【Python 打造高效文件分类工具】
【Python】 打造高效文件分类工具
- 一、代码整体结构
- 二、关键代码解析
- (一)初始化部分
- (二)界面创建部分
- (三)核心功能部分
- (四)其他辅助功能部分
- 三、运行与使用
- 四、示图
- 五、作者有话说
该代码基于 Python 的 tkinter 库实现了 “文件分类工具 - 优化版” 图形化桌面应用。用户能通过界面选择文件夹和要分类的文件类型,支持全选或自定义部分文件扩展名进行分类。采用多线程技术执行文件整理任务,避免界面卡顿且可中途停止。利用 os.scandir 高效遍历文件并批量分组处理,对大文件(超 500MB)增加延迟处理并记录日志。通过消息队列记录整理过程,包含跳过文件、移动文件及错误信息等,支持将日志保存为文本文件。整理完成后显示总文件数、成功移动数、失败次数和跳过文件数等统计信息,还可直接打开整理后的文件夹查看结果。
一、代码整体结构
我们的文件分类工具基于 Python 的 Tkinter 库构建,Tkinter 是 Python 的标准 GUI(Graphical User Interface,图形用户界面)库,它提供了丰富的组件来创建交互式应用程序。整个代码围绕一个名为FileOrganizerApp的类展开,这个类负责管理界面元素、用户交互以及文件整理的核心逻辑。
二、关键代码解析
(一)初始化部分
class FileOrganizerApp:def __init__(self, root):self.root = rootself.root.title("文件分类工具-优化版")self.root.geometry("800x600")# 初始化统计变量self.total_files = 0self.moved_count = 0self.error_count = 0self.current_progress = 0# 初始化文件类型选择相关变量self.all_files_var = tk.BooleanVar()self.checkbox_vars = {}self.checkboxes = {}self.preset_extensions = ["txt", "doc", "docx", "pdf", "jpg","png", "gif", "mp3", "mp4", "xls","xlsx", "zip", "rar", "ppt", "pptx"]# 创建消息队列self.log_queue = queue.Queue()self.create_widgets()self.running = Falseself.stop_event = threading.Event()在__init__ 方法中,我们首先设置了应用程序窗口的标题和初始大小。接着,初始化了一系列统计变量,用于记录整理过程中的文件总数、成功移动的文件数、出错的文件数以及当前的进度。
为了让用户能够选择要分类的文件类型,我们定义了all_files_var布尔变量用于全选功能,checkbox_vars字典来存储每个文件扩展名对应的复选框状态,checkboxes字典用于存储复选框组件,preset_extensions列表则列出了我们预设支持分类的文件扩展名。
消息队列log_queue用于在不同线程间传递日志信息,确保界面的流畅更新。最后,调用create_widgets方法创建界面元素,并初始化一些控制变量。
(二)界面创建部分
def create_widgets(self):# 文件夹选择部分frame_top = ttk.Frame(self.root, padding=10)frame_top.pack(fill=tk.X)self.btn_select = ttk.Button(frame_top, text="选择文件夹", command=self.select_directory)self.btn_select.pack(side=tk.LEFT, padx=5)self.path_var = tk.StringVar()self.entry_path = ttk.Entry(frame_top, textvariable=self.path_var, width=60)self.entry_path.pack(side=tk.LEFT, padx=5, fill=tk.X, expand=True)# 文件类型选择部分type_frame = ttk.LabelFrame(self.root, text="选择要分类的文件类型", padding=10)type_frame.pack(fill=tk.BOTH, expand=True, pady=5)# 全选复选框ttk.Checkbutton(type_frame,text="全部分类",variable=self.all_files_var,command=self.toggle_checkboxes).grid(row=0, column=0, sticky=tk.W, padx=5)# 创建扩展名复选框for idx, ext in enumerate(self.preset_extensions):self.checkbox_vars[ext] = tk.BooleanVar()cb = ttk.Checkbutton(type_frame,text=ext.upper(),variable=self.checkbox_vars[ext])cb.grid(row=idx // 5 + 1, column=idx % 5, sticky=tk.W, padx=5)self.checkboxes[ext] = cb# 控制按钮部分frame_controls = ttk.Frame(self.root, padding=10)frame_controls.pack(fill=tk.X)self.btn_start = ttk.Button(frame_controls, text="开始整理", command=self.start_organize)self.btn_start.pack(side=tk.LEFT, padx=5)self.btn_stop = ttk.Button(frame_controls, text="停止", command=self.stop_organize, state=tk.DISABLED)self.btn_stop.pack(side=tk.LEFT, padx=5)# 保存日志按钮self.btn_save_log = ttk.Button(frame_controls, text="保存日志", command=self.save_log, state=tk.DISABLED)self.btn_save_log.pack(side=tk.LEFT, padx=5)# 查看文件按钮,初始状态为禁用self.btn_view_files = ttk.Button(frame_controls, text="查看文件", command=self.open_folder, state=tk.DISABLED)self.btn_view_files.pack(side=tk.LEFT, padx=5)# 日志显示部分frame_log = ttk.Frame(self.root, padding=10)frame_log.pack(fill=tk.BOTH, expand=True)self.log_area = scrolledtext.ScrolledText(frame_log, wrap=tk.WORD)self.log_area.pack(fill=tk.BOTH, expand=True)# 进度条self.progress = ttk.Progressbar(self.root, orient=tk.HORIZONTAL, mode='determinate')self.progress.pack(fill=tk.X, padx=10, pady=5)
create_widgets方法负责构建应用程序的整个界面。它分为几个主要部分:
- 文件夹选择部分:包含一个按钮btn_select用于打开文件选择对话框,以及一个输入框entry_path用于显示用户选择的文件夹路径。
- 文件类型选择部分:通过一个标签框架type_frame包含一个全选复选框和多个文件扩展名复选框。全选复选框的command参数绑定到toggle_checkboxes方法,用于切换所有扩展名复选框的状态。
- 控制按钮部分:包括开始整理按钮btn_start、停止按钮btn_stop(初始状态为禁用)、保存日志按钮btn_save_log(初始状态为禁用)和查看文件按钮btn_view_files(初始状态为禁用)。这些按钮分别绑定到对应的功能方法。
- 日志显示部分:使用scrolledtext.ScrolledText组件创建一个可滚动的文本区域log_area,用于显示文件整理过程中的日志信息。
- 进度条部分:通过ttk.Progressbar创建一个水平进度条progress,用于直观展示文件整理的进度。
(三)核心功能部分
def start_organize(self):if not self.path_var.get():messagebox.showwarning("警告", "请先选择要整理的文件夹")returnif self.running:returnself.running = Trueself.stop_event.clear()self.btn_start['state'] = tk.DISABLEDself.btn_stop['state'] = tk.NORMALself.btn_save_log['state'] = tk.DISABLEDself.btn_view_files['state'] = tk.DISABLEDself.progress['value'] = 0self.log_area.delete(1.0, tk.END)# 启动队列处理self.process_log_queue()self.update_progress()worker = threading.Thread(target=self.organize_files, daemon=True)worker.start()
start_organize方法是启动文件整理流程的入口。首先,它检查用户是否选择了要整理的文件夹路径,如果没有则弹出警告框提示用户。然后,检查当前是否已经在运行整理任务,如果是则直接返回。
接着,设置运行状态变量running为True,清除停止事件stop_event,并根据任务状态更新界面按钮的状态,清空进度条和日志区域。
为了确保日志能够及时更新,调用process_log_queue方法启动日志队列处理,同时调用update_progress方法开始更新进度条。最后,创建一个新的线程来执行核心的文件整理逻辑organize_files,并将线程设置为守护线程,这样当主线程结束时,该线程也会自动结束。
def organize_files(self):target_dir = self.path_var.get()try:# 使用更高效的scandir遍历文件files = []with os.scandir(target_dir) as entries:for entry in entries:if entry.is_file():files.append(entry.name)self.total_files = len(files)processed_files = 0# 批量分组处理文件selected_exts = Noneif not self.all_files_var.get():selected_exts = {ext for ext, var in self.checkbox_vars.items() if var.get()}file_groups = defaultdict(list)skipped_count = 0for filename in files:if self.stop_event.is_set():break_, ext = os.path.splitext(filename)ext = ext.lower().lstrip('.') if ext else 'no_extension'if selected_exts is None or ext in selected_exts:file_groups[ext].append(filename)else:skipped_count += 1# 处理跳过的文件self.log_queue.put(f"已跳过 {skipped_count} 个未选类型的文件")# 批量移动文件total_to_process = sum(len(v) for v in file_groups.values())processed = 0for ext, filenames in file_groups.items():if self.stop_event.is_set():breakdest_dir = os.path.join(target_dir, ext)os.makedirs(dest_dir, exist_ok=True)for filename in filenames:if self.stop_event.is_set():breakfile_path = os.path.join(target_dir, filename)try:# 大文件处理(超过500MB时增加延迟)file_size = os.path.getsize(file_path)if file_size > 500 * 1024 * 1024:self.log_queue.put(f"正在处理大文件: {filename} ({file_size // 1024 // 1024}MB)")time.sleep(0.5)shutil.move(file_path, os.path.join(dest_dir, filename))self.moved_count += 1# 每处理50个文件更新一次日志if self.moved_count % 50 == 0:self.log_queue.put(f"已移动 {self.moved_count} 个文件")except Exception as e:self.error_count += 1self.log_queue.put(f"错误: {filename} ({str(e)})")processed += 1self.current_progress = (processed / total_to_process) * 100self.root.after(10, self.organize_complete)except Exception as e:self.log_queue.put(f"系统错误: {str(e)}")self.root.after(10, self.organize_complete)
organize_files方法是文件分类的核心逻辑所在。它首先获取用户选择的目标文件夹路径target_dir。然后,使用os.scandir函数更高效地遍历目标文件夹中的所有文件,将文件列表存储在files变量中,并记录文件总数total_files。
接下来,根据用户在界面上选择的文件类型进行分组处理。如果用户选择了全部分类(all_files_var为True),则selected_exts为None,表示处理所有文件;否则,通过列表推导式获取用户勾选的文件扩展名集合selected_exts。
使用defaultdict创建file_groups字典,将文件按扩展名分组。在遍历文件过程中,如果文件类型不在用户选择的范围内,则跳过该文件并记录跳过的文件数。
在批量移动文件阶段,首先计算需要处理的文件总数total_to_process。对于每个文件组,创建对应的目标文件夹(如果不存在),然后逐个移动文件。在移动文件时,增加了对大文件(超过 500MB)的处理逻辑,当遇到大文件时,在日志中记录并增加 0.5 秒的延迟,以避免在处理大文件时导致系统卡顿。同时,每成功移动 50 个文件,在日志中记录已移动的文件数。如果移动过程中出现错误,记录错误信息并增加错误计数。
在整个过程中,根据已处理文件数和总文件数实时更新当前进度current_progress。最后,通过root.after方法在 10 毫秒后调用organize_complete方法,用于处理整理完成后的后续操作。
(四)其他辅助功能部分
def stop_organize(self):self.stop_event.set()self.log_queue.put("正在停止整理进程...")
stop_organize方法用于停止文件整理任务。它通过设置stop_event事件,通知正在执行文件整理的线程停止操作,并在日志队列中添加停止进程的提示信息。
def process_log_queue(self):try:while True:msg = self.log_queue.get_nowait()self.log_area.insert(tk.END, msg + "\n")self.log_area.see(tk.END)except queue.Empty:passself.root.after(100, self.process_log_queue)
process_log_queue方法负责从日志队列log_queue中获取日志信息,并将其显示在日志区域log_area中。它通过一个循环不断尝试从队列中获取消息,使用get_nowait方法避免阻塞。如果队列为空,捕获queue.Empty异常并跳过。每次获取并显示消息后,通过root.after方法设置 100 毫秒后再次调用自身,以实现实时更新日志。
def update_progress(self):self.progress['value'] = self.current_progressself.root.after(100, self.update_progress)
update_progress方法用于更新进度条的显示。它将当前进度current_progress的值设置到进度条progress上,并通过root.after方法设置 100 毫秒后再次调用自身,以实现进度条的实时更新。
def organize_complete(self):self.running = Falseself.btn_start['state'] = tk.NORMALself.btn_stop['state'] = tk.DISABLEDself.btn_save_log['state'] = tk.NORMAL# 整理完成后启用查看文件按钮self.btn_view_files['state'] = tk.NORMALself.current_progress = 100stats_message = (f"\n整理完成:\n"f"总文件数: {self.total_files}\n"f"成功移动: {self.moved_count}\n"f"失败次数: {self.error_count}\n"f"跳过文件: {self.total_files - self.moved_count - self.error_count}")self.log_queue.put(stats_message)messagebox.showinfo("整理统计", stats_message)
organize_complete方法在文件整理完成后被调用。它首先将运行状态变量running设置为False,并恢复界面按钮的初始状态,启用开始按钮、禁用停止按钮、启用保存日志按钮和查看文件按钮。同时,将进度条设置为 100%。
然后,生成整理统计信息字符串stats_message,包含总文件数、成功移动的文件数、失败次数和跳过的文件数。将统计信息添加到日志队列中,并通过messagebox.showinfo弹出对话框显示整理统计结果。
def save_log(self):log_text = self.log_area.get(1.0, tk.END)file_path = filedialog.asksaveasfilename(defaultextension=".txt", filetypes=[("Text files", "*.txt")])if file_path:try:with open(file_path, 'w', encoding='utf-8') as f:f.write(log_text)messagebox.showinfo("保存成功", "日志已成功保存。")except Exception as e:messagebox.showerror("保存失败", f"保存日志时出现错误:{str(e)}")
save_log方法用于将日志区域中的内容保存为文本文件。它首先获取日志区域的所有文本内容log_text,然后通过filedialog.asksaveasfilename打开文件保存对话框,让用户选择保存路径和文件名。如果用户选择了保存路径,尝试将日志内容写入文件。如果保存成功,弹出提示框告知用户;如果保存过程中出现错误,捕获异常并弹出错误提示框。
def open_folder(self):folder = self.path_var.get()if folder:try:if os.name == 'nt': # Windows 系统os.startfile(folder)elif os.name == 'posix': # Linux 或 macOS 系统webbrowser.open(folder)except Exception as e:messagebox.showerror("错误", f"打开文件夹时出错: {str(e)}")
open_folder方法用于在文件整理完成后,打开用户选择的目标文件夹。它
首先获取用户在界面上选择的文件夹路径folder。如果路径存在,根据当前操作系统类型进行不同的操作:对于 Windows 系统,使用os.startfile函数打开文件夹;对于 Linux 或 macOS 系统,使用webbrowser.open函数打开文件夹。如果在打开过程中出现异常,捕获异常并通过messagebox.showerror弹出错误提示框,告知用户打开文件夹时出现的错误信息。
三、运行与使用
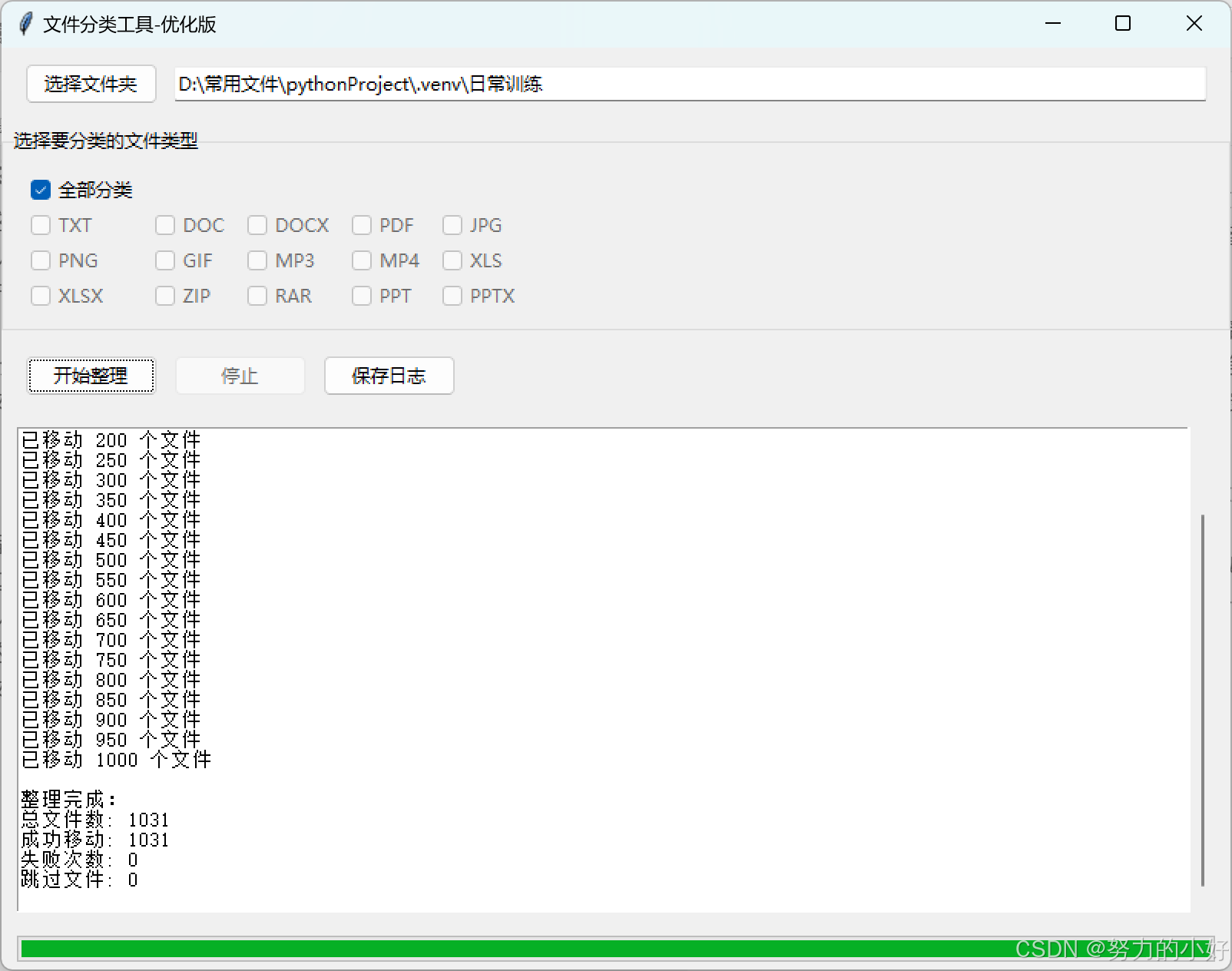
当你运行这段代码时,会弹出一个图形化界面的文件分类工具窗口。在窗口中,你可以通过点击 “选择文件夹” 按钮选择需要整理文件的文件夹路径,该路径会显示在输入框中。
在 “选择要分类的文件类型” 区域,你可以选择 “全部分类”,也可以单独勾选需要分类的文件扩展名类型,如 “TXT”“JPG”“PDF” 等。完成选择后,点击 “开始整理” 按钮,工具将开始扫描文件夹内的文件,并按照你选择的类型进行分类整理。
在整理过程中,进度条会实时显示整理进度,日志区域会记录整理过程中的详细信息,包括每个文件的处理情况、错误信息等。如果在整理过程中你想停止操作,可以点击 “停止” 按钮。整理完成后,你可以点击 “保存日志” 按钮将整理过程中的日志信息保存为文本文件,也可以点击 “查看文件” 按钮直接打开整理后的文件夹查看分类结果。
四、示图
五、作者有话说
代码功能已经过严格测试,确认无误。然而,值得注意的是,测试集的大小仅为3个G,相对而言规模较小,因此无法百分之百保证在所有情况下均无任何问题。鉴于此,强烈建议在使用之前做好数据备份,以防万一出现数据丢失的情况。如果您在使用过程中发现任何bug或问题,欢迎随时留言反馈,作者将及时响应并进行相应的修改。
相关文章:

【Python 打造高效文件分类工具】
【Python】 打造高效文件分类工具 一、代码整体结构二、关键代码解析(一)初始化部分(二)界面创建部分(三)核心功能部分(四)其他辅助功能部分 三、运行与使用四、示图五、作者有话说 …...
| FastGPT+DeepSeek 本地部署)
水务+AI应用探索(一)| FastGPT+DeepSeek 本地部署
在当下的科技浪潮中,AI 无疑是最炙手可热的焦点之一,其强大的能力催生出了丰富多样的应用场景,广泛渗透到各个行业领域。对于水务行业而言,AI 的潜力同样不可估量。为了深入探究 AI 在水务领域的实际应用成效,切实掌握…...

基于若依开发的工程项目管理系统开源免费,用于工程项目投标、进度及成本管理的OA 办公开源系统,非常出色!
一、简介 今天给大家推荐一个基于 RuoYi-Flowable-Plus 框架二次开发的开源工程项目管理系统,专为工程项目的投标管理、项目进度控制、成本管理以及 OA 办公需求设计。 该项目结合了 Spring Boot、Mybatis、Vue 和 ElementUI 等技术栈,提供了丰富的功能…...

最新Apache Hudi 1.0.1源码编译详细教程以及常见问题处理
1.最新Apache Hudi 1.0.1源码编译 2.Flink、Spark、Hive集成Hudi 1.0.1 3.flink streaming写入hudi 目录 1. 版本介绍 2. 安装maven 2.1. 下载maven 2.2. 设置环境变量 2.3. 添加Maven镜像 3. 编译hudi 3.1. 下载hudi源码 3.2. 修改hudi源码 3.3. 修改hudi-1.0.1/po…...

设计模式-工厂模式
设计模式 - 工厂模式 工厂模式(Factory Pattern)是一种创建型设计模式,它通过定义一个用于创建对象的接口,让子类决定实例化哪一个类,从而使得一个类的实例化延迟到子类。工厂模式通过将对象创建的逻辑抽象化…...

基于opencv的HOG+角点匹配教程
1. 引言 在计算机视觉任务中,特征匹配是目标识别、图像配准和物体跟踪的重要组成部分。本文介绍如何使用 HOG(Histogram of Oriented Gradients,方向梯度直方图) 和 角点检测(Corner Detection) 进行特征匹…...

《深度学习》——调整学习率和保存使用最优模型
调整学习率 在使用 PyTorch 进行深度学习训练时,调整学习率是一个重要的技巧,合适的学习率调整策略可以帮助模型更好地收敛。 PyTorch 提供了多种调整学习率的方法,下面将详细介绍几种常见的学习率调整策略及实例代码: torch.opt…...

Ubuntu22.04配置cuda/cudnn/pytorch
Ubuntu22.04配置cuda/cudnn/pytorch 安装cuda官网下载.run文件并且安装/etc/profile中配置cuda环境变量 cudnn安装官网找cuda版本对应的cudnn版本下载复制相应文件到系统文件中 安装pytorch官网找cuda对应版本的pytorchpython代码测试pytorch-GPU版本安装情况 安装cuda 官网下…...

通俗理解-L、-rpath和-rpath-link编译链接动态库
一、参考资料 链接选项 rpath 的应用和原理 | BewareMyPower的博客 使用 rpath 和 rpath-link 确保 samba-util 库正确链接-CSDN博客 编译参数-Wl和rpath的理解_-wl,-rpath-CSDN博客 Using LD, the GNU linker - Options Directory Options (Using the GNU Compiler Colle…...

【Golang】GC探秘/写屏障是什么?
之前写了 一篇【Golang】内存管理 ,有了很多的阅读量,那么我就接着分享一下Golang的GC相关的学习。 由于Golang的GC机制一直在持续迭代,本文叙述的主要是Go1.9版本及以后的GC机制,该版本中Golang引入了 混合写屏障大幅度地优化了S…...
命令详解:head)
Linux(Centos 7.6)命令详解:head
1.命令作用 将每个文件的前10行打印到标准输出(Print the first 10 lines of each FILE to standard output) 2.命令语法 Usage: head [OPTION]... [FILE]... 3.参数详解 OPTION: -c, --bytes[-]K,打印每个文件的前K字节-n, --lines[-],打印前K行而…...
)
【工具变量】上市公司网络安全治理数据(2007-2023年)
网络安全是国家安全体系的重要组成部分,是确保金融体系稳定运行、维护市场信心的关键。网络安全治理是指通过一系列手段和措施,维护网络安全,保护网络环境的稳定和安全,旨在确保公司网络系统免受未经授权的访问、攻击和破坏&#…...

watermark解释
在 Apache Flink 中,Watermark 是处理事件时间(Event Time)的核心机制,用于解决流处理中因数据乱序或延迟到达而导致的窗口计算不准确问题。理解 Watermark 的关键在于以下几点: 1. 事件时间 vs. 处理时间 事件时间&…...
Transformer 模型介绍(四)——编码器 Encoder 和解码器 Decoder
上篇中讲完了自注意力机制 Self-Attention 和多头注意力机制 Multi-Head Attention,这是 Transformer 核心组成部分之一,在此基础上,进一步展开讲一下编码器-解码器结构(Encoder-Decoder Architecture) Transformer 模…...

Linux安装Minio
1、下载rpm包 2、rpm 安装 rpm -ivh xx.rpm3、通过查看minion状态,查看其配置文件位置 systemctl start minio可以根据情况自定义修改配置文件内容,这里暂时不做修改 4、创建数据文件和日志文件,一般在/usr/local/ 5、编写启动脚本 #!/bi…...
)
JAVA EE初阶 - 预备知识(三)
一、中间件 中间件是一种处于操作系统和应用程序之间的软件,它能够为分布式应用提供交互、资源共享、数据处理等功能,是现代软件架构中不可或缺的一部分。下面从多个方面为你详细介绍中间件: 定义与作用 定义:中间件是连接两个或…...

百度热力图数据获取,原理,处理及论文应用6
目录 0、数据简介0、示例数据1、百度热力图数据日期如何选择1.1、其他实验数据的时间1.2、看日历1.3、看天气 2、百度热力图几天够研究?部分文章统计3、数据原理3.1.1 ** 这个比较重要,后面还会再次出现。核密度的值怎么理解?**3.1.2 Csv->…...

tcp连接的11种状态及常见问题。
tcp链接整体流程,如下图所示: TCP协议在连接的建立和终止过程中涉及11种状态,这些状态反映了连接的不同阶段。以下是每种状态的详细说明: 1. CLOSED 初始状态,表示没有活动的连接或连接已完全关闭。当应用程序关闭连…...

宝塔面板开始ssl后,使用域名访问不了后台管理
宝塔面板后台开启ssl访问后,用的证书是其他第三方颁发的证书 再使用 域名/xxx 的形式:https://域名:xxx/xxx 访问后台,结果出现如下,不管使用 http 还是 https 的路径访问都进不后台管理 这个时候可以使用 https://ip/xxx 的方式来…...

5.日常英语笔记
sprouted tater 发芽的土豆 fluid 液体,流体 The doctor recommended drinking plenty of fluids 医生建议多喝流质 适应新环境 adapt to the new environment adjust to the new surroundings get used to the new setting accommodate oneself to the new circu…...

利用工业相机及多光谱图像技术助力医疗美容皮肤AI检测方案
随着年轻人对皮肤的管理要求越来越高,“科技护肤”已成为线下医疗美业护肤行业转型升级之趋势。如何利用先进的图像识别技术和AI大数据分析,为医生和消费者提供个性化的皮肤诊断分析和护肤建议,利用工业相机及多光谱成像技术完美实现这一可能…...

qt QOpenGLTexture详解
1. 概述 QOpenGLTexture 是 Qt5 提供的一个类,用于表示和管理 OpenGL 纹理。它封装了 OpenGL 纹理的创建、分配存储、绑定和设置像素数据等操作,简化了 OpenGL 纹理的使用。 2. 重要函数 构造函数: QOpenGLTexture(const QImage &image,…...

【Zookeeper如何实现分布式锁?】
Zookeeper如何实现分布式锁? 一、ZooKeeper分布式锁的实现原理二、ZooKeeper分布式锁的实现流程三、示例代码四、总结一、ZooKeeper分布式锁的实现原理 ZooKeeper是一个开源的分布式协调服务,它提供了一个分布式文件系统的接口,可以用来存储和管理分布式系统的配置信息。 …...

mysql 学习16 视图,存储过程,存储函数,触发器
视图, 存储过程, 存储函数 触发器...
HTML(一))
(前端基础)HTML(一)
前提 W3C:World Wide Web Consortium(万维网联盟) Web技术领域最权威和具有影响力的国际中立性技术标准机构 其中标准包括:机构化标准语言(HTML、XML) 表现标准语言(CSS) 行为标准…...

go设置镜像代理
前言 在 Go 开发中,如果直接从官方源(https://proxy.golang.org)下载依赖包速度较慢,可以通过设置 镜像代理 来加速依赖包的下载。以下是增加 Go 镜像代理的详细方法: 一、设置 Go 镜像代理 1. 使用环境变量设置代理…...

matlab数据处理:创建网络数据
% 创建网格数据 [X, Y] meshgrid(x_data, y_data); 如 x_data [1 2 3 4] X 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 XY_data [X(:), Y(:)]; % 将X和Y合并成一个向量 X(:)表示将矩阵排成一列 XY_data 1 …...

在企业内部私有化部署 DeepSeek 或其他 AI 大模型时,基于一般场景的最低硬件配置建议
1. 中央处理器(CPU) 核心数:至少 4 核心,支持多线程任务。频率:至少 2.5 GHz。CPU 型号:Intel Core i5 或更高(如 i7 或 i9),或 AMD Ryzen 5000 系列以上。多核支持&…...
)
DeepSeek 助力 Vue 开发:打造丝滑的颜色选择器(Color Picker)
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 Deep…...
:样式_Style的用法)
【ArcGIS Pro二次开发】(87):样式_Style的用法
.Stylx类型的文件即为样式库文件,保存了符号样式。 1、根据名字获取当前工程中的style //获取当前工程中的所有style var ProjectStyles Project.Current.GetItems<StyleProjectItem>();//根据名字找出指定的style StyleProjectItem style ProjectStyles.F…...
)
Jetson Agx Orin平台JP6.0-r36.3版本修复了vi模式下的原始图像损坏(线条伪影)
1.问题描述 这是JP-6.0 GA/ l4t-r36.3.0的一个已知问题 通过vi模式捕获的图像会导致异常线条 参考下面的快照来演示这些线伪影 这个问题只能通过VI模式进行修复,不应该通过LibArgus看到。 此外,这是由于内存问题。 由于upstream已经将属性名称更改为“dma-noncoherent”…...
,训练自己的聊天机器人)
nlp|微调大语言模型初探索(2),训练自己的聊天机器人
前言 上篇文章记录了具体的微调语言大模型步骤,以及在微调过程中可能遇见的各种报错,美中不足的是只是基于开源数据集的微调,今天来记录一下怎么基于自己的数据集去微调大语言模型,训练自己的智能机器人!!&…...

如何搭建Wi-Fi CVE漏洞测试环境:详细步骤与设备配置
引言 随着Wi-Fi技术的普及,Wi-Fi网络成为了现代通信的重要组成部分。然而,Wi-Fi网络的安全性始终是一个备受关注的话题。通过漏洞扫描和安全测试,网络管理员可以及早发现并修复Wi-Fi设备中存在的安全隐患。本篇文章将详细介绍如何搭建Wi-Fi …...

【三维重建】FeatureGS:特征值优化的几何精度和伪影减少3DGS的重构
文章:https://arxiv.org/pdf/2501.17655 标题:FeatureGS: Eigenvalue-Feature Optimization in 3D Gaussian Splatting for Geometrically Accurate and Artifact-Reduced Reconstruction 文章目录 摘要一、引言二、相关工作:3D特征三、算法3…...

请解释一下Standford Alpaca格式、sharegpt数据格式-------deepseek问答记录
1 Standford Alpaca格式 json格式数据。Stanford Alpaca 格式是一种用于训练和评估自然语言处理(NLP)模型的数据格式,特别是在指令跟随任务中。它由斯坦福大学的研究团队开发,旨在帮助模型理解和执行自然语言指令。以下是该格式的…...
)
WPS的AI助手进化跟踪(灵犀+插件)
Ver V0.0 250216: 如何给WPS安装插件用以支持其他大模型LLM V0.1 250217: WPS的灵犀AI现在是DeepSeek R1(可能是全参数671B) 前言 WPS也有内置的AI,叫灵犀,之前应是自已的LLM模型,只能说是属于“能用,有好过无”,所…...

本地事务简介
本地事务简介 1 事务基本性质 数据库事务的几个特性:原子性(Automicity)、一致性(Consistency)、隔离性或独立性(islation)和持久性(Durability),简称ACID。 原子性:一系列的操作,其整体不可拆分,要么同时成功&#…...
)
Python入门全攻略(七)
面向对象-基础 类和对象 类是一个抽象的概念,对象是一个具体的概念。类是对象的模板和蓝图,用来定义对象的属性和方法,对象是类的实例,具有具体的属性和行为。 类的定义 使用class关键字加上类名来定义类,在类的代码块中,我们可以写一些函数,这些函数是对一类对象共…...

SpringBoot 统一功能处理之拦截器、数据返回格式、异常处理
目录 拦截器 一、什么是拦截器 二 拦截器的使用 三 拦截路径配置 四 拦截器的执行流程 统一数据返回格式 统一异常处理 拦截器 一、什么是拦截器 拦截器是Spring框架提供的核心功能之一,主要用来拦截用户的请求,在指定方法前后,根据业务…...

Javascript网页设计案例:通过PDF.js实现一款PDF阅读器,包括预览、页面旋转、页面切换、放大缩小、黑夜模式等功能
前言 目前功能包括: 切换到首页。切换到尾页。上一页。下一页。添加标签。标签管理页面旋转页面随意拖动双击后还原位置 其实按照自己的预期来说,有很多功能还没有开发完,配色也没有全都搞完,先发出来吧,后期有需要…...

js考核第三题
题三:随机点名 要求: 分为上下两个部分,上方为显示区域,下方为控制区域。显示区域显示五十位群成员的学号和姓名,控制区域由开始和结束两个按钮 组成。点击开始按钮,显示区域里的内容开始滚动,…...

新型基于Go语言的恶意软件利用Telegram作为C2通信渠道
研究人员发现了一种新型后门恶意软件,使用Go语言编写,并利用Telegram作为其命令与控制(C2)通信渠道。尽管该恶意软件似乎仍处于开发阶段,但它已经具备完整的功能,能够执行多种恶意活动。这种创新的C2通信方…...
)
【Python 语法】Python 正则表达式(regular expressions, regex)
1. 基本语法1.1 字符匹配1.2 元字符1.3 特殊字符1.4 分组和捕获1.5 断言2. 常用函数2.1 `re.match()`2.2 `re.search()`2.3 `re.findall()`2.4 `re.sub()`2.5 `re.split()`3. 进阶用法3.1 捕获组3.2 非捕获组3.3 预查Python 中的**正则表达式(regular expressions, regex)**是…...

STM32 如何使用DMA和获取ADC
目录 背景 摇杆的原理 程序 端口配置 ADC 配置 DMA配置 背景 DMA是一种计算机技术,允许某些硬件子系统直接访问系统内存,而不需要中央处理器(CPU)的介入,从而减轻CPU的负担。我们可以通过DMA来从外设…...

【原创】vue-element-admin-plus完成编辑页面中嵌套列表功能
前言 vue-element-admin-plus对于复杂业务的支持程度确实不怎么样,我这里就遇到了编辑页面中还要嵌套列表的真实案例,比如字典,主字典嵌套子信息,类似于一个树状结构。目前vue-element-admin-plus给出的例子是无法满足这个需求的…...
程序控制)
Java零基础入门笔记:(3)程序控制
前言 本笔记是学习狂神的java教程,建议配合视频,学习体验更佳。 【狂神说Java】Java零基础学习视频通俗易懂_哔哩哔哩_bilibili Scanner对象 之前我们学的基本语法中我们并没有实现程序和人的交互,但是Java给我们提供了这样一个工具类&…...

拷打,数据库面经!
数据库必会面试题 1. 请解释数据库中的MVCC(多版本并发控制)机制,并说明其在MySQL InnoDB中的具体实现方式? 答案: MVCC是一种通过维护数据的历史版本实现高并发的技术,允许读操作不阻塞写操作࿰…...

Docker+DockerCompose+Harbor安装
安装docker # 安装yum工具 yum install yum-utils -y# 配置yum源 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo# 安装docker yum install -y docker-ce-25.0.3 docker-ce-cli-25.0.3 containerd.io# 加载镜像 systemctl d…...
Reward Centering(一))
论文笔记(七十二)Reward Centering(一)
Reward Centering(一) 文章概括摘要1 奖励中心化理论 文章概括 引用: article{naik2024reward,title{Reward Centering},author{Naik, Abhishek and Wan, Yi and Tomar, Manan and Sutton, Richard S},journal{arXiv preprint arXiv:2405.0…...

在springboot加vue项目中加入图形验证码
后端 首先先要创建一个CaptchaController的类,可以在下面的代码中看到 在getCaptcha的方法里面写好了生成随机的4位小写字母或数字的验证码,然后通过BufferedImage类变为图片,顺便加上了干扰线。之后把图片转为Base64编码方便传给前端 为了…...