windows下本地部署安装hadoop+scala+spark-【不需要虚拟机】
注意版本依赖【本实验版本如下】
Hadoop 3.1.1
spark 2.3.2
scala 2.111.依赖环境
1.1 java
安装java并配置环境变量【如果未安装搜索其他教程】
环境验证如下:
C:\Users\wangning>java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)
1.2 hadoop安装
下载地址:https://hadoop.apache.org/releases.html
本案例下载:hadoop-3.1.1.tar.gz 或者直接访问:
https://hadoop.apache.org/release/3.1.1.html1.2.1 hadoop安装

环境变量新增:HADOOP_HOME 值,本地安装目录(根据实际更改)D:\apps\hadoop-3.3.6
path增加%HADOOP_HOME%\bin 和 %HADOOP_HOME%\sbin
验证hadoop是否安装好:
C:\Users\wangning>hadoop version
Hadoop 3.1.1
Source code repository https://github.com/apache/hadoop -r 2b9a8c1d3a2caf1e733d57f346af3ff0d5ba529c
Compiled by leftnoteasy on 2018-08-02T04:26Z
Compiled with protoc 2.5.0
From source with checksum f76ac55e5b5ff0382a9f7df36a3ca5a0
This command was run using /D:/apps/hadoop-3.1.1/share/hadoop/common/hadoop-common-3.1.1.jar
1.2.2 修改hadoop配置文件
修改hadoop的配置文件,这些配置文件决定了hadoop是否能正常启动
配置文件的位置:在%HADOOP_HOME%\etc\hadoop\
core-site.xml, -- 是全局配置
hdfs-site.xml, --hdfs的局部配置。
mapred-site.xml -- mapred的局部配置。
a:在coresite.xml下的配置:
添加
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>b: hdfs文件都可以建立在本地监听的这个服务下
在hdfs-site.xml下的配置:
添加
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/D:/apps/hadoop-3.1.1/data/namenode</value> </property><property><name>dfs.datanode.data.dir</name><value>/D:/apps/hadoop-3.1.1/data/datanode</value> </property></configuration>在Hadoop3.1.1的安装目录下新建data文件夹,再data下,新建namenode和datanode 文件夹,

yarn-site.xml下的配置:
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
mapred-site.xml文件下的配置:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
1.2.3 配置文件下载
下载的hadoop安装包默认是在linux环境下运行的,如果需要在windows中启动,需要额外增加两个步骤
a、下载对应版本的bin文件包,替换本机hadoop安装目录下的bin包
https://github.com/cdarlint/winutilsb、将对应版本bin包中的hadoop.dll这个文件放在本机的C:\Windows\System32下

step4: 启动hadoop
进入sbin目录中,用 管理员模式启动cmd:
先初始化NameNode:hdfs namenode -format

再运行start-dfs.cmd,
再运行start-yarn.cmd
运行完上述命令,会出现2*2个窗口,如果没有报错继续,如果报错根据错误定位原因。
在cmd中输入jps,如果返回如下几个进程,就说明启动成功了

1.2.4 访问验证
http://localhost:8088 ——查看应用管理界面ResourceManager

http://localhost:9870 ——NameNode界面

1.3 Spark安装
spark下载路径:[根据自己的版本进行下载]
https://archive.apache.org/dist/spark/spark-2.3.2/
下载对应的预编译文件:[spark-2.3.2-bin-hadoop2.7.tgz]下载后解压到路径,配置环境变量:
SPARK_HOME 变量值:Spark 的解压目录,例如 C:\Spark
编辑 Path,添加:%SPARK_HOME%\bin验证 Spark:[cmd下执行:spark-shell]
C:\Users\wangning>spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://DESKTOP-8B1BDRS.mshome.net:4040
Spark context available as 'sc' (master = local[*], app id = local-1737362793261).
Spark session available as 'spark'.
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 2.3.2/_/Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_261)
Type in expressions to have them evaluated.
Type :help for more informationui页面验证:http://localhost:4040
1.4 Scala安装
下载scala
https://www.scala-lang.org/download/2.11.0.html
下载后执行安装,比如安装目录为:D:\apps\scala-2.11.0

配置环境变量:
SCALA_HOME
配置完执行验证
C:\Users\wangning>scala -version
Scala code runner version 2.11.0 -- Copyright 2002-2013, LAMP/EPFLC:\Users\wangning>scala
Welcome to Scala version 2.11.0 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_261).
Type in expressions to have them evaluated.
Type :help for more information.scala> print("hello scala")
hello scala
scala>2. 创建scala项目
增加scala插件

2.1 项目初始化
对应的pom.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>untitled</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><spark.version>2.3.2</spark.version><scala.version>2.11</scala.version></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.0</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>2.11.0</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.4</version><scope>test</scope></dependency><dependency><groupId>org.specs</groupId><artifactId>specs</artifactId><version>1.2.5</version><scope>test</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_${scala.version}</artifactId><version>${spark.version}</version></dependency></dependencies></project>2.2 coding
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._object WordCount_local {def main(args: Array[String]) {// if (args.length < 1) {// System.err.println("Usage: <file>")// System.exit(1)// }val conf = new SparkConf().setMaster("local").setAppName("HuiTest") //本地调试需要// val conf = new SparkConf() //onlineval sc = new SparkContext(conf)// val line = sc.textFile(args(0)) //online
// val line = sc.textFile("hdfs://localhost:9000/user/words.txt") //本地调试val line = sc.textFile("file:///D:/file/words.txt")line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println)sc.stop()}
}
2.3 打包
1. File->Project Structure



注意接下来删除除了jar包和compile output之外的所有jar,否则执行阶段会报错
执行相关操作:
C:\Windows\system32>hdfs dfs -ls hdfs://localhost:9000/C:\Windows\system32>hdfs dfs -mkdir hdfs://localhost:9000/user/C:\Windows\system32>hdfs dfs -ls hdfs://localhost:9000/
Found 1 items
drwxr-xr-x - wangning supergroup 0 2025-01-22 18:09 hdfs://localhost:9000/userC:\Windows\system32>hdfs dfs -put D:/file/words.txt hdfs://localhost:9000/user/words.txt
put: `/file/words.txt': No such file or directoryC:\Windows\system32>hdfs dfs -put file:///D:/file/words.txt hdfs://localhost:9000/user/words.txtC:\Windows\system32>
C:\Windows\system32>hdfs dfs -cat hdfs://localhost:9000/user/words.txt
hello
hello spark
hello redis
hello flink
hello doris
C:\Windows\system32>2.4 执行验证
cmd下执行:
# 查看编译是否成功jar tf D:\code\testcode\t6\out\artifacts\untitled_jar\untitled.jar | findstr "WordCount_local"# 运行代码
spark-submit --master local --name huihui --class WordCount_local D:\code\testcode\t6\out\artifacts\untitled_jar\untitled.jar查看运行结果如下:
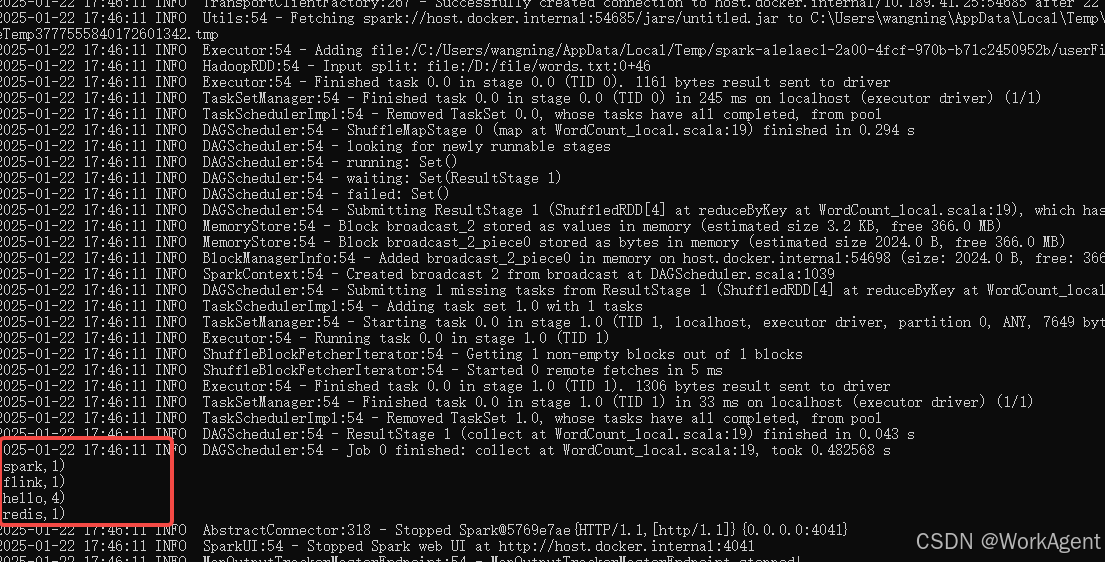
相关文章:

windows下本地部署安装hadoop+scala+spark-【不需要虚拟机】
注意版本依赖【本实验版本如下】 Hadoop 3.1.1 spark 2.3.2 scala 2.11 1.依赖环境 1.1 java 安装java并配置环境变量【如果未安装搜索其他教程】 环境验证如下: C:\Users\wangning>java -version java version "1.8.0_261" Java(TM) SE Runti…...

GitHub 仓库的 Archived 功能详解:中英双语
GitHub 仓库的 Archived 功能详解 一、什么是 GitHub 仓库的 “Archived” 功能? 在 GitHub 上,“Archived” 是一个专门用于标记仓库状态的功能。当仓库被归档后,它变为只读模式,所有的功能如提交代码、创建 issue 和 pull req…...

银行卡三要素验证接口:方便快捷地实现银行卡核验功能
银行卡三要素验证API:防止欺诈交易的有力武器 随着互联网的发展,电子支付方式也越来越普及。在支付过程中,银行卡是最常用的支付工具之一。然而,在一些支付场景中,需要对用户的银行卡信息进行验证,以确保支…...

Banana JS,一个严格子集 JavaScript 的解释器
项目地址:https://github.com/shajunxing/banana-js 特色 我的目标是剔除我在实践中总结的JavaScript语言的没用的和模棱两可的部分,只保留我喜欢和需要的,创建一个最小的语法解释器。只支持 JSON 兼容的数据类型和函数,函数是第…...

引领未来科技潮流:Web3 前沿发展趋势
随着技术不断发展,我们正站在一个全新的互联网时代的门槛上,Web3的出现正在重新定义互联网的构架和运作方式。Web3,作为互联网的下一代发展趋势,其核心思想是去中心化、开放与用户主权。与现有的Web2.0相比,Web3更加注…...

OpenCV:在图像中添加高斯噪声、胡椒噪声
目录 在图像中添加高斯噪声 高斯噪声的特性 添加高斯噪声的实现 给图像添加胡椒噪声 实现胡椒噪声的步骤 相关阅读 OpenCV:图像处理中的低通滤波-CSDN博客 OpenCV:高通滤波之索贝尔、沙尔和拉普拉斯-CSDN博客 OpenCV:图像滤波、卷积与…...
 20中安装Nvidia驱动)
在深度Linux (Deepin) 20中安装Nvidia驱动
文章创作不易,麻烦大家点赞关注收藏一键三连。 在Deepin上面跑Tensorflow, pytorch等人工智能框架不是一件容易的事情。特别是如果你要使用GPU,就得有nvidia的驱动。默认情况下Deepin系统自带的是nouveau开源驱动。这是没办法用tensorflow的。下面内容是…...
)
PC端实现PDF预览(支持后端返回文件流 || 返回文件URL)
一、使用插件 插件名称:vue-office/pdf 版本:2.0.2 安装插件:npm i vue-office/pdf^2.0.2 1、“vue-office/pdf”: “^2.0.2”, 2、 npm i vue-office/pdf^2.0.2 二、代码实现 // 引入组件 (在需要使用的页面中直接引入&#x…...

【ESP32】ESP-IDF开发 | WiFi开发 | UDP用户数据报协议 + UDP客户端和服务器例程
1. 简介 UDP协议(User Datagram Protocol),全称用户数据报协议,它是一种面向非连接的协议,面向非连接指的是在正式通信前不必与对方先建立连接, 不管对方状态就直接发送。至于对方是否可以接收到这些数据内…...

OpenAI的真正对手?DeepSeek-R1如何用强化学习重构LLM能力边界——DeepSeek-R1论文精读
2025年1月20日,DeepSeek-R1 发布,并同步开源模型权重。截至目前,DeepSeek 发布的 iOS 应用甚至超越了 ChatGPT 的官方应用,直接登顶 AppStore。 DeepSeek-R1 一经发布,各种资讯已经铺天盖地,那就让我们一起…...

es数据同步
Logstash 是 Elastic 技术栈中的一个技术,它是一个数据采集引擎,可以从数据库采集数据到 ES 中。可以通过设置 自增 ID 主键 或 更新时间 来控制数据的自动同步: 自增 ID 主键:Logstatsh 会有定时任务,如果发现有主键…...
)
【JavaScript笔记】01- 原型及原型链(面试高频内容)
前言 JavaScript作为前端入门三件套之一,也是前端求职的必会知识,重要性不言而喻。 这个系列分享个人学习JavaScript的记录,和大家一起学习讨论。 下面介绍关于原型&原型链的相关重要知识点。 1、构造函数创建对象 function Student(…...

【Python】第五弹---深入理解函数:从基础到进阶的全面解析
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】【Linux系统编程】【MySQL】【Python】 目录 1、函数 1.1、函数是什么 1.2、语法格式 1.3、函数参数 1.4、函数返回值 1.5、变量作用域 1.6、函数…...
(数字三角形、摘花生、最低通行费用、方格取数、传纸条))
动态规划DP 数字三角形模型(模型分析+例题分析+C++代码实现)(数字三角形、摘花生、最低通行费用、方格取数、传纸条)
总体概览 数字三角形 原题链接 AcWing 898.数字三角形 题目描述 给定一个如下图所示的数字三角形,从顶部出发,在每一结点可以选择移动至其左下方的结点或移动至其右下方的结点,一直走到底层,要求找出一条路径,使路…...

2025 最新flutter面试总结
目录 1.Dart是值传递还是引用传递? 2.Flutter 是单引擎还是双引擎 3. StatelessWidget 和 StatefulWidget 在 Flutter 中有什么区别? 4.简述Dart语音特性 5. Navigator 是什么?在 Flutter 中 Routes 是什么? 6、Dart 是不是…...

Java后端之AOP
AOP:面向切面编程,本质是面向特定方法编程 引入依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId></dependency>示例:记录…...

JS中对数组的操作哪些会改变原数组哪些不会?今天你一定要记下!
JavaScript 数组方法:变更原数组与不变更原数组的区别 在 JavaScript 中,数组是非常常见且重要的数据结构。作为开发者,我们常常需要使用数组方法来处理数组数据。但是,数组的不同方法会以不同的方式影响原数组,它们可…...

ubuntu x64下交叉编译ffmpeg到目标架构为aarch架构的系统
参考链接 https://blog.csdn.net/qq_46396470/article/details/137794498...
:Java设计模式)
Java进阶(二):Java设计模式
目录 设计模式 一.建模语言 二.类之间的关系 1.依赖关系 2.关联关系 3.聚合关系 4.组合关系 5.继承关系 6.实现关系 三.面向对象设计原则 单一职责原则 开闭原则 里氏替换原则 依赖倒置 接口隔离原则 迪米特原则 组合/聚合(关联关系)复用原则 四.23种设计模式…...
使用cv2.add()函数实现多图像叠加)
python学opencv|读取图像(四十二)使用cv2.add()函数实现多图像叠加
【1】引言 前序学习过程中,掌握了灰度图像和彩色图像的掩模操作: python学opencv|读取图像(九)用numpy创建黑白相间灰度图_numpy生成全黑图片-CSDN博客 python学opencv|读取图像(四十)掩模:三…...

DIY QMK量子键盘
最近放假了,趁这个空余在做一个分支项目,一款机械键盘,量子键盘取自固件名称QMK(Quantum Mechanical Keyboard)。 键盘作为计算机或其他电子设备的重要输入设备之一,通过将按键的物理动作转换为数字信号&am…...

【公式】卢布贬值风险:义乌到俄罗斯贸易的汇率陷阱
卢布贬值风险:义乌到俄罗斯贸易的汇率陷阱 具体实例与推演 假设一位中国义乌的商人,计划出口一批价值100万人民币的商品到俄罗斯。最初的汇率是1人民币兑换100卢布。 初始状态: 商品价值:100万人民币初始汇率:1人民币…...
)
1月27(信息差)
🌍喜大普奔,适用于 VS Code 的 GitHub Copilot 全新免费版本正式推出,GitHub 全球开发者突破1.5亿 🎄Kimi深夜炸场:满血版多模态o1级推理模型!OpenAI外全球首次!Jim Fan:同天两款国…...

Linux常见问题解决方法--1
常见安全工具、设备 工具 端口及漏洞扫描:Namp、Masscan 抓包:Wireshark,Burpsuite、Fiddler、HttpCanary Web自动化安全扫描:Nessus、Awvs、Appscan、Xray 信息收集:Oneforall、hole 漏洞利用:MSF、…...

Python 数据清洗与处理常用方法全解析
在数据处理与分析过程中,缺失值、重复值、异常值等问题是常见的挑战。本文总结了多种数据清洗与处理方法:缺失值处理包括删除缺失值、固定值填充、前后向填充以及删除缺失率高的列;重复值处理通过删除或标记重复项解决数据冗余问题࿱…...

《企业应用架构模式》笔记
领域逻辑 表模块和数据集一起工作-> 先查询出一个记录集,再根据数据集生成一个(如合同)对象,然后调用合同对象的方法。 这看起来很想service查询出一个对象,但调用的是对象的方法,这看起来像是充血模型…...

顶刊JFR|ROLO-SLAM:首个针对不平坦路面的车载Lidar SLAM系统
摘要 基于激光雷达(LiDAR)的同步定位与地图构建(SLAM)被认为是在恶劣环境中提供定位指导的一种有效方法。然而,现成的基于激光雷达的SLAM方法在经过不平坦地形时,尤其是在垂直方向相关的部分,会…...

第05章 09 使用Lookup绘制地形数据高程着色图
在VTK(Visualization Toolkit)中,可以使用颜色查找表(Lookup Table,简称LUT)来根据高程数据对地形进行着色。以下是一个示例代码,展示了如何使用VTK和C来读取地形数据,并使用颜色查找…...
)
【深度学习入门_机器学习理论】K近邻法(KNN)
本部分主要为机器学习理论入门_K近邻法(KNN),书籍参考 “ 统计学习方法(第二版)”。 学习目标: 了解k近邻算法的基本概念、原理、应用;熟悉k近邻算法重要影响要素;熟悉kd树原理与优化应用。 开始本算法之…...

基于Django的Boss直聘IT岗位可视化分析系统的设计与实现
【Django】基于Django的Boss直聘IT岗位可视化分析系统的设计与实现(完整系统源码开发笔记详细部署教程)✅ 目录 一、项目简介二、项目界面展示三、项目视频展示 一、项目简介 该系统采用Python作为主要开发语言,利用Django这一高效、安全的W…...

编程语言中的常见Bug及解决方案
在编程过程中,不同语言有其独特的特性和挑战,这也导致了各种常见Bug的出现。本文将总结几种主流编程语言中的常见Bug,包括JavaScript、Python、C/C、Java和Go,并提供相应的解决方案和案例。 一、JavaScript中小数相加精度不准确的…...

DeepSeek API 的获取与对话示例
代码文件下载:Code 在线链接:Kaggle | Colab 文章目录 注册并获取API环境依赖设置 API单轮对话多轮对话流式输出更换模型 注册并获取API 访问 https://platform.deepseek.com/sign_in 进行注册并登录: 新用户注册后将赠送 10 块钱余额&#…...

数据库SQLite和SCADA DIAView应用教程
课程简介 此系列课程大纲主要包含七个课时。主要使用到的开发工具有:SQLite studio 和 SCADA DIAView。详细的可成内容大概如下: 1、SQLite 可视化管理工具SQLite Studio :打开数据库和查询数据;查看视频 2、创建6个变量&#x…...
)
Elasticsearch+kibana安装(简单易上手)
下载ES( Download Elasticsearch | Elastic ) 将ES安装包解压缩 解压后目录如下: 修改ES服务端口(可以不修改) 启动ES 记住这些内容 验证ES是否启动成功 下载kibana( Download Kibana Free | Get Started Now | Elastic ) 解压后的kibana目…...
自动化构建打包、部署(Jenkins + maven+ gitlab+tomcat))
(CICD)自动化构建打包、部署(Jenkins + maven+ gitlab+tomcat)
一、平滑发布与灰度发布 **什么叫平滑:**在发布的过程中不影响用户的使用,系统不会因发布而暂停对外服务,不会造成用户短暂性无法访问; **什么叫灰度:**发布后让部分用户使用新版本,其它用户使用旧版本&am…...
—— 启动模式)
Android源码阅读笔记(二)—— 启动模式
Android源码阅读笔记(二)—— 启动模式初章 1、为什么学习启动模式 Activity的启动模式其实是一个在面试中经常会被关注的问题,那么它的重要性体现在哪里? A:在多数的开发场景中,我们似乎也没有怎么关注过…...

AndroidCompose Navigation导航精通2-过渡动画与路由切换
目录 前言路由切换NavControllerBackStackEntry过渡动画过渡原理缩放动画渐隐动画滑动动画动画过渡实战前言 在当今的移动应用开发中,导航是用户与应用交互的核心环节。随着 Android Compose 的兴起,它为开发者提供了一种全新的、声明式的方式来构建用户界面,同时也带来了更…...
)
PCL ——LevenbergMarquardt非线性最小二乘法拟合圆柱(C++详细过程版)
目录 一、算法概述1、圆柱方程2、LM算法流程二、代码实现三、结果展示一、算法概述 目前求解非线性最小二乘问题常用算法有高斯-牛顿方法(Gauss-Newton algorithm,GN 算法)、列文伯格-马夸尔特方法(Levenberg-Marquardt algorithm,LM 算法)。本文采用 LM 算法进行圆柱拟合。 …...

GD32的GD库开发
所有的Cortex-M处理器都有相同的SysTick定时器,因为CMSIS-Core头文件中定义了一个名为SysTick的结构体。 这个定时器可以用作延时函数,不管是STM32的芯片还是GD32,AT32的芯片,delay函数都可以这么写,只要它是cortex-M…...

DeepSeek R1:推理模型新纪元与价格战
标题:DeepSeek R1:推理模型新纪元与价格战 文章信息摘要: DeepSeek R1的发布标志着推理模型研究的重要转折点,其采用四阶段强化学习训练方法,结合监督微调和拒绝采样,显著提升了模型的推理能力。这一进展不…...

一文简单回顾Java中的String、StringBuilder、StringBuffer
简单说下String、StringBuilder、StringBuffer的区别 String、StringBuffer、StringBuilder在Java中都是用于处理字符串的,它们之间的区别是String是不可变的,平常开发用的最多,当遇到大量字符串连接的时候,就用StringBuilder&am…...

机器学习:支持向量机
支持向量机(Support Vector Machine)是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的广义线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。 假设两类数据可以被 H x : w T x…...

简单的停车场管理系统的C语言实现示例
以下是一个简单的停车场管理系统的C语言实现示例。该示例使用结构体来管理停车场的车位信息,并提供基本车辆进入、离开以及显示停车场状态功能。 #include <stdio.h> #include <stdlib.h> #include <string.h>#define MAX_SLOTS 10 // 最大车位数…...
指令系统基础)
网络工程师 (3)指令系统基础
一、寻址方式 (一)指令寻址 顺序寻址:通过程序计数器(PC)加1,自动形成下一条指令的地址。这是计算机中最基本、最常用的寻址方式。 跳跃寻址:通过转移类指令直接或间接给出下一条指令的地址。跳…...

基于Python的智慧物业管理系统
【Python】基于Python的智慧物业管理系统(完整系统源码开发笔记详细部署教程)✅ 目录 一、项目背景二、研究目的三、项目意义四、项目功能五、项目创新点六、开发技术介绍七、项目界面展示(部分展示,详细看视频)八、项…...

使用 Vue 3 的 watchEffect 和 watch 进行响应式监视
Vue 3 的 Composition API 引入了 <script setup> 语法,这是一种更简洁、更直观的方式来编写组件逻辑。结合 watchEffect 和 watch,我们可以轻松地监视响应式数据的变化。本文将介绍如何使用 <script setup> 语法结合 watchEffect 和 watch&…...

环境变量
目录 一.概念介绍 1.1命令行参数 二.一个例子,一个环境变量 2.1查看环境变量 2.2如何理解环境变量呢?存储的角度 2.3环境变量最开始从哪里来的呢? 概括: 1. 环境变量的存储 2. 命令查找过程 3. 环境变量表和命令行参数…...

Scale AI 创始人兼 CEO采访
Scale AI 创始人兼 CEO 亚历山大王(Alexander Wang)首次亮相节目接受采访。他的公司专注于为人工智能工具提供准确标注的数据。早在 2022 年,王成为世界上最年轻的白手起家亿万富翁。 美国在全球人工智能竞赛中的地位,以及它与中…...

MongoDB中常用的几种高可用技术方案及优缺点
MongoDB 的高可用性方案主要依赖于其内置的 副本集 (Replica Set) 和 Sharding 机制。下面是一些常见的高可用性技术方案: 1. 副本集 (Replica Set) 副本集是 MongoDB 提供的主要高可用性解决方案,确保数据在多个节点之间的冗余存储和自动故障恢复。副…...

【Erdas实验教程】001:Erdas2022下载及安装教程
文章目录 一、Erdas2022安装教程1. 安装主程序2. 拷贝补丁3. 安装LicenseServer4. 运行软件 二、Erdas2022下载地址 一、Erdas2022安装教程 Erdas2022全新界面如下: 1. 安装主程序 下载安装包并解压,以管理员身份运行 “setup.exe” 或 “setup.vbs”&…...