Python中的简单爬虫
文章目录
- 一. 基于FastAPI之Web站点开发
- 1. 基于FastAPI搭建Web服务器
- 2. Web服务器和浏览器的通讯流程
- 3. 浏览器访问Web服务器的通讯流程
- 4. 加载图片资源代码
- 二. 基于Web请求的FastAPI通用配置
- 1. 目前Web服务器存在问题
- 2. 基于Web请求的FastAPI通用配置
- 三. Python爬虫介绍
- 1. 什么是爬虫
- 2. 爬虫的基本步骤
- 3. 安装requests模块
- 4. 爬取照片
- ① 查看index.html
- ② 爬取照片步骤
- ③ 获取index.html代码
- ④ 解析index.html代码获取图片url
- ⑤ 通过图片url获取图片
- 四. 使用Python爬取GDP数据
- 1. gdp.html
- 2. zip函数的使用
- 3.爬取GDP数据
- 五. 多任务爬虫实现
- 1. 为什么用多任务
- 2. 多任务爬取数据
- 3. 多任务代码实现
- 六. 数据可视化
- 1. 什么是数据可视化
- 2. pyecharts模块
- 3. 通过pyecharts模块创建饼状图
- 4. 完整代码
- 5. 小结
- 七. Logging日志模块
- 1. logging日志的介绍
- 2. logging日志级别介绍
- 3. logging日志的使用
- 4. logging日志在Web项目中应用
- 5. 小结
一. 基于FastAPI之Web站点开发
1. 基于FastAPI搭建Web服务器
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn# 创建FastAPI框架对象
app = FastAPI()# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index.html")
def main():with open("source/html/index.html", "rb") as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="text/html"# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="text/html")# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
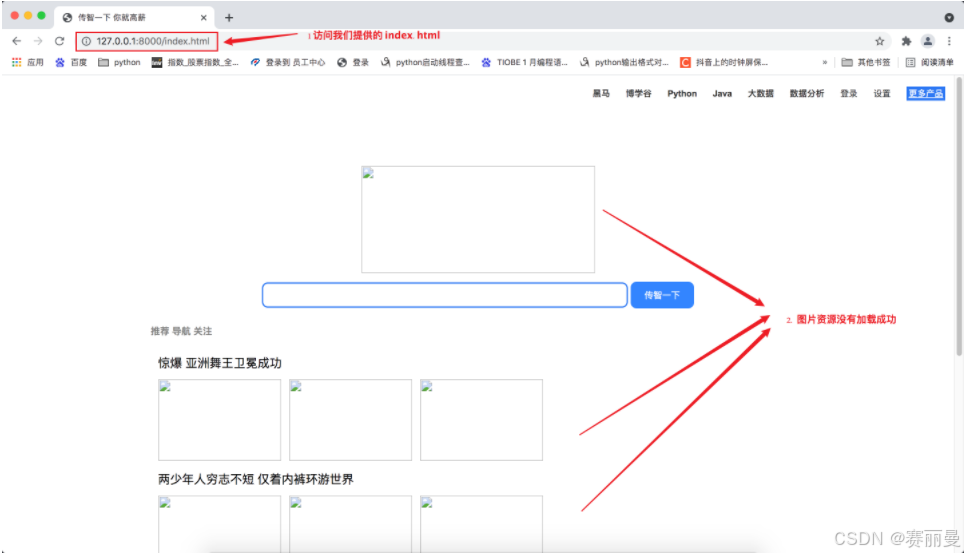
2. Web服务器和浏览器的通讯流程
实际上Web服务器和浏览器的通讯流程过程并不是一次性完成的, 这里html代码中也会有访问服务器的代码, 比如请求图片资源。

那像0.jpg、1.jpg、2.jpg、3.jpg、4.jpg、5.jpg、6.jpg这些访问来自哪里呢 ?
答:它们来自index.html

3. 浏览器访问Web服务器的通讯流程

浏览器访问Web服务器的通讯流程:
浏览器(127.0.0.1/index.html) ==> 向Web服务器请求index.htmlWeb服务器(返回index.html) ==>浏览器浏览器解析index.html发现需要0.jpg ==>发送请求给Web服务器请求0.jpgWeb服务器收到请求返回0.jpg ==>浏览器接受0.jpg
通讯过程能够成功的前提:
浏览器发送的0.jpg请求, Web服务器可以做出响应, 也就是代码如下
# 当浏览器发出对图片 0.jpg 的请求时, 函数返回相应资源
@app.get("/images/0.jpg")
def func_01():with open("source/images/0.jpg", "rb") as f:data = f.read()print(data)return Response(content=data, media_type="jpg")
4. 加载图片资源代码
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn# 创建FastAPI框架对象
app = FastAPI()@app.get("/images/0.jpg")
def func_01():with open("source/images/0.jpg", "rb") as f:data = f.read()print(data)return Response(content=data, media_type="jpg")@app.get("/images/1.jpg")
def func_02():with open("source/images/1.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/2.jpg")
def func_03():with open("source/images/2.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/3.jpg")
def func_04():with open("source/images/3.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/4.jpg")
def func_05():with open("source/images/4.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/5.jpg")
def func_06():with open("source/images/5.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/6.jpg")
def func_07():with open("source/images/6.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/index.html")
def main():with open("source/html/index.html", "rb") as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="text/source"# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="text/html")# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
二. 基于Web请求的FastAPI通用配置
1. 目前Web服务器存在问题
# 返回0.jpg
@app.get("/images/0.jpg")
def func_01():with open("source/images/0.jpg", "rb") as f:data = f.read()print(data)return Response(content=data, media_type="jpg")# 返回1.jpg
@app.get("/images/1.jpg")
def func_02():with open("source/images/1.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")# 返回2.jpg
@app.get("/images/2.jpg")
def func_03():with open("source/images/2.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")
对以上代码观察,会发现每一张图片0.jpg、1.jpg、2.jpg就需要一个函数对应, 如果我们需要1000张图片那就需要1000个函数对应, 显然这样做代码的重复太多了.
2. 基于Web请求的FastAPI通用配置
# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):# 这里open()的路径就是 ==> f"source/images/0.jpg"with open(f"source/images/{path}", "rb") as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="jpg")# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="jpg")
完整代码
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn# 创建FastAPI框架对象
app = FastAPI()# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):# 这里open()的路径就是 ==> f"source/images/0.jpg"with open(f"source/images/{path}", "rb") as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="jpg")# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="jpg")@app.get("/{path}")
def get_html(path: str):with open(f"source/html/{path}", 'rb') as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="text/source"# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="text/html")# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
运行结果

三. Python爬虫介绍
1. 什么是爬虫
网络爬虫:
又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取网络信息的程序或者脚本,另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
通俗理解:
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来. 就像一只虫子在一幢楼里不知疲倦地爬来爬去.
你可以简单地想象: 每个爬虫都是你的「分身」。就像孙悟空拔了一撮汗毛,吹出一堆猴子一样
**百度:**其实就是利用了这种爬虫技术, 每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。
有了这样的特性, 对于一些自己公司数据量不足的小公司, 这个时候还想做数据分析就可以通过爬虫获取同行业的数据然后进行分析, 进而指导公司的策略指定。
2. 爬虫的基本步骤
基本步骤:
-
起始URL地址
-
发出请求获取响应数据
-
对响应数据解析
-
数据入库
3. 安装requests模块
- requests : 可以模拟浏览器的请求
- 官方文档 :http://cn.python-requests.org/zh_CN/latest/
- 安装 :pip install requests
快速入门(requests三步走):
# 导入模块
import requests
# 通过requests.get()发送请求
# data保存返回的响应数据(这里的响应数据不是单纯的html,需要通过content获取html代码)
data = requests.get("http://www.baidu.com")
# 通过data.content获取html代码
data = data.content.decode("utf-8")
4. 爬取照片
① 查看index.html
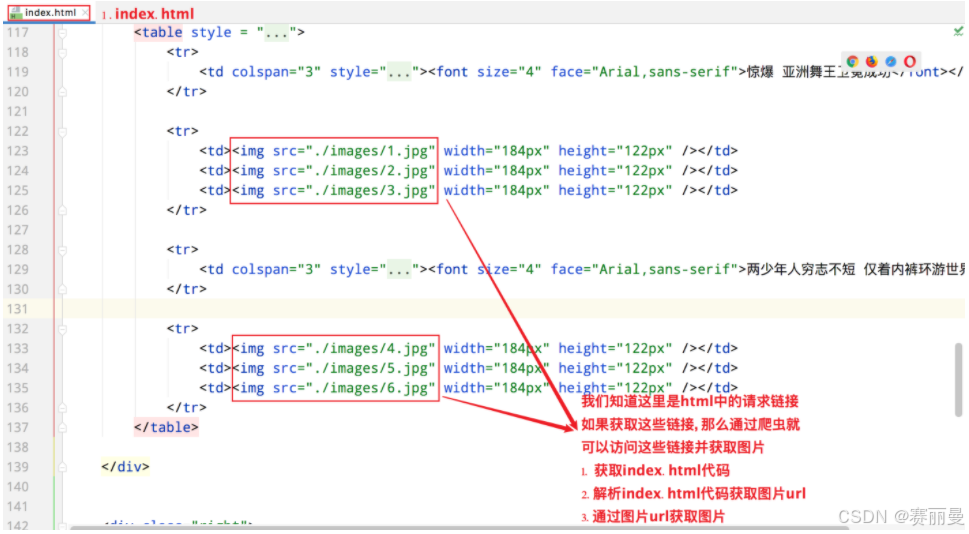
② 爬取照片步骤
- 获取index.html代码
- 解析index.html代码获取图片url
- 通过图片url获取图片
③ 获取index.html代码
# 通过爬虫向index.html发送请求
# requests.get(网址): 向一个网址发送请求,和在浏览器中输入网址是一样的
data = requests.get("http://127.0.0.1:8000/index.html")
# content可以把requests.get()获取的返回值中的html内容获取到
data = data.content.decode("utf-8")
④ 解析index.html代码获取图片url
# 获取图片的请求url
def get_pic_url():# 通过爬虫向index.html发送请求# requests.get(网址): 向一个网址发送请求,和在浏览器中输入网址是一样的data = requests.get("http://127.0.0.1:8000/index.html")# content可以把requests.get()获取的返回值中的html内容获取到data = data.content.decode("utf-8")# html每一行都有"\n", 对html进行分割获得一个列表data = data.split("\n")# 创建一个列表存储所有图片的url地址(也就是图片网址)url_list = []for url in data:# 通过正则解析出所有的图片urlresult = re.match('.*src="(.*)" width.*', url)if result is not None:# 把解析出来的图片url添加到url_list中url_list.append(result.group(1))return url_list
⑤ 通过图片url获取图片
# 把爬取到的图片保存到本地
def save_pic(url_list):# 通过num给照片起名字 例如:0.jpg 1.jpg 2.jpgnum = 0for url in url_list:# 通过requests.get()获取每一张图片pic = requests.get(f"http://127.0.0.1:8000{url[1:]}")# 保存每一张图片with open(f"./source/spyder/{num}.jpg", "wb") as f:f.write(pic.content)num += 1
完整代码
# 把爬取到的图片保存到本地
def save_pic(url_list):# 通过num给照片起名字 例如:0.jpg 1.jpg 2.jpgnum = 0for url in url_list:# 通过requests.get()获取每一张图片pic = requests.get(f"http://127.0.0.1:8000{url[1:]}")# 保存每一张图片with open(f"./source/spyder/{num}.jpg", "wb") as f:f.write(pic.content)num += 1
四. 使用Python爬取GDP数据
1. gdp.html
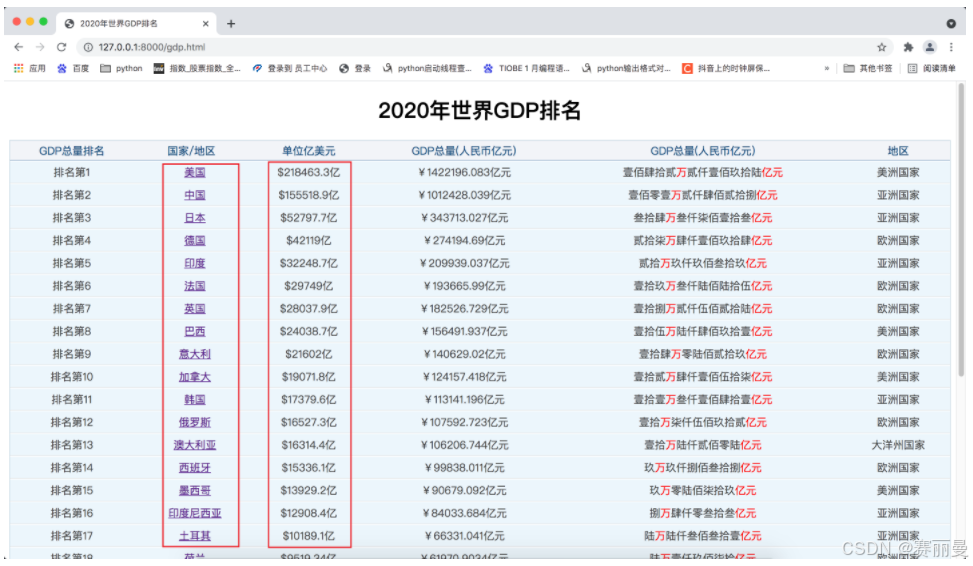
通过访问 http://127.0.0.1:8080/gdp.html 可以获取2020年世界GDP排名. 在这里我们通过和爬取照片一样的流程步骤获取GDP数据。
2. zip函数的使用
zip() 函数: 用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表.
a = [1, 2, 3]
b = [4, 5, 6]
c = [4, 5, 6, 7, 8]
# 打包为元组的列表
zipped = zip(a, b)
# 注意使用的时候需要list转化
print(list(zipped))
>>> [(1, 4), (2, 5), (3, 6)]# 元素个数与最短的列表一致
zipped = zip(a, c)
# 注意使用的时候需要list转化
print(list(zipped))
>>> [(1, 4), (2, 5), (3, 6)]
3.爬取GDP数据
import requests
import re# 存储爬取到的国家的名字
country_list = []
# 存储爬取到的国家gdp的数据
gdp_list = []# 获取gdp数据
def get_gdp_data():global country_listglobal gdp_list# 获取gdp的html数据data = requests.get("http://localhost:8000/gdp.html")# 对获取数据进行解码data = data.content.decode("utf8")# 对gdp的html数据进行按行分割data_list = data.split("\n")for i in data_list:# 对html进行解析获取<国家名字>country_result = re.match('.*<a href=""><font>(.*)</font></a>', i)# 匹配成功就存放到列表中if country_result is not None:country_list.append(country_result.group(1))# 对html进行解析获取<gdp数据>gdp_result = re.match(".*¥(.*)亿元", i)# 匹配成功就存储到列表中if gdp_result is not None:gdp_list.append(gdp_result.group(1))# 把两个列表融合成一个列表gdp_data = list(zip(country_list, gdp_list))print(gdp_data)if __name__ == '__main__':get_gdp_data()
五. 多任务爬虫实现
1. 为什么用多任务
在我们的案例中, 我们只是爬取了2个非常简单的页面, 这两个页面的数据爬取并不会使用太多的时间, 所以我们也没有太多的考虑效率问题.
但是在真正的工作环境中, 我们爬取的数据可能非常的多, 如果还是使用单任务实现, 这时候就会让我们爬取数据的时间很长, 那么显然使用多任务可以大大提升我们爬取数据的效率
2. 多任务爬取数据
实际上实现多任务并不难, 只需要使用多任务就可以了
3. 多任务代码实现
# 获取gdp
def get_gdp_data():pass# 获取照片
def get_pic():passif __name__ == '__main__':p1 = multiprocessing.Process(target=get_picp2 = multiprocessing.Process(target=get_gdp_data)p1.start()p2.start()
六. 数据可视化
1. 什么是数据可视化

数据可视化:顾名思义就是让数据看的到, 他的作用也很明显, 让人们不用再去阅读枯燥无味的数据, 一眼看去就可以明白数据是什么, 数据间的关系是什么, 更好的让我们通过数据发现潜在的规律进而进行商业决策。
2. pyecharts模块

概况 :
Echarts 是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可. 而 Python 是门富有表达力的语言,很适合用于数据处理. 当数据分析遇上数据可视化时pyecharts 诞生了.
特性 :
- 简洁的API设计,使用如丝滑般流畅,支持链式调用
- 囊括了**30+**种常见图表,应有尽有
- 支持主流Notebook 环境,Jupyter Notebook 和JupyterLab
- 可轻松集成至Flask, Django等主流Web框架
- 高度灵活的配置项,可轻松搭配出精美的图表
- 详细的文档和示例,帮助开发者更快的上手项目
- 多达400+地图文件以及原生的百度地图,为地理数据可视化提供强有力的支持
3. 通过pyecharts模块创建饼状图
导入模块
# 导入饼图模块
from pyecharts.charts import Pie
# 导入配置选项模块
import pyecharts.options as opts
初始化饼状图:
Pie()函数: 创建饼图
opts.InitOpts参数: Pie(init_opts=opts.InitOpts(width=“1400px”, height=“800px”))
init_opts: 指定参数名
opts.InitOpts: 配置选项
**width=“1400px” height=“800px” 😗*界面的宽度和高度
# 创建饼图并设置这个界面的长和高
# px:像素单位
pie = Pie(init_opts=opts.InitOpts(width="1400px", height="800px"))
给饼图添加数据:
add()函数:
参数1: 名称
参数2: 具体数据, 数据类型为==>[(a,b),(a,b),(a,b)]==>a为数据名称,b为数据大小
参数3: 标签设置 label_opts=opts.LabelOpts(formatter=‘{b}:{d}%’) 符合百分比的形式
# 给饼图添加数据
pie.add("GDP",data,label_opts=opts.LabelOpts(formatter='{b}:{d}%')
)
给饼图添设置标题:
set_global_opts()函数 :
title_opts=opts.TitleOpts : 设置标题
title=“2020年世界GDP排名”, subtitle=“美元” : 设置主标题和副标题
# 给饼图设置标题
pie.set_global_opts(title_opts=opts.TitleOpts(title="2020年世界GDP排名", subtitle="美元"))
保存数据:
# 保存结果
pie.render()
4. 完整代码
import requests
import re
# 导入饼图模块
from pyecharts.charts import Pie
# 导入配置选项模块
import pyecharts.options as opts# 存储爬取到的国家的名字
country_list = []
# 春初爬取到的国家gdp的数据
gdp_list = []def get_gdp_data():global country_listglobal gdp_list# 获取gdp的html数据data = requests.get("http://localhost:8000/gdp.html")# 对获取数据进行解码data = data.content.decode("utf8")# 对gdp的html数据进行按行分割data_list = data.split("\n")for i in data_list:# 对html进行解析获取<国家名字>country_result = re.match('.*<a href=""><font>(.*)</font></a>', i)# 匹配成功就存放到列表中if country_result is not None:country_list.append(country_result.group(1))# 对html进行解析获取<gdp数据>gdp_result = re.match(".*¥(.*)亿元", i)# 匹配成功就存储到列表中if gdp_result is not None:gdp_list.append(gdp_result.group(1))# 创建一个饼状图显示GDP前十的国家
def data_view_pie():# 获取前十的过的GDP数据, 同时让数据符合[(),()...]的形式data = list(zip(country_list[:10], gdp_list[:10]))# 创建饼图pie = Pie(init_opts=opts.InitOpts(width="1400px", height="800px"))# 给饼图添加数据pie.add("GDP",data,label_opts=opts.LabelOpts(formatter='{b}:{d}%'))# 给饼图设置标题pie.set_global_opts(title_opts=opts.TitleOpts(title="2020年世界GDP排名", subtitle="美元"))# 保存结果pie.render()if __name__ == '__main__':# 获取GDP数据get_gdp_data()# 生成可视化饼图data_view_pie()
5. 小结
可视化
- Pie()函数 : 创建饼图
- add()函数 : 添加数据
- set_global_opts()函数 : 设置标题
- render()函数 : 保存数据
七. Logging日志模块
1. logging日志的介绍
在现实生活中,记录日志非常重要,比如:银行转账时会有转账记录;飞机飞行过程中,会有个黑盒子(飞行数据记录器)记录着飞机的飞行过程,那在咱们python程序中想要记录程序在运行时所产生的日志信息,怎么做呢?
可以使用 logging 这个包来完成
记录程序日志信息的目的是:
- 可以很方便的了解程序的运行情况
- 可以分析用户的操作行为、喜好等信息
- 方便开发人员检查bug
2. logging日志级别介绍
日志等级可以分为5个,从低到高分别是:
- DEBUG
- INFO
- WARNING
- ERROR
- CRITICAL
日志等级说明:
- DEBUG:程序调试bug时使用
- INFO:程序正常运行时使用
- WARNING:程序未按预期运行时使用,但并不是错误,如:用户登录密码错误
- ERROR:程序出错误时使用,如:IO操作失败
- CRITICAL:特别严重的问题,导致程序不能再继续运行时使用,如:磁盘空间为空,一般很少使用
- 默认的是WARNING等级,当在WARNING或WARNING之上等级的才记录日志信息。
- 日志等级从低到高的顺序是: DEBUG < INFO < WARNING < ERROR < CRITICAL
3. logging日志的使用
在 logging 包中记录日志的方式有两种:
- 输出到控制台
- 保存到日志文件
日志信息输出到控制台的示例代码:
import logginglogging.debug('这是一个debug级别的日志信息')
logging.info('这是一个info级别的日志信息')
logging.warning('这是一个warning级别的日志信息')
logging.error('这是一个error级别的日志信息')
logging.critical('这是一个critical级别的日志信息')
运行结果:
WARNING:root:这是一个warning级别的日志信息
ERROR:root:这是一个error级别的日志信息
CRITICAL:root:这是一个critical级别的日志信息
说明:
- 日志信息只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING
logging日志等级和输出格式的设置:
import logging# 设置日志等级和输出日志格式
logging.basicConfig(level=logging.DEBUG,format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')logging.debug('这是一个debug级别的日志信息')
logging.info('这是一个info级别的日志信息')
logging.warning('这是一个warning级别的日志信息')
logging.error('这是一个error级别的日志信息')
logging.critical('这是一个critical级别的日志信息')
运行结果:
2019-02-13 20:41:33,080 - hello.py[line:6] - DEBUG: 这是一个debug级别的日志信息
2019-02-13 20:41:33,080 - hello.py[line:7] - INFO: 这是一个info级别的日志信息
2019-02-13 20:41:33,080 - hello.py[line:8] - WARNING: 这是一个warning级别的日志信息
2019-02-13 20:41:33,080 - hello.py[line:9] - ERROR: 这是一个error级别的日志信息
2019-02-13 20:41:33,080 - hello.py[line:10] - CRITICAL: 这是一个critical级别的日志信息
代码说明:
- level 表示设置的日志等级
- format 表示日志的输出格式, 参数说明:
- %(levelname)s: 打印日志级别名称
- %(filename)s: 打印当前执行程序名
- %(lineno)d: 打印日志的当前行号
- %(asctime)s: 打印日志的时间
- %(message)s: 打印日志信息
日志信息保存到日志文件的示例代码:
import logginglogging.basicConfig(level=logging.DEBUG,format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',filename="log.txt",filemode="w")logging.debug('这是一个debug级别的日志信息')
logging.info('这是一个info级别的日志信息')
logging.warning('这是一个warning级别的日志信息')
logging.error('这是一个error级别的日志信息')
logging.critical('这是一个critical级别的日志信息')
运行结果:

4. logging日志在Web项目中应用
使用logging日志示例:
- 程序入口模块设置logging日志的设置
# 导入FastAPI模块from fastapi import FastAPI# 导入响应报文Response模块from fastapi import Response# 导入服务器uvicorn模块import uvicorn# 导入日志模块import logging# 配置日志logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',filename="log.txt",filemode="w")
- 访问index.html时进行日志输出,示例代码:
# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):# 这里open()的路径就是 ==> f"source/images/0.jpg"with open(f"source/images/{path}", "rb") as f:data = f.read()# 打loglogging.info("访问了" + path)# return 返回响应数据# Response(content=data, media_type="jpg")# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="jpg")
- 访问gdp.html时进行日志输出,示例代码:
@app.get("/{path}")
def get_html(path: str):with open(f"source/html/{path}") as f:data = f.read()# 打loglogging.info("访问了" + path)# return 返回响应数据# Response(content=data, media_type="text/source"# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="text/html")
logging日志:

通过日志信息我们得知, index.html被访问了2次, gdp.html被访问了2次.
说明:
- logging日志配置信息在程序入口模块设置一次,整个程序都可以生效。
- logging.basicConfig 表示 logging 日志配置操作
5. 小结
- 记录python程序中日志信息使用 logging 包来完成
- logging日志等级有5个:
- DEBUG
- INFO
- WARNING
- ERROR
- CRITICAL
- 打印(记录)日志的函数有5个:
- logging.debug函数, 表示: 打印(记录)DEBUG级别的日志信息
- logging.info函数, 表示: 打印(记录)INFO级别的日志信息
- logging.warning函数, 表示: 打印(记录)WARNING级别的日志信息
- logging.error函数, 表示: 打印(记录)ERROR级别的日志信息
- logging.critical函数, 表示: 打印(记录)CRITICAL级别的日志信息
相关文章:

Python中的简单爬虫
文章目录 一. 基于FastAPI之Web站点开发1. 基于FastAPI搭建Web服务器2. Web服务器和浏览器的通讯流程3. 浏览器访问Web服务器的通讯流程4. 加载图片资源代码 二. 基于Web请求的FastAPI通用配置1. 目前Web服务器存在问题2. 基于Web请求的FastAPI通用配置 三. Python爬虫介绍1. 什…...

网络安全原理与技术思考题/简答题
作业1(第1章、第2章、第8章) 1. 网络安全的基本属性有哪些?简单解释每个基本属性的含义。网络安全的扩展属性包括哪些? 基本属性: 1.机密性(Confidentiality): 含义:确保信息不被未授权的用户…...

技术周刊 | 前端真的凉了吗?2024 前端趋势解读
大家好,我是童欧巴。见字如面,万事胜意。 小雪已过,大家勿忘添衣御寒,欢迎来到第 135 期周刊。 大厨推荐 2024 前端趋势 The Software House 公司发布的前端状态调查报告,本版是迄今为止最全面的调查,共…...

Qt常用控件之按钮类控件
目录 QPushButton 添加图标 添加快捷键 QRadioButton 关于toggled 模拟点餐功能 QCheckBox 刚刚 QWidget 中涉及到的各种 属性/函数/使用方法,针对接下来要介绍的 Qt 的各种控件都是有效的,因为各种控件都是继承自 QWidget 的 接下来本篇博客就学…...

Wonder3D本地部署到算家云搭建详细教程
Wonder3D简介 Wonder3D仅需2至3分钟即可从单视图图像中重建出高度详细的纹理网格。Wonder3D首先通过跨域扩散模型生成一致的多视图法线图与相应的彩色图像,然后利用一种新颖的法线融合方法实现快速且高质量的重建。 本文详细介绍了在算家云搭建Wonder3D的流程以及…...

景联文科技:高质量数据采集标注服务引领AI革新
在当今这个数字化时代,数据已经成为推动社会进步和产业升级的关键资源。特别是在人工智能领域,高质量的数据是训练出高效、精准的AI模型的基础。景联文科技是一家专业的数据采集与标注公司,致力于为客户提供高质量的数据处理服务,…...

企业面试真题----阿里巴巴
1.HashMap为什么不是线程安全的? 首先hashmap就是为单线程设计的,并不适合于多线程环境,而hashmap的线程不安全原因主主要是以下两个原因: 死循环 死循环问题发生在jdk1.8之前(不包含1.8),造…...

极狐GitLab 17.6 正式发布几十项与 DevSecOps 相关的功能【四】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

【C++知识总结2】C++里面的小配角cout和cin
一、引入 第一个关于输入输出的C代码 #include<iostream> // std是C标准库的命名空间名,C将标准库的定义实现都放到这个命名空间中 using namespace std; int main() {cout<<"Hello world!!!"<<endl;return 0; } 1. 使用cout标准输出…...
与时间序列预测应用)
门控循环单元(GRU)与时间序列预测应用
一、GRU简介 门控循环单元(Gated Recurrent Unit,简称GRU)是一种简化版的LSTM(长短期记忆网络),专门用于解决长序列中的梯度消失问题。与LSTM相比,GRU具有更简单的结构和较少的参数,…...
授权)
Spring Boot 3 集成 Spring Security(2)授权
文章目录 授权配置 SecurityFilterChain基于注解的授权控制自定义权限决策 在《Spring Boot 3 集成 Spring Security(1)》中,我们简单实现了 Spring Security 的认证功能,通过实现用户身份验证来确保系统的安全性。Spring Securit…...
)
互联网摸鱼日报(2024-11-22)
互联网摸鱼日报(2024-11-22) 36氪新闻 学习马斯克不丢人,脸书也开始改造自己了 旅游行业趋势变了,增长还能从哪里寻找? 大厂入局后,小型小游戏团队能否继续喝一口汤? 一拥而上的“跨界咖啡”,是“走心”…...

RNN并行化——《Were RNNs All We Needed?》论文解读
InfoPaperhttps://arxiv.org/abs/2410.01201GitHubhttps://github.com/lucidrains/minGRU-pytorch个人博客地址http://myhz0606.com/article/mini_rnn 最近在看并行RNN相关的paper,发现很多都利用了Parallel Scanning算法。本文将从Parallel Scanning算法开始&…...

机器学习周志华学习笔记-第6章<支持向量机>
机器学习周志华学习笔记-第6章<支持向量机> 卷王,请看目录 6支持向量机6.1 函数间隔与几何间隔6.1.1 函数间隔6.1.2 几何间隔 6.2 最大间隔与支持向量6.3 对偶问题6.4 核函数6.5 软间隔支持向量机6.6 支持向量机6.7核方法 6支持向量机 支持向量机是一种经典…...

IP反向追踪技术,了解一下?
DOSS(拒绝服务)攻击是现在比较常见的网络攻击手段。想象一下,有某个恶意分子想要搞垮某个网站,他就会使用DOSS攻击。这种攻击常常使用的方式是IP欺骗。他会伪装成正常的IP地址,让网络服务器以为有很多平常的请求&#…...
备赛--扩展外设之UART1的原理与应用(十二))
2025蓝桥杯(单片机)备赛--扩展外设之UART1的原理与应用(十二)
一、串口1的实现原理 a.查看STC15F2K60S2数据手册: 串口一在590页,此款单片机有两个串口。 串口1相关寄存器: SCON:串行控制寄存器(可位寻址) SCON寄存器说明: 需要PCON寄存器的SMOD0/PCON.6为0,使SM0和SM…...

Linux 使用gdb调试core文件
core文件和gdb调试 什么是 core 文件?产生core文件的原因?core 文件的控制和生成路径gdb 调试core 文件引用和拓展 什么是 core 文件? 当程序运行过程中出现Segmentation fault (core dumped)错误时,程序停止运行,并产…...

Python后端flask框架接收zip压缩包方法
一、用base64编码发送,以及接收 import base64 import io import zipfile from flask import request, jsonifydef unzip_and_find_png(zip_data):# 使用 BytesIO 在内存中处理 zip 数据with zipfile.ZipFile(io.BytesIO(zip_data), r) as zip_ref:extracted_paths…...

【21-30期】Java技术深度剖析:从分库分表到微服务的核心问题解析
🚀 作者 :“码上有前” 🚀 文章简介 :Java 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 文章题目:Java技术深度剖析:从分库分表到微服务的核心问题解析 摘要: 本…...

Linux 中 find 命令使用详解
目录 一:基本语法二:搜索路径1、限制递归层级2、排除指定路径 三:匹配条件1、按照文件名搜索2、按文件类型搜索3、按文件大小搜索4、按文件权限搜索5、按文件所有者或所属组搜索6、按文件修改时间搜索 四:执行操作1、输出满足条件…...

云服务器部署WebSocket项目
WebSocket是一种在单个TCP连接上进行全双工通信的协议,其设计的目的是在Web浏览器和Web服务器之间进行实时通信(实时Web) WebSocket协议的优点包括: 1. 更高效的网络利用率:与HTTP相比,WebSocket的握手只…...

林业产品智能推荐引擎:Spring Boot篇
1 绪论 1.1 选题背景 网络技术和计算机技术发展至今,已经拥有了深厚的理论基础,并在现实中进行了充分运用,尤其是基于计算机运行的软件更是受到各界的关注。计算机软件可以针对不同行业的营业特点以及管理需求,设置不同的功能&…...

【C++】LeetCode:LCR 077. 排序链表
题干 LCR 077. 排序链表 给定链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 解法:归并排序 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(null…...

git教程
文章目录 简介:使用教程:(1)安装git:(2)设置用户名和邮箱作为标识符:(3)建立本地仓库:本地仓库作用:(1)将文件…...

报表工具功能对比:免费易上手的山海鲸报表 vs 庞大用户群体的Tableau
在数据报表与分析领域,随着大数据技术的不断发展和企业数字化转型的深入,市面上涌现出了众多报表工具,为用户提供多元化的选择。对于企业数据分析师、IT人员及管理层来说,选择一款适合自己的报表工具至关重要。本文将从多个角度对…...

鸿蒙原生应用开发及部署:首选华为云,开启HarmonyOS NEXT App新纪元
目录 前言 HarmonyOS NEXT:下一代操作系统的愿景 1、核心特性和优势 2、如何推动应用生态的发展 3、对开发者和用户的影响 华为云服务在鸿蒙原生应用开发中的作用 1、华为云ECS C系列实例 (1)全维度性能升级 (2ÿ…...

CSS之3D转换
三维坐标系 三维坐标系其实就是指立体空间,立体空间是由3个轴共同组成的。 x轴:水平向右注意:x右边是正值,左边是负值 y轴:垂直向下注意:y下面是正值,上面是负值 z轴:垂直屏幕注意:往外面是正值,往里面是负值 3D移动 translat…...

uni-app初学笔记:文件路径与作用
components:可复用的组件pages:页面(可见/不可见)static:静态资源,存放图片视频等 (相当于vue项目的 assets)mainjs:Vue初始化入口文件App.vue:应用配置,用来配置App全局样式以及监听pages.json :配置页面路…...

子组件中$emit和update更新传递变量
vue2.6之后才可以使用update更新,vue2.6以下版本使用input和v-model 需求描述:蒙层上展示弹窗,弹窗点击关闭,需要向父传递关闭的信息 方法1,简便直接传递变量visible(或者不改名isModalVisible也是可以的…...

浅谈Python库之lxml
一、基本介绍 lxml 是一个用 Python 编写的库,它提供了对 XML 和 HTML 文档的解析和操作功能。它使用 C 语言编写的 libxml2 和 libxslt 库作为后端,因此解析速度非常快,并且能够处理大型文档。lxml 支持 XPath 和 XSLT,这使得它在…...

spring boot框架漏洞复现
spring - java开源框架有五种 Spring MVC、SpringBoot、SpringFramework、SpringSecurity、SpringCloud spring boot版本 版本1: 直接就在根下 / 版本2:根下的必须目录 /actuator/ 端口:9093 spring boot搭建 1:直接下载源码打包 2:运行编译好的jar包:actuator-testb…...

IDEA插件CamelCase,快速转变命名格式
在IDEA上大小写转换的快捷键是 CtrlshitU 其它的格式转换的快捷键是 shitaltu 安装方法: file-settings-plugins-在marketplace搜索“CamelCase”-点击安装。 安装成功设置后,重新打开idea 下载完成后 点击 Apply 和OK 此刻就可以选中命名 并使用快捷…...
,其中的10个选了一个master,另外10个选了另一个master,怎么办?)
Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?
大家好,我是锋哥。今天分享关于【Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?】面试题。希望对大家有帮助; Elasticsearch中的节…...

Spring Boot 集成 Knife4j 的 Swagger 文档
在开发微服务应用时,API 文档的生成和维护是非常重要的一环。Swagger 是一个非常流行的 API 文档工具,可以帮助我们自动生成 RESTful API 的文档,并提供了一个友好的界面供开发者测试 API。本文将介绍如何在 Spring Boot 项目中集成 Knife4j …...

C# 创建快捷方式文件和硬链接文件
C# 创建快捷方式文件和硬链接文件 引言什么是快捷方式什么是硬链接文件硬链接与快捷方式不同 实现创建快捷方式文件实现创建硬链接文件小结 引言 什么是快捷方式 平常我们最常window桌面上点击的左下角带小箭头的文件就是快捷方式了,大家都很熟悉它。快捷方式是Wi…...

Linux高阶——1123—服务器基础服务器设备服务器基础能力
目录 1、服务器基础 1、服务器基本概述 2、服务器设计之初解决的问题 网络穿透 网络数据设备间的收发 3、服务器的类型C/S、B/S 2、服务器设备 将自己的服务器软件部署上线 3、代理服务器负载均衡,以及地址绑定方式 4、服务器的基础能力 1、服务器基础 1…...

LabVIEW串口通讯速度
LabVIEW串口通讯能达到的速度 LabVIEW支持高效的串口通讯,通过优化设置,理论上可以实现每次接收一个字节时达到1ms甚至更短的周期。不过,实际性能会受到以下因素的限制: 波特率(Baud Rate):…...

Jmeter中的监听器
3)监听器 1--查看结果树 用途 调试测试计划:查看每个请求的详细信息,帮助调试和修正测试计划。分析响应数据:查看服务器返回的响应数据,验证请求是否成功。检查错误:识别和分析请求失败的原因。 配置步骤…...
)
缺失的第一个正数(java)
题目描述: 给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。 请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。 示例 1: 输入:nums [1,2,0] 输出:3 解释:范围 […...

跨部门文件共享安全:平衡协作与风险的关键策略
在现代企业中,跨部门协作已成为推动业务发展的关键因素。然而,随着信息的自由流动和共享,文件安全风险也随之增加。如何在促进跨部门协作的同时,确保文件共享的安全性,成为了一个亟待解决的问题。 一、明确文件分类与…...

一键AI换脸软件,支持表情控制,唇形同步Facefusion-3.0.0发布!支持N卡和CPU,一键启动包
嗨,小伙伴们!还记得小编之前介绍的FaceFusion 2.6.1吗?今天给大家带来超级exciting的消息 —— FaceFusion 3.0.0闪亮登场啦! 🌟 3.0.0版本更新 🏗️ 全面重构:修复了不少小虫子,运行更稳定,再也不怕突然罢工啦! 😀 Live Portrait功能:新增…...

我要成为算法高手-递归篇
目录 题目1:汉诺塔题目2:合并两个有序链表题目3:反转链表题目4:两两交换链表中的结点题目5:Pow(x,n) 题目1:汉诺塔 面试题 08.06. 汉诺塔问题 - 力扣(LeetCode) 解题思路࿱…...

Git 提交的相对引用
Git 提交的相对引用 在 Git 中,使用 ~ 和 ^ 符号可以帮助你更灵活地引用提交历史中的特定提交。以下是这些符号的具体用法和示例: 1. ~(波浪号) ~ 符号用于指向上一个或多个父提交。它总是沿着第一个父提交的链向上追溯。 HEA…...

国内首家! 阿里云人工智能平台 PAI 通过 ITU 国际标准测评
近日,阿里云人工智能平台 PAI 顺利通过中国信通院组织的 ITU-T AICP-GA(Technical Specification for Artificial Intelligence Cloud Platform:General Architecture)国际标准和《智算工程平台能力要求》国内标准一致性测评&…...

CDAF / PDAF 原理 | PDAF、CDAF 和 LAAF 对比 | 图像清晰度评价指标
注:本文为 “CDAF / PDAF 原理 | PDAF、CDAF 和 LAAF 对比 | 图像清晰度评价指标” 几篇相关文章合辑。 文章中部分超链接、图片异常受引用之前的原文所限。 相机自动对焦原理 TriumphRay 于 2020-01-16 18:59:41 发布 凸透镜成像原理 这一部分大家中学应该就学过…...
)
小米C++ 面试题及参考答案下(120道面试题覆盖各种类型八股文)
指针和引用的区别?怎么实现的? 指针和引用有以下一些主要区别。 从概念上来说,指针是一个变量,它存储的是另一个变量的地址。可以通过指针来间接访问所指向的变量。例如,我们定义一个整型指针int *p;,它可以指向一个整型变量的内存地址。而引用是一个别名,它必须在定义的…...

WPF异步UI交互功能的实现方法
前面的文章我们提及过,异步UI的基础实现。基本思路主要是开启新的UI线程,并通过VisualTarget将UI线程上的Visual(即RootVisual)连接到主线程上的UI上即可渲染显示。 但是,之前的实现访问是没有交互能力的,视觉树上的UI并不能实现…...
(持续更新))
2024 java大厂面试复习总结(一)(持续更新)
10年java程序员,2024年正好35岁,2024年11月公司裁员,记录自己找工作时候复习的一些要点。 java基础 hashCode()与equals()的相关规定 如果两个对象相等,则hashcode一定也是相同的两个对象相等,对两个对象分别调用eq…...

TCP/IP学习笔记
TCP\IP从实际应用的五层结构开始,自顶而下的去分析每一层。 TCP/IP五层架构概述 学术上面是TCP/IP四层架构,OSI/ISO是七层架构,实际中使用的是TCP/IP五层架构。 数据链路层 ICMP数据包分析 Wireshark抓包分析ICMP协议_wireshark抓ping包分析…...

基于IPMI的服务器硬件监控指标解读
在现代化数据中心中,服务器的稳定运行对于保障业务连续性至关重要。为了实时掌握服务器的健康状况,运维团队需要借助高效的监控工具。监控易作为一款功能强大的监控软件,支持使用IPMI(Intelligent Platform Management Interface&…...