BFS-FloodFill 算法 解决最短路问题 多源 解决拓扑排序
文章目录
- 一、FloodFill 算法
- [733. 图像渲染](https://leetcode.cn/problems/flood-fill/description/)
- 2.思路
- 3.代码
- [200. 岛屿数量](https://leetcode.cn/problems/number-of-islands/description/)
- 2.思路
- 3.代码
- [LCR 105. 岛屿的最大面积](https://leetcode.cn/problems/ZL6zAn/description/)
- 2.思路
- 3.代码
- [130. 被围绕的区域](https://leetcode.cn/problems/surrounded-regions/description/)
- 2.思路
- 3.代码
- 二、最短路径
- [1926. 迷宫中离入口最近的出口](https://leetcode.cn/problems/nearest-exit-from-entrance-in-maze/description/)
- 2.思路
- 3.代码
- [433. 最小基因变化](https://leetcode.cn/problems/minimum-genetic-mutation/description/)
- 2.思路
- 3.代码
- [LCR 108. 单词接龙](https://leetcode.cn/problems/om3reC/description/)
- 2.思路
- 3.代码
- [675. 为高尔夫比赛砍树](https://leetcode.cn/problems/cut-off-trees-for-golf-event/description/)-hard待研究
- 2.思路
- 3.代码
- 三、多源 BFS
- [LCR 107. 01 矩阵](https://leetcode.cn/problems/2bCMpM/description/)
- 2.思路
- 3.代码
- [1020. 飞地的数量](https://leetcode.cn/problems/number-of-enclaves/description/)
- 2.思路
- 3.代码
- [1765. 地图中的最高点](https://leetcode.cn/problems/map-of-highest-peak/description/)
- 2.思路
- 3.代码
- [1162. 地图分析](https://leetcode.cn/problems/as-far-from-land-as-possible/description/)
- 2.思路
- 3.代码
- 四、拓扑排序
- [207. 课程表](https://leetcode.cn/problems/course-schedule/description/)
- 2.思路
- 3.代码
- [210. 课程表 II](https://leetcode.cn/problems/course-schedule-ii/description/)
- 2.思路
- 3.代码
- [LCR 114. 火星词典](https://leetcode.cn/problems/Jf1JuT/description/)-hard待研究
- 2.思路
- 示例解释
- 3.代码
一、FloodFill 算法
洪水灌溉,可以用BFS也可以用DFS
//辅助数组visited中存放所有节点
//初始化为0,访问过后设置为1
void BFS (Graph G, int v){ //按广度优先非递归遍历连通图Gcout<<v; visited[v] = 1; //访问第v个顶点queue<int> q; //辅助队列Q初始化,置空q.push(v); //v进队while(!q.empty()){ //队列非空q.pop(); //队头元素出队并置为ufor (int i = 0; i < G.vexnum; i++) {int w = G.vex[i];if (G.edge[k][i] && !visited[i]) {//v和i有边且没有被访问cout << w;q.push(w);visited[i] = 1;}}}
}
//调用
void BFStraverse(graph) {for (int v = 0; v < G.vexnum; ++v)visited[v] = 0;for (int v = 0; v < G.vexnum; ++v)if (!visited[v])BFS(G, G.vex[v]);
}733. 图像渲染
有一幅以 m x n 的二维整数数组表示的图画 image ,其中 image[i][j] 表示该图画的像素值大小。你也被给予三个整数 sr , sc 和 color 。你应该从像素 image[sr][sc] 开始对图像进行上色 填充 。
为了完成 上色工作:
- 从初始像素开始,将其颜色改为 `color`。- 对初始坐标的 **上下左右四个方向上** 相邻且与初始像素的原始颜色同色的像素点执行相同操作。- 通过检查与初始像素的原始颜色相同的相邻像素并修改其颜色来继续 **重复** 此过程。- 当 **没有** 其它原始颜色的相邻像素时 **停止** 操作。
最后返回经过上色渲染 修改 后的图像 。
示例 1:
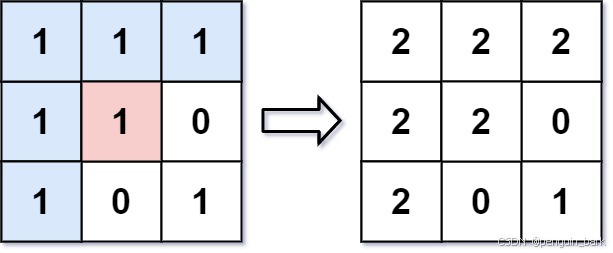
**输入:**image = [[1,1,1],[1,1,0],[1,0,1]],sr = 1, sc = 1, color = 2
输出:[[2,2,2],[2,2,0],[2,0,1]]
解释:在图像的正中间,坐标 (sr,sc)=(1,1) (即红色像素),在路径上所有符合条件的像素点的颜色都被更改成相同的新颜色(即蓝色像素)。
注意,右下角的像素 没有 更改为2,因为它不是在上下左右四个方向上与初始点相连的像素点。
示例 2:
**输入:**image = [[0,0,0],[0,0,0]], sr = 0, sc = 0, color = 0
输出:[[0,0,0],[0,0,0]]
**解释:**初始像素已经用 0 着色,这与目标颜色相同。因此,不会对图像进行任何更改。
2.思路
使用一个队列来存储待处理的像素点,将起始点加入队列并将其颜色替换为目标颜色,然后不断从队列中取出像素点,检查其上下左右相邻的像素点,如果相邻像素点的颜色与起始点的原始颜色相同,则将其颜色替换为目标颜色并加入队列,直到队列为空
3.代码
class Solution {
public:// BFS 函数用于执行广度优先搜索,对图像中与起始点颜色相同且相连通的区域进行颜色替换void BFS(std::vector<std::vector<int>>& image, int sr, int sc, int currColor, int color) {// 定义一个队列,用于存储待处理的像素点,每个像素点用一个 std::pair<int, int> 表示,分别代表行和列std::queue<std::pair<int, int>> q;// 将起始点加入队列q.push({sr, sc});// 立即将起始点的颜色替换为目标颜色,避免后续重复处理该点image[sr][sc] = color;// 当队列不为空时,继续处理队列中的像素点while (!q.empty()) {// 取出队列头部的像素点int x = q.front().first, y = q.front().second;// 将该像素点从队列中移除q.pop();// 检查当前像素点左侧的像素点if (y - 1 >= 0 && image[x][y - 1] == currColor) {// 若左侧像素点存在且颜色与起始点的原始颜色相同// 将其颜色替换为目标颜色image[x][y - 1] = color;// 将该像素点加入队列,以便后续处理其相邻像素点q.push({x, y - 1});}// 检查当前像素点右侧的像素点if (y + 1 < image[0].size() && image[x][y + 1] == currColor) {// 若右侧像素点存在且颜色与起始点的原始颜色相同// 将其颜色替换为目标颜色image[x][y + 1] = color;// 将该像素点加入队列,以便后续处理其相邻像素点q.push({x, y + 1});}// 检查当前像素点上方的像素点if (x - 1 >= 0 && image[x - 1][y] == currColor) {// 若上方像素点存在且颜色与起始点的原始颜色相同// 将其颜色替换为目标颜色image[x - 1][y] = color;// 将该像素点加入队列,以便后续处理其相邻像素点q.push({x - 1, y});}// 检查当前像素点下方的像素点if (x + 1 < image.size() && image[x + 1][y] == currColor) {// 若下方像素点存在且颜色与起始点的原始颜色相同// 将其颜色替换为目标颜色image[x + 1][y] = color;// 将该像素点加入队列,以便后续处理其相邻像素点q.push({x + 1, y});}}}// floodFill 函数是对外提供的接口,用于调用 BFS 函数完成图像填充操作std::vector<std::vector<int>> floodFill(std::vector<std::vector<int>>& image, int sr, int sc, int color) {// 获取起始点的当前颜色int currColor = image[sr][sc];// 若起始点的当前颜色与目标填充颜色不同,则调用 BFS 函数进行填充if (currColor != color) {BFS(image, sr, sc, currColor, color);}// 返回填充后的图像return image;}
};
200. 岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
**输入:**grid = [["1","1","1","1","0"],["1","1","0","1","0"],["1","1","0","0","0"],["0","0","0","0","0"]
]
**输出:**1示例 2:
**输入:**grid = [["1","1","0","0","0"],["1","1","0","0","0"],["0","0","1","0","0"],["0","0","0","1","1"]
]
**输出:**32.思路
遍历整个二维数组,返回有多少个完全被0隔开的岛屿1。广度优先搜索的过程,只要队列不为空,就从队列中取出一个位置的坐标。针对这个位置,检查其上下左右四个相邻位置。若相邻位置在网格范围内、值为 '1' 且未被访问过,就将该相邻位置的坐标加入队列,并标记为已访问。通过这种方式,不断扩展当前岛屿所覆盖的范围,直至队列为空,意味着当前岛屿的所有位置都已被访问过。visited默认是 false
3.代码
class Solution {
public:bool visited[301][301];int numIslands(vector<vector<char>>& grid) {queue<pair<int, int>> q;int r = grid.size();int c = grid[0].size();int ret = 0;for (int i = 0; i < r; ++i) {for (int j = 0; j < c; ++j) {if (grid[i][j] == '1' && visited[i][j] == false) {ret++;q.push({i, j});visited[i][j] = true;while (!q.empty()) {int x = q.front().first, y = q.front().second;q.pop();if(y-1>=0 && grid[x][y-1] == '1' && visited[x][y-1] == false){q.push({x, y-1});visited[x][y-1] = true;}if(y+1<grid[0].size() && grid[x][y+1] == '1' && visited[x][y+1] == false){q.push({x, y+1});visited[x][y+1] = true;}if(x-1>=0 && grid[x-1][y] == '1' && visited[x-1][y] == false){q.push({x-1, y});visited[x-1][y] = true;}if(x+1<grid.size() && grid[x+1][y] == '1' && visited[x+1][y] == false){q.push({x+1, y});visited[x+1][y] = true;}}}}}return ret;}
};
LCR 105. 岛屿的最大面积
给定一个由 0 和 1 组成的非空二维数组 grid ,用来表示海洋岛屿地图。
一个 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
找到给定的二维数组中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
示例 1:
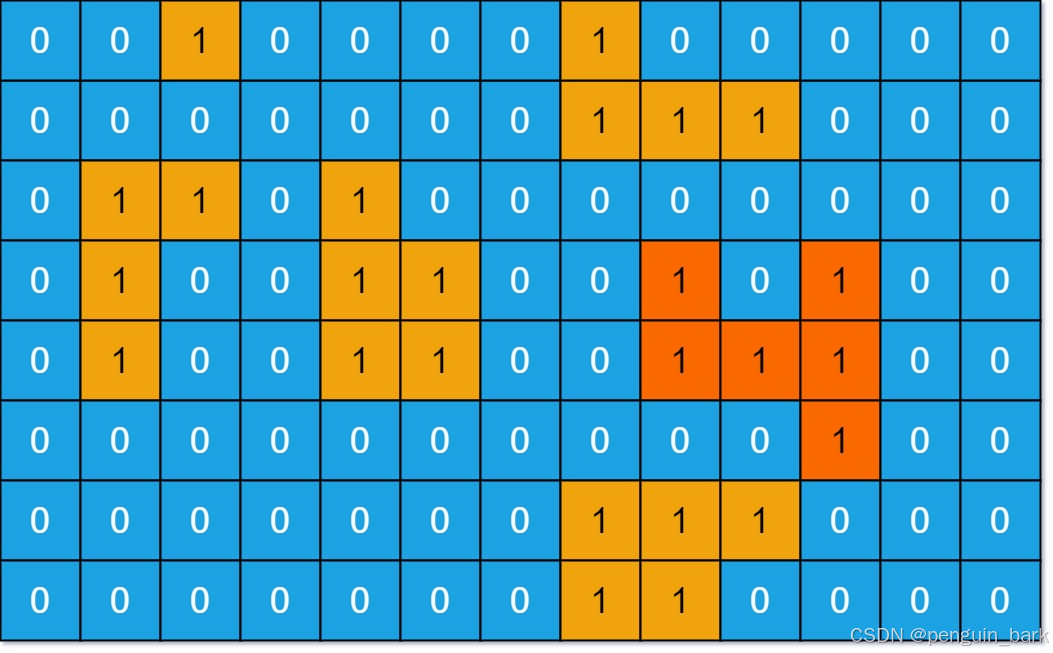
**输入: **grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]]
**输出: **6
**解释: **对于上面这个给定矩阵应返回 `6`。注意答案不应该是 `11` ,因为岛屿只能包含水平或垂直的四个方向的 `1` 。
示例 2:
**输入: **grid = [[0,0,0,0,0,0,0,0]]
**输出: **0
2.思路
初始化相关变量:定义一个 visited 二维布尔数组,用于标记网格中每个位置是否已被访问;获取网格的行数和列数;创建一个队列用于 BFS;初始化最大岛屿面积为 0。
遍历网格:使用两层嵌套的 for 循环遍历整个网格。对于每个未被访问且值为 1(表示陆地)的位置,将其标记为已访问,并将其作为一个新岛屿的起始点。
BFS 搜索当前岛屿:将起始点加入队列,开始 BFS 过程。在 BFS 中,从队列中取出一个位置,检查其上下左右四个相邻位置。若相邻位置合法(在网格范围内)、为陆地且未被访问过,则将该相邻位置标记为已访问,岛屿面积加 1,并将其加入队列继续搜索。
更新最大岛屿面积:当当前岛屿的 BFS 搜索结束后,将该岛屿的面积与之前记录的最大岛屿面积进行比较,取较大值更新最大岛屿面积。
3.代码
class Solution {
public:// 用于标记网格中每个位置是否被访问过的二维数组bool visited[51][51];int maxAreaOfIsland(std::vector<std::vector<int>>& grid) {// 获取网格的行数int r = grid.size();// 获取网格的列数int c = grid[0].size();// 定义一个队列,用于广度优先搜索(BFS),存储待处理的网格位置std::queue<std::pair<int, int>> q;// 用于记录最大岛屿面积int ret = 0;// 遍历网格的每一行for (int i = 0; i < r; ++i) {// 遍历网格的每一列for (int j = 0; j < c; ++j) {// 如果当前位置未被访问过且为陆地(值为 1)if (!visited[i][j] && grid[i][j] == 1) {// 标记当前位置为已访问visited[i][j] = true;// 初始化当前岛屿的面积,起始点面积为 1int sum = 1;// 将当前位置加入队列,准备进行 BFSq.push({i, j});// 开始 BFS 过程,只要队列不为空,就继续处理while (!q.empty()) {// 获取队列头部元素的行和列坐标int x = q.front().first, y = q.front().second;// 从队列中移除头部元素q.pop();// 检查当前位置左侧的位置if (y - 1 >= 0 && grid[x][y - 1] == 1 && !visited[x][y - 1]) {// 若左侧位置合法、为陆地且未被访问过,当前岛屿面积加 1sum++;// 标记左侧位置为已访问visited[x][y - 1] = true;// 将左侧位置加入队列q.push({x, y - 1});}// 检查当前位置右侧的位置if (y + 1 < c && grid[x][y + 1] == 1 && !visited[x][y + 1]) {// 若右侧位置合法、为陆地且未被访问过,当前岛屿面积加 1sum++;// 标记右侧位置为已访问visited[x][y + 1] = true;// 将右侧位置加入队列q.push({x, y + 1});}// 检查当前位置上方的位置if (x - 1 >= 0 && grid[x - 1][y] == 1 && !visited[x - 1][y]) {// 若上方位置合法、为陆地且未被访问过,当前岛屿面积加 1sum++;// 标记上方位置为已访问visited[x - 1][y] = true;// 将上方位置加入队列q.push({x - 1, y});}// 检查当前位置下方的位置if (x + 1 < r && grid[x + 1][y] == 1 && !visited[x + 1][y]) {// 若下方位置合法、为陆地且未被访问过,当前岛屿面积加 1sum++;// 标记下方位置为已访问visited[x + 1][y] = true;// 将下方位置加入队列q.push({x + 1, y});}}// 更新最大岛屿面积ret = std::max(ret, sum);}}}// 返回最大岛屿面积return ret;}
};
130. 被围绕的区域
给你一个 m x n 的矩阵 board ,由若干字符 'X' 和 'O' 组成,捕获 所有 被围绕的区域:
- **连接:**一个单元格与水平或垂直方向上相邻的单元格连接。- **区域:连接所有 **`'O'` 的单元格来形成一个区域。- **围绕:**如果您可以用 `'X'` 单元格 **连接这个区域**,并且区域中没有任何单元格位于 `board` 边缘,则该区域被 `'X'` 单元格围绕。
通过 原地 将输入矩阵中的所有 'O' 替换为 'X' 来 捕获被围绕的区域。你不需要返回任何值。
示例 1:
**输入:**board = [[“X”,“X”,“X”,“X”],[“X”,“O”,“O”,“X”],[“X”,“X”,“O”,“X”],[“X”,“O”,“X”,“X”]]
输出:[[“X”,“X”,“X”,“X”],[“X”,“X”,“X”,“X”],[“X”,“X”,“X”,“X”],[“X”,“O”,“X”,“X”]]
解释:
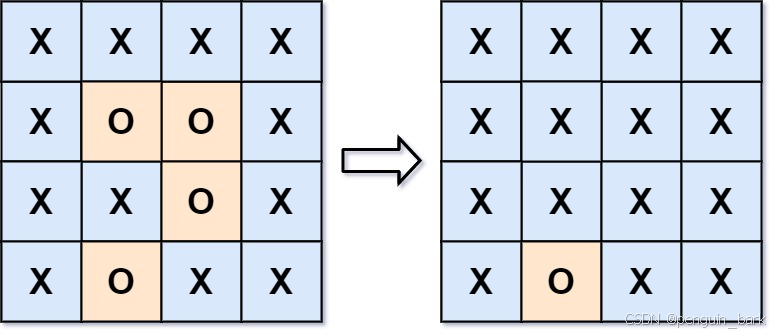
在上图中,底部的区域没有被捕获,因为它在 board 的边缘并且不能被围绕。
示例 2:
**输入:**board = [[“X”]]
输出:[[“X”]]
2.思路
注意是X和O不是数字0,。
找出边界上的 'O':遍历矩阵的四条边界,将边界上的 'O' 加入队列,并标记为已访问。
广度优先搜索(BFS):从队列中的边界 'O' 开始进行 BFS 遍历,将与这些边界 'O' 相连的所有 'O' 都标记为已访问。
替换未标记的 'O':遍历整个矩阵,将未被标记为已访问的 'O' 替换为 'X'。
3.代码
class Solution {
public:// 用于标记矩阵中每个位置是否已被访问bool visited[201][201];void solve(std::vector<std::vector<char>>& board) {// 获取矩阵的行数int r = board.size();// 如果矩阵为空,直接返回if (r == 0) return;// 获取矩阵的列数int c = board[0].size();// 用于进行广度优先搜索(BFS)的队列,存储位置信息std::queue<std::pair<int, int>> q;// 第一步:将边界上的 'O' 加入队列并标记为已访问// 遍历矩阵的左右边界for (int i = 0; i < r; ++i) {// 检查左边界的元素是否为 'O' 且未被访问过if (board[i][0] == 'O' && !visited[i][0]) {// 标记该位置为已访问visited[i][0] = true;// 将该位置加入队列q.push({i, 0});}// 检查右边界的元素是否为 'O' 且未被访问过if (board[i][c - 1] == 'O' && !visited[i][c - 1]) {// 标记该位置为已访问visited[i][c - 1] = true;// 将该位置加入队列q.push({i, c - 1});}}// 遍历矩阵的上下边界for (int j = 0; j < c; ++j) {// 检查上边界的元素是否为 'O' 且未被访问过if (board[0][j] == 'O' && !visited[0][j]) {// 标记该位置为已访问visited[0][j] = true;// 将该位置加入队列q.push({0, j});}// 检查下边界的元素是否为 'O' 且未被访问过if (board[r - 1][j] == 'O' && !visited[r - 1][j]) {// 标记该位置为已访问visited[r - 1][j] = true;// 将该位置加入队列q.push({r - 1, j});}}// 第二步:进行广度优先搜索(BFS),标记与边界 'O' 相连的所有 'O'while (!q.empty()) {// 取出队列的队首元素int x = q.front().first, y = q.front().second;// 将队首元素出队q.pop();// 检查当前位置左侧元素是否为 'O' 且未被访问过if (y - 1 >= 0 && board[x][y - 1] == 'O' && !visited[x][y - 1]) {// 标记该位置为已访问visited[x][y - 1] = true;// 将该位置加入队列q.push({x, y - 1});}// 检查当前位置右侧元素是否为 'O' 且未被访问过if (y + 1 < c && board[x][y + 1] == 'O' && !visited[x][y + 1]) {// 标记该位置为已访问visited[x][y + 1] = true;// 将该位置加入队列q.push({x, y + 1});}// 检查当前位置上方元素是否为 'O' 且未被访问过if (x - 1 >= 0 && board[x - 1][y] == 'O' && !visited[x - 1][y]) {// 标记该位置为已访问visited[x - 1][y] = true;// 将该位置加入队列q.push({x - 1, y});}// 检查当前位置下方元素是否为 'O' 且未被访问过if (x + 1 < r && board[x + 1][y] == 'O' && !visited[x + 1][y]) {// 标记该位置为已访问visited[x + 1][y] = true;// 将该位置加入队列q.push({x + 1, y});}}// 第三步:将未被标记的 'O' 转换为 'X'for (int i = 0; i < r; ++i) {for (int j = 0; j < c; ++j) {// 检查当前位置是否为 'O' 且未被访问过if (board[i][j] == 'O' && !visited[i][j]) {// 将该位置的 'O' 替换为 'X'board[i][j] = 'X';}}}}
};
二、最短路径
边权为1或者边权相同就可以,相当于从起点有多个单位从不同路线同时向终点移动,且每个单位每次移动距离一样
//求顶点u到其他顶点的最短路径
void BFS_Distance(Graph G, int v) {for (i = 0; i < G.vexnum; ++i) {dis[i] = INT_MAX;//初始化路径长度path[i] = -1;//最短路径的前驱}dis[v] = 0;visited[v] = 1;q.push(v);while (!q.empty()) {int tmp = q.front();q.pop();for (int i = 0; i < G.vexnum; i++) {int w = G.vex[i];if (G.edge[tmp][i] && !visited[i]) {dis[w] = dis[tmp] + 1;path[w] = tmp;visited[w] = 1;q.push(w);}}}
}1926. 迷宫中离入口最近的出口
给你一个 m x n 的迷宫矩阵 maze (下标从 0 开始),矩阵中有空格子(用 '.' 表示)和墙(用 '+' 表示)。同时给你迷宫的入口 entrance ,用 entrance = [entrancerow, entrancecol] 表示你一开始所在格子的行和列。
每一步操作,你可以往 上,下,左 或者 右 移动一个格子。你不能进入墙所在的格子,你也不能离开迷宫。你的目标是找到离 entrance 最近 的出口。出口 的含义是 maze 边界 上的 空格子。entrance 格子 不算 出口。
请你返回从 entrance 到最近出口的最短路径的 步数 ,如果不存在这样的路径,请你返回 -1 。
示例 1:

输入:maze = [["+","+",".","+"],[".",".",".","+"],["+","+","+","."]], entrance = [1,2]
输出:1
解释:总共有 3 个出口,分别位于 (1,0),(0,2) 和 (2,3) 。
一开始,你在入口格子 (1,2) 处。
- 你可以往左移动 2 步到达 (1,0) 。
- 你可以往上移动 1 步到达 (0,2) 。
从入口处没法到达 (2,3) 。
所以,最近的出口是 (0,2) ,距离为 1 步。示例 2:

输入:maze = [["+","+","+"],[".",".","."],["+","+","+"]], entrance = [1,0]
输出:2
解释:迷宫中只有 1 个出口,在 (1,2) 处。
(1,0) 不算出口,因为它是入口格子。
初始时,你在入口与格子 (1,0) 处。
- 你可以往右移动 2 步到达 (1,2) 处。
所以,最近的出口为 (1,2) ,距离为 2 步。示例 3:

输入:maze = [[".","+"]], entrance = [0,0]
输出:-1
解释:这个迷宫中没有出口。2.思路
初始化:将入口位置加入队列,并标记为已访问,同时初始化步数为 0。
BFS 遍历:
- 当队列不为空时,记录当前队列的大小,这个大小代表当前层的节点数量。
- 遍历当前层的所有节点,对于每个节点,检查它是否为出口(在迷宫边界且不是入口),如果是则返回当前步数。
- 若不是出口,检查该节点的上、下、左、右四个相邻节点,如果相邻节点在迷宫范围内、未被访问过且为通路,则标记为已访问并加入队列。
注意:层遍历的特性来保证首次找到的出口就是距离入口最近的出口,所以每层找完都向外扩张了一层
步数更新:遍历完当前层的所有节点后,步数加 1。
结果判断:如果队列为空还没有找到出口,则返回 -1。
3.代码
class Solution {
public:// 用于标记迷宫中每个位置是否已被访问bool visited[101][101];int nearestExit(std::vector<std::vector<char>>& maze, std::vector<int>& entrance) {// 获取迷宫的行数int r = maze.size();// 获取迷宫的列数int c = maze[0].size();// 用于进行广度优先搜索(BFS)的队列,存储位置信息std::queue<std::pair<int, int>> q;// 将入口位置加入队列q.push({entrance[0], entrance[1]});// 标记入口位置为已访问visited[entrance[0]][entrance[1]] = true;// 初始化步数为 0int ret = 0;// 当队列不为空时,继续进行 BFS 遍历while (!q.empty()) {// 记录当前队列的大小,即当前层的节点数量int size = q.size();// 遍历当前层的所有节点for (int i = 0; i < size; ++i) {// 取出队列的队首元素int x = q.front().first, y = q.front().second;// 将队首元素出队q.pop();// 判断当前位置是否到出口了if ((x == 0 || y == 0 || x == r - 1 || y == c - 1) &&(x != entrance[0] || y != entrance[1])) {// 如果是出口,返回当前步数return ret;}// 检查当前位置左侧元素是否为通路且未被访问过if (y - 1 >= 0 && visited[x][y - 1] == false &&maze[x][y - 1] == '.') {// 标记该位置为已访问visited[x][y - 1] = true;// 将该位置加入队列q.push({x, y - 1});}// 检查当前位置右侧元素是否为通路且未被访问过if (y + 1 < maze[0].size() && visited[x][y + 1] == false &&maze[x][y + 1] == '.') {// 标记该位置为已访问visited[x][y + 1] = true;// 将该位置加入队列q.push({x, y + 1});}// 检查当前位置上方元素是否为通路且未被访问过if (x - 1 >= 0 && visited[x - 1][y] == false &&maze[x - 1][y] == '.') {// 标记该位置为已访问visited[x - 1][y] = true;// 将该位置加入队列q.push({x - 1, y});}// 检查当前位置下方元素是否为通路且未被访问过if (x + 1 < maze.size() && visited[x + 1][y] == false &&maze[x + 1][y] == '.') {// 标记该位置为已访问visited[x + 1][y] = true;// 将该位置加入队列q.push({x + 1, y});}}// 遍历完当前层的所有节点后,步数加 1++ret;}// 如果队列为空还没有找到出口,返回 -1return -1;}
};
433. 最小基因变化
基因序列可以表示为一条由 8 个字符组成的字符串,其中每个字符都是 'A'、'C'、'G' 和 'T' 之一。
假设我们需要调查从基因序列 start 变为 end 所发生的基因变化。一次基因变化就意味着这个基因序列中的一个字符发生了变化。
- 例如,`"AACCGGTT" --> "AACCGGTA"` 就是一次基因变化。
另有一个基因库 bank 记录了所有有效的基因变化,只有基因库中的基因才是有效的基因序列。(变化后的基因必须位于基因库 bank 中)
给你两个基因序列 start 和 end ,以及一个基因库 bank ,请你找出并返回能够使 start 变化为 end 所需的最少变化次数。如果无法完成此基因变化,返回 -1 。
注意:起始基因序列 start 默认是有效的,但是它并不一定会出现在基因库中。
示例 1:
**输入:**start = "AACCGGTT", end = "AACCGGTA", bank = ["AACCGGTA"]
**输出:**1示例 2:
**输入:**start = "AACCGGTT", end = "AAACGGTA", bank = ["AACCGGTA","AACCGCTA","AAACGGTA"]
**输出:**2示例 3:
**输入:**start = "AAAAACCC", end = "AACCCCCC", bank = ["AAAACCCC","AAACCCCC","AACCCCCC"]
**输出:**32.思路
基因变了之后如果不在bank里就不能这么变。
数据预处理:将基因库 bank 中的所有基因序列存入一个无序集合 set 中,方便后续快速判断某个基因序列是否在基因库内。同时检查目标基因序列 endGene 是否在基因库中,若不在则直接返回 -1,表示无法完成转变。
初始化:把起始基因序列 startGene 加入队列 q 作为 BFS 的起始点,并将其标记为已访问,存入 visited 集合。初始化变化步数 ret 为 0。
BFS 遍历:
- 当队列不为空时,记录当前队列的大小
size,它代表当前层的基因序列数量。 - 遍历当前层的所有基因序列,对于每个基因序列:
- 检查其是否等于目标基因序列
endGene,若是则返回当前步数ret,由于是层序遍历,所以都是同时往外扩张,当start 和end 序列相等时,所用的步数最少 - 遍历该基因序列的每一个位置,尝试将该位置的碱基替换为其他三种可能的碱基(A、C、G、T)。
- 检查替换后的基因序列是否在基因库中且未被访问过,若是则将其加入队列
q并标记为已访问。
- 检查其是否等于目标基因序列
步数更新:遍历完当前层的所有基因序列后,将步数 ret 加 1。
结果判断:若队列为空仍未找到目标基因序列,则返回 -1,表示无法完成转变。
3.代码
class Solution {
public:int minMutation(std::string startGene, std::string endGene,std::vector<std::string>& bank) {// 定义一个无序集合 set,用于存储基因库中的所有基因序列,方便快速查找// 遍历基因库 bank,将其中的每个基因序列插入到集合 set 中unordered_set<string> set(bank.begin(), bank.end());// 检查目标基因序列 endGene 是否在基因库 set// 中,若不在则无法完成转变,直接返回 -1if (set.find(endGene) == set.end())return -1;// 定义一个队列 q,用于进行广度优先搜索(BFS),将起始基因序列 startGene// 加入队列std::queue<std::string> q;q.push(startGene);// 初始化变化步数 ret 为 0int ret = 0;// 定义一个字符数组 bases,包含所有可能的碱基(A、C、G、T)char base[] = {'A', 'C', 'G', 'T'};// 定义一个无序集合 visited,用于记录已经访问过的基因序列,避免重复处理std::unordered_set<std::string> visited;// 将起始基因序列 startGene 标记为已访问,加入 visited 集合visited.insert(startGene);// 当队列 q 不为空时,继续进行 BFS 遍历while (!q.empty()) {// 记录当前队列的大小 size,即当前层的基因序列数量int size = q.size();// 遍历当前层的所有基因序列for (int i = 0; i < size; ++i) {// 取出队列 q 的队首元素,即当前要处理的基因序列std::string tmp = q.front();// 将队首元素从队列中移除q.pop();// 检查当前基因序列是否等于目标基因序列// endGene,若是则返回当前步数 retif (tmp == endGene) {return ret;}// 遍历当前基因序列的每一个位置for (int j = 0; j < tmp.length(); ++j) {// 保存当前位置的原始碱基char original = tmp[j];// 尝试将当前位置的碱基替换为其他三种可能的碱基for (int k = 0; k < 4; ++k) {// 将当前位置的碱基替换为新的碱基tmp[j] = base[k];// 检查替换后的基因序列是否在基因库 set 中且未被访问过if (set.find(tmp) != set.end() &&visited.find(tmp) == visited.end()) {// 若满足条件,则将替换后的基因序列加入队列 qq.push(tmp);// 并将其标记为已访问,加入 visited 集合visited.insert(tmp);}}// 恢复当前位置的原始碱基,以便继续处理下一个位置tmp[j] = original;}}// 遍历完当前层的所有基因序列后,将步数 ret 加 1ret++;}// 若队列为空仍未找到目标基因序列,返回 -1 表示无法完成转变return -1;}
};
LCR 108. 单词接龙
在字典(单词列表) wordList 中,从单词 beginWord 和 endWord 的 **转换序列 **是一个按下述规格形成的序列:
- 序列中第一个单词是 `beginWord` 。- 序列中最后一个单词是 `endWord` 。- 每次转换只能改变一个字母。- 转换过程中的中间单词必须是字典 `wordList` 中的单词。
给定两个长度相同但内容不同的单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
示例 1:
**输入:**beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
**输出:**5
**解释:**一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。示例 2:
**输入:**beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
**输出:**0
**解释:**endWord "cog" 不在字典中,所以无法进行转换。
2.思路
和基因题目差不多,数据范围变大了,26的字母。“单词接龙” 无法完成转换时返回 0;“最小基因变化” 无法完成转变时返回 -1。“单词接龙” 中起始单词算一步,所以步数初始值为 1;“最小基因变化” 中步数初始值为 0。
3.代码
class Solution {
public:int ladderLength(string beginWord, string endWord,vector<string>& wordList) {// 定义一个无序集合 wordSet,用于存储字典中的所有单词,方便快速查找// 遍历字典 wordList,将其中的每个单词插入到集合 wordSet 中unordered_set<string> wordSet(wordList.begin(), wordList.end());// 检查目标单词 endWord 是否在字典 wordSet// 中,若不在则无法完成转换,直接返回 0if (wordSet.find(endWord) == wordSet.end())return 0;// 定义一个队列 q,用于进行广度优先搜索(BFS),将起始单词 beginWord// 加入队列queue<string> q;q.push(beginWord);// 初始化转换步数 step 为 1,因为起始单词算一步int step = 1;// 定义一个无序集合 visited,用于记录已经访问过的单词,避免重复处理unordered_set<string> visited;// 将起始单词 beginWord 标记为已访问,加入 visited 集合visited.insert(beginWord);// 定义所有可能的字母char base[] = {'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i','j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r','s', 't', 'u', 'v', 'w', 'x', 'y', 'z'};// 当队列 q 不为空时,继续进行 BFS 遍历while (!q.empty()) {// 记录当前队列的大小 size,即当前层的单词数量int size = q.size();// 遍历当前层的所有单词for (int i = 0; i < size; ++i) {// 取出队列 q 的队首元素,即当前要处理的单词string current = q.front();// 将队首元素从队列中移除q.pop();// 检查当前单词是否等于目标单词 endWord,若是则返回当前步数 stepif (current == endWord) {return step;}// 遍历当前单词的每一个位置for (int j = 0; j < current.length(); ++j) {// 保存当前位置的原始字母char tmp = current[j];// 尝试将当前位置的字母替换为其他 25 种可能的字母for (int k = 0; k < 26; k++) {// 将当前位置的字母替换为新的字母current[j] = base[k];// 检查替换后的单词是否在字典 wordSet 中且未被访问过if (wordSet.find(current) != wordSet.end() &&visited.find(current) == visited.end()) {// 若满足条件,则将替换后的单词加入队列 qq.push(current);// 并将其标记为已访问,加入 visited 集合visited.insert(current);}}// 恢复当前位置的原始字母,以便继续处理下一个位置current[j] = tmp;}}// 遍历完当前层的所有单词后,将步数 step 加 1step++;}// 若队列为空仍未找到目标单词,返回 0 表示无法完成转换return 0;}
};
675. 为高尔夫比赛砍树-hard待研究
你被请来给一个要举办高尔夫比赛的树林砍树。树林由一个 m x n 的矩阵表示, 在这个矩阵中:
- `0` 表示障碍,无法触碰- `1` 表示地面,可以行走- `比 1 大的数` 表示有树的单元格,可以行走,数值表示树的高度
每一步,你都可以向上、下、左、右四个方向之一移动一个单位,如果你站的地方有一棵树,那么你可以决定是否要砍倒它。
你需要按照树的高度从低向高砍掉所有的树,每砍过一颗树,该单元格的值变为 1(即变为地面)。
你将从 (0, 0) 点开始工作,返回你砍完所有树需要走的最小步数。 如果你无法砍完所有的树,返回 -1 。
可以保证的是,没有两棵树的高度是相同的,并且你至少需要砍倒一棵树。
示例 1:
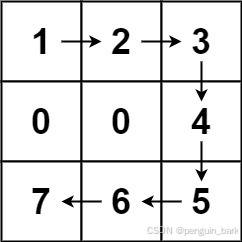
**输入:**forest = [[1,2,3],[0,0,4],[7,6,5]]
**输出:**6
**解释:**沿着上面的路径,你可以用 6 步,按从最矮到最高的顺序砍掉这些树。
示例 2:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
**输入:**forest = [[1,2,3],[0,0,0],[7,6,5]]
**输出:**-1
**解释:**由于中间一行被障碍阻塞,无法访问最下面一行中的树。示例 3:
**输入:**forest = [[2,3,4],[0,0,5],[8,7,6]]
**输出:**6
**解释:**可以按与示例 1 相同的路径来砍掉所有的树。
(0,0) 位置的树,可以直接砍去,不用算步数。2.思路
砍树要按从矮到高的顺序,路过某棵树不一定非要砍,可以往回走,起点不一定是地面。
- 找出所有树的位置和高度:遍历二维网格,记录所有树的位置和高度,并按照树的高度进行排序。
- 计算从当前位置到下一棵树的最短路径:使用广度优先搜索(BFS)算法计算从当前位置到下一棵树的最短移动步数。
- 依次砍树:按照树的高度从小到大的顺序,依次计算从当前位置到下一棵树的最短路径,并累加步数。如果在某一步无法到达下一棵树,返回 -1。
3.代码
#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>using namespace std;class Solution {
private:vector<vector<int>> directions = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};// BFS 计算从 start 到 end 的最短路径int bfs(const vector<vector<int>>& forest, const pair<int, int>& start, const pair<int, int>& end) {int rows = forest.size();int cols = forest[0].size();vector<vector<bool>> visited(rows, vector<bool>(cols, false));queue<pair<pair<int, int>, int>> q;q.push({start, 0});visited[start.first][start.second] = true;while (!q.empty()) {auto [pos, steps] = q.front();q.pop();if (pos == end) {return steps;}for (const auto& dir : directions) {int newRow = pos.first + dir[0];int newCol = pos.second + dir[1];if (newRow >= 0 && newRow < rows && newCol >= 0 && newCol < cols &&forest[newRow][newCol] > 0 && !visited[newRow][newCol]) {q.push({{newRow, newCol}, steps + 1});visited[newRow][newCol] = true;}}}return -1;}public:int cutOffTree(vector<vector<int>>& forest) {int rows = forest.size();int cols = forest[0].size();vector<pair<int, pair<int, int>>> trees;// 找出所有树的位置和高度for (int i = 0; i < rows; ++i) {for (int j = 0; j < cols; ++j) {if (forest[i][j] > 1) {trees.emplace_back(forest[i][j], make_pair(i, j));}}}// 按树的高度排序sort(trees.begin(), trees.end());pair<int, int> current = {0, 0};int totalSteps = 0;// 依次砍树for (const auto& [_, target] : trees) {int steps = bfs(forest, current, target);if (steps == -1) {return -1;}totalSteps += steps;current = target;}return totalSteps;}
};
三、多源 BFS
单源最短路径:只有一个起点和一个终点,求最短路径。多源最短路径:有多个起点到一个终点的最短路径。多源BFS:用BFS解决边权为1的多源最短路径。
解决:把所有起点当作一个大起点,就变成了单源最短路径,把所有起点放到队列里,一层一层往外扩展
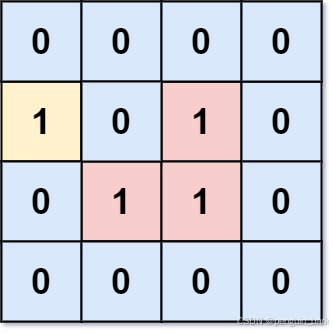
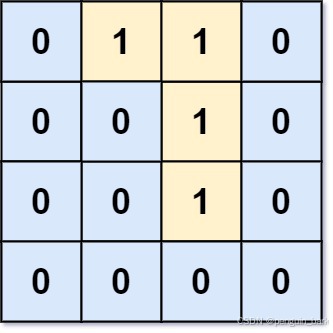
LCR 107. 01 矩阵
给定一个由 0 和 1 组成的矩阵 mat ,请输出一个大小相同的矩阵,其中每一个格子是 mat 中对应位置元素到最近的 0 的距离。
两个相邻元素间的距离为 1 。
示例 1:
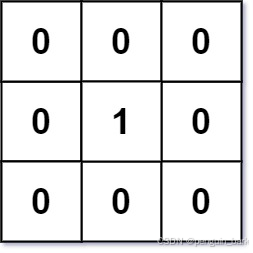
**输入:**mat =** **[[0,0,0],[0,1,0],[0,0,0]]
**输出:**[[0,0,0],[0,1,0],[0,0,0]]示例 2:
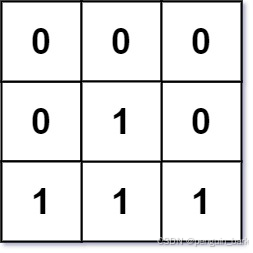
**输入:**mat = [[0,0,0],[0,1,0],[1,1,1]]
**输出:**[[0,0,0],[0,1,0],[1,2,1]]2.思路
用二维矩阵ans存储最短距离,初始值全为0;使用二维矩阵vis存储每个位置是否扩散过,初始值为false。
将所有0加入队列,并将其vis置为true(标记扩散)
只要队列不为空,弹出队首元素,并向四个方向扩散(更新ans)、加入队尾、标记扩散。
注意,扩散更新ans应该与标记vis、加入队尾同步进行。如果是在弹出队列的时候标记扩散,而在扩散的时候不标记,在当前一轮的广度搜索中,可能重复计算。
下面是图示:
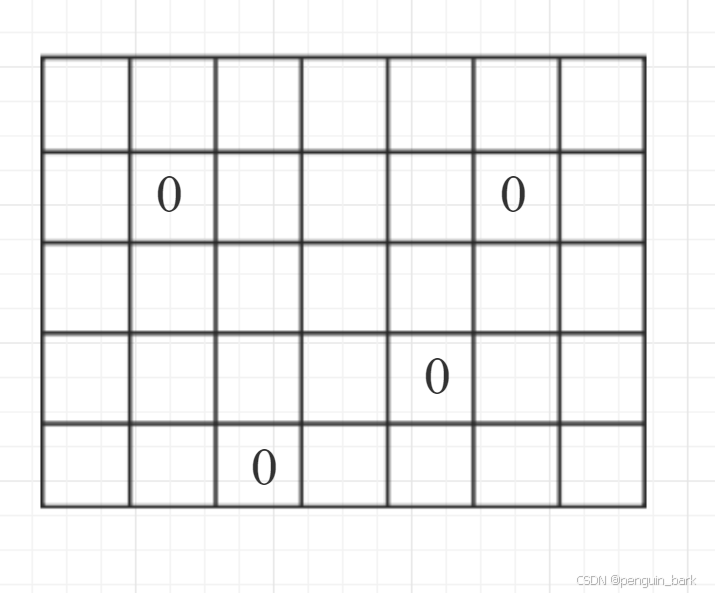
初始状态时的mat矩阵

将所有0加入队列,并标记访问
弹出0、扩散四个方向更新ans、标记vis。
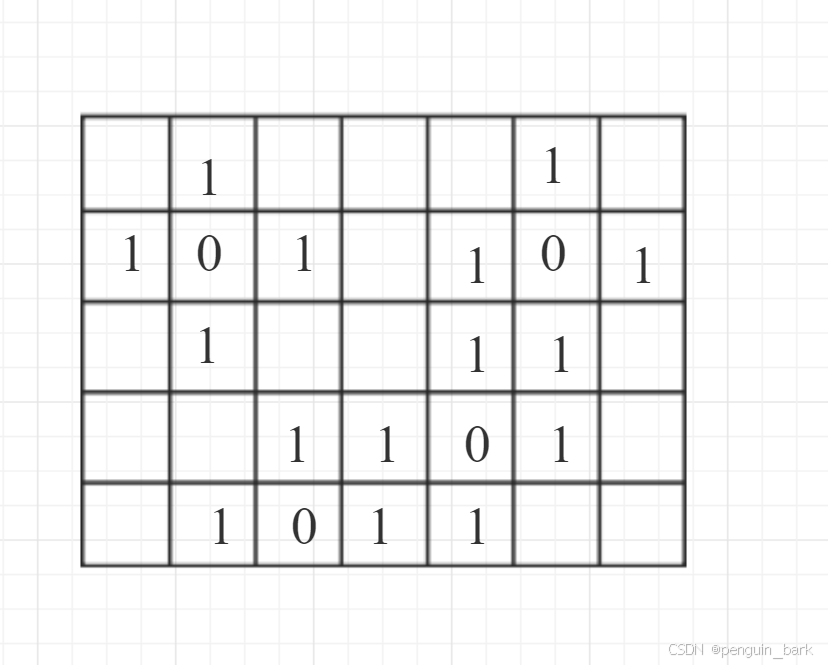
弹出1、扩散四个方向更新ans、标记vis。
弹出2…扩散结束,队列为空。
3.代码
注意:这里不需要严格区分不同层次的元素,所以在while后面没有写for,其实按照模板加上for也不会错,具体来说,队列里的元素顺序不会影响最终结果,因为无论元素在队列里的先后顺序如何,只要按照 BFS 的规则不断扩展,每个位置第一次被访问时的距离一定是最短的。
class Solution {
public:vector<vector<int>> updateMatrix(vector<vector<int>>& mat) {// 获取矩阵的行数int rows = mat.size();// 获取矩阵的列数int cols = mat[0].size();// 初始化结果矩阵 ans,用于存储每个位置到最近 0 的距离,初始值都为 0vector<vector<int>> ans(rows, vector<int>(cols, 0));// 初始化访问标记矩阵 vis,用于标记每个位置是否已被访问,初始值都为 falsevector<vector<bool>> vis(rows, vector<bool>(cols, false));// 初始化队列 q,用于 BFS 遍历queue<pair<int, int>> q;// 遍历矩阵 mat,将所有值为 0 的位置加入队列 q,并标记为已访问for (int i = 0; i < rows; ++i) {for (int j = 0; j < cols; ++j) {if (mat[i][j] == 0) {// 值为 0 的位置到最近 0 的距离为 0ans[i][j] = 0;// 标记该位置为已访问vis[i][j] = true;// 将该位置加入队列 qq.push({i, j});}}}// 当队列 q 不为空时,继续进行 BFS 遍历while (!q.empty()) {// 取出队首元素的横坐标int x = q.front().first;// 取出队首元素的纵坐标int y = q.front().second;// 将队首元素从队列中移除q.pop();// 检查当前位置的左侧位置if (y - 1 >= 0 && vis[x][y - 1] == false) {// 将左侧位置加入队列 qq.push({x, y - 1});// 标记左侧位置为已访问vis[x][y - 1] = true;// 左侧位置到最近 0 的距离为当前位置到最近 0 的距离加 1ans[x][y - 1] = ans[x][y] + 1;}// 检查当前位置的右侧位置if (y + 1 < cols && vis[x][y + 1] == false) {// 将右侧位置加入队列 qq.push({x, y + 1});// 标记右侧位置为已访问vis[x][y + 1] = true;// 右侧位置到最近 0 的距离为当前位置到最近 0 的距离加 1ans[x][y + 1] = ans[x][y] + 1;}// 检查当前位置的上方位置if (x - 1 >= 0 && vis[x - 1][y] == false) {// 将上方位置加入队列 qq.push({x - 1, y});// 标记上方位置为已访问vis[x - 1][y] = true;// 上方位置到最近 0 的距离为当前位置到最近 0 的距离加 1ans[x - 1][y] = ans[x][y] + 1;}// 检查当前位置的下方位置if (x + 1 < rows && vis[x + 1][y] == false) {// 将下方位置加入队列 qq.push({x + 1, y});// 标记下方位置为已访问vis[x + 1][y] = true;// 下方位置到最近 0 的距离为当前位置到最近 0 的距离加 1ans[x + 1][y] = ans[x][y] + 1;}}// 返回结果矩阵 ansreturn ans;}
};
1020. 飞地的数量
给你一个大小为 m x n 的二进制矩阵 grid ,其中 0 表示一个海洋单元格、1 表示一个陆地单元格。
一次 移动 是指从一个陆地单元格走到另一个相邻(上、下、左、右)的陆地单元格或跨过 grid 的边界。
返回网格中** 无法 **在任意次数的移动中离开网格边界的陆地单元格的数量。
示例 1:
**输入:**grid = [[0,0,0,0],[1,0,1,0],[0,1,1,0],[0,0,0,0]]
**输出:**3
**解释:**有三个 1 被 0 包围。一个 1 没有被包围,因为它在边界上。示例 2:
**输入:**grid = [[0,1,1,0],[0,0,1,0],[0,0,1,0],[0,0,0,0]]
**输出:**0
**解释:**所有 1 都在边界上或可以到达边界。2.思路
思路参考上面 130. 被围绕的区域,思路差不多。
3.代码
class Solution {
public:// 用于标记网格中每个单元格是否已被访问bool visited[501][501];int numEnclaves(std::vector<std::vector<int>>& grid) {// 获取网格的行数int r = grid.size();// 获取网格的列数int c = grid[0].size();// 用于进行广度优先搜索(BFS)的队列,存储单元格的坐标std::queue<std::pair<int, int>> q;// 遍历网格的左右边界for (int i = 0; i < r; ++i) {// 检查左边界的元素是否为 1 且未被访问过if (!visited[i][0] && grid[i][0] == 1) {// 标记该位置为已访问visited[i][0] = true;// 将该位置加入队列q.push({i, 0});}// 检查右边界的元素是否为 1 且未被访问过if (grid[i][c - 1] == 1 && !visited[i][c - 1]) {// 标记该位置为已访问visited[i][c - 1] = true;// 将该位置加入队列q.push({i, c - 1});}}// 遍历网格的上下边界for (int j = 0; j < c; ++j) {// 检查上边界的元素是否为 1 且未被访问过if (grid[0][j] == 1 && !visited[0][j]) {// 标记该位置为已访问visited[0][j] = true;// 将该位置加入队列q.push({0, j});}// 检查下边界的元素是否为 1 且未被访问过if (grid[r - 1][j] == 1 && !visited[r - 1][j]) {// 标记该位置为已访问visited[r - 1][j] = true;// 将该位置加入队列q.push({r - 1, j});}}// 进行广度优先搜索(BFS)while (!q.empty()) {// 取出队列的队首元素,获取其横坐标int x = q.front().first;// 取出队列的队首元素,获取其纵坐标int y = q.front().second;// 将队首元素从队列中移除q.pop();// 检查当前位置左侧元素是否为 1 且未被访问过if (y - 1 >= 0 && grid[x][y - 1] == 1 && !visited[x][y - 1]) {// 标记该位置为已访问visited[x][y - 1] = true;// 将该位置加入队列q.push({x, y - 1});}// 检查当前位置右侧元素是否为 1 且未被访问过if (y + 1 < c && grid[x][y + 1] == 1 && !visited[x][y + 1]) {// 标记该位置为已访问visited[x][y + 1] = true;// 将该位置加入队列q.push({x, y + 1});}// 检查当前位置上方元素是否为 1 且未被访问过if (x - 1 >= 0 && grid[x - 1][y] == 1 && !visited[x - 1][y]) {// 标记该位置为已访问visited[x - 1][y] = true;// 将该位置加入队列q.push({x - 1, y});}// 检查当前位置下方元素是否为 1 且未被访问过if (x + 1 < r && grid[x + 1][y] == 1 && !visited[x + 1][y]) {// 标记该位置为已访问visited[x + 1][y] = true;// 将该位置加入队列q.push({x + 1, y});}}// 用于存储飞地的数量int ret = 0;// 遍历整个网格for (int i = 0; i < r; ++i) {for (int j = 0; j < c; ++j) {// 如果当前单元格的值为 1 且未被访问过,则它是飞地if (grid[i][j] == 1 && !visited[i][j]) {// 飞地数量加 1ret++;}}}// 返回飞地的数量return ret;}
};
1765. 地图中的最高点
给你一个大小为 m x n 的整数矩阵 isWater ,它代表了一个由 陆地 和 水域 单元格组成的地图。
- 如果 `isWater[i][j] == 0` ,格子 `(i, j)` 是一个 **陆地** 格子。- 如果 `isWater[i][j] == 1` ,格子 `(i, j)` 是一个 **水域** 格子。
你需要按照如下规则给每个单元格安排高度:
- 每个格子的高度都必须是非负的。- 如果一个格子是 **水域** ,那么它的高度必须为 `0` 。- 任意相邻的格子高度差 **至多** 为 `1` 。当两个格子在正东、南、西、北方向上相互紧挨着,就称它们为相邻的格子。(也就是说它们有一条公共边)
找到一种安排高度的方案,使得矩阵中的最高高度值 最大 。
请你返回一个大小为 m x n 的整数矩阵 height ,其中 height[i][j] 是格子 (i, j) 的高度。如果有多种解法,请返回 任意一个 。
**示例 1:**下面是输出图
**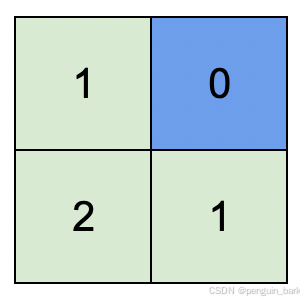
**
输入:isWater = [[0,1],[0,0]]
输出:[[1,0],[2,1]]
解释:上图展示了给各个格子安排的高度。
蓝色格子是水域格,绿色格子是陆地格。示例 2:下面是输出图
**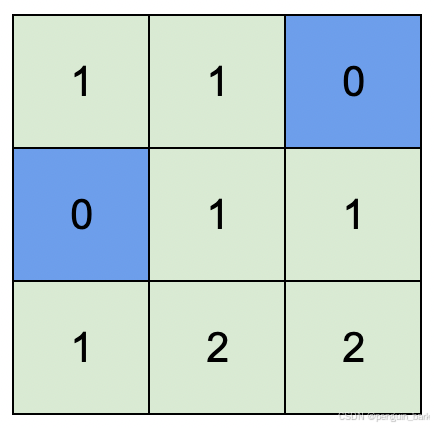
**
输入:isWater = [[0,0,1],[1,0,0],[0,0,0]]
输出:[[1,1,0],[0,1,1],[1,2,2]]
解释:所有安排方案中,最高可行高度为 2 。
任意安排方案中,只要最高高度为 2 且符合上述规则的,都为可行方案。2.思路
上面图是输出图,0是水,题目中的数值可以转化成,走几步找到最近的水源,也可以理解成,从水源出发,走几步可以遍历所有的陆地。
思路和 LCR 107. 01 矩阵 差不多
地图中的最高点:将矩阵中值为 1 的位置(水域)作为起始点,因为水域高度固定为 0。代码中当 isWater[i][j] == 1 时,将该位置加入队列并标记为已访问,结果矩阵 ans 中该位置的值设为 0,mat[ i ] [ j ] == 0。
3.代码
class Solution {
public:vector<vector<int>> highestPeak(vector<vector<int>>& isWater) {int rows = isWater.size();int cols = isWater[0].size();// 初始化结果矩阵 ans,用于存储每个位置的高度,初始值都为 0vector<vector<int>> ans(rows, vector<int>(cols, 0));// 初始化访问标记矩阵 vis,用于标记每个位置是否已被访问,初始值都为 falsevector<vector<bool>> vis(rows, vector<bool>(cols, false));// 初始化队列 q,用于 BFS 遍历queue<pair<int, int>> q;// 遍历矩阵 isWater,将所有水域(值为 1 的位置)加入队列 q,并标记为已访问for (int i = 0; i < rows; ++i) {for (int j = 0; j < cols; ++j) {if (isWater[i][j] == 1) {// 水域位置高度为 0ans[i][j] = 0;// 标记该位置为已访问vis[i][j] = true;// 将该位置加入队列 qq.push({i, j});}}}// 当队列 q 不为空时,继续进行 BFS 遍历while (!q.empty()) {// 取出队首元素的横坐标int x = q.front().first;// 取出队首元素的纵坐标int y = q.front().second;// 将队首元素从队列中移除q.pop();// 检查当前位置的上方位置if (x - 1 >= 0 && !vis[x - 1][y]) {// 上方位置的高度为当前位置高度加 1ans[x - 1][y] = ans[x][y] + 1;// 标记上方位置为已访问vis[x - 1][y] = true;// 将上方位置加入队列 qq.push({x - 1, y});}// 检查当前位置的下方位置if (x + 1 < rows && !vis[x + 1][y]) {// 下方位置的高度为当前位置高度加 1ans[x + 1][y] = ans[x][y] + 1;// 标记下方位置为已访问vis[x + 1][y] = true;// 将下方位置加入队列 qq.push({x + 1, y});}// 检查当前位置的左侧位置if (y - 1 >= 0 && !vis[x][y - 1]) {// 左侧位置的高度为当前位置高度加 1ans[x][y - 1] = ans[x][y] + 1;// 标记左侧位置为已访问vis[x][y - 1] = true;// 将左侧位置加入队列 qq.push({x, y - 1});}// 检查当前位置的右侧位置if (y + 1 < cols && !vis[x][y + 1]) {// 右侧位置的高度为当前位置高度加 1ans[x][y + 1] = ans[x][y] + 1;// 标记右侧位置为已访问vis[x][y + 1] = true;// 将右侧位置加入队列 qq.push({x, y + 1});}}// 返回结果矩阵 ansreturn ans;}
};
1162. 地图分析
你现在手里有一份大小为 n x n 的 网格 grid,上面的每个 单元格 都用 0 和 1 标记好了。其中 0 代表海洋,1 代表陆地。
请你找出一个海洋单元格,这个海洋单元格到离它最近的陆地单元格的距离是最大的,并返回该距离。如果网格上只有陆地或者海洋,请返回 -1。
我们这里说的距离是「曼哈顿距离」( Manhattan Distance):(x0, y0) 和 (x1, y1) 这两个单元格之间的距离是 |x0 - x1| + |y0 - y1| 。
示例 1:
**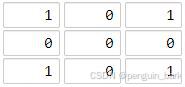
**
**输入:**grid = [[1,0,1],[0,0,0],[1,0,1]]
**输出:**2
**解释: **
海洋单元格 (1, 1) 和所有陆地单元格之间的距离都达到最大,最大距离为 2。示例 2:
**
**
**输入:**grid = [[1,0,0],[0,0,0],[0,0,0]]
**输出:**4
**解释: **
海洋单元格 (2, 2) 和所有陆地单元格之间的距离都达到最大,最大距离为 4。2.思路
3.代码
class Solution {
public:int maxDistance(vector<vector<int>>& mat) {// 获取矩阵的行数int rows = mat.size();// 获取矩阵的列数int cols = mat[0].size();// 初始化结果矩阵 ans,用于存储每个位置到最近 0 的距离,初始值都为 0vector<vector<int>> ans(rows, vector<int>(cols, 0));// 初始化访问标记矩阵 vis,用于标记每个位置是否已被访问,初始值都为 falsevector<vector<bool>> vis(rows, vector<bool>(cols, false));// 初始化队列 q,用于 BFS 遍历queue<pair<int, int>> q;// 遍历矩阵 mat,将所有值为 0 的位置加入队列 q,并标记为已访问for (int i = 0; i < rows; ++i) {for (int j = 0; j < cols; ++j) {if (mat[i][j] == 1) {// 值为 0 的位置到最近 0 的距离为 0ans[i][j] = 0;// 标记该位置为已访问vis[i][j] = true;// 将该位置加入队列 qq.push({i, j});}}}// 当队列 q 不为空时,继续进行 BFS 遍历while (!q.empty()) {// 取出队首元素的横坐标int x = q.front().first;// 取出队首元素的纵坐标int y = q.front().second;// 将队首元素从队列中移除q.pop();// 检查当前位置的左侧位置if (y - 1 >= 0 && vis[x][y - 1] == false) {// 将左侧位置加入队列 qq.push({x, y - 1});// 标记左侧位置为已访问vis[x][y - 1] = true;// 左侧位置到最近 0 的距离为当前位置到最近 0 的距离加 1ans[x][y - 1] = ans[x][y] + 1;}// 检查当前位置的右侧位置if (y + 1 < cols && vis[x][y + 1] == false) {// 将右侧位置加入队列 qq.push({x, y + 1});// 标记右侧位置为已访问vis[x][y + 1] = true;// 右侧位置到最近 0 的距离为当前位置到最近 0 的距离加 1ans[x][y + 1] = ans[x][y] + 1;}// 检查当前位置的上方位置if (x - 1 >= 0 && vis[x - 1][y] == false) {// 将上方位置加入队列 qq.push({x - 1, y});// 标记上方位置为已访问vis[x - 1][y] = true;// 上方位置到最近 0 的距离为当前位置到最近 0 的距离加 1ans[x - 1][y] = ans[x][y] + 1;}// 检查当前位置的下方位置if (x + 1 < rows && vis[x + 1][y] == false) {// 将下方位置加入队列 qq.push({x + 1, y});// 标记下方位置为已访问vis[x + 1][y] = true;// 下方位置到最近 0 的距离为当前位置到最近 0 的距离加 1ans[x + 1][y] = ans[x][y] + 1;}}int ret = 0;for (int i = 0; i < rows; ++i) {for (int j = 0; j < cols; ++j) {ret = max(ret, ans[i][j]);}}return ret==0?-1:ret;}
};
四、拓扑排序
找到做事情的先后顺序,结果可能不是唯一的。应用:判断有向图中是否有环
- 找出图中入度为0的点,然后输出
- 删除与该点的连接边
- 重复前面操作直到没有入度为0的点为止(可能有环)
207. 课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对 `[0, 1]` 表示:想要学习课程 `0` ,你需要先完成课程 `1` 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
**输入:**numCourses = 2, prerequisites = [[1,0]]
**输出:**true
**解释:**总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
**输入:**numCourses = 2, prerequisites = [[1,0],[0,1]]
**输出:**false
**解释:**总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
2.思路
edges用于存储边,indeg用于存储每个节点入度为多少。首先初始化这两个变量,构建边和计算每个节点的入度,之后将入度为0的节点放到队列当中,拓扑排序:判断从a->b是否有边,如果有就将a放到队列当中,并且将b的入度减一,结束时,判断已访问数量是否等于总课程数量。
邻接矩阵:空间: (O(V^2)) 时间:(O(V^2 + E)),其中 (V) 是节点数(课程数),(E) 是边数(依赖关系数)
邻接表:空间: (O(V + E)) 时间:总体时间复杂度为 (O(V + E))
resize:如果新的大小比原来大,在容器末尾添加元素;如果新的大小比原来小,会删除超出部分的元素。可以指定初始值
reserve:它只改变容器的容量(即容器能够容纳的元素数量),而不改变容器的大小(即实际存储的元素数量)。
大小(size),实际存储的元素个数
容量(capacity),容器在不重新分配内存的情况下能够容纳的最大元素个数
3.代码
邻接矩阵:
class Solution {
public:vector<vector<int>> edges; // 存储边bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {vector<int> indeg(numCourses, 0);// 存储每个节点入度为多少edges.resize(numCourses);for (auto& e : edges) {e.resize(numCourses, 0);}// bi->aifor (auto& pair : prerequisites) {int ai = pair[0];int bi = pair[1];edges[bi][ai] = 1;++indeg[ai]; // 入度增加}queue<int> q;for (int i = 0; i < indeg.size(); ++i) {if (indeg[i] == 0)q.push(i);}int visited = 0;while (!q.empty()) {++visited;int tmp = q.front();q.pop();// 遍历当前节点的所有邻接节点for (int i = 0; i<numCourses; ++i) {if(edges[tmp][i] == 1){--indeg[i];if(indeg[i] == 0){q.push(i);}}}}return visited==numCourses;}
};
邻接表:
class Solution {
public:vector<std::vector<int>> edges; // 存储边vector<int> indeg; // 存储每个节点入度为多少bool canFinish(int numCourses, std::vector<std::vector<int>>& prerequisites) {// 初始化邻接表edges.resize(numCourses);indeg.resize(numCourses);// 构建邻接表和计算入度for (auto& pair : prerequisites) {int ai = pair[0];int bi = pair[1];edges[bi].push_back(ai); // 将 ai 加入 bi 的邻接表++indeg[ai]; // 入度增加}// 将入度为 0 的节点加入队列std::queue<int> q;for (int i = 0; i < indeg.size(); ++i) {if (indeg[i] == 0)q.push(i);}int visited = 0;while (!q.empty()) {++visited;int tmp = q.front();q.pop();// 遍历当前节点的所有邻接节点(使用邻接表的方式)for (int neighbor : edges[tmp]) {--indeg[neighbor]; // 邻接节点的入度减 1if (indeg[neighbor] == 0) {q.push(neighbor); // 若邻接节点入度变为 0,加入队列}}}return visited == numCourses;}
};
210. 课程表 II
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
- 例如,想要学习课程 `0` ,你需要先完成课程 `1` ,我们用一个匹配来表示:`[0,1]` 。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
示例 1:
**输入:**numCourses = 2, prerequisites = [[1,0]]
**输出:**[0,1]
**解释:**总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 `[0,1] 。`示例 2:
**输入:**numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]]
**输出:**[0,2,1,3]
**解释:**总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。
因此,一个正确的课程顺序是 `[0,1,2,3]` 。另一个正确的排序是 `[0,2,1,3]` 。
示例 3:
**输入:**numCourses = 1, prerequisites = []
**输出:**[0]2.思路
初始化数据结构:
- 创建一个
numCourses * numCourses的邻接矩阵edges来表示课程之间的依赖关系,初始时所有元素为 0。 - 创建一个长度为
numCourses的入度数组indeg,用于记录每门课程的前置课程数量,初始时所有元素为 0。
构建图和计算入度:
- 遍历
prerequisites数组,对于每一个依赖关系[ai, bi],表示学习课程ai之前需要先学习课程bi。 - 在邻接矩阵
edges中,将edges[bi][ai]设置为 1,表示存在从bi到ai的边。 - 同时,将课程
ai的入度(即indeg[ai])加 1。
初始化队列:
- 遍历入度数组
indeg,将入度为 0 的课程加入队列q。入度为 0 的课程表示没有前置课程,可以直接学习。
拓扑排序过程:
- 当队列
q不为空时,取出队列头部的课程tmp,将其加入结果数组ret中,表示该课程可以开始学习。 - 遍历所有课程,检查与
tmp存在依赖关系的课程i(即edges[tmp][i] == 1)。 - 对于这些课程
i,将其入度减 1。如果减 1 后入度变为 0,说明其所有前置课程都已学习完,将其加入队列q。
结果判断:
- 拓扑排序结束后,检查结果数组
ret的长度是否等于numCourses。 - 如果相等,说明可以完成所有课程的学习,返回
ret作为课程的学习顺序;否则,说明图中存在环,无法完成所有课程的学习,返回一个空数组。
3.代码
class Solution {
public:// 邻接矩阵,用于存储课程之间的依赖关系std::vector<std::vector<int>> edges;std::vector<int> findOrder(int numCourses, std::vector<std::vector<int>>& prerequisites) {vector<int> indeg(numCourses, 0);// 存储每个节点入度为多少// 调整邻接矩阵的大小,使其为 numCourses 行edges.resize(numCourses);// 对邻接矩阵的每一行进行初始化,使其有 numCourses 列,初始值都为 0for (int i = 0; i < edges.size(); ++i) {edges[i].resize(numCourses, 0);}// 遍历先决条件数组,构建邻接矩阵和更新入度数组for (auto& e : prerequisites) {// 获取当前依赖关系中需要学习的课程int ai = e[0];// 获取当前依赖关系中的前置课程int bi = e[1];// 在邻接矩阵中标记从 bi 到 ai 存在依赖关系edges[bi][ai] = 1;// 增加课程 ai 的入度++indeg[ai];}// 创建一个队列,用于存储入度为 0 的课程std::queue<int> q;// 遍历入度数组,将入度为 0 的课程加入队列for (int i = 0; i < indeg.size(); ++i) {if (indeg[i] == 0) {q.push(i);}}// 用于存储课程的学习顺序std::vector<int> ret;// 当队列不为空时,进行拓扑排序操作while (!q.empty()) {// 取出队列头部的课程int tmp = q.front();// 将队列头部的课程从队列中移除q.pop();// 将该课程添加到学习顺序结果中ret.push_back(tmp);// 遍历所有课程,检查与当前课程存在依赖关系的课程for (int i = 0; i < numCourses; ++i) {// 如果存在从当前课程 tmp 到课程 i 的依赖关系if (edges[tmp][i] == 1) {// 减少课程 i 的入度--indeg[i];// 如果课程 i 的入度变为 0,说明其前置课程都已学习完,可以加入队列if (indeg[i] == 0) {q.push(i);}}}}// 判断是否能完成所有课程if (ret.size() != numCourses) {// 如果学习顺序结果中的课程数量不等于总课程数,说明存在环,无法完成所有课程,返回空数组return {};}// 若能完成所有课程,返回课程的学习顺序return ret;}
};
LCR 114. 火星词典-hard待研究
现有一种使用英语字母的外星文语言,这门语言的字母顺序与英语顺序不同。
给定一个字符串列表 words ,作为这门语言的词典,words 中的字符串已经 按这门新语言的字母顺序进行了排序 。
请你根据该词典还原出此语言中已知的字母顺序,并 按字母递增顺序 排列。若不存在合法字母顺序,返回 "" 。若存在多种可能的合法字母顺序,返回其中 任意一种 顺序即可。
字符串 s 字典顺序小于 字符串 t 有两种情况:
- 在第一个不同字母处,如果 `s` 中的字母在这门外星语言的字母顺序中位于 `t` 中字母之前,那么 `s` 的字典顺序小于 `t` 。- 如果前面 `min(s.length, t.length)` 字母都相同,那么 `s.length < t.length` 时,`s` 的字典顺序也小于 `t` 。
示例 1:
**输入:**words = ["wrt","wrf","er","ett","rftt"]
**输出:**"wertf"示例 2:
**输入:**words = ["z","x"]
**输出:**"zx"示例 3:
**输入:**words = ["z","x","z"]
**输出:**""
**解释:**不存在合法字母顺序,因此返回 ""。2.思路
示例解释
- 从
"wrt"和"wrf"这两个单词来看,它们的前两个字母"wr"相同,而第三个字母不同,一个是"t"一个是"f",并且"wrt"在"wrf"前面,这就表明在火星语言的字典序里,'t'排在'f'前面。 - 从
"wrf"和"er"来看,因为"wrf"在前,"er"在后,而"w"和"e"是第一个不同的字母,所以'w'排在'e'前面。 - 从
"er"和"ett"来看,"er"在前,"ett"在后,'e'相同,第二个字母不同,所以'r'排在't'前面。 - 从
"ett"和"rftt"来看,"ett"在前,"rftt"在后,第一个字母不同,所以'e'排在'r'前面。
3.代码
#include <iostream>
#include <vector>
#include <string>
#include <queue>
#include <unordered_map>class Solution {
public:std::string alienOrder(std::vector<std::string>& words) {// 邻接表,graph[i] 存储字母 i 指向的字母集合std::vector<std::vector<char>> graph(26);// 合并入度和出现标记,值为 -1 表示出现过但未统计入度,非负表示入度std::unordered_map<char, int> states;// 遍历所有单词,统计出现的字母for (const auto& word : words) {for (char c : word) {if (states.find(c) == states.end()) {states[c] = -1; // 标记字母出现过}}}// 构建图和计算入度for (int i = 0; i < words.size() - 1; ++i) {const std::string& word1 = words[i];const std::string& word2 = words[i + 1];int minLen = std::min(word1.length(), word2.length());bool foundDifference = false;for (int j = 0; j < minLen; ++j) {if (word1[j] != word2[j]) {char u = word1[j];char v = word2[j];bool edgeExists = false;for (char neighbor : graph[u - 'a']) {if (neighbor == v) {edgeExists = true;break;}}if (!edgeExists) {graph[u - 'a'].push_back(v);if (states[v] == -1) {states[v] = 1; // 初始化入度为 1} else {++states[v]; // 入度加 1}}foundDifference = true;break;}}// 如果一个单词是另一个单词的前缀,且长单词在前,顺序不合理if (!foundDifference && word1.length() > word2.length()) {return "";}}// 将入度为 0 的字母加入队列std::queue<char> q;for (const auto& pair : states) {if (pair.second == 0 || pair.second == -1) {q.push(pair.first);}}// 存储拓扑排序的结果std::string result;while (!q.empty()) {char u = q.front();q.pop();result += u;// 遍历当前字母的所有邻接字母for (char v : graph[u - 'a']) {--states[v];if (states[v] == 0) {q.push(v);}}}// 如果结果的长度不等于出现过的字母数量,说明存在环,无法得到有效字典序if (result.length() != states.size()) {return "";}return result;}
};相关文章:

BFS-FloodFill 算法 解决最短路问题 多源 解决拓扑排序
文章目录 一、FloodFill 算法[733. 图像渲染](https://leetcode.cn/problems/flood-fill/description/)2.思路3.代码 [200. 岛屿数量](https://leetcode.cn/problems/number-of-islands/description/)2.思路3.代码 [LCR 105. 岛屿的最大面积](https://leetcode.cn/problems/ZL6…...

USB2.03.0接口区分usb top工具使用
一. USB2.0 & 3.0接口支持区分 1.1. 颜色判断 USB接口的颜色并不是判断版本的可靠标准,但根据行业常见规范分析如下: USB接口颜色与版本对照表: 接口颜色常见版本内部触点数量传输速度黑色USB2.04触点480 Mbps (60 MB/s)白色USB2.0(多…...

2025百度快排技术分析:模拟点击与发包算法的背后原理
一晃做SEO已经15年了,2025年还有人问我如何做百度快速排名,我能给出的答案就是:做好内容的前提下,多刷刷吧!百度的SEO排名算法一直是众多SEO从业者研究的重点,模拟算法、点击算法和发包算法是百度快速排名的…...

idea 2019.3常用插件
idea 2019.3常用插件 文档 idea 2019.3常用插件idea 2023.3.7常用插件 idea 2019.3常用插件 插件名称插件版本说明1AceJump3.5.9AceJump允许您快速将插入符号导航到编辑器中可见的任何位置。只需按“ctrl;”,键入一个字符,然后在Ace Jump…...
)
【Python 学习 / 5】函数详解(定义、参数、作用域、lambda、内置函数)
文章目录 一、函数1. 定义函数1.1 基本函数定义1.2 带参数的函数1.3 带返回值的函数 2. 参数传递2.1 位置参数2.2 默认参数2.3 可变参数2.3.1 使用*args2.3.2 使用**kwargs 2.4 参数的混合使用 3. 作用域3.1 局部和全局变量3.2 global 关键字输出: 3.3 nonlocal关键…...

WPF7-数据绑定基础
1. WPF数据绑定试验 1.1. 数据绑定的核心实现1.2. {Binding}语法1.3. 理解 DataContext 1. WPF数据绑定试验 以下是一个简单的 WPF 数据绑定示例,使用两个TextBox控件分别表示Name和Age来进行进行数据绑定试验。 数据模型类 创建一个 Person 类,包含…...

http 与 https 的区别?
HTTP(超文本传输协议)和 HTTPS(安全超文本传输协议)是互联网通信的基础协议。随着网络技术的发展和安全需求的提升,HTTPS变得越来越重要。本文将深入探讨HTTP与HTTPS之间的区别,包括其工作原理、安全性、性能、应用场景及未来发展等。 1. HTTP与HTTPS的基本概念 1.1 HT…...
 - Flink按键分区状态(Keyed State))
大数据学习(49) - Flink按键分区状态(Keyed State)
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…...

IP 路由基础 | 路由条目生成 / 路由表内信息获取
注:本文为 “IP 路由” 相关文章合辑。 未整理去重。 IP 路由基础 秦同学学学已于 2022-04-09 18:44:20 修改 一. IP 路由产生背景 我们都知道 IP 地址可以标识网络中的一个节点,并且每个 IP 地址都有自己的网段,各个网段并不相同…...

COBOL语言的移动应用开发
COBOL语言的移动应用开发探讨 引言 在信息技术快速发展的今天,移动应用开发已成为各行各业不可或缺的一部分。许多企业和开发者纷纷转向使用新兴的编程语言和开发工具,以满足不断变化的用户需求。然而,作为一种历史悠久的编程语言ÿ…...
TCP协议(Transmission Control Protocol)
TCP协议,即传输控制协议,其最大的特征就是对传输的数据进行可靠、高效的控制,其段格式如下: 源端口和目的端口号表示数据从哪个进程来,到哪个进程去,四位报头长度表示的是TCP头部有多少个4字节,…...

C语言数组之二维数组
C语言 主要内容 数组 二维数组 数组 二维数组 定义 二维数组本质上是一个行列式的组合,也就是说二维数组由行和列两部分组成,属于多维数组。二维数组数据是通过行列进行解读。二维数组可被视为一个特殊的一维数组,相当于二维数组又是一…...

计算机专业知识【软件开发中的常用图表:E - R图、HIPO、DFD、N - S、PAD详解】
在软件开发过程中,有许多种图表工具被用于不同阶段的设计和分析,帮助开发者更清晰地理解系统结构、数据流程和算法逻辑。下面将详细介绍E - R图、HIPO图、DFD图、N - S图和PAD图,包括它们的样子和用途。 一、E - R图(实体 - 联系…...

多人协同开发 —— Git Aoneflow工作流
一、Aoneflow工作流核心架构 #mermaid-svg-rwTOe9qYwzG3wkdy {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-rwTOe9qYwzG3wkdy .error-icon{fill:#552222;}#mermaid-svg-rwTOe9qYwzG3wkdy .error-text{fill:#552222…...

VSCode运行Go程序报错:Unable to process `evaluate`: debuggee is running
如果使用默认的VSCode的服务器来运行Go程序,那么使用fmt.Scan函数输入数据的时候就会报错,我们需要修改launch.json文件,将Go程序运行在shell终端上。 main.go package mainimport "fmt"func main() {var n intfmt.Scan(&n)v…...
)
Mybatis高级(动态SQL)
目录 一、动态SQL 1.1 数据准备: 1.2 <if>标签 1.3<trim> 标签 1.4<where>标签 1.5<set>标签 1.6 <foreach>标签 1.7<include> 标签 一、动态SQL 动态SQL是Mybatis的强⼤特性之⼀,能够完成不同条件下不同…...

在 Vue 3 中使用 Lottie 动画:实现一个加载动画
在现代前端开发中,动画是提升用户体验的重要元素之一。Lottie 是一个流行的动画库,它允许我们使用 JSON 文件来渲染高质量的动画。本文将介绍如何在 Vue 3 项目中集成 Lottie 动画,并实现一个加载动画效果。 如果对你有帮助请帮忙点个&#x…...

建筑行业安全技能竞赛流程方案
一、比赛时间: 6月23日8:30分准时到场;9:00-10:00理论考试;10:10-12:00现场隐患答疑;12:00-13:30午餐;下午13:30-15:30现场…...

Mybatisplus自定义sql
文章目录 引言流程 引言 mybatisplus最擅长的将where里面的语句给简便化,而不用我们自己写标签来实现条件查询 但是很多公司规范我们将sql写在mapper层中,不能写在service中 而且一些语句查询的不同select count(*) xxx from xxx 也难以用mp来实现 如何…...

情书网源码 情书大全帝国cms7.5模板
源码介绍 帝国cms7.5仿《情书网》模板源码,同步生成带手机站带采集。适合改改做文学类的网站。 效果预览 源码获取 情书网源码 情书大全帝国cms7.5模板...

基于Unity引擎的网络通信架构深度解析——以NetworkConnectionController为例
一、架构概览与设计理念 本文将以重构后的NetworkConnectionController为核心,深入分析基于Unity引擎的MMO网络通信架构设计。该模块采用分层设计思想,通过连接池管理、流量控制、心跳监测等多维度技术手段,构建了一个高性能、可扩展的网络通…...

C#学习之DataGridView控件
目录 一、DataGridView控件常用属性、方法、事件汇总表 1. 常用方法、属性和事件汇总 二、DataGridView 控件的常用方法调用 1. DataBind() 方法 2. Clear() 方法 3. Refresh() 方法 4. Sort() 方法 5. ClearSelection() 方法 6. BeginEdit() 方法 7. EndEdit() 方法…...

midjourney 一 prompt 提示词
midjourney 不需要自然语言的描述,它只需要关键词即可。 一个完整的Midjourney prompt通常包括三个部分 图片提示(Image Prompts)、文本提示(Text Prompt)和参数(Parameters)。 1、图片提示(…...

谈谈 wait 和 notify
目录 1 wait()方法 2 notify()⽅法 3 wait 和 sleep 的区别 多线程调度是随机的, 很多时候希望多个线程能够按照咱们规定的顺序来执行. 完成线程之间的配合工作. wait和notify就是一个用来协调线程顺序的重要工具. 这俩方法都是 Object 提供的方法. 随便找个对象࿰…...

250214-java类集框架
引言 类集框架本质上相当于是容器,容器装什么东西由程序员指定 1.单列集合 单列集合是list和set,list的实现类有ArrayList和LinkedList,前者是数组实现,后者是链表实现。list和set,前者有序、可重复,后者…...

Python学习心得异常处理
有些代码在操作的过程当中,如果不注意其所限定的条件,可能在输入函数值时引发一些程序的报错,这样为了让代码自己能做到抛除异常操作的情况,就得让代码具有排除异常的能力。下面的一些操作就使得代码具有该功能,处理异…...

【机器学习】线性回归 多项式线性回归
【机器学习系列】 KNN算法 KNN算法原理简介及要点 特征归一化的重要性及方式线性回归算法 线性回归与一元线性回归 线性回归模型的损失函数 多元线性回归 多项式线性回归 多项式线性回归 V1.0多项式回归多项式回归的公式 特征代换超越函数作为特征向量维度 V1.0 多项式回归 …...

链表和list
链表和list 算法题中的经典操作:用空间代替时间 双链表头插顺序: 1.先修改新结点的左右指针 2.然后修改结点y的左指针 3.最后修改哨兵位的右指针 双链表在任意位置(p)之后插入…...

vscode的一些实用操作
1. 焦点切换(比如主要用到使用快捷键在编辑区和终端区进行切换操作) 2. 跳转行号 使用ctrl g,然后输入指定的文件内容,即可跳转到相应位置。 使用ctrl p,然后输入指定的行号,回车即可跳转到相应行号位置。...

sass中@import升级@use的使用区别与案例
在 Sass 中,import 和 use 都用于模块化代码,但二者有显著区别。以下是主要差异和具体案例说明: 核心区别对比 特性 import (旧版) use (新版) 作用域 全局作用域(变量/混合易冲突) 局部作用域(需通过…...

基于单片机ht7038 demo
单片机与ht7038 demo,三相电能表,电量数据包括电流电压功能,采用免校准方法 列表 ht7038模块/CORE/core_cm3.c , 17273 ht7038模块/CORE/core_cm3.h , 85714 ht7038模块/CORE/startup_stm32f10x_hd.s , 15503 ht7038模块/CORE/startup_stm32…...

基于YOLO11深度学习的胃肠道息肉智能检测分割与诊断系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战、目标分割、人工智能
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...

CViewState::InitializeColumns函数分析之_hdsaColumnStates的结构
CViewState::InitializeColumns函数分析之_hdsaColumnStates的结构 // Set up saved column state only if the saved state // contains information other than "nothing". if (_hdsaColumnStates) { UINT cStates DSA_GetItemCount(_hdsaColumnS…...

商淘云中英文外贸电商系统,助力传统企业杨帆出海
在全球经济一体化的浪潮下,传统企业纷纷渴望拓展海外市场,寻求新的增长机遇。然而,语言障碍、复杂的跨境交易流程、多元的支付体系以及迥异的消费习惯,如同重重壁垒,阻碍着传统企业扬帆出海的步伐。此时,商…...

--- Mysql事务 ---
什么是事务 因为事务的存在,可以使得多条sql语句一起执行,并且只有全部执行成功或全部执行失败俩种结果,保证了数据的安全,也使得这些sql语句拥有了原子性,隔离性,一致性,持久性(AC…...

FreeRTOS第7篇:内存的“精打细算”——堆管理与内存分配
文/指尖动听知识库-星愿 文章为付费内容,商业行为,禁止私自转载及抄袭,违者必究!!! 文章专栏:深入FreeRTOS内核:从原理到实战的嵌入式开发指南 引言:嵌入式系统的“仓库管理员” 想象你是一家繁忙仓库的管理员:货物(内存块)需要被高效存取,货架(堆空间)必须避免…...
:市场真的“有效”吗?中英双语)
有效市场理论(Efficient Market Hypothesis,简称 EMH):市场真的“有效”吗?中英双语
有效市场理论(EMH):市场真的“有效”吗? 1. 什么是有效市场理论? 📌 有效市场理论(Efficient Market Hypothesis,简称 EMH) 是由美国经济学家 尤金法玛(Eug…...

STM32 HAL库USART串口中断编程:演示数据丢失
目录 一、开发环境 二、配置STM32CubeMX 三、代码实现与部署 四、运行结果: 五、注意事项 上面讨论过,HAL_UART_Receive最容易丢数据了,可以考虑用中断来实现,但是HAL_UART_Receive_IT还不能直接用,容易数据丢失,实际工作中不会这样用,本文介绍STM32F103 HAL库函数…...

MapReduce的工作原理及其在大数据处理中的应用
MapReduce是一种由Google提出的面向大数据并行处理的计算模型、框架和平台,它通过将复杂的数据处理任务分解为两个简单的阶段——Map(映射)和Reduce(归约),实现了分布式并行计算,极大地提高了数…...
使用cv2.minEnclosingCircle函数实现图像轮廓圆形标注)
python学opencv|读取图像(六十六)使用cv2.minEnclosingCircle函数实现图像轮廓圆形标注
【1】引言 前序学习过程中,已经掌握了使用cv2.boundingRect()函数实现图像轮廓矩形标注,相关文章链接为:python学opencv|读取图像(六十五)使用cv2.boundingRect()函数实现图像轮廓矩形标注-CSDN博客 这篇文章成功在图…...
Direct交换机、Topic交换机、声明队列交换机)
SpringCloud系列教程:微服务的未来(二十四)Direct交换机、Topic交换机、声明队列交换机
前言 在现代消息队列系统中,交换机是实现消息传递和路由的核心组件。本文将重点探讨三种常见的交换机类型:Direct交换机、Topic交换机和声明队列交换机。通过对这三种交换机的详细分析,我们将学习它们的工作原理、应用场景以及如何在实际项目…...

云创智城充电系统:基于 SpringCloud 的高可用、可扩展架构详解-多租户、多协议兼容、分账与互联互通功能实现
在新能源汽车越来越普及的今天,充电基础设施的管理和运营变得越来越重要。云创智城充电系统,就像一个超级智能管家,为新能源充电带来了全新的解决方案,让充电这件事变得更方便、更高效、更安全。 一、厉害的技术架构,让…...

iOS事件传递和响应
背景 对于身处中小公司且业务不怎么复杂的程序员来说,很多技术不常用,你可能看过很多遍也都大致了解,但是实际让你讲,不一定讲的清楚。你可能说,我以独当一面,应对自如了,但是技术的知识甚多&a…...
——差分运算、延迟算子、AR(p)模型)
时间序列分析(四)——差分运算、延迟算子、AR(p)模型
此前篇章: 时间序列分析(一)——基础概念篇 时间序列分析(二)——平稳性检验 时间序列分析(三)——白噪声检验 一、差分运算 差分运算的定义:差分运算是一种将非平稳时间序列转换…...
朴素贝叶斯分类器(Naive Bayes Classifier)cv::ml::NormalBayesClassifier的使用)
OpenCV机器学习(6)朴素贝叶斯分类器(Naive Bayes Classifier)cv::ml::NormalBayesClassifier的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::ml::NormalBayesClassifier 是 OpenCV 机器学习模块中的一部分,用于实现朴素贝叶斯分类器(Naive Bayes Classifier&a…...

Nginx 反向代理 MinIO 及 ruoyi-vue-pro 配置 MinIO 详解
目录 前言1. nginx配置2. 配置minio(Demo要点)3. 实战要点3.1 前端配置3.2 后端配置3.3 应用前言 如何在ruoyi-vue-pro上使用minio上传文件,通过Ngnix再次转发路径 相关的minio推荐阅读: 云服务器中的MinIO 配置 HTTPS 过程(图文)详细分析Java中的Minio类各API(附win配…...

python黑帽子第二版netcat分析
源码 import argparse import socket import shlex import subprocess import sys import textwrap import threadingdef execute(cmd):cmd cmd.strip()if not cmd:returnoutput subprocess.check_output(shlex.split(cmd), stderrsubprocess.STDOUT)return output.decode()…...

【Android开发】华为手机安装包安装失败“应用是非正式版发布版本,当前设备不支持安装”问题解决
问题描述 我们将Debug版本的安装包发送到手机上安装,会发现华为手机有如下情况 解决办法 在文件gradle.properties中粘贴代码: android.injected.testOnlyfalse 最后点击“Sync now”,等待重新加载gradle资源即可 后面我们重新编译Debug安装…...

dify实现分析-rag-文档内容提取
dify实现分析-rag-文档内容提取 概述 在文章《dify实现原理分析-上传文件创建知识库总体流程》中已经介绍了,文件上传后索引构建的总体流程,本文介绍其中的“Extract: 提取文档内容:这里会按段落或整页来获取文档内容”步骤的实现。 这一步的主要功能…...

腾讯云API+chatbox
腾讯云的限时免费接口:知识引擎原子能力 对话-原子能力相关接口-API 中心-腾讯云 本接口调用DeepSeek系列模型限时免费。即日至北京时间2025年2月25日23:59:59,所有腾讯云用户均可享受DeepSeek-V3、DeepSeek-R1模型限时免费服务,单账号限制接…...