C++11的一些特性
目录
一、C++11简介
二、统一的列表初始化
2.1 {}初始化
2.2 std::initializer_list
三、声明
3.1 auto
3.2 decltype
3.3 nullptr
四、范围for循环
五、智能指针
5.1 RAII
5.2 智能指针的原理
5.3 std::auto_ptr
5.4 std::unique_ptr
六、STL的一些更新
七、右值引用和移动语义
7.1 左值引用和右值引用
7.2 右值引用使用场景和意义
7.3 完美转发
八、关于类的一些变化
九、可变参数模板
十、lambda表达式
10.1 lambda表达式语法
10.2 函数对象与lambda表达式
十一、包装器
十二、线程库
12.1 thread类的简单介绍
12.2 线程函数参数
12.3 原子性操作库(atomic)
12.4 lock_guard与unique_lock
一、C++11简介
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为C++11之前的最新C++标准名称。不过由于C++03(TC1)主要是对C++98标准中的漏洞进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛化和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率,实际项目开发中也应用得比较多。
二、统一的列表初始化
2.1 {}初始化
在C++98中,标准允许使用花括号{}对数组或者结构体元素进行统一的列表初始值设定。C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。创建对象时也可以使用列表初始化方式调用构造函数初始化
struct Point {int _x;int _y; };class Date { public:Date(int year, int month, int day):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;} private:int _year;int _month;int _day; };int main() {int array1[] = { 1, 2, 3, 4, 5 };int array2[5] = { 0 };int array3[4]{ 1, 3, 5, 7 };Point p1 = { 1, 2 };Point p2{ 2, 4 };// C++11中列表初始化也可以适用于new表达式中int* pa = new int[4]{ 0 };Date d1(2022, 1, 1); // old style// C++11支持的列表初始化,这里会调用构造函数初始化Date d2{ 2022, 1, 2 };Date d3 = { 2022, 1, 3 };return 0; }2.2 std::initializer_list
std::initializer_list的介绍文档
std::initializer_list是什么类型
std::initializer_list使用场景
std::initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器就增加
std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator=的参数,这样就可以用大括号赋值
http://www.cplusplus.com/reference/list/list/list/
http://www.cplusplus.com/reference/vector/vector/vector/http://www.cplusplus.com/reference/vector/vector/operator=/
http://www.cplusplus.com/reference/map/map/map/
模拟实现的vector也支持{}初始化和赋值namespace myvector {template<class T>class vector {public:typedef T* iterator;vector(initializer_list<T> l){_start = new T[l.size()];_finish = _start + l.size();_endofstorage = _start + l.size();iterator vit = _start;typename initializer_list<T>::iterator lit = l.begin();while (lit != l.end()){*vit++ = *lit++;}//for (auto e : l)// *vit++ = e;}vector<T>& operator=(initializer_list<T> l) {vector<T> tmp(l);std::swap(_start, tmp._start);std::swap(_finish, tmp._finish);std::swap(_endofstorage, tmp._endofstorage);return *this;}private:iterator _start;iterator _finish;iterator _endofstorage;}; }
三、声明
3.1 auto
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局部的变量默认就是自动存储类型,所以auto就没什么价值了。C++11中废弃auto原来的用法,将其用于实现自动类型推断。这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初始化值的类型。
int main() {int i = 10;auto p = &i; auto pf = strcpy;cout << typeid(p).name() << endl;cout << typeid(pf).name() << endl;map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };//map<string, string>::iterator it = dict.begin();auto it = dict.begin();return 0; }3.2 decltype
关键字decltype将变量的类型声明为表达式指定的类型
template<class T1, class T2> void F(T1 t1, T2 t2) {decltype(t1 * t2) ret;cout << typeid(ret).name() << endl; } int main() {const int x = 1;double y = 2.2;decltype(x * y) ret; // ret的类型是doubledecltype(&x) p; // p的类型是int*cout << typeid(ret).name() << endl;cout << typeid(p).name() << endl;F(1, 'a');return 0; }3.3 nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针
#ifndef NULL #ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif #endif
四、范围for循环
C++11 引入了范围
for循环(range-basedforloop),这是一个简化的for循环,用来遍历容器或数组中的元素。相比传统的for循环,范围for循环的语法更加简洁,且无需显式使用迭代器或索引。
范围 for 循环的基本语法: for (declaration : container) { // code to operate on each element }declaration:声明一个变量,该变量将表示容器中当前的元素。 container:一个容器(如数组、std::vector、std::list 等)或支持迭代的对象。// 遍历 std::vector void test1() {std::vector<int> vec = {10, 20, 30, 40, 50};// 范围for循环遍历vectorfor (int x : vec) {std::cout << x << " ";} }// 使用引用避免拷贝(修改元素) void test2() {std::vector<int> vec = {1, 2, 3, 4, 5};// 使用引用修改元素for (int& x : vec) {x *= 2; // 将每个元素乘以 2}// 打印修改后的结果for (int x : vec) {std::cout << x << " ";} }// 使用常量引用避免拷贝(只读取元素) void test3() {std::vector<int> vec = {1, 2, 3, 4, 5};// 使用常量引用来避免拷贝for (const int& x : vec) {std::cout << x << " ";} }范围for循环的使用,可以使代码更简洁,不需要显式声明迭代器或索引。减少潜在的越界访问,避免直接操作索引。在使用引用时,可以避免不必要的元素拷贝。但是无法使用
break或continue来跳过特定的元素(与传统的for循环相比),可以通过其他方式(例如条件判断)实现类似功能。对于不支持迭代的容器(如某些自定义容器),范围for循环不可用。
五、智能指针
5.1 RAII
RAII(Resource Acquisition Is Initialization)是一种利用对象生命周期来控制程序资源(如内存、文件句柄、网络连接、互斥量等等)的简单技术。在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在对象析构的时候释放资源。借此,我们实际上把管理一份资源的责任托管给了一个对象。这样做不需要显式地释放资源,并且使对象所需的资源在其生命期内始终保持有效。
// 使用RAII思想设计的SmartPtr类 template<class T> class SmartPtr { public:SmartPtr(T* ptr = nullptr): _ptr(ptr){}~SmartPtr(){if (_ptr)delete _ptr;} private:T* _ptr; }; int div() {int a, b;cin >> a >> b;if (b == 0)throw invalid_argument("除0错误");return a / b; } void Func() {ShardPtr<int> sp1(new int);ShardPtr<int> sp2(new int);cout << div() << endl; }int main() {try {Func();}catch (const exception& e){cout << e.what() << endl;}return 0; }5.2 智能指针的原理
上述的SmartPtr还不能将其称为智能指针,因为它还不具有指针的行为。指针可以解引用,也可以通过->去访问所指空间中的内容,AutoPtr模板类中还得需要将* 、->进行重载,才可让其像指针一样去使用
template<class T> class SmartPtr { public:SmartPtr(T* ptr = nullptr): _ptr(ptr){}~SmartPtr(){if (_ptr)delete _ptr;}T& operator*() { return *_ptr; }T* operator->() { return _ptr; } private:T* _ptr; }; struct Date {int _year;int _month;int _day; }; int main() {SmartPtr<int> sp1(new int);*sp1 = 10cout << *sp1 << endl;SmartPtr<int> sparray(new Date);// sparray.operator->()->_year = 2018;// sparray->->_year这里语法上为了可读性,省略了一个->sparray->_year = 2018;sparray->_month = 1;sparray->_day = 1; }简单来说,智能指针的原理就是借助RAII特性,重载operator*和opertaor->,使其具有像指针一样的行为
5.3 std::auto_ptr
C++98版本的库中就提供了auto_ptr的智能指针。auto_ptr的实现原理是,管理权转移的思想,下面简化模拟实现了一份myspace::auto_ptr来了解它的原理
// C++98 管理权转移 auto_ptr namespace myspace {template<class T>class auto_ptr{public:auto_ptr(T* ptr):_ptr(ptr){}auto_ptr(auto_ptr<T>& sp):_ptr(sp._ptr){// 管理权转移sp._ptr = nullptr;}auto_ptr<T>& operator=(auto_ptr<T>& ap){// 检测是否为自己给自己赋值if (this != &ap){// 释放当前对象中资源if (_ptr)delete _ptr;// 转移ap中资源到当前对象中_ptr = ap._ptr;ap._ptr = NULL;}return *this;}~auto_ptr(){if (_ptr){cout << "delete:" << _ptr << endl;delete _ptr;}}// 像指针一样使用T& operator*(){return *_ptr;}T* operator->(){return _ptr;}private:T* _ptr;}; }int main() {std::auto_ptr<int> sp1(new int);std::auto_ptr<int> sp2(sp1); // 管理权转移// sp1悬空*sp2 = 10;cout << *sp2 << endl;cout << *sp1 << endl;return 0; }
auto_ptr的设计问题主要源于它的拷贝语义和所有权转移方式,这在多种情况下导致了资源管理问题、错误的所有权转移、以及不兼容现代 C++ 的移动语义。std::unique_ptr和std::shared_ptr作为 C++11 标准中的替代品,不仅改进了资源管理的安全性,也更符合现代 C++ 的设计理念。因此,应该避免使用,并尽可能地使用更现代的智能指针类型。5.4 std::unique_ptr
C++11中开始提供更靠谱的unique_ptr,unique_ptr的实现原理是简单粗暴的防拷贝,下面简化模拟实现了一份UniquePtr来了解它的原理
// C++11库才更新智能指针实现 // C++11出来之前,boost库中有scoped_ptr/shared_ptr/weak_ptr // C++11将boost库中智能指针精华部分吸收了过来 // C++11->unique_ptr/shared_ptr/weak_ptr // unique_ptr/scoped_ptr // 原理:简单粗暴 -- 防拷贝 namespace myspace {template<class T>class unique_ptr{public:unique_ptr(T* ptr):_ptr(ptr){}~unique_ptr(){if (_ptr){cout << "delete:" << _ptr << endl;delete _ptr;}}// 像指针一样使用T& operator*(){return *_ptr;}T* operator->(){return _ptr;}unique_ptr(const unique_ptr<T>&sp) = delete;unique_ptr<T>& operator=(const unique_ptr<T>&sp) = delete;private:T* _ptr;}; }int main() {/*myspace::unique_ptr<int> sp1(new int);myspace::unique_ptr<int> sp2(sp1);*/std::unique_ptr<int> sp1(new int);//std::unique_ptr<int> sp2(sp1);return 0; }5.5 std::shared_ptr
C++11中开始提供更靠谱的并且支持拷贝的shared_ptr,shared_ptr的原理是通过引用计数的方式来实现多个shared_ptr对象之间共享资源。
- shared_ptr在其内部,给每个资源都维护了着一份计数,用来记录该份资源被几个对象共享。
- 在对象被销毁时(也就是析构函数调用),就说明自己不使用该资源了,对象的引用计数减一。
- 如果引用计数是0,就说明自己是最后一个使用该资源的对象,必须释放该资源;
- 如果不是0,就说明除了自己还有其他对象在使用该份资源,不能释放该资源,否则其他对象就成野指针了。
// 引用计数支持多个拷贝管理同一个资源,最后一个析构对象释放资源 namespace myspace {template<class T>class shared_ptr{public:shared_ptr(T* ptr = nullptr):_ptr(ptr), _pRefCount(new int(1)), _pmtx(new mutex){}shared_ptr(const shared_ptr<T>& sp):_ptr(sp._ptr), _pRefCount(sp._pRefCount), _pmtx(sp._pmtx){AddRef();}void Release(){_pmtx->lock();bool flag = false;if (--(*_pRefCount) == 0 && _ptr){cout << "delete:" << _ptr << endl;delete _ptr;delete _pRefCount;flag = true;}_pmtx->unlock();if (flag == true){delete _pmtx;}}void AddRef(){_pmtx->lock();++(*_pRefCount);_pmtx->unlock();}shared_ptr<T>& operator=(const shared_ptr<T>& sp){//if (this != &sp)if (_ptr != sp._ptr){Release();_ptr = sp._ptr;_pRefCount = sp._pRefCount;_pmtx = sp._pmtx;AddRef();}return *this;}int use_count(){return *_pRefCount;}~shared_ptr(){Release();}// 像指针一样使用T& operator*(){return *_ptr;}T* operator->(){return _ptr;}T* get() const{return _ptr;}private:T* _ptr;int* _pRefCount;mutex* _pmtx;};// 简化版本的weak_ptr实现template<class T>class weak_ptr{public:weak_ptr():_ptr(nullptr){}weak_ptr(const shared_ptr<T>& sp):_ptr(sp.get()){}weak_ptr<T>& operator=(const shared_ptr<T>& sp){_ptr = sp.get();return *this;}T& operator*(){return *_ptr;}T* operator->(){return _ptr;}private:T* _ptr;}; } // shared_ptr智能指针是线程安全的吗? // 是的,引用计数的加减是加锁保护的。但是指向的资源不是线程安全的 // 指向堆上资源的线程安全问题是访问的人处理的,智能指针不管,也管不了 // 引用计数的线程安全问题,是智能指针要处理的 int main() {myspace::shared_ptr<int> sp1(new int);myspace::shared_ptr<int> sp2(sp1);myspace::shared_ptr<int> sp3(sp1);myspace::shared_ptr<int> sp4(new int);myspace::shared_ptr<int> sp5(sp4);//sp1 = sp1;//sp1 = sp2;//sp1 = sp4;//sp2 = sp4;//sp3 = sp4;*sp1 = 2;*sp2 = 3;return 0; }
六、STL的一些更新
新容器
新接口
七、右值引用和移动语义
7.1 左值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
int main() {// 以下的p、b、c、*p都是左值int* p = new int(0);int b = 1;const int c = 2;// 以下几个是对上面左值的左值引用int*& rp = p;int& rb = b;const int& rc = c;int& pvalue = *p;// 左值引用只能引用左值,不能引用右值。int a = 10;int& ra1 = a; // ra为a的别名//int& ra2 = 10; // 编译失败,因为10是右值// const左值引用既可引用左值,也可引用右值。const int& ra3 = 10;const int& ra4 = a;return 0; }1.左值引用只能引用左值,不能引用右值。 2.但是const左值引用既可引用左值,也可引用右值右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。右值引用就是对右值的引用,给右值取别名。
int main() {double x = 1.1, y = 2.2;int&& rr1 = 10;const double&& rr2 = x + y;rr1 = 20;rr2 = 5.5; // 报错// 右值引用只能右值,不能引用左值。int&& r1 = 10;// error C2440: “初始化”: 无法从“int”转换为“int &&”// message : 无法将左值绑定到右值引用int a = 10;int&& r2 = a;// 右值引用可以引用move以后的左值int&& r3 = std::move(a);return 0; }1. 右值引用只能右值,不能引用左值 2. 但是右值引用可以move以后的左值7.2 右值引用使用场景和意义
我们知道,左值引用做参数和做返回值都可以提高效率。为了更好地演示,我们需要使用自定义的string来作为例子,因为库中的更加完整,不便演示。
void func1(myspace::string s) {} void func2(const myspace::string& s) {} int main() {myspace::string s1("hello world");// func1和func2的调用 左值引用做参数减少了拷贝,提高效率func1(s1);func2(s1);// string operator+=(char ch) 传值返回存在深拷贝// string& operator+=(char ch) 传左值引用没有拷贝提高了效率s1 += '!';return 0; }如果函数返回对象是一个局部变量,出了函数作用域就不存在了,此时不能使用左值引用返回,只能传值返回。例如:myspace::string to_string(int value)函数中可以看到,这里只能使用传值返回,传值返回会导致至少1次拷贝构造
namespace myspace {myspace::string to_string(int value){bool flag = true;if (value < 0){flag = false;value = 0 - value;}myspace::string str;while (value > 0){int x = value % 10;value /= 10;str += ('0' + x);}if (flag == false){str += '-';}std::reverse(str.begin(), str.end());return str;} } int main() {// 在myspace::string to_string(int value)函数中可以看到,这里// 只能使用传值返回,传值返回会导致至少1次拷贝构造// (如果是一些旧一点的编译器可能是两次拷贝构造)。myspace::string ret1 = myspace::to_string(1234);myspace::string ret2 = myspace::to_string(-1234);return 0; }to_string的返回值是一个右值,用这个右值构造ret2,如果没有移动构造,调用就会匹配调用拷贝构造,因为const左值引用是可以引用右值的,这里就是一个深拷贝。
右值引用和移动语义能够解决上述问题,在自定义的myspace::string中增加移动构造。移动构造本质是将参数右值的资源移动过来,占为已有,那么就不用做深拷贝了,所以它叫做移动构造,移动别人的资源来构造自己
// 移动构造 namespace myspace {string(string&& s):_str(nullptr), _size(0), _capacity(0){cout << "string(string&& s) -- 移动语义" << endl;swap(s);} } int main() {myspace::string ret2 = myspace::to_string(-1234);return 0; }// 再运行上面to_string的两个调用,此时没有调用深拷贝的拷贝构造, // 而是调用了移动构造,移动构造中没有新开空间,拷贝数据,所以效率提高了。增加移动赋值函数,再去调用myspace::to_string(1234),不过这次是将
myspace::to_string(1234)返回的右值对象赋值给ret1对象,这时调用的是移动构造。// 移动赋值 string& operator=(string&& s) {cout << "string& operator=(string&& s) -- 移动语义" << endl;swap(s);return *this; } int main() {myspace::string ret1;ret1 = myspace::to_string(1234);return 0; } // 运行结果: // string(string&& s) -- 移动语义 // string& operator=(string&& s) -- 移动语义有些场景下,可能需要用右值去引用左值实现移动语义,此时可以通过move函数将左值转化为右值。C++11中,std::move()函数位于头文件中,该函数名字具有迷惑性,它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义
template<class _Ty> inline typename remove_reference<_Ty>::type&& move(_Ty&& _Arg) _NOEXCEPT {// forward _Arg as movablereturn ((typename remove_reference<_Ty>::type&&)_Arg); }int main() {myspace::string s1("hello world");// 这里s1是左值,调用的是拷贝构造myspace::string s2(s1);// 这里我们把s1 move处理以后, 会被当成右值,调用移动构造// 但是这里要注意,一般是不会这样用的,因为我们会发现s1的资源被转移给了s3,s1被置空了。myspace::string s3(std::move(s1));return 0; }7.3 完美转发
模板中的&& 万能引用
void Fun(int& x) { cout << "左值引用" << endl; } void Fun(const int& x) { cout << "const 左值引用" << endl; } void Fun(int&& x) { cout << "右值引用" << endl; } void Fun(const int&& x) { cout << "const 右值引用" << endl; } // 模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。 // 模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力, // 但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值, // 我们希望能够在传递过程中保持它的左值或者右值的属性, 就需要用我们下面学习的完美转发 template<typename T> void PerfectForward(T&& t) {Fun(t); } int main() {PerfectForward(10); // 右值int a;PerfectForward(a); // 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b); // const 左值PerfectForward(std::move(b)); // const 右值return 0; }std::forward 完美转发在传参的过程中保留对象原生类型属性
void Fun(int& x) { cout << "左值引用" << endl; } void Fun(const int& x) { cout << "const 左值引用" << endl; } void Fun(int&& x) { cout << "右值引用" << endl; } void Fun(const int&& x) { cout << "const 右值引用" << endl; } // std::forward<T>(t)在传参的过程中保持了t的原生类型属性。 template<typename T> void PerfectForward(T&& t) {Fun(std::forward<T>(t)); } int main() {PerfectForward(10); // 右值int a;PerfectForward(a); // 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b); // const 左值PerfectForward(std::move(b)); // const 右值return 0; }
八、关于类的一些变化
我们知道,在C++类中,有6个默认成员函数:构造函数、析构函数、拷贝构造函数、拷贝赋值重载、取地址重载、const 取地址重载,C++11 新增了两个:移动构造函数和移动赋值运算符重载。
如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造完全类似)
如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
强制生成默认函数的关键字default : C++11可以让你更好的控制要使用的默认函数。假设你要使用某个默认的函数,但是因为一些原因这个函数没有默认生成。比如:我们提供了拷贝构造,就不会生成移动构造了,那么我们可以使用default关键字显示指定移动构造生成
class Person { public:Person(const char* name = "", int age = 0):_name(name), _age(age){}Person(const Person& p):_name(p._name), _age(p._age){}Person(Person&& p) = default; private:myplace::string _name;int _age; }; int main() {Person s1;Person s2 = s1;Person s3 = std::move(s1);return 0; }禁止生成默认函数的关键字delete : 如果能想要限制某些默认函数的生成,在C++98中,是该函数设置成private,并且只声明补丁已,这样只要其他人想要调用就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数
class Person { public:Person(const char* name = "", int age = 0):_name(name), _age(age){}Person(const Person& p) = delete; private:myplace::string _name;int _age; }; int main() {Person s1;Person s2 = s1;Person s3 = std::move(s1);return 0; }
override关键字用于标识一个成员函数是重写(Override)基类的虚函数。它确保了派生类中的函数正确地覆盖了基类中的虚函数。如果基类中的函数没有被正确重写,编译器会给出错误提示。这有助于避免函数签名错误或意外的行为。
- 在派生类中,
override用来标明该函数是对基类虚函数的重写。- 如果基类中的虚函数被误拼写或签名不匹配,编译器会在编译时提供错误提示。
class Base { public:virtual void display() {std::cout << "Base class display function." << std::endl;} };class Derived : public Base { public:// 使用override来确保该函数正确覆盖基类的display函数void display() override {std::cout << "Derived class display function." << std::endl;} };int main() {Derived d;d.display(); // 输出:Derived class display function.return 0; }
final关键字用于表示类或成员函数不能再被继承或重写。它的使用有两个主要场景:
- 类的
final:将一个类标记为final,表示这个类不能作为基类进行继承。如果类被声明为final,那么不能再继承该类。- 成员函数的
final:将一个成员函数标记为final,表示这个函数不能在派生类中被重写。class Base { public:virtual void display() {std::cout << "Base class display function." << std::endl;} };class Derived final : public Base { // Derived类不能再被继承 public:void display() override {std::cout << "Derived class display function." << std::endl;} };// 下面的代码会导致编译错误,因为Derived是final类,不能被继承 // class AnotherDerived : public Derived {}; class AnotherDerived : public Base { // 正常继承自Base类 public:void display() override {std::cout << "AnotherDerived class display function." << std::endl;} };class AnotherBase { public:virtual void show() final { // show函数不能被重写std::cout << "AnotherBase class show function." << std::endl;} };class AnotherDerived : public AnotherBase { public:// 下面的代码会报错,因为show函数是final的,不能在派生类中重写// void show() override { std::cout << "AnotherDerived class show function." << std::endl; } };int main() {Derived d;d.display(); // 输出:Derived class display function.AnotherDerived another;another.display(); // 输出:AnotherDerived class display function.return 0; }
九、可变参数模板
C++11的新特性可变参数模板,能够让自己创建可以接受可变参数的函数模板和类模板,相比C++98/03,类模版和函数模版中只能含固定数量的模版参数,可变模版参数无疑是一个巨大的改进。然而由于可变模版参数比较抽象,使用起来需要一定的技巧,此处仅带读者掌握一些基础的可变参数模板特性
这是一个基本可变参数的函数模板// Args是一个模板参数包,args是一个函数形参参数包 // 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。 template <class ...Args> void ShowList(Args... args) {}如同我们熟悉的printf一样,可以接受0到任意个参数带有省略号的参数args就是一个可变模版参数,我们把带省略号的参数称为“参数包”,它里面包含了0到N(N>=0)个模版参数。我们无法直接获取参数包args中的每个参数的,
只能通过展开参数包的方式来获取参数包中的每个参数,这是使用可变模版参数的一个主要特点,也是最大的难点,即如何展开可变模版参数。由于语法不支持使用args[i]这样方式获取可变参数,所以我们的用一些其他方法获取参数包的值
- 递归函数方式展开参数包
// 递归终止函数 template <class T> void ShowList(const T& t) {cout << t << endl; } // 展开函数 template <class T, class ...Args> void ShowList(T value, Args... args) {cout << value << " ";ShowList(args...); } int main() {ShowList(1);ShowList(1, 'A');ShowList(1, 'A', std::string("sort"));return 0; }
- 逗号表达式展开参数包
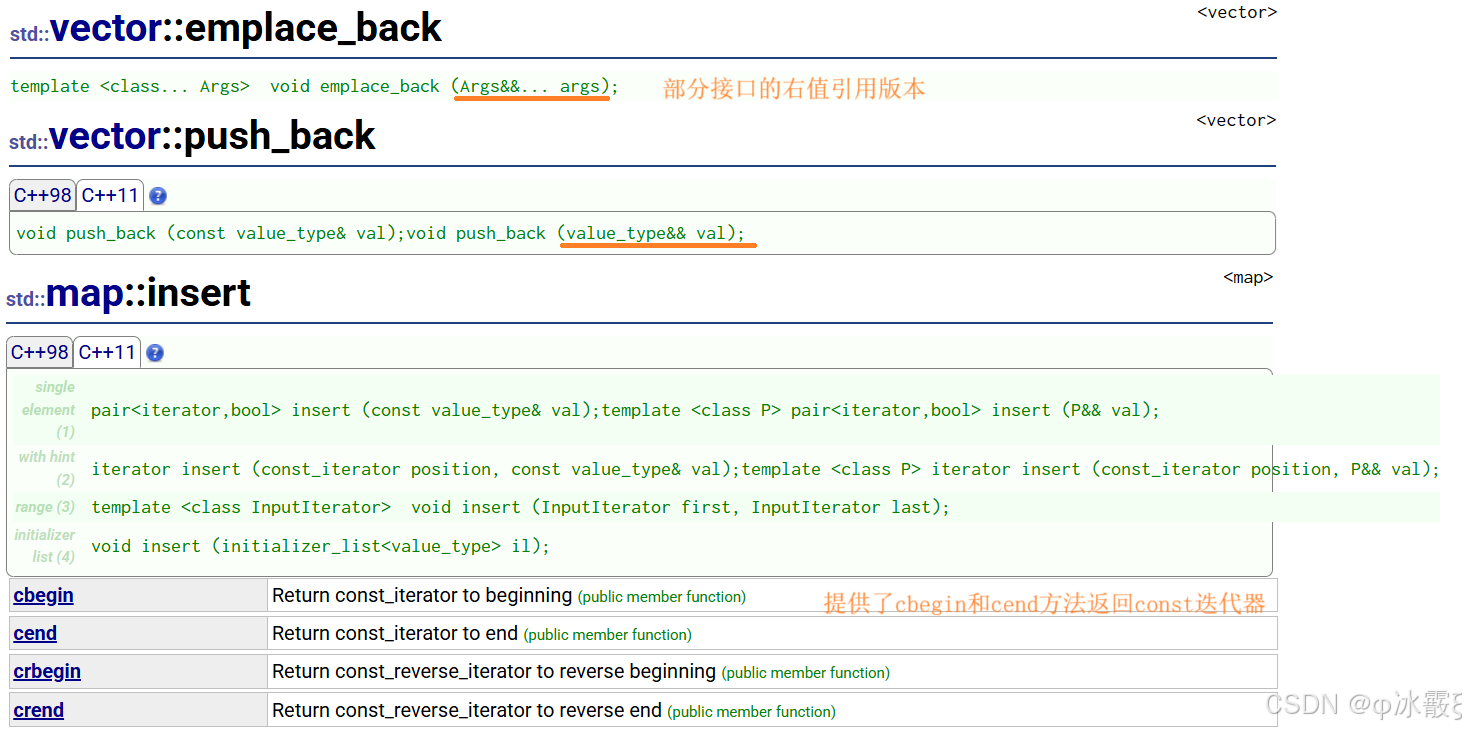
template <class T> void PrintArg(T t) {cout << t << " "; } //展开函数 template <class ...Args> void ShowList(Args... args) {int arr[] = { (PrintArg(args), 0)... };cout << endl; } int main() {ShowList(1);ShowList(1, 'A');ShowList(1, 'A', std::string("sort"));return 0; }STL容器中的empalce相关接口函数
emplace系列的接口,支持模板的可变参数,并且万能引用template <class... Args> void emplace_back (Args&&... args);class MyClass { public:MyClass(int x, double y) {this->x = x;this->y = y;std::cout << "MyClass(" << x << ", " << y << ") constructed\n";}void print() const {std::cout << "MyClass(" << x << ", " << y << ")\n";}private:int x;double y; };int main() {std::cout << "Using emplace_back:\n";std::vector<MyClass> v1;v1.emplace_back(10, 20.5); // 直接在容器内部构造对象std::cout << "\nUsing insert:\n";std::vector<MyClass> v2;v2.insert(v2.end(), MyClass(10, 20.5)); // 先构造对象,再插入std::cout << "\nPrinting contents of vectors:\n";v1[0].print(); // 输出 emplace_back 插入的对象v2[0].print(); // 输出 insert 插入的对象return 0; }std::vector::emplace_back
std::list::emplace_back
十、lambda表达式
在C++98中,如果想要对一个数据集合中的元素进行排序,可以使用std::sort方法,但是如果待排序元素为自定义类型,需要用户定义排序时的比较规则,非常麻烦。在C++11语法中的Lambda表达式可以更好地解决这个问题
int main() {vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._price < g2._price; });sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._price > g2._price; });sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._evaluate < g2._evaluate; });sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._evaluate > g2._evaluate; }); }10.1 lambda表达式语法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement}
- [capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
- (parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
- mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
- ->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
- {statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为空。因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情。
lambda表达式实际上可以理解为无名函数,该函数无法直接调用,如果想要直接调用,可借助auto将其赋值给一个变量。
int main() {// 最简单的lambda表达式, 该lambda表达式没有任何意义[] {};// 省略参数列表和返回值类型,返回值类型由编译器推导为intint a = 3, b = 4;[=] {return a + 3; };// 省略了返回值类型,无返回值类型auto fun1 = [&](int c) {b = a + c; };fun1(10)cout << a << " " << b << endl;// 各部分都很完善的lambda函数auto fun2 = [=, &b](int c)->int {return b += a + c; };cout << fun2(10) << endl;// 复制捕捉xint x = 10;auto add_x = [x](int a) mutable { x *= 2; return a + x; };cout << add_x(10) << endl;return 0; }[var]:表示值传递方式捕捉变量var [=]:表示值传递方式捕获所有父作用域中的变量(包括this) [&var]:表示引用传递捕捉变量var [&]:表示引用传递捕捉所有父作用域中的变量(包括this) [this]:表示值传递方式捕捉当前的this指针注意事项
- 父作用域指包含lambda函数的语句块
- 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
- 捕捉列表不允许变量重复传递,否则就会导致编译错误。比如:[=, a]: = 已经以值传递方式捕捉了所有变量,捕捉a重复
- 在块作用域以外的lambda函数捕捉列表必须为空。
- 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
- lambda表达式之间不能相互赋值,即使看起来类型相同
10.2 函数对象与lambda表达式
函数对象,又称为仿函数,即可以像函数一样使用的对象,其实就是在类中重载了operator()运算符的类对象
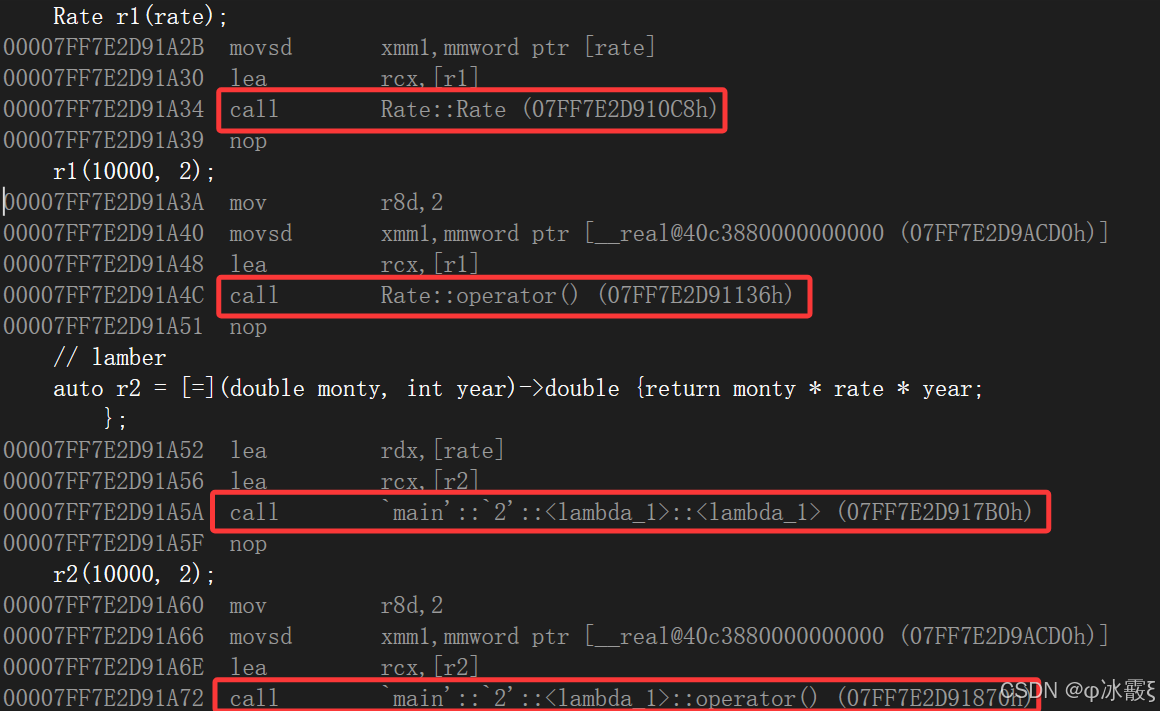
class Rate { public:Rate(double rate) : _rate(rate){}double operator()(double money, int year){return money * _rate * year;} private:double _rate; }; int main() {// 函数对象double rate = 0.49;Rate r1(rate);r1(10000, 2);// lamberauto r2 = [=](double monty, int year)->double {return monty * rate * year;};r2(10000, 2);return 0; }从使用方式上来看,函数对象与lambda表达式完全一样。函数对象将rate作为其成员变量,在定义对象时给出初始值即可,lambda表达式通过捕获列表可以直接将该变量捕获到。实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()
十一、包装器
function包装器 也叫作适配器。C++中的function本质是一个类模板,也是一个包装器。它主要具有以下这些强大的作用
函数的多态性(统一接口):
std::function可以让我们将不同类型的函数(普通函数、函数指针、Lambda、仿函数等)包装成一个统一的接口。这使得我们能够以相同的方式使用它们,而不需要关心函数的具体实现。例如,你可能有不同类型的函数或回调函数,但它们的签名相同。使用
std::function可以让你在不关心函数类型的情况下统一处理这些函数。提高灵活性和可扩展性:
std::function可以存储和传递任何可以调用的对象,包括普通函数、Lambda 表达式、类成员函数、或者其他函数对象。这使得它成为许多 C++ 库(如标准库中的算法)的核心组件,提供了高灵活性。简化回调机制的实现: 在很多设计模式中,比如事件驱动的编程,回调函数的使用非常普遍。
std::function提供了一个简洁的方式来处理回调函数,避免了使用原始函数指针或复杂的函数对象。类型安全: 与函数指针相比,
std::function提供了更好的类型安全性。函数指针只能指向某一特定类型的函数,而std::function可以根据类型自动调整,并且可以捕获 Lambda 中的局部变量,实现更灵活的封装。
#include <functional> template<class F, class T> T useF(F f, T x) {static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return f(x); } double f(double i) {return i / 2; } struct Functor {double operator()(double d){return d / 3;} }; int main() {// 函数名std::function<double(double)> func1 = f;cout << useF(func1, 11.11) << endl;// 函数对象std::function<double(double)> func2 = Functor();cout << useF(func2, 11.11) << endl;// lamber表达式std::function<double(double)> func3 = [](double d)->double { return d /4; };cout << useF(func3, 11.11) << endl;return 0; }std::bind函数定义在头文件中,是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象(callable object),生成一个新的可调用对象来“适应”原对象的参数列表。一般而言,我们用它可以把一个原本接收N个参数的函数fn,通过绑定一些参数,返回一个接收M个(M可以大于N)参数的新函数。同时,使用std::bind函数还可以实现参数顺序调整等操作
// 原型如下: template <class Fn, class... Args> /* unspecified */ bind (Fn&& fn, Args&&... args); // with return type (2) template <class Ret, class Fn, class... Args> /* unspecified */ bind (Fn&& fn, Args&&... args);调用bind的一般形式:auto newCallable = bind(callable,arg_list); //其中,newCallable本身是一个可调用对象,arg_list是一个逗号分隔的参数列表, //对应给定的callable的参数。当我们调用newCallable时,newCallable会调用callable, //并传给它arg_list中的参数// 使用举例 #include <functional> int Plus(int a, int b) {return a + b; } class Sub { public:int sub(int a, int b){return a - b;} }; int main() {//表示绑定函数plus 参数分别由调用 func1 的第一,二个参数指定std::function<int(int, int)> func1 = std::bind(Plus, placeholders::_1,placeholders::_2);//auto func1 = std::bind(Plus, placeholders::_1, placeholders::_2);//func2的类型为 function<void(int, int, int)> 与func1类型一样//表示绑定函数 plus 的第一,二为: 1, 2auto func2 = std::bind(Plus, 1, 2);cout << func1(1, 2) << endl;cout << func2() << endl;Sub s;// 绑定成员函数std::function<int(int, int)> func3 = std::bind(&Sub::sub, s,placeholders::_1, placeholders::_2);// 参数调换顺序std::function<int(int, int)> func4 = std::bind(&Sub::sub, s,placeholders::_2, placeholders::_1);cout << func3(1, 2) << endl;cout << func4(1, 2) << endl;return 0; }
十二、线程库
12.1 thread类的简单介绍
在C++11之前,涉及到多线程问题,都是和平台相关的,比如windows和linux下各有自己的接口,这使得代码的可移植性比较差。C++11中最重要的特性就是对线程进行支持了,使得C++在并行编程时不需要依赖第三方库,而且在原子操作中还引入了原子类的概念。要使用标准库中的线程,必须包含< thread >头文件
函数名 功能 thread() 构造一个线程对象,没有关联任何线程函数,即没有启动任何线程 thread(fn,
args1, args2,
...)构造一个线程对象,并关联线程函数fn,args1,args2,...为线程函数的
参数get_id() 获取线程id jionable() 线程是否还在执行,joinable代表的是一个正在执行中的线程。 jion() 该函数调用后会阻塞住线程,当该线程结束后,主线程继续执行 detach() 在创建线程对象后马上调用,用于把被创建线程与线程对象分离开,分离
的线程变为后台线程,创建的线程的"死活"就与主线程无关1. 线程是操作系统中的一个概念,线程对象可以关联一个线程,用来控制线程以及获取线程的状态
2. 当创建一个线程对象后,没有提供线程函数,该对象实际没有对应任何线程。#include <thread> int main() {std::thread t1;cout << t1.get_id() << endl;return 0; }//get_id()的返回值类型为id类型,id类型实际为std::thread命名空间下封装的一个类, //该类中包含了一个结构体:// vs下查看 typedef struct { /* thread identifier for Win32 */void* _Hnd; /* Win32 HANDLE */unsigned int _Id; } _Thrd_imp_t;3. 当创建一个线程对象后,并且给线程关联线程函数,该线程就被启动,与主线程一起运行。线程函数一般情况下可按照以下三种方式提供:函数指针、lambda表达式、函数对象
#include <iostream> #include <thread> using namespace std;void ThreadFunc(int a) {cout << "Thread1" << a << endl; } class TF { public:void operator()(){cout << "Thread3" << endl;} }; int main() {// 线程函数为函数指针thread t1(ThreadFunc, 10);// 线程函数为lambda表达式thread t2([] {cout << "Thread2" << endl; });// 线程函数为函数对象TF tf;thread t3(tf);t1.join();t2.join();t3.join();cout << "Main thread!" << endl;return 0; }4. thread类是防拷贝的,不允许拷贝构造以及赋值,但是可以移动构造和移动赋值,即将一个线程对象关联线程的状态转移给其他线程对象,转移期间不意向线程的执行。
5. 可以通过jionable()函数判断线程是否是有效的,如果是以下任意情况,则线程无效
- 采用无参构造函数构造的线程对象
- 线程对象的状态已经转移给其他线程对象
- 线程已经调用jion或者detach结束
6.并发与并行的区别
特性 并发(Concurrency) 并行(Parallelism) 执行方式 任务交替执行,在单核或少数处理器上分时执行 任务同时执行,在多个处理器核心上并行运行 硬件需求 不需要多个核心,单核 CPU 也可以实现并发 需要多个处理器核心或计算单元才能实现并行 实现方式 任务之间切换、异步、非阻塞 多个任务完全独立并同时执行 重点 任务的组织和调度(如何高效切换任务) 同时执行多个任务,通常是为了提高性能 适用场景 IO 密集型任务(例如文件读取、网络请求等) CPU 密集型任务(例如大数据处理、科学计算等) 12.2 线程函数参数
线程函数的参数是以值拷贝的方式拷贝到线程栈空间中的,因此,即使线程参数为引用类型,在线程中修改后也不能修改外部实参,因为其实际引用的是线程栈中的拷贝,而不是外部实参
#include <thread> void ThreadFunc1(int& x) {x += 10; } void ThreadFunc2(int* x) {*x += 10; } int main() {int a = 10;// 在线程函数中对a修改,不会影响外部实参,因为:线程函数参数虽然是引用方式,但其实际引用的是线程栈中的拷贝thread t1(ThreadFunc1, a);t1.join();cout << a << endl;// 如果想要通过形参改变外部实参时,必须借助std::ref()函数thread t2(ThreadFunc1, std::ref(a);t2.join();cout << a << endl;// 地址的拷贝thread t3(ThreadFunc2, &a);t3.join();cout << a << endl;return 0; }如果是类成员函数作为线程参数时,必须将this作为线程函数参数。12.3 原子性操作库(atomic)
多线程最主要的问题是共享数据带来的问题(即线程安全)。如果共享数据都是只读的,那么没问题,因为只读操作不会影响到数据,更不会涉及对数据的修改,所以所有线程都会获得同样的数据。但是,当一个或多个线程要修改共享数据时,就会产生很多潜在的麻烦
//在下面的代码中 //多个线程(t1 和 t2)在修改全局变量 sum 时没有进行同步, //导致多个线程可能同时访问和修改 sum, //从而引发竞态条件,最终的结果是不可预测的。#include <iostream> #include <thread> //#include <mutex> //解决方法一 //#include <atomic> //解决方法二 using namespace std;//atomic_long sum{ 0 }; //解决方法二 //std::mutex m; //解决方法一 unsigned long sum = 0L; void fun(size_t num) {for (size_t i = 0; i < num; ++i){//m.lock(); //解决方法一sum++;//m.unlock(); //解决方法一} } int main() {cout << "Before joining,sum = " << sum << std::endl;thread t1(fun, 10000000);thread t2(fun, 10000000);t1.join();t2.join();cout << "After joining,sum = " << sum << std::endl;return 0; }C++98中传统的解决方式是对共享修改的数据可以加锁保护,但是加锁有一个缺陷,只要一个线程在对sum++时,其他线程就会被阻塞,会影响程序运行的效率,而且锁如果控制不好,还容易造成死锁。因此C++11中引入了原子操作。所谓原子操作,即不可被中断的一个或一系列操作,C++11引入的原子操作类型,使得线程间数据的同步变得非常高效
在C++11中,程序员不需要对原子类型变量进行加锁解锁操作,线程能够对原子类型变量互斥的访问。更为普遍的,程序员可以使用atomic类模板,定义出需要的任意原子类型atmoic<T> t; // 声明一个类型为T的原子类型变量t原子类型通常属于"资源型"数据,多个线程只能访问单个原子类型的拷贝,因此在C++11中,原子类型只能从其模板参数中进行构造,不允许原子类型进行拷贝构造、移动构造以及operator=等,为了防止意外,标准库已经将atmoic模板类中的拷贝构造、移动构造、赋值运算符重载默认删除掉了
12.4 lock_guard与unique_lock
在多线程环境下,如果想要保证某个变量的安全性,只要将其设置成对应的原子类型即可,即高效又不容易出现死锁问题。但是有些情况下,我们可能需要保证一段代码的安全性,那么就只能通过锁的方式来进行控制。
比如:一个线程对变量number进行加一100次,另外一个减一100次,每次操作加一或者减一之后,输出number的结果,要求:number最后的值为1#include <thread> #include <mutex> int number = 0; mutex g_lock; int ThreadProc1() {for (int i = 0; i < 100; i++){g_lock.lock();++number;cout << "thread 1 :" << number << endl;g_lock.unlock();}return 0; } int ThreadProc2() {for (int i = 0; i < 100; i++){g_lock.lock();--number;cout << "thread 2 :" << number << endl;g_lock.unlock();}return 0; }int main() {thread t1(ThreadProc1);thread t2(ThreadProc2);t1.join();t2.join();cout << "number:" << number << endl;system("pause");return 0; }对于上面的代码,锁控制不好时,可能会造成死锁,最常见的比如在锁中间代码返回,或者在锁的范围内抛异常。为此,C++11采用RAII的方式对锁进行了封装,即lock_guard和unique_lock。
1. std::mutexC++11提供的最基本的互斥量,该类的对象之间不能拷贝,也不能进行移动。只能被一个线程持有,其他线程尝试获取锁时会被阻塞,直到锁被释放。
mutex最常用的三个函数
函数名 函数功能 lock() 上锁:锁住互斥量 unlock() 解锁:释放对互斥量的所有权 try_lock() 尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻
塞线程函数调用lock()时,可能会发生以下三种情况:
- 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁
- 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住
- 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)
线程函数调用try_lock()时,可能会发生以下三种情况:
- 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock释放互斥量
- 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉
- 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)
2. std::recursive_mutex
其允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同。
3. std::timed_mutex
比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until() 。
- try_lock_for()
接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与
std::mutex 的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
- try_lock_until()
接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住,
如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。4. std::recursive_timed_mutex
这是
std::recursive_mutex和std::timed_mutex的结合体
std::lock_gurad 是 C++11 中定义的模板类template<class _Mutex> class lock_guard { public:// 在构造lock_gard时,_Mtx还没有被上锁explicit lock_guard(_Mutex& _Mtx): _MyMutex(_Mtx){_MyMutex.lock();}// 在构造lock_gard时,_Mtx已经被上锁,此处不需要再上锁lock_guard(_Mutex& _Mtx, adopt_lock_t): _MyMutex(_Mtx){}~lock_guard() _NOEXCEPT{_MyMutex.unlock();}lock_guard(const lock_guard&) = delete;lock_guard& operator=(const lock_guard&) = delete; private:_Mutex& _MyMutex; };lock_guard类模板主要是通过RAII的方式,对其管理的互斥量进行了封装,在需要加锁的地方,只需要用上述介绍的任意互斥体实例化一个lock_guard,调用构造函数成功上锁,出作用域前,lock_guard对象要被销毁,调用析构函数自动解锁,可以有效避免死锁问题。
然而lock_guard太单一,用户没有办法对该锁进行控制,因此C++11又提供了unique_lock。
与lock_gard类似,unique_lock类模板也是采用RAII的方式对锁进行了封装,并且也是以独占所有权的方式管理mutex对象的上锁和解锁操作,即其对象之间不能发生拷贝。在构造(或移动(move)赋值)时,unique_lock 对象需要传递一个 Mutex 对象作为它的参数,新创建的unique_lock 对象负责传入的 Mutex 对象的上锁和解锁操作。使用以上类型互斥量实例化unique_lock的对象时,自动调用构造函数上锁,unique_lock对象销毁时自动调用析构函数解锁,可以很方便的防止死锁问题。
unique_lock更加的灵活,提供了更多的成员函数:
- 上锁/解锁操作:lock、try_lock、try_lock_for、try_lock_until和unlock
- 修改操作:移动赋值、交换(swap:与另一个unique_lock对象互换所管理的互斥量所有权)、释放(release:返回它所管理的互斥量对象的指针,并释放所有权)
- 获取属性:owns_lock(返回当前对象是否上了锁)、operator bool()(与owns_lock()的功能相同)、mutex(返回当前unique_lock所管理的互斥量的指针)。
相关文章:

C++11的一些特性
目录 一、C11简介 二、统一的列表初始化 2.1 {}初始化 2.2 std::initializer_list 三、声明 3.1 auto 3.2 decltype 3.3 nullptr 四、范围for循环 五、智能指针 5.1 RAII 5.2 智能指针的原理 5.3 std::auto_ptr…...

【打卡day3】字符串类
例如统计字符个数,字符大小写转换 题目描述:输入一行字符串,计算A-Z大写字母出现的次数 思路: 1 定义一个整型数组,初始化为0,存储每个字母出现的次数,下标0对应字母A, 2,定义字…...

图像滑块对比功能的开发记录
背景介绍 最近,公司需要开发一款在线图像压缩工具,其中的一个关键功能是让用户直观地比较压缩前后的图像效果。因此,我们设计了一个对比组件,它允许用户通过拖动滑块,动态调整两张图像的显示区域,从而清晰…...

【音视频】ffplay常用命令
一、 ffplay常用命令 -x width:强制显示宽度-y height:强制显示高度 强制以 640*360的宽高显示 ffplay 2.mp4 -x 640 -y 360 效果如下 -fs 全屏显示 ffplay -fs 2.mp4效果如下: -an 禁用音频(不播放声音)-vn 禁…...

初识Linux
文章目录 初识Linux:从开源哲学到技术生态的全面解析一、Linux的背景与发展简史:从代码实验到数字基础设施1.1 起源与开源基因1.2 技术哲学之争1.3 GNU/Linux的融合 二、开源:Linux的核心竞争力与生态力量2.1 法律保障与四大自由2.2 社区协作…...

基于遗传算法的IEEE33节点配电网重构程序
一、配电网重构原理 配电网重构(Distribution Network Reconfiguration, DNR)是一项优化操作,旨在通过改变配电网中的开关状态,优化电力系统的运行状态,以达到降低网损、均衡负载、改善电压质量等目标。配电网重构的核…...

manus对比ChatGPT-Deep reaserch进行研究类学术相关数据分析!谁更胜一筹?
没有账号,只能挑选一个案例 一夜之间被这个用全英文介绍全华班出品的新爆款国产AI产品的小胖刷频。白天还没有切换语言的选项,晚上就加上了。简单看了看团队够成,使用很长实践的Monica创始人也在其中。逐渐可以理解,重心放在海外产…...

线程通信---java
线程 我们知道,线程是进程的最小执行单位,一个进程可以拥有多个线程,那么就会引入两个问题: 多个线程之间如何进行通信多个线程对同一个数据进行操作,如何保证程序正确执行,也就是线程安全问题 线程的常…...

python面试常见题目
1、python 有几种数据类型 数字:整形 (int),浮点型 (float)布尔 ( bool):false true字符串 (string)列表 (list)元组 (tuple)字典 &…...

Python中与字符串操作相关的30个常用函数及其示例
以下是Python中与字符串操作相关的30个常用函数及其示例: 1. str.capitalize() 将字符串的第一个字符大写,其余字符小写。 s "hello world" print(s.capitalize()) # 输出: Hello world2. str.lower() 将字符串中的所有字符转换为小写。…...
)
2025年渗透测试面试题总结-小某鹏汽车-安全工程师(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 小鹏汽车-安全工程师 一、XXE漏洞与SSRF漏洞 1. XXE(XML External Entity)漏洞…...

kafka + flink +mysql 案例
假设你有两个Kafka主题:user_activities_topic 和 product_views_topic,并且你希望将user_activities_topic中的数据写入到user_activities表,而将product_views_topic中的数据写入到product_views表。 maven <dependencies><!-- …...

Windows下配置Flutter移动开发环境以及AndroidStudio安装和模拟机配置
截止 2025/3/9 ,版本更新到了 3.29.1 ,但是为了防止出现一些奇怪的bug,我安装的还是老一点的,3.19,其他版本的安装同理。AndroidStudio用的是 2024/3/1 版本。 — 1 环境变量(Windows) PUB_H…...

【工具类】Springboot 项目日志打印项目版本和构建时间
博主介绍:✌全网粉丝22W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...

p5.js:模拟 n个彩色小球在一个3D大球体内部弹跳
向 豆包 提问:编写一个 p5.js 脚本,模拟 42 个彩色小球在一个3D大球体内部弹跳。每个小球都应留下一条逐渐消失的轨迹。大球体应缓慢旋转,并显示透明的轮廓线。请确保实现适当的碰撞检测,使小球保持在球体内部。 cd p5-demo copy…...

RISC-V医疗芯片工程师复合型转型的路径与策略
从RISC-V到医疗芯片:工程师复合型转型的路径与策略 一、引言 1.1 研究背景 在科技快速发展的当下,芯片技术已然成为推动各行业进步的核心驱动力之一。其中,RISC-V 架构作为芯片领域的新兴力量,正以其独特的优势迅速崛起,对整个芯片产业的格局产生着深远影响。RISC-V 架…...

HTML 文本格式化
HTML 文本格式化 在构建网页的过程中,文本的格式化是一个至关重要的环节。HTML(HyperText Markup Language)提供了丰富的标签和属性来帮助我们实现各种文本格式化的需求。本文将详细介绍HTML中常见的文本格式化方法,包括字体、颜…...

基于RNN+微信小程序+Flask的古诗词生成应用
项目介绍 平台采用B/S结构,后端采用主流的Flask框架进行开发,古诗词生成采用RNN模型进行生成,客户端基于微信小程序开发。是集成了Web后台开发、微信小程序开发、人工智能(RNN)等多个领域的综合性应用,是课…...

【算法】图论 —— Dijkstra算法 python
引入 求非负权边的单源最短路 时间复杂度 O( m l o g n mlogn mlogn) 模板 https://www.luogu.com.cn/problem/P4779 import heapq as hq def dijkstra(s): # dis表示从s到i的最短路 dis [float(inf)] * (n 1) # vis表示i是否出队列 vis [0] * (n 1) q [] dis[s…...
、ZoneDateTime(时区时间))
Java:LocalDatTime(代替Calendar)、ZoneDateTime(时区时间)
文章目录 Local(代替Calendar)方法:获取当前代码 LocalDate(年月日星期)LocalTime(时分秒纳秒)LocalDateTime(最常用:年月日时分秒纳秒)ZoneId 时区表示方法 ZoneDateTime(时区时间)方法世界标准时间&#…...

HOW - React 如何在在浏览器绘制之前同步执行 - useLayoutEffect
目录 useEffect vs useLayoutEffectuseEffectuseLayoutEffect主要区别总结选择建议注意事项 useLayoutEffect 使用示例测量 DOM 元素的尺寸和位置示例:自适应弹出框定位 同步更新样式以避免闪烁示例:根据内容动态调整容器高度 图像或 Canvas 绘制前的准备…...

PyTorch系列教程:编写高效模型训练流程
当使用PyTorch开发机器学习模型时,建立一个有效的训练循环是至关重要的。这个过程包括组织和执行对数据、参数和计算资源的操作序列。让我们深入了解关键组件,并演示如何构建一个精细的训练循环流程,有效地处理数据处理,向前和向后…...

VS2019,VCPKG - 为VS2019添加VCPKG
文章目录 VS2019,VCPKG - 为VS2019添加VCPKG概述笔记前置条件迁出vcpkg到本地验证库安装更新已经安装的库删除指定的包安装VS2019能用的boostvcpkg 2025.02.14 版本可以给VS2019用用VCPKG的好处备注END VS2019,VCPKG - 为VS2019添加VCPKG 概述 开源工程用到了VCPKG管理的包。…...

linux下 jq 截取json文件信息
背景:通过‘登录名‘ 获取该对象的其他个人信息如名字。 环境准备:麒麟操作系统V10 jq安装包 jq安装包获取方式:yum install jq 或 使用附件中的rpm 或 git自行下载 https://github.com/stedolan/jq/releases/download/ 实现过程介绍&am…...

测试大语言模型在嵌入式设备部署的可能性-ollama本地部署测试
前言 当今各种大语言模型百花齐放,为了方便使用者更加自由的使用大模型,将大模型变成如同棒球棍一样每个人都能用,并且顺手方便的工具,本地私有化具有重要意义。 本次测试使用ollama完成模型下载,过程简单快捷。 1、进…...

C语言基础系列【21】memcpy、memset
博主介绍:程序喵大人 35- 资深C/C/Rust/Android/iOS客户端开发10年大厂工作经验嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手《C20高级编程》《C23高级编程》等多本书籍著译者更多原创精品文章,首发gzh,见文末👇…...
)
云曦春季开学考复现(2025)
Crypto 划水的dp和dq 下载附件后是简单的RSA算法题,之所以说简单是因为给了公钥e 趁热打铁,昨天刚学的RSA,既然有p有q,也有e,而np*q,可以算出欧拉函数值phi(p-1)*(q-1&…...

探秘 Netty 通信中的 SslHandler 类:保障网络通信安全的基石
引言 在当今数字化时代,网络安全是每一个应用程序都必须重视的关键因素。尤其是在数据传输过程中,防止数据被窃取、篡改至关重要。Netty 作为一个高性能的网络编程框架,为开发者提供了强大的功能来构建可靠的网络应用。其中,SslH…...

Llama factory微调后的模型怎么通过ollama发布
接上一篇博客:用Llama Factory单机多卡微调Qwen2.5时报torch.OutOfMemoryError: CUDA out of memory的解决办法_llama-factory cuda out of memory-CSDN博客 把Lora模块和其基模型merge到一起之后,就可以通过ollama之类的框架提供服务了。不过还是有些格式转换的工作要做: …...

ubuntu 20.04下ZEDmini安装使用
提前安装好显卡驱动和cuda,如果没有安装可以参考我的这两篇文章进行安装: ubuntu20.04配置YOLOV5(非虚拟机)_ubuntu20.04安装yolov5-CSDN博客 ubuntu20.04安装显卡驱动及问题总结_乌班图里怎么备份显卡驱动-CSDN博客 还需要提前…...

CmBacktrace的学习跟移植思路
学习移植CmBacktrace需要从理解其核心功能、适用场景及移植步骤入手,结合理论学习和实践操作。以下是具体的学习思路与移植思路: 一、学习思路 理解CmBacktrace的核心功能 CmBacktrace是针对ARM Cortex-M系列MCU的错误追踪库,支持自动诊断Har…...

Android Glide 缓存模块源码深度解析
一、引言 在 Android 开发领域,图片加载是一个极为常见且关键的功能。Glide 作为一款被广泛使用的图片加载库,其缓存模块是提升图片加载效率和性能的核心组件。合理的缓存机制能够显著减少网络请求,降低流量消耗,同时加快图片显示…...

蓝桥杯备赛:炮弹
题目解析 这道题目是一道模拟加调和级数,难的就是调和级数,模拟过程比较简单。 做法 这道题目的难点在于我们在玩这个跳的过程,可能出现来回跳的情况,那么为了解决这种情况,我们采取的方法是设定其的上限步数。那么…...

死锁问题分析工具
使用 gdb 调试 gdb ./your_program (gdb) run (gdb) thread apply all bt还可以分析pthread_mutex内部,查看owen字段分析哪个线程占用的锁,一个可能的 pthread_mutex 内部结构可以大致表示为: typedef struct pthread_mutex_t {int state; …...

装饰器模式--RequestWrapper、请求流request无法被重复读取
目录 前言一、场景二、原因分析三、解决四、更多 前言 曾经遇见这么一段代码,能看出来是把request又重新包装了一下,核心信息都不会改变 后面了解到这叫 装饰器模式(Decorator Pattern) :也称为包装模式(Wrapper Pat…...

MTK Android12 桌面上显示文件管理器图标
文章目录 需求解决 需求 在MTK平台上,Android12的文件管理器图标未显示在桌面,但在设置里面可以看到,文件管理器是安装的。根据客户要求,需要将文件管理器的图标显示在桌面上。解决 路径:packages/apps/DocumentsUI/…...

SpringBoot实现文件上传
1. 配置文件上传限制 application.yml spring:servlet:multipart:max-file-size: 10MBmax-request-size: 10MB2. 创建文件上传控制器 import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RestController; import…...
)
【开源免费】基于SpringBoot+Vue.JS青年公寓服务平台(JAVA毕业设计)
本文项目编号 T 233 ,文末自助获取源码 \color{red}{T233,文末自助获取源码} T233,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

django中视图作用和视图功能 以及用法
在 Django REST Framework(DRF)中,视图(View)是处理 HTTP 请求并返回响应的核心组件。DRF 提供了多种视图类,适用于不同的场景和需求。以下是 DRF 中常见的视图类及其作用、使用方法的详细说明: 一、DRF 视图的分类 DRF 的视图可以分为以下几类: 基于函数的视图(Func…...

大语言模型在患者交互任务中的临床使用评估框架
An evaluation framework for clinical use of large language models in patient interaction tasks An evaluation framework for clinical use of large language models in patient interaction tasks | Nature Medicine 2025.1 收到时间:2023 年 8 月 8 日 …...

Python—类class复习
Python——类(class)复习 根据类来创建对象的方法被称为实例化 因此学会使用类(class)来进行编程就是初步进入面向对象编程的大门 1.1 创建和使用类 首先编写一个小狗的简单类Dog,它表示的不是特定的小狗ÿ…...
)
QT | 信号与槽(超详解)
前言 对qt信号和槽的详细解释 💓 个人主页:普通young man-CSDN博客 ⏩ 文章专栏:C_普通young man的博客-CSDN博客 ⏩ 本人giee: 普通小青年 (pu-tong-young-man) - Gitee.com 若有问题 评论区见📝 🎉欢迎大家点赞&am…...

Codecraft-17 and Codeforces Round 391 E. Bash Plays with Functions 积性函数
题目链接 题目大意 定义函数 f r ( n ) f_r(n) fr(n) : 在 r 0 r0 r0时,为满足 p p p ⋅ \cdot ⋅ q n qn qn , 且 g c d ( p , q ) 1 gcd(p,q)1 gcd(p,q)1 的有序对 ( p , q ) (p,q) (p,q) 个数;在 r r r ≥ \geq ≥ 1 1 1时࿰…...

粉尘环境下的智能生产革命 ——助力矿山行业实现高效自动化作业
在矿山开采领域,运输系统是保障生产连续性的核心环节。然而,粉尘弥漫、环境恶劣、设备分散等问题,长期制约着矿山运输的效率与安全性。传统的集中式控制系统难以适应复杂工况,而远程分布式 IO 模块与 PLC 的深度融合,正…...

更新vscode ,将c++11更新到c++20
要在CentOS系统中安装最新版本的GCC,你可以使用SCL(Software Collections)仓库,它提供了开发工具的最新版本。以下是安装步骤: 1、 添加SCL仓库: 首先,添加CentOS的SCL仓库,该仓库…...

Numpy实训:读取并分析iris数据集中鸢尾花的相关数据
实训中相关数据集,请联系博主邮箱"1438077481qq.com",在邮箱内发送"iris.csv"即可快速获取,无任何套路,秉承开源精神! 1、导入模块 #导入模块 import numpy as np import csv 2、获取数据 iri…...

nats jetstream server code 分析
对象和缩写 jetstream导入两个对象:stream and consumer,在stream 之上构造jetstreamapi。在nats代码中,以下是一些常见的缩写 1.mset is stream 2.jsX is something of jetstream 3.o is consumer 代码分析 对于producer ,发送…...

德鲁伊连接池
德鲁伊连接池(Druid Connection Pool)是一个开源的Java数据库连接池项目,用于提高数据库连接的性能和可靠性。德鲁伊连接池通过复用数据库连接、定时验证连接的可用性、自动回收空闲连接等机制,有效减少了数据库连接的创建和销毁开…...

Python从入门到精通1:FastAPI
引言 在现代 Web 开发中,API 是前后端分离架构的核心。FastAPI 凭借其高性能、简洁的语法和自动文档生成功能,成为 Python 开发者的首选框架。本文将从零开始,详细讲解 FastAPI 的核心概念、安装配置、路由设计、请求处理以及实际应用案例&a…...

C语言经典案例-菜鸟经典案例
1.输入某年某月某日,判断这一天是这一年的第几天? //输入某年某月某日,判断这一天是这一年的第几天? #include <stdio.h>int isLeapYear(int year) {// 闰年的判断规则:能被4整除且(不能被100整除或…...