Python Selenium库入门使用,图文详细。附网页爬虫、web自动化操作等实战操作。
文章目录
- 前言
- 1 创建conda环境安装Selenium库
- 2 浏览器驱动下载(以Chrome和Edge为例)
- 3 基础使用(以Chrome为例演示)
- 3.1 与浏览器相关的操作
- 3.1.1 打开/关闭浏览器
- 3.1.2 访问指定域名的网页
- 3.1.3 控制浏览器的窗口大小
- 3.1.4 前进/后退/刷新页面
- 3.1.5 获取网页基本信息
- 3.1.6 打开新窗口、窗口切换
- 3.1.7 其他设置(隐藏窗口、禁用GPU加速、禁用沙盒、禁用共享内存)
- 3.2 定位并访问、操作网页元素
- 3.2.1 通过XPath定位网页元素(CSDN首页为例)
- 3.2.2 点击元素
- 3.2.3 清空输入框、输入文本
- 3.2.4 获取元素信息(文本、属性、标签名、大小、位置、是否显示、是否启用)
- 3.2.5 对元素执行鼠标操作(悬停、左键点击、右键点击、双击)
- 3.2.6 对元素执行键盘操作(输入字母、空格、制表符、回车、Ctrl+...)
- 3.3 滚轮操作
- 3.4 延时等待
- 4 实战
- 4.1 实战一:自动化搜索并统计打印结果
- 4.2 实战二:知网论文信息查询
前言
- 本文介绍Windows系统下Python的Selenium库的使用,并且附带网页爬虫、web自动化操作等实战教程,图文详细,内容全面。如有错误欢迎指正,有相关问题欢迎评论私信交流。
- 什么是Selenium库:Selenium是一个用于Web应用程序测试和网页爬虫的自动化测试工具。它可以驱动浏览器执行特定的行为,模拟真实用户操作网页的场景。
- Selenium的常见用途:
- 网络爬虫:从动态网页获取信息、采集社交平台的公开信息等,并通过程序自动处理保存。
- 自动化操作:自动完成重复的表单输入、验证网站各项功能是否正常运行、验证不同浏览器的表现等
- 官方教程文档:官方教程文档
1 创建conda环境安装Selenium库
- conda创建一个新的python环境:
conda create -n selenium python=3.11
- 激活创建的python环境:
conda activate selenium
- 安装selenium:
pip install selenium
2 浏览器驱动下载(以Chrome和Edge为例)
- 驱动的作用:驱动充当Selenium代码和浏览器之间的翻译器,其提供了统一的接口来控制不同的浏览器
- Selenium程序、驱动、浏览器之间的关系
Selenium程序 → 浏览器驱动 → 浏览器↑ ↑ ↑
发送命令 → 转换命令 → 执行操作↓ ↓ ↓
接收结果 ← 转换结果 ← 返回结果
- 下载Chrome浏览器驱动:
- 查看Chrome版本信息(打开Chrome浏览器 → 点击右上角三个点 → 设置 → 关于Chrome):


我这里版本是131.0.6778.265(正式版本) - 进入下载页面,选择与Chrome版本最接近的驱动版本复制链接进行下载:
选择与Chrome版本最接近的驱动版本,复制操作系统对应的驱动的链接

在浏览器地址栏输入上述链接回车,浏览器会自动下载驱动

下载完成会得到这样一个压缩文件,这里面就是驱动:

解压压缩包得到这样三个文件,记住驱动文件夹的位置:

- 查看Chrome版本信息(打开Chrome浏览器 → 点击右上角三个点 → 设置 → 关于Chrome):
- 下载Edge浏览器驱动
-
查看Edge版本信息(打开Edge浏览器 → 点击右上角三个点 → 设置 → 关于Microsoft Edge):


我这儿版本是131.0.2903.146 -
进入下载页面,选择与Edge版本最接近的版本点击对应的下载按钮即可:

得到如下压缩包:

解压后得到如下文件,记住驱动的位置:

-
3 基础使用(以Chrome为例演示)
3.1 与浏览器相关的操作
3.1.1 打开/关闭浏览器
- webdriver.Chrome():初始化并打开浏览器
- quit():关闭浏览器
# 导入必要的库
from selenium import webdriver # Selenium的核心包
from selenium.webdriver.chrome.service import Service # Chrome驱动服务类# 设置ChromeDriver路径
# driver_path指定了ChromeDriver可执行文件的本地路径
# Service类用于创建ChromeDriver服务实例
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化Chrome浏览器
# webdriver.Chrome()会启动一个新的Chrome浏览器实例
# service参数告诉Selenium使用哪个ChromeDriver服务
browser = webdriver.Chrome(service=service)# 关闭浏览器
# quit()方法会完全关闭浏览器及其所有相关进程
browser.quit()
3.1.2 访问指定域名的网页
- get():打开网页
# 导入和初始化部分与3.1相同
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Servicedriver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)
browser = webdriver.Chrome(service=service)# 使用get()方法访问指定URL
# get()方法会等待页面加载完成后才继续执行后续代码
browser.get("https://www.baidu.com")# time.sleep()添加延时
# 程序会在此处暂停5秒,方便观察页面加载情况
# 注意:在实际项目中应该使用显式等待或隐式等待替代sleep
time.sleep(5)# 关闭浏览器
browser.quit()
3.1.3 控制浏览器的窗口大小
- set_window_size():设置窗口的固定长宽
- maximize_window():最大化窗口
- minimize_window():最小化窗口
- fullscreen_window():全屏显示窗口
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)# 打开百度
browser.get("https://www.baidu.com")# 方法1:设置固定大小
browser.set_window_size(800, 600) # 设置为800x600像素
time.sleep(2) # 等待2秒观察效果# 方法2:最大化窗口
browser.maximize_window()
time.sleep(2)# 方法3:最小化窗口
browser.minimize_window()
time.sleep(2)# 方法4:全屏显示
browser.fullscreen_window()
time.sleep(2)# 获取当前窗口大小
window_size = browser.get_window_size()
print(f"当前窗口大小:宽度={window_size['width']}px,高度={window_size['height']}px")# 关闭浏览器
browser.quit()
3.1.4 前进/后退/刷新页面
- back():后退
- forward():前进
- refresh():刷新
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)# 访问第一个页面:百度
browser.get("https://www.baidu.com")
time.sleep(2) # 等待页面加载# 访问第二个页面:必应
browser.get("https://www.bing.com")
time.sleep(2)# 后退到百度
browser.back()
time.sleep(2)
print("当前页面标题:", browser.title) # 显示当前页面标题,验证是否回到百度# 前进到必应
browser.forward()
time.sleep(2)
print("当前页面标题:", browser.title) # 显示当前页面标题,验证是否前进到必应# 刷新当前页面
browser.refresh()
time.sleep(2)# 关闭浏览器
browser.quit()
3.1.5 获取网页基本信息
- title():获取网页标题
- current_url():获取当前网址
- name():获取浏览器名称
- page_source():获取页面源码
- window_handles():获取所有窗口句柄
- current_window_handle():获取当前窗口句柄
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)# 访问百度
browser.get("https://www.baidu.com")
time.sleep(2) # 等待页面加载# 1. 获取网页标题
title = browser.title
print("网页标题:", title)# 2. 获取当前网址
current_url = browser.current_url
print("当前网址:", current_url)# 3. 获取浏览器名称
browser_name = browser.name
print("浏览器名称:", browser_name)# 4. 获取页面源码(前50个字符)
page_source = browser.page_source
print("页面源码(前50个字符):", page_source[:50])# 5. 获取当前窗口句柄
current_handle = browser.current_window_handle
print("当前窗口句柄:", current_handle)# 6. 获取所有窗口句柄
all_handles = browser.window_handles
print("所有窗口句柄:", all_handles)# 7. 获取浏览器的能力(capabilities)
capabilities = browser.capabilities
print("浏览器版本:", capabilities.get('browserVersion', 'Unknown'))
print("浏览器名称:", capabilities.get('browserName', 'Unknown'))
print("平台名称:", capabilities.get('platformName', 'Unknown'))# 关闭浏览器
browser.quit()
3.1.6 打开新窗口、窗口切换
在Selenium中,我们可以通过以下方法实现窗口切换:
- window_handles:获取所有窗口句柄
- current_window_handle:获取当前窗口句柄
- switch_to.window():切换到指定窗口
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import time# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.baidu.com")try:# 1. 获取初始窗口句柄main_window = browser.current_window_handleprint("主窗口句柄:", main_window)# 2. 打开新窗口(点击链接在新窗口打开)browser.execute_script("window.open('https://www.bing.com', '_blank');")time.sleep(2)# 3. 获取所有窗口句柄all_handles = browser.window_handlesprint("所有窗口句柄:", all_handles)# 4. 切换到新窗口(最后打开的窗口)browser.switch_to.window(all_handles[-1])print("当前页面标题:", browser.title) # 应显示必应的标题time.sleep(2)# 5. 切回主窗口browser.switch_to.window(main_window)print("切回主窗口,当前页面标题:", browser.title) # 应显示百度的标题time.sleep(2)# 6. 遍历所有窗口示例print("\n遍历所有窗口:")for handle in all_handles:browser.switch_to.window(handle)print(f"窗口句柄: {handle}")print(f"页面标题: {browser.title}")print(f"当前URL: {browser.current_url}")print("---")time.sleep(1)except Exception as e:print(f"发生错误: {e}")finally:browser.quit()

3.1.7 其他设置(隐藏窗口、禁用GPU加速、禁用沙盒、禁用共享内存)
- add_argument():添加一些其他设置选项。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options # 导入 Options# 配置无头浏览器、禁用GPU加速、禁用沙盒、禁用共享内存
chrome_options = Options()
chrome_options.add_argument('--headless') # 启用无头模式
chrome_options.add_argument('--disable-gpu') # 禁用GPU加速
chrome_options.add_argument('--no-sandbox') # 禁用沙盒
chrome_options.add_argument('--disable-dev-shm-usage') # 禁用共享内存# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器时传入配置
browser = webdriver.Chrome(service=service, options=chrome_options)try:# 设置隐式等待时间browser.implicitly_wait(10)# 打开必应搜索页面browser.get("https://www.bing.com")print("已打开必应搜索页面")except Exception as e:print(f"发生错误: {e}")finally:browser.quit()print("浏览器已关闭")
3.2 定位并访问、操作网页元素
- 网页元素是构成网页的基本组成部分,是HTML文档中的各种标签所创建的对象。在自动化测试和网页操作中,我们需要定位元素以便进行交互操作,获取其相关信息。
- Selenium定位网页元素的方法:
- ID定位:find_element(By.ID, “element-id”)
- 名称定位:find_element(By.NAME, “element-name”)
- 类名定位:find_element(By.CLASS_NAME, “class-name”)
- 标签名定位:find_element(By.TAG_NAME, “tag-name”)
- XPath定位:find_element(By.XPATH, “//xpath-expression”)
- CSS选择器定位:find_element(By.CSS_SELECTOR, “css-selector”)
- 链接文本定位:find_element(By.LINK_TEXT, “link-text”)
- 部分链接文本定位:find_element(By.PARTIAL_LINK_TEXT, “partial-text”)
3.2.1 通过XPath定位网页元素(CSDN首页为例)
XPath是一种在XML和HTML文档中查找元素的强大语言,其结合浏览器不用去看网页源码就能很方便的定位网页元素。
-
首先通过浏览器打开需要定位的元素所在的网页:

-
按F12进入开发者模式,点击图中开发者窗口左上角的图标,点击元素,这时鼠标滑过网页的每一个元素下面的源码都会快速定位到该元素的对应源码


-
这时我们把鼠标移动到需要定位的元素上面,点击鼠标左键,然后鼠标移动到该元素的源码部分,鼠标右键单击打开菜单,在菜单中选择复制-复制XPath(或者复制完整 XPath)即可得到该元素的XPath


-
有了元素的XPath,便可以通过selenium的find_element方法获取这个元素,随后对其进行交互操作、获取相关信息等。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Servicedef locate_search_button():# 设置 ChromeDriver 的路径driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"service = Service(driver_path)# 初始化 Chrome 浏览器并打开browser = webdriver.Chrome(service=service)browser.get("https://www.csdn.net/")# 通过xpath定位搜索按钮element = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]/span')# 打印元素文本print("找到搜索按钮,文本内容:", element.text)# 关闭浏览器browser.quit()if __name__ == "__main__":locate_search_button()

3.2.2 点击元素
- click():点击元素
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 定位并点击搜索按钮search_button = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]')search_button.click()print("成功点击搜索按钮")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2) # 等待2秒看效果browser.quit()

3.2.3 清空输入框、输入文本
- clear():清空输入框
- send_keys():输入文本
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try: # 定位搜索框search_input = browser.find_element(By.XPATH, '//*[@id="toolbar-search-input"]')# 清空输入框search_input.clear()# 输入文本search_input.send_keys("Python Selenium")print("成功输入文本")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2) # 等待2秒看效果browser.quit()


3.2.4 获取元素信息(文本、属性、标签名、大小、位置、是否显示、是否启用)
- text():获取元素文本
- get_attribute():获取元素某些属性
- tag_name():获取元素标签名
- size():获取元素大小
- location():获取元素位置
- is_displayed():判断元素是否显示
- is_enabled():判断元素是否启用
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 定位搜索按钮element = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]')# 获取元素的各种属性print("元素文本:", element.text)print("class属性:", element.get_attribute("class"))print("标签名:", element.tag_name)print("元素大小:", element.size)print("元素位置:", element.location)print("是否显示:", element.is_displayed())print("是否启用:", element.is_enabled())except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2)browser.quit()

3.2.5 对元素执行鼠标操作(悬停、左键点击、右键点击、双击)
使用 ActionChains 类可以对元素执行以下鼠标操作:
- move_to_element():鼠标悬停
- click():鼠标左键点击
- context_click():鼠标右键点击
- double_click():鼠标双击
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.action_chains import ActionChains# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 定位搜索按钮element = browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]')# 创建 ActionChains 对象actions = ActionChains(browser)# 鼠标悬停actions.move_to_element(element).perform()print("执行鼠标悬停")time.sleep(1)# 鼠标点击actions.click(element).perform()print("执行鼠标点击")time.sleep(1)# 鼠标右键actions.context_click(element).perform()print("执行鼠标右键")time.sleep(1)# 双击actions.double_click(element).perform()print("执行鼠标双击")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2)browser.quit()

3.2.6 对元素执行键盘操作(输入字母、空格、制表符、回车、Ctrl+…)
使用 Keys 类可以执行以下键盘操作:
- send_keys():输入文本
- Keys.BACK_SPACE:退格键
- Keys.SPACE:空格键
- Keys.TAB:制表键
- Keys.ENTER/Keys.RETURN:回车键
- Keys.CONTROL + ‘a’:全选(Ctrl+A)
- Keys.CONTROL + ‘c’:复制(Ctrl+C)
- Keys.CONTROL + ‘v’:粘贴(Ctrl+V)
- Keys.CONTROL + ‘x’:剪切(Ctrl+X)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try: # 定位搜索框search_input = browser.find_element(By.XPATH, '//*[@id="toolbar-search-input"]')# 1. 基本输入search_input.send_keys("Python")print("输入文本:Python")time.sleep(1)# 2. 空格search_input.send_keys(Keys.SPACE)search_input.send_keys("Selenium")print("输入空格和文本:Python Selenium")time.sleep(1)# 3. 全选文本 (Ctrl+A)actions = ActionChains(browser)actions.key_down(Keys.CONTROL).send_keys('a').key_up(Keys.CONTROL).perform()print("全选文本")time.sleep(1)# 4. 复制文本 (Ctrl+C)actions.key_down(Keys.CONTROL).send_keys('c').key_up(Keys.CONTROL).perform()print("复制文本")time.sleep(1)# 5. 删除文本(退格键)search_input.send_keys(Keys.BACK_SPACE)print("删除文本")time.sleep(1)# 6. 粘贴文本 (Ctrl+V)actions.key_down(Keys.CONTROL).send_keys('v').key_up(Keys.CONTROL).perform()print("粘贴文本")time.sleep(1)# 7. 制表键search_input.send_keys(Keys.TAB)print("按下Tab键")time.sleep(1)# 8. 回车搜索search_input.send_keys(Keys.RETURN)print("按下回车键执行搜索")except Exception as e:print(f"发生错误: {e}")finally:import timetime.sleep(2)browser.quit()

3.3 滚轮操作
- 最常用且最可靠的方法是使用 JavaScript 来控制滚动
- execute_script():执行JavaScript脚本
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)
browser.get("https://www.csdn.net/")try:# 1. 滚动到页面底部browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")print("滚动到页面底部")time.sleep(1)# 2. 滚动到页面顶部browser.execute_script("window.scrollTo(0, 0);")print("滚动到页面顶部")time.sleep(1)# 3. 向下滚动500像素browser.execute_script("window.scrollBy(0, 500);")print("向下滚动500像素")time.sleep(1)# 4. 使用 PageDown 键滚动actions = ActionChains(browser)actions.send_keys(Keys.PAGE_DOWN).perform()print("使用 PageDown 键滚动")time.sleep(1)# 5. 滚动到特定元素try:element = browser.find_element(By.CLASS_NAME, "toolbar-container")browser.execute_script("arguments[0].scrollIntoView();", element)print("滚动到特定元素位置")time.sleep(1)except Exception as e:print(f"未找到目标元素: {e}")# 6. 平滑滚动到底部browser.execute_script("""window.scrollTo({top: document.body.scrollHeight,behavior: 'smooth'});""")print("平滑滚动到底部")time.sleep(2)# 7. 模拟无限滚动加载last_height = browser.execute_script("return document.body.scrollHeight")scroll_attempts = 3 # 限制滚动次数,避免无限循环for i in range(scroll_attempts):browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")print(f"执行第 {i+1} 次滚动加载")time.sleep(2)new_height = browser.execute_script("return document.body.scrollHeight")if new_height == last_height:print("已到达页面底部")breaklast_height = new_heightexcept Exception as e:print(f"发生错误: {e}")finally:time.sleep(2)browser.quit()

3.4 延时等待
- implicitly_wait:设置隐式等待时间。隐式等待是一个全局设置,设置后对整个浏览器会话中的所有操作都生效;它告诉WebDriver在查找元素时,如果元素不存在,应该等待多长时间;在设定的时间内,WebDriver会定期重试查找元素的操作。
- WebDriverWait:创建显式等待对象。它允许我们设置最长等待时间和检查的时间间隔;与隐式等待不同,显式等待可以针对特定元素设置具体的等待条件;它提供了更精确的等待控制。
- until:等待直到条件满足。它接受一个期望条件(EC)作为参数,在超时之前反复检查该条件是否满足;如果条件满足则返回结果,如果超时则抛出TimeoutException异常。
- until_not:等待直到条件不满足。与until相反,它等待一个条件变为false;常用于等待某个元素消失或某个状态结束的场景。
- expected_conditions:预定义的期望条件集合。包含多种常用的等待条件,如:
- presence_of_element_located:等待元素在DOM中出现
- visibility_of_element_located:等待元素可见
- element_to_be_clickable:等待元素可点击
- all_of:等待多个条件同时满足
- poll_frequency:设置轮询频率。定义了在显式等待过程中检查条件的时间间隔;默认是0.5秒检查一次;可以根据实际需求调整以优化性能。
- ignored_exceptions:设置要忽略的异常。在等待过程中可以指定某些异常被忽略而继续等待;常用于处理特定的临时性错误,如StaleElementReferenceException。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)try:# 1. 设置隐式等待时间(全局设置)browser.implicitly_wait(10)print("设置隐式等待时间:10秒")# 打开测试网页browser.get("https://www.csdn.net/")# 2. 显式等待 - 等待特定元素可见try:search_input = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.ID, "toolbar-search-input")))print("成功找到搜索框元素")except TimeoutException:print("等待搜索框超时")# 3. 显式等待 - 等待元素可点击try:login_button = WebDriverWait(browser, 5).until(EC.element_to_be_clickable((By.CLASS_NAME, "login-btn")))print("登录按钮可以点击")except TimeoutException:print("等待登录按钮可点击超时")# 4. 自定义等待条件def custom_condition(driver):element = driver.find_element(By.CLASS_NAME, "toolbar-container")return element.is_displayed() and element.get_attribute("style") != "display: none;"try:WebDriverWait(browser, 8).until(custom_condition)print("自定义条件满足")except TimeoutException:print("等待自定义条件超时")# 5. 多条件组合等待try:# 等待多个条件都满足wait = WebDriverWait(browser, 10)condition = wait.until(EC.all_of(EC.presence_of_element_located((By.CLASS_NAME, "toolbar-container")),EC.visibility_of_element_located((By.ID, "toolbar-search-input"))))print("多个条件都满足")except TimeoutException:print("等待多个条件超时")# 6. 使用until_not等待条件不成立try:# 等待加载动画消失loading_spinner = WebDriverWait(browser, 5).until_not(EC.presence_of_element_located((By.CLASS_NAME, "loading-spinner")))print("加载动画已消失")except TimeoutException:print("等待加载动画消失超时")# 7. 带有轮询间隔的等待try:# 设置轮询间隔为0.5秒wait = WebDriverWait(browser, timeout=10, poll_frequency=0.5)element = wait.until(EC.presence_of_element_located((By.CLASS_NAME, "toolbar-container")))print("使用自定义轮询间隔成功找到元素")except TimeoutException:print("使用自定义轮询间隔等待超时")# 8. 忽略特定异常的等待try:# 忽略 StaleElementReferenceException 异常wait = WebDriverWait(browser, 10, ignored_exceptions=[NoSuchElementException])element = wait.until(EC.presence_of_element_located((By.ID, "toolbar-search-input")))print("忽略特定异常后成功找到元素")except TimeoutException:print("忽略特定异常后等待超时")except Exception as e:print(f"发生错误: {e}")finally:time.sleep(2)browser.quit()

4 实战
4.1 实战一:自动化搜索并统计打印结果
- 本代码演示打开bing搜索界面搜索关键词“CSDN”,获取搜索结果并打印每个结果的基本信息。
- 代码思路:
- 使用
get()方法打开bing搜索界面 - 使用
find_element()方法定位搜索输入框元素 - 使用
send_keys()方法输入关键字和回车按键执行搜索 - 使用
find_elements()方法通过"b_algo"类名进行筛选,查看搜索界面源码可以知道搜索结果元素都是"b_algo"类。 - 综合使用
find_element()、text()、get_attribute()方法获取每个搜索结果的标题、链接、描述等信息,所使用的属性值、类名也是通过查看源码获得的,通过前文介绍的元素定位方法可以很容易的知道。
- 使用
- 注意:由于不同搜索结果之间存在一定的差异,所以不一定每一个搜索结果都能获得完整的信息,这个需要自己结合源码对示例代码进行修改。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器并打开
browser = webdriver.Chrome(service=service)try:# 设置隐式等待时间browser.implicitly_wait(10)# 打开必应搜索页面browser.get("https://www.bing.com")print("已打开必应搜索页面")# 查找搜索框并输入关键词search_input = browser.find_element(By.ID, "sb_form_q")search_input.send_keys("CSDN")search_input.send_keys(Keys.RETURN)print("已输入搜索关键词:CSDN")# 稍等待搜索结果加载time.sleep(2)# 获取搜索结果search_results = browser.find_elements(By.CLASS_NAME, "b_algo")print(f"\n找到 {len(search_results)} 条搜索结果:\n")# 打印搜索结果for index, result in enumerate(search_results, 1):try:# 获取标题和链接title_element = result.find_element(By.CSS_SELECTOR, "h2 a")title = title_element.textlink = title_element.get_attribute("href")# 获取描述 (直接获取 b_caption 的文本内容)description = result.find_element(By.CLASS_NAME, "b_caption").text# 打印结果print(f"结果 {index}:")print(f"标题: {title}")print(f"链接: {link}")print(f"描述: {description}")print("-" * 80)except Exception as e:print(f"处理第 {index} 条结果时出错: {str(e)}")continueexcept Exception as e:print(f"发生错误: {e}")finally:# 等待一段时间后关闭浏览器time.sleep(2)browser.quit()print("浏览器已关闭")



4.2 实战二:知网论文信息查询
- 本代码演示打开知网高级检索界面,通过设置学科专业(计算机)和学校单位(北京邮电大学)进行论文检索,并按下载量排序获取前20条论文的详细信息。
- 代码思路:
- 使用get()方法打开知网高级检索界面
- 使用maximize_window()方法将窗口最大化,确保所有元素可见
- 通过XPATH定位并点击"学科专业导航",清除已选学科,展开工学类别并选中计算机专业
- 使用send_keys()方法在学校单位输入框中填入"北京邮电大学"
- 点击检索按钮开始搜索
- 点击下载量排序选项,对结果进行排序
- 使用execute_script()方法控制页面向下滚动700像素
- 使用循环遍历前20条搜索结果,通过XPATH定位每条论文的各项信息
- 注意事项:
- 代码中使用了多处time.sleep()来确保页面加载完成,实际使用时可根据网络情况调整等待时间
- XPATH路径的获取是通过浏览器开发者工具复制得到,需要注意网页结构变化可能导致定位失效
- 使用try-except结构进行异常处理,确保程序运行的稳定性
- 最后使用quit()方法关闭浏览器,释放资源
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 设置 ChromeDriver 的路径
driver_path = "E:\\ProgramFiles\\_CodeTools\\ChromeDriver\\chromedriver.exe"
service = Service(driver_path)# 初始化 Chrome 浏览器
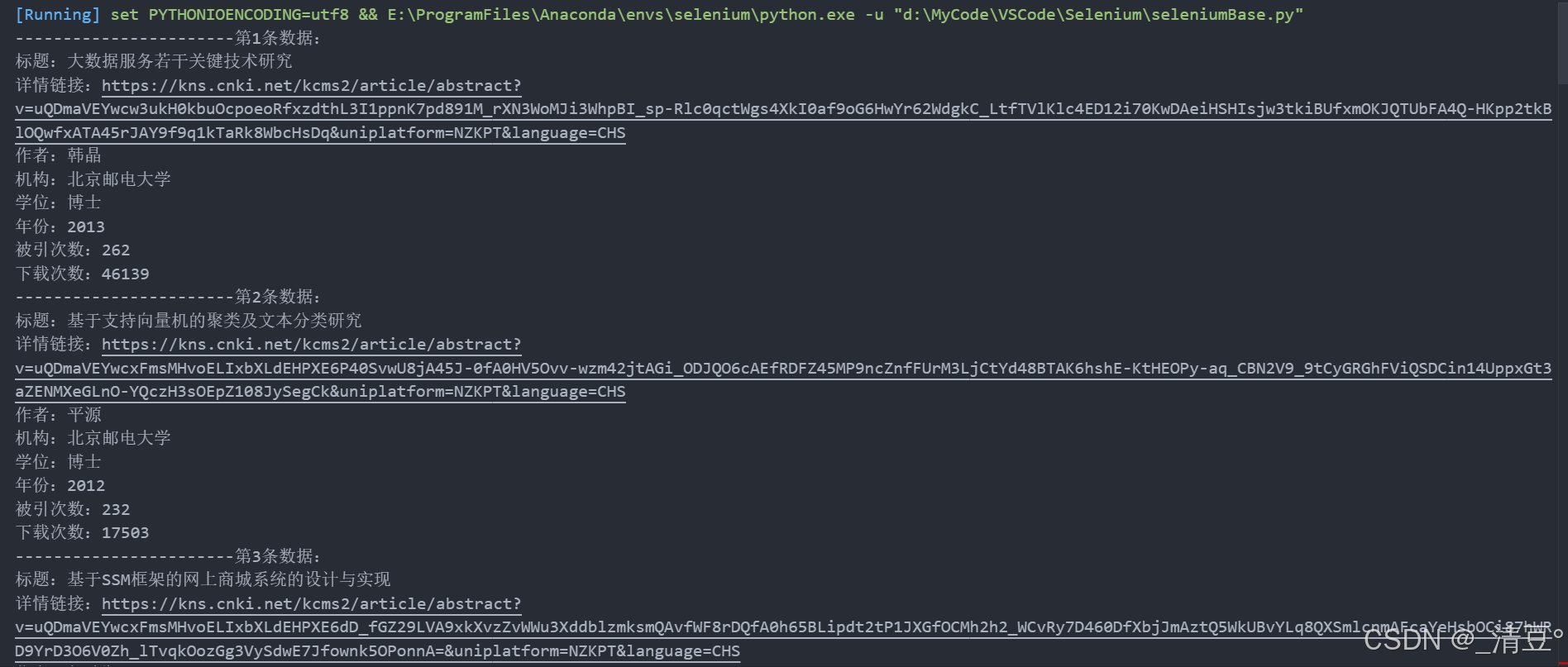
browser = webdriver.Chrome(service=service)try:# 设置隐式等待时间browser.implicitly_wait(10)browser.get("https://epub.cnki.net/kns/advsearch?classid=RDS33BAY")time.sleep(1)# 窗口最大化browser.maximize_window()time.sleep(1)# 点击学科专业导航browser.find_element(By.XPATH, '//*[@id="XuekeNavi_Div"]/div/div/div/div/div[1]/a[2]').click()time.sleep(1)# 点击清除取消所有选中的学科browser.find_element(By.XPATH, '//*[@id="XuekeNavi_Div"]/div/div/div/div/div[2]/a[2]').click()time.sleep(1)# 点击展开工学browser.find_element(By.XPATH, '//*[@id="08"]').click()time.sleep(1)# 点击选中计算机browser.find_element(By.XPATH, '//*[@id="9UG2UB8R"]/li[8]/ul/li[12]/div/i[2]').click()time.sleep(1)# 往学校单位输入框填写内容browser.find_element(By.XPATH, '//*[@id="inputAndSelect"]/input').send_keys("北京邮电大学")time.sleep(1)# 点击检索按钮browser.find_element(By.XPATH, "/html/body/div[2]/div[3]/div/div[3]/div[1]/div[2]/div[1]/div[9]").click()time.sleep(1)# 点击按照下载量排序browser.find_element(By.XPATH, '//*[@id="orderList"]/li[6]').click()time.sleep(1)# 向下翻动700pxbrowser.execute_script("window.scrollBy(0, 700);")time.sleep(1)for i in range(20):title = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[2]/a',).textdetail_link = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[2]/a',).get_attribute("href")author = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[3]/a',).textinstitution = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[4]/a/font',).textdegree = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[5]',).textyear = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[6]',).textcited_count = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[7]',).textdownload_count = browser.find_element(By.XPATH,f'//*[@id="gridTable"]/div/div[2]/div/table/tbody/tr[{i+1}]/td[8]',).textprint(f"-----------------------第{i+1}条数据:")print(f"标题:{title}")print(f"详情链接:{detail_link}")print(f"作者:{author}")print(f"机构:{institution}")print(f"学位:{degree}")print(f"年份:{year}")print(f"被引次数:{cited_count}")print(f"下载次数:{download_count}")except Exception as e:print(f"发生错误: {e}")finally:browser.quit()print("浏览器已关闭")
相关文章:

Python Selenium库入门使用,图文详细。附网页爬虫、web自动化操作等实战操作。
文章目录 前言1 创建conda环境安装Selenium库2 浏览器驱动下载(以Chrome和Edge为例)3 基础使用(以Chrome为例演示)3.1 与浏览器相关的操作3.1.1 打开/关闭浏览器3.1.2 访问指定域名的网页3.1.3 控制浏览器的窗口大小3.1.4 前进/后…...

AI华佗?港中大、深圳大数据研究院提出医疗推理大模型HuatuoGPT-o1
编辑 | 白菜叶 OpenAI o1 的突破凸显了通过增强推理能力来提高自然语言大模型(LLM)的应用潜力。然而,大多数推理研究都集中在数学任务上,而医学等领域尚未得到充分探索。 医学领域虽然不同于数学,但鉴于医疗保健的高…...

openEuler22.03系统使用Kolla-ansible搭建OpenStack
Kolla-ansible 是一个利用 Ansible 自动化工具来搭建 OpenStack 云平台的开源项目,它通过容器化的方式部署 OpenStack 服务,能够简化安装过程、提高部署效率并增强系统的可维护性。 前置环境准备: 系统:openEuler-22.03-LTS-SP4 配置&…...

uni-app无限级树形组件简单实现
因为项目一些数据需要树形展示,但是官网组件没有。现在简单封装一个组件在app中使用,可以无线嵌套,展开,收缩,获取子节点数据等。 简单效果 组件TreeData <template><view class"tree"><te…...

初学stm32 --- ADC单通道采集
目录 ADC寄存器介绍(F1) ADC控制寄存器 1(ADC_CR1) ADC控制寄存器 2(ADC_CR2) ADC采样时间寄存器1(ADC_SMPR1) ADC采样时间寄存器2(ADC_SMPR2) ADC规则序列寄存器 1(ADC_SQR1) ADC规则序列寄存器 2(ADC_SQR2) ADC规则序列寄存器 3(ADC_SQR3) AD…...

css盒子水平垂直居中
目录 1采用flex弹性布局: 2子绝父相margin:负值: 3.子绝父相margin:auto: 4子绝父相transform: 5通过伪元素 6table布局 7grid弹性布局 文字 水平垂直居中链接:文字水平垂直居中-CSDN博客 以下为盒子…...

django基于Python的智能停车管理系统
1.系统概述 1.定义:Django 基于 Python 的智能停车管理系统是一个利用 Django 框架构建的软件系统,用于高效地管理停车场的各种事务,包括车辆进出记录、车位预订、收费管理等诸多功能。 2.目的:它的主要目的是提高停车场的运营效…...

Rabbit Rocket kafka 怎么实现消息有序消费和延迟消费的
在消息队列系统中,像 RabbitMQ、RocketMQ 和 Kafka 这样的系统,都支持不同的方式来实现消息的有序消费和延迟消费。下面我们分别探讨这些系统中如何实现这两种需求: 1. RabbitMQ:实现消息有序消费和延迟消费 有序消费࿱…...

Kafka 会丢消息吗?
目录 01 生产者(Producer) 02 消息代理(Broker) 03 消费者(Consumer) 来源:Kafka 会丢消息吗? Kafka 会丢失信息吗? 许多开发人员普遍认为,Kafka 的设计本身就能保证不会丢失消息。然而,Kafka 架构和配置的细微差别会导致消息的丢失。我们需要了解它如何以及何时…...

状态模式详解与应用
状态模式(State Pattern),是一种行为型设计模式。它允许一个对象在其内部状态改变时改变它的行为,使得对象看起来似乎修改了它的类。通过将不同的行为封装在不同的状态类中,状态模式可以避免大量的条件判断语句&#x…...

红队工具使用全解析:揭开网络安全神秘面纱一角
红队工具使用全解析:揭开网络安全神秘面纱一角 B站红队公益课:https://space.bilibili.com/350329294 学习网盘资源链接:https://pan.quark.cn/s/4079487939e8 嘿,各位网络安全爱好者们!在风云变幻的网络安全战场上&am…...

【Spring】Redis缓存+ehcache
文章目录 基于Spring的RedisehcacheRedis 缓存配置Cacheable 注解CacheEvict 注解缓存配置 基于Spring的Redisehcache Redis 缓存配置 在项目中添加 Redis 的依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot…...

【硬件介绍】Type-C接口详解
一、Type-C接口概述 Type-C接口特点:以其独特的扁头设计和无需区分正反两面的便捷性而广受欢迎。这种设计大大提高了用户的使用体验,避免了传统USB接口需要多次尝试才能正确插入的问题。Type-C接口内部结构:内部上下两排引脚的设计虽然可能不…...

网络传输层TCP协议
传输层TCP协议 1. TCP协议介绍 TCP(Transmission Control Protocol,传输控制协议)是一个要对数据的传输进行详细控制的传输层协议。 TCP 与 UDP 的不同,在于TCP是有连接、可靠、面向字节流的。具体来说,TCP设置了一大…...

Git 基础——《Pro Git》
⭐获取 Git 仓库 获取 Git 仓库有两种方式: 将未进行版本控制的本地目录转换为 Git 仓库。从其他服务器克隆一个已存在的 Git 仓库。 在已存在目录中初始化 Git 仓库 进入目标目录 在 Linux 上:$ cd /home/user/my_project在 macOS 上:$ c…...
)
数据结构与算法之二叉树: LeetCode 654. 最大二叉树 (Ts版)
最大二叉树 https://leetcode.cn/problems/maximum-binary-tree/ 描述 给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最大值递归地在最大值 左边 的 子数组前缀上 构建左子树递归地在最大值…...

学习记录:C++宏定义包含多条语句,使用注意事项
应该使用 do - while(0) 结构的情况 在条件语句(如 if - else、switch - case)或循环语句(如 for、while、do - while)中使用宏: 当宏定义包含多条语句且会在上述语句中使用时,使用 do - while(0) 可确保…...

PHP 使用 Redis
PHP 使用 Redis PHP 是一种广泛使用的服务器端编程语言,而 Redis 是一个高性能的键值对存储系统。将 PHP 与 Redis 结合使用,可以为 Web 应用程序提供快速的读写性能和丰富的数据结构。本文将详细介绍如何在 PHP 中使用 Redis,包括安装、连接、基本操作以及一些高级应用。 …...
)
项目开发实践——基于SpringBoot+Vue3实现的在线考试系统(五)
文章目录 一、学生管理模块功能实现1、添加学生功能实现1.1 页面设计1.2 前端功能实现1.3 后端功能实现1.4 效果展示2、学生管理功能实现2.1 页面设计2.2 前端功能实现2.3 后端功能实现2.3.1 后端查询接口实现2.3.2 后端编辑接口实现2.3.3 后端删除接口实现2.4 效果展示二、代码…...

下载并安装MySQL
在Linux系统上下载并安装数据库(以MySQL为例)的步骤如下: 一、下载MySQL 访问MySQL官网 打开浏览器,访问MySQL的官方网站:https://www.mysql.com/。 进入下载页面 在MySQL官网首页,找到并点击“Downloads…...
)
【C++入门】详解(中)
目录 💕1.函数的重载 💕2.引用的定义 💕3.引用的一些常见问题 💕4.引用——权限的放大/缩小/平移 💕5. 不存在的空引用 💕6.引用作为函数参数的速度之快(代码体现) Ǵ…...

计算机视觉算法实战——车道线检测
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 车道线检测是计算机视觉领域的一个重要研究方向,尤其在自动驾驶和高级驾驶辅助…...

基于http协议的天气爬虫
该系统将基于目前比较流行的网络爬虫技术, 对网站上的天气数据进行查询分析, 最终使客户能够通过简单的操作, 快速, 准确的获取目标天气数据。主要包括两部分的功能, 第一部分是天气数据查询, 包括时间段数…...

自然语言处理基础:全面概述
自然语言处理基础:全面概述 什么是NLP及其重要性、NLP的核心组件、NLU与NLG、NLU与NLG的集成、NLP的挑战以及NLP的未来 自然语言处理(NLP)是人工智能(AI)中最引人入胜且具有影响力的领域之一。它驱动着我们日常使用的…...

软件架构考试基础知识 002:进程的状态与其切换
进程状态转换的说明 在操作系统中,进程的状态表示其当前的执行情况和资源占用情况。进程状态的转换反映了操作系统如何管理和调度进程。以下是进程状态转换的说明: 1. 三态模型(Three-state Model) 三态模型是最基础的进程状态模…...

【Linux系列】Curl 参数详解与实践应用
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

VsCode对Arduino的开发配置
ps:我的情况是在对esp32进行编译、烧录时,找不到按钮,无法识别Arduino文件,适合已经有ini文件的情况。 1.在vscode中安装拓展 2.打开设置,点击右上角,转到settings.json文件 3.复制以下代码并保存 {"…...

【Pandas】pandas Series rtruediv
Pandas2.2 Series Binary operator functions 方法描述Series.add()用于对两个 Series 进行逐元素加法运算Series.sub()用于对两个 Series 进行逐元素减法运算Series.mul()用于对两个 Series 进行逐元素乘法运算Series.div()用于对两个 Series 进行逐元素除法运算Series.true…...

VUE3 自定义指令的介绍
自定义指令的概述 在 Vue 中,自定义指令是一种机制,允许开发者在模板中直接操作 DOM 元素,执行一些低级别的操作。Vue 提供了几个内置指令(如 v-if、v-for、v-model 等),但当我们需要一些特定功能时&#…...

RedisDB双机主从同步性能测试
安装redisDB 主节点 apt install redis-server修改配置 /etc/redis/redis.conf bind 0.0.0.0save "" # 禁止RDB持久化 #save 900 1 #save 300 10 #save 60 10000appendonly no # 禁止AOF持久化重启服务 systemctl restart redis-server从节点配置文件 bind 0.…...

【汇编】x86汇编编程寄存器资源心中有数
1. CPU状态及控制寄存器 TR,GDTR,LDTRcr0-cr3EFLAGS 等等 2. 业务计算寄存器(我起的名字) 业务寄存器用于访问内存、参数传递、数据传递、计算。 段寄存器6个: cs,ds,es,ss&…...

一.项目课题 <基于TCP的文件传输协议实现>
客户端代码 需要cJSON.c文件和cJSON.h文件 在这里插入代码片#include "myheadth.h" #include "myfun.h"#define TIME 10 int sockfd; void heartbeat(int signum) {cJSON* root cJSON_CreateObject();cJSON_AddStringToObject(root,"request"…...
)
【数据结构学习笔记】19:跳表(SkipList)
介绍 跳表是一个能在 O ( n l o g n ) O(nlogn) O(nlogn)时间完成查找、插入、删除的数据结构,相比于树形结构优点就是很好写(所以也用于实现Redis ZSet)。其核心思想就是维护一个元素有序的,能随机提升索引层数的链表。最下面一…...

Cocos Creator 3.8 修改纹理像素值
修改的代码: import { _decorator, Component, RenderTexture, Sprite, Texture2D, ImageAsset, SpriteFrame, Vec2, gfx, director, log, math, v2 } from cc;const { ccclass, property } _decorator;ccclass(GradientTransparency) export class GradientTrans…...

【Linux】网络层
目录 IP协议 协议头格式 网段划分 2中网段划分的方式 为什么要进行网段划分 特殊的IP地址 IP地址的数量限制 私有IP地址和公有IP地址 路由 IP协议 在通信时,主机B要把数据要给主机C,一定要经过一条路径选择,为什么经过路由器G后&…...

单片机Day1
目录 一.什么是单片机? 二.单片机的组成 三.封装形式 四.优势 五.分类 通用型: 专用型: 按处理的二进制位可以分为: 六.应用: 七.发展趋势 1.增加CPU的数据总线宽度。 2.存储器的发展。 3.片内1/0的改进 …...

django基于 Python 的考研学习系统的设计与实现
以下是对Django基于Python的考研学习系统的设计与实现: 一、系统概述 Django基于Python的考研学习系统是一个为考研学子提供一站式学习辅助的平台。它整合了丰富的学习资源、学习计划制定、学习进度跟踪以及交流互动等功能,旨在满足考生在备考过程中的…...

openCvSharp 计算机视觉图片找茬
一、安装包 <PackageReference Include"OpenCvSharp4" Version"4.10.0.20241108" /> <PackageReference Include"OpenCvSharp4.runtime.win" Version"4.10.0.20241108" /> 二、准备两张图片 三、编写代码 using OpenCv…...

深入学习 Python 爬虫:从基础到实战
深入学习 Python 爬虫:从基础到实战 前言 Python 爬虫是一个强大的工具,可以帮助你从互联网上抓取各种数据。无论你是数据分析师、机器学习工程师,还是对网络数据感兴趣的开发者,爬虫都是一个非常实用的技能。在本文中ÿ…...
)
【Web安全】SQL 注入攻击技巧详解:UNION 注入(UNION SQL Injection)
【Web安全】SQL 注入攻击技巧详解:UNION 注入(UNION SQL Injection) 引言 UNION注入是一种利用SQL的UNION操作符进行注入攻击的技术。攻击者通过合并两个或多个SELECT语句的结果集,可以获取数据库中未授权的数据。这种注入技术要…...

【DAPM杂谈之一】DAPM作用与内核文档解读
本文主要分析DAPM的设计与实现 内核的版本是:linux-5.15.164,下载链接: Linux内核下载 主要讲解有关于DAPM相关的知识,会给出一些例程并分析内核如何去实现的 /****************************************************************…...
)
计算机网络之---防火墙与入侵检测系统(IDS)
防火墙与入侵检测系统(IDS) 防火墙(Firewall) 和 入侵检测系统(IDS, Intrusion Detection System) 都是网络安全的关键组件,但它们的作用、功能和工作方式有所不同。 防火墙 防火墙是网络安全的一种设备或软件&#…...

HTML中meta的用法
学习网络空间安全专业,每个人有每个人的学法和选择。不论他选择什么,哪都是他自己的选择,这就是大多数视频教学的博主教学的步骤都不同原因之一。有人选择丢掉大部分理论直接学习网安,而我,选择了捡起大部分理论学习网…...
)
前端学习-事件流,事件捕获,事件冒泡以及阻止冒泡以及相应案例(二十八)
目录 前言 事件流与两个阶段说明 说明 事件捕获 目标 说明 事件冒泡 目标 事件冒泡概念 简单理解 阻止冒泡 目标 语法 注意 综合示例代码 总结 前言 梳洗罢,独倚望江楼。过尽千帆皆不是,斜晖脉脉水悠悠。肠断白蘋洲 事件流与两个阶段说明…...

国产OS移植工业物联网OPC-UA协议
国家对于工业互联网、基础软件等关键领域的重视程度不断提升,为工业领域的硬件与软件国产化提供了坚实的政策保障。国产操作系统对工业物联网的一些重要领域的适配支持一直在推进。本次通过国产UOS系统移植测试OPC-UA协议。 1、OPC UA通信协议 OPC UA 协议…...

第25章 汇编语言--- 信号量与互斥锁
信号量(Semaphore)和互斥锁(Mutex,全称Mutual Exclusion Object)是两种用于管理对共享资源的访问的同步机制。它们在多线程或多进程编程中非常重要,可以确保同一时间只有一个线程或进程能够访问特定的资源&…...

写个自己的vue-cli
写个自己的vue-cli 1.插件代码2. 发布流程3. 模板代码讲解3.1 vue2模板的运行流程:3.2 vue3模板的运行流程: 1.插件代码 写一个自己的vue-cli插件 插件地址:插件地址 流程: 实现简单版 vue-cli 步骤文档1. 项目初始化 - 创建项目文件夹 qsl-vue-cli - …...
)
使用new Vue创建Vue 实例并使用$mount挂载到元素上(包括el选项和$mount区别)
new Vue({...}) 是创建一个新的 Vue 实例的方式。你可以通过传递一个选项对象来配置这个实例。常见的选项包括: •data:定义组件的数据属性。 •el:指定 Vue 实例应该挂载到哪个 DOM 元素上(通常是一个选择器字符串,如…...

【理论】测试框架体系TDD、BDD、ATDD、MBT、DDT介绍
一、测试框架是什么 测试框架是一组用于创建和设计测试用例的指南或规则。框架由旨在帮助 QA 专业人员更有效地测试的实践和工具的组合组成。 这些指南可能包括编码标准、测试数据处理方法、对象存储库、存储测试结果的过程或有关如何访问外部资源的信息。 A testing framewo…...

机器学习全流程解析:数据导入到服务上线全阶段介绍
目录 1. 数据导入 2. 数据预处理 3. 超参数搜索与优化 4. 模型训练 5. 模型评估 6. 模型压缩与优化 7. 模型注册与版本管理 8. 服务上线与部署 总结 1. 数据导入 数据源:数据库、文件系统、API等。数据格式:CSV、JSON、SQL 数据库表、Parquet …...