markdown存储到faiss向量数据库
目录
- 一、faiss接收的数据接口
- 二、Markdown文件切分并处理为document列表
- 1.markdown分割器
- 2.文本分割器
- 3.添加文件名
- 三、整体流程
- 源代码
一、faiss接收的数据接口

add_docunments接收的documents是一个document对象的列表。
Document 对象的列表(List of Documents),是 LangChain 中的一种数据结构。每个 Document 对象包含两个主要属性:
-
metadata:文档的元数据- 这里包含
file_name(文件名) - 例如:
{'file_name': '01-通过-史国阳-硕士-算法岗.md'}
- 这里包含
-
page_content:文档的实际内容- 包含简历的具体文本内容
- 被分成了多个片段(chunks)
数据结构示例:
documents = [Document(metadata={'file_name': '01-通过-xxx-硕士-算法岗.md'},page_content='# 基本信息\n\n**姓名:** xxx\n...'),Document(metadata={'file_name': '01-通过-xxx-硕士-算法岗.md'},page_content='- **广联达科技股份有限公司**\n...'),# ... 更多 Document 对象
]
这种结构通常用于:
- 文档向量化
- 文本分块处理
- 构建向量数据库
- 文档检索和问答系统
在之前的faiss学习的例子中,就是使用的这种对象列表。每一个document都有数据内容和相应的元信息,元信息可以用来存储一些标识符、属性、限制这类,以方便进行条件查询。
二、Markdown文件切分并处理为document列表
1.markdown分割器

让我解释这个 MarkdownHeaderTextSplitter 的初始化:
from langchain.text_splitter import MarkdownHeaderTextSplitter# 定义要分割的标题级别
headers_to_split_on = [("#", "header1"), # H1 标题("##", "header2"), # H2 标题("###", "header3"), # H3 标题
]# 创建分割器实例
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on,strip_headers=False # 保留标题在分割后的文本中
)
这个分割器的作用是:
- 根据 Markdown 标题层级分割文本
- 每个分割后的片段会包含其对应的标题信息
参数说明:
-
headers_to_split_on:定义要识别的标题级别- 每个元组包含 (标题符号, 元数据键名)
- 例如:(“#”, “header1”) 表示 H1 标题
-
strip_headers=False:True: 移除分割后文本中的标题False: 保留标题在文本中
使用示例:
text = """
# 个人简历## 教育背景
本科毕业于北京大学## 工作经验
### 公司A
担任软件工程师
### 公司B
担任高级工程师
"""splits = markdown_splitter.split_text(text)
# 结果示例:
# [
# Document(
# page_content="# 个人简历",
# metadata={"header1": "个人简历"}
# ),
# Document(
# page_content="## 教育背景\n本科毕业于北京大学",
# metadata={"header1": "个人简历", "header2": "教育背景"}
# ),
# ...
# ]
这种分割方式特别适合:
- 结构化处理 Markdown 文档
- 保留文档的层级结构
- 基于标题进行文档检索
- 问答系统中的上下文管理
切分器自动将markdown处理为document列表
2.文本分割器

让我解释这个文本分割器的配置:
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=500, # 每个文本块的最大token数chunk_overlap=50 # 相邻文本块之间的重叠token数
)
这是一个使用 tiktoken 编码器的递归文本分割器,主要参数:
-
chunk_size=500- 每个文本块的最大长度(以token为单位)
- token是GPT模型的基本处理单位
- 500 tokens 大约对应 375-425 个汉字或 150-200 个英文单词
-
chunk_overlap=50- 相邻文本块之间重叠的token数
- 用于保持上下文连贯性
- 防止句子或段落在分割时被生硬切断
使用示例:
text = """这是一个很长的文档,需要被分割成小块。
这样可以更好地处理和分析。每个块都会包含一定数量的文本。
相邻的块之间会有一些重叠,确保上下文的连续性。"""chunks = text_splitter.split_text(text)
# 结果会是多个较小的、有重叠的文本块
这种分割方式的优点:
- 使用 tiktoken(OpenAI的分词器)确保准确的token计数
- 递归分割保证更自然的文本边界
- 重叠部分维持了上下文连贯性
- 适合后续的向量化和语义搜索
3.添加文件名
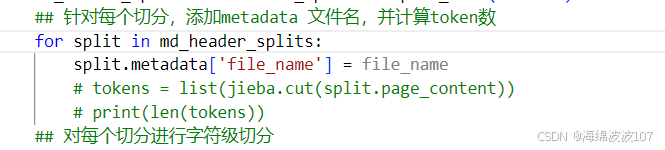
保证每个简历块都有名字,防止简历块分割之后,因为没有名字,六神无主了。因为有的时候发现简历中会带导师、博导师名字。分割之后,会认为这个博导师名字占有了这个简历内容。
三、整体流程
所以,不仅需要有该数据的接口,也要有转换为该接口的方法,两者都需要。就像两个齿轮,尺寸要契合才能一起运动。
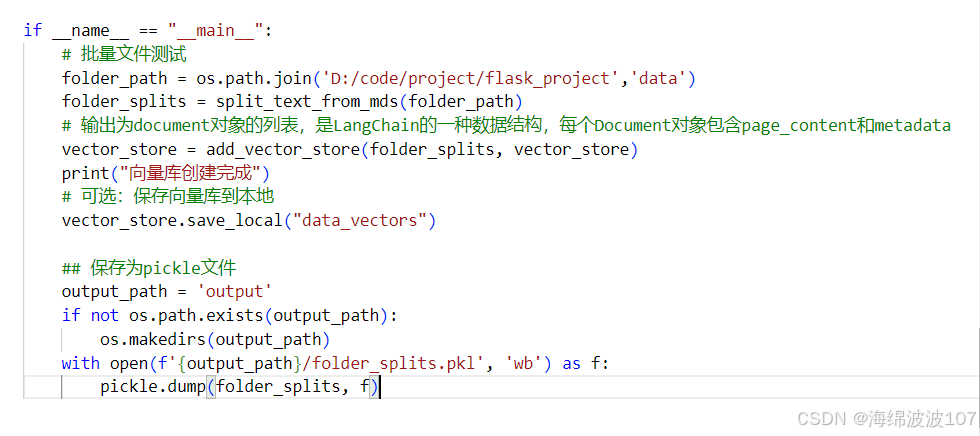
源代码
import os
import jieba
import time
import pickle
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings, OllamaEmbeddings
from langchain_openai import OpenAIEmbeddings
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
from uuid import uuid4
from langchain_core.documents import Document
OPENAI_API_KEY='sk-xxx'# 初始化embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large",api_key=OPENAI_API_KEY)
# 初始化index
index = faiss.IndexFlatL2(len(embeddings.embed_query("hello world")))# 初始化vector_store
vector_store = FAISS(embedding_function=embeddings,index=index,docstore=InMemoryDocstore(),index_to_docstore_id={},
)# 批量读取 markdown 文件并处理
def split_text_from_mds(folder_path):text_splits = []for filename in os.listdir(folder_path):if filename.endswith(".md"):file_splits = process_markdown(filename, folder_path)text_splits.extend(file_splits)return text_splitsdef process_markdown(file_name, folder_path):## 读取文件print(f"Processing file: {file_name}")file_path = os.path.join(folder_path, file_name)with open(file_path, 'r', encoding='utf-8') as file:content = file.read()md_header_splits = markdown_splitter.split_text(content)## 针对每个切分,添加metadata 文件名,并计算token数for split in md_header_splits:split.metadata['file_name'] = file_name# tokens = list(jieba.cut(split.page_content))# print(len(tokens))## 对每个切分进行字符级切分 ## todo:容易把相同快切断char_splits = text_splitter.split_documents(md_header_splits)return char_splits# 切分器
## Markdown header split
headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),("###", "Header 3"),("####", "Header 4"),("#####", "Header 5"),("######", "Header 6"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on, strip_headers=False)## Char-level splits
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=500, chunk_overlap=50
)def add_vector_store(documents, vector_store):"""将文档添加到已有的向量库中Args:documents: 文档列表,每个文档包含文本内容和元数据vector_store: 已初始化的FAISS向量库实例Returns:添加文档后的FAISS向量库实例"""try:# 生成文档的唯一标识符uuids = [str(uuid4()) for _ in range(len(documents))]# 记录开始时间start_time = time.time()vector_store.add_documents(documents=documents, ids=uuids)# 计算处理时间process_time = time.time() - start_timeprint(f"向量化处理耗时: {process_time:.2f} 秒")return vector_storeexcept Exception as e:print(f"创建向量库时发生错误: {str(e)}")raiseif __name__ == "__main__":# 批量文件测试folder_path = os.path.join('D:/code/project/flask_project','data')folder_splits = split_text_from_mds(folder_path)# 输出为document对象的列表,是LangChain的一种数据结构,每个Document对象包含page_content和metadatavector_store = add_vector_store(folder_splits, vector_store)print("向量库创建完成")# 可选:保存向量库到本地vector_store.save_local("data_vectors")## 保存为pickle文件output_path = 'output'if not os.path.exists(output_path):os.makedirs(output_path)with open(f'{output_path}/folder_splits.pkl', 'wb') as f:pickle.dump(folder_splits, f)相关文章:

markdown存储到faiss向量数据库
目录 一、faiss接收的数据接口二、Markdown文件切分并处理为document列表1.markdown分割器2.文本分割器3.添加文件名 三、整体流程源代码 一、faiss接收的数据接口 add_docunments接收的documents是一个document对象的列表。 Document 对象的列表(List of Document…...

开源cJson用法
cJSON cJSON是一个使用C语言编写的JSON数据解析器,具有超轻便,可移植,单文件的特点,使用MIT开源协议。 cJSON项目托管在Github上,仓库地址如下: https://github.com/DaveGamble/cJSON 使用Git命令将其拉…...

SSL,TLS协议分析
写在前面 工作中总是会接触到https协议,也知道其使用了ssl,tls协议。但对其细节并不是十分的清楚。所以,就希望通过这篇文章让自己和读者朋友们都能对这方面知识有更清晰的理解。 1:tls/ssl协议的工作原理 1.1:设计的…...
)
华为路由器、交换机、AC、新版本开局远程登录那些坑(Telnet、SSH/HTTP避坑指南)
关于华为设备远程登录配置开启的通用习惯1、HTTP/HTTPS相关服务 http secure-server enablehttp server enable 2、Telnet服务telnet server enable3、SSH服务stelnet server enablessh user admin authentication-type password 「模拟器、工具合集」复制整段内容 链接&…...
)
Redis的数据结构(基本)
安装完成后,在任意目录输入redis-server命令即可启动Redis: redis-server 我们可以进入redis命令行窗口 Redis安装完成后就自带了命令行客户端:redis-cli,使用方式如下: redis-cli [options] [commonds] 其中常见…...

分布式锁 Redis vs etcd
为什么要实现分布式锁?为什么需要分布式锁,分布式锁的作用是什么,哪些场景会使用到分布式锁?分布式锁的实现方式有哪些分布式锁的核心原理是什么 如何实现分布式锁redis(自旋锁版本)etcd 的分布式锁(互斥锁(信号控制)版本) 分布式锁对比redis vs etcd 总结 为什么要实现分布式…...

docker中jenkins流水线式部署GitLab中springboot项目
本质就是将java项目拉取下来,并自动打包成docker镜像,运行 首先启动一个docker的jenkins 如果没有镜像使用我的镜像 通过网盘分享的文件:jenkins.tar 链接: https://pan.baidu.com/s/1VJOMf6RSIQbvW_V1zFD7eQ?pwd6666 提取码: 6666 放入服…...

甘蔗叶片图像元素含量的回归预测多模型实现【含私人数据集】
完整源码项目包获取→点击文章末尾名片! 基于python的小样本学习,完成对甘蔗叶片图像元素含量的回归预测 数据集这边我提供,包含91个样本,共182个图像,要求全部数据集保密,不能对外公开或泄露;…...

uniapp:钉钉小程序需要录音权限及调用录音
{// ... 其他配置项"mp-dingtalk": {"permission": {"scope.userLocation" : {"desc" : "系统希望获得您的定位用于确认您周围的设施数据"},"scope.bluetooth" : {"desc" : "你的蓝牙权限将用于小…...

Qt仿音乐播放器:媒体类
一、铺垫 我暂时只会音频系列的操作,我只能演示音频部分;但是QMediaPlayer是一个可以播放视频、音频的类;请同学们细读官方文档; 二、头文件 #include<QMediaPlayer> 头文件 #include<QMediaPlaylist> 三、演…...

Flink-CDC 全面解析
Flink-CDC 全面解析 一、CDC 概述 (一)什么是 CDC CDC 即 Change Data Capture(变更数据获取),其核心要义在于严密监测并精准捕获数据库内发生的各种变动情况,像数据的插入、更新以及删除操作࿰…...

HarmonyOS中实现上拉加载下拉刷新
参考网址:Refresh-滚动与滑动-ArkTS组件-ArkUI(方舟UI框架)-应用框架 - 华为HarmonyOS开发者 1.数据基类 //根据自己的业务数据扩展此类 //注意:一定要继承Object export class PullToRefreshBean extends Object{name: string …...

【轻松学C:编程小白的大冒险】--- C语言简介 02
在编程的艺术世界里,代码和灵感需要寻找到最佳的交融点,才能打造出令人为之惊叹的作品。而在这座秋知叶i博客的殿堂里,我们将共同追寻这种完美结合,为未来的世界留下属于我们的独特印记。 【轻松学C:编程小白的大冒险】…...

MySQL安装,配置教程
一、Linux在线yum仓库安装 打开MySQL官方首页,链接为:https://www.mysql.com/ 界面如下: 在该页面中找到【DOWNOADS】选项卡,点击进入下载页面。 在下载界面中,可以看到不同版本的下载链接,这里选择【My…...

项目实战——使用python脚本完成指定OTA或者其他功能的自动化断电上电测试
前言 在嵌入式设备的OTA场景测试和其他断电上电测试过程中,有的场景发生在夜晚或者随时可能发生,这个时候不可能24h人工盯着,需要自动化抓取串口日志处罚断电上电操作。 下面的python脚本可以实现自动抓取串口指定关键词,然后触发…...

多活架构的实现原理与应用场景解析
一、多活架构为何如此重要? 企业的业务运营与各类线上服务紧密相连,从日常的购物消费、社交娱乐,到金融交易、在线教育等关键领域,无一不依赖于稳定可靠的信息系统。多活架构的重要性愈发凸显,它宛如一位忠诚的卫士,为业务的平稳运行保驾护航。 回想那些因系统故障引发的…...

01-springclound
OpenFeign OpenFeign的日志级别 GateWay GateWay自定义过滤器 自定义过滤器,实现Order接口 数字小的先执行 GateWay传递用户信息 1、需要在网关搞定登录校验,将用户信息保存到请求头 2、网关到微服务 通过 springmvc的拦截器 来处理,将用户…...

Pandas-RFM会员价值度模型
文章目录 一. 会员价值度模型介绍二. RFM计算与显示1. 背景2. 技术点3. 数据4. 代码① 导入模块② 读取数据③ 数据预处理Ⅰ. 数据清洗, 即: 删除缺失值, 去掉异常值.Ⅱ. 查看清洗后的数据Ⅲ. 把前四年的数据, 拼接到一起 ④ 计算RFM的原始值⑤ 确定RFM划分区间⑥ RFM计算过程⑦…...

Java基础知识面试题
1.Java语言的特点? 1.一面向对象(封装,继承,多态); 2.平台无关性( Java 虚拟机实现平台无关性);(类是一种定义对象的蓝图或模板)3.支持多线程( C 语言没有内…...

WebSocket监听接口
在Vue.js中使用WebSocket来监听接口其实相对简单。WebSocket是一种在单个TCP连接上进行全双工通信的协议,通常用于需要实时数据更新的场景,比如聊天应用、实时通知等。 以下是一个在Vue.js中使用WebSocket的示例: 1. 创建Vue项目 如果你还…...

Kotlin语言的编程范式
Kotlin语言的编程范式 Kotlin是一种现代的编程语言,旨在提高开发效率,减少代码复杂度。在过去几年中,Kotlin在Android开发中获得了极大的普及,同时也逐渐被用在服务器端、Web开发、数据科学等多个领域。本文将深入探讨Kotlin的编…...

【权限管理】Apache Shiro学习教程
Apache Shiro 是一个功能强大且灵活的安全框架,主要用于身份认证(Authentication)、授权(Authorization)、会话管理(Session Management)和加密(Cryptography)。它旨在为…...

网络安全 信息收集入门
1.信息收集定义 信息收集是指收集有关目标应用程序和系统的相关信息。这些信息可以帮助攻击者了解目标系统的架构、技术实现细节、运行环境、网络拓扑结构、安全措施等方面的信息,以便我们在后续的渗透过程更好的进行。 2.收集方式-主动和被动收集 ①收集方式不同…...

Java Web开发进阶——RESTful API设计与开发
随着分布式系统和微服务架构的流行,RESTful API已成为现代Web应用中后端与前端、第三方系统交互的重要方式。本节将深入探讨RESTful API的设计原则、实现方式以及如何使用Spring Boot开发高效、可靠的RESTful服务。 1. 理解RESTful API的设计原则 1.1 什么是RESTfu…...

图片已经在windows上旋转了,但是在linux上仍然显示不正常
公司接了一个linux产品的售后工作,我们现在的产品都是android。linux设备如果要播放竖屏的图片在linux主板上。需要将图片旋转下才能正常播放。 我拿到图片以后,就用window图片编辑器打开了图片如下图左。选择逆时针选择了90 然后另存图片为如下图右。 …...
——国内大数据产业链分布结构)
关于大数据的基础知识(二)——国内大数据产业链分布结构
成长路上不孤单😊😊😊😊😊😊 【14后😊///计算机爱好者😊///持续分享所学😊///如有需要欢迎收藏转发///😊】 今日分享关于大数据的基础知识(二&a…...

Flutter鸿蒙化 在鸿蒙应用中添加Flutter页面
前言 今天这节课我们讲一下 在鸿蒙应用中添加Flutter页面。 作用: 之前有很多朋友和网友问我鸿蒙能不能使用Flutter开发,他们的项目已经用Flutter开发成熟了有什么好的方案呢,今天讲到这个就可以很好的解决他们的问题,例如我们正式项目中可能是一部分native 开发 一部分…...
)
【递归,搜索与回溯算法 综合练习】深入理解暴搜决策树:递归,搜索与回溯算法综合小专题(二)
优美的排列 题目解析 算法原理 解法 :暴搜 决策树 红色剪枝:用于剪去该节点的值在对应分支中,已经被使用的情况,可以定义一个 check[ ] 紫色剪枝:perm[i] 不能够被 i 整除,i 不能够被 per…...

Perl语言的语法
Perl语言概述及其应用 引言 Perl语言是一种通用的高级编程语言,由拉里沃尔(Larry Wall)于1987年首次发布。Perl语言的设计目标是简化文本处理和报告生成,同时也提供了强大的功能以用于系统管理、网络编程、数据库交互等多种场景…...

ELK+filebeat+kafka
ELKfilebeatkafka elkelk的架构数据流向ELK的部署 filebeatzookeeperkafkazopkeeprzookeeper的工作机制zookeeper的特点zookeeper的数据架构zookeeper的安装 kafka消息队列消息队列的应用场景消息队列的模式kafka组件的名称 elk elk的架构 elk:统一日志收集系统 …...

WPF系列九:图形控件EllipseGeometry
简介 EllipseGeometry用于绘制一个椭圆的形状。它通常与其他图形元素结合使用,比如 Path 或者作为剪切区域来定义其他元素的外形。 定义椭圆:EllipseGeometry 用来定义一个椭圆或者圆的几何形状。参与绘制:可以被用作 Path 元素的数据&…...

2025新年源码免费送
2025很开门很开门的源码免费传递。不需要馒头就能获取4套大开门源码。 听泉偷宝,又进来偷我源码啦👊👊👊。欢迎偷源码 🔥🔥🔥 获取免费源码以及更多源码,可以私信联系我 我们常常…...

离线录制激光雷达数据进行建图
目前有一个2D激光雷达,自己控制小车运行一段时间,离线获取到激光雷达数据后运行如下代码进行离线建图。 roslaunch cartographer_ros demo_revo_lds.launch bag_filename:/home/firefly/AutoCar/data/rplidar_s2/2025-01-08-02-08-33.bag实际效果如下 d…...
)
Scala分布式语言二(基础功能搭建、面向对象基础、面向对象高级、异常、集合)
章节3基础功能搭建 46.函数作为值三 package cn . itbaizhan . chapter03 // 函数作为值,函数也是个对象 object FunctionToTypeValue { def main ( args : Array [ String ]): Unit { //Student stu new Student() /*val a ()>{"GTJin"…...

AI中的神经元与权重矩阵之间的关系;神经元连接角度看行和列的意义
AI中的神经元与权重矩阵之间的关系 目录 AI中的神经元与权重矩阵之间的关系神经元连接角度看行和列的意义AI中的神经元概念 在人工智能领域,特别是神经网络中,神经元是基本的计算单元,它是对生物神经元的一种抽象模拟。就像生物神经元接收来自其他神经元的电信号,经过处理后…...
+图片自适应)
前端中常用的单位度量(px,rpx,rem,em,vw,vh)+图片自适应
文章目录 前端中常用的单位度量vw/vh 的场景应用px/rem/em 之间的转换关系项目中的rem 应用根元素 font-size 设置为16px 的应用惯例自适应之图片应用1. 使用 max-width 和 max-height2. 使用 object-fit 属性3. 使用 background-image 模拟图片展示 前端中常用的单位度量 px&…...

Attention计算中的各个矩阵的维度都是如何一步步变化的?
在Transformer模型中,各个矩阵的维度变化是一个关键的过程,涉及到输入、编码器、解码器和输出等多个阶段。以下是详细的维度变化过程: 输入阶段 输入序列:假设输入序列的长度为seq_len,每个单词或标记通过词嵌入&…...

Golang学习笔记_23——error补充
Golang学习笔记_20——error Golang学习笔记_21——Reader Golang学习笔记_22——Reader示例 文章目录 error补充1. 基本错误处理2. 自定义错误3. 错误类型判断3.1 类型断言3.2 类型选择 4. panic && recover 源码 error补充 1. 基本错误处理 在Go中,函数…...

DB-Engines Ranking 2025年1月数据库排行
DB-Engines Ranking 2025年1月数据库排行 DB-Engines排名根据数据库管理系统的受欢迎程度进行排名。排名每月更新一次。 2025年1月,共有423个数据库进入排行。 排行榜 Oracle Oracle 连续三月稳居榜首,排名稳定。2025 年 1 月分数较上月增 5.03&#x…...

积分与签到设计
积分 在交互系统中,可以通过看视频、发评论、点赞、签到等操作获取积分,获取的积分又可以参与排行榜、兑换优惠券等,提高用户使用系统的积极性,实现引流。这些功能在很多项目中都很常见,关于功能的实现我的思路如下。 …...

用 Python 绘制可爱的招财猫
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 招财猫,也被称为“幸运猫”,是一种象征财富和好运的吉祥物,经常…...

用 HTML5 Canvas 和 JavaScript 实现炫酷跨年烟花特效
一、引言 跨年夜,五彩斑斓、绚丽绽放的烟花是最令人期待的视觉盛宴之一。在网页端,我们能否通过技术手段复现这一梦幻场景呢?答案是肯定的。本文将深入剖析一段使用 HTML5 Canvas 和 JavaScript 实现的跨年烟花特效源码,带你领略前端技术创造的惊艳画面。 用 HTML5 Canvas…...

什么是数据湖?大数据架构的未来趋势
💖 欢迎来到我的博客! 非常高兴能在这里与您相遇。在这里,您不仅能获得有趣的技术分享,还能感受到轻松愉快的氛围。无论您是编程新手,还是资深开发者,都能在这里找到属于您的知识宝藏,学习和成长…...

Spring boot接入xxl-job
Spring boot接入xxl-job 导入maven包加入配置增加配置类创建执行器类(写job的业务逻辑)去控制台中配置job 导入maven包 <dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>…...

Flutter pubspec.yaml 使用方式
Flutter pubspec.yaml 使用方式 pubspec.yaml 是 Flutter 项目中最重要的配置文件之一,用于管理应用的基本信息、依赖项、资源以及构建配置等内容。 1. 基本结构和字段 基本信息 name: my_flutter_app # 应用的名称 description: A new Flutter project …...

Elixir语言的学习路线
Elixir语言的学习路线 Elixir是一种动态、通用的编程语言,特别适合用于构建可扩展和维护性强的应用程序。它基于Erlang虚拟机(BEAM),因其高并发性和容错能力而广受欢迎。近年来,Elixir在Web开发(特别是与P…...

看不懂scatter、gather的来
1.torch.scatter 这是out-of-place版本(相对于in-place版本),它会返回一个新的张量。 torch.Tensor.scatter_ 就是in-place版本,它直接修改自身,返回的也是自身 Tensor.scatter_(dim, index, src, *, reduceNone) →…...

系统思考—问题分析
爱因斯坦说过:“如果我有1小时拯救世界,我会花55分钟去确认问题为何,只用5分钟寻找解决方案。” 这个看似简单的道理,却蕴藏着解决复杂问题的智慧。真正的问题,往往隐藏在现象的背后。解决问题的关键,不在…...

【C】编译与链接
在本文章里面,我们讲会讲解C语言程序是如何从我们写的代码一步步变成计算机可以执行的二进制指令,并最终执行的。C语言程序运行主要包括两大步骤 -- 编译和链接,接下来我们就来一一讲解。 目录 1 翻译环境和运行环境 2 翻译环境 1&#…...

如何用Python编程实现自动整理XML发票文件
传统手工整理发票耗时费力且易出错,而 XML 格式发票因其结构化、标准化的特点,为实现发票的自动化整理与保存提供了可能。本文将详细探讨用python来编程实现对 XML 格式的发票进行自动整理。 一、XML 格式发票的特点 结构化数据:XML 格式发票…...