【Spring】SpringBoot整合ShardingSphere并实现多线程分批插入10000条数据(进行分库分表操作)。

??个人主页:哈__
期待您的关注

目录
一、ShardingSphere简介
?1.Sharding-JDBC
2.Sharding-Proxy?
3.Sharding-Sidecar(TBD)?
二、为什么用到ShardingSphere?
三、数据分片
四、SpringBoot整合ShardingSphere
1.创建我们的数据库ds0和ds1。分别创建我们的表格order0,order1,order2。(两个数据库都运行一下)
2.引入依赖
3.添加配置文件。创建application.yml
4.创建我们的框架结构
一、ShardingSphere简介
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。----来自官方
1.Sharding-JDBC
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
2.Sharding-Proxy
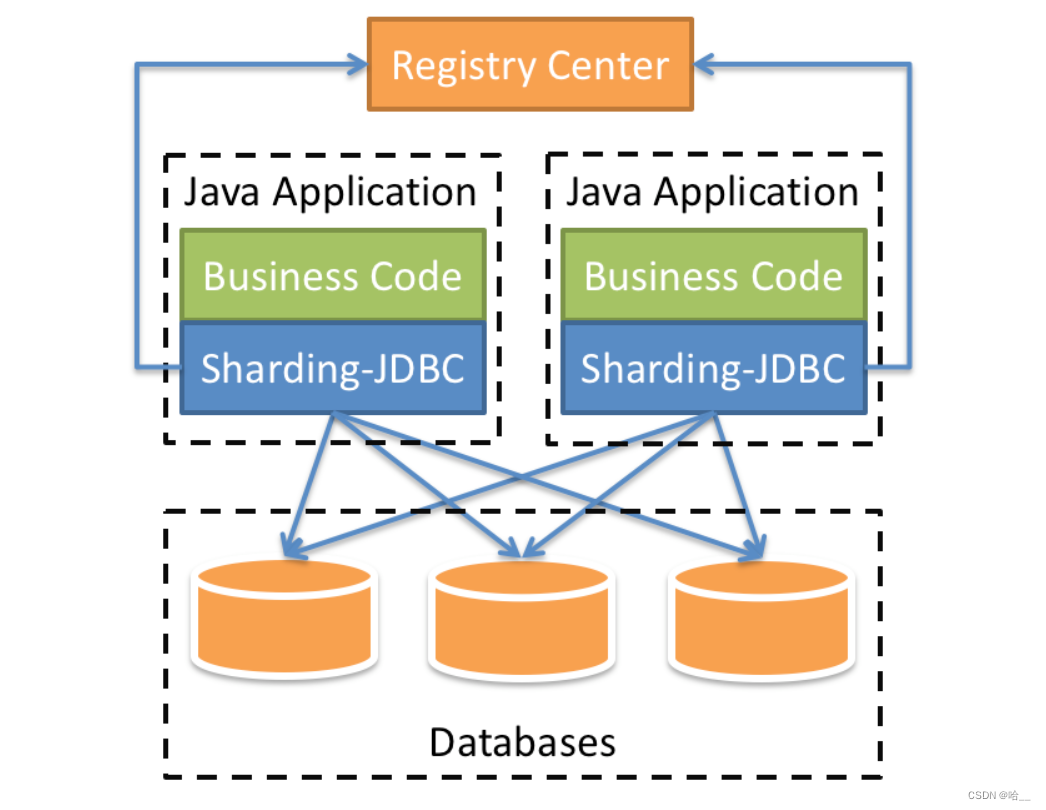
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL版本,它可以使用任何兼容MySQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench等)操作数据,对DBA更加友好。
- 向应用程序完全透明,可直接当做MySQL使用。
- 适用于任何兼容MySQL协议的客户端。
3.Sharding-Sidecar(TBD)
定位为Kubernetes或Mesos的云原生数据库代理,以DaemonSet的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即Database Mesh,又可称数据网格。
Database Mesh的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互有效的梳理。使用Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
二、为什么用到ShardingSphere
从性能方面来说,由于关系型数据库大多采用B+树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的IO次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
从可用性的方面来讲,服务化的无状态型,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于DBA的运维压力就会增大。数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在1TB之内,是比较合理的范围。
在传统的关系型数据库无法满足互联网场景需要的情况下,将数据存储至原生支持分布式的NoSQL的尝试越来越多。 但NoSQL对SQL的不兼容性以及生态圈的不完善,使得它们在与关系型数据库的博弈中始终无法完成致命一击,而关系型数据库的地位却依然不可撼动。
三、数据分片
水平分片又称为横向拆分。它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表),如下图所示。
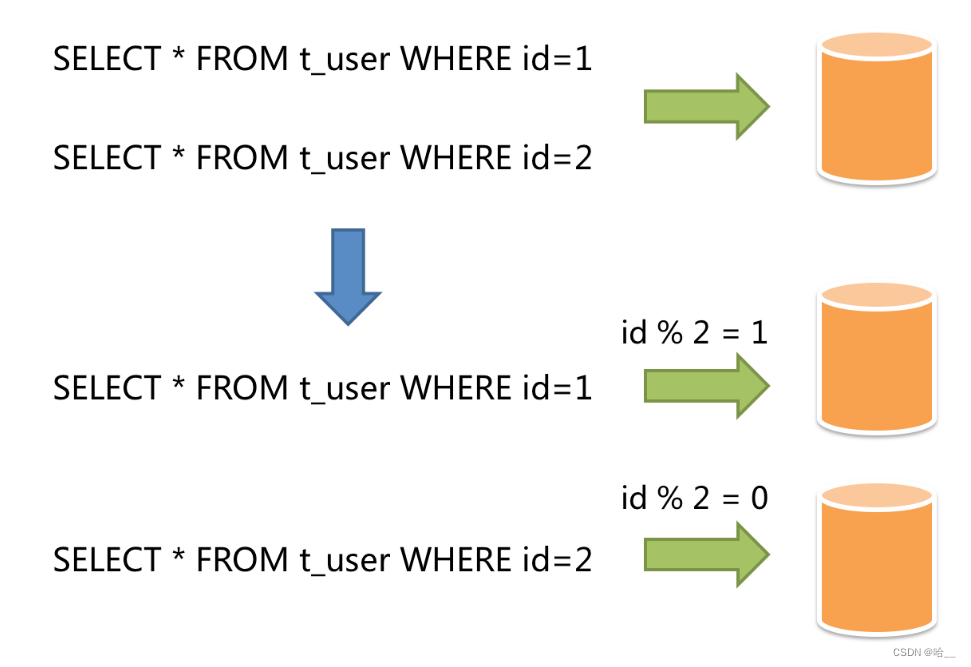
简单的来说,水平分片就是把一张大表的数据进行一个水平切割,将切割出来的不同的部分添加到不同的表当中,我们举这样的一个例子,在一家银行当中,最开始只开放了一个业务窗口,因为一开始的业务量不大,一个窗口足以解决这一天当中的所有问题,但是由于业务员的出色的业务能力,越来越多的人开始到这个银行办理业务了,这时一个窗口就不够了,需要多开几个窗口分担业务压力。我们这样设定一下,一共开放5个窗口,去哪个窗口取决于个人的身份证最后一位%5取余+1,如果是X那么就直接到1号窗口。
那么对于实际的业务来说,我们也是如此,一张订单表我们可以根据订单号进行取余操作分配表。
除了分表之外我们还可以分库,具体的思想还是一致的。
四、SpringBoot整合ShardingSphere
1.创建我们的数据库ds0和ds1。分别创建我们的表格order0,order1,order2。(两个数据库都运行一下)
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for t_order0
-- ----------------------------
DROP TABLE IF EXISTS `t_order0`;
CREATE TABLE `t_order0` (`order_id` bigint(20) NOT NULL AUTO_INCREMENT,`user_id` int(11) NOT NULL,`order_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Compact;-- ----------------------------
-- Table structure for t_order1
-- ----------------------------
DROP TABLE IF EXISTS `t_order1`;
CREATE TABLE `t_order1` (`order_id` bigint(20) NOT NULL AUTO_INCREMENT,`user_id` int(11) NOT NULL,`order_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Compact;-- ----------------------------
-- Table structure for t_order2
-- ----------------------------
DROP TABLE IF EXISTS `t_order2`;
CREATE TABLE `t_order2` (`order_id` bigint(20) NOT NULL AUTO_INCREMENT,`user_id` int(11) NOT NULL,`order_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Compact;SET FOREIGN_KEY_CHECKS = 1;
2.引入依赖
这里的依赖是为了实现我的们的目标,进行多线程分库分表插入。
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.0.0</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.18</version></dependency>
3.添加配置文件。创建application.yml
我来讲解一下这些配置文件都是干啥的,都写到注释了。
spring:shardingsphere:props:#d打印Sql语句sql-show: truedatasource:#创建我们的ds0数据源ds0:#下边这些都是老套路了driver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/ds0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=truepassword: 2020type: com.zaxxer.hikari.HikariDataSourceusername: root#创建我们的ds1数据源ds1:#一样的老套路driver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/ds1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=truepassword: 2020type: com.zaxxer.hikari.HikariDataSourceusername: rootnames: ds0,ds1#这里就比较重要了,这里是定义我们的分库分表的规则rules:sharding:#分片算法sharding-algorithms:#为分库定义一个算法 到底是如何分的库custom-db-inline:props:# 这里是具体的算法,我们根据userId取余进行分库,余数是几就分到ds几algorithm-expression: ds$->{user_id%2}type: INLINE# 如何分表custom-table-inline:props:# 根据orderId取余分表algorithm-expression: t_order$->{order_id%3}type: INLINEtables:# 这是我们的逻辑表 因为我们根本没有t_order这个表,这是我们的t_order0 1 2抽象出来的t_order:# 这是我们的真实表actual-data-nodes: ds$->{0..1}.t_order$->{0..2}database-strategy:standard:# 分库算法的名称 也就是上边的sharding-algorithm-name: custom-db-inlinesharding-column: user_idtable-strategy:standard:# 分表算法名称sharding-algorithm-name: custom-table-inlinesharding-column: order_id
async:executor:thread:core_pool_size: 5max_pool_size: 20queue_capacity: 90000name:prefix: async-
mybatis-plus:global-config:db-config:id-type: assign_id
4.创建我们的框架结构
三层Order的代码如下。
// Order实体
@Data
@TableName("t_order")
@SuppressWarnings("serial")
public class Order extends Model<Order> {@TableId(type = IdType.ASSIGN_ID)private Long orderId;private Integer userId;private String orderName;@Overridepublic Serializable pkVal() {return this.orderId;}
}//mapper
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}//Order的service接口
public interface OrderService extends IService<Order> {
}//接口实现
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
}
ExecutorConfig,配置我们的线程池。
@Configuration
public class ExecutorConfig {@Value("${async.executor.thread.core_pool_size}")private int corePoolSize;@Value("${async.executor.thread.max_pool_size}")private int maxPoolSize;@Value("${async.executor.thread.queue_capacity}")private int queueCapacity;@Value("${async.executor.thread.name.prefix}")private String namePrefix;@Bean(name = "asyncServiceExecutor")public Executor asyncServiceExecutor() {//在这里修改ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();//配置核心线程数executor.setCorePoolSize(corePoolSize);//配置最大线程数executor.setMaxPoolSize(maxPoolSize);//配置队列大小executor.setQueueCapacity(queueCapacity);//配置线程池中的线程的名称前缀executor.setThreadNamePrefix(namePrefix);// rejection-policy:当pool已经达到max size的时候,如何处理新任务// CALLER_RUNS:不在新线程中执行任务,而是有调用者所在的线程来执行executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());//执行初始化executor.initialize();return executor;}
}
创建AsyncService接口和实现类。
public interface AsyncService {void add(List<Order> orderList, CountDownLatch countDownLatch);
}@Service
@Slf4j
public class AsyncServiceImpl implements AsyncService {@Resourceprivate OrderServiceImpl orderService;@Async("asyncServiceExecutor")@Transactional(rollbackFor = Exception.class)@Overridepublic void add(List<Order> orderList, CountDownLatch countDownLatch) {try {log.debug(Thread.currentThread().getName()+"开始插入数据");orderService.saveBatch(orderList);log.debug(Thread.currentThread().getName()+"插入数据完成");}finally {countDownLatch.countDown();}}
}
要使用多线程异步调用要在启动程序上加上注解。
@SpringBootApplication
@EnableAsync
@EnableTransactionManagement
public class ShardingSphereApplication {public static void main(String[] args) {SpringApplication.run(ShardingSphereApplication.class, args);}}
现在来看我们的AysncController。我定义了一个getData的方法,用于模拟生成我们的数据,当然我设置的名称都差不多,一共一万条数据,通过user_id进行分库,通过order_id进行分表,userId使用的是for循环的i索引,orderId使用的是雪花算法生成的Id序列。
在testAsyncInsert方法中。使用ListUtils的方法进行数据切片,每两千条数据切割成一个list,然后执行异步添加操作。待所有线程执行完毕之后,打印输出语句。
@RestController
public class AsyncController {@Autowiredprivate AsyncService asyncService;@GetMapping("/test")public String testAsyncInsert(){CountDownLatch c;try {List<Order> data = getData();List<List<Order>> partition = ListUtil.partition(data, 2000);c= new CountDownLatch(partition.size());for (List<Order> list : partition) {asyncService.add(list,c);}c.await();}catch (Exception e){e.printStackTrace();}finally {System.out.println("所有的数据插入完毕");}return "执行完毕";}private List<Order> getData(){List<Order> list = new ArrayList<>();for(int i = 0;i<10000;i++){Order o = new Order();o.setOrderName("苹果"+i);o.setUserId(i+1);list.add(o);}return list;}
}
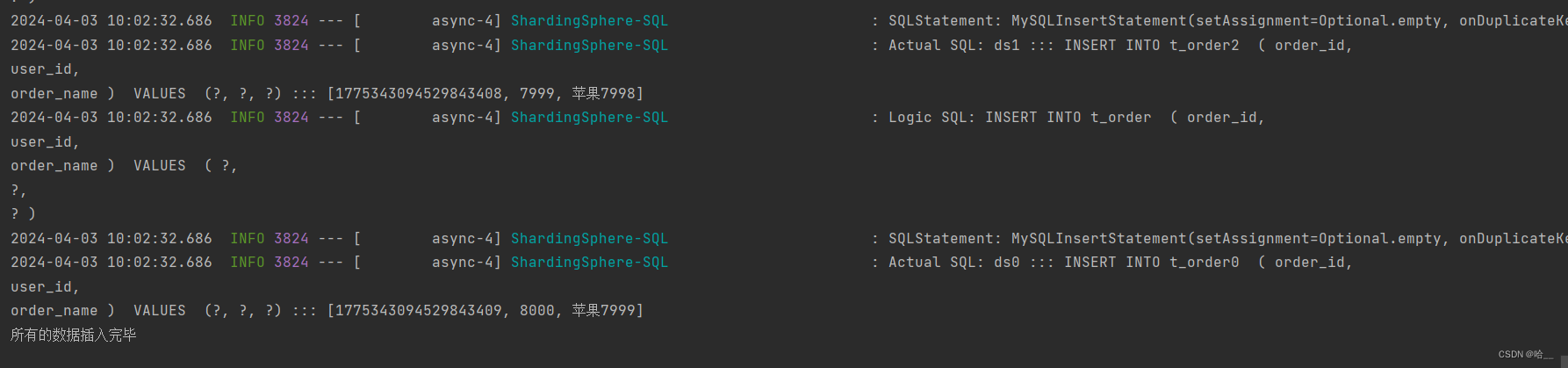
看结果。 大家可以自己去验证一下。

相关文章:
。)
【Spring】SpringBoot整合ShardingSphere并实现多线程分批插入10000条数据(进行分库分表操作)。
??个人主页:哈__ 期待您的关注 目录 一、ShardingSphere简介 ?1.Sharding-JDBC 2.Sharding-Proxy? 3.Sharding-Sidecar(TBD)? 二、为什么用到ShardingSphere? 三、数据分片 四、SpringBoot整合ShardingSphere 1.创建我们的数据…...

Python中的ast.literal_eval:安全地解析字符串为Python对象
Python中的ast.literal_eval:安全地解析字符串为Python对象 什么是ast.literal_eval?为什么说它是“安全”的? 如何使用ast.literal_eval?示例1:将字符串转换为列表示例2:将字符串转换为字典示例3ÿ…...

前端用json-server来Mock后端返回的数据处理
<html><body><div class"login-container"><h2>登录</h2><div class"login-form"><div class"form-group"><input type"text" id"username" placeholder"请输入用户名&q…...

【linux】文件与目录命令 - mv
文章目录 1. 基本用法2. 常用参数3. 用法举例4. 注意事项 mv 命令用于移动或重命名文件和目录,是 Linux 系统中管理文件的重要工具之一。它既能移动文件到指定路径,也能重命名文件或目录。 1. 基本用法 语法: mv [选项] 源文件 目标文件 mv…...

OSPF - LSA对照表
LSA的三要素,如何唯一表示一条LSA Type:表示是几类的LSA Link-id:这个比较特殊,不同的LSA的Link-ID不同 Advertising router:谁产生的LSA 常用的就是1、2、3、4、5、7型LSA 点击蓝字跳转LSA详细介绍(持续更新中…...

Mongodb基础sqL
------------------------------------------数据库------------------------------ (2).查看所有数据库 show dbs (3).选择数据库,如果不存在则隐式创建这个数据库 use 数据库名 ------------------------------------------集合------------------------------ …...

uniapp开发u-icon图标不显示问题
uniapp开发图标用u-icon不显示,换成uv-icon就可以了 插件市场从这里下载:uv-ui 破釜沉舟之兼容vue32、app、h5、小程序等多端,灵活导入,利剑出击 - DCloud 插件市场 组件库看这个:介绍 | 我的资料管理-uv-ui 是全面兼…...

宁德时代2025年Verify入职测评语言理解及数字推理真题SHL题库汇总、考情分析
宁德时代社招Verify入职测评对薪酬有着重要影响,其规定正确率达到80%才能顺利通过测评。这体现了公司对人才专业素养与能力的严格要求,旨在筛选出真正符合岗位需求的优秀人才。测评内容涵盖了专业知识、技能运用、逻辑思维等多方面,只有综合能…...

Spring Data Elasticsearch简介
一、Spring Data Elasticsearch简介 1 SpringData ElasticSearch简介 Elasticsearch是一个实时的分布式搜索和分析引擎。它底层封装了Lucene框架,可以提供分布式多用户的全文搜索服务。 Spring Data ElasticSearch是SpringData技术对ElasticSearch原生API封装之后的产物,它通…...

即插即用,无缝集成各种模型,港科大蚂蚁等发布Edicho:图像编辑一致性最新成果!
文章链接:https://arxiv.org/pdf/2412.21079 项目链接:https://ezioby.github.io/edicho/ 亮点直击 显式对应性引导一致性编辑:通过将显式图像对应性融入扩散模型的去噪过程,改进自注意力机制与分类器自由引导(CFG&…...
弹性布局 (Flex))
鸿蒙开发(29)弹性布局 (Flex)
概述 弹性布局(Flex)提供更加有效的方式对容器中的子元素进行排列、对齐和分配剩余空间。常用于页面头部导航栏的均匀分布、页面框架的搭建、多行数据的排列等。 容器默认存在主轴与交叉轴,子元素默认沿主轴排列,子元素在主轴方…...

华为 Sensor 省电策略调研
华为EMUI 9.0.0.187(C00E57R1P15) 无该功能 华为EMUI 9.1.0.321(C00E320R1P1) 之后有sensor管控 一、华为 Sensor 省电策略 1. Sensor 类别只配置非唤醒类Sensor 2. 手机静止情况,应用不可见时达到1分钟࿰…...

Kotlin语言的网络编程
Kotlin语言的网络编程 Kotlin作为一种现代的编程语言,其简洁、安全和高效的特性使得在开发各种应用时得到广泛认可。尤其是在网络编程方面,Kotlin凭借其与Java的高度兼容性以及丰富的库支持,使得网络操作变得更加简单易用。本文将详细探讨Ko…...

redis:安装部署、升级以及失败回退
安装部署 一、准备工作 1. 检查系统要求 确保你的服务器满足 Redis 的基本要求: 操作系统:支持的 Linux 发行版(如 Ubuntu, CentOS)内存:至少 4GB(根据实际应用需求调整)CPU:单核或多核 CPU磁盘空间:足够的磁盘空间用于数据存储和日志记录2. 更新系统软件包 在开始…...

3. ML机器学习
1.人工智能与机器学习的关系 机器学习是人工智能的一个重要分支,是人工智能的一个子集。它无需显式编程,而是通过数据和算法使机器能够自动学习和改进,从而实现智能行为。机器学习依赖于算法来识别数据中的模式,并通过这些模式做出…...

在高德地图上加载3DTilesLayer图层模型/天地瓦片
1. 引入必要的库 Three.js:一个用于创建和显示3D图形的JavaScript库。vuemap/three-layer:一个Vue插件,它允许你在高德地图中添加Three.js图层。vuemap/layer-3dtiles:一个用于处理3D Tiles格式数据的Vue插件,可以用来…...

用户使用LLM模型都在干什么?
Anthropic 对用户与 Claude 3.5 Sonnet 的大量匿名对话展开分析,主要发现及相关情况如下: 使用用途分布 软件开发主导:在各类使用场景中,软件开发占比最高,其中编码占 Claude 对话的 15% - 25%,网页和移动应…...
模式)
2 抽象工厂(Abstract Factory)模式
抽象工厂模式 1.1 分类 (对象)创建型 1.2 提出问题 家具店里有沙发、椅子、茶几等产品。产品有不同风格,如现代、北欧、工业。希望确保客户收到的产品风格统一,并可以方便地添加新产品和风格。 1.3 解决方案 提供一个创建一…...

数据结构-串
串的实现 在C语言中所使用的字符串就是串的数据类型的一种。 串的存储结构 定长顺序存储表示 类似于线性表的顺序存储结构,用一组连续的存储单元存储串值的字符序列。 #define MAXLEN 255 //预定义最大串长为255 typedef struct SString {char ch[MAXLEN]; …...
广度优先遍历(BFS,Breadth First Search)算法与源程序)
C#,图论与图算法,有向图(Direct Graph)广度优先遍历(BFS,Breadth First Search)算法与源程序
1 图的广度优先遍历 图的广度优先遍历(或搜索)类似于树的广度优先遍历(参见本文的方法2)。这里唯一需要注意的是,与树不同,图可能包含循环,因此我们可能再次来到同一个节点。为了避免多次处理节…...

使用ElasticSearch查询
从一个query body开始 {"query": {"bool": {"disable_coord": true,"must": [{"match": {"enabled": "1"}},{"range": {"effectTime": {"lt": "2017-06-13 13:33:…...
python-can 库的安装与环境配置)
PyCharm+RobotFramework框架实现UDS自动化测试——(一)python-can 库的安装与环境配置
从0开始学习CANoe使用 从0开始学习车载测试 相信时间的力量 星光不负赶路者,时光不负有心人。 文章目录 1. 概述2.安装 python-can 库—基于pycharm在对应的工程下3. 在任意盘中安装环境4. 导入 can 模块语法5. 配置 CAN 接口6.CANoe设备连接语法 1. 概述 本专栏主…...

C# 值类型和引用类型详解
简介 在 C# 中,值类型和引用类型是两个基础的数据类型类别,它们的主要区别在于 存储位置 和 赋值方式。 值类型 值类型存储的是数据本身,分配在 栈 (Stack) 中。当一个值类型变量被赋值给另一个变量时,会复制值。 值类型的特点…...
)
计算机网络 —— 网络编程(TCP)
计算机网络 —— 网络编程(TCP) TCP和UDP的区别TCP (Transmission Control Protocol)UDP (User Datagram Protocol) 前期准备listen (服务端)函数原型返回值使用示例注意事项 accpect (服务端)函数原型返回…...

[Unity Shader] Shader基础光照3:环境光与自发光
在Unity中,光照是场景渲染的关键组成部分。正确使用环境光和自发光能够大大提高场景的真实感和视觉效果。本篇文章将详细介绍Unity中的环境光和自发光的基本概念,以及如何在编辑器和Shader中进行操作和实现。 1. 环境光(Ambient Light) 1.1 环境光的定义 环境光是场景中…...

云原生安全风险分析
一、什么是云原生安全 云原生安全包含两层含义: 面向云原生环境的安全具有云原生特征的安全 0x1:面向云原生环境的安全 面向云原生环境的安全的目标是防护云原生环境中基础设施、编排系统和微服务等系统的安全。 这类安全机制不一定具备云原生的特性…...

Redis 安装与配置指南
Redis 安装与配置指南 目录 安装说明 Linux 安装 Redis 3.0 压缩包上传服务器编译和安装修改配置启动 Redis关闭 Redis 卸载 RedisRedis 集群配置 Master 主库配置启动 Master 节点的 Redis 和 Sentinel客户登录验证Slave 从库配置查看集群数据验证 安装说明 Linux 安装 R…...
)
C语言Day13(c程序设计小红书+pta)
目录 (一)用函数调用实现,把最小的数字放在最前面,把最大的放在最后边 (二)使数字向后移m位 (三)用户自定义数据类型: (四)候选人计票数 &am…...

C++二十三种设计模式之迭代器模式
C二十三种设计模式之迭代器模式 一、组成二、特点三、目的四、缺点五、示例代码 一、组成 抽象聚合类:存储集合元素,声明管理集合元素接口。 具体聚合类:实现管理集合元素接口。 抽象迭代器类:声明访问和遍历聚合类元素的接口。 …...
)
【AI游戏】使用强化学习玩 Flappy Bird:从零实现 Q-Learning 算法(附完整资源)
1. 引言 Flappy Bird 是一款经典的休闲游戏,玩家需要控制小鸟穿过管道,避免碰撞。虽然游戏规则简单,但实现一个 AI 来自动玩 Flappy Bird 却是一个有趣的挑战。本文将介绍如何使用 Q-Learning 强化学习算法来训练一个 AI,使其能够…...

VSCode 中的 launch.json 配置使用
VSCode 中的 launch.json 配置使用 在 VSCode 中,launch.json 文件用于配置调试设置,特别是用来定义如何启动和调试你的应用。它允许你配置不同的调试模式、运行参数和调试选项。 基本结构 launch.json 文件位于 .vscode 文件夹内,可以通过…...

深度学习算法:开启智能时代的钥匙
引言 深度学习作为机器学习的一个分支,近年来在图像识别、自然语言处理、语音识别等多个领域取得了革命性的进展。它的核心在于构建多层的神经网络,通过模仿人脑处理信息的方式,让机器能够从数据中学习复杂的模式。 深度学习算法的基本原理…...

Clojure语言的并发编程
Clojure语言的并发编程 引言 在现代软件开发中,并发编程成为了处理多个任务、提高应用效率和响应速度的重要手段。尤其是在多核处理器逐渐成为主流的今天,如何高效利用这些计算资源是每个开发者面临的挑战。Clojure作为一种函数式编程语言,…...

MySQL学习记录1【DQL和DCL】
SQL学习记录 该笔记从DQL处开始记录 DQL之前值得注意的点 字段 BETWEEN min AND max 可以查询区间[min, max]的数值如果同一个字段需要满足多个OR条件,可以采取 字段 IN(数值1, 数值2, 数值3....)LIKE语句 字段 LIKE ___%%% 表示模糊匹配,_匹配一个字段…...

EasyExcel的应用
一、简单使用 引入依赖: 这里我们可以使用最新的4.0.2版本,也可以选择之前的稳定版本,3.1.x以后的版本API大致相同,新的版本也会向前兼容(3.1.x之前的版本,部分API可能在高版本被废弃)&…...

JS控制对应数据隐藏
首先需要获得到所有的input框,并声明一个空对象来存放,遍历所有的复选框,将他们中选中的放入对象,并设置键值为true,然后执行checkFalseValues(result)函数 function hideItem() {let checkboxes $(.setting_box inp…...

【剑指Offer刷题系列】数据流中的中位数
目录 问题描述示例示例 1: 思路解析方法一:使用两个堆(最大堆和最小堆)核心思路详细步骤示例分析优势适用场景 代码实现Python 实现(方法一:使用两个堆) 测试代码复杂度分析方法一:使…...

RabbitMQ高级篇之MQ可靠性 数据持久化
文章目录 消息丢失的原因分析内存存储的缺陷如何确保 RabbitMQ 的消息可靠性?数据持久化的三个方面持久化对性能的影响持久化实验验证性能对比Spring AMQP 默认持久化总结 消息丢失的原因分析 RabbitMQ 默认使用内存存储消息,但这种方式带来了两个主要问…...

C 语言奇幻之旅 - 第16篇:C 语言项目实战
目录 引言1. 项目规划1.1 需求分析与设计1.1.1 项目目标1.1.2 功能需求1.1.3 技术实现方案 2. 代码实现2.1 模块化编程2.1.1 学生信息模块2.1.2 成绩管理模块 2.2 调试与测试2.2.1 调试2.2.2 测试2.2.4 测试结果 3. 项目总结3.1 代码优化与重构3.1.1 代码优化3.1.2 代码重构 3.…...

[笔记] 使用 Jenkins 实现 CI/CD :从 GitLab 拉取 Java 项目并部署至 Windows Server
随着软件开发节奏的加快,持续集成(CI)和持续部署(CD)已经成为确保软件质量和加速产品发布的不可或缺的部分。Jenkins作为一款广泛使用的开源自动化服务器,为开发者提供了一个强大的平台来实施这些实践。然而…...

Git最便捷的迁移方式
#当公司要求git需要迁移时,你是不是感觉到束手无策。今天带来给大家最快,最便捷的迁移方式 这个命令是用于重命名git仓库中的远程仓库名。在这个命令中,我们将远程仓库的名字从"origin"改为"old-origin"。 git remote …...

【颜色分类--荷兰国旗问题】
问题 给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums , 原地 对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。必须在不使用库内置的 sort 函数的情况下…...

xrdp连接闪退情况之一
错误核查 首先使用命令vim ~/.xsession-errors,当里面的报错信息为WARNING **: Could not make bus activated clients aware of XDG_CURRENT_DESKTOPGNOME environment variable:Failed to execute child process “dbus-launch” (No such file or directory)&am…...

KubeVirt 进阶:设置超卖比、CPU/MEM 升降配、在线磁盘扩容
前两篇文章,我们分别介绍 Kubevirt 的安装、基本使用 以及 将 oVirt 虚拟机迁移到 KubeVirt,我们留了两个ToDo,一个是本地磁盘的动态分配,一个是固定 IP 的需求,本期我们先解决第一个,本地磁盘的动态分配。…...
leetcode39组合总和)
(回溯法)leetcode39组合总和
第一个2开头,下面的子节点的集合元素均为2,5,3 但是在5开头,下面的子节点集合元素均为5,3 带着这个图的思路确定i和index的传递值 backtracking(i, nums,8,sum);用的是i而不是i1 // ConsoleApplication3.cpp : 此文件包含 "main" 函数。程序…...

【数据结构】二叉搜索树
目录 1. 二叉搜索树的概念 2. 二叉搜索树的性能分析 3.二叉搜索树的实现 3. 1.二叉搜索树的插入 3.2. 二叉搜索树的查找 3.3. 二叉搜索树的删除 3.4. 二叉搜索树的实现代码 4. 二叉搜索树key和key/value两种使用场景 4.1 key搜索场景: 4.2 key/value搜索场…...

高可用虚拟IP-keepalived
个人觉得华为云这个文档十分详细:使用虚拟IP和Keepalived搭建高可用Web集群_弹性云服务器 ECS_华为云 应用场景:虚拟IP技术。虚拟IP,就是一个未分配给真实主机的IP,也就是说对外提供数据库服务器的主机除了有一个真实IP外还有一个…...

CSS语言的多线程编程
CSS语言的多线程编程 引言 在现代Web开发中,CSS(层叠样式表)被广泛用于给网页添加样式。然而,CSS本身是一种声明性语言,在设计上并没有直接支持多线程编程的功能。实际上,CSS的解析和应用是由浏览器的渲染…...
)
电脑之一键备份系统(One Click Backup System for Computer)
电脑之一键备份系统 相信使用电脑的的人都遇到过,电脑系统崩溃,开机蓝屏等原因,这个时候你急着用电脑办公,电脑却给你罢工是多么气人了,其实可以给电脑做一个系统备份。 最近每天都有系统蓝屏崩溃,这个实难…...

R语言的正则表达式
R语言中的正则表达式深度解析 正则表达式(Regular Expressions,简称Regex)是一种用于描述字符串匹配规则的工具,广泛应用于数据处理、文本分析、数据清洗等多个领域。在R语言中,正则表达式被广泛应用于字符串的处理和…...