文件系统惹(细)
目录
块概念
分区
inode
ext2文件系统
Boot Sector
Super Block
GDP(group descriptor table)
Block Bitmap(块位图)
Inode Bitmap (inode位图)
Data Block
inode和Datablock映射
目录和文件名
路径解析
路径缓存
块概念
os文件系统访问磁盘,不是以扇区为单位的,而是以块为单位的,一般是4KB(也就是连续的8个扇区)(可以调整大小)。
磁盘就是⼀个三维数组,我们把它看待成为⼀个"⼀维数组",数组下标就是LBA,每个元素都是扇区
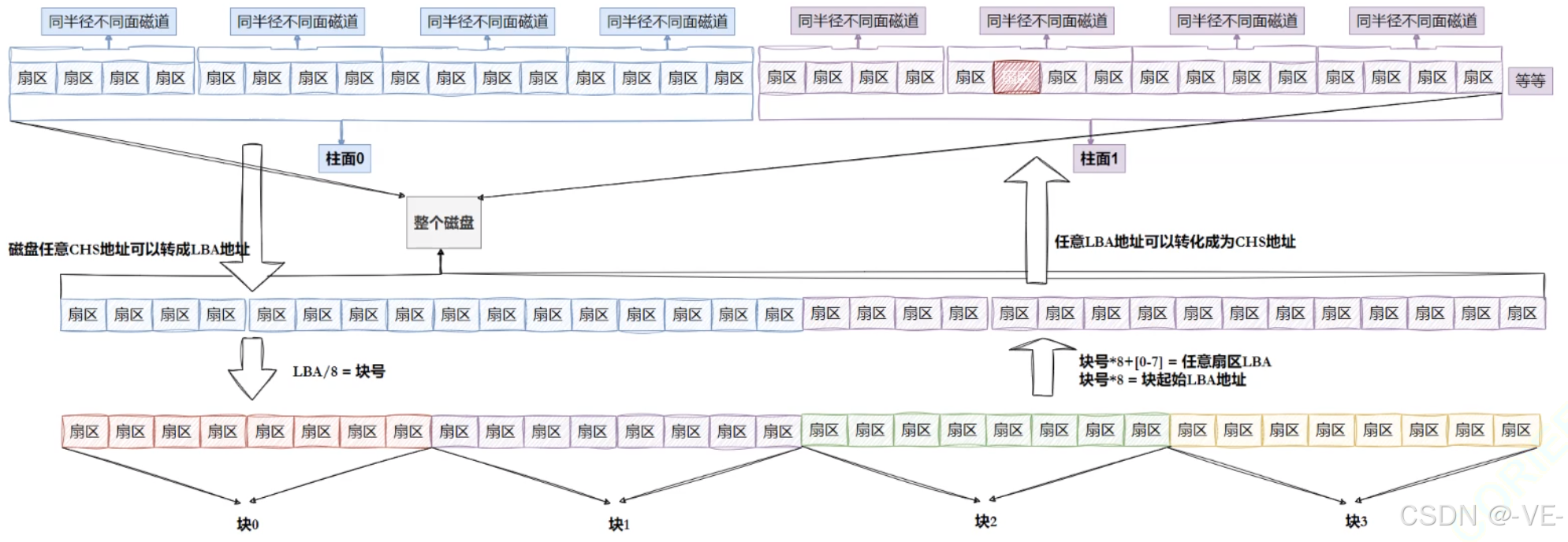
文件系统使用磁盘块,是以4KB为单位的。
分区
inode
liunx下文件=文件内容+文件属性,并且内容和属性是分开存储的。文件内容存储在Data Block中。
文件的属性存储在inode table中。linux中任何的正常文件都要有自己的属性集合。虽然每一个文件的属性内容可能不一样,但是每一个文件都要有相同类型的属性,所以文件的属性可以用一个结构体来描述(大小就一定了)。这个结构体所连成的表上的一个节点就叫做inode(大小固定,一般是128bytes)
struct inode {struct hlist_node i_hash; /* 哈希表 */struct list_head i_list; /* 索引节点链表 */struct list_head i_dentry; /* 目录项链表 */unsigned long i_ino; /* 节点号 */atomic_t i_count; /* 引用记数 */umode_t i_mode; /* 访问权限控制 */unsigned int i_nlink; /* 硬链接数 */uid_t i_uid; /* 使用者id */gid_t i_gid; /* 使用者id组 */kdev_t i_rdev; /* 实设备标识符 */loff_t i_size; /* 以字节为单位的文件大小 */struct timespec i_atime; /* 最后访问时间 */struct timespec i_mtime; /* 最后修改(modify)时间 */struct timespec i_ctime; /* 最后改变(change)时间 */unsigned int i_blkbits; /* 以位为单位的块大小 */unsigned long i_blksize; /* 以字节为单位的块大小 */unsigned long i_version; /* 版本号 */unsigned long i_blocks; /* 文件的块数 */unsigned short i_bytes; /* 使用的字节数 */spinlock_t i_lock; /* 自旋锁 */struct rw_semaphore i_alloc_sem; /* 索引节点信号量 */struct inode_operations *i_op; /* 索引节点操作表 */struct file_operations *i_fop; /* 默认的索引节点操作 */struct super_block *i_sb; /* 相关的超级块 */struct file_lock *i_flock; /* 文件锁链表 */struct address_space *i_mapping; /* 相关的地址映射 */struct address_space i_data; /* 设备地址映射 */struct dquot *i_dquot[MAXQUOTAS]; /* 节点的磁盘限额 */struct list_head i_devices; /* 块设备链表 */struct pipe_inode_info *i_pipe; /* 管道信息 */struct block_device *i_bdev; /* 块设备驱动 */unsigned long i_dnotify_mask; /* 目录通知掩码 */struct dnotify_struct *i_dnotify; /* 目录通知 */unsigned long i_state; /* 状态标志 */unsigned long dirtied_when; /* 首次修改时间 */unsigned int i_flags; /* 文件系统标志 */unsigned char i_sock; /* 可能是个套接字吧 */atomic_t i_writecount; /* 写者记数 */void *i_security; /* 安全模块 */__u32 i_generation; /* 索引节点版本号 */union {void *generic_ip; /* 文件特殊信息 */};
};每一个文件都有其对应的inode,里面包含了与该文件有关的一些信息。
文件系统先格式化出 inode 和 block 块,假设某文件的权限和属性信息存放到 inode 4 号位置,这个 inode 记录了实际存储文件数据的 block 号,由此,操作系统就能快速地找到文件数据的存储位置。
注意:
3. Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,分析 inode 所记录的权限与用户是否符合,找到文件数据所在的block,读出数据。
4. ⽂件名属性并未纳⼊到inode数据结构内部
ext2文件系统
上面已经介绍了块和inode结构体(先描述),可是操作系统是怎么将这些管理起来的呢(再组织)?
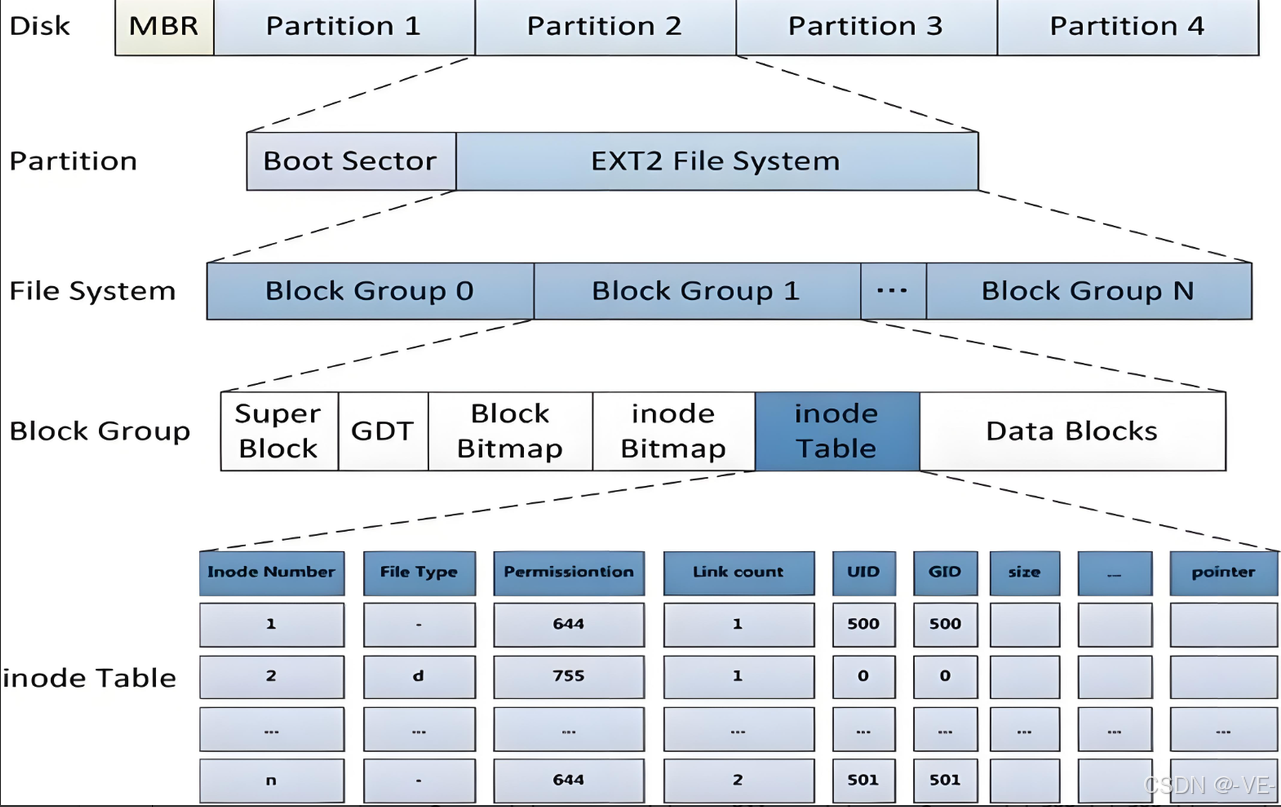
Boot Sector
Super Block
struct ext2_super_block {
__le32 s_inodes_count; /* Inodes count */
__le32 s_blocks_count; /* Blocks count */
__le32 s_r_blocks_count; /* Reserved blocks count */
__le32 s_free_blocks_count; /* Free blocks count */
__le32 s_free_inodes_count; /* Free inodes count */
__le32 s_first_data_block; /* First Data Block */
__le32 s_log_block_size; /* Block size */
__le32 s_log_frag_size; /* Fragment size */
__le32 s_blocks_per_group; /* # Blocks per group */
__le32 s_frags_per_group; /* # Fragments per group */
__le32 s_inodes_per_group; /* # Inodes per group */
__le16 s_inode_size; /* size of inode structure */
。。。。。。。
};GDP(group descriptor table)
块组描述符表(是用来管理这个组块的),描述块组的属性信息,整个分区分为多少个块组就有多少个块组描述符表。每一个块组描述表都存放着一个块组的信息,如这个块组从哪开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。
注意块组描述描述符表在每一个块组的开头都有一份拷贝。
struct ext2_group_desc
{
__le32 bg_block_bitmap; /* Blocks bitmap block */
__le32 bg_inode_bitmap; /* Inodes bitmap */
__le32 bg_inode_table; /* Inodes table block*/
__le16 bg_free_blocks_count; /* Free blocks count */
__le16 bg_free_inodes_count; /* Free inodes count */
__le16 bg_used_dirs_count; /* Directories count */
__le16 bg_pad;
__le32 bg_reserved[3];
};Block Bitmap(块位图)
每个位(bit)对应块组(block group)中的一个数据块(data block)。
-
1 表示对应的数据块已被占用。
-
0 表示数据块空闲可用。
用于快速分配和释放数据块。
Inode Bitmap (inode位图)
每个位对应块组中的一个inode(索引节点)。
-
1 表示对应的inode已被占用。
-
0 表示inode空闲。
用于管理文件/目录的元数据(如权限、大小等)的分配。
-
物理存储
每个位图占用一个完整的块(block),块大小由文件系统定义(如1KB、4KB等)。-
例如,4KB的块可存储
4 * 1024 * 8 = 32,768个位,管理对应数量的数据块或inode。
-
-
逻辑表示
位数组按顺序排列,索引从0开始,直接映射到块组内的资源。 -
与块组的关系
-
每个块组独立维护自己的block bitmap和inode bitmap,实现分布式管理,减少竞争和碎片化。
-
超级块(superblock)和组描述符(group descriptor)记录位图的位置(前面提到了)
Data Block
inode和Datablock映射
然后需要确定该inode号属于哪个块组。每个块组中的inode数量应该是固定的,可以通过超级块中的s_inodes_per_group字段获得。假设超级块中有这个信息,那么块组号应该是(inode号 - 1)除以每个块组的inode数量,因为inode号通常从1开始。例如,如果每个块组有8192个inode,那么inode号8193属于第二个块组(索引从0开始的话,可能是块组1)。
确定了块组之后,接下来需要找到该块组的组描述符。组描述符里会有该块组的inode表的起始块号。然后,计算在该块组内的inode索引,即(inode号 - 1)% s_inodes_per_group。接着,用这个索引乘以inode的大小(比如128字节或256字节,由超级块中的s_inode_size决定),得到在inode表中的偏移量。这样就能找到该inode的具体位置了。
读取到inode结构之后,里面应该包含文件的元数据,比如模式(文件类型和权限)、用户和组ID、大小、时间戳等等。另外,inode中有直接块指针、间接指针、双重间接、三重间接指针等,用于定位文件的数据块。对于小文件,直接块指针就足够了;大文件则需要通过间接块来扩展寻址。
然后,要获取文件的内容,需要根据inode中的块指针读取相应的数据块。每个块指针指向一个数据块,数据块中存储着文件的实际内容。如果是目录的话,数据块中的内容会是目录条目,包含文件名和对应的inode号等信息。但题目中已经知道inode号,所以如果是普通文件,直接读取这些数据块即可得到文件内容。
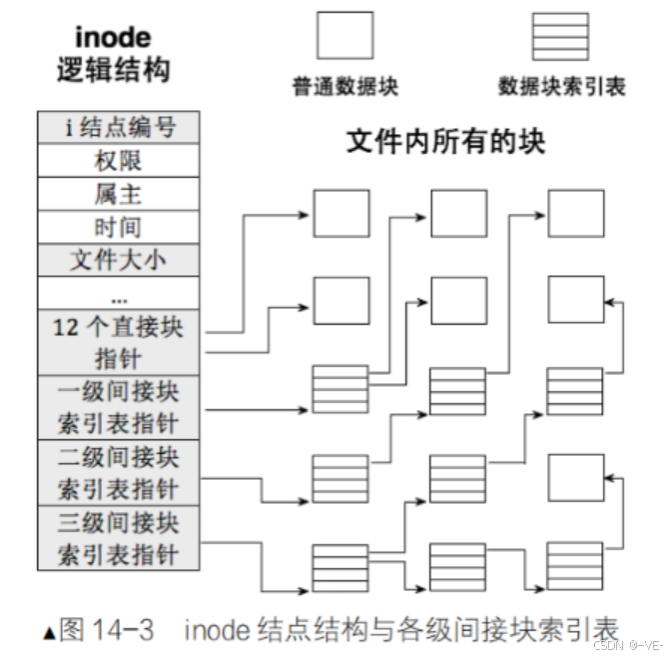
我们在来看一下新建一个文件是如何完成的吧:
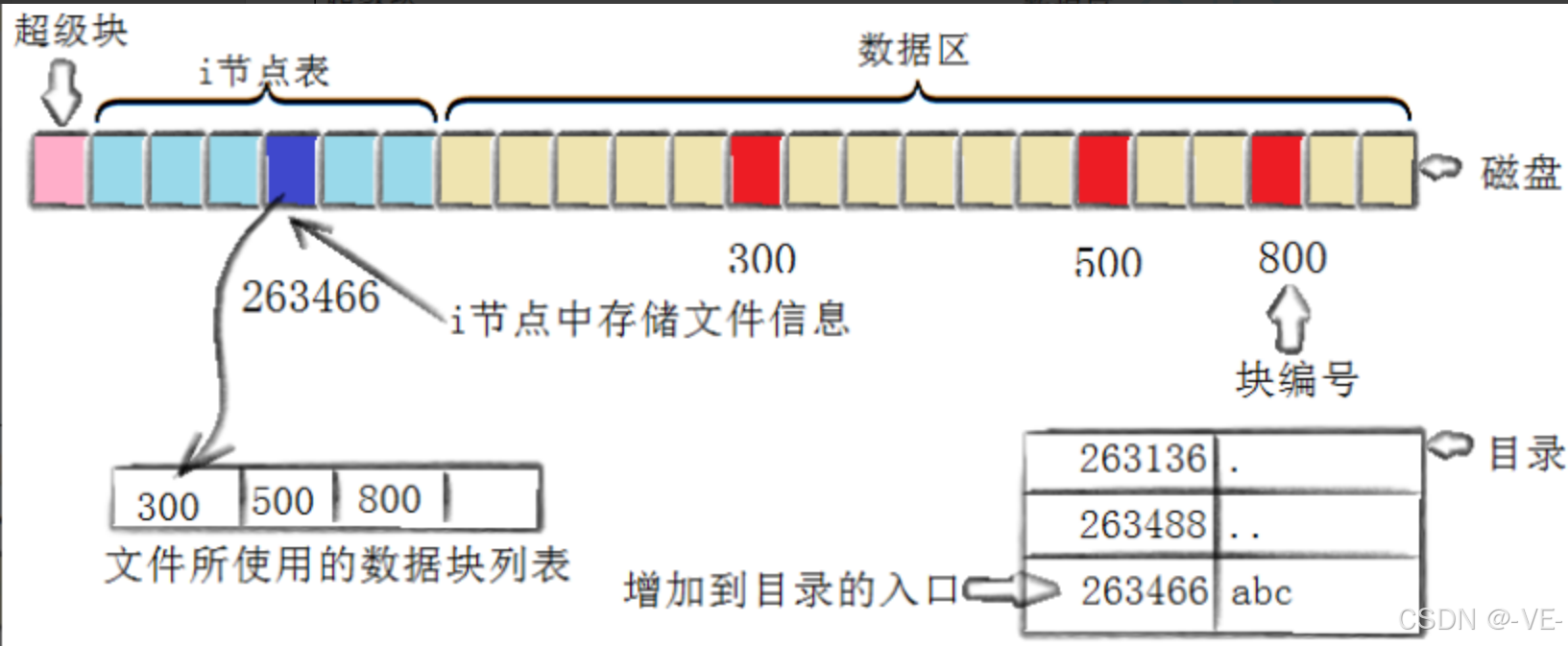
目录和文件名
目录是文件,磁盘上是没有目录的概念的,都是文件属性+文件内容,对于目录的属性就不用多说了,目录的内容保存的是文件名+文件对应的inode号。
所以可以看到对于一个你要访问的文件,以一定要知道这个文件的路径,只有知道了路径你才能找打这个文件所在的文件夹,然后才能通过你提供的文件名来找到对应的inode号,才算是真正地找到了文件。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char *argv[]) {if (argc != 2) {fprintf(stderr, "Usage: %s <directory>\n", argv[0]);exit(EXIT_FAILURE);}DIR *dir = opendir(argv[1]); // 系统调⽤,⾃⾏查阅if (!dir) {perror("opendir");exit(EXIT_FAILURE);}struct dirent *entry;while ((entry = readdir(dir)) != NULL) { if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..")== 0) continue;printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);}closedir(dir);return 0;
}路径解析
聪明的读者已经发现了问题,我们当前工作目录也是一个文件,所以要访问他还是需要打开他的上级目录,那就还要打开他的上上级目录。。。。
⽽实际上,任何⽂件,都有路径,访问⽬标⽂件,⽐如: /home/whb/code/test/test/test.c 都要从根⽬录开始,依次打开每⼀个⽬录,根据⽬录名,依次访问每个⽬录下指定的⽬录,直到访问 到test.c。这个过程叫做Linux路径解析。
那么路径都是谁提供的:
路径缓存
struct dentry
{atomic_t d_count;unsigned int d_flags; /* protected by d_lock */spinlock_t d_lock; /* per dentry lock */struct inode *d_inode; /* Where the name belongs to - NULL is* negative *//** The next three fields are touched by __d_lookup. Place them here* so they all fit in a cache line.*/struct hlist_node d_hash; /* lookup hash list */struct dentry *d_parent; /* parent directory */struct qstr d_name;struct list_head d_lru; /* LRU list *//** d_child and d_rcu can share memory*/union{struct list_head d_child; /* child of parent list */struct rcu_head d_rcu;} d_u;struct list_head d_subdirs; /* our children */struct list_head d_alias; /* inode alias list */unsigned long d_time; /* used by d_revalidate */struct dentry_operations *d_op;struct super_block *d_sb; /* The root of the dentry tree */void *d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILINGstruct dcookie_struct *d_cookie; /* cookie, if any */
#endifint d_mounted;unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};
每个⽂件其实都要有对应的dentry结构,包括普通⽂件。这样所有被打开的⽂件,就可以在内存中
相关文章:
)
文件系统惹(细)
目录 块概念 分区 inode ext2文件系统 Boot Sector Super Block GDP(group descriptor table) Block Bitmap(块位图) Inode Bitmap (inode位图) Data Block inode和Datablock映射 目录和文件名 …...

中望CAD c#二次开发 ——VS环境配置
新建类库项目:下一步 下一步 下一步: 或直接: 改为: <Project Sdk"Microsoft.NET.Sdk"> <PropertyGroup> <TargetFramework>NET48</TargetFramework> <LangVersion>pr…...

Centos7安装Clickhouse单节点部署
部署流程 1、关闭防火墙&沙盒 关闭防火墙并关闭开机自启动 systemctl stop firewalld && systemctl disable firewalld查看selinux状态是否为disabled,否则修改 [rootlocalhost ~]# getenforce Enforcing修改为disabled vim /etc/selinux/config…...

4.SpringSecurity在分布式环境下的使用
参考 来源于黑马程序员: 手把手教你精通新版SpringSecurity 分布式认证概念说明 分布式认证,即我们常说的单点登录,简称SSO,指的是在多应用系统的项目中,用户只需要登录一次,就可以访 问所有互相信任的应…...

使用 Notepad++ 编辑显示 MarkDown
Notepad 是一款免费的开源文本编辑器,专为 Windows 用户设计。它是替代记事本(Notepad)的最佳选择之一,因为它功能强大且轻量级。Notepad 支持多种编程语言和文件格式,并可以通过插件扩展其功能。 Notepad 是一款功能…...

Spring 框架数据库操作常见问题深度剖析与解决方案
Spring 框架数据库操作常见问题深度剖析与解决方案 在 Java 开发的广阔天地中,Spring 框架无疑是开发者们的得力助手,尤其在数据库操作方面,它提供了丰富且强大的功能。然而,就像任何技术一样,在实际项目开发过程中&a…...

第一天:爬虫介绍
每天上午9点左右更新一到两篇文章到专栏《Python爬虫训练营》中,对于爬虫有兴趣的伙伴可以订阅专栏一起学习,完全免费。 键盘为桨,代码作帆。这趟为期30天左右的Python爬虫特训即将启航,每日解锁新海域:从Requests库的…...

ECP在Successfactors中paylisp越南语乱码问题
导读 pyalisp:ECP中显示工资单有两种方式,一种是PE51,一种是hrform,PE51就是划线的那种, 海外使用的比较多,国内基本没人使用,hrform就是pdf,可以编辑pdf,这个国内相对使用的人 比…...

Express 中间件分类
一、 按功能用途分类 1. 应用级中间件 这类中间件应用于整个 Express 应用程序,会对每个进入应用的请求进行处理。通过 app.use() 方法挂载,可用于执行一些全局性的任务,像日志记录、请求预处理、设置响应头这类操作。 const express req…...

基于Multi-Runtime的云原生多态微服务:解耦基础设施与业务逻辑的革命性实践
引言:当微服务遭遇复杂性爆炸 在分布式系统复杂度指数级增长的今天,一线开发者平均需要处理27种不同的基础设施组件配置。CNCF最新研究报告指出,采用Multi-Runtime架构可减少83%的非功能性代码编写量,同时使分布式原语࿰…...

flutter isolate到底是啥
在 Flutter 中,Isolate 是一种实现多线程编程的机制,下面从概念、工作原理、使用场景、使用示例几个方面详细介绍: 概念 在 Dart 语言(Flutter 开发使用的编程语言)里,每个 Dart 程序至少运行在一个 Isol…...

Http connect timed out
客户向云端服务请求时,连接云端域名显示连接超时,为什么呢,偶尔会有。 java.net.SocketTimeoutException: connect timed out at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketI…...

Flutter 异步编程利器:Future 与 Stream 深度解析
目录 一、Future:处理单次异步操作 1. 概念解读 2. 使用场景 3. 基本用法 3.1 创建 Future 3.2 使用 then 消费 Future 3.3 特性 二、Stream:处理连续异步事件流 1. 概念解读 2. 使用场景 3. 基本用法 3.1 创建 Stream 3.2 监听 Stream 3.…...

langchain实现的内部问答系统及本地化替代方案
主旨:问答系统搭建使用langchain要token,本文目的在于一、解析langchain调用过程,二、不使用langchain规避token,而使用本地化部署的方案方向。主要是本地向量化库的建立。 文章目录 主旨:问答系统搭建使用langchain要…...

“新旗手”三星Galaxy S25系列,再次定义了AI手机的进化方向
一年多前,三星Galaxy S24系列正式发布,作为首款由Galaxy AI赋能的AI手机,带来了即圈即搜、通话实时翻译、AI扩图等“神奇能力”。 彼时AI手机还是一个新物种,没有明确的产品定义,体验上也没有“标准答案”。三星Galax…...

JVM的类加载器
什么是类加载器? 类加载器:JVM只会运行二进制文件,类加载器的作用就是将字节码文件加载到JVM中,从而Java 程序能够启动起来。 类加载器有哪些? 启动类加载器(BootStrap ClassLoader):加载JAVA HOME/jre/lib目录下的库…...

Node.js中的模块化:从原理到实践
目录 一、为什么需要模块化? 二、Node.js模块类型解析 2.1 核心模块 2.2 文件模块 2.3 第三方模块 三、CommonJS规范深度解析 3.1 模块加载原理 3.2 模块缓存机制 3.3 循环依赖处理 四、ES Modules新特性 4.1 基本用法 4.2 与CommonJS的差异比较 五、模…...

LLM论文笔记 6: Training Compute-Optimal Large Language Models
Arxiv日期:2022.3.29机构:Google DeepMind 关键词 scaling lawpower law参数量FLOPStokes 核心结论 1. 当前大多数大语言模型(如 GPT-3 和 Gopher)在计算预算分配上存在问题,模型参数过大而训练数据不足 2. 计算预算…...
,数仓建模方法(星型模型,雪花模型,星座模型)和步骤)
数仓:核心概念,数仓系统(ETL,数仓分层,数仓建模),数仓建模方法(星型模型,雪花模型,星座模型)和步骤
数仓建模的核心概念 事实表(Fact Table): 存储业务过程的度量值(如销售额、订单数量等)。 通常包含外键,用于关联维度表。 维度表(Dimension Table): 存储描述性信息&…...

markdown|mermaid|typora绘制流程图的连接线类型怎么修改?
1、使用typora绘制流程图。别人例子里面的连线是圆弧,我的画出来就是带折线的 这是卖家秀: 这是买家秀: 无语了有没有? 犹豫了片刻我决定一探究竟(死磕)。 Typora --> 文件 --> 偏好设置 --》 mar…...

理解WebGPU 中的 GPUDevice :与 GPU 交互的核心接口
在 WebGPU 开发中, GPUDevice 是一个至关重要的对象,它是与 GPU 进行交互的核心接口。通过 GPUDevice ,开发者可以创建和管理 GPU 资源(如缓冲区、纹理、管线等),并提交命令缓冲区以执行渲染和计算任…...
:金融投资与公司经营中的隐形陷阱(中英双语))
庞氏骗局(Ponzi Scheme):金融投资与公司经营中的隐形陷阱(中英双语)
庞氏骗局:金融投资与公司经营中的隐形陷阱 庞氏骗局(Ponzi Scheme),这个词在金融史上屡见不鲜。从投资骗局到企业经营中的资本运作,庞氏骗局的核心逻辑始终如一:用后来的资金填补前面的缺口,营…...

【黑马点评】 使用RabbitMQ实现消息队列——3.批量获取1k个用户token,使用jmeter压力测试
【黑马点评】 使用RabbitMQ实现消息队列——3.批量获取用户token,使用jmeter压力测试 3.1 需求3.2 实现3.2.1 环境配置3.2.2 修改登录接口UserController和实现类3.2.3 测试类 3.3 使用jmeter进行测试3.4 测试结果3.5 将用户登录逻辑修改回去3.6 批量删除生成的用户…...

前端调用串口通信
项目录结构 node项目 1) 安装serialport npm install serialport 2)编写index.js 1 const SerialPort require(serialport); 2 var senddata [0x02];//串口索要发送的数据源 3 var port new SerialPort(COM3);//连接串口COM3 4 port.on(open, fun…...

微信小程序请求大模型监听数据块onChunkReceived方法把数据解析成json
自己写的真是案例,onChunkReceived监听到的数据块发现监听到的内容不只是一个块,有时候会是多块,所以自己加了一个循环解析的过程,不知道大家监听到的数据情况是否一致。 在网上翻阅大量资料有的说引入js文件,亲测无效…...

SQL Server STUFF 函数的用法及应用场景
在 SQL Server 中,STUFF 函数是一种强大的字符串处理工具,常用于删除指定位置的字符并插入新的字符。通过这个函数,开发者能够灵活地修改字符串,从而在数据处理、字符串拼接和格式化等方面大显身手。本文将深入探讨 STUFF 函数的语…...

Qt使用CipherSqlite插件访问加密的sqllite数据库
1.下载 git clone https://github.com/devbean/QtCipherSqlitePlugin.git 2.编译CipherSqlite插件 使用qt打开QtCipherSqlitePlugin项目,并构建插件 3.将构建的插件复制到安装目录 4.使用DB Browser (SQLCipher)创建数据库并加密 5.qt使用Ciphe…...
 A200S 203560)
美国哈美顿零件号A203560 HAMILTON 10µl 1701 N CTC (22S/3) A200S 203560
零件号a61092-01 hamilton ml600 电源 110-220 vac 61092-01 零件号a81322 hamilton 1001 tll 1ml 注射器带塞子 81322 零件号a61710-01 hamilton ml600 探头支架 管架 61710-01 零件号a61614-01 hamilton ml600 填充管 12 ga 1219mm 4.57ml 61614-01 零件号a61615-01 ham…...

深入理解 Rust 的迭代器:从基础到高级
1. 迭代器的基础概念 1.1 什么是迭代器? 迭代器是一种设计模式,允许我们逐个访问集合中的元素,而无需暴露集合的内部结构。在 Rust 中,迭代器通过实现 Iterator trait 来定义。该 trait 主要包含一个方法: pub trai…...

聊聊 IP 地址和端口号的区别
在计算机网络中,两个基本概念对于理解设备如何通过网络进行通信至关重要。IP 地址和端口号是 TCP/IP 的典型特征,其定义如下:IP 地址是分配给连接到网络的每台机器的唯一地址,用于定位机器并与其通信。相反,端口号用于…...

地图打包注意事项
地图打包 (注意不能大写 后缀也不能) 需要文件 objects_n 文件夹 (内部大量png文件和plist文件).map.png 小地图tiles_n_n.plist 和tiles_n_n.png 文件sceneAtlasSplitConfigs合并.txt 文件放入 objects_n文件夹 内部(.png文件…...

代码随想录算法营Day38 | 62. 不同路径,63. 不同路径 II,343. 整数拆分,96. 不同的二叉搜索树
62. 不同路径 这题的限制是机器人在m x n的网格的左上角,每次只能向下走一格或者向右走一格。问到右下角有多少条不同路径。这个动态规划的初始状态是第一行和第一列的格子的值都是1,因为机器人只能向右走一格或者向下走一格,所以第一行和第…...

科普:数据仓库中的“指标”和“维度”
在数据仓库中,指标和维度是两个核心概念,它们对于数据分析和业务决策至关重要。以下是对这两个概念的分析及举例说明: 一、指标 定义: 指标是用于衡量业务绩效的关键数据点,通常用于监控、分析和优化企业的运营状况。…...

`Pinia` + `Formily` + `useTable` 实现搜索条件缓存方案
Pinia + Formily + useTable 实现搜索条件缓存方案 背景 在当前的应用体验中,每当用户刷新页面或退出系统时,之前的搜索条件就会消失不见。为了进一步提升工作效率并增强用户体验,希望能够实现这样一个功能:即使用户进行了页面刷新或是暂时离开了平台,再次返回时也能自动…...

Trader Joe‘s EDI 需求分析
Trader Joes成立于1967年,总部位于美国加利福尼亚州,是一家独特的零售商,专注于提供高质量且价格合理的食品。公司经营范围涵盖了各类杂货、冷冻食品、健康食品以及独特的本地特色商品。 EDI需求分析 电子数据交换(EDIÿ…...

【BUG】conda虚拟环境下,pip install安装直接到全局python目录中
问题描述 conda虚拟环境下,有的虚拟环境的python不能使用(which python时直接使用全局路径下的python),且pip install也会安装到全局路径中,无法安装到conda虚拟环境中。 解决方案 查看虚拟环境的PIP缓存默认路径&…...

用Shader glsl实现一个简单的PBR光照模型
PBR模型定义了各种光照属性,如基础颜色、金属度、粗糙度等,就像给物体设定各种 “性格特点”。顶点着色器负责把顶点从模型空间转换到裁剪空间,同时计算一些用于光照计算的参数,就像给顶点 “搬家” 并准备好 “行李”。而片段着色…...

Linux系统使用ollama本地安装部署DeepSeekR1 + open-webui
Linux系统使用ollama本地安装部署DeepSeekR1 open-webui 1. 首先,下载安装ollama #下载安装脚本并执行 curl -fsSL https://ollama.com/install.sh | sh #安装完成后查看ollama版本 ollama --version2. 使用ollama下载deepseek #不同的参数规格对硬件有不同的要…...

学习星开源在线考试教育系统
学习星开源考试系统 项目介绍 项目概述: 学习星在线考试系统是一款基于Java和Vue.js构建的前后端分离的在线考试解决方案。它旨在为教育机构、企业和个人提供一个高效、便捷的在线测试平台,支持多种题型,包括但不限于单选题、多选题、判断…...

树莓派通过手机热点,无线连接PC端电脑,进行远程操作
树莓派通过手机热点实现无线连接具有以下几点优势: 1.该方式能够联网,方便在项目开发时下载一些数据包。 2.该方式能够通过手机端查看树莓派IP地址(有些情况树莓派ip地址会发生改变) 借鉴链接如下: 树莓派的使用网线及无线连接方法及手机…...

【工业安全】-CVE-2022-35561- Tenda W6路由器 栈溢出漏洞
文章目录 1.漏洞描述 2.环境搭建 3.漏洞复现 4.漏洞分析 4.1:代码分析 4.2:流量分析 5.poc代码: 1.漏洞描述 漏洞编号:CVE-2022-35561 漏洞名称:Tenda W6 栈溢出漏洞 威胁等级:高危 漏洞详情࿱…...

Windows环境管理多个node版本
前言 在实际工作中,如果我们基于Windows系统开发,同时需要维护老项目,又要开发新项目,且不同项目依赖的node版本又不同时,那么就需要根据项目切换不同的版本。本文使用Node Version Manager(nvm࿰…...
)
git 沙盒 下(二)
url :Learn Git Branching 高级git 多次Rebase 最开始我先把bugFix分支先rebase到main上,之后再把c7合并到c6 ,之后就差合并为一个分支了,但是无论移动c7还是another分支都无法合并,都会在原地停留 后来根据提示最…...

基于JavaSpringmvc+myabtis+html的鲜花商城系统设计和实现
基于JavaSpringmvcmyabtishtml的鲜花商城系统设计和实现 🍅 作者主页 网顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 🍅 查看下方微信号获取联系方式 承接各种定制系…...

vue-plugin-hiprint (vue2
页面效果 <template><div><div class"d-flex flex-column mt5"><div class"d-flex flex-row " style"margin-bottom: 10px;justify-content: center;"><!-- 纸张大小 A3、A4 等 --><div class"paper&quo…...

网站地址栏怎么变成HTTPS开头?
在当今的数字世界中,网络安全已成为不可或缺的一部分。对于网站管理员和所有者来说,确保访问者数据的安全和隐私至关重要。HTTPS是一种加密的通信协议,通过在客户端和服务器之间建立安全连接来保护数据传输。将网站从HTTP升级到HTTPS不仅提升…...

手机用流量怎样设置代理ip?
互联网各领域资料分享专区(不定期更新): Sheet...

Web渗透实战--XSS 常用语句以及绕过思路
Web渗透实战–XSS 常用语句以及绕过思路 0x01:干货 - XSS 测试常用标签语句 0x0101: 标签 <!-- 点击链接触发 - JavaScript 伪协议 --><a hrefjavascript:console.log(1)>XSS1</a> <!-- 字符编码绕过 - JavaScript 伪协议 -->&…...

哈希表-两个数的交集
代码随想录-刷题笔记 349. 两个数组的交集 - 力扣(LeetCode) 内容: 集合的使用 , 重复的数剔除掉,剩下的即为交集,最后加入数组即可。 class Solution {public int[] intersection(int[] nums1, int[] nums2) {Set<Integer…...

“数字+实体“双引擎发力树莓集团打造翠屏区首个智慧产业孵化标杆
2025 年 2 月 13 日,宜宾市翠屏区招商引资项目集中签约活动圆满举行。树莓集团产业合作总监童曦鸣代表企业出席并签约,将在翠屏区打造数字经济示范项目。 此次签约,树莓集团将以 “数字 实体” 双引擎发力。在数字产业化方面,凭…...