同步异步日志系统-日志器的实现
该模块是针对于前几个模块的整合,也是直接面向客户所使用的,对于该模块的实现,我们基于:继承+建造者设计模式来实现;
因此我们需要抽象出一个日志器抽象基类;
该基类提供的接口如下:
1、 debug();//站在用户的角度来说就是我只需要调用该接口就能完成debug版本日志消息的输出;但是站在日志器的角度来看就是,我日志器通过该接口先收集用户的日志信息,然后根据输出等级来决定是不是要实际落地这条消息,如果当前消息高于输出等级限制,那么我们会利用该日志消息封装一个更为详细的一个日志对象,然后利用日志器的格式化对象格式化成指定字符串,最后在完成实际落地!
同理对于,info、warning、error、fatal、unknown这几个接口的实现也是一样的;
2、 该基类还需要提供一个完成实际落地的接口log();来完成实际落地,该接口根据不同的日志器采用不同的实现,因此该接口必须是虚接口;
管理成员:
格式化对象;
vector数组,用来存放各种落地方向;
日志输出限制等级;
互斥锁;保证日志器是线程安全的;
日志器名称;(用于唯一标识一个日志器)
同步日志器
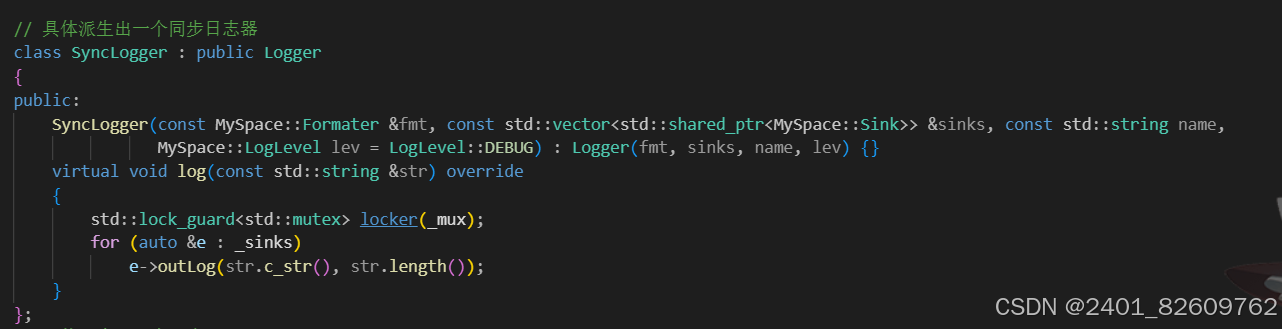
基于抽象基类所作的工作,同步日志器所做的工作就很简单,同步日志器只需要重写log()接口完成实际落地就可以了:
同步日志器的落地方式也是比较简单的就是直接向落地方向中写入就好:
为此同步日志器的设计代码如下:
异步日志器
异步日志器呢就比较复杂一点了,为什么呢?
因为异步日志器与同步日志器不同,异步日志器不会完成日志消息的实际落地,异步日志器是将自己的日志消息落地到一个“缓冲区”中,由异步线程完成从缓冲区中取出数据来完成实际落地!
下面我们来具体聊一聊异步日志器的工作流程:
首先,我们的工作线程落地不在向实际方向落地而是向“缓冲区”中落地,由我们的异步线程来从缓冲区中取出数据来完成实际落地;
因此这是一个典型的生产者消费者模型,在这个过程中我们需要维护,生产者&生产者 生产者&消费者之间的互斥关系,因此我们需要一把锁 同时需要两个条件变量分别用来维护生产者消费者之间的同步关系,当缓冲区满了,我们需要阻塞生产者线程,让消费者线程来;当缓冲区为空了,我们需要阻塞消费者线程,让生产者来进行生产活动!
这些都没问题!可是在实际开发中,锁与锁的冲突无疑是比较严重的,因为这把锁每时每刻除了有生产者和生产者在竞争也有生产者和消费者在竞争,竞争是比较激烈的,这样的话就会导致整个异步日志器的工作效率比较低,为此为了减少锁的冲突,提高效率,我们可以采用双缓冲区的作法
双缓冲区的工作流程是这样的,工作线程呢现在将数据全部放进生产缓冲区中,而异步线程只从消费缓冲区中拿数据,只有当消费缓冲区中的数据没了的时候我们才交换两个缓冲区,这时候我们消费者才需要去申请锁,而在一般情况下,我们生产者和消费者都不是关心的同一个缓冲区,我们自然也就不必每次都去申请锁,这样就减少了生产者和消费者之间的锁冲突,提高了整体工作效率!
当然,如果在消费缓冲区为空了同时生产缓冲区也为空了,那么就没有交换的必要了,我们就阻塞异步线程;
如果生产缓冲区被打满了,那么我们也就可以阻塞生产者,让消费者继续消费一会!
缓冲区实现
上面交代了异步日志器工作流程,最为异步日志器必不可少的一环,我们先来实现缓冲区;
该缓冲区采用面向字节流的设计思想,不需要设计成为一个个string类型的缓冲区,因为设计成string类型的话,异步线程在取的时候就只能取一个落地一个,会增加IO次数,降低IO效率;同时异步线程在取string字符串的时候,需要自己先定义一个string缓冲区在来取,这又是一次没必要拷贝!为此我们的缓冲区采用面向字节流的思想!用户可以自主决定一次性从缓冲区中读取多少字节的数据!
该缓冲区提供的功能:
write();用户只需要调用write接口就能向缓冲区中写入数据;
begin();返回可读位置的指针,注意这里并没有实现read()接口,如果实现该接口的话,那么上层在读取的时候必须先定义一个缓冲区来读取,这势必会造成一次不必要的拷贝!
AbleReadSize();可读数据长度;
AbleWriteSize();可写数据长度;
moveRead();移动读指针;
moveWrite();移动写指针;
reset();将读写指针置0;(交换缓冲区之前,需要对消费缓冲区做的动作)
swap();//交换两个缓冲区;
管理的成员:
vector
读指针
写指针
具体实现
//buffer.hpp
#pragma once
/*
异步缓冲区:
功能:暂时接收工作线程发送的日志信息提供接口:
write接口:外界向缓冲区插入数据
begin();//可写位置指针
AbleWriteSize();//可写空间
AbleReadSize();//可读空间
moveRead()/moveWrite();//读写指针移动
reset();//复位
swap();//交换
成员:
vector<char>
read_index;
write_index;
*/
#include <iostream>
#include <vector>
#include <cassert>
namespace MySpace
{
#define DEFAULT_BUFFER_SIZE 10 * 1024 * 1024 // 10M
#define DEFAULT_BUFFER_THRESHOLD 80 * 1024 * 1024 // 80M//阈值
#define DEFAULT_BUFFER_INCREMENT 10 * 1024 * 1024 // 10M//增量class Buffer{public:Buffer(size_t cap = DEFAULT_BUFFER_SIZE) : _q(cap) {}bool write(const char *str, int len){// 如果可写空间不够?//有两种作法:1、扩容;//2、由外部直接在插入执前做插入判断,如果实际插入的大小<=AbleWriteSize()那么就直接插入即可;如果大于了,那么由外部进行阻塞!//这里的话我们缓冲区提供的是扩容操作//但是实际会不会扩容完全由用户控制//如果用户做插入检查,那么就不会发生扩容//如果用户不做插入检查,那么就会发生扩容EableEnoughSpace(len);// 进行拷贝std::copy(str, str + len, _q.begin() + _write_index);// 更新write指针moveWrite(len);return true;}const char *begin(){return &_q[_read_index];}// 可写空间size_t AbleWriteSize(){return _q.size() - _write_index;}// 可读空间大小size_t AbleReadSize(){return _write_index - _read_index;}void swap(Buffer &bf){_q.swap(bf._q);std::swap(_write_index, bf._write_index);std::swap(_read_index, bf._read_index);}void reset(){_write_index = _read_index = 0;}void moveRead(size_t len){assert(len + _read_index <= _write_index);_read_index += len;}bool empty(){return _write_index == _read_index;}private:void moveWrite(size_t len){assert(_write_index + len <= _q.size());_write_index += len;}void EableEnoughSpace(int len){if (len > AbleWriteSize()){//扩容也是有讲究的//在没到达阈值之前快速扩;//达到阈值过后线性扩!size_t newSize = _q.size() < DEFAULT_BUFFER_THRESHOLD ? 2 * _q.size() : _q.size() + DEFAULT_BUFFER_INCREMENT;_q.resize(newSize);}}std::vector<char> _q;size_t _read_index = 0;size_t _write_index = 0;};} // namespace MySpace异步工作器实现
异步工作器模块实际上就是双缓冲区与异步线程的整合;
工作线程通过与异步线程交互来完成异步日志器的工作输出;
异步工作器提供的功能:
push:工作线程通过该接口向缓冲区添加数据;
stop();工作线程可以通过调用该接口来停止异步工作器的工作;
管理成员:
双缓冲区;
互斥锁;
两个条件变量;
_stop;停止标志
回调函数(也就是实际处理逻辑,消费数据怎么处理,由外部决定)
异步工作线程
代码实现
//looper.hpp
#pragma once
#include "buffer.hpp"
/*
异步工作器模块:
功能:异步处理主线程的日志消息,完成日志消息的实际落地
提供接口:
stop();//停止异步工作器
push();//方便工作线程向异步工作器提供数据
成员:
1、双缓冲区(生&消
2、互斥锁(保护生产者&生产者 消费者&生产者)
3、双条件变量(双缓冲区都为空,则阻塞异步线程;若生产缓冲区不够了,阻塞生产者)
4、异步线程
5、停止标志
6、实际处理逻辑(具体如何实现交给外部来决定,实现解耦)
*/
#include <atomic>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <functional>
namespace MySpace
{using func_t = std::function<void(Buffer &)>;class AsyncLooper{public:AsyncLooper(const func_t &f, bool safe = true) : _work(f), _stop(false), _t(&AsyncLooper::threadRuning, this), _safe(safe){}~AsyncLooper(){stop();}void stop(){_stop = true;_conCond.notify_all();_t.join();}void push(const char *str, int len){if (_stop)return;{std::unique_lock<std::mutex> locker(_mux);// 唤醒条件:或者实际写入的长度小于可写入的长度// 安全模式下执行if (_safe){_proCond.wait(locker, [&]() -> bool{ return len <= _proBuf.AbleWriteSize(); });}// 非安全模式下直接插入,不考虑空间问题,少了会自动扩容_proBuf.write(str, len);}// 唤醒消费者,有数据来消费了_conCond.notify_all();}private:void threadRuning(){while (true){// 尝试交换if (_conBuf.empty()){std::unique_lock<std::mutex> locker(_mux);// 唤醒条件:生产者队列不为空或者_stop标志被置true// 阻塞条件:生产者队列为空并且_stop置false;_conCond.wait(locker, [&]() -> bool{ return _proBuf.empty() == false || _stop; });if (_stop && _proBuf.empty())break;// 生产者缓冲区有数据被唤醒_conBuf.reset();_conBuf.swap(_proBuf);}_proCond.notify_all();_work(_conBuf);}_proCond.notify_all();}bool _safe = true;Buffer _proBuf; // 生产缓冲区Buffer _conBuf; // 消费缓冲区std::mutex _mux;std::condition_variable _proCond; // 生产者条件队列std::condition_variable _conCond; // 消费者条件队列std::atomic<bool> _stop; // 停止标志std::thread _t; // 异步线程func_t _work; // 实际处理逻辑};
} // nam;espace在该异步工作器模块中,我们提供了两种模式,安全模式和非安全模式;
处于非安全模式下的生产者线程在向缓冲区插入数据的时候不会发生扩容;
而处于安全模式下的生产者线程在向缓冲区插入数据的时候不会发生扩容,因为会被阻塞!
建造者模式
现在同步日志器与异步日志器都已经建立好了,但是每次使用之前都需要我们自己将日志器所需要的零件构造好,很是麻烦,为此我们可以采用兼着做模式来帮我们完成零件构造的过程;
首先抽象出一个抽象建造者:
该建造者可以帮我们建造任何零件;
同时该建造者还具有根据零件完成组装的功能,这个根据具体的建造者建有关系,因此我们需要提供一个组装接口,该接口是虚接口:
日志器管理模块实现
上面的功能已经差不多将日志系统的大厦建立起来了,可是上面建立的日志器只能在当前作用域使用,要是在其它作用域使用的话,那么就需要我们来传参完成,使用起来非常不方便!
可不可以设计一种管理器,该管理器可以将所创建出来的日志器都管理起来,同时这个管理器是全局唯一的,哪里都可以使用,我们只需要通过向该管理器告知日志器名称就能返回给我们指定日志器;答案是可以的!
该日志器管理类:
1、管理已创建的日志器
2、可以同通过该管理器在全局任意地方根据日志器名称获取日志器
3、该管理器默认提供一个标准输出的同步日志器
4、该管理器为单例对象,全局只有一个管理器对象
提供接口:
getInstance();//获取日志管理器对象
addLogger();//添加日志器
isExists();//日志器是否存在
getLogger();//获取日志器
getRootLogger();//获取默认日志器
管理成员;
unordered_map<string ,shared_ptr> _loggers;
mutex保证日志管理器对象的线程安全
默认日志器对象 (同步标输出)
代码
//logger.hpp
#pragma once
/*
日志器模块或者说写入方式模块
日志器是直接暴露给用户的
功能:完成用户交给日志器的具体日志打印工作
设计思想:
为此站在用户的角度来说就是
我只要将日志消息传递给日志器,日志器就能帮助我们完成日志的输出
因此日志器要提供一些接口来供用户传入日志消息
而站在日志器的角度来说,我通过上诉接口获取到了用户的日志信息,日志器要做的工作就是
根据用户传进来的日志信息封装一个日志对象
然后利用格式化类对象格式化日志对象
然后再使用一个落地接口完成最终落地!一个日志器的落地方向可能不止一种,为此我们需要一个容器来保存落地方向
日志器也需要知道如何格式化对象,为此他需要一个格式化对象
多线程情况下,有可能多个线程使用同一个日志器对同一个落地方向进行输出,会造成线程安全,需要一把锁
日治器也需要一个限制等级来维护日志器正对那些等级的日志进行实际落地,那些日志不进行输出;
日志器也需要一个名字来标识唯一日志器如果具体细分的话,日志器分为:同步日志器、异步日志器
为此为了方便管理日志器,可以采用继承的设计层次
*/
#include "util.hpp"
#include "level.hpp"
#include "format.hpp"
#include "sink.hpp"
#include "looper.hpp"
#include <mutex>
#include <stdarg.h>
#include <unordered_map>
namespace MySpace
{
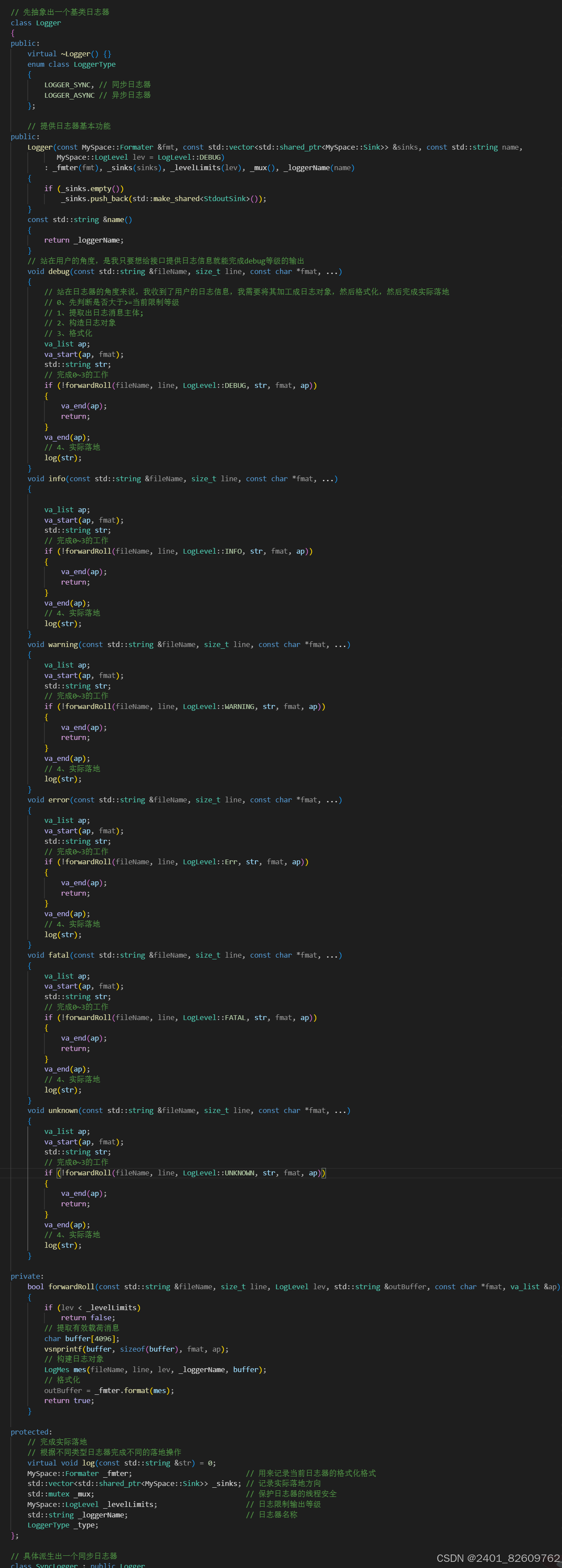
// 先抽象出一个基类日志器
class Logger
{
public:
virtual ~Logger() {}
enum class LoggerType
{
LOGGER_SYNC, // 同步日志器
LOGGER_ASYNC // 异步日志器
};// 提供日志器基本功能
public:
Logger(const MySpace::Formater& fmt, const std::vector<std::shared_ptr<MySpace::Sink>>& sinks, const std::string name,
MySpace::LogLevel lev = LogLevel::DEBUG, LoggerType type = LoggerType::LOGGER_SYNC)
: _fmter(fmt), _sinks(sinks), _levelLimits(lev), _mux(), _loggerName(name)
{
if (_sinks.empty())
_sinks.push_back(std::make_shared<StdoutSink>());
}
const std::string& name()
{
return _loggerName;
}
// 站在用户的角度,是我只要想给接口提供日志信息就能完成debug等级的输出
void debug(const std::string& fileName, size_t line, const char* fmat, ...)
{
// 站在日志器的角度来说,我收到了用户的日志信息,我需要将其加工成日志对象,然后格式化,然后完成实际落地
// 0、先判断是否大于>=当前限制等级
// 1、提取出日志消息主体;
// 2、构造日志对象
// 3、格式化
va_list ap;
va_start(ap, fmat);
std::string str;
// 完成0~3的工作
if (!forwardRoll(fileName, line, LogLevel::DEBUG, str, fmat, ap))
{
va_end(ap);
return;
}
va_end(ap);
// 4、实际落地
log(str);
}
void info(const std::string& fileName, size_t line, const char* fmat, ...)
{va_list ap;
va_start(ap, fmat);
std::string str;
// 完成0~3的工作
if (!forwardRoll(fileName, line, LogLevel::INFO, str, fmat, ap))
{
va_end(ap);
return;
}
va_end(ap);
// 4、实际落地
log(str);
}
void warning(const std::string& fileName, size_t line, const char* fmat, ...)
{
va_list ap;
va_start(ap, fmat);
std::string str;
// 完成0~3的工作
if (!forwardRoll(fileName, line, LogLevel::WARNING, str, fmat, ap))
{
va_end(ap);
return;
}
va_end(ap);
// 4、实际落地
log(str);
}
void error(const std::string& fileName, size_t line, const char* fmat, ...)
{
va_list ap;
va_start(ap, fmat);
std::string str;
// 完成0~3的工作
if (!forwardRoll(fileName, line, LogLevel::Err, str, fmat, ap))
{
va_end(ap);
return;
}
va_end(ap);
// 4、实际落地
log(str);
}
void fatal(const std::string& fileName, size_t line, const char* fmat, ...)
{
va_list ap;
va_start(ap, fmat);
std::string str;
// 完成0~3的工作
if (!forwardRoll(fileName, line, LogLevel::FATAL, str, fmat, ap))
{
va_end(ap);
return;
}
va_end(ap);
// 4、实际落地
log(str);
}
void unknown(const std::string& fileName, size_t line, const char* fmat, ...)
{
va_list ap;
va_start(ap, fmat);
std::string str;
// 完成0~3的工作
if (!forwardRoll(fileName, line, LogLevel::UNKNOWN, str, fmat, ap))
{
va_end(ap);
return;
}
va_end(ap);
// 4、实际落地
log(str);
}private:
bool forwardRoll(const std::string& fileName, size_t line, LogLevel lev, std::string& outBuffer, const char* fmat, va_list& ap)
{
if (lev < _levelLimits)
return false;
// 提取有效载荷消息
char buffer[4096];
vsnprintf(buffer, sizeof(buffer), fmat, ap);
// 构建日志对象
LogMes mes(fileName, line, lev, _loggerName, buffer);
// 格式化
outBuffer = _fmter.format(mes);
return true;
}protected:
// 完成实际落地
// 根据不同类型日志器完成不同的落地操作
virtual void log(const std::string& str) = 0;
MySpace::Formater _fmter; // 用来记录当前日志器的格式化格式
std::vector<std::shared_ptr<MySpace::Sink>> _sinks; // 记录实际落地方向
std::mutex _mux; // 保护日志器的线程安全
MySpace::LogLevel _levelLimits; // 日志限制输出等级
std::string _loggerName; // 日志器名称
LoggerType _type;
};// 具体派生出一个同步日志器
class SyncLogger : public Logger
{
public:
SyncLogger(const MySpace::Formater& fmt, const std::vector<std::shared_ptr<MySpace::Sink>>& sinks, const std::string name,
MySpace::LogLevel lev = LogLevel::DEBUG) : Logger(fmt, sinks, name, lev, LoggerType::LOGGER_SYNC) {}
virtual void log(const std::string& str) override
{
std::lock_guard<std::mutex> locker(_mux);
for (auto& e : _sinks)
e->outLog(str.c_str(), str.length());
}
};
// 具体派生出一个异步日器
class AsyncLogger : public Logger
{
public:
AsyncLogger(const MySpace::Formater& fmt, const std::vector<std::shared_ptr<MySpace::Sink>>& sinks, const std::string name,
MySpace::LogLevel lev = LogLevel::DEBUG, bool safe = true) : Logger(fmt, sinks, name, lev, LoggerType::LOGGER_SYNC), _looper(std::bind(&AsyncLogger::realLog, this, std::placeholders::_1), safe)
{
}
virtual void log(const std::string& str) override
{
_looper.push(str.c_str(), str.size());
}
private:
void realLog(Buffer& bf)
{
for (auto& e : _sinks)
e->outLog(bf.begin(), bf.AbleReadSize());
bf.moveRead(bf.AbleReadSize());
}
MySpace::AsyncLooper _looper;
};// 创建日志器所需要的零件
class Builder
{
public:
virtual ~Builder() {}
void buildLoggerName(const std::string name)
{
_loggerName = name;
}
void buildLoggerType(Logger::LoggerType type = Logger::LoggerType::LOGGER_SYNC)
{
_type = type;
}
void buildFormater(const std::string& fmt = "")
{
if (fmt == "")
_fmt = Formater();
else
_fmt = Formater(fmt);
}
void buildLevelLimits(LogLevel lev = LogLevel::DEBUG)
{
_levelLimits = lev;
}
// 建造异步建造器时时所使用
void EnableSafe(bool flag)
{
_safe = flag;
}
template <class T, class... Args>
void buildSink(Args... args)
{
_sinks.push_back(SinkFactory::createSink<T>(args...));
}
// 根据零件组合一个具体对象
virtual std::shared_ptr<Logger> build() = 0;protected:
bool _safe = true; // 异步日志器建造需要(默认安全)
std::string _loggerName;
Logger::LoggerType _type;
Formater _fmt;
MySpace::LogLevel _levelLimits;
std::vector<std::shared_ptr<MySpace::Sink>> _sinks;
};// 局部日志器建造
class LocalLoggerBuilder : public Builder
{
public:
virtual std::shared_ptr<Logger> build() override
{
std::shared_ptr< std::vector<std::shared_ptr<MySpace::Sink>>> sp(&_sinks, [](std::vector < std::shared_ptr<MySpace::Sink>>*ptr)->void {
ptr->clear();
});
if (_type == Logger::LoggerType::LOGGER_SYNC)
return std::make_shared<SyncLogger>(_fmt, _sinks, _loggerName, _levelLimits);
else
return std::make_shared<AsyncLogger>(_fmt, _sinks, _loggerName, _levelLimits, _safe);
}
};
/*
创建一个日志器管理类:
该类提供的作用:
1、管理已创建的日志器
2、可以同通过该管理器在全局任意地方根据日志器名称获取日志器
3、该管理器默认提供一个标标准输出的日志器
4、该管理器为单例对象,全局只有一个管理器对象
提供接口:
getInstance();//获取日志管理器对象
addLogger();//添加日志器
isExists();//日志器是否存在
getLogger();//获取日志器
getRootLogger();//获取默认日志器
管理成员;
unordered_map<string ,shared_ptr<Logger>> _loggers;
mutex保证日志管理器对象的线程安全
默认日志器对象 (同步标输出)
*/
class loggerManager
{
public:
static loggerManager& getInstance()
{
static loggerManager lo;
return lo;
}
void addLogger(std::shared_ptr<Logger>& ptr)
{
if (isExists(ptr->name()))
return;
_loggers[ptr->name()] = ptr;
}
bool isExists(const std::string& name)
{
auto it = _loggers.find(name);
if (it == _loggers.end())
return false;
return true;
}
std::shared_ptr<Logger> getLogger(const std::string& name)
{
if (isExists(name))
return _loggers[name];
return nullptr;
}
std::shared_ptr<Logger> getRootLogger()
{
return _root;
}private:
loggerManager()
{
LocalLoggerBuilder lo;
lo.buildFormater();
lo.buildLevelLimits();
lo.buildLoggerName("root");
lo.buildLoggerType();
lo.buildSink<StdoutSink>();
_root = lo.build();
std::string name("root");
_loggers[name] = _root;
}
loggerManager(const loggerManager&) = delete;
loggerManager(loggerManager&&) = delete;
std::unordered_map<std::string, std::shared_ptr<Logger>> _loggers;
std::mutex _mux;
std::shared_ptr<Logger> _root; // 默认日志器
};
// 全局日志器建造者//改日志器建造者是配合日志器管理对象来使用的
// 与局部日志器建造者的唯一区别就是多了一步将构建出来的日志器添加进日志器管理对象的步骤
// 省去了用户需要手动添加的过程
class GobalLoggerBuilder : public Builder
{
public:
virtual std::shared_ptr<Logger> build() override
{
std::shared_ptr< std::vector<std::shared_ptr<MySpace::Sink>>> sp(&_sinks, [](std::vector < std::shared_ptr<MySpace::Sink>>* ptr)->void {
ptr->clear();
});
std::shared_ptr<Logger> it(nullptr);
if (_type == Logger::LoggerType::LOGGER_SYNC)
it = std::make_shared<SyncLogger>(_fmt, _sinks, _loggerName, _levelLimits);
else
it = std::make_shared<AsyncLogger>(_fmt, _sinks, _loggerName, _levelLimits, _safe);
//_sinks.clear();
loggerManager::getInstance().addLogger(it);
return it;
}
};
}
相关文章:

同步异步日志系统-日志器的实现
该模块是针对于前几个模块的整合,也是直接面向客户所使用的,对于该模块的实现,我们基于:继承建造者设计模式来实现; 因此我们需要抽象出一个日志器抽象基类; 该基类提供的接口如下: 1、 debug();//站在用户的角度来说就是我只需要…...
)
webpack 项目优化(一)
一、构建速度优化 缩小文件处理范围 module: {rules: [{test: /\.js$/,exclude: /node_modules/, // 排除第三方库include: path.resolve(__dirname, src), // 限定处理范围use: babel-loader}] }利用缓存 Webpack 5 内置持久化缓存(直接配置)࿱…...

【撰写技巧】基金项目撰写跟踪交流会
基金申请书撰写完成后,提交前的审查是一个非常关键的步骤,这决定了你提交的材料是否符合要求,是否具备足够的说服力,以及是否能够通过专家评审。审查主要可以分为自我审查和团队审查两个层面。以下是基金申请书审查的主要内容和注…...

vue学习笔记
结合目录,点击阅读 文章目录 案例1:第一行vue代码App.vue引入Person.vue案例:改变变量的值案例:改变对象属性值案例:toRefs进行解包案例:给名字首字母大写案例:监视变量值的变化案例࿱…...

前端构建工具——Webpack和Vite的主要区别
目录 1. 设计理念2. 性能表现3. 使用场景4. 配置复杂度5. 生态系统6. 性能对比总结7. 选择建议 1. 设计理念 Webpack 设计理念:Webpack是一个通用的模块打包工具,它将项目中的各种资源(如JavaScript、CSS、图片等)视为模块&…...

Letsencrypt+certbot为域名免费配置ssl
1、基础概念 Let’s Encrypt 是一个提供免费 SSL/TLS 证书的认证机构,它的目标是让互联网上的通信更加安全,特别是普及 HTTPS。通过 Let’s Encrypt 提供的证书,网站可以使用加密连接,保护用户的数据传输。 Certbot 是一个由电子…...

达梦数据库针对慢SQL,收集统计信息清除执行计划缓存
前言:若遇到以下场景,大概率是SQL走错了执行计划: 1、一条SQL在页面上查询特别慢,但拿到数据库终端执行特别快 2、一条SQL在某种检索条件下查询特别慢,但拿到数据库终端执行特别快 此时,可以尝试按照下述步…...

IDEA通过Contince接入Deepseek
Deepseek 的出色表现,上期【Deepseek得两种访问方式与本地部署】 安装Continue插件 第一步、下载插件 在编辑栏【File】->设置【Settiings】或快捷键【CtrlAltS】,弹窗的左侧导航树,选择【plugins】,在marketplace 搜索【Continue】,点…...

Windows 10 ARM工控主板CAN总线实时性能测试
在常规的Windows系统中支持CAN总线应用,需要外接CAN总线适配器,通常为USB转CAN模块或PCI接口CAN卡。实时性本身是CAN总线的显著特性之一,但由于Windows并非实时操作系统,应用程序容易受到系统CPU负载影响,导致调度周期…...

深入理解无锁队列与C++原子操作
文章目录 深入理解无锁队列与C原子操作引言原子操作基础什么是原子操作?内存顺序(Memory Order) 无锁队列实现环形缓冲区队列(单生产者/单消费者)链表式无锁队列(多生产者/多消费者) 关键问题与…...

OpenGL: QOpenGLShaderProgram
一、QOpenGLShaderProgram 编译过程的封装 1、bool addShaderFromSourceCode(QGLShader::ShaderType type, const char * source); 2、bool addShaderFromSourceFile(QGLShader::ShaderType type, const QString & fileName); 3、virtual bool link(); 4、bool bind(); 5、…...

【网络编程】之数据链路层
【网络编程】之数据链路层 数据链路层基本介绍基本功能常见协议 以太网什么是以太网以太网协议帧格式数据链路层的以太网帧报文如何封装/解封装以及分用以太网通信原理传统的以太网与集线器现代以太网与交换机碰撞域的概念 Mac地址基本概念为什么要使用Mac地址而不是使用IP地址…...

HTTP 和 TCP/IP-傻傻分不清
HTTP 和 TCP/IP 是计算机网络中不同层次的协议,它们的核心区别在于功能和所属的网络层次。以下是详细对比: 1. 所属网络层次 TCP/IP 定位:TCP/IP 是一个协议族(包含多个协议),涵盖网络通信的传输层和网络层…...

【SQL】SQL约束
🎄约束 📢作用:是用于限制存储再表中的数据。可以再创建表/修改表时添加约束。 📢目的:保证数据库中数据的正确、有效性和完整性。 📢对于一个字段可以同时添加多个约束。 🎄常用约束: 约束分类 约束 描述关键字非…...
测试用例CAPL代码全解析⑧】)
【ISO 14229-1:2023 UDS诊断(ECU复位0x11服务)测试用例CAPL代码全解析⑧】
ISO 14229-1:2023 UDS诊断【ECU复位0x11服务】_TestCase08 作者:车端域控测试工程师 更新日期:2025年02月17日 关键词:UDS诊断协议、ECU复位服务、0x11服务、ISO 14229-1:2023 TC11-008测试用例 用例ID测试场景验证要点参考条款预期结果TC…...

解决vue-awesome-swiper 4.x + swiper 5.x 分页pagination配置不生效问题
这次给的需求需要实现几个轮播图,我打算用swiper来做。刚开始我参照同事之前实现的swiper,复制到我的新页面中,是可用的。但是这次的需求需要有底下的分页pagination,而且因为版本比较老,比较难找到配置项。这里说一下…...

Spring Boot 开发入门
文章来源:开发您的第一个 Spring Boot 应用程序 (Developing Your First Spring Boot Application) _ Spring Boot3.4.0中文文档(官方文档中文翻译)|Spring 教程 —— CADN开发者文档中心 本节介绍如何开发一个小型的 “Hello World!” Web 应用程序&…...
)
MATLAB算法实战应用案例精讲-【数模应用】空间插值(附MATLAB、R语言和python代码实现)
目录 前言 算法原理 什么是插值? 为什么要插值? 常见插值方法 插值方法选择 GIS中常用的空间分析方法 一、空间插值 二、缓冲区分析 三、空间统计 四、领域分析 五、网络分析 六、多标准决策 插值分析 插值应用示例 空间插值的类型 不同工具箱中的空间插值工…...

碰一碰发视频@技术原理与实现开发步骤
碰一碰发视频系统:技术原理与实现方案解析 引言 近年来,随着移动支付和近场通信技术(NFC)的普及,“碰一碰”功能逐渐成为商家与用户交互的新入口。通过“碰一碰加盟”模式,企业可以快速赋能线下商户&…...

14.学成在线开发小结
1.统计两张表的数据,表1和表2是一对多的关系,如果既要统计表1又要统计表2的数据,要分开进行统计,否则表1一条数据在表2中可能有多条数据对应,导致表1的数据被多次统计。 2.nacos配置文件的数据读取不到可能原因有&…...

图像处理之CSC
CSC 是 Color Space Conversion(色彩空间转换)的缩写,它涉及图像处理中的亮度、饱和度、对比度和色度等参数的调整。这些参数是图像处理中的核心概念,通常用于描述和操作图像的颜色信息。 以下是亮度、饱和度、对比度和色度与 CS…...
及其实现)
数据结构:顺序表(Sequence List)及其实现
什么是顺序表? 顺序表是一种最简单的数据结构,它就像一排连续的小房子,每个房子里都住着一个数据元素。这些房子是按顺序排列的,每个房子都有一个门牌号(下标),我们可以通过门牌号快速找到对应…...

微信云开发小程序音频播放踩坑记录 - 从熄屏播放到iOS静音
在开发小程序冥想功能时,我们遇到了几个棘手的问题:用户反馈手机熄屏后音频停止、iOS设备播放没声音、冥想音频没有访问计数和CDN缓存优化等。本文将分享这些问题的解决过程和实践经验。 微信小程序简称:Moodo 微信小程序全程:AIMoodo心情日记系统 简…...

Python基础
https://www.w3schools.com/https://docs.python.org/3/ Python 介绍 Python是跨平台的,它可以运行在Windows、Mac和各种Linux/Unix系统上。在Windows上写Python程序,放到Linux上也是能够运行的。 要开始学习Python编程,首先就得把Python安装…...

基于Go语言 XTA AI聊天界面实现
项目开源地址: XTA-AI-SDK 人工智能技术的迅速发展,AI聊天应用变得越来越流行。本文将介绍如何使用Go语言和LCL库( Lazarus Component Library)创建一个功能丰富的AI聊天界面。项目主要包含以下模块: 项目背景 本项目旨在为开发…...

线上项目报错OOM常见原因、排查方式、解决方案
概述 OutOfMemoryError(OOM)是 Java 应用程序中常见的问题,通常是由于应用程序占用的内存超过了 JVM 分配的最大内存限制。在 Spring Boot 项目中,OOM 问题可能由多种原因引起。 1. OOM 的常见原因 OOM 通常由以下几种情况引起&…...
:多模态大模型实战——让AI看懂世界)
AI大模型零基础学习(6):多模态大模型实战——让AI看懂世界
从“文字交互”到“全感官认知”的维度突破 一、多模态大模型:AI的“五感觉醒” 1.1 基础概念重塑 单模态局限:传统大模型仅处理文本(如ChatGPT) 多模态进化: 输入:支持文本、图像、音频、视频、3D模型 …...
)
基于Spring Boot+Vue的宠物服务管理系统(源码+文档)
项目简介 宠物服务管理系统实现了以下功能: 基于Spring BootVue的宠物服务管理系统的主要使用者分为用户管理模块,由于系统运行在互联网络中,一些游客或者病毒恶意进行注册,产生大量的垃圾用户信息,管理员可以对这些…...
)
简要分析LeetCode树经典题目(Java)
目录 开场白 实战环节 准备工作 遍历问题 LeetCode144. 二叉树的前序遍历 方法一 方法二 LeetCode94. 二叉树的中序遍历 LeetCode145. 二叉树的后序遍历 方法一 方法二 LeetCode102. 二叉树的层序遍历 LeetCode103. 二叉树的锯齿形层序遍历 LeetCode107. 二叉树的…...

vue3开发打年兽功能
1.效果 WeChat_20250217192041 2.代码 2.1 index.vue <template><div class"pages"><TopNavigationYleftTitle"打年兽"ruleIconColor"#fff"backgroundImage""svgIpcn"backIcon4"gradientBackgroundColor&q…...

动手学Agent——Day2
文章目录 一、用 Llama-index 创建 Agent1. 测试模型2. 自定义一个接口类3. 使用 ReActAgent & FunctionTool 构建 Agent 二、数据库对话 Agent1. SQLite 数据库1.1 创建数据库 & 连接1.2 创建、插入、查询、更新、删除数据1.3 关闭连接建立数据库 2. ollama3. 配置对话…...

如何在 GitHub 中创建一个空目录 ?
GitHub 是开发人员必不可少的工具,它提供了存储、共享和协作代码的平台。一个常见的问题是如何在 GitHub 存储库中创建一个空目录或文件夹。GitHub 不支持直接创建空目录。但是,有一种解决方法是使用一个虚拟文件,通常是一个 .gitkeep 文件。…...

3. 导入官方dashboard
官方dashboard:https://grafana.com/grafana/dashboards 1. 点击仪表板 - 新建 - 导入 注:有网络的情况想可以使用ID,无网络情况下使用仪表板josn文件 2. 在官方dashboard网页上选择符合你现在数据源的dashboard - 点击进入 3. 下拉网页选…...

前端知识速记--HTML篇:HTML5的新特性
前端知识速记–HTML篇:HTML5的新特性 一、语义化标签 HTML5引入了许多新的语义化标签,如 <header>、<footer>、<article>、<section> 等。这些标签不仅提高了网页的可读性和结构性,还有助于SEO(搜索引擎…...
)
【数据分享】1929-2024年全球站点的逐年降雪深度数据(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、能见度等指标,说到气象数据,最详细的气象数据是具体到气象监测站点的数据! 有关气象指标的监测站点数据,之前我们分享过1929-2024年全球气象站…...

鸿蒙面试题
1.0penHarmony的系统架构是怎样的? 2.电话服务的框架? 3.OpenHarmony与HarmonyOS有啥区别?...
)
pdf-extract-kit paddle paddleocr pdf2markdown.py(效果不佳)
GitHub - opendatalab/PDF-Extract-Kit: A Comprehensive Toolkit for High-Quality PDF Content Extraction https://github.com/opendatalab/PDF-Extract-Kit pdf2markdown.py 运行遇到的问题: 错误: -------------------------------------- C Tra…...
驱动程序设计)
基于STM32、HAL库、RX8025T(I2C接口)驱动程序设计
一、简介: RX8025T 是一款低功耗、高精度的实时时钟芯片,具有以下特性: I2C 接口通信 内置 32.768 kHz 晶振 提供秒、分、时、日、月、年等时间信息 支持温度补偿,提高时间精度 低功耗设计,适合电池供电的应用 二、I2C初始化: #include "stm32l4xx_hal.h&…...

基于Ubuntu+vLLM+NVIDIA T4高效部署DeepSeek大模型实战指南
一、 前言:拥抱vLLM与T4显卡的强强联合 在探索人工智能的道路上,如何高效地部署和运行大型语言模型(LLMs)一直是一个核心挑战。尤其是当我们面对资源有限的环境时,这个问题变得更加突出。原始的DeepSeek-R1-32B模型虽…...

【Go语言快速上手】第二部分:Go语言进阶之并发编程
文章目录 一、并发编程1. goroutine:创建和调度 goroutine2. channel:无缓冲 channel、有缓冲 channel、select 语句2.1 无缓冲 channel2.2 有缓冲 channel2.3 select 语句 3. sync 包:Mutex、RWMutex、WaitGroup 等同步原语3.1 Mutex&#x…...

《机器学习数学基础》补充资料:四元数、点积和叉积
《机器学习数学基础》第1章1.4节介绍了内积、点积的有关概念,特别辨析了内积空间、欧几里得空间;第4章4.1.1节介绍了叉积的有关概念;4.1.2节介绍了张量积(也称外积)的概念。 以上这些内容,在不同资料中&…...

蓝桥杯篇---IAP15F2K61S2矩阵键盘
文章目录 前言简介矩阵键盘的工作原理1.行扫描2.检测列状态3.按键识别 硬件连接1.行线2.列线 矩阵键盘使用步骤1.初始化IO口2.扫描键盘3.消抖处理4.按键识别 示例代码:4x4矩阵键盘扫描示例代码:优化后的矩阵键盘扫描注意事项1.消抖处理2.扫描频率3.IO口配…...
通过小型语言模型尽可能简单地解释 Transformer
介绍 在过去的几年里,我阅读了无数关于 Transformer 网络的文章,观看了许多视频。其中大部分都非常好,但我很难理解 Transformer 架构,而其背后的主要直觉(上下文敏感嵌入)则更容易掌握。在做演讲时&#…...

GcExcel
GcExcel 简述:GcExcel Java 是一款基于 Java 平台,支持批量创建、编辑、打印、导入/导出Excel文件的服务端表格组件,能够高性能处理和高度兼容 Excel。功能特性(图1)文档查询(图2)...

封装红黑树实现map和set
" 喜欢了你十年,却用整个四月,编织了一个不爱你的谎言。 " 目录 1 源码及其框架分析 2 模拟实现map和set 2.1 实现出复用红黑树的框架 2.2 支持iterator迭代器的实现 2.2.1 代码实现和--这两个运算符 2.3 map支持[ ] Hello,大家…...

Redis进阶使用
在日常工作中,使用Redis有什么需要注意的? 设置合适的过期时间。尽量避免大key问题,避免用字符串存储过大的数据;避免集合的数据量太大,要定期清除。 常用的数据结构有哪些?用在什么地方? 按…...

【ISO 14229-1:2023 UDS诊断全量测试用例清单系列:第四节】
ISO 14229-1:2023 UDS诊断服务测试用例全解析(Read DTC Information0x19服务) 作者:车端域控测试工程师 更新日期:2025年2月13日 关键词:UDS诊断协议、0x19服务、DTC信息读取、ISO 14229-1:2023、ECU测试 一、服务功能…...

使用Node.js进行串口通信
目录 一、 安装 serialport 库二.、实现方法1.打开串口并配置参数2. 向串口传递信息3. 接收串口信息4. 处理错误5. 关闭串口6. 使用解析器7. 获取串口列表 三、 完整示例代码 一、 安装 serialport 库 首先,需要安装 serialport 库。可以通过 npm 安装:…...

vue3+elementplus新建项目
更新node.js和npm node.js官网更新指南 可以根据自己的操作系统进行选择 我的电脑操作系统是mac os所以我的步骤如下 # Download and install nvm: curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.1/install.sh | bash# in lieu of restarting the shell \. &…...

【网络安全 | 漏洞挖掘】跨子域账户合并导致的账户劫持与删除
未经许可,不得转载。 文章目录 概述正文漏洞成因概述 在对目标系统进行安全测试时,发现其运行着两个独立的域名——一个用于司机用户,一个用于开发者/企业用户。表面上看,这两个域名各自独立管理账户,但测试表明它们在处理电子邮件变更时存在严重的逻辑漏洞。该漏洞允许攻…...