Deepseek-强化学习算法(通俗易懂版)
首先先贴一张Deepseek核心技术的梳理图:
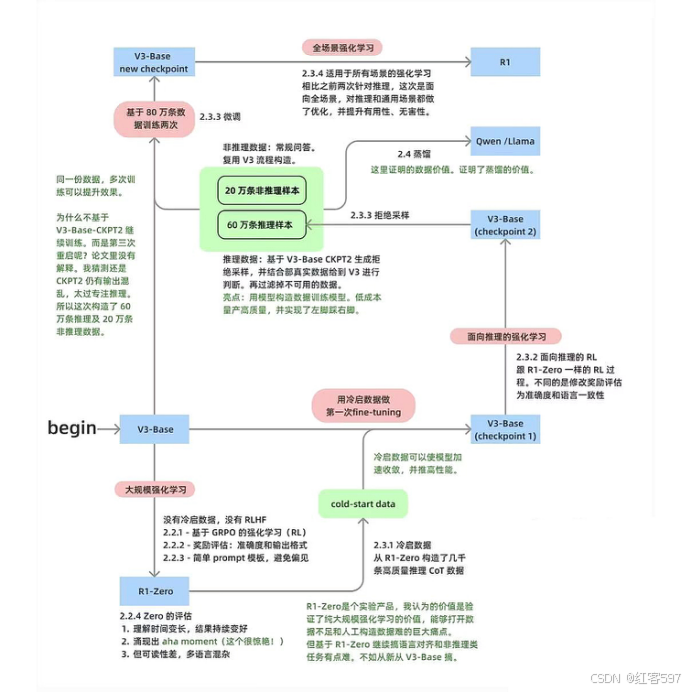
上图详细了讲述了Deepseek主要在哪些阶段用了强化学习方法(GRPO)
1.GRPO算法
GRPO是一种用于提高语言模型推理能力的强化学习算法。它在DeepSeekMath论文中,在数学推理的背景下被提出。GRPO 对传统的近端策略优化(PPO)进行了修改,无需值函数模型。相反,它从组得分中估计基线,减少了内存使用和计算开销。GRPO 现在也被 Qwen 团队使用,它可以与基于规则 / 二进制的奖励以及通用奖励模型一起使用,以提高模型的实用性。
-
采样:使用当前策略为每个提示生成多个输出。
-
奖励评分:使用奖励函数对每个生成结果进行评分,奖励函数可以是基于规则的或基于结果的。
-
优势计算:将生成输出的平均奖励用作基线。然后,相对于此基线计算组内每个解决方案的优势。在组内对奖励进行归一化。
-
策略优化:策略试图最大化 GRPO 目标,该目标包括计算出的优势和一个 KL 散度项。这与 PPO 在奖励中实现 KL 项的方式不同。
-
策略更新:根据计算得到的相对优势 ,更新策略模型的参数 θ。更新的目标是增加具有正相对优势的动作的概率,同时减少具有负相对优势的动作的概率。
-
KL散度约束:为了防止策略更新过于剧烈,GRPO在更新过程中引入了KL散度约束。通过限制新旧策略之间的KL散度,确保策略分布的变化在可控范围内。
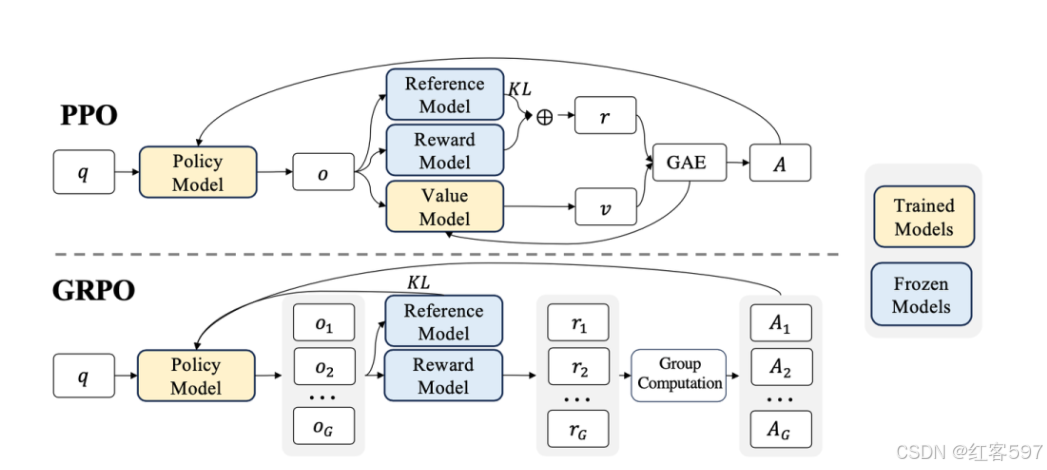
2.GRPO跟PPO算法的区别
首先GRPO只用到了三个模型,分别是奖励模型(权重冻结),基准模型(权重冻结)和策略模型。而不像PPO需要一个价值模型来评估状态价值,降低策略估计方差。
PPO的策略网络主要通过最大化目标函数![]() ,从而更新策略网络的参数。价值网络通过最小化损失函数,来更新价值网络的参数。其中目标函数为
,从而更新策略网络的参数。价值网络通过最小化损失函数,来更新价值网络的参数。其中目标函数为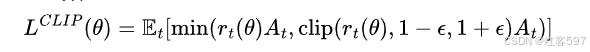 At是优势函数,可以用
At是优势函数,可以用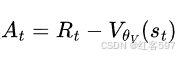 计算。
计算。
价值损失函数为通常使用均方误差(MSE)损失,即![]() ,即,
,即,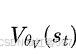 是根据当前参数对状态的价值估计,而
是根据当前参数对状态的价值估计,而![]() 。
。
而GRPO则是在同一个问题 q 上采样多份输出 o 1 , o 2 , … , o G ,把这组输出一起送进奖励模型(或规则),,得到奖励分 r 1 , r 2 , … , r G,再把 r = { r 1 , r 2 , … , r G } 做一个归一化(如减去平均值再除以标准差),从而得出分组内的相对水平。这样就形成了相对奖励 r。最后我们会把这个相对奖励赋给该输出对应的所有 token 的优势函数。就能更好地推断哪些输出更好。由此,就能对每个输出的所有 token 做相对评分,无须明确地学到一个价值函数。
PPO 算法常将 KL 散度作为惩罚项放入负奖励中,GRPO 则是把 KL 惩罚从即时奖励中拿了出去,其 KL 计算相对独立,不直接与即时奖励关联来影响策略更新的奖励部分,在处理上与 PPO 有明显不同。GRPO将KL 正则放在了策略网络更新的目标函数中,用来限制策略和一个参考策略(通常是初始 SFT 模型或当前 θold} 之间的差异不要过大,以防止训练崩坏。
关于分组相对奖励的获得主要基于相互间的比较与排序。
3.GRPO 与 PPO、DPO 算法对比
(一)算法原理对比
GRPO:基于策略梯度,利用 GAE 进行优势估计,通过调整参数λ \lambdaλ平衡偏差和方差,以优化策略参数实现累积奖励最大化。
PPO:同样基于策略梯度,采用截断的优势目标函数(clipped surrogate objective)。通过对重要性采样比进行裁剪,将其限制在一定区间内,防止策略更新过大导致不稳定,保障策略更新在可控范围。
DPO:直接偏好优化算法,其核心是基于人类偏好数据直接优化策略。与 GRPO 和 PPO 从环境奖励中学习不同,DPO 通过比较不同策略生成的轨迹,利用偏好信息来更新策略,使策略更符合人类期望。DPO 的损失函数主要基于策略之间的相对优势来构建。
(二)优势估计方式对比
GRPO:采用 GAE,结合多个时间步的奖励和价值估计计算优势,能在偏差和方差间灵活权衡,适应不同环境和任务需求。
PPO:使用普通优势估计或结合 GAE(部分实现中),在优势估计时主要通过裁剪重要性采样比来稳定策略更新,对优势估计的准确性依赖相对较弱。
DPO:不依赖传统的优势估计,而是依据人类偏好数据。通过对不同策略轨迹的偏好排序,直接反映策略的优劣,避免了优势估计过程中的误差积累。
(三)策略更新方式对比
GRPO:根据 GAE 计算的优势值更新策略网络和价值网络,通过优化演员 - 评论家结构,使策略逐渐向最优方向调整,更新过程相对平滑稳定。
PPO:利用裁剪后的优势目标函数更新策略,在策略更新时考虑新旧策略的比例关系,防止更新幅度过大。通过多次迭代优化策略,在保证稳定性的同时追求性能提升。
DPO:基于人类偏好的对比损失来更新策略。通过最大化偏好策略轨迹的概率,最小化非偏好策略轨迹的概率,使策略直接向符合人类偏好的方向更新。
(四)目标的区别:
GRPO 和 PPO 的目标是优化策略网络以最大化累积奖励,DPO 有所不同,其目标不是直接最大化累积奖励,而是优化策略以拟合奖励函数所诱导的排序偏好。
4.再来谈谈RLHF跟DPO的区别
RLHF(Reinforcement Learning from Human Feedback)即基于人类反馈的强化学习,其原理是将人类的反馈信息融入强化学习框架,使模型学习到符合人类偏好和价值观的行为策略。具体步骤一般如下:
- 数据收集与标注:利用预训练模型生成初始数据,邀请人类标注者按标准对其进行质量打分、排序或提出修改意见等标注。
- 奖励模型训练:从标注数据中提取文本词汇、句法等相关特征,选择神经网络等合适架构构建奖励模型,以标注反馈为输入训练模型,使其能预测人类偏好。
- 策略优化:确定策略网络,用强化学习算法以奖励模型的信号为反馈对其优化,让策略网络根据状态生成动作并获奖励反馈,通过最大化累积奖励调整参数,采样新数据更新网络,经多轮迭代提升性能。
- 评估与迭代:用独立测试集评估策略网络,根据与人类标注一致性等指标判断效果,再据此调整流程,如收集更多数据、调整模型结构或改进训练方法等,重复步骤进行优化。

相关文章:
)
Deepseek-强化学习算法(通俗易懂版)
首先先贴一张Deepseek核心技术的梳理图: 上图详细了讲述了Deepseek主要在哪些阶段用了强化学习方法(GRPO) 1.GRPO算法 GRPO是一种用于提高语言模型推理能力的强化学习算法。它在DeepSeekMath论文中,在数学推理的背景下被提出。G…...

[展示]Webrtc NoiseSuppressor降噪模块嵌入式平台移植
最近在尝试把WebRtc的NoiseSuppressor模块移植到嵌入式平台,现在已经移植了,尝试了下效果,降噪效果很显著,噪声带被显著抑制了 降噪前: 降噪后:...

了解 RAG 第二部分:经典 RAG 的工作原理
在本系列的第一篇文章中,我们介绍了检索增强生成 (RAG) ,解释了扩展传统大型语言模型 (LLM)功能的必要性。我们还简要概述了 RAG 的核心思想:从外部知识库检索上下文相关的信息,以确保 LLM 生成准确且最新的信息,而不会…...

剖析IO原理和零拷贝机制
目录 1 Linux的五种IO模型1.1 模型调用的函数1.1.1 recv函数1.1.2 select函数1.1.3 poll函数1.1.4 epoll函数1.1.5 sigaction函数 1.2 IO模型1.2.1 阻塞IO模型1.2.2 非阻塞IO模型1.2.3 IO复用模型1.2.4 信号驱动IO模型1.2.5 异步IO模型1.2.6 IO模型比较 2 Java的BIO、NIO、AIO2…...

【论文精读】MapTR:用于在线矢量化高精地图构建的结构化建模与学习
论文地址: MAPTR: STRUCTURED MODELING AND LEARNING FOR ONLINE VECTORIZED HD MAP CONSTRUCTION 源代码:MapTR 摘要 High-definition(HD Map)map为自动驾驶场景提供了丰富且精确的环境信息,是自动驾驶系统规划中不…...
——后端图片模块开发)
云图库平台(五)——后端图片模块开发
目录 一、需求分析二、库表设计三、图片的处理如何实现图片的上传和下载创建图片的业务流程如何对图片进行解析 四、创建并使用对象存储五、后端操作对象存储初始化客户端通用能力类文档上传文件下载 一、需求分析 管理员功能: 图片的上传和创建:仅管理…...
RedHat背景与环境配置)
Linux红帽:RHCSA认证知识讲解(一)RedHat背景与环境配置
Linux红帽:RHCSA认证知识讲解(一)RedHat背景与环境配置 前言一、RedHat公司背景二、RedHat环境安装步骤三、windows使用远程工具连接环境并上传文件到redhat方法: 前言 在接下来的博客中,我们从基础开始将介绍红帽Linu…...

【Linux】基于UDP/TCP套接字编程与守护进程
目录 一、网路套接字编程 (一)基础概念 1、源IP地址与目的IP地址 2、端口号 3、TCP与UDP 4、网络字节序 (二)套接字编程接口 1、socket 常见API 2、sockaddr结构 (三)UDP套接字 1、UDP服务器创建…...

Linux CentOS 上 Ollama 的安装与部署:从入门到实践
Linux CentOS 上 Ollama 的安装与部署:从入门到实践 随着人工智能技术的快速发展,大语言模型(LLMs)的应用场景越来越广泛。Ollama 作为一个轻量级的 AI 模型管理工具,为开发者提供了便捷的模型部署和管理解决方案。本文将详细介绍如何在 Linux CentOS 系统上安装和部署 O…...

大数据学习之任务流调度系统Azkaban、Superset可视化系统
一.任务流调度系统Azkaban 1.课程介绍 2.为什么需要工作流调度系统 3.AZKABAN是什么 4.AZKABAN下载 5.制作安装包 6.tar包准备 7.MYSQL配置AZKABAN 8.配置EXECUTOR SERVER 9.配置WEBSERVER 10.单作业实战_yaml语言(今天稍晚更新) 11.单作业实战 12.多作业依赖实战 13.失败自动重…...
应用程序安全)
网络空间安全(2)应用程序安全
前言 应用程序安全(Application Security,简称AppSec)是一个综合性的概念,它涵盖了应用程序从开发到部署,再到后续维护的整个过程中的安全措施。 一、定义与重要性 定义:应用程序安全是指识别和修复应用程序…...

UDP、TCP的区别
UDP(用户数据报协议)和TCP(传输控制协议)是两种常用的传输层协议,它们在数据传输方式、可靠性和应用场景等方面有显著区别。以下是它们的主要区别: ### 1. 连接方式 - **TCP**:面向连接。通信前…...

Linux 第二次脚本作业
1、需求:判断192.168.1.0/24网络中,当前在线的ip有哪些,并编写脚本打印出来。 2、设计一个 Shell 程序,在/userdata 目录下建立50个目录,即 user1~user50,并设置每个目录的权限,其中其他用户的权…...

高清下载油管视频到本地
下载工具并安装: yt-dlp官网地址: GitHub - yt-dlp/yt-dlp: A feature-rich command-line audio/video downloader ffmpeg官网地址: Download FFmpeg 注:记住为其添加环境变量 操作命令: 该指令表示以720p码率下载VIDEO_UR…...
)
Linux 命令大全完整版(07)
2. linux 系统设置命令 ulimit 功能说明:控制 shell 程序的资源。语法:ulimit [-aHS][-c <core 文件上限>][-d <数据节区大小>][-f <文件大小>][-m <内存大小>][-n <文件数目>][-p <缓冲区大小>][-s <堆叠大小…...

基于CentOS7安装kubesphere和Kubernetes并接入外部ES收集日志
一、修改所有节点主机名 主节点就修改成master hostnamectl set-hostname master 然后输入bash刷新当前主机名 工作节点1就修改成node1 hostnamectl set-hostname node1 然后输入bash刷新当前主机名 二、全部节点安装依赖并同步时间 yum -y install socat conntrack ebta…...

Javascript网页设计案例:通过PDFLib实现一款PDF分割工具,分割方式自定义-完整源代码,开箱即用
功能预览 一、工具简介 PDF 分割工具支持以下核心功能: 拖放或上传 PDF 文件:用户可以通过拖放或点击上传 PDF 文件。两种分割模式: 指定范围:用户可以指定起始页和结束页,提取特定范围的内容。固定间距:用户可以设置间隔页数(例如每 5 页分割一次),工具会自动完成分…...

高速差分信号的布线
差分信号如何在PCB上布线? 1.差分信号必须保证线间距相等,禁止打过孔或者放置元器件 2.差分信号必须打孔时,必须要保证伴随屏蔽地过孔(缝合定位孔),减少信号干扰问题。 3.差分信号走线弯曲位置推荐&#…...

用openresty和lua实现壁纸投票功能
背景 之前做了一个随机壁纸接口,但是不知道大家喜欢对壁纸的喜好,所以干脆在实现一个投票功能,让用户给自己喜欢的壁纸进行投票。 原理说明 1.当访问http://demo.com/vote/时,会从/home/jobs/webs/imgs及子目录下获取图片列表&…...

智能测试执行 利用算法 利用图像识别、自然语言处理等技术实现自动化测试执行
以下将从Web应用和移动应用两个方面,给出利用图像识别、自然语言处理等技术实现自动化测试执行的实例,并附上部分代码示例。 Web应用自动化测试实例:模拟用户登录操作测试 需求理解 对于一个Web应用的登录功能进行自动化测试,我们可以结合自然语言处理理解测试用例描述,…...

AI学习之-阿里天池
阿里天池(Tianchi)是阿里巴巴集团旗下的一个数据科学与人工智能竞赛平台,致力于推动数据科学和人工智能的发展。在天池平台上,人们可以参与各种数据竞赛和挑战,解决实际问题,提升数据科学技能。天池平台提供…...

AGI觉醒假说的科学反驳:从数学根基到现实约束的深度解析
文章目录 引言:AGI觉醒论的核心迷思一、信息论视角:意识产生的熵约束1.1 香农熵的物理极限1.2 量子退相干的时间屏障二、数学根基:形式系统的自指困境2.1 哥德尔不完备定理的现代诠释三、概念解构:AGI觉醒假说的认知陷阱3.1 术语混淆的迷雾3.2 拟人化谬误的认知根源四、意识…...

SpringMVC的基本使用
controller标记一个类是控制器类 RequestMapping 进行路由映射可以是类也可以是方法,路由的/可以不加,但建议加上 1)简单的映射返回一个hello RequestMapping("/m1")public String m1() { return "hello";} 2&#x…...
)
【漫话机器学习系列】103.学习曲线(Learning Curve)
学习曲线(Learning Curve)详解 1. 什么是学习曲线? 学习曲线(Learning Curve)是机器学习和深度学习领域中用于评估模型性能随训练过程变化的图示。它通常用于分析模型的学习能力、是否存在过拟合或欠拟合等问题。 从…...

ubuntu-24.04.1-desktop 中安装 QT6.7
ubuntu-24.04.1-desktop 中安装 QT6.7 1 环境准备1.1 安装 GCC 和必要的开发包:1.2 Xshell 连接 Ubuntu2 安装 Qt 和 Qt Creator:2.1 下载在线安装器2.2 在虚拟机中为文件添加可执行权限2.3 配置镜像地址运行安装器2.4 错误:libxcb-xinerama.so.0: cannot open shared objec…...

MQTT实现智能家居------2、写MQTT程序的思路
举个最简单的例子: 手机------服务器-------家具 我们这里只看手机和家具的客户端: 手机:1)需要连接服务器 2)需要发布指令给服务器到家里的家具 3)接受来自于家里家具的异常状况 4)保持心…...

【个人开发】deepspeed+Llama-factory 本地数据多卡Lora微调【完整教程】
文章目录 1.背景2.微调方式2.1 关键环境版本信息2.2 步骤2.2.1 下载llama-factory2.2.2 准备数据集2.2.3 微调模式2.2.3.1 zero-1微调2.2.3.2 zero-2微调2.2.3.3 zero-3微调2.2.3.4 单卡Lora微调 2.2.4 实验2.2.4.1 实验1:多GPU微调-zero12.2.4.2 实验2:…...

DeepSeek 从入门到精通:全面掌握 DeepSeek 的核心功能与应用
引言 DeepSeek 是一款功能强大的工具(或平台/框架,具体根据实际定义),广泛应用于数据分析、人工智能、自动化任务等领域。无论你是初学者还是资深开发者,掌握 DeepSeek 的核心功能和应用场景都将为你的工作和学习带来…...

“国补”带火手机换新,出售旧手机应如何保护个人信息安全
在“国补”政策的推动下,手机换新热潮正席卷而来。“国补”以其诱人的补贴力度,成功激发了消费者更换手机的热情。无论是渴望体验最新技术的科技爱好者,还是对旧手机性能不满的普通用户,都纷纷投身到这场手机换新的浪潮之中。 随着大量消费者参与手机换新,二手手机市场迎来…...
- 设置渲染管线)
驱动开发系列39 - Linux Graphics 3D 绘制流程(二)- 设置渲染管线
一:概述 Intel 的 Iris 驱动是 Mesa 中的 Gallium 驱动,主要用于 Intel Gen8+ GPU(Broadwell 及更新架构)。它负责与 i915 内核 DRM 驱动交互,并通过 Vulkan(ANV)、OpenGL(Iris Gallium)、或 OpenCL(Clover)来提供 3D 加速。在 Iris 驱动中,GPU Pipeline 设置 涉及…...

Windows使用docker部署fastgpt出现的一些问题
文章目录 Windows使用docker部署FastGPT出现的一些问题1.docker部署pg一直重启的问题2.重启MongoDB之后一直出现“Waiting for MongoDB to start...”3.oneapi启动不了failed to get gpt-3.5-turbo token encoder Windows使用docker部署FastGPT出现的一些问题 1.docker部署pg一…...

六十天前端强化训练之第一天HTML5语义化标签深度解析与博客搭建实战
欢迎来到编程星辰海的博客讲解 目录 一、语义化标签的核心价值 1.1 什么是语义化? 1.2 核心优势 二、语义标签详解与使用场景 2.1 布局容器标签 2.2 内容组织标签 三、博客结构搭建实战 3.1 完整HTML结构 3.2 核心结构解析 3.3 实现效果说明 四、学习要点…...

Oracle中补全时间的处理
在实际数据处理的过程中,存在日期不连续的问题,可能会导致数据传到前后端出现异常,为了避免这种问题,通常会从数据端进行日期不全的处理: 以下为补全年份的案例: with x as (select 开始年份 (…...

PHP课程预约小程序源码
📱 课程预约小程序:为您专属定制的便捷预约新体验 在这个快节奏的时代,我们深知每一位瑜伽爱好者、普拉提追随者以及培训机构管理者对高效、便捷服务的迫切需求。因此,我们匠心独运,推出了一款基于PHPUniApp框架开发的…...
: error: #29: expected an expression error: #40: expected an identifier)
(200): error: #29: expected an expression error: #40: expected an identifier
这是因为你乱加define导致你的define与变量名重复就会出现,他找不到错误只会抱着两个错...

一文讲解Redis中的常用命令
①、操作字符串的命令有: SET key value:设置键 key 的值为 value。GET key:获取键 key 的值。DEL key:删除键 key。INCR key:将键 key 存储的数值增一。DECR key:将键 key 存储的数值减一。 ②、操作列表…...
智能交通系统(Intelligent Transportation Systems):智慧城市中的交通革新
智能交通系统(Intelligent Transportation Systems, ITS)是利用先进的信息技术、通信技术、传感技术、计算机技术以及自动化技术等,来提升交通系统效率和安全性的一种交通管理方式。ITS通过收集和分析交通数据,智能化地调度、控制…...

Node.js 登录鉴权
目录 Session express-session 配置 express-session 函数 ts 要配置声明文件 express-session.d.ts express-session 使用 express-session 带角色 Token 什么是 JWT token jsonwebtoken 使用 jsonwebtoken 带角色 Session express 使用 express-session 管理会话&…...

EPSON L3118彩色喷墨打印机灯全闪故障维修一例
一台EPSON L3118彩色喷墨打印机,故障时开机灯全闪烁,一般来说这种故障问题都不太大,要么就是打印机内部卡纸了,要么就是传感器故障,一般情况下卡纸的问题比较多… …; 但是遇到一用户又菜又爱玩,…...

在 Mac ARM 架构的 macOS 系统上启用 F1 键作为 Snipaste 的截屏快捷键
在 Mac ARM 架构的 macOS 系统上启用 F1 键作为 Snipaste 的截屏快捷键,主要涉及到两个方面:确保 F1 键作为标准功能键工作 和 在 Snipaste 中设置 F1 为快捷键。 因为 Mac 默认情况下,F1-F12 键通常用作控制屏幕亮度、音量等系统功能的快捷键…...

基于AT89C51单片机的教室智能照明控制系统
点击链接获取Keil源码与Project Backups仿真图: https://download.csdn.net/download/qq_64505944/90419908?spm1001.2014.3001.5501 C16 部分参考设计如下: 摘 要 本项目的智能教室灯光控制系统通过合理的软硬件设计,有效地提升了教室…...
)
JavaSE学习笔记25-反射(reflection)
反射 在Java中,反射(Reflection) 是一种强大的机制,允许程序在运行时检查和操作类、方法、字段等信息。通过反射,可以动态地创建对象、调用方法、访问字段,甚至修改私有成员。反射的核心类是 java.lang.re…...

ctf网络安全题库 ctf网络安全大赛答案
此题解仅为部分题解,包括: 【RE】:①Reverse_Checkin ②SimplePE ③EzGame 【Web】①f12 ②ezrunner 【Crypto】①MD5 ②password ③看我回旋踢 ④摩丝 【Misc】①爆爆爆爆 ②凯撒大帝的三个秘密 ③你才是职业选手 一、 Re ① Reverse Chec…...
旋转位置编码(ROPE)详解:从Transformer到现代前沿
旋转位置编码(ROPE)详解:从Transformer到现代前沿 标签:NLP, Transformer, 位置编码, ROPE, 深度学习, 机器学习 摘要:本文详细介绍了旋转位置编码(ROPE)在Transformer模型中的应用࿰…...

ROS2机器人开发--服务通信与参数通信
服务通信与参数通信 在 ROS 2 中,服务(Services)通信和参数(Parameters)通信是两种重要的通信机制。服务是基于请求和响应的双向通信机制。参数用于管理节点的设置,并且参数通信是基于服务通信实现的。 1 …...

安全运维,等保测试常见解决问题。
1. 未配置口令复杂度策略。 # 配置密码安全策略 # vi /etc/pam.d/system-auth # local_users_only 只允许本机用户。 # retry 3 最多重复尝试3次。 # minlen12 最小长度为12个字符。 # dcredit-1 至少需要1个数字字符。 # ucredit-1 至少需要1个大…...

【数据标准】数据标准化是数据治理的基础
导读:数据标准化是数据治理的基石,它通过统一数据格式、编码、命名与语义等,全方位提升数据质量,确保准确性、完整性与一致性,从源头上杜绝错误与冲突。这不仅打破部门及系统间的数据壁垒,极大促进数据共享…...

Java 18~20 新特性
文章目录 一、Java 18 新特性1.1、UTF-8 作为默认字符集(JEP 400)1.2、简易 Web 服务器(JEP 408)1.3、代码片段标签 snippet(JEP 413)1.4、使用方法句柄重新实现反射核心(JEP 416)1.…...

程序员学商务英语之At the Hotel
Dialogue-3 Room service-Cleaning the Room客房服务-打扫房间 A: Who will do the dishes after dinner tonight? 今晚饭后谁来洗碗? B: It’s your turn. 轮到你了。 Go do the room right now. clean the room去打扫房间。Doing the laundry is the last thi…...

探秘路由表:网络世界的导航地图
一、引言 在当今数字化时代,网络已经成为我们生活中不可或缺的一部分。无论是浏览网页、观看视频,还是进行在线办公、游戏娱乐,我们都在与网络进行着频繁的交互。而在这背后,网络中的数据传输就如同现实生活中的快递配送…...