java基础面试篇
目录
1.概念
1.1说一下Java的特点
1.2Java为什么是跨平台的?
1.3 JVM、JDK、JRE三者关系?
1.4为什么Java解释和编译都有?
1.5 jvm是什么?
1.6 编译型语言和解释型语言的区别?
1.7 Python和Java区别是什么?
2. 数据类型
2.1 八种基本的数据类型
2.2 long和int可以互转吗 ?
2.3 数据类型转换方式你知道哪些?
2.4 类型互转会出现什么问题吗?
2.5 为什么用bigDecimal 不用double ?
2.6 装箱和拆箱是什么?
2.7 Java为什么要有Integr?
2.8 Integer相比int有什么优点?
2.9 那为什么还要保留int类型?
2.10 说一下 integer的缓存
3.面向对象
3.1怎么理解面向对象?简单说说封装继承多态
3.2 多态体现在哪几个方面?
3.3 多态解决了什么问题?
3.4 面向对象的设计原则你知道有哪些吗??
3.5 重载与重写有什么区别?
3.6 抽象类和普通类区别?
3.7 Java抽象类和接口的区别是什么?
3.8 抽象类能加final修饰吗?
3.9 接口里面可以定义哪些方法?
3.10 抽象类可以被实例化吗?
3.11 接口可以包含构造函数吗?
3.12 解释Java中的静态变量和静态方法
3.13 非静态内部类和静态内部类的区别?
3.14 非静态内部类可以直接访问外部方法,编译器是怎么做到的?
3.15 有一个父类和子类,都有静态的成员变量、静态构造方法和静态方法,在我new一个子类对象的时候,加载顺序是怎么样的?
4. 深拷贝和浅拷贝
4.1 深拷贝和浅拷贝的区别?
4.2 实现深拷贝的三种方法是什么?
5. 泛型
5.1 什么是泛型?
6.对象
6.1 java创建对象有哪些方式?
6.2 New出的对象什么时候回收?
7.反射
7.1 什么是反射?
7.2 反射在你平时写代码或者框架中的应用场景有哪些?
8.注解
8.1 能讲一讲java注解的原理么?
8.2 Java注解的作用域呢?
9.异常
9.1 介绍一下Java异常
9.2 Java异常处理有哪些?
9.3 抛出异常为什么不用throws?
9.4 try catch中的语句运行情况
try{return “a”} fianlly{return “b”}这条语句返回啥??
10.Object
10.1 == 与 equals 有什么区别?
10.2 StringBuffer和StringBuild区别是什么?
11.Java1.8新特性
11.1 Java中stream的API介绍一下
11.2 Stream流的并行API是什么?
11.3 completableFuture怎么用的?
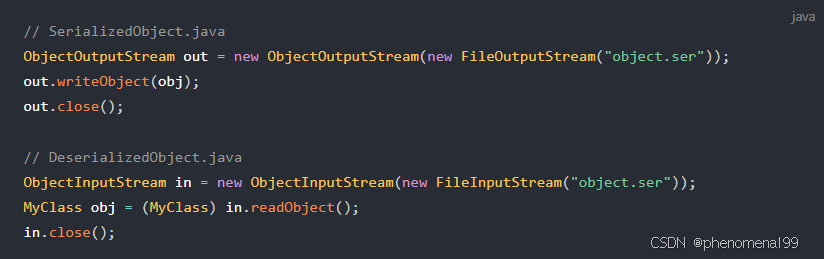
12. 序列化
12.1 怎么把一个对象从一个jvm转移到另一个jvm????
12.2 序列化和反序列化让你自己实现你会怎么做?
12.3 将对象转为二进制字节流具体怎么实现?
13. 设计模式
13.1 volatile和sychronized如何实现单例模式??
13.2 几种单例模式的实现方式
13.3 代理模式和适配器模式有什么区别?
14. I/O
14.1 Java怎么实现网络IO高并发编程?
14.2 BIO、NIO、AIO区别是什么?
14.3 NIO是怎么实现的?
Native方法解释一下
解释一下final关键字
1.概念
1.1说一下Java的特点
主要有以下的特点:
平台无关性:Java的“编写一次,运行无处不在”哲学是其最大的特点之一。Java编译器将源代码编译成字节码,该字节码可以在任何安装了JVM的系统上运行。
面向对象:Java是一门严格的面向对象编程语言,几乎一切都是对象。面向对象编程(OOP)特性使得代码更易于维护和重用,包括类(class)、对象(object)、继承(inheritance)、多态(polymorphism)、抽象(abstraction)和封装(encapsulation)。
内存管理:Java有自己的垃圾回收机制,自动管理内存和回收不再使用的对象。这样,开发者不需要手动管理内存,从而减少内存泄漏和其他内存相关的问题。
1.2Java为什么是跨平台的?
Java 能支持跨平台,主要依赖于 JVM 关系比较大。JVM也是一个软件,不同的平台有不同的版本。我们编写的Java源码,编译后会生成一种 .class 文件,称为字节码文件。Java虚拟机就是负责将字节码文件翻译成特定平台下的机器码然后运行。也就是说,只要在不同平台上安装对应的JVM,就可以运行字节码文件,运行我们编写的Java程序。而这个过程中,我们编写的Java程序没有做任何改变,仅仅是通过JVM这一”中间层“,就能在不同平台上运行,真正实现了”一次编译,到处运行“的目的。编译的结果不是生成机器码,而是生成字节码,字节码不能直接运行,必须通过JVM翻译成机器码才能运行。不同平台下编译生成的字节码是一样的,但是由JVM翻译成的机器码却不一样。所以,运行Java程序必须有JVM的支持,因为编译的结果不是机器码,所以,运行Java程序必须有JVM的支持,因为编译的结果不是机器码,必须要经过JVM的再次翻译才能执行。即使你将Java程序打包成可执行文件(例如 .exe),仍然需要JVM的支持。跨平台的是Java程序!!不是JVM。JVM是用C/C++开发的,编译后的机器码,不能跨平台,不同平台下需要安装不同版本的JVM。
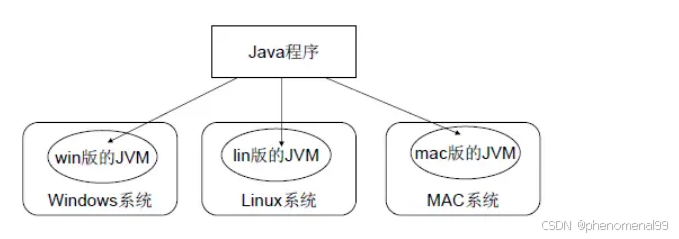
1.3 JVM、JDK、JRE三者关系?
· JVM是Java虚拟机,是Java程序运行的环境。它负责将Java字节码(由Java编译器生成)解释或编译成机器码,并执行程序。JVM提供了内存管理、垃圾回收、安全性等功能,使得Java程序具备跨平台性。
· JRE是Java运行时环境,是Java程序运行所需的最小环境。它包含了JVM和一组Java类库,,用于支持Java程序的执行。JRE不包含开发工具,只提供Java程序运行所需的运行环境。
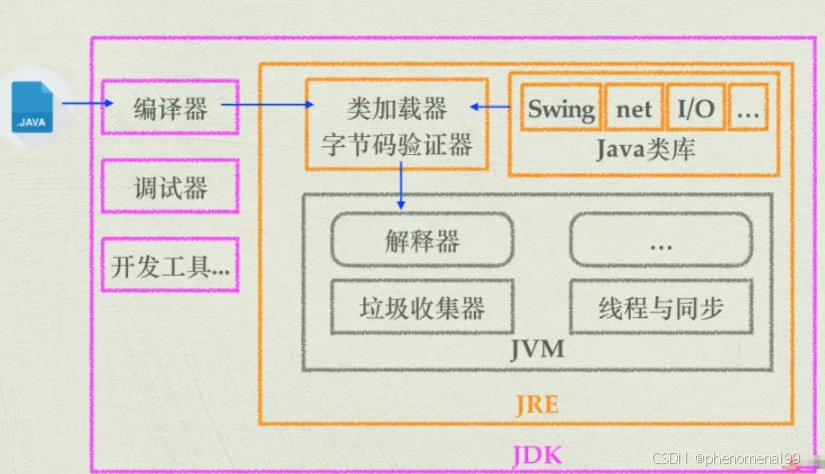
· JDK是Java开发工具包,是开发Java程序所需的工具集合。它包含了JVM、编译器(javac)、调试器(jdb)等开发工具,以及一系列的类库(如Java标准库和开发工具库)。JDK提供了开发、编译、调试和运行Java程序所需的全部工具和环境。
1.4为什么Java解释和编译都有?
首先在Java经过编译之后生成字节码文件,接下来进入JVM中,就有两个步骤编译和解释。 如下图:
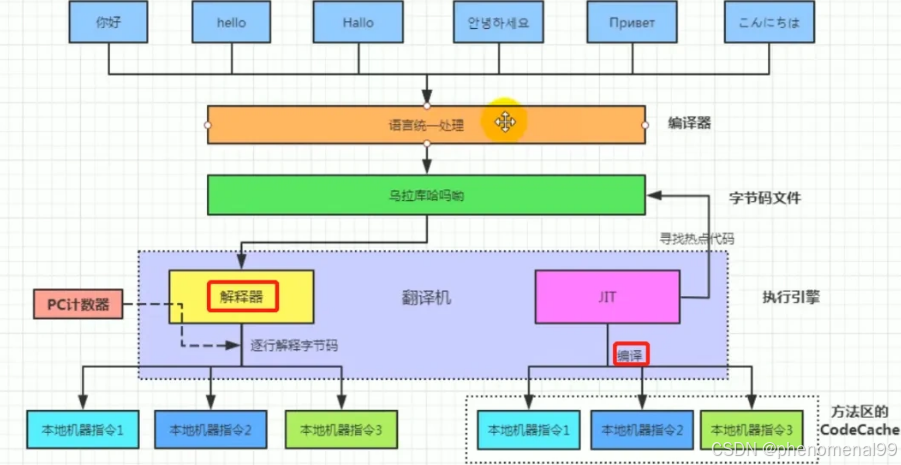
编译性:
- Java源代码首先被编译成字节码,JIT 会把编译过的机器码保存起来,以备下次使用。
解释性:
• JVM中一个方法调用计数器,当累计计数大于一定值的时候,就使用JIT进行编译生成机器码文件。否则就是用解释器进行解释执行,然后字节码也是经过解释器进行解释运行的。
所以Java既是编译型也是解释性语言,默认采用的是解释器和编译器混合的模式。
1.5 jvm是什么?
JVM是 java 虚拟机,主要工作是解释自己的指令集(即字节码)并映射到本地的CPU指令集和OS的系统调用。
JVM屏蔽了与操作系统平台相关的信息,使得Java程序只需要生成在Java虚拟机上运行的目标代码(字节码),就可在多种平台上不加修改的运行,这也是Java能够“一次编译,到处运行的”原因。
1.6 编译型语言和解释型语言的区别?
- 典型的编译型语言如C、C++,典型的解释型语言如Python、JavaScript。
- 编译型语言:在程序执行之前,整个源代码会被编译成机器码或者字节码,生成可执行文件。执行时直接运行编译后的代码,速度快,但跨平台性较差。
- 解释型语言:在程序执行时,逐行解释执行源代码,不生成独立的可执行文件。通常由解释器动态解释并执行代码,跨平台性好,但执行速度相对较慢。
1.7 Python和Java区别是什么?
- Java是一种已编译的编程语言,Java编译器将源代码编译为字节码,而字节码则由Java虚拟机执行
- python是一种解释语言,翻译时会在执行程序的同时进行翻译。
2. 数据类型
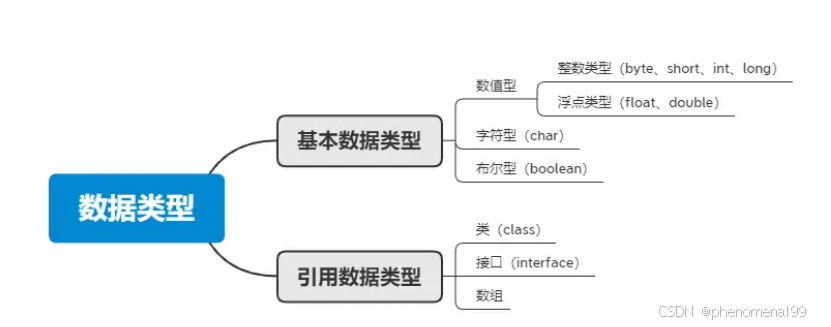
2.1 八种基本的数据类型
Java支持数据类型分为两类: 基本数据类型和引用数据类型。基本数据类型共有8种,可以分为三类:
- 数值型:整数类型(byte、short、int、long)和浮点类型(float、double)
- 字符型:char
- 布尔型:boolean
8种基本数据类型的默认值、位数、取值范围,如下表所示:
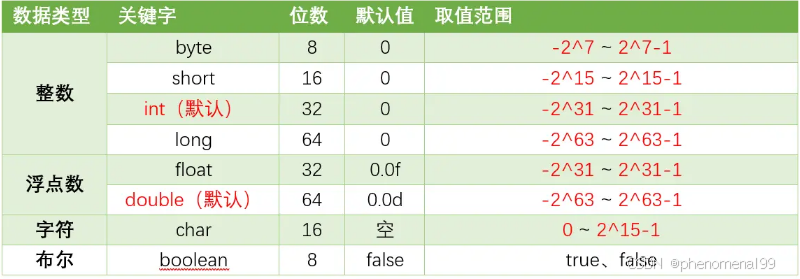
Float和Double的最小值和最大值都是以科学记数法的形式输出的,结尾的“E+数字”表示E之前的数字要乘以10的多少倍。结尾的“E+数字”表示E之前的数字要乘以10的多少倍。
注意一下几点:
- java八种基本数据类型的字节数:1字节(byte、boolean)、 2字节(short、char)、4字节(int、float)、8字节(long、double)
- 浮点数的默认类型为double(如果需要声明一个常量为float型,则必须要在末尾加上f或F)
- 整数的默认类型为int(声明Long型在末尾加上l或者L)
- 八种基本数据类型的包装类:除了char的是Character、int类型的是Integer,其他都是首字母大写
- char类型是无符号的,不能为负,所以是0开始的。
2.2 long和int可以互转吗 ?
可以的,Java中的long和int可以相互转换。由于long类型的范围比int类型大,因此将int转换为long是安全的,而将long转换为int可能会导致数据丢失或溢出!
将int转换为long可以通过直接赋值或强制类型转换来实现。例如:
int intNum = 10;
long longNum = intNum; //自动转换,安全将long转换为int需要使用强制类型转换,但需要注意潜在的数据丢失或溢出问题。
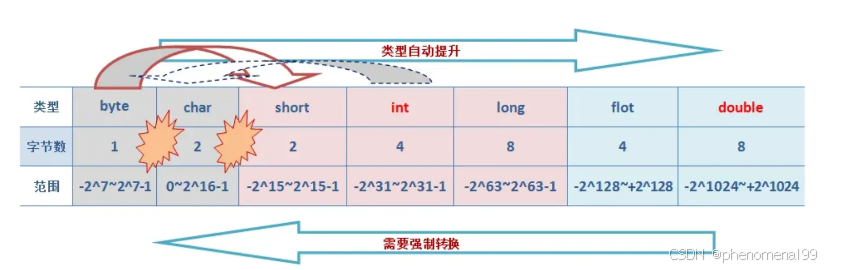
例如:
long longNum = 100L;
int intNum = (int)longNum; //强制类型转换,可能会导致数据丢失或溢出在将long转换为int时,如果longNum的值超出了int类型的范围,转换结果将是截断后的低位部分。因此,在进行转换之前,建议先检查longNum的值是否在int类型的范围内以避免数据丢失或溢出的问题。
2.3 数据类型转换方式你知道哪些?
- 自动类型转换(隐式转换):当目标类型的范围大于源类型时,Java会自动将源类型转换为目标类型,不需要显式的类型转换。例如,将
int转换为long、将float转换为double等。 - 强制类型转换(显式转换):当目标类型的范围小于源类型时,需要使用强制类型转换将源类型转换为目标类型。这可能导致数据丢失或溢出,例如,将
long转换为int、将double转换为int等。语法为:目标类型 变量名 = (目标类型) 源类型。 - 字符串转换:Java提供了将字符串表示的数据转换为其他类型数据的方法,例如,将字符串转换为整型
int,可以使用Integer.parseInt()方法,将字符串转换为浮点型double可以使用Double.parseDouble()方法等。 - 数值之间的转换:java提供了一些数值类型之间的转换方法,如将整型转换为字符型、将字符型转换为整型等。这些转换方式可以通过类型的包装类来实现,例如
Character类、Integer类等提供了相应的转换方法。

public static void main(String[] args) {int num=Integer.parseInt("100"); //将字符串s转换为十进制的数字,默认为十进制System.out.println(num);}radix代表转换的进制,不写默认为十进制。
2.4 类型互转会出现什么问题吗?
- 数据丢失:当将一个范围较大的数据类型转换为一个范围较小的数据类型时,可能会发生数据丢失,例如,将一个
long类型的值转换为int类型时,如果long值超出了int类型的范围,转换结果将是截断后的低位部分,高位部分的数据将丢失。 - 数据溢出:与数据丢失相反,当将一个范围较小的数据类型转换为一个范围较大的数据类型时,可能会发生数据溢出。例如,将一个
int类型的值转换为long类型时,转换结果会填充额外的高位空间,但原始数据仍然保持不变。 - 精度损失:在进行浮点数类型的转换时,可能会发生精度损失。由于浮点数的表示方式不同,将一个单精度浮点数(
float)转换为双精度浮点数(double)时,精度可能会损失。 - 类型不匹配导致的错误:在进行类型转换时,需要确保源类型和目标类型是兼容的。如果两者不兼容,会导致编译错误或运行时错误。
2.5 为什么用bigDecimal 不用double ?
double会出现精度丢失的问题,double执行的是二进制浮点运算,二进制有些情况下不能准确的表示一个小数,就像十进制不能准确的表示1/3(1/3=0.3333...),也就是说二进制表示小数的时候只能够表示能够用1/(2^n)的和的任意组合,但是0.1不能够精确表示,因为它不能够表示成为1/(2^n)的和的形式。
例如:
System.out.println(0.05 + 0.01);
System.out.println(1.0 - 0.42);
System.out.println(4.015 * 100);
System.out.println(123.3 / 100);输出:0.060000000000000005
0.5800000000000001
401.49999999999994
1.2329999999999999可以看到在Java中进行浮点数运算的时候,会出现丢失精度的问题。那么我们如果在进行商品价格计算的时候,就会出现问题。很有可能造成我们手中有0.06元,却无法购买一个0.05元和一个0.01元的商品。因为如上所示,他们两个的总和为0.060000000000000005。这无疑是一个很严重的问题!!尤其是当电商网站的并发量上去的时候,出现的问题将是巨大的。可能会导致无法下单,或者对账出现问题。而 Decimal 是精确计算 , 所以一般牵扯到金钱的计算 , 都使用 Decimal。
import java.math.BigDecimal;public class BigDecimalExample {public static void main(String[] args) {BigDecimal num1 = new BigDecimal("0.1");BigDecimal num2 = new BigDecimal("0.2");BigDecimal sum = num1.add(num2);BigDecimal product = num1.multiply(num2);System.out.println("Sum: " + sum);System.out.println("Product: " + product);}
}//输出
Sum: 0.3
Product: 0.02这样的使用BigDecimal可以确保精确的十进制数值计算,避免了使用double可能出现的舍入误差。需要注意的是,在创建BigDecimal对象时,应该使用字符串作为参数,而不是直接使用浮点数值,以避免浮点数精度丢失。
2.6 装箱和拆箱是什么?
装箱(Boxing)和拆箱(Unboxing)是将基本数据类型和对应的包装类之间进行转换的过程。
Integer i = 10; //自动装箱
int n = i; //自动拆箱自动装箱主要发生在两种情况,一种是赋值时,另一种是在方法调用的时候。
赋值时:这是最常见的一种情况,在Java 1.5以前我们需要手动地进行转换才行,而现在所有的转换都是由编译器来完成。
//自动装箱之前
Integer iObject = Integer.valueOf(3);
Int iPrimitive = iObject.intValue()//after java5
Integer iObject = 3;
int iPrimitive = iObject;方法调用时:
当我们在方法调用时,我们可以传入原始数据值或者对象,同样编译器会帮我们进行转换。
public static Integer show(Integer iParam){System.out.println("autoboxing example - method invocation i: " + iParam);return iParam;}// autoboxing and unboxing in method invocation
show(3); //autoboxing
int result = show(3); //unboxing because return type of method is Integer自动装箱的弊端:
自动装箱有一个问题,那就是在一个循环中进行自动装箱操作的情况,如下面的例子就会创建多余的对象,影响程序的性能。
Integer sum = 0;
for(int i=1000; i<5000; i++){ sum+=i;} 上面的代码sum+=i可以看成sum = sum + i,但是+这个操作符不适用于Integer对象,首先sum进行自动拆箱操作,进行数值相加操作,最后发生自动装箱操作转换成Integer对象。其内部变化如下:
int result = sum.intValue() + i;
Integer sum = new Integer(result);由于我们这里声明的sum为Integer类型,在上面的循环中会创建将近4000个无用的Integer对象,在这样庞大的循环中,会降低程序的性能并且加重了垃圾回收的工作量,因此在我们编程时,需要注意到这一点,避免因为自动装箱引起的性能问题。
2.7 Java为什么要有Integr?
也即问为什么要有包装类?
(1)Integer对应是int类型的包装类,就是把int类型包装成Object对象,对象封装有很多好处,可以把属性也就是数据跟处理这些数据的方法结合在一起,比如Integer就有parseInt()等方法来专门处理int型相关的数据。(2)另一个非常重要的原因就是在Java中绝大部分方法或类都是用来处理类类型对象的,如ArrayList集合类就只能以类作为他的存储对象,而这时如果想把一个int型的数据存入list是不可能的,必须把它包装成类,也就是Integer才能被List所接受。所以Integer的存在是很必要的。
在Java中泛型只能使用引用类型,而不能使用基本类型,基本类型和引用类型不能直接进行转换,必须使用包装类来实现。例如,将一个int类型的值转换为String类型,必须首先将其转换为Integer类型,然后再转换为String类型。
int i = 10;
Integer integer = new Integer(i);
String str = integer.toString();
System.out.println(str);2.8 Integer相比int有什么优点?
int是Java中的原始数据类型,而Integer是int的包装类。
Integer和 int 的区别:
- 基本类型和引用类型:首先,int是一种基本数据类型,而Integer是一种引用类型。基本数据类型是Java中最基本的数据类型,它们是预定义的,不需要实例化就可以使用。而引用类型则需要通过实例化对象来使用。这意味着,使用int来存储一个整数时,不需要任何额外的内存分配,而使用Integer时,必须为对象分配内存。在性能方面,基本数据类型的操作通常比相应的引用类型快。
- 自动装箱和拆箱:其次,Integer作为int的包装类,它可以实现自动装箱和拆箱。自动装箱是指将基本类型转化为相应的包装类类型,而自动拆箱则是将包装类类型转化为相应的基本类型。这使得Java程序员更加方便地进行数据类型转换。例如,当我们需要将int类型的值赋给Integer变量时,Java可以自动地将int类型转换为Integer类型。同样地,当我们需要将Integer类型的值赋给int变量时,Java可以自动地将Integer类型转换为int类型。
- 空指针异常:另外,int变量可以直接赋值为0,而Integer变量必须通过实例化对象来赋值。如果对一个未经初始化的Integer变量进行操作,就会出现空指针异常。这是因为它被赋予了null值,而null值是无法进行自动拆箱的。
2.9 那为什么还要保留int类型?
包装类是引用类型,对象的引用和对象本身是分开存储的,而对于基本类型数据,变量对应的内存块直接存储数据本身。因此,基本类型数据在读写效率方面,要比包装类高效。除此之外,在64位JVM上,在开启引用压缩的情况下,一个Integer对象占用16个字节的内存空间,而一个int类型数据只占用4字节的内存空间,前者对空间的占用是后者的4倍。
基本的变量类型只有一块存储空间(分配在stack中), 而引用类型有两块存储空间(一块在stack中,一块在heap中)

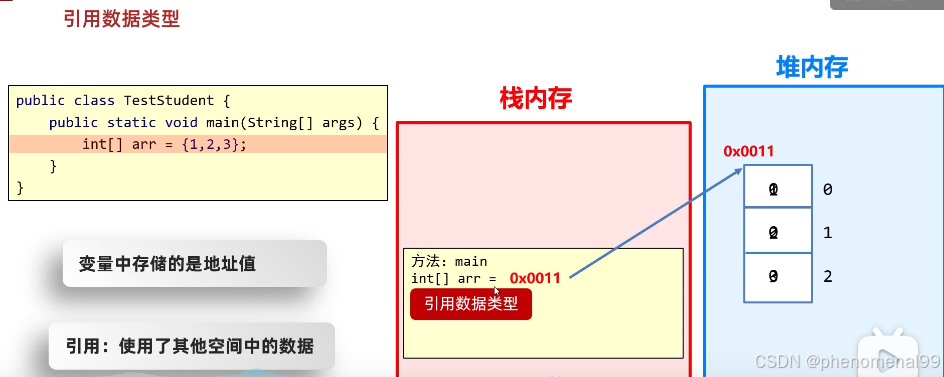
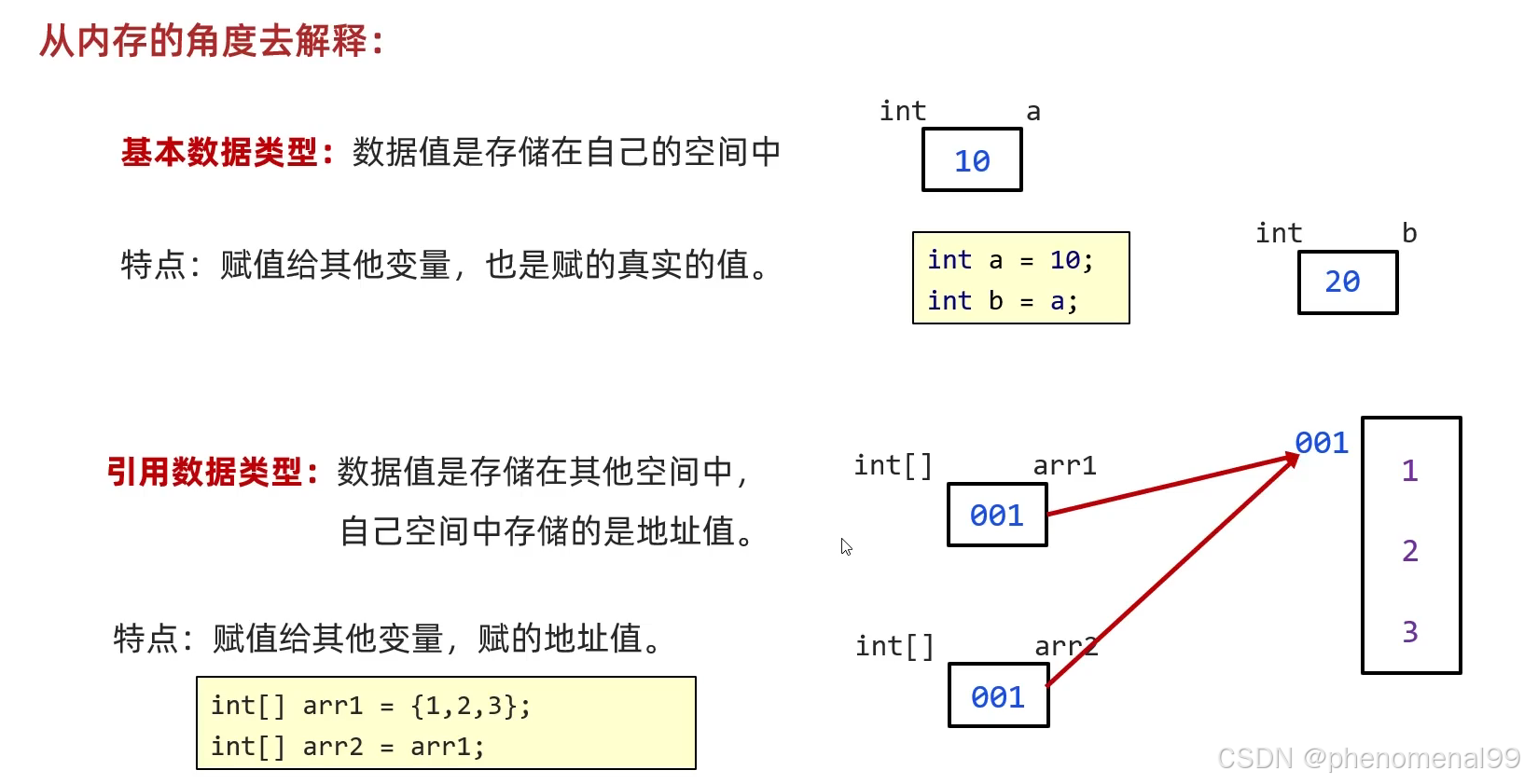

传递基本数据类型时,传递的是真实的数据,形参的改变,不影响实际参数的值。

传递引用数据类型时,传递的是地址值,形参的改变,影响实际参数的值。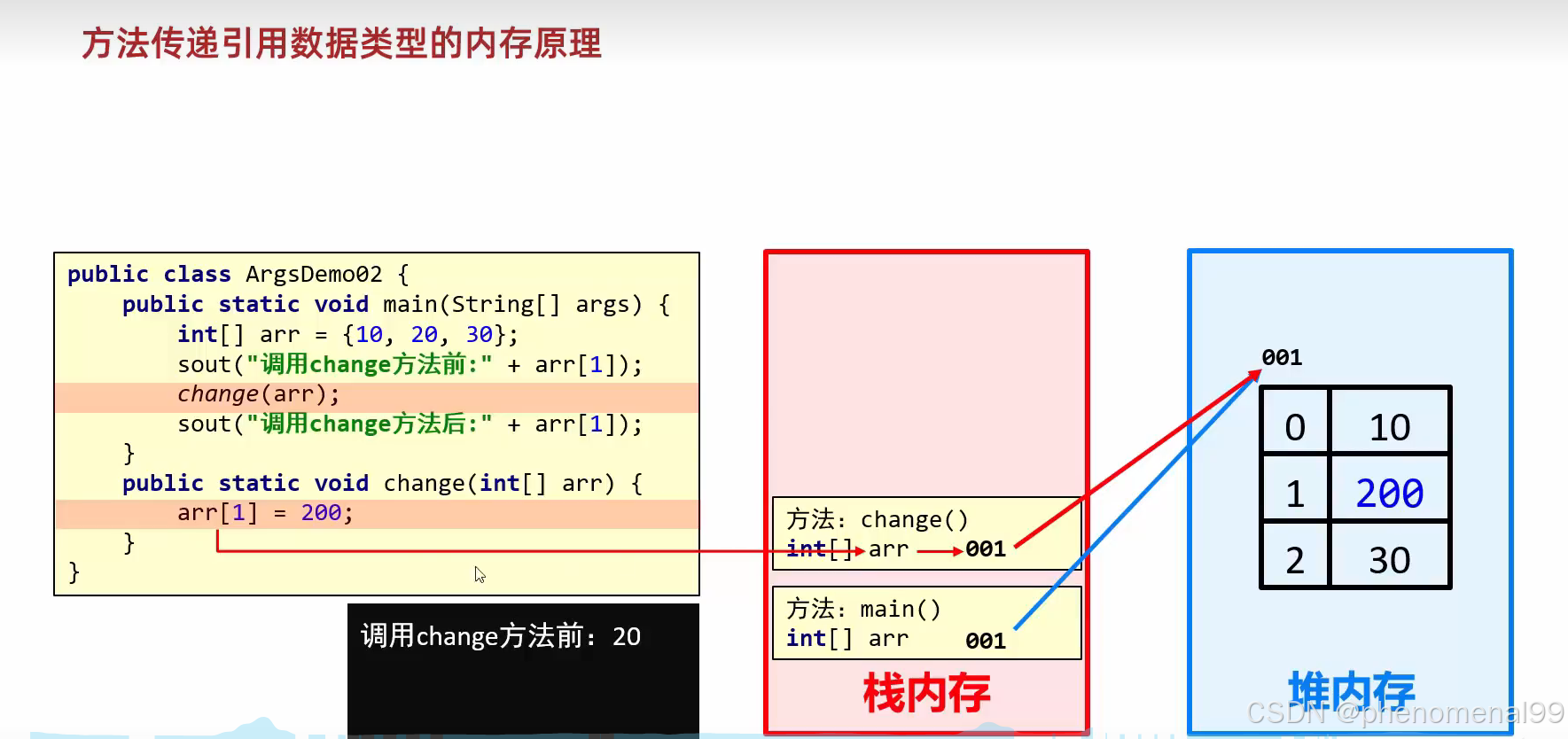
也就是说,不管是读写效率,还是存储效率,基本类型都比包装类高效。
2.10 说一下 integer的缓存
Java的Integer类内部实现了一个静态缓存池,用于存储特定范围内的整数值对应的Integer对象。默认情况下,这个范围是-128至127。当通过Integer.valueOf(int)方法创建一个在这个范围内的整数对象时,并不会每次都生成新的对象实例,而是复用缓存中的现有对象,会直接从内存中取出,不需要新建一个对象。
3.面向对象
3.1怎么理解面向对象?简单说说封装继承多态
面向对象是一种编程范式,它将现实世界中的事物抽象为对象,对象具有属性(称为字段或属性)和行为(称为方法)。面向对象编程的设计思想是以对象为中心,通过对象之间的交互来完成程序的功能,具有灵活性和可扩展性,通过封装和继承可以更好地应对需求变化。
Java面向对象的三大特性包括:封装、继承、多态:
- 封装:封装是指将对象的属性(数据)和行为(方法)结合在一起,对外隐藏对象的内部细节,仅通过对象提供的接口与外界交互。封装的目的是增强安全性和简化编程,使得对象更加独立。
- 继承:继承是一种可以使得子类自动共享父类数据结构和方法的机制。它是代码复用的重要手段,通过继承可以建立类与类之间的层次关系,使得结构更加清晰。
- 多态:多态是指允许不同类的对象对同一消息作出响应。即同一个接口,使用不同的实例而执行不同操作。多态性可以分为编译时多态(重载)和运行时多态(重写)。
3.2 多态体现在哪几个方面?
- 方法重载:方法重载是指同一类中可以有多个同名方法,它们具有不同的参数列表(参数类型、数量或顺序不同)。虽然方法名相同,但根据传入的参数不同,编译器会在编译时确定调用哪个方法。
- 方法重写:方法重写是指子类能够提供对父类中同名方法的具体实现。在运行时,JVM会根据对象的实际类型确定调用哪个版本的方法。这是实现多态的主要方式。示例:在一个动物类中,定义一个
sound方法,子类Dog可以重写该方法以实现bark,而Cat可以实现meow。 - 接口与实现:多态也体现在接口的使用上,多个类可以实现同一个接口,并且用接口类型的引用来调用这些类的方法。这使得程序在面对不同具体实现时保持一贯的调用方式。例:多个类(如
Dog,Cat)都实现了一个Animal接口,当用Animal类型的引用来调用makeSound方法时,会触发对应的实现。 - 向上转型和向下转型:在Java中,可以使用父类类型的引用指向子类对象,这是向上转型。通过这种方式,可以在运行时期采用不同的子类实现。向下转型是将父类引用转回其子类类型但在执行前需要确认引用实际指向的对象类型以避免
ClassCastException。
代码示例:
// 基类 Animal
class Animal {public void sound() {System.out.println("Animal makes a sound");}
}// 子类 Dog
class Dog extends Animal {@Overridepublic void sound() {System.out.println("Dog barks");}public void wagTail() {System.out.println("Dog wags its tail");}
}// 子类 Cat
class Cat extends Animal {@Overridepublic void sound() {System.out.println("Cat meows");}public void scratch() {System.out.println("Cat scratches");}
}public class Main {public static void main(String[] args) {// 创建 Dog 和 Cat 的对象Animal myAnimal = new Dog(); // 向上转型myAnimal.sound(); // 输出 "Dog barks"// 向下转型:将 Animal 转换为 Dog 类型Dog myDog = (Dog) myAnimal; // 强制类型转换myDog.wagTail(); // 输出 "Dog wags its tail"// 同样,我们可以尝试将 Animal 转换为 Cat 类型Animal myCat = new Cat(); // 向上转型myCat.sound(); // 输出 "Cat meows"// 向下转型:将 Animal 转换为 Cat 类型Cat myRealCat = (Cat) myCat; // 强制类型转换myRealCat.scratch(); // 输出 "Cat scratches"}
}
3.3 多态解决了什么问题?
多态是指子类可以替换父类,在实际的代码运行过程中,调用子类的方法实现。多态这种特性也需要编程语言提供特殊的语法机制来实现,比如继承、接口类。
多态可以提高代码的扩展性和复用性,是很多设计模式、设计原则、编程技巧的代码实现基础。比如策略模式、基于接口而非实现编程、依赖倒置原则、里式替换原则、利用多态去掉冗长的 if-else 语句等等。(策略模式:是一种行为设计模式,它定义了一系列算法,并将每个算法封装起来,使它们可以互相替换。策略模式使得算法可以独立于使用它的客户而变化。简单来说,策略模式将不同的算法封装成不同的策略类,客户端可以根据需要选择不同的策略来完成任务,而不需要修改客户端的代码。)
策略模式的组成:
- Context(上下文):它是使用某种策略的类,它包含一个对策略对象的引用。
- Strategy(策略接口):它是一个接口或抽象类,定义了所有具体策略类实现的方法。
- ConcreteStrategy(具体策略):这些类实现了 Strategy 接口,并提供具体的算法实现。
策略模式的优点:
- 可以避免使用大量的
if-else或switch语句来选择不同的算法。 - 代码更加清晰和可扩展,可以根据需要添加新的策略。
- 客户端可以动态地选择策略。
示例:计算费用的策略模式
假设我们有一个商店,计算运费的方式有几种:普通运输、加急运输和国际运输。使用策略模式来封装这些运费计算策略。
1. 定义策略接口:
// 策略接口
interface ShippingStrategy {double calculateShippingCost(Order order);
}
2. 创建具体策略类:
// 普通运输策略
class RegularShipping implements ShippingStrategy {@Overridepublic double calculateShippingCost(Order order) {return 10.0; // 固定的运费}
}// 加急运输策略
class ExpeditedShipping implements ShippingStrategy {@Overridepublic double calculateShippingCost(Order order) {return 25.0; // 加急运费}
}// 国际运输策略
class InternationalShipping implements ShippingStrategy {@Overridepublic double calculateShippingCost(Order order) {return 50.0; // 国际运费}
}
3. 定义 Order 类:
class Order {private double weight;public Order(double weight) {this.weight = weight;}public double getWeight() {return weight;}
}
4. 创建 Context 类来使用策略:
class ShippingContext {private ShippingStrategy shippingStrategy;// 设置策略public void setShippingStrategy(ShippingStrategy shippingStrategy) {this.shippingStrategy = shippingStrategy;}// 计算运费public double calculateShipping(Order order) {return shippingStrategy.calculateShippingCost(order);}
}
5. 使用策略模式:
public class StrategyPatternExample {public static void main(String[] args) {Order order = new Order(10.0); // 订单重量 10kgShippingContext context = new ShippingContext();// 使用普通运输context.setShippingStrategy(new RegularShipping());System.out.println("Regular Shipping Cost: " + context.calculateShipping(order));// 使用加急运输context.setShippingStrategy(new ExpeditedShipping());System.out.println("Expedited Shipping Cost: " + context.calculateShipping(order));// 使用国际运输context.setShippingStrategy(new InternationalShipping());System.out.println("International Shipping Cost: " + context.calculateShipping(order));}
}
输出:
Regular Shipping Cost: 10.0
Expedited Shipping Cost: 25.0
International Shipping Cost: 50.0
解释:
ShippingStrategy是策略接口,定义了运费计算的行为。RegularShipping、ExpeditedShipping和InternationalShipping是具体的策略类,实现了ShippingStrategy接口并提供不同的运费计算方式。ShippingContext是上下文类,它持有一个ShippingStrategy的实例,并通过该策略来计算运费。你可以随时切换策略,而不需要修改上下文类的代码。
3.4 面向对象的设计原则你知道有哪些吗??
- 单一职责原则(SRP):一个类应该只有一个引起它变化的原因,即一个类应该只负责一项职责。
- 开放封闭原则(OCP):软件实体应该对扩展开放,对修改封闭。例子:通过制定接口来实现这一原则,比如定义一个图形类,然后让不同类型的图形继承这个类,而不需要修改图形类本身。
- 里氏替换原则(LSP):子类对象应该能够替换掉所有父类对象。例子:一个正方形是一个矩形,但如果修改一个矩形的高度和宽度时,正方形的行为应该如何改变就是一个违反里氏替换原则的例子。
- 接口隔离原则(ISP):客户端不应该依赖那些它不需要的接口,即接口应该小而专。例子:通过接口抽象层来实现底层和高层模块之间的解耦,比如使用依赖注入。
- 依赖倒置原则(DIP):高层模块不应该依赖低层模块,二者都应该依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。例子:如果一个公司类包含部门类,应该考虑使用合成/聚合关系,而不是将公司类继承自部门类。
- 最少知识原则 (Law of Demeter):一个对象应当对其他对象有最少的了解,只与其直接的朋友交互。
3.5 重载与重写有什么区别?
- 重载(Overloading)指的是在同一个类中,可以有多个同名方法,它们具有不同的参数列表(参数类型、参数个数或参数顺序不同),编译器根据调用时的参数类型来决定调用哪个方法。
- 重写(Overriding)指的是子类可以重新定义父类中的方法,方法名、方法名、参数列表和返回类型必须与父类中的方法一致,通过@override注解来明确表示这是对父类方法的重写。
重载是指在同一个类中定义多个同名方法,而重写是指子类重新定义父类中的方法。
3.6 抽象类和普通类区别?
- 实例化:普通类可以直接实例化对象,而抽象类不能被实例化,只能被继承。
- 方法实现:普通类中的方法可以有具体的实现,而抽象类中的方法可以有实现也可以没有实现。
- 继承:一个类可以继承一个普通类,而且可以继承多个接口;而一个类只能继承一个抽象类,但可以同时实现多个接口。
- 实现限制:普通类可以被其他类继承和使用,而抽象类一般用于作为基类,被其他类继承和扩展使用。
3.7 Java抽象类和接口的区别是什么?
两者的特点:
- 抽象类用于描述类的共同特性和行为,可以有成员变量、构造方法和具体方法。适用于有明显继承关系的场景。
- 接口用于定义行为规范,可以多实现,只能有常量和抽象方法(Java 8 以后可以有默认方法和静态方法)。适用于定义类的能力或功能。
两者的区别:
- 实现方式:实现接口的关键字为implements,继承抽象类的关键字为extends。一个类可以实现多个接口,但一个类只能继承一个抽象类。所以,使用接口可以间接地实现多重继承。
- 方法方式:接口只有定义,不能有方法的实现,java 1.8中可以定义default方法体,而抽象类可以有定义与实现,方法可在抽象类中实现。
- 访问修饰符:接口成员变量默认为public static final,必须赋初值,不能被修改;其所有的成员方法都是public、abstract的。抽象类中成员变量默认default,可在子类中被重新定义,也可被重新赋值;抽象方法被abstract修饰,不能被private、static、synchronized和native等修饰,必须以分号结尾,不带花括号。
- 变量:抽象类可以包含实例变量和静态变量,而接口只能包含常量(即静态常量)。
3.8 抽象类能加final修饰吗?
不能,Java中的抽象类是用来被继承的,而final修饰符用于禁止类被继承或方法被重写,因此,抽象类和final修饰符是互斥的,不能同时使用。
3.9 接口里面可以定义哪些方法?
- 抽象方法
抽象方法是接口的核心部分,所有实现接口的类都必须实现这些方法。抽象方法默认是 public 和abstract,这些修饰符可以省略。
public interface Animal {void makeSound();
}- 默认方法
默认方法是在 Java 8 中引入的,允许接口提供具体实现。实现类可以选择重写默认方法。
public interface Animal {void makeSound();default void sleep() {System.out.println("Sleeping...");}
}- 静态方法
静态方法也是在 Java 8 中引入的,它们属于接口本身,可以通过接口名直接调用,而不需要实现类的对象。
public interface Animal {void makeSound();static void staticMethod() {System.out.println("Static method in interface");}}- 私有方法
私有方法是在 Java 9 中引入的,用于在接口中为默认方法或其他私有方法提供辅助功能。这些方法不能被实现类访问,只能在接口内部使用。
public interface Animal {void makeSound();default void sleep() {System.out.println("Sleeping...");logSleep();}private void logSleep() {System.out.println("Logging sleep");}}public interface Animal {void makeSound();
}3.10 抽象类可以被实例化吗?
不能!在Java中,抽象类本身不能被实例化,这意味着不能使用new关键字直接创建一个抽象类的对象。抽象类的存在主要是为了被继承,它通常包含一个或多个抽象方法(由abstract关键字修饰且无方法体的方法),这些方法需要在子类中被实现。抽象类可以有构造器,这些构造器在子类实例化时会被调用,以便进行必要的初始化工作。然而,这个过程并不是直接实例化抽象类,而是创建了子类的实例,间接地使用了抽象类的构造器。例:
public abstract class AbstractClass {public AbstractClass() {// 构造器代码}public abstract void abstractMethod();}public class ConcreteClass extends AbstractClass{public ConcreteClass() {super(); // 调用抽象类的构造器}@Overridepublic void abstractMethod() {//实现抽象方法}
}//下面的代码可以运行
ConcreteClass obj = new ConcreteClass();
在这个例子中,ConcreteClass继承了AbstractClass并实现了抽象方法abstractMethod()。当我们创建ConcreteClass的实例时,AbstractClass的构造器被调用,但这并不意味着AbstractClass被实例化;实际上,我们创建的是ConcreteClass的一个对象。简而言之,抽象类不能直接实例化,但通过继承抽象类并实现所有抽象方法的子类是可以被实例化的。
3.11 接口可以包含构造函数吗?
在接口中,不可以有构造方法,在接口里写入构造方法时,编译器提示:Interfaces cannot have constructors,因为接口不会有自己的实例的,所以不需要有构造函数。为什么呢?构造函数就是初始化class的属性或者方法,在new的一瞬间自动调用,那么问题来了Java的接口,都不能new 那么要构造函数干嘛呢?根本就没法调用。
3.12 解释Java中的静态变量和静态方法
在Java中,静态变量和静态方法是与类本身关联的,而不是与类的实例(对象)关联,它们在内存中只存在一份,可以被类的所有实例共享。
静态变量(也称为类变量)是在类中使用static关键字声明的变量。它们属于类而不是任何具体的对象。主要的特点:
- 共享性:所有该类的实例共享同一个静态变量。如果一个实例修改了静态变量的值,其他实例也会看到这个更改。
- 初始化:静态变量在类被加载时初始化,只会对其进行一次分配内存。
- 访问方式:静态变量可以直接通过类名访问,也可以通过实例访问,但推荐使用类名。

静态方法是在类中使用static关键字声明的方法。类似于静态变量,静态方法也属于类,而不是任何具体的对象。主要的特点:
- 无实例依赖:静态方法可以在没有创建类实例的情况下调用。对于静态方法来说,不能直接访问非静态的成员变量或方法,因为静态方法没有上下文的实例。
- 访问静态成员:静态方法可以直接调用其他静态变量和静态方法,但不能直接访问非静态成员。
- 多态性:静态方法不支持重写(Override),但可以被隐藏(Hide)。
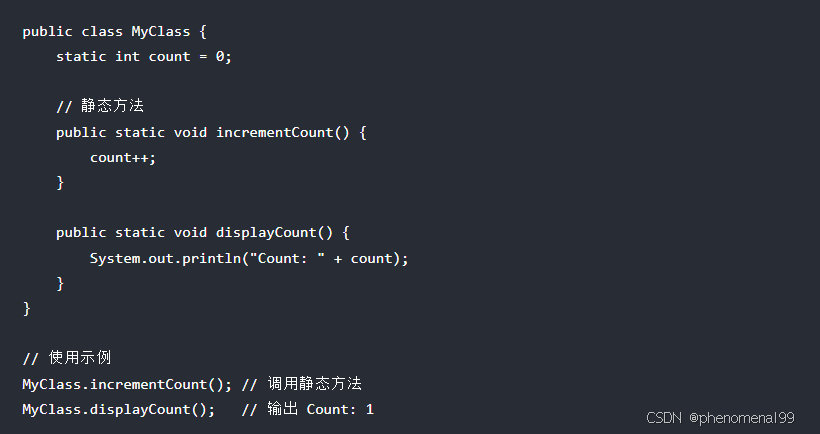
使用场景:
- 静态变量:常用于需要在所有对象间共享的数据,如计数器、常量等。
- 静态方法:常用于助手方法(utility methods)、获取类级别的信息或者是没有依赖于实例数据处理。
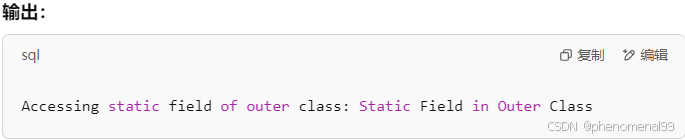
3.13 非静态内部类和静态内部类的区别?
区别包括:
- 非静态内部类依赖于外部类的实例,而静态内部类不依赖于外部类的实例。
- 非静态内部类可以访问外部类的实例变量和方法,而静态内部类只能访问外部类的静态成员。
- 非静态内部类不能定义静态成员,而静态内部类可以定义静态成员。
- 非静态内部类在外部类实例化后才能实例化,而静态内部类可以独立实例化。
- 非静态内部类可以访问外部类的私有成员,而静态内部类不能直接访问外部类的私有成员,需要通过实例化外部类来访问。
class OuterClass {private static String staticField = "Static Field in Outer Class";// 静态内部类static class StaticInnerClass {public void display() {System.out.println("Accessing static field of outer class: " + staticField);}}
}public class Main {public static void main(String[] args) {// 直接通过类名访问静态内部类OuterClass.StaticInnerClass inner = new OuterClass.StaticInnerClass();inner.display();}
}
3.14 非静态内部类可以直接访问外部方法,编译器是怎么做到的?
非静态内部类可以直接访问外部方法是因为编译器在生成字节码时会为非静态内部类维护一个指向外部类实例的引用。这个引用使得非静态内部类能够访问外部类的实例变量和方法。编译器会在生成非静态内部类的构造方法时,将外部类实例作为参数传入,并在内部类的实例化过程中建立外部类实例与内部类实例之间的联系,从而实现直接访问外部方法的功能。
3.15 有一个父类和子类,都有静态的成员变量、静态构造方法和静态方法,在我new一个子类对象的时候,加载顺序是怎么样的?
- 在创建子类对象之前,首先会加载父类的静态成员变量和静态代码块(构造方法无法被
static修饰,因此这里是静态代码块)。这个加载是在类首次被加载时进行的,且只会发生一次。 - 接下来,加载子类的静态成员变量和静态代码块。这一过程也只发生一次,即当首次使用子类的相关代码时。
- 之后,执行实例化子类对象的过程。这时会呼叫父类构造方法,然后是子类的构造方法。
具体加载顺序可以简要总结为:
- 父类静态成员变量、静态代码块(如果有)
- 子类静态成员变量、静态代码块(如果有)
- 父类构造方法(实例化对象时)
- 子类构造方法(实例化对象时)
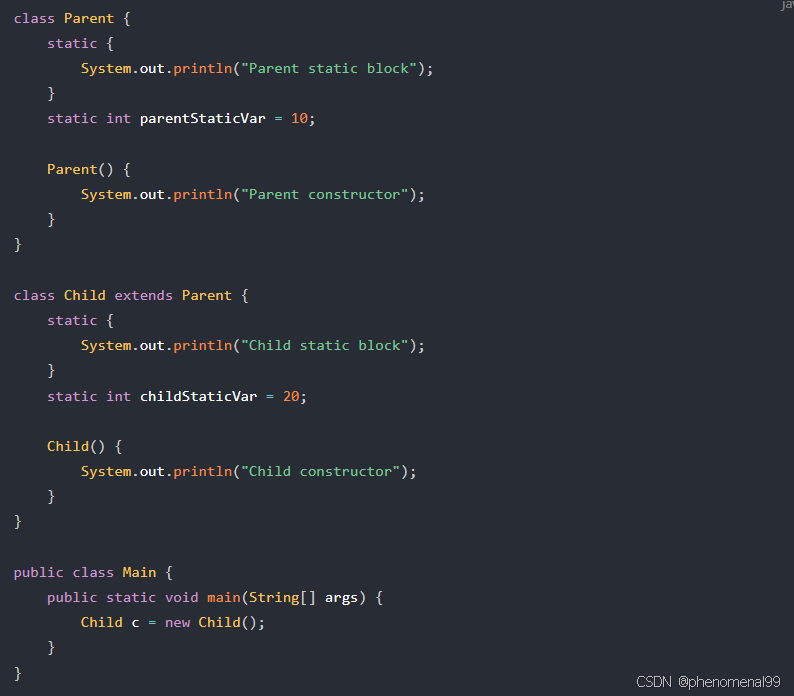
 从输出可以看出,在创建
从输出可以看出,在创建 Child 类型对象时,首先执行父类的静态块,然后是子类的静态块,最后才是父类和子类的构造函数。这清晰地展示了加载的顺序。
4. 深拷贝和浅拷贝
4.1 深拷贝和浅拷贝的区别?
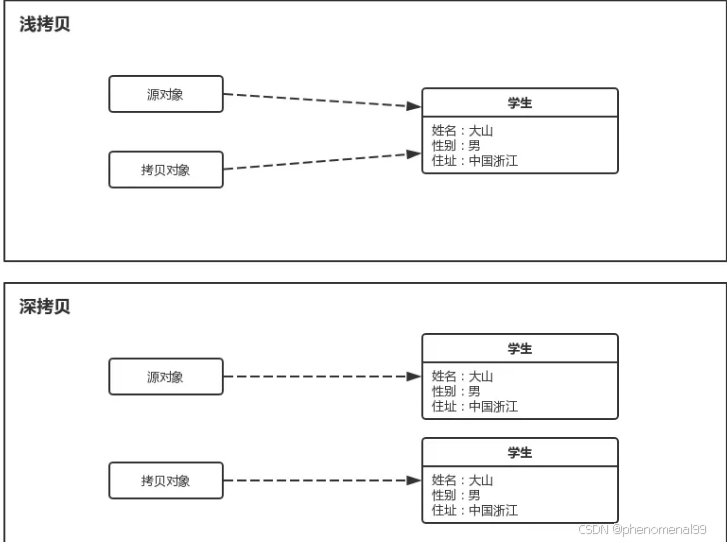
- 浅拷贝是指只复制对象本身和其内部的值类型字段,但不会复制对象内部的引用类型字段。换句话说,浅拷贝只是创建一个新的对象,然后将原对象的字段值复制到新对象中,但如果原对象内部有引用类型的字段,只是将引用复制到新对象中,两个对象指向的是同一个引用对象。
- 深拷贝是指在复制对象的同时,将对象内部的所有引用类型字段的内容也复制一份,而不是共享引用。换句话说,深拷贝会递归复制对象内部所有引用类型的字段,生成一个全新的对象以及其内部的所有对象。
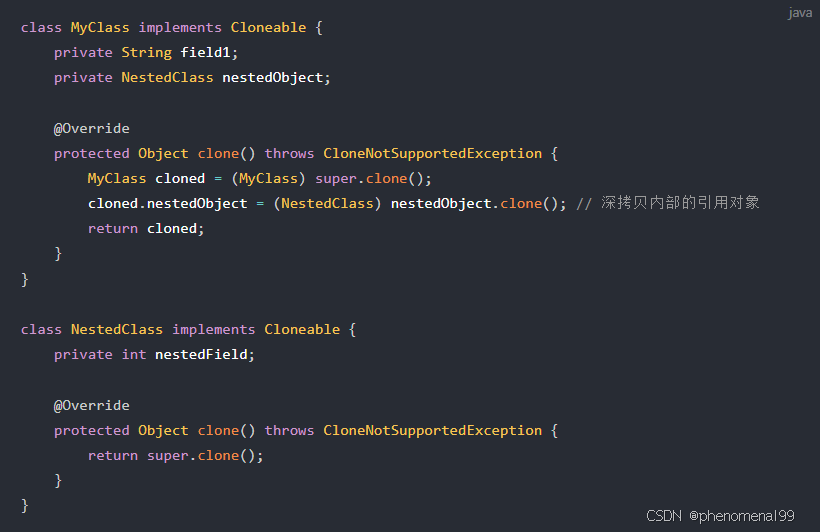
4.2 实现深拷贝的三种方法是什么?
实现 Cloneable 接口并重写 clone() 方法
这种方法要求对象及其所有引用类型字段都实现 Cloneable 接口,并且重写 clone() 方法。在 clone() 方法中,通过递归克隆引用类型字段来实现深拷贝。
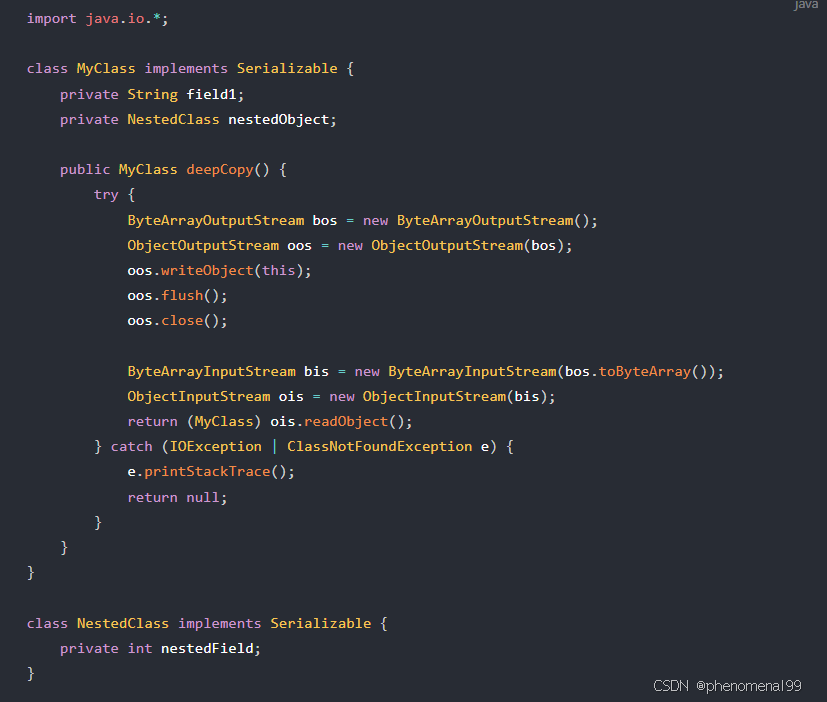
使用序列化和反序列化
通过将对象序列化为字节流,再从字节流反序列化为对象来实现深拷贝。要求对象及其所有引用类型字段都实现 Serializable 接口。
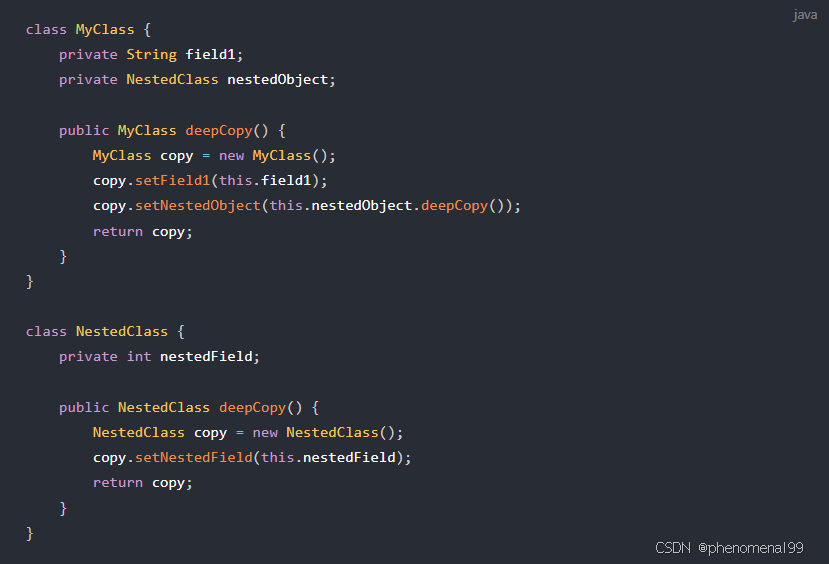
手动递归复制
针对特定对象结构,手动递归复制对象及其引用类型字段。适用于对象结构复杂度不高的情况。
5. 泛型
5.1 什么是泛型?
泛型是 Java 编程语言中的一个重要特性,它允许类、接口和方法在定义时使用一个或多个类型参数,这些类型参数在使用时可以被指定为具体的类型。这些类型参数在使用时可以被指定为具体的类型。
为什么需要泛型?
- 适用于多种数据类型执行相同的代码

如果没有泛型,要实现不同类型的加法,每种类型都需要重载一个add方法;通过泛型,我们可以复用为一个方法:

- 泛型中的类型在使用时指定,不需要强制类型转换(类型安全,编译器会检查类型)
看下这个例子:

我们在使用上述list中,list中的元素都是Object类型(无法约束其中的类型),所以在取出集合元素时需要人为的强制类型转化到具体的目标类型,且很容易出现java.lang.ClassCastException异常。引入泛型,它将提供类型的约束,提供编译前的检查:

6.对象
6.1 java创建对象有哪些方式?
在Java中,创建对象的方式有多种,常见的包括:
使用new关键字:通过new关键字直接调用类的构造方法来创建对象。
使用Class类的newInstance()方法:通过反射机制,可以使用Class类的newInstance()方法创建对象。
Myclass obj = (Myclass)Class.forName("com.example.Myclass").newInstance();使用Constructor类的newInstance()方法:同样是通过反射机制,可以使用Constructor类的newInstance()

使用clone()方法:如果类实现了Cloneable接口,可以使用clone()方法复制对象。

使用反序列化:通过将对象序列化到文件或流中,然后再进行反序列化来创建对象。
6.2 New出的对象什么时候回收?
通过过关键字new创建的对象,由Java的垃圾回收器(Garbage Collector)负责回收,垃圾回收器的工作是在程序运行过程中自动进行的,它会周期性地检测不再被引用的对象,并将其回收释放内存。具体来说,Java对象的回收时机是由垃圾回收器根据一些算法来决定的,要有以下几种情况:
- 引用计数法:某个对象的引用计数为0时,表示该对象不再被引用,可以被回收。
- 可达性分析算法:从根对象(如方法区中的类静态属性、方法中的局部变量等)出发,通过对象之间的引用链进行遍历,如果存在一条引用链到达某个对象,则说明该对象是可达的,反之不可达,不可达的对象将被回收。
- 终结器(Finalizer):如果对象重写了
finalize()方法,垃圾回收器会在回收该对象之前调用finalize()方法,对象可以在finalize()方法中进行一些清理操作。然而,终结器机制的使用不被推荐,因为它的执行时间是不确定的,可能会导致不可预测的性能问题。
7.反射
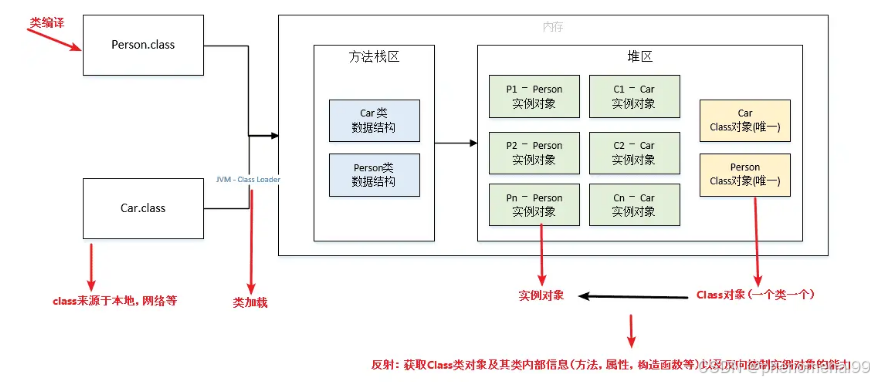
7.1 什么是反射?
Java 反射机制是在运行状态中,对于任意一个类,都能够知道这个类中的所有属性和方法,对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为Java 语言的反射机制。(反射详解请参考个人博客:https://blog.csdn.net/m0_50345460/article/details/141950998)
反射具有以下特性:
- 运行时类信息访问:反射机制允许程序在运行时获取类的完整结构信息,包括类名、包名、父类、实现的接口、构造函数、方法和字段等。
- 动态对象创建:可以使用反射API动态地创建对象实例,即使在编译时不知道具体的类名。这是通过Class类的newInstance()方法或Constructor对象的newInstance()方法实现的。
- 动态方法调用:可以在运行时动态地调用对象的方法,包括私有方法这通过Method类的invoke()方法实现,允许你传入对象实例和参数值来执行方法。
- 访问和修改字段值:反射还允许程序在运行时访问和修改对象的字段值,即使是私有的。这是通过Field类的get()和set()方法完成的。
7.2 反射在你平时写代码或者框架中的应用场景有哪些?
1.加载数据库驱动
我们的项目底层数据库有时是用mysql,有时用oracle,需要动态地根据实际情况加载驱动类,这个时候反射就有用了,假设 com.mikechen.java.myqlConnection,com.mikechen.java.oracleConnection这两个类我们要用。这时候我们在使用 JDBC 连接数据库时使用 Class.forName()通过反射加载数据库的驱动程序,如果是mysql则传入mysql的驱动类,而如果是oracle则传入的参数就变成另一个了。

2.配置文件加载
Spring 框架的 IOC(动态加载管理 Bean),Spring通过配置文件配置各种各样的bean,你需要用到哪些bean就配哪些,spring容器就会根据你的需求去动态加载,你的程序就能健壮地运行。
Spring通过XML配置模式装载Bean的过程:
- 将程序中所有XML或properties配置文件加载入内存
- Java类里面解析xml或者properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息
- 使用反射机制,根据这个字符串获得某个类的Class实例
- 动态配置实例的属性
例如:
配置文件

实体类

解析配置文件内容
// 解析xml或properties里面的内容,得到对应实体类的字节码字符串以及属性信息
public static String getName(String key) throws IOException {Properties properties = new Properties();FileInputStream in = new FileInputStream("D:\IdeaProjects\AllDemos\language-specification\src\main\resources\application.properties");properties.load(in);in.close();return properties.getProperty(key);
}利用反射获取实体类的Class实例,创建实体类的实例对象,调用方法
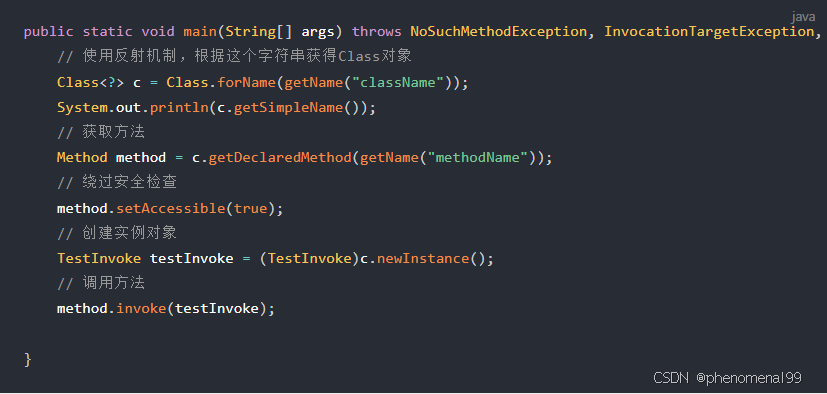
运行结果:

8.注解
8.1 能讲一讲java注解的原理么?
注解本质是一个继承了Annotation的特殊接口,其具体实现类是Java运行时生成的动态代理类。我们通过反射获取注解时,返回的是Java运行时生成的动态代理对象,通过代理对象调用自定义注解的方法,会最终调用AnnotationInvocationHandler的invoke方法,该方法会从memberValues这个Map中索引出对应的值。而memberValues的来源是Java常量池。(注解详解请参考个人博客:https://blog.csdn.net/m0_50345460/article/details/141529888)
8.2 Java注解的作用域呢?
注解的作用域(Scope)指的是注解可以应用在哪些程序元素上,例如类、方法、字段等。Java注解的作用域可以分为三种:
- 类级别作用域:用于描述类的注解,通常放置在类定义的上面,可以用来指定类的一些属性,如类的访问级别、继承关系、注释等。
- 方法级别作用域:用于描述方法的注解,通常放置在方法定义的上面,可以用来指定方法的一些属性如方法的访问级别、返回值类型、异常类型、注释等。
- 字段级别作用域:用于描述字段的注解,通常放置在字段定义的上面,可以用来指定字段的一些属性,如字段的访问级别、默认值、注释等。
除了这三种作用域,Java还提供了其他一些注解作用域,例如构造函数作用域和局部变量作用域。这些注解作用域可以用来对构造函数和局部变量进行描述和注释。
9.异常
9.1 介绍一下Java异常
Java异常类层次结构图:
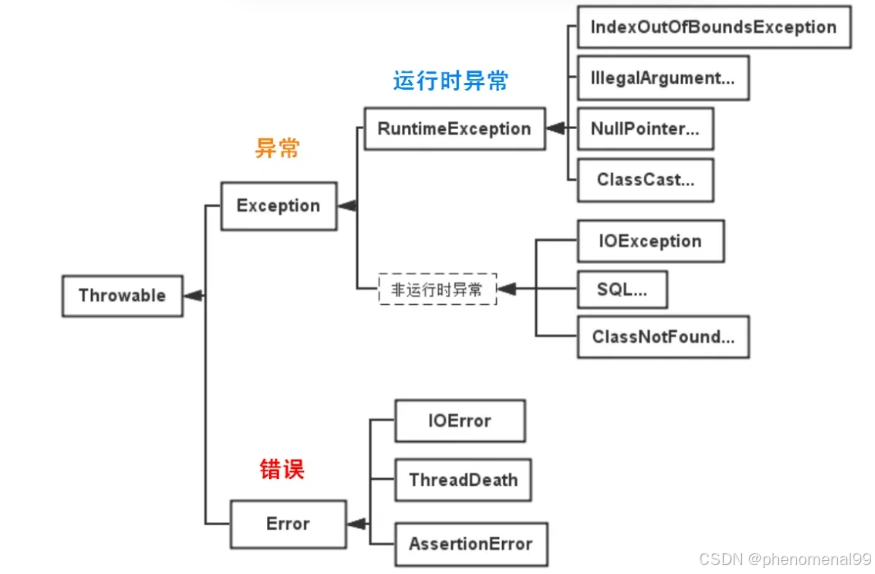
Java的异常体系主要基于两大类:Throwable类及其子类。Throwable有两个重要的子类:Error和Exception,它们分别代表了不同类型的异常情况。
- Error(错误):表示运行时环境的错误。错误是程序无法处理的严重问题如系统崩溃、虚拟机错误、动态链接失败等。通常,程序不应该尝试捕获这类错误。如OutOfMemoryError、StackOverflowError等。
- Exception(异常):表示程序本身可以处理的异常条件。异常分为两大类:
- 非运行时异常:这类异常在编译时期就必须被捕获或者声明抛出。它们通常是外部错误,如文件不存在(FileNotFoundException)、类未找到(ClassNotFoundException)等。非运行时异常强制程序员处理这些可能出现的问题,增强了程序的健壮性。
- 运行时异常:这类异常包括运行时异常(RuntimeException)和错误(Error)。运行时异常由程序错误导致,如空指针访问(NullPointerException)、数组越界(ArrayIndexOutOfBoundsException)等。运行时异常是不需要在编译时强制捕获或声明的。
9.2 Java异常处理有哪些?
异常处理是通过使用try-catch语句块来捕获和处理异常。以下是Java中常用的异常处理方式:
- try-catch语句块:用于捕获并处理可能抛出的异常。try块中包含可能抛出异常的代码,catch块用于捕获并处理特定类型的异常。可以有多个catch块来处理不同类型的异常。

- throw语句:用于手动抛出异常。可以根据需要在代码中使用throw语句主动抛出特定类型的异常。

- throws关键字:用于在方法声明中声明可能抛出的异常类型。如果一个方法可能抛出异常,但不想在方法内部进行处理,可以使用throws关键字将异常传递给调用者来处理。

- finally块:用于定义无论是否发生异常都会执行的代码块,通常用于释放资源,确保资源的正确关闭。

9.3 抛出异常为什么不用throws?
如果异常是未检查异常或者在方法内部被捕获和处理了,那么就不需要使用throws。
- Unchecked Exceptions:未检查异常(unchecked exceptions)是继承自RuntimeException类或Error类的异常,编译器不强制要求进行异常处理。因此,对于这些异常,不需要在方法签名中使用throws来声明。示例包括NullPointerException、ArrayIndexOutOfBoundsException等。
- 捕获和处理异常:另一种常见情况是,在方法内部捕获了可能抛出的异常,并在方法内部处理它们,而不是通过throws子句将它们传递到调用者。这种情况下,方法可以处理异常而无需在方法签名中使用throws。
9.4 try catch中的语句运行情况
try块中的代码将按顺序执行,如果抛出异常,将在catch块中进行匹配和处理,然后程序将继续执行catch块之后的代码。如果没有匹配的catch块,异常将被传递给上一层调用的方法。
try{return “a”} fianlly{return “b”}这条语句返回啥??
finally块中的return语句会覆盖try块中的return返回,因此,该语句将返回"b"
10.Object
10.1 == 与 equals 有什么区别?
对于字符串变量来说,使用"=="和"equals"比较字符串时,其比较方法不同。"=="比较两个变量本身的值,即两个对象在内存中的首地址,"equals"比较字符串包含内容是否相同。
对于非字符串变量来说,如果没有对equals()进行重写的话,"==" 和 "equals"方法的作用是相同的,都是用来比较对象在堆内存中的首地址,即用来比较两个引用变量是否指向同一个对象。
- ==:比较的是两个字符串内存地址(堆内存)的数值是否相等,属于数值比较;
- equals():比较的是两个字符串的内容,属于内容比较。
== 主要用于比较基本数据类型的值或引用数据类型的内存地址,equals 方法默认比较内存地址,但很多类会重写该方法来比较对象内容。
10.2 StringBuffer和StringBuild区别是什么?
区别:
- String 是 Java 中基础且重要的类,被声明为 final class,是不可变字符串,因为它的不可变性,所以拼接字符串时候会产生很多无用的中间对象,如果频繁的进行这样的操作对性能有所影响。
- StringBuffer 就是为了解决大量拼接字符串时产生很多中间对象问题而提供的一个类。它提供了append 和 add 方法,可以将字符串添加到已有序列的末尾或指定位置,它的本质是一个线程安全的可修改的字符序列。在很多情况下我们的字符串拼接操作不需要线程安全,所以 StringBuilder 登场了。
- StringBuilder 是 JDK1.5 发布的,它和 StringBuffer 本质上没什么区别,就是去掉了保证线程安全的那部分,减少了开销。
速度:
- 一般情况下,速度从快到慢为 StringBuilder > StringBuffer > String,当然这是相对的,不是绝对的。
使用场景:
- 操作少量的数据使用 String。
- 单线程操作大量数据使用 StringBuilder。
- 多线程操作大量数据使用 StringBuffer。

11.Java1.8新特性
11.1 Java中stream的API介绍一下
Java 8引入了Stream API,它提供了一种高效且易于使用的数据处理方式,特别适合集合对象的操作,如过滤、映射、排序等。Stream API不仅可以提高代码的可读性和简洁性,还能利用多核处理器的优势进行并行处理。例:
案例1:过滤并收集满足条件的元素
问题场景:从一个列表中筛选出所有长度大于3的字符串,并收集到一个新的列表中。
没有Stream API的做法:
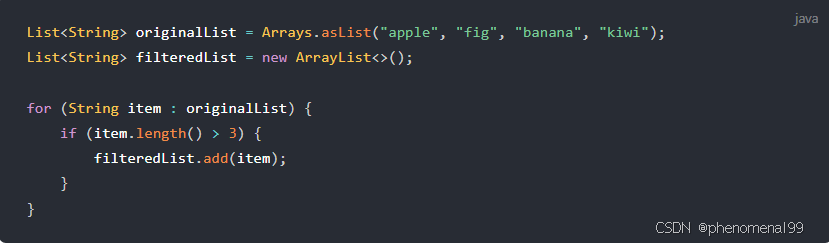
这段代码需要显式地创建一个新的ArrayList,并通过循环遍历原列表,手动检查每个元素是否满足条件,然后添加到新列表中。
使用Stream API的做法:

这里,我们直接在原始列表上调用.stream()方法创建了一个流,使用.filter()中间操作筛选出长度大于3的字符串,最后使用.collect(Collectors.toList())终端操作将结果收集到一个新的列表中。代码更加简洁明了,逻辑一目了然。
案例2:计算列表中所有数字的总和
问题场景:计算一个数字列表中所有元素的总和。
没有Stream API的做法:

这个传统的for-each循环遍历列表中的每一个元素,累加它们的值来计算总和。
使用Stream API的做法:

通过Stream API,我们可以先使用.mapToInt()将Integer流转换为IntStream(这是为了高效处理基本类型),然后直接调用.sum()方法来计算总和,极大地简化了代码。
11.2 Stream流的并行API是什么?
是 ParallelStream。并行流(ParallelStream)就是将源数据分为多个子流对象进行多线程操作,然后将处理的结果再汇总为一个流对象,底层是使用通用的 fork/join 池来实现,即将一个任务拆分成多个“小任务”并行计算,再把多个“小任务”的结果合并成总的计算结果。
Stream串行流与并行流的主要区别:
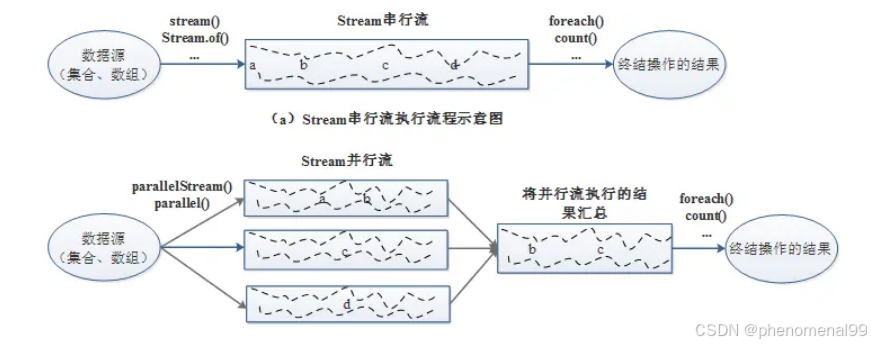
对CPU密集型的任务来说,并行流使用ForkJoinPool线程池,为每个CPU分配一个任务,这是非常有效率的,但是如果任务不是CPU密集的,而是I/O密集的,并且任务数相对线程数比较大,那么直接用ParallelStream并不是很好的选择。
11.3 completableFuture怎么用的?
CompletableFuture是由Java 8引入的,在Java8之前我们一般通过Future实现异步。
- Future用于表示异步计算的结果,只能通过阻塞或者轮询的方式获取结果,而且不支持设置回调方法,Java 8之前若要设置回调一般会使用guava的ListenableFuture,回调的引入又会导致臭名昭著的回调地狱(下面的例子会通过ListenableFuture的使用来具体进行展示)。
- CompletableFuture对Future进行了扩展,可以通过设置回调的方式处理计算结果,同时也支持组合操作,支持进一步的编排,同时一定程度解决了回调地狱的问题。
回调方法解释:是指将一个方法作为参数传递给另一个方法,并由被传递的那个方法在适当的时候调用这个方法。这通常用于事件驱动编程或者异步操作中。回调方法可以通过接口、匿名类或Lambda表达式来实现。例子:
假设我们有一个 Worker 类,它需要执行一个任务,然后在任务完成时调用回调方法通知调用者。
// 定义一个回调接口
interface TaskCallback {void onComplete(String result);
}// 定义一个执行任务的类
class Worker {public void doWork(TaskCallback callback) {// 执行任务System.out.println("工作开始...");// 假设任务执行完毕,调用回调方法String result = "任务完成!";callback.onComplete(result);}
}// 主类
public class Main {public static void main(String[] args) {Worker worker = new Worker();// 使用回调方法worker.doWork(new TaskCallback() {@Overridepublic void onComplete(String result) {// 回调方法在任务完成后被调用System.out.println("回调方法被调用: " + result);}});}
}
输出:

下面将举例来说明,我们通过ListenableFuture、CompletableFuture来实现异步的差异。假设有三个操作step1、step2、step3存在依赖关系,其中step3的执行依赖step1和step2的结果。
Future(ListenableFuture)的实现(回调地狱)如下:
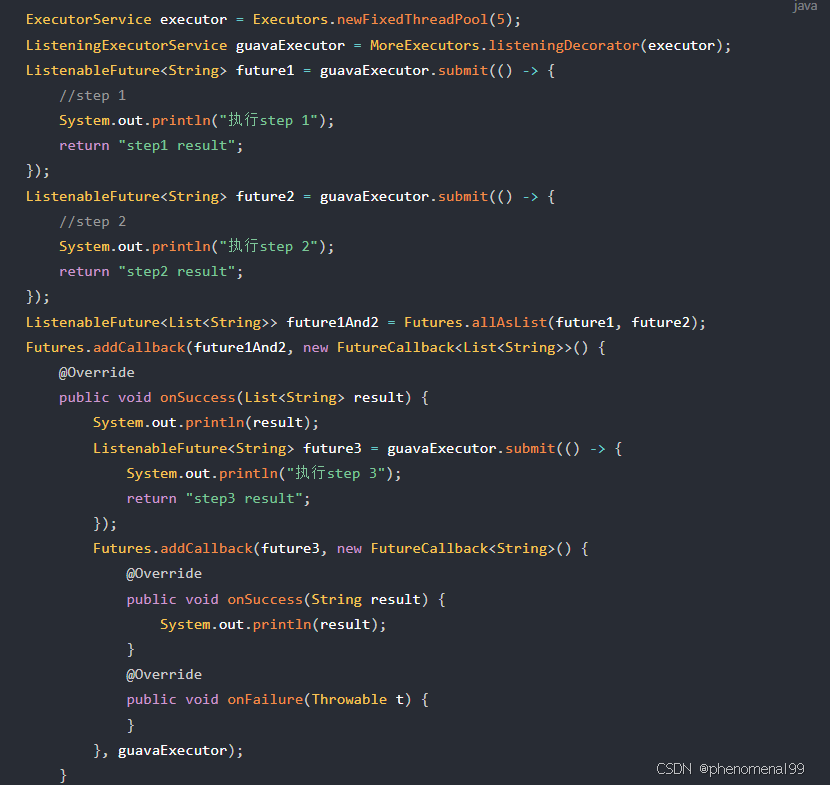
 CompletableFuture的实现如下:
CompletableFuture的实现如下:
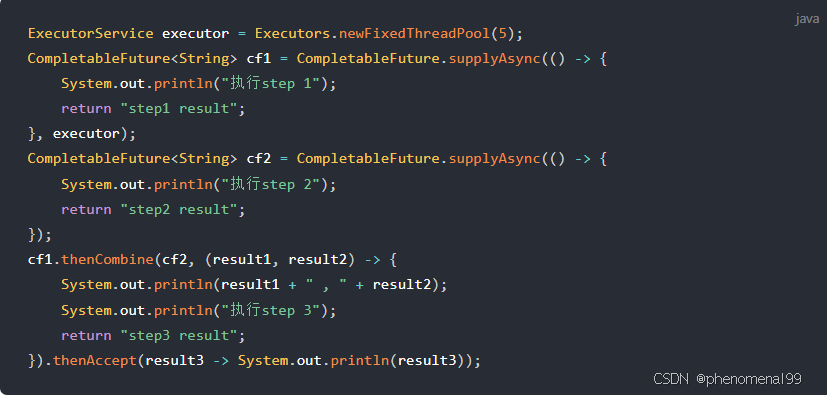
显然,CompletableFuture的实现更为简洁,可读性更好。
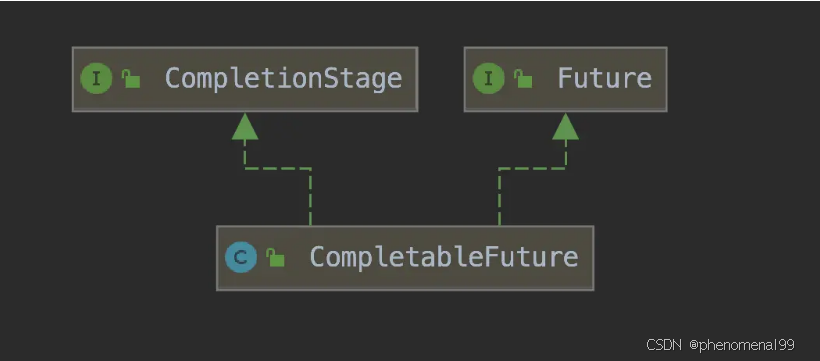
CompletableFuture实现了两个接口(如上图所示):Future、CompletionStage。
- Future表示异步计算的结果,CompletionStage用于表示异步执行过程中的一个步骤(Stage),这个步骤可能是由另外一个CompletionStage触发的,随着当前步骤的完成,也可能会触发其他一系列CompletionStage的执行。
- 从而我们可以根据实际业务对这些步骤进行多样化的编排组合,CompletionStage接口正是定义了这样的能力,我们可以通过其提供的thenAppy、thenCompose等函数式编程方法来组合编排这些步骤。
12. 序列化
12.1 怎么把一个对象从一个jvm转移到另一个jvm????
- 使用序列化和反序列化:将对象序列化为字节流,并将其发送到另一个 JVM,然后在另一个 JVM 中反序列化字节流恢复对象。这可以通过 Java 的 ObjectOutputStream 和 ObjectInputStream 来实现。
- 使用消息传递机制:利用消息传递机制,比如使用消息队列(如 RabbitMQ、Kafka)或者通过网络套接字进行通信,将对象从一个 JVM 发送到另一个。这需要自定义协议来序列化对象并在另一个 JVM 中反序列化。
- 使用远程方法调用(RPC):可以使用远程方法调用框架,如 gRPC,来实现对象在不同 JVM 之间的传输。远程方法调用可以让你在分布式系统中调用远程 JVM 上的对象的方法。
- 使用共享数据库或缓存:将对象存储在共享数据库(如 MySQL、PostgreSQL)或共享缓存(如 Redis)中,让不同的 JVM 可以访问这些共享数据。这种方法适用于需要共享数据但不需要直接传输对象的场景。
12.2 序列化和反序列化让你自己实现你会怎么做?
Java 默认的序列化虽然实现方便,但却存在安全漏洞、不跨语言以及性能差等缺陷。
- 无法跨语言: Java 序列化目前只适用基于 Java 语言实现的框架,其它语言大部分都没有使用 Java 的序列化框架,也没有实现 Java 序列化这套协议。因此,如果是两个基于不同语言编写的应用程序相互通信,则无法实现两个应用服务之间传输对象的序列化与反序列化。
- 容易被攻击:Java 序列化是不安全的,我们知道对象是通过在 ObjectInputStream 上调用 readObject()方法进行反序列化的,这个方法其实是一个神奇的构造器,它可以将类路径上几乎所有实现了Serializable 接口的对象都实例化,这也就意味着,在反序列化字节流的过程中该方法可以执行任意类型的代码,这是非常危险的。
- 序列化后的流太大:序列化后的二进制流大小能体现序列化的性能。序列化后的二进制数组越大,占用的存储空间就越多,存储硬件的成本就越高。如果我们是进行网络传输,则占用的带宽就更多,这时就会影响到系统的吞吐量。
我会考虑用主流序列化框架,比如FastJson、Protobuf来替代Java 序列化。
12.3 将对象转为二进制字节流具体怎么实现?
其实,像序列化和反序列化,无论这些可逆操作是什么机制,都会有对应的处理和解析协议,例如加密和解密,TCP的粘包和拆包,序列化机制是通过序列化协议来进行处理的,和 class 文件类似,它其实是定义了序列化后的字节流格式,然后对此格式进行操作,生成符合格式的字节流或者将字节流解析成对象。
在Java中通过序列化对象流来完成序列化和反序列化:
- ObjectOutputStream:通过writeObject()方法做序列化操作。
- ObjectInputStrean:通过readObject()方法做反序列化操作。
只有实现了Serializable或Externalizable接口的类的对象才能被序列化,否则抛出异常!
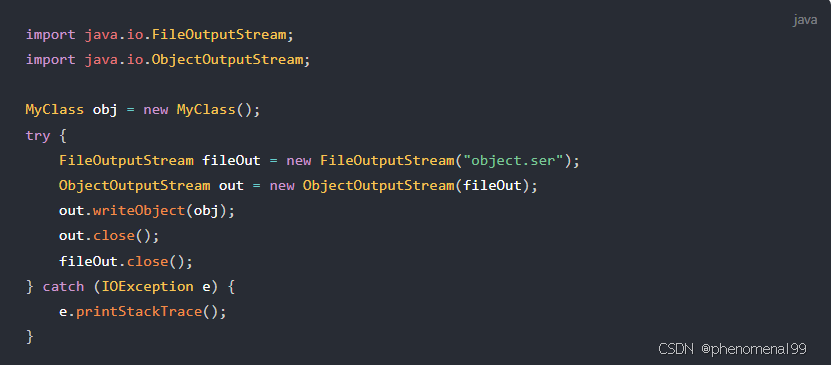
实现对象序列化:
- 让类实现Serializable接口:

- 创建输出流并写入对象:
实现对象反序列化:
- 创建输入流并读取对象:
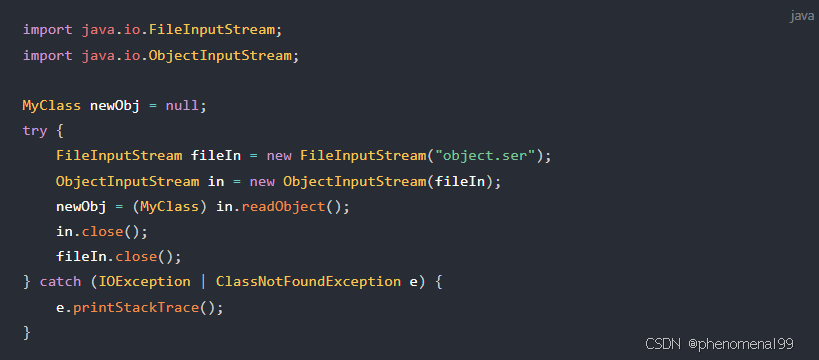
通过以上步骤,对象obj会被序列化并写入到文件"object.ser"中,然后通过反序列化操作,从文件中读取字节流并恢复为对象newObj。这种方式可以方便地将对象转换为字节流用于持久化存储、网络传输等操作。需要注意的是,要确保类实现了Serializable接口,并且所有成员变量都是Serializable的才能被正确序列化。
13. 设计模式
13.1 volatile和sychronized如何实现单例模式??

正确的双重检查锁定模式需要需要使用 volatile。volatile主要包含两个功能。
- 保证可见性。使用 volatile 定义的变量,将会保证对所有线程的可见性。
- 禁止指令重排序优化。
由于 volatile 禁止对象创建时指令之间重排序,所以其他线程不会访问到一个未初始化的对象,从而保证安全性。
volatile关键字:在Java中,volatile 关键字是用于声明变量的一种修饰符,它确保了多个线程对该变量的访问是可见的,并且不会发生线程缓存的优化,从而保证了变量的最新值能够即时地被所有线程读取。
volatile的工作原理:
-
可见性保证:当一个线程修改了一个
volatile变量的值,其他线程能够立即看到这个值。这是通过禁止JVM和硬件对该变量的值进行本地缓存和重排序来实现的。换句话说,volatile保证了对该变量的所有写操作对于所有线程都是“即时可见”的。 -
禁止重排序:
volatile变量的读写操作不会被重排序,即在代码中先写volatile变量再读时,确保在执行读操作时已经执行了之前的写操作。这有助于避免某些并发问题,比如在没有volatile的情况下,可能会出现写操作被推迟或重排序,导致其他线程无法读取到最新的数据。
示例:
public class VolatileExample {private static volatile boolean flag = false;public static void main(String[] args) {Thread writerThread = new Thread(() -> {try {Thread.sleep(1000); // 模拟一些处理flag = true;System.out.println("Flag set to true");} catch (InterruptedException e) {e.printStackTrace();}});Thread readerThread = new Thread(() -> {while (!flag) {// 不断检查flag}System.out.println("Flag is now true");});writerThread.start();readerThread.start();}
}
在这个例子中,flag 是一个 volatile 变量,写线程在等待1秒后将 flag 设置为 true。读线程则不断地检查 flag 是否变为 true。由于 flag 是 volatile,写线程对 flag 的修改能够立即被读线程看到,确保程序正确运行。
volatile不能保证原子性
需要注意的是,volatile 只保证可见性,并不保证原子性。如果多个线程需要对某个变量进行复合操作(如自增操作),则仍然需要使用其他同步机制(如 synchronized 或 Atomic 类)。
13.2 几种单例模式的实现方式
1. 饿汉式单例(线程安全,类加载时就实例化)
public class Singleton {// 在类加载时就创建单例对象private static final Singleton instance = new Singleton();// 私有构造方法,避免外部创建对象private Singleton() {}// 提供全局访问点public static Singleton getInstance() {return instance;}
}
优点:
- 类加载时就会创建实例,确保线程安全。
- 实现简单,直接。
缺点:
- 即使不使用这个单例对象,实例也会被创建,导致在某些情况下可能会浪费资源。
2. 静态内部类(推荐方式,线程安全,延迟加载,性能好)
public class Singleton {// 静态内部类实现单例private Singleton() {}// 静态内部类,只有在调用getInstance时才会加载SingletonInstanceprivate static class SingletonHelper {// 静态初始化器,JVM保证线程安全private static final Singleton instance = new Singleton();}public static Singleton getInstance() {return SingletonHelper.instance;}
}
优点:
- 线程安全,JVM在加载静态内部类时会确保实例化过程的原子性。
- 延迟加载,只有在首次调用
getInstance()时才会创建实例。 - 代码简洁,性能较好,适用于大多数场景。
缺点:
- 如果没有实际的需要使用多线程并发访问,可能会显得有些过于复杂。
3.枚举式单例(最推荐,防止反序列化破坏单例)
public enum Singleton {INSTANCE;public void doSomething() {System.out.println("Singleton doing something!");}
}
优点:
- 简单明了,枚举类可以天然地防止反射和序列化攻击。
- 线程安全,JVM保证单例的唯一性。
- 推荐用于不需要复杂逻辑的单例模式。
缺点:
- 适用场景较为有限,通常适合没有复杂构造的单例。
枚举详解参考个人博客:https://blog.csdn.net/m0_50345460/article/details/142877618
13.3 代理模式和适配器模式有什么区别?
- 目的不同:代理模式主要关注控制对对象的访问,而适配器模式则用于接口转换不兼容的类能够一起工作。
- 结构不同:代理模式一般包含抽象主题、真实主题和代理三个角色,适配器模式包含目标接口、适配器和被适配者三个角色。
- 应用场景不同:代理模式常用于添加额外功能或控制对对象的访问,适配器模式常用于让不兼容的接口协同工作。
14. I/O
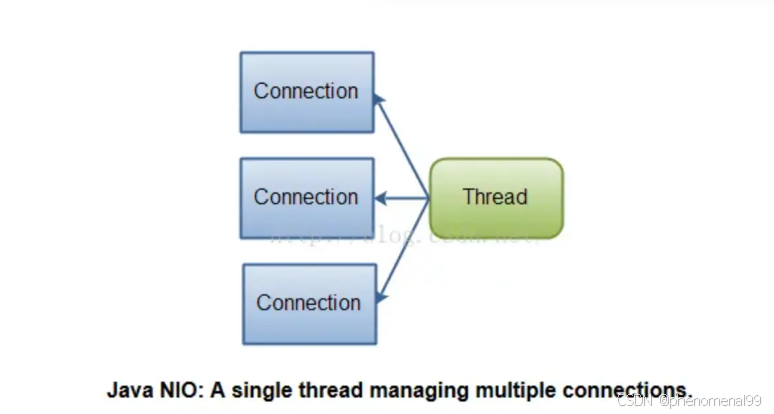
14.1 Java怎么实现网络IO高并发编程?
可以用 Java NIO ,是一种同步非阻塞的I/O模型,也是I/O多路复用的基础。
传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据,返回读到的数据, 如果使用BIO要想要并发处理多个客户端的i/o,那么会使用多线程模式,一个线程专门处理一个客户端 io,这种模式随着客户端越来越多,所需要创建的线程也越来越多,会急剧消耗系统的性能。
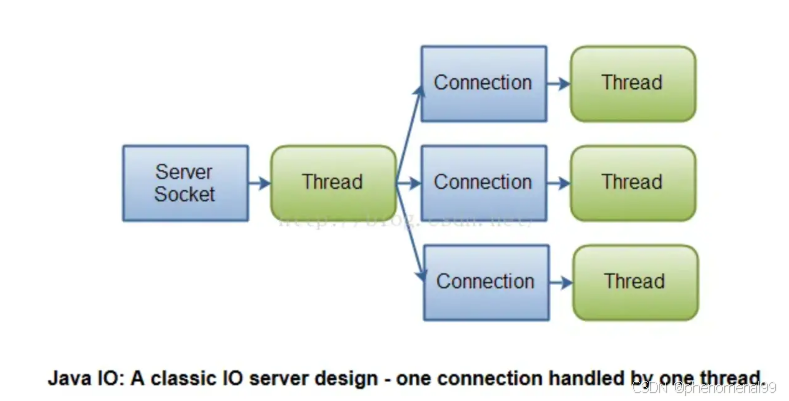
NIO 是基于I/O多路复用实现的,它可以只用一个线程处理多个客户端I/O,如果你需要同时管理成千上万的连接,但是每个连接只发送少量数据,例如一个聊天服务器,用NIO实现会更好一些。
14.2 BIO、NIO、AIO区别是什么?
- BIO(blocking IO):就是传统的 java.io 包,它是基于流模型实现的,交互的方式是同步、阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。优点是代码比较简单、直观;缺点是 IO 的效率和扩展性很低,容易成为应用性能瓶颈。
- NIO(non-blocking IO) :Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层高性能的数据操作方式。
- AIO(Asynchronous IO) :是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的 IO操作方式,所以人们叫它 AIO(Asynchronous IO),异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
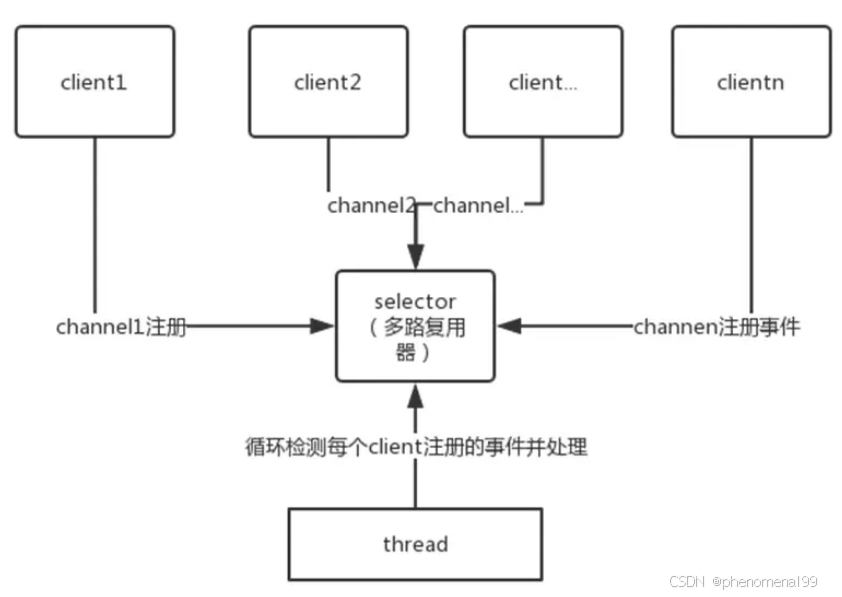
14.3 NIO是怎么实现的?
NIO是一种同步非阻塞的IO模型,所以也可以叫NON-BLOCKINGIO。同步是指线程不断轮询IO事件是否就绪,非阻塞是指线程在等待IO的时候,可以同时做其他任务。
同步的核心就Selector(I/O多路复用),Selector代替了线程本身轮询IO事件,避免了阻塞同时减少了不必要的线程消耗;非阻塞的核心就是通道和缓冲区,当IO事件就绪时,可以通过写到缓冲区,保证IO的成功,而无需线程阻塞式地等待。
NIO由一个专门的线程处理所有IO事件,并负责分发。事件驱动机制,事件到来的时候触发操作,不需要阻塞的监视事件。线程之间通过wait,notify通信,减少线程切换。
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
Native方法解释一下
在Java中,native方法是一种特殊类型的方法,它允许Java代码调用外部的本地代码,即用C、C++或其他语言编写的代码。native关键字是Java语言中的一种声明,用于标记一个方法的实现将在外部定义。
在Java类中,native方法看起来与其他方法相似,只是其方法体由native关键字代替,没有实际的实现代码。例如:

要实现native方法,你需要完成以下步骤:
- 生成JNI头文件:使用javah工具从你的Java类生成C/C++的头文件,这个头文件包含了所有native方法的原型。
- 编写本地代码:使用C/C++编写本地方法的实现,并确保方法签名与生成的头文件中的原型匹配。
- 编译本地代码:将C/C++代码编译成动态链接库(DLL,在Windows上),共享库(SO,在Linux上)
- 加载本地库:在Java程序中,使用System.loadLibrary()方法来加载你编译好的本地库,这样JVM就能找到并调用native方法的实现了。
解释一下final关键字
1.final用于变量
当 final 修饰一个变量时,该变量的值一旦被赋值后,就不能再修改。常见的应用场景有常量的定义。
特点:
final修饰的变量在初始化后不能再改变。- 如果是基本数据类型,表示值不可变;如果是引用类型,表示引用不可变,但对象的内容仍然可以修改。
示例(引用类型):
public class FinalReferenceExample {public static void main(String[] args) {final StringBuilder sb = new StringBuilder("Hello");sb.append(" World"); // 可以修改对象的内容// sb = new StringBuilder("New String"); // 编译错误,引用不可变System.out.println(sb); // 输出:Hello World}
}
在这个例子中,sb 是 final 引用,意味着我们不能再让 sb 引用其他的 StringBuilder 对象,但可以修改 sb 所指向的对象的内部状态。
2.
final用于方法
当一个方法被 final 修饰时,表示该方法不能被子类重写。这个特性通常用于防止子类修改父类中的某些核心功能。
3.
final用于类
当一个类被 final 修饰时,表示该类不能被继承。这样做通常是为了防止类的继承或扩展,确保类的行为不会被子类修改。
4.
final用于方法参数
当 final 修饰方法参数时,表示该参数在方法内不能被修改。
相关文章:

java基础面试篇
目录 1.概念 1.1说一下Java的特点 1.2Java为什么是跨平台的? 1.3 JVM、JDK、JRE三者关系? 1.4为什么Java解释和编译都有? 1.5 jvm是什么? 1.6 编译型语言和解释型语言的区别? 1.7 Python和Java区别是什么&#…...

Java Map实现类面试题
Java Map实现类面试题 HashMap Q1: HashMap的实现原理是什么? HashMap基于哈希表实现,使用数组链表红黑树(Java 8)的数据结构。 public class HashMapPrincipleExample {// 模拟HashMap的基本结构public class SimpleHashMap&…...
)
Vue2+Three.js加载并展示一个三维模型(提供Gitee源码)
目录 一、案例截图 二、安装Three.js 三、代码实现 四、Gitee源码 一、案例截图 二、安装Three.js npm install three 三、代码实现 模型资源我是放在public文件夹下面的: 完整代码: <template><div><div ref"container&qu…...

Spark内存并行计算框架
spark核心概念 spark集群架构 spark集群安装部署 spark-shell的使用 通过IDEA开发spark程序 1. Spark是什么 Apache Spark™ is a unified analytics engine for large-scale data processingspark是针对于大规模数据处理的统一分析引擎 spark是在Hadoop基础上的改进&…...

DeepSeek等LLM对网络安全行业的影响
大家好,我是AI拉呱,一个专注于人工智领域与网络安全方面的博主,现任资深算法研究员一职,兼职硕士研究生导师;热爱机器学习和深度学习算法应用,深耕大语言模型微调、量化、私域部署。曾获多次获得AI竞赛大奖,拥有多项发明专利和学术论文。对于AI算法有自己独特见解和经验…...

【QT】QLinearGradient 线性渐变类简单使用教程
目录 0.简介 1)qtDesigner中 2)实际执行 1.功能详述 3.举一反三的样式 0.简介 QLinearGradient 是 Qt 框架中的一个类,用于定义线性渐变效果(通过样式表设置)。它可以用来填充形状、背景或其他图形元素࿰…...

可狱可囚的爬虫系列课程 15:防盗链反爬虫的处理
一、防盗链了解 防盗链是一种技术手段,主要用于防止其他网站通过直接链接的方式使用本网站的资源(如图片、文件等),从而节省带宽和服务器资源。当其他网站尝试直接链接到受保护的资源时,服务器会根据设置的规则判断请求…...

Vue组件:从使用到原理的深度解析
一、什么是Vue组件? 组件是Vue的核心特性之一,它允许开发者将UI拆分为独立可复用的代码片段。每个组件本质上是一个Vue实例,具有自己的: 模板(Template) 数据(Data) 方法…...
+ 前端页面调试)
SpringBoot接入DeepSeek(硅基流动版)+ 前端页面调试
文章目录 前言正文一、项目环境二、项目代码2.1 pom.xml2.2 DeepSeekController.java2.3 启动类2.4 logback-spring.xml2.5 application.yaml2.6 index.html 三、页面调试3.1 参数提示3.2 开始请求3.3 手动断开 前言 作为一个Java程序员,了解前沿科技技术ÿ…...
)
Lua的table(表)
Lua表的基本概念 Lua中的表(table)是一种多功能数据结构,可以用作数组、字典、集合等。表是Lua中唯一的数据结构机制,其他数据结构如数组、列表、队列等都可以通过表来实现。 表的实现 Lua的表由两部分组成: 数组部分…...

图片爬取案例
修改前的代码 但是总显示“失败” 原因是 修改之后的代码 import requests import os from urllib.parse import unquote# 原始URL url https://cn.bing.com/images/search?viewdetailV2&ccidTnImuvQ0&id5AE65CE4BE05EE7A79A73EEFA37578E87AE19421&thidOIP.TnI…...
】以Python爬虫为眼,洞察金融科技监管风云)
【Python爬虫(90)】以Python爬虫为眼,洞察金融科技监管风云
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取,还涉及数据处理与分析。无论是新手小白还是进阶开发…...

idea + Docker + 阿里镜像服务打包部署
一、下载docker desktop软件 官网下载docker desktop,需要结合wsl使用 启动成功的画面(如果不是这个画面例如一直处理start或者是stop需要重新启动,不行就重启电脑) 打包成功的镜像在这里,如果频繁打包会导致磁盘空间被占满,需…...

C#模拟退火算法
模拟退火算法:寻找最优解的神奇 “退火之旅” 在生活中,我们都见过铁匠打铁。铁匠把烧得通红的铁块不断捶打,然后慢慢冷却,这样打造出来的金属制品才更坚固耐用。模拟退火算法就从这个退火过程中获得灵感,在计算机的数…...

网络安全防御模型
目录 6.1 网络防御概述 一、网络防御的意义 二、被动防御技术和主动防御技术 三、网络安全 纵深防御体系 四、主要防御技术 6.2 防火墙基础 一、防火墙的基本概念 二、防火墙的位置 1.防火墙的物理位置 2.防火墙的逻辑位置 3. 防火墙的不足 三、防火墙技术类型 四…...

APP自动化实战
APP自动化能做什么? 请看示例(实现批量的视频,封面功能复用能力(实现效果参考抖音号:71403700901) APP自动化实战-操作剪映APP PO模式 1. PO模式介绍 PO(Page Object)…...

Unity基础——资源导入
一.资源来源 1.Assert Store(Unity资源官方网站) (1)用于制作游戏的优质资源 | Unity Asset Store (2)或则通过Unity项目打开 2.外部资源 (1)淘宝 (2)找外…...

JMeter性能问题
性能测试中TPS上不去的几种原因 性能测试中TPS上不去的几种原因_tps一直上不去-CSDN博客 网络带宽 连接池 垃圾回收机制 压测脚本 通信连接机制 数据库配置 硬件资源 压测机 业务逻辑 系统架构 CPU过高什么原因 性能问题分析-CPU偏高 - 西瓜汁拌面 - 博客园 US C…...

形式化数学编程在AI医疗中的探索路径分析
一、引言 1.1 研究背景与意义 在数字化时代,形式化数学编程和 AI 形式化医疗作为前沿领域,正逐渐改变着我们的生活和医疗模式。形式化数学编程是一种运用数学逻辑和严格的形式化语言来描述和验证程序的技术,它通过数学的精确性和逻辑性,确保程序的正确性和可靠性。在软件…...

DeepSeek开源周Day1:FlashMLA引爆AI推理性能革命!
项目地址:GitHub - deepseek-ai/FlashMLA 开源日历:2025-02-24起 每日9AM(北京时间)更新,持续五天! 一、开源周震撼启幕 继上周预告后,DeepSeek于北京时间今晨9点准时开源「FlashMLA」,打响开源周五连…...

nginx 配置https
参考文档:nginx 文档 -- nginx官网|nginx下载安装|nginx配置|nginx教程 配置 HTTPS 服务器 HTTPS 服务器优化 SSL 证书链 单个 HTTP/HTTPS 服务器 基于名称的 HTTPS 服务器 具有多个名称 的 SSL 证书 服务器名称指示 兼容性 要配置 HTTPS 服务器,ssl…...

GhostBottleneck; InvertedResidual;Squeeze and Excite 是什么,怎么用
GhostBottleneck; InvertedResidual;Squeeze and Excite 是什么,怎么用 目录 GhostBottleneck; InvertedResidual;Squeeze and Excite 是什么,怎么用GhostBottleneckInvertedResidualSqueeze and Excite(SE)GhostBottleneck 概念: GhostBottleneck 是在轻量级神经网…...

Docker启动ES容器打包本地镜像
文章目录 1、安装 Docker2、下载镜像3、查看已下载的镜像4、 保存和加载镜像5、.tar 文件与 Docker 镜像的关系6、如何从 .tar 文件加载 Docker 镜像7、为什么需要 .tar 文件?8、ES 8.x版本无法启动8.1 问题原因8.2 解决方案8.3 提交容器为新镜像 1、安装 Docker 如…...

XXE漏洞:原理、危害与修复方法详解
目录 一、XXE漏洞概述二、XXE漏洞原理三、XXE漏洞危害1. 任意文件读取2. 命令执行3. 拒绝服务攻击(DoS)4. SSRF攻击四、XXE漏洞修复方法1. 禁用外部实体JavaPythonPHP2. 输入验证和过滤3. 安全配置服务器4. 升级解析器版本五、总结一、XXE漏洞概述 XXE(XML External Entity…...

android keystore源码分析
架构 Android Keystore API 和底层 Keymaster HAL 提供了一套基本的但足以满足需求的加密基元,以便使用访问受控且由硬件支持的密钥实现相关协议。 Keymaster HAL 是由原始设备制造商 (OEM) 提供的动态加载库,密钥库服务使用它来提供由硬件支持的加密服…...

状态模式
状态(State)模式属于行为型模式的一种。 状态模式允许对象在其内部状态改变时改变其行为,使其看上去就像改变了自身所属的类一样。 状态模式是为了把一大串if...else...的逻辑给分拆到不同的状态类中,使得将来增加状态比较容易。…...

C++ | 面向对象 | 类
👻类 👾语法格式 class className{Access specifiers: // 访问权限DataType variable; // 变量returnType functions() { } // 方法 };👾访问权限 class className {public:// 公有成员protected:// 受保护成员private:// 私有成员 }…...

鸿蒙-AVPlayer
compileVersion 5.0.2(14) 音频播放 import media from ohos.multimedia.media; import common from ohos.app.ability.common; import { BusinessError } from ohos.base;Entry Component struct AudioPlayer {private avPlayer: media.AVPlayer | nu…...
)
Android移动应用开发实践-1-下载安装和简单使用Android Studio 3.5.2版本(频频出错)
一、下载安装 1.Android Studio3.5.2下载地址:Android Studio3.5.2下载地址 其他版本下载地址:其他版本下载地址 2.安装教程(可以多找几个看看) 安装 | 手把手教你Android studio 3.5.2安装(安装教程)_a…...

从.m3u8到.mp4:使用批处理脚本完成视频处理的完整指南
这里介绍一个Windows批处理脚本(Windows Batch Script),主要用于处理 .m3u8 ts 视频文件的下载和合并功能。 以下是程序的主要功能和逻辑流程: 功能概述 参数检查与路径处理: 检查是否传递了文件或文件夹路径作为参数…...

qt5的中文乱码问题,QString、QStringLiteral 为 UTF-16 编码
qt5的中文乱码问题一直没有很明确的处理方案。 今天处理进程间通信时,也遇到了qt5乱码问题,一边是设置的GBK,一边设置的是UTF8,单向通信约定采用UTF8。 发送端保证发的是UTF8字符串,因为UTF8在网络数据包中没有字节序…...

Gurobi 并行计算的一些问题
最近尝试用 gurobi 进行并行计算,即同时用多个 cpu 核计算 gurobi 的 model,但是发现了不少问题。总体来看,gurobi 对并行计算的支持并不是那么好。 gurobi 官方对于并行计算的使用在这个网址,并有下面的大致代码: i…...

Vue3 中如何实现响应式系统中的依赖收集和更新队列的解耦?
一、问题解析:为什么需要解耦? 在响应式系统中,依赖收集(追踪数据与视图的关联关系)和更新队列(批量处理数据变化带来的副作用)是两个核心但职责不同的模块。 Vue3 通过以下设计实现解耦&…...

vue项目中动态添加类名样式不生效问题
一、问题描述 在vue项目中使用:class{tableContent: summary}给元素动态添加了类名tableContent,运行代码后查看类名已经添加成功但样式并未生效。 二、问题产生原因并解决 刚开始把样式写在了<style lang"scss" scoped></style>中&#x…...
)
供应链管理系统--升鲜宝门店收银系统功能解析,登录、主界面、会员 UI 设计图(一)
供应链管理系统--升鲜宝门店收银系统功能解析,登录、主界面 会员 UI 设计图(一)...

用AI写游戏3——deepseek实现kotlin android studio greedy snake game 贪吃蛇游戏
项目下载 https://download.csdn.net/download/AnalogElectronic/90421306 项目结构 就是通过android studio 建空项目,改下MainActivity.kt的内容就完事了 ctrlshiftalts 看项目结构如下 核心代码 MainActivity.kt package com.example.snakegame1// MainA…...

设计模式的引入
面向对象设计原则 1. 软件设计固有的复杂性2. 面向对象设计原则2.1 引入2.2 依赖倒置原则2.3 开放封闭原则2.4 单一职责原则2.5 Liskov 替换原则( LSP)2.6 接口隔离原则( ISP)2.7 优先使用对象组合,而不是类继承2.8 封…...

P8697 [蓝桥杯 2019 国 C] 最长子序列
P8697 [蓝桥杯 2019 国 C] 最长子序列 题目 分析代码 题目 分析 先分析一波xdm 题意呢就是在s中找有多少个能和t匹配的字符,注意:连续匹配,输出连续的次数 欧克,开始分析,首先,哎~字母!还强调…...

基于阿里云PAI平台快速部署DeepSeek大模型实战指南
一、DeepSeek大模型:企业级AI应用的新标杆 1.1 为什么选择DeepSeek? 近期,DeepSeek系列模型凭借其接近GPT-4的性能和开源策略,成为全球开发者关注的焦点。在多项国际评测中,DeepSeek-R1模型在推理能力、多语言支持和…...

【java进阶】java多态深入探讨
前言 在Java的编程宇宙中,多态是极为关键的概念,它宛如一条灵动的纽带,串联起面向对象编程的诸多特性,赋予程序宛如生命般的动态活力与高度灵活性。透彻理解多态,不仅是提升代码质量的关键,更是开启高效编程大门的钥匙。 一、多态的定义与本质 多态,从概念层面来讲,…...

蓝桥杯备赛-拔河
问题描述 小明是学校里的一名老师,他带的班级共有 nn 名同学,第 ii 名同学力量值为 aiai。在闲暇之余,小明决定在班级里组织一场拔河比赛。 为了保证比赛的双方实力尽可能相近,需要在这 nn 名同学中挑选出两个队伍,…...
 Zookeeper在HBase中的应用是什么?)
Zookeeper(67) Zookeeper在HBase中的应用是什么?
Zookeeper 在 HBase 中起到了至关重要的作用,主要用于协调和管理 HBase 集群中的多个组件。具体来说,Zookeeper 在 HBase 中的应用包括以下几个方面: Master 选举:HBase 集群中可以有多个 Master 节点,但只有一个处于…...
--static继承)
java后端开发day20--面向对象进阶(一)--static继承
(以下内容全部来自上述课程) 1.static–静态–共享 static表示静态,是java中的一个修饰符,可以修饰成员方法,成员变量。 1.静态变量 被static修饰的成员变量,叫做静态变量。 特点: 被该类…...

IDEA使用Maven方式构建SpringBoot项目
1、环境准备 确保你已经安装了以下工具: Java JDK(推荐 JDK 8 或更高版本) IntelliJ IDEA(推荐使用最新版本) 2、创建 Spring Boot 项目 (1) 打开 IntelliJ IDEA。 (2)…...

Spring Boot2.0之十 使用自定义注解、Json序列化器实现自动转换字典类型字段
前言 项目中经常需要后端将字典类型字段值的中文名称返回给前端。通过sql中关联字典表或者自定义函数不仅影响性能还不能使用mybatisplus自带的查询方法,所以推荐使用自定义注解、Json序列化器,Spring的缓存功能实现自动转换字典类型字段。以下实现Spri…...

C#问题解决方案 --- 生成软件hash,生成文件hash
生成软件hash值: private string GetEXEHashString() {//获得软件哈希值Process currProcess Process.GetCurrentProcess();string filePath currProcess.MainModule.FileName;string hashEXE string.Empty;using (FileStream fs new FileStream(filePath, Fil…...

云计算如何解决延迟问题?
在云计算中,延迟(latency)指的是从请求发出到收到响应之间的时间间隔。延迟过高可能会严重影响用户体验,特别是在需要实时响应的应用中,如在线游戏、视频流、金融交易等。云计算服务如何解决延迟问题,通常依…...

多模态人物视频驱动技术回顾与业务应用
一种新的商品表现形态,内容几乎存在于手淘用户动线全流程,例如信息流种草内容、搜索消费决策内容、详情页种草内容等。通过低成本、高时效的AIGC内容生成能力,能够从供给端缓解内容生产成本高的问题,通过源源不断的低成本供给倒推…...

鸿蒙中连接手机可能遇到的问题
连接权限问题:手机开启了严格的权限管理机制,若未授予鸿蒙设备连接所需的权限,如蓝牙连接时未开启蓝牙权限,或者 USB 连接时未允许设备进行调试、文件传输等操作,就会导致连接失败。例如,当使用鸿蒙平板通过…...
110. 平衡二叉树,257. 二叉树的所有路径*,404. 左叶子之和,222.完全二叉树的节点个数[打卡自用])
15.代码随想录算法训练营第十五天|(递归)110. 平衡二叉树,257. 二叉树的所有路径*,404. 左叶子之和,222.完全二叉树的节点个数[打卡自用]
15.代码随想录算法训练营第十五天|(递归)110. 平衡二叉树,257. 二叉树的所有路径*,404. 左叶子之和,222.完全二叉树的节点个数 给定一个二叉树,判断它是否是 平衡二叉树 示例 1: 输入…...