顺序表,单链表,双链表,循环链表(01星球)
文章目录
- 数据结构前导------C语言复习
- 程序为什么要被编译器编译之后才能运行
- 编译器把C语言程序转换成可以执行的机器码的过程做了什么
- 宏定义
- typedef 关键字
- 全局变量和局部变量
- 常量
- 字符的输入输出
- 运算符
- 冯诺依曼架构
- 存储器容量
- 数据类型
- 指针
- 指针本质
- 为什么需要指针
- 数组
- 数组指针和指针数组
- 结构体
- 结构体变量的声明/定义
- 使用typedef创建类型别名
- 结构体指针
- 访问成员变量:用“.”还是“->”?
- 函数:指针与函数
- 传参--本质是创建副本
- 数据结构
- 逻辑结构
- 存储结构
- 线性结构
- 顺序表
- 代码
- 优势
- 劣势
- 应⽤场景
- 顺序表的效率分析
- 单链表
- 概念
- 头指针和头节点
- 不带头结点的单链表的插⼊操作
- 带头结点的单链表的插⼊操作
- 代码示例(带头节点)
- 优劣势
- 双向链表
- 代码实现(带头节点)
- 循环链表
- 代码实现(带头结点)
数据结构前导------C语言复习
程序为什么要被编译器编译之后才能运行
因为计算机能够识别的只有机器语言,机器语言就是由二进制0和1构成。所以为了让计算机执行我们写的程序,必须翻译成计算机能够识别的机器语言程序(目标程序)。
编译器把C语言程序转换成可以执行的机器码的过程做了什么
1).预处理:展开头文件/宏替换/去掉注释/条件编译
2).编译:检查语法,生成汇编代码
3).汇编:把汇编代码转化成二进制的机器码
4).链接合成可执行的程序,并对声明在其他目标文件找到对应的定义
宏定义
#define 定义宏,使用 #define 定义常量来增强可读性。
宏定义在C语言源程序中允许用一个标识符来表示一个字符串,称为“宏” ,被定义为“宏”的标识符称为“宏名”。
定义宏:#define 宏名 替换文本 (替换文本”可以是任意常数、表达式、字符串等。)
例如: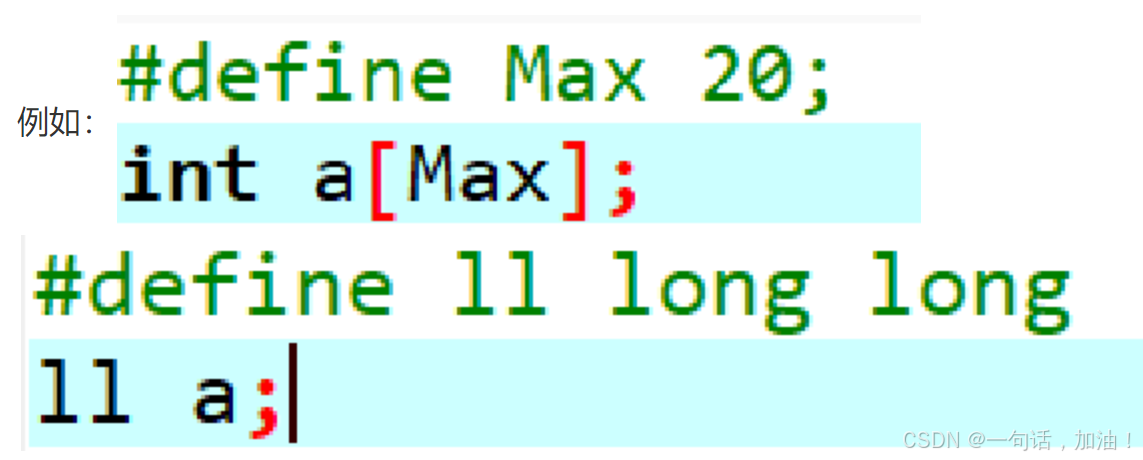
typedef 关键字
typedef 是 C 和 C++ 语言中的一个关键字,用于为现有的数据类型定义一个新的名称。
它通常用于简化复杂的类型声明或为某种类型创建更具描述性的名称。
typedef 并不创建新的数据类型,而是为现有的数据类型创建一个别名。
语法:typedef 原数据类型 新数据类型;

常用于结构体:

全局变量和局部变量
(1)在程序中,局部变量和全局变量的名称可以相同,但是在函数内,如果两个名字相同,会使用局部变量值,全局变量不会被使用。
(2)函数的参数,形式参数,被当作该函数内的局部变量,如果与全局变量同名它们会优先使用。
(3)当局部变量被定义时,系统不会对其初始化,必须自行对其初始化。定义全局变量时,系统会自动对其初始化,全局变量默认值 0(char:‘\0’,指针类型NULL)
常量
常量:是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量
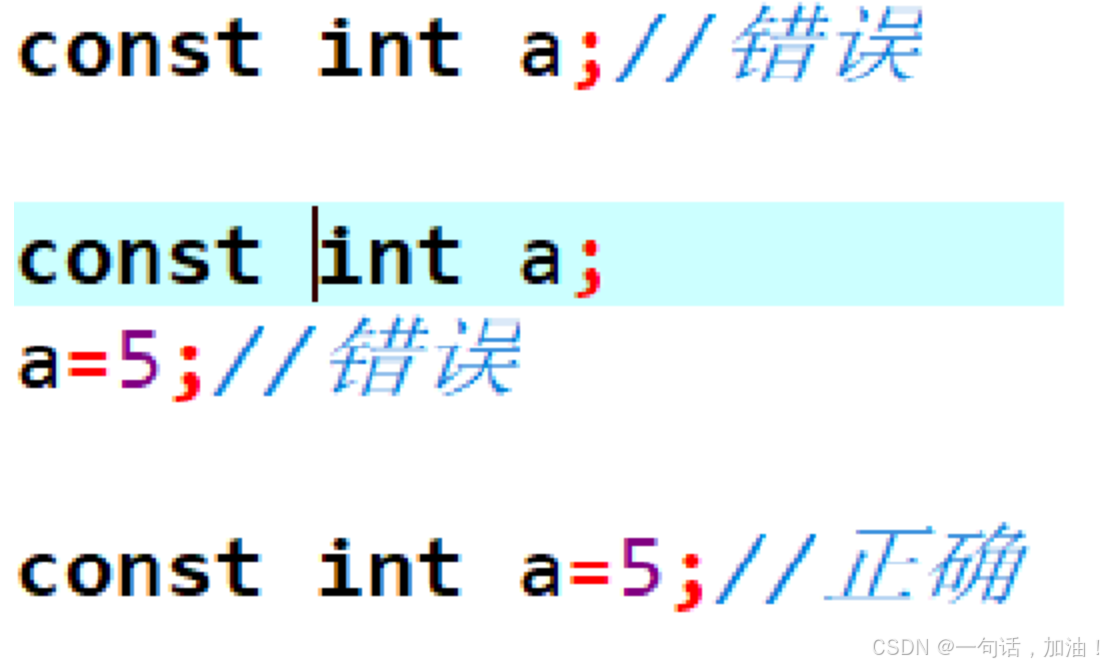
使用#define或者const声明(const 声明常量要在一个语句内完成)
字符的输入输出
scanf()和printf()函数
注意读入字符变量:用getchar()吞回车或者空格
运算符
-
/ 整除(向下取整)
-
++ 自增 a++ ++a区别
-
– 自减 同上
-
三目运算符 ?:
-
位操作符:直接对二进制位进行操作
-
<< 左移 a<<x a左移x位,左移一位相当于乘2
-
右移
-
~取反
-
|按位或 有1为1
-
&按位与 同1为1 通常用来对某些位清0或保留某些位
例:a 的高八位清 0 , 保留低八位, 可作 a&255 运算 ( 255 的二进制数为0000000011111111) -
^按位异或 不同为1
实现两个值的交换,而不必使用临时变量。
例如交换两个整数a=10100001,b=00000110的值,可通过下列语句实现:
a = a^b; //a=10100111
b = b^a; //b=10100001
a = a^b; //a=00000110
冯诺依曼架构
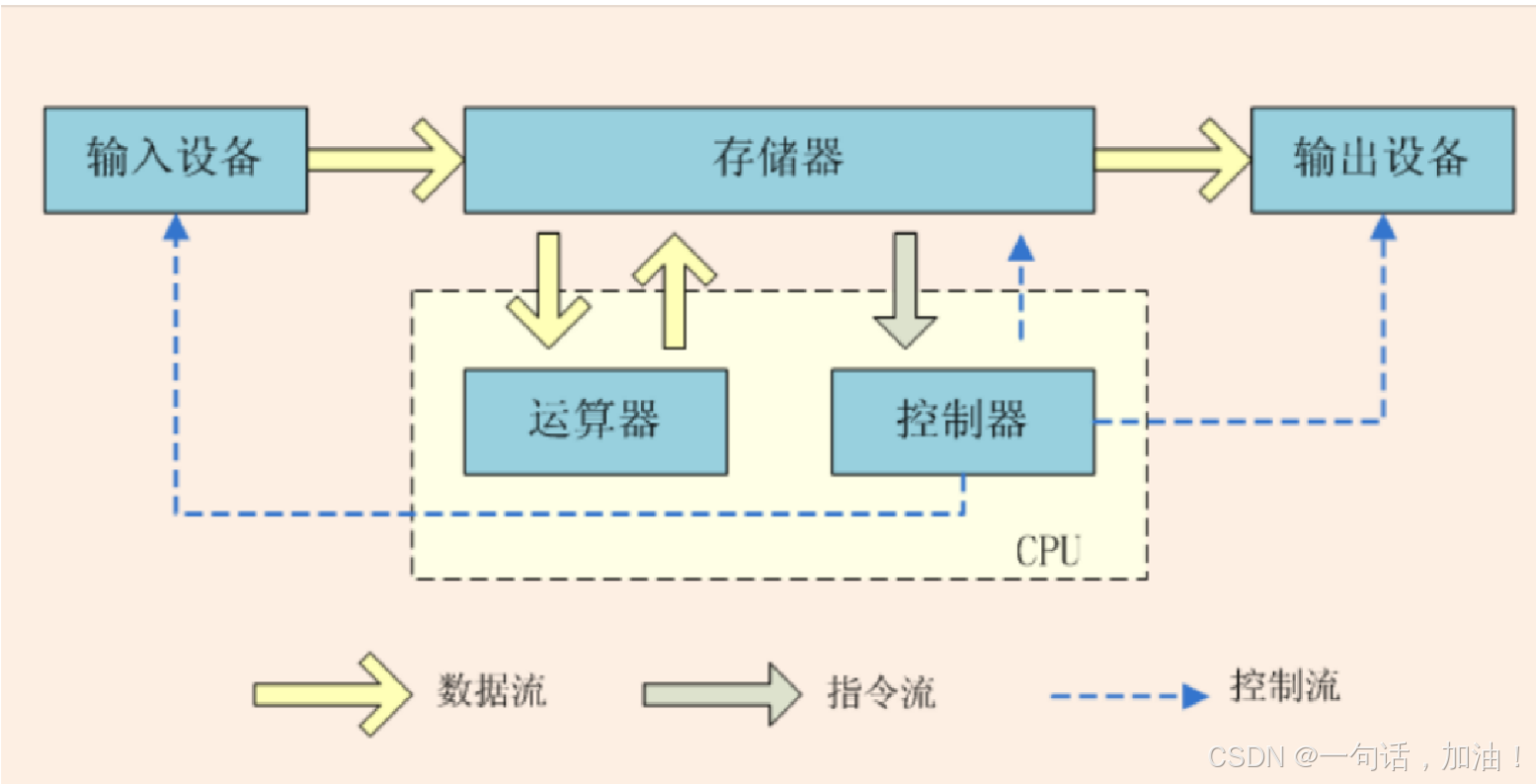
机器语言:计算机可以将二进制代码存储在内存中,并且执行这些代码。
二进制位:也称为位(bit), 基数为2 的数字中的 0 或 1,它是信息的基本组成元素。
指令:计算机硬件所能理解并服从的命令(也是二进制位串)。
在计算机内部,指令和数据并没有本质的区别,它们都是以二进制形式存储的。
汇编语言:以助记符形式表示的机器指令。
高级语言:高级编程语言 C+ +、 Java 等可移植的语言,由一些单词和代数符号组成,可以由编译器转换为汇编语言。
存储器容量
在描述存储容量:1bit 1byte(1B) 1KB 1MB 1GB 1TB
在存储器,一个二进制位称为1bit。
1B:字节,1B=8bit
1B 1KB 1MB 1GB 1TB 由小到大,换算单位是2^10即1024
数据类型
数据类型:定义内存空间⼤⼩的⼀个代名词,⽅便编译器能够合理的转换为对应的指令来操作内存空间。
以64位系统为例:
char 1B
int 4B
long long 8B
float 4B
double 8B
一个特殊的数据类型,指针,是存放数据的内存单元地址。
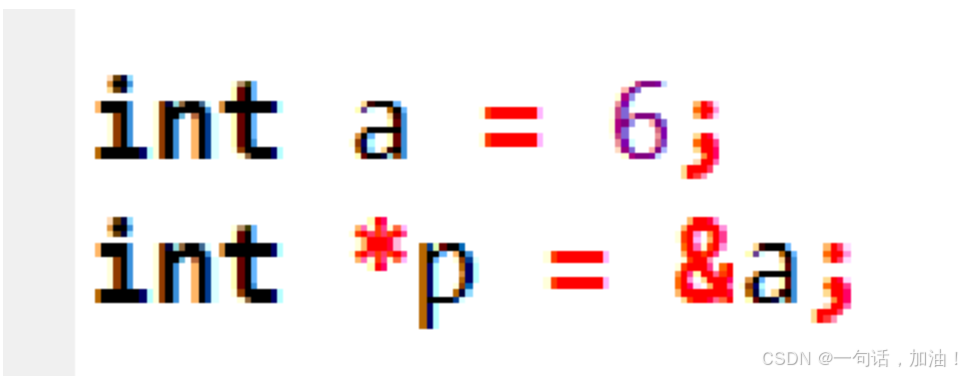
指针
为了便于管理,在按字节编址的存储器中,以8位(1字节)的大小构成一个存储单元。
计算机系统的内存拥有大量的存储单元,若按字节编址,每个存储单元的大小为1字节,为了便于管理,必须为每个存储单元编号,该编号就是存储单元的“地址”,每个存储单元拥有一个唯一的地址。
内存地址通常以十六进制形式给出。
存储内存地址的变量就是指针类型的。
64位系统中 指针类型 占 8B 32位系统中 指针类型 占 4B
指针本质
-
本质就是一个地址值(操作系统给的),变量。
-
内存地址是什么?
内存地址只是一个十六进制的数字(0x),表示内存区域。在计算机上,内存的容量以字节为基本单位。 也就是说,存储器地址表示1字节(8bit )的存储区域。 -
指针指向的本质:地址赋值
-
多重指针:间接寻址/指针链
-
‘ &’:引用,取地址符
‘*’:解引用,取值符号 -
指针变量除了可以存放变量的地址外,还可以存放其他数据的地址,例如可以存放数组和函数的地址。
为什么需要指针
- 在不同区域之间的代码可以共享数据(直接通过指针指向相同的内存空间),特别是结构体,一个结构体中有很多数据,一个结构体变量就会占用大量空间。用指针去共享节省时间和内存。
- 指针占用的字节数是相同的。在(硬件/操作系统)数据存储按字节存储的。指针不同于一般变量,存的是变量的地址,在同一架构下地址长度都是相同的,所有不同类型的指针长度都一样。一般32位系统,指针长度为4个字节,64位则是8个字节。
- 一些操作必须使用指针, 例如申请内存。。。malloc
- 可以用指针搞一些复杂的结构-链表/树/图。。多重指针(二级指针)
数组
数组(Array)也是一种复合数据类型,它由一系列相同类型的元素组成。
数组元素在内存中连续存放。
在 C 语言中,数组名是一个指向数组第一个元素的指针常量,也就是说,它存储的是数组第一个元素的地址,并且不能被修改。
数组名的两层含义:做数组名时 代指整个数组(空间)。做指针常量时,保存数组第一个元素的地址。
数组指针和指针数组
数组指针:一个指针保存着数组的地址
指针数组:数组中的每个变量是指针类型
看p是数组指针还是针数组,先看[] ,再看*, []比星号优先级更高

结构体
数组允许定义可存储相同类型数据项的变量。
结构体是C编程中另一种用户自定义的可用的数据类型,它允许存储不同类型的数据项。
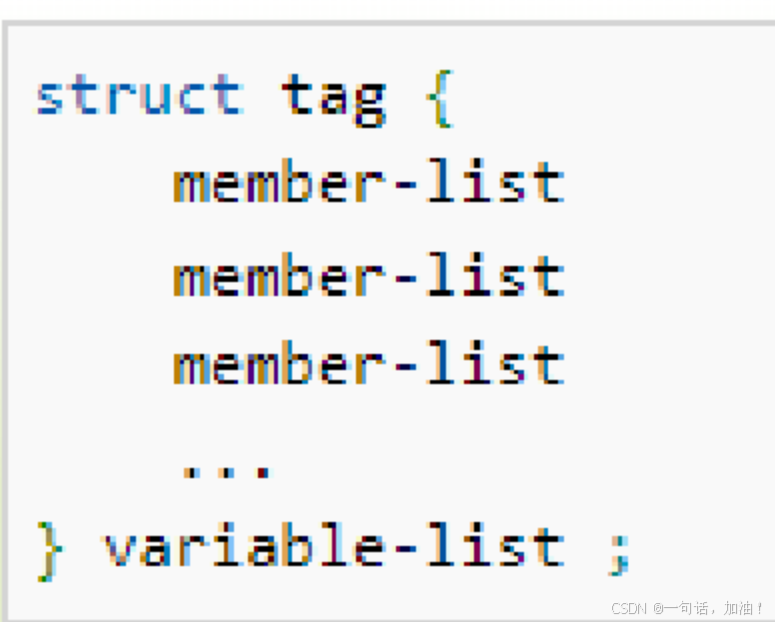
- struct:声明结构体的关键字
- tag 是结构体标签,是一个可选的标志,它是用来引用该结构体的快速标记。
- member-list 是标准的变量定义,比如 int i; 或者 float f,或者其他有效的变量定义。
- 成员后面用分号;隔开,结构类型定义的末尾也有个分号;
- variable-list 结构变量,是可选的,定义在结构的末尾,最后一个分号之前,可以指定一个或多个结构变量。
结构体变量的声明/定义
- 类型定义和变量声明分开

- 类型定义的同时声明变量

使用typedef创建类型别名

结构体指针
结构体指针:结构体中的变量在内存中连续存放,结构体指针指向第一个变量。
type 指的是该结构体
type1 指的是结构体指针

访问成员变量:用“.”还是“->”?
通过结构体变量访问成员变量,用 “.”
通过结构体指针变量访问成员变量,用 “->”
函数:指针与函数
1.函数名是一个指针,保存函数地址入口。函数名是函数的入口地址。函数的入口地址称为函数指针。

传参–本质是创建副本
(1)实参与形参
(2)值传递,指针传递,引用传递
指针传递本质是值传递。
C语言无引用传递,引用传递是C++的。
函数调用–也可以理解为是创建副本
数据结构
数据结构:逻辑结构+存储结构
逻辑结构
线性逻辑结构:数据之间的关系是线性的(一对一):线性表、栈、队列
非线性逻辑结构:树型结构(一对多);图形结构(多对多)
存储结构
顺序存储:逻辑上相邻的元素,在存储器中的位置也是相邻的===》数组
链式存储:逻辑上相邻的元素,在存储器中的位置可以不相邻的,但是得实现逻辑上的相邻===》链表
索引存储,散列存储(Hash)
线性结构
如果⼀个数据元素序列满⾜:
-
除第⼀个和最后⼀个数据元素外,每个数据元素只有⼀个前驱数据元素和⼀个后继数据元素;
-
第⼀个数据元素没有前驱数据元素;
-
最后⼀个数据元素没有后继数据元素;
我们称这样的结构就叫做 线性结构
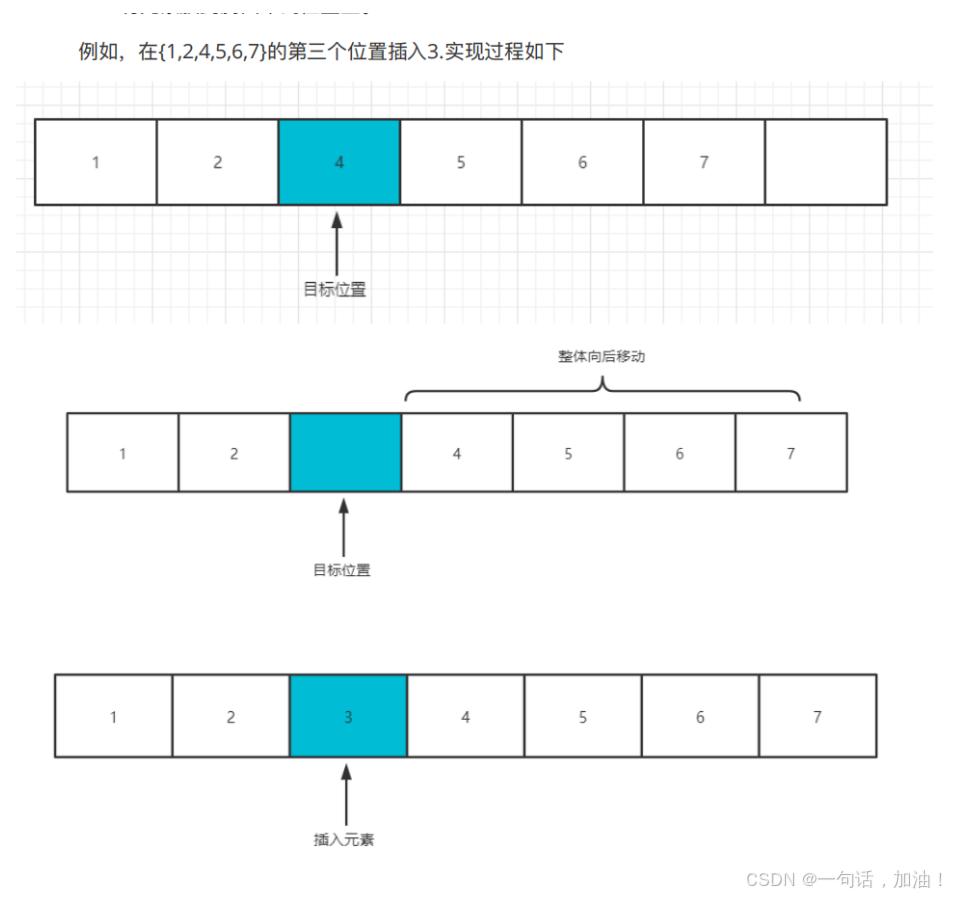
顺序表
在计算机内存中,顺序表是以数组的形式保存的线性表。也就是⼀组地址连续的存储单元依次存储
数据元素的线性结构。
在数组中,我们会先申请⼀段连续的内存空间,然后把数组以此存⼊内存当中,中间没有⼀点空
隙。这就是⼀种顺序表存储数据的⽅式。对于顺序表的基本操作有:增(add),删(remove),改
(set),查(find),插(insert)。
代码
#include <iostream>
using namespace std;
#define MAXSIZE 100 //顺序表可能达到的最大长度
typedef struct {int* data; //指针模拟开数组 int length; //顺序表中元素实际个数
}SqList;
//初始化
SqList initial() {SqList s;s.data = (int*)malloc(sizeof(int)*MAXSIZE);if (s.data == NULL) { printf("内存分配失败!"); }s.length = 0;return s;
}
//增(顺序插入元素)
void add(SqList* L, int element) {//先判满if (L->length < MAXSIZE) {L->data[L->length] = element;L->length++;}else {printf("顺序表空间已满,不能插入!");}
}
//增(在指定下标插入元素)
void insert(SqList* L, int index, int element) {//先判满if (L->length < MAXSIZE) {//空出i下标位置,让其后数据往后移动for (int j = L->length - 1; j >= index; j--) {L->data[j + 1] = L->data[j];}L->data[index] = element;L->length++;}else {printf("顺序表空间已满,不能插入!");}
}
//查找,在线性表中查找元素element,若该元素不存在则,返回-1,存在则返回下标
int find(SqList* L, int element) {for (int i = 0; i < L->length; i++) {if (L->data[i] == element) {return i;}}return -1;
}
//删除指定元素element
void deleteList(SqList* L, int element) {int index = find(L, element);if (index == -1) {printf("被删除元素不存在");return;}for (int i = index; i < L->length; i++) {L->data[i] = L->data[i + 1];}L->length--;
}
//打印顺序表
void printSq(SqList L) {for (int i = 0; i < L.length; i++) {printf("%d ", L.data[i]);}printf("\n");
}
int main() {SqList L;L = initial();add(&L, 6);add(&L, 3);add(&L, 7);add(&L, 9);printSq(L); //6 3 7 9insert(&L, 2, 1); printSq(L); // 6 3 1 7 9deleteList(&L, 9);printSq(L); //6 3 1 7printf("%d", find(&L, 3)); // 1
}
优势
因为数据在数组中按顺序存储,可以通过数组下标直接访问,因此顺序表的查找定位元素很快。
劣势
插⼊和删除元素都需要⼤量的操作。
因为数组在声明的时候需要确定⻓度,因此顺序表的⻓度是确定的。若需要扩⼤顺序表⻓度,有
需要⼤量的操作,不够灵活。(要将该数组中的元素全部copy到另外⼀个数组)
由于数据⼤⼩的不可测性,有时会浪费掉⼤量的空间。
应⽤场景
总之,顺序表适⽤于那些不需要对于数据进⾏⼤量改动的结构。
顺序表的效率分析
综上所述,可以得出。顺序表对于插⼊、删除⼀个元素的时间复杂度是O(n)。
因为顺序表⽀持随机访问,顺序表读取⼀个元素的时间复杂度为O(1)。因为我们是通过下标访
问的,所以时间复杂度是固定的,和问题的规模⽆关。
最⼤的优点是空间利⽤率⾼。最⼤的缺点是⼤⼩固定。
单链表
概念
链表的每个节点只包含⼀个指针域。叫做单链表(即构成链表的每个节点只有⼀个指向后
继节点的指针)
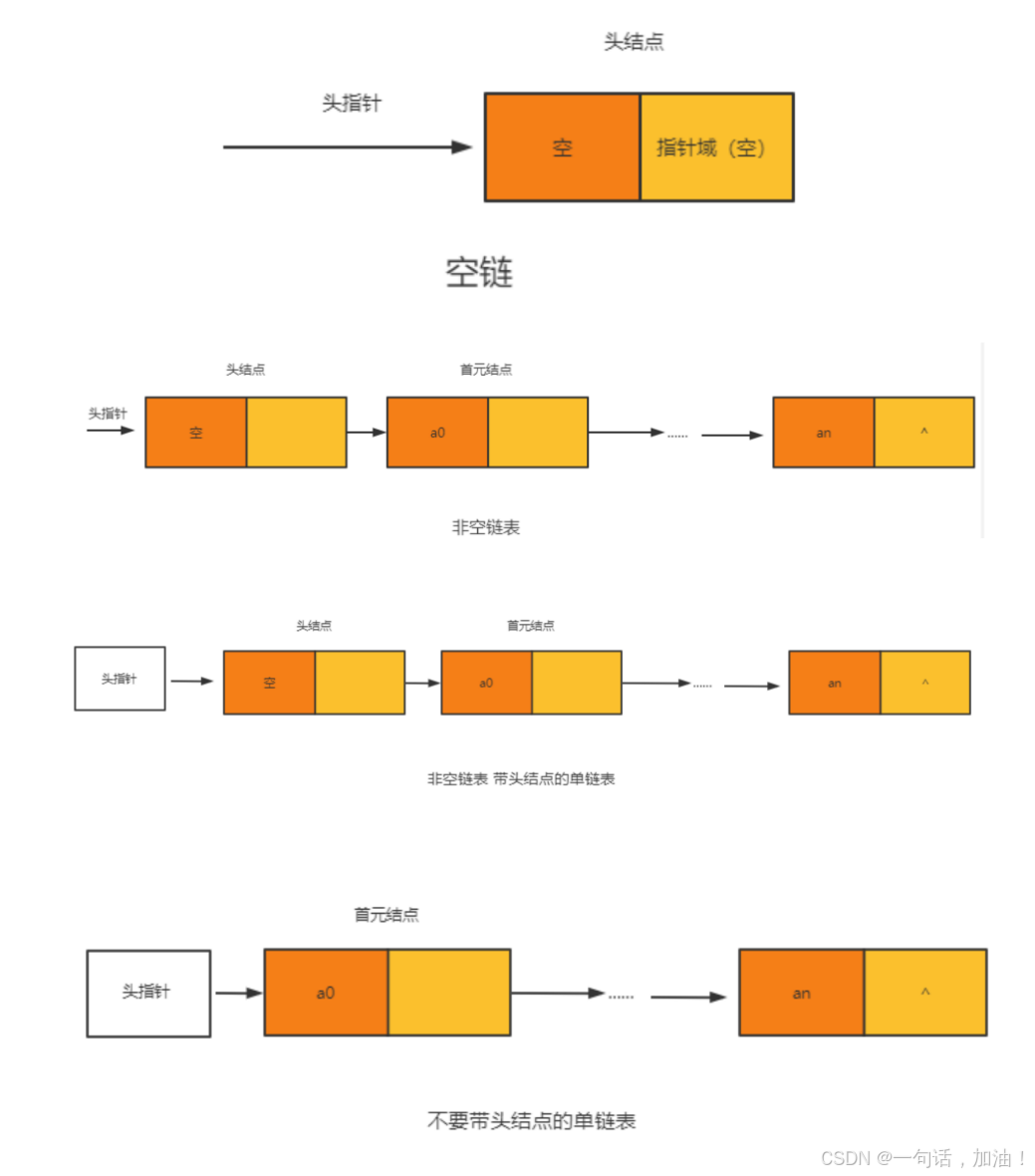
头指针和头节点
单链表有带头节点和不带头节点两种结构。
链表中,第⼀个结点存储的位置叫头指针,如果链表有头结点,那么头指针就是指向头结
点的指针。
头指针所指的不存在数据元素的第⼀个结点就叫做头结点(⽽头结点⼜指向⾸元结点)。
头结点⼀般不放数据(有的时候也是放的,⽐如链表的⻓度,⽤做监视)。
存放第⼀个数据元素的结点叫做第⼀个数据元素结点,也叫做⾸元结点
带头结点的好处就是,⽅便对于链表的操作。对于空表、⾮空表的情况以及对于⾸元结点都可以
进⾏统⼀的处理。
不带头结点的单链表的插⼊操作
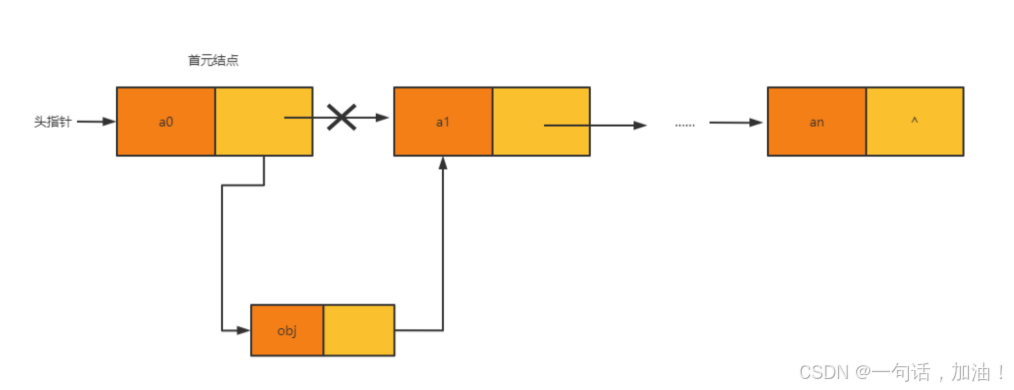
带头结点的单链表的插⼊操作
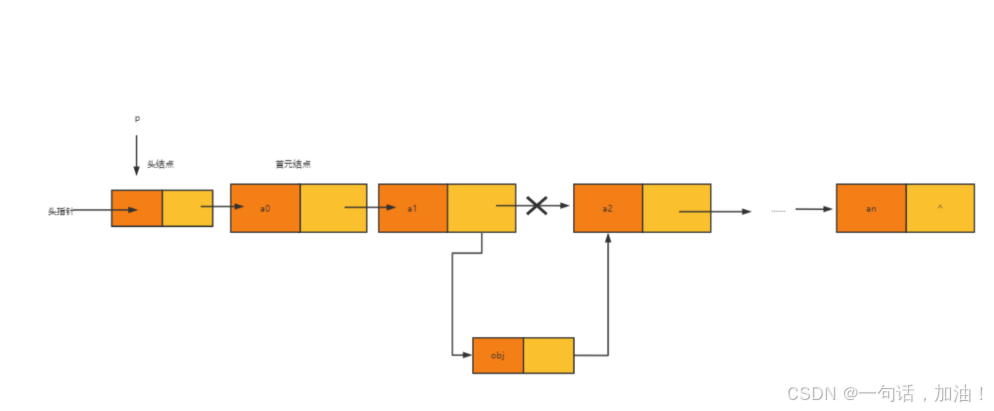
代码示例(带头节点)
#include <iostream>
using namespace std;
typedef struct Node {int data; //数据域struct Node* next; //指针域
}Node,*LinkList;//初始化
LinkList initial() {Node* s = (Node*)malloc(sizeof(Node));if (s == NULL) {cout << "分配内存失败!" << endl;exit(1); //内存分配失败则退出程序}s->next = NULL;return s;
}//遍历单链表
void print(LinkList L) {Node* p = L->next;while (p != NULL) {cout << p->data<<" ";p = p->next;}cout << endl;
}//查找,查找指定元素的节点
Node* find(LinkList& L,int element) {Node* p = L->next;while (p != NULL) {if (p->data==element) {return p;}p = p->next;}cout << "查找失败!该元素不存在" << endl;return NULL;
}//头插
void head_insert(LinkList& L, int element) {Node* s = (Node*)malloc(sizeof(Node)); //申请一个节点s->data = element; //把数据放入节点 s->next = L->next;L->next = s;
}//尾插
void rear_insert(LinkList&L, int element){Node* p = L->next;//遍历找出尾节点while(p!=NULL&&p->next!=NULL){p=p->next;}Node* s = (Node*)malloc(sizeof(Node));s->data = element;s->next =NULL;p->next = s;
}//中间插,在指定元素后插入元素
void middle_insert(LinkList& L, int elementUp ,int elementDown){Node* p = find(L,elementUp);if(p==NULL){cout<<"中间插入操作失败"<<endl;return;}Node* s = (Node*) malloc(sizeof(Node));s->data = elementDown;s->next = p->next;p->next = s;
}//删除
void deleteList(LinkList& L,int element){Node* p = L->next;Node* q =L;while(p!=NULL&&p->next!=NULL){//TODOif(p->data==element){break;}q=p;p=p->next;}if(q!=NULL&&p!=NULL){q->next = p->next;free(p);}
}
int main() {LinkList L = initial();head_insert(L, 1);head_insert(L, 3);head_insert(L, 6);cout<<"头插之后:"<<endl;print(L); //6 3 1rear_insert(L,9);rear_insert(L,0);cout<<"尾插之后:"<<endl;print(L); //6 3 1 9 0middle_insert(L,1,8);cout<<"中间插入之后:"<<endl;print(L); //6 3 1 8 9 0deleteList(L,1);cout<<"删除之后:"<<endl;print(L); //6 3 8 9 0
}

优劣势
优势
增删比顺序表高效
劣势
修查没顺序表高效
双向链表
代码实现(带头节点)
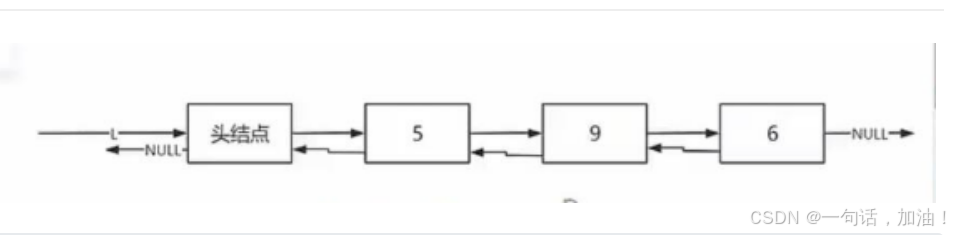
#include <iostream>
using namespace std;
//定义一个结构体,表示每个节点信息
typedef struct Node{int data; //数据域struct Node* pre; //指针域,指向前一个节点struct Node* next; //指向后一个节点的地址
}Node,*LinkList;//初始化双链表
LinkList initial(){Node* s =(Node*)malloc(sizeof(Node));if(s==NULL){cout<<"初始化失败!"<<endl;exit(1);}s->next=s->pre=NULL;return s;
}//查找元素所在的节点
Node* find(LinkList& L, int element){Node* p = L->next;while(p!=NULL){if(p->data==element){return p;}p = p->next;}cout<<"你要查找的元素所在的节点不存在!"<<endl;return NULL;
}//遍历双链表
void print(LinkList L){Node* p = L->next;while(p!=NULL){cout<<p->data<<" ";p=p->next;}cout<<endl;
}//头插
void head_insert(LinkList& L, int element){Node* s =(Node*) malloc(sizeof(Node));s->data = element;s->next = L->next;s->pre = L;L->next = s;if(s->next!=NULL){s->next->pre = s;}
}//尾插
void rear_insert(LinkList& L, int element){Node* p = L->next;while(p != NULL&&p->next!=NULL){p=p->next;}Node* s =(Node*)malloc(sizeof(Node));s->data = element;s->next = p->next;s->pre = p;p->next = s;}//中间插
void middle_insert(LinkList& L,int element1, int element){Node* p = L->next;Node* q = L;while(p!=NULL&&p->next!=NULL){if(p->data==element1){break;}q=p;p=p->next;}Node* s =(Node*)malloc(sizeof(Node));s->data = element;s->next = p;s->pre = q;q->next = s;p->pre = s;
}//删除指定元素的节点
void deleteLinkList(LinkList& L,int element){Node* s = find(L,element);Node* p = s->pre;p->next = s->next;if(s->next!=NULL){s->next->pre = p;}
}
int main(){//初始化LinkList L = initial();head_insert(L,1);head_insert(L,3);head_insert(L,6);print(L); //6 3 1rear_insert(L,7);rear_insert(L,9);print(L); //6 3 1 7 9middle_insert(L,1,8);print(L); //6 3 8 1 7 9deleteLinkList(L,1);print(L); //6 3 8 7 9
}
循环链表
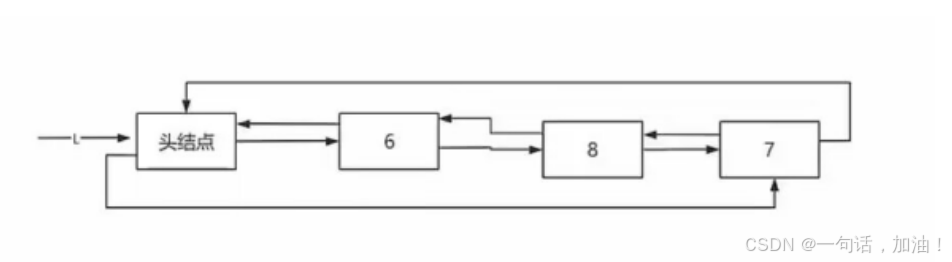
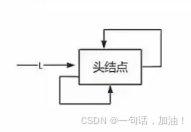
代码实现(带头结点)
#include <iostream>
using namespace std;
//定义一个结构体,表示每个节点信息
typedef struct Node{int data; //数据域struct Node* pre; //指针域,指向前一个节点struct Node* next; //指向后一个节点的地址
}Node,*LinkList;//初始化循环链表
LinkList initial(){Node* s =(Node*)malloc(sizeof(Node));if(s==NULL){cout<<"初始化失败!"<<endl;exit(1);}s->next=s->pre=s;return s;
}//查找元素所在的节点
Node* find(LinkList& L, int element){Node* p = L->next;while(p!=L){if(p->data==element){return p;}p = p->next;}cout<<"你要查找的元素所在的节点不存在!"<<endl;return NULL;
}//遍历双链表
void print(LinkList L){Node* p = L->next;while(p!=L){cout<<p->data<<" ";p=p->next;}cout<<endl;
}//头插
void head_insert(LinkList& L, int element){Node* s =(Node*) malloc(sizeof(Node));s->data = element;s->next = L->next;s->pre = L;L->next = s;s->next->pre = s;
}//尾插
void rear_insert(LinkList& L, int element){Node* p = L->next;while(p->next!=L){p=p->next;}Node* s =(Node*)malloc(sizeof(Node));s->data = element;s->next = p->next;s->pre = p;p->next = s;}//中间插
void middle_insert(LinkList& L,int element1, int element){Node* p = L->next;Node* q = L;while(p->next!=L){if(p->data==element1){break;}q=p;p=p->next;}Node* s =(Node*)malloc(sizeof(Node));s->data = element;s->next = p;s->pre = q;q->next = s;p->pre = s;
}//删除指定元素的节点
void deleteLinkList(LinkList& L,int element){Node* s = find(L,element);Node* p = s->pre;p->next = s->next;s->next->pre = p;
}
int main(){//初始化LinkList L = initial();head_insert(L,1);head_insert(L,3);head_insert(L,6);print(L); //6 3 1rear_insert(L,7);rear_insert(L,9);print(L); //6 3 1 7 9middle_insert(L,1,8);print(L); //6 3 8 1 7 9deleteLinkList(L,1);print(L); //6 3 8 7 9
}
相关文章:
)
顺序表,单链表,双链表,循环链表(01星球)
文章目录 数据结构前导------C语言复习程序为什么要被编译器编译之后才能运行编译器把C语言程序转换成可以执行的机器码的过程做了什么宏定义typedef 关键字全局变量和局部变量常量字符的输入输出运算符冯诺依曼架构存储器容量数据类型指针指针本质为什么需要指针 数组数组指针…...

代码社区开源协议
开源协议是一种法律文件,用于规定开源软件的使用、修改和分发条件。它平衡了开发者和使用者的权益,同时推动开放协作与技术创新。以下是常见的开源协议及其特点和适用场景: 常见开源协议列表及介绍 1. MIT License 特点:非常宽…...
自习室座位预约管理系统(SpringBoot后端+Vue管理端)(高级版)【论文+源码+SQL脚本】)
[免费]微信小程序(图书馆)自习室座位预约管理系统(SpringBoot后端+Vue管理端)(高级版)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序(图书馆)自习室座位预约管理系统(SpringBoot后端Vue管理端)(高级版),分享下哈。 项目视频演示 【免费】微信小程序(图书馆)自习室座位预约管理系统(SpringBoot后端Vue管理端)(高级版…...

树莓派:更新源
发行版本 Debian 一直维护着至少三个发行版本:“稳定版(stable)”,“测试版(testing)”和“不稳定版(unstable)”。 发行版目录 下一代 Debian 正式发行版的代号为 bullseye — 发布…...

树与二叉树的遍历
我们平时用的树都是二叉树 一、一些基础概念 1. 树就是一种:一对多的数据结构。树离不开递归,因为“树”就是“树”中有“树”。 二叉树就是 :空树 或者 每个结点的子结点个数小于等于2。 满二叉树: 除叶子结点外所有结点的…...

Web基础:HTML快速入门
HTML基础语法 HTML(超文本标记语言) 是用于创建网页内容的 标记语言,通过定义页面的 结构和内容 来告诉浏览器如何呈现网页。 超文本(Hypertext) 是一种通过 链接(Hyperlinks) 将不同文本、图像…...
)
异常(8)
今天补充一些异常的细节,帮助大家更好的理解异常. 注:关于异常的处理方式 异常的种类有很多,我们要根据不同的业务场景来决定. 对于比较严重的问题(例如和算钱相关的场景),应该让程序直接崩溃,防止造成更严重的结果 对于不太严重的问题(大多数场景),可以记录错误日志,并通过…...

平时作业
java作业 package zuoye; public class zuoye02 {public static int Random(int n) {return (int)(n * Math.random());}public static void main(String[] args) {int n 100;//System.out.println(Random(n));int[]random new int[50];for(int i 0; i <50; i) {rand…...

宇树人形机器人开源模型
1. 下载源码 https://github.com/unitreerobotics/unitree_ros.git2. 启动Gazebo roslaunch h1_description gazebo.launch3. 仿真效果 H1 GO2 B2 Laikago Z1 4. VMware: vmw_ioctl_command error Invalid argument 这个错误通常出现在虚拟机环境中运行需要OpenGL支持的应用…...

**ResNet-SE + MFCC** 训练框架,包括 **数据加载、训练流程**,以及 **混淆矩阵** 可视化示例
1. 依赖库安装 如果你还没安装相关库,请先执行: pip install torch torchaudio torchvision scikit-learn matplotlib tqdm2. 数据加载 这里假设你有一个 音频分类数据集,其文件结构如下: dataset/ │── train/ │ ├──…...
)
Golang | 每日一练 (5)
💢欢迎来到张胤尘的技术站 💥技术如江河,汇聚众志成。代码似星辰,照亮行征程。开源精神长,传承永不忘。携手共前行,未来更辉煌💥 文章目录 Golang | 每日一练 (5)题目参考答案线程与协程线程切换…...

搞定python之四----函数、lambda和模块
本文是《搞定python》系列专栏的第四篇,通过代码演示列python自定义函数、lambda和模块的用法。本文学习完成后,python的基础知识就完了。后面会学习面向对象的内容。 1、自定义函数 # 测试python自定义函数# 有参数,没有返回值 def say_he…...

算法分享———进制转换通用算法
模板一:任意(K)进制转10进制 将k进制的x转化为10进制的x ll x0; for(int i1;i<n;i) { xx*ka[i]; } cout<<x<<endl;模板二:十进制转m进制 ll x; cin>>x; while(x) { a[cnt]x%k; x/k; } reverse(a1,a1cnt);…...

Proser:新增指令批次发送功能
Proser中的批次发送功能,是通过指令集进行管理的。 起初设计时,希望指令集窗口自身包含指令的编辑功能,这部分功能与传输窗口的功能重合度高,所以设计上进行了简化,由用户在传输窗口输入指令,添加到指令集窗…...

rpc grpc
RPC Remote Procedure Call,远程过程调用,是用来屏蔽分布式计算中的各种调用细节,使得调用远端的方法就像调用本地的一样。 客户端与服务端沟通的过程 客户端发送数据(以字节流的方式);(编码)服务端接受…...

AI赋能铁道安全巡检探索智能巡检新时代,基于YOLOv7全系列【tiny/l/x】参数模型开发构建铁路轨道场景下轨道上人员行为异常检测预警系统
在交通强国的战略引领下,中国铁路网如巨龙般纵贯大江南北,将五湖四海紧密相连,极大地促进了人员出行与物流运输的便捷性。然而,随着铁路线路的不断扩展,管理层面的安全问题也日益凸显。历史上,多起与铁路相…...

Kubernetes安全:集群保护的最佳实践
随着容器化技术的广泛应用,Kubernetes已经成为企业IT基础设施的重要组成部分。然而,Kubernetes集群的复杂性也带来了独特的安全挑战。如何在动态变化的云原生环境中保障集群的安全性,成为每一位运维工程师和安全专家关注的焦点。本文将详细探…...

R+VIC模型融合实践技术应用及未来气候变化模型预测
在气候变化问题日益严重的今天,水文模型在防洪规划,未来预测等方面发挥着不可替代的重要作用。目前,无论是工程实践或是科学研究中都存在很多著名的水文模型如SWAT/HSPF/HEC-HMS等。虽然,这些软件有各自的优点;但是&am…...

前端开发:混合技术栈的应用
目录 前言 混合技术栈的优势 移动端开发嵌入H5 1、场景描述 2、实现方法 3、源码示例 OC项目嵌入Swift的使用 1、场景描述 2、实现方法 3、源码示例 HarmonyOS开发中嵌入WebView 1、权限配置 2、加载网页 结束语 前言 随着技术的不断进步,软件开发领域…...

Machine Learning: 十大基本机器学习算法
机器学习算法分类:监督学习、无监督学习、强化学习 基本的机器学习算法: 线性回归、支持向量机(SVM)、最近邻居(KNN)、逻辑回归、决策树、k平均、随机森林、朴素贝叶斯、降维、梯度增强。 机器学习算法大致可以分为三类: 监督学习算法 (Sup…...
)
react实现一个列表的拖拽排序(react实现拖拽)
需求场景: 我的项目里需要实现一个垂直列表的拖拽排序,效果图如下图: 技术调研: 借用antd Table实现: 我的项目里使用了antd,antd表格有一个示例还是挺像的,本来我想用Table实现࿰…...

通过mybatis的拦截器对SQL进行打标
1、背景 在我们开发的过程中,一般需要编写各种SQL语句,万一生产环境出现了慢查询,那么我们如何快速定位到底是程序中的那个SQL出现的问题呢? 2、解决方案 如果我们的数据访问层使用的是mybatis的话,那么我们可以通过…...

【MySQL】MySQL服务器——mysqld
1.MySQL服务器 是名为 mysqld 的数据库服务器程序,和“主机”(host)不一样是一个多线程的单进程管理对磁盘和内存中数据库的访问支持并发的客户端连接支持多个存储引擎,常见的存储引擎包括InnoDB、MyISAM、Memory、Archive支持事…...
)
JAVA面试_进阶部分_Java JVM:垃圾回收(GC 在什么时候,对什么东西,做了什么事情)
在什么时候: 首先需要知道,GC又分为minor GC 和 Full GC(major GC)。Java堆内存分为新生代和老年代,新生代 中又分为1个eden区和两个Survior区域。 一般情况下,新创建的对象都会被分配到eden区ÿ…...

【探秘海洋伤痕】海洋环境污染损害的警世启示
在地球这个蓝色星球上,广袤无垠的海洋孕育了无数生命,支撑着地球的生态平衡与人类的生存发展。然而,随着工业化和现代化的加速,海洋环境遭受的伤害日益严重,海洋环境污染损害成为了我们必须直面的严峻问题。本文将带您…...
与拦截器(Interceptor))
过滤器(Filter)与拦截器(Interceptor)
在Java Web开发中,**拦截器(Interceptor)和过滤器(Filter)**都用于在请求处理过程中拦截和处理HTTP请求或响应,但它们有不同的应用场景和工作原理。下面将详细解释它们的区别,并提供代码演示。 …...

智慧城市运行管理服务平台建设方案
随着城市化的快速发展,城市运行管理面临着前所未有的挑战。智慧城市的概念应运而生,旨在通过信息技术手段提升城市管理效率和居民生活质量。智慧城市运行管理服务平台作为智慧城市建设的核心组成部分,其建设方案的科学性和前瞻性至关重要。 …...

Java是怎么解决并发问题的?
Happens-Before规则(前言) Happens-Before规则 是 Java 内存模型(JMM)中用于定义线程间操作可见性和有序性的一种规范。它的核心目的是:确保一个线程的某些操作结果对其他线程是可见的,并且这些操作在时间上的顺序不会被重排序破…...
)
使用 Chrome Flags 设置(适用于 HTTP 站点开发)
使用 Chrome Flags 设置(适用于 HTTP 站点开发) 在 Chrome 地址栏输入:chrome://flags/在搜索框输入 “Insecure origins” 或 “Allow invalid certificates”。找到 “Insecure origins treated as secure” 选项(或者 #allow-…...

解锁 AI 开发的无限可能:邀请您加入 coze-sharp 开源项目
大家好!今天我要向大家介绍一个充满潜力的开源项目——coze-sharp!这是一个基于 C# 开发的 Coze 客户端,旨在帮助开发者轻松接入 Coze AI 平台,打造智能应用。项目地址在这里:https://github.com/zhulige/coze-sharp&a…...

【Swift】面向协议编程之HelloWorld
定义一个协议(protocol),swift 中可以对protocol 进行扩展(extension)通过协议的扩展可以对函数有默认的实现 protocol Sleepable {func sleep() } protocol Eatable {func eat() } extension Eatable {func eat() {print("eat food")} }在类(class)或结…...
)
图神经网络学习笔记—纯 PyTorch 中的多 GPU 训练(专题十二)
对于许多大规模的真实数据集,可能需要在多个 GPU 上进行扩展训练。本教程将介绍如何通过 torch.nn.parallel.DistributedDataParallel 在 PyG 和 PyTorch 中设置多 GPU 训练管道,而无需任何其他第三方库(如 PyTorch Lightning)。请注意,此方法基于数据并行。这意味着每个 …...

Linux云计算SRE-第二十周
完成ELK综合案例里面的实验,搭建完整的环境 一、 1、安装nginx和filebeat,配置node0(10.0.0.100),node1(10.0.0.110),node2(10.0.0.120),采用filebeat收集nignx日志。 #node0、node1、node2采用以下相同方式收集ngin…...

springcloud gateway搭建及动态获取nacos注册的服务信息信息
前言 Spring Cloud Gateway 通过集成 Nacos 服务发现,可以动态获取注册到 Nacos 的微服务实例信息,并根据服务名(Service Name)自动生成路由规则或手动配置路由规则,实现请求的动态路由和负载均衡。 一个最简单的网关就…...
)
SSM基础专项复习6——Spring框架AOP(3)
系列文章 1、SSM基础专项复习1——SSM项目整合-CSDN博客 2、SSM基础专项复习2——Spring 框架(1)-CSDN博客 3、SSM基础专项复习3——Spring框架(2)-CSDN博客 4、SSM基础专项复习4——Maven项目管理工具(1ÿ…...

【嵌入式linux】网口和USB热插拔检测
在Linux常常需要对网口和USB等外设接口进行插拔检测,从而执行部分初始化操作。下面简要介绍Linux的Netlink机制,并在C程序中使用Linux的Netlink机制完成网口和USB口插拔检测。 Netlink 是 Linux 内核与用户空间进程通信的一种机制,主要用于内…...
—类和对象(中) ③拷贝构造函数)
C++(13)—类和对象(中) ③拷贝构造函数
文章目录 一、拷贝构造函数的基本概念1.1 什么是拷贝构造函数?1.2 拷贝构造函数的调用场景 二、拷贝构造函数的核心特性2.1 拷贝构造函数的参数2.2 默认拷贝构造函数 三、深拷贝与浅拷贝3.1 浅拷贝的问题 四、拷贝构造函数的实际应用4.1 何时需要显式定义拷贝构造函…...

【GPT入门】第17课 RAG向量检索分类、原理与优化
【GPT入门】第16课 RAG向量检索分类、原理与优化 1.向量检索概念1.1 文本检索的两类方式1.2 向量的定义1.3 文本向量(Text Embeddings)1.4 文本向量如何得到1.5 向量间相似度计算1.6 向量数据库功能对比1.7 open ai发布的两个向量模型2.向量数据库1.8 向量检索的优化3.检索后…...
)
Operator <=> (spaceship operator)
operator <>动机 在C20以前定义比较运算符:其他比较运算符基于<和实现 struct Type {int value;// 相等运算符friend bool operator(const Type& a, const Type& b) {return a.value b.value;}// 不等运算符friend bool operator!(const Type&a…...

队列的简单例题
题目如下 模拟队列 首先你要明白队列的话 只有队尾才能进行新增,也就是入队 只有队首才能出队,也就是删除 队首队尾指针一开始默认都是0 相当于队列中一开始是有一个元素的就是 0的位置 队首指针head0 队尾指针tail0 1.入队也就是队尾要先赋值…...

Calibre-Web-Automated:打造你的私人图书馆
有没有小伙伴在工作、学习或生活中喜欢保存一些书籍或PDF文件,结果过一段时间想找的时候却怎么也找不到,最后只能无奈放弃?你是否已经厌倦了手动管理电子书的繁琐?是否梦想拥有一个私人图书馆,随时随地都能轻松访问自己…...

第27周JavaSpringboot 前后端联调
电商前后端联调课程笔记 一、项目启动与环境搭建 1.1 项目启动 在学习电商项目的前后端联调之前,需要先掌握如何启动项目。项目启动是整个开发流程的基础,只有成功启动项目,才能进行后续的开发与调试工作。 1.1.1 环境安装 环境安装是项…...

【实战ES】实战 Elasticsearch:快速上手与深度实践-8.2.1AWS OpenSearch无服务器方案
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 8.2.1AWS OpenSearch 无服务器方案深度解析与实践指南1. Serverless架构的核心价值与行业趋势1.1 传统Elasticsearch集群的运维挑战1.2 Serverless技术演进路线技术特性对比…...

鸿蒙开发者社区资源的重要性
鸿蒙系统,作为华为公司自主研发的操作系统,旨在为各类智能设备提供统一的平台。它不仅支持手机、平板电脑等移动设备,还涵盖了物联网(IoT)设备和其他智能家居产品。鸿蒙系统的开发环境和工具链对于开发者来说至关重要&…...

【QT】事件系统入门——QEvent 基础与示例
一、事件介绍 事件是 应用程序内部或者外部产生的事情或者动作的统称 在 Qt 中使用一个对象来表示一个事件。所有的 Qt 事件均继承于抽象类 QEvent。事件是由系统或者 Qt 平台本身在不同的时刻发出的。当用户按下鼠标、敲下键盘,或者是窗口需要重新绘制的时候&…...

⚡️Jolt -- 通过JSON配置来处理复杂数据转换的工具
简介:一个能够通过JSON配置(特定的语法)来处理复杂数据转换的工具。 比如将API响应转换为内部系统所需的格式,或者处理来自不同来源的数据结构差异。例如,将嵌套的JSON结构扁平化,或者重命名字段࿰…...

2025-03-13 禅修-错误的做法
摘要: 2025-03-13 禅修-错误的做法 禅修-错误的做法 我们今天的课程是这个禅修防误。主要是有一些我们所明令禁止的。在整个禅修过程中,会对我们禅修出现一些弊端的这部分,我们会给大家介绍。第一,在禅修中要防止自由联想,防止幻…...

uni-app学习笔记——自定义模板
一、流程 1.这是一个硬性的流程,只要按照如此程序化就可以实现 二、步骤 1.第一步 2.第二步 3.第三步 4.每一次新建页面,都如第二步一样;可以选择自定义的模版(vue3Setup——这是我自己的模版),第二步的…...

【医院绩效管理专题】8.医院绩效数据的收集与整理方法:洞察现状,引领未来
医院成本核算、绩效管理、运营统计、内部控制、管理会计专题索引 一、引言 在当今医疗行业竞争日益激烈的背景下,医院绩效管理已成为提升医疗服务质量、优化运营效率、增强综合竞争力的关键因素。而绩效数据的收集与整理作为绩效管理的基础环节,其科学性、准确性和完整性直…...

麒麟系统如何安装Anaconda
在银河麒麟操作系统(Kylin OS)中安装 Anaconda 的步骤相对简单,以下是基于搜索结果整理的详细安装指南: 步骤 1:下载 Anaconda 安装脚本 打开浏览器,访问 Anaconda 官方下载页面。选择适合 Linux 系统的安…...