C++:Map和Set
目录
一、关联式容器
二、键值对
三、树形结构的关联式容器
A.set的模板参数列表
B.set的构造
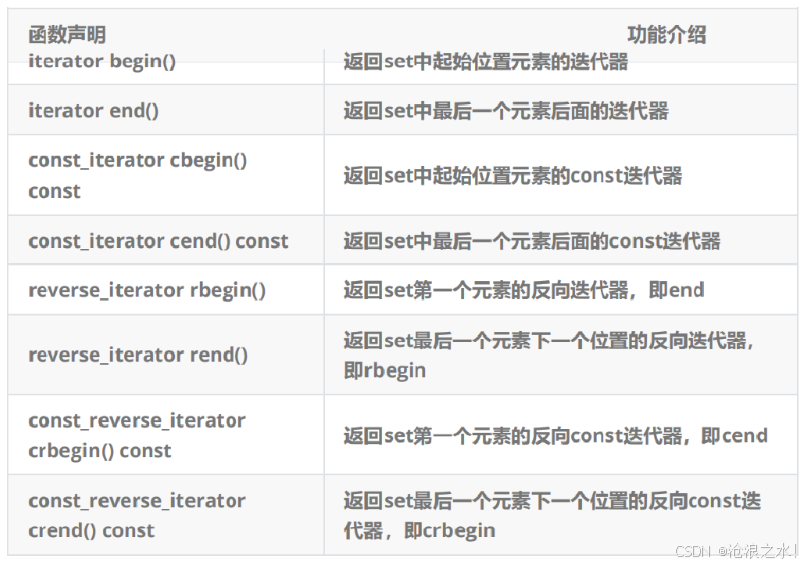
C.set的迭代器
D.set的容量
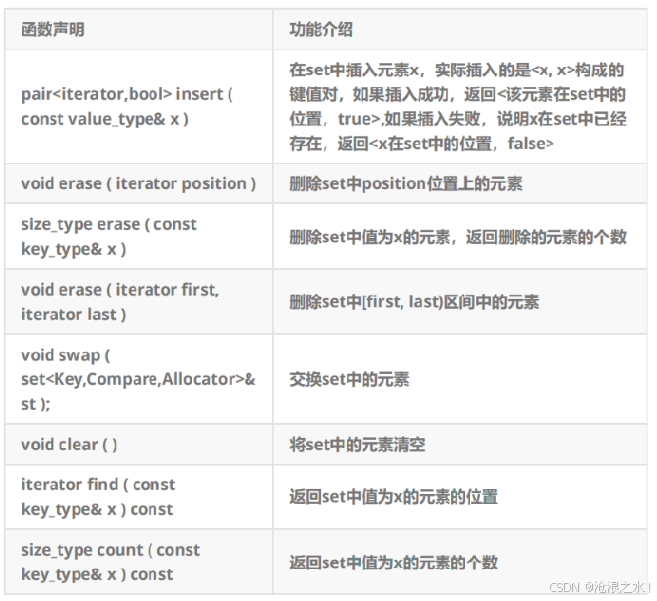
E.set的修改操作
F.set的使用举例
A.map的模板参数列表
B.map的构造
C.map的迭代器
D.map的容量
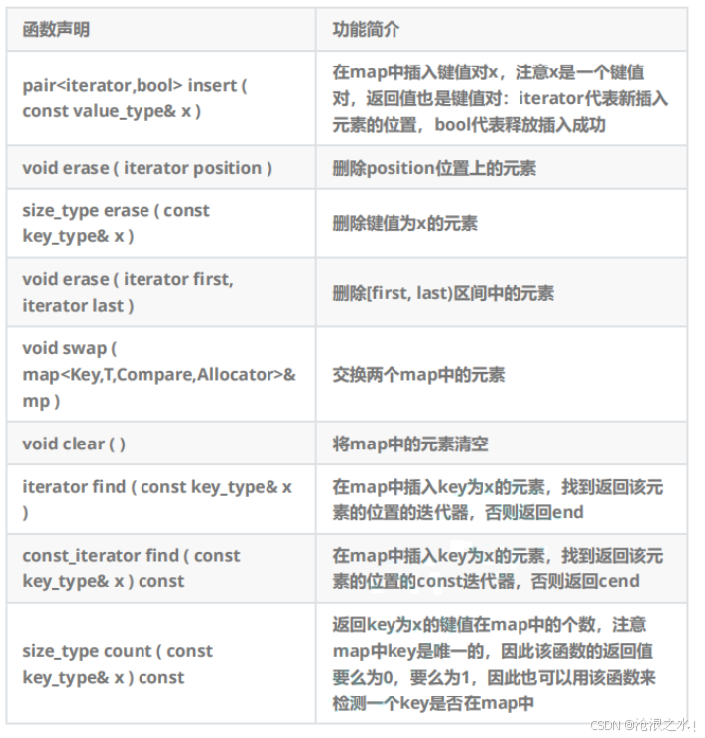
E.map中元素的修改
operator[ ]
insert()
一、关联式容器
初级阶段我们接触的STL容器比如vector,string,list,deque,forward_list等,这些容器被称为序列式容器,底层为线性序列的数据结构,里面存储的是元素本身。那么也就存在存储的还有并不是本身那么简单的容器!那就是关联式容器,那么有什么区别呢?关联式容器也是用来存储数据的,与序列容器不同的是,其存的是<key,value>结构的键值对! 在数据检索时比序列式容器效率更高!
搜索模型
在实际搜索中有两个搜索模型:Key的搜索模型和Key/Value的搜索模型Key的搜索模型:
简单来说就是在一个搜索树,搜索树中的内容是一个一个的关键值,而通过一定的查找手段可以确定一个值在不在这个树内,在实际应用情境中可以在闸机,门禁等地方遇到这个搜索模型,通过给定的信息在已有的信息库中进行搜索,如果有就同一进入,如果没有就禁止进入
Key/Value的搜索模型:
这种搜索模型有两个功能,一个功能是进行搜索Key在不在这个搜索树内,第二个功能是用来通过Key可以查找Value的值,在实际应用情景中可以在字典,统计单词出现的次数中见到,在后面也会进行一些举例来更好的理解这种场景的意义所在。
二、键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量 key 和 value,key 代表键值,value 表示与 key 对应的信息。
比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
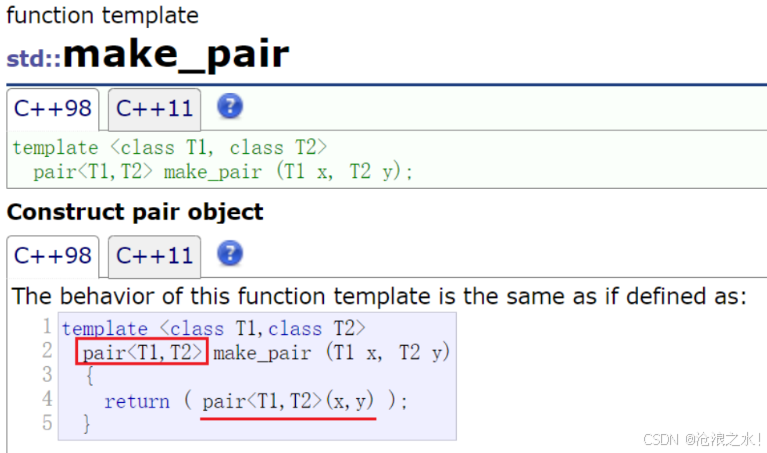
//map 中存放的元素是一个个的键值对(即 pair 对象)
//map中存的是一个pair结构体,key和value被封装在里面
template <class T1, class T2>
struct pair
{typedef T1 first_type; // 键值对中key的类型typedef T2 second_type; // 键值对中value的类型T1 first; // first相当于keyT2 second; // second相当于value//构造函数pair(): first(T1()), second(T2()){}//拷贝构造函数pair(const T1& a, const T2& b): first(a), second(b){}
};int main()
{//构造一个 pair 对象(键值对):std::pair<int, int> p(10, 20);//利用 make_pair 函数模板构造一个 pair 对象(键值对),//通过传递给 make_pair 的参数隐式推导出来。std::pair<int,int> p = std::make_pair(10,20); // 常用这种构造方式return 0;
}
三、树形结构的关联式容器
根据应用场景的不同,STL 总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、set、multimap、multiset。
这四种容器的共同点是:使用平衡搜索树(即 红黑树 )作为其底层结果,容器中的元素是一个有序的序列。
<set>
- set 是按照一定次序存储元素的容器。
- 在 set 中,元素的 value 也标识它(value 就是 key,类型为 T),并且每个 value 必须是唯一的。set 中的元素不能在容器中修改(元素总是 const),但是可以从容器中插入或删除它们。
- 在内部,set 中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。
- set 容器通过 key 访问单个元素的速度通常比 unordered_set 容器慢,但它们允许根据顺序对子集进行直接迭代。
- set 在底层是用二叉搜索树(红黑树)实现的。

A.set的模板参数列表
1、T:set 中存放元素的类型,实际在底层存储 <value, value> 的键值对。
2、Compare:set 中元素默认按照小于 (< 升序)来比较。一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(比如自定义类型),需要用户自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
小于(< 升序),less。
大于(> 降序),定义 set 时模板参数中要写上 greater。
3、Alloc:set 中元素空间的管理方式,使用 STL 提供的空间配置器管理。
使用 set 时,需要包含头文件 #include <set>。

B.set的构造

C.set的迭代器
D.set的容量

E.set的修改操作
F.set的使用举例
void test_set()
{// 用数组array中的元素构造setint array[] = { 1, 3, 5, 7, 9, 2, 4, 3 };set<int> s(array, array+sizeof(array)/sizeof(array));cout << s.size() << endl;s.insert(4); // 4已经在set中了,不会插入cout << s.size() << endl; // 获取set元素个数// 正向打印set中的元素,从打印结果中可以看出:set可以去重for (auto& e : s)cout << e << " ";cout << endl;// 使用迭代器逆向打印set中的元素for (auto it = s.rbegin(); it != s.rend(); ++it)cout << *it << " ";cout << endl;// 两种查找元素方式:// 1、algorithm文件中的find函数,底层是暴力查找,全部节点遍历一遍,效率低,O(N)// auto ret = find(s.begin(), s.end(), 4); // 2、set的成员函数,O(logN)auto ret = s.find(4); // 这里需要判断一下,若找到,返回该元素的迭代器,若没有找到,返回s中最后一个元素后面的迭代器if (ret != s.end()){s.erase(ret); // 删除元素方式1,删除迭代器ret指向的元素}s.erase(5); // 删除元素方式2:删除值为5的元素// set中值为3的元素出现了几次 -- 1次(会去重)cout << s.count(3) << endl;
}注意:set 是不允许数据冗余的,使用 set 迭代器遍历 set 中的元素,可以得到一个有序序列,这样就达到了对一对数据排序+去重的效果。
- 与 map / multimap 不同,map / multimap 中存储的是真正的键值对 <key, value>,set 中只放 value,但在底层实际存放的是由 <value, value> 构成的键值对。
- set 中插入元素时,只需要插入 value 即可,不需要构造键值对。
- set 中的元素不可以重复(因此可以使用 set 进行去重)。
- 使用 set 的迭代器遍历 set 中的元素,可以得到有序序列。
- set 中的元素默认按照小于来比较。
- set 中查找某个元素,时间复杂度为:O(logn),set 中增删查改都是 O(logN)。
- set 中的元素不允许修改(为什么? 因为 set 内部实现是基于哈希表的,哈希表中的元素是根据元素的哈希值来进行存储和查找的。如果一个元素被修改了,那么它的哈希值也会发生变化,这样就会导致原来存储该元素的位置无法再次找到该元素,从而破坏了 set 的内部结构。)
- set 中的底层使用二叉搜索树(红黑树)来实现。
<map>
- map 是关联容器,它按照特定的次序(按照 key 来比较)存储由键值 key 和值 value 组合而成的元素。
- 在 map 中,键值 key 通常用于排序和唯一地标识元素,而值 value 中存储与此键值 key 关联的内容。键值 key 和值 value 的类型可能不同,并且在 map 的内部,key 与 value 通过成员类型 value_type 绑定在一起,为其取别名称为 pair: typedef pair<const key, T> value_type;
- 在内部,map 中的元素总是按照键值 key 进行比较排序的。
- map 中通过键值访问单个元素的速度通常比 unordered_map 容器慢,但 map 允许根据顺序对元素进行直接迭代(即对 map 中的元素进行迭代时,可以得到一个有序的序列)。
- map 支持下标访问符,即在[ ]中放入 key,就可以找到与 key 对应的 value。
- map 通常被实现为二叉搜索树,更准确的说:平衡二叉搜索树(红黑树)。

A.map的模板参数列表
1、key:键值对中 key 的类型。
2、T:键值对中 value 的类型。
3、Compare:比较器的类型,map 中的元素是按照 key 来比较的,缺省情况下按照 小于 (< 升序)来比较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)。
小于(< 升序),less。
大于(> 降序),定义 map 时模板参数中要写上 greater。
4、Alloc:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的空间配置器。在使用 map 时,需要包含头文件 #include <map>。

B.map的构造

C.map的迭代器

D.map的容量
当 key 不在 map 中时,通过 operator 获取对应 value 时会发生什么问题?
注意 :在元素访问时,有一个与 operator[] 类似的操作 at()(该函数不常用)函数,都是通过 key 找到与 key 对应的 value 然后返回其引用,不同的是:当 key 不存在时,operator[] 用默认 value 与 key 构造键值对然后插入,返回该默认 value,at() 函数直接抛异常。


E.map中元素的修改
#include <string>
#include <map>void TestMap()
{map<string, string> m;// 向map中插入元素的方式:// 将键值对<"peach","桃子">插入map中,用pair直接来构造键值对m.insert(pair<string, string>("peach", "桃子"));// 将键值对<"peach","桃子">插入map中,用make_pair函数来构造键值对m.insert(make_pair("banan", "香蕉"));// 借用operator[]向map中插入元素
/*operator[]的原理是:用<key, T()>构造一个键值对,然后调用insert()函数将该键值对插入到map中如果key已经存在,插入失败,insert函数返回该key所在位置的迭代器如果key不存在,插入成功,insert函数返回新插入元素所在位置的迭代器operator[]函数最后将insert返回值键值对中的value返回
*/// 将<"apple", "">插入map中,插入成功,返回value的引用,将“苹果”赋值给该引用结果,m["apple"] = "苹果";// key不存在时抛异常//m.at("waterme") = "水蜜桃";cout << m.size() << endl;// 用迭代器去遍历map中的元素,可以得到一个按照key排序的序列for (auto& e : m)cout << e.first << "--->" << e.second << endl;cout << endl;// map中的键值对key一定是唯一的,如果key存在将插入失败auto ret = m.insert(make_pair("peach", "桃色"));if (ret.second)cout << "<peach, 桃色>不在map中, 已经插入" << endl;elsecout << "键值为peach的元素已经存在:" << ret.first->first << "--->" << ret.first->second << "插入失败" << endl;// 删除key为"apple"的元素m.erase("apple");if (1 == m.count("apple"))cout << "apple还在" << endl;elsecout << "apple被吃了" << endl;
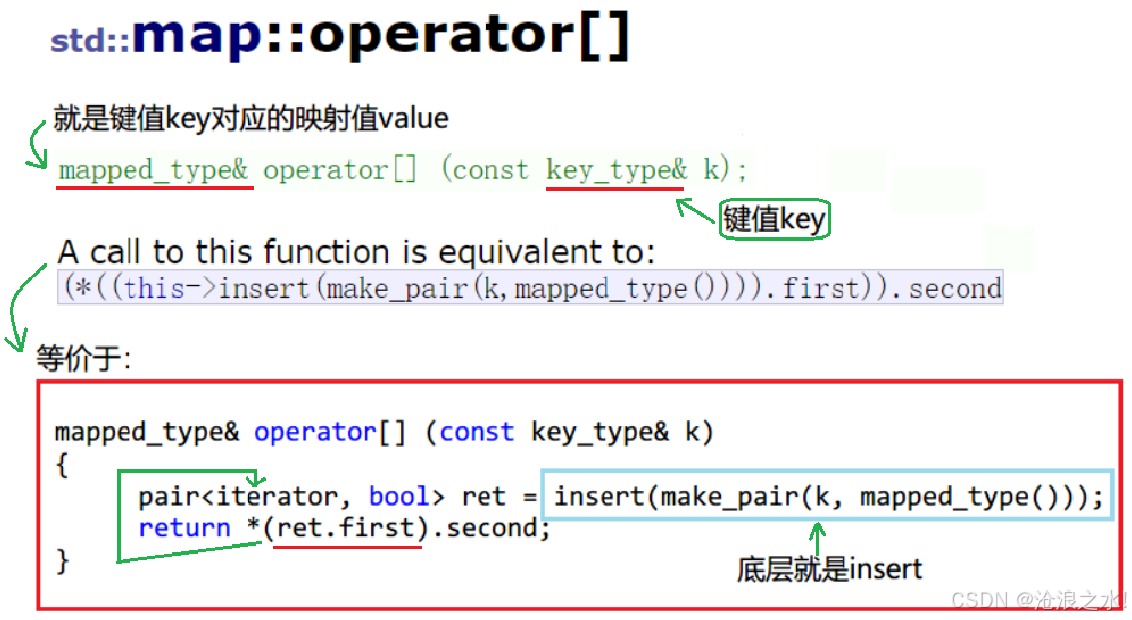
}operator[ ]
前面学习的 vector 容器里面的 vector::operator[] 是传入元素下标,返回对该元素的引用。而 map 中的 operator[ ]访问元素函数,和其它容器有挺大区别的,已经不是传统的数组下标访问了。operator[ ] 底层实际上调用的 insert() 函数。
那么对这句进行解析:(*((this->insert(make_pair(k,mapped_type()))).first)).second
在理解这句前,要首先知道insert调用的结果是pair<iterator,bool> insert (const value_type& val),返回的是一个pair键值对,这里通过this指针调用了insert函数,再对所得到的键值对取它的first元素,也就是迭代器,再对迭代器进行解引用,迭代器指向的就是插入元素的位置,对迭代器的second解引用得到的就是Key_Value中的Value值
因此通过[]得到的返回值其实是通过Key来访问到Value值,如果没有Key会优先创建出Key的值,再对Value值进行一些访问修改等操作…
- map中的元素是键值对
- map中的key是唯一的,并且不能修改
- 默认按照小于的方式对key进行比较
- map中的元素如果用迭代器去遍历,可以得到一个有序的序列
- map的底层为平衡搜索树(红黑树),查找效率比较高
- 支持[]操作符,operator[]中实际进行插入查找
map容器中的 map::operator[ ] 是传入键值 key,通过该元素的 key 查找并判断是否在 map 中:
如果在 map 中,说明 insert 插入失败,insert 函数返回的 pair 对象会带出指向该元素的迭代器,通过这个迭代器,我们可以拿到该元素 key 对应的映射值 value,然后函数返回其对应映射值 value 的引用。
如果不在 map 中,说明 insert 插入成功,插入了这个新元素 <key, value()>,然后函数返回其对应映射值 value 的引用。
注意:这里插入新元素时,该 value() 是一个缺省值,是调用 value 类型的默认构造函数构造的一个匿名对象。(比如是 string 类型就调用 string 的默认构造)使用 map::operator[] 函数,传入元素的键值 key:
- 如果 key 在map中,返回 key 对应映射值 value 的引用。
- 如果 key 不在map中,插入该元素 < key, value() >,返回 key 对应映射值 value 的引用。
- 拿到函数返回的映射值 value,我们可以对其修改。
这个函数即有查找功能,也有插入功能,还可以修改
map<string, string> dict;// 这里的意思是,先插入pair("tree", ""),再修改"tree"对应的value值为"树" dict["tree"] = "树";// 等价于: dict["tree"]; // 插入pair("string", "") dict["tree"] = "树"; // "tree"已存在,修改了"tree"对应的value值为"树"类似的成员函数 map::at 在元素存在时和 map::operator[] 具有相同的行为,区别在于,当元素不存在时 map::at 会抛出异常。
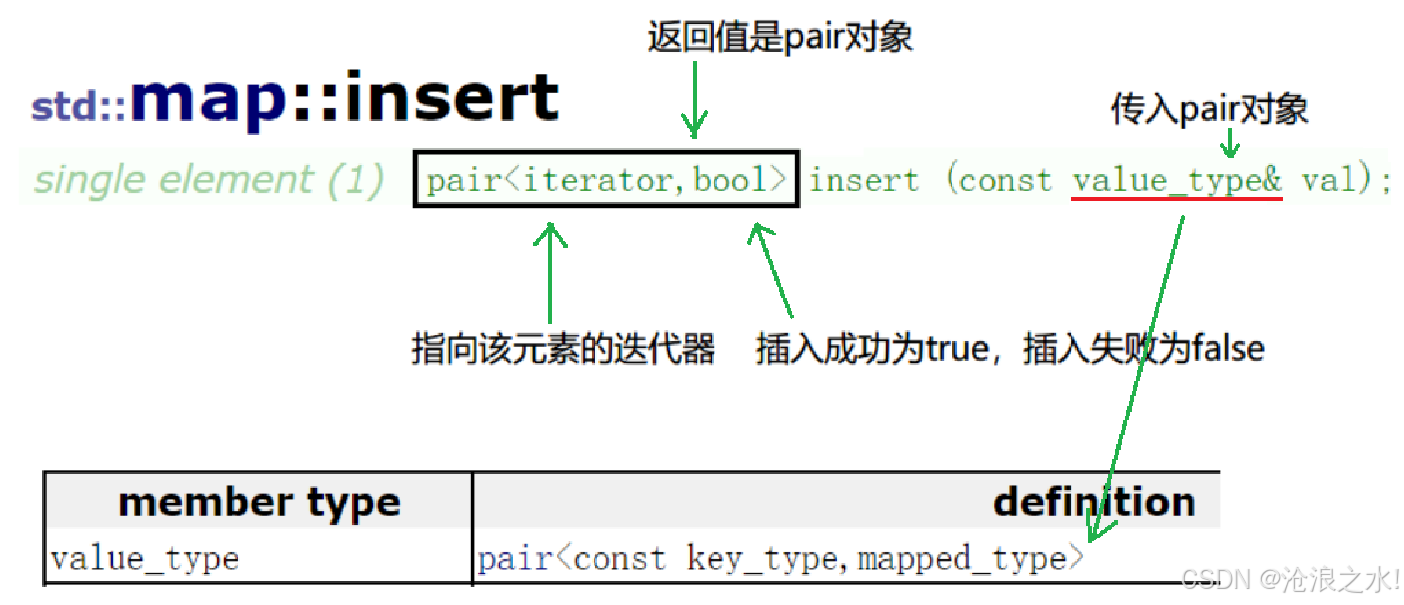
insert()
功能:向 map 中插入元素(pair 对象)时,先通过该元素的 key 查找并判断是否在 map 中:
- 如果在,返回一个 pair 对象:<指向该元素的迭代器, false>。
- 如果不在,插入该元素 <key, value>,返回一个 pair 对象:<指向该元素的迭代器, true>。
定义 map,向 map 中插入元素(键值对),map 有两种插入元素方式:一般用第二种。
// 定义map
map<string, string> dict;// 向map中插入元素,2种方式:
// 1、将键值对<"sort", "排序">插入map中,直接构造pair匿名对象(键值对)
dict.insert(pair<string, string>("sort", "排序"));// 2、将键值对<"sort", "排序">插入map中,用make_pair函数来构造pair对象(键值对)
dict.insert(make_pair("left", "左边"));
dict.insert(make_pair("tree", "树"));用迭代器遍历 map 元素:
需要注意的是,遍历 map 中元素的方式和其它迭代器有些不同,下面这种是错误示范:
这里的 it 是指向当前元素的迭代器,解引用 *it 是一个 pair 对象(键值对),而 map 中没有流插入运算符的重载,所以不能这样输出。
// 错误示范 map<string, string>::iterator it = dict.begin(); while (it != dict.end()) {// cout << *it << endl; // error!it++; }这里调用的是 it.operator*() 解引用运算符重载函数,所以 *it 只是得到了当前节点中存储 pair <key,value> 结构体。key 和 value 是一起封装在 pair 结构体中的,不能直接把 key 和 value 输出出来,除非重载了专门针对输出 pair<key,value> 结构体中数据的流插入运算符,比如:ostream& operator << (ostream& out, const pair<K, V>& kv);
迭代器遍历map元素的两种方式:
// 迭代器遍历map
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{ /* 1、迭代器是像指针一样的类型* 对当前元素的迭代器it解引用(*it)可以得到当前节点中存储的数据:即pair对象(键值对),然后用'.'再去访问pair对象中的kv值* 这里调用的是it.operator*() 解引用运算符重载函数,返回值为:pair对象的引用*/cout << (*it).first << ", " << (*it).second << endl;/* 2、迭代器箭头->,返回当前迭代器指向j的地址(指针):pair<string, int>*,实际上是调用的operator->()函数* 该指针再使用'->'就可以取到(pair对象)里面的kv值,即first和second* 代码为:it->->first,但可读性太差,编译器进行了特殊处理,省略掉了一个箭头,保持了程序的可读性*/// 一般结构体的指针才会使用'->'来访问成员,所以当迭代器管理的节点中的数据是结构体的时候,就可以用'->'cout << it->first << ", " << it->second << endl; // 常用这种写法it++;
}【举例】统计单词出现的次数
第一种解法,定义 map,遍历 str,向 map 中插入元素(键值对):
string str[] = { "sort","sort", "tree","sort", "node", "tree","sort", "sort", };// 定义map
map<string, int> Map;// 遍历str
for (auto& e : str) // 传引用,避免string深拷贝
{// 先查找判断当前单词是否已经在Map中了auto ret = Map.find(e);if (ret == Map.end()) // 如果不在Map中,返回Map中最后一个元素后面的迭代器{Map.insert(make_pair(e, 1)); // 插入pair对象(键值对),即<单词,单词出现次数>}else // 如果在Map中,返回该元素的迭代器{ret->second++; // 单词出现的次数+1}
}// 遍历map,这里的e是map的元素(即pair对象),打印<单词,单词出现次数>
for (auto& e : Map)
{cout << e.first << ", " << e.second << endl;
}上述解法,先查找当前单词是否在 map 中,如果不在,则插入,但是在插入函数内又会查找一次,找到插入的位置,有点冗余。
第二种解法,插入元素时,insert 本来就有查找功能:
void test_map()
{string str[] = { "sort", "sort", "tree", "sort", "node", "tree", "sort", "sort", };// 定义mapmap<string, int> count_map;// 遍历strfor (auto& e : str){// 插入元素auto ret = count_map.insert(make_pair(e, 1));// insert返回值类型是:pair<map<string, int>::iterator, bool>// 插入失败,说明该元素已存在于map中,函数返回一个pair对象// 即:pair<指向该元素的迭代器, false>if (ret.second == false){(ret.first)->second++; // 对当前元素的value值加1}}// 遍历map,这里的e是map的元素(即pair对象)for (auto& e : count_map){cout << e.first << ", " << e.second << endl;}
}第三种解法:
使用 map::operator[] 函数根据当前元素的键值 key 查找,判断该元素是否在 map 中,如果在,返回其映射值 value 的引用,如果不在,当成新元素插入,并返回其映射值 value 的引用。
若元素 e 存在,返回其对应映射值 value,并加 1。
若元素 e 不存在,则插入,返回其对应映射值 value,并加 1。
string str[] = { "sort", "sort", "tree", "sort", "node", "tree", "sort", "sort", };// 定义map
map<string, int> Map;// 使用operator[]函数
for (auto& e : str)
{Map[e]++;
}// 遍历map,打印< 单词,单词出现次数 >
for (auto& e : Map)
{cout << e.first << ", " << e.second << endl;
}[总结]
- map 中的的元素是键值对(pair 结构体)。
- map 中的 key 是唯一的,并且不能修改,只能修改 key 对应的映射值 value。
- 默认按照小于的方式对 key 进行比较。
- map 中的元素如果用迭代器去遍历,可以得到一个有序的序列。
- map 的底层为平衡搜索树(红黑树),查找效率比较高,时间复杂度为 O(logN)。
- 支持 [ ] 操作符,operator[ ] 中实际进行插入查找,即在 [] 中放入 key,就可以找到与 key 对应的 value。
<multiset>

- multiset 是按照特定顺序存储元素的容器,其中元素是可以重复的。
- multiset 中,元素的 value 也会识别它(因为 multiset 中本身存储的就是 <value, value> 组成的键值对,因此 value 本身就是 key,key 就是 value,类型为 T),multiset 元素的值不能在容器中进行修改(因为元素总是 const 的),但可以从容器中插入或删除。
- 在内部,multiset 中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则进行排序。
- multiset 容器通过 key 访问单个元素的速度通常比 unordered_multiset 容器慢,但当使用迭代器遍历时会得到一个有序序列。
- multiset 底层结构为二叉搜索树(红黑树)。
【注意】
- multiset 中在底层中存储的是 <value, value> 的键值对。
- mtltiset 的插入接口中只需要插入即可。
- 与 set 的区别是,multiset 中的元素可以重复,set 中的 value 是唯一的。
- 使用迭代器对 multiset 中的元素进行遍历,可以得到有序的序列。
- multiset 中的元素不能修改。
- 在 multiset 中找某个元素,时间复杂度为 O(logN)。
- multiset 的作用:可以对元素进行排序。
#include <set>void TestSet()
{int array[] = { 4, 1, 3, 9, 6, 4, 5, 8, 4, 4 };// 注意:multiset在底层实际存储的是<int, int>的键值对multiset<int> s(array, array + sizeof(array)/sizeof(array[0]));for (auto& e : s)cout << e << " ";cout << endl;// 1 3 4 4 4 4 5 6 8 9cout << s.count(4) << endl; // 运行结果:3cout << s.count(3) << endl; // 运行结果:1return 0;
}<multimap>

- multimap 是关联式容器,它按照特定的顺序,存储由 key 和 value 映射成的键值对<key, value>,其中多个键值对之间的 key 是可以重复的。
- 在 multimap 中,通常按照 key 排序和唯一地标识元素,而映射的 value 存储与 key 关联的内容。key 和 value 的类型可能不同,通过 multimap 内部的成员类型 value_type 组合在一起,value_type 是组合 key 和 value 的键值对:typedef pair<const Key, T> value_type;
- 在内部,multimap 中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对 key 进行排序的。
- multimap 通过 key 访问单个元素的速度通常比 unordered_multimap 容器慢,但是使用迭代器直接遍历 multimap 中的元素可以得到关于 key 有序的序列。
- multimap 在底层用二叉搜索树(红黑树)来实现。
【注意】
multimap 和 map 的唯一不同就是:map 中的 key 是唯一的,而 multimap 中的 key 是可以重复的。
multimap 中的接口可以参考 map,功能都是类似的。
注意 :
- multimap 中的 key 是可以重复的。
- multimap 中的元素默认将 key 按照小于来比较。
- multimap 中没有重载 operator[ ] 操作(为什么?因为 multimap 中的元素是按照键值有序存储的,而 operator[ ] 操作需要通过键值来访问元素,这样会破坏 multimap 中元素的有序性。因此,multimap 只提供了通过迭代器来访问元素的方式,如 find()、lower_bound()、upper_bound() 等函数)。
- 使用时与 map 包含的头文件相同
相关文章:

C++:Map和Set
目录 一、关联式容器 二、键值对 三、树形结构的关联式容器 A.set的模板参数列表 B.set的构造 C.set的迭代器 D.set的容量 E.set的修改操作 F.set的使用举例 A.map的模板参数列表 B.map的构造 C.map的迭代器 D.map的容量 E.map中元素的修改 operator[ ] insert()…...

【Unity Shader编程】之顶点着色器
来一张AI提供的资料 在shader编程中,定义的结构体,有些是会被自动赋值,有些是必须要手动赋值的,这就涉及到了语义, 例如 struct appdata{float4 vertex : POSITION;float vertex2;float2 uv : TEXCOORD0;};结构体里面定…...

Hive之[Hive]详细安装步骤
hive 是依赖hadoop中的hdfs作为存储,依赖mysql管理元数据 master节点 集群环境 master 192.168.204.130 slave1 192.168.204.131 slave2 192.168.204.132组件下载地址 https://archive.apache.org/dist/hive/hive-1.2.2/ 或 链接: https://pan.baidu.com/s/1…...

3.【线性代数】——矩阵乘法和逆矩阵
三 矩阵乘法和逆矩阵 1. 矩阵乘法1.1 常规方法1.2 列向量组合1.3 行向量组合1.4 单行和单列的乘积和1.5 块乘法 2. 逆矩阵2.1 逆矩阵的定义2.2 奇异矩阵2.3 Gauss-Jordan 求逆矩阵2.3.1 求逆矩阵 ⟺ \Longleftrightarrow ⟺解方程组2.3.2 Gauss-Jordan求逆矩阵 1. 矩阵乘法 1.…...

手动配置IP
手动配置IP,需要考虑四个配置项: 四个配置项 IP地址、子网掩码、默认网关、DNS服务器 IP地址:格式表现为点分十进制,如192.168.254.1 子网掩码:用于区分网络位和主机位 【子网掩码的二进制表达式一定是连续的&#…...

unity is running as administrator 管理员权限问题
每次打开工程弹出unity is running as administrator的窗口 unity版本2022.3.34f1,电脑系统是win 11系统解决方法一:解决方法二: unity版本2022.3.34f1,电脑系统是win 11系统 每次打开工程都会出现unity is running as administr…...

AI在电竞比分网中的主要应用场景
AI在电竞体育比分网的数据应用非常广泛,能够显著提升数据分析、预测、用户体验和商业价值。以下是AI在电竞比分网中的主要应用场景: 1. 实时数据采集与分析 比赛数据实时更新:AI通过自动化系统实时采集比赛数据(如击杀数、经济差、…...

消息中间件:RabbitMQ镜像集群部署配置全流程
目录 1、特点 2、RabbitMQ的消息传递模式 2.1、简单模式(Simple Mode) 2.2、工作队列模式(Work Queue Mode) 2.3、发布/订阅模式(Publish/Subscribe Mode) 2.4、路由模式(Routing Mode&am…...

TCP的拥塞控制
什么是TCP的拥塞控制?它的工作原理是什么?为什么需要拥塞控制? TCP拥塞控制简介 想象一下,你和一群朋友在一条狭窄的小路上跑步。如果每个人都拼命跑,小路很快就会变得拥挤不堪,大家互相碰撞,…...

Jenkins 配置 Git Repository 五
Jenkins 配置 Git Repository 五 这里包含了 Freestyle project 任务类型 和 Pipeline 任务类型 关于 Git 仓库的配置,如下 不同的任务类型,只是在不同的模块找到 配置 Git 仓库 找到 Git 仓库配置位置之后,所有的任务类型配置都是一样的 …...

父组件中循环子组件调用
父组件中循环子组件调用 父组件 //father.vue <template><view><view v-for"(item,index) in list"><son ref"son"></son></view><buton click"submit">123</buton></view> </templ…...
工具使用说明)
【网络安全.渗透测试】Cobalt strike(CS)工具使用说明
目录 前言 一、工具显著优势 二、安装 Java 运行环境 三、实验环境搭建要点 四、核心操作流程详解 (一)环境准备与连接步骤 (二)主机上线与深度渗透流程 五、其他实用功能应用指南 (一)office 宏 payload 应用 (二)Https Payload 应用 (三)信息收集策略 …...

C++ 设计模式-建造者模式
以下是一个完整的C建造者模式示例,包含产品类、建造者接口、具体建造者、指挥者以及测试代码: #include <iostream> #include <string> #include <memory>// 产品类:汽车 class Car { public:void setBody(const std::str…...

【Unity3D】Unable to detect SDK in the selected directory
某天突然发现SDK选中自己的目录 或 打安卓包时 提示SDK Tools相关的报错 打开Android Studio的SDK Manager更新Android SDK Tools...

QML使用ChartView绘制饼状图
一、工程配置 首先修改CMakeLists.txt,按下图修改: find_package(Qt6 6.4 REQUIRED COMPONENTS Quick Widgets) PRIVATEtarget_link_libraries(appuntitledPRIVATE Qt6::QuickPRIVATE Qt6::Widgets )其次修改main.cpp,按下图修改ÿ…...

ollama本地部署 deepseek离线模型安装 一套从安装到UI运行
一、安装本地ollama 1、下载ollama (1)百度网盘windows版本 通过网盘分享的文件:OllamaSetup.exe 链接: https://pan.baidu.com/s/15ca6WAzrc4wWph5H9BEOzw 提取码: 283u (2)进入官网:Ollama 2、选择你的系统 等待下载完成就可以了。 注:这…...

【linux】ubunbu切换到root
在 Ubuntu 中切换到 root 用户有几种方法,具体取决于你的需求和权限配置。以下是常见的几种方式: 1. 使用 sudo 临时切换到 root 如果你当前用户有 sudo 权限,可以使用以下命令临时切换到 root 用户: bash sudo -i 或者࿱…...
和思维树(TOT)谁更胜一筹)
推理框架对比:ReAct、思维链(COT)和思维树(TOT)谁更胜一筹
推理框架作为 AI 解决复杂问题的核心机制,正逐渐成为研究和应用的焦点。ReAct、思维链(Chain-of-Thought,CoT)(Chain-of-Thought (CoT):引导大型语言模型解决问题的有效策略)和思维树࿰…...

electron.vite 项目创建以及better-sqlite3数据库使用
1.安装electron.vite npm create quick-start/electronlatest中文官网:https://cn.electron-vite.org/ 2. 安装项目依赖 npm i3.修改 electron-builder 配置文件 appId: com.electron.app productName: text33 directories:buildResources: build files:- !**/.v…...

Dockerfiles 的 Top 10 常见 DevOps/SRE 面试问题及答案
1. RUN 和 CMD 之间有什么区别? RUN : 在镜像构建过程中执行命令,创建一个新的层。通常用于安装软件包。 示例: RUN apt-get update && apt-get install -y curlCMD : 指定容器启动时默认运行的命令。它在运行时执行,而不是在构建过程…...

Sentinel——Spring Boot 应用接入 Sentinel 后内存开销增长计算方式
接入 Sentinel 对 Spring Boot 应用的内存消耗影响主要取决于 规则数量、资源数量、监控粒度、并发量 等因素。 1. 核心内存消耗来源 (1) Sentinel 核心库 默认依赖:Sentinel Core 本身占用较小,通常在 10~50MB(取决于资源数量和规则复杂度…...

domain 网络安全 网络安全域
文章目录 1、域的概述 1.1、工作组与域1.2、域的特点1.3、域的组成1.4、域的部署概述1.5、活动目录1.6、组策略GPO 2、域的部署实验 2.1、建立局域网,配置IP2.2、安装活动目录2.3、添加用户到指定域2.4、将PC加入域2.5、实验常见问题 3、OU(组织单位…...
提升算法类cv::ml::Boost)
OpenCV机器学习(2)提升算法类cv::ml::Boost
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::ml::Boost 是 OpenCV 机器学习模块中的一部分,用于实现提升算法(Boosting Algorithms)。Boosting 是一种…...

【Java 面试 八股文】框架篇
框架篇 1. Spring框架中的单例bean是线程安全的吗?2. 什么是AOP?3. 你们项目中有没有使用到AOP?4. Spring中的事务是如何实现的?5. Spring中事务失效的场景有哪些?6. Spring的bean的生命周期?7. Spring中的…...

基于HAL库的按钮实验
实验目的 掌握STM32 HAL库的GPIO输入配置方法。 实现通过按钮控制LED亮灭(支持轮询和中断两种模式)。 熟悉STM32CubeMX的外部中断(EXTI)配置流程。 实验硬件 开发板:STM32系列开发板(如STM32F103C8T6、N…...

TCP 端口号为何位于首部前四个字节?协议设计的智慧与启示
知乎的一个问题很有意思:“为什么在TCP首部中要把TCP的端口号放入最开始的四个字节?” 这种问题很适合我这种搞历史的人,大年初一我给出了一个简短的解释,但仔细探究这个问题,我们将会获得 TCP/IP 被定义的过程。 文…...
)
前端实现在PDF上添加标注(1)
前段时间接到一个需求,用户希望网页上预览PDF,同时能在PDF上添加文字,划线,箭头和用矩形框选的标注,另外还需要对已有的标注进行修改,删除。 期初在互联网上一通搜索,对这个需求来讲发现了两个问…...

Springboot 中如何使用Sentinel
在 Spring Boot 中使用 Sentinel 非常方便,Spring Cloud Alibaba 提供了 spring-cloud-starter-alibaba-sentinel 组件,可以快速将 Sentinel 集成到你的 Spring Boot 应用中,并利用其强大的流量控制和容错能力。 下面是一个详细的步骤指南 …...

如何优化React应用的性能?
文章目录 1. 引言2. 渲染优化2.1 使用 React.memo 避免不必要的重新渲染2.2 使用 shouldComponentUpdate 或 PureComponent2.3 使用 useMemo 和 useCallback 3. 异步渲染与懒加载3.1 使用 React.lazy 和 Suspense 实现懒加载3.2 分割代码(Code-Splitting)…...

ES的java操作
ES的java操作 一、添加依赖 在pom文件中添加依赖包 <dependencies><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.8.0</version></dependency><!-- elastic…...

八大排序——简单选择排序
目录 1.1基本操作: 1.2动态图: 1.3代码: 代码解释 1. main 方法 2. selectSort 方法 示例运行过程 初始数组 每轮排序后的数组 最终排序结果 代码总结 1.1基本操作: 选择排序(select sorting)也…...

算法学习笔记之贪心算法
导引(硕鼠的交易) 硕鼠准备了M磅猫粮与看守仓库的猫交易奶酪。 仓库有N个房间,第i个房间有 J[i] 磅奶酪并需要 F[i] 磅猫粮交换,硕鼠可以按比例来交换,不必交换所有的奶酪 计算硕鼠最多能得到多少磅奶酪。 输入M和…...
 二叉树)
【数据结构】(8) 二叉树
一、树形结构 1、什么是树形结构 根节点没有前驱,其它节点只有一个前驱(双亲/父结点)。所有节点可以有 0 ~ 多个后继,即分支(孩子结点)。每个结点作为子树的根节点,这些子树互不相交。 2、关于…...

前端大屏适配方案:从设计到实现的全流程指南
引言 随着数据可视化需求的增长,大屏展示项目在前端开发中越来越常见。然而,大屏开发面临独特的挑战: 屏幕分辨率多样:从1080P到4K甚至8K,如何保证清晰度?布局复杂:多图表、多组件如何合理排列…...

10. Hbase Compaction命令
一. 什么是Compaction 在 HBase 中,频繁进行数据插入、更新和删除操作会生成许多小的 HFile,当 HFile 数量增多时,会影响HBase的读写性能。此外,垃圾数据的存在也会增加存储需求。因此,定期进行 Compact操作ÿ…...

完善sql盲注中的其他函数 dnslog+sqlmap外带数据
2. 布尔盲注 布尔盲注是通过观察应用程序的响应(如页面内容、HTTP 状态码等)来判断查询条件是否为真。 <?php // 数据库连接配置 $host localhost; $dbname testdb; $user root; $password password; // 创建数据库连接 $conn new mysqli($ho…...

Python 识别图片和扫描PDF中的文字
目录 工具与设置 Python 识别图片中的文字 Python 识别图片中的文字及其坐标位置 Python 识别扫描PDF中的文字 注意事项 在处理扫描的PDF和图片时,文字信息往往无法直接编辑、搜索或复制,这给信息提取和分析带来了诸多不便。手动录入信息不仅耗时费…...

Java 有哪些锁,他们的区别是什么
Java 锁的分类 Java 中的锁可以从多个维度进行分类: 悲观锁 vs. 乐观锁公平锁 vs. 非公平锁独占锁 (互斥锁) vs. 共享锁 (读写锁)可重入锁 vs. 不可重入锁自旋锁偏向锁 vs. 轻量级锁 vs. 重量级锁 (JVM 锁优化) 1. synchronized 关键字: 类型: 悲观锁…...
)
CSS实现单行、多行文本溢出显示省略号(…)
在网页设计中,我们常常遇到这样的情况:文本内容太长,无法完全显示在一个固定的区域内。为了让界面看起来更整洁,我们可以使用省略号(…)来表示内容溢出。这不仅能提升用户体验,还能避免内容溢出…...

网络协议/MQTT Paho.MQTT客户端库接口基础知识
开源c版mqtt客户端:https://github.com/eclipse-paho/paho.mqtt.cMQTT 客户端与服务器之间支持的通信协议主要包括: 协议地址格式加密默认端口适用场景服务器地址示例TCPtcp://不加密1883局域网或对安全性要求不高的场景tcp://localhost:1883TLS/SSLssl://加密8883对安全性要…...
)
VSCode C/C++ 开发环境完整配置及常见问题(自用)
这里主要记录了一些与配置相关的内容。由于网上教程众多,部分解决方法并不能完全契合我遇到的问题,因此我选择以自己偏好的方式,对 VSCode 进行完整的配置,并记录在使用过程中遇到的问题及解决方案。后续内容也会持续更新和完善。…...
`:实现高效的并发通信)
深入解析 Go 中的 `io.Pipe()`:实现高效的并发通信
在 Go 语言中,io.Pipe() 是一个强大且灵活的工具,用于在不同的 goroutine 之间实现高效的同步和通信。它通过创建一对连接的 I/O 流,允许数据在管道的两端安全地传递。本文将详细介绍 io.Pipe() 的工作原理、主要特点、使用方法以及一些实际应…...
)
【Kubernetes】常用命令全解析:从入门到实战(中)
🐇明明跟你说过:个人主页 🏅个人专栏:《Kubernetes航线图:从船长到K8s掌舵者》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是k8s 2、K8s的核心功能 二、资…...
C语言算法)
嵌入式八股文面试题(二)C语言算法
相关概念请查看文章:C语言概念。 1. 如何实现一个简单的内存池? 简单实现: #include <stdio.h> #include <stdlib.h>//内存块 typedef struct MemoryBlock {void *data; // 内存块起始地址struct MemoryBlock *next; // 下一个内…...

Proxmox VE 8.3 qm 方式导入ESXi Linux OVA UEFI模式虚拟机
前言 实现esxi ova uefi 虚拟机导入到pve,Linux UEFI 都支持 创建一个105虚拟机 qm 参数使用参考,以下可以根据自己的实际情况执行调整 esxi 导出虚拟机参考 #vmid (100 - 999999999) vmid=105# qm vm name...

人工智能浪潮下脑力劳动的变革与重塑:挑战、机遇与应对策略
一、引言 1.1 研究背景与意义 近年来,人工智能技术发展迅猛,已成为全球科技领域的焦点。从图像识别、语音识别到自然语言处理,从智能家居、智能交通到智能医疗,人工智能技术的应用几乎涵盖了我们生活的方方面面,给人…...

【线性代数】1行列式
1. 行列式的概念 行列式的符号表示: 行列式的计算结果:一个数 计算模型1:二阶行列式 二阶行列式: 三阶行列式: n阶行列式: 🍎计算行列式 计算模型2:上三角形行列式 上三角形行列式特征:主对角线下皆为0。 上三角形行列式: 化上三角形通用方法:主对角线下,…...

厘米和磅的转换关系
在排版和设计领域,厘米(cm)和磅(pt)都是常用的长度度量单位,它们之间的转换关系基于特定的换算标准,下面为你详细介绍: 基本换算关系 磅是印刷行业常用的长度单位,1英寸…...

vant4 van-list组件的使用
<van-listv-if"joblist && joblist.length > 0"v-model:loading"loading":finished"finished":immediate-check"false"finished-text"没有更多了"load"onLoad">// 加载 const loading ref(fals…...

QT 异步编程之多线程
一、概述 1、在进行桌面应用程序开发的时候,假设应用程序在某些情况下需要处理比较复制的逻辑,如果只有一个线程去处理,就会导致窗口卡顿,无法处理用户的相关操作。这种情况下就需要使用多线程,其中一个线程处理窗口事…...