朴素贝叶斯分类器
一、生成模型(学习)(Generative Model) vs 判别模型(学习)(Discriminative Model)
结论:贝叶斯分类器是生成模型
1、官方说明
生成模型对联合概率 p(x, y)建模, 判别模型对条件概率 p(y | x)进行建模。
2、通俗理解
生成模型重点在于“生成”过程。比如你想做一道菜,生成模型就像是在研究各种食材(x)和菜的口味(y)同时出现的“配方”,它试图去了解整个“烹饪过程”中,食材和口味是如何一起搭配出现的,是从整体上把握“食材+口味”这个组合出现的概率。
判别模型重点在于评判。还是用做菜举例,判别模型就像是在已经知道食材(x)的情况下,去评判这道菜会是什么口味(y)。它不关心整个“烹饪过程”,只关心在给定食材这个前提下,不同口味出现的可能性,是从结果导向的角度,去判断在x出现的情况下,y出现的概率。
3、举例
以水果分类问题为例
判别学习算法:如果我们要找到一条直线把两类水果分开, 这条直线可以称作边界, 边界的两边是不同类别的水果;
生成学习算法:如果我们分别为樱桃和猕猴桃生成一个模型来描述他们的特征, 当要判断一个新的样本是什么水果时, 可以将该样本带入两种水果的模型, 比较看新的样本是更像樱桃还是更像猕猴桃。
二、生成学习算法
以水果分类问题为例
1、数学符号说明
y = 0:样本是樱桃
y = 1:样本是猕猴桃
p(y):类的先验概率, 表示每一类出现的概率。
p(x | y):样本出现的条件概率
- p(x | y=0)对樱桃的特征分布建模,
- p(x | y=1)对猕猴桃的特征分布建模。
p(y | x):类的后验概率
注:
- 先验概率:就是在没看到具体证据之前,基于已有经验或知识对事件发生概率的初步判断。
- 后验概率:就是在看到具体证据之后,结合先验概率和新证据,对事件发生概率的更新判断。
2、贝叶斯公式
计算出样本属于每一类的概率:

分类问题只需要预测类别, 只需要比较样本属于每一类的概率, 选择概率值最大的那一类即可, 因此, 分类器的判别函数表示为:

因为p(y)p(x | y)=p(x , y),而p(x)是一个常数,故贝叶斯公式计算公式计算需要p(x , y)值,它对联合概率进行建模, 与生成模型的定义一致, 因此是生成学习算法
三、朴素贝叶斯分类器
假设特征向量的分量之间相互独立
样本的特征向量 x,根据条件概率公式可知该样本属于某一类ci的概率为:

由于假设特征向量各个分量相互独立, 因此有:

是特征向量 x 的各个分量, p(x)对于所有类别来说都是相等的, 因此用一个常数 Z 来表示。
1、离散型特征
计算公式:

特殊情况
在计算条件概率时, 如果
为 0, 即特征分量的某个取值在某一类训练样本中一次都没出现, 则会导致特征分量取到这个值时的预测函数为 0。 可以使用拉普拉斯平滑(Laplace smoothing) 来处理这种情况。
具体做法就是给分子和分母同时加上一个正整数, 给分子加上 1, 分母加上特征分量取值的 k 种情况,这样就可以保证所有类的条件概率之和还是 1, 并且避免了预测结果为 0 的情况。

类 出现的概率为:

最终分类判别函数可以写成:

2、连续型特征
假设特征向量的分量服从一维正态分布
计算公式:

样本属于某一类 的概率:

最终分类判别函数可以写成:

上述两种特征唯一区别在于计算方法不一样
四、代码实现连续型特证朴素贝叶斯分类器
1、算法流程
(1) 收集训练样本;
(2) 计算各类别的先验概率 ;
(3) 计算每个类别下各特征属性 xj的条件概率 ;
(4) 计算后验概率 ;
(5) 将待分类样本归类到后验概率最大的类别中。
2、数据集选择
iris 数据集。包含 150 个数据样本, 分为 3 类, 每类 50 个数据, 每个数据包含 4个属性, 即特征向量的维数为 4。
3、需要安装的 Python 库
numPy:数值计算库
pandas:数据操作和分析库
sklearn:机器学习的 Python 库
pip install numpy
pip install pandas
pip install scikit-learn4、手动实现(分步骤代码)
1)收集训练样本
def loadData(filepath):""":param filepath: csv:return: list"""data_df = pd.read_csv(filepath)data_list = np.array(data_df) data_list = data_list.tolist() # 将pandas DataFrame转换成Numpy的数组再转换成列表print("Loaded {0} samples successfully.".format(len(data_list)))return data_list# 按ratio比例划分训练集与测试集
def splitData(data_list, ratio):""":param data_list:all data with list type:param ratio: train date's ratio:return: list type of trainset and testset"""train_size = int(len(data_list) * ratio)random.shuffle(data_list) #随机打乱列表元素trainset = data_list[:train_size]testset = data_list[train_size:]return trainset, testset# 按类别划分数据
def seprateByClass(dataset):""":param dataset: train data with list type:return: seprate_dict:separated data by class;info_dict:Number of samples per class(category)"""seprate_dict = {}info_dict = {}for vector in dataset:if vector[-1] not in seprate_dict:seprate_dict[vector[-1]] = []info_dict[vector[-1]] = 0seprate_dict[vector[-1]].append(vector)info_dict[vector[-1]] += 1return seprate_dict, info_dict主函数中调用
data_list = loadData('IrisData.csv')trainset, testset = splitData(data_list, 0.7)dataset_separated, dataset_info = seprateByClass(trainset)2) 计算各类别的先验概率
def calulateClassPriorProb(dataset, dataset_info):"""calculate every class's prior probability:param dataset: train data with list type:param dataset_info: Number of samples per class(category):return: dict type with every class's prior probability"""dataset_prior_prob = {}sample_sum = len(dataset)for class_value, sample_nums in dataset_info.items():dataset_prior_prob[class_value] = sample_nums / float(sample_sum)return dataset_prior_prob主函数中调用
prior_prob = calulateClassPriorProb(trainset, dataset_info)3) 计算每个类别下各特征属性 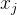 的条件概率
的条件概率
先计算均值和方差
def mean(number_list):number_list = [float(x) for x in number_list] # str to numberreturn sum(number_list) / float(len(number_list))def var(number_list):number_list = [float(x) for x in number_list]avg = mean(number_list)var = sum([math.pow((x - avg), 2) for x in number_list]) / float(len(number_list))return var# 计算每个属性的均值和方差
def summarizeAttribute(dataset):"""calculate mean and var of per attribution in one class:param dataset: train data with list type:return: len(attribution)'s tuple ,that's (mean,var) with per attribution"""dataset = np.delete(dataset, -1, axis=1) # delete label# zip函数将数据样本按照属性分组为一个个列表,然后可以对每个属性计算均值和标准差。summaries = [(mean(attr), var(attr)) for attr in zip(*dataset)]return summaries# 按类别提取数据特征
def summarizeByClass(dataset_separated):"""calculate all class with per attribution:param dataset_separated: data list of per class:return: num:len(class)*len(attribution){class1:[(mean1,var1),(),...],class2:[(),(),...]...}"""summarize_by_class = {}for classValue, vector in dataset_separated.items():summarize_by_class[classValue] = summarizeAttribute(vector)return summarize_by_class #返回的是某类别各属性均值方差的列表主函数中调用 :
summarize_by_class = summarizeByClass(dataset_separated)计算条件概率
def calculateClassProb(input_data, train_Summary_by_class):"""calculate class conditional probability through multiplyevery attribution's class conditional probability per class:param input_data: one sample vectors:param train_Summary_by_class: every class with every attribution's (mean,var):return: dict type , class conditional probability per class of this input data belongs to which class"""prob = {}p = 1for class_value, summary in train_Summary_by_class.items():prob[class_value] = 1for i in range(len(summary)):mean, var = summary[i]x = input_data[i]exponent = math.exp(math.pow((x - mean), 2) / (-2 * var))p = (1 / math.sqrt(2 * math.pi * var)) * exponentprob[class_value] *= preturn prob4) 计算后验概率并将待分类样本归类到后验概率最大的类别中
主函数中使用
# 下面对测试集进行预测correct = 0 # 预测的准确率for vector in testset:input_data = vector[:-1]label = vector[-1]prob = calculateClassProb(input_data, summarize_by_class)result = {}for class_value, class_prob in prob.items():p = class_prob * prior_prob[class_value]result[class_value] = ptype = max(result, key=result.get)print(vector)print(type)if type == label:correct += 1print("predict correct number:{}, total number:{}, correct ratio:{}".format(correct, len(testset), correct / len(testset)))
5、手动实现(整体代码)
# 导入需要用到的库
import pandas as pd
import numpy as np
import random
import math# 载入数据集
def loadData(filepath):""":param filepath: csv:return: list"""data_df = pd.read_csv(filepath)data_list = np.array(data_df) # 将pandas DataFrame转换成Numpy的数组再转换成列表data_list = data_list.tolist()print("Loaded {0} samples successfully.".format(len(data_list)))return data_list# 划分训练集与测试集
def splitData(data_list, ratio):""":param data_list:all data with list type:param ratio: train date's ratio:return: list type of trainset and testset"""train_size = int(len(data_list) * ratio)random.shuffle(data_list) #随机打乱列表元素trainset = data_list[:train_size]testset = data_list[train_size:]return trainset, testset# 按类别划分数据
def seprateByClass(dataset):""":param dataset: train data with list type:return: seprate_dict:separated data by class;info_dict:Number of samples per class(category)"""seprate_dict = {}info_dict = {}for vector in dataset:if vector[-1] not in seprate_dict:seprate_dict[vector[-1]] = []info_dict[vector[-1]] = 0seprate_dict[vector[-1]].append(vector)info_dict[vector[-1]] += 1return seprate_dict, info_dict# 计算先验概率
def calulateClassPriorProb(dataset, dataset_info):"""calculate every class's prior probability:param dataset: train data with list type:param dataset_info: Number of samples per class(category):return: dict type with every class's prior probability"""dataset_prior_prob = {}sample_sum = len(dataset)for class_value, sample_nums in dataset_info.items():dataset_prior_prob[class_value] = sample_nums / float(sample_sum)return dataset_prior_prob# 计算均值的函数
def mean(number_list):number_list = [float(x) for x in number_list] # str to numberreturn sum(number_list) / float(len(number_list))# 计算方差的函数
def var(number_list):number_list = [float(x) for x in number_list]avg = mean(number_list)var = sum([math.pow((x - avg), 2) for x in number_list]) / float(len(number_list))return var# 计算每个属性的均值和方差
def summarizeAttribute(dataset):"""calculate mean and var of per attribution in one class:param dataset: train data with list type:return: len(attribution)'s tuple ,that's (mean,var) with per attribution"""dataset = np.delete(dataset, -1, axis=1) # delete label# zip函数将数据样本按照属性分组为一个个列表,然后可以对每个属性计算均值和标准差。summaries = [(mean(attr), var(attr)) for attr in zip(*dataset)]return summaries# 按类别提取数据特征
def summarizeByClass(dataset_separated):"""calculate all class with per attribution:param dataset_separated: data list of per class:return: num:len(class)*len(attribution){class1:[(mean1,var1),(),...],class2:[(),(),...]...}"""summarize_by_class = {}for classValue, vector in dataset_separated.items():summarize_by_class[classValue] = summarizeAttribute(vector)return summarize_by_class #返回的是某类别各属性均值方差的列表# 计算条件概率
def calculateClassProb(input_data, train_Summary_by_class):"""calculate class conditional probability through multiplyevery attribution's class conditional probability per class:param input_data: one sample vectors:param train_Summary_by_class: every class with every attribution's (mean,var):return: dict type , class conditional probability per class of this input data belongs to which class"""prob = {}p = 1for class_value, summary in train_Summary_by_class.items():prob[class_value] = 1for i in range(len(summary)):mean, var = summary[i]x = input_data[i]exponent = math.exp(math.pow((x - mean), 2) / (-2 * var))p = (1 / math.sqrt(2 * math.pi * var)) * exponentprob[class_value] *= preturn probif __name__ == '__main__':data_list = loadData('IrisData.csv')trainset, testset = splitData(data_list, 0.7)dataset_separated, dataset_info = seprateByClass(trainset)summarize_by_class = summarizeByClass(dataset_separated)prior_prob = calulateClassPriorProb(trainset, dataset_info)# 下面对测试集进行预测correct = 0 # 预测的准确率for vector in testset:input_data = vector[:-1]label = vector[-1]prob = calculateClassProb(input_data, summarize_by_class)result = {}for class_value, class_prob in prob.items():p = class_prob * prior_prob[class_value]result[class_value] = ptype = max(result, key=result.get)print(vector)print(type)if type == label:correct += 1print("predict correct number:{}, total number:{}, correct ratio:{}".format(correct, len(testset), correct / len(testset)))
6、使用 sklearn 库实现
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载iris数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7)# 初始化朴素贝叶斯分类器(这里使用高斯朴素贝叶斯)
gnb = GaussianNB()
# 使用训练集训练朴素贝叶斯分类器
gnb.fit(X_train, y_train)
# 使用测试集进行预测
y_pred = gnb.predict(X_test)
# 计算预测的准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: {}".format(accuracy))
相关文章:

朴素贝叶斯分类器
一、生成模型(学习)(Generative Model) vs 判别模型(学习)(Discriminative Model) 结论:贝叶斯分类器是生成模型 1、官方说明 生成模型对联合概率 p(x, y)建模&#x…...
—术语和定义)
商用车电子电气零部件电磁兼容条件和试验(2)—术语和定义
写在前面 本系列文章主要讲解商用车电子/电气零部件或系统的传导抗干扰、传导发射和辐射抗干扰、电场辐射发射以及静电放电等试验内容及要求,高压试验项目内容及要求。 若有相关问题,欢迎评论沟通,共同进步。(*^▽^*) 目录 商用车电子电气…...

SimpleFOC01|基于STM32F103+CubeMX,移植核心的common代码
导言 如上图所示,进入SimpleFOC官网,点击Github下载源代码。 如上图所示,找到仓库。 comom代码的移植后,simpleFOC的移植算是完成一大半。simpleFOC源码分为如下5个部分,其中communication是跟simpleFOC上位机通讯&a…...

物联网之传感器技术
引言 在数字化浪潮席卷全球的今天,物联网(IoT)已成为推动各行各业变革的重要力量。而物联网传感器,作为物联网感知层的核心技术,更是扮演着不可或缺的角色。它们如同人类的五官,能够感知物理世界中的各种信…...

React:构建用户界面的JavaScript库
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

基于TypeScript封装 `axios` 请求工具详解
TypeScript 项目中,封装一个详细的 axios 请求工具可以提高代码的可维护性、可重用性,并让请求逻辑与业务逻辑分离。以下是一个详细的封装示例,包括请求拦截器、响应拦截器、错误处理、以及类型定义。 1. 安装 Axios 首先,确保你…...

ElasticSearch在Windows环境搭建测试
引子 也持续关注大数据相关内容一段时间,大数据内容很多。想了下还是从目前项目需求侧出发,进行相关学习。Elasticsearch(ES)是位于 Elastic Stack(ELK stack) 核心的分布式搜索和分析引擎。Logstash 和 B…...

通信与网络安全管理之ISO七层模型与TCP/IP模型
一.ISO参考模型 OSI七层模型一般指开放系统互连参考模型 (Open System Interconnect 简称OSI)是国际标准化组织(ISO)和国际电报电话咨询委员会(CCITT)联合制定的开放系统互连参考模型,为开放式互连信息系统提供了一种功能结构的框架。 它从低到高分别是…...

高级运维:shell练习2
1、需求:判断192.168.1.0/24网络中,当前在线的ip有哪些,并编写脚本打印出来。 vim check.sh #!/bin/bash# 定义网络前缀 network_prefix"192.168.1"# 循环遍历1-254的IP for i in {1..254}; do# 构造完整的IP地址ip"$network_…...

三相无刷电机控制|FOC理论04 - 克拉克变换 + 帕克变换的最终目标
导言 通过坐标系旋转,将电机中复杂的三相交流信号映射到与转子磁场同步的旋转参考系中,将动态问题转化为静态问题。这种方法的优点在于: 简化了控制逻辑。实现了转矩Iq和磁通Id的解耦。提供了直流量控制的可能性,大大提高了控制效…...

SAP FICO资产模块各元素基本关系总结
文章目录 【SAP系统研究】 #SAP #FICO #资产会计 ①:每个折旧表包含多个折旧范围,折旧范围用于设置资产的平行折旧,如不同的折旧范围可以更新不同的总账,更新不同的科目等。 ②:折旧表是要分配给公司代码的ÿ…...

Elasticsearch快速入门
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分,提供核心的数据存储、搜索、分析功能 elasticsearch之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术。那么什么是倒排索引呢? Elasticsearch…...

【Java数据结构】二叉树相关算法
第一题:获取二叉树中结点个数 得到二叉树结点个数,如果结点为空则返回0,然后再用递归计算左树结点个数根结点(1个)右树结点个数。 public int nodeSize(Node root){if (root null)return 0;return nodeSize1(root.l…...

30分钟内搭建一个全能轻量级springboot 3.4 + 脚手架 <1> 5分钟快速创建一个springboot web项目
快速导航 <1> 5分钟快速创建一个springboot web项目 <2> 5分钟集成好最新版本的开源swagger ui,并使用ui操作调用接口 <3> 5分钟集成好druid并使用druid自带监控工具监控sql请求 <4> 5分钟集成好mybatisplus并使用mybatisplus generator自…...

vue3学习日记6 - Layout
最近发现职场前端用的框架大多为vue,所以最近也跟着黑马程序员vue3的课程进行学习,以下是我的学习记录 视频网址: Day2-17.Layout-Pinia优化重复请求_哔哩哔哩_bilibili 学习日记: vue3学习日记1 - 环境搭建-CSDN博客 vue3学…...

1/14 C++
练习:将图形类的获取周长和获取面积函数设置成虚函数,完成多态 再定义一个全局函数,能够在该函数中实现:无论传递任何图形,都可以输出传递的图形的周长和面积 #include <iostream>using namespace std; class Sh…...

【Uniapp-Vue3】页面生命周期onLoad和onReady
一、onLoad函数 onLoad在页面载入时触发,多用于页面跳转时进行参数传递。 我们在跳转的时候传递参数name和age: 接受参数: import {onLoad} from "dcloudio/uni-app"; onLoad((e)>{...}) 二、onReady函数 页面生命周期函数中的onReady其…...

使用 configparser 读取 INI 配置文件
使用 configparser 读取 INI 配置文件 适合于读取 .ini 格式的配置文件。 配置文件示例 (config.ini): [DEFAULT] host localhost port 3306 [database] user admin password secret import configparser# 创建配置解析器 config configparser.ConfigParser()# 读取配…...

类模板的使用方法
目录 类模板的使用方法 1.类模板语法 2.类模板和函数模板区别 3.类模板中成员函数创建时机 4.类函数对象做函数参数 5.类模板和继承 6.类模板成员函数类外实现 7.类模板分文件编写 person.hpp 实现cpp文件: 8.类模板与友元 9.类模板案例 MyArray.hpp …...

docker mysql5.7如何设置不区分大小写
环境 docker部署,镜像是5.7,操作系统是centos 操作方式 mysql 配置文件是放在 /etc/mysql/mysql.conf.d/mysqld.cnf, vim /etc/mysql/mysql.conf.d/mysqld.cnf lower_case_table_names1 重启mysql容器 验证 SHOW VARIABLES LIKE low…...

Docker与虚拟机的区别及常用指令详解
在现代软件开发中,容器化和虚拟化技术已经成为不可或缺的工具。Docker和虚拟机(VM)是两种常见的技术, 它们都可以帮助开发者在不同的环境中运行应用程序。然而,它们的工作原理和使用场景有很大的不同。本文将详细探讨D…...

C#异步和多线程,Thread,Task和async/await关键字--12
目录 一.多线程和异步的区别 1.多线程 2.异步编程 多线程和异步的区别 二.Thread,Task和async/await关键字的区别 1.Thread 2.Task 3.async/await 三.Thread,Task和async/await关键字的详细对比 1.Thread和Task的详细对比 2.Task 与 async/await 的配合使用 3. asy…...
作业)
第一次作业三种方式安装mysql(Windows和linux下)作业
在Windows11上安装sever(服务)端和客户端 server端安装 打开官网MySQL 进入到主页 点击DOWMLOAD 进入下载界面 点击下方MySQL Community (GPL) Downloads 进入社区版mysql下载界面 点击 MySQL Community Server 进入server端下载 选择8.4.3LTS&…...

ubuntu官方软件包网站 字体设置
在https://ubuntu.pkgs.org/22.04/ubuntu-universe-amd64/xl2tpd_1.3.16-1_amd64.deb.html搜索找到需要的软件后,点击,下滑, 即可在Links和Download找到相关链接,下载即可, 但是找不到ros的安装包, 字体设…...

深拷贝与浅拷贝
作者简介: 一个平凡而乐于分享的小比特,中南民族大学通信工程专业研究生在读,研究方向无线联邦学习 擅长领域:驱动开发,嵌入式软件开发,BSP开发 作者主页:一个平凡而乐于分享的小比特的个人主页…...

No one knows regex better than me
No one knows regex better than me 代码分析,传了两个参数zero,first,然后$second对两个所传的参数进行了拼接 好比:?zero1&first2 传入后就是: 12 然后对$second进行了正则匹配,匹配所传入的参数是否包含字符串Yeedo|wa…...
-集合)
scala基础学习(数据类型)-集合
文章目录 集合创建集合isEmpty获取数据添加元素删除元素常见方法交集 &差集 diff --并集 unionto stringto listto Arrayto Map其余常用方法 集合 Scala Set(集合)是没有重复的对象集合,所有的元素都是唯一的。 Scala 集合分为可变的和不可变的集合。 默认情…...

如何使用 Excel 进行多元回归分析?
多元回归分析,一种统计方法,用来探索一个因变量(即结果变量)与多个自变量(即预测变量)之间的关系。广泛用于预测、趋势分析以及因果关系的分析。 听起来这个方法很复杂,但其实在 Excel 中可以很…...

思维转换:突破思维桎梏,创造更高效的工作与生活
在现代职场和生活中,我们经常面临着各种挑战和问题,有时候虽然付出了很多努力,但依然难以找到更有效的解决方案。这时,或许我们需要的不是更多的努力,而是一次“思维转换”。这一概念看似简单,但它背后却蕴…...

ClickHouse-CPU、内存参数设置
常见配置 1. CPU资源 1、clickhouse服务端的配置在config.xml文件中 config.xml文件是服务端的配置,在config.xml文件中指向users.xml文件,相关的配置信息实际是在users.xml文件中的。大部分的配置信息在users.xml文件中,如果在users.xml文…...

Spring Boot 项目启动后自动加载系统配置的多种实现方式
Spring Boot 项目启动后自动加载系统配置的多种实现方式 在 Spring Boot 项目中,可以通过以下几种方式实现 在项目启动完成后自动加载系统配置缓存操作 的需求: 1. 使用 CommandLineRunner CommandLineRunner 是一个接口,可以用来在 Spring…...

scrapy库解决ja3/tls指纹验证问题
pip install curl_cffi0.7.4 pip install scrapy-fingerprint0.1.3seetings.py打开中间件 DOWNLOADER_MIDDLEWARES { "scrapy_fingerprint.fingerprintmiddlewares.FingerprintMiddleware": 100 }yield scrapy.Request(urlurl,callbackself.parse) 改为以下 from sc…...

二进制、八进制、十进制和十六进制的相互转换
printf 函数 printf 函数是 C 语言中用于将格式化的数据输出到标准输出(通常是屏幕)的函数。它位于 stdio.h 头文件中,因此在使用之前需要包含该头文件。 printf 函数的格式说明符 格式说明符说明示例%d 或 %i输出或输入十进制有符号整数p…...

分布式缓存redis
分布式缓存redis 1 redis单机(单节点)部署缺点 (1)数据丢失问题:redis是内存存储,服务重启可能会丢失数据 (2)并发能力问题:redis单节点(单机)部…...

day08_Kafka
文章目录 day08_Kafka课程笔记一、今日课程内容一、消息队列(了解)**为什么消息队列就像是“数据的快递员”?****实际意义**1、产生背景2、消息队列介绍2.1 常见的消息队列产品2.2 应用场景2.3 消息队列中两种消息模型 二、Kafka的基本介绍1、…...

fbx 环境搭建
python 3.7 3.8 版本支持 https://github.com/Shiiho11/FBX-Python-SDK-for-Python3.x 只有python3.7 https://www.autodesk.com/developer-network/platform-technologies/fbx-sdk-2020-3 scipy安装: python安装scipy_scipy1.2.1库怎么安装-CSDN博客 smpl 2 fbx…...

【大数据】机器学习------神经网络模型
一、神经网络模型 1. 基本概念 神经网络是一种模拟人类大脑神经元结构的计算模型,由多个神经元(节点)组成,这些节点按照不同层次排列,通常包括输入层、一个或多个隐藏层和输出层。每个神经元接收来自上一层神经元的输…...

YOLOv5训练长方形图像详解
文章目录 YOLOv5训练长方形图像详解一、引言二、数据集准备1、创建文件夹结构2、标注图像3、生成标注文件 三、配置文件1、创建数据集配置文件2、选择模型配置文件 四、训练模型1、修改训练参数2、开始训练 五、使用示例1、测试模型2、评估模型 六、总结 YOLOv5训练长方形图像详…...
)
【Vim Masterclass 笔记11】S06L24 + L25:Vim 文本的插入、变更、替换与连接操作同步练习(含点评课)
文章目录 S06L24 Exercise 06 - Inserting, Changing, Replacing, and Joining1 训练目标2 操作指令2.1. 打开 insert-practice.txt 文件2.2. 练习 i 命令2.3. 练习 I 命令2.4. 练习 a 命令2.5. 练习 A 命令2.6. 练习 o 命令2.7. 练习 O 命令2.8. 练习 j 命令2.9. 练习 R 命令2…...

【计算机网络】深入浅出计算机网络
第一章 计算机网络在信息时代的作用 计算机网络已由一种通信基础设施发展成一种重要的信息服务基础设施 CNNIC 中国互联网网络信息中心 因特网概述 网络、互联网和因特网 网络(Network)由若干结点(Node)和连接这些结点的链路…...

HTTP详解——HTTP基础
HTTP 基本概念 HTTP 是超文本传输协议 (HyperText Transfer Protocol) 超文本传输协议(HyperText Transfer Protocol) HTTP 是一个在计算机世界里专门在 两点 之间 传输 文字、图片、音视频等 超文本 数据的 约定和规范 1. 协议 约定和规范 2. 传输 两点之间传输…...

ubuntu 安装 python
一、安装python依赖的包。 sudo apt-get install -y make zlib1g zlib1g-dev build-essential libbz2-dev libsqlite3-dev libssl-dev libxslt1-dev libffi-dev openssl python3-tklibsqlite3-dev需要在python安装之前安装,如果用户操作系统已经安装python环境&…...

CSS:定位
CSS定位核心知识点详解 CSS定位是网页布局中的重要概念,它允许开发者将元素放置在页面的指定位置。以下是对CSS定位所有相关详细重要知识点的归纳: 为什么要使用定位: 小黄色块在图片上移动,吸引用户的眼球。 当我们滚动窗口的…...

ros2笔记-7.1 机器人导航介绍
7.1 机器人导航介绍 7.1.1 同步定位与地图构建 想要导航,就是要确定当前位置跟目标位置。确定位置就是定位问题。 手机的卫星导航在室内 受屏蔽,需要其他传感器获取位置信息。 利用6.5 章节的仿真,打开并运行 会发现轨迹跟障碍物都被记录…...

一些常见的Java面试题及其答案
Java基础 1. Java中的基本数据类型有哪些? 答案:Java中的基本数据类型包括整数类型(byte、short、int、long)、浮点类型(float、double)、字符类型(char)和布尔类型(boo…...

今日总结 2025-01-14
学习目标 掌握运用 VSCode 开发 uni - app 的配置流程。学会将配置完善的项目作为模板上传至 Git,实现复用。项目启动 创建项目:借助 Vue - Cli 方式创建项目,推荐从国内地址 https://gitee.com/dcloud/uni - preset - vue/repository/archiv…...

图像处理|开运算
开运算是图像形态学中的一种基本操作,通常用于去除小的噪声点,同时保留目标物体的整体形状。它结合了 腐蚀 和 膨胀 操作,且顺序为 先腐蚀后膨胀(先腐蚀后膨胀,胀开了,开运算)。 开运算的作用 …...
和后台(Spring boot)实现的低代码开发平台)
基于当前最前沿的前端(Vue3 + Vite + Antdv)和后台(Spring boot)实现的低代码开发平台
项目是一个基于当前最前沿的前端技术栈(Vue3 Vite Ant Design Vue,简称Antdv)和后台技术栈(Spring Boot)实现的低代码开发平台。以下是对该项目的详细介绍: 一、项目概述 项目名称:lowcode-s…...
)
ASP.NET Core - 依赖注入(三)
ASP.NET Core - 依赖注入(三) 4. 容器中的服务创建与释放 4. 容器中的服务创建与释放 我们使用了 IoC 容器之后,服务实例的创建和销毁的工作就交给了容器去处理,前面也讲到了服务的生命周期,那三种生命周期中对象的创…...

Unity 视频导入unity后,播放时颜色变得很暗很深,是什么原因导致?
视频正常播放时的颜色: 但是,当我在unity下,点击视频播放按钮时,视频的颜色立马变得十分昏暗: 解决办法: 将File—BuildSettings—PlayerSettings—OtherSettings下的Color Space改为:Gamma即可…...