Milvus 2.5:全文检索上线,标量过滤提速,易用性再突破!


01.
概览
我们很高兴为大家带来 Milvus 2.5 最新版本的介绍。
在 Milvus 2.5 里,最重要的一个更新是我们带来了“全新”的全文检索能力,之所以说“全新”主要是基于以下两点:
第一,对于全文检索基于的 BM25 算法,我们采用的是 Sparse-BM25,基于 sparse vector 实现的 BM25 在存储效率、检索性能上都打开了更多的空间,同时也融合在了 Milvus 以向量为核心检索范式的产品理念里;
第二,我们首次在 Milvus 里引入了原始文本插入和查询的能力,不需要用户手动将文本转成 sparse vector,这使得 Milvus 朝着非结构化数据处理的方向迈进了一步。
而这两点在 Milvus 2.5 正是一个开始,在 2.5 发版的同时我们更新了 Milvus 产品路线图(https://milvus.io/docs/roadmap.md),在 Milvus 后续的产品迭代中,我们会着眼于从非结构化数据的处理、搜索质量与效率、数据管理和技术驱动降本这四大方向演进 Milvus 的各项能力,在 AI 数据爆发时代背景下做好既能“存得下”、又能“看得见”的数据基础设施。
02.
以向量为特色的全文检索功能
以典型的 RAG 场景为例,尽管语义搜索可以有更好的上下文感知和意图理解,但当用户的问题需要搜索具体的专有名词、序列号,又或者完全匹配一个短语时,具有关键词匹配能力的全文检索往往可以拿到更准确的结果。为了支持社区中对于全文检索的需求,Milvus 在 2.4 版本推出稀疏向量功能的时候,采用了额外的 pymilvus model library 中的 BM25 模块来进行文本稀疏向量的生成。然而这种外挂的实现也带来了只能单机使用,词表等参数无法动态更新以及管理困难等一系列痛点,而 Milvus 2.5 的全文检索将一次性解决这些问题。
Milvus 2.5 通过内置 Sparse-BM25 的方式对全文检索的核心组件进行了原生支持,具体包括:
基于 tantivy 构建的分词器:我们选择融入 tantivy 蓬勃发展的生态
原始文档的进出能力:支持直接插入和查询文本数据
BM25 相关性打分:基于 sparse vector 相似度来实现
首先,值得注意的是分词器的部分,对于有搜索引擎经验的用户来说其重要程度不言而喻,我们选择融入了发展良好的 tantivy 生态,基于 tantivy 构建了我们分词器的基础功能,而未来除了更多分词功能的支持和可观测性的优化之外,我们会探索基于深度学习的 tokenizer 和 stemmer 策略来进一步优化全文检索的表现。以下是在 Milvus 2.5 中使用和配置分词器的示例代码:
# 分词器配置
schema.add_field(field_name='text', datatype=DataType.VARCHAR, max_length=65535, enable_analyzer=True, # 在该列上开启分词器analyzer_params={"type": "english"}, # 配置分词器参数,此处选择 english 模版,此外也支持细粒度配置enable_match=True, # 构建针对 Text_Match 的倒排索引
)其次,在原始文档的处理方面,我们通过全文检索功能打开了这块的能力,用户所需要配置的是预定义在 schema 里,通过 add_function 方法新增一个从原始数据到 sparse vector 的 mapping 步骤,而这之后的增删改查等数据流都可以通过操作原始文档来完成,内部我们将其形象地称之为“Doc in Doc out”。而这只是在 2.5 迈出的第一步,在后续的大版本中,我们将对 dense/sparse embedding 新增 Data in Data out 的全面支持,我们的目标是构建非结构化数据与向量的映射来完成数据进出 Milvus 的能力。
# 在 schema 上定义好原始文本数据与向量的映射关系
bm25_function = Function(name="text_bm25_emb",input_field_names=["text"], # 输入的文本字段output_field_names=["sparse"], # 内部映射的 sparse 向量字段function_type=FunctionType.BM25, # 处理映射关系的模型
)schema.add_function(bm25_function)
...
# 支持原始文本进出
MilvusClient.insert('demo', [{'text': 'Artificial intelligence was founded as an academic discipline in 1956.'},{'text': 'Alan Turing was the first person to conduct substantial research in AI.'},{'text': 'Born in Maida Vale, London, Turing was raised in southern England.'},
])MilvusClient.search(collection_name='demo', data=['Who started AI research?'],anns_field='sparse',limit=3
)而在 BM25 相关性打分方面,我们采用了独特的 sparse vector 方案来做底层的实现,进而能充分利用 sparse vector 的优势,包括但不限于:
对长上下文 Query 可以构建图索引来加速搜索;
基于量化和 WAND 的 drop_ratio 等技术手段做近似匹配来提升性能;
更重要的是对于 Milvus 本身的产品而言,统一了语义检索和全文检索的表达方式,使用体验以及技术优化。
# 创建 sparse 列上的索引
index_params.add_index(field_name="sparse",index_type="AUTOINDEX", # 默认 WAND 索引metric_type="BM25" # 通过 metric_type 配置相关性打分
)# search 时可配置参数来加速搜索
search_params = {'params': {'drop_ratio_search': 0.6}, # WAND 的搜索参数配置可加速搜索}作为原生的向量数据库,Milvus 引入全文检索功能对基于 dense vector 的搜索能力进行了扩展,方便了用户构建更高质量的 AI 应用。在 Sparse-BM25 方面我们无疑是个探索者,但可以预见的是还有更多的优化手段能在未来尝试,相信这条路上将有更多旖旎风光可以分享给大家。
与全文检索同时推出的还有 Text Match 功能,该功能同样构建在分词的基础之上,通过 enable_match=True 开启。与全文检索不同的是它着重于关键词匹配,省去了文段相关性打分的能力,因此它的使用场景主要在匹配和过滤。需要注意的是 Text Match 中的 Query Text 的处理是分词后 OR 的逻辑,例如在下面的例子中,结果将返回 text 字段上含有 vector 或者 database 的所有文档。
filter = "TEXT_MATCH(text, 'vector database')"如果您的场景需要既匹配 vector 又匹配 database,那么您需要写两个单独的 Text Match 并叠加 AND 的方式以达成目的。
filter = "TEXT_MATCH(text, 'vector') and TEXT_MATCH(text, 'database')"03.
标量过滤性能大幅提升
对于标量过滤性能的重视源于我们发现无论是在图片搜索场景如自动驾驶找 corner case 的应用,或是在企业知识库的复杂 RAG 场景中,向量检索与元数据过滤的结合,会使得查询性能和准确度上都取得极大的增益,因此很适合企业级用户在大规模数据的应用场景下进行业务落地。
然而,在真实场景下,不同的数据过滤量、数据分布和查询模式都会对性能和结果产生影响,这块涉及到诸多算法、执行链路和存储索引上的优化,功能层面上在 Milvus 2.5 我们基本上补足了 Scalar Index 上的索引类型,其中新增的部分包括:BitMap Index,Array Inverted Index,以及对 Varchar 文本字段分词后的 Inverted Index 等,这些索引在一些具体且实际的场景都能拿到很好的优化效果。
具体来说:
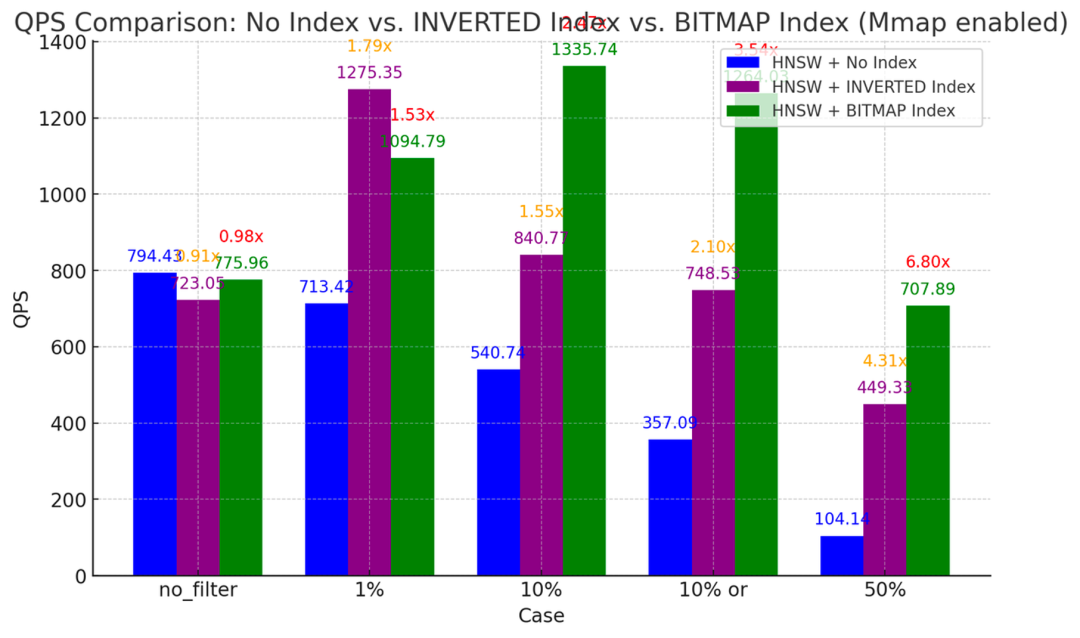
1、BitMap Index 可用于加速标签过滤(常用算子包括 in,array_contains 等),适用于字段类别数据(data cardinality)较少的场景,原理就是针对某行数据是否在某列上具有某个 value 来实现的,有就是 1, 没有就是 0,然后维护一个 BitMap 列表。以下图表展示了我们基于某客户业务场景下做的性能测试对比,这个场景的数据量是 5 亿,数据类别是 20,不同的值有不同的分布占比(1%,5%,10%,50%),在不同的过滤量的表现也有差别,在 50% 的过滤量下我们通过 BitMap Index 可以拿到 6.8 倍的性能收益。此外值得注意的是,随着 cardinality 的增加,相比于 BitMap Index, Inverted Index 将表现出更均衡的性能。
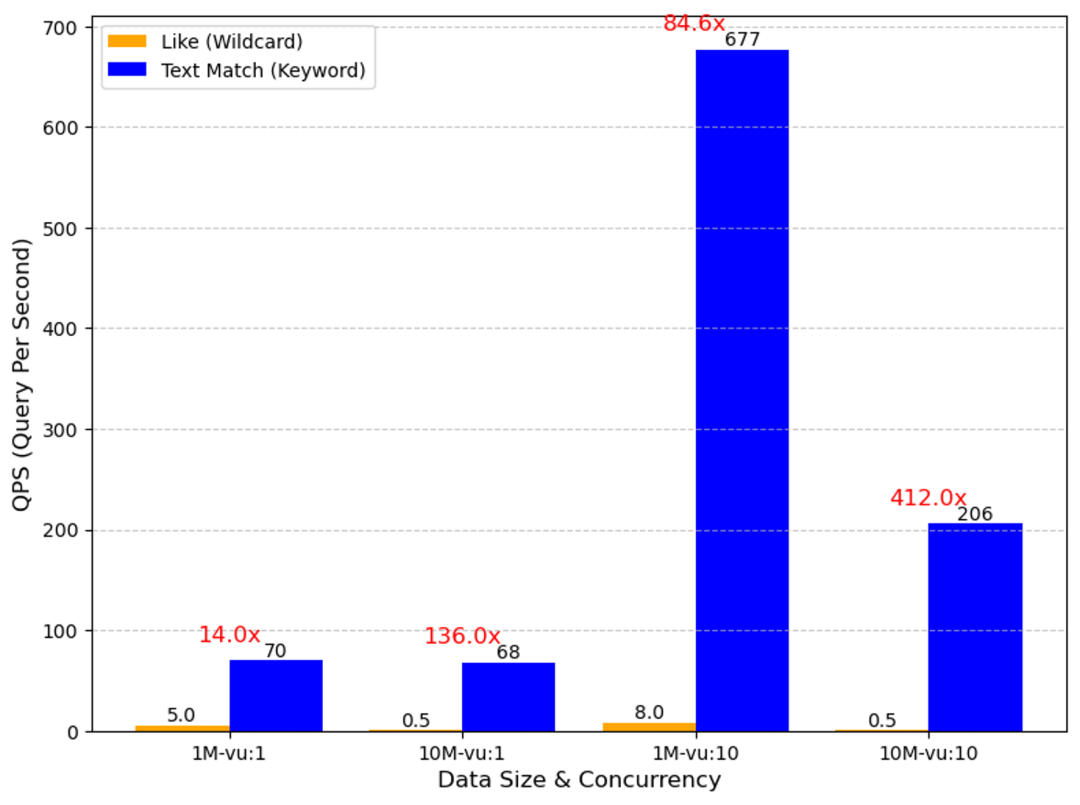
2、Text Match 是基于文本字段分词后的 Inverted Index 做的,其性能表现远超我们在 2.4 提供的 Wildcard Match(即 like + %)功能,从内部的测试结果来看 Text Match 的优势非常明显,尤其在并发查询的场景下,最多可以拿到 400 倍的 QPS 提升。
而在 JSON 数据的处理方面,我们计划在 2.5.x 的后续版本中推出针对用户指定的 key 来建倒排索引以及默认针对 key 的位置建立位置索引,预期这两块都会对 JSON 和 Dynamic Field 的查询性能提供很大帮助,更多的信息我们计划在后续的 release note 和技术博客中展示,敬请期待!
04.
易用性提升
此外值得一提的还有易用性的提升。这个版本我们向开源用户推出了 Cluster Management WebUI 工具,这是针对数据库管理员等专业人士提供的 Milvus 可观测性工具,通过访问集群端口 + 9091/webui 这个后缀用户可以轻松访问 Milvus 的集群信息和运行时状态,如各节点的内存、segment、slow query 信息等,以往一些诊断难的系统问题也可以通过这个工具方便快速地定位排查。虽然目前还只是 beta 版本,但未来我们也计划融入更多可诊断、可交互、可 AI 辅助的能力,帮助用户更省心地管理好 Milvus 集群。
最后一点是文档和 SDK/API 的优化,我们从 2.4 起持续投入了很多时间和精力来建设这块的能力,希望通过更合理的文档结构、更易懂的图表介绍、更好用的 SDK 以及像 ASK AI 这样更智能的交互形式来帮助用户更好地使用 Milvus,相信您在阅读 2.5.x 系列的新文档内容时也会感受到这份努力。但文档优化之路并非一朝一夕,其成果也不可能一蹴而就,我们还将持续优化和调整文档结构与内容,希望和社区用户共同成长,也欢迎大家通过各类渠道给我们反馈文档 bug 和优化建议。
在 Milvus 2.5 这个版本里,我们和社区一同贡献了 13 个新功能以及多个系统级优化,由于篇幅有限,这里就不一一列举了,欢迎访问我们的 release note(https://milvus.io/docs/release_notes.md) 以及官方文档,获取更多信息!
今晚 8 点,Milvus 资深产品经理张粲宇将在直播间全面解读 Milvus 2.5 的新功能及优化,同时 RWKV 高级大模型算法工程师岳紫寅将分享 Milvus 在 RWKV 的应用实践,请点击下方“预约”,共享这场技术碰撞之旅!
作者介绍

张粲宇
Zilliz 高级产品经理
推荐阅读




相关文章:

Milvus 2.5:全文检索上线,标量过滤提速,易用性再突破!
01. 概览 我们很高兴为大家带来 Milvus 2.5 最新版本的介绍。 在 Milvus 2.5 里,最重要的一个更新是我们带来了“全新”的全文检索能力,之所以说“全新”主要是基于以下两点: 第一,对于全文检索基于的 BM25 算法,我们采…...
)
Windows常用DOS指令(附案例)
文章目录 1.dir 查看当前目录2.cd 进入指定目录3.md 创建指定目录4.cd> 创建指定文件5.rd 删除指定空目录6.del 删除指定文件7.copy 复制文件8.xcopy 批量复制9.ren 改名10.type 在命令行空窗口打开文件11.cls 清空DOS命令窗口12.chkdsk 检查磁盘使用情况13.time 显示和设置…...
)
搜索二维矩阵 II(java)
题目描述 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。每列的元素从上到下升序排列。 代码思路: 用暴力算法: class Solution {public boolean searchMatrix(…...

Webpack 的构建流程
Webpack 的构建流程可以概括为以下几个步骤: 1. 初始化: Webpack 读取配置文件(webpack.config.js),合并默认配置和命令行参数,初始化Compiler对象。 2. 构建依赖图: 从入口文件开始递归地分…...

Kylin Server V10 下 RocketMQ 主备自动切换模式部署
一、NameServer简介 NameServer 是一个注册中心,提供服务注册和服务发现的功能。NameServer 可以集群部署,集群中每个节点都是对等的关系,节点之间互不通信。 服务注册 Broker 启动的时候会向所有的 NameServer 节点进行注册,注意这里是向集群中所有的 NameServer 节点注册…...

Linux启动中出现“psi: inconsistent task state!”错误可能原因
在Linux系统中,psi: inconsistent task state! 异常日志通常与 PSI(Pressure Stall Information)相关。PSI 是 Linux 内核中的一个特性,用于监控系统资源的压力情况,如 CPU、内存和 I/O 等。该日志信息表明在处理任务状…...

FCBP 认证考试要点摘要
理论知识 数据处理与分析:包括数据的收集、清洗、转换、存储等基础操作,以及数据分析方法,如描述性统计分析、相关性分析、数据挖掘算法等的理解和应用 。数据可视化:涉及图表类型的选择与应用,如柱状图、折线图、饼图…...
——设置服务、关闭端口)
ubuntu防火墙入门(一)——设置服务、关闭端口
本机想通过git clone gitgithub.com:skumra/robotic-grasping.git下载代码,firewall-config中需要为当前区域的防火墙开启SSH服务吗 是的,如果你想通过 git clone gitgithub.com:skumra/robotic-grasping.git 使用 SSH 协议从 GitHub 下载代码࿰…...

yt6801 ubuntu有线连接驱动安装
耀世16pro的有线网卡驱动安装 下载地址: YT6801 千兆PCIE以太网控制器芯片 1. 创建安装目录 mkdir yt68012. 解压驱动文件 unzip yt6801-linux-driver-1.0.27.zip -d yt68013. 进入驱动目录 cd yt68014. 安装驱动 以 root 权限运行安装脚本: sudo su ./yt_ni…...

ASP.NET Core Web API 控制器
文章目录 一、基类:ControllerBase二、API 控制器类属性三、使用 Get() 方法提供天气预报结果 在深入探讨如何编写自己的 PizzaController 类之前,让我们先看一下 WeatherController 示例中的代码,了解它的工作原理。 在本单元中,…...

【论文笔记】Tool Learning with Foundation Models 论文笔记
Tool Learning with Foundation Models 论文笔记 文章目录 Tool Learning with Foundation Models 论文笔记摘要背景:工作: 引言工具学习的发展本文工作(大纲&目录) 背景2.1 工具使用的认知起源2.2 工具分类:用户界…...

STM32 + CubeMX + 串口 + IAP升级
这篇文章分享一个简单的串口IAP Demo,实现使用串口更新我们自己的App程序。 目录 一、IAP简介二、Stm32CubeMx配置三、Boot代码及配置1、代码2、配置 四、App代码及配置1、代码2、配置 五、效果展示 一、IAP简介 IAP介绍可以在网上找找,相关资料很多&am…...

Oracle-—系统包使用
文章目录 系统包dbms_redefinition 系统包 dbms_redefinition 功能介绍:该包体可以实现将Oracle库下的表在线改为分区结构或者重新定义; 说明:在检查表是否可以重定义和开始重定义的过程中,按照表是否存在主键,参数 o…...

使用Hugo和GitHub Pages创建静态网站个人博客
不需要服务器,不需要域名,不需要数据库,可以选择模版,内容为Markdown格式。 Hugo:https://gohugo.io 文档:https://gohugo.io/getting-started/quick-start/ 中文文档:https://www.gohugo.or…...

群晖系统证书延期
群晖系统默认证书过期了 接下来操作续期证书 一直下一步会让下载一个压缩包里面包含私钥和签发证书请求 下载后解压出来 在群晖里用证书续期 对以前的证书签署签发请求 选择刚刚解压出来的证书 执行完成后会下载一个压缩包,解压出来就会得到新证书 给群晖新增证书 选…...

android shader gl_Position是几个分量
在Android的OpenGL ES中,gl_Position是顶点着色器(Vertex Shader)的一个内置输出变量,它用于指定顶点在裁剪空间(Clip Space)中的位置。gl_Position是一个四维向量(4-component vectorÿ…...

JAVA练习-ArrayList数组
需求 建立3个Student类的实例 原始数组: public class Student {private String name;private int score;public Student(String name, int score) {this.name name;this.score score;}Overridepublic String toString() {return name "的分数࿱…...
_kaic)
springboot339javaweb的新能源充电系统pf(论文+源码)_kaic
毕 业 设 计(论 文) 题目:新能源充电系统的设计与实现 摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解…...
、快排的优化、内省排序,排序总结)超详细!!!!)
数据结构——排序第三幕(深究快排(非递归实现)、快排的优化、内省排序,排序总结)超详细!!!!
文章目录 前言一、非递归实现快排二、快排的优化版本三、内省排序四、排序算法复杂度以及稳定性的分析总结 前言 继上一篇博客基于递归的方式学习了快速排序和归并排序 今天我们来深究快速排序,使用栈的数据结构非递归实现快排,优化快排(三路…...

Jackson:Java对象和JSON字符串的转换处理库使用指南
Jackson介绍 Jackson 是一个非常流行的 Java JSON 处理库,它能够将 Java 对象与 JSON 字符串相互转换。 Jackson 工具主要用于将请求的参数(例如前端发送的 JSON 数据)和响应的数据(例如后端返回给前端的数据)转换成…...

mac maven编译出现问题
背景 进行maven install 命令,报错: [ERROR] COMPILATION ERROR : [INFO] ------------------------------------------------------------- [ERROR] No compiler is provided in this environment. Perhaps you are running on a JRE rather than a J…...

深入讲解Spring Boot和Spring Cloud,外加图书管理系统实战!
很抱歉,我的疏忽,说了这么久还没有给大家详细讲解过Spring Boot和Spring Cloud,那今天给大家详细讲解一下。 大家可以和下面这三篇博客一起看: 1、Spring Boot 和 Spring Cloud 微服务开发实践详解https://blog.csdn.net/speaking_me/artic…...

【AIGC】2023-ICCV-用于高保真语音肖像合成的高效区域感知神经辐射场
2023-ICCV-Efficient Region-Aware Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis 用于高保真语音肖像合成的高效区域感知神经辐射场摘要1. 引言2. 相关工作3. 方法3.1 准备工作和问题设置3.2 三平面哈希表示3.3. 区域注意模块3.4 训练细节 4. 实验4.1…...

如何写一份优质技术文档
作者简介: 本文作者拥有区块链创新专利30,是元宇宙标准化工作组成员、香港web3标准工作组成员,参与编写《数据资产确权与交易安全评价标准》、《链接元宇宙:应用与实践》、《香港Web3.0标准化白皮书》等标准,下面提供…...

ML 系列:第 35 节 - 机器学习中的数据可视化
ML 系列:第 35 天 - 机器学习中的数据可视化 文章目录 一、说明二、数据可视化2.1 直方图2.2 箱线图2.3 散点图2.4 条形图2.5 线图2.6 热图 三、结尾 一、说明 描述性统计和数据可视化是理解和解释机器学习数据的基础。它们有助于总结和直观地呈现数据,…...

存储服务器一般做是做什么阵列?详细列举一下
存储服务器通常使用 RAID(Redundant Array of Independent Disks) 阵列技术来管理磁盘,以提高数据的性能、可靠性和可用性。所选择的 RAID 类型取决于存储服务器的具体用途和需求,比如性能要求、容量需求、容错能力等。 以下是存…...

uniapp使用扩展组件uni-data-select出现的问题汇总
前言 不知道大家有没有学习过我的这门课程那,《uniCloud云开发Vue3版本官方推荐用法》,这么课程已经得到了官方推荐,想要快速上手unicloud的小伙伴们,可以学习一下这么课程哦,不要忘了给一键三连呀。 在录制这门课程…...
导致部分缺失)
pdf.js 预览pdf的时候发票数据缺失显示不全:字体加载出错(缺失)导致部分缺失
首先,排除后端返回的PDF文件流是没有问题的: 但是在vue项目中是这样的: 明显是显示不全,F12查看报错信息,有以下警告: pdf.js:2153 Warning: Error during font loading: The CMap “baseUrl” paramet…...
】之外观模式(Facade Pattern))
【设计模式】【结构型模式(Structural Patterns)】之外观模式(Facade Pattern)
1. 设计模式原理说明 外观模式(Facade Pattern) 是一种结构型设计模式,它提供了一个统一的接口,用来访问子系统中的一群接口。外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。通过隐藏子系统的复杂…...

Redis使用场景-缓存-缓存穿透
前言 之前在针对实习面试的博文中讲到Redis在实际开发中的生产问题,其中缓存穿透、击穿、雪崩在面试中问的最频繁,本文加了图解,希望帮助你更直观的了解缓存穿透😀 (放出之前写的针对实习面试的关于Redis生产问题的博…...

介绍 Apache Spark 的基本概念和在大数据分析中的应用
Apache Spark 是一个开源的大数据处理框架,它提供了快速、通用、可扩展的数据处理能力。Spark可以处理大规模数据集,并且在内存中进行数据操作,从而实现高速的数据处理和分析。 Spark的核心概念是弹性分布式数据集(Resilient Dis…...

OpenCPN-插件之Dashboard Tactics
1:相关链接Dashboard Tactics :: OpenCPN Dashboard Tactics Plugin rgleason/dashboard_tactics_pi: OpenCPN dashboard built-in plugin merger with external tactics_pi plugin NMEAconverter :: OpenCPN 2:显示样式 3:代码 这个插件…...

【LeetCode面试150】——20有效的括号
博客昵称:沈小农学编程 作者简介:一名在读硕士,定期更新相关算法面试题,欢迎关注小弟! PS:哈喽!各位CSDN的uu们,我是你的小弟沈小农,希望我的文章能帮助到你。欢迎大家在…...
)
JWT介绍和结合springboot项目实践(登录、注销授权认证管理)
目录 一、JWT介绍(一)基本介绍(二)jwt有哪些库1、jjwt(Java JWT)2、nimbus - jwt - jwt - api 和 nimbus - jwt - jwt - impl3、spring - security - jwt(已弃用,但在旧项目中有参考…...

Linux 下安装 Golang环境
Linux 下安装 Golang 获取Golang下载地址 安装 进入终端,登入root来到应用安装目录使用 wget 下载解压文件配置环境变量查看golang版本,测试是否配置成功GO设置代理环境变量 本篇教程 以 centos7 为环境基础 不使用软件包管理器安装,原因&am…...

「Mac畅玩鸿蒙与硬件36」UI互动应用篇13 - 数字滚动抽奖器
本篇将带你实现一个简单的数字滚动抽奖器。用户点击按钮后,屏幕上的数字会以滚动动画的形式随机变动,最终显示一个抽奖数字。这个项目展示了如何结合定时器、状态管理和动画实现一个有趣的互动应用。 关键词 UI互动应用数字滚动动画效果状态管理用户交…...
)
安装使用Ubuntu18.04超级大全集最初版(anaconda,pycharm,代理,c/c++环境)
本文介绍ubuntu1804中我目前用到的环境的完整配置,包括ubuntu安装软件,更新环境变量等都有涉及。图片非常多,能给的连接和材料都给了。希望能帮助到新同学。 目录 目录 目录 环境及镜像文件 安装Ubuntu 编辑 开机之后 编辑 更新…...
)
Redis设计与实现第16章 -- Sentinel 总结1(初始化、主从服务器获取信息、发送信息、接收信息)
Sentinel是Redis的高可用解决方案:由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主…...

ChatGPT科研应用、论文写作、课题申报、数据分析与AI绘图
随着人工智能技术的飞速发展,ChatGPT等先进语言模型正深刻改变着科研工作的面貌。从科研灵感的激发、论文的高效撰写,到课题的成功申报,乃至复杂数据的深度分析与可视化呈现,AI技术均展现出前所未有的潜力。其实众多科研前沿工作者…...

OceanBase数据库系列之:基于docker快速安装OceanBase数据库,基于linux服务器快速部署OceanBase数据库
OceanBase数据库系列之:基于docker快速安装OceanBase数据库,基于linux服务器快速部署OceanBase数据库 一、docker快速安装OceanBase数据库下载OceanBase数据库镜像查看镜像启动OceanBase数据库查看OceanBase数据库是否启动成功 二、基于linux部署OceanBa…...
——qiankun线上服务代理到本地)
无星的微前端之旅(四)——qiankun线上服务代理到本地
这个方式其实是我在上家公司的时候体验过,觉得确实很有意思。 所以这里来逆推一下实现方式。 解决了什么痛点 1.开发一个模块,需要启动2-3个项目 在微前端的开发过程中,如果我们要在主应用中看效果,我们至少需要启动一个主应用&am…...

鸿蒙进阶篇-Stage模型、UIAbility
“在科技的浪潮中,鸿蒙操作系统宛如一颗璀璨的新星,引领着创新的方向。作为鸿蒙开天组,今天我们将一同踏上鸿蒙基础的探索之旅,为您揭开这一神奇系统的神秘面纱。” 各位小伙伴们我们又见面了,我就是鸿蒙开天组,下面让我们进入今…...

快速上手:如何开发一个实用的 Edge 插件
在日常浏览网页时,背景图片能够显著提升网页的视觉体验。如果你也想为自己的浏览器页面添加个性化背景图片,并希望背景图片设置能够持久保存,本文将介绍如何通过开发一个自定义Edge插件来实现这一功能。我们将涵盖保存背景设置到插件选项页&a…...

java缓存技术点介绍
1. 缓存(Cache): • 缓存是指用于存储数据的临时存储区域,以便快速访问。在Java中,缓存通常用于存储频繁访问的对象、结果集或其他数据。 2. 缓存命中率(Cache Hit Ratio): • 缓存命…...

【单片机毕业设计12-基于stm32c8t6的智能称重系统设计】
【单片机毕业设计12-基于stm32c8t6的智能称重系统设计】 前言一、功能介绍二、硬件部分三、软件部分总结 前言 🔥这里是小殷学长,单片机毕业设计篇12-基于stm32c8t6的智能称重系统设计 🧿创作不易,拒绝白嫖可私 一、功能介绍 ----…...

音视频流媒体直播/点播系统EasyDSS互联网视频云平台介绍
随着互联网技术的飞速发展,音视频流媒体直播已成为现代社会信息传递与娱乐消费的重要组成部分。在这样的背景下,EasyDSS互联网视频云平台应运而生,它以高效、稳定、便捷的特性,为音视频流媒体直播领域带来了全新的解决方案。 1、产…...

3dtile平移子模型以及修改 3D Tiles 模型的模型矩阵z平移
第一段代码:应用平移变换到子模型 这段代码的目的是获取子模型的变换矩阵,并将其平移 10 个单位。 if (submodel) {// 获取当前子模型的变换矩阵let transform submodel.transform// 创建一个向上的平移矩阵,平移 10 个单位let translation…...

JavaScript中类数组对象及其与数组的关系
JavaScript中类数组对象及其与数组的关系 1. 什么是类数组对象? 类数组对象是指那些具有 length 属性且可以通过非负整数索引访问元素的对象。虽然这些对象看起来像数组,但它们并不具备真正数组的所有特性,例如没有继承 Array.prototype 上…...
 - 04)
【机器学习】机器学习学习笔记 - 监督学习 - 逻辑回归分类朴素贝叶斯分类支持向量机 SVM (可分类、可回归) - 04
逻辑回归分类 import numpy as np from sklearn import linear_modelX np.array([[4, 7], [3.5, 8], [3.1, 6.2], [0.5, 1], [1, 2], [1.2, 1.9], [6, 2], [5.7, 1.5], [5.4, 2.2]]) y np.array([0, 0, 0, 1, 1, 1, 2, 2, 2])# 逻辑回归分类器 # solver:求解器&a…...

Python脚本文件开头两行#!/usr/bin/python和# -*- coding: utf-8 -*-的作用
Linux环境下,Python脚本代码文件,比如test.py,文件的第一行一般要指定解释器,使用Linux的Shebang的形式指定,第二行一般指定编码格式。 首行指定解释器工具,使用方式如下: # 第1种方式&#x…...