基于大数据爬虫+Python+数据可视化大屏的慧游数据爬虫与推荐分析系统(源码+论文+PPT+部署文档教程等)
博主介绍:**CSDN毕设辅导第一人、**全网粉丝50W+,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流
**技术范围:**SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
??文末获取源码联系??
???精彩专栏推荐订阅???不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐?
Java项目精品实战案例《100套》
Java微信小程序项目实战《100套》
大数据项目实战《100套》
Python项目实战《100套》
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

系统介绍:
在信息化时代,数据已成为洞悉行业趋势、指导决策的重要资源。广东省,作为中国的经济大省和旅游大省,拥有丰富的旅游资源和庞大的旅游市场。近年来,随着国内外旅游需求的持续增长,广东旅游业呈现出多元化和个性化的发展趋势。面对海量而杂乱的网络数据,如何有效地进行信息的提取、处理与分析,成为了提升旅游服务质量和市场竞争力的关键。Python作为一种强大的编程语言,以其简洁的语法和丰富的数据分析库,成为进行旅游数据分析的理想工具。通过Python实现的自动化数据收集和分析流程,能够为广东旅游业提供科学的决策支持,同时为游客提供个性化的旅游推荐。

基于Python的广东旅游数据分析不仅具有理论研究价值,更具备实践应用的重要性。从理论层面来看,该分析可以丰富旅游学科的研究方法,将数据科学与旅游管理相结合,开辟新的跨学科研究领域。从实践层面来讲,通过对广东旅游数据的深入分析,能够帮助政府和企业掌握旅游市场的实时动态,优化资源配置,提高经营效率;对于游客而言,可以根据分析结果获得更为精准的旅游信息,规划出更加合适的旅行计划。

此外,该分析还能够预测旅游市场的潜在风险,为旅游安全管理提供参考依据。总体而言,基于Python的广东旅游数据分析项目对于推动广东乃至全国的旅游产业发展,提升旅游体验质量,具有深远的社会和经济意义。

网络爬虫
网络爬虫原理
网络爬虫最常用于各个搜索引擎,一般作为搜索引擎的核心模块[23],主要提供信息获取功能。通常情况下,网络爬虫是一段用于抓取 HTML 文档数据,并对下载的网页整理、建索引的程序或脚本。网络爬虫主要包含页面采集、页面解析、链接处理几个子模块。图 2-4 展示了网络爬虫的结构。

网络爬虫的工作流程
图 2-4 网络爬虫结构

网络爬虫的一般工作流程为:确定好要爬取的网站,从给定的初始 URL 链接队列中取出一个 URL,自动分析页面上的文本信息存入数据库中、提取页面上未访问过的 URL 加入待访问 URL 队列,重复以上操作,直到满足爬行停止的条件为止,上述循环过程通常称为网络爬行,图2-5 展示了网络爬虫的工作流程。
图 2-5 网络爬虫工作流程
-
网络爬虫的队列

程序上交给用户进行使用时,需要提供程序的操作流程图,这样便于用户容易理解程序的具体工作步骤,现如今程序的操作流程都有一个大致的标准,即先通过登录页面提交登录数据,通过程序验证正确之后,用户才能在程序功能操作区页面操作对应的功能。
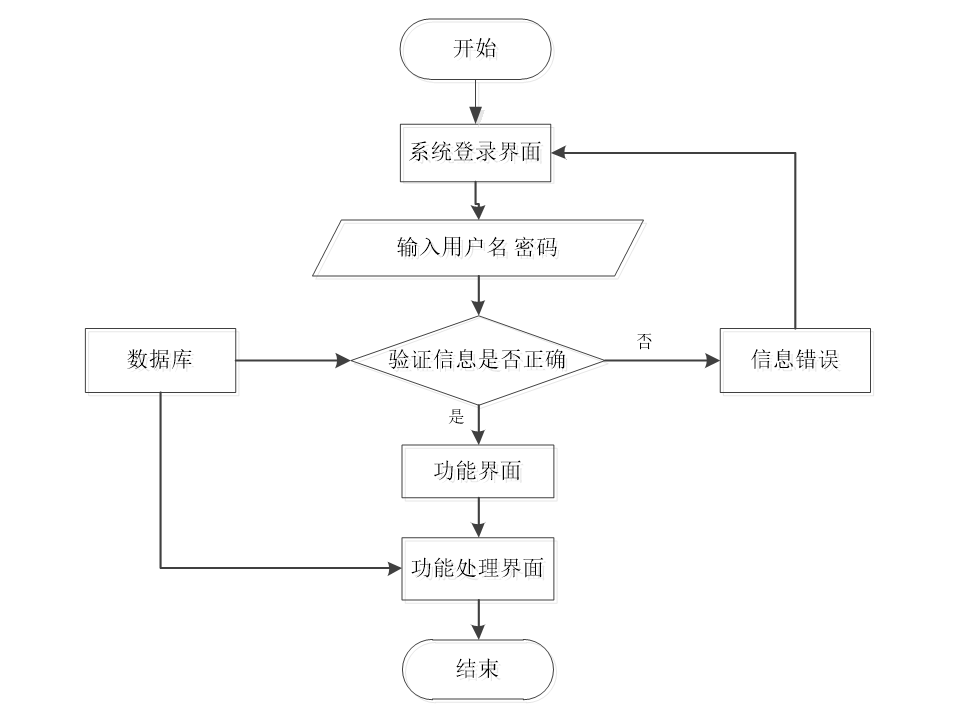
程序操作流程图
首先前端通过Vue和axios发送HTTP请求到后端的登录接口。在后端接收登录请求的Controller会使用`@RequestParam Map<String, Object> params`来接收前端传递的用户参数,用户名和密码。然后后端根据接收到的参数创建一个查询条件封装对象MyBatis的EntityWrapper用于构建查询条件。接着在业务层,调用相应的service方法来查询数据库中是否存在匹配的用户信息。这个查询方法Login()会将前端传递的对象参数传递到后台的DAO层,进行数据库的交互操作。如果存在符合条件的用户,则会返回相关的用户信息。最后在后端控制器中将查询结果封装成响应体,通过`return R.ok().put(“data”, userService.selecView(ew))`将用户信息返回给前端。前端收到响应后,可以通过调用Vue、ElementUI等组件来渲染登录结果,例如显示用户信息或者跳转到相应的页面。
系统架构设计
系统架构设计是软件开发过程中至关重要的一环。首先是模型层(Model),模型层通常对应着数据库或者其他数据源,它负责与数据库进行交互,执行各种数据操作,并将处理后的数据传递给控制器层。模型层的设计应该简洁清晰,尽可能减少与视图和控制器的耦合,以提高代码的可维护性和可重用性。
其次是视图层(View)通常是通过网页、移动应用界面或者其他用户界面来展示数据。视图层与用户交互,接受用户的输入,并将输入传递给控制器层进行处理。在MVC三层架构中,视图层应该尽量保持简单,只负责数据的展示和用户交互,不涉及业务逻辑的处理,以保持视图层的清晰度和可复用性,最后是控制器层(Controller),每个层都有特定的职责和功能,通过分层架构设计,实现代码模块化,为软件开发提供了一种有效的架构模式。系统架构如图4-1所示。

详细视频演示
请文末卡片dd我获取更详细的演示视频

功能截图:
在系统前台首页,调用`$route(newValue)`方法监听路由变化,根据当前的路由地址来确定活动菜单的索引,并且根据路由的哈希部分(即URL的`#`后面的部分)来判断是否需要滚动页面到顶部或者某个特定元素的位置。如果不是首页,会将页面滚动到指定元素处,否则滚动到页面顶部。另外通过`headportrait()`方法用于更新组件渲染点前用户头像。在用户登录后,后端返回了新的用户信息,需要及时更新页面上的用户头像信息。
按照软件工程的流程来说,在系统的详细设计与实现阶段,要把模块、视图、模板进行相应的组合完成一个个所需的功能,此章将会把设计中模块一一说明如何设计和实现的。
5.1前台功能实现
当人们打开系统的网址后,首先看到的就是首页界面。在这里,人们能够看到系统的导航条,通过导航条导航进入各功能展示页面进行操作。系统首页界面如图5-1所示:

图5-1系统首页界面
在注册流程中,用户在Vue前端填写必要信息(如用户名、密码等)并提交。前端将这些信息通过HTTP请求发送到Python后端。后端处理这些信息,检查用户名是否唯一,并将新用户数据存入MySQL数据库。完成后,后端向前端发送注册成功的确认,前端随后通知用户完成注册。这个过程实现了新用户的数据收集、验证和存储。系统注册页面如图5-2所示:

图5-2系统注册详细页面
广东景点:在广东景点页面的输入栏中输入标题和地址进行查询,可以查看到广东景点详细信息,并进行评论或收藏操作;广东景点页面如图5-3所示:

图5-3广东景点详细页面
在个人中心页面可以对个人中心、修改密码、我的收藏进行详细操作;如图5-4所示:

图5-4个人中心界面
5.2管理员功能实现
在登录流程中,用户首先在Vue前端界面输入用户名和密码。这些信息通过HTTP请求发送到Python后端。后端接收请求,通过与MySQL数据库交互验证用户凭证。如果认证成功,后端会返回给前端,允许用户访问系统。这个过程涵盖了从用户输入到系统验证和响应的全过程。如图5-5所示。


图5-5管理员登录界面
管理员进入主页面,主要功能包括对系统首页、用户、广东景点、系统管理、个人资料等进行操作。管理员主页面如图5-6所示:

图5-6管理员主界面
用户功能实现是在Django后端部分,您需要创建一个新的应用,然后在该应用下创建一个模型(models.py)来定义用户的数据结构,使用Django的ORM来处理与MySQL数据库的交互,包括用户信息的查询、添加或删除等操作。接着,在views.py中编写视图逻辑来处理前端请求,使用Django的URL路由(urls.py)将请求映射到相应的视图函数。对于数据的验证和序列化,可以使用Django的表单或序列化器来实现。在前端Vue.js部分,将创建相应的Vue组件,在这些组件中使用axios或其他HTTP库与Django后端的API进行交互,实现用户信息的查看,修改或删除等功能。状态管理可以通过Vuex来维护,比如在store目录下定义用户模块的状态、突变、动作和获取器。如图5-7所示:

图5-7用户界面
广东景点功能实现是在Django后端部分,您需要创建一个新的应用,然后在该应用下创建一个模型(models.py)来定义广东景点的数据结构,使用Django的ORM来处理与MySQL数据库的交互,包括广东景点信息的查询、添加、删除或爬取数据等操作。接着,在views.py中编写视图逻辑来处理前端请求,使用Django的URL路由(urls.py)将请求映射到相应的视图函数。对于数据的验证和序列化,可以使用Django的表单或序列化器来实现。在前端Vue.js部分,将创建相应的Vue组件,在这些组件中使用axios或其他HTTP库与Django后端的API进行交互,实现广东景点信息的查看、修改、查看评论或删除等功能。状态管理可以通过Vuex来维护,比如在store目录下定义广东景点模块的状态、突变、动作和获取器。如图5-8所示:

图5-8广东景点管理界面
管理员点击系统管理,在系统公告页面输入标题可以查询,添加或删除系统公告列表,并对系统公告进行查看、修改和删除等操作;还可以对系统公告分类、关于我们、系统简介、轮播图管理进行详细操作。如图5-9所示:

图5-9系统管理界面
5.3数据采集
本程序数据爬取使用经典的requests、urllib包进行数据爬取,爬取的网站为广东省旅游信息,广东省旅游信息有较强的反爬机制,采用cookie的形式进行封装,再进行数据获取。
定义一个Scrapy爬虫类`guangdonglvyouSpider`,用于爬取指定网站的旅游信息。`name`定义了爬虫的名称,`spiderUrl`指定了目标网站的URL,`start_urls`将目标网站的URL按分号拆分成一个列表,作为爬取的起始URL。`protocol`和`hostname`用于定义协议和主机名,暂时为空。`realtime`用于指定是否实时获取数据,初始化为False。
代码如下所示。
# 广东景点
class GuangdongSpider(scrapy.Spider):
name = ‘guangdongSpider’
spiderUrl = ‘https://you.ctrip.com/sight/guangzhou152/s0-p{}.html;https://you.ctrip.com/sight/shenzhen26/s0-p{}.html;https://you.ctrip.com/sight/zhuhai27/s0-p{}.html;https://you.ctrip.com/sight/foshan207/s0-p{}.html;https://you.ctrip.com/sight/dongguan212/s0-p{}.html;https://you.ctrip.com/sight/shantou215/s0-p{}.html’
start_urls = spiderUrl.split(“;”)
protocol = ‘’
hostname = ‘’
realtime = False
headers = {
“Cookie”:“输入自己的cookie”
} realtime = False
使用parse方法中进行一些初始化操作和判断条件。首先,通过urlparse函数解析self.spiderUrl得到URL的协议和主机名,并将其分别赋值给self.protocol和self.hostname。 然后,通过platform.system().lower()获取当前操作系统的名称,并将其转换为小写字母,保存在plat变量中。 接着,判断条件如果不是实时爬取(self.realtime为False)并且当前操作系统是Linux或Windows,建立数据库连接,并将连接对象赋值给connect变量。获取数据库的游标对象,并将其赋值给cursor变量,调用table_exists函数检查数据库中是否存在名为’5nw5u40i_guangdonglvyou’的表,如果存在就执行关闭游标和连接,调用temp_data函数,最后返回。代码如下所示。
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == ‘linux’ or plat == ‘windows’):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, ‘5nw5u40i_guangdonglvyou’) == 1:
cursor.close()
connect.close()
self.temp_data()
return
使用Scrapy爬虫的回调函数,进行解析详情页面,从response的meta中获取字段对象fileds,最后对其进行赋值和处理。代码如下所示。
def detail_parse(self, response):
fields = response.meta[‘fields’]
try:
fields[“detail”] = str( emoji.demojize(response.css(‘’‘div.detail-des_lists’‘’).extract_first()))
except:
pass
return fields
5.4数据处理
在基于Python的广东省人口流动数据分析平台开发中,数据集处理是至关重要的环节。以下是我详细的数据集处理流程:
首先通过多种途径获取人口信息数据集,或者包括爬取招聘网站的数据。其次,一旦获得了数据集,接下来需要进行数据清洗和预处理。数据清洗是为了确保数据的质量和完整性,包括去除重复项、处理缺失值、纠正错误数据等。预处理则包括数据格式化、标准化、转换等,以便后续的分析和应用。数据清洗使用的是pandas库进行分析,结合Scrapy框架进行数据爬取和清洗,确保数据的准确性和可用性。数据存储采用了MySQL,确保数据的安全和可扩展性。
创建一个MySQL数据库的连接引擎,使用root用户和密码为123456来连接名为spider5nw5u40i的数据库,使用pandas的read_sql函数从数据库中读取数据。代码如下所示。
def pandas_filter(self):
engine = create_engine(‘MySQL+pyMySQL😕/root:123456@localhost/spider5nw5u40icharset=UTF8MB4’)
df = pd.read_sql(‘select * from ****guangdonglvyoulimit 50****’, con = engine)
首先,检查DataFrame对象df是否存在重复的行,使用’df.drop_duplicates()'函数删除对象中重复行。调用’df.isnull()'函数检测对象df’中的缺失值。随后调用’df.dropna()'函数删除具有缺失值的行。'df.fillna(value=‘暂无’)‘函数将对象df中的缺失值替换为指定的值’暂无’。代码如下所示。
df.duplicated()
df.drop_duplicates()
df.isnull()
df.dropna()
df.fillna(value = ‘暂无’)
生成一个包含200个介于0到1000之间的随机整数的数组a,然后定义了一个布尔条件cond,用于筛选满足a在100到800之间的元素。生成一个包含10万个符合标准正态分布的随机数的数组b,定义一个布尔条件cond,用于筛选满足b的绝对值大于3的元素。
创建一个形状为10000行3列的DataFrame df2,其中的数据是符合标准正态分布的随机数。定义一个布尔条件cond,用于筛选在df2中任意一列的值大于三倍标准差的行。该行代码使用索引操作df2[cond].index,获取满足条件cond的行的索引。删除具有指定索引的行,并返回更新后的对象df2。代码如下所示。
a = np.random.randint(0, 1000, size = 200)
cond = (a<=800) & (a>=100)
a[cond]
b = np.random.randn(100000)
cond = np.abs(b) > 3 * 1
b[cond]
df2 = pd.DataFrame(data = np.random.randn(10000,3))
cond = (df2 > 3*df2.std()).any(axis = 1)
index = df2[cond].index
df2.drop(labels=index,axis = 0)
移除HTML标签,首先,检查html参数是否为None,如果是则返回空字符串。然后使用正则表达式模式匹配HTML标签的正则表达式(<[^>]+>),并通过re.sub函数将匹配到的HTML标签替换为空字符串。最后使用strip函数去除字符串两端的空白字符,并返回处理后的结果。代码如下所示。
def remove_html(self, html):
if html == None:
return ‘’
pattern = re.compile(r’<[^>]+>‘, re.S)
return pattern.sub(’', html).strip()
进行数据库连接,首先从设置中获取数据库的连接参数,包括数据库类型、主机地址、端口号、用户名和密码。如果没有指定数据库名称,则尝试从self.databaseName中获取。然后根据数据库类型选择相应的数据库连接方式,如果是MySQL,则使用pyMySQL库进行连接,否则使用pymssql库进行连接。最后返回连接对象connect。代码如下所示。
def db_connect(self):
type = self.settings.get(‘TYPE’, ‘MySQL’)
host = self.settings.get(‘HOST’, ‘localhost’)
port = int(self.settings.get(‘PORT’, 3306))
user = self.settings.get(‘USER’, ‘root’)
password = self.settings.get(‘PASSWORD’, ‘123456’)
try:
database = self.databaseName
except:
database = self.settings.get(‘DATABASE’, ‘’)
if type == ‘MySQL’:
connect = pyMySQL.connect(host=host, port=port, db=database, user=user, passwd=password, charset=‘utf8’)
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
将处理好的数据进行数据存储,定义一个包含插入语句的sql字符串,目标数据库表是guangdonglvyou,列名包括id、jobname、salary等,从表5nw5u40i_guangdonglvyou中选择符合条件的数据,将这些数据插入到目标表中。执行sql语句,将临时数据插入到目标表中,最后提交事务和关闭数据库连接。部分代码如下所示。
plat = platform.system().lower()
if not self.realtime and (plat == ‘linux’ or plat == ‘windows’):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, ‘3zot8a0f_guangdonglvyou’) == 1:
cursor.close()
connect.close()
self.temp_data()
ReturnpageNum = 1 + 1
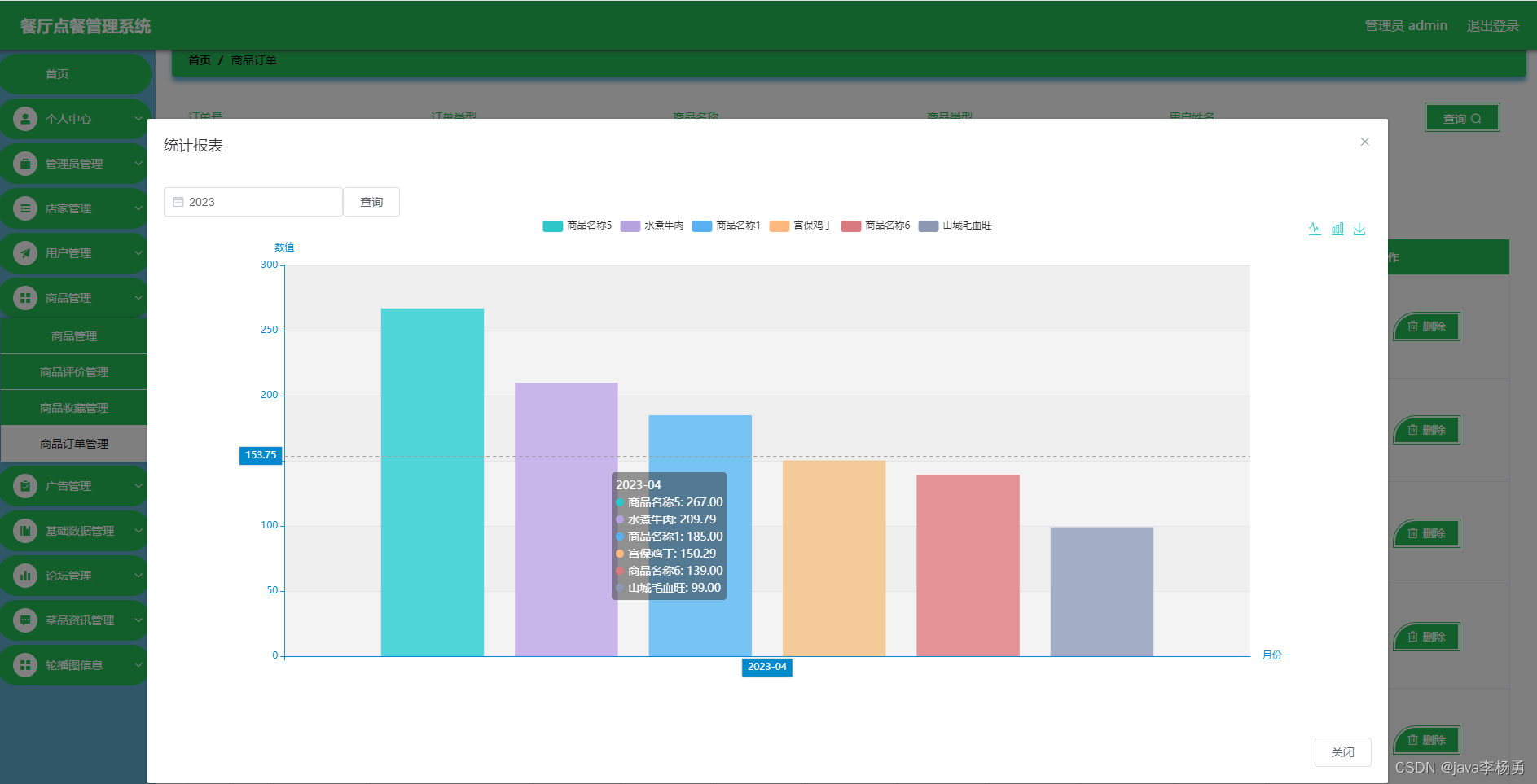
5.5数据可视化大屏
管理员进行爬取数据后可以在看板页面查看到系统简介、词云展示、人口数据分析、城市人口统计、年份人口总数统计、旅游信息总数、人口数据总数、旅游信息详情等实时的分析图进行可视化管理;看板大屏选择了Echart作为数据可视化工具,它是一个使用JavaScript实现的开源可视化库,能够无缝集成到Java Web应用中。Echart的强大之处在于其丰富的图表类型和高度的定制化能力,使得管理人员可以通过直观的图表清晰地把握人口数据的各项数据。为了实现对人口数据信息的自动化收集和更新,我们采用了Apache Spark作为爬虫技术的基础。Spark的分布式计算能力使得系统能够高效地处理大规模数据,无论是从互联网上抓取最新的人口数据信息,还是对内部数据进行ETL(提取、转换、加载)操作,都能够保证数据的实时性和准确性。
对收集到的大量数据进行存储和分析。看板页面如图5-10所示:
图5-10看板详细页面
论文参考:




1 绪 ?论
1.1研究背景与意义
1.2系统研究现状
1.3 论文主要工作内容
2 系统关键技术
2.1 java简介
2.2 MySQL数据库
2.3 B/S结构
2.4 SpringBoot框架
2.5 VUE框架
3 系统分析
3.1 系统可行性分析
3.1.1 技术可行性
3.1.2 操作可行性
3.1.3 经济可行性
3.1.4 法律可行性
3.2 系统性能分析
3.3 系统功能分析
3.4 系统流程分析
3.4.1 数据开发流程
3.4.2 用户登录流程
3.4.3 系统操作流程
3.4.4 添加信息流程
3.4.5 修改信息流程
3.4.6 删除信息流程
4 系统设计
4.1 系统概要
4.2 系统结构设计
4.3数据库设计
4.3.1 数据库设计原则
4.3.3 数据库表设计
4.4 系统时序图
4.4.1 注册时序图
4.4.2 登录时序图
4.4.3 管理员修改用户信息时序图
4.4.4 管理员管理系统信息时序图
5 系统的实现
5.1前台功能实现
5.1.1系统首页页面
5.1.2个人中心
5.2后台管理员功能实现
6 系统测试
6.1 测试环境
6.2 测试目的
6.3 测试概述
6.4 单元测试
6.4.1 注册测试
6.4.2 登录测试
6.5 集成测试
结 ?论
参考文献
致 ?谢
代码实现:
/*** 登录相关*/
@RequestMapping("users")
@RestController
public class UserController{@Autowiredprivate UserService userService;@Autowiredprivate TokenService tokenService;/*** 登录*/@IgnoreAuth@PostMapping(value = "/login")public R login(String username, String password, String role, HttpServletRequest request) {UserEntity user = userService.selectOne(new EntityWrapper<UserEntity>().eq("username", username));if(user != null){if(!user.getRole().equals(role)){return R.error("权限不正常");}if(user==null || !user.getPassword().equals(password)) {return R.error("账号或密码不正确");}String token = tokenService.generateToken(user.getId(),username, "users", user.getRole());return R.ok().put("token", token);}else{return R.error("账号或密码或权限不对");}}/*** 注册*/@IgnoreAuth@PostMapping(value = "/register")public R register(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);if(userService.selectOne(new EntityWrapper<UserEntity>().eq("username", user.getUsername())) !=null) {return R.error("用户已存在");}userService.insert(user);return R.ok();}/*** 退出*/@GetMapping(value = "logout")public R logout(HttpServletRequest request) {request.getSession().invalidate();return R.ok("退出成功");}/*** 密码重置*/@IgnoreAuth@RequestMapping(value = "/resetPass")public R resetPass(String username, HttpServletRequest request){UserEntity user = userService.selectOne(new EntityWrapper<UserEntity>().eq("username", username));if(user==null) {return R.error("账号不存在");}user.setPassword("123456");userService.update(user,null);return R.ok("密码已重置为:123456");}/*** 列表*/@RequestMapping("/page")public R page(@RequestParam Map<String, Object> params,UserEntity user){EntityWrapper<UserEntity> ew = new EntityWrapper<UserEntity>();PageUtils page = userService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.allLike(ew, user), params), params));return R.ok().put("data", page);}/*** 信息*/@RequestMapping("/info/{id}")public R info(@PathVariable("id") String id){UserEntity user = userService.selectById(id);return R.ok().put("data", user);}/*** 获取用户的session用户信息*/@RequestMapping("/session")public R getCurrUser(HttpServletRequest request){Integer id = (Integer)request.getSession().getAttribute("userId");UserEntity user = userService.selectById(id);return R.ok().put("data", user);}/*** 保存*/@PostMapping("/save")public R save(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);if(userService.selectOne(new EntityWrapper<UserEntity>().eq("username", user.getUsername())) !=null) {return R.error("用户已存在");}userService.insert(user);return R.ok();}/*** 修改*/@RequestMapping("/update")public R update(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);userService.updateById(user);//全部更新return R.ok();}/*** 删除*/@RequestMapping("/delete")public R delete(@RequestBody Integer[] ids){userService.deleteBatchIds(Arrays.asList(ids));return R.ok();}
}
推荐项目:
基于大数据爬虫+数据可视化的农村产权交易与数据可视化平台
基于SpringBoot+数据可视化+大数据二手电子产品需求分析系统
基于SpringBoot+数据可视化+协同过滤算法的个性化视频推荐系统
基于大数据+爬虫+数据可视化的的亚健康人群数据可视化平台
基于SpringBoot+大数据+爬虫+数据可视化的的媒体社交与可视化平台
基于大数据+爬虫+数据可视化+SpringBoot+Vue的智能孕婴护理管理与可视化平台系统
基于大数据+爬虫+数据可视化+SpringBoot+Vue的虚拟证券交易平台
基于大数据+爬虫技术+数据可视化的国漫推荐系统
基于大数据爬虫+Hadoop+数据可视化+SpringBoo的电影数据分析与可视化平台
基于python+大数据爬虫技术+数据可视化+Spark的电力能耗数据分析与可视化平台
基于SpringBoot+Vue四川自驾游攻略管理系统设计和实现
基于SpringBoot+Vue+安卓APP计算机精品课程学习系统设计和实现
基于Python+大数据城市景观画像可视化系统设计和实现
基于大数据+Hadoop的豆瓣电子图书推荐系统设计和实现
基于微信小程序+Springboot线上租房平台设计和实现-三端
2022-2024年最全的计算机软件毕业设计选题大全
基于Java+SpringBoot+Vue前后端分离手机销售商城系统设计和实现
基于Java+SpringBoot+Vue前后端分离仓库管理系统设计实现
基于SpringBoot+uniapp微信小程序校园点餐平台详细设计和实现
基于Java+SpringBoot+Vue+echarts健身房管理系统设计和实现
基于JavaSpringBoot+Vue+uniapp微信小程序实现鲜花商城购物系统
基于Java+SpringBoot+Vue前后端分离摄影分享网站平台系统?
基于Java+SpringBoot+Vue前后端分离餐厅点餐管理系统设计和实现
基于Python热门旅游景点数据分析系统设计与实现
项目案例:






为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
源码获取:
大家点赞、收藏、关注、评论啦 、查看???获取联系方式???
精彩专栏推荐订阅:在下方专栏???
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐?
Java项目精品实战案例《100套》
Java微信小程序项目实战《100套》
Python项目实战《100套》
相关文章:
)
基于大数据爬虫+Python+数据可视化大屏的慧游数据爬虫与推荐分析系统(源码+论文+PPT+部署文档教程等)
博主介绍:**CSDN毕设辅导第一人、**全网粉丝50W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流 **技术范围:**S…...

Linux系统安装es详细教程
一、下载es及插件 从下面的网址进行对应es版本的下载https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.2-linux-x86_64.tar.gz ,想要不同版本的es只需更换对应的版本号即可。 插件下载地址(ik分词器、pinyin等)es…...

分布式搜索引擎之elasticsearch基本使用3
分布式搜索引擎之elasticsearch基本使用3 1.部署单点es 1.1.创建网络 因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络: docker network create es-net1.2.加载镜像 这里我们采用elasticsearch的7.12.1版本的镜像&…...

进程间通信-----信号
进程间通信-----信号 信号:进程间异步通知的机制。是一种在操作系统中用于进程间通信和控制的机制。它可以用于多种场景,例如进程间通信、异常处理、线程同步等。常见的信号有SIGINT(中断信号)、SIGTERM(终止信号&…...

机器学习基础-线性回归和逻辑回归
目录 基本概念和定义 线性回归 逻辑回归 线性回归中的最小二乘法和梯度下降法 最小二乘法 梯度下降法 参数调整策略 梯度下降类型 梯度下降的调参的基本操作 过拟合和欠拟合的概念及处理方法 过拟合(Overfitting) 欠拟合(Underfi…...

低代码引擎插件开发:开启开发的便捷与创新之路
OneCode授权演示 一、低代码引擎与插件开发的概述 在当今快节奏的软件开发领域,低代码引擎正逐渐崭露头角。低代码引擎旨在让开发人员能够以最少的代码量创建功能丰富的应用程序,而其中的关键组成部分便是插件开发。低代码引擎通过提供可视化的开发环境…...

【C++】18.继承
文章目录 1.继承的概念及定义1.1 继承的概念1.2 继承定义1.2.1定义格式1.2.2继承关系和访问限定符1.2.3继承基类成员访问方式的变化 1.3 继承类模板 2.基类和派生类对象赋值转换3.继承中的作用域3.1 隐藏规则:3.2 考察继承作用域相关选择题 4.派生类的默认成员函数4…...

R语言基础| 中级绘图
写在前面 前面第六章的图形主要是展示单分类变量或连续型变量的分布情况。本章主要研究二元变量或多元变量关系的可视化。更多教程可参考: R语言基础学习手册 图片集锦: 11.1 散点图 1)添加最佳拟合曲线的散点图: 绘制汽车重…...

TANGO - 数字人全身动作生成
文章目录 一、关于 TANGO演示视频(YouTube)📝发布计划 二、⚒️安装克隆存储库构建环境 三、🚀训练和推理1、推理2、为自定义字符创建图形 一、关于 TANGO TANGO 是 具有分层音频运动嵌入 和 扩散插值的共语音手势视频再现 由东…...

从configure.ac到构建环境:解析Mellanox OFED内核模块构建脚本
在软件开发过程中,特别是在处理复杂的内核模块如Mellanox OFED(OpenFabrics Enterprise Distribution)时,构建一个可移植且高效的构建系统至关重要。Autoconf和Automake等工具在此过程中扮演着核心角色。本文将深入解析一个用于准备Mellanox OFED内核模块构建环境的Autocon…...

深入理解 Android 中的 KeyguardManager
深入理解 Android 中的 KeyguardManager 引言 在 Android 系统中,KeyguardManager 是一个重要的系统服务,负责管理设备的锁屏界面(Keyguard)。锁屏界面是设备安全性的第一道防线,用于防止未经授权的用户访问设备。Ke…...
在Vue3项目中使用svg-sprite-loader
1.普通的svg图片使用方式 1.1 路径引入 正常我们会把项目中的静态资源放在指定的一个目录,例如assets,使用起来就像 <img src"../assets/svgicons/about.svg" /> 1.2封装组件使用 显然上面的这种方法在项目开发中不太适用,每次都需…...
命令详解:pwd)
Linux(Centos 7.6)命令详解:pwd
1.命令作用 显示当前工作目录的完整路径(Print Working Directory) 2.命令语法 Usage: pwd [-LP] 3.参数详解 -L,显示逻辑路径,遵循符号链接;这是默认选项。-P,显示物理路径,不遵循符号链接。 4.常用用例 1.-L参…...

【iOS Swift Moya 最新请求网络框架封装通用】
【iOS Swift Moya 最新请求网络框架封装通用】 前言框架结构1.API定义(TargetType)2. 配置MoyaProvider3. 网络管理器4. 使用示例注意事项进一步优化 前言 设计一个基于Moya的网络请求框架,可以提供灵活的网络请求管理,例如设置请…...
)
【算法学习】——设施选址问题(动态规划)
题目描述 在一条高速公路附近有 V 个村庄,选择 P 个村庄在其附近建立邮局,要求每个村庄到最近的邮局的距离和最小(1<V<300,1<P<30)。 问题分析 这个问题是一个经典的设施选址问题(Facility Location Problem&#…...

Linux——修改文件夹的所属用户组和用户
一、命令 举例: 授权 MOT17 文件夹 给 hust_xxx 用户: sudo chown -R hust_xxx:hust_xxx MOT17参考 Linux授权文件夹给用户...

我用Ai学Android Jetpack Compose之Text
这篇开始学习各种UI元素,答案来自 通义千问,通义千问没法生成图片,图片是我补充的。 下述代码只要复制到第一个工程,做一些import操作,一般import androidx.compose包里的东西,即可看到预览效果。完整工程代…...

H5通过URL Scheme唤醒手机地图APP
1.高德地图 安卓URL Scheme:baidumap:// 官方文档:https://lbs.amap.com/api/amap-mobile/guide/android/navigation IOS URL Scheme:iosamap:// 官方文档:https://lbs.amap.com/api/amap-mobile/guide/ios/navi HarmonyOS NEXT U…...

【Java数据结构】二叉树
1.树型结构 1.1树的概念 树是一种非线性的数据结构,由n个结点组成的具有层次关系的集合。下面是它的特点: 根结点是没有前驱的结点(没有父结点的结点)子结点之间互不相交除了根结点外,其它结点都只有一个父结点n个结…...

Golang设计模式目录
go语言实现设计模式 1 文章目录: 1.1 创建型模式 1.Golang设计模式之工厂模式2.Golang设计模式之抽象工厂模式3.Golang设计模式之单例模式4.Golang设计模式之建造者模式5.Golang设计模式之原型模式 1.2 结构型模式 6.Golang设计模式之适配器模式7.Golang设计模式之桥…...

vue3+Echarts+ts实现甘特图
项目场景: vue3Echartsts实现甘特图;发布任务 代码实现 封装ganttEcharts.vue <template><!-- Echarts 甘特图 --><div ref"progressChart" class"w100 h100"></div> </template> <script lang"ts&qu…...
)
nginx-灰度发布策略(split_clients)
一. 简述: 基于客户端的灰度发布(也称为蓝绿部署或金丝雀发布)是一种逐步将新版本的服务或应用暴露给部分用户,以确保在出现问题时可以快速回滚并最小化影响的技术。对于 Nginx,可以通过配置和使用不同的模块来实现基于…...

SQL中聚类后字段数据串联字符串方法研究
在 SQL 中,使用 聚类(GROUP BY) 后将某个字段的数据串联为一个字符串,常见的方法包括以下几种,取决于数据库管理系统(DBMS)的具体支持功能: 1. 使用 GROUP_CONCAT (MySQL…...

vue3组件化开发优势劣势分析,及一个案例
Vue 3 组件化开发的优势和劣势 优势 可复用性: 组件可以重复使用,减少代码冗余,提高开发效率。 可以在不同的项目中复用组件,提升开发速度。 可维护性: 组件化开发使得代码结构清晰,易于维护。 每个…...

Springboot SAP Docker 镜像打包问题
问题类1,sapjco.jar 未识别到:Caused by: java.lang.NoClassDefFoundError: com/sap/conn/jco/ext/DestinationDataProvider 1./deploy/lib/ 文件下放sapjco3.jar、libsapjco3.so、sapjco3.dll 2.docker文件核心内容: COPY /deploy/lib/sap…...

nmap探测Web服务
HTTP服务 探测基本认证信息 nmap --script http-auth [目标]探测默认账户 nmap --scripthttp-default-accounts -p [端口] [目标]检查是否存在风险方法 nmap --script http-methods [目标]探测访问一个网页的时间 nmap --scripthttp-chrono -p 80 [目标]提取HTTP注释信息 nmap…...
)
【学习总结|DAY028】后端Web实战(部门管理)
在 Web 后端开发领域,构建高效、规范且功能完备的系统是核心目标。本文将围绕 Tlias 智能学习辅助系统的后端开发展开,详细阐述从开发准备工作到各部门管理功能实现,以及日志技术应用的全过程,为开发者提供全面的实践参考。 一、…...

Servlet 和 Spring MVC:区别与联系
前言 在 Java Web 开发中,Servlet 和 Spring MVC 是两个重要的技术。Servlet 是 Java Web 的基础组件,而 Spring MVC 是一个高级 Web 框架,建立在 Servlet 的基础之上,提供了强大的功能和易用性。这篇文章将从定义、原理、功能对…...

【君正T31开发记录】12.编译工具相关总结及介绍
移植交叉工具包的时候,发现这是很多工具的集合包;以及写makefile的时候,也需要了解下这些工具的作用及用法,这里总结记录一下常见的工具及相关用法。 g C编译器,用于编译C源代码文件,这个很常见࿰…...

Python 开发框架搭建简单博客系统:代码实践与应用
在当今数字化时代,博客作为一种流行的信息分享和交流平台,拥有广泛的受众。Python 以其强大的功能和丰富的库,为构建博客系统提供了理想的技术支持。本文将详细介绍如何利用 Python 开发框架搭建一个简单博客系统,包括功能实现、代…...
)
Java 正则表达式入门与应用(详细版)
正则表达式(Regular Expression,简称Regex)是一种文本模式匹配工具,在许多编程语言中都得到了广泛应用。Java 作为一种强大的编程语言,提供了对正则表达式的内建支持,使得在字符串处理、数据验证和文本解析…...

高效内存管理与调试技巧:深入解析 AddressSanitizer
在现代 C开发中,内存管理是一个至关重要但也容易出错的领域。即使使用了智能指针和其他高效工具,复杂的项目仍可能出现内存泄漏、非法访问等问题。为了解决这些问题,Google 开发了一个强大的工具——AddressSanitizer (ASan)。本文将详细介绍…...

力扣第137题:只出现一次的数字 II C语言解法
力扣第137题:只出现一次的数字 II C语言解法 题目描述 给定一个整数数组 nums,其中每个元素出现三次,除了一个元素出现一次。找出那个只出现一次的元素。 说明: 你的算法应该具有线性时间复杂度。你不可以使用额外的空间&…...
)
【Qt】控件概述和QWidget核心属性1(enabled、geometry、windowTitle、windowIcon、QRC机制)
一、控件概念 界面上各种元素、各种部分的统称(如按钮、输入框、下拉框、单选复选框...) Qt作为GUI开发框架,内置了各种的常用控件,并支持自定义控件。 二、控件体系发展 1.没有完全的控件,需要使用绘图API手动绘制…...
)
25年1月更新。Windows 上搭建 Python 开发环境:PyCharm 安装全攻略(文中有安装包不用官网下载)
python环境没有安装的可以点击这里先安装好python环境,python环境安装教程 安装 PyCharm IDE 获取 PyCharm PyCharm 提供两种主要版本——社区版(免费)和专业版(付费)。对于初学者和个人开发者而言,社区…...
——面向对象与UML)
软件工程大复习之(四)——面向对象与UML
4.1 面向对象概述 面向对象(OO)是一种编程范式,它将数据和处理数据的方法封装在对象中。面向对象的主要概念包括: 对象:实例化的数据和方法的集合。类:对象的蓝图或模板。封装:隐藏对象的内部…...
)
前端基础函数算法整理应用(sort+reduce+date+双重for循环)
文章目录 基础函数算法reduce 函数算法sort 函数算法时间排序1. 对日期字符串数组进行排序2. 对包含日期对象的数组进行排序3. 对包含时间戳的数组进行排序4. 对包含日期时间信息的对象数组进行排序 基础函数算法 一、排序算法 冒泡排序(Bubble Sort) …...

web系统漏洞攻击靶场
摘 要 互联网极速发展的同时,也会带来一些安全性的风险,一些不为人知的安全问题也逐渐暴露出来。近年来,媒体不断披露了许多网络安全事故,许多网络应用程序被黑客攻击,导致内部数据外泄,人们开始认识到网络…...
)
苍穹外卖-day07(Spring Cache 购物车业务逻辑)
内容 缓存菜品缓存套餐添加购物车查看购物车清空购物车 功能实现:缓存商品、购物车 效果图: 1. 缓存菜品 1.1 问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增…...

win10 VS2019上libtorch库配置过程
win10 VS2019上libtorch库配置过程 0 引言1 获取libtorch2 在VS上配置使用libtorch库3 结语 0 引言 💻💻AI一下💻💻 libtorch库是一个用于深度学习的C库,是PyTorch的官方C前端。它提供了用于构建和训练深度学习模…...

git 常用命令和本地合并解决冲突
目录 一、常用命令 二、本地可视化合并分支解决冲突 一、常用命令 最近,使用mac电脑,无法直接使用小乌龟进行可视化操作,现在记录一些常用命令。 拉取: git clone <git url> 仅拉起某个单独分支: git clo…...

Elasticsearch 创建索引 Mapping映射属性 索引库操作 增删改查
Mapping Type映射属性 mapping是对索引库中文档的约束,有以下类型。 text:用于分析和全文搜索,通常适用于长文本字段。keyword:用于精确匹配,不会进行分析,适用于标签、ID 等精确匹配场景。integer、long…...

Objective-C语言的数据结构
Objective-C语言中的数据结构 Objective-C是一种面向对象的编程语言,其在苹果公司的软件开发中得到了广泛应用。它主要用于开发macOS和iOS应用程序。虽然Objective-C有许多丰富的特性,但在程序设计中,数据结构仍然是构建任何应用程序的基础。…...

智能水文:ChatGPT等大语言模型如何提升水资源分析和模型优化的效率
大语言模型与水文水资源领域的融合具有多种具体应用,以下是一些主要的应用实例: 1、时间序列水文数据自动化处理及机器学习模型: ●自动分析流量或降雨量的异常值 ●参数估计,例如PIII型曲线的参数 ●自动分析降雨频率及重现期 ●…...

ETL的工作原理
ETL的工作原理 什么是ETL_云计算主题库-阿里云 ETL的工作原理可以分为三个主要的步骤:Extract(提取)、Transform(转换)、Load(加载)。 工作步骤 描述 Extract (提取)…...

黑马头条平台管理实战
黑马头条 08平台管理 1.开始准备和开发思路1.1.开发网关1.2编写admin-gateway 代码 2.开发登录微服务2.1编写登录微服务 3.频道管理4.敏感词管理5.用户认证审核6.自媒体文章人工审核99. 最后开发中碰到的问题汇总1.关于nacos 配置 问题2.在开发频道管理新增频道后端无法接收到前…...
架构详细解析:原理与器件选型指南)
电池管理系统(BMS)架构详细解析:原理与器件选型指南
BMS(电池管理系统)架构详细讲解 从你提供的BMS(Battery Management System)架构图来看,主要涉及到电池监控模块、通信模块、功率控制模块等部分。下面我将详细讲解该架构的各个功能模块及其工作原理。 1. 电池管理核…...

SpringBoot环境和Maven配置
SpringBoot环境和Maven配置 1. 环境准备2. Maven2.1 什么是Maven2.2 为什么要学 Maven2.3 创建一个 Maven项目2.4 Maven核心功能2.4.1 项目构建2.4.2 依赖管理2.4.3 Maven Help插件 2.5 Maven 仓库2.5.1本地仓库2.5.2 中央仓库2.5.3 私有服务器, 也称为私服 2.6 Maven设置国内源…...

lambda用法及其原理
目录 lambda形式lambda用法1.sort降序2.swap3.捕捉列表 习题解题 lambda形式 [capture-list](parameters)->return type{function boby}[capture-list]:[捕捉列表]用于捕捉函数外的参数,可以为空,但不能省略;(parameters) &am…...
vim直接修改postgresql表文件的简单实例)
Postgresql源码(139)vim直接修改postgresql表文件的简单实例
1 前言 PG可以用pageinspect方便的读取查看表文件。本篇介绍一种用vim查看、编辑的方法,案例比较简单,主要分享原理。 修改表文件和controlfile是非常危险的行为,请不要在生产尝试。 2 用例 简化问题,用简单编码的数据类型。 d…...