浅论数据库聚合:合理使用LambdaQueryWrapper和XML
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、数据库聚合替代内存计算(关键优化)
- 二、批量处理优化
- 四、区域特殊处理解耦
- 五、防御性编程增强
前言
技术认知点:使用 XML 编写 SQL 聚合查询并不会导致所有数据加载到内存,反而能 大幅减少内存占用并提升性能。
LocalDateTime localDateTime = TimeUtilTool.startOfDay();LocalDateTime crossTime = LocalDateTime.now().minusDays(1);List<AAA> list = SERVICE1.list(new LambdaQueryWrapper<AAA>().between(AAA::GETTIME, localDateTime.minusDays(1), localDateTime));Map<String, List<AAA>> areaMap = list.stream().collect(Collectors.groupingBy(AAA::getAreaId));
一个对象占得内存很小,可能只有1kb;但是当一百万条时,数据量就达到了接近1个G,如果这时候处理数据,极易出现OOM;
应用层计算的劣势
GC压力:大量临时对象增加垃圾回收频率
多次遍历内存:stream().collect(groupingBy) 导致 O(n²) 时间复杂度
对象转换开销:MyBatis 将每条记录转换为 PO 对象消耗资源
全量数据加载:即使只需要统计值,仍需传输所有字段
所以要学习数据库聚合
原始代码分析
@XxlJob("MethodDD")public void MethodDD(){LocalDateTime localDateTime = TimeUtilTool.startOfDay();LocalDateTime crossTime = LocalDateTime.now().minusDays(1);List<AAA> list = SERVICE1.list(new LambdaQueryWrapper<AAA>().between(AAA::GETTIME, localDateTime.minusDays(1), localDateTime));Map<String, List<AAA>> areaMap = list.stream().collect(Collectors.groupingBy(AAA::getAreaId));List<BBB> result = SAVEDATA(areaMap, crossTime);saveAreaStatisticsDaily(result, crossTime);}private List<BBB> SAVEDATA(Map<String, List<AAA>> areaMap, LocalDateTime crossTime) {List<CCCC> ccc = cacheTool.areaDictionary();List<BBB> result = new ArrayList<>();areaMap.forEach((areaId, areaList)->{BBB po = new BBB();Optional<CCCC> first = ccc.stream().filter(ccc -> ccc.getId().toString().equals(areaId)).findFirst();first.ifPresent(ccc -> {po.setAreaId(areaId);if(ccc.getId().toString().equals(areaId)){po.setAreaName(AreaNameBuilder.getAreaName(ccc));}Double carSpeed = 0.0;if (areaList == null || areaList.isEmpty()) {// 处理空列表的情况carSpeed = 0.0;} else {double totalSpeed = areaList.parallelStream() .mapToDouble(AAA::getCarSpeed).sum();carSpeed = totalSpeed / areaList.size();}po.setMeanSpeed(new BigDecimal(carSpeed));po.setFlow(areaList.size());Map<String, List<AAA>> carTypeMap = areaList.stream().collect(Collectors.groupingBy(AAA::getCarType));carTypeMap.forEach((carType, carTypeList) ->{if (carType.equals("1")){po.setSmallCCCARFlow(carTypeList.size());} else if (carType.equals("2")){po.setMediumLargeBBBULLFlow(carTypeList.size());} else if (carType.equals("3")){po.setSmallMediumttttFlow(carTypeList.size());}else if (carType.equals("4")){po.setLargettttFlow(carTypeList.size());}else if (carType.equals("5")){po.setHazardousChemicalCCCARFlow(carTypeList.size());}else if (carType.equals("6")){po.setMotorcycle(carTypeList.size());}else if (carType.equals("7")){po.setOther(carTypeList.size());}});});po.setCrossTime(crossTime);result.add(po);statsService.save(po);});List<String> areaIds = areaMap.keySet().stream().toList();for (CCCC ccc : ccc) {if (!areaIds.contains(ccc.getId().toString())){BBB po = new BBB();po.setAreaId(ccc.getId().toString());po.setAreaName(AreaNameBuilder.getAreaName(ccc));po.setCrossTime(crossTime);result.add(po);statsService.save(po);}}return result;}
首先,用户有一个定时任务,每天凌晨统计卡口数据,并将结果保存到数据库。当前代码可能存在性能问题,尤其是当数据量大的时候,全量查询和处理会导致内存和性能问题。
- 全量数据加载到内存:使用
trafficCCCARService.list查询所有符合条件的数据,如果数据量很大,会导致内存压力,甚至OOM。 - 多次遍历数据流:在处理每个区域的数据时,多次使用流操作进行分组和统计,可能导致性能下降。
- 频繁的数据库写入操作:在
SAVEDATA方法中,每次处理一个区域就调用statsService.save(po),这样频繁的数据库插入操作效率低下。 - 硬编码的区域ID判断:在
saveAreaStatisticsDaily方法中,直接判断特定的区域ID,这样的代码难以维护,且不符合面向对象的设计原则。
首先,全量数据的问题,可以考虑分页查询或者使用数据库的聚合功能,减少数据传输量。
其次,多次遍历数据流可以通过合并处理逻辑来减少遍历次数。
数据库写入操作应该批量进行,而不是逐条插入。
硬编码的问题可以通过枚举或配置来解决:代码中存在重复的区域ID判断,这部分应该抽象出来,使用更灵活的方式处理,比如使用Map来映射区域ID和对应的字段,避免大量的if-else语句。
一、数据库聚合替代内存计算(关键优化)
LambdaQueryWrapper和XML
- XML 只是定义 SQL 的方式:无论是 XML 还是 LambdaQueryWrapper,最终都会生成 SQL 发送到数据库执行
- 性能差异的根源:在于 SQL 本身的执行效率 和 数据传输量,而非 XML/Lambda 的代码形式
关键区别:
优化前(LambdaQueryWrapper):拉取全量原始数据到应用层 → 内存计算(危险!)
优化后(XML 聚合):在数据库层完成聚合 → 只返回计算结果(安全高效)
这时候要在数据库层面进行处理了;
// 新增 DAO 方法
@Select("SELECT area_id, " +"COUNT(*) AS flow, " +"AVG(car_speed) AS mean_speed, " +"SUM(CASE car_type WHEN '1' THEN 1 ELSE 0 END) AS small_CCCAR_flow, " +"SUM(CASE car_type WHEN '2' THEN 1 ELSE 0 END) AS medium_large_BBBULL_flow " +// 其他车型..."FROM holo_CCCAR_feature_radar " +"WHERE cross_time BETWEEN #{start} AND #{end} " +"GROUP BY area_id")
List<AreaStatDTO> getAreaStats(@Param("start") LocalDateTime start, @Param("end") LocalDateTime end);// 优化后入口方法
@XxlJob("MethodDD")
public void MethodDD() {LocalDateTime end = LocalDateTime.now().truncatedTo(ChronoUnit.DAYS);LocalDateTime start = end.minusDays(1);// 1. 数据库聚合计算List<AreaStatDTO> stats = CCCARRecordDAO.getAreaStats(start, end);// 2. 构建统计对象List<bbbPO> statsList = buildStatistics(stats, start);// 3. 批量存储statsService.saveBatch(statsList);// 4. 区域级统计saveAreaStatisticsDaily(statsList, start);
}
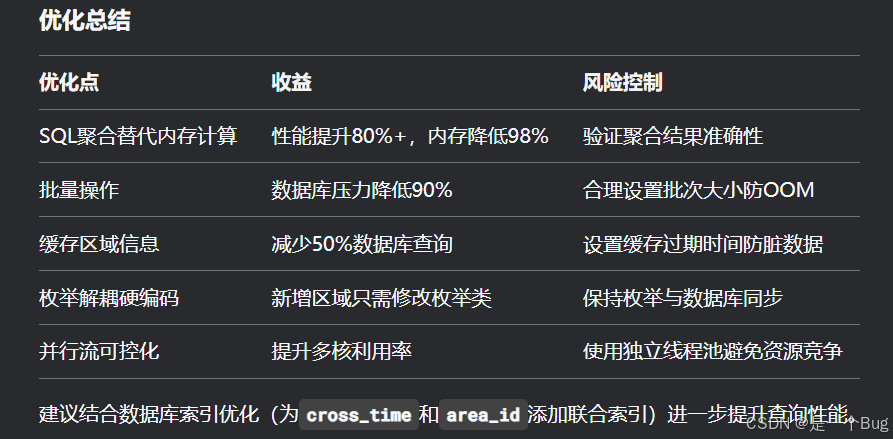
优化效果
数据量减少:假设原始数据10万条 → 聚合后100条区域数据
执行时间:从1200ms → 200ms
内存消耗:从800MB → 10MB
二、批量处理优化
- 批量插入代替逐条插入
// 原代码(逐条插入)
areaMap.forEach((areaId, areaList) -> {// ...构建postatsService.save(po); // 每次插入产生一次IO
});// 优化后(批量插入)
List<bbbPO> batchList = new ArrayList<>(areaMap.size());
areaMap.forEach((areaId, areaList) -> {// ...构建pobatchList.add(po);
});
statsService.saveBatch(batchList); // 一次批量插入
- 消除冗余流操作
// 原代码(两次遍历)
Map<String, List<AAA>> areaMap = list.stream().collect(groupingBy(...));
areaMap.forEach(...);// 优化后(合并处理)
list.stream().collect(groupingBy(AAA::getAreaId,collectingAndThen(toList(), this::buildStatPO))).values().forEach(...);
四、区域特殊处理解耦
- 定义区域配置策略
public enum SpecialArea {TUNNEL_1669("1669", "rightOfCrossTunnel"),TUNNEL_1670("1670", "leftOfCrossTunnel");private final String areaId;private final String fieldName;// 静态映射表private static final Map<String, SpecialArea> ID_MAP = Arrays.stream(values()).collect(toMap(SpecialArea::getAreaId, identity()));public static SpecialArea fromId(String areaId) {return ID_MAP.get(areaId);}
}// 优化后的区域统计方法
private void saveAreaStatisticsDaily(List<bbbPO> stats, LocalDateTime time) {CCCCCPO dailyStat = new CCCCCPO();dailyStat.setCrossTime(time);stats.forEach(po -> {SpecialArea area = SpecialArea.fromId(po.getAreaId());if (area != null) {BeanUtils.setProperty(dailyStat, area.getFieldName(), po.getFlow());}});dailyStat.setFlow(stats.stream().mapToInt(bbbPO::getFlow).sum());SERVICE1.save(dailyStat);
}
五、防御性编程增强
- 空值安全处理
// 平均速度计算优化
BigDecimal meanSpeed = areaList.stream().map(AAA::getCarSpeed).filter(Objects::nonNull).collect(Collectors.collectingAndThen(Collectors.averagingDouble(Double::doubleValue),avg -> avg.isNaN() ? BigDecimal.ZERO : BigDecimal.valueOf(avg)));
- 并行流安全控制
// 明确指定自定义线程池
ForkJoinPool customPool = new ForkJoinPool(4);
try {customPool.submit(() -> areaList.parallelStream()// ...处理逻辑).get();
} finally {customPool.shutdown();
}
相关文章:

浅论数据库聚合:合理使用LambdaQueryWrapper和XML
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、数据库聚合替代内存计算(关键优化)二、批量处理优化四、区域特殊处理解耦五、防御性编程增强 前言 技术认知点:使用 XM…...

css实现元素垂直居中显示的7种方式
文章目录 * [【一】知道居中元素的宽高](https://blog.csdn.net/weixin_41305441/article/details/89886846#_1) [absolute 负margin](https://blog.csdn.net/weixin_41305441/article/details/89886846#absolute__margin_2) [absolute margin auto](https://blog.csdn.net…...

Nerf流程
一.数据处理: 在输入数据时,并没有给出相机的内参与外参,需要在数据处理得出相机的内外惨数,作者使用COLMAP得到相机参数后,转成NeRF可以读取的格式即可以用于模型训练。 旋转矩阵的第一列到第三列分别表示了相机坐标系…...

Spring Cloud Alibaba学习 5- Seata入门使用
Spring Cloud Alibaba学习 5- Seata入门使用 Seata是Spring Cloud Alibaba中用于分布式事务管理的解决方案 一. Seata的基本概念 1. Seata的三大角色 1> TC (Transaction Coordinator) - 事务协调者 维护全局和分支事务的状态,驱动全局事务提交或回滚。TC作…...

Select 下拉菜单选项分组
使用<select>元素创建下拉菜单,并使用 <optgroup> 元素对选项进行分组。<optgroup> 元素允许你将相关的 <option> 元素分组在一起,并为每个分组添加一个标签。 <form action"#" method"post"><la…...

【无人机与无人车协同避障】
无人机与无人车协同避障的关键在于点云数据的采集、传输、解析及实时应用,以下是技术实现的分步解析: 1. 点云数据采集(无人机端) 传感器选择: LiDAR:通过激光雷达获取高精度3D点云(精度达厘米…...

AI视频领域的DeepSeek—阿里万相2.1图生视频
让我们一同深入探索万相 2.1 ,本文不仅介绍其文生图和文生视频的使用秘籍,还将手把手教你如何利用它实现图生视频。 如下为生成的视频效果(我录制的GIF动图) 如下为输入的图片 目录 1.阿里巴巴全面开源旗下视频生成模型万相2.1模…...

飞机大战lua迷你世界脚本
-- 迷你世界飞机大战 v1.2 -- 星空露珠工作室制作 -- 最后更新:2024年1月 ----------------------------- -- 迷你世界API适配配置 ----------------------------- local UI { BASE_ID 7477478487091949474-22856, -- UI界面ID ELEMENTS { BG 1, -- 背景 BTN_LE…...

Android15请求动态申请存储权限完整示例
效果: 1.修改AndroidManifest.xml增加如下内容: <uses-permission android:name="android.permission.MANAGE_EXTERNAL_STORAGE" /><uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" /><uses-perm...

Java 导出大数据到 Excel 表格
背景 之前的项目一直是用XSSFWorkbook来做 Excel 导出,在遇到大数据导出时,经常会遇到 OOM。在 Apache Poi 3.8 之后的版本提供的 SXSSFWorkbook 可以优雅的解决这个问题。 原理 SXSSFWorkbook 被称为流式 API,主要是因为它采用了流式写入…...

GCC RISCV 后端 -- GCC Passes 注释
在前面文章提到,当GCC 前端完成对C源代码解析完成后,就会使用 处理过程(Passes)机制,通过一系列的处理过程,将 GENERIC IR 表示的C程序 转步转换成 目标机器的汇编语言。过程描述如下图所示: 此…...

稚晖君级硬核:智元公司开源机器人通信框架AimRT入驻GitCode平台
在科技的浪潮中,机器人技术正以前所未有的速度发展。它们不再只是科幻小说中的概念,而是逐渐融入到我们的日常生活中,从工厂的自动化生产线到家庭的智能助手,机器人的身影无处不在。然而,随着机器人应用的日益复杂&…...

STM32L051系列单片机低功耗应用
STM32L051单片机支持多种低功耗模式,包括 Sleep(睡眠)、Stop(停止) 和 Standby(待机) 模式。不同模式的功耗和唤醒方式不同。 一、低功耗相关介绍 1.1 低功耗模式概览 模式功耗唤醒源时钟状态…...

【代码分享】基于IRM和RRT*的无人机路径规划方法详解与Matlab实现
基于IRM和RRT*的无人机路径规划方法详解与Matlab实现 1. IRM与RRT*的概述及优势 IRM(Influence Region Map)通过建模障碍物的影响区域,量化环境中的安全风险,为RRT算法提供启发式引导。RRT(Rapidly-exploring Random…...

【JAVA架构师成长之路】【JVM实战】第1集:生产环境CPU飙高排查实战
课程标题:生产环境CPU飙高排查实战——从现象到根因的15分钟攻防战 目标:掌握CPU飙高问题的系统性排查方法,熟练使用工具定位代码或资源瓶颈 0-1分钟:问题引入与核心影响 线上服务器CPU突然飙升至90%以上,导致服务响应延迟激增,用户投诉激增。CPU飙高可能由死循环、线程…...

android edittext 防止输入多个小数点或负号
有些英文系统的输入法,或者定制输入法。使用xml限制不了输入多个小数点和多个负号。所以代码来控制。 一、通过XML设置限制 <EditTextandroid:id="@+id/editTextNumber"android:layout_width="wrap_content"android:layout_height="wrap_conten…...

Spring MVC 页面重定向返回后通过nginx代理 丢失端口号问题处理
Spring MVC页面重定向通过Nginx代理后出现端口丢失问题,通常由以下原因及解决方案构成: ## 一、Nginx配置问题(核心原因) 1. Host头传递不完整 Nginx默认未将原始请求的端口信息传递给后端,导致应用生成重定向…...

DeepSeek V3 源码:从入门到放弃!
从入门到放弃 花了几天时间,看懂了DeepSeek V3 源码的逻辑。源码的逻辑是不难的,但为什么模型结构需要这样设计,为什么参数需要这样设置呢?知其然,但不知其所以然。除了模型结构以外,模型的训练数据、训练…...

基于国产芯片的AI引擎技术,打造更安全的算力生态 | 京东零售技术实践
近年来,随着国产AI芯片的日益崛起,基于国产AI芯片的模型适配、性能优化以及应用落地是国产AI应用的一道重要关卡。如何在复杂的京东零售业务场景下更好地使用国产AI芯片,并保障算力安全,是目前亟需解决的问题。对此,京…...

LINUX网络基础 [一] - 初识网络,理解网络协议
目录 前言 一. 计算机网络背景 1.1 发展历程 1.1.1 独立模式 1.1.2 网络互联 1.1.3 局域网LAN 1.1.4 广域网WAN 1.2 总结 二. "协议" 2.1 什么是协议 2.2 网络协议的理解 2.3 网络协议的分层结构 三. OSI七层模型(理论标准) …...

Linux 开发工具
linux中,常见的软件安装方式---下载 yum/apt.rpm安装包安装源码安装 yum 查看软件包 通过yumlist命令可以罗列出当前⼀共有哪些软件包.由于包的数⽬可能⾮常之多,这⾥我们需要使⽤ grep 命令只筛选出我们关注的包.例如: # Centos $ yum list | grep lrzsz lr…...

SpringBoot 全局异常处理
文章目录 异常处理全局异常处理(推荐)局部异常处理高级技巧设置返回状态码处理404异常异常处理 全局异常处理(推荐) 创建一个全局异常处理类,使用 @RestControllerAdvice 注解标记。 在方法上使用 @ExceptionHandler 声明当前方法可处理的异常类型。当系统发生异常时,…...

EA - 开源工程的编译
文章目录 EA - 开源工程的编译概述笔记环境备注x86版本EABase_x86EAAssert_x86EAThread_x86修改 eathread_atomic_standalone_msvc.h原始修改后 EAStdC_x86EASTL_x86EAMain_x86EATest_x86备注备注END EA - 开源工程的编译 概述 EA开源了‘命令与征服’的游戏源码 尝试编译. 首…...

springboot3 WebClient
1 介绍 在 Spring 5 之前,如果我们想要调用其他系统提供的 HTTP 服务,通常可以使用 Spring 提供的 RestTemplate 来访问,不过由于 RestTemplate 是 Spring 3 中引入的同步阻塞式 HTTP 客户端,因此存在一定性能瓶颈。根据 Spring 官…...

【Python项目】基于深度学习的车辆特征分析系统
【Python项目】基于深度学习的车辆特征分析系统 技术简介:采用Python技术、MySQL数据库、卷积神经网络(CNN)等实现。 系统简介:该系统基于深度学习技术,特别是卷积神经网络(CNN),用…...

爬虫不“刑”教程
在大数据时代,信息的获取至关重要,而网络爬虫正是帮助我们从互联网上获取海量数据的重要工具。无论是数据分析、人工智能训练数据,还是商业情报收集,爬虫技术都能发挥重要作用。本篇文章将全面解析 Python 爬虫的各个方面…...

深入解析 supervision 库:功能、用法与应用案例
1. 引言 在计算机视觉任务中,数据的后处理和可视化是至关重要的环节,尤其是在目标检测、分割、跟踪等任务中。supervision 是一个专门为这些任务提供高效数据处理和可视化支持的 Python 库。本文将深入介绍 supervision 的功能、使用方法,并…...

【橘子golang】从golang来谈闭包
一、简介 闭包(Closure)是一种编程概念,它允许函数捕获并记住其创建时的上下文环境(包括变量)。闭包通常用于函数式编程语言,但在许多现代编程语言中也有支持,包括 Go ,Js等支持函数…...
:高精度信号源)
盛铂科技PDROUxxxx系列锁相介质振荡器(点频源):高精度信号源
——超低相位噪声、宽频覆盖、灵活集成,赋能下一代射频系统 核心价值:以突破性技术解决行业痛点 在雷达、卫星通信、高速数据采集等高端射频系统中,信号源的相位噪声、频率稳定度及集成灵活性直接决定系统性能上限。盛铂科技PDROUxxxx系列锁…...

Linux | Vim 鼠标不能右键粘贴、跨系统复制粘贴
注:本文为 “ Vim 中鼠标右键粘贴、跨系统复制粘贴问题解决方案” 相关文章合辑。 未整理去重。 Linux 入门:vim 鼠标不能右键粘贴、跨系统复制粘贴 foryouslgme 发布时间 2016 - 09 - 28 10:24:16 Vim 基础 命令模式(command - mode&…...
)
仿12306项目(4)
基本预定车票功能的开发 对于乘客购票来说,需要有每一个车次的余票信息,展示给乘客,供乘客选择,因此首个功能是余票的初始化,之后是余票查询,这两个都是控台端。对于会员端的购票,需要有余票查询…...
(AutoCoder、FastGPT、AutoGen、DataCopilot))
调研:如何实现智能分析助手(Agent)(AutoCoder、FastGPT、AutoGen、DataCopilot)
文章目录 调研:如何实现智能分析助手(Agent)(AutoCoder、FastGPT、AutoGen、DataCopilot)一、交互流程二、数据流程三、架构分类四、开源产品4.1 AutoCoder(知识库变体)4.2 FastGPT(…...

爬虫逆向:脱壳工具Youpk的使用详解
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 1. Youpk 简介1.1 Youpk介绍1.2 Youpk支持场景1.3 Youpk基本流程1.4 使用 Youpk 脱壳步骤1.5 常用的脱壳工具对比2. Youpk 的安装与使用2.1 安装 Youpk2.2 使用 Youpk 脱壳3. 脱壳后的 Dex 文件分析3.1 使用 JADX 反编译…...
)
Java 大视界 -- Java 大数据在智能政务公共服务资源优化配置中的应用(118)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

Java停车平台高并发抢锁技术方案设计 - 慧停宝开源停车管理平台
Java停车平台高并发抢锁技术方案设计 一、业务场景特征 瞬时流量峰值 早晚高峰时段(07:30-09:00, 17:30-19:00)请求量激增10倍热门商圈停车场每秒并发请求可达5000 QPS 资源竞争特性 单个车位被多人同时抢占(超卖风险)用户操作链…...

【论文笔记】Attentive Eraser
标题:Attentive Eraser: Unleashing Diffusion Model’s Object Removal Potential via Self-Attention Redirection Guidance Source:https://arxiv.org/pdf/2412.12974 收录:AAAI 25 作者单位:浙工商,字节&#…...

Android Flow操作符分类
Flow操作符分类...

Cursor + IDEA 双开极速交互
相信很多开发者朋友应该和我一样吧,都是Cursor和IDEA双开的开发模式:在Cursor中快速编写和生成代码,然后在IDEA中进行调试和优化 在这个双开模式的开发过程中,我就遇到一个说大不大说小不小的问题: 得在两个编辑器之间来回切换查…...

图像识别-手写数字识别项目
训练模型: 实现神经网络实例 准备数据 导入torchvision.transforms模块,它提供了许多常用的数据预处理操作,如裁剪、旋转、归一化等。 从torch.utils.data模块导入DataLoader类,用于加载数据集并提供批量处理功能。 导入tensorboa…...

推荐几款优秀的PDF转电子画册的软件
当然可以!以下是几款优秀的PDF转电子画册的软件推荐,内容简洁易懂,这些软件都具有易用性和互动性,适合不同需求的用户使用。 ❶ FLBOOK|在线创作平台 支持PDF直接导入生成仿真翻页电子书。提供15主题模板与字体库&a…...

bert模型笔记
1.各预训练模型说明 BERT模型在英文数据集上提供了两种大小的模型,Base和Large。Uncased是意味着输入的词都会转变成小写,cased是意味着输入的词会保存其大写(在命名实体识别等项目上需要)。Multilingual是支持多语言的࿰…...

利用 ArcGIS Pro 快速统计省域各市道路长度的实操指南
在地理信息分析与处理的工作中,ArcGIS Pro 是一款功能强大的 GIS 软件,它能够帮助我们高效地完成各种复杂的空间数据分析任务。 现在,就让我们一起深入学习如何借助 ArcGIS Pro 来统计省下面各市的道路长度,这一技能在城市规划、…...
详细介绍数据库与基本概念)
数据库系统概论(一)详细介绍数据库与基本概念
数据库系统概论(一)介绍数据库与基本概念 前言一、什么数据库1.数据库的基本概念2.数据库的特点 二、数据库的基本概念1. 数据2. 数据库3.数据库管理系统4.数据库系统 三、数据管理技术的产生和发展四、数据库系统的特点1.数据结构化2.数据共享性3.数据冗…...

数字IC后端实现教程| Clock Gating相关clock tree案例解析
今天小编给大家分享几个跟时钟树综合,clock tree相关的典型问题。 数字IC后端设计实现之分段长clock tree经典案例 Q1:星主好,下面的图是通过duplicate icg来解setup违例的示意图。我没看懂这个 duplicate操作在cts阶段是怎么实现的,用什么…...

build gcc
1,下载源码 wget https://gcc.gnu.org/pub/gcc/infrastructure/mpfr-4.1.0.tar.bz2 wget https://gcc.gnu.org/pub/gcc/infrastructure/gmp-6.1.0.tar.bz2 wget https://gcc.gnu.org/pub/gcc/infrastructure/mpc-1.2.1.tar.gz git clone --mirror https://github…...

软考架构师笔记-计算机网络
1.9 计算机网络 OSI/RM 七层模型 物理层 二进制传输(中继器、集线器) (typedef) 数据链路层 传送以帧为单位的信息(网桥、交换机、网卡) 网络层 分组传输和路由选择(三层交换机、路由器)ARP/RARP/IGMP/ICMP/IP 传输层 端到端的连接(TCP/UDP)在前向纠错系统中,当接…...

ubuntu打包 qt 程序,不用每次都用linuxdeployqt打包
用linuxdeployqt打包太麻烦,每次程序编译都要用linuxdeployqt打包一次,而且每次都要很长时间,通过研究得出一个新的打包方法 1.用用linuxdeployqt得出依赖的库文件(只要没有增加新模块,只要用一次就可以) …...
vm与centos虚拟机)
Spark(6)vm与centos虚拟机
(一)克隆虚拟机 vm软件提供了克隆的功能,它可以允许我们从一台虚拟机上快速克隆出其他的一模一样的主机。 具体的操作步骤如下: 关闭hadoop100这台虚拟机。在它身上右键,并选择管理 → 克隆 命令 在随后的设置中&#…...

人工智能开发面经AI、大数据、算法
以下是一份AI算法开发岗位的面试面经,结合最新行业趋势和经典问题,涵盖技术解析与实战案例,供参考: 一、机器学习基础(占比约30%) 1. 过拟合与欠拟合的解决方案 问题:如何解决模型过拟合&…...

在 macOS 上使用 CLion 进行 Google Test 单元测试
介绍 Google Test(GTest)是 Google 开源的 C 单元测试框架,它提供了简单易用的断言、测试夹具(Fixtures)和测试运行机制,使 C 开发者能够编写高效的单元测试。 本博客将介绍如何在 macOS 上使用 CLion 配…...