论文速读|Matrix-SSL:Matrix Information Theory for Self-Supervised Learning.ICML24
论文地址:Matrix Information Theory for Self-Supervised Learning
代码地址:https://github.com/yifanzhang-pro/matrix-ssl
bib引用:
@article{zhang2023matrix,title={Matrix Information Theory for Self-Supervised Learning},author={Zhang, Yifan and Tan, Zhiquan and Yang, Jingqin and Weiran, Huang and Yuan, Yang},journal={arXiv preprint arXiv:2305.17326},year={2023}
}
InShort
提出Matrix - SSL方法,结合矩阵信息理论统一视角,改进自监督学习,在图像和语言任务中表现优异,探讨了有效秩与维度坍缩等相关理论。
- 研究背景
- 对比学习与非对比学习:对比学习通过对齐相似对象、分离不相似对象学习表示;非对比学习如SimSiam、Barlow Twins等不使用负样本,最大熵编码框架为部分非对比学习方法提供统一视角。
- 理论研究现状:对比学习的理论探索聚焦于对比损失的分解和理解;非对比学习的理论研究揭示了其与其他方法的联系。
- 方法
- 矩阵信息理论基础:定义矩阵熵、矩阵KL散度和矩阵交叉熵等概念,用于衡量矩阵间差异,为后续损失函数设计提供理论依据。
- Matrix - SSL算法:提出Matrix - SSL,结合矩阵均匀性损失和矩阵对齐损失。前者使特征矩阵的交叉协方差矩阵与单位矩阵对齐,后者直接对齐自协方差矩阵,提升表示学习效果。
- 与其他损失的关系:证明最大熵编码(MEC)损失与矩阵均匀性损失的等价性(在常数项和因子范围内),建立有效秩与矩阵KL散度的闭式关系。
- 实验
- 实验设置:在ImageNet数据集上进行自监督学习实验,采用ResNet50作为骨干网络,设置特定的数据增强、优化器和超参数。
- 评估结果:在线性评估、迁移学习和半监督学习任务中,Matrix - SSL均优于SimCLR、BYOL等基线方法。在ImageNet线性评估中,100轮预训练的Matrix - SSL比SimCLR的Top - 1准确率高4.6%;在MS - COCO迁移学习任务中,400轮预训练的Matrix - SSL比MoCo v2和BYOL性能提升3%以上。
- 消融实验:研究对齐损失比例和矩阵对数实现的泰勒展开阶数对性能影响,确定(\gamma = 1)和泰勒展开阶数为4时效果最佳。
- 语言模型应用:提出用矩阵交叉熵损失微调大语言模型,在数学推理数据集GSM8K上,相比标准交叉熵损失,使用Matrix - LLM损失微调的Llemma - 7B模型准确率提升3.1%。
- 结论:提供矩阵信息理论视角理解和改进自监督学习,为未来算法设计提供思路,有望推动机器学习领域发展。
摘要
最大熵编码框架为 SimSiam、Barlow Twins 和 MEC 等许多非对比学习方法提供了统一的视角。受该框架的启发,我们引入了 Matrix-SSL,这是一种利用矩阵信息理论将最大熵编码损失解释为矩阵均匀性损失的新方法。此外,Matrix-SSL 通过无缝整合矩阵对齐损失,直接对齐不同分支中的协方差矩阵,增强了最大熵编码方法。实验结果表明,在线性评估设置下,MatrixSSL 在 ImageNet 数据集上优于最先进的方法,在迁移学习任务中,MatrixSSL 在 MS-COCO 上的性能优于最先进的方法。具体来说,在 MS-COCO 上执行迁移学习任务时,我们的方法仅用 400 个 epoch 就比以前的 SOTA 方法(如 MoCo v2 和 BYOL)高出 3.3%,而预训练则需要 800 个 epoch。我们还尝试通过使用矩阵交叉熵损失微调 7B 模型,将表示学习引入语言建模机制,在 GSM8K 数据集上比标准交叉熵损失高出 3.1%。
Introduction
对比学习方法(Chen 等人,2020a;He 等人,2020)专注于使相似的对象紧密对齐,同时拉开不相似对象的距离。这种基于直观原则的方法带来了深刻而有趣的见解。例如,SimCLR 已被证明在相似性图上执行谱聚类(spectral clustering)(Tan 等人,2023b;HaoChen 等人,2021),并且 Wang 和 Isola(2020)强调了对比损失的两个关键方面:对齐和均匀性。
对齐损失可确保相似对象紧密映射,而均匀性损失则促进了均匀分布的输出特征空间,从而保留了最大信息。值得注意的是,许多现有的对比方法(Wu et al., 2018;He et al., 2020;Logeswaran & Lee, 2018;Tian et al., 2020a;Hjelm等人,2018 年;Bachman et al., 2019;Chen et al., 2020a) 可以被视为这两种损失类型的具体实现,这一观点简化了对它们核心机制的理解。
同时,人们对不使用负样本的非对比学习方法越来越感兴趣,例如 BYOL(Grill 等人,2020 年)、SimSiam(Chen 和 He,2021 年)、Barlow Twins(Zbontar 等人,2021 年)、VICReg(Bardes 等人,2021 年)等。其中,Liu 等人(2022 年)提出了一个有趣的理论框架,称为最大熵编码,提议在从相同输入的不同增强中计算出的两个特征矩阵 z 1 z_1 z1、 z 2 z_2 z2之间最大化以下损失:
L M E C = − μ l o g d e t ( I d + λ Z 1 Z 2 ⊤ ) . \mathcal{L}_{MEC}=-\mu log det\left(I_{d}+\lambda Z_{1} Z_{2}^{\top}\right) . LMEC=−μlogdet(Id+λZ1Z2⊤).
虽然乍一看可能并不明显,但上述损失函数鼓励对特征嵌入进行最大熵编码,这与对比学习方法中的均匀性损失类似。事实证明,这种公式自然涵盖了其他几种非对比方法(如 SimSiam、Barlow Twins)的损失函数,并且由此产生的算法 MEC 在性能上超过了以前的方法(Liu 等人,2022 年)(在 BYOL 中使用的逐元素对齐损失,如(|z_1 - z_2|_2),可以看作是这种 MEC 损失中的低阶泰勒展开项)。然而,对比方法和非对比方法的比较揭示了一些差异:
| Learning Method | Loss Function |
|---|---|
| Contrastive Learning Non-contrastive Learning | Uniformity + Alignment Uniformity |
这一观察自然促使我们提出一个更广泛、更具探索性的问题。在本文中,我们肯定地回答了这个问题,提出了一种方法,这种方法不仅整合了对比学习和非对比学习范式的优势,而且还增强了这些优势。
The existing maximum entropy encoding framework, however, does not explicitly differentiate between feature matrices from different branches, hindering its integration with alignment loss.
然而,现有的最大熵编码框架并没有明确区分来自不同分支的特征矩阵,这阻碍了它与对齐损失的集成。
为了弥补这一差距,我们引入了矩阵信息理论。 By extending classical concepts like entropy, Kullback–Leibler (KL) divergence, and cross-entropy to matrix analogs,我们提供了对相关损失函数的更丰富表示。值得注意的是,我们发现像 SimSiam、BYOL、Barlow Twins 和 MEC 这样的方法可以被重新解释为利用基于矩阵交叉熵(MCE)的损失函数,这是以前未被探索的联系(见定理 4.1)。
我们提出的算法 Matrix-SSL 将矩阵对齐损失纳入非对比方法中,从而提高了经验性能。这种双重关注为表示学习提供了额外的信息和更丰富的信号。
Matrix-SSL 包括 Matrix-Uniformity(矩阵均匀性)和 Matrix-Alignment(矩阵对齐)损失组件。
Matrix-Uniformity 将特征矩阵 z 1 z_1 z1和 z 2 z_2 z2的互协方差矩阵与单位矩阵 I d I_d Id对齐,而 Matrix-Alignment 则专注于对齐它们的自协方差矩阵(见图 1)。作为副产品,我们观察到有效秩和矩阵 KL 之间的封闭形式关系,这表明有效秩可以成为衡量各种机器学习方法性能的有力指标(见第 3.4 节)。
在实验评估中,Matrix-SSL 在 ImageNet 数据集上的表现优于最先进的方法(如 SimCLR、BYOL、SimSiam、Barlow Twins、VICReg 等)。特别是在线性评估设置下,“我们的方法”仅用 100 个 epoch 的预训练就能比 SimCLR 的 100 个 epoch 预训练效果高出 4.6%。对于像 COCO 检测和 COCO 实例分割这样的迁移学习任务,“我们的方法”在仅用 400 个 epoch 的情况下比之前的最先进方法如 MoCo v2 和 BYOL 表现更好,效果高出最多达 3%,而这些对比方法需要 800 个 epoch 的预训练。
我们进一步将表示学习引入语言建模领域,并使用矩阵交叉熵损失来微调大型语言模型,在 GSM8K 数据集上的数学推理任务中取得了最先进的结果,比标准交叉熵损失的效果高出 3.1%。
贡献总结:
• 我们证明了非对比学习中 MEC 损失和矩阵均匀性损失(直至常数项和因子)的等效性,以及有效秩和矩阵 KL 之间的封闭式关系。
• 我们为对比和非对比学习方法提供了均匀性损失加对齐损失的统一视角。
• 我们在各种任务下实证验证了我们的方法,包括图像分类任务的线性评估、对象检测和实例分割任务的迁移学习,以及数学推理任务的大型语言模型微调。
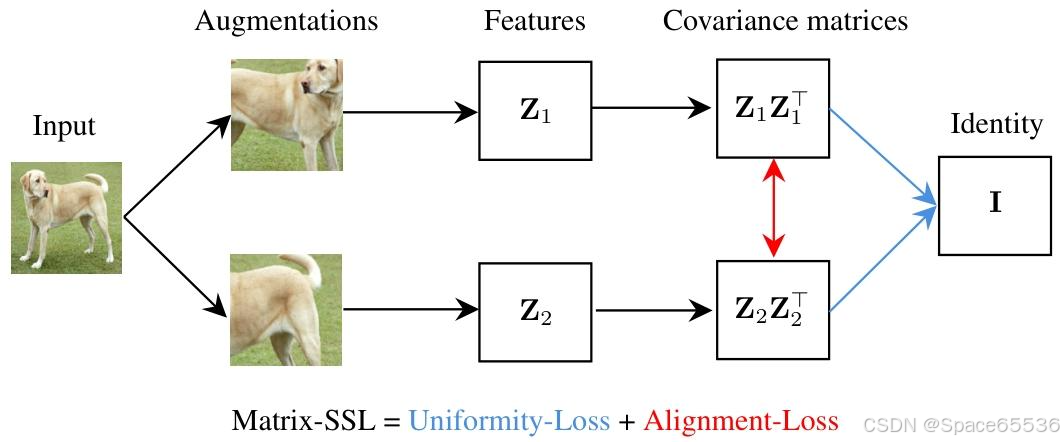
Figure 1. Illustration of the Matrix-SSL architecture. 首先是图像输入层,接着是数据增强和特征提取,然后形成协方差矩阵( Z 1 Z 1 ⊤ Z_{1} Z_{1}^{\top} Z1Z1⊤和 Z 2 Z 2 ⊤ Z_{2} Z_{2}^{\top} Z2Z2⊤)。
9.结论
在本文中,我们提供了一个矩阵信息论视角,用于理解和改进自我监督学习方法。我们相信,我们的观点不仅会提供对自我监督学习方法的精致和替代理解,而且还会成为未来设计越来越健壮和有效的算法的催化剂。
补充1:关于文中提到的KL散度
论文中提及KL散度(Kullback–Leibler Divergence),主要用于衡量两个概率分布之间的差异,在矩阵信息理论的框架下,与自监督学习方法的设计、理解和优化相关。
- 理论基础:在论文提出的矩阵信息理论中,对经典信息论概念进行拓展,定义了矩阵KL散度。对于两个正半定矩阵 P , Q ∈ R n × n P,Q \in \mathbb{R}^{n ×n} P,Q∈Rn×n,矩阵KL散度定义为 M K L ( P ∥ Q ) = t r ( P l o g P − P l o g Q − P + Q ) MKL(P \| Q)=tr(P log P - P log Q - P + Q) MKL(P∥Q)=tr(PlogP−PlogQ−P+Q)。这一概念为对比不同矩阵提供了有力工具,是后续理论推导和损失函数设计的基础。
- 与损失函数关系:论文证明了总编码率(TCR)损失与基于矩阵交叉熵(MCE)和矩阵KL散度的损失之间存在紧密联系。定理4.1表明,在特定条件下,TCR损失可以转化为正则化协方差矩阵与缩放单位矩阵之间的MCE/MKL损失。这种联系揭示了不同损失函数之间的内在一致性,为理解和改进自监督学习方法提供了新视角。在实际应用中,通过调整相关参数,可利用这种联系优化损失函数,提升模型性能。
- 解释学习过程:矩阵KL散度用于解释自监督学习过程中的一些现象。有效秩与矩阵KL散度之间存在闭形式关系,命题6.1指出 e r a n k ( 1 B Z Z ⊤ ) = d e x p ( M K L ( 1 B Z Z ⊤ ∥ 1 d I d ) ) erank(\frac{1}{B} Z Z^{\top})=\frac{d}{exp (MKL(\frac{1}{B} Z Z^{\top} \| \frac{1}{d} I_{d}))} erank(B1ZZ⊤)=exp(MKL(B1ZZ⊤∥d1Id))d。在自监督学习训练中,矩阵KL散度(或MCE)会逐渐减小,意味着特征协方差矩阵 1 B Z Z ⊤ \frac{1}{B} Z Z^{\top} B1ZZ⊤会逐渐与 1 d I d \frac{1}{d} I_{d} d1Id对齐。这解释了为什么在训练过程中有效秩会增加,以及模型如何学习到更有效的数据表示,帮助理解自监督学习方法的收敛行为和性能提升机制。
- 优化模型性能:在设计损失函数时,利用矩阵KL散度的最小化性质。例如,在矩阵对齐损失中,通过优化矩阵KL散度,使不同分支的协方差矩阵对齐,为模型提供更多信息和更丰富的信号,增强模型学习能力,从而提升在图像分类、目标检测、实例分割以及语言模型微调等任务中的性能。
补充2:关于论文提及的矩阵均匀性损失怎么促进特征有效分离和强化特征差异的
应用到跨模态图文对比学习中的例子:特征提取与矩阵构建、损失函数设计、联合训练与优化
- 特征提取与矩阵构建:对于输入的图像数据,利用如ResNet等卷积神经网络进行特征提取,得到图像特征向量,进而构建图像特征矩阵;对于文本数据,使用Transformer等模型获取文本特征表示,形成文本特征矩阵。假设输入一张水果图像和一段描述水果的文本,图像经ResNet50提取特征后得到特征矩阵( Z 1 − i m a g e Z_{1 - image} Z1−image),文本经BERT处理后得到特征矩阵( Z 1 − t e x t Z_{1 - text} Z1−text) ,对其进行增强变换,获得另一组特征矩阵( Z 2 − i m a g e Z_{2 - image} Z2−image)和( Z 2 − t e x t Z_{2 - text} Z2−text)。
- 损失函数设计:在图像 - 文本对比学习中,结合矩阵均匀性损失和矩阵对齐损失进行优化。矩阵均匀性损失使图像与文本的交叉协方差矩阵与单位矩阵对齐,公式为
L M a t r i x − U n i f o r m i t y ( Z i m a g e , Z t e x t ) = M C E ( 1 d I d , C ( Z i m a g e , Z t e x t ) ) \mathcal{L}_{Matrix - Uniformity}(Z_{image}, Z_{text}) = MCE(\frac{1}{d}I_{d}, C(Z_{image}, Z_{text})) LMatrix−Uniformity(Zimage,Ztext)=MCE(d1Id,C(Zimage,Ztext)),
以此促进特征的均匀分布。矩阵对齐损失则关注图像和文本自协方差矩阵的对齐,公式为 L M a t r i x − A l i g n m e n t ( Z i m a g e , Z t e x t ) = − t r ( C ( Z i m a g e , Z t e x t ) ) + γ ⋅ M C E ( C ( Z i m a g e , Z i m a g e ) , C ( Z t e x t , Z t e x t ) ) \mathcal{L}_{Matrix - Alignment}(Z_{image}, Z_{text}) = -tr(C(Z_{image}, Z_{text}))+\gamma \cdot MCE(C(Z_{image}, Z_{image}), C(Z_{text}, Z_{text})) LMatrix−Alignment(Zimage,Ztext)=−tr(C(Zimage,Ztext))+γ⋅MCE(C(Zimage,Zimage),C(Ztext,Ztext)),
通过调整(\gamma)控制对齐程度,强化特征之间的关联。 - 联合训练与优化:将图像和文本数据同时输入模型,以矩阵均匀性损失和矩阵对齐损失之和作为总损失
( L M a t r i x − S S L = L M a t r i x − U n i f o r m i t y + L M a t r i x − A l i g n m e n t \mathcal{L}_{Matrix - SSL}=\mathcal{L}_{Matrix - Uniformity}+\mathcal{L}_{Matrix - Alignment} LMatrix−SSL=LMatrix−Uniformity+LMatrix−Alignment) ,采用随机梯度下降等优化算法对模型进行训练。在训练过程中,不断调整模型参数,使损失函数最小化,从而学习到更有效的图像和文本特征表示,提升模型在跨模态任务中性能。
【关于非对比学习方法更关注特征的均匀分布】:
非对比学习方法通过设计特定的损失函数,使得模型学习到的特征在空间中尽可能均匀地分布,避免特征聚集在某些局部区域。这有助于模型捕捉到数据更全面的特征,提升其泛化能力。
- 原理:在非对比学习中,假设我们有一个图像数据集,里面包含各种不同类别的图像。以最大熵编码(MEC)损失为例,公式为( L M E C = − μ l o g d e t ( I d + d B ϵ 2 Z 1 Z 2 ⊤ ) \mathcal{L}_{MEC}=-\mu log det\left(I_{d}+\frac{d}{B \epsilon^{2}} Z_{1} Z_{2}^{\top}\right) LMEC=−μlogdet(Id+Bϵ2dZ1Z2⊤)),其中( Z 1 Z_1 Z1)和( Z 2 Z_2 Z2)是对同一输入图像进行不同增强变换后得到的特征矩阵。这个损失函数鼓励特征嵌入的最大熵编码,本质上就是让特征在特征空间中分布得更均匀。从直观上理解,当特征均匀分布时,每个特征维度都能携带独特的信息,就像在一个二维平面上,如果所有点都聚集在一个小区域,那么很多区域的信息就被忽略了;而当这些点均匀分布时,整个平面的信息都能被充分利用。在实际的图像特征学习中,均匀分布的特征可以更好地描述图像的不同属性,使得模型对不同图像的区分能力更强。
- 示例:假设有一个包含猫、狗、汽车三类图像的数据集。使用非对比学习方法训练模型时,模型会尝试让猫的图像特征、狗的图像特征以及汽车的图像特征在特征空间中均匀分布。比如,在一个三维的特征空间中,猫的特征点不会都集中在一个角落,而是会均匀地散布在空间的某个区域;狗和汽车的特征点也会各自均匀地分布在不同区域,并且这些区域之间有明显的区分度。这样,当遇到一张新的猫的图像时,模型可以根据其特征在均匀分布的特征空间中的位置,更准确地判断它属于猫这一类。如果特征不是均匀分布,比如猫和狗的特征点有很多重叠,那么模型在区分这两类图像时就容易出错。
【假如有些猫和有些狗有相似的特征呢?比如黑猫和黑狗,这种情况学习两种辨别性特征的可行性】:
在存在相似特征的情况下,如黑猫和黑狗,该方法仍能有效学习两种视觉对象的表征,主要通过以下几个方面来实现:
矩阵均匀性损失促进特征分离:矩阵均匀性损失使得特征分布更加均匀,即便黑猫和黑狗存在相似特征,在均匀分布的特征空间中,它们也会被分配到不同的区域。以二维特征空间为例,假设一个维度代表颜色相关特征,另一个维度代表形状相关特征。虽然黑猫和黑狗在颜色(黑色)上相似,但在形状上有差异。均匀性损失会促使模型将黑猫和黑狗的特征在形状维度上充分展开,避免因颜色相似而聚集在一起,从而使模型能够区分两者。
矩阵对齐损失强化特征差异:矩阵对齐损失通过对齐不同分支的协方差矩阵,进一步突出了黑猫和黑狗之间的特征差异。模型会学习到黑猫和黑狗各自独特的特征组合模式。比如,黑猫可能具有独特的面部斑纹和体型特征,黑狗虽然颜色相同,但面部和体型特征不同。矩阵对齐损失使得模型能够捕捉到这些细微差异,在协方差矩阵层面强化这种区分,进而更好地区分黑猫和黑狗。
数据增强增加特征多样性:在训练过程中,通常会使用多种数据增强技术,如随机裁剪、颜色抖动、高斯模糊等。对于黑猫和黑狗的图像,数据增强会引入更多的差异。例如,对黑猫进行颜色抖动可能使其黑色呈现出不同的灰度变化,而对黑狗进行相同操作时,由于其毛发质地等差异,变化效果会有所不同。这些通过增强引入的差异有助于模型学习到更多区分两者的特征,即使它们原本有相似的颜色特征,也能在多样化的增强特征中找到区分点。
模型学习能力与特征挖掘:深度神经网络本身具有强大的学习能力。面对黑猫和黑狗的相似特征,模型会自动挖掘其他更具区分性的特征。如黑猫和黑狗的眼睛形状、耳朵形态等细节特征,模型在训练过程中会逐渐关注到这些特征,并将其融入到特征表示中。结合矩阵信息理论的损失函数,模型能够更有效地利用这些挖掘到的特征,从而准确地区分两种视觉对象的表征。
【或者说:那扩展到图像和文本的匹配关系:文本1:黑猫;文本2:黑狗;图像1:黑猫的图像;图像2:黑猫的图像,这种情况下应用Matrix-SSL的解释】:特征提取、矩阵构建、损失函数计算
特征提取与矩阵构建:利用预训练的图像模型(如ResNet)和文本模型(如BERT)分别对图像和文本进行特征提取。对图像1和图像2提取特征后得到图像特征矩阵 Z i m a g e 1 Z_{image1} Zimage1、 Z i m a g e 2 Z_{image2} Zimage2,对文本1和文本2提取特征后得到文本特征矩阵 Z t e x t 1 Z_{text1} Ztext1、 Z t e x t 2 Z_{text2} Ztext2。这些特征矩阵包含了图像和文本的语义信息,例如图像特征矩阵可能编码了黑猫的颜色、形状、姿态等视觉特征,文本特征矩阵则包含了“黑猫”“黑狗”这些词汇所蕴含的语义信息 。
矩阵均匀性损失的作用:计算图像与文本之间的矩阵均匀性损失,如 L M a t r i x − U n i f o r m i t y ( Z i m a g e 1 , Z t e x t 1 ) = M C E ( 1 d I d , C ( Z i m a g e 1 , Z t e x t 1 ) ) \mathcal{L}_{Matrix - Uniformity}(Z_{image1}, Z_{text1}) = MCE(\frac{1}{d}I_{d}, C(Z_{image1}, Z_{text1})) LMatrix−Uniformity(Zimage1,Ztext1)=MCE(d1Id,C(Zimage1,Ztext1))。这一损失促使图像和文本的交叉协方差矩阵向单位矩阵对齐,使得特征分布更均匀。在这个例子中,对于“黑猫”的图像和文本,均匀性损失会让模型学习到两者在特征表示上的一致性,同时避免特征过于集中在某些相似维度(如“黑色”这一特征维度)。即使黑猫和黑狗在颜色上有相似性,但均匀性损失会推动模型在其他维度(如形状、品种特征等)挖掘差异,从而更准确地匹配“黑猫”的图像和文本。
矩阵对齐损失的作用:矩阵对齐损失
L M a t r i x − A l i g n m e n t ( Z i m a g e 1 , Z t e x t 1 ) = − t r ( C ( Z i m a g e 1 , Z t e x t 1 ) ) + γ ⋅ M C E ( C ( Z i m a g e 1 , Z i m a g e 1 ) , C ( Z t e x t 1 , Z t e x t 1 ) ) \mathcal{L}_{Matrix - Alignment}(Z_{image1}, Z_{text1}) = -tr(C(Z_{image1}, Z_{text1}))+\gamma \cdot MCE(C(Z_{image1}, Z_{image1}), C(Z_{text1}, Z_{text1})) LMatrix−Alignment(Zimage1,Ztext1)=−tr(C(Zimage1,Ztext1))+γ⋅MCE(C(Zimage1,Zimage1),C(Ztext1,Ztext1))
用于直接对齐图像和文本的自协方差矩阵。在“黑猫”的图像和文本匹配中,它帮助模型强化图像和文本特征之间的关联。比如,图像中黑猫独特的外貌特征(如绿色的眼睛、黑色的毛发质感)与文本“黑猫”所蕴含的相关语义特征通过矩阵对齐损失得到更好的匹配。而对于“黑狗”的文本和“黑猫”的图像,由于两者自协方差矩阵差异较大,矩阵对齐损失会使得模型减少对它们的匹配度,从而正确区分不同的图像 - 文本对。
整体匹配判断:通过最小化矩阵均匀性损失和矩阵对齐损失的总和
(即 L M a t r i x − S S L = L M a t r i x − U n i f o r m i t y + L M a t r i x − A l i g n m e n t \mathcal{L}_{Matrix - SSL}=\mathcal{L}_{Matrix - Uniformity}+\mathcal{L}_{Matrix - Alignment} LMatrix−SSL=LMatrix−Uniformity+LMatrix−Alignment),模型能够学习到图像和文本之间的准确匹配关系。在这个例子中,“黑猫”的图像1与文本1之间的损失会在训练过程中逐渐减小,表明模型认为它们是匹配的;而图像1与文本2(“黑狗”)之间的损失会相对较大,模型能够识别出这两者不匹配。这样,模型就可以在图像和文本之间建立有效的匹配关系,即使存在相似特征的干扰,也能准确判断图像和文本是否对应 。
补充3:代码
参考:https://github.com/yifanzhang-pro/Matrix-SSL/blob/master/main_pretrain.py
Matrix-SSL 损失函数由 Matrix-Uniformity Loss 和 Matrix-Alignment Loss 两部分组成:
L Matrix-SSL = L Matrix-Uniformity + L Matrix-Alignment L_{\text{Matrix-SSL}} = L_{\text{Matrix-Uniformity}} + L_{\text{Matrix-Alignment}} LMatrix-SSL=LMatrix-Uniformity+LMatrix-Alignment
其中:
-
Matrix-Uniformity Loss 旨在使特征的协方差矩阵接近单位矩阵,以促进特征的均匀分布:
L Matrix-Uniformity ( Z 1 , Z 2 ) = MCE ( 1 d I d , C ( Z 1 , Z 2 ) ) L_{\text{Matrix-Uniformity}}(Z_1, Z_2) = \text{MCE}\left(\frac{1}{d}I_d, C(Z_1, Z_2)\right) LMatrix-Uniformity(Z1,Z2)=MCE(d1Id,C(Z1,Z2))
其中 ( C ( Z 1 , Z 2 ) = 1 B Z 1 H B Z 2 ⊤ C(Z_1, Z_2) = \frac{1}{B} Z_1 H_B Z_2^\top C(Z1,Z2)=B1Z1HBZ2⊤ ),( H B H_B HB ) 是用于中心化的矩阵。 -
Matrix-Alignment Loss 通过对协方差矩阵之间的差异进行对齐:
L Matrix-Alignment ( Z 1 , Z 2 ) = − tr ( C ( Z 1 , Z 2 ) ) + γ ⋅ MCE ( C ( Z 1 , Z 1 ) , C ( Z 2 , Z 2 ) ) L_{\text{Matrix-Alignment}}(Z_1, Z_2) = -\text{tr}(C(Z_1, Z_2)) + \gamma \cdot \text{MCE}(C(Z_1, Z_1), C(Z_2, Z_2)) LMatrix-Alignment(Z1,Z2)=−tr(C(Z1,Z2))+γ⋅MCE(C(Z1,Z1),C(Z2,Z2))
其中 ( γ \gamma γ) 是权重因子,用于调整对齐损失的贡献。
最小化矩阵均匀性损失和矩阵对齐损失的总和:
mec_loss = (loss_func(p1, z2, lamda_inv) + loss_func(p2, z1, lamda_inv)) * 0.5 / args.m
mce_loss = (mce_loss_func(p2, z1, correlation=True, logE=False, lamda=args.mce_lambd, mu=args.mce_mu, order=args.mce_order, align_gamma=args.align_gamma)+ mce_loss_func(p1, z2, correlation=True, logE=False, lamda=args.mce_lambd, mu=args.mce_mu, order=args.mce_order, align_gamma=args.align_gamma)+ args.gamma * mce_loss_func(p2, z1, correlation=False, logE=False, lamda=args.mce_lambd, mu=args.mce_mu, order=args.mce_order, align_gamma=args.align_gamma)+ args.gamma * mce_loss_func(p1, z2, correlation=False, logE=False, lamda=args.mce_lambd, mu=args.mce_mu, order=args.mce_order, align_gamma=args.align_gamma)) * 0.5
# mec_loss = mec_loss + mce_loss * 1.
# scaled loss by lamda
# loss = -1 * mec_loss * lamda_inv
loss = mce_loss
具体来说:
1. 矩阵的均匀性损失:
mec_loss = (loss_func(p1, z2, lamda_inv) + loss_func(p2, z1, lamda_inv)) * 0.5 / args.mdef loss_func(p, z, lamda_inv, order=4):p = gather_from_all(p)z = gather_from_all(z)p = F.normalize(p)z = F.normalize(z)c = p @ z.Tc = c / lamda_inv power_matrix = csum_matrix = torch.zeros_like(power_matrix)for k in range(1, order+1):if k > 1:power_matrix = torch.matmul(power_matrix, c)if (k + 1) % 2 == 0:sum_matrix += power_matrix / kelse: sum_matrix -= power_matrix / ktrace = torch.trace(sum_matrix)return trace
2. 矩阵对齐损失:
mce_loss = (mce_loss_func(p2, z1, correlation=True, logE=False, lamda=args.mce_lambd, mu=args.mce_mu, order=args.mce_order, align_gamma=args.align_gamma)+ mce_loss_func(p1, z2, correlation=True, logE=False, lamda=args.mce_lambd, mu=args.mce_mu, order=args.mce_order, align_gamma=args.align_gamma)+ args.gamma * mce_loss_func(p2, z1, correlation=False, logE=False, lamda=args.mce_lambd, mu=args.mce_mu, order=args.mce_order, align_gamma=args.align_gamma)+ args.gamma * mce_loss_func(p1, z2, correlation=False, logE=False, lamda=args.mce_lambd, mu=args.mce_mu, order=args.mce_order, align_gamma=args.align_gamma)) * 0.5...
def mce_loss_func(p, z, lamda=1., mu=1., order=4, align_gamma=0.003, correlation=True, logE=False):p = gather_from_all(p)z = gather_from_all(z)p = F.normalize(p)z = F.normalize(z)m = z.shape[0]n = z.shape[1]# print(m, n)J_m = centering_matrix(m).detach().to(z.device)if correlation:P = lamda * torch.eye(n).to(z.device)Q = (1. / m) * (p.T @ J_m @ z) + mu * torch.eye(n).to(z.device)else:P = (1. / m) * (p.T @ J_m @ p) + mu * torch.eye(n).to(z.device)Q = (1. / m) * (z.T @ J_m @ z) + mu * torch.eye(n).to(z.device)return torch.trace(- P @ matrix_log(Q, order))
最后,总损失的计算:
total_loss = mec_loss + mce_loss
# 可以根据需要进行缩放等操作
# 例如:total_loss = -1 * total_loss * lamda_inv
loss = total_loss
相关文章:

论文速读|Matrix-SSL:Matrix Information Theory for Self-Supervised Learning.ICML24
论文地址:Matrix Information Theory for Self-Supervised Learning 代码地址:https://github.com/yifanzhang-pro/matrix-ssl bib引用: article{zhang2023matrix,title{Matrix Information Theory for Self-Supervised Learning},author{Zh…...
)
左叶子之和(力扣404)
这道题需要将左右子树的左叶子结点之和不断返回给该左右子树的父节点,这是典型的后序遍历。如果大家对于二叉树的遍历不熟悉的话,可以先去看一下我的关于二叉树遍历的博客。否则直接看这道题是很容易懵逼的。熟悉了二叉树的遍历之后,大家可以…...

微信小程序使用picker根据接口给的省市区的数据实现省市区三级联动或者省市区街道等多级联动
接口数据如上图 省市区多级联动,都是使用的一个接口通过传参父类的code。返回我们想要的数据 比如获取省就直接不要参数。市就把省得code传给接口,区就把市的code作为参数。 <picker mode"multiSelector" :range"mulSelect1" …...

iconfont等图标托管网站上传svg显示未轮廓化解决办法
打开即时设计 即时设计 - 可实时协作的专业 UI 设计工具 导入图标后拖入画板里面,右键选择轮廓化 将图标导出...
)
Mysql索引(学习自用)
目录 一、索引概述 优缺点 二、索引结构 1、索引数据结构 2、索引支持结构 3、B树 4、B树 5、hash索引 6、为啥采用B树索引 三、索引分类 四、索引语法 五、索引性能分析 5.1查看执行频率 5.2慢查询日志 5.3profiling 5.4explain 六、索引使用规则 6.1验证索…...

封装svg图片展示及操作组件——svgComponent——js技能提升
template部分 <template><div class"canvas-wrapper" ref"canvasWrapper"><svg:viewBox"computedViewBox"ref"svgCanvas"xmlns"http://www.w3.org/2000/svg"xmlns:xlink"http://www.w3.org/1999/xlink…...

数据从前端传到后端入库过程分析
数据从前端传到后端入库过程分析 概述 积累了一些项目经验,成长为一个老程序员了,自认为对各种业务和技术都能得心应手的应对了,殊不知很多时候我们借助了搜索引擎的能力,当然现在大家都是通过AI来武装自己。 今天要分析的话题是…...

【Pytest】结构介绍
1.目录结构介绍 project_root/ │ ├── tests/ # 测试用例存放目录 │ ├── __init__.py │ ├── test_module1.py │ ├── module1.py # 被测试的模块 ├── conftest.py # pytest配置文件,可定义fixture和钩子函数 ├── py…...

每日十题八股-2025年1月23日
1.快排为什么时间复杂度最差是O(n^2) 2.快排这么强,那冒泡排序还有必要吗? 3.如果要对一个很大的数据集,进行排序,而没办法一次性在内存排序,这时候怎么办? 4.面试官:你的…...
)
mysql相关知识(详细)
一、什么是数据库? 概念:数据库(Database,简称DB),长期存放在计算机内,有组织,可共享的大量数据的集合,是一个数据"仓库"。作用:存放管理数据分类:关系型数据库、NoSQL数…...

C++ 静态变量static的使用方法
static概述: static关键字有三种使用方式,其中前两种只指在C语言中使用,第三种在C中使用。 静态局部变量(C) 静态全局变量/函数(C) 静态数据成员/成员函数(C) 静态局部变量 静态局部变量&…...

对grid布局有哪些了解【css】
CSS Grid 布局是现代网页设计中非常强大的布局方式之一,它能够使你以更加灵活且直观的方式来设计网页的布局,特别适用于复杂的多行多列的布局。它允许你在网页上创建非常精确的网格,帮助你把内容放置在多个行和列中。 1. Grid 布局的基本概念…...

IOS 安全机制拦截 window.open
摘要 在ios环境,在某些情况下执行window.open不生效 一、window.open window.open(url, target, windowFeatures) 1. url:「可选参数」,表示你要加载的资源URL或路径,如果不传,则打开一个url地址为about:blank的空…...
低空飞行器零部件供应商国内外厂家)
低空经济(9)低空飞行器零部件供应商国内外厂家
低空飞行器零部件供应商国内外厂家 1.概述2.国内供应商2.1 动力系统2.2 航电系统2.3 机身结构部件2.4 传动系统2.5 液压系统与气动系统 3.国外供应商3.1 动力系统3.2 航电系统3.3 机身结构部件3.4 传动系统3.5 液压与气动系统 tips:资料来自网络,仅供参考…...

3b1b线性代数基础
零、写在前面 3b1b之前没认真看,闲了整理整理。 一、向量 学习物理的时候,向量是空间中的箭头。由其方向和长度决定。 学习数据结构的时候,向量是有序的数字列表。向量的每一维度有着不同含义。 线性代数中,我们通常认为**向量…...

困境如雾路难寻,心若清明步自轻---2024年创作回顾
文章目录 前言博客创作回顾第一次被催更第一次获得证书周榜几篇博客互动最多的最满意的引发思考的 写博契机 碎碎念时也运也部分经验 尾 前言 今年三月份,我已写下一篇《近一年多个人总结》,当时还没开始写博客。四月份写博后,就顺手将那篇总…...

SAP 中的三种内表
文章目录 1 : Introduction2 : Summary3: Reerence document4 : Example 1 : Introduction In the abap development we deal with data and the carrier is internal table . it is transfered in the whole programe. In the interview we offten meet it . What is the dif…...

从0到1学习机器学习实践--1 安装Anaconda
机器学习首先安装conda环境,这个是比较靠谱手把手执行的安装教程 最新最全(亲测)的conda安装教程和虚拟环境安装环境配置...

整合管理输入、工具与技术 、输出
过程输入工具与技术输出制定项目章程1.项目立项文件2.协议3.事业环境因素4.组织过程资产1.专家判断2.数据收集头脑风暴、焦点小组、访谈3.人际关系与团队技能冲突管理、引导、会议管理4.会议1.项目章程2.假设日志制订项目管理计划1.项目章程2.其他过程输出3.事业环境因素4.组织…...

sed — 流编辑器:从入门到精通
内容速览 简介 sed(Stream Editor)是一个功能强大的文本处理工具,广泛应用于文本文件的自动化编辑和批量处理。它通过逐行读取文件内容并在内存中的临时缓冲区(即“模式空间”)中处理文本,实现高效的文本…...

【玩转全栈】----Django基本配置和介绍
目录 Django基本介绍: Django基本配置: 安装Django 创建项目 创建app 注册app Django配置路由URL Django创建视图 启动项目 Django基本介绍: Django是一个开源的、基于Python的高级Web框架,旨在以快速、简洁的方式构建高质量的Web…...

【Linux】文件操作、系统IO相关操作、inode和输入输出重定向
⭐️个人主页:小羊 ⭐️所属专栏:Linux 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 1、理解文件1.1 狭义理解1.2 广义理解1.3 文件操作1.4 系统角度 2、系统文件IO2.1 文件相关操作2.2 文件描述符2.3 重定向 3、动静…...

Prometheus+grafana实践:Doris数据库的监控
文章来源:乐维社区 Doris数据库背景 Doris(Apache Doris)是一个现代化的MPP(Massive Parallel Processing,大规模并行处理)数据库,主要用于在线分析处理(OLAP)场景。 D…...
)
c语言(转义字符)
前言: 内容: 然后记一下转义字符 \? 在书写连续多个问号时使用,防止他们被解析成三字母词 \ 用于表示字符常量 \\ 用于表示一个反斜杠,防止他被解析为一个转义序列符 \n 换行 \r …...

TOGAF之架构标准规范-信息系统架构 | 数据架构
TOGAF是工业级的企业架构标准规范,信息系统架构阶段是由数据架构阶段以及应用架构阶段构成,本文主要描述信息系统架构阶段中的数据架构阶段。 如上所示,信息系统架构(Information Systems Architectures)在TOGAF标准规…...

快速排序:一种高效的排序算法
前言 排序是最基本和最常用的操作之一。无论是数据处理、搜索优化,还是各种应用程序的内部逻辑,排序算法的选择都直接影响到程序的性能。快速排序(Quick Sort)作为一种典型的分治算法,以其平均时间复杂度 O(n log n) 和优越的实际表现,成为了现代编程中最常用的排序算法…...

PHP:从入门到进阶的编程之旅
在Web开发的广阔天地中,PHP(Hypertext Preprocessor,超文本预处理器)无疑是一颗璀璨的明星。自1995年问世以来,PHP凭借其开源、跨平台、易于学习和使用的特性,迅速成为Web开发领域中最受欢迎的语言之一。本…...

Windows的docker中安装gitlab
一.Windows的docker中安装gitlab 1.通过阿里云拉取镜像 docker pull registry.cn-hangzhou.aliyuncs.com/lab99/gitlab-ce-zh 2.在本地创建备份数据的目录 mkdir -p D:home/software/gitlab/etc mkdir -p D:home/software/gitlab/logs mkdir -p D:home/software/gitlab/dat…...
无线局域网WLAN)
计算机网络 (58)无线局域网WLAN
前言 无线局域网WLAN(Wireless Local Area Network)是一种利用无线通信技术将计算机设备互联起来,构成可以互相通信和实现资源共享的网络体系。 一、定义与特点 定义: WLAN通过无线信道代替有线传输介质连接两个或多个设备形成一个…...

LeetCode: 45.跳跃游戏II
跟着carl学算法,本系列博客仅做个人记录,建议大家都去看carl本人的博客,写的真的很好的! 代码随想录 LeetCode: 45.跳跃游戏II 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示…...

Blazo-Blazor Web App项目结构
让我们还是从创建项目开始,来一起了解下Blazor Web App的项目情况 创建项目 呈现方式 这里我们可以看到需要选择项目的呈现方式,有以上四种呈现方式 ● WebAssembly ● Server ● Auto(Server and WebAssembly) ● None 纯静态界面静态SSR呈现方式 WebAs…...

汇编语法及相关指令
1.汇编指令的基本格式: <opcode>{<cond>}{s} <Rd>, <Rn>, <shifter_operand> opcode:指令的功能码,用来表示当前指令的作用 cond:条件码,需要在指令执行之前先判断条件受否满足&…...
)
数据结构——堆(介绍,堆的基本操作、堆排序)
我是一个计算机专业研0的学生卡蒙Camel🐫🐫🐫(刚保研) 记录每天学习过程(主要学习Java、python、人工智能),总结知识点(内容来自:自我总结网上借鉴࿰…...

linux+docker+nacos+mysql部署
一、下载 docker pull mysql:5.7 docker pull nacos/nacos-server:v2.2.2 docker images 二、mysql部署 1、创建目录存储数据信息 mkdir ~/mysql cd ~/mysql 2、运行 MySQL 容器 docker run -id \ -p 3306:3306 \ --name mysql \ -v $PWD/conf:/etc/mysql/conf.d \ -v $PWD/…...

10个非常基础的 Javascript 问题
Javascript是一种用于Web开发的编程语言。JavaScript在网络的客户端上运行。 根据MDN,JavaScript(通常缩写为JS)是一种轻量级的,解释性的,面向对象的语言,具有一流的功能,并且最著名的是Web页面…...

SCP收容物221~225
注 :此文接SCP收容物211~215,本文只供开玩笑 ,与steve_gqq_MC合作 --------------------------------------------------------------------------------------------------------------------------------- 目录 scp-221 scp-222 scp-223 scp-224 scp-225 s…...

基于迁移学习的ResNet50模型实现石榴病害数据集多分类图片预测
完整源码项目包获取→点击文章末尾名片! 番石榴病害数据集 背景描述 番石榴 (Psidium guajava) 是南亚的主要作物,尤其是在孟加拉国。它富含维生素 C 和纤维,支持区域经济和营养。不幸的是,番石榴生产受到降…...
 协议)
网络(三) 协议
目录 1. IP协议; 2. 以太网协议; 3. DNS协议, ICMP协议, NAT技术. 1. IP协议: 1.1 介绍: 网际互连协议, 网络层是进行数据真正传输的一层, 进行数据从一个主机传输到另一个主机. 网络层可以将数据主机进行传送, 那么传输层保证数据可靠性, 一起就是TCP/IP协议. 路径选择: 确…...

【mptcp】ubuntu18.04和MT7981搭建mptcp测试环境操作说明
目录 安装ubuntu18.04,可以使用虚拟机安装... 2 点击安装VMware Tool 2 更新ubuntu18.04源... 4 安装ifconfig指令工具包... 5 安装vim工具包... 5...

递归的本质
字节面试题叠罗汉,很遗憾没想出来,看了答案挺巧妙的,但是居然是个案例题。。。 复习一下递归的本质 正面解决问题 利用子问题来解决 可以通过规约推导的,基本可以用递归解决! 在写这道算法题时,我想规…...

如何使用tmux !
在tmux的界面按住shift,就可以和普通linux界面一样!!!!!!!! 单击右键可以复制粘贴,滚动鼠标可以上下翻页!!!!…...

【Vim Masterclass 笔记25】S10L45:Vim 多窗口的常用操作方法及相关注意事项
文章目录 S10L45 Working with Multiple Windows1 水平分割窗口2 在水平分割的新窗口中显示其它文件内容3 垂直分割窗口4 窗口的关闭5 在同一窗口水平拆分出多个窗口6 关闭其余窗口7 让四个文件呈田字形排列8 光标在多窗口中的定位9 调节子窗口的尺寸大小10 变换子窗口的位置11…...
)
C语言练习(16)
猴子吃桃问题。猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个。第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半加一个。到第10天早上想再吃时,见只剩一个桃子了…...

【0x0012】HCI_Delete_Stored_Link_Key命令详解
目录 一、命令参数 二、命令格式及参数 2.1. HCI_Delete_Stored_Link_Key 命令格式 2.2. BD_ADDR 2.3. Delete_All 三、生成事件及参数 3.1. HCI_Command_Complete事件 3.2. Status 3.3. Num_Keys_Deleted 四、命令执行流程 4.1. 命令发送阶段 4.2. 控制器处理阶段…...
)
学习ASP.NET Core的身份认证(基于JwtBearer的身份认证10)
基于Cookie传递token的主要思路是通过用户身份验证后,将生成的token保存到Response.Cookies返回客户端,后续客户端访问服务接口时会自动携带Cookie到服务端以便验证身份。之前一直搞不清楚的是服务端程序如何从Cookie读取token进行认证(一般都…...

应用层协议 HTTP 讲解实战:从0实现HTTP 服务器
🌈 个人主页:Zfox_ 🔥 系列专栏:Linux 目录 一:🔥 HTTP 协议 🦋 认识 URL🦋 urlencode 和 urldecode 二:🔥 HTTP 协议请求与响应格式 🦋 HTTP 请求…...

Linux权限管理:从用户切换到文件权限
在Linux系统中,权限管理是确保系统安全和资源合理分配的核心机制。它通过用户和用户组的管理、文件权限的设置以及特殊权限的使用,实现了对系统资源的精细控制。 一、用户切换:su 和 sudo 1. 用户切换命令 su su(switch user&a…...

PyQt5超详细教程终篇
PyQt5超详细教程 前言 接: [【Python篇】PyQt5 超详细教程——由入门到精通(序篇)](【Python篇】PyQt5 超详细教程——由入门到精通(序篇)-CSDN博客) 建议把代码复制到pycahrm等IDE上面看实际效果,方便理…...

Alibaba Spring Cloud 四 Seata 的核心组件:TC
Seata 的 Transaction Coordinator (TC) 是分布式事务架构中的核心组件之一,它负责管理全局事务的生命周期,包括事务的创建、状态维护以及协调各分支事务的提交和回滚。以下是有关 TC 的详细解析及其配置和使用方法: 1. TC 的核心功能 全局事…...
)
机器学习-线性回归(简单回归、多元回归)
这一篇文章,我们主要来理解一下,什么是线性回归中的简单回归和多元回归,顺便掌握一下特征向量的概念。 一、简单回归 简单回归是线性回归的一种最基本形式,它用于研究**一个自变量(输入)与一个因变量&…...