SparX实战:使用SparX实现图像分类任务(一)
摘要
SparX是一种新提出的稀疏跨层连接机制,旨在提升视觉Mamba和Transformer网络的性能。该论文由香港大学的俞益洲教授及其研究团队撰写,并将在AAAI 2025会议上发表。论文的主要目标是解决现有视觉模型在跨层特征聚合方面的不足,尤其是在计算复杂度较高的Mamba模型中[5][6][7]。
创新点
SparX的创新之处在于其引入了两种不同类型的网络层:神经节层(Ganglion Layer)和普通层(Normal Layer)。神经节层具有更高的连接性和复杂性,能够支持多层特征的聚合和交互,而普通层则具有较低的连接性和复杂性。通过交错这两种层,SparX实现了高效的跨层特征交互和重用,从而在模型大小、计算成本和准确率之间取得了良好的平衡。
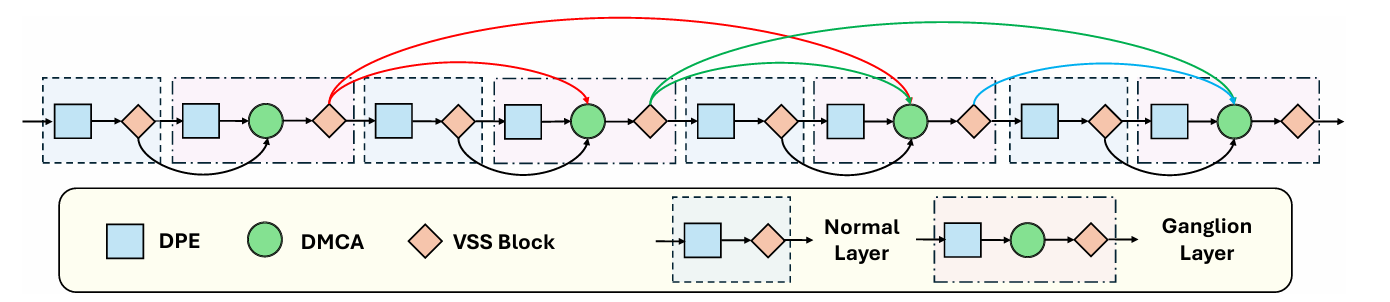
方法
SparX的设计灵感来源于人类视觉系统中的神经节细胞,旨在通过稀疏连接机制来提高特征的交互性和重用性。具体而言,SparX通过以下步骤实现其目标:
-
层的设计:构建神经节层和普通层,前者用于高复杂度的特征聚合,后者用于低复杂度的特征处理。
-
交错连接:将这两种层交错堆叠,形成新的视觉骨干网络,增强了不同层之间的特征互补性。
-
高效聚合:通过输入相关的依赖方式进行特征聚合,减少冗余特征,提高网络的表征能力.
效果
SparX在多个视觉任务中表现出色,尤其是在图像分类、语义分割和目标检测等领域。实验结果显示,基于SparX的模型在ImageNet-1K数据集上的Top-1准确率显著提高。例如,SparX-Mamba-T模型的Top-1准确率从82.5%提升至83.5%,而SparX-Swin-T模型相比于Swin-T模型也实现了1.3%的准确率提升。
实验结果
在实验中,SparX展示了其在不同视觉任务上的优越性能。具体结果包括:
-
SparX-Mamba-T:在224x224的输入尺寸下,FLOPs为5.2G,参数量为25M,Top-1准确率达到83.5%。
-
SparX-Mamba-S:在相同输入尺寸下,FLOPs为9.3G,参数量为47M,Top-1准确率为84.2%。
-
SparX-Mamba-B:在224x224的输入尺寸下,FLOPs为15.9G,参数量为84M,Top-1准确率为84.5%[4][6][9].
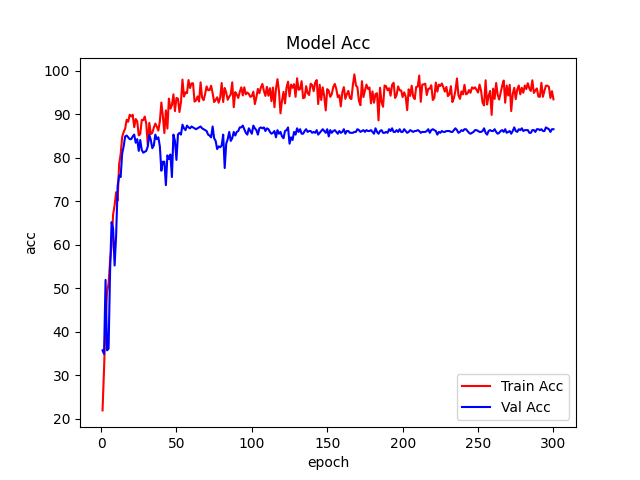
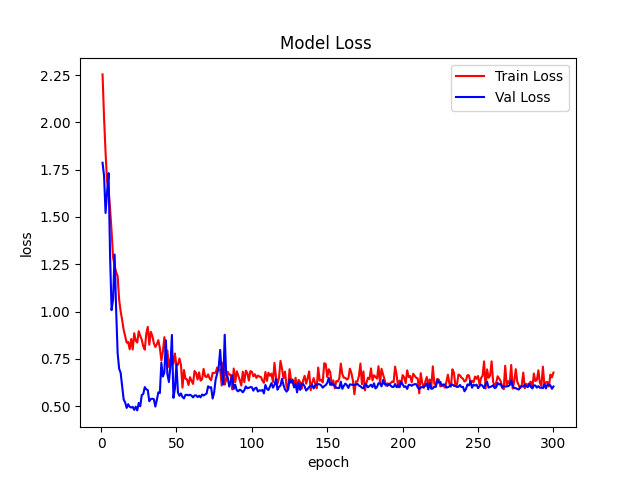
本文使用SparX模型实现图像分类任务,模型选择sparx_mamba_b,在植物幼苗分类任务ACC达到了86%+。
通过深入阅读本文,您将能够掌握以下关键技能与知识:
-
数据增强的多种策略:包括利用PyTorch的
transforms库进行基本增强,以及进阶技巧如CutOut、MixUp、CutMix等,这些方法能显著提升模型泛化能力。 -
SparX模型的训练实现:了解如何从头开始构建并训练SparX,涵盖模型定义、数据加载、训练循环等关键环节。
-
混合精度训练:学习如何利用PyTorch自带的混合精度训练功能,加速训练过程同时减少内存消耗。
-
梯度裁剪技术:掌握梯度裁剪的应用,有效防止梯度爆炸问题,确保训练过程的稳定性。
-
分布式数据并行(DP)训练:了解如何在多GPU环境下使用PyTorch的分布式数据并行功能,加速大规模模型训练。
-
可视化训练过程:学习如何绘制训练过程中的loss和accuracy曲线,直观监控模型学习状况。
-
评估与生成报告:掌握在验证集上评估模型性能的方法,并生成详细的评估报告,包括ACC等指标。
-
测试脚本编写:学会编写测试脚本,对测试集进行预测,评估模型在实际应用中的表现。
-
学习率调整策略:理解并应用余弦退火策略动态调整学习率,优化训练效果。
-
自定义统计工具:使用
AverageMeter类或其他工具统计和记录训练过程中的ACC、loss等关键指标,便于后续分析。 -
深入理解ACC1与ACC5:掌握图像分类任务中ACC1(Top-1准确率)和ACC5(Top-5准确率)的含义及其计算方法。
-
指数移动平均(EMA):学习如何在模型训练中应用EMA技术,进一步提升模型在测试集上的表现。
若您在以上任一领域基础尚浅,感到理解困难,推荐您参考我的专栏“经典主干网络精讲与实战”,该专栏从零开始,循序渐进地讲解上述所有知识点,助您轻松掌握深度学习中的这些核心技能。
安装包
安装timm
使用pip就行,命令:
pip install timm
mixup增强和EMA用到了timm。
数据增强Cutout和Mixup
为了提高模型的泛化能力和性能,我在数据预处理阶段加入了Cutout和Mixup这两种数据增强技术。Cutout通过随机遮挡图像的一部分来强制模型学习更鲁棒的特征,而Mixup则通过混合两张图像及其标签来生成新的训练样本,从而增加数据的多样性。实现这两种增强需要安装torchtoolbox。安装命令:
pip install torchtoolbox
Cutout实现,在transforms中。
from torchtoolbox.transform import Cutout
# 数据预处理
transform = transforms.Compose([transforms.Resize((224, 224)),Cutout(),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
需要导入包:from timm.data.mixup import Mixup,
定义Mixup,和SoftTargetCrossEntropy
mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=12)criterion_train = SoftTargetCrossEntropy()
Mixup 是一种在图像分类任务中常用的数据增强技术,它通过将两张图像以及其对应的标签进行线性组合来生成新的数据和标签。
参数详解:
mixup_alpha (float): mixup alpha 值,如果 > 0,则 mixup 处于活动状态。
cutmix_alpha (float):cutmix alpha 值,如果 > 0,cutmix 处于活动状态。
cutmix_minmax (List[float]):cutmix 最小/最大图像比率,cutmix 处于活动状态,如果不是 None,则使用这个 vs alpha。
如果设置了 cutmix_minmax 则cutmix_alpha 默认为1.0
prob (float): 每批次或元素应用 mixup 或 cutmix 的概率。
switch_prob (float): 当两者都处于活动状态时切换cutmix 和mixup 的概率 。
mode (str): 如何应用 mixup/cutmix 参数(每个’batch’,‘pair’(元素对),‘elem’(元素)。
correct_lam (bool): 当 cutmix bbox 被图像边框剪裁时应用。 lambda 校正
label_smoothing (float):将标签平滑应用于混合目标张量。
num_classes (int): 目标的类数。
EMA
EMA(Exponential Moving Average)在深度学习中是一种用于模型参数优化的技术,它通过计算参数的指数移动平均值来平滑模型的学习过程。这种方法有助于提高模型的稳定性和泛化能力,特别是在训练后期。以下是关于EMA的总结,表达进行了优化:
EMA概述
EMA是一种加权移动平均技术,其中每个新的平均值都是前一个平均值和当前值的加权和。在深度学习中,EMA被用于模型参数的更新,以减缓参数在训练过程中的快速波动,从而得到更加平滑和稳定的模型表现。
工作原理
在训练过程中,除了维护当前模型的参数外,还额外保存一份EMA参数。每个训练步骤或每隔一定步骤,根据当前模型参数和EMA参数,按照指数衰减的方式更新EMA参数。具体来说,EMA参数的更新公式通常如下:
EMA new = decay × EMA old + ( 1 − decay ) × model_parameters \text{EMA}_{\text{new}} = \text{decay} \times \text{EMA}_{\text{old}} + (1 - \text{decay}) \times \text{model\_parameters} EMAnew=decay×EMAold+(1−decay)×model_parameters
其中,decay是一个介于0和1之间的超参数,控制着旧EMA值和新模型参数值之间的权重分配。较大的decay值意味着EMA更新时更多地依赖于旧值,即平滑效果更强。
应用优势
- 稳定性:EMA通过平滑参数更新过程,减少了模型在训练过程中的波动,使得模型更加稳定。
- 泛化能力:由于EMA参数是历史参数的平滑版本,它往往能捕捉到模型训练过程中的全局趋势,因此在测试或评估时,使用EMA参数往往能获得更好的泛化性能。
- 快速收敛:虽然EMA本身不直接加速训练过程,但通过稳定模型参数,它可能间接地帮助模型更快地收敛到更优的解。
使用场景
EMA在深度学习中的使用场景广泛,特别是在需要高度稳定性和良好泛化能力的任务中,如图像分类、目标检测等。在训练大型模型时,EMA尤其有用,因为它可以帮助减少过拟合的风险,并提高模型在未见数据上的表现。
具体实现如下:
import logging
from collections import OrderedDict
from copy import deepcopy
import torch
import torch.nn as nn_logger = logging.getLogger(__name__)class ModelEma:def __init__(self, model, decay=0.9999, device='', resume=''):# make a copy of the model for accumulating moving average of weightsself.ema = deepcopy(model)self.ema.eval()self.decay = decayself.device = device # perform ema on different device from model if setif device:self.ema.to(device=device)self.ema_has_module = hasattr(self.ema, 'module')if resume:self._load_checkpoint(resume)for p in self.ema.parameters():p.requires_grad_(False)def _load_checkpoint(self, checkpoint_path):checkpoint = torch.load(checkpoint_path, map_location='cpu')assert isinstance(checkpoint, dict)if 'state_dict_ema' in checkpoint:new_state_dict = OrderedDict()for k, v in checkpoint['state_dict_ema'].items():# ema model may have been wrapped by DataParallel, and need module prefixif self.ema_has_module:name = 'module.' + k if not k.startswith('module') else kelse:name = knew_state_dict[name] = vself.ema.load_state_dict(new_state_dict)_logger.info("Loaded state_dict_ema")else:_logger.warning("Failed to find state_dict_ema, starting from loaded model weights")def update(self, model):# correct a mismatch in state dict keysneeds_module = hasattr(model, 'module') and not self.ema_has_modulewith torch.no_grad():msd = model.state_dict()for k, ema_v in self.ema.state_dict().items():if needs_module:k = 'module.' + kmodel_v = msd[k].detach()if self.device:model_v = model_v.to(device=self.device)ema_v.copy_(ema_v * self.decay + (1. - self.decay) * model_v)加入到模型中。
#初始化
if use_ema:model_ema = ModelEma(model_ft,decay=model_ema_decay,device='cpu',resume=resume)# 训练过程中,更新完参数后,同步update shadow weights
def train():optimizer.step()if model_ema is not None:model_ema.update(model)# 将model_ema传入验证函数中
val(model_ema.ema, DEVICE, test_loader)
针对没有预训练的模型,容易出现EMA不上分的情况,这点大家要注意啊!
项目结构
SparX_Demo
├─data1
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
├─kernels
│ └─selective_scan
│ ├─csrc
│ ├─setup.py
│ ├─test_selective_scan.py
│ ├─test_selective_scan_easy.py
│ └─test_selective_scan_speed.py
├─models
│ └─dfformer.py
├─mean_std.py
├─makedata.py
├─train.py
└─test.py
mean_std.py:计算mean和std的值。
makedata.py:生成数据集。
kernels:Mamba库文件,需要安装。
train.py:训练models文件下DFFormer的模型
dfformer:来源官方代码,在官方的模型基础上做了一些修改。
计算mean和std
在深度学习中,特别是在处理图像数据时,计算数据的均值(mean)和标准差(standard deviation, std)并进行归一化(Normalization)是加速模型收敛、提高模型性能的关键步骤之一。这里我将详细解释这两个概念,并讨论它们如何帮助模型学习。
均值(Mean)
均值是所有数值加和后除以数值的个数得到的平均值。在图像处理中,我们通常对每个颜色通道(如RGB图像的三个通道)分别计算均值。这意味着,如果我们的数据集包含多张图像,我们会计算所有图像在R通道上的像素值的均值,同样地,我们也会计算G通道和B通道的均值。
标准差(Standard Deviation, Std)
标准差是衡量数据分布离散程度的统计量。它反映了数据点与均值的偏离程度。在计算图像数据的标准差时,我们也是针对每个颜色通道分别进行的。标准差较大的颜色通道意味着该通道上的像素值变化较大,而标准差较小的通道则相对较为稳定。
归一化(Normalization)
归一化是将数据按比例缩放,使之落入一个小的特定区间,通常是[0, 1]或[-1, 1]。在图像处理中,我们通常会使用计算得到的均值和标准差来进行归一化,公式如下:
Normalized Value = Original Value − Mean Std \text{Normalized Value} = \frac{\text{Original Value} - \text{Mean}}{\text{Std}} Normalized Value=StdOriginal Value−Mean
注意,在某些情况下,为了简化计算并确保数据非负,我们可能会选择将数据缩放到[0, 1]区间,这时使用的是最大最小值归一化,而不是基于均值和标准差的归一化。但在这里,我们主要讨论基于均值和标准差的归一化,因为它能保留数据的分布特性。
为什么需要归一化?
-
加速收敛:归一化后的数据具有相似的尺度,这有助于梯度下降算法更快地找到最优解,因为不同特征的梯度更新将在同一数量级上,从而避免了某些特征因尺度过大或过小而导致的训练缓慢或梯度消失/爆炸问题。
-
提高精度:归一化可以改善模型的泛化能力,因为它使得模型更容易学习到特征之间的相对关系,而不是被特征的绝对大小所影响。
-
稳定性:归一化后的数据更加稳定,减少了训练过程中的波动,有助于模型更加稳定地收敛。
如何计算和使用mean和std
-
计算全局mean和std:在整个数据集上计算mean和std。这通常是在训练开始前进行的,并使用这些值来归一化训练集、验证集和测试集。
-
使用库函数:许多深度学习框架(如PyTorch、TensorFlow等)提供了计算mean和std的便捷函数,并可以直接用于数据集的归一化。
-
动态调整:在某些情况下,特别是当数据集非常大或持续更新时,可能需要动态地计算mean和std。这通常涉及到在训练过程中使用移动平均(如EMA)来更新这些统计量。
计算并使用数据的mean和std进行归一化是深度学习中的一项基本且重要的预处理步骤,它对于加速模型收敛、提高模型性能和稳定性具有重要意义。新建mean_std.py,插入代码:
from torchvision.datasets import ImageFolder
import torch
from torchvision import transformsdef get_mean_and_std(train_data):train_loader = torch.utils.data.DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)mean = torch.zeros(3)std = torch.zeros(3)for X, _ in train_loader:for d in range(3):mean[d] += X[:, d, :, :].mean()std[d] += X[:, d, :, :].std()mean.div_(len(train_data))std.div_(len(train_data))return list(mean.numpy()), list(std.numpy())if __name__ == '__main__':train_dataset = ImageFolder(root=r'data1', transform=transforms.ToTensor())print(get_mean_and_std(train_dataset))
数据集结构:

运行结果:
([0.3281186, 0.28937867, 0.20702125], [0.09407319, 0.09732835, 0.106712654])
把这个结果记录下来,后面要用!
生成数据集
我们整理还的图像分类的数据集结构是这样的
data
├─Black-grass
├─Charlock
├─Cleavers
├─Common Chickweed
├─Common wheat
├─Fat Hen
├─Loose Silky-bent
├─Maize
├─Scentless Mayweed
├─Shepherds Purse
├─Small-flowered Cranesbill
└─Sugar beet
pytorch和keras默认加载方式是ImageNet数据集格式,格式是
├─data
│ ├─val
│ │ ├─Black-grass
│ │ ├─Charlock
│ │ ├─Cleavers
│ │ ├─Common Chickweed
│ │ ├─Common wheat
│ │ ├─Fat Hen
│ │ ├─Loose Silky-bent
│ │ ├─Maize
│ │ ├─Scentless Mayweed
│ │ ├─Shepherds Purse
│ │ ├─Small-flowered Cranesbill
│ │ └─Sugar beet
│ └─train
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
新增格式转化脚本makedata.py,插入代码:
import glob
import os
import shutilimage_list=glob.glob('data1/*/*.png')
print(image_list)
file_dir='data'
if os.path.exists(file_dir):print('true')#os.rmdir(file_dir)shutil.rmtree(file_dir)#删除再建立os.makedirs(file_dir)
else:os.makedirs(file_dir)from sklearn.model_selection import train_test_split
trainval_files, val_files = train_test_split(image_list, test_size=0.3, random_state=42)
train_dir='train'
val_dir='val'
train_root=os.path.join(file_dir,train_dir)
val_root=os.path.join(file_dir,val_dir)
for file in trainval_files:file_class=file.replace("\\","/").split('/')[-2]file_name=file.replace("\\","/").split('/')[-1]file_class=os.path.join(train_root,file_class)if not os.path.isdir(file_class):os.makedirs(file_class)shutil.copy(file, file_class + '/' + file_name)for file in val_files:file_class=file.replace("\\","/").split('/')[-2]file_name=file.replace("\\","/").split('/')[-1]file_class=os.path.join(val_root,file_class)if not os.path.isdir(file_class):os.makedirs(file_class)shutil.copy(file, file_class + '/' + file_name)
完成上面的内容就可以开启训练和测试了。
SparX代码
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils import checkpoint
from collections import OrderedDict
from einops import rearrange, repeat
from timm.models.layers import DropPath
from timm.models.registry import register_model
from timm.data import IMAGENET_DEFAULT_STD, IMAGENET_DEFAULT_MEANimport selective_scan_cuda_oflextry:from csm_triton import CrossScanTriton, CrossMergeTriton
except:from .csm_triton import CrossScanTriton, CrossMergeTritonclass SelectiveScanOflex(torch.autograd.Function):@staticmethod@torch.cuda.amp.custom_fwddef forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, nrows=1, backnrows=1, oflex=True):ctx.delta_softplus = delta_softplusout, x, *rest = selective_scan_cuda_oflex.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1, oflex)ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)return out@staticmethod@torch.cuda.amp.custom_bwddef backward(ctx, dout, *args):u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensorsif dout.stride(-1) != 1:dout = dout.contiguous()du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_oflex.bwd(u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1)return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None, None)class LayerScale(nn.Module):def __init__(self, dim, init_value=1e-5):super().__init__()self.weight = nn.Parameter(torch.ones(dim, 1, 1, 1)*init_value, requires_grad=True)self.bias = nn.Parameter(torch.zeros(dim), requires_grad=True)def forward(self, x):x = F.conv2d(x, weight=self.weight, bias=self.bias, groups=x.shape[1])return xclass LayerNorm2d(nn.LayerNorm):def forward(self, x):x = x.permute(0, 2, 3, 1)x = super().forward(x)x = x.permute(0, 3, 1, 2)return x.contiguous()class GroupNorm(nn.GroupNorm):"""Group Normalization with 1 group.Input: tensor in shape [B, C, H, W]"""def __init__(self, num_channels, **kwargs):super().__init__(num_groups=1, num_channels=num_channels, **kwargs)class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1)self.dwconv = nn.Conv2d(hidden_features, hidden_features, kernel_size=3, padding=1, groups=hidden_features) self.act = act_layer()self.fc2 = nn.Conv2d(hidden_features, in_features, kernel_size=1)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = x + self.dwconv(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x# =====================================================
class SparXSS2D(nn.Module):def __init__(self,# basic dims ===========d_model=96,d_state=16,ssm_ratio=1,dt_rank="auto",norm_layer=LayerNorm2d,act_layer=nn.SiLU,d_conv=3,dropout=0.0,dt_min=0.001,dt_max=0.1,dt_init="random",dt_scale=1.0,dt_init_floor=1e-4,initialize="v0",stage_dense_idx=None,layer_idx=None,max_dense_depth=None,dense_step=None,is_cross_layer=None,dense_layer_idx=None,sr_ratio=1,cross_stage=False, ):factory_kwargs = {"device": None, "dtype": None}super().__init__()d_inner = int(d_model * ssm_ratio)self.layer_idx = layer_idxself.d_inner = d_innerdt_rank = math.ceil(d_model / 16) if dt_rank == "auto" else dt_rankself.d_conv = d_convk_group = 4# in proj =======================================self.in_proj = nn.Conv2d(d_model, d_inner, kernel_size=1)self.act = act_layer()self.is_cross_layer = is_cross_layerif is_cross_layer:if dense_layer_idx == stage_dense_idx[0]:intra_dim = d_modelinner_dim = d_model * dense_layer_idxelse:count = 1 if cross_stage else 0for item in stage_dense_idx:if item == dense_layer_idx:breakcount += 1count = min(max_dense_depth, count)intra_dim = d_model * countinner_dim = d_model * (dense_step - 1)current_d_dim = int(intra_dim + inner_dim)self.d_norm = norm_layer(current_d_dim)del self.in_projself.d_proj = nn.Sequential(nn.Conv2d(current_d_dim, current_d_dim, kernel_size=3, padding=1, groups=current_d_dim, bias=False),nn.BatchNorm2d(current_d_dim),nn.GELU(),nn.Conv2d(current_d_dim, d_model*2, kernel_size=1),nn.GELU(),)self.channel_padding = d_inner - d_inner//3*3self.q = nn.Sequential(self.get_sr(d_model, sr_ratio),nn.Conv2d(d_model, d_model, kernel_size=1, bias=False),nn.BatchNorm2d(d_model),)self.k = nn.Sequential(self.get_sr(d_model, sr_ratio),nn.Conv2d(d_model, d_model, kernel_size=1, bias=False),nn.BatchNorm2d(d_model),)self.v = nn.Sequential(nn.Conv2d(d_model, d_model, kernel_size=1, bias=False),nn.BatchNorm2d(d_model),)self.in_proj = nn.Sequential(nn.Conv2d(d_model*3, d_model*3, kernel_size=3, padding=1, groups=d_model*3),nn.GELU(),nn.Conv2d(d_model*3, int(d_inner//3*3), kernel_size=1, groups=3), )# conv =======================================if d_conv > 1:self.conv2d = nn.Conv2d(d_inner, d_inner, kernel_size=d_conv, groups=d_inner, padding=(d_conv-1)//2)# out proj =======================================self.out_norm = norm_layer(d_inner)self.out_proj = nn.Conv2d(d_inner, d_model, kernel_size=1)self.x_proj = [nn.Linear(d_inner, (dt_rank + d_state * 2), bias=False, **factory_kwargs)for _ in range(k_group)]self.x_proj_weight = nn.Parameter(torch.stack([t.weight for t in self.x_proj], dim=0).view(-1, d_inner, 1))del self.x_projself.dropout = nn.Dropout(dropout) if dropout > 0. else nn.Identity()if initialize in ["v0"]:# dt proj ============================self.dt_projs = [self.dt_init(dt_rank, d_inner, dt_scale, dt_init, dt_min, dt_max, dt_init_floor, **factory_kwargs)for _ in range(k_group)]self.dt_projs_weight = nn.Parameter(torch.stack([t.weight for t in self.dt_projs], dim=0)) # (K, inner, rank)self.dt_projs_bias = nn.Parameter(torch.stack([t.bias for t in self.dt_projs], dim=0)) # (K, inner)del self.dt_projs# A, D =======================================self.A_logs = self.A_log_init(d_state, d_inner, copies=k_group, merge=True) # (K * D, N)self.Ds = self.D_init(d_inner, copies=k_group, merge=True) # (K * D)elif initialize in ["v1"]:# simple init dt_projs, A_logs, Dsself.Ds = nn.Parameter(torch.ones((k_group * d_inner)))self.A_logs = nn.Parameter(torch.randn((k_group * d_inner, d_state))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1self.dt_projs_weight = nn.Parameter(torch.randn((k_group, d_inner, dt_rank)))self.dt_projs_bias = nn.Parameter(torch.randn((k_group, d_inner))) elif initialize in ["v2"]:# simple init dt_projs, A_logs, Dsself.Ds = nn.Parameter(torch.ones((k_group * d_inner)))self.A_logs = nn.Parameter(torch.zeros((k_group * d_inner, d_state))) # A == -A_logs.exp() < 0; # 0 < exp(A * dt) < 1self.dt_projs_weight = nn.Parameter(0.1 * torch.rand((k_group, d_inner, dt_rank)))self.dt_projs_bias = nn.Parameter(0.1 * torch.rand((k_group, d_inner))) @staticmethoddef get_sr(dim, sr_ratio):if sr_ratio > 1:sr = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=sr_ratio+1, stride=sr_ratio, padding=(sr_ratio+1)//2, groups=dim, bias=False),nn.BatchNorm2d(dim),nn.GELU(),)else:sr = nn.Identity()return sr@staticmethoddef dt_init(dt_rank, d_inner, dt_scale=1.0, dt_init="random", dt_min=0.001, dt_max=0.1, dt_init_floor=1e-4, **factory_kwargs):dt_proj = nn.Linear(dt_rank, d_inner, bias=True, **factory_kwargs)# Initialize special dt projection to preserve variance at initializationdt_init_std = dt_rank**-0.5 * dt_scaleif dt_init == "constant":nn.init.constant_(dt_proj.weight, dt_init_std)elif dt_init == "random":nn.init.uniform_(dt_proj.weight, -dt_init_std, dt_init_std)else:raise NotImplementedError# Initialize dt bias so that F.softplus(dt_bias) is between dt_min and dt_maxdt = torch.exp(torch.rand(d_inner, **factory_kwargs) * (math.log(dt_max) - math.log(dt_min))+ math.log(dt_min)).clamp(min=dt_init_floor)# Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759inv_dt = dt + torch.log(-torch.expm1(-dt))with torch.no_grad():dt_proj.bias.copy_(inv_dt)return dt_proj@staticmethoddef A_log_init(d_state, d_inner, copies=-1, device=None, merge=True):# S4D real initializationA = repeat(torch.arange(1, d_state + 1, dtype=torch.float32, device=device),"n -> d n",d=d_inner,).contiguous()A_log = torch.log(A) # Keep A_log in fp32if copies > 0:A_log = repeat(A_log, "d n -> r d n", r=copies)if merge:A_log = A_log.flatten(0, 1)A_log = nn.Parameter(A_log)A_log._no_weight_decay = Truereturn A_log@staticmethoddef D_init(d_inner, copies=-1, device=None, merge=True):# D "skip" parameterD = torch.ones(d_inner, device=device)if copies > 0:D = repeat(D, "n1 -> r n1", r=copies)if merge:D = D.flatten(0, 1)D = nn.Parameter(D) # Keep in fp32D._no_weight_decay = Truereturn Ddef _selective_scan(self, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=True, nrows=None, backnrows=None, ssoflex=False):return SelectiveScanOflex.apply(u, delta, A, B, C, D, delta_bias, delta_softplus, nrows, backnrows, ssoflex)def _cross_scan(self, x):return CrossScanTriton.apply(x)def _cross_merge(self, x):return CrossMergeTriton.apply(x)def forward_ssm(self, x, to_dtype=False, force_fp32=False):dt_projs_weight = self.dt_projs_weightdt_projs_bias = self.dt_projs_biasA_logs = self.A_logsDs = self.DsB, D, H, W = x.shapeD, N = A_logs.shapeK, D, R = dt_projs_weight.shapeL = H * Wxs = self._cross_scan(x)x_dbl = F.conv1d(xs.reshape(B, -1, L), self.x_proj_weight, bias=None, groups=K)dts, Bs, Cs = torch.split(x_dbl.reshape(B, K, -1, L), [R, N, N], dim=2)dts = F.conv1d(dts.reshape(B, -1, L), dt_projs_weight.reshape(K * D, -1, 1), groups=K)xs = xs.reshape(B, -1, L)dts = dts.contiguous().reshape(B, -1, L)As = -torch.exp(A_logs.to(torch.float)) # (k * c, d_state)Bs = Bs.contiguous().reshape(B, K, N, L)Cs = Cs.contiguous().reshape(B, K, N, L)Ds = Ds.to(torch.float) # (K * c)delta_bias = dt_projs_bias.reshape(-1).to(torch.float)if force_fp32:xs = xs.to(torch.float32)dts = dts.to(torch.float32)Bs = Bs.to(torch.float32)Cs = Cs.to(torch.float32)ys = self._selective_scan(xs, dts, As, Bs, Cs, Ds, delta_bias,delta_softplus=True,ssoflex=True)y = self._cross_merge(ys.reshape(B, K, -1, H, W))y = self.out_norm(y.reshape(B, -1, H, W))if to_dtype:y = y.to(x.dtype)return ydef forward(self, x, shortcut):if self.is_cross_layer:s = self.d_proj(self.d_norm(shortcut))k, v = torch.chunk(s, 2, dim=1)q = self.q(x)k = self.k(k)v = self.v(v)B, C, H, W = x.shapesr_H, sr_W = q.shape[2:]g_dim = q.shape[1] // 4q = q.reshape(-1, g_dim, sr_H*sr_W)k = k.reshape(-1, g_dim, sr_H*sr_W)v = v.reshape(-1, g_dim, H*W)attn = F.scaled_dot_product_attention(q, k, v).reshape(B, -1, H, W)if (H, W) == (sr_H, sr_W):x = q.reshape(B, -1, H, W)x = torch.cat([x, attn, v.reshape(B, -1, H, W)], dim=1)x = rearrange(x, 'b (c g) h w -> b (g c) h w', g=3).contiguous() ### channel shuffle for efficiencyx = self.in_proj(x)if self.channel_padding > 0:if self.channel_padding == 1:pad = torch.mean(x, dim=1, keepdim=True)x = torch.cat([x, pad], dim=1)else:pad = rearrange(x, 'b c h w -> b (h w) c')pad = F.adaptive_avg_pool1d(pad, self.channel_padding)pad = rearrange(pad, 'b (h w) c -> b c h w', h=H, w=W)x = torch.cat([x, pad], dim=1)else:x = self.in_proj(x)if self.d_conv > 1:x = self.conv2d(x)x = self.act(x)x = self.forward_ssm(x) x = self.out_proj(x)x = self.dropout(x)return xclass SparXVSSBlock(nn.Module):def __init__(self,hidden_dim=0,drop_path=0,norm_layer=LayerNorm2d,ssm_d_state=16,ssm_ratio=1,ssm_dt_rank="auto",ssm_act_layer=nn.SiLU,ssm_conv=3,ssm_drop_rate=0,ssm_init="v0",mlp_ratio=4,mlp_act_layer=nn.GELU,mlp_drop_rate=0,use_checkpoint=False,post_norm=False,layer_idx=None,stage_dense_idx=None,max_dense_depth=None,dense_step=None,is_cross_layer=None,dense_layer_idx=None,sr_ratio=1,cross_stage=False,ls_init_value=1e-5,**kwargs,):super().__init__()self.use_checkpoint = use_checkpointself.post_norm = post_normself.pos_embed = nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, padding=1, groups=hidden_dim)self.norm = norm_layer(hidden_dim)self.op = SparXSS2D(d_model=hidden_dim, d_state=ssm_d_state,ssm_ratio=ssm_ratio,dt_rank=ssm_dt_rank,norm_layer=norm_layer,act_layer=ssm_act_layer,d_conv=ssm_conv,dropout=ssm_drop_rate,initialize=ssm_init,layer_idx=layer_idx,stage_dense_idx=stage_dense_idx,max_dense_depth=max_dense_depth,dense_step=dense_step,is_cross_layer=is_cross_layer,dense_layer_idx=dense_layer_idx,sr_ratio=sr_ratio,cross_stage=cross_stage,**kwargs,)self.drop_path = DropPath(drop_path) if drop_path > 0 else nn.Identity()self.norm2 = norm_layer(hidden_dim)mlp_hidden_dim = int(hidden_dim * mlp_ratio)self.mlp = Mlp(in_features=hidden_dim, hidden_features=mlp_hidden_dim, act_layer=mlp_act_layer, drop=mlp_drop_rate)if ls_init_value is not None:self.layerscale_1 = LayerScale(hidden_dim, init_value=ls_init_value)self.layerscale_2 = LayerScale(hidden_dim, init_value=ls_init_value)else:self.layerscale_1 = nn.Identity()self.layerscale_2 = nn.Identity()def _forward(self, x, shortcut):x = x + self.pos_embed(x)x = self.layerscale_1(x) + self.drop_path(self.op(self.norm(x), shortcut)) # Token Mixerx = self.layerscale_2(x) + self.drop_path(self.mlp(self.norm2(x))) # FFNshortcut = xreturn (x, shortcut)def forward(self, x):input, shortcut = xif isinstance(shortcut, (list, tuple)):shortcut = torch.cat(shortcut, dim=1)if self.use_checkpoint and input.requires_grad:return checkpoint.checkpoint(self._forward, input, shortcut, use_reentrant=True)else:return self._forward(input, shortcut)class SparXMamba(nn.Module):def __init__(self,in_chans=3, num_classes=1000, depths=[2, 2, 5, 2], dims=[96, 192, 384, 768],ssm_d_state=1,ssm_ratio=[2, 2, 2, 2],ssm_dt_rank="auto",ssm_act_layer=nn.SiLU, ssm_conv=5,ssm_drop_rate=0.0, ssm_init="v0",mlp_ratio=[4, 4, 4, 4],mlp_act_layer=nn.GELU,mlp_drop_rate=0.0,ls_init_value=[None, None, 1, 1],stem_type='v1',drop_path_rate=0,norm_layer=GroupNorm,use_checkpoint=[0, 0, 0, 0],dense_config=None,sr_ratio=[8, 4, 2, 1],**kwargs,):super().__init__()self.num_classes = num_classesself.num_layers = len(depths)if isinstance(dims, int):dims = [int(dims * 2 ** i_layer) for i_layer in range(self.num_layers)]self.num_features = dims[-1]self.dims = dimsdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay ruledense_idx = []for i in range(4):dense_step = dense_config['dense_step'][i]dense_start = dense_config['dense_start'][i]d_idx = [i for i in range(depths[i] - 1, dense_start - 1, -dense_step)][::-1]dense_idx.append(d_idx)dense_config.update(dense_idx=dense_idx)self.dense_config = dense_configself.cross_stage = dense_config['cross_stage']self.patch_embed = nn.Sequential(nn.Conv2d(in_chans, dims[0]//2, kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(dims[0]//2),nn.GELU(),nn.Conv2d(dims[0]//2, dims[0], kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(dims[0]))if stem_type == 'v2':self.patch_embed = nn.Sequential(nn.Conv2d(in_chans, dims[0]//2, kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(dims[0]//2),nn.GELU(), nn.Conv2d(dims[0]//2, dims[0]//2, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(dims[0]//2),nn.GELU(),nn.Conv2d(dims[0]//2, dims[0], kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(dims[0]))self.layers = nn.ModuleList()for i_layer in range(self.num_layers):downsample = nn.Sequential(nn.Conv2d(self.dims[i_layer], self.dims[i_layer+1], kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(self.dims[i_layer+1]),) if (i_layer < self.num_layers - 1) else nn.Identity()self.layers.append(self._make_layer(dim = self.dims[i_layer],drop_path = dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],use_checkpoint=use_checkpoint[i_layer],norm_layer=norm_layer,downsample=downsample,ssm_d_state=ssm_d_state,ssm_ratio=ssm_ratio[i_layer],ssm_dt_rank=ssm_dt_rank,ssm_act_layer=ssm_act_layer,ssm_conv=ssm_conv,ssm_drop_rate=ssm_drop_rate,ssm_init=ssm_init,mlp_ratio=mlp_ratio[i_layer],mlp_act_layer=mlp_act_layer,mlp_drop_rate=mlp_drop_rate,ls_init_value=ls_init_value[i_layer],max_dense_depth=dense_config["max_dense_depth"][i_layer],dense_step=dense_config["dense_step"][i_layer],dense_idx=dense_config["dense_idx"][i_layer],sr_ratio=sr_ratio[i_layer],cross_stage=self.cross_stage[i_layer],**kwargs,))self.classifier = nn.Sequential(norm_layer(self.num_features),nn.AdaptiveAvgPool2d(1),nn.Flatten(1),nn.Linear(self.num_features, num_classes), )self.apply(self._init_weights)def _init_weights(self, m: nn.Module):if isinstance(m, (nn.Linear, nn.Conv2d)):nn.init.trunc_normal_(m.weight, std=0.02)if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2d, nn.GroupNorm)):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)@staticmethoddef _make_layer(dim=96, drop_path=[0, 0], use_checkpoint=False, norm_layer=nn.LayerNorm,downsample=nn.Identity(),ssm_d_state=16,ssm_ratio=1,ssm_dt_rank="auto", ssm_act_layer=nn.SiLU,ssm_conv=3,ssm_drop_rate=0.0, ssm_init="v0",mlp_ratio=4.0,mlp_act_layer=nn.GELU,mlp_drop_rate=0.0,ls_init_value=None,max_dense_depth=None,dense_step=None,dense_idx=None,sr_ratio=1,cross_stage=False,**kwargs,):depth = len(drop_path)blocks = []for d in range(depth):if d in dense_idx:is_cross_layer = Truedense_layer_idx = delse:is_cross_layer = Falsedense_layer_idx = Noneblocks.append(SparXVSSBlock(hidden_dim=dim, drop_path=drop_path[d],norm_layer=norm_layer,ssm_d_state=ssm_d_state,ssm_ratio=ssm_ratio,ssm_dt_rank=ssm_dt_rank,ssm_act_layer=ssm_act_layer,ssm_conv=ssm_conv,ssm_drop_rate=ssm_drop_rate,ssm_init=ssm_init,mlp_ratio=mlp_ratio,mlp_act_layer=mlp_act_layer,mlp_drop_rate=mlp_drop_rate,ls_init_value=ls_init_value,use_checkpoint=(d<use_checkpoint),layer_idx=d,max_dense_depth=max_dense_depth,dense_step=dense_step,is_cross_layer=is_cross_layer,stage_dense_idx=dense_idx,dense_layer_idx=dense_layer_idx,sr_ratio=sr_ratio,cross_stage=cross_stage,))return nn.Sequential(OrderedDict(blocks=nn.Sequential(*blocks,),downsample=downsample,))def layer_forward(self, layers, x, s, d_cfg):dense_step, dense_start, max_dense_depth, dense_idx, cross_stage = d_cfginner_list = []cross_list = []if s is not None:if cross_stage: cross_list.append(s)else: inner_list.append(s)for idx, layer in enumerate(layers.blocks):if idx in dense_idx: input = (x, inner_list)if len(cross_list) > 0:inner_list.extend(cross_list)x, s = layer(input)cross_list.append(s)inner_list = []else:input = (x, None)x, s = layer(input)inner_list.append(s)if (max_dense_depth is not None) and len(cross_list) > max_dense_depth:cross_list = cross_list[-max_dense_depth:]x = layers.downsample(x)return xdef forward(self, x):d_cfg = self.dense_configx = self.patch_embed(x)s = Nonefor idx, layer in enumerate(self.layers):dense_step = d_cfg['dense_step'][idx]dense_start = d_cfg['dense_start'][idx]max_dense_depth = d_cfg['max_dense_depth'][idx]dense_idx = d_cfg['dense_idx'][idx]cross_stage = d_cfg['cross_stage'][idx]_d_cfg = (dense_step, dense_start, max_dense_depth, dense_idx, cross_stage)x = self.layer_forward(layer, x, s, _d_cfg)s = xx = self.classifier(x)return xdef _cfg(url=None, **kwargs):return {'url': url,'num_classes': 1000,'input_size': (3, 224, 224),'crop_pct': 0.9,'interpolation': 'bicubic', # 'bilinear' or 'bicubic''mean': IMAGENET_DEFAULT_MEAN,'std': IMAGENET_DEFAULT_STD,'classifier': 'classifier',**kwargs,} @register_model
def sparx_mamba_t(pretrained=False, **kwargs):dense_config = {'dense_step': [1, 1, 2, 1],'dense_start': [100, 1, 0, 0],'max_dense_depth': [100, 100, 3, 100],'cross_stage': [False, False, False, False],}model = SparXMamba(depths=[2, 2, 7, 2],dims=[96, 192, 320, 512],sr_ratio=[8, 4, 2, 1],dense_config=dense_config,**kwargs)model.default_cfg = _cfg(crop_pct=0.9)if pretrained:pretrained = 'https://github.com/LMMMEng/SparX/releases/download/v1/sparx_mamba_tiny_in1k.pth'state_dict = torch.hub.load_state_dict_from_url(url=pretrained, map_location="cpu", check_hash=True)model.load_state_dict(state_dict)return model@register_model
def sparx_mamba_s(pretrained=False, **kwargs):dense_config = {'dense_step': [1, 1, 3, 1],'dense_start': [100, 1, 0, 0],'max_dense_depth': [100, 100, 3, 100],'cross_stage': [False, False, False, False],}model = SparXMamba(depths=[2, 2, 17, 2],dims=[96, 192, 328, 544],sr_ratio=[8, 4, 2, 1],stem_type='v2',dense_config=dense_config,**kwargs)model.default_cfg = _cfg(crop_pct=0.95)if pretrained:pretrained = 'https://github.com/LMMMEng/SparX/releases/download/v1/sparx_mamba_small_in1k.pth'state_dict = torch.hub.load_state_dict_from_url(url=pretrained, map_location="cpu", check_hash=True)model.load_state_dict(state_dict)return model@register_model
def sparx_mamba_b(pretrained=False, **kwargs):dense_config = {'dense_step': [1, 1, 3, 2],'dense_start': [100, 1, 0, 2],'max_dense_depth': [100, 100, 3, 100],'cross_stage': [False, False, False, False],}model = SparXMamba(depths=[2, 2, 21, 3],dims=[120, 240, 396, 636],sr_ratio=[8, 4, 2, 1],stem_type='v2',dense_config=dense_config,**kwargs)model.default_cfg = _cfg(crop_pct=0.95)if pretrained:pretrained = 'https://github.com/LMMMEng/SparX/releases/download/v1/sparx_mamba_base_in1k.pth'state_dict = torch.hub.load_state_dict_from_url(url=pretrained, map_location="cpu", check_hash=True)model.load_state_dict(state_dict)return model
相关文章:
)
SparX实战:使用SparX实现图像分类任务(一)
摘要 SparX是一种新提出的稀疏跨层连接机制,旨在提升视觉Mamba和Transformer网络的性能。该论文由香港大学的俞益洲教授及其研究团队撰写,并将在AAAI 2025会议上发表。论文的主要目标是解决现有视觉模型在跨层特征聚合方面的不足,尤其是在计…...
)
vue事件总线(原理、优缺点)
目录 一、原理二、使用方法三、优缺点优点缺点 四、使用注意事项具体代码参考: 一、原理 在Vue中,事件总线(Event Bus)是一种可实现任意组件间通信的通信方式。 要实现这个功能必须满足两点要求: (1&#…...

[c语言日寄]assert函数功能详解
【作者主页】siy2333 【专栏介绍】⌈c语言日寄⌋:这是一个专注于C语言刷题的专栏,精选题目,搭配详细题解、拓展算法。从基础语法到复杂算法,题目涉及的知识点全面覆盖,助力你系统提升。无论你是初学者,还是…...

08-Elasticsearch
黑马商城作为一个电商项目,商品的搜索肯定是访问频率最高的页面之一。目前搜索功能是基于数据库的模糊搜索来实现的,存在很多问题。 首先,查询效率较低。 由于数据库模糊查询不走索引,在数据量较大的时候,查询性能很…...

贪心算法-条约游戏II
hello 大家好!今天开写一个新章节,每一天一道算法题。让我们一起来学习算法思维吧! /*** 计算到达数组最后一个元素的最小跳跃次数* param {number[]} nums - 输入的整数数组* return {number} - 最小跳跃次数*/ function jump(nums) {// 数…...

Hive:内部表和外部表,内外转换
内部表和外部表 内部表示例 给表添加数据 外部表示例 给表添加数据 外部表示例 用location指定表目录位置,那么表的位置在实际指定的位置,但是可以被映射 外部表和内部表的区别 删除表后使用show tables in shao; 已经没有被删除的表,说明元数据已经被删除(mysql里面存放),但是…...

AndroidCompose Navigation导航精通1-基本页面导航与ViewPager
文章目录 前言基本页面导航库依赖导航核心部件简单NavHost实现ViewPagerPager切换逻辑图阐述Pager导航实战前言 在当今的移动应用开发中,导航是用户与应用交互的核心环节。随着 Android Compose 的兴起,它为开发者提供了一种全新的、声明式的方式来构建用户界面,同时也带来…...

基于ESP8266的多功能环境监测与反馈系统开发指南
项目概述 本系统集成了物联网开发板、高精度时钟模块、环境传感器和可视化显示模块,构建了一个智能环境监测与反馈装置。通过ESP8266 NodeMCU作为核心控制器,结合DS3231实时时钟、DHT11温湿度传感器、光敏电阻和OLED显示屏,实现了环境参数的…...

十三先天记
没有一刻,只有当下在我心里。我像星星之间的空间一样空虚。他们是我看到的第一件事,我知道的第一件事。 在接下来的时间里,我意识到我是谁,我是谁。我知道星星在我上方,星球的固体金属体在我脚下。这个支持我的世界是泰…...

JVM垃圾回收器的原理和调优详解!
全文目录: 开篇语前言摘要概述垃圾回收器分类及原理1. Serial 垃圾回收器2. Parallel 垃圾回收器3. CMS 垃圾回收器4. G1 垃圾回收器 源码解析示例代码 使用案例分享案例 1:Web 服务的 GC 调优案例 2:大数据任务的 GC 优化 应用场景案例垃圾回…...

TypeScript 学习 -类型 - 5
类 属性必须初始化 在构造函数中赋值在定义时给一个默认值 子类 子类构造函数必须使用 super() 修饰符 默认是 publicprivate 只能在当前类中被调用protected 只能在当前类 或 子类中被调用readonly 一定要被初始化, 不可以修改static 静态成员 / 静态函数 构造函数 如果被定义…...

Django 项目中使用 MySQL 数据库的完整指南
在现代 Web 开发中,数据库是应用程序的核心组件之一。Django 作为一个强大的 Python Web 框架,默认支持多种数据库后端,包括 SQLite、PostgreSQL 和 MySQL。本文将详细介绍如何在 Django 项目中使用 MySQL 作为数据库,并实现多环境(开发、测试、生产)的配置管理。 ©…...

单片机基础模块学习——PCF8591芯片
一、A/D、D/A模块 A——Analog 模拟信号:连续变化的信号(很多传感器原始输出的信号都为此类信号)D——Digital 数字信号:只有高电平和低电平两种变化(单片机芯片、微控制芯片所能处理的都是数字信号) 下面…...

gradle和maven的区别以及怎么选择使用它们
目录 区别 1. 配置方式 2. 依赖管理 3. 构建性能 4. 灵活性和扩展性 5. 多项目构建 如何选择使用 选择 Maven 的场景 选择 Gradle 的场景 区别 1. 配置方式 Maven: 使用基于 XML 的 pom.xml 文件进行配置。所有的项目信息、依赖管理、构建插件等都在这个文…...

【面试】【前端】前端网络面试题总结
一、前端网络面试题总结 网络相关知识是前端开发的核心内容之一,面试中通常会考察协议、网络模型、性能优化及常见网络问题的处理。以下是针对前端网络面试题的总结: (一)协议森林(大话网络协议) 网络协议…...

Qt 5.14.2 学习记录 —— 이십일 Qt网络和音频
文章目录 1、UDP带有界面的Udp服务器(回显服务器) 2、TCP回显服务器 3、HTTP客户端4、音频 和Linux的网络一样,Qt封装了Linux的网络API,即Socket API。网络编程是在应用层写,需要传输层支持,传输层有UDP和T…...
)
C++小病毒-1.0勒索(更新次数:2)
内容供学习使用,不得转卖,代码复制后请1小时内删除,此代码会危害计算机安全,谨慎操作 在C20环境下,并在虚拟机里运行此代码!,病毒带来后果自负! 使用时请删除在main()里的注释,并修改位置至C:\\(看我代码注释)//可以改成WIN Main() #include <iostream> #i…...

labelimg闪退的解决办法
其实就是你的python版本太高不稳定不支持labelimg 标记时出现闪退 问题原因:python版本过高 解决方案 第一步: 在python3.9以上的版本运行软件会闪退,这个时候我们需要创建一个3.9或者及以下的虚拟环境 conda cr…...

使用脚本执行地理处理工具
确定工具箱的别名,查看当前使用的arcgis的许可级别,确保工具可访问后,即可使用脚本执行工具. 操作方法 1.在arcmap中打开目标地图 2.打开python窗口 3.创建一个变量,引用要裁剪的输入要素类 in_features "<路径>" 4.创建一个变量,引用用于裁剪的图层 cl…...
)
【数据分享】2014-2025年我国道路数据(免费获取/全国/分省)
道路数据是我们在各项研究中经常使用的数据!道路数据虽然很常用,但是却基本没有能下载最近年份道路数据的网站,所以很多人不知道如何获到道路数据。 本次我们给大家分享的是2014-2025年的全国范围的道路数据!数据格式为shp矢量格…...

Mybatis-plus 更新 Null 的策略踩坑记
一个bug 在一个管理页面,有一个非必填字段被设置成空了并提交更新,再次打开的时候,发现字段还在,并没有被更新成功。 使用的数据库映射框架是 Mybatis-plus ,对于Mybatis 在更新字段的时候会对空进行校验,…...

图解 script 标签中的 async 和 defer 属性
<script> 当浏览器解析到这个标签时,它会立即停止解析HTML文档,转而去加载并执行这个脚本。这意味着如果将<script>放在页面顶部,它可能会延迟整个页面的加载速度,因为浏览器必须等待脚本执行完毕才能继续解析HTML。…...

C++ Lambda 表达式的本质及原理分析
目录 1.引言 2.Lambda 的本质 3.Lambda 的捕获机制的本质 4.捕获方式的实现与底层原理 5.默认捕获的实现原理 6.捕获 this 的机制 7.捕获的限制与注意事项 8.总结 1.引言 C 中的 Lambda 表达式是一种匿名函数,最早在 C11 引入,用于简化函数对象的…...

08.OSPF 特殊区域及其他特性
OSPF 特殊区域及其他特性 一. 前言OSPF的四个特殊区域Stub末梢区域Totally Stub完全末梢区域NSSATotally NSSA完全的NSSA二.Stub 区域和 Totally Stub 区域(1)网络规模变大引发的问题(2)传输区域和末端区域(3)Stub 区域(4)Totally Stub 区域三.NSSA 区域和 Totally NSS…...

计网week1+2
计网 一.概念 1.什么是Internet 节点:主机及其运行的应用程序、路由器、交换机 边:通信链路,接入网链路主机连接到互联网的链路,光纤、网输电缆 协议:对等层的实体之间通信要遵守的标准,规定了语法、语义…...

日志收集Day008
1.zk集群优化 修改zookeeper的堆内存大小,一般情况下,生产环境给到2G足以,如果规模较大可以适当调大到4G。 (1)配置ZK的堆内存 vim /app/softwares/zk/conf/java.env export JAVA_HOME/sortwares/jdk1.8.0_291 export JVMFLAGS"-Xms2…...

使用PC版本剪映制作照片MV
目录 制作MV模板时长调整拖动边缘缩短法分割删除法变速法整体调整法 制作MV 导入音乐 导入歌词 点击歌词 和片头可以修改字体: 还可以给字幕添加动画效果: 导入照片,自动创建照片轨: 修改片头字幕:增加两条字幕轨&…...

性能测试全链路监控模式有哪些?
目录 性能测试全链路监控的模式有哪些呢? 1. 调用链追踪(Trace) 2. 分布式追踪与日志聚合 3. 实时性能指标采集 4. 资源利用率监控 5. 自动化测试与回滚机制 6. 用户体验质量(QoE)评估 性能测试中的全链路监控模…...

【吉林乡镇界】面图层shp格式arcgis数据乡镇名称和编码wgs84无偏移内容测评
标题中的“吉林省乡镇界面图层shp格式arcgis数据乡镇名称和编码wgs84无偏移”揭示了这是一个地理信息系统(GIS)相关的数据集,主要用于描绘吉林省的乡镇边界。这个数据集包含了一系列的文件,它们是ArcGIS软件能够识别和处理的Shape…...
:搭建客服系统智能体)
SpringAI 搭建智能体(二):搭建客服系统智能体
在现代人工智能应用中,智能体(Agent) 是一个重要的概念,它的核心能力是自主性与灵活性。一个智能体不仅能够理解用户的需求,还能拆解任务、调用工具完成具体操作,并在复杂场景中高效运行。在本篇博客中&…...
在Spring框架中的实践体现)
JAVA设计模式:依赖倒转原则(DIP)在Spring框架中的实践体现
文章目录 一、DIP原则深度解析1.1 核心定义1.2 现实比喻 二、Spring中的DIP实现机制2.1 传统实现 vs Spring实现对比 三、Spring中DIP的完整示例3.1 领域模型定义3.2 具体实现3.3 高层业务类3.4 配置类 四、Spring实现DIP的关键技术4.1 依赖注入方式对比4.2 自动装配注解 五、D…...

LeetCode题练习与总结:N 叉树的前序遍历--589
一、题目描述 给定一个 n 叉树的根节点 root ,返回 其节点值的 前序遍历 。 n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔(请参见示例)。 示例 1: 输入:root [1,null,3,2,4,nu…...

WebSocket 详解:全双工通信的实现与应用
目录 一、什么是 WebSocket?(简介) 二、为什么需要 WebSocket? 三、HTTP 与 WebSocket 的区别 WebSocket 的劣势 WebSocket 的常见应用场景 WebSocket 握手过程 WebSocket 事件处理和生命周期 一、什么是 WebSocket…...
)
【漫话机器学习系列】064.梯度下降小口诀(Gradient Descent rule of thume)
梯度下降小口诀 为了帮助记忆梯度下降的核心原理和关键注意事项,可以用以下简单口诀来总结: 1. 基本原理 损失递减,梯度为引:目标是让损失函数减少,依靠梯度指引方向。负梯度,反向最短:沿着负…...

Vue 3 中的 TypeScript:接口、自定义类型与泛型
在 Vue 3 中,TypeScript 提供了强大的类型系统,帮助我们更好地管理代码的类型安全。通过使用 接口(Interface)、自定义类型(Type Aliases) 和 泛型(Generics),我们可以编…...

[SaaS] 内容创意生产平台
1.即梦 2.讯飞绘镜 typemovie 3.Krea.ai 4.Pika 5.runway 6.pixVerse 7....
)
低代码系统-产品架构案例介绍、明道云(十一)
明道云HAP-超级应用平台(Hyper Application Platform),其实就是企业级应用平台,跟微搭类似。 通过自设计底层架构,兼容各种平台,使用低代码做到应用搭建、应用运维。 企业级应用平台最大的特点就是隐藏在冰山下的功能很深…...
)
2025年1月26日(超声波模块:上拉或下拉电阻)
添加上拉或下拉电阻是在电子电路设计和嵌入式系统编程中常用的一种技术手段,下面为你详细解释其含义、作用和应用场景。 基本概念 在数字电路里,引脚的电平状态通常有高电平(逻辑 1)和低电平(逻辑 0)两种…...
】深度循环神经网络(Deep Recurrent Neural Network,DRNN)原理和实现)
【自然语言处理(NLP)】深度循环神经网络(Deep Recurrent Neural Network,DRNN)原理和实现
文章目录 介绍深度循环神经网络(DRNN)原理和实现结构特点工作原理符号含义公式含义 应用领域优势与挑战DRNN 代码实现 个人主页:道友老李 欢迎加入社区:道友老李的学习社区 介绍 **自然语言处理(Natural Language Pr…...
---函数)
C语言学习阶段性总结(五)---函数
函数构成五要素: 1、返回值类型 2、函数名 3、参数列表(输入) 4、函数体 (算法) 5、返回值 (输出) 返回值类型 函数名 (参数列表) { 函数体; return 返回值; } void 类型…...

C++初阶—string类
第一章:为什么要学习string类 1.1 C语言中的字符串 C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想&…...

Solon Cloud Gateway 开发:Route 的过滤器与定制
RouteFilterFactory 是专为路由过滤拦截处理设计的接口。对应路由配置 filters 1、内置的路由过滤器 过滤器工厂本置前缀说明与示例AddRequestHeaderFilterFactoryAddRequestHeader添加请求头 (AddRequestHeaderDemo-Ver,1.0)AddResponseHeaderFilterFactoryAddResponseHeade…...

【MySQL】 数据类型
欢迎拜访:雾里看山-CSDN博客 本篇主题:【MySQL】 数据类型 发布时间:2025.1.27 隶属专栏:MySQL 目录 数据类型分类数值类型tinyint类型数值越界测试结果说明 bit类型基本语法使用注意事项 小数类型float语法使用注意事项 decimal语…...

基于vue和elementui的简易课表
本文参考基于vue和elementui的课程表_vue实现类似课程表的周会议列表-CSDN博客,原程序在vue3.5.13版本下不能运行,修改两处: 1)slot-cope改为v-slot 2)return background-color:rgb(24 144 255 / 80%);color: #fff; …...

vim的多文件操作
[rootxxx ~]# vim aa.txt bb.txt cc.txt #多文件操作 next #下一个文件 prev #上一个文件 first #第一个文件 last #最后一个文件 快捷键: ctrlshift^ #当前和上个之间切换 说明:快捷键ctrlshift^,…...

spring spring-boot spring-cloud发布以及适配
https://spring.io/blog/2024/10/01/from-spring-framework-6-2-to-7-0 看了 spring 的官网,提到 2025 年 spring 会跟随 jdk 25 LTS发布后,接着发布 Spring Framework 7.0 GA,与之对应 spring 系列的组件版本情况如下。 Spring Framework版…...

【快速上手】阿里云百炼大模型
为了创建自己的知识库,本文介绍一下阿里云的百炼大模型,方便大家快速上手!快速查询自己想要的内容。 一、入口页 阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台 二、大模型的选择 首先前提条件是 1、账号不能欠费 2、需…...

Linux:多线程[2] 线程控制
了解: Linux底层提供创建轻量级进程/进程的接口clone,通过选择是否共享资源创建。 vfork和fork都调用的clone进行实现,vfork和父进程共享地址空间-轻量级进程。 库函数pthread_create调用的也是底层的clone。 POSIX线程库 与线程有关的函数构…...

010 mybatis-PageHelper分页插件
文章目录 添加依赖配置PageHelper项目中使用PageHelper注意事项 PageHelper分页插件介绍 https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/en/HowToUse.md 使用方法 添加依赖 <dependency><groupId>com.github.pagehelper</groupId>&l…...

【huawei】云计算的备份和容灾
目录 1 备份和容灾 2 灾备的作用? ① 备份的作用 ② 容灾的作用 3 灾备的衡量指标 ① 数据恢复时间点(RPO,Recoyery Point Objective) ② 应用恢复时间(RTO,Recoyery Time Objective) 4…...