循环神经网络:从基础到应用的深度解析
🍛循环神经网络(RNN)概述
循环神经网络(Recurrent Neural Network, RNN)是一种能够处理时序数据或序列数据的深度学习模型。不同于传统的前馈神经网络,RNN具有内存单元,能够捕捉序列中前后信息之间的依赖关系。RNN在自然语言处理、语音识别、时间序列预测等领域中具有广泛的应用。
RNN的核心思想是通过循环结构使网络能够记住前一个时刻的信息。每一个时间步,输入不仅依赖于当前的输入数据,还依赖于前一时刻的状态,从而使得RNN能够处理时序信息。
🍛循环神经网络的基本单元
RNN的基本单元由以下部分组成:
- 输入(Input):在每个时间步,输入当前时刻的数据。
- 隐藏状态(Hidden State):每个时间步都有一个隐藏状态,代表对当前输入及前一时刻信息的记忆。
- 输出(Output):根据当前输入和隐藏状态生成输出。
在数学上,RNN的计算可以表示为以下公式:
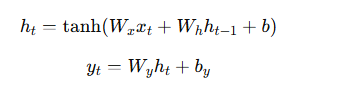
🍛循环神经网络的网络结构
RNN的网络结构可以分为以下几种类型:
- 单层RNN:最简单的RNN结构,只包括一个隐藏层。
- 多层RNN(堆叠RNN):通过堆叠多个RNN层,增加模型的复杂性和表达能力。
- 双向RNN(BiRNN):双向RNN同时考虑了从前往后和从后往前的时序信息,能够获得更加丰富的上下文信息。
- 深度循环神经网络(DRNN):通过增加网络的深度(堆叠多个RNN层)来提高模型的表示能力。
🍛长短时记忆网络(LSTM)
传统的RNN在处理长序列数据时存在梯度消失和梯度爆炸的问题,长短时记忆网络(LSTM)通过引入门控机制来解决这一问题。
LSTM通过使用三个门(输入门、遗忘门和输出门)来控制信息的流动。LSTM的更新过程如下:
- 遗忘门:决定忘记多少旧的信息。
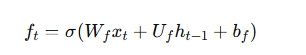
输入门:决定当前时刻的输入信息有多少更新到记忆单元。
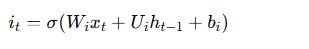
输出门:决定记忆单元的多少信息输出到当前的隐藏状态。
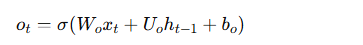
记忆更新:根据遗忘门和输入门更新记忆单元的状态。
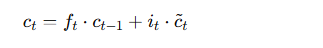
🍛双向循环神经网络(BiRNN)和深度循环神经网络(DRNN)
- 双向RNN(BiRNN):为了捕捉从前到后的信息,双向RNN通过在两个方向上运行两个独立的RNN来获取完整的上下文信息。通过这种结构,BiRNN能够更好地处理具有复杂依赖关系的时序数据。
公式如下:
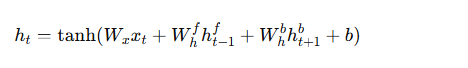
深度循环神经网络(DRNN):通过堆叠多个RNN层,形成深度结构,DRNN能够捕捉更高层次的特征和时序依赖。多层的RNN允许网络从更抽象的层次进行学习。
🍛序列标注与应用
RNN在序列标注任务中的应用非常广泛,尤其是在自然语言处理(NLP)领域。常见的任务包括:
- 命名实体识别(NER):识别文本中的人物、地点、组织等实体。
- 词性标注(POS Tagging):标注每个单词的词性(如名词、动词等)。
- 语音识别:将语音信号转化为文字。
- 情感分析:分析文本的情感倾向。
通过在RNN的输出层使用Softmax激活函数,可以实现多分类任务,如对每个时间步的输入数据进行分类。
🍛代码实现与示例
以下是一个简单的基于PyTorch的RNN模型实现,用于文本分类任务,代码仅供参考
import torch
import torch.nn as nn
import torch.optim as optim# 定义RNN模型
class RNNModel(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(RNNModel, self).__init__()self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):# x: 输入的序列数据out, _ = self.rnn(x) # 获取RNN的输出out = out[:, -1, :] # 只取最后一个时间步的输出out = self.fc(out)return out# 参数设置
input_size = 10 # 输入特征的维度
hidden_size = 50 # 隐藏层的维度
output_size = 2 # 输出的类别数(例如,二分类问题)# 创建模型
model = RNNModel(input_size, hidden_size, output_size)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 示例输入数据
inputs = torch.randn(32, 5, input_size) # 32个样本,每个样本有5个时间步,输入特征维度为10
labels = torch.randint(0, 2, (32,)) # 随机生成标签,2类# 训练过程
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()print(f"Loss: {loss.item()}")
🍛实战(IMDB影评数据集)
环境准备
pip install torch torchvision torchaudio torchtext
完整源码
代码仅供参考
import torch
import torch.nn as nn
import torch.optim as optim
import torchtext
from torchtext.datasets import IMDB
from torchtext.data import Field, BucketIterator# 数据预处理
TEXT = Field(sequential=True, tokenize='spacy', include_lengths=True)
LABEL = Field(sequential=False, use_vocab=True, is_target=True)# 下载IMDB数据集
train_data, test_data = IMDB.splits(TEXT, LABEL)# 构建词汇表并用预训练的GloVe词向量初始化
TEXT.build_vocab(train_data, vectors='glove.6B.100d', min_freq=10)
LABEL.build_vocab(train_data)# 创建训练和测试数据迭代器
train_iterator, test_iterator = BucketIterator.splits((train_data, test_data),batch_size=64,device=torch.device('cuda' if torch.cuda.is_available() else 'cpu'),sort_within_batch=True,sort_key=lambda x: len(x.text)
)# 定义RNN模型
class RNNModel(nn.Module):def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, dropout):super(RNNModel, self).__init__()self.embedding = nn.Embedding(input_dim, embedding_dim)self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers=n_layers, dropout=dropout, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, text, text_lengths):embedded = self.embedding(text)packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths, batch_first=True, enforce_sorted=False)packed_output, hidden = self.rnn(packed_embedded)output = self.dropout(hidden[-1])return self.fc(output)# 超参数设置
input_dim = len(TEXT.vocab)
embedding_dim = 100
hidden_dim = 256
output_dim = len(LABEL.vocab)
n_layers = 2
dropout = 0.5# 初始化模型、损失函数和优化器
model = RNNModel(input_dim, embedding_dim, hidden_dim, output_dim, n_layers, dropout)
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()# 将模型和数据转移到GPU(如果可用)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
criterion = criterion.to(device)# 训练模型
def train(model, iterator, optimizer, criterion):model.train()epoch_loss = 0epoch_acc = 0for batch in iterator:text, text_lengths = batch.textlabels = batch.labeloptimizer.zero_grad()# 预测predictions = model(text, text_lengths).squeeze(1)# 计算损失和准确率loss = criterion(predictions, labels)acc = binary_accuracy(predictions, labels)# 反向传播loss.backward()optimizer.step()epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)# 计算二分类准确率
def binary_accuracy(predictions, labels):preds = torch.argmax(predictions, dim=1)correct = (preds == labels).float()return correct.sum() / len(correct)# 测试模型
def evaluate(model, iterator, criterion):model.eval()epoch_loss = 0epoch_acc = 0with torch.no_grad():for batch in iterator:text, text_lengths = batch.textlabels = batch.labelpredictions = model(text, text_lengths).squeeze(1)loss = criterion(predictions, labels)acc = binary_accuracy(predictions, labels)epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)# 训练过程
N_EPOCHS = 5
for epoch in range(N_EPOCHS):train_loss, train_acc = train(model, train_iterator, optimizer, criterion)test_loss, test_acc = evaluate(model, test_iterator, criterion)print(f'Epoch {epoch+1}/{N_EPOCHS}')print(f'Train Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
-
数据预处理:
- 我们使用了torchtext库来下载和处理IMDB影评数据集。
- 通过
Field定义了文本和标签的预处理方法。tokenize='spacy'表示使用Spacy库进行分词。 build_vocab方法用来建立词汇表,并加载GloVe预训练词向量。
-
模型定义:
-
RNNModel
类定义了一个基础的循环神经网络模型。它包含:
- 一个嵌入层(Embedding),将词汇映射为向量。
- 一个RNN层,处理序列数据。
- 一个全连接层,将隐藏状态映射为最终的输出(情感分类)。
-
我们在RNN层中使用了
pack_padded_sequence来处理不同长度的序列。
-
-
训练和评估:
- 训练和评估函数
train和evaluate分别用于训练和评估模型。 - 使用
Adam优化器和CrossEntropyLoss损失函数进行训练。
- 训练和评估函数
-
准确率计算:
binary_accuracy函数计算预测结果的准确率,适用于二分类问题。
模型评估
模型会输出每个epoch的训练损失和准确率,以及测试损失和准确率,具体结果可以参考下图
注意:en_core_web_sm模型配置下载
🍛总结
循环神经网络(RNN)及其变种如LSTM、BiRNN和DRNN在处理时序数据和序列标注任务中表现出色。尽管RNN存在梯度消失问题,但通过改进的结构(如LSTM和GRU)和双向结构,我们可以更好地捕捉时序数据中的长期依赖。随着深度学习技术的不断进步,RNN及其变种将在更多的实际应用中展现出强大的性能
🍛参考文献
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
结果可以参考下图
注意:en_core_web_sm模型配置下载
🍛总结
循环神经网络(RNN)及其变种如LSTM、BiRNN和DRNN在处理时序数据和序列标注任务中表现出色。尽管RNN存在梯度消失问题,但通过改进的结构(如LSTM和GRU)和双向结构,我们可以更好地捕捉时序数据中的长期依赖。随着深度学习技术的不断进步,RNN及其变种将在更多的实际应用中展现出强大的性能
🍛参考文献
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
Graves, A., & Schmidhuber, J. (2005). Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks, 18(5-6), 602-610.

相关文章:

循环神经网络:从基础到应用的深度解析
🍛循环神经网络(RNN)概述 循环神经网络(Recurrent Neural Network, RNN)是一种能够处理时序数据或序列数据的深度学习模型。不同于传统的前馈神经网络,RNN具有内存单元,能够捕捉序列中前后信息…...

LeetCode 100.相同的树
题目: 给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。 如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。 思路:灵神 代码: class Solution {public boolean…...

序列化与反序列化
序列化是将对象转换为可被存储或传输的格式,例如将对象转换为字节流或字符串。序列化的过程可以将对象的状态保存下来,以便在需要时可以重新创建对象。 反序列化则是将序列化的对象转换回原始的对象形式,以便可以使用和操作这些对象。 序列…...

spring boot打包fat jar
所谓fat jar就是包含所有依赖的jar以及其他开发的代码的jar包。可以通过java -jar xxx.jar直接启动运行,不需要部署到tomcat中间件就能运行。 接下来我们使用maven进行打包: (1)在需要带包的主模块的pom中添加build依赖…...

2021年美亚杯电子数据取证大赛-个人赛
资格赛-案件背景 2021年10月某日早上,本市一个名为"大路建设"的高速公路工地主管发现办公室的计算机被加密并无法开启,其后收到了勒索通知。考虑到高速公路的基建安全,主管决定报警。警方调查人员到达现场取证,发现办公…...

用 React 编写一个笔记应用程序
这篇文章会教大家用 React 编写一个笔记应用程序。用户可以创建、编辑、和切换 Markdown 笔记。 1. nanoid nanoid 是一个轻量级和安全的唯一字符串ID生成器,常用于JavaScript环境中生成随机、唯一的字符串ID,如数据库主键、会话ID、文件名等场景。 …...

泛型擦除是什么?
泛型擦除(Type Erasure)是Java编译器在编译泛型代码时的一种机制,它的目的是确保泛型能够与JAVA的旧版本(即不支持泛型的版本)兼容。泛型擦除会在编译时移除泛型类型信息,并将泛型类型替换为其非泛型的上限类型(通常是Object) 详细解释 在Java中&#…...

鸿蒙Next星河版基础代码
目录: 1、鸿蒙箭头函数的写法2、鸿蒙数据类型的定义3、枚举的定义以及使用4、position绝对定位及层级zIndex5、字符串的拼接转换以及数据的处理(1)字符串转数字(2)数字转字符串(3)布尔值转换情况(4)数组的增删改查 6、三元表达式7、鸿蒙for循环的几种写法7.1、基本用…...

物联网智能项目:智能家居系统的设计与实现
物联网(Internet of Things,IoT)技术正在迅速改变我们的生活方式,特别是在智能家居、工业自动化、环境监控等领域。物联网智能项目通过将设备、传感器、控制器等通过互联网连接,实现设备间的智能交互,带来高效、便捷和智能的体验。本文将介绍一个典型的物联网智能家居项目…...

STL算法之set相关算法
STL一共提供了四种与set(集合)相关的算法,分别是并集(union)、交集(intersection)、差集(difference)、对称差集(symmetric difference)。 目录 set_union set_itersection set_difference set_symmetric_difference 所谓set,可细分为数学上定义的和…...

STM32主要功能
STM32 是由意法半导体(STMicroelectronics)推出的一系列基于 ARM Cortex-M 内核的微控制器(MCU)。STM32 微控制器广泛应用于嵌入式系统中,因其高性能、低功耗、丰富的外设接口和多种封装形式而被广泛采用。其主要功能和…...

【数据结构】--ArrayList与顺序表
文章目录 1. 线性表2. 顺序表3. ArrayList简介4. MyArrayList的实现5. ArrayList使用5.1 ArrayList的构造5.2 ArrayList常见操作5.3 ArrayList的遍历5.4 ArrayList的扩容机制 6. ArrayList的具体使用6.1 简单的洗牌算法6.2 杨辉三角 1. 线性表 线性表(linear list&…...
)
多线程篇-3--java内存模型(主内存,共享内存,三大特性,指定重排)
Java内存模型 Java Memory Model,简称JMM,本身是一种抽象的概念,实际上并不存在,它描述的是一组规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素࿰…...

Android Studio的AI工具插件使用介绍
Android Studio的AI工具插件使用介绍 一、前言 Android Studio 的 AI 工具插件具有诸多重要作用,以下是一些常见的方面: 代码生成与自动补全 代码优化与重构 代码解读 学习与知识获取 智能搜索与资源推荐实际使用中可以添加注释,解读某段代…...

【Yarn Bug】 yarn 安装依赖出现的网络连接问题
最近,在初始化 Ant Design Pro 前端脚手架过程中,使用 yarn 安装依赖时遇到了网络连接问题,具体错误信息提示为 info There appears to be trouble with your network connection. Retrying...。通过百度查询,得知出现这种问题的原…...

Vue3的Setup语法动态获取Dom或调用子组件方法
官方文档:https://cn.vuejs.org/api/composition-api-setup.html#composition-api-setup 获取Dom <template><div class"todo" ref"todoDom" click"handleClick"></div> </template><script lang"t…...
-附Matlab免费代码)
中科院一区算法KO-K均值优化算法(K-means Optimizer)-附Matlab免费代码
首先,使用K-means算法在每次迭代中建立聚类区域的形心向量,然后KO提出两种移动策略,以在开发和探索能力之间建立平衡。每次迭代中探索或开发的移动策略的决定取决于一个参数,该参数将被设计为识别每个搜索代理是否在访问的区域中过…...

python数据可视化销量柱状图练习
需求: 假设某店铺的商品销量分为 线上销量 和 线下销量: 使用 叠加柱状图 分别显示线上和线下销量。 在柱状图中添加每种商品的总销量。 图表美观,包含图例、网格、颜色区分等。 代码实现: import matplotlib.pyplot as plt imp…...

甘特图全面指南:原理、制作与实际案例
甘特图(Gantt Chart)是一种用于项目管理的直观工具,以条形图的形式展示任务的时间进度和依赖关系。它通过简单明了的视觉效果帮助团队跟踪任务进展,分配资源并优化时间安排。本文将深入介绍甘特图的定义、制作方法,以及…...

如何创建 MySQL 数据库的副本 ?
MySQL 是一个广泛使用的开源数据库系统,它提供了多种数据库复制的方法。此功能对于确保跨不同环境的数据可用性和完整性至关重要。 管理 MySQL 数据库通常需要创建数据库的副本。这个任务被称为 MySQL 数据库复制,对于备份、测试、服务器迁移和其他关键…...

基于YOLO模型的目标检测与识别实现在ESP32-S3 EYE上全流程部署
前言 文章首发于 基于YOLO模型的目标检测与识别实现在ESP32-S3 EYE上全流程部署 文章目录 前言项目环境安装ESP-IDF安装开发环境运行环境 训练数据集准备添加自定义数据集 下载预训练模型训练 YOLO 模型模型量化和格式转换模型结果评估训练损失评估指标模型推理 模型部署部署环…...

2411C++,CXImage简单使用
介绍 CxImage是一个可非常简单快速的加载,保存,显示和转换图像的C类. 文件格式和链接的C库 Cximage对象基本上是加了一些成员变量来保存有用信息的一个位图: class CxImage{...protected:void* pDib; //包含标题,调色板,像素BITMAPINFOHEADER head; //标准头文件CXIMAGEINFO…...
)
Java对象与XML互相转换(xstream)
依赖 <dependency><groupId>com.thoughtworks.xstream</groupId><artifactId>xstream</artifactId><version>1.4.18</version></dependency> 实体类 package com.itheima.util;import lombok.AllArgsConstructor; import lom…...

计算机视觉工程师紧张学习中!
在当今这个日新月异的科技时代,计算机视觉作为人工智能的重要分支,正以前所未有的速度改变着我们的生活和工作方式。为了紧跟时代步伐,提升自我技能,一群怀揣梦想与热情的计算机视觉设计开发工程师们聚集在了本次线下培训活动中。…...

网关整合sentinel无法读取nacos配置问题分析
sentinel无法读取nacos配置问题分析 1.spring-cloud-gateway整合sentinel2.问题现象3.原因猜测4.源码分析4. 结语 最近公司需要上线一个集约项目,虽然为内网项目,但曾经有过内网被攻破,导致内部系统被攻击的案例,且集约系统同时在…...

速盾:高防 CDN 中高级缓存有什么用?
在高防 CDN(Content Delivery Network,内容分发网络)的服务体系里,高级缓存功能犹如一颗强大的 “性能优化引擎”,对于提升网站或应用的运行效率、减轻源站压力以及改善用户体验等诸多方面都发挥着极为关键的作用。 一…...

大数据期末笔记
第一章、大数据概述 人类的行为及产生的事件的一种记录称之为数据。 1、大数据时代的特征,并结合生活实例谈谈带来的影响。 (一)特征 1、Volume 规模性:数据量大。 2、Velocity高速性:处理速度快。数据的生成和响…...

Qt详解QUiLoader 动态加载UI文件
文章目录 详解 QUiLoader 模块的使用1. QUiLoader 简介1.1 应用场景 2. 准备工作2.1 添加模块依赖2.2 引入头文件 3. 使用 QUiLoader 加载界面3.1 示例代码form.uimain.cpp 4. 常用方法详解4.1 load函数原型作用参数返回值示例代码 4.2 createWidget函数原型作用参数返回值示例…...

Android -- 简易音乐播放器
Android – 简易音乐播放器 播放器功能:* 1. 播放模式:单曲、列表循环、列表随机;* 2. 后台播放(单例模式);* 3. 多位置同步状态回调;处理模块:* 1. 提取文件信息:音频文…...

云平台与阿里云服务器使用
云平台 云就是一堆远程计算机组成的集群。 计算就是各种软件服务。 云平台就是远程计算机集群提供的的各种服务所组成的远程服务平台。 云平台提供的服务主要可以分为三个类别: I 服务 P服务 S服务 i就是基础设施服务infrastructure p就是平台服务platform …...

Dart 中 initializer lists
在 Dart 中,initializer lists 是构造函数的一种特性,允许你在进入构造函数体之前对某些字段进行初始化或进行检查。这些字段包括 final 字段,因为 final 字段必须在构造函数体运行之前被初始化。 以下是它的几个关键点和适用场景࿱…...

02.06、回文链表
02.06、[简单] 回文链表 1、题目描述 编写一个函数,检查输入的链表是否是回文的。 2、解题思路: 快慢指针找中点: 利用快慢指针的技巧来找到链表的中间节点。慢指针 slow 每次移动一步,而快指针 fast 每次移动两步。这样&…...

linux中限定特定用户使用crontab
在Linux中,crontab(cron table)是用来定时执行任务的工具。默认情况下,任何用户(包括普通用户)都可以为自己的账户创建和管理crontab条目,但前提是这个用户拥有对/var/spool/cron/crontabs目录的…...
)
Oracle Universal Unique Identifier (UUID)
本文介绍Oracle生成全局唯一ID的函数SYS_GUID,后续会对SYS_GUID和Sequence两种方法进行比较。 SYS_GUID 函数生成并返回一个由 16 个字节组成的全局唯一标识符(RAW 值)。在大多数平台上,生成的标识符由主机标识符、调用该函数的进…...

LangChain——加载知识库文本文档 PDF文档
文档加载 这涵盖了如何加载目录中的所有文档。 在底层,默认情况下使用 UnstructedLoader。需要安装依赖 pip install unstructuredpython导入方式 from langchain_community.document_loaders import DirectoryLoader我们可以使用 glob 参数来控制加载特定类型文…...

shell编程3,参数传递+算术运算
声明! 学习视频来自B站up主 泷羽sec 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&#…...

Spring boot之BeanDefinition介绍
在spring框架中IOC容器进行bean的创建和管理。Bean的创建是一个比较复杂的过程,它并不像我们创建对象一样只是直接new一下就行,虽然有些bean确实就是New一下。但在Spring中可以通过一些途径对bean进行增强扩展。在这个过程中,BeanDefinition作…...

JAVA:Spring Boot 3 实现 Gzip 压缩优化的技术指南
1、简述 随着 Web 应用的用户量和数据量增加,网络带宽和页面加载速度逐渐成为瓶颈。为了减少数据传输量,提高用户体验,我们可以使用 Gzip 压缩 HTTP 响应。本文将介绍如何在 Spring Boot 3 中实现 Gzip 压缩优化。 2、配置 Spring Boot 3 对…...

探索 IntelliJ IDEA 中 Spring Boot 运行配置
前言 IntelliJ IDEA 作为一款功能强大的集成开发环境(IDE),为 Spring Boot 应用提供了丰富的运行配置选项,定义了如何在 IntelliJ IDEA 中运行 Spring Boot 应用程序,当从主类文件运行应用程序时,IDE 将创建…...

Java学习,反射
Java反射是Java编程语言的一个重要特性,它允许程序在运行时查看任意对象所属的类,获取类的内部信息(包括构造器、字段和方法等),并能动态地调用对象的方法或构造器。 反射概念 反射(Reflection)…...

应急响应靶机——Windows挖矿事件
载入虚拟机,开启虚拟机: (账户密码:administrator/zgsf123) 发现登录进去就弹出终端界面,自动运行powshell命令,看来存在计划任务,自动下载了一些文件,之后就主动结束退…...

0017. shell命令--tac
目录 17. shell命令--tac 功能说明 语法格式 选项说明 实践操作 注意事项 17. shell命令--tac 功能说明 Linux 的 tac 命令用于按行反向输出文件内容,与 cat 命令的输出顺序相反。非常有趣,好记。也就是说,当我们使用tac命令查看文件内…...

富文本编辑器图片上传并回显
1.概述 在代码业务需求中,我们会经常涉及到文件上传的功能,通常来说,我们存储文件是不能直接存储到数 据库中的,而是以文件路径存储到数据库中;但是存储文件的路径到数据库中又会有一定的问题,就是 浏览…...

深入学习MapReduce:原理解析与基础实战
标题:深入学习MapReduce:原理解析与基础实战 MapReduce是一种分布式计算框架,用于大规模数据的处理和分析。作为Hadoop生态系统的核心组件,MapReduce凭借其简单的编程模型和强大的并行计算能力,广泛应用于大数据领域。…...

医院数据库优化:提升性能与响应时间的关键策略
一、引言 在当今数智化时代,医院信息系统不仅要追踪管理伴随人流、财流、物流所产生的管理信息,还应支持以病人医疗信息记录为中心的整个医疗、科学、科研活动,提高整个医院的运作效率。但随着信息化系统积累数据的增长,特别是病…...

OpenAI Whisper 语音识别 模型部署及接口封装
环境配置: 一、安装依赖: pip install -U openai-whisper 或者,以下命令会从这个存储库拉取并安装最新的提交,以及其Python依赖项: pip install githttps://github.com/openai/whisper.git 二、安装ffmpeg: cd …...

设计模式 外观模式 门面模式
结构性模式-外观模式 门面模式 适用场景:如果你需要一个指向复杂子系统的直接接口, 且该接口的功能有限, 则可以使用外观模式。 不用关心后面的查询具体操作 /*** 聚合查询接口*/ RestController RequestMapping("/search") Slf…...

AI智算-正式上架GPU资源监控概览 Grafana Dashboard
下载链接 https://grafana.com/grafana/dashboards/22424-ai-gpu-20241127/...

颜色分类
颜色分类 给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地 对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sort 函数…...

使用 pycharm 新建使用 conda 虚拟 python 环境的工程
1. conda 常见命令复习: conda env list // 查看 conda 环境列表 conda activate xxxenv // 进入指定 conda 环境2. 环境展示: 2.1. 我的物理环境的 Python 版本为 3.10.9: 2.2. 我的 conda 虚拟环境 env_yolov9_python_3_8 中的 pyth…...