【Linux系统】分页式存储管理

分页式存储管理
1、虚拟地址和页表的由来
思考一下,如果在没有虚拟内存和分页机制的情况下,每一个用户程序在物理内存上所对应的空间必须是连续的,如下图:
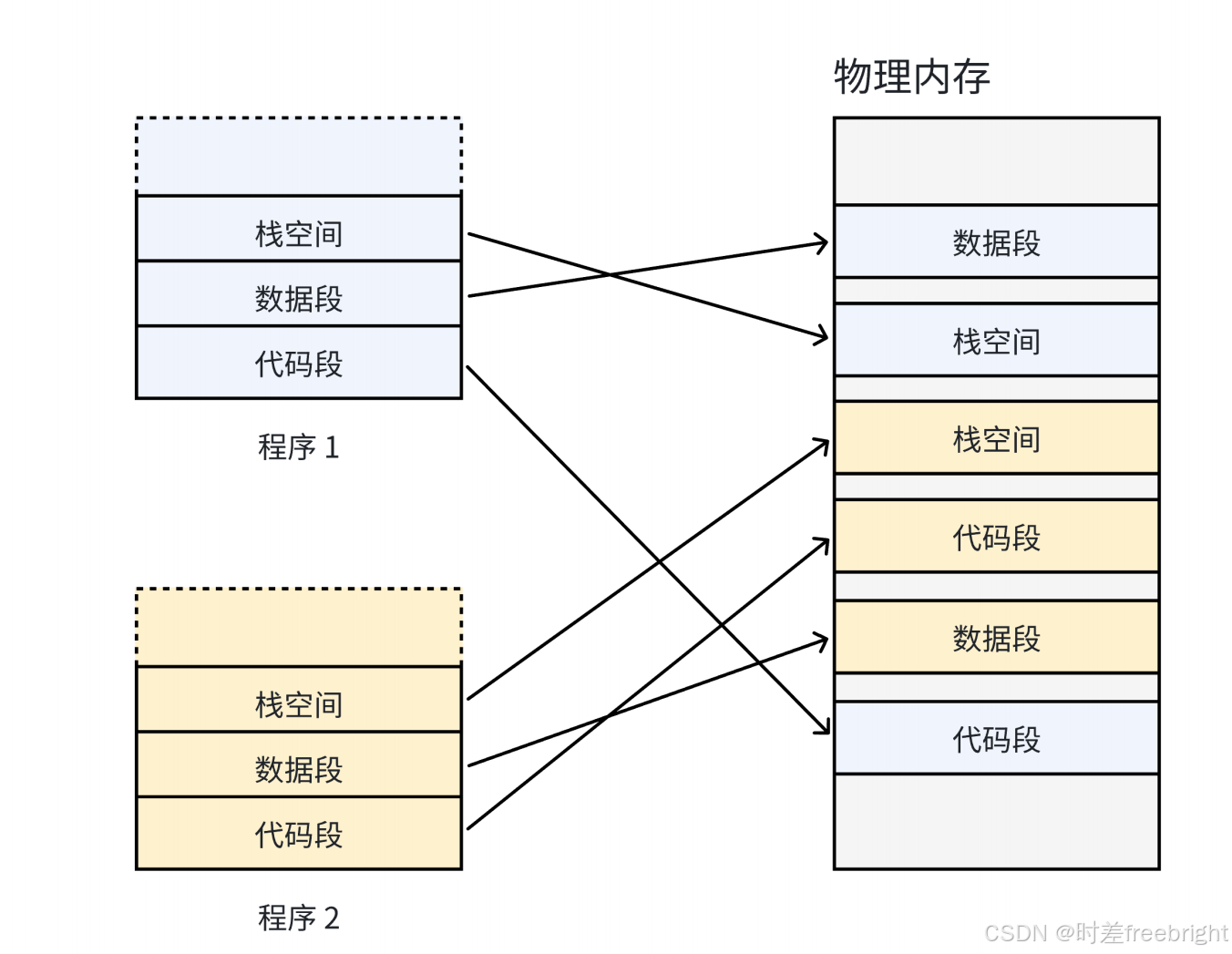
因为每一个程序的代码、数据长度都是不一样的,按照这样的映射方式,物理内存将会被分割成各种离散的、大小不同的块。经过一段运行时间之后,有些程序会退出,那么它们占据的物理内存空间可以被回收,导致这些物理内存都是以很多碎片的形式存在。
怎么办呢?我们希望操作系统提供给用户的空间必须是连续的,但是物理内存最好不要连续。 此时虚拟内存和分页便出现了,如下图所示:
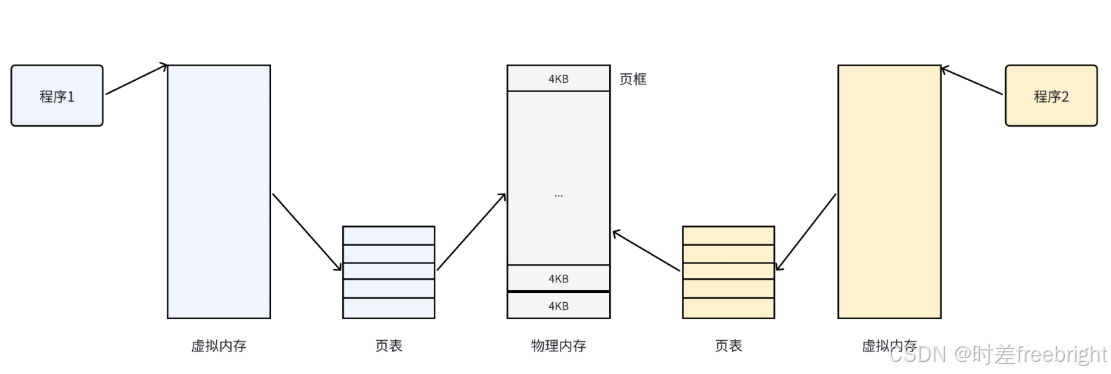
把物理内存按照一个固定的长度的页框进行分割,有时叫做物理页。每个页框包含一个物理页 (page) 。一个页的大小等于页框的大小。大多数32位体系结构支持4KB的页,而64位体系结构一般会支持8KB的页。区分一页和一个页框是很重要的:
- 页框是一个存储区域;
- 页是一个数据块,可以存放在任何页框或磁盘中。
有了这种机制,CPU便并非是直接访问物理内存地址,而是通过虚拟地址空间来间接的访问物理内存地址。所谓的虚拟地址空间,是操作系统为每一个正在执行的进程分配的一个逻辑地址,在32位机上,其范围从0 ~ 4G-1。
操作系统通过将虚拟地址空间和物理内存地址之间建立映射关系,也就是页表,这张表上记录了每一对页和页框的映射关系,能让CPU间接的访问物理内存地址。
总结一下,其思想是将虚拟内存下的逻辑地址空间分为若干页,将物理内存空间分为若干页框,通过页表便能把连续的虚拟内存,映射到若干个不连续的物理内存页。这样就解决了使用连续的物理内存造成的碎片问题。
2、物理内存管理
假设一个可用的物理内存有 4GB 的空间。按照一个页框的大小 4KB进行划分,4GB的空间就是4GB / 4KB = 1048576个页框。有这么多的物理页,操作系统肯定是要将其管理起来的,操作系统需要知道哪些页正在被使用,哪些页空闲等等。
struct page结构
内核用struct page结构表示系统中的每个物理页,出于节省内存的考虑,struct page中使用了大量的联合体union。
struct page
{// ....
};
其中比较重要的几个参数:
1、flags:用来存放页的状态。这些状态包括页是不是脏的,是不是被锁定在内存中等。flag的每一位单独表示一种状态,所以它至少可以同时表示出32种不同的状态。这些标志定义在<linux/page-flags.h>中。其中一些比特位非常重要,如PG_locked用于指定页是否锁定,PG_uptodate用于表示页的数据已经从块设备读取并且没有出现错误。
#define 未使用 (1<<0)
#define 正在使用 (1<<1)
#define 被锁定在内存中 (1<<2)
....
2、_mapcount:表示在页表中有多少项指向该页,也就是这一页被引用了多少次。当计数值变为-1时,就说明当前内核并没有引用这一页,于是在新的分配中就可以使用它。
3、virtual:是页的虚拟地址。通常情况下,它就是页在虚拟内存中的地址。有些内存(即所谓的高端内存)并不永久地映射到内核地址空间上。在这种情况下,这个域的值为NULL,需要的时候,必须动态地映射这些页。
page 结构管理数组
在 Linux 内核中实际上存在一个这样的数组 struct page mem_map[N] ,用该数组将每个页结构组织管理起来,将对页结构的管理转换为对数组这样的数据结构的增删查改工作。
在数组中,每个 page 结构都有自己的下标,而每个下标和page的地址可以相互转换:
- 物理地址 = 下标 * 4KB
- 下标 = 物理地址 / 4KB
既然 page 是用于描述物理内存的,则可以理解成:只要找到了 page,page 有下标,就等同于找到了物理内存!!
因此我们之前学习的:文件缓冲区,其实就是一个 page 的列表!!!
page 结构的内存存储
要注意的是struct page与物理页相关,而并非与虚拟页相关。而系统中的每个物理页都要分配一个这样的结构体,让我们来算算对所有这些页都这么做,到底要消耗掉多少内存。
假设struct page占 40 个字节的内存吧,假定系统的物理页为 4KB 大小,系统有 4GB 物理内存。那么系统中共有页面1048576个(1兆个),所以描述这么多页面的page结构体消耗的内存只不过 40MB,相对系统 4GB 内存而言,仅是很小的一部分罢了。因此,要管理系统中这么多物理页面,这个代价并不算太大。
要知道的是,页的大小对于内存利用和系统开销来说非常重要,页太大,页页必然会剩余较大不能利用的空间(页内碎片)。页太小,虽然可以减小页内碎片的大小,但是页太多,会使得页表太长而占用内存,同时系统频繁地进行页转化,加重系统开销。因此,页的大小应该适中,通常为512B - 8KB,Windows 系统的页框大小为 4KB。
3、页表
虚拟地址空间
实际上没有真正的存储资源的虚拟地址空间,虚拟地址空间中全是一个个虚拟地址,通过页表映射到物理地址空间
物理地址空间是实际的物理内存,由RAM组成,每个物理地址直接对应一个物理内存单元,因此可以真正存储数据
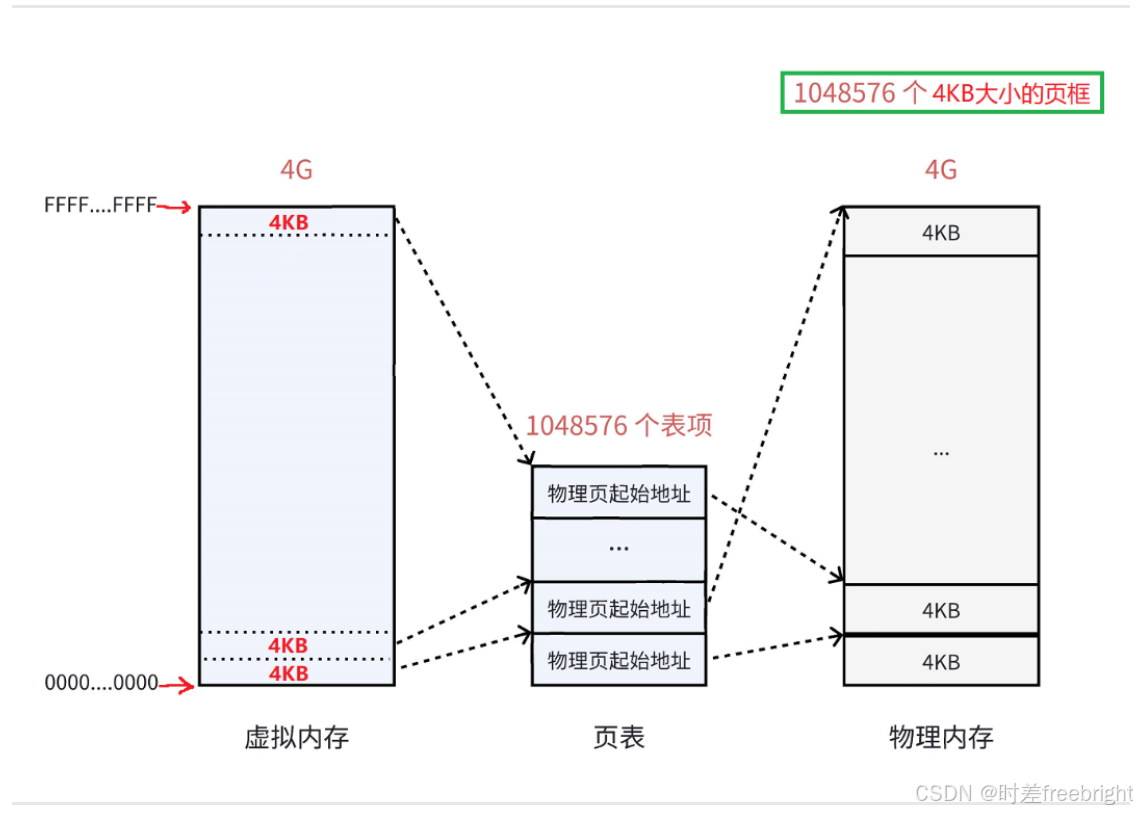
页表中的每一个表项,指向一个物理页的开始地址。在 32 位系统中,虚拟内存的最大空间是 4GB,这是每一个用户程序都拥有的虚拟内存空间。既然需要让 4GB 的虚拟内存全部可用,那么页表中就需要能够表示这所有的 4GB 空间,那么就一共需要 4GB / 4KB = 1048576 个表项。如下图所示:
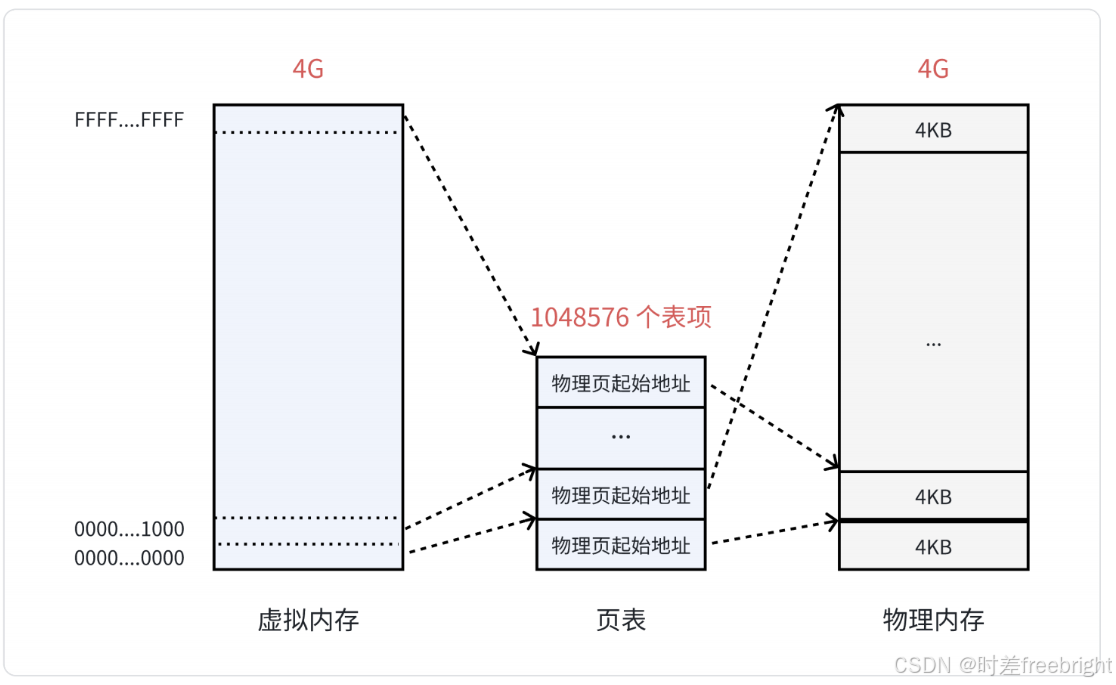
虚拟内存看上去被虚线“分割”成一个个单元,其实并不是真的分割,虚拟内存仍然是连续的。这个虚线的单元仅仅表示它与页表中每一个表项的映射关系,并最终映射到相同大小的一个物理内存页上。
页表中的物理地址,与物理内存之间,是随机的映射关系,哪里可用就指向哪里(物理页)。虽然最终使用的物理内存是离散的,但是与虚拟内存对应的线性地址是连续的。处理器在访问数据、获取指令时,使用的都是线性地址,只要它是连续的就可以了,最终都能够通过页表找到实际的物理地址。
引入多级页表思想:
在32位系统中,地址的长度是4个字节,那么页表中的每一个表项就是占用4个字节。所以页表占据的总空间大小就是:1048576 * 4 = 4MB 的大小。也就是说映射表自己本身,就要占用4MB / 4KB = 1024个物理页。这会存在哪些问题呢?
- 回想一下,当初为什么使用页表,就是要将进程划分为一个个页可以不用连续的存放在物理内存中,但是此时页表就需要1024个连续的页框,似乎和当时的目标有点背道而驰了……
- 此外,根据局部性原理可知,很多时候进程在一段时间内只需要访问某几个页就可以正常运行了。因此也没有必要一次让所有的物理页都常驻内存。
解决需要大容量页表的最好方法是:把页表看成普通的文件,对它进行离散分配,即对页表再分页,由此形成多级页表的思想。
为了解决这个问题,可以把这个单一页表拆分成1024个体积更小的映射表。如下图所示。这样一来,1024(每个表中的表项个数)* 1024(表的个数),仍然可以覆盖4GB的物理内存空间。
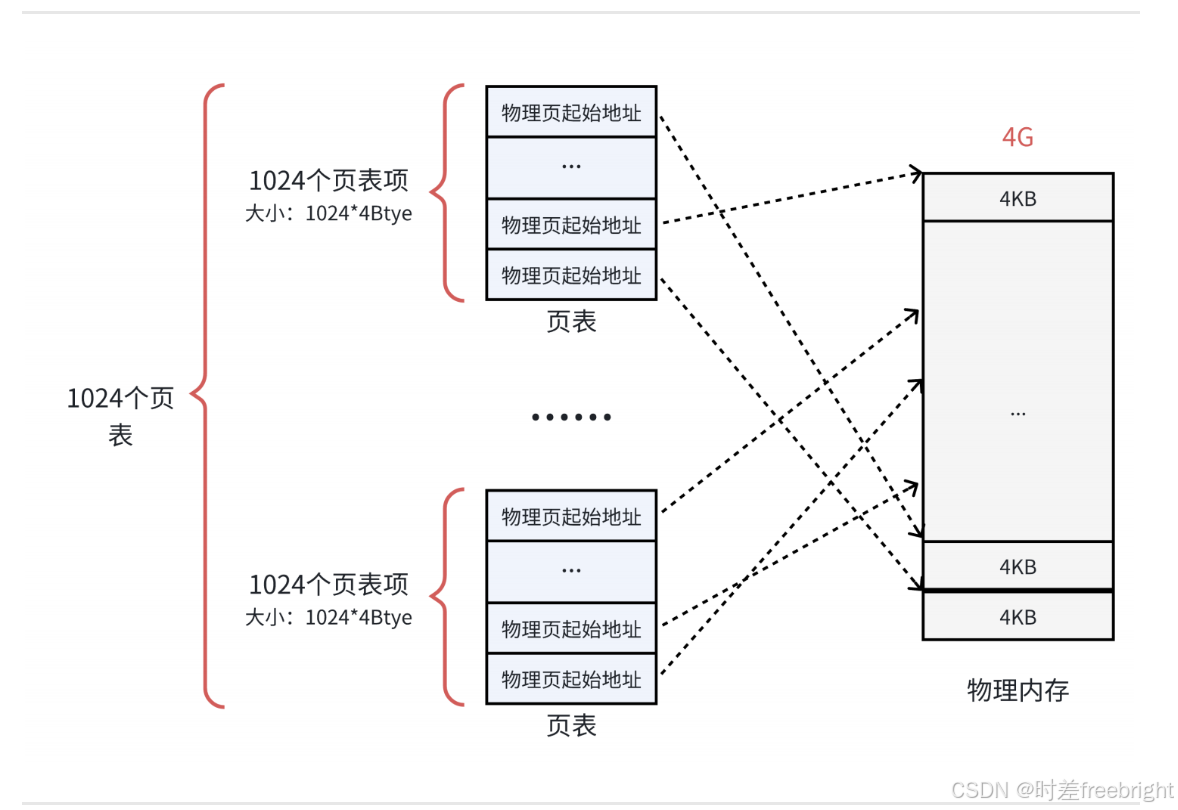
这里的每一个表,就是真正的页表,所以一共有1024个页表。一个页表自身占用4KB,那么1024个页表一共就占用了4MB的物理内存空间,和之前没差别啊?
从总数上看是这样,但是一个应用程序是不可能完全使用全部的4GB空间的,也许只要几十个页表就可以了。例如:一个用户程序的代码段、数据段、栈段,一共就需要10 MB的空间,那么使用3个页表就足够了。
计算过程:
每一个页表项指向一个4KB的物理页,那么一个页表中1024个页表项,一共能覆盖4MB的物理内存;
那么10MB的程序,向上对齐取整之后(4MB的倍数,就是12MB),就需要3个页表就可以了。
总的来说,因为一个进程不可能用完所有物理内存,因此页表也不需要一次性开辟这么多,可能只需两三张页表就够用了,所以一个进程的页表结构是远远小于4MB的
4、页目录结构
到目前为止,每一个页框都被一个页表中的一个表项来指向了,那么这1024个页表也需要被管理起来。管理页表的表称之为页目录表,形成二级页表。如下图所示:
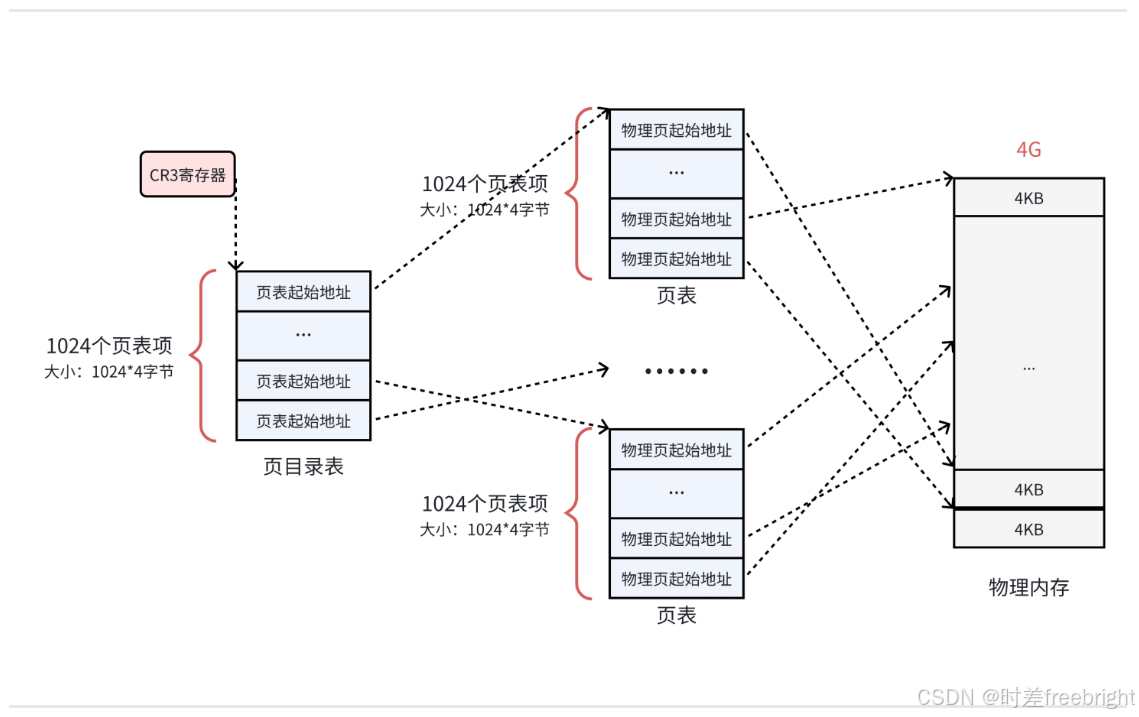
- 所有页表的物理地址被页目录表项指向。
- 页目录的物理地址被CR3寄存器指向,这个寄存器中,保存了当前正在执行任务的页目录地址。
所以操作系统在加载用户程序的时候,不仅仅需要为程序内容来分配物理内存,还需要为用来保存程序的页目录和页表分配物理内存。
5、两级页表的地址转换
下面以一个逻辑地址为例。将逻辑地址(000000000000, 000000000001, 111111111111)转换为物理地址的过程:
1、在32位处理器中,采用 4KB 的页大小,则虚拟地址中低 12 位为页偏移,剩下高 20 位给页表,分成两级,每个级别占 10 个 bit(10+10)。
2、CR3 寄存器读取页目录起始地址,再根据一级页号查页目录表,找到下一级页表在物理内存中存放位置。
3、根据二级页号查表,找到最终想要访问的内存块号。
4、结合页内偏移量得到物理地址。
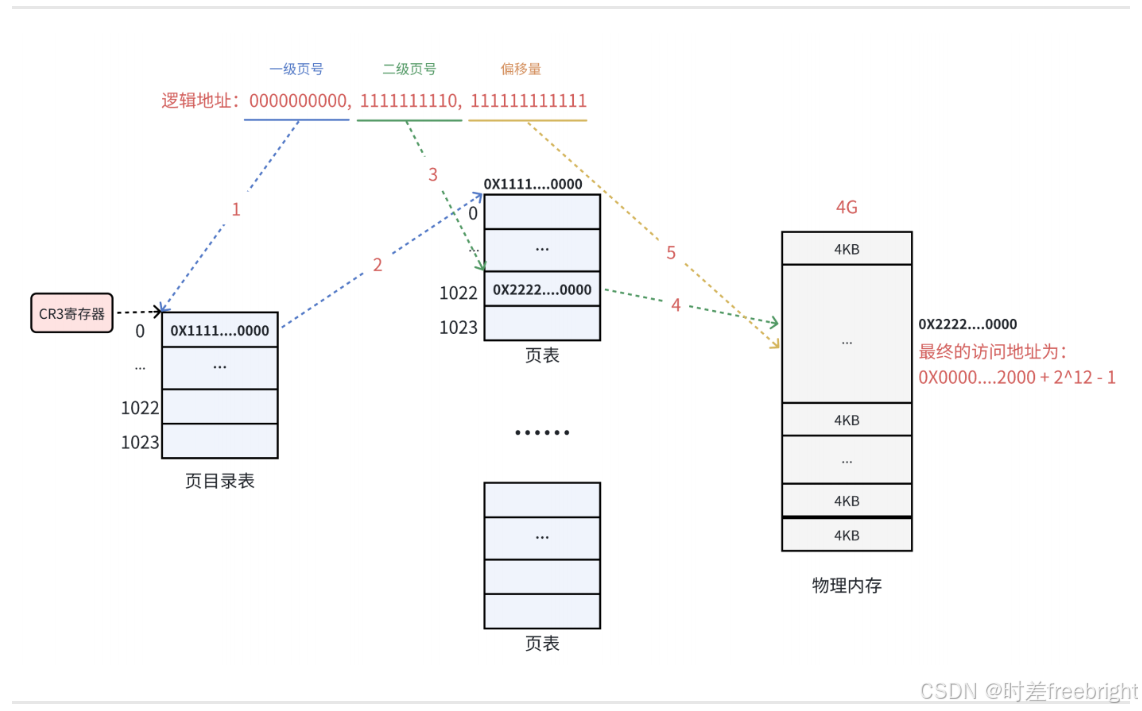
简单来说,在32位处理器中,一个页大小为 4 KB,等于 4 * 1024 字节,给每个字节分配一个位置,则需要用一个 12 位的数据来表示(4 * 1024 = 2^12 = 12 位),因此可以用数据的 12 个比特位表示一个页,而在32位处理器中,一个地址的大小为 32 位,则用该地址的低 12 位表示一个具体的页内地址。
前面文章讲解了,本系统使用的是 二级页表结构,一个页目录表包含 1024 个页表,一个页表包含 1024 个页地址,因此,我们可以用 10 位比特表示 页目录表 的表号,用于索引页目录表中的某个具体的页表,接着再用 10 位比特表示 一个页表 的表号,用于索引页表中的某个页地址,此处我们需要的 20 位比特位不就刚好可以从 一个地址 的高 20 位中取吗?
综上所述,在32位处理器中,一个地址的高 20 位用于表示 页目录表 和 页表中的索引号,低 12 位表示一个具体的页内地址。
5、页框的首地址的低12位为 0
一个物理页的地址一定是 4KB 对齐的,低12位是用于表示整个 4KB 的,因此页框的首地址的低12位为 0,因而页表只需 20 个比特位就够了,因为低12位不用存
看一下内核源码:你可以发现页表本质上就是一个
unsigned long类型的数组!!

但是
unsigned long这 32 位中的低 12 位总不能闲置吧页表项剩下的 12 个比特位存储的就是页表条目的各种标记位:权限、命中……!!!!
再查看源码:页表标志位的源码,可以看到就是 0~11 共 12 位!!!!

因此,对于页表来说,每个页表项存储着一个物理地址,该物理地址数据的前 20 位用于存储实际的页框的首地址,后 12 位存储标志位!(页表目录没有这所谓的标志位,因为页表目录的目录项存储的地址就完整的指向下一级的页表或页表目录)
6、以上其实就是MMU的工作流程。
MMU (Memory Manage Unit) 是一种硬件电路,其速度很快,主要工作是进行内存管理,地址转换只是它承接的业务之一。
到这里其实还有个问题:MMU 要先进行两次页表查询确定物理地址,在确认了权限等问题后,MMU再将这个物理地址发送到总线,内存收到之后开始读取对应地址的数据并返回。那么当页表变为N级时,就变成了 N 次检索 +1 次读写。可见,页表级数越多查询的步骤越多,对于CPU来说等待时间越长,效率越低。
让我们现在总结一下:单级页表对连续内存要求高,于是引入了多级页表,但是多级页表也是一把双刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。
有没有提升效率的办法呢?
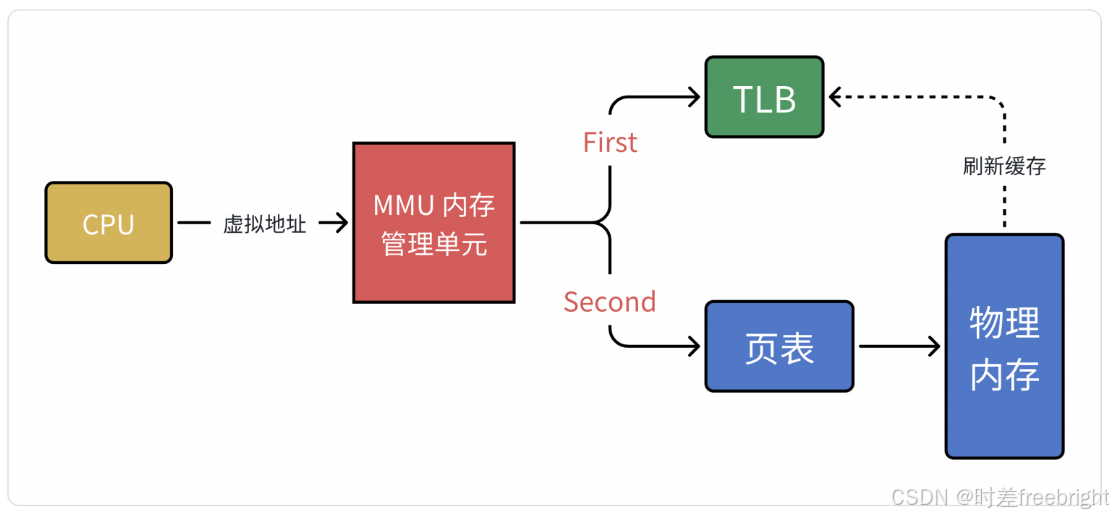
计算机科学中的所有问题,都可以通过添加一个中间层来解决。MMU 引入了新武器,江湖人称快表的 TLB(其实,就是缓存)
当 CPU 给 MMU 传新虚拟地址之后,MMU 先去问 TLB 那边有没有,如果有就直接拿到物理地址发到总线给内存,齐活。但 TLB 容量比较小,难免发生 Cache Miss,这时候 MMU 还有保底的老武器页表,在页表中找到之后 MMU 除了把地址发到总线传给内存,还把这条映射关系给到 TLB,让它记录一下刷新缓存。
再看虚拟地址空间
实际上,虚拟地址空间就是一块存储着许多的地址的内存空间,地址空间内也会以 4KB 为单位分区,实际上还是连续的,分区是为了好理解,这块空间中每个虚拟地址最终都会对应到具体一个字节的物理地址。
根据上图的知识点,因为虚拟地址是从 0x0000~0xFFFF,不可能每个具体的虚拟地址都能指向对应一个页表表项(占用内存没必要),因此每个4KB 的虚拟内存块的首位地址会指向一个页表表项,而该虚拟内存块的首位地址也就刚好通过页表表项映射到物理地址的一个页框的首位地址,虚拟地址的其他地址想要通过页表找到对应的物理内存地址,则是先通过该虚拟地址的高10 位地址查询页表目录,次高 10 位地址查询二级页表,剩下的低 12 位地址则作为偏移量,与在二级页表中查到的物理地址的一个页框的首位地址相加,最后得到该虚拟地址的真正对应物理地址!
虚拟地址到物理地址的映射
- 虚拟地址空间:
- 虚拟地址空间通常为 4GB( 32 位地址空间),从
0x00000000到0xFFFFFFFF。- 每个虚拟地址被划分为多个4KB大小的页。
- 页表结构:
- 页表通常采用多级结构,如两级页表或多级页表。
- 每个页表项包含物理页的起始地址和其他信息(如有效位、读写权限等)。
两级页表(以32位地址为例)
- 虚拟地址的划分:
- 32位地址空间被划分为页,每页4KB。
- 每个页的大小为4KB,即 212212 字节。
- 页表项的结构:
- 一级页表(Page Directory):每个表项指向一个二级页表(Page Table)。
- 二级页表:每个表项指向一个物理页。
- 地址转换过程:
- 高10位(第22-31位):用于索引一级页表(Page Directory),选择一个二级页表。
- 次高10位(第12-21位):用于索引二级页表(Page Table),选择一个物理页。
- 低12位(第0-11位):作为偏移量,与物理页的起始地址相加,得到最终的物理地址。
这样通过:高10位、次高10位 索引页表,本质上是通过这 10 位,体现出来的数值,像数组下标一样索引页表“数组”,这样就是一种 O(1) 级别的算法,使得查询索引地址快速
通过这样索引页表得到页框物理地址+偏移量的方式就一定能找到某个字节的物理地址!!!
而这就为什么我们语言中数据都是有类型的,int 大小需要 4 字节,只需通过“连续偏移量”就能找到对应物理地址
根据地址,我们查询页表获得页框起始物理地址+页内偏移量的方式可以访问任何一个字节的物理地址位置
在这个物理位置基础上加上语言层面的各个类型的大小,就能连续访问获取整个大小数据类型的数据!
6、缺页异常
设想,CPU MMU 的虚拟地址,在 TLB 和页表都没有找到对应的物理页,该怎么办呢?其实这就是缺页异常 Page Fault,它是一个由硬件中断触发的可以由软件逻辑纠正的错误。
假如目标内存页在物理内存中没有对应的物理页或者存在但无对应权限,CPU 就无法获取数据,这种情况下 CPU 会报告一个缺页错误。
由于 CPU 有数据就无法进行计算,CPU 罢工了用户进程也就出现了缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler 处理。
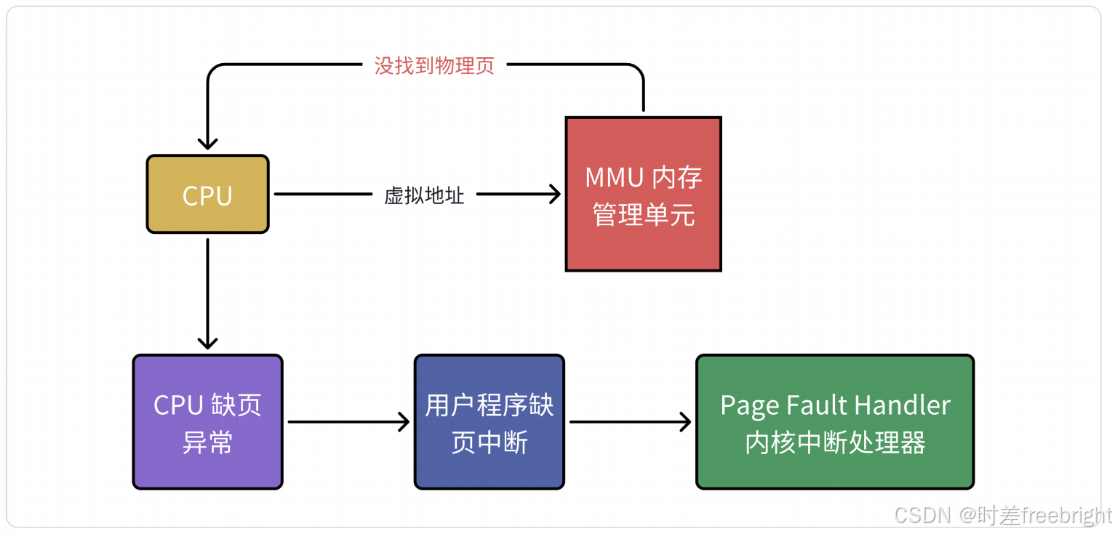
缺页中断会交给 Page Fault Handler 处理,其根据缺页中断的不同类型会进行不同的处理:
-
Hard Page Fault 也被称为 Major Page Fault,翻译为硬缺页错误/主要缺页错误,这时物理内存中没有对应的物理页,需要 CPU 打开磁盘设备读取到物理内存中,再让 MMU 建立虚拟地址和物理地址的映射。(也就是内存中没有该页面,页表中也没有)
-
Soft Page Fault 也被称为 Minor Page Fault,翻译为软缺页错误/次要缺页错误,这时物理内存中是存在对应物理页的,只不过可能是其他进程调入的,发出缺页异常的进程不知道而已,此时 MMU 只需要建立映射即可,无需从磁盘读取写入内存,一般出现在多进程共享内存区域。(也就是内存中有该页面,但页表中没有)
-
Invalid Page Fault 翻译为无效缺页错误,比如进程访问的内存地址越界访问,又比如对空指针解引用内核就会报 segment fault 错误中断进程直接挂掉。(也就是错误访问了)
7、虚拟地址到物理地址的相关转换
虚拟地址到物理地址的转换工作是由 MMU 完成的:
MMU 不会很复杂
对于 MMU 来说,因为仅仅是使用虚拟地址查页表这点操作,没必要用某种复杂的算法,因此注定了 MMU 的内部工作原理不会很复杂!
问题:这个地址转换工作是否可以使用软件来做?
答:原理简单当然可以用软件实现,但是软件太慢了,会导致大量的 CPU 周期浪费,CPU 通过虚拟地址得到物理地址的操作是需要进行很多次的,过于高频,硬件比软件快得多!
CPU的实模式和保护模式
CPU其实有一种实模式和保护模式,起初内存还未形成页表时,CPU为实模式:可以直接访问物理地址,而页表形成后就切换到保护模式,通过 MMU 查页表得到物理地址
CPU具体是如何访问物理内存
可以看这篇博客:【Linux系统】深入硬件:解析CPU如何访问物理内存-CSDN博客
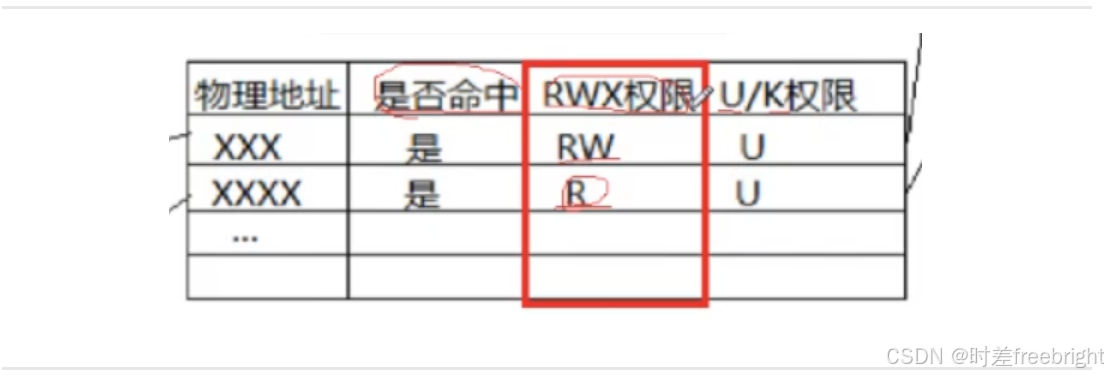
8、页表条目的权限位
页表每个条目对应的物理地址,在页表状态栏中有权限位
下面这段修改一个字符串常量,会使程序崩溃: 是因为该代码在页表中条目的权限位为只读权限
CPU运行该程序时,MMU查询页表发现这个字符串为只读权限,因此修改常量字符串时MMU会报错,触发硬件中断,进入内核执行对应的中断处理例程,操作系统向该进程发送信号,杀掉该进程
char *message = "hello";
message[0] = "o"; // 报错!!!
在C++中,当你定义一个字符串常量(如
"hello"),它通常会被存储在程序的只读数据段或文本段中。这些段中的内存页面由操作系统设置为只读权限,以防止意外修改,确保程序的稳定性和安全性。当你尝试通过指针
message修改这个字符串常量时,实际上是在尝试修改位于只读内存区域的数据。现代CPU和操作系统使用内存管理单元(MMU)来管理和保护内存。当程序尝试对只读内存进行写操作时,MMU会检测到这一违反权限的行为,并触发一个异常(在x86架构上这通常是一个页错误或段错误)。具体来说,以下是发生的过程:
- 程序执行:程序试图执行
message[0] = 'o';,这意在修改字符串的第一个字符。- MMU检查:MMU查询页表,发现该地址对应的页面权限是只读的。
- 触发异常:由于尝试对只读页面进行写入操作,MMU触发一个硬件中断,通常是页错误(Page Fault)或段错误(Segmentation Fault)。
- 进入内核模式:CPU切换到内核模式,操作系统接管并处理这个中断。
- 中断处理:操作系统执行相应的中断处理例程(ISR),检查错误类型。
- 信号发送:对于页错误或段错误,操作系统通常会向进程发送一个SIGSEGV信号(Segmentation Violation Signal)。
- 进程终止:默认情况下,接收到SIGSEGV信号会导致进程被立即终止,从而避免潜在的不稳定状态。
修改只读数据触发的错误是什么类型的中断?
硬件中断 or 软件中断
简单来说:我认为,修改只读数据是由 MMU 这个硬件产生的异常,应该是硬件中断
当程序尝试修改位于只读页面中的字符串常量时,触发的是硬件中断。具体来说,这是由内存管理单元(MMU)检测到权限违规而引发的**页错误(Page Fault)或段错误(Segmentation Fault)**以下是更详细的解释:
硬件中断 vs. 软件中断
- 硬件中断:
- 定义:由硬件设备(如I/O设备、定时器、MMU等)触发的中断。
- 特点:通常是由于外部事件或硬件检测到异常情况而产生的。例如,MMU检测到非法内存访问、CPU检测到除零错误等。
- 触发机制:硬件设备通过中断请求线(IRQ)向CPU发出信号,CPU响应并处理这些中断。
- 软件中断:
- 定义:由软件指令(如
int指令、系统调用等)显式触发的中断。 - 特点:通常用于请求操作系统服务或执行特定的操作。例如,用户程序通过系统调用请求文件操作、进程创建等。
- 触发机制:程序执行特定的指令来引发中断,CPU根据中断向量表(IVT)跳转到相应的中断处理例程。
- 定义:由软件指令(如
程序在页表上的权限是何时被设置的?
答:在加载的时候,可执行程序在编译时就已经划分好了数据段和代码段!
1、链接器和编译器的角色
- 编译阶段:当程序被编译时,编译器会根据代码和数据的不同特性,将它们划分为不同的段(section)。例如,代码段(.text)通常包含程序的执行指令,而数据段(如 .data 和 .bss)则包含全局变量和静态变量。
- 链接阶段:链接器负责将编译后的目标文件组合成一个可执行文件。它会根据各个段的属性,确定哪些段应该被标记为只读(如代码段),哪些段应该是可读写的(如数据段)。
2、加载器的角色
- 加载阶段:当操作系统启动一个程序时,加载器(Loader)负责将可执行文件从磁盘加载到内存中。在这个过程中,加载器会读取可执行文件的元数据(如ELF或PE格式的头部信息),这些元数据包含了每个段的起始地址、大小以及访问权限。
- 创建页表项:加载器会根据这些元数据,在页表中为每个段创建相应的页表项,并设置适当的权限标志位。例如:
- 代码段:通常会被设置为只读(Read/Execute, RX),以防止代码被意外修改。
- 数据段:通常会被设置为可读写(Read/Write, RW),以便程序可以修改这些数据。
- 堆和栈:通常会被设置为可读写(RW),并且栈可能还会被设置为不可执行(No Execute, NX),以防止栈溢出攻击。
相关文章:

【Linux系统】分页式存储管理
分页式存储管理 1、虚拟地址和页表的由来 思考一下,如果在没有虚拟内存和分页机制的情况下,每一个用户程序在物理内存上所对应的空间必须是连续的,如下图: 因为每一个程序的代码、数据长度都是不一样的,按照这样的映射…...

cmd执行mysql命令
安装mysql之后如果想使用cmd执行mysql命令,需要怎么操作呢,下面一起看一下。 安装mysql之后,如果直接去cmd窗口执行MySQL命令,窗口可能会提示mysql不是可执行命令。 需要配置系统的环境变量,将mysql的安装路径配置系…...

第一天:Linux内核架构、文件系统和进程管理
目录 Linux核心概念学习笔记一、Linux内核架构(一)内核的任务(二)实现策略(三)内核的组成部分(四)内核源文件目录结构二、Linux文件系统(一)文件系统架构(二)虚拟文件系统的数据结构三、Linux进程管理(一)进程相关概念(二)进程的层次结构(三)新进程创建机制(…...

QT:信号和槽
目录 1.概念 2.信号和槽的使用 2.1代码的方式使用 2.1.1.使用connect关联 2.2图形化界面的方式使用 2.2.1使用流程 2.2.2使用名字关联槽函数 3.自定义信号和槽函数 3.1自定义槽函数 3.2自定义信号 4.总结 1.概念 信号和槽是QT特有的一种机制,信号和槽都是…...

【Linux系统】线程:认识线程、线程与进程统一理解
一、更新认知 之前的认知 进程:一个执行起来的程序。进程 内核数据结构 代码和数据线程:执行流,执行粒度比进程要更细。是进程内部的一个执行分值 更新认识: a. 进程是承担分配系统资源的基本实体b. 线程是OS调度的基本单位 …...
)
蓝桥杯字串简写(二分)
输入 4 abababdb a b 输出 6 思路: 如果暴力,o(n**2),超时,想到可以先与处理一下,记录c1出现的位置,再根据c2的位置用二分法看前面有多少个符合条件的c1。 why二分: 代码:一些…...

【C语言】指针详细解读3
1. 数组名的理解 我们使用指针一般访问数组内容时,我们可能会这样写: int arr[10] {1,2,3,4,5,6,7,8,9,10}; int *p &arr[0]; 这⾥我们使⽤ &arr[0] 的⽅式拿到了数组第⼀个元素的地址,但是其实数组名本来就是地址,⽽…...

Python爬虫-如何正确解决起点中文网的无限debugger
前言 本文是该专栏的第45篇,后面会持续分享python爬虫干货知识,记得关注。 本文以起点中文网为例子,针对起点中文网使用控制台调试出现无限debugger的情况,要如何解决? 针对该问题,笔者在正文将介绍详细而又轻松的解决方法。废话不多说,下面跟着笔者直接往下看正文详细…...
:详细解读字节跳动最新论文——音频+姿态控制人类视频生成OmniHuman-1)
畅游Diffusion数字人(15):详细解读字节跳动最新论文——音频+姿态控制人类视频生成OmniHuman-1
Diffusion models代码解读:入门与实战 前言:昨晚字节跳动刚发布了一篇音频+姿态控制人类视频生成OmniHuman-1的论文,效果非常炸裂,并且是基于最新的MM-DiT架构,今天博主详细解读一下这一技术。 目录 贡献概述 方法详解 音频条件注入 Pose条件注入 参考图片条件注入 …...
-QT-C/C++ - QT Dock Widget)
Windows图形界面(GUI)-QT-C/C++ - QT Dock Widget
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 一、概述 二、使用场景 1. 工具栏 2. 侧边栏 3. 调试窗口 三、常见样式 1. 停靠位置 2. 浮动窗口 3. 可关闭 4. 可移动 四、属性设置 1. 设置内容 2. 获取内容 3. 设置标题 …...

MIT AppInventor v2.74更新的内容
MIT v2.74更新的内容如下: 新的 UI 选择器提示 向菜单、调色板和设计视图添加键盘导航 更新至 Google Blockly 版本 10 按住 Shift 并拖动以选择多个块 当值被拖近并且没有空闲插槽时,文本等块会自动合并并展开列表 将块拖到边缘时工作区会自动滚动 新的…...

使用 Ollama 在 Windows 环境部署 DeepSeek 大模型实战指南
文章目录 前言Ollama核心特性 实战步骤安装 Ollama验证安装结果部署 DeepSeek 模型拉取模型启动模型 交互体验命令行对话调用 REST API 总结个人简介 前言 近年来,大语言模型(LLM)的应用逐渐成为技术热点,而 DeepSeek 作为国产开…...

Hackmyvm whitedoor
简介 难度:简单 靶机地址: 环境 kali:192.168.194.9 靶机:192.168.194.24 扫描 nmap -sT -sV -A -T4 192.168.194.24 -p- -Pn 三个服务,ftp匿名登录、ssh连接以及web服务 ftp里面只有一个没用的README文件 访问…...

02/06 软件设计模式
目录 一.创建型模式 抽象工厂 Abstract Factory 构建器 Builder 工厂方法 Factory Method 原型 Prototype 单例模式 Singleton 二.结构型模式 适配器模式 Adapter 桥接模式 Bridge 组合模式 Composite 装饰者模式 Decorator 外观模式 Facade 享元模式 Flyw…...

Java的Integer缓存池
Java的Integer缓冲池? Integer 缓存池主要为了提升性能和节省内存。根据实践发现大部分的数据操作都集中在值比较小的范围,因此缓存这些对象可以减少内存分配和垃圾回收的负担,提升性能。 在-128到 127范围内的 Integer 对象会被缓存和复用…...

[特殊字符] ChatGPT-4与4o大比拼
🔍 ChatGPT-4与ChatGPT-4o之间有何不同?让我们一探究竟! 🚀 性能与速度方面,GPT-4-turbo以其优化设计,提供了更快的响应速度和处理性能,非常适合需要即时反馈的应用场景。相比之下,G…...
真题解析 中国电子学会全国青少年软件编程等级考试)
2024年12月 Scratch 图形化(二级)真题解析 中国电子学会全国青少年软件编程等级考试
202412 Scratch 图形化(二级)真题解析 中国电子学会全国青少年软件编程等级考试 一、单选题(共25题,共50分) 第 1 题 小猫初始位置和方向如下图所示,下面哪个选项能让小猫吃到老鼠?( ) A. B. …...
)
【2025】camunda API接口介绍以及REST接口使用(3)
前言 在前面的两篇文章我们介绍了Camunda的web端和camunda-modeler的使用。这篇文章主要介绍camunda结合springboot进行使用,以及相关api介绍。 该专栏主要为介绍camunda的学习和使用 🍅【2024】Camunda常用功能基本详细介绍和使用-下(1&…...

35.Word:公积金管理中心文员小谢【37】
目录 Word1.docx Word2.docx Word2.docx 注意本套题还是与上一套存在不同之处 Word1.docx 布局样式的应用设计页眉页脚位置在水平/垂直方向上均相对于外边距居中排列:格式→大小对话框→位置→水平/垂直 按下表所列要求将原文中的手动纯文本编号分别替换…...

关于使用numpy进行数据解析性能优化的几点认识
前言:数据解析的性能严重影响用户体验,针对需要批量处理的数据,考虑使用numpy自定义矢量化计算函数提升数据解析的性能。下面的表述都是网上查找的资料,仅供大家参考,具体情况还是需要具体分析的。 1. 使用numpy自定义…...
)
扣子平台的选择器节点:让智能体开发更简单,扣子免费系列教程(17)
欢迎来到涛涛聊AI。今天,我们来聊聊一个非常实用的工具——扣子平台的选择器节点。即使你不是计算机专业人员,但对计算机操作比较熟悉,这篇文章也能帮你快速上手。我们会从基础知识讲起,一步步带你了解选择器节点的使用方法和应用…...

java s7接收Byte字节,接收word转16位二进制
1图: 2.图: try {List list getNameList();//接收base64S7Connector s7Connector S7ConnectorFactory.buildTCPConnector().withHost("192.168.46.52").withPort(102).withTimeout(1000) //连接超时时间.withRack(0).withSlot(3).build()…...

学习日记250205
一.论文 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 二、计划: 理一下微调相关的文章 三. )——( 明天认真学习了,不能再打这么久的星露谷了!!࿰…...

位置-速度双闭环PID控制详解与C语言实现
目录 概述 1 控制架构解析 1.1 级联控制结构 1.2 性能对比 2 数学模型 2.1 位置环(外环) 2.2 速度环(内环) 3 C语言完整实现 3.1 控制结构体定义 3.2 初始化函数 3.3 双环计算函数 4 参数整定指南 4.1 整定步骤 4.2 典型参数范围 5 关键优化技术 5.1 速度前馈 …...

21.2.1 基本操作
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 Excel的基本操作步骤: 1、打开Excel:定义了一个Application对象: Microsoft.Office.Interop.E…...
制作工具)
Python-基于PyQt5,Pillow,pathilb,imageio,moviepy,sys的GIF(动图)制作工具
前言:在抖音,快手等社交平台上,我们常常见到各种各样的GIF动画。在各大评论区里面,GIF图片以其短小精悍、生动有趣的特点,被广泛用于分享各种有趣的场景、搞笑的瞬间、精彩的动作等,能够快速吸引我们的注意…...

c++ stl 遍历算法和查找算法
概述: 算法主要由头文件<algorithm> <functional> <numeric> 提供 <algorithm> 是所有 STL 头文件中最大的一个,提供了超过 90 个支持各种各样算法的函数,包括排序、合并、搜索、去重、分解、遍历、数值交换、拷贝和…...

Java学习进阶路线
Java基础 Java Web 前端HTML/css/js,J2EE(Servlet/jsp),数据库(Mysql/oracle) Java开发框架 Spring MVC/Mybatis/Herbernate/maven 《Java编程思想》 深入了解java基础 Java设计模式 《Effective j…...

探寻系统响应的奥秘:为何常用以 e 为底的指数组合表示
一、引言 在工程与科学领域的系统分析中,常常会发现系统响应多以 e e e 为底的指数组合来表示。从电路系统里的电流电压变化,到机械系统的振动情况,再到控制系统的动态特性,这种表示方法无处不在。那么,究竟是什么原…...

java 进阶教程_Java进阶教程 第2版
第2版前言 第1版前言 语言基础篇 第1章 Java语言概述 1.1 Java语言简介 1.1.1 Java语言的发展历程 1.1.2 Java的版本历史 1.1.3 Java语言与C/C 1.1.4 Java的特点 1.2 JDK和Java开发环境及工作原理 1.2.1 JDK 1.2.2 Java开发环境 1.2.3 Java工作原理 1.…...

Ext文件系统
文件内容属性 被打开的文件在内存中,没有被打开的文件在磁盘里文件系统的工作就是根据路径帮我们找到在磁盘上的文件 磁盘(硬件) 磁盘的存储结构 磁头在传动臂的运动下共同进退,向磁盘写入的时候是向柱面批量写入的 OS文件系统访…...

C++滑动窗口技术深度解析:核心原理、高效实现与高阶应用实践
目录 一、滑动窗口的核心原理 二、滑动窗口的两种类型 1. 固定大小的窗口 2. 可变大小的窗口 三、实现细节与关键点 1. 窗口的初始化 2. 窗口的移动策略 3. 结果的更新时机 四、经典问题与代码示例 示例 1:和 ≥ target 的最短子数组(可变窗口…...
 -> 兼容JS的类Web开发(四) -> 常见组件(一))
【HarmonyOS之旅】基于ArkTS开发(三) -> 兼容JS的类Web开发(四) -> 常见组件(一)
目录 1 -> List 1.1 -> 创建List组件 1.2 -> 添加滚动条 1.3 -> 添加侧边索引栏 1.4 -> 实现列表折叠和展开 1.5 -> 场景示例 2 -> dialog 2.1 -> 创建Dialog组件 2.2 -> 设置弹窗响应 2.3 -> 场景示例 3 -> form 3.1 -> 创建…...

【加餐】使⽤指针实现链表
【加餐】使⽤指针实现链表 面向过程方式和面向对象方式(把面向过程的封装一下就行了)是两种不同的编程方法论...

用 Python 绘制爱心形状的简单教程
1. 引言 在本教程中,我们将学习如何使用 Python 和 Matplotlib 库来绘制一个简单的爱心形状。这是一个有趣且简单的项目,适合初学者练习图形绘制和数据可视化。 2. 环境准备 首先,确保您的系统上安装了 Python 和 Matplotlib 库。如果还未…...

DeepSeek安装
安装运行环境 https://ollama.com/ 安装验证 cmd指令 ollama -v 安装运行模型 https://ollama.com/library/deepseek-r1:14b-qwen-distill-q4_K_M 例如: ollama run deepseek-r1:1.5b-qwen-distill-q4_K_M 结果 再次使用时,直接cmd运行上一步的ru…...

Git--使用教程
Git的框架讲解 Git 是一个分布式版本控制系统,其架构设计旨在高效地管理代码版本,支持分布式协作,并确保数据的完整性和安全性。 Git 的核心组件: 工作区(Working Directory): - 作区是你在本…...

【HTML性能优化】提升网站加载速度:GZIP、懒加载与资源合并
系列文章目录 01-从零开始学 HTML:构建网页的基本框架与技巧 02-HTML常见文本标签解析:从基础到进阶的全面指南 03-HTML从入门到精通:链接与图像标签全解析 04-HTML 列表标签全解析:无序与有序列表的深度应用 05-HTML表格标签全面…...

C#从XmlDocument提取完整字符串
方法1:通过XmlDocument的OuterXml属性,见XmlDocument类 该方法获得的xml字符串是不带格式的,可读性差 方法2:利用XmlWriterSettings控制格式等一系列参数,见XmlWriterSettings类 例子: using System.IO; …...

wordpress每隔24小时 随机推荐一个指定分类下的置顶内容。
在WordPress中实现每隔24小时随机推荐一个指定分类下的置顶内容,可以通过以下步骤实现: 1. 创建自定义函数 在主题的functions.php文件中添加以下代码,用于创建一个定时任务,每隔24小时随机选择一个置顶文章并存储到选项中&…...

《chatwise:DeepSeek的界面部署》
ChatWise:DeepSeek的界面部署 摘要 本文详细描述了DeepSeek公司针对其核心业务系统进行的界面部署工作。从需求分析到技术实现,再到测试与优化,全面阐述了整个部署过程中的关键步骤和解决方案。通过本文,读者可以深入了解DeepSee…...

HTTP请求响应周期步骤
一个典型的 HTTP 请求/响应周期 从建立连接开始,经过客户端向服务器发送请求、服务器处理请求并返回响应,最终关闭连接。这个过程可以分为多个阶段,以下是详细的步骤: 一、建立连接(TCP连接) 客户端发起连接请求:在HTTP通信中,客户端通常是浏览器,首先通过 DNS 查询…...

synchronized, volatile 在 DCL 的作用
背景 最近在看设计模式,在单例模式的 Double Check Lock(DCL)中,存在两个关键字:volatile & synchronized。 之前都知道 DCL 怎么写,直接套娃。但是这两关键字在单例里面的作用还没深究过,…...
)
Java进阶笔记(中级)
-----接Java进阶笔记(初级)----- 目录 集合多线程 集合 ArrayList 可以通过List来接收ArrayList对象(因为ArrayList实现了List接口) 方法:接口名 柄名 new 实现了接口的类(); PS: List list new ArrayList();遍历…...

人生总有终点,不必好高骛远
夕阳西下,我漫步在河堤上。河水缓缓流淌,倒映着天边最后一抹晚霞。岸边垂柳依依,枝条轻拂水面,荡起一圈圈涟漪。这涟漪由近及远,渐渐消散在暮色中,如同我们每个人在时间长河中泛起的微澜。 记得年少时&…...

C#中堆和栈的区别
C#中的堆(Heap)和栈(Stack)详解 基本概念 栈(Stack) 栈是一个后进先出(LIFO)的内存结构由系统自动分配和释放存储空间连续,大小固定主要用于存储值类型和对象引用 堆…...

如何利用i18n实现国际化
1.首先新建i18.js文件 // i18n配置 import { createI18n } from vue-i18n // import ElementPlus from element-plus import zhCn from element-plus/es/locale/lang/zh-cn import zh from ./zh-cn import en from ./en import ru from ./ru const messages {en_US: {...en,//…...

SpringMVC响应
第一章:数据处理及跳转 1. 结果跳转方式 ①.ModelAndView 设置ModelAndView对象 , 根据view的名称 , 和视图解析器跳到指定的页面 . <bean id"templateResolver" class"org.thymeleaf.spring4.templateresolver.SpringResourceTemplateResolv…...

深入理解特征值与稳定性密码:以弹簧 - 质量 - 阻尼典型二阶系统为例
从看特征值决定稳定性的原因 摘要 本文以弹簧 - 质量 - 阻尼系统这一典型二阶系统为研究对象,深入剖析特征值决定系统稳定性的内在原因。通过详细的数学推导和直观的物理意义阐释,全面揭示了特征值与系统稳定性之间的紧密关联,为理解和分析…...

python pandas 读取合并单元格并保留合并信息
读取合并单元格并保留合并信息 当我们只是使用 pandas 的 read_excel 方法读取 Excel 文件时,我们可能会遇到一个很棘手的问题:合并单元格的信息将会丢失,从而导致我们的数据出现重复或缺失的情况。 在本篇文章中将介绍使用 pandas 正确地读…...