深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。

文章目录
- 文本特征提取的方法
- 1. 基础方法
- 1.1 词袋模型(Bag of Words, BOW)
- 工作原理
- 举例
- 优点
- 缺点
- 1.2 TF-IDF(Term Frequency-Inverse Document Frequency)
- 工作原理
- 举例
- 优点
- 缺点
- 1.3 TF-IDF的改进——BM25
- 优化
- 1.4 N-Gram 模型
- 工作原理
- 举例
- 优点
- 缺点
- 2. 词向量(Word Embeddings)
- 2.1 Word2Vec
- 工作原理
- 举例
- 优点
- 缺点
- 2.2 FastText
- 工作原理
- 优点
- 缺点
- 3. 预训练模型:BERT(Bidirectional Encoder Representations from Transformers)
- 工作原理
- 优点
- 缺点
- 总结
- LSTM(Long Short-Term Memory)
- LSTM 的核心部件
- LSTM 的公式和工作原理
- (1) 遗忘门(Forget Gate)
- (2) 输入门(Input Gate)
- (3) 更新记忆单元状态
- (4) 输出门(Output Gate)
- LSTM 的流程总结
- LSTM 的优点
- LSTM 的局限性
- 热门专栏
- 机器学习
- 深度学习
文本特征提取的方法
1. 基础方法
1.1 词袋模型(Bag of Words, BOW)
词袋模型最简单的方法。它将文本表示为一个词频向量,不考虑词语的顺序或上下文关系,只统计每个词在文本中出现的频率。
工作原理
- 构建词汇表:对整个语料库中的所有词汇建立一个词汇表(也称为词典)。每个文档中的每个词都与词汇表中的一个位置对应。
- 生成词频向量:对于每个文本(文档),生成一个与词汇表长度相同的向量。向量中每个元素表示该词在文档中出现的次数(或者是否出现,用二进制表示)。
举例
假设有两个句子:
- 句子 1:
猫 喜欢 鱼 - 句子 2:
狗 不 喜欢 鱼
词汇表 = [“猫”, “狗”, “喜欢”, “不”, “鱼”]
- 句子 1 的词袋向量表示为:[1, 0, 1, 0, 1]
- 句子 2 的词袋向量表示为:[0, 1, 1, 1, 1]
优点
- 简单直观,易于实现,有效地表示词频信息。
缺点
- 忽略词序:词袋模型无法捕捉词语的顺序,因此在语义表达上有局限。
- 高维稀疏:对于大词汇表,词袋模型会生成非常长的特征向量,大多数元素为 0,容易导致稀疏矩阵,影响计算效率。
- 受到常见词的影响:常见词(如 “the”、“and” 等)可能在各类文档中频繁出现,但对语义贡献较少,词袋模型会受到这些高频词的影响,降低模型的效果。
1.2 TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF 是对词袋模型的改进,它为词语赋予不同的权重,来衡量每个词在文档中的重要性。与词袋模型相比,TF-IDF 不仅考虑词频,还考虑词的普遍性,以避免常见词(如"the"、“and”)的影响。
工作原理
- TF(词频):计算某个词在文档中出现的频率。
T F ( t , d ) = 词 t 在文档 d 中的出现次数 文档 d 的总词数 TF(t,d)=\frac{词t在文档d中的出现次数}{文档d的总词数} TF(t,d)=文档d的总词数词t在文档d中的出现次数 - IDF(逆文档频率):衡量词在整个语料库中的普遍性,出现频率越低的词权重越高。
I D F ( t ) = log ( N 1 + D F ( t ) ) IDF(t)=\log\left(\frac{N}{1 + DF(t)}\right) IDF(t)=log(1+DF(t)N)- 其中 N N N是文档总数, D F ( t ) DF(t) DF(t)是包含词 t t t的文档数。
- TF - IDF:将 T F TF TF和 I D F IDF IDF相乘,得到词在特定文档中的权重:
T F − I D F ( t , d ) = T F ( t , d ) × I D F ( t ) TF - IDF(t,d)=TF(t,d)\times IDF(t) TF−IDF(t,d)=TF(t,d)×IDF(t)
举例
对于句子“猫 喜欢 鱼”和“狗 不 喜欢 鱼”,假设 “喜欢” 出现在所有文档中,IDF 会给它较低的权重,而像 “猫”、“狗” 这样的词会有较高的 IDF 权重,因为它们只出现在一部分文档中。
优点
- 更准确地反映词的重要性,避免了词袋模型中常见词占主导地位的情况。尤其适用于文本分类任务。
缺点
- 稀疏矩阵:虽然词频的权重经过调整,但词汇表的大小仍然很大,容易产生稀疏矩阵问题。
- 忽略词序:仍然无法捕捉词语之间的顺序和上下文关系。
1.3 TF-IDF的改进——BM25
BM25对TF和IDF进行加权,同时考虑文档长度对相关性的影响,使得对较短和较长文档的评分更加合理。
BM25 的计算公式如下:
B M 25 ( q , d ) = ∑ t ∈ q I D F ( t ) ⋅ T F ( t , d ) ⋅ ( k 1 + 1 ) T F ( t , d ) + k 1 ⋅ ( 1 − b + b ⋅ ∣ d ∣ a v g d l ) BM25(q,d)=\sum_{t\in q}IDF(t)\cdot\frac{TF(t,d)\cdot(k_1 + 1)}{TF(t,d)+k_1\cdot(1 - b + b\cdot\frac{|d|}{avgdl})} BM25(q,d)=t∈q∑IDF(t)⋅TF(t,d)+k1⋅(1−b+b⋅avgdl∣d∣)TF(t,d)⋅(k1+1)
其中:
- q q q 是查询, d d d 是文档, t t t 是查询中的词。
- I D F IDF IDF是与 T F − I D F TF - IDF TF−IDF相似的逆文档频率。
- T F TF TF是词频。
- k 1 k_1 k1 是调节词频饱和度的参数,通常取值范围为 [ 1.2 , 2.0 ] [1.2,2.0] [1.2,2.0]。
- b b b 是调节文档长度的参数,通常取值范围为 [ 0.0 , 1.0 ] [0.0,1.0] [0.0,1.0], b = 0.75 b = 0.75 b=0.75是一个常用的设置。
- ∣ d ∣ |d| ∣d∣是文档的长度(词数), a v g d l avgdl avgdl是语料库中文档的平均长度。
TF-IDF 中的 IDF(逆文档频率)使用 log N d f ( t ) \log\frac{N}{df(t)} logdf(t)N来衡量词的普遍性。然而这种计算方式可能会导致在某些极端情况下(如 df(t) = 0 )出现不合理的结果。
BM25 对 IDF 进行了小改进,以提高在极端情况下的稳定性:
I D F ( t ) = log N − d f ( t ) + 0.5 d f ( t ) + 0.5 IDF(t)=\log\frac{N - df(t)+ 0.5}{df(t)+ 0.5} IDF(t)=logdf(t)+0.5N−df(t)+0.5
这种改进的 IDF 计算在文档数量较少或者某个词的出现频率极高时,能提供更合理的 IDF 值,增加了 BM25 的稳定性。
优化
相比于 TF-IDF,BM25 主要做了以下改进:
- 非线性词频缩放:通过 k 1 k_1 k1 控制词频TF饱和 ,避免 TF 值无限增大导致的偏差。
- 文档长度归一化:使用参数 b b b调整文档长度对评分的影响,防止长文档得分偏高。
- 改进的 IDF 计算:使用平滑后的 IDF 计算,保证在极端情况下的稳定性。
- 查询词频考虑:在评分中更合理地衡量查询中词频的影响,提高了对复杂查询的检索效果。
1.4 N-Gram 模型
N-Gram 模型是一种基于词袋模型的扩展方法,它通过将词组作为特征,来捕捉词语的顺序信息。
工作原理
-
N-Gram 是指在文本中提取连续的 n 个词组成的词组作为特征。当 n=1 时,即为 unigram(单词级别特征);当 n=2 时,即为 bigram(双词组特征);当 n=3 时,即为 trigram(词三元组特征)。
-
在提取 N-Gram 时,模型不仅关注单个词,还捕捉到词与词之间的顺序和依赖关系。例如,2-Gram 模型会将句子分解为相邻的两词组合。
举例
对于句子“猫 喜欢 吃 鱼”,2-Gram 模型会提取出以下特征:
- [“猫 喜欢”, “喜欢 吃”, “吃 鱼”]
优点
- 能捕捉到顺序和依赖关系,比单词级别的特征表达更丰富。n 越大,模型捕捉的上下文信息越多。
缺点
- 维度膨胀:n 值越大,特征向量的维度会急剧增加,容易导致稀疏矩阵和计算复杂度升高。
- 对长文本,N-Gram 模型可能会生成非常多的组合,计算资源消耗较大。
2. 词向量(Word Embeddings)
词向量是现代 NLP 中的关键特征提取方法,能够捕捉词语的语义信息。常见的词向量方法包括 Word2Vec、GloVe、和 FastText。词向量的核心思想是将每个词表示为一个低维的、密集的向量,词向量之间的相似性能够反映词语的语义相似性。
2.1 Word2Vec
Word2Vec 是一种使用浅层神经网络学习词向量的模型,由 Google 在 2013 年提出。它有两种模型架构:CBOW 和 Skip-gram。
工作原理
- CBOW(Continuous Bag of Words):根据上下文中的词语来预测中心词。模型输入是上下文词语,输出是预测的中心词。
- Skip-gram:与 CBOW 相反,它是根据中心词来预测上下文中的词语。
举例
对于一个句子 “猫 喜欢 吃 鱼”,CBOW 会使用上下文 [“猫”, “吃”, “鱼”] 来预测 “喜欢”,而 Skip-gram 则会使用 “喜欢” 来预测上下文。
优点
- 语义相似性:Word2Vec 生成的词向量能够捕捉词语之间的语义相似性。例如,“king” 和 “queen” 的词向量会非常相近。
- 稠密向量:与词袋模型和 TF-IDF 生成的高维稀疏向量不同,Word2Vec 生成的词向量是低维的密集向量(如 100 维或 300 维),更加高效。
缺点
- 无法处理 OOV(未登录词):如果测试集中出现了训练集中未见过的词,Word2Vec 无法为其生成词向量。
- 上下文无关:Word2Vec 生成的词向量是固定的,无法根据上下文变化来调整词向量。
2.2 FastText
FastText 是 Facebook 提出的词向量方法,它是 Word2Vec 的改进版。FastText 通过将词分解为n-gram字符级别的子词,捕捉词的形态信息。
工作原理
- FastText 将词分解为多个字符 n-gram,然后对每个 n-gram 生成词向量。通过这种方式,FastText 可以捕捉到词语内部的形态信息,尤其对拼写错误或未登录词有较好的处理能力。
优点
- 处理 OOV(未登录词):因为 FastText 基于子词生成词向量,它能够为未见过的词生成向量表示。
- 考虑词形信息:能够捕捉词的形态变化,例如词根、前缀、后缀等。
缺点
- 计算复杂度较高:相比 Word2Vec,FastText 需要对每个词生成多个 n-gram,因此计算量更大。
3. 预训练模型:BERT(Bidirectional Encoder Representations from Transformers)
BERT 是一种基于 Transformer 架构的预训练语言模型,由 Google 于 2018 年提出。与传统的词向量方法不同,BERT 通过双向的 Transformer 网络,能够生成上下文相关的动态词向量。
工作原理
- 双向Transformer:BERT 同时从词语的前后上下文学习词的表示,而不像传统的模型只从前向或后向学习。这样,BERT 能够捕捉到更丰富的语义信息。
- 预训练任务:
- 遮蔽语言模型(Masked Language Model, MLM):在训练时,BERT 会随机遮蔽部分词语,并要求模型预测这些词,从而让模型学到上下文的双向依赖关系。
- 下一句预测(Next Sentence Prediction, NSP):训练时,BERT 要预测两句话是否是连续的句子对,这让模型能够学习句子级别的关系。
优点
- 上下文相关词向量:BERT 生成的词向量是上下文相关的。例如,“bank” 在句子 “I went to the bank” 和 “The river bank” 中会有不同的向量表示。
- 强大的语义理解能力:BERT 在问答、阅读理解、文本分类等任务中表现非常好,能够捕捉到复杂的语义关系。
缺点
- 计算资源需求大:BERT 是一个深层的 Transformer 模型,预训练和微调都需要大量的计算资源,训练时间较长。
- 较慢的推理速度:由于模型较大,在实际应用中推理速度较慢,尤其在实时任务中。
BERT详细参考历史/后续文章:[深度学习笔记——GPT、BERT、T5]
总结
| 方法 | 工作原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 词袋模型(BOW) | 将文本表示为词频向量,不考虑词序和上下文。 | 简单直观,易实现,能够有效表示词频信息。 | 忽略词序,生成高维稀疏向量。 | 文本分类、信息检索 |
| TF-IDF | 基于词袋模型,考虑词在文档中的频率以及整个语料库中的普遍性,赋予不同词权重。 | 反映词的重要性,避免常见词主导影响,适用于文本分类。 | 生成稀疏矩阵,无法捕捉词序和上下文关系。 | 文本分类、关键词提取 |
| BM25 | 基于 TF-IDF 的改进,考虑词频、文档长度、词重要性等因素,以计算每个词对文档匹配的相关性得分。 非线性词频缩放、 文档长度归一化、 改进的 IDF 计算 | 更好地反映词在文档中的相关性,更适合信息检索,适用于长文档,计算匹配更准确。 | 对参数敏感,适用性依赖于超参数调优,不能捕捉上下文关系。 | 信息检索、文档排名 |
| N-Gram | 捕捉连续 n 个词作为特征,考虑词序信息。 | 能捕捉词语的顺序和依赖关系,n 越大捕捉的上下文信息越多。 | 维度膨胀,计算资源消耗大。 | 语言模型、短文本分类 |
| Word2Vec | 使用浅层神经网络学习词向量,有 CBOW 和 Skip-gram 两种架构。 | 词向量能捕捉语义相似性,生成低维稠密向量,效率高。 | 无法处理未登录词(OOV),词向量上下文无关。 | 词嵌入、相似度计算、文本分类 |
| FastText | 将词分解为字符 n-gram,生成词向量,捕捉词的形态信息。 | 能处理未登录词,捕捉词形信息,适合拼写错误和变形词。 | 计算复杂度高于 Word2Vec。 | 词嵌入、拼写纠错、文本分类 |
| BERT | 基于双向 Transformer,通过预训练生成上下文相关的词向量,支持 Masked Language Model 和 Next Sentence Prediction。 | 生成上下文相关词向量,语义理解强,适用于复杂 NLP 任务。 | 需要大量计算资源,训练和推理时间长。 | 问答系统、文本分类、阅读理解 |
- 传统方法:如词袋模型、TF-IDF 和 N-Gram 易于实现,但无法捕捉语义和上下文信息。
- 词向量方法:如 Word2Vec 和 FastText 通过词嵌入表示词语的语义关系,适合语义相似度计算、文本分类等任务。FastText 能够处理未登录词。
- 预训练模型:如 BERT,能够生成上下文相关的动态词向量,适用于更复杂的自然语言处理任务,但对计算资源的要求更高。
LSTM(Long Short-Term Memory)
LSTM 是 RNN 的一种改进版本,旨在解决 RNN 的长时间依赖问题。LSTM 通过引入记忆单元(cell state) 和门控机制(gates) 来有效地控制信息流动,使得它在长序列建模中表现优异。
LSTM 的核心部件

LSTM 的核心结构由以下几部分组成:
- 记忆单元(Cell State):贯穿整个序列的数据流【图中的C】,能够存储序列中的重要信息,允许网络长时间保留重要的信息。
- 隐藏状态(Hidden State):每个时间步的输出,LSTM 通过它来决定当前的输出和对下一时间步的传递信息。【RNN中就有】
- 三个门控机制(Forget Gate、Input Gate、Output Gate):通过这些门控机制,LSTM 可以选择性地遗忘、存储、或者输出信息(具体在图中的结构参考下面具体介绍)。
LSTM 中最重要的概念是记忆单元状态和门控机制,它们帮助网络在长时间序列中保留重要的历史信息。
在 LSTM 中,隐藏状态是对当前时间步的即时记忆(短期记忆),而记忆单元是对整个序列中长期信息的存储(长期记忆)。
- 遗忘门(Forget Gate):根据当前输入和前一个时间步的隐藏状态,决定记忆单元哪些信息需要被遗忘;
- 输入门(Input Gate):根据当前输入和前一时间步的隐藏状态,决定当前时间步输入对记忆单元的影响;
- 输出门(Output Gate):根据当前的输入和前一时间步的隐藏状态以及记忆单元状态,决定当前时间步隐藏状态的输出/影响;(输出内容是从记忆单元中提取的信息);
LSTM 的公式和工作原理
在 LSTM 中,每个时间步 ( t ) 的计算分为以下几步:
图像参考:LSTM(长短期记忆网络)
(1) 遗忘门(Forget Gate)

- 计算公式:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f\cdot[h_{t - 1},x_t]+b_f) ft=σ(Wf⋅[ht−1,xt]+bf)- f t f_t ft:遗忘门的输出,值介于0到1之间,表示记忆单元中的每个值需要被保留的比例。
- h t − 1 h_{t - 1} ht−1:上一时间步的隐藏状态(短期记忆)。
- x t x_t xt:当前时间步的输入。
- W f W_f Wf、 b f b_f bf:遗忘门的权重和偏置。
- σ \sigma σ:sigmoid函数,将值限制在0到1之间。
遗忘门的作用:它根据当前输入和前一个时间步的隐藏状态,选择哪些来自过去的记忆单元信息需要被遗忘。
(2) 输入门(Input Gate)

- 计算公式:
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i\cdot[h_{t - 1},x_t]+b_i) it=σ(Wi⋅[ht−1,xt]+bi)- i t i_t it:输入门的输出,值介于0到1之间,表示是否更新记忆单元。
- W i W_i Wi、 b i b_i bi:输入门的权重和偏置。
- 候选记忆生成:
C ~ t = tanh ( W c ⋅ [ h t − 1 , x t ] + b c ) \tilde{C}_t=\tanh(W_c\cdot[h_{t - 1},x_t]+b_c) C~t=tanh(Wc⋅[ht−1,xt]+bc)- C ~ t \tilde{C}_t C~t:候选记忆,是根据当前输入生成的新的记忆内容,值在 [ − 1 , 1 ] [- 1,1] [−1,1]之间。
- W c W_c Wc、 b c b_c bc:生成候选记忆的权重和偏置。
输入门的作用:输入门通过 sigmoid 激活函数决定当前输入 ( x t x_t xt ) 和前一时间步的隐藏状态 ( h t − 1 h_{t-1} ht−1 ) 对记忆单元的影响。结合候选记忆 ( C ~ t \tilde{C}_t C~t),输入门决定是否将当前输入的信息入到记忆单元中。
(3) 更新记忆单元状态

- 记忆单元状态更新公式:
C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t=f_t*C_{t - 1}+i_t*\tilde{C}_t Ct=ft∗Ct−1+it∗C~t- f t ∗ C t − 1 f_t*C_{t - 1} ft∗Ct−1:遗忘门决定了哪些来自前一时间步的记忆单元信息被保留。
- i t ∗ C ~ t i_t*\tilde{C}_t it∗C~t:输入门决定了新的候选记忆 C ~ t \tilde{C}_t C~t需要被加入到记忆单元中的比例。
记忆单元的作用:记忆单元 ( C t C_t Ct ) 根据遗忘门和输入门的输出,保留了来自过去的长期信息,使得重要的历史信息能够长时间存储。
(4) 输出门(Output Gate)
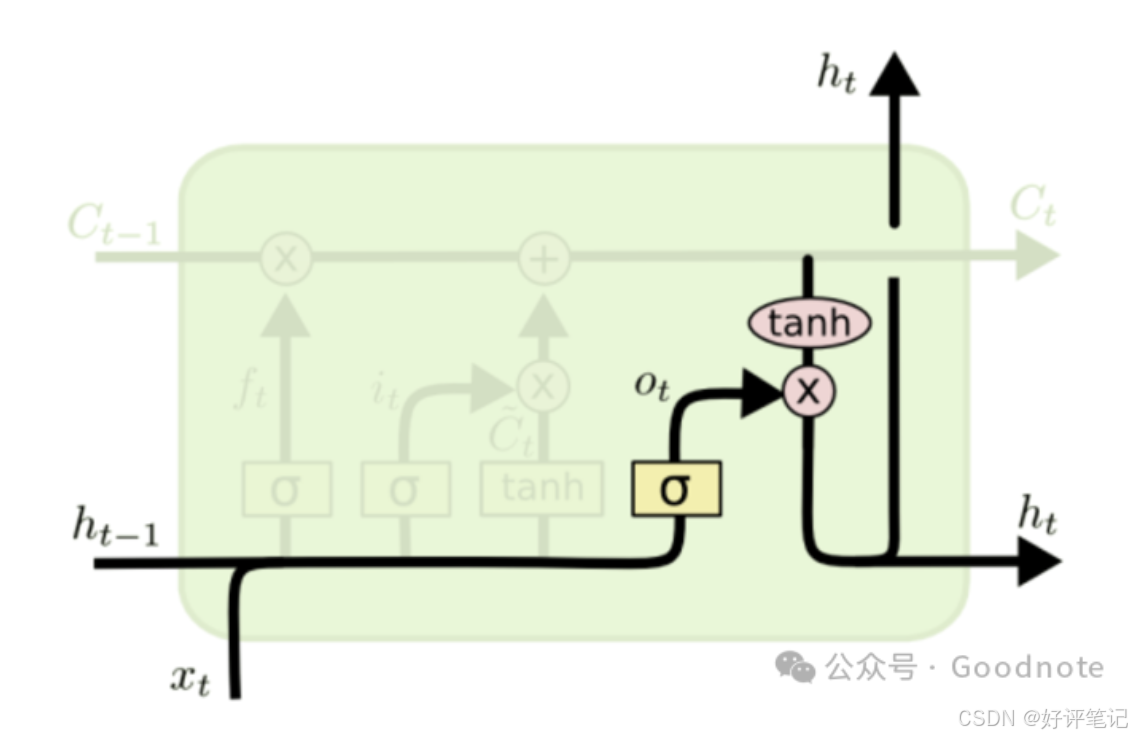
输出门控制从记忆单元中提取多少信息作为当前时间步的隐藏状态 h t h_t ht 并输出。
- 计算公式:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o\cdot[h_{t - 1},x_t]+b_o) ot=σ(Wo⋅[ht−1,xt]+bo)- o t o_t ot:输出门的输出,决定隐藏状态的输出比例。
- W o W_o Wo、 b o b_o bo:输出门的权重和偏置。
- 生成当前隐藏状态:
h t = o t ∗ tanh ( C t ) h_t=o_t*\tanh(C_t) ht=ot∗tanh(Ct)- tanh ( C t ) \tanh(C_t) tanh(Ct):对当前的记忆单元状态 C t C_t Ct进行非线性变换,生成当前时间步的隐藏状态。
- 输出门 o t o_t ot决定了多少信息从记忆单元状态 C t C_t Ct中提取,并输出为当前时间步的隐藏状态。
输出门的作用:输出门根据当前的输入和前一时间步的隐藏状态以及记忆单元状态,决定当前的隐藏状态 ( h t h_t ht ) 的值,它不仅作为当前时间步的输出,还会传递到下一时间步。
LSTM 的流程总结
在每个时间步 ( t t t ),LSTM 会执行以下步骤:
- 遗忘门:根据当前输入和前一个时间步的隐藏状态,控制哪些来自上一个时间步的记忆单元信息需要被保留或遗忘。
- 输入门:根据当前输入和前一时间步的隐藏状态,决定当前输入信息是否更新到记忆单元中,通过候选记忆生成新的信息。
- 记忆单元状态更新:根据遗忘门和输入门的输出,更新当前时间步的记忆单元状态 ( C t C_t Ct )。
- 输出门:根据当前的输入和记忆单元状态,控制当前时间步的隐藏状态 ( h t h_t ht ) 的输出,隐藏状态会传递到下一时间步,作为当前的输出结果。
LSTM 的优点
LSTM 通过引入门控机制,可以选择性地控制信息的流动;记忆单元可以有效地保留长期信息,避免了传统 RNN 中的梯度消失问题。因此,LSTM 能够同时处理短期和长期的依赖关系,尤其在需要保留较长时间跨度信息的任务中表现优异。
LSTM 的局限性
LSTM 的门控机制使得它的结构复杂,训练时间较长,需要更多的计算资源,尤其是在处理大规模数据时。依赖于序列数据的时间步信息,必须按顺序处理每个时间步,难以并行化处理序列数据。
热门专栏
机器学习
机器学习笔记合集
深度学习
深度学习笔记合集
相关文章:

深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。 文章目录 文本特征提取的方法1. 基础方法1.1 词袋模型(Bag of Words, BOW)工作…...

超分辨率体积重建实现术前前列腺MRI和大病理切片组织病理学图像的3D配准
摘要: 磁共振成像(MRI)在前列腺癌诊断和治疗中的应用正在迅速增加。然而,在MRI上识别癌症的存在和范围仍然具有挑战性,导致即使是专家放射科医生在检测结果上也存在高度变异性。提高MRI上的癌症检测能力对于减少这种变异性并最大化MRI的临床效用至关重要。迄今为止,这种改…...
)
React第二十五章(受控组件/非受控组件)
React 受控组件理解和应用 React 受控组件 受控组件一般是指表单元素,表单的数据由React的 State 管理,更新数据时,需要手动调用setState()方法,更新数据。因为React没有类似于Vue的v-model,所以需要自己实现绑定事件…...
插槽)
Vue演练场基础知识(七)插槽
为学习Vue基础知识,我动手操作通关了Vue演练场,该演练场教程的目标是快速体验使用 Vue 是什么感受,设置偏好时我选的是选项式 单文件组件。以下是我结合深入指南写的总结笔记,希望对Vue初学者有所帮助。 文章目录 十五. 插槽插槽…...

16 分布式session和无状态的会话
在我们传统的应用中session存储在服务端,减少服务端的查询压力。如果以集群的方式部署,用户登录的session存储在该次登录的服务器节点上,如果下次访问服务端的请求落到其他节点上就需要重新生成session,这样用户需要频繁的登录。 …...

docker 部署 java 项目详解
在平常的开发工作中,我们经常需要部署项目,开发测试完成后,最关键的一步就是部署。今天我们以若依项目为例,总结下部署项目的整体流程。简单来说,第一步:安装项目所需的中间件;第二步࿱…...

csapp笔记——2.3节整数运算
目录 无符号加法 补码加法 补码的非 无符号乘法 补码乘法 乘以常数 除以2的幂 无符号加法 对于的整数x,y,定义表示将x与y的和截为w位 由此推得检测无符号加法是否溢出得方法是判断结果是否比x,y中的任何一个小。 无符号数的逆元定义为使得的y&am…...

【阅读笔记】基于图像灰度梯度最大值累加的清晰度评价算子
本文介绍的是一种新的清晰度评价算子,基于图像灰度梯度最大值累加 一、概述 目前在数字图像清晰度评价函数中常用的评价函数包括三类:灰度梯度评价函数、频域函数和统计学函数,其中灰度梯度评价函数具有计算简单,评价效果好等优…...

Docker 系列之 docker-compose 容器编排详解
文章目录 前言一、Docker-compose简介二、Docker-compose 的安装三、Docker-compose卸载四、Docker-compose常用命令4.1 Docker-compose命令格式4.2 docker-compose up4.3 docker-compose ps4.4 docker-compose stop4.5 docker-compose -h4.6 docker-compose down4.7 docker-co…...

C++资料
InterviewGuide 首页 - 八股精 Releases halfrost/LeetCode-Go GitHub GitHub - GrindGold/CppGuide: 「C/C学习面试指南」一份涵盖大部分 C 程序员所需要掌握的知识。入门、进阶、深入、校招、社招,准备 C 学习& 面试,首选 CppGuide࿰…...
)
7-Zip Mark-of-the-Web绕过漏洞复现(CVE-2025-0411)
免责申明: 本文所描述的漏洞及其复现步骤仅供网络安全研究与教育目的使用。任何人不得将本文提供的信息用于非法目的或未经授权的系统测试。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我们联系,我们将尽快处理并删除相关内容。 0x0…...

将本地项目上传到 GitLab/GitHub
以下是将本地项目上传到 GitLab 的完整步骤,从创建仓库到推送代码的详细流程: 1. 在 GitLab 上创建新项目 登录 GitLab,点击 New project。选择 Create blank project。填写项目信息: Project name: 项目名称(如 my-p…...

基于SpringBoot+WebSocket的前后端连接,并接入文心一言大模型API
前言: 本片博客只讲述了操作的大致流程,具体实现步骤并不标准,请以参考为准。 本文前提:熟悉使用webSocket 如果大家还不了解什么是WebSocket,可以参考我的这篇博客: rWebSocket 详解:全双工…...

2.2.3 代码格式与风格指南
编写清晰、规范的代码是提高代码可读性、可维护性和团队协作效率的关键。虽然好多人说工控行业都是一帮电工,没有什么素质,这完全是误解,任何程序所在的行业,都需要个人保证其代码风格能够很好与团队进行协作,在过去一…...

数仓的数据加工过程-ETL
ETL代表Extract Transform和Load。ETL将所有三个数据库功能组合到一个工具中,以从一个数据库获取数据并将其放入另一个数据库。 提取:提取是从数据库中提取(读取)信息的过程。在此阶段,从多个或不同类型的来源收集数据。 转换:转…...
)
类与对象(中)
类的6个默认成员函数 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下 6 个默认成员函数。默认成员函数:用户没有显式实现,编译器会生…...

FastExcel的使用
前言 FastExcel 是一款基于 Java 的开源库,旨在提供快速、简洁且能解决大文件内存溢出问题的 Excel 处理工具。它兼容 EasyExcel,提供性能优化、bug 修复,并新增了如读取指定行数和将 Excel 转换为 PDF 的功能。 FastExcel 的主要功能 高性…...

微信小程序1.3 开发工具的使用2
内容提要 1.1 编辑器区域 1.2 调试器区域 1.3 工具栏区域 1.4 云开发 1.5 常用快捷键 1.1 编辑器区域 1.2 调试器区域 1.3 工具栏区域 1.4 云开发 1.5 常用快捷键...

pytest自动化测试 - pytest夹具的基本概念
<< 返回目录 1 pytest自动化测试 - pytest夹具的基本概念 夹具可以为测试用例提供资源(测试数据)、执行预置条件、执行后置条件,夹具可以是函数、类或模块,使用pytest.fixture装饰器进行标记。 1.1 夹具的作用范围 夹具的作用范围: …...

个人网站搭建
搭建 LNMP环境搭建: LNMP环境指:Linux Nginx MySQL/MariaDB PHP,在debian上安装整体需要300MB的磁盘空间。MariaDB 是 MySQL 的一个分支,由 MySQL 的原开发者维护,通常在性能和优化上有所改进。由于其轻量化和与M…...

doris:Insert Into Values
INSERT INTO VALUES 语句支持将 SQL 中的值导入到 Doris 的表中。INSERT INTO VALUES 是一个同步导入方式,执行导入后返回导入结果。可以通过请求的返回判断导入是否成功。INSERT INTO VALUES 可以保证导入任务的原子性,要么全部导入成功,要么…...

Linux 环境变量
目录 一、环境变量的基本概念 1.常见环境变量 2.查看环境变量方法 3.几个环境变量 环境变量:PATH 环境变量:HOME 环境变量:SHELL 二、和环境变量相关的命令 三、库函数getenv,setenv 四、环境变量和本地变量 五、命令行…...

人工智能在数字化转型中的角色:从数据分析到智能决策
引言 在数字化转型浪潮中,人工智能(AI)正迅速崛起,成为推动企业创新和变革的关键力量。面对日益复杂的市场环境和激烈的行业竞争,企业亟需借助技术手段提高运营效率、优化决策过程,并增强市场竞争力。而AI…...

Spring Boot 自动配置
目录 什么是自动配置? Spring 加载 Bean ComponentScan Import 导入类 导入 ImportSelector 接口的实现类 SpringBoot 原理分析 EnableAutoConfiguration Import(AutoConfigurationImportSelector.class) AutoConfigurationPackage SpringBoot 自动配置流…...
实用系统框架构建初探(下.代码部分))
PyQt6医疗多模态大语言模型(MLLM)实用系统框架构建初探(下.代码部分)
医疗 MLLM 框架编程实现 本医疗 MLLM 框架结合 Python 与 PyQt6 构建,旨在实现多模态医疗数据融合分析并提供可视化界面。下面从数据预处理、模型构建与训练、可视化界面开发、模型 - 界面通信与部署这几个关键部分详细介绍编程实现。 6.1 数据预处理 在医疗 MLLM 框架中,多…...

【LC】1148. 文章浏览 I
题目描述: Views 表: ------------------------ | Column Name | Type | ------------------------ | article_id | int | | author_id | int | | viewer_id | int | | view_date | date | ----------------------…...

Linux学习笔记——网络管理命令
一、网络基础知识 TCP/IP四层模型 以太网地址(MAC地址): 段16进制数据 IP地址: 子网掩码: 二、接口管命令 ip命令:字符终端,立即生效,重启配置会丢失 nmcli命令:字符…...

Arduino大师练成手册 --控制 OLED
要在 Arduino 上使用 U8glib 库控制带有 7 个引脚的 SPI OLED 显示屏,你可以按照以下步骤进行: 7pin OLED硬件连接 GND:连接到 Arduino 的 GND 引脚。 VCC:连接到 Arduino 的 5V 引脚。 D0(或 SCK/CLK)…...

2024年终总结
距离放假还有一个小时,闲来无事,写篇总结。 最近关注我的朋友不少,关注我的多半都是因为几篇博客。既然关注了,我也想分享点工作中的经验给大家。 今年的节点是跳槽。 4月份跳槽的,跳槽之前呢在上家公司还有3W多奖金…...

Kafka 消费端反复 Rebalance: `Attempt to heartbeat failed since group is rebalancing`
文章目录 Kafka 消费端反复 Rebalance: Attempt to heartbeat failed since group is rebalancing1. Rebalance 过程概述2. 错误原因分析2.1 消费者组频繁加入或退出2.1.1 消费者故障导致频繁重启2.1.2. 消费者加入和退出导致的 Rebalance2.1.3 消费者心跳超时导致的 Rebalance…...

【Linux】Linux编译器-g++、gcc、动静态库
只要积极创造,机遇无时不有;只要善于探索,真理无处不在。💓💓💓 目录 ✨说在前面 🍋知识点一:Linux编译器-g、gcc •🌰1. 背景知识 •🌰2. gcc如何完成 •…...

android12源码中用第三方APK替换原生launcher
一、前言 如何用第三方的apk替换原生launcher呢?我是参考着这位大神的博客https://blog.csdn.net/hyu001/article/details/131044358做的,完美实现。 这边博客中又加入了我个人的一些改变,整理的。 二、步骤 1.在/packages/apps/MyApp文件…...
)
Ubuntu20.04 深度学习环境配置(持续完善)
文章目录 常用的一些命令安装 Anaconda创建conda虚拟环境查看虚拟环境大小 安装显卡驱动安装CUDA安装cuDNN官方仓库安装 cuDNN安装 cuDNN 库验证 cuDNN 安装确认 CUDA 和 cuDNN 是否匹配: TensorRT下载 TensorRT安装 TensorRT 本地仓库配置 GPG 签名密钥安装 Tensor…...

Java 实现Excel转HTML、或HTML转Excel
Excel是一种电子表格格式,广泛用于数据处理和分析,而HTM则是一种用于创建网页的标记语言。虽然两者在用途上存在差异,但有时我们需要将数据从一种格式转换为另一种格式,以便更好地利用和展示数据。本文将介绍如何通过 Java 实现 E…...

jQuery小游戏
jQuery小游戏(一) 嘻嘻,今天我们来写个jquery小游戏吧 首先,我们准备一下写小游戏需要准备的佩饰,如果:图片、音乐、搞怪的小表情 这里我准备了一些游戏中需要涉及到的图片 游戏中使用到的方法 eval() 函…...
)
Cpp::静态 动态的类型转换全解析(36)
文章目录 前言一、C语言中的类型转换二、为什么C会有四种类型转换?内置类型 -> 自定义类型自定义类型 -> 内置类型自定义类型 -> 自定义类型隐式类型转换的坑 三、C强制类型转换static_castreinterpret_castconst_castdynamic_cast 四、RTTI总结 前言 Hell…...
)】)
【PostgreSQL内核学习 —— (WindowAgg(一))】
WindowAgg 窗口函数介绍WindowAgg理论层面源码层面WindowObjectData 结构体WindowStatePerFuncData 结构体WindowStatePerAggData 结构体eval_windowaggregates 函数update_frameheadpos 函数 声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊…...

SQL-leetcode—1158. 市场分析 I
1158. 市场分析 I 表: Users ----------------------- | Column Name | Type | ----------------------- | user_id | int | | join_date | date | | favorite_brand | varchar | ----------------------- user_id 是此表主键(具有唯一值的列ÿ…...

opensips中各个模块的解释
模块名称作用说明aaa_diameter提供基于 Diameter 协议的认证、授权和计费服务,适用于移动运营商和ISP的计费系统。aaa_radius提供基于 RADIUS 协议的认证、授权和计费功能,常用于无线网络接入和VPN等场景。auth_jwt用于支持基于 JSON Web Token (JWT) 的…...

【C++初阶】第11课—vector
文章目录 1. 认识vector2. vector的遍历3. vector的构造4. vector常用的接口5. vector的容量6. vector的元素访问7. vector的修改8. vector<vector\<int\>>的使用9. vector的使用10. 模拟实现vector11. 迭代器失效11.1 insert插入数据内部迭代器失效11.2 insert插入…...
Spring Boot项目构建、Bootstrap基础知识)
SpringBoot开发(二)Spring Boot项目构建、Bootstrap基础知识
1. Spring Boot项目构建 1.1. 简介 基于官方网站https://start.spring.io进行项目的创建. 1.1.1. 简介 Spring Boot是基于Spring4框架开发的全新框架,设计目的是简化搭建及开发过程,并不是对Spring功能上的增强,而是提供了一种快速使用Spr…...

vim如何设置自动缩进
:set autoindent 设置自动缩进 :set noautoindent 取消自动缩进 (vim如何使设置自动缩进永久生效:vim如何使相关设置永久生效-CSDN博客)...

Jenkins上生成的allure report打不开怎么处理
目录 问题背景: 原因: 解决方案: Jenkins上修改配置 通过Groovy脚本在Script Console中设置和修改系统属性 步骤 验证是否清空成功 进一步的定制 也可以使用Nginx去解决 使用逆向代理服务器Nginx: 通过合理调整CSP配置&a…...

ASP.NET Blazor托管模型有哪些?
今天我们来说说Blazor的三种部署方式,如果大家还不了解Blazor,那么我先简单介绍下Blazor Blazor 是一种 .NET 前端 Web 框架,在单个编程模型中同时支持服务器端呈现和客户端交互性: ● 使用 C# 创建丰富的交互式 UI。 ● 共享使用…...

使用 Confluent Cloud 的 Elasticsearch Connector 部署 Elastic Agent
作者:来自 Elastic Nima Rezainia Confluent Cloud 用户现在可以使用更新后的 Elasticsearch Sink Connector 与 Elastic Agent 和 Elastic Integrations 来实现完全托管且高度可扩展的数据提取架构。 Elastic 和 Confluent 是关键的技术合作伙伴,我们很…...

二叉树的最小深度力扣--111
目录 题目 思路 代码 题目 给定一个二叉树,找出其最小深度。 最小深度是从根节点到最近叶子节点的最短路径上的节点数量。 说明:叶子节点是指没有子节点的节点。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出࿱…...
进行SQLite数据库编辑和前端展示的基本操作)
PySide(PyQT)进行SQLite数据库编辑和前端展示的基本操作
以SQLite数据库为例,学习数据库的基本操作,使用QSql模块查询、编辑数据并在前端展示。 SQLite数据库的基础知识: https://blog.csdn.net/xulibo5828/category_12785993.html?fromshareblogcolumn&sharetypeblogcolumn&sharerId1278…...

ARM64平台Flutter环境搭建
ARM64平台Flutter环境搭建 Flutter简介问题背景搭建步骤1. 安装ARM64 Android Studio2. 安装Oracle的JDK3. 安装 Dart和 Flutter 开发插件4. 安装 Android SDK5. 安装 Flutter SDK6. 同意 Android 条款7. 运行 Flutter 示例项目8. 修正 aapt2 报错9. 修正 CMake 报错10. 修正 N…...

Linux系统编程:进程状态和进程优先级/nice
目录 一,相对于OS的进程状态 1.1运行状态 1.2阻塞状态 1.3挂起状态 二,并发执行与进程切换 2.1,CPU并发执行 2.2进程切换 三,Linux内核管理进程状态的方法 3.1查看进程状态 3.2R状态 3.3S状态 3.4D状态 3.5T状态 3.6X状态 3.7Z状态 3.8孤儿进程 四,进程优先级 …...
python)
【算法】数论基础——唯一分解定理(算术基本定理)python
目录 定义进入正题热身训练实战演练总结 定义 唯一分解定理:也叫做算数基本定理: 任意一个大于1的整数N,都可以唯一分解为若干个质数的乘积 换句话说,任何大于1的整数n可以表示为: 例如: 30 2^1 * 3^1 * 5^1 100 2^2…...