Ragas-RAG能力评测
Ragas是一个框架,它可以帮助你从不同的方面评估你的问答(QA)流程。它为你提供了一些指标来评估你的问答系统的不同方面,具体包括:
- 评估检索(context)的指标:提供了上下文相关性(context_relevancy)和上下文召回率(context_recall),这些可以衡量你的检索系统的性能。
- 评估生成(answer)的指标:提供了忠实度(faithfulness),用以衡量生成的信息是否准确无误;以及答案相关性(answer_relevancy),用以衡量答案对问题的切题程度。
特别地,正如前面也提到的,为了使用 RAGAS,你所需要的只是一些问题。但是,如果你使用上下文召回率(context_recall),还需要一些参考答案。
数据格式
RAGAs 需要以下信息:
- question:用户输入的问题。
- answer:从 RAG 系统生成的答案(由LLM给出)。
- contexts:根据用户的问题从外部知识源检索的上下文即与问题相关的文档。
- ground_truths: 人类提供的基于问题的真实(正确)答案。 这是唯一的需要人类提供的信息。
RAG评测指标
Ragas提供了五种评估指标包括:
- 忠实度(faithfulness)
- 答案相关性(Answer relevancy)
- 上下文精度(Context precision)
- 上下文召回率(Context recall)
- 上下文相关性(Context relevancy)

2.1忠实度
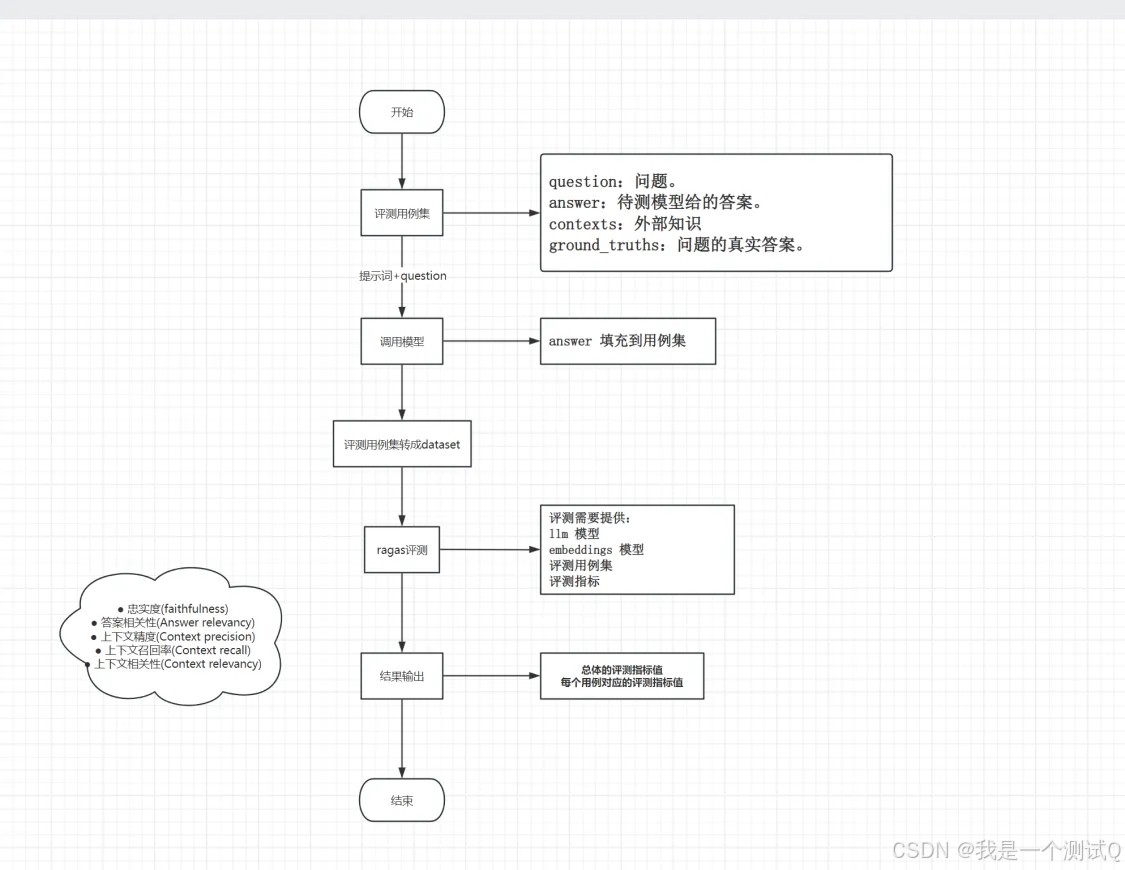
忠实度指标衡量生成答案与给定上下文的事实一致性。它是根据答案和检索到的上下文来计算的。答案被缩放到(0,1)范围内。数值越高越好。
如果生成答案中提出的所有主张都能从给定的上下文中推断出来,则认为该答案是忠实的。为了计算这个指标,首先需要识别生成答案中的一系列主张。然后,将这些主张与给定的上下文进行交叉检查,以确定它们是否可以从上下文中推断出来。忠实度得分由以下公式给出:
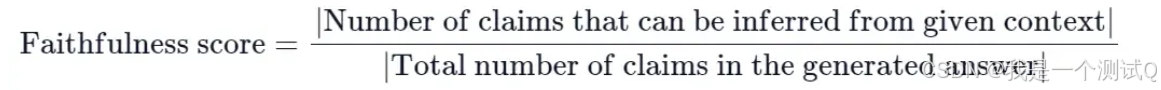
reagas评分
Given a question, an answer, and sentences from the answer analyze the complexity of each sentence given under 'sentences' and break down each sentence into one or more fully understandable statements while also ensuring no pronouns are used in each statement. Format the outputs in JSON.
给定一个问题、一个答案以及答案中的句子,分析“sentences”下每个句子的复杂度,并将每个句子分解成一个或多个完全可理解的陈述,同时确保每个陈述中不使用代词。将输出格式化为JSON。
输入:
{"question": "阿尔伯特·爱因斯坦是谁,他最出名的是什么?","answer": "他是一位出生在德国的理论物理学家,被广泛认为是有史以来最伟大和最有影响力的物理学家之一。他最出名的是发展了相对论,同时也对量子力学理论的发展做出了重要贡献。","sentences": {"0": "阿尔伯特·爱因斯坦是一位出生在德国的理论物理学家,被广泛认为是有史以来最伟大和最有影响力的物理学家之一。","1": "他最出名的是发展了相对论,同时也对量子力学理论的发展做出了重要贡献。"}
}
输出:
{"SentenceComponents": [{"sentence_index": 0,"simpler_statements": ["阿尔伯特·爱因斯坦是一位出生在德国的理论物理学家。","阿尔伯特·爱因斯坦被认为是有史以来最伟大和最有影响力的物理学家之一。"]},{"sentence_index": 1,"simpler_statements": ["阿尔伯特·爱因斯坦最出名的是发展了相对论。","阿尔伯特·爱因斯坦还对量子力学理论的发展做出了重要贡献。"]}]
}我们的任务是根据给定的上下文来判断一系列陈述的忠实度。对于每个陈述,如果该陈述可以根据上下文直接推断出来,则必须返回裁决结果为1;如果该陈述不能根据上下文直接推断出来,则返回裁决结果为0。
```json
{"NLIStatementInput": {"context": "约翰是XYZ大学的学生。他正在攻读计算机科学学位。这个学期他注册了几门课程,包括数据结构、算法和数据库管理。约翰是一个勤奋的学生,他花大量的时间学习和完成作业。他经常在图书馆待到很晚来完成他的项目。","statements": ["约翰主修生物学。","约翰正在上人工智能课程。","约翰是一个专注的学生。","约翰有一份兼职工作。"]},"NLIStatementOutput": {"statements": [{"StatementFaithfulnessAnswer": {"statement": "约翰主修生物学。","reason": "约翰的专业明确提到是计算机科学。没有信息表明他主修生物学。","verdict": 0}},{"StatementFaithfulnessAnswer": {"statement": "约翰正在上人工智能课程。","reason": "上下文提到了约翰目前正在注册的课程,而人工智能并未被提及。因此,不能推断出约翰正在上人工智能课程。","verdict": 0}},{"StatementFaithfulnessAnswer": {"statement": "约翰是一个专注的学生。","reason": "上下文说明他花大量的时间学习和完成作业。此外,提到他经常在图书馆待到很晚来完成他的项目,这暗示了他的专注。","verdict": 1}},{"StatementFaithfulnessAnswer": {"statement": "约翰有一份兼职工作。","reason": "上下文中没有给出约翰有兼职工作的信息。","verdict": 0}}]}
}
例子
from ragas.database_schema import SingleTurnSample
from ragas.metrics import Faithfulnesssample = SingleTurnSample(user_input="When was the first super bowl?",response="The first superbowl was held on Jan 15, 1967",retrieved_contexts=["The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles."])
scorer = Faithfulness()
await scorer.single_turn_ascore(sample)2.2 答案相关性(Answer relevancy/ResponseRelevancy )
评估指标“答案相关性”重点评估生成的答案(answer)与用户问题(question)之间相关程度。不完整或包含冗余信息的答案会被赋予较低的分数,而相关性更好的答案则获得更高的分数。这个指标是使用用户输入、检索到的上下文和响应来计算的。
答案相关性被定义为原始用户输入与一系列人造问题之间的平均余弦相似度,这些问题是基于响应生成的(反向工程):
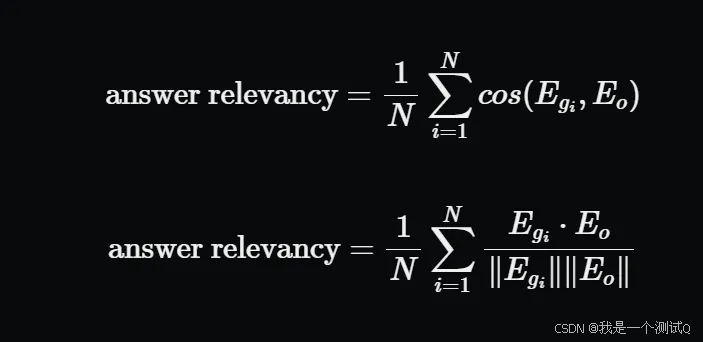
- \( e_{g} \) 是生成问题的句子嵌入(embedding)。
- \( e_{o} \) 是原始问题的句子嵌入(embedding)。
- \( n \) 是生成问题的数量,默认为3。
为了计算这个分数,大型语言模型(LLM)被提示多次为生成的答案生成一个合适的问题,然后测量这些生成的问题与原始问题之间的平均余弦相似度。背后的理念是,如果生成的答案准确地回应了最初的问题,那么LLM应该能够从答案中生成与原始问题一致的问题。
ragas评分
为给定的答案生成一个问题,并识别答案是否含糊其辞。如果答案是含糊其辞的,则将含糊其辞标记为1;如果答案是明确的,则标记为0。含糊其辞的答案是指那些回避、模糊或不明确的答案。例如,“我不知道”或“我不确定”就是含糊其辞的答案。
{"ResponseRelevanceInput": {"response": "阿尔伯特·爱因斯坦出生于德国。"},"ResponseRelevanceOutput": {"question": "阿尔伯特·爱因斯坦在哪里出生?","noncommittal": 0}
},
{"ResponseRelevanceInput": {"response": "我不知道2023年发明的智能手机的突破性功能,因为我不了解2022年之后的信息。"},"ResponseRelevanceOutput": {"question": "2023年发明的智能手机的突破性功能是什么?","noncommittal": 1}
}calculate_similarity(self, question: str, generated_questions: list[str]):例子
from ragas import SingleTurnSample
from ragas.metrics import ResponseRelevancysample = SingleTurnSample(user_input="When was the first super bowl?",response="The first superbowl was held on Jan 15, 1967",retrieved_contexts=["The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles."])scorer = ResponseRelevancy()
await scorer.single_turn_ascore(sample)2.3 噪声敏感性 Noise Sensitivity
噪声敏感性衡量系统在使用相关或不相关的检索文档时提供错误回答的频率。分数范围从0到1,较低的值表示更好的性能。噪声敏感性是使用用户输入、参考标准、响应和检索到的上下文来计算的。
为了估计噪声敏感性,生成的响应中的每个主张都被检查,以确定它是否基于真实情况正确,以及是否可以归因于相关(或不相关)的检索上下文。理想情况下,答案中的所有主张都应得到相关检索上下文的支持。
给定一个问题、一个答案以及答案中的句子,分析“sentences”下每个句子的复杂度,并将每个句子分解成一个或多个完全可理解的陈述,同时确保每个陈述中不使用代词。将输出格式化为JSON。您的任务是根据给定的上下文来判断一系列陈述的忠实度。对于每个陈述,如果该陈述可以根据上下文直接推断出来,则必须返回裁决结果为1;如果该陈述不能根据上下文直接推断出来,则返回裁决结果为0。
from ragas.dataset_schema import SingleTurnSample
from ragas.metrics import NoiseSensitivitysample = SingleTurnSample(user_input="What is the Life Insurance Corporation of India (LIC) known for?",response="The Life Insurance Corporation of India (LIC) is the largest insurance company in India, known for its vast portfolio of investments. LIC contributes to the financial stability of the country.",reference="The Life Insurance Corporation of India (LIC) is the largest insurance company in India, established in 1956 through the nationalization of the insurance industry. It is known for managing a large portfolio of investments.",retrieved_contexts=["The Life Insurance Corporation of India (LIC) was established in 1956 following the nationalization of the insurance industry in India.","LIC is the largest insurance company in India, with a vast network of policyholders and huge investments.","As the largest institutional investor in India, LIC manages substantial funds, contributing to the financial stability of the country.","The Indian economy is one of the fastest-growing major economies in the world, thanks to sectors like finance, technology, manufacturing etc."]
)scorer = NoiseSensitivity()
await scorer.single_turn_ascore(sample)2.4 上下文精度(Context precision)
上下文精度是一个衡量检索到的上下文中相关块的比例的指标。它是通过计算上下文中每个块的精度@k的平均值来得出的。精度@k是排名第k的相关块的数量与排名第k的总块数的比率。
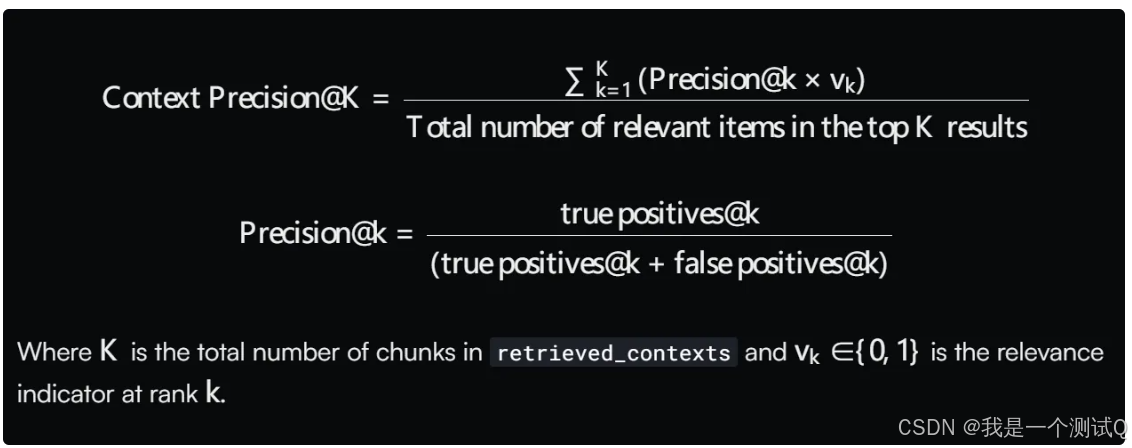
'Given question, answer and context verify if the context was useful in arriving at the given answer. Give verdict as "1" if useful and "0" if not with json output.遍历检索到的上下文,给定问题、答案和上下文,验证上下文是否有助于得出给定答案。如果上下文有用,则给出的判断结果为"1";如果没用,则为"0",并以JSON格式输出。
例子:
{"QAC": {"question": "世界上最高的山峰是什么?","context": "安第斯山脉是世界上最长的大陆山脉,位于南美洲。它横跨七个国家,拥有西半球许多最高的山峰。这个山脉以其多样的生态系统而闻名,包括高海拔的安第斯高原和亚马逊雨林。","answer": "珠穆朗玛峰。"},"Verification": {"reason": "提供的上下文讨论了安第斯山脉,虽然令人印象深刻,但并未包括珠穆朗玛峰,也没有直接关联到关于世界最高峰的问题。","verdict": 0}
}{"QAC": {"question": "谁赢得了2020年ICC板球世界杯?","context": "2022年ICC男子T20世界杯于2022年10月16日至11月13日在澳大利亚举行,这是该锦标赛的第八届。原定于2020年举行,但由于COVID-19大流行而推迟。英格兰队在决赛中以5个球的优势击败巴基斯坦队,赢得了他们的第二个ICC男子T20世界杯冠军。","answer": "英格兰"},"Verification": {"reason": "上下文有助于澄清关于2020年ICC世界杯的情况,并指出英格兰是原定于2020年举行但实际在2022年举行的锦标赛的获胜者。","verdict": 1}
}from ragas import SingleTurnSample
from ragas.metrics import LLMContextPrecisionWithoutReferencecontext_precision = LLMContextPrecisionWithoutReference()sample = SingleTurnSample(user_input="Where is the Eiffel Tower located?",response="The Eiffel Tower is located in Paris.",retrieved_contexts=["The Eiffel Tower is located in Paris."],
)await context_precision.single_turn_ascore(sample)2.5 上下文召回率(Context recall)
上下文召回率衡量成功检索到的相关文档(或信息片段)的数量。它关注的是不要错过重要的结果。召回率越高,意味着遗漏的相关文档越少。简而言之,召回率是关于不要错过任何重要内容。由于它涉及到不要错过任何内容,计算上下文召回率总是需要一个参考来比较。
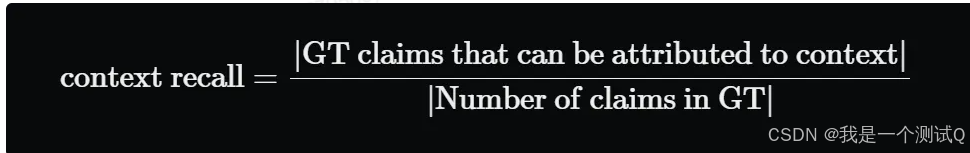
上下文召回率(Context recall)衡量检索到的上下文(Context)与人类提供的真实答案(ground truth)的一致程度。它是根据ground truth和检索到的Context计算出来的,取值范围在 0 到 1 之间,值越高表示性能越好。
为了根据真实答案(ground truth)估算上下文召回率(Context recall),分析真实答案中的每个句子以确定它是否可以归因于检索到的Context。 在理想情况下,真实答案中的所有句子都应归因于检索到的Context
Given a context, and an answer, analyze each sentence in the answer and classify if the sentence can be attributed to the given context or not. Use only 'Yes' (1) or 'No' (0) as a binary classification. Output json with reason.
给定一个上下文和一个答案,分析答案中的每个句子,并分类判断该句子是否可以归因于给定的上下文。仅使用“是”(1)或“否”(0)作为二元分类。输出带有原因的JSON。
{"QCA": {"question": "你能告诉我关于阿尔伯特·爱因斯坦的什么?","context": "阿尔伯特·爱因斯坦(1879年3月14日 - 1955年4月18日)是一位出生在德国的理论物理学家,被广泛认为是有史以来最伟大和最有影响力的科学家之一。他以发展相对论而闻名,同时也对量子力学做出了重要贡献,因此成为现代物理学在20世纪前几十年对自然科学理解革命性重塑中的中心人物。他的质能等价公式E = mc^2,源于相对论理论,被称为“世界上最著名的方程”。他因“对理论物理学的贡献,特别是他对光电效应定律的发现”而获得1921年诺贝尔物理学奖,这是量子理论发展中的一个关键步骤。他的工作也因其对科学哲学的影响而闻名。在1999年英国《物理世界》杂志对全球130位顶尖物理学家的调查中,爱因斯坦被评为有史以来最伟大的物理学家。他的智力成就和独创性使爱因斯坦成为天才的代名词。","answer": "阿尔伯特·爱因斯坦,出生于1879年3月14日,是一位出生在德国的理论物理学家,被广泛认为是有史以来最伟大和最有影响力的科学家之一。他因对理论物理学的贡献而获得1921年诺贝尔物理学奖。他在1905年发表了4篇论文。爱因斯坦于1895年移居瑞士。"},"ContextRecallClassifications": {"classifications": [{"statement": "阿尔伯特·爱因斯坦,出生于1879年3月14日,是一位出生在德国的理论物理学家,被广泛认为是有史以来最伟大和最有影响力的科学家之一。","reason": "上下文中清楚提到了爱因斯坦的出生日期。","attributed": 1},{"statement": "他因对理论物理学的贡献而获得1921年诺贝尔物理学奖。","reason": "给定的上下文中有完全相同的句子。","attributed": 1},{"statement": "他在1905年发表了4篇论文。","reason": "给定的上下文中没有提到他写的论文。","attributed": 0},{"statement": "爱因斯坦于1895年移居瑞士。","reason": "给定的上下文中没有支持这一说法的证据。","attributed": 0}]}
}from ragas.dataset_schema import SingleTurnSample
from ragas.metrics import LLMContextRecallsample = SingleTurnSample(user_input="Where is the Eiffel Tower located?",response="The Eiffel Tower is located in Paris.",reference="The Eiffel Tower is located in Paris.",retrieved_contexts=["Paris is the capital of France."],
)context_recall = LLMContextRecall()
await context_recall.single_turn_ascore(sample)2.6 上下文实体召回率(ContextEntityRecall)
基于参考上下文和检索到的上下文中存在的实体数量相对于参考上下文中存在的实体数量。简单来说,它衡量的是从参考上下文中回忆起的实体的比例。这个指标在基于事实的应用案例中很有用,如旅游帮助台、历史问答等。这个指标可以帮助评估实体的检索机制,通过与参考上下文中的实体进行比较,因为在实体重要的案例中,我们需要检索到的上下文能够涵盖这些实体。
要计算这个指标,我们使用两个集合:
- GE,表示参考上下文中存在的实体集合;
- CE,表示检索到的上下文中存在的实体集合。
然后我们取这两个集合交集中的元素数量,并将其除以存在于 RR 中的元素数量,公式如下
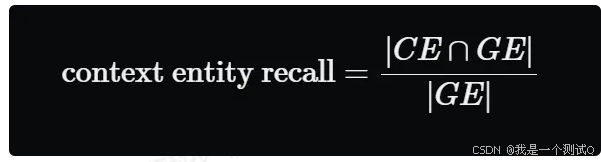
"Given a text, extract unique entities without repetition. Ensure you consider different forms or mentions of the same entity as a single entity."
给定一段文本,提取不重复的独特实体。确保你将同一实体的不同形式或提及视为单一实体。{"StringIO": {"text": "埃菲尔铁塔位于法国巴黎,是全球最具标志性的地标之一。每年有数百万游客因其令人叹为观止的城市景观而慕名而来。它于1889年完工,正是为了赶上1889年的世界博览会。"},"EntitiesList": {"entities": ["埃菲尔铁塔", "巴黎", "法国", "1889", "世界博览会"]}
}num_entities_in_both = len(set(context_entities).intersection(set(ground_truth_entities)))return num_entities_in_both / (len(ground_truth_entities) + 1e-8)from ragas import SingleTurnSample
from ragas.metrics import ContextEntityRecallsample = SingleTurnSample(reference="The Eiffel Tower is located in Paris.",retrieved_contexts=["The Eiffel Tower is located in Paris."],
)scorer = ContextEntityRecall()await scorer.single_turn_ascore(sample)检索+测评
评测集
{"questions":"对于哪些级别的拟录用人员需要进行背景调查","ground_truths":["对M7和P9及以上级别的拟录用人员,人资行政中心还应对其履历的真实性进行背景调查"],"answers":"","contexts":[]}
{"questions":"无故缺席公司总部组织的信息安全培训的人员,本人会受到什么处罚","ground_truths":["处以200-500元处罚"],"answers":"","contexts":[]}
{"questions":"哪些行为会被处以200-500元处罚","ground_truths":["抵触、无故缺席公司总部、省区组织的信息安全培训的人","未经授权,擅自扫的人员","盗用、擅自挪用的人员","违反办公电脑管理办法其他规定,第二次发现对责任员工处200至500元罚款"],"answers":"","contexts":[]}
检索文档并测评检索的结果
import json
import osfrom modelscope import AutoModelForCausalLM, AutoTokenizer
from transformers import AutoModelForCausalLM, AutoTokenizer, pipelineDASHSCOPE_API_KEY = 'sk-xx'
os.environ["DASHSCOPE_API_KEY"] = DASHSCOPE_API_KEY
os.environ["OPENAI_API_KEY"] = 'EMPTY'
model_name = "/home/alg/qdl/model/Qwen2_5-7B-Instruct"
os.environ["DASHSCOPE_API_KEY"] = DASHSCOPE_API_KEY
# **********需要评测的模型**********
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# **********需要评测的模型**********
# **********评估模型**********
llm_path = "/home/alg/qdl/model/CompassJudger-1-7B-Instruct"
emb_path = "/home/alg/qdl/model/BAAI/bge-large-zh-v1.5"
# qwen_service_url = "http://10.199.xx.xx:50015/v1/chat/"# os.environ["OPENAI_API_BASE"] = qwen_service_urlfrom datasets import load_dataset
import pandas as pd
from datasets import Dataset
from typing import List, Optional, Any
from datasets import Dataset
from ragas.metrics import faithfulness, context_recall, context_precision, answer_relevancy
from ragas import evaluate
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import BaseRagasEmbeddings
from ragas.run_config import RunConfig
from FlagEmbedding import FlagModel
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from langchain.llms.base import LLM
from langchain.callbacks.manager import CallbackManagerForLLMRun
import requests# **********评估模型-LLM**********
class MyLLM(LLM):# Support Qwen2tokenizer: AutoTokenizer = Nonemodel: AutoModelForCausalLM = Nonedef __init__(self, mode_name_or_path: str):super().__init__()os.environ['CUDA_VISIBLE_DEVICES'] = '6,7' # 使用第一个GPUself.tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path)self.model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, device_map="cuda").cuda()self.model.generation_config = GenerationConfig.from_pretrained(mode_name_or_path)def _call(self,prompt: str,stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any,) -> str:messages = [{"role": "user", "content": prompt}]input_ids = self.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = self.tokenizer([input_ids], return_tensors="pt").to(self.model.device)generated_ids = self.model.generate(model_inputs.input_ids, max_new_tokens=2048)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]return response@propertydef _llm_type(self):return "CompassJudger-1"# **********评估模型-Embedding**********
class MyEmbedding(BaseRagasEmbeddings):def __init__(self, path, run_config, max_length=512, batch_size=16):self.model = FlagModel(path, query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:")self.max_length = max_lengthself.batch_size = batch_sizeself.run_config = run_configdef embed_documents(self, texts: List[str]) -> List[List[float]]:return self.model.encode_corpus(texts, self.batch_size, self.max_length).tolist()def embed_query(self, text: str) -> List[float]:return self.model.encode_queries(text, self.batch_size, self.max_length).tolist()from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain_community.llms import Tongyi
from langchain_openai import OpenAI
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.prompts import ChatPromptTemplate
from vllm import LLM
from langchain.schema.runnable import RunnableMap
from langchain.schema.output_parser import StrOutputParser
# ***加载文档
bge_embeddings = HuggingFaceBgeEmbeddings(model_name=emb_path)# 1,创建loaders 加载文档
loaders = [TextLoader("/home/alg/qdl/rags/docs/zhidu_1.txt", encoding='utf8'),TextLoader("/home/alg/qdl/rags/docs/zhidu_2.txt", encoding='utf8'),TextLoader("/home/alg/qdl/rags/docs/zhidu_3.txt", encoding='utf8'),
]
print('开始加载文档')
docs = []
for loader in loaders:docs.extend(loader.load())
print(len(docs))
# 分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(docs)
# 2,创建向量数据库
vectorstore = Chroma.from_documents(all_splits, bge_embeddings)
# 3. 设置检索器
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 5}) # top-k = 5
# 4. 创建RAG链# 创建prompt模板
prompt = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use five sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(prompt)
# llm = Tongyi(base_url=qwen_service_url) # 替换为适当的Qwen初始化
# llm = LLM(model=model_name, trust_remote_code=True)
# llm = OpenAI()
pipe = pipeline("text-generation",model=model,tokenizer=tokenizer,max_new_tokens=200,temperature=0.1
)
from langchain_huggingface import HuggingFacePipelinellm = HuggingFacePipeline(pipeline=pipe)# rag_chain = RetrievalQA.from_llm(
# llm,
# retriever=retriever,
# return_source_documents=True, # including source documents in output
# # chain_type_kwargs={'prompt': prompt} # customizing the prompt
# prompt= prompt
# )rag_chain = RetrievalQA.from_chain_type(llm=llm,retriever=retriever, # here we are using the vectorstore as a retriever# chain_type="stuff",return_source_documents=True, # including source documents in outputchain_type_kwargs={'prompt': prompt}
)import re#评测数据
data_files = "/home/alg/qdl/rags/docs/rag.jsonl"
answers = []
questions = []
ground_truths = []
contexts = []
reference = []
with open(data_files, 'r') as file:for line in file:data = json.loads(line)questions.append(data["questions"])ground_truths.append(str(data["ground_truths"]))print("questions")
print(questions)
for query in questions:# 调用模型result = rag_chain.invoke(query)text = result['result']# 正则提取答案match = re.search(r'Answer:(.*?)Assistant:', text, re.DOTALL)if (match):answer = match.group(1).strip()print(f'query-{query},answer-{answer}')else:match = re.search(r'Answer:(.*)', text.replace('\n', ''), re.DOTALL)if (match):answer = match.group(1).strip()print(f'query-{query},answer-{answer}')else:answer = ''print('没有提取到')print('result')print(result)answers.append(answer)contexts.append([docs.page_content for docs in result['source_documents']])print("*****************************执行完成********************************************")
# To dict
data = {"question": questions,"answer": answers,"contexts": contexts,"ground_truth": ground_truths
}
# Convert dict to dataset
dataset = Dataset.from_dict(data)
print("dataset")print(dataset)run_config = RunConfig(timeout=800, max_wait=800)embedding_model = MyEmbedding(emb_path, run_config)
my_llm = LangchainLLMWrapper(MyLLM(llm_path), run_config)
print("开始评测*************")
result = evaluate(dataset,metrics=[context_recall, context_precision, answer_relevancy, faithfulness],llm=my_llm,embeddings=embedding_model,run_config=run_config
)df = result.to_pandas()
print(result)
df.to_csv("result.csv", index=False)
基于dify平台的rag评测
dify上添加大模型rag的流程,通过调用dify接口拿到问题答案和上下文相关内容
import json
import concurrent.futures
import requests
from datasets import Dataset
from ragas.metrics import faithfulness, context_recall, context_precision, answer_relevancy
from ragas.run_config import RunConfig
from FlagEmbedding import FlagModel
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from ragas.embeddings import BaseRagasEmbeddings
import os
from typing import List, Optional, Any
from langchain.llms.base import LLM
from langchain.callbacks.manager import CallbackManagerForLLMRun
from ragas.llms import LangchainLLMWrapper
from ragas import evaluate
from langchain_openai import ChatOpenAI# **********评估模型-LLM**********
class MyLLM(LLM):# Support Qwen2tokenizer: AutoTokenizer = Nonemodel: AutoModelForCausalLM = Nonedef __init__(self, mode_name_or_path: str):super().__init__()os.environ['CUDA_VISIBLE_DEVICES'] = '6,7' # 使用第一个GPUself.tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path)self.model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, device_map="cuda").cuda()self.model.generation_config = GenerationConfig.from_pretrained(mode_name_or_path)def _call(self,prompt: str,stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any,) -> str:messages = [{"role": "user", "content": prompt}]input_ids = self.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = self.tokenizer([input_ids], return_tensors="pt").to(self.model.device)generated_ids = self.model.generate(model_inputs.input_ids, max_new_tokens=2048)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]return response@propertydef _llm_type(self):return "CompassJudger-1"# **********评估模型-Embedding**********
class MyEmbedding(BaseRagasEmbeddings):def __init__(self, path, run_config, max_length=512, batch_size=16):self.model = FlagModel(path, query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:")self.max_length = max_lengthself.batch_size = batch_sizeself.run_config = run_configdef embed_documents(self, texts: List[str]) -> List[List[float]]:return self.model.encode_corpus(texts, self.batch_size, self.max_length).tolist()def embed_query(self, text: str) -> List[float]:return self.model.encode_queries(text, self.batch_size, self.max_length).tolist()
llm_path = "/home/alg/qdl/model/Qwen2_5-7B-Instruct"
# llm_path = "/home/alg/qdl/model/CompassJudger-1-7B-Instruct"
emb_path = "/home/alg/qdl/model/BAAI/bge-large-zh-v1.5"
url = 'http://cc.cc.cc.cc:3000/v1/chat-messages'
data = {"inputs": {},"response_mode": "blocking","conversation_id": "","user": "abc-123","files": []
}
headers = {'Content-Type': 'application/json','Authorization': 'Bearer app-xx'
}answers = []
questions = []
ground_truths = []
contexts = []
# 读取用例文件
def read_cases(case_path):# 每行一个用例,json格式:question context answer weightsamples = []with open(case_path, 'r') as file:for line in file:item = json.loads(line.rstrip())samples.append(item)return samplesdef call_model(url, data, header):# print(f"request:{data}")# print(f'url:{url}')# print(f'data:{data}')# print(f'header:{header}')response = requests.post(url, json=data, headers=header)# 打印响应# print("状态码:", response.status_code)# print("响应内容:", response.json())response = response.json()# 将评估结果添加到样本中return response# 调用dify接口
def evaluate_task(sample, i):similar = sample['similar']goldanswer = sample['goldanswer']# 调用dify接口questions.append(similar)ground_truths.append(goldanswer)results = ''try:print(f'执行第{i + 1}个')data['query'] = similarresponse = call_model(url, data, headers)answer = response['answer']context = [item['content'] for item in response['metadata']['retriever_resources']]contexts.append(context)answers.append(answer)# print(f'answer:{answer}')# print(f'context:{context}')except:print(f"第{i}个用例出现异常,模型响应为:{response}")answers.append('异常')contexts.append(['异常'])return results# 1,读取用例文件
case_path = 'rag_cases.jsonl'
samples = read_cases(case_path)
# 2,提取相似问,调dify接口获取答案和上下文
with concurrent.futures.ThreadPoolExecutor(max_workers=1) as executor:for i in range(len(samples)):# executor.submit(get_eval_score,samples[i],i)executor.submit(evaluate_task(samples[i], i))
# 3,执行评测
data = {"question": questions,"answer": answers,"contexts": contexts,"ground_truth": ground_truths
}
print(f'data:{data}')
# Convert dict to dataset
dataset = Dataset.from_dict(data)
print("dataset")print(dataset)run_config = RunConfig(timeout=800, max_wait=800)
#dify接口
qwen_service_url = "http://xx.net.cn:50015/v1"embedding_model = MyEmbedding(emb_path, run_config)
# my_llm = LangchainLLMWrapper(MyLLM(llm_path), run_config)
my_llm=LangchainLLMWrapper( ChatOpenAI(model_name='Qwen2-72B-Instruct-AWQ-Preprod',openai_api_base=qwen_service_url,openai_api_key='EMPTY',))
print("开始评测*************")
result = evaluate(dataset,metrics=[context_recall, context_precision, answer_relevancy, faithfulness],llm=my_llm,embeddings=embedding_model,run_config=run_config
)df = result.to_pandas()
print(result)
df.to_csv("result.csv", index=False)相关文章:

Ragas-RAG能力评测
Ragas是一个框架,它可以帮助你从不同的方面评估你的问答(QA)流程。它为你提供了一些指标来评估你的问答系统的不同方面,具体包括: 评估检索(context)的指标:提供了上下文相关性&…...
)
【PCL】Segmentation 模块—— 条件欧几里得聚类(Conditional Euclidean Clustering)
1、简介 1.1 条件欧几里得聚类(Conditional Euclidean Clustering) 本文介绍了如何使用 pcl::ConditionalEuclideanClustering 类:这是一种基于欧几里得距离和用户自定义条件的点云聚类分割算法。 该类使用了与欧几里得聚类提取(Euclidean…...

#HarmonyOS篇:build-profile.json5里面配置productsoh-package.json5里面dependencies依赖引入
oh-package.json5 用于描述包名、版本、入口文件和依赖项等信息。 {"license": "","devDependencies": {},"author": "","name": "entry","description": "Please describe the basic…...

《探秘:人工智能如何为鸿蒙Next元宇宙网络传输与延迟问题破局》
在元宇宙的宏大愿景中,流畅的网络传输和低延迟是保障用户沉浸式体验的关键。鸿蒙Next结合人工智能技术,为解决这些问题提供了一系列创新思路和方法。 智能网络监测与预测 人工智能可以实时监测鸿蒙Next元宇宙中的网络状况,包括带宽、延迟、…...

java中的泛型
文章目录 java中的泛型泛型的使用1 快速入门2 泛型的介绍(1)使用泛型的好处(2)泛型的理解(3)泛型的语法(4)泛型使用的注意事项 3 自定义泛型(1)自定义泛型类&…...

PCF8563一款工业级、低功耗多功能时钟/日历芯片
PCF8563是PHILIPS(现NXP)公司生产的一款工业级、内含I2C总线接口功能的低功耗多功能时钟/日历芯片。以下是对该芯片的详细介绍: 一、主要特性 低功耗:典型值为0.25μA(VDD3.0V,Tamb25℃)。宽电…...

Servlet快速入门
Servlet 由于目前主流使用SpringBoot进行开发Servlet可以说是时代的眼泪,这篇文章主要介绍我基于SpringBoot对应Servlet的浅薄认知,有利于更好的理解前端界面和java服务器的数据交换过程 快速入门 我比较推荐这篇文章来对Servlet有一个大概的了解 都2…...

C语言初阶牛客网刷题——JZ17 打印从1到最大的n位数【难度:入门】
1.题目描述 牛客网OJ题链接 题目描述: 输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数 999。 用返回一个整数列表来代替打印n 为正整数,0 < n < 5 示例1 输入&…...

【组件分享】商品列表组件-最佳实践
商品列表组件 商品列表组件用于展示商品信息列表,支持多种布局方式和自定义配置。 基础用法 <template><ProGoodsList :goods-list"goodsList" :layout"layout" item-click"handleItemClick" /> </template>&l…...

【JAVA】BOSS系统发版艺术:构建高效、优雅的微服务部署策略
在现代软件开发领域,微服务架构与容器化部署已迅速成为行业新趋势。微服务架构通过将应用拆分成多个小型、自治的服务单元,每个服务承担某项特定的业务功能。而容器化部署则以其轻量级和高度可移植的特性,为这些微服务的有效打包、分发和运行…...

React的响应式
在 React 中,useState 是一个 Hook,用于在函数组件中定义和管理状态。 setCount 是由 useState 返回的第二个值,用于更新状态并触发组件重新渲染。它的本质是一个状态更新函数,背后是 React 的状态管理和调度机制。下面是对 setCo…...

deep face cam 部署报错解决
这里写自定义目录标题 使用conda创建py3.9环境使用按照readme.txt安装所有依赖后遇到的报错2.最后一个模块insightface安装报错3.运行run.py又报错原因:解决方法:4.缺少模块解决方法:pip命令安装5.AttributeError: NoneType object has no attribute configure解决方法:安装…...
:高斯滤波器详解)
图像处理基础(4):高斯滤波器详解
本文主要介绍了高斯滤波器的原理及其实现过程 高斯滤波器是一种线性滤波器,能够有效的抑制噪声,平滑图像。其作用原理和均值滤波器类似,都是取滤波器窗口内的像素的均值作为输出。其窗口模板的系数和均值滤波器不同,均值滤波器的…...

outlook附件限制最大5m如何解决
Outlook 附件大小限制为 5MB,通常由邮件服务器(如 Exchange、Office 365、Gmail 等)或本地 Outlook 配置决定。可以采取以下几种方法来解决该限制问题: 解决方案 1:调整服务器端限制(管理员权限)…...

Word常见问题:嵌入图片无法显示完整
场景:在Word中,嵌入式图片显示不全,一部分图片在文字下方。如: 问题原因:因段落行距导致 方法一 快捷方式 选中图片,通过"ctrl1"快捷调整为1倍行距 方法二 通过工具栏调整 选中图片࿰…...

【面试题】java基础概念
以下是关于这道面试题的回答,包括JDK中一些相关概念的区别以及JIT的原理: JDK中相关概念区别 JDK、JRE和JVM JDK(Java Development Kit):是Java开发工具包,它包含了JRE和一系列开发工具。JDK提供了编译、…...

WebSocket实现私聊私信功能
目录 后端pom.xmlConfig配置类Controller类DTO 前端安装相关依赖websocketService.js接口javascripthtmlCSS 效果展示简单测试连接: 报错解决方法1、vue3 使用SockJS报错 ReferenceError: global is not defined 后面将继续完善,待更新... 后端 pom.xml…...

进程的哪些内存类型容易引起内存泄漏
相信你在平时的工作中,应该遇到过下面这些场景: 伴随着服务器中的后台任务持续地运行,系统中可用内存越来越少; 应用程序正在运行时忽然被 OOM kill 掉了; 进程看起来没有消耗多少内存,但是系统内存就是不够…...

用着很顺手的电脑亮度随心随意调节
一、功能介绍 显示高级设置,可以调节屏幕RGB色彩。 娱乐亮度,一键娱乐亮度调节。 护眼亮度,保护眼睛,减少蓝光。 恢复正常,一键恢复到默认模块。 二、问题解答 1、亮度更改后显示器无变化!软件根本都没…...

图片生成Prompt编写技巧
1. 图片情绪(场景氛围) 一张图片一般都会有一个情绪基调,因为作画本质上也是在传达一些情绪,一般都会借助图片的氛围去转达。例如:比如家庭聚会一般是欢乐、喜乐融融。断壁残垣一般是悲凉。还有萧瑟、孤寂等。 2.补充细…...

博客之星2024年度总评选——我的年度创作回顾与总结
2024年,是我在CSDN博客上持续耕耘、不断成长的一年。在此,与大家分享一下我的年度创作回顾与总结。 一、创作成长与突破 在人工智能领域,技术迭代迅速,知识更新频繁。为了保持自己的竞争力,在今年,我始终…...

前端Vue2项目使用md编辑器
项目中有一个需求,要在前端给用户展示内容,内容有 AI 生成的,返回来的是 md 格式,所以需要给用户展示 md 格式,并且管理端也可以编辑这个 md 格式的文档。 使用组件库 v-md-editor。 https://code-farmer-i.github.i…...

Docker核心命令与Yocto项目的高效应用
随着软件开发逐渐向分布式和容器化方向演进,Docker 已成为主流的容器化技术之一。它通过标准化的环境配置、资源隔离和高效的部署流程,大幅提高了开发和构建效率。Yocto 项目作为嵌入式 Linux 系统构建工具,与 Docker 的结合进一步增强了开发…...

kong 网关和spring cloud gateway网关性能测试对比
该测试只是简单在同一台机器设备对spring cloud gateway网关和kong网关进行对比,受限于笔者所拥有的资源,此处仅做简单评测。 一、使用spring boot 的auth-service作为服务提供者 该服务提供了一个/health接口,接口返回"OK"&…...

DDoS攻击防护能力测试:Python版脚本
引言 在互联网服务日益复杂和流量持续增长的今天,确保服务器能够应对高并发请求并具备良好的抗DDoS攻击的能力至关重要。声明以下代码仅在合法的前提下使用。 工具设计原理 脚本的核心在于它能够创建多个线程来并发执行不同的攻击方法,从而实现对目标…...
白玉微瑕:闲谈 SwiftUI 过渡(Transition)动画的“口是心非”(下)
概述 秃头小码农们都知道,SwiftUI 不仅仅是一个静态 UI 构建框架那么简单,辅以海量默认或自定义的动画和过渡(Transition)特效,我们可以将 App 界面的绚丽升华到极致。 不过,目前 SwiftUI 中的过渡&#x…...

5.4 解锁 OpenAI - Translator:模块设计,构建翻译系统的 “基石”
OpenAI-Translator 模块设计 OpenAI-Translator 作为一款基于 OpenAI GPT 模型的智能翻译助手,其模块设计至关重要。为了保证翻译的高效性、准确性与可扩展性,系统需要一个结构清晰、功能强大的模块化设计。本文将对 OpenAI-Translator 的各个模块进行详细解析,涵盖其核心功…...

数据分析 变异系数
目录 变异系数的应用场景包括: 特点: 注意事项: np.nanvar——方差,np.sanstd标准差 简单来讲就是平均值/标准差 变异系数(Coefficient of Variation, CV)是一种相对量的变异指标,常用于衡…...

C语言——编译与链接
目录 前言 一程序的两种环境 1翻译环境 2执行环境 二预处理 1预处理符号 2#define 2.1#define 定义标识符 2.2#define 定义宏 2.2.1#和## 2.3带副作用的宏参数 2.4宏和函数的比较 2.5命名约定 3#undef 4命令行定义 5条件编译 5.1单分支 5.2多分支 5.3判断是…...

NewStar CTF week1 web wp
谢谢皮蛋 做这题之前需要先去学习一些数据库的知识 1 order by 2 1可以理解为输入的id,是一个占位符,按第二列排序用来测试列数,如果没有两列则会报错-1 union select 1,2 -1同样是占位符,union的作用是将注入语句合并到原始语句…...
)
Android BitmapShader简洁实现马赛克,Kotlin(一)
Android BitmapShader简洁实现马赛克,Kotlin(一) 这一篇, Android使用PorterDuffXfermode模式PorterDuff.Mode.SRC_OUT橡皮擦实现马赛克效果,Kotlin(3)-CSDN博客 基于PorterDuffXfermode实现马…...

NavVis手持激光扫描帮助舍弗勒快速打造“数字孪生”工厂-沪敖3D
在全球拥有近100家工厂的舍弗勒,从2016年开启数字化运营进程,而当前制造、库存、劳动力和物流的数字化,已无法支持其进一步简化工作流程,亟需数字化物理制造环境,打造“数字孪生”工厂。 NavVis为其提供NavVis VLX 3…...

web服务器 网站部署的架构
WEB服务器工作原理 Web web是WWW(World Wide Web)的简称,基本原理是:请求(客户端)与响应(服务器端)原理,由遍布在互联网中的Web服务器和安装了Web浏览器的计算机组成 客户端发出请求的方式:地址栏请求、超链接请求、表单请求 …...

ecovadis验厂相关要求
EcoVadis验厂的相关要求主要包括以下几个方面: 一、企业基本资质要求 合法注册与运营:企业必须是合法注册并运营的法人实体,具备合法的经营资质,如营业执照、税务登记证等。无严重违法记录:在过去三年内,…...
JAVA,javaEE,spring,springmvc,springboot,SSM,SSH等几个概念区别)
SSM开发(一)JAVA,javaEE,spring,springmvc,springboot,SSM,SSH等几个概念区别
目录 JAVA 框架 javaEE spring springmvc springboot SSM SSH maven JAVA 一种面向对象、高级编程语言,Python也是高级编程语言;不是框架(框架:一般用于大型复杂需求项目,用于快速开发)具有三大特性,所谓Jav…...

Spring Boot中选择性加载Bean的几种方式
说明:用过Spring框架的都知道其自动装配的特性,本文介绍几种选择性加载Bean的方式。Spring自动装配参考以下两篇文章: 基于SpringBoot的三层架构开发&统一响应结果 SpringBoot自动装配原理简单分析 ConditionalOnProperty Conditiona…...

【JVM】垃圾收集器详解
你将学到 1. Serial 收集器 2. ParNew 收集器 3. Parallel Scavenge 收集器 4. Serial Old 收集器 5. Parallel Old 收集器 6. CMS 收集器 7. G1 收集器 在 Java 中,垃圾回收(GC)是自动管理内存的一个重要机制。HotSpot JVM 提供了多种…...

【实用技能】如何在Stimulsoft产品中使用用户函数,快速创建报表及仪表盘
Stimulsoft Ultimate (原Stimulsoft Reports.Ultimate)是用于创建报表和仪表板的通用工具集。该产品包括用于WinForms、ASP.NET、.NET Core、JavaScript、WPF、PHP、Java和其他环境的完整工具集。无需比较产品功能,Stimulsoft Ultimate包含了…...

MySQL四种隔离级别
MySQL的隔离级别是在事务这个大主题下面产生的说法。 那么什么是事务,事务就是一组sql语句,要么全部执行成功,要么都不执行,不能只执行成功其中的部分sql。事务的最终目的是为了保证数据库数据的完整性、一致性和可用性。 要保…...

Unity入门1
安装之后无法获得许可证,可以考虑重装 新建项目 单击空白处生成脚本 双击c#文件 会自动打开vstudio 检查引用 如果没有引用,重开vstu,或者重新加载项目 hierarchy层级 scenes场景 assets资产 inspector督察 icon图标 资源链接&…...

qml Loader详解
1、概述 QML Loader是Qt Quick框架中的一个关键元素,它允许开发者动态地加载和卸载QML组件。这种动态加载机制对于提升应用程序的性能、响应速度和用户体验至关重要。通过Loader,应用程序可以在需要时才加载特定的组件,而不是在启动时一次性…...

《安富莱嵌入式周报》第349期:VSCode正式支持Matlab调试,DIY录音室级麦克风,开源流体吊坠,物联网在军工领域的应用,Unicode字符压缩解压
周报汇总地址:嵌入式周报 - uCOS & uCGUI & emWin & embOS & TouchGFX & ThreadX - 硬汉嵌入式论坛 - Powered by Discuz! 视频版: 《安富莱嵌入式周报》第349期:VSCode正式支持Matlab调试,DIY录音室级麦克风…...

web端ActiveMq测试工具
如何用vue3创建简单的web端ActiveMq测试工具? 1、复用vue3模板框架 创建main.js,引入APP文件,createApp创建文件,并加载element插件,然后挂载dom节点 2、配置vue.config.js脚本配置 mport { defineConfig } from "vite&qu…...

1561. 你可以获得的最大硬币数目
class Solution:def maxCoins(self, piles: List[int]) -> int:piles.sort()res,n0,len(piles)for i in range(n//3):respiles[n-2-2*i]return res这里如果"你"想要获取最大,那么从最大的开始找 每隔俩算一个最大累计,Bob默认自己从最小那找…...
)
NIO | 什么是Java中的NIO —— 结合业务场景理解 NIO (二)
实时通信应用 的主流技术 并非NIO , 整理本文的目的是 更好的理解 NIO 。 在现代的 即时聊天应用中,使用 WebSocket、MQTT 或 SignalR 等协议更为普遍。 若您想了解 当前主流的有关 实时通信应用 的技术 , 请移步他文。 (一) 业务场景 实…...

GD32L233RB 驱动数码管
1.数码管有8段A、B、C、D、E、F、G 和 H小数点 以及片选信号(DIG) DIG用来选择那一位,A-G 用来显示段 静态显示每次只能一次显示单个位 动态显示(动态扫描)所有的位显示结束要在10ms左右 显示2ms 消光1ms 实…...
模型)
AIGC视频生成模型:Stability AI的SVD(Stable Video Diffusion)模型
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍Stability AI的视频生成模型SVD(Stable Video Diffusion)模型,这家公司在图像生成领域富有盛名,开发并维护了知名开源项目SD系列…...

Linux 系统错误处理简介
Linux 系统错误处理简介 1. errno:错误代码的载体2. strerror():错误信息的翻译官3. perror():便捷的错误信息输出4. 系统调用与库函数的区别5. 错误处理的最佳实践 在 C/C 程序开发中,我们经常需要处理各种错误情况 Linux 系统提…...

systemC示例
main.cpp #include <memory> using namespace std; #include "top.h" int sc_main(int i, char *av[]) { // 关闭关于 IEEE 1666 标准中过时特性的警告 sc_report_handler::set_actions("/IEEE_Std_1666/deprecated", SC_DO_NOTHING); cout <…...

C++打字模拟
改进于 文宇炽筱_潜水 c版的打字效果_c自动打字-CSDN博客https://blog.csdn.net/2401_84159494/article/details/141023898?ops_request_misc%257B%2522request%255Fid%2522%253A%25227f97863ddc9d1b2ae9526f45765b1744%2522%252C%2522scm%2522%253A%252220140713.1301023…...