卷积神经网络
卷积神经网络
-
随着输入数据规模的增大,计算机视觉的处理难度也大幅增加。 64 × 64 × 3 64 \times 64 \times 3 64×64×3 的图片特征向量维度为12288,而 1000 × 1000 × 3 1000 \times 1000 \times 3 1000×1000×3 的图片数据量达到了300万。随着数据维度的增加,神经网络的参数量也会急剧上升。如果使用标准的全连接神经网络,参数量会达到30亿。为了有效处理大规模数据,卷积神经网络(Convolution NN)成为了计算机视觉中的关键技术。与标准的全连接网络不同,CNN能够通过卷积运算减少参数数量,从而避免过拟合和计算瓶颈,并有效处理大规模图片数据。
-
卷积操作通过卷积核覆盖图像的局部区域,将对应元素相乘后,相加生成一个单一数值。重复进行这个过程,卷积核逐步在图像上滑动,最终生成一个新的矩阵(特征图),矩阵元素的每个数值代表该区域的特征强度。
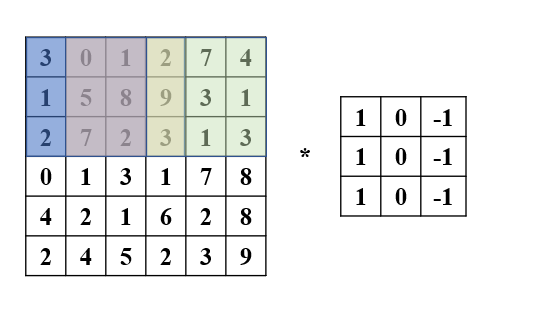
-
使用特定的 3 × 3 3 \times 3 3×3 卷积核(例如 [ 1 0 − 1 1 0 − 1 1 0 − 1 ] \begin{bmatrix}1 & 0 & -1\\ 1 & 0 & -1\\ 1 & 0 & -1\end{bmatrix} 111000−1−1−1 )可以有效检测图像中的垂直边缘,使用特定的 3 × 3 3 \times 3 3×3 卷积核(例如 [ 1 1 1 0 0 0 − 1 − 1 − 1 ] \begin{bmatrix}1 & 1 & 1\\ 0 & 0 & 0\\ -1 & -1 & -1\end{bmatrix} 10−110−110−1 )可以有效检测图像中的水平边缘。 6 × 6 6 \times 6 6×6 图像经过卷积后输出的 4 × 4 4 \times 4 4×4 矩阵揭示了图像中垂直边缘的存在和位置。当图像较小时,检测到的边缘可能较粗。在更高分辨率的图像中,检测效果会更加精准。在更复杂的网络结构中,卷积层可以堆叠使用,以逐步提取更高级的特征。
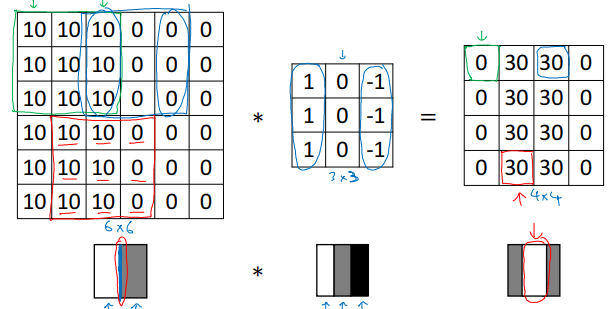
-
卷积运算不仅可以检测边缘,还能够区分由亮到暗和由暗到亮的过渡,这被称为正边与负边。当图像亮度从左到右发生翻转时,卷积结果中的数值符号也会发生变化(例如从30变为-30)。如果对正负边缘不感兴趣,可以对卷积结果取绝对值,忽略过渡的方向性。
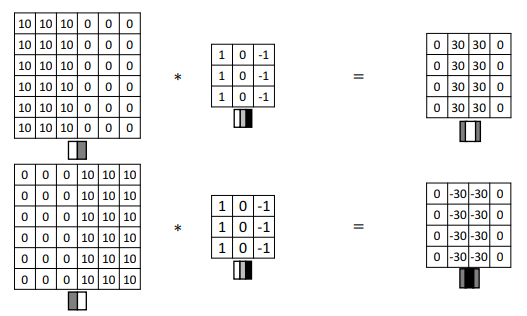
-
通过不同的 3 × 3 3 \times 3 3×3 卷积核,可以检测到更复杂的边缘模式。在小尺寸图像(如 6 × 6 6 \times 6 6×6 )中,卷积运算可能出现过渡带,但在大尺寸图像(如 1000 × 1000 1000 \times 1000 1000×1000 )中,这些过渡带会变得更清晰,边缘检测效果更加显著。每个卷积核的输出数值代表对应区域的边缘强度和方向性。
-
除了上述卷积核外,还有其他不同类型的卷积核,但这些手工设计的卷积核在特定任务上表现良好,但在复杂场景下可能存在局限性。
Sobel卷积核:使用 [ 1 0 − 1 2 0 − 2 1 0 − 1 ] \begin{bmatrix}1 & 0 & -1 \\ 2 & 0 & -2 \\ 1 & 0 & -1 \end{bmatrix} 121000−1−2−1 ,在中间一行增加权重,使边缘检测更加鲁棒。
Scharr卷积核:使用更大权重的 [ 3 0 − 3 10 0 − 10 3 0 − 3 ] \begin{bmatrix}3 & 0 & -3 \\ 10 & 0 & -10 \\ 3 & 0 & -3 \end{bmatrix} 3103000−3−10−3 ,在特定场景下检测效果更好。
-
在深度学习中, 3 × 3 3 \times 3 3×3 卷积核的9个数值可以被当作参数,通过反向传播算法进行学习和优化。在这种情况下,神经网络可以学习到不仅仅是垂直和水平的边缘特征,还可以检测到任意角度的边缘,甚至是更加复杂、无法预设的特征。这种参数学习的思想极大提升了卷积神经网络在边缘检测和特征提取方面的灵活性和泛化能力。
从此,卷积神经网络不再局限于手工设计的卷积核,而是通过大量数据和训练过程,自动学习最优的卷积核参数。
-
在卷积操作中,使用一个 f × f f \times f f×f 的卷积核对一个 n × n n \times n n×n 的图像进行卷积,输出的尺寸会变为 ( n − f + 1 ) × ( n − f + 1 ) (n-f+1) \times (n-f+1) (n−f+1)×(n−f+1) 。但是这样会有两个问题:
缩小问题:每次卷积操作都会使图像尺寸减小,经过多层卷积后,图像可能会缩小到 1 × 1 1 \times 1 1×1 ,这对深度网络的训练和特征提取不利。
边缘信息丢失:图像的边缘像素点在卷积操作中较少被覆盖,导致边缘信息在特征提取过程中被忽略。
为了解决图像尺寸缩小和边缘信息丢失的问题,可以在图像边缘进行填充(Padding),即在图像四周填充额外的像素。
在填充了 p p p 个像素后,输出尺寸可以用公式表示为:( n + 2 p − f + 1 ) × ( n + 2 p − f + 1 ) (n + 2p - f + 1) \times (n + 2p - f + 1) (n+2p−f+1)×(n+2p−f+1)
当 f f f 为奇数时,可以保证对称填充,使得图像四周的填充均匀,避免不对称填充导致的信息偏差。同时,奇数维卷积核有一个明确的中心像素点,这对于特征对齐和定位更加方便,也使得网络在不同位置的像素点都能均匀地参与特征提取。
-
Valid卷积:不进行填充( p = 0 p=0 p=0 ),输出尺寸为 ( n − f + 1 ) × ( n − f + 1 ) (n-f+1) \times (n-f+1) (n−f+1)×(n−f+1) 。
Same卷积:填充足够的像素,使得输出尺寸与输入尺寸相同。对于奇数维的卷积核,填充量为 ( f − 1 ) / 2 (f−1)/2 (f−1)/2 。在构建卷积神经网络时,推荐使用Same卷积来保持图像尺寸,减少信息损失。
在实际应用中,通常使用0填充,即在边缘添加像素值为0的填充值。
-
**步幅(stride)**是控制卷积操作中卷积核移动步长的重要参数。通过调整步幅,可以决定每次卷积核滑动时跳过多少像素。当步幅为2时, 3 × 3 3 \times 3 3×3 的卷积核在 7 × 7 7 \times 7 7×7 的图像上卷积,每次移动跳过2个像素,相较于步幅为1时,卷积核的移动距离更大。
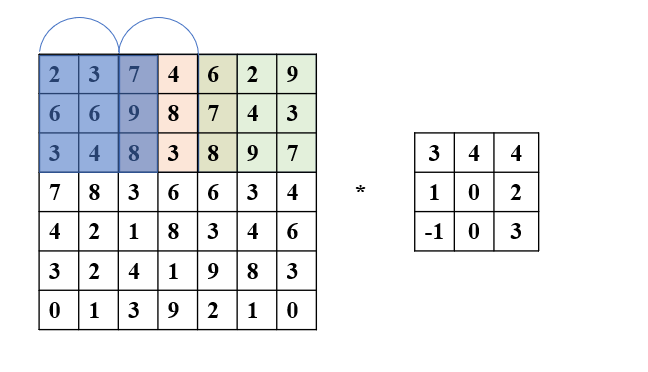
卷积操作的输出尺寸为
⌊ n + 2 p − f s + 1 ⌋ × ⌊ n + 2 p − f s + 1 ⌋ \lfloor \frac{n+2p-f}{s}+1 \rfloor \times \lfloor \frac{n+2p-f}{s}+1 \rfloor ⌊sn+2p−f+1⌋×⌊sn+2p−f+1⌋
其中, n n n 是输入图像的尺寸, p p p 是填充大小, f f f 是卷积核的尺寸, s s s 是步幅。如果公式中的商不是整数,通常需要向下取整。这意味着当卷积核不能完全覆盖图像时,只有当卷积核完全位于图像内时才进行计算。
-
彩色图像通常是由多个颜色通道(如红、绿、蓝)组成的,每个通道对应一个二维的灰度图像。以 6 × 6 × 3 6 \times 6 \times 3 6×6×3 的图像为例,3表示颜色通道数,图像的高度和宽度为 6 × 6 6 \times 6 6×6 。为了进行卷积操作,需要使用一个三维的卷积核,例如 3 × 3 × 3 3 \times 3 \times 3 3×3×3 的卷积核,它与图像的三个颜色通道相匹配。
如果只想检测图像红色通道的边缘,可以将第一个卷积核设为 [ 1 0 − 1 1 0 − 1 1 0 − 1 ] \begin{bmatrix}1 & 0 & - 1 \\ 1 & 0 & - 1 \\ 1 & 0 & - 1 \\\end{bmatrix} 111000−1−1−1 ,而绿色和蓝色通道全为0。把这三个矩阵堆叠在一起形成一个 3 × 3 × 3 3 \times 3 \times 3 3×3×3 的矩阵,可以形成一个检测红色通道垂直边界的卷积核。
如果不关心垂直边界在哪个颜色通道,可以使用三个通道都是 [ 1 0 − 1 1 0 − 1 1 0 − 1 ] \begin{bmatrix}1 & 0 & - 1 \\ 1 & 0 & - 1 \\ 1 & 0 & - 1 \\ \end{bmatrix} 111000−1−1−1 的卷积核。
-
卷积神经网络会使用多个卷积核来检测不同的特征。例如,一个卷积核可以用于检测垂直边缘,另一个用于检测水平边缘。将不同卷积核的输出堆叠在一起,得到多通道的输出结果,这样就可以同时捕捉到不同的特征。最后图像输出的通道数由使用的卷积核数量决定。
-
卷积神经网络中的卷积层,通过两个卷积核对一个三维图像进行卷积处理,得到两个不同的 4 × 4 4 \times 4 4×4 矩阵。每个卷积核提取图像的不同特征,使用每个卷积核的卷积结果,加上偏差并应用非线性激活函数(如ReLU),得到最终的 4 × 4 4 \times 4 4×4 矩阵输出。最后将两个 4 × 4 4 \times 4 4×4 矩阵堆叠,形成一个 4 × 4 × 2 4 \times 4 \times 2 4×4×2 的三维输出,这就是卷积层的输出。
前向传播过程为 z [ 1 ] = ω [ 1 ] a [ 0 ] + b [ 1 ] z^{[1]} = \omega^{[1]} a^{[0]} + b^{[1]} z[1]=ω[1]a[0]+b[1] ,其中 a [ 0 ] a^{[0]} a[0] 是输入, ω [ 1 ] \omega^{[1]} ω[1] 是卷积核, b [ 1 ] b^{[1]} b[1] 是偏差。执行卷积操作相当于执行一个线性变换(加权和),然后加上偏差,最后应用非线性激活函数。
-
卷积层的输入通常标记为 n H [ l − 1 ] × n W [ l − 1 ] × n c [ l − 1 ] n_H^{[l-1]} \times n_W^{[l-1]} \times n_c^{[l-1]} nH[l−1]×nW[l−1]×nc[l−1] ,表示上一层的激活值。输出图像的维度为 n H [ l ] × n W [ l ] × n c [ l ] n_H^{[l]} \times n_W^{[l]} \times n_c^{[l]} nH[l]×nW[l]×nc[l] ,其大小由卷积核、步幅、填充等因素决定。
卷积操作的输出高度为 n H [ l ] = ⌊ n H [ l − 1 ] + 2 p − f s + 1 ⌋ n_H^{[l]} = \lfloor\frac{n_H^{[l-1]} + 2p - f}{s} + 1\rfloor nH[l]=⌊snH[l−1]+2p−f+1⌋ (其中 n H [ l − 1 ] n_H^{[l-1]} nH[l−1] 是上一层的高度, p p p 是padding, f f f 是卷积核大小, s s s 是步幅)。输出宽度 n W [ l ] = ⌊ n W [ l − 1 ] + 2 p − f s + 1 ⌋ n_W^{[l]} = \lfloor\frac{n_W^{[l-1]} + 2p - f}{s} + 1\rfloor nW[l]=⌊snW[l−1]+2p−f+1⌋ 。
输出图像的深度(即通道数)由使用的卷积核的数量决定。例如,如果有2个卷积核,输出将是 n H [ l ] × n W [ l ] × 2 n_H^{[l]} \times n_W^{[l]} \times 2 nH[l]×nW[l]×2 ,如果有10个卷积核,输出将是 n H [ l ] × n W [ l ] × 10 n_H^{[l]} \times n_W^{[l]} \times 10 nH[l]×nW[l]×10 。每个卷积核的通道数必须与输入图像的通道数一致,对于一个 n H [ l − 1 ] × n W [ l − 1 ] × n c n_H^{[l-1]} \times n_W^{[l-1]} \times n_c nH[l−1]×nW[l−1]×nc 的图像输入,卷积核的尺寸必须为 f × f × n c [ l − 1 ] f \times f \times n_c^{[l-1]} f×f×nc[l−1] 。
通过使用多个卷积核,卷积层的总参数数量为 f [ l ] × f [ l ] × n c [ l − 1 ] × n c [ l ] f^{[l]} \times f^{[l]} \times n_c^{[l-1]} \times n_c^{[l]} f[l]×f[l]×nc[l−1]×nc[l] ,其中 n c [ l ] n_c^{[l]} nc[l] 是该层的卷积核数量。偏差是每个卷积核对应的一个实数,通常表示为一个 1 × 1 × 1 × n c [ l ] 1\times1\times1\times n_c^{[l]} 1×1×1×nc[l] 的四维张量。
无论输入图片的大小(如 1000 × 1000 1000\times1000 1000×1000 或 5000 × 5000 5000\times5000 5000×5000 ),卷积层的参数数量都是固定的。该特性有助于减少过拟合,因为参数数量不随输入图像的大小变化。
-
假定想要构建一个深度卷积神经网络,我们会输入一张维度 39 × 39 × 3 39 \times 39 \times 3 39×39×3 的图片。

最终,从图片中提取出1960维的特征向量,再输入到后面的全连接层进行进一步处理。随着网络层数的增加,图像尺寸逐渐减小,从 39 × 39 39\times 39 39×39 到 37 × 37 37\times 37 37×37,再到 17 × 17 17\times 17 17×17 ,最后到 7 × 7 7\times 7 7×7。通道数逐渐增加 ,从3到10,再到20,最后到40。
-
池化层通过降低数据的空间维度(高度和宽度)来减少模型参数的数量,从而减小模型的存储需求。池化层还降低了计算的复杂度,因为池化层减少了需要处理的数据量。池化有助于防止过拟合,因为它使得神经网络不依赖于某个特定的位置或小的变动,从而提高了对输入图像特征的鲁棒性。
-
最大池化:对于每个卷积核,最大池化从输入特征图中提取最大值。池化区域是一个 2 × 2 2 \times 2 2×2 矩阵,步幅为2,意味着每次在 2 × 2 2 \times 2 2×2 的区域内计算最大值并移动2步。
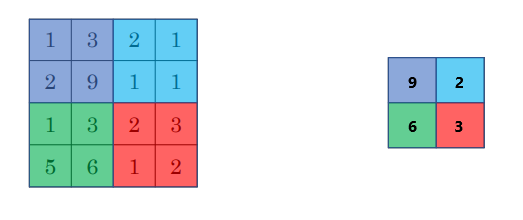
池化层的超参数为卷积核大小 f f f 和步幅 s s s,池化层的输出维度计算方式和卷积层相同。
三维池化层输出的维度将是池化操作应用于每个通道后的结果,通常会降低图像的空间分辨率,但保持通道数不变,即输出的通道数与输入相同。
平均池化:取池化区域的平均值。
最大池化通常用于大多数卷积神经网络中,它能够保留图像中的关键特征(例如边缘或角点),并且效果非常好。
平均池化虽然较少使用,但在一些深度神经网络中,尤其是图像较大的情况下,可能会用到平均池化来对输入的特征图进行下采样。
池化层是一个固定操作,所有的计算都是基于池化区域的最大值或平均值,且没有需要学习的参数。梯度下降并不涉及池化层的参数学习。在最大池化中,通常使用的超参数是 f = 2 f = 2 f=2 , s = 2 s = 2 s=2 ,这会将输入的高度和宽度缩小一半。
池化层的主要目的是降低空间分辨率,但保持深层特征的重要信息。最大池化通过选择最大值来保留重要的特征点,从而增强网络的泛化能力。
-
池化操作没有可训练的参数,但它会影响到梯度的传播。池化层会根据输入特征图的区域来决定如何进行下采样,例如:
最大池化:在某个区域内,选择最大值,并将该最大值作为输出。在反向传播时,只有当最大值位置的节点被选择时,才会传递梯度,其它位置的梯度为零。
平均池化:对某个区域内的所有值取平均,反向传播时,梯度会均匀地分配到该区域的每个位置。
因此,池化层不会像卷积层一样影响权重的更新,但池化会影响反向传播中梯度的分配。
-
想要构建一个卷积神经网络来识别手写数字。采用类似LeNet-5架构,输入是一张 32 × 32 × 3 32 \times 32 \times 3 32×32×3 的RGB图片,输出是一个softmax层,用于分类。

随着网络加深,激活值数量逐渐减少。
卷积层的参数数量相对较少,主要由卷积核的大小和数量决定。全连接层占据了大部分参数量。如FC3权重矩阵为 120 × 400 120 \times 400 120×400,FC4权重矩阵为 84 × 120 84 \times 120 84×120。
常见模式是逐层减小高度和宽度,同时增加通道数量。一般采用多个卷积层后接一个池化层,再接多个卷积层后接另一个池化层,将矩阵平整化为一维向量后,最后连全连接层和Softmax层的模式。网络设计要注意激活值的变化,避免激活值尺寸下降过快,导致信息丢失。
-
卷积层在神经网络中有两个主要优势:参数共享和稀疏连接。
参数共享是指卷积网络利用同一个卷积核(特征检测器)在输入图片的不同区域共享参数。例如,一个检测垂直边缘的卷积核可以用于检测图片左上角、右下角或其他任意区域的垂直边缘。参数共享可以大幅减少需要训练的参数数量,并且共享的参数适用于整张图片的所有区域,使得特征检测器能够更高效地提取有用特征。这些参数对于图像中高阶特征(如眼睛、猫脸)同样适用,增强网络的通用性。
稀疏连接是指卷积操作中,每个输出单元只连接到输入中的一个局部区域,而非与整个输入相连。稀疏连接降低了参数数量,因为仅需计算局部区域的值。每个输出单元的计算仅依赖于相关的输入区域,与不相关的输入无关,避免了全连接的冗余,防止过拟合。
-
卷积神经网络之所以高效,第一个原因是参数数量显著减少,使得模型训练更快,对小数据集更有效,避免过拟合。卷积核为5×5,数量为6,则每个卷积核26个参数(包括偏差)。
第二个原因是卷积网络能够对图片中物体的位置变化具有鲁棒性,即使图片中某物体平移了一定距离,卷积网络仍能正确识别,即能捕捉平移不变性。因为卷积层共享的卷积核和稀疏连接特性,使得网络对输入图片的特征提取具有更强的适应性。
相关文章:

卷积神经网络
卷积神经网络 随着输入数据规模的增大,计算机视觉的处理难度也大幅增加。 64 64 3 64 \times 64 \times 3 64643 的图片特征向量维度为12288,而 1000 1000 3 1000 \times 1000 \times 3 100010003 的图片数据量达到了300万。随着数据维度的增加&am…...

SparrowRTOS系列:链表版本内核
前言 Sparrow RTOS是笔者之前写的一个极简性RTOS,初代版本只有400行,后面笔者又添加了消息队列、信号量、互斥锁三种IPC机制,使之成为一个较完整、堪用的内核,初代版本以简洁为主,使用数组和表作为任务挂载的抽象数据…...

【redis初阶】环境搭建
目录 一、Ubuntu 安装 redis 二、Centos7 安装 redis 三、Centos8 安装 redis 四、redis客户端介绍 redis学习🥳 一、Ubuntu 安装 redis 使用 apt 安装 apt install redis -y 查看redis版本 redis-server --version 支持远程连接…...
解决透视 n 点问题(Perspective-n-Point, PnP)函数solvePnP()的使用)
OpenCV相机标定与3D重建(54)解决透视 n 点问题(Perspective-n-Point, PnP)函数solvePnP()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 根据3D-2D点对应关系找到物体的姿态。 cv::solvePnP 是 OpenCV 库中的一个函数,用于解决透视 n 点问题(Perspective-n-Po…...

shell脚本回顾1
1、shell 脚本写出检测 /tmp/size.log 文件如果存在显示它的内容,不存在则创建一个文件将创建时间写入。 一、 ll /tmp/size.log &>/dev/null if [ $? -eq 0 ];then cat /tmp/size.log else touch /tmp/size.log echo date > /tmp/size.log fi二、 if …...

HarmonyOS命令行工具
作为一个从Android转过来的鸿蒙程序猿,在开发过程中不由自主地想使用类似adb命令的命令行工具去安装/卸载应用,往设备上推或者拉去文件,亦或是抓一些日志。但是发现在鸿蒙里边,华为把命令行工具分的很细,种类相当丰富 …...

V少JS基础班之第四弹
一、 前言 第四弹内容是操作符。 本章结束。第一个月的内容就完成了, 是一个节点。 下个月我们就要开始函数的学习了。 我们学习完函数之后。很多概念就可以跟大家补充说明了。 OK,那我们就开始本周的操作符学习 本系列为一周一更,计划历时6…...

从前端视角看设计模式之创建型模式篇
设计模式简介 "设计模式"源于GOF(四人帮)合著出版的《设计模式:可复用的面向对象软件元素》,该书第一次完整科普了软件开发中设计模式的概念,他们提出的设计模式主要是基于以下的面向对象设计原则ÿ…...

网络应用技术 实验七:实现无线局域网
一、实验简介 在 eNSP 中构建无线局域网,并实现全网移动终端互相通信。 二、实验目的 1 、理解无线局域网的工作原理; 2 、熟悉无线局域网的规划与构建过程; 3 、掌握无线局域网的配置方法; 三、实验学时 2 学时 四、实…...

Kotlin 循环语句详解
文章目录 循环类别for-in 循环区间整数区间示例1:正向遍历示例2:反向遍历 示例1:遍历数组示例2:遍历区间示例3:遍历字符串示例4:带索引遍历 while 循环示例:计算阶乘 do-while 循环示例…...

B+树的原理及实现
文章目录 B树的原理及实现一、引言二、B树的特性1、结构特点2、节点类型3、阶数 三、B树的Java实现1、节点实现2、B树操作2.1、搜索2.2、插入2.3、删除2.4、遍历 3、B树的Java实现示例 四、总结 B树的原理及实现 一、引言 B树是一种基于B树的树形数据结构,它在数据…...

ArkTS 基础语法:声明式 UI 描述与自定义组件
1. ArkTS 简介 ArkTS 是 HarmonyOS 应用开发中的一种编程语言,它结合了 TypeScript 的类型检查和声明式 UI 描述方式,帮助开发者更高效地构建用户界面。 2. 声明式 UI 描述 ArkTS 使用声明式语法来定义 UI 结构,通过组件、属性和事件配置实…...

list的模拟实现详解
文章目录 list的模拟实现list的迭代器begin()和end() list的模拟实现 #pragma once #include<iostream> #include<list>using namespace std;namespace wbc {// 类模版template<class T>struct list_node // 链表的节点{T _data;list_node<T>* _next;…...

图解Git——分支的新建与合并《Pro Git》
⭐分支的新建与合并 先引入一个实际开发的工作流: 开发某个网站。为实现某个新的需求,创建一个分支。在这个分支上开展工作。 正在此时,你突然接到一个电话说有个很严重的问题需要紧急修补。你将按照如下方式来处理: 切换到你…...

SQLite 语法快速入门
SQLite 是一个软件库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。 提供一个免费的在线SQLite编辑器 (0)常用命令 # 格式化 .header on .mode column .timer on# 查看表格 .tables# 查看表结构(建表语句) .schema …...

高速光电探测器设计 PIN APD铟镓砷TIA放大脉冲误码测试800-1700nm
高速光电探测器PIN APD铟镓砷TIA放大脉冲误码测试800-1700nm (对标:索雷博APD431A) (对标:索雷博APD431A) (对标:索雷博APD431A) 规格参数: 波长范围:800-1700nm 输出带宽:DC-400MHz(-3dB&…...

【Linux】【内存】Buddy内存分配基础 NUMA架构
【Linux】【内存】Buddy内存分配基础 NUMA架构 NUMA架构 在 NUMA 架构中,计算机的多个 CPU 被划分为不同的处理单元,每个处理单元有一个本地内存。这些内存被称为内存节点(memory node)。处理器尽量访问自己的本地内存 node_da…...

【机器学习:十九、反向传播】
1. 计算图和导数 计算图的概念 计算图(Computation Graph)是一种有向无环图,用于表示数学表达式中的计算过程。每个节点表示一个操作或变量,每条边表示操作的依赖关系。通过计算图,可以轻松理解和实现反向传播。 计算…...

使用中间件自动化部署java应用
为了实现你在 IntelliJ IDEA 中打包项目并通过工具推送到两个 Docker 服务器(172.168.0.1 和 172.168.0.12),并在推送后自动或手动重启容器,我们可以按照以下步骤进行操作: 在 IntelliJ IDEA 中配置 Maven 或 Gradle 打…...

Vue.js开发入门:从零开始搭建你的第一个项目
前言 嘿,小伙伴们!今天咱们来聊聊 Vue.js,一个超火的前端框架。如果你是编程小白,别怕,跟着我一步步来,保证你能轻松上手,搭建起属于自己的第一个 Vue 项目。Vue.js 可能听起来有点高大上&#…...

基于大语言模型的组合优化
摘要:组合优化(Combinatorial Optimization, CO)对于提高工程应用的效率和性能至关重要。随着问题规模的增大和依赖关系的复杂化,找到最优解变得极具挑战性。在处理现实世界的工程问题时,基于纯数学推理的算法存在局限…...
)
mySQL安装(LINUX)
一、1. 下载并安装MySQL官方的 Yum Repository 1、连接云服务器,进入opt 2、下载安装包 wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm 3、解压 rpm -ivh mysql-community-release-el7-5.noarch.rpm 4、安装 yum install mysql-commu…...

【机器学习】农业 4.0 背后的智慧引擎:机器学习助力精准农事决策
我的个人主页 我的领域:人工智能篇,希望能帮助到大家!!!👍点赞 收藏❤ 在当今数字化浪潮汹涌澎湃之际,农业领域正经历着一场前所未有的深刻变革,大踏步迈向农业 4.0时代。这一时代…...

在 Azure 100 学生订阅中新建一台 Ubuntu VPS,并通过 Docker 部署 Nginx 服务器
今天来和大家分享一下如何在 Azure 100 学生订阅中创建一台 Ubuntu VPS,并在其上通过 Docker 部署 Nginx 服务器。在这个过程中,我们将一步步走过每一个细节,希望能帮助到大家。 Docker 和 Nginx 简介 Docker 是一个开源的容器化平台&#…...

快速、可靠且高性价比的定制IP模式提升芯片设计公司竞争力
作者:Karthik Gopal,SmartDV Technologies亚洲区总经理 智权半导体科技(厦门)有限公司总经理 无论是在出货量巨大的消费电子市场,还是针对特定应用的细分芯片市场,差异化芯片设计带来的定制化需求也在芯片…...

Linux常用命令大全
mv详解目录 Linux 常用命令大全 1. ls 指令 2. touch 指令 3. pwd 指令 4. mkdir 指令 5. cd 指令 6. rmdir 和 rm 指令 7. man 指令 8. cp 指令 9. mv 指令 10. cat 指令 11. more 指令 12. less 指令 13. head 指令 14. tail 指令 15. find 指令 16. grep 指…...

K-均值聚类算法
K-均值聚类算法是一种常用的无监督学习算法,用于将数据集划分为K个不同的簇。它的基本思想是通过迭代将样本点划分到最相邻的簇中,以最小化各个簇内的平均距离。下面我们来详细讲解K-均值聚类算法的步骤及其优缺点。 步骤: 1. 随机选择K个质…...

Windows 环境下安装和启动 Redis 服务
在 Windows 环境下安装和启动 Redis 服务可以通过多种方式实现,下面将详细介绍几种常见的方法。我们将重点介绍通过 Chocolatey 包管理器、Docker 容器以及 MSOpenTech 提供的官方移植版来安装 Redis。 方法一:使用 Chocolatey 安装 Redis Chocolatey …...

关于在windows系统中编译ffmpeg并导入到自己项目中这件事
关于在windows系统中编译ffmpeg并导入到自己项目中这件事 前因(可跳过不看) 前阵子由于秋招需求,写了一个简易的安卓播放器,最终因为时间问题还有一些功能没有实现着实可惜,如:倍速播放,快进操…...

实战开发:基于用户反馈筛选与分析系统的实现
引言 在当今的数字化社会中,用户反馈是企业决策的重要依据。无论是电商平台、社交网络,还是产品服务,收集用户反馈并加以分析,有助于提升用户体验,改善服务质量。然而,面对海量的用户反馈,如何有…...
)
Android SystemUI——服务启动流程(二)
在 Andorid 系统源码中,package/apps下放的是系统内置的一些 APP,例如 Settings、Camera、Phone、Message 等等。而在 framework/base/package 下,它们也是系统的 APP,SystemUI 就在此目录下。它控制着整个 Android 系统的界面&am…...

拷贝构造函数
文章目录 一、4. 拷贝构造函数 今天我们来学习拷贝构造函数。 一、4. 拷贝构造函数 如果⼀个构造函数的第⼀个参数是自身类型的引用,且任何额外的参数都有默认值,则此叫做拷贝构造函数,也就是说拷贝构造是⼀个特殊的构造函数。 它的形式是这…...

解析OVN架构及其在OpenStack中的集成
引言 随着云计算技术的发展,虚拟化网络成为云平台不可或缺的一部分。为了更好地管理和控制虚拟网络,Open Virtual Network (OVN) 应运而生。作为Open vSwitch (OVS) 的扩展,OVN 提供了对虚拟网络抽象的支持,使得大规模部署和管理…...

面试加分项:Android Framework PMS 全面概述和知识要点
在Android面试时,懂得越多越深android framework的知识,越为自己加分。 目录 第一章:PMS 基础知识 1.1 PMS 定义与工作原理 1.2 PMS 的主要任务 1.3 PMS 与相关组件的交互 第二章:PMS 的核心功能 2.1 应用安装与卸载机制 2.2 应用更新与版本管理 2.3 组件管理 第…...
)
征服Windows版nginx(2)
1.配置Nginx 编辑Nginx的配置文件(通常是nginx.conf),找到安装Nginx位置,如下路径: D:\nginx-1.26.2\conf 双击打开nginx.CONF编辑,在http块中添加一个新的server块,用于指定Vue项目的静态文件…...
QML states和transitions的使用
一、介绍 1、states Qml states是指在Qml中定义的一组状态(States),用于管理UI元素的状态转换和属性变化。每个状态都包含一组属性值的集合,并且可以在不同的状态间进行切换。 通过定义不同的状态,可以在不同的应用场…...

flask_sqlalchemy relationship 子表排序
背景: 使用flask_sqlalchemy 的orm 时总不可避免的遇到子表排序问题 材料: 省略 制作: 直接看下面2段代码片段(一对多关系组合),自行理解: 1、多的一方实体 from .exts import db from f…...

python+pymysql
python操作mysql 一、python操作数据库 1、下载pymysql 库, 方法一:pip3 install pymysql 或pip install pymysql 方法二:在pycharm中setting下载pymysql 2、打开虚拟机上的数据库 3、pymysql连接 dbpymysql.Connection(host&qu…...

HAL库 中断相关函数
目录 中断相关函数 函数:HAL_SuspendTick()和HAL_ResumeTick() 涉及手册: 涉及寄存器: 涉及位: 函数:HAL_UART_IRQHandler(&huart3) 存在位置: 拓展: 函数:HAL_UARTEx…...

薪资协商注意事项
根据从AI(豆包kimi)中查询的内容,以及实际面试中的经验,进行整理,供大家参考: 薪资构成:了解薪水的固定工资、绩效、补贴、奖金及其他福利等具体构成。 进行沟通时需要确认清楚是税前还是税后沟…...
)
【机器学习】Kaggle实战Rossmann商店销售预测(项目背景、数据介绍/加载/合并、特征工程、构建模型、模型预测)
文章目录 1、项目背景2、数据介绍3、数据加载3.1 查看数据3.2 空数据处理3.2.1 训练数据3.2.2 测试数据3.3.3 商店数据处理3.3.4 销售时间关系 4、合并数据5、特征工程6、构建训练数据和测试数据7、数据属性间相关性系数8、提取模型训练的数据集9、构建模型9.1 定义评价函数9.2…...

简化计算步骤以减少误差
简化计算步骤以减少误差 同样一个计算问题,若能减少运算次数,既可以节省计算机的计算时间,还可以减小舍人误差。 例 计算 x 255 x^{255} x255的值. 如果逐个相乘要用 254 次乘法,但若写成 x 255 x ⋅ x 2 ⋅ x 4 ⋅ x 8 ⋅…...

利用AI大模型和Mermaid生成流程图
核心点1:利用大模型生成流程图的语句(Code) 确定业务流程: 用户需要明确要绘制的业务流程,包括主要步骤、决策点以及各步骤之间的关系。将确定的业务流程以文字形式描述出来。 生成Mermaid代码: 将描述好的…...

SqlServer 杂项知识整理
目录 一. decimal字段类型二. 查询时加锁 一. decimal字段类型 ⏹decimal(8,3): 整数5位,小数3位。一共8位。 如果输入 20,会自动格式化为 20.000如果输入 20.1,会自动格式化为 20.100 -- 给数据库新增一个字段,类型要求是decimal类型 ALT…...

【Uniapp-Vue3】@import导入css样式及scss变量用法与static目录
一、import导入css样式 在项目文件中创建一个common文件夹,下面创建一个css文件夹,里面放上style.css文件,编写的是公共样式,我们现在要在App.vue中引入该样式。 在App.vue中引入该样式,这样就会使样式全局生效&#…...

Maven 中 scope=provided 和 optional=true 的区别
先说效果,maven依赖声明中加了<scope>provided</scope>,或者加了<optional>true</optional>,从效果上看是一样的,都会中断依赖传递,观察下图: 图中,项目B分别依赖了C和…...

自动化测试与智能化测试的区别和关系
自动化测试与智能化测试的区别和关系 在现代软件开发过程中,测试环节是保证软件质量的重要组成部分。随着技术的不断进步,传统的手工测试方法逐渐无法满足高效、精确的需求,自动化测试(Automated Testing)应运而生。近…...

django在线考试系统
Django在线考试系统是一种基于Django框架开发的在线考试平台,它提供了完整的在线考试解决方案。 一、系统概述 Django在线考试系统旨在为用户提供便捷、高效的在线考试环境,满足教育机构、企业、个人等不同场景下的考试需求。通过该系统,用…...

centos9设置静态ip
CentOS 9 默认使用 NetworkManager 管理网络,而nmcli是 NetworkManager 命令行接口的缩写,是一个用来进行网络配置、管理网络连接的命令工具,可以简化网络设置,尤其是在无头(没有图形界面)环境下。 1、 cd…...

使用postMessage解决iframe与父页面传参
接收传递的消息时,可以将 window.addEventListener(message, function(e) { console.log(e.data) }) 写法,更换为 window.onmessage async function(e) {} 可以避免消息发送后,多次接收该参数 父页面js IframeEvent(){const send …...