【论文翻译】DeepSeek-V3论文翻译——DeepSeek-V3 Technical Report——第一部分:引言与模型架构
论文原文链接:DeepSeek-V3/DeepSeek_V3.pdf at main · deepseek-ai/DeepSeek-V3 · GitHub
特别声明,本文不做任何商业用途,仅作为个人学习相关论文的翻译记录。本文对原文内容直译,一切以论文原文内容为准,对原文作者表示最大的敬意。如有任何侵权请联系我下架相关文章。
目录
DeepSeek-V3 技术报告
摘要
1. 引言
2. 架构
2.1. 基本架构
2.1.1. 多头潜在注意力
2.1.2. 无辅助损失负载均衡的 DeepSeekMoE
2.2 多标记预测
DeepSeek-V3 技术报告
摘要
我们提出了 DeepSeek-V3,这是一种强大的专家混合(MoE)语言模型,总参数量为 6710 亿,其中每个 token 仅激活 370 亿参数。为了实现高效推理和成本效益高的训练,DeepSeek-V3 采用了多头潜在注意力(MLA)和 DeepSeekMoE 结构,这些结构在 DeepSeek-V2 中已得到充分验证。此外,DeepSeek-V3 首次引入了一种无辅助损失的负载均衡策略,并设定了多 token 预测训练目标,以实现更强的性能。我们在 14.8 万亿个多样化且高质量的 token 上对 DeepSeek-V3 进行了预训练,随后通过监督微调和强化学习阶段充分发挥其能力。全面评估表明,DeepSeek-V3 的性能优于其他开源模型,并达到了与领先的闭源模型相当的水平。尽管性能卓越,DeepSeek-V3 的完整训练仅需 278.8 万 H800 GPU 小时。此外,其训练过程异常稳定。在整个训练过程中,我们未曾遇到不可恢复的损失峰值,也未进行任何回滚。模型检查点可在以下地址获取:GitHub - deepseek-ai/DeepSeek-V3

图 1 | DeepSeek-V3 及其对比模型的基准测试性能。
1. 引言
近年来,大型语言模型(LLMs)正经历快速迭代和演进(Anthropic, 2024; Google, 2024; OpenAI, 2024a),逐步缩小与人工通用智能(AGI)之间的差距。除了闭源模型之外,开源模型(包括 DeepSeek 系列(DeepSeek-AI, 2024a,b,c; Guo et al., 2024)、LLaMA 系列(AI@Meta, 2024a,b; Touvron et al., 2023a,b)、Qwen 系列(Qwen, 2023, 2024a,b)以及 Mistral 系列(Jiang et al., 2023; Mistral, 2024))也在不断取得重大进展,努力缩小与闭源模型的性能差距。为了进一步推动开源模型能力的边界,我们扩大了模型规模,并推出 DeepSeek-V3——一个拥有 6710 亿参数的专家混合(MoE)模型,其中每个 token 仅激活 370 亿参数。
从前瞻性角度出发,我们始终追求强大的模型性能和经济可控的计算成本。因此,在架构方面,DeepSeek-V3 仍采用多头潜在注意力(MLA)(DeepSeek-AI, 2024c)以实现高效推理,并采用 DeepSeekMoE(Dai et al., 2024)以优化训练成本。这两种架构在 DeepSeek-V2(DeepSeek-AI, 2024c)中已被验证,能够在保证稳健模型性能的同时,实现高效训练和推理。除了基础架构之外,我们还引入了两种额外策略以进一步提升模型能力。首先,DeepSeek-V3 首次提出了一种无辅助损失(auxiliary-loss-free)策略(Wang et al., 2024a)来实现负载均衡,旨在减少负载均衡对模型性能的负面影响。其次,DeepSeek-V3 采用了多 token 预测训练目标,我们观察到这一方法能够在多个评测基准上提升整体性能。
为了实现高效训练,我们支持 FP8 混合精度训练,并对训练框架进行了全面优化。低精度训练已成为高效训练的一个重要解决方案(Dettmers et al., 2022; Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b),其发展与硬件能力的进步密切相关(Luo et al., 2024; Micikevicius et al., 2022; Rouhani et al., 2023a)。在本研究中,我们引入了一种 FP8 混合精度训练框架,并首次在超大规模模型上验证了其有效性。通过支持 FP8 计算与存储,我们在加速训练的同时减少了 GPU 内存使用。此外,在训练框架方面,我们设计了 DualPipe 算法,以实现高效的流水线并行(pipeline parallelism)。该算法减少了流水线气泡(pipeline bubbles),并通过计算-通信重叠(computation-communication overlap)隐藏了大部分训练过程中的通信开销。该重叠机制确保在模型规模进一步扩大的情况下,只要保持计算与通信比率恒定,我们仍能在多个节点上部署细粒度专家,并实现接近零的 all-to-all 通信开销。此外,我们还开发了高效的跨节点 all-to-all 通信内核,以充分利用 InfiniBand(IB)和 NVLink 带宽。此外,我们精心优化了内存占用,使得 DeepSeek-V3 的训练无需依赖昂贵的张量并行(tensor parallelism)。综合以上优化,我们成功实现了高效的训练流程。
在预训练过程中,我们在 14.8 万亿高质量且多样化的 token 上训练 DeepSeek-V3。整个预训练过程异常稳定。在整个训练过程中,我们未曾遇到不可恢复的损失峰值,也未进行任何回滚操作。接下来,我们为 DeepSeek-V3 进行两阶段的上下文长度扩展。在第一阶段,我们将最大上下文长度扩展至 32K;在第二阶段,进一步扩展至 128K。随后,我们对 DeepSeek-V3 的基础模型进行后训练,包括监督微调(SFT) 和 强化学习(RL),以使其对齐人类偏好,并进一步释放其潜力。在后训练阶段,我们从 DeepSeek-R1 系列模型中蒸馏推理能力,同时精心维护模型的准确性与生成长度之间的平衡。
我们在一系列全面的基准测试上对 DeepSeek-V3 进行了评估。尽管其训练成本经济,综合评估结果表明 DeepSeek-V3-Base 是当前最强的开源基础模型,特别是在代码和数学方面表现突出。其聊天版本(chat version)同样优于其他开源模型,并在一系列标准化和开放式基准测试上 达到了与领先闭源模型(如 GPT-4o 和 Claude-3.5-Sonnet)相当的性能。
最后,我们再次强调 DeepSeek-V3 的经济训练成本,其训练成本已在表 1 中总结,并通过我们优化的算法、框架和硬件的协同设计得以实现。在预训练阶段,DeepSeek-V3 每训练 1 万亿个 token 仅需 18 万 H800 GPU 小时,即在我们拥有 2048 张 H800 GPU 的集群上,仅需 3.7 天。因此,我们在不到两个月内完成了整个预训练,总计耗费 266.4 万 GPU 小时。加上11.9 万 GPU 小时的上下文长度扩展训练和 5000 GPU 小时的后训练,DeepSeek-V3 完整训练总共仅耗费 278.8 万 GPU 小时。假设 H800 GPU 的租赁价格为每小时 2 美元,则我们的总训练成本仅为 557.6 万美元。需要注意的是,上述成本仅包括 DeepSeek-V3 的正式训练成本,并不包括先前关于架构、算法或数据的研究和消融实验的相关费用。

表 1 | DeepSeek-V3 的训练成本(假设 H800 GPU 的租赁价格为每 GPU 小时 2 美元)。
我们的主要贡献包括:
架构:创新的负载均衡策略与训练目标
-
在 DeepSeek-V2 高效架构的基础上,我们首创了一种无辅助损失(auxiliary-loss-free)的负载均衡策略,最大程度地减少了负载均衡对模型性能的负面影响。
-
我们研究了多 token 预测(MTP)目标,并证明其有助于提升模型性能。此外,该目标还能用于推测解码(speculative decoding),以加速推理过程。
预训练:迈向极致的训练效率
-
我们设计了 FP8 混合精度训练框架,并首次在超大规模模型上验证了 FP8 训练的可行性和有效性。
-
通过算法、框架和硬件的协同设计,我们克服了跨节点 MoE 训练中的通信瓶颈,实现了近乎完整的计算-通信重叠,大幅提升训练效率并降低训练成本,使得我们能够在不增加额外开销的情况下进一步扩展模型规模。
-
仅耗费 266.4 万 H800 GPU 小时,我们在 14.8 万亿 token 上完成了 DeepSeek-V3 的预训练,产出了当前最强的开源基础模型。此外,预训练后的后续训练阶段仅需 10 万 GPU 小时。
后训练:从 DeepSeek-R1 进行知识蒸馏
-
我们提出了一种创新方法,将长链式思维(Long Chain-of-Thought, CoT)模型(特别是 DeepSeek-R1 系列的一款模型)的推理能力蒸馏到标准 LLM(尤其是 DeepSeek-V3)中。
-
在此过程中,我们巧妙地将 R1 的验证(verification)和反思(reflection)模式融入 DeepSeek-V3,显著提升其推理能力。同时,我们也精准控制了 DeepSeek-V3 的输出风格和生成长度。
核心评估结果总结
-
知识能力:(1)在 MMLU、MMLU-Pro 和 GPQA 等教育类基准测试上,DeepSeek-V3 超越所有其他开源模型,分别获得 88.5(MMLU)、75.9(MMLU-Pro)和 59.1(GPQA) 的成绩。其表现可媲美领先的闭源模型(如 GPT-4o 和 Claude-Sonnet-3.5),缩小了开源模型与闭源模型在该领域的差距。(2)在事实性知识(factuality)基准测试中,DeepSeek-V3 在 SimpleQA 和 Chinese SimpleQA 上表现优越,在开源模型中排名第一。尽管在英文事实知识(SimpleQA)上仍略逊于 GPT-4o 和 Claude-Sonnet-3.5,但在中文事实知识(Chinese SimpleQA)上超越了这些模型,展现了其在中文事实性知识上的优势。
-
代码、数学与推理能力:(1)在所有非长链 CoT(non-long-CoT)的开源和闭源模型中,DeepSeek-V3 在数学相关基准测试上达到了当前最佳水平。值得注意的是,在 MATH-500 这样的特定基准上,它甚至超越了 o1-preview,展现出强大的数学推理能力。(2)在编程相关任务中,DeepSeek-V3 在 LiveCodeBench 等编程竞赛基准测试中表现最佳,巩固了其在该领域的领先地位。在工程相关任务上,虽然 DeepSeek-V3 略逊于 Claude-Sonnet-3.5,但仍远超所有其他模型,在各种技术基准上展现出强劲的竞争力。
在本文的其余部分,我们将详细介绍 DeepSeek-V3 的架构(第 2 节)。接着,我们介绍计算集群、训练框架、FP8 训练支持、推理部署策略,以及对未来硬件设计的建议。随后,我们描述预训练过程,包括训练数据构建、超参数设置、长上下文扩展技术、相关评测及讨论(第 4 节)。接下来,我们讨论后训练阶段,包括监督微调(SFT)、强化学习(RL)、对应评测及讨论(第 5 节)。最后,我们总结本文内容,讨论 DeepSeek-V3 现存的局限性,并提出未来研究的潜在方向(第 6 节)。
2. 架构
我们首先介绍 DeepSeek-V3 的基本架构,该架构采用多头潜在注意力 MLA 以提高推理效率,并使用 DeepSeekMoE 以优化训练成本。随后,我们提出多token预测 MTP 训练目标,该目标在多个评测基准上表现出对整体性能的提升。对于其他未明确提及的细节,DeepSeek-V3仍遵循DeepSeek-V2的设置。
2.1. 基本架构
DeepSeek-V3的基本架构仍然基于Transformer框架。为了提高推理效率和优化训练成本,DeepSeek-V3采用MLA和DeepSeekMoE,这两种架构在DeepSeek-V2中已被充分验证。与DeepSeek-V2相比,DeepSeek-V3额外引入了一种无辅助损失负载均衡策略,用于缓解在确保负载均衡过程中对模型性能造成的影响。

图2 | DeepSeek-V3基本架构示意图。继承DeepSeek-V2的设计,我们采用MLA和DeepSeekMoE以实现高效推理和经济训练
图2展示了DeepSeek-V3的基本架构,我们将在本节简要回顾MLA和DeepSeekMoE的细节。
2.1.1. 多头潜在注意力
在注意力机制中,DeepSeek-V3采用 MLA 架构。设 𝑑 表示嵌入维度, 表示注意力头的数量,
表示每个头的维度,
∈
表示在某个注意力层中第𝑡个token的注意力输入。MLA 的核心是对注意力键(Key)和值(Value)进行低秩联合压缩,以减少推理时的键值 KV 缓存:

其中, ∈
是键(Key)和值(Value)的压缩潜在向量;
(≪
) 表示KV压缩维度;
∈
是下投影矩阵;
和
∈
分别是键和值的上投影矩阵;
∈
是用于生成解耦键(decoupled key)的矩阵,该键携带旋转位置编码RoPE(Su et al., 2024);RoPE(·) 表示应用RoPE矩阵的运算;[·; ·] 表示向量拼接。需要注意的是,在MLA中,仅需缓存蓝框标记的向量,即
和
,这大大减少了KV缓存需求,同时仍能保持与标准多头注意力MHA(Vaswani et al., 2017)相当的性能。
对于注意力查询(queries),我们同样执行低秩压缩,这可以减少训练期间的激活内存占用:

其中, ∈
是查询(query)的压缩潜在向量;
(≪
) 表示查询压缩维度;
∈
和
∈
分别是查询的下投影矩阵和上投影矩阵;
∈
是用于生成解耦查询(decoupled queries)的矩阵,该查询携带旋转位置编码RoPE。
最终,注意力查询 、键
和值
结合后生成最终的注意力输出
:

其中, ∈
表示输出投影矩阵。
2.1.2. 无辅助损失负载均衡的 DeepSeekMoE
DeepSeekMoE 的基本架构。对于前馈网络(FFNs),DeepSeek-V3 采用 DeepSeekMoE 架构(Dai et al., 2024)。与 GShard(Lepikhin et al., 2021)等传统 MoE 架构相比,DeepSeekMoE 使用更细粒度的专家(experts),并将部分专家隔离为共享专家。设 为第 𝑡 个 token 的 FFN 输入,我们计算其 FFN 输出
如下:
 其中,𝑁𝑠 和 𝑁𝑟 分别表示共享专家和路由专家的数量;
其中,𝑁𝑠 和 𝑁𝑟 分别表示共享专家和路由专家的数量; 和
分别表示第 𝑖 个共享专家和第 𝑖 个路由专家;𝐾𝑟 表示激活的路由专家数量;
是第 𝑖 个专家的门控值(gating value);
是 token 对专家的亲和度(token-to-expert affinity);
是第 𝑖 个路由专家的中心向量(centroid vector);Topk(·, 𝐾) 表示从所有路由专家计算出的亲和度分数中选取最高的 𝐾 个分数的集合。与 DeepSeek-V2 略有不同,DeepSeek-V3 采用 sigmoid 函数计算亲和度分数,并在所有被选中的亲和度分数之间进行归一化,以生成最终的门控值。
无辅助损失负载均衡。对于 MoE 模型,专家负载不均衡会导致路由崩溃(Shazeer et al., 2017),并在专家并行的场景中降低计算效率。传统的解决方案通常依赖于辅助损失(Fedus et al., 2021;Lepikhin et al., 2021)来避免负载不均衡。然而,过大的辅助损失会损害模型的性能(Wang et al., 2024a)。为了在负载均衡和模型性能之间实现更好的平衡,我们开创了一种无辅助损失的负载均衡策略(Wang et al., 2024a),以确保负载均衡。具体来说,我们为每个专家引入一个偏置项 ,并将其添加到对应的亲和度分数
中,以确定 top-K 路由:

注意,偏置项仅用于路由。门控值(gating value),即将与 FFN 输出相乘的值,仍然来自于原始的亲和度分数 。 在训练过程中,我们会持续监控每个训练步骤中整个批次的专家负载。在每个步骤结束时,如果对应的专家超载,我们将偏置项减少 𝛾;如果对应的专家负载不足,我们将其增加 𝛾,其中 𝛾 是一个超参数,称为偏置更新速度(bias update speed)。通过这种动态调整,DeepSeek-V3 在训练过程中保持专家负载平衡,并且相比于仅通过纯辅助损失来鼓励负载平衡的模型,能够实现更好的性能。
互补的序列级辅助损失。尽管 DeepSeek-V3 主要依赖于无辅助损失策略来实现负载平衡,但为了防止单个序列内部出现极端的不平衡,我们还使用了一个互补的序列级平衡损失:

其中,平衡因子 𝛼 是一个超参数,对于 DeepSeek-V3 来说将赋予一个极小的值;1(·) 表示指示函数;𝑇 表示序列中的标记数。序列级平衡损失鼓励每个序列的专家负载保持平衡。
节点限制路由。与 DeepSeek-V2 使用的设备限制路由类似,DeepSeek-V3 也使用了一种受限路由机制,以限制训练过程中的通信成本。简而言之,我们确保每个标记最多只会发送到 𝑀 个节点,这些节点是根据分布在每个节点上的专家的前 个亲和度分数的总和来选择的。在这个约束下,我们的 MoE 训练框架几乎可以实现完全的计算-通信重叠。
无Token丢弃。由于有效的负载平衡策略,DeepSeek-V3 在整个训练过程中保持良好的负载平衡。因此,DeepSeek-V3 在训练期间不会丢弃任何Token。此外,我们还实施了特定的部署策略,以确保推理过程中的负载平衡,因此 DeepSeek-V3 在推理过程中也不会丢弃Token。
2.2 多标记预测
受到 Gloeckle 等人(2024)的启发,我们为 DeepSeek-V3 设定了一个多标记预测(MTP)目标,将预测范围扩展到每个位置的多个未来标记。一方面,MTP 目标可以密集化训练信号,可能提高数据效率。另一方面,MTP 可以使模型预先规划其表示,以便更好地预测未来的标记。图 3 展示了我们的 MTP 实现。与 Gloeckle 等人(2024)通过独立输出头并行预测 𝐷 个额外标记不同,我们依次预测额外的标记,并在每个预测深度保持完整的因果链条。在本节中,我们介绍了 MTP 实现的细节。
MTP 模块。具体而言,我们的 MTP 实现使用 𝐷 个顺序模块来预测 𝐷 个额外的标记。第 𝑘 个 MTP 模块由一个共享嵌入层 Emb(·)、一个共享输出头 OutHead(·)、一个 Transformer 块 TRM𝑘 (·) 和一个投影矩阵 𝑀𝑘 ∈ 组成。对于第 𝑖 个输入标记
,在第 𝑘 个预测深度,我们首先将第 𝑖 个标记在第 (𝑘−1) 深度的表示
∈
与第 (𝑖+𝑘) 个标记的嵌入 𝐸𝑚𝑏(
) ∈
结合,并进行线性投影:

其中,[·; ·] 表示拼接操作。特别地,当 𝑘 = 1 时,指的是由主模型给出的表示。需要注意的是,对于每个 MTP 模块,它的嵌入层与主模型共享。组合后的
作为 Transformer 块第 𝑘 深度的输入,以生成当前深度的输出表示
:

其中,𝑇 表示输入序列的长度,𝑖:𝑗 表示切片操作(包括左右边界)。最后,以 作为输入,共享的输出头将计算第 𝑘 个附加预测 token 的概率分布
∈
,其中 𝑉 是词汇表的大小:
![]()
输出头 OutHead(·) 将表示映射到 logits,并随后应用 Softmax(·) 函数来计算第 𝑘 个附加 token 的预测概率。同时,对于每个 MTP 模块,它的输出头与主模型共享。我们保持预测的因果链的原则与 EAGLE (Li et al., 2024b) 类似,但它的主要目标是推测解码 (Leviathan et al., 2023; Xia et al., 2023),而我们利用 MTP 来改进训练。
MTP 训练目标。在每个预测深度,我们计算交叉熵损失 :

其中,𝑇 表示输入序列的长度, 表示第 𝑖 个位置的真实标记,
表示给定 𝑘-th MTP 模块的预测概率。最后,我们计算所有深度的 MTP 损失的平均值,并将其乘以一个权重因子 𝜆,得到最终的 MTP 损失 LMTP,该损失作为 DeepSeek-V3 的附加训练目标:

MTP 在推理中的应用。我们的 MTP 策略主要旨在提升主模型的性能,因此,在推理过程中,我们可以直接丢弃 MTP 模块,主模型可以独立且正常地运行。此外,我们还可以将这些 MTP 模块重新用于推测解码,以进一步提升生成的延迟表现。
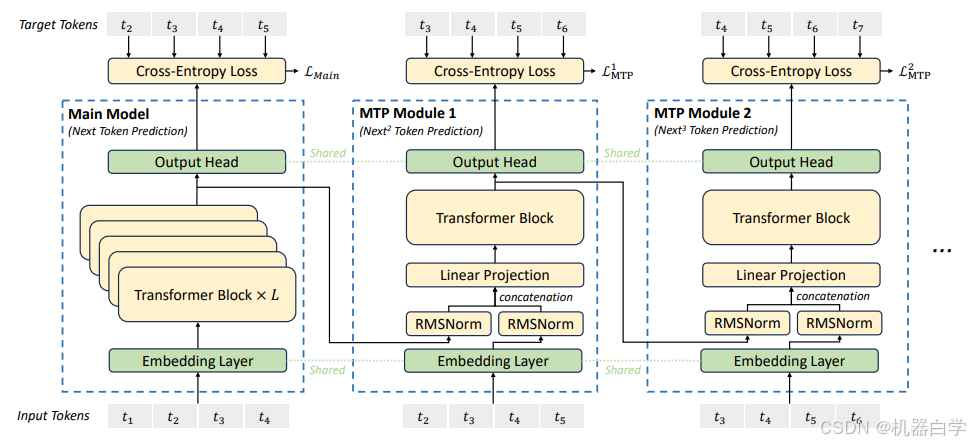
图3 | 我们的多Token预测(MTP)实现示意图。我们在每一层保留完整的因果链,以预测每个标记。
引言和架构部分翻译至此结束,下一部分将继续翻译后续内容——训练的硬件设施设计。
https://blog.csdn.net/qq_58718853/article/details/145530458
相关文章:

【论文翻译】DeepSeek-V3论文翻译——DeepSeek-V3 Technical Report——第一部分:引言与模型架构
论文原文链接:DeepSeek-V3/DeepSeek_V3.pdf at main deepseek-ai/DeepSeek-V3 GitHub 特别声明,本文不做任何商业用途,仅作为个人学习相关论文的翻译记录。本文对原文内容直译,一切以论文原文内容为准,对原文作者表示…...
)
渗透利器:Burp Suite 联动 XRAY 图形化工具.(主动扫描+被动扫描)
Burp Suite 联动 XRAY 图形化工具.(主动扫描被动扫描) Burp Suite 和 Xray 联合使用,能够将 Burp 的强大流量拦截与修改功能,与 Xray 的高效漏洞检测能力相结合,实现更全面、高效的网络安全测试,同时提升漏…...

【Redis】redis 存储的列表如何分页和检索
博主介绍:✌全网粉丝22W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...
)
医疗影响分割 | 使用 Swin UNETR 训练自己的数据集(3D医疗影像分割教程)
<Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images> 代码地址:unetr 论文地址:https://arxiv.org/pdf/2201.01266 一、下载代码 在Github上下载代码,然后进入SWINUNETR,前两个是针对两个数据集(BRATS21、BTCV)的操作,这里…...

前端学习路径
🚀 前言 本文不仅包含学习路径,还整合了 300小时精选资源 和 开发者必备工具链,助你构建完整知识体系! 🔧 开发工具全家桶 工具类型推荐工具使用场景代码编辑器VS Code 插件市场主力开发工具,必装插件&am…...

Day84:数据可视化
数据可视化是数据分析的重要组成部分,它能直观地展现数据规律,使复杂数据变得易懂。Python 提供了多个数据可视化库,其中最常用的是 Matplotlib 和 Seaborn。今天,我们将学习如何使用这些工具绘制折线图、柱状图、散点图等。 1. 安装和导入库 如果你的 Python 没有安装 Ma…...

iOS主要知识点梳理回顾-3-运行时消息机制
运行时(runtime) 运行时是OC的重要特性,也是OC动态性的根本支撑。动态,如果利用好了,扩展性就很强。当然了,OC的动态性只能算是一个一般水平。与swift、java这种强类型校验的语言相比,OC动态性很…...

JSON是什么
JSON 简介 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于 JavaScript 的一个子集,但独立于编程语言,广泛用于 Web 应用中的数据交换。…...

three-tile-vue 开发测试
three-tile 在 github 上开源半年多,已有140余颗星,目前性能和功能已能满足生产环境使用,是替代cesium的一种轻量级解决方案。让我没想到的是第一个商用的竟然是老外。 最近,测试了three-tile在vue中的使用,效果还可以…...
)
Acwing-基础算法课笔记之基础算法(差分)
Acwing-基础算法课笔记之基础算法(差分) 一、一维差分1、差分的概念2、差分思想 二、二维差分操作流程 一、一维差分 1、差分的概念 对于一个给定的序列a,它的差分序列b定义为: b [ 1 ] a [ 1 ] b[1]a[1] b[1]a[1],…...

c语言判断一个文件的文件格式
在 Linux 下使用 C 语言判断一个文件的文件格式,通常需要检查文件的头信息(也称为“幻数”或“魔数”)。不同的文件格式在文件头有特定的字节序列,这些字节序列可以用来确定文件的类型。以下是一个基本的示例,展示了如…...
----打印函数(printf、 sprintf)的实现)
e2studio开发RA2E1(12)----打印函数(printf、 sprintf)的实现
e2studio开发RA2E1.12--打印函数printf、 sprintf的实现 概述视频教学样品申请硬件准备参考程序源码下载新建工程工程模板保存工程路径芯片配置工程模板选择时钟设置UART配置UART属性配置设置e2studio堆栈e2studio的重定向printf设置R_SCI_UART_Open()函数原型回调函数user_uar…...

C++编译期优化 ---分支预计__builtin_expect
在编写程序逻辑的时候,使用了大量的if-else 分支,为了程序尽可能的高效运行,会考虑把可能性更高的条件写在前面,这样程序的平均运行时间会更短。 gcc提供了一种方式,可以让编译器自行优化 __builtin_expect(expr,bool)…...

ASP.NET Core SignalR的协议协商
SignalR支持多种服务器推送方式:Websocket、Server-Sent Events、长轮询。默认按顺序尝试。F12查看协商过程。websocket和HTTP是不同的协议,为什么能用同一个端口。在【开发人员工具】的【网络】页签中看WebSocket通信过程。 协议协商问题 集群中协议协…...

问卷数据分析|SPSS实操之独立样本T检验
适用条件: 检验分类变量和定量变量之间的差异 分类变量只能为二分类变量,如性别 1.选择分析--比较平均值--独立样本检验 2. 在下方选择性别(分类变量) 3. 点击定义组,组1输入1,组2输入2 4.在上方填入定量…...

Vue事件处理 - 按键修饰符
Vue 渐进式JavaScript 框架 基于Vue2的学习笔记 - Vue事件处理 - 按键修饰符 目录 按键修饰符 常见修饰符 绑定按键事件 绑定事件 优化回车修饰符 多个按键 直接绑定数字 总结 按键修饰符 常见修饰符 .esc .up .down .left .right . space .ctrl .shift .delete 绑定…...

PostgreSQL错误: 编码“UTF8“的字符0x0xe9 0x94 0x99在编码“WIN1252“没有相对应值
错误介绍 今天遇到一个错误,记录一下 2025-02-10 17:04:35.264 HKT [28816] 错误: 编码"WIN1252"的字符0x0x81在编码"UTF8"没有相对应值 2025-02-10 17:04:35.264 HKT [28816] 错误: 编码"UTF8"的字符0x0xe9 0x94 0x99在编码&quo…...

使用OBS推流,大华摄像头 srs服务器播放
说明: ffmpeg可以推流,但是是命令行方式不太友好,还可以使用主流的OBS开源推流软件,可从官网Open Broadcaster Software | OBS 下载最新版本,目前很多网络主播都是用它做直播。该软件支持本地视频文件以及摄像头推流。…...
)
Ollama部署DeepSeek(windows or ubuntu)
Ollama(官网是https://ollama.com/)是一个专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计的开源框架。它简化了大型语言模型的部署过程,提供了轻量级与可扩展的架构,使得研究人员、开发人员和爱好者能够更加方便地在本地…...
)
2、k8s 二进制安装(详细)
k8s 二进制安装 IP规划初始化部署 etcd 集群在 etcd01 节点上操作准备cfssl证书生成工具,加权生成etcd证书上传etcd软件包启动 etcd 服务 部署 Master 组件部署 Worker Node 组件node 节点安装 docker部署组件 部署 CNI 网络组件部署 flannel简介部署 部署 Calico简…...

02、QLExpress从入门到放弃,相关API和文档
QLExpress从入门到放弃,相关API和文档 一、属性开关 public class ExpressRunner {private boolean isTrace;private boolean isShortCircuit;private boolean isPrecise; }/*** 是否需要高精度计算*/ private boolean isPrecise false;高精度计算在会计财务中非常重要&…...

在 Visual Studio Code 与微信开发者工具中调试使用 emscripten 基于 C 生成的 WASM 代码
最近在尝试将一些 C/C、Lua 项目挪到 Web 上跑, 接触到了 emscripten. 这里会介绍下在 Visual Studio Code 与微信开发者工具中调试使用 emscripten 基于 C 生成的 WASM 代码 (WebAssembly) 的一些方法. Emscripten 与 WebAssebmly WebAssembly 是一种新的编码方式, 可以在现代…...

计算机毕业设计——Springboot的社区维修平台旅游管理
📘 博主小档案: 花花,一名来自世界500强的资深程序猿,毕业于国内知名985高校。 🔧 技术专长: 花花在深度学习任务中展现出卓越的能力,包括但不限于java、python等技术。近年来,花花更…...

Oracle常见语法
一、求交集 SELECT column1, column2 FROM table1 INTERSECT SELECT column1, column2 FROM table2;INTERSECT 操作符是 Oracle 和一些其他数据库(如 PostgreSQL 和 SQL Server)特有的集合操作符,在 MySQL 中并不直接支持。MYSQL同效果代码&a…...

[2025年最新]2024.3版本idea无法安装插件问题解决
背景 随着大模型的持续发展,特别年前年后deepseek的优异表现,编程过程中,需要解决ai来辅助编程,因此需要安装一些大模型插件 问题描述 在线安装插件的时候会遇到以下问题: 1.数据一直在加载,加载的很满 2.点…...

说一下 jvm 有哪些垃圾回收器?
JVM 垃圾回收器对比表 垃圾回收器类型工作方式回收方式停顿时间适用场景优点缺点常见问题常见配置Serial GC串行单线程,STW年轻代:复制算法 老年代:标记-整理长小内存、单核CPU,如桌面应用或嵌入式设备简单高效,适用于…...

【Linux】--- 进程间的通信
【Linux】--- 进程间的通信 一、进程间通信的介绍1、进程间通信的概念2、进程间通信的目的3、 进程间通信的本质/前提4、进程间通信的分类 二、管道1、什么是管道2、匿名管道(1)匿名管道的原理(2)pipe函数(3࿰…...
)
GlusterFS 深度洞察:从架构原理到案例实践的全面解读(上)
文章目录 一.GlusterFS简介二.GlusterFS原理架构三.适用场景四.Glusterfs与其他存储产品对比五.部署GlusterFS集群六. 使用heketi将glusterfs接入k8s作为后端存储 一.GlusterFS简介 GlusterFS是一个免费的开源分布式文件系统,具有无中心节点、堆栈式设计、全局统一…...
登录(附关键源码))
实现限制同一个账号最多只能在3个客户端(有电脑、手机等)登录(附关键源码)
如上图,我的百度网盘已登录设备列表,有一个手机,2个windows客户端。手机设备有型号、最后登录时间、IP等。windows客户端信息有最后登录时间、操作系统类型、IP地址等。这些具体是如何实现的?下面分别给出android APP中采集手机信…...

C#综合知识点面试集锦
在.NET Core 框架的面试中,可能会涉及基础概念、核心组件、依赖注入、性能优化等多方面的知识点,以下为你详细介绍: 基础概念 .NET Core 概述 定义与特点:解释 .NET Core 是一个跨平台、开源、模块化且高性能的通用开发框架,能在 Windows、Linux、macOS 等操作系统上运行…...
:机械制表的三项重大创新(中英双语))
宝珀(Blancpain):机械制表的三项重大创新(中英双语)
宝珀(Blancpain):机械制表的创新先驱 本文灵感来源: 瑞士钟表业决定逆流而上,杀出一条生路,宝珀更是坚定地宣称“我们永远只做机械表”,它拒绝了石英技术。制表师们在提高腕表的技艺和品质、实…...

稠密架构和稀疏架构
稠密架构和稀疏架构 flyfish 稠密架构 参数使用方面:稠密架构中的大部分参数在每次计算时都会被使用。也就是说,对于输入的每一个样本,模型的所有或大部分参数都会参与到计算过程中。计算特点:计算密集,需要对大量的…...

SpringCloud - Gateway 网关
前言 该博客为Sentinel学习笔记,主要目的是为了帮助后期快速复习使用 学习视频:7小快速通关SpringCloud 辅助文档:SpringCloud快速通关 源码地址:cloud-demo 一、简介 官网:https://spring.io/projects/spring-clou…...

【如何掌握CSP-J 信奥赛中的排序算法】
要掌握CSP-J信奥赛中的排序算法,需要系统学习基础排序算法的原理、实现和应用场景。以下是分阶段的学习路径和建议: 一、必掌握的排序算法清单 CSP-J阶段需重点掌握以下算法(按考察频率排序): 冒泡排序(B…...

3. CSS中@scope
说说你对 CSS 中scope 的了解 <style>/* scope规则 */scope (#app) {.box {width: 100px;height: 100px;background-color: red;}} </style> <div id"app"><div class"box"></div> </div>CSS 中的scope 是一个相对较新…...

基于雷达和摄像头的无人机轨迹识别与激光照射控制研究
标题:基于雷达和摄像头的无人机轨迹识别与激光照射控制研究 内容:1.摘要 摘要:本文研究了基于雷达和摄像头的无人机轨迹识别与激光照射控制。通过对雷达和摄像头数据的融合处理,实现了对无人机轨迹的精确识别。同时,利用激光照射技术对无人机…...

Response 和 Request 介绍
怀旧网个人博客网站地址:怀旧网,博客详情:Response 和 Request 介绍 1、HttpServletResponse 1、简单分类 2、文件下载 通过Response下载文件数据 放一个文件到resources目录 编写下载文件Servlet文件 public class FileDownServlet exten…...

读 DeepSeek-R1 论文笔记
DeepSeek-R1:通过强化学习激发大语言模型的推理能力 DeepSeek-AI 摘要 我们推出第一代推理模型DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero作为无需监督微调(SFT)预训练阶段、直接通过大规模强化学习(RL)训练的基础模型,展现出卓越的推理能力。…...

【算法-动态规划】、魔法卷轴: 两次清零机会整个数组最大累加和
【算法-动态规划】、魔法卷轴: 两次清零机会整个数组最大累加和 文章目录 一、dp1.1 题意理解1.2 整体思路1.3 具体思路1.4 代码 二、多语言解法 一、dp 1.1 题意理解 nums 数组, 有正负0, 使用最多两次魔法卷轴, 希望使数组整体的累加和尽可能大. 求尽可能大的累加和 其实就…...

蓝桥杯C语言组:分治问题研究
蓝桥杯C语言组分治问题研究 摘要 本文针对蓝桥杯C语言组中的分治问题展开深入研究,详细介绍了分治算法的原理、实现方法及其在解决复杂问题中的应用。通过对经典例题的分析与代码实现,展示了分治算法在提高编程效率和解决实际问题中的重要作用ÿ…...
(JavaScript生态中最流行的包管理工具,主要用于Node.js项目的依赖管理))
npm介绍(Node Package Manager)(JavaScript生态中最流行的包管理工具,主要用于Node.js项目的依赖管理)
文章目录 **核心功能****常用命令****关键文件****npm vs 其他工具****最佳实践**官方资源 npm(Node Package Manager)是 JavaScript 生态中最流行的包管理工具,主要用于 Node.js 项目的依赖管理。以下是核心要点: 核心功能 依赖管…...

小白零基础如何搭建CNN
1.卷积层 在PyTorch中针对卷积操作的对象和使用的场景不同,如有1维卷积、2维卷积、 3维卷积与转置卷积(可以简单理解为卷积操作的逆操作),但它们的使用方法比较相似,都可以从torch.nn模块中调用,需要调用的…...
:负载均衡)
【分布式架构理论3】分布式调用(1):负载均衡
文章目录 零、三种不同的负载均衡一、常见行业负载均衡方案1. 电商与互联网服务2. 金融与支付系统3. 云计算与分布式存储 二、负载均衡策略概述1. 无状态负载均衡(强调公平性)2. 有状态的负载均衡(强调正确性) 三、 总结 零、三种…...
)
QT 5.15.2 开发地图ArcGIS 100.15.6(ArcGIS Runtime SDK for Qt)
QT 5.15.2ArcGIS下载 Downloads | ArcGIS Runtime API for Qt | Esri Developer ArcGIS安装(略)参考 Display a map | ArcGIS Maps SDK for Qt | Esri Developer QT新建工程 步骤1 步骤2 步骤3 步骤4(选择Topographic不需要KEY) 步骤5&a…...

细读 React | React Router 路由切换原理
2022 北京冬奥会开幕式 此前一直在疑惑,明明 pushState()、replaceState() 不触发 popstate 事件,可为什么 React Router 还能挂载对应路由的组件呢? 翻了一下 history.js 源码,终于知道原因了。 源码 假设项目路由设计如下&#…...
)
kubernetes学习-Helm 包管理器(十二)
一、Helm解释 Helm:Kubernetes 的软件包管理器 Helm 被誉为查找、分享及使用 Kubernetes 软件组件的最佳途径。作为 Kubernetes 包的管理工具,Helm 专注于管理名为 chart 的软件包。以下是 Helm 所具备的核心功能: 创建新 chart࿱…...
)
PbootCMS最新代码注入漏洞(CNVD-2025-01710、CVE-2024-12789)
PbootCMS是一套高效、简洁、 强悍的可免费商用的CMS源码,使用PHPMySQL开发,能够满足各类企业网站开发建设的需要。 国家信息安全漏洞共享平台于2025-01-14公布该程序存在代码注入漏洞。 漏洞编号:CNVD-2025-01710、CVE-2024-12789 影响产品…...

网络安全与AI:数字经济发展双引擎
在2025年年初,一场科技攻防战引发了全球关注。国产人工智能DeepSeek的爆火,伴随着大规模的网络攻击事件,将网络安全的重要性推上了风口浪尖。 在此背景下,我们计划探讨网络安全与人工智能如何为数字经济发展提供强大动力。网络安…...

【DeepSeek × Postman】请求回复
新建一个集合 在 Postman 中创建一个测试集合 DeepSeek API Test,并创建一个关联的测试环境 DeepSeek API Env,同时定义两个变量 base_url 和 api_key 的步骤如下: 1. 创建测试集合 DeepSeek API Test 打开 Postman。点击左侧导航栏中的 Co…...

如何将网站提交百度收录完整SEO教程
百度收录是中文网站获取流量的重要渠道。本文以我的网站,www.mnxz.fun(当然现在没啥流量) 为例,详细讲解从提交收录到自动化维护的全流程。 一、百度收录提交方法 1. 验证网站所有权 1、登录百度搜索资源平台 2、选择「用户中心…...