专栏《赛博算命之梅花易数的JAVA实现》* #前言:API1.定义2.已经学习过的API3.如何使用帮助文档: 一、…...

CAN总线的CC帧和FD帧之间如何仲裁
为满足CAN总线日益提高的带宽需求,博世公司于2012年推出CAN FD(具有灵活数据速率的CAN)标准,国际标准化组织(ISO)2015年通过ISO 11898-1:2015标准,正式将CAN FD纳入国际标准,以示区别…...

提升 React 应用性能:使用 React Profiler 进行性能调优
前言 在现代前端开发中,性能优化是一个不可忽视的重要环节。在 React 生态系统中,React Profiler 是一个强大的工具,它可以帮助我们检测和优化应用的性能。 本文将通过通俗易懂的语言介绍 React Profiler 的作用,并展示如何使用它…...
 和 toBase64()的区别)
【QT】-toUtf8() 和 toBase64()的区别
toUtf8() 和 toBase64() 在 Qt 中是两个不同的函数,它们用于不同的目的: toUtf8():将 QString 转换为 UTF-8 编码的字节数组(QByteArray)。 toBase64():将字节数组(通常是二进制数据࿰…...

Git 面试问题,解决冲突
1.问题描述 在多人协作开发中,当多个开发者在同一文件的同一部分进行修改并提交时,Git 无法自动合并这些更改,从而产生代码冲突(Conflict)。冲突的代码会被 Git 标记出来,需要开发者手动解决。 冲突原因 多…...

天梯赛训练L1-031——L1-040
天梯赛训练L1-031——L1-040 L1-031 到底是不是太胖了 import math n int(input()) for i in range(n):h,w map(int,input().split())w / 2biaozhun (h - 100)* 0.9if math.fabs(biaozhun - w) < biaozhun * 0.1:print("You are wan mei!")elif w < biaoz…...
)
C语言 —— 此去经年梦浪荡魂音 - 深入理解指针(卷二)
目录 1. 数组名与地址 2. 指针访问数组 3.一维数组传参本质 4.二级指针 5. 指针数组 6. 指针数组模拟二维数组 1. 数组名与地址 我们先看下面这个代码: int arr[10] { 1,2,3,4,5,6,7,8,9,10 };int* p &arr[0]; 这里我们使用 &arr[0] 的方式拿到了数…...

面试中文版示例
各位老师好,我是*** ,2010 年毕业于****大学,信息管理与信息系统专 业,获得管理学学士学位,同时学习了*****,取得国家中级物流师认证。 在校期间多次获得一、二等奖学金。作为文艺部部长,经常…...

C++多线程编程 4.condition_variable 条件变量
概念: std::condition_variable 是 C 标准库中用于实现线程间同步的类。它提供了等待和通知的机制,使得线程可以等待某个条件成立时被唤醒,或者在满足某个条件时通知其他等待的线程。 语法: #include <condition_variable&g…...

基于51单片机的12864模拟示波器proteus仿真
地址: https://pan.baidu.com/s/12SGtyqAYKOAjx6rjtTz5Nw 提取码:1234 仿真图: 芯片/模块的特点: AT89C52/AT89C51简介: AT89C51 是一款常用的 8 位单片机,由 Atmel 公司(现已被 Microchip 收…...
)
C++数据结构哈希表的实现(开散列实现、闭散列实现)
C哈希 1. 哈希概念 哈希作为数据结构时,是一种通过某种哈希函数使元素的存储位置与它的关键码之间建立一一映射的关系,在查找时通过该函数就能快速找到该元素,平均时间复杂度为 O ( 1 ) \rm O(1) O(1) ,且遍历结果是无序的。 …...
)
显著性检测分类(数据集和评估指标总结)
一:RGB显著性检测 常用数据集 其中有DUTS,ECSSD,DUT-OMRON,PASCAL-S,HKU-IS,SOD,SOC,MSRA-B (1)DUTS:DUTS-TR(训练集):10553张,DUT…...

【R语言】使用DESeq2对微生物组进行差异分析
代码展示: asv <- read.delim(paste0(input,_0.5wen.10050.asv_table.txt), row.names 1, sep \t, stringsAsFactors FALSE, check.names FALSE) group <- read.delim(paste0(group2_,input,.txt),row.names 1,sep \t) asv <- asv1 #将变量转换为因…...

什么是广播系统语言传输指数 STIPA
广播系统语言传输指数(STIPA) 是用于评估公共广播系统中语音信号传输质量的国际标准指标,主要用于衡量语音清晰度和可懂度。以下是其关键信息: 1. 定义与作用 STIPA(Speech Transmission Index for Public…...

【Json—RPC框架】:宏定义不受命名空间限制,续行符的错误使用造成的bug
为什么不受命名空间的限制? 宏处理在预处理阶段, 预处理在编译之前,编译才进行语法分析,语义分析。命名空间也只能限制这部分。 在Json-RPC框架的实现中,遇到如下问题。一开始以为是在实现日志宏的时候,有…...
使用)
解决前端文字超高度有滚动条的情况下padding失效(el-scrollbar)使用
<div class"detailsBlocksContent"><div>测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试…...
)
失败的面试经历(ʘ̥∧ʘ̥)
一.面向对象的三大特性 1.封装:将对象内部的属性私有化,外部对象不能够直接访问,但是可以提供一些可以使外部对象操作内部属性的方法。 2.继承:类与类之间会有一些相似之处,但也会有一些异处,使得他们与众…...
-大数据调度工具对比)
大数据学习(70)-大数据调度工具对比
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

Description of a Poisson Imagery Super Resolution Algorithm 论文阅读
Description of a Poisson Imagery Super Resolution Algorithm 1. 研究目标与意义1.1 研究目标1.2 实际意义2. 创新方法与模型2.1 核心思路2.2 关键公式与推导2.2.1 贝叶斯框架与概率模型2.2.2 MAP估计的优化目标2.2.3 超分辨率参数α2.3 对比传统方法的优势3. 实验验证与结果…...

PIP离线安装包
获得离线包 pip freeze >requirements.txt pip download -rrequirements.txt 可以看到pip开始下载依赖包列表中的所有依赖包 安装离线包 如果你希望完全从本地 .whl 文件安装依赖,而不从 PyPI 或其他外网源下载任何包,可以使用 --no-index 参数来…...

动静态库区别
目录 示例 动静态库区别 定义和链接方式 文件大小 内存使用 更新和维护 加载时间 依赖关系 适用场景 动静态库总结 示例 Linux系统中ls也是一个进程,它运行也得依赖动态库,那么学习动静态库区别是有必要的!!!…...

剑指 Offer II 076. 数组中的第 k 大的数字
comments: true edit_url: https://github.com/doocs/leetcode/edit/main/lcof2/%E5%89%91%E6%8C%87%20Offer%20II%20076.%20%E6%95%B0%E7%BB%84%E4%B8%AD%E7%9A%84%E7%AC%AC%20k%20%E5%A4%A7%E7%9A%84%E6%95%B0%E5%AD%97/README.md 剑指 Offer II 076. 数组中的第 k 大的数字 …...

容联云大模型应用入选甲子光年AI Agent产业图谱
近日,甲子光年发布《2025中国AI Agent行业研究报告》,旨在系统梳理AI Agent技术演进与产业重构路径,展示行业标杆厂商及先锋实践。 容联云凭借卓越的Copilot & Agent产品和解决方案,以及在银行、保险等领域的成熟应用验证&…...

机器学习——深入浅出理解朴素贝叶斯算法
文章目录 引言一、朴素贝叶斯定理概述1.从贝叶斯定理说起2.朴素贝叶斯的“朴素”之处3.朴素贝叶斯算法的应用 二、朴素贝叶斯算法的优缺点三、python代码实现案例1.导入库2.数据预处理3.模型训练4.模型评估5.完整代码 四、总结 引言 朴素贝叶斯算法,一个听起来充满…...
与四次挥手(Four-way Wave))
TCP/IP协议中三次握手(Three-way Handshake)与四次挥手(Four-way Wave)
TCP/IP协议中三次握手(Three-way Handshake)与四次挥手(Four-way Wave) 一、TCP三次握手(Three-way Handshake)二、TCP四次挥手(Four-way Wave)三、常见问题解答总结为什么三次握手不…...
 BCD)
【CF】Day9——Codeforces Round 953 (Div. 2) BCD
B. New Bakery 题目: 思路: 被标签害了,用什么二分( 很简单的思维题,首先如果a > b,那么全选a就行了,还搞啥活动 否则就选 b - a 天来搞活动,为什么? 首先如果我…...
AI知识库工具测评)
【AI知识管理系统】(一)AI知识库工具测评
嘿,朋友们!🧐你们有没有想过,咱们平日里那些一闪而过的知识笔记、各种碎片化的idea,记录下来之后都是怎么管理的呀? 还有啊,咱们读过的那些书,大家会不会随手写点东西记录一下呢?📝要知道,如果不写的话,很可能过不了多久就全忘得一干二净啦。 😭那多年前记下的…...

Model Context Protocol 的生命周期
生命周期阶段 生命周期分为三个主要阶段: 初始化阶段 (Initialization) 客户端与服务器建立协议版本兼容性。交换并协商能力。分享实现细节。客户端必须发送 initialize 请求,包含支持的协议版本、客户端能力和客户端实现信息。服务器必须响应其自身能力…...

hot100_part_堆
不该要求事情一开始就是完美。 堆排序 【从堆的定义到优先队列、堆排序】 10分钟看懂必考的数据结构——堆_哔哩哔哩_bilibili 排序算法:堆排序【图解代码】_哔哩哔哩_bilibili 堆定义 堆必须是完全二叉树,从上到下,从左到右不能用空缺。…...

CoreData 调试警告:多个 NSEntityDescriptions 声明冲突的解决
概述 目前在苹果生态 App 的开发中,CoreData 数据库仍然是大部分中小应用的优先之选。不过,运行时 CoreData 常常产生各种“絮絮叨叨”的警告不禁让初学的秃头小码农们云里雾里。 这不,对于下面这一大段 CoreData 警告,大家是否一…...
】矩阵、CNN、RNN)
【白话神经网络(二)】矩阵、CNN、RNN
全连接层 回顾前面学过的知识: 一个最简单的神经网络,就是ywxb 套上一个激活函数。 如果有多个输入,那就是多个w和x 如果有多个输出,那就再来一行公式,多一组w和b 要是神经元多了的话,公式密密麻麻的&…...

map容器练习:使用map容器识别统计单词个数
题目链接:单词识别_牛客题霸_牛客网 对map的使用不太熟悉的同学可以参考:超详细介绍map(multimap)的使用-CSDN博客 题目解析 输入一个英文句子,把句子中的单词(不区分大小写)按出现次数按从多到少把单词和次数在屏幕…...

DeepSeek 是否被过度吹捧了?
DeepSeek 作为中国人工智能领域的后起之秀,其技术进展引发了广泛关注和讨论。然而,DeepSeek 是否被过度吹捧仍然值得客观分析。 DeepSeek 的确取得了不错的成果,不过可能没有媒体宣传和人们想象中那么重大。它的轰动性主要在于以低廉的成本达…...
与下载)
前端大文件上传(分片上传)与下载
文章目录 一、问题二、思路1、选择文件2、校验文件是否符合规范3、文件切片上传4、分片上传注意点5、大文件下载 一、问题 日常业务中难免出现前端需要向后端传输大型文件的情况,这时单次的请求不能满足传输大文件的需求,就需要用到分片上传 业务需求为…...