大模型思维链推理的进展、前沿和未来分析

大模型思维链推理的综述:进展、前沿和未来
"Chain of Thought Reasoning: A State-of-the-Art Analysis, Exploring New Horizons and Predicting Future Directions."
思维链推理的综述:进展、前沿和未来
摘要:思维链推理,作为人类智能的基本认知过程,在人工智能和自然语言处理领域引起了极大的关注。然而,这一领域仍然缺乏全面的综述。为此,我们迈出了第一步,全面而广泛地呈现了这一研究领域的深入调查。我们使用X-of-Thought(思维X)来广泛地指代思维链推理。
具体来说,我们根据方法的分类系统地组织了当前的研究,包括XoT构建、XoT结构变体和增强的XoT。此外,我们描述了XoT在前沿应用中的使用,涵盖了规划、工具使用和蒸馏。此外,我们讨论了挑战并探讨了一些未来的发展方向,包括忠实度、多模态和理论。我们希望这份综述能够成为寻求在思维链推理领域创新的研究者的宝贵资源。
1 引言
预训练语言模型(PLMs)能够自动从无标签文本中学习通用表示,并通过在下游任务上的微调实现出色的性能(Devlin等人,2019年;Raffel等人,2020年;Radford和Narasimhan,2018年)。最近,扩大语言模型的规模显著提高了性能,并带来了许多惊喜,例如突现能力(Wei等人,2022a;Schaeffer等人,2023年)。因此,自然语言处理的范式正从预训练加微调转变为预训练加上下文学习。然而,到目前为止,大规模语言模型(LLMs)在复杂推理任务上,如数学推理(Cobbe等人,2021年;Patel等人,2021年)、常识推理(Talmor等人,2021年;Mihaylov等人,2018年)等,仍有相当大的改进空间。
为了提升LLMs在复杂推理任务中的表现,Wei等人(2022b)探索了上下文学习的扩展方法,首次引入了思维链(CoT)提示的概念。Kojima等人(2022年)发现,仅通过在提示中添加一句“让我们一步步来”,便能让LLMs在无需人类注释的情况下,实现零样本思维链推理。这些研究突显了思维链在增强模型复杂推理能力以及优化其推理和规划技能方面的关键作用。
随着时间的推移,X-of-thought(XoT)在NLP领域迅速崛起,犹如雨后春笋般涌现。众多研究者纷纷投身于XoT相关工作,如自动XoT构建(Kojima等人,2022年;Zhang等人,2023f;Xu等人,2023年)、XoT结构变体(Chen等人,2022a;Ning等人,2023年;Lei等人,2023a;Yao等人,2023b)等。为了与原始的CoT概念区分开来,我们采用XoT这一集体术语,泛指逐步推理方法的应用。
然而,这些方法和数据集尚未经过系统性的回顾和分析。为了填补这一空白,我们提出这项工作来进行对XoT家族的全面和详细分析。尽管已经有一些综述讨论了思维链,但它们仅限于特定方面,例如使用提示的LLM推理(Qiao等人,2023年)和思维链提示策略(Yu等人,2023c)。
相比之下,我们的综述不仅提供了对他们已经涵盖的主题的更全面和全面的讨论,还包括了额外的主题和讨论,如XoT构建、XoT结构变体和前沿应用等。具体来说,在本文中,我们首先介绍了相关背景和初步知识(第2节)。此外,我们从多个角度仔细分类了XoT系列工作,并完成了深入分析(第4节),包括XoT构建方法(4.1节)、XoT结构变体(4.2节)和XoT增强方法(4.3节)。
然后,我们提供了XoT在前沿领域的实际应用(第5节)。为了激发XoT后续工作的灵感,我们提供了对这一领域未来研究潜在途径的见解(第6节)。最后,我们比较并讨论了现有的方法(第7节)。

2 背景和初步
2.1 背景
近年来,计算能力飞速提升,大型语言模型如雨后春笋般涌现(Brown等人,2020年;OpenAI,2023年;Touvron等人,2023a;Scao等人,2022年;Touvron等人,2023b;Zhao等人,2023b)。这些模型规模持续扩大,催生了许多新功能,如上下文学习与思维链推理(Brown等人,2020年;Wei等人,2022b,a;Schaeffer等人,2023年)。
Brown 等人(2020)揭示了大规模语言模型在上下文学习(ICL)方面的卓越表现。ICL 将输入-输出映射融入提示文本,使现有的 LLMs 在无需额外微调的情况下具备可比性能。然而,这种端到端方法在处理复杂推理任务时仍面临挑战。
Wei团队(2022b)揭示了一种强大的方法来增强LLMs的推理能力,即通过在演示中引入逐步推理过程。这种被称为思维链提示的技术,使模型能够更准确地把握问题的复杂性和推理路径。此外,它还生成了一系列详细的推理步骤,为我们提供了一个清晰的模型认知视角,从而进一步提升了模型的可解释性。
2.2 基础
在本篇中,我们深入探讨了使用LLMs进行思维链推理的初步知识,并援引了Qiao等人(2023年)的研究。以问题Q、提示T和概率语言模型PLM为输入,模型将输出理由R和答案A。我们首先关注上下文场景,其中演示不涉及推理链。我们的目标是最大化答案A的可能性,具体公式如(1,2)所示。
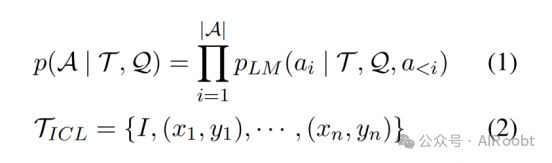
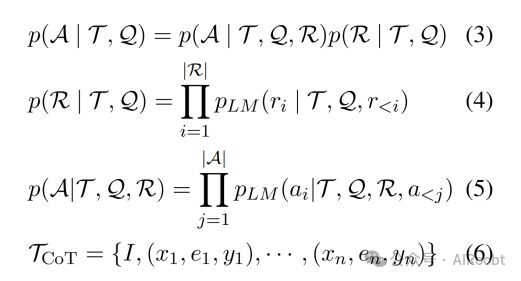
3 基准测试
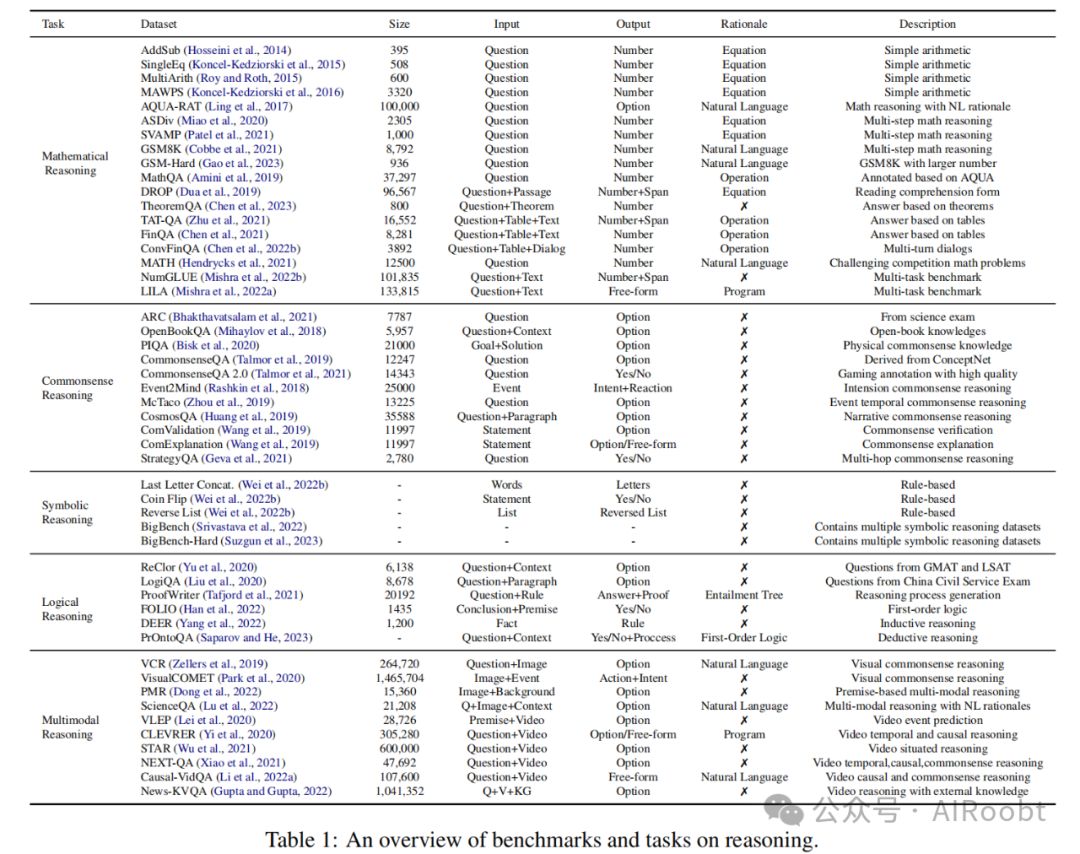
3.1 数学推理
数学推理通常用来衡量模型的推理能力。早期的基准测试包含简单的算术运算(Hosseini等人,2014年;Koncel-Kedziorski等人,2015年;Roy和Roth,2015年;Koncel-Kedziorski等人,2016年)。Ling等人(2017年)以自然语言形式标记了推理过程,而Amini等人(2019年)在AQUA的基础上,通过以程序形式标记推理过程进行了构建。后来的基准测试(Miao等人,2020年;Patel等人,2021年;Cobbe等人,2021年;Gao等人,2023年)包含了更复杂和多样化的问题。(Zhu等人,2021年;Chen等人,2021年,2022b年)需要基于表格内容进行推理。
还有一些通用基准测试(Hendrycks等人,2021年;Mishra等人,2022a,b年)和阅读理解形式的基准测试(Dua等人,2019年;Chen等人,2023年)。最近,(Yu等人,2021a年)通过使用层次推理和知识,赋予了预训练模型数学推理的能力。
3.2 常识推理
常识推理是基于通常在日常生活世界中普遍知晓和普遍感知的知识进行推断、判断和理解的过程。如何获取和理解常识知识是模型面对常识推理时面临的主要障碍。许多基准测试和任务都集中在常识理解上(Talmor等人,2019年,2021年;Bhakthavatsalam等人,2021年;Mihaylov等人,2018年;Geva等人,2021年;Huang等人,2019年;Bisk等人,2020年),事件时间常识推理(Rashkin等人,2018年;Zhou等人,2019年)和常识验证(Wang等人,2019年)。
3.3 符号推理
符号推理是一种模拟人类思维方式的任务,对于LLMs来说具有一定的挑战性。目前,最常用的符号推理任务包括最后一个字母串联、抛硬币和反转列表等。此外,协作基准测试BigBench和BigBench-Hard也包含了几个符号推理数据集,如状态跟踪和对象计数。
3.4 逻辑推理
逻辑推理有三种方法:演绎推理、归纳推理和溯因推理。演绎推理从一般前提中推导出结论,例如Liu等人(2020年)、Yu等人(2020年)、Tafjord等人(2021年)和Han等人(2022年)。归纳推理从特殊案例中推导出一般结论,例如Yang等人(2022年)。溯因推理为观察到的现象提供合理的解释,例如Saparov和He(2023年)。这些方法在不同领域都有广泛的应用,可以帮助我们更好地理解和解决问题。
3.5 多模态推理
在现实世界中,推理还涉及除文本之外的其他模态信息,其中视觉模态最为普遍。为此,提出了许多视觉多模态推理的基准测试(Zellers等人,2019年;Park等人,2020年;Dong等人,2022年;Lu等人,2022年),其中ScienceQA(Lu等人,2022年)注释了推理过程,是使用最广泛的视觉多模态推理基准测试。视频多模态推理(Lei等人,2020年;Yi等人,2020年;Wu等人,2021年;Xiao等人,2021年;Li等人,2022a年;Gupta和Gupta,2022年)更具挑战性,因为它与视觉多模态推理相比引入了额外的时间信息。
3.6 指标
准确率是衡量模型分类能力的关键指标,广泛应用于多项选择题(Ling等人,2017年;Mihaylov等人,2018年;Liu等人,2020年;Lu等人,2022年)和是非判断任务(Talmor等人,2021年;Geva等人,2021年;Han等人,2022年)。
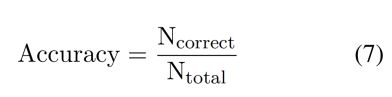
EM和F1是评估自由形式(Mishra等人,2022年;Wang等人,2019年;Yi等人,2020年)和跨度提取(Dua等人,2019年;Zhu等人,2021年;Mishra等人,2022年)任务的关键指标。这两个指标均以词符级别进行计算,为研究者提供了客观、精确的数据支持。
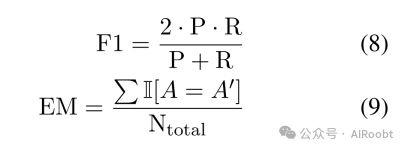
其中P和R分别代表精确度和召回率,EM计算预测和答案完全相同的比例。
4 方法
在本篇中,我们深入探讨了X-of-thought(思维X)推理的三个方面:首先是X-of-thought的构建过程(在4.1节),其次是其结构变体的解析(在4.2节),最后是增强X-of-thought的有效方法(在4.3节)。
4.1 构建方法
经过深入研究,我们将X-of-thought的构建划分为三大类:1)手动XoT;2)自动XoT;3)半自动XoT。详细说明见下文。
4.1.1 手动XoT
虽然大型语言模型在少量样本的上下文学习中表现良好,但在推理任务上仍有局限。为挖掘其潜力,一种可行方法是在示例中呈现多种思考形式。
Wei等人(2022b)首次提出思维链提示(Few-shot CoT),通过手动提供自然语言形式的理由来演示。为了进一步确保推理过程中的确定性并减少推理路径和答案之间的不一致性,PAL(Gao等人,2023)、PoT(Chen等人,2022a)和NLEP(Zhang等人,2023e)
利用编程语言作为注释理由,将问题解决转化为可执行的Python程序。同时,为了同时利用自然语言和编程语言的优势并提高推理输出的置信度,MathPrompter(Imani等人,2023)使用零样本思维链提示生成多个代数表达式或Python函数,这些可以相互验证并提高结果的可靠性。此外,由于示例中的推理复杂性,如包含更多推理步骤的链,会导致性能提升,Fu等人(2023a)提出了基于复杂度的提示,其中在高复杂度理由之间进行投票以得出最终答案。
手动构建的X-of-thought方法通过引入逐步的中间推理步骤,丰富了上下文学习。这类方法使大型语言模型(LLMs)能够模仿并生成推理过程。尽管手动XoT方法提高了人类理解和应对复杂任务(如数学推理、常识推理、符号推理等)的可解释性和可靠性,但其手动注释理由的成本较高,且存在示范选择困难和任务泛化等问题。为了克服这些挑战,研究者们正努力自动构建推理路径,详见§4.1.2。
4.1.2 自动XoT
思维链提示(Wei等人,2022b)通过在少量样本设置中使用特定任务示例激发了LLMs的复杂推理能力,这限制了可扩展性和泛化能力。为了减少手工制作的少量样本示例的成本,Kojima等人(2022)提出了零样本CoT,通过在问题后引入一个魔法短语“让我们一步步来”,使LLMs能够以零样本的方式生成推理链。然而,零样本CoT存在推理路径质量差、错误多的问题。由于示范的多样性在推理链生成中起着至关重要的作用,Auto-CoT(Zhang等人,2023f)通过聚类和代表性示例选择自动生成示范,提高了多样性并一致性地匹配或超过了Few-shot CoT的性能。COSP(Wan等人,2023)引入了问题的输出熵来辅助示范选择。
Xu等人(2023)提出了Reprompting,通过迭代使用Gibbs采样来找到有效的CoT提示。同时,推理链中的一些错误来自遗漏步骤的错误,Wang等人(2023f)将零样本CoT扩展到计划和解决(PS)提示,通过设计一个计划将整个任务划分为更小的子任务,并根据计划执行子任务,带有更详细的指令。LogiCoT(Zhao等人,2023c)使用符号逻辑来验证零样本推理过程,从而减少推理中的错误。
此外,PoT(Chen等人,2022a)也探索了语言模型,如Codex,通过添加“让我们一步步编写Python程序...”,在零样本设置中生成可执行的Python程序来解决数学问题,这减少了中间推理步骤中的错误。一些工作引入了代理来解决推理问题。例如,Agent Instruct(Crispino等人,2023a)利用代理生成与任务相关的、有信息量的指令,指导LLMs执行零样本推理。
与传统手动XoT相比,自动XoT采用零样本提示工程或采样技术,具备高度可扩展性,且能在无需人类干预的情况下实现跨领域泛化。然而,由于缺乏人类对齐,自动生成的思维链可能导致质量不高、产生幻觉以及事实不一致等问题。因此,在§4.1.3中提到了半自动方式构建XoT的必要性。
4.1.3 半自动XoT
半自动XoT方法结合了手动和自动构建方法的优点。Shao等人(2023)提出了合成提示,利用少数人工注释的示例来提示模型通过交替的前向-后向过程生成更多示例,并选择有效的示范以激发更好的推理,缓解了AutoCoT中缺乏人类对齐的问题。尽管之前的工作解决了手动注释的问题,示范选择也可以显著影响性能。Automate-CoT(Shum等人,2023)采用强化学习与方差降低的策略梯度策略来估计黑盒语言模型中每个示例的重要性,激发更好的示范选择。
同样,Lu等人(2023b)提出了PromptPG,它利用策略梯度来学习在表格推理中选择示范。Ye和Durrett(2023)最初使用两个代理指标来评估每个示例,然后在示例中搜索以找到在银标开发集中产生最佳性能的示范。同时,Pitis等人(2023)提出了Boosted Prompting,这是一种提示集成方法来提高性能,它在遇到当前示范难以处理的问题时,通过迭代扩展示例。Zou等人(2023)引入了Meta-CoT,它根据问题类别自动选择示范,消除了特定任务提示设计的需求。
半自动XoT方法通过减轻手动标注负担、引入人类对齐信号和示范选择策略,提高了推理能力和稳定性。同时,它实现了高成本效益的领域泛化。尽管示范选择问题仍需深入研究,但这一方法已经取得了显著进展。
4.2 XoT结构变体
原始思维链是链式结构,通过自然语言描述中间推理步骤。本文将介绍三种结构变体:链式变体、树状变体和图状变体,以优化原始链式结构。
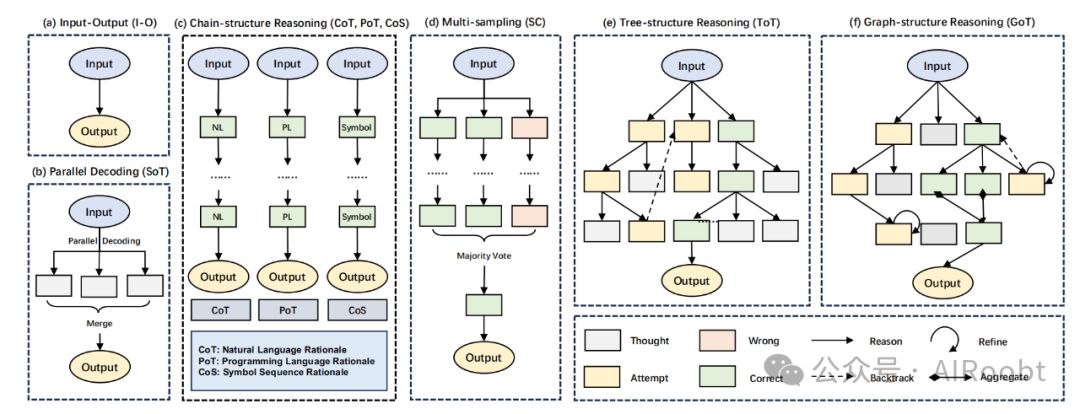
图2展示了推理的发展过程,从直接的输入/输出,到链式结构,再到树和图结构。
链式结构 PAL(Gao等人,2023年)和 PoT(Chen等人,2022a)引入编程语言来描述推理过程,从而将推理问题转化为可执行程序的实现,以获得最终答案。由于程序执行是确定性的并且能够准确执行算术计算,这种方法在数学推理中表现出色。此外,符号序列是另一种思维表示类型。
符号链(Chain-of-Symbol,Hu等人,2023a)在规划期间用简化的符号链表示表示复杂环境,这减少了模拟环境的复杂性。链式结构变体如图2(c,d)所示。思维算法(Algorithm of Thought,Sel等人,2023)将算法能力注入模型,通过添加基于算法的示例使模型的推理更加逻辑化。它没有树搜索(Long,2023;Yao等人,2023b)的巨大搜索空间,节省了计算资源并取得了出色的性能。
树状结构 原始的链式结构本质上限制了探索范围。通过结合树状结构和树搜索算法,模型获得了在推理过程中有效探索和回溯的能力(Long,2023;Yao等人,2023b),如图2(e)所示。结合对中间思维的自我评估,模型可以实现全局最优解。ToT(思维链)的推理过程涉及不确定性,这可能导致级联错误。TouT(Mo和Xin,2023)在推理中引入了蒙特卡洛dropout,考虑了不确定性。Yu等人(2023b)深入研究了类似的问题,利用它们的解决方案提升LLMs复杂的推理能力。这些类似的问题呈现出树状结构,最终汇聚解决主要问题。
然而,当前的思维树在选择任务上有很大的局限性,需要为每个任务设计特定的提示,这阻碍了它的广泛应用。SoT(Ning等人,2023)是树状结构的另一种变体,它将问题分解为可以并行处理并同时解决的子问题,以加快推理速度。然而,它的实用性仅限于可并行分解的问题,不适用于复杂推理任务。
图状结构 与树相比,图引入了循环和环,带来了更复杂的拓扑关系,并允许建模更复杂的推理,如图2(f)所示。GoT(Besta等人,2023;Lei等人,2023a)将中间思维视为图中的节点,结合探索和回溯操作,并与思维树相比额外引入了聚合和细化操作。额外的操作,聚合和细化,在复杂任务中激发了更好的推理。然而,它面临着与思维树相同的困境,即任务限制和较差的泛化能力。此外,它的推理成本增加了。与明确构建思维图的GoT不同,ResPrompt(Jiang等人,2023a)在提示文本中引入了思维之间的残差连接,允许不同步骤的推理相互交互。
随着模型从线性链过渡到层次化的树和复杂的图,解决复杂问题的能力强化。然而,拓扑复杂性的增加限制了相关方法的应用,降低了泛化能力。将基于复杂拓扑结构的方法扩展到通用领域是未来研究的主要挑战。
4.3 XoT增强方法
在本文中,我们将深入探讨XoT增强策略。通过五个主要类别的详细解析:验证与细化(4.3.1)、问题分解(4.3.2)、外部知识利用(4.3.3)、投票与排名(4.3.4)以及提升效率(4.3.5),为您提供全面的XoT优化指南。
4.3.1 验证和改进
思维链推理往往倾向于产生幻觉,导致错误的推理步骤。中间推理步骤中的错误又可能触发一系列错误。引入验证以获得反馈,随后根据这些反馈细化推理过程,可以有效地减轻这种现象,类似于人类反思的过程。
图3描述了验证和细化的概述。
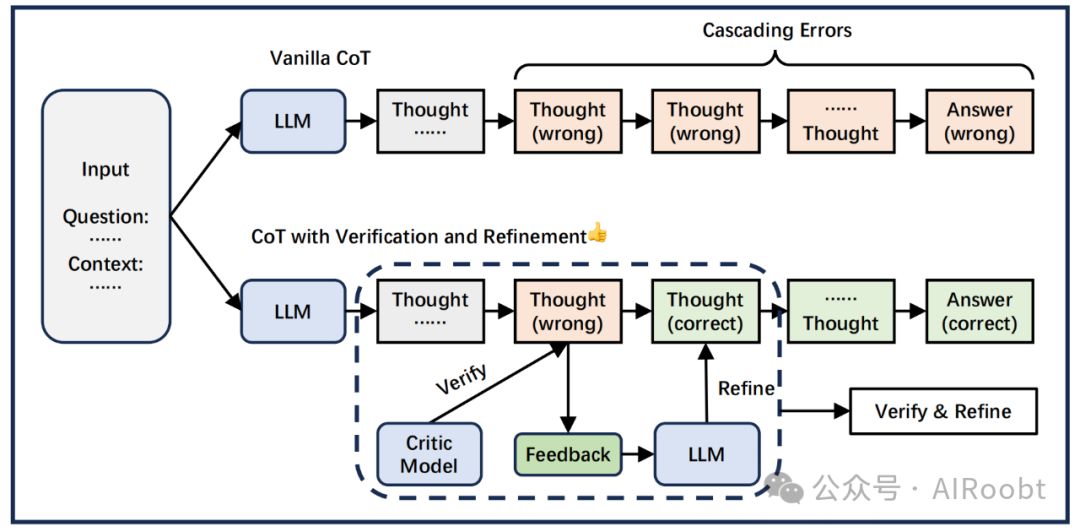
图3:验证和改进减少推理中的级联错误。
VerifyCoT(Ling等人,2023年)设计了一种自然程序,这是一种演绎推理形式,允许模型产生准确的推理步骤,每个后续步骤严格基于前一步。DIVERSE(Li等人,2022c)使用投票机制来排除错误答案,然后对每个推理步骤进行细粒度的验证。SCREWS(Shridhar等人,2023)认为后修改的结果并不一定优于原始结果,因此它引入了一个选择模块来在原始和修改之间选择更好的结果。为了便于知识密集型任务,Verify-and-Edit(Zhao等人,2023a)引入外部知识来重新推理不确定的示例,减少推理中的事实错误。一些研究努力尝试挖掘模型的内部知识。
为了解决事实错误,一些研究尝试挖掘LLMs的内在知识。他们在回答问题之前从模型中获取知识(Dhuliawala等人,2023年;Zheng等人,2023年)。Ji等人(2023年)进一步验证了内在知识的正确性,Liu等人(2023b)通过强化学习提高了内在知识获取的准确性。
不一致性是推理中的另一个主要挑战,Dua等人(2022年)迭代地使用先前的推理结果作为提示,直到模型给出一致的答案。Paul等人(2023年)训练一个批评模型来提供关于推理过程的结构化反馈。Self-Refine(Madaan等人,2023)执行迭代自我反馈和细化以减轻推理中的错误。与Self-Refine相比,Reflexion(Shinn等人,2023)引入了强化学习进行反思,这也带来了决策能力。同时,一些工作引入了反向推理(Yu等人,2023a)进行验证。
RCoT(Xue等人,2023)研究了推理链重构问题,揭示了推理过程中的错误。FOBAR(Jiang等人,2023b)和Self Verification(Weng等人,2022)两种方法分别通过从答案中推断问题条件进行验证。FOBAR负责推断问题变量,而Self Verification关注推断问题条件。然而,Huang等人(2023a)发现,在没有外部反馈的情况下,LLMs难以自我纠正,甚至可能导致性能下降。
LLM推理,一种无监督学习方法,反馈信号在其核心推理步骤中发挥着关键作用。有效的反馈能减少推理中的错觉现象,然而,如何获取恰当的反馈并精确地调整仍需深入探索。
4.3.2 问题分解
X-of-thought推理的核心在于逐步解决问题。然而,传统的思维链推理方法并未明确地展示这一过程,而是采用了一次性生成的方式。在本节中,我们将深入探讨问题分解法,它能够明确且逐步地解决问题,具体概述见图4。
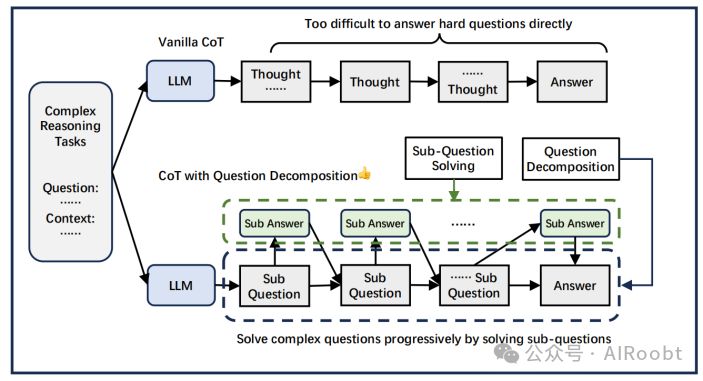
图 4:问题分解通过逐步解决简单的子问题来解决复杂问题。
Wang等人(2022a)迭代地从模型中获取知识,在多跳QA中取得进展。Zhou等人(2023b)提出了Least-to-Most提示,最初以自顶向下的方式将问题分解为子问题,随后,它一次解决一个子问题,并利用它们的解决方案来促进后续子问题。Successive Prompting(Dua等人,2022)采取了与Least-to-Most提示类似的方法,不同之处在于它采用了交错的子问题和答案的分解,而不是两阶段分解。上述方法没有为各种子问题制定定制解决方案。
Decomposed Prompting(Khot等人,2023)设计了一个模块化共享库,每个库专门针对一类子问题,可以为不同类别的子问题定制更有效的解决方案。除了一般任务,一些工作专注于表格推理中的问题分解。BINDER(Cheng等人,2023)以神经符号方式将推理映射到程序,并通过程序执行器(如Python或SQL)获得最终答案。Ye等人(2023)引入了DATER,它将大型表格分解为较小的表格,将复杂问题分解为简单问题。前者减少了不相关信息,后者减少了推理的复杂性。
直接应对复杂问题固然富有挑战,但通过自顶向下的分解策略将问题拆解为若干简单子问题逐步攻克,难度自然降低。更妙的是,每个子问题都可以追溯到特定的推理步骤,使得推理过程更加透明且易于理解。尽管目前大多数工作已经采用这种方法,但基于反向推理的自底向上分解策略仍值得在未来的研究中进一步探讨。
4.3.3 利用外部知识
模型参数化知识有限且过时,导致面对知识密集任务时容易出现错误。引入外部知识可有效减轻此现象,如图5所示。
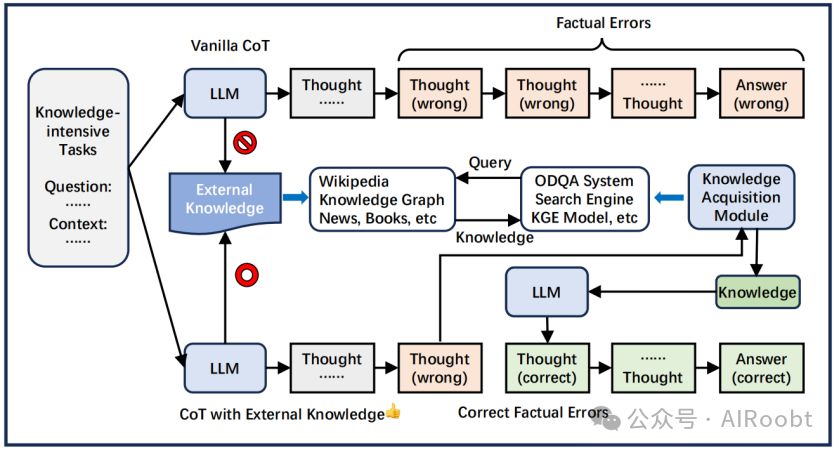
图5:引入外部知识可以减少推理中的事实错误。
Lu等人(2023a)在提示中引入多语言词典以增强机器翻译。Li等人(2023d)提出了知识链(CoK-Li),通过查询生成器从知识库中获取结构化知识以执行知识引导推理。Wang等人(2023b)(CoK-Wang)也从知识库中检索结构化知识。此外,它估计了推理链的事实性和忠实度,并提示模型重新思考不可靠的推理,这减轻了CoK-Li中的知识检索错误。KD-CoT(Wang等人,2023c)通过多轮QA方法解决事实推理问题。他们设计了一个反馈增强的检索器,在每轮QA中检索相关外部知识以校准推理过程。其他研究使用模型自己的记忆作为外部知识。例如,Memory-of-Thought(Li和Qiu,2023)首先进行预思考,将高置信度的思维保存到外部记忆,在推理期间,它让LLM回忆相关记忆以辅助推理。
预训练模型在结束时固定参数化知识,导致其在知识容量和更新方面的不足。尽管引入外部知识有所缓解,但仍非完美之策。为根本解决问题,持续学习(Lange等人,2022年;Wang等人,2023年)成为未来研究的希望之路。
4.3.4 投票和排名
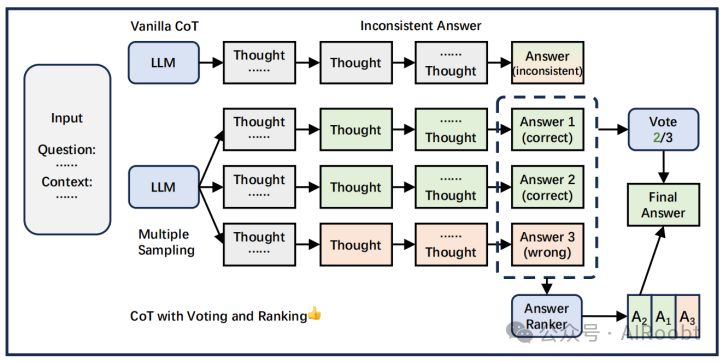
图 6:投票和排序通过从多个采样中选择最终答案来减少不一致性。
一些方法采用排名,如(Cobbe等人,2021年),它训练一个验证器通过排名选择高置信度的推理链。同时,其他方法通过投票机制选择推理链。Self-consistency(Wang等人,2023j)通过基于最终答案的采样推理链的多数投票选择最一致的答案。此外,(Fu等人,2023a)提出了Complex CoT,它利用基于复杂度的投票策略,倾向于选择由更复杂的推理链生成的答案。然而,基于答案的投票机制没有考虑推理链的正确性。
一些方法采用排名来选择推理链。例如,Cobbe等人(2021)训练了一个验证器来通过排名选择高置信度的推理链。另外一些方法则采用投票机制来选择推理链。Self-consistency(Wang等人,2023j)通过基于最终答案的采样推理链的多数投票选择了最一致的答案。此外,Fu等人(2023a)提出了Complex CoT,它利用基于复杂度的投票策略来倾向于选择由更复杂的推理链生成的答案。然而,基于答案的投票机制并没有考虑到推理链的正确性。
Miao等人(2023年)在投票时考虑了推理步骤,这可以同时获得一致的答案和可信赖的推理过程。此外,为了考虑跨链中间步骤之间的关系,Yoran等人(2023年)在推理链之间混合信息,并选择最相关的事实对多个推理链进行元推理。GRACE(Khalifa等人,2023年)通过对比学习训练一个鉴别器,并使用这个鉴别器对每个中间推理步骤进行排名。以前的方法基于概率分布进行抽样,而Diversity-of-Thought(Naik等人,2023年)通过使用不同的指令提示获得多个推理路径。
在集成学习中,多重抽样是一种有效的减少不确定性的方法,它通过投票和排名来实现。与单样本方法相比,多重抽样展示了显著的性能提升,已经成为当前X-of-thought研究中的常用技术之一。未来,将推理链整合到投票中仍然是研究的一个重要领域。
4.3.5 效率
LLM推理和手动注释的推理链带来了昂贵的开销。Aggarwal等人(2023年)通过动态调整样本数量提高自一致性,这可以在边际性能下降的情况下显著降低推理成本。Ning等人(2023年)并行地分解问题并同时处理它们,减少了推理时间开销。但它无法处理复杂问题。Zhang等人(2023b)通过选择性跳过一些中间层并随后在另一个前向传递中验证草稿来加速推理。
Diao等人(2023年)借鉴了主动学习的思想,对具有高不确定性的示例进行注释,减少了人工注释成本。大规模语言模型展示了巨大的能力,但它们也带来了巨大的开销。在未来的研究工作中,平衡性能和开销之间的权衡可能需要大量的关注。
5 前沿应用
5.1 工具使用
尽管大型语言模型(LLMs)展现出惊人的知识广度,但它们也面临着一些挑战。其中包括无法及时获取最新新闻、在处理非领域内知识时可能出现的错误认知,以及在复杂推理任务如数学计算和符号推理方面的表现欠佳。然而,通过赋予LLMs访问外部工具的能力,我们可以提升其推理能力并整合外部知识,使其能够更有效地进行信息检索和环境交互。
MRKL(Karpas等,2022年)引入了一种包含可扩展模块(称为专家)和路由器的新框架。这些专家可以是神经网络或符号形式。然而,这项研究主要集中在概念化和专门针对数学计算训练LLM,而没有深入实现其他模块内容。TALM(Parisi等,2022年a)和Toolformer(Schick等,2023年)将文本为中心的方法与辅助工具结合,以增强语言模型的能力。他们采用自监督机制启动性能增强,从一组有限的工具提示开始。类似地,HuggingGPT(Shen等,2023年)利用视觉和语音模型处理来自不同模态的信息,从而赋予LLMs多模态理解和生成的能力。
另一个问题是如何选择适当的工具。LATM(Cai等,2023年)使LLMs能够在不同任务中生成通用的API,而GEAR(Lu等,2023年c)则通过使用较小的模型来委派工具的基础和执行,从而考虑工具使用的效率。
将用户请求转换为API格式通常并不容易,现有方法在促进多次工具调用和纠正查询错误方面存在局限性。为了解决这个问题,ReAct(Yao等,2023年c)整合了推理和行动的优势,相互增强和补充,提高了问题解决能力。ART(Paranjape等,2023年)使用任务库选择相关的工具使用和推理链。MM-REACT(Yang等,2023年)进一步利用视觉专家实现多模态推理和行动。
ReAct(Yao等,2023年c)是一种新型的解决方案,它整合了推理和行动的优势,相互增强和补充,提高了问题解决能力。与现有方法相比,ReAct更加灵活和高效。ART(Paranjape等,2023年)使用任务库选择相关的工具使用和推理链。MM-REACT(Yang等,2023年)则进一步利用视觉专家实现多模态推理和行动。这些方法都有其独特的优势和特点。
上述研究工作集中在设计工具(或API)以增强LLMs在各个领域的能力。将XoT与工具结合有效应对了LLMs面临的挑战。X-of-thought推理使模型能够有效地引出、跟踪和更新行动计划,同时管理异常情况。同时,行动操作促进模型与外部资源(如知识库和环境)的交互,使其能够收集额外信息。为了评估工具的能力,API-Bank(Li等,2023年c)和MetaTool(Huang等,2023年c)引入了综合基准,提供了评估工具增强型LLMs性能和有效性的坚实基础。
5.2 规划
LLMs在处理复杂问题时,需分解为连续步骤与子任务。尽管思维链(CoT)提供了规划方法,但在解决高度复杂的问题时显得不足,且缺乏回溯评估与错误纠正能力。
许多研究将思维链的框架扩展到各种形式,以进一步增强规划能力。树形思维(Tree-of-Thought,Yao等,2023b)使LLMs能够在树中考虑多种推理路径并自我评估以确定下一步行动。在需要全局决策的情况下,ToT允许通过深度优先搜索或广度优先搜索等技术进行前向或后向探索。通过规划进行推理(Reasoning via Planning,RAP,Hao等,2023年)也将问题划分为树,并通过蒙特卡洛树搜索算法进行探索,使用LLMs作为世界模型和推理代理。
另一种方法,图形思维(Graph of Thought,GoT,Yao等,2023d),使用图节点表示各个思维并利用外部图神经网络进行组织。LLM+P(Liu等,2023年a)和LLM+DP(Dagan等,2023年)促进LLMs生成规划域定义语言(PDDL)(Gerevini,2020)。PDDL有助于分解复杂问题并利用专业模型进行规划,然后将结果转换为自然语言供LLM处理。然而,需要注意的是,这些方法使用树/图/PDDL节点来表示思维,这在表示形式上有局限性,只能处理特定的规划问题。
另一种技术是提高模型纠正错误和总结历史经验的能力。自我改进(Self-Refine,Madaan等,2023年)采用了一种独特的方法,即使用同一模型评估并反馈模型生成的输出。反思(Reflexion,Shinn等,2023年)使模型能够反思并纠正之前行动中的错误,类似于文本格式的强化学习,并将记忆划分为长期和短期成分。然而,当出现计划外错误时,Reflexion无法更新计划。AdaPlanner(Sun等,2023年)引入了自适应闭环计划改进,根据环境反馈迭代细化任务计划。ISR-LLM(Zhou等,2023年c)将自我改进与PDDL结合,在长时间顺序任务中取得了更高的成功率。同时,LATS(Zhou等,2023年a)利用基于语言模型的蒙特卡洛树搜索进行更灵活的规划过程。
规划与强大工具(Ruan等,2023)或智能代理(Crispino等,2023b)相结合,大大增强了推理能力。ToRA(Gou等,2023)创新性地设计了一款带有外部工具的数学专业代理,而AutoUI(Zhang和Zhang,2023)则能直接与多模态环境互动,避免视觉输入转化为文本的过程,从而大幅提升推理效率并减少误传风险。
通过整合搜索、图形和定义语言等技术,规划增强方法为传统顺序规划注入新活力。同时,一些综合性方法致力于提升LLMs的长期规划能力和抗错性能。
5.3 思维链蒸馏
通过蒸馏推理步骤,大型语言模型(LLM)可以自我改进以解决复杂问题。Huang等(2022年)采用了一种自一致性LLM,从未标记数据生成思维链。随后利用这些链条微调模型,增强其广泛的推理能力。Zelikman等(2022年)提出了STaR,一种使用自循环引导策略改进语言模型推理能力的小样本学习方法。SECToR(Zhang和Parkes,2023年)使用思维链获取算术答案,然后微调模型以直接生成答案而无需思维链。
通过蒸馏推理步骤,大型语言模型(LLM)能够自我改进以应对复杂问题。Huang等人(2022年)提出了一种自一致性LLM,从未经标记的数据中生成思维链。随后,利用这些思维链对模型进行微调,从而增强其广泛的推理能力。Zelikman等人(2022年)则提出了STaR,这是一种基于自循环引导策略改进语言模型推理能力的小样本学习方法。而SECToR(Zhang和Parkes,2023年)则利用思维链获取算术答案,并在此基础上对模型进行微调,使其能够直接生成答案而无需思维链。
思维链是一种新兴能力,主要在大型语言模型中观察到。尽管小型模型中进展有限,但通过蒸馏等技术提升其思维链能力是可行的。Magister等人(2023年)展示了如何使用较大教师模型生成推理链微调T5,并使用外部计算器解决答案,从而显著提高各种数据集上的任务性能。Ho等人(2023年)则通过生成和筛选多条推理路径以丰富多样性。
许多努力旨在通过使用未标注(或很少标注)数据和自一致性(Wang等,2023j)来减少人工成本。Hsieh等(2023年)使用提示从少量标注/未标注数据生成答案,然后生成理由,提示语言模型为给定答案提供推理。SCoTD(Li等,2023年)发现,从教师模型中为每个实例采样多条推理链对于提高学生模型的能力至关重要。SCOTT(Wang等,2023h)在生成教师模型的理由时使用对比解码(Li等,2022b;O'Brien和Lewis,2023年)。
此外,为了解决快捷方式问题,它在训练学生模型时采用反事实推理目标。DialCoT(Han等,2023年)将推理步骤分解为多轮对话,并使用PPO算法选择正确路径。Jie等(2023年);Wang等(2023i)为数学问题添加了特殊标记。这种高层次信息提高了推理步骤的一致性。
本研究采用了共享范式,借助具有高度推理能力的LLMs生成思维链,并将其凝练至较小的模型中。我们强化了大规模模型的采样策略,例如采用多路径采样、一致性解码或对比解码,从而提升蒸馏过程的有效性。这一策略带来了思维链的多样性和准确性,对小规模模型的蒸馏同样有益。然而,语言模型在多维度能力上需要权衡与平衡。Fu等人(2023年b)指出,过度依赖于特定任务的思维链能力可能会损害模型解决广泛问题的表现。
6 未来方向
尽管思维链推理在众多任务中展示出强大的性能,但仍面临一些有待探索的挑战。本节概述了未来研究的三个前沿领域:多模态思维链推理(§6.1)、真实的思维链推理(§6.2)和思维链推理理论(§6.3)。
6.1 多模态思维链
从单一模态的文本到视觉-文本的多模态转换引入了更丰富的信息,同时也带来了更多的挑战。一些研究尝试通过微调多模态模型在多模态场景中生成高质量的思维链来探索思维链推理。Multimodal-CoT(Zhang等,2023年g)首先微调多模态模型生成思维链,然后在这些理由上进行推理以获得最终答案。然而,它受到推理过程线性限制的影响,并且在不同模态之间的交互方面存在困难。为了解决Multimodal-CoT遇到的挑战,Yao等(2023年d)提出了思维图(Graph-of-Thought,GoT),将思维过程建模为图。它将推理链解析为思维图,通过捕捉非顺序的信息交互,使思维过程的表示更加真实。这一措施通过图形结构打破了线性结构的限制,并进一步提高了性能。
此外,Yao等(2023年a)提出了超图思维(Hypergraph-of-Thought,HoT),用超图取代思维图,使模型具有更好的高阶多跳推理和多模态比较判断能力。同时,一些工作采用了基于知识蒸馏的方法。T-SciQ(Wang等,2023年d)从LLM生成高质量的思维链理由作为微调信号,并引入了一种新颖的数据混合策略,以生成适用于不同问题的有效样本。
上述研究在小模型和微调场景中探索了多模态推理,这被视为多模态思维链推理领域的初步尝试。我们认为,结合上下文学习的视频多模态推理应该成为未来研究的重点。一方面,与图像相比,视频引入了额外的时间信息,具有内在的链条关系。通过思维链推理,可以自然地连接不同帧中的信息,显式建模时间关系,这非常适合视频多模态推理。另一方面,小模型在能力上有限,需要微调才能获得思维链能力。更糟糕的是,多模态推理链难以获取,这进一步加剧了挑战。
相比之下,当前的视觉-语言基础模型(VLMs)(Alayrac等,2022年;Li等,2023年a;Wang等,2022年b;Huang等,2023年b;Peng等,2023年;Yu等,2021年b)具有强大的视觉-语言理解能力,已经能够在文本和图像交错的上下文中进行学习。它们为结合上下文学习的思维链推理提供了坚实基础。利用思维链进行视频推理仍然是一个未被充分探索的领域,只有少数研究涉及。CoMT(Hu等,2023年b)在视频推理中结合了快思维和慢思维,并引入了规划的树搜索策略,首次在视频多模态推理中应用了思维链。
研究者们虽已探索用思维链推理处理多模态任务,但之前的工作集中在如何构建高质量的微调数据,仍面临诸多挑战待解。
- 如何统一视觉和语言特征以引出更好的多模态理解。
- 如何在不进行微调的情况下使用VLMs进行思维链推理。
- 如何将图像多模态推理适应到视频多模态推理。
6.2 真实度
研究揭示,思维链推理容易导致幻觉现象,如事实错误和上下文不一致。语言模型作为统计模型,受数据噪声和知识遗忘影响,幻觉现象难以避免。
一些工作专注于减轻事实错误。He等(2023年a)引入外部知识来评估推理链,并通过投票过滤掉包含事实错误的链条,但不进行纠正。Wang等(2023年b)采用了类似的方法,不同之处在于额外引入了反思机制以纠正低评分的推理。Zhao等(2023年a)通过一致性过滤掉低置信度的推理,并指导模型基于相关外部知识重新推理。虽然上述方法在知识密集型任务中表现良好,但在解决上下文不一致性挑战方面却有所不足。Zhang等(2023年d)探索了推理过程中幻觉滚雪球现象。其他一些研究旨在解决不一致性问题。Radhakrishnan等(2023年)观察到,模型在处理简单问题时更为真实。因此,通过问题分解来提高真实度。Faithful CoT(Lyu等,2023年)最初生成符号推理链,然后确定性地执行符号函数,以减轻推理不一致性。Lanham等(2023年)探讨了影响真实度的因素,提供了经验性视角。研究发现,不同任务的真实度不同,随着模型规模的增加,真实度下降。CoNLI(Lei等,2023年b)提出了一种后编辑策略以减少幻觉。SynTra(Jones等,2023年)在易引发幻觉的合成数据集上进行前缀调优,然后将此能力转移到实际任务中。
尽管在解决大型语言模型幻觉问题上付出诸多努力,但这些举措仅在一定程度上缓解了问题。要彻底提升大型语言模型的真实性仍需长途跋涉。我们梳理了未来研究的方向如下:
- 提高识别推理过程中的幻觉现象的能力。
- 提高外部知识检索和利用的准确性,以减少事实错误。
- 提高识别和纠正上下文不一致和逻辑错误的能力,这更具挑战性。
- 如何从根本上消除幻觉现象,例如通过特定的预训练方法。
6.3 思维链理论
一些研究从实践角度出发,为实际操作提供指导。Madaan和Yazdanbakhsh(2022)将提示分解为符号、模式和文本三个部分,通过反事实提示探究思维链的影响。Wang等人(2023年a)分析了示范选择的影响,发现推理链的正确性影响有限,而问题的相关性和正确的推理顺序更为关键。Tang等人(2023年)探讨了语义的作用,研究发现思维链推理在很大程度上依赖于预训练期间引入的语义知识,在符号推理方面表现不佳。
其他一些研究从理论上分析,探索潜在的原理和内部机制。Li等(2023年e)将思维链推理解构为一个多步骤组合函数。他们表明,思维链减少了上下文学习处理复杂问题的复杂性。Feng等(2023年)理论证明了一个固定大小的Transformer足以完成计算任务和动态规划任务,并支持思维链。Merrill和Sabharwal(2023年)观察到,思维链可以增强推理能力,随着中间推理步骤数量的增加,改进幅度也增加。Wu等(2023年)利用基于梯度的特征归因方法探索思维链对输出的影响。结果表明,思维链对问题中的扰动和变化表现出鲁棒性。此外,有一些观点认为,思维链能力源自预训练阶段的代码数据(Madaan等,2022年;Zhang等,2023年c),但目前没有系统的工作来证实这一观点。
当前对思维链理论的研究仍处于初步探索阶段。我们总结了未来的研究方向如下:
- 探索思维链能力的来源,以实现思维链推理的有针对性改进。
- 从理论上分析思维链相对于上下文学习的优势,并探索其能力边界。
7 讨论
7.1 思维链构建比较
现有的三种构建思维链方法包括:(1)手动标注推理链;(2)模型自动生成推理链;(3)半自动生成,通过少量手动标注的推理链实现自动扩展。
我们观察到,手动构建方法(Wei等,2022b;Gao等,2023年)面临与上下文学习类似的挑战,即示范选择、指令格式化等(Dong等,2023年)。这导致其应用困难重重,并且阻碍了跨不同任务的转移能力。自动构建方法(Zhang等,2023年f;Chen等,2022年a;Xu等,2023年)缺乏高质量标注的指导,导致性能不足。得益于手动标注带来的信号,半自动方法(Shum等,2023年;Shao等,2023年)可以通过自引导和类似技术生成高质量的推理链,有效解决了以往方法面临的挑战。在取得优异性能的同时,还能轻松实现跨不同任务的转移。
7.2 验证/改进与规划的比较
规划与基于验证/改进的方法有诸多共通之处,均依赖于反馈机制以调整行为。但规划方法涵盖决策过程,而基于验证/改进的方法仅纠正中间错误,不涉及高层次认知过程。
LLM(法律逻辑推理)的推理过程常常陷入幻觉,导致事实和逻辑错误。然而,验证与编辑的方法(Ling等,2023;Zhao等,2023a;Madaan等,2023;Shinn等,2023)有效地检验了推理过程的准确性,并对可能产生幻觉的推理步骤进行了优化。这些方法的运用极大地降低了推理过程中连锁错误和幻觉现象的发生率。
规划方法在2023年由Long等人提出,Yao等在同年b、c篇章中进一步发展。Liu等人在2023年的a篇文章中阐述了这一方法。Shinn等在2023年的研究成果中,将决策过程融入推理过程中。他们通过评估中间推理步骤的反馈,进行探索和回溯,以实现全局层面上的最优解决方案。这种方法的专业性体现在处理复杂问题上,特别是在应对复杂的多跳推理和规划任务时,能够展现出显著的性能提升。
7.3 弥补固有缺陷
LLM在推理方面面临诸多固有挑战,如外部信息访问受限、算术错误和不一致推理。为应对这些问题,可将特定职责分配给专用模块或模型,实现巧妙规避。
针对模型在访问外部信息方面的局限性,(Li等,2023年d;Wang等,2023年b;Lu等,2023年a;Schick等,2023年;Karpas等,2022年;Yoran等,2023年)利用知识库、搜索引擎和开放域问答系统等外部知识资源。一些工作引入了计算器来解决算术错误(Schick等,2023年;Karpas等,2022年;Parisi等,2022年b)。代码执行是确定性的,一些工作通过引入代码执行器提高推理过程的一致性(Gao等,2023年;Chen等,2022年a;Bi等,2023年;Imani等,2023年)。我们认为,将LLM用作中央规划和推理的代理,将特定子任务委托给专用子模型,是未来在复杂场景中应用大模型的潜在途径(Wang等,2023年e;Xi等,2023年)。
7.4 其他工作
在本章中,我们将列出其他代表早期尝试思维链推理或专为特定领域设计的工作。Katz等(2022年);Zhang等(2022年)提供了基准和资源。一些工作经验性地证明了思维链提示的有效性(Lampinen等,2022年;Ye和Durrett,2022年;Arora等,2023年),Shi等(2023年)探索了多语言思维链推理。其他工作专注于特定领域,如机器翻译(He等,2023年b)、情感分析(Fei等,2023年)、句子嵌入(Zhang等,2023年a)、摘要(Wang等,2023年k)、算术(Lee和Kim,2023年)和表格推理(Chen,2023年;Jin和Lu,2023年)等。此外,一些研究利用特定的预训练来增强某些能力,如数学推理(Lewkowycz等,2022年;Zhao等,2022年)。
8 结论
本文对现有的思维链推理研究进行了广泛的调查,提供了对该领域的全面回顾。我们介绍了广义思维链(X-of-Thought)的概念,并从多个角度审视了X-of-Thought推理的进展。此外,我们还探讨了X-of-Thought在前沿领域的应用。我们还强调了目前这一研究面临的挑战,并展望了未来的前景。据我们所知,这项调查是对思维链推理的首次系统性探索。我们的目标是为对思维链推理感兴趣的研究人员提供全面的概述,希望这项调查能促进该领域的进一步研究。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
相关文章:

大模型思维链推理的进展、前沿和未来分析
大模型思维链推理的综述:进展、前沿和未来 "Chain of Thought Reasoning: A State-of-the-Art Analysis, Exploring New Horizons and Predicting Future Directions." 思维链推理的综述:进展、前沿和未来 摘要:思维链推理&#…...

windows上利用MinGW编译hiredis
1、下载 hiredis https://github.com/redis/hiredis 2、利用CMake生成Makefile文件 CMAKE_BUILD_TYPE: 默认空的时候是Release的。如果需要Debug则自行修改。 执行Configure的时候选择MinGW(确保MinGW已经安装,并且已加入到环境变量) 3、执行…...

06-RabbitMQ基础
目录 1.初识MQ 1.1.同步调用 1.2.异步调用 1.3.技术选型 2.RabbitMQ 2.1.安装 2.2.收发消息 2.2.1.交换机 2.2.2.队列 2.2.3.绑定关系 2.2.4.发送消息 2.3.数据隔离 2.3.1.用户管理 2.3.2.virtual host 3.SpringAMQP 3.1.导入Demo工程 3.2.快速入门 3.2.1.消…...

Spring Boot 的自动配置,以rabbitmq为例,请详细说明
Spring Boot 的自动配置特性能够大大简化集成外部服务和组件的配置过程。以 RabbitMQ 为例,Spring Boot 通过 spring-boot-starter-amqp 提供了自动配置支持,开发者只需在应用中添加相关依赖并配置必要的属性,Spring Boot 会自动配置所需的连…...

ros2-4.1 服务通信介绍
服务是ROS图中节点之间的另一种通信方法。服务分为客户端和服务端,客户端发送请求给服务端,服务端可以根据客户端的请求做一些处理,然后返回结果给客户端。也称为为请求-响应模型。 服务和话题的不同之处,话题是没有返回的&#…...

如何 cURL Elasticsearch:进入 Shell
作者:来自 Elastic Philipp Krenn Kibana 的控制台是开始使用 Elasticsearch 的 REST API 的最简单方法 - 语法突出显示、自动完成、格式化、导出 cURL、JavaScript 或 Python。而且你不必担心正确的端点、身份验证等。但是有时,如果 Kibana 不可用、你…...
)
【信息系统项目管理师】高分论文:论信息系统项目的风险管理(人民医院的信息系统)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 论文1、规划风险管理2、项目风险识别3、风险定性分析4、风险定量分析5、制定风险应对6、实施风险应对计划7、监督风险论文 2022年6月,我作为项目经理承担了XX县人民医院的信息系统建设,该项目总投资300万,其…...

安装和配置 Apache 及 PHP
安装和配置 Apache 及 PHP # 1. 停止当前 Apache 服务 sudo apachectl stop# 2. 清除现有的 Apache 配置和文件 sudo rm -rf /etc/apache2 sudo rm -rf /usr/sbin/httpd sudo rm -rf /Library/WebServer# 3. 使用 Homebrew 安装 Apache brew install httpd# 4. 启动 Apache su…...

jenkins入门12-- 权限管理
Jenkins的权限管理 由于jenkins默认的权限管理体系不支持用户组或角色的配置,因此需要安装第三发插件来支持角色的配置,我们使用Role-based Authorization Strategy 插件 只有项目读权限 只有某个项目执行权限...

虚功、达朗贝尔原理和拉格朗日方程
本文先引入虚位移,从虚功和虚功原理出发,介绍达朗贝尔原理(d’Alembert’s principle) 和 拉格朗日方程(Lagrange’s equations)。 1. 虚功 力学系统的虚位移(virtual displacement)或称无限小位移(infinitesimal displacement)是指力学系统的位形(configuration …...

面向对象分析和设计OOA/D,UML,GRASP
目录 什么是分析和设计? 什么是面向对象的分析和设计? 迭代开发 UML 用例图 交互图 基于职责驱动设计 GRASP 常见设计原则 什么是分析和设计? 分析,强调是对问题和需求的调查研究,不是解决方案。例如&#x…...
)
【Linux】记录一下考RHCE的学习过程(七)
年底了,公司接的北京地铁轨道交通的项目做不完了,一百多列地铁的设备都得调,派我出差了几周,这几天才回来,出差累死了实在是没办法更新。(YOASOBI的二开票还没抢到ToT,哭死,看看回滚…...
学习基础)
【深度学习】深度(Deep Learning)学习基础
深度学习(Deep Learning) 深度学习是一种基于人工神经网络的机器学习方法,通过多个层次(深度)的神经网络从数据中自动学习特征和模式。它是人工智能的一个核心领域,尤其在处理复杂数据(如图像、…...

121 买入股票的最佳时机
思路1: 买的那天一定是卖的那天之前的最小值。 每到一天,维护那天之前的最小值即可。 假设第一天是最小值,最大值初始化为0,当以后某天的价格小于最小值时,将最小值更新 当天价格大于最小值,说明有利可图…...

JVM之Java内存模型
Java内存模型(Java Memory Model,简称JMM)是Java虚拟机(JVM)规范中定义的一套规则,用于描述多线程环境下变量如何被访问和同步。在多线程编程中,内存模型的重要性不言而喻,它直接关系…...

matlab系列专栏-快捷键速查手册
目录 1在命令窗口(Command Window)中 2. 在编辑器(Editor)(m文件)中 1在命令窗口(Command Window)中 1)【↑、↓】——切换到之前、之后运行过的命令,可以重复按多次来达到想要的命令。 2)【Tab】——自动补全。在Command窗口,…...

快手一面-面经
1. RPC和Http的区别? RPC(Remote Procedure Call,远程过程调用)和 HTTP(HyperText Transfer Protocol,超文本传输协议)是两种不同的通信机制,它们有不同的用途、工作原理和应用场景…...

<style lang=“scss“ scoped>: 这是更常见的写法,也是官方文档中推荐的写法
这两种写法在大多数情况下是没有区别的,它们都是 Vue.js 单文件组件 (.vue 文件) 中用来定义组件私有样式的方式。 两种写法: <style lang"scss" scoped>: 这是更常见的写法,也是官方文档中推荐的写法。<style scoped l…...

cerebro关闭ssl
cerebro连接es报错 io.netty.handler.codec.DecoderException: javax.net.ssl.SSLHandshakeException: (certificate_unknown) Received fatal alert: certificate_unknown 在cerebro的application.conf配置文件中添加 play.ws.ssl.loose.acceptAnyCertificate true Disab…...

网络安全常见的问题
1. 什么是 DDoS 攻击?如何防范? 答:DDoS 攻击是指利用大量的计算机或者其他网络设备,同时向目标网络或者服务器 发送 大量的数据流量,以致其无法正常工作,从而导致网络瘫痪或者服务器宕机的攻击行 为。 …...
)
Eclipse配置Tomcat服务器(最全图文详解)
前言: 本章使用图文讲解如何在Eclipse开发工具中配置Tomcat服务器、如何创建和启动JavaWeb工程,欢迎童鞋们互相交流。觉得不错可以三连订阅喔。 目标: 一、配置Tomcat服务器 1. 切换Eclipse视图 2. 打开菜单 3. 找到服务选项 4. 选择…...

mv指令详解
🏝️专栏:https://blog.csdn.net/2301_81831423/category_12872319.html 🌅主页:猫咪-9527-CSDN博客 “欲穷千里目,更上一层楼。会当凌绝顶,一览众山小。” 目录 基本语法 主要功能 常用选项详解 1. …...

SQL从入门到实战
学前须知 sqlzoo数据介绍 world nobel covid ge game、goal、eteam teacher、dept movie、casting、actor 基础语句 select&from SELECT from WORLD Tutorial - SQLZoo 基础查询select单列&多列&所有列&别名应用 例题一 SELECT name, continent, population …...

回归中医传统 重铸中医之魂 — 薛应中 —
最近做了一个20次课的讲义纲要,每节课都是中医理念下某一类疾病的认知与诊疗,或是一个重大健康观念的辨析,准备陆续和各届人士一起探讨。 下面就算是一个序言,主要是做一个自我介绍,将自己的一点心得,结合我的行医经历,以及学习中医的治学之道等,做一个开场白。 (一)中医的有…...

什么是面向对象?
面向对象编程(Object-Oriented Programming,简称OOP)是一种流行的编程方法,它以对象和类为基础构建软件。该编程范式围绕“对象”这一基本概念展开,其中对象被视为包含数据和行为的软件构件。以下是对面向对象编程的深…...

HDFS读写流程
因为namenode维护管理了文件系统的元数据信息,这就造成了不管是读还是写数据都是基于NameNode开始的,也就是说NameNode成为了HDFS访问的唯一入口。入口地址是:http://nn_host:8020。 一、写数据流程 1.1 Pipeline管道、ACK应答响应 Pipeline…...

HDFS Federation联邦机制
一、当前HDFS体系架构 1.1 简介 当前的HDFS架构有两个主要的层: 命名空间(namespace) HDFS体系结构中的命名空间层由文件,块和目录组成。该层支持与名称空间相关的文件系统操作,例如创建,删除࿰…...

机器学习周报-ModernTCN文献阅读
文章目录 摘要Abstract 0 提升有效感受野(ERF)1 相关知识1.1 标准卷积1.2 深度分离卷积(Depthwise Convolution,DWConv)1.3 逐点卷积(Pointwise Convolution,PWConv)1.4 组卷积(Grou…...

QT RC_FILE 应用程序图标设置
1.先做一个app.ico 文件,并将文件放入资源文件夹中 2.打开QT项目的.pro文件在最下面增加 RC_FILE $$PWD/res/app.rc 3.在资源文件夹中创建一个app.rc文件。在QT开发工具中编辑并输入下在内容 IDI_ICON1 ICON "app.ico" 4.测试效果...

5G学习笔记之SNPN系列之网络选择
目录 0. NPN系列 1. 概述 2. 自动网络选择 3. 手动网络选择 0. NPN系列 1. NPN概述 2. NPN R18 3. 【SNPN系列】SNPN ID和广播消息 4. 【SNPN系列】UE入网和远程配置 5. 【SNPN系列】SNPN选择 6. PNI-NPN 1. 概述 对于某个特定的UE,可以仅支持SNPN接入模式&#x…...
——筑梦之路)
k8s helm部署kafka集群(KRaft模式)——筑梦之路
添加helm仓库 helm repo add bitnami "https://helm-charts.itboon.top/bitnami" --force-update helm repo add grafana "https://helm-charts.itboon.top/grafana" --force-update helm repo add prometheus-community "https://helm-charts.itboo…...

Redis学习笔记
目录 Nosql概述 为什么用Nosql 什么是Nosql Nosql四大分类 Redis入门 概述 Windows安装 Linux安装 测试性能 基础知识 五大数据类型 Redis-Key String(字符串) List(列表) Set(集合) Hash(哈希) Zset(有…...

mysql递归查询语法WITH RECURSIVE
WITH RECURSIVE 是 SQL 中用于执行递归查询的语法,特别适合于处理层级结构或递归数据(如树形结构、图结构)。递归查询可以反复引用自己来查询多层次的数据,而无需写多个嵌套查询。 基本语法结构: WITH RECURSIVE CTE…...
)
Go语言之十条命令(The Ten Commands of Go Language)
Go语言之十条命令 Go语言简介 Go语言(又称Golang)是由Google开发的一种开源编程语言,首次公开发布于2009年。Go语言旨在提供简洁、高效、可靠的软件开发解决方案,特别强调并发编程和系统编程。 Go语言的基本特征 静态强类…...

Visual Studio 2022 C++ gRPC 环境搭建
文章目录 1、gRPC 安装2、创建项目2.1、创建 “空的解决方案”2.2、新建 gRPCServer 和 gRPCClient 项目2.3、创建 proto 文件 2、为 gRPC 服务端和客服端项目配置 protobuf 编译2.1、protobuf 配置2.2、gRPCServer 项目配置2.3、gRPCClient 项目配置 3、测试3.1、启动服务端程…...

2024AAAI SCTNet论文阅读笔记
文章目录 SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation摘要背景创新点方法Conv-Former Block卷积注意力机制前馈网络FFN 语义信息对齐模块主干特征对齐共享解码头对齐 总体架构backbone解码器头 对齐损失 实验SOTA效果对比Cit…...

【Java从入门到放弃 之 final 关键字】
final 关键字 final 关键字final 字段final 函数列表中的参数final 方法final 类 final 关键字 Java中里面有final这个关键字,这个关键字总体上是用来表达” 不能被改变“ 这个意思的。我们使用这个关键字表达不能被改变,有两种使用场景,有三…...

【U8+】用友U8软件中,出入库流水输出excel的时候提示报表输出引擎错误。
【问题现象】 通过天联高级版客户端登录拥有U8后, 将出入库流水输出excel的时候,提示报表输出引擎错误。 进行报表输出时出现错误,错误信息:找不到“fd6eea8b-fb40-4ce4-8ab4-cddbd9462981.htm”。 如果您正试图从最近使用的文件列…...

文本区域提取和分析——Python版本
目录 1. 图像预处理 2. 文本区域提取 3. 文本行分割 4. 文本区域分析 5. 应用举例 总结 文本区域提取和分析是计算机视觉中的重要任务,尤其在光学字符识别(OCR)系统、文档分析、自动化数据录入等应用中有广泛的应用。其目标是从图像中提…...
)
数据库介绍(不同数据库比较)
文章目录 **一、关系型数据库(RDBMS)****1. MySQL****优点**:**缺点**:**适用场景**: **2. PostgreSQL****优点**:**缺点**:**适用场景**: **3. Oracle Database****优点**ÿ…...
)
注意力的简单理解,有哪些注意力(Attention)
注意力(Attention) 目录 注意力(Attention)掩码注意力机制自注意力、交叉注意力、掩码注意力的不同点适应场景及举例多头注意分层注意力(Hierarchical Attention)协同注意力(Co - Attention)自注意力(Self - Attention) 简单理解:自注意力就像是一个句子(或序列)内…...

基于Python的投资组合收益率与波动率的数据分析
基于Python的投资组合收益率与波动率的数据分析 摘要:該文通过研究马科维茨的投资组合模型,并将投资组合模型应用到包含6只金融股票的金融行业基金中。首先通过开源的财经接口Tushare获取股票原始数据,接着利用数据分析的黄金组合库…...

《Opencv》图像的旋转
一、使用numpy库实现 np.rot90(img,-1) 后面的参数为-1时事顺时针旋转,为1时是逆时针旋转。 import cv2 import numpy as np img cv2.imread(./images/kele.png) """方法一""" # 顺时针90度 rot_1 np.rot90(img,-1) # 逆时针90度…...

Python 22:注释
1. 定义: 用熟悉的语言对代码进行解释说明。注释不会被执行。 2. 注释分类 单行注释:只能对一行代码进行注释。放在要注释的代码后面,用#进行分隔,中间至少空2个空格,保证代码规范。 print("hello world10"…...

python:利用神经网络技术确定大量离散点中纵坐标可信度的最高集中区间
当我们有许多离散点并想要确定纵坐标在某个区间内的可信度时,我们可以使用神经网络模型来解决这个问题。下面是一个使用Python编写的示例代码,展示了如何使用神经网络来确定大量离散点中纵坐标可信度的最高集中区间。 import numpy as np from sklearn.…...

计算机软件保护条例
(2001年12月20日中华人民共和国国务院令第339号公布 根据2011年1月8日《国务院关于废止和修改部分行政法规的决定》第一次修订 根据2013年1月30日《国务院关于修改〈计算机软件保护条例〉的决定》第二次修订) 第一章 总则 第一条 为了保护计算机软件著作权人的权益&#…...

CM3/4启动流程
CM3/4启动流程 1. 启动模式2. 启动流程 1. 启动模式 复位方式有三种:上电复位,硬件复位和软件复位。 当产生复位,并且离开复位状态后,CM3/4 内核做的第一件事就是读取下列两个 32 位整数的值: 从地址 0x0000 0000 处取…...

gaussdb中怎么查询一个表有多少GB
在 GaussDB 中,你可以通过多种方法查询一个表的大小,包括使用系统视图和内置函数。以下是几种常见的方法: 1. 使用 pg_total_relation_size 函数 pg_total_relation_size 函数返回一个表及其所有索引和 TOAST 数据的总大小。 示例查询 SE…...

2025-01-06 Unity 使用 Tip2 —— Windows、Android、WebGL 打包记录
文章目录 1 Windows2 Android2.1 横版 / 竖版游戏2.2 API 最低版本2.3 目标帧率2.3.1 targetFrameRate2.3.2 vSyncCount2.3.3 Unity 默认设置以及推荐设置2.3.4 Unity 帧率托管 3 WebGL3.1 平台限制3.2 打包报错记录 13.3 打包报错记录 2 最近尝试将写的小游戏打包ÿ…...

OP-TEE环境飞腾密码引擎编程指南
【写在前面】 飞腾开发者平台是基于飞腾自身强大的技术基础和开放能力,聚合行业内优秀资源而打造的。该平台覆盖了操作系统、算法、数据库、安全、平台工具、虚拟化、存储、网络、固件等多个前沿技术领域,包含了应用使能套件、软件仓库、软件支持、软件适…...