无监督学习入门指南:从原理到实践
目录
1 无监督学习基础
1.1 核心目标
1.2 理论基础
1.3 应用层面
2 聚类分析
2.1 相似性度量
2.2 聚类算法
2.2.1 K-均值聚类
2.2.2 密度聚类:DBSCAN
2.2.3 谱聚类
3 降维技术
3.1 线性
3.2 非线性
3.3 降维技术面临关键问题
4 概率密度估计
4.1 参数估计
4.2 非参数估计
4.3 改进的估计
5 生成模型
5.1 显式密度模型
5.2 隐式密度模型
5.3 扩散模型
1 无监督学习基础
无监督学习是机器学习中一个极其重要且富有挑战性的分支。与监督学习需要标注数据不同,无监督学习直接面对原始、未标注的数据,试图发现数据中隐藏的结构和规律。这就像是让计算机像人类一样,自主地从周围环境中学习和理解世界,而不需要老师的指导。
从数据的角度来看,无监督学习处理的是形如{x₁, x₂, ..., xₙ}的数据集,其中每个xᵢ是一个数据样本,可能是图像、文本、声音等任何形式。这些数据没有与之对应的标签y,这使得学习任务变得更具挑战性,因为系统需要自己定义什么是"相似"或"不同",什么样的模式是"有意义的"。
无监督学习主要解决三类问题:聚类、降维和密度估计。这些方法帮助我们理解数据的内在结构,发现数据中的隐藏模式,并降低数据的复杂度。
1.1 核心目标
模式发现。它试图找出数据中的规律性和结构,例如数据是否形成了天然的群组(聚类),数据是否存在某种周期性变化,或者数据是否具有某种特定的分布特征。这种发现对于理解数据的本质特征至关重要。
表示学习。无监督学习致力于找到数据的更好表示方式,可能是更紧凑的(降维),更有意义的(特征学习),或者更容易理解的形式。好的表示可以揭示数据的内在结构,并为后续的学习任务奠定基础。
生成建模。通过学习数据的概率分布,无监督学习可以生成与原始数据类似的新样本。这不仅需要理解数据的表面特征,还需要捕捉数据的深层统计规律。
1.2 理论基础
概率论为无监督学习提供了基本框架。我们经常需要估计数据的概率分布P(X),这可以通过参数化模型(如高斯混合模型)或非参数方法(如核密度估计)来实现。最大似然估计和贝叶斯推断是两个核心的概率建模工具。
信息论也在无监督学习中扮演重要角色。互信息(Mutual Information)可以用来度量特征之间的相关性,熵(Entropy)可以衡量数据的不确定性,KL散度(Kullback-Leibler Divergence)则可以度量两个分布之间的差异。
另一个重要的理论基础是流形学习。它假设高维数据实际上位于一个低维流形上,这为诸多降维算法提供了理论支撑。如,t-SNE和UMAP这样的算法就是基于这一思想设计的。
1.3 应用层面
评估问题:由于没有标准答案(标签),很难客观评价无监督学习的效果。我们通常需要设计特定的评估指标,如聚类的轮廓系数(Silhouette Coefficient)或重构误差等。
模型选择:如何确定模型的复杂度(如聚类的数量、降维的维度)往往需要启发式方法或交叉验证来解决。
可解释性:无监督学习发现的模式和结构需要领域专家的解释才能变得有意义。这种解释有时候具有主观性。
在数据预处理中,它可以用于特征工程、异常检测和数据清洗。 在探索性数据分析中,它帮助研究者理解数据的基本特征和结构。 在深度学习中,它可以用于预训练,帮助模型学习更好的特征表示。 在推荐系统中,它可以发现用户的兴趣模式和物品的相似关系。
2 聚类分析
聚类分析是数据挖掘和机器学习中的一个基础问题,其核心目标是将相似的数据对象自动分组到同一个簇中,而将不相似的对象分到不同簇中。这个看似简单的目标实际上涉及了许多深刻的问题,比如如何定义相似性,如何确定最优的簇的数量,以及如何处理不同形状和大小的簇等。
2.1 相似性度量
我们需要理解相似性度量这个基础概念。在聚类分析中,相似性(或距离)的定义直接影响聚类的结果。常用的距离度量包括:
欧氏距离:最常用的距离度量,表示空间中两点之间的直线距离。其数学表达式为: d(x,y) = √(Σ(xᵢ-yᵢ)²)
曼哈顿距离:表示在直角坐标系中两点之间的距离,计算为所有坐标差值的绝对值之和。 d(x,y) = Σ|xᵢ-yᵢ|
余弦相似度:主要用于高维空间中计算两个向量的夹角余弦值,特别适用于文本聚类。 cos(θ) = (x·y)/(||x||·||y||)
马哈拉诺比斯距离:考虑了数据的协方差结构,能够处理数据的尺度和相关性。
2.2 聚类算法
聚类是无监督学习中最基础也最常用的方法之一。它的目标是将相似的数据点分组到一起,形成多个群集。
2.2.1 K-均值聚类
划分式聚类方法是最基础的聚类方法之一,典型代表是K-means算法。这类方法通过迭代优化来最小化某个目标函数。K-means的优势在于简单直观、计算效率高,但缺点是需要预先指定簇的数量,且对初始值敏感,同时只能发现球形的簇。改进版本如K-medoids能够更好地处理离群点,而模糊C均值(Fuzzy C-means)则引入了软分配的概念。
K-均值是最简单也最广泛使用的聚类算法。其核心思想是通过迭代优化来最小化各个数据点到其所属类别中心的距离平方和。算法步骤如下:
- 随机选择K个中心点
- 重复以下步骤直到收敛:
- 将每个数据点分配到最近的中心点
- 重新计算每个类别的中心点位置
这里是一个简单的Python实现:
import numpy as np
from sklearn.cluster import KMeansdef simple_kmeans(X, n_clusters=3, max_iters=100):# 随机初始化聚类中心centroids = X[np.random.choice(X.shape[0], n_clusters, replace=False)]for _ in range(max_iters):# 计算每个点到所有中心的距离distances = np.sqrt(((X - centroids[:, np.newaxis])**2).sum(axis=2))# 分配类别labels = np.argmin(distances, axis=0)# 更新中心点new_centroids = np.array([X[labels == k].mean(axis=0) for k in range(n_clusters)])# 检查是否收敛if np.all(centroids == new_centroids):breakcentroids = new_centroidsreturn labels, centroids2.2.2 密度聚类:DBSCAN
密度基础的聚类方法,如DBSCAN(密度基于的带噪声的空间聚类应用)和OPTICS,能够发现任意形状的簇。这类方法基于密度连通性的概念,将密度相连的区域划分为一个簇。DBSCAN的主要优势在于:
- 不需要预先指定簇的数量
- 能够发现任意形状的簇
- 对噪声数据具有较强的鲁棒性
- 只需要两个参数:邻域半径ε和最小点数MinPts
实现步骤:
计算距离:计算所有点之间的距离,通常使用欧氏距离。
找出邻域点:对于每个点,找出其邻域内的点(距离小于
eps的点)。确定核心点:找到所有邻域内点的数量大于等于
minPts的核心点。扩展聚类:
选择一个未访问过的核心点,开始一个新的聚类。
使用广度优先搜索(BFS)扩展聚类,将邻域内的点加入聚类。
如果邻域点也是核心点,将其邻域内的点也加入队列。
标记噪声点:未被访问的点标记为噪声点。
import numpy as np
from collections import dequedef euclidean_distance(p1, p2):"""计算两个点之间的欧氏距离"""return np.sqrt(np.sum((p1 - p2) ** 2))def dbscan(X, eps, minPts):"""DBSCAN算法实现"""n = X.shape[0]visited = np.zeros(n, dtype=bool)cluster_labels = np.full(n, -1, dtype=int)cluster_id = 0# 预计算所有点对的距离dist_matrix = np.sqrt(((X[:, np.newaxis] - X) ** 2).sum(axis=2))# 找出每个点的邻域内的点的索引neighbors = [np.where(dist_matrix[i] <= eps)[0] for i in range(n)]for i in range(n):if not visited[i]:visited[i] = Trueif len(neighbors[i]) < minPts:cluster_labels[i] = -1 # 噪声点else:# 开始一个新的聚类cluster_labels[i] = cluster_idqueue = deque()queue.extend(neighbors[i])while queue:current_point = queue.popleft()if not visited[current_point]:visited[current_point] = Trueif len(neighbors[current_point]) >= minPts:cluster_labels[current_point] = cluster_idqueue.extend(neighbors[current_point])else:cluster_labels[current_point] = -1 # 噪声点cluster_id += 1return cluster_labels
2.2.3 谱聚类
谱聚类则采用了完全不同的思路,它首先构建数据点之间的相似度图,然后利用图的拉普拉斯矩阵的特征向量来进行聚类。这种方法特别适合处理非球形簇,但计算复杂度较高,且参数选择较为困难。
import numpy as np
from sklearn.metrics.pairwise import rbf_kernel
from scipy.linalg import eigh
from sklearn.cluster import KMeansdef spectral_clustering(X, n_clusters, gamma=1.0, normalized=True):# 计算相似度矩阵S = rbf_kernel(X, gamma=gamma)# 计算度矩阵D = np.diag(np.sum(S, axis=1))# 计算拉普拉斯矩阵if normalized:# 计算D的逆平方根D_inv_sqrt = np.linalg.inv(np.sqrt(D))# 计算归一化的拉普拉斯矩阵L = np.eye(X.shape[0]) - np.dot(np.dot(D_inv_sqrt, S), D_inv_sqrt)else:# 计算未归一化的拉普拉斯矩阵L = D - S# 求解拉普拉斯矩阵的特征值和特征向量eigvals, eigvecs = eigh(L)# 获取最小的k个特征向量(排除第一个特征向量)k = n_clustersembedding = eigvecs[:, 1:k+1]# 对特征向量进行L2归一化embedding = embedding / np.linalg.norm(embedding, axis=1, keepdims=True)# 使用KMeans进行聚类kmeans = KMeans(n_clusters=k)clusters = kmeans.fit_predict(embedding)return clusters在实际应用中,聚类分析面临着几个关键挑战:
- 簇的数量确定:虽然有肘部法则、轮廓系数等方法,但在实践中仍然较难确定最优的簇数。
- 聚类结果的评估:由于缺乏ground truth,需要使用内部指标(如轮廓系数、Davies-Bouldin指数)和外部指标(如互信息、兰德指数)来评估聚类质量。
- 高维数据的处理:在高维空间中,距离度量变得不那么有意义(维数灾难),需要结合降维技术或使用特殊的相似性度量。
- 大规模数据处理:某些算法(如层次聚类)在处理大规模数据时计算复杂度过高,需要使用近似算法或采样技术。
3 降维技术
降维技术是处理高维数据的重要工具,其核心目标是在保持数据重要特征的同时,将数据映射到更低维的空间。这个过程不仅能够减少数据的存储和计算开销,还能够帮助我们发现数据的本质结构,消除噪声,并实现数据的可视化。
从理论基础来看,降维技术基于一个重要假设:高维数据通常具有某种内在的低维结构。这就是所谓的"流形假设",即虽然数据表面上是高维的,但实际上可能位于一个低维流形上。这个理论基础启发了许多降维算法的设计。
3.1 线性
线性降维技术假设数据可以通过线性变换映射到低维空间。其中最经典的是主成分分析(PCA)。PCA的核心思想是找到数据方差最大的方向,将数据投影到这些方向上。从数学角度看,这等价于对数据协方差矩阵进行特征值分解:
- 首先中心化数据:X' = X - μ
- 计算协方差矩阵:S = (1/n)X'ᵀX'
- 求解特征值方程:SV = VΛ
- 选择最大的k个特征值对应的特征向量作为投影矩阵
PCA的优点是计算简单、理论清晰,而且保证了在均方误差意义下的最优性。但它也有局限性,主要是无法捕捉非线性关系。
另一个重要的线性降维方法是线性判别分析(LDA),虽然它通常用于监督学习,但其降维思想值得关注。LDA试图找到既能最大化类间距离又能最小化类内距离的投影方向。
PCA的Python实现:
import numpy as npdef pca(X, n_components):# 中心化数据X_centered = X - np.mean(X, axis=0)# 计算协方差矩阵cov_matrix = np.cov(X_centered.T)# 计算特征值和特征向量eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix)# 选择最大的n_components个特征向量idx = eigenvalues.argsort()[::-1]eigenvectors = eigenvectors[:, idx]components = eigenvectors[:, :n_components]# 投影数据return np.dot(X_centered, components)3.2 非线性
非线性降维技术则能够处理更复杂的数据结构。流行的方法包括:
t-SNE(t-distributed Stochastic Neighbor Embedding)是一种特别适合数据可视化的非线性降维技术。它的核心思想是:
- 在高维空间中用高斯分布描述点对之间的相似度
- 在低维空间中用t分布描述点对之间的相似度
- 通过最小化这两个分布之间的KL散度来优化低维表示
UMAP(Uniform Manifold Approximation and Projection)是近年来流行的降维方法,它基于黎曼几何和代数拓扑的理论,比t-SNE有更好的理论基础,而且计算效率更高。UMAP的特点是:
- 能够更好地保持数据的全局结构
- 计算速度快
- 理论基础扎实
- 可以处理大规模数据集
自编码器(Autoencoder)是一种基于神经网络的降维方法。它通过一个编码器将数据压缩到低维潜在空间,然后通过解码器重构原始数据。训练目标是最小化重构误差:
- 编码器:f(x) = z(将高维数据x映射到低维表示z)
- 解码器:g(z) = x'(将低维表示z重构为原始维度的数据x')
- 优化目标:min ||x - g(f(x))||²
3.3 降维技术面临关键问题
维度的选择:如何确定合适的目标维度是一个重要问题。常用的方法包括:
- 保持解释方差的比例(在PCA中)
- 观察重构误差的变化
- 使用交叉验证
计算效率:对于大规模数据集,某些降维方法(如t-SNE)的计算成本很高。解决方案包括:
- 使用近似算法
- 先用PCA降维,再应用非线性方法
- 采用批处理或流式处理
特征的可解释性:降维后的特征往往失去了原始的物理意义。为了提高可解释性,可以:
- 使用稀疏降维方法
- 分析特征的贡献度
- 结合领域知识进行解释
随着深度学习的发展,新的降维技术不断涌现,比如变分自编码器(VAE)和对抗自编码器(AAE)等。这些方法不仅能够学习数据的低维表示,还能够生成新的数据样本,为降维技术开辟了新的应用场景。
降维技术的选择需要根据具体问题来决定:
- 如果数据近似线性,且需要保持可解释性,选择PCA
- 如果主要目的是可视化,选择t-SNE或UMAP
- 如果需要处理非线性关系且有大量数据,考虑自编码器
- 如果需要生成能力,考虑VAE或AAE
4 概率密度估计
概率密度估计是统计学和机器学习中的一个基础问题,其目标是根据观测数据来推断随机变量的概率分布。这个问题的重要性体现在多个方面:它能帮助我们理解数据的生成过程,为异常检测提供基础,并且在生成模型中扮演着核心角色。
4.1 参数估计
参数密度估计假设数据来自某个特定的分布族(如高斯分布),估计问题就转化为确定分布的参数。最常用的参数估计方法包括:
最大似然估计(MLE)是最基础的方法,其核心思想是选择能够最大化观测数据出现概率的参数值。对于独立同分布的数据{x₁, ..., xₙ},似然函数为: L(θ) = ∏ᵢ p(xᵢ|θ)
通常我们会最大化对数似然: log L(θ) = Σᵢ log p(xᵢ|θ)
最大后验估计(MAP)则引入了参数的先验分布,通过贝叶斯定理结合先验知识和观测数据: θ_MAP = argmax_θ p(θ|X) ∝ p(X|θ)p(θ)
一个重要的参数模型是高斯混合模型(GMM),它假设数据由多个高斯分布的加权和生成: p(x) = Σₖ πₖ N(x|μₖ,Σₖ)
GMM的参数通常通过EM算法估计:
- E步:计算每个数据点属于各个组件的后验概率
- M步:更新组件的权重、均值和协方差矩阵
4.2 非参数估计
核密度估计(KDE)是最常用的非参数方法,它通过在每个数据点上放置一个核函数并求和来估计密度:
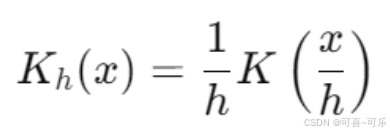
其中K是核函数,h是带宽参数。核函数的选择包括:
- 高斯核:K(u) = (1/√(2π))exp(-u²/2)
- Epanechnikov核:K(u) = (3/4)(1-u²),|u|≤1
- 矩形核:K(u) = 1/2,|u|≤1
以下是使用高斯核的简单实现:
import numpy as np
from scipy.stats import gaussian_kdedef simple_kde(X, x_grid, bandwidth=0.5):n = len(X)kde = np.zeros_like(x_grid)for x_i in X:# 使用高斯核kde += np.exp(-0.5 * ((x_grid - x_i) / bandwidth)**2)kde = kde / (n * bandwidth * np.sqrt(2 * np.pi))return kde带宽选择是KDE中的关键问题,常用方法有:
- Silverman's rule of thumb
- 交叉验证
- 自适应带宽方法
直方图方法是最简单的非参数估计方法,但在选择箱宽和起点时存在主观性。现代改进包括:
- 变宽直方图
- 平均移位直方图
- 自适应直方图
最近邻方法基于数据点的局部密度来估计概率密度,其思想是密度与最近邻点间距离成反比。
4.3 改进的估计
规范化流(Normalizing Flows)通过一系列可逆变换将简单分布(如标准正态分布)映射到复杂分布:
- 优势是可以精确计算似然
- 支持高效的采样
- 可以处理复杂的多峰分布
自回归模型将联合分布分解为条件分布的乘积: p(x₁,...,xₙ) = ∏ᵢ p(xᵢ|x₁,...,xᵢ₋₁)
这些方法在实践中面临几个关键挑战:
- 维度灾难:在高维空间中,数据变得稀疏,密度估计变得困难。解决方案包括:
- 降维预处理
- 使用结构化模型
- 采用深度学习方法
- 模型选择:如何选择合适的模型和参数是一个关键问题。常用方法包括:
- 交叉验证
- 信息准则(AIC、BIC)
- 模型平均
- 计算效率:某些方法(如KDE)在大规模数据集上计算开销大。改进方法包括:
- 使用快速算法(如FFT)
- 数据采样
- 并行计算
5 生成模型
生成模型是一类能够学习数据分布并生成与训练数据类似的新样本的模型。与判别模型不同,生成模型试图理解数据是如何产生的,它们学习的是联合概率分布P(X,Y)或数据的边缘分布P(X),这使得它们能够执行更丰富的任务,如数据生成、缺失值填补、异常检测等。
5.1 显式密度模型
显式密度模型直接定义并最大化数据的似然函数。这类模型包括:
变分自编码器(VAE)是一种重要的显式密度模型,它结合了神经网络和变分推断。VAE的核心思想是:
- 使用编码器网络将输入数据x映射到潜在空间的分布q(z|x)
- 使用解码器网络从潜在变量z重构数据p(x|z)
- 优化目标包括重构误差和KL散度: L = E[log p(x|z)] - KL(q(z|x)||p(z))
这个目标函数的两项分别确保了重构质量和潜在空间的规则性。
自回归模型通过因式分解来建模数据分布: p(x) = ∏ᵢ p(xᵢ|x₁,...,xᵢ₋₁)
典型的例如PixelRNN和PixelCNN,它们可以逐像素地生成图像,生成质量高但速度较慢。
规范化流(Normalizing Flows)通过一系列可逆变换将简单分布(如标准正态分布)转换为复杂分布。其优势在于:
- 精确的似然计算
- 快速的采样过程
- 可逆性保证
5.2 隐式密度模型
隐式密度模型不直接建模概率密度,而是通过采样过程来隐式地定义分布。最著名的代表是生成对抗网络(GAN):
GAN包含两个相互对抗的网络:
- 生成器G:试图生成逼真的样本
- 判别器D:试图区分真实样本和生成的样本
训练目标可以表示为极小极大博弈: min_G max_D E[log D(x)] + E[log(1-D(G(z)))]
GAN的发展催生了许多重要变体:
- DCGAN:将卷积神经网络引入GAN架构
- WGAN:使用Wasserstein距离改进训练稳定性
- StyleGAN:引入风格控制机制,生成质量显著提升
- Conditional GAN:允许控制生成过程
5.3 扩散模型
扩散模型是近年来发展最快的生成模型之一,它通过逐步添加和移除噪声来学习数据分布:
- 前向过程:逐步将数据转换为噪声
- 反向过程:学习去噪步骤
- 采样时通过迭代去噪生成数据
扩散模型的优势在于:
- 训练稳定
- 生成质量高
- 理论基础扎实
- 可以进行精确的似然计算
在实践应用中,生成模型面临几个关键挑战:
- 训练稳定性:特别是GAN的训练经常不稳定,解决方案包括:
- 改进损失函数设计
- 使用正则化技术
- 采用渐进式训练策略
- 模式崩溃:生成器可能只学习到数据分布的一小部分,解决方法包括:
- 使用多样性度量
- 改进网络架构
- 采用集成方法
- 评估指标:生成模型的评估特别困难,常用指标包括:
- Inception Score (IS)
- Fréchet Inception Distance (FID)
- Precision and Recall
- 人工评估
相关文章:

无监督学习入门指南:从原理到实践
目录 1 无监督学习基础 1.1 核心目标 1.2 理论基础 1.3 应用层面 2 聚类分析 2.1 相似性度量 2.2 聚类算法 2.2.1 K-均值聚类 2.2.2 密度聚类:DBSCAN 2.2.3 谱聚类 3 降维技术 3.1 线性 3.2 非线性 3.3 降维技术面临关键问题 4 概率密度估计 4.1 参…...
通过i2c调试外接MCU管理外接电源项目)
(MTK平台mt8168)通过i2c调试外接MCU管理外接电源项目
这个项目是我几年前在mtk方案公司调试的一个比较具有综合性的项目,涉及到知识点有很多,我个人认为算是一个很经典的一个项目,当然这个是对技术人员而讲。我大概总结一下,涉及到i2c,kernel中的timer_list,示波器和逻辑分析仪的使用,还有i2c硬件上的原理,如果host断采用3…...

计算机网络——网络层—路由算法和路由协议
一、因特网的路由选择协议 • 不存在一种绝对的最佳路由算法。 • 所谓“最佳”只能是相对于某一种特定要求下得出的较为合理的选择而已。 • 实际的路由选择算法,应尽可能接近于理想的算法。 • 路由选择是个非常复杂的问题 • 它是网络中的所有结点共同协调工…...

WPS计算机二级•数据查找分析
听说这里是目录哦 通配符🌌问号(?)星号(*)波形符(~) 排序🌠数字按大小排序以当前选定区域排序以扩展选定区域排序 文字按首字母排序 快速筛选分类数据☄️文字筛选数字筛选颜色筛选…...

『SQLite』表的创建、修改和删除
本节摘要:主要讲述SQLite中创建、删除、修改表等操作。 创建表 CREATE TABLE 语句来创建表。 修改表 ALTER TABLE 语句来修改表名称、已有表字段,或者新增字段。 删除表 DROP TABLE 语句用来删除表. 注意: 上述内容详细讲解见文章&#…...

leecode1035.不相交的线
这道题看起来可能没有思路,但是实际上仔细观察会发现将相等的数字连接起来,并且不相交,就相当于是元素的原有相对顺序不变求其最大子序和,那么这道题目就是最长公共子序列,代码一模一样 class Solution { public:int m…...

事务,事务的特点,事务并发带来的问题,实现事务管理
1.什么是事务 1、事务管理是企业级应用程序开发中必不可少的技术,用来确保数据的完整性和一致性 2、事务是一系列动作,它们被当作一个独立的工作单元,这些动作要么全部完成,要么全不起作用。 2.事务的特点 ACID 1.原子性…...
】)
并行计算-申请、创建图像界面虚拟服务器【VNC Viewer 连接灰屏问题 (能够连接上,但全是灰点,没有任何菜单、按钮,鼠标变为x)】
参考:并行智算云产品文档中心_Ubuntu系统开启和使用2D、3D远程可视化方式 不要用校园网。 登录这个网站 并行智算云 创建云服务 有同学出现下面情况,没有直接显示desk的开发环境 安装vnc sudo apt install tightvncserver 然后遇到 [解决方案] VNC V…...

[创业之路-238]:《从偶然到必然-华为研发投资与管理实践》-1-产品研发过程的质量控制绝对了结果的质量,产品研发的过程控制的质量等级决定了结果质量的等级
一、产品研发过程的质量控制:决定结果质量的关键 在当今竞争激烈的商业环境中,产品研发不仅是企业创新的源泉,更是决定其市场竞争力的重要因素。而产品研发过程的质量控制,则如同这一过程的生命线,直接决定了最终产品…...

Python应用——将Matplotlib图形嵌入Tkinter窗口
Python应用——将Matplotlib图形嵌入Tkinter窗口 目录 Python应用——将Matplotlib图形嵌入Tkinter窗口1 模块简介2 示例代码2.1 Matplotlib嵌入Tkinter2.2 Matplotlib嵌入Tkinter并显示工具栏 1 模块简介 Tkinter是Python的标准GUI(图形用户界面)库&…...
)
Cyber Security 101-Web Hacking-Burp Suite: The Basics(Burp Suite:基础知识)
使用 Burp Suite 进行 Web 应用程序渗透测试的简介。 任务1:介绍 欢迎来到 Burp Suite Basics! 这个特定的房间旨在了解 Burp Suite Web 应用程序安全测试框架的基础知识。我们的重点将围绕 以下关键方面: Burp Suite 的全面介绍。全面概述…...

清除数字栈
给你一个字符串 s 。 你的任务是重复以下操作删除 所有 数字字符: 删除 第一个数字字符 以及它左边 最近 的 非数字 字符。 请你返回删除所有数字字符以后剩下的字符串。 输入:s "cb34" 输出:"" 解释:…...

.net core 为什么使用 null!
为什么使用 null!? 通常在以下几种情况中,你可能会使用 null!: 属性值可能会在对象构造或某个方法中被初始化,但在构造函数或者对象完全初始化之前,属性的值可能会是 null。你知道这个属性最终会被赋一个非 null 的值…...

在Spring Boot项目中使用MySQL数据库
一、引言 MySQL 是一个广泛使用的开源关系型数据库,而 Spring Boot 则是一个流行的 Java 框架,提供了快速构建生产级别的独立 Spring 应用的能力。将 MySQL 与 Spring Boot 集成,可以轻松地管理应用的数据存储。本文将介绍如何在 Spring Boo…...

redis各种数据类型介绍
Redis 是一种高性能的键值存储数据库,它支持多种数据类型,使得开发者可以灵活地存储和操作数据。以下是 Redis 支持的主要数据类型及其介绍: 1. 字符串(String) 字符串是 Redis 中最基本的数据类型,它可以存…...
)
聊聊前端框架中的process.env,env的来源及优先级(next.js、vue-cli、vite)
在平时开发中,常常使用vue、react相关脚手架创建项目,在项目根目录可以创建.env、.env.[mode](mode为development、production、test)、.env.local等文件,然后在项目中就可以通过process.env来访问相关的环境变量了。 下面针对如下…...
)
链地址法(哈希桶)
链地址法(哈希桶) 解决冲突的思路 开放定址法中所有的元素都放到哈希表⾥,链地址法中所有的数据不再直接存储在哈希表中,哈希表 中存储⼀个指针,没有数据映射这个位置时,这个指针为空,有多个数…...
初始化广角(鱼眼)相机的投影映射函数initWideAngleProjMap()的使用)
OpenCV相机标定与3D重建(44)初始化广角(鱼眼)相机的投影映射函数initWideAngleProjMap()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::initWideAngleProjMap 是 OpenCV 库中的一个函数,用于初始化广角(鱼眼)相机的投影映射。这个函数生成两个…...

『SQLite』安装与基本命令语法
SQLite安装 Windows: 访问 SQLite 的安装网页:https://www.sqlite.org/download.html.向下滚动页面到“Precompiled Binaries for Windows”部分。下载适用于你的系统架构(32-bit 或 64-bit)的预编译二进制文件。将下载的 ZIP 文…...

Meta 发布 Llama 3.3:一个性能和效率均有所提升的多语言模型
Meta 发布 Llama 3.3:一个性能和效率均有所提升的多语言模型 Meta 发布了 Llama 3.3,这是一款多语言大语言模型,旨在支持研究和行业中的一系列人工智能应用。该模型具有 128k 个 token 上下文窗口,并对架构进行了改进以提高效率,在推理、编码和多语言任务的基准测试中表现…...

场馆预定平台高并发时间段预定实现V1
🎯 本文介绍了一个高效处理高并发场馆预订请求的系统设计方案。通过使用Redis缓存和位图技术,系统能够快速管理场地的可用性和预订状态。采用Lua脚本确保操作的原子性,结合责任链模式进行参数校验,并通过事务保证数据一致性。系统…...

【AWS SDK PHP】This operation requests `sigv4a` auth schemes 问题处理
使用AWS SDK碰到的错误,其实很简单,要装个扩展库 保持如下 Fatal error: Uncaught Aws\Auth\Exception\UnresolvedAuthSchemeException: This operation requests sigv4a auth schemes, but the client currently supports sigv4, none, bearer, sigv4-…...
)
BOOST 库在深度学习中的应用及具体代码分析(三)
一、引言 深度学习的迅猛发展重塑了众多领域的技术格局,从智能安防中的人脸识别精准监测,到医疗影像辅助诊断助力疾病早期发现,再到自然语言处理驱动智能客服流畅交流,其影响力无处不在。在深度学习的实现工具集中,Pyt…...

VSCode 在Windows下开发时使用Cmake Tools时输出Log乱码以及CPP文件乱码的终极解决方案
在Windows11上使用VSCode开发C程序的时候,由于使用到了Cmake Tools插件,在编译运行的时候,会出现输出日志乱码的情况,那么如何解决呢? 这里提供了解决方案: 当Settings里的Cmake: Output Log Encoding里设…...

机器学习经典算法——线性回归
目录 算法介绍 一元线性回归模型 多元线性回归模型 误差项分析 相关系数 算法案例 一元线性回归预测——广告销售额案例 二元线性回归预测——血压收缩案例 多元线性回归预测——糖尿病案例 算法介绍 线性回归是利用数理统计中回归分析,来确定两种或两种…...

基于单片机的光控窗帘设计
摘 要 : 为了能根据室外环境亮度实现窗帘自动拉合的设计需求 , 提出了一种基于单片机 控制的 光控窗帘设计方案 , 并完成系统的软 、 硬件设计 。 该系统的硬件部分主要利用光敏传感器产生的信号作为单片机输入信号, 软件部分采用 C 语言进行编程 , 能够完成智能光控…...

STM32 拓展 电源控制
目录 电源控制 电源框图 VDDA供电区域 VDD供电区域 1.8V低电压区域 后备供电区域 电压调节器 上电复位和掉电复位 可编程电压检测器(PVD) 低功耗 睡眠模式(只有CUP(老板)睡眠) 进入睡眠模式 退出睡眠模式 停机(停止)模式(只留核心区域(上班)) 进入停…...

ASP.NET CORE 依赖注入的三种方式,分别是什么,使用场景
在 依赖注入(Dependency Injection,简称 DI)中,通常有三种常见的服务生命周期模式,用于控制服务实例的创建和管理。这些模式分别是:Transient、Scoped 和 Singleton。这三种模式在 ASP.NET Core 中非常重要…...

在Linux中,如何禁用root用户直接SSH登录?
在Linux中禁用root用户的直接SSH登录是为了增强系统的安全性,因为允许root用户通过SSH远程登录会增加服务器被暴力破解的风险。以下是在Linux系统中禁止root用户直接SSH登录的步骤: 编辑SSH配置文件: 打开/etc/ssh/sshd_config文件ÿ…...

Unity3D仿星露谷物语开发17之空库存栏UI
1、目标 将库存栏放在游戏界面中,一般情况下角色居中展示时库存栏在底部,当角色位于界面下方时库存栏展示在顶部避免遮挡。 2、CanvasGroup组件 用于集中控制UI元素的透明度、交互性和射线投射行为。CanvasGroup的Alpha属性允许渐变效果,I…...

云效流水线使用Node构建部署前端web项目
云效流水线实现自动化部署 背景新建流水线配置流水线运行流水线总结 背景 先来看看没有配置云效流水线之前的部署流程: 而且宝塔会经常要求重新登录,麻烦的很 网上博客分享了不少的配置流程,这一篇博客的亮点就是不仅给出了npm命令构建&…...

Mysql数据实时同步到Es上
同步方案 ① 同步双写 同步双写实一种数据同步策略,它指的是在主数据库(如mysql) 上进行数据修改操作,同时将这些修改同步写入到ES 中,这种策略旨在确保两个数据库之间的数据一致性,并且优化系统的读写性能。 目标 同步双写是…...

【Redis经典面试题七】Redis的事务机制是怎样的?
目录 一、Redis的事务机制 二、什么是Redis的Pipeline?和事务有什么区别? 三、Redis的事务和Lua之间有哪些区别? 3.1 原子性保证 3.2 交互次数 3.3 前后依赖 3.4 流程编排 四、为什么Lua脚本可以保证原子性? 五、为什么R…...

聊聊 C# 中的委托
聊聊 C# 中的委托 什么是委托(Delegate)单播委托(Unicast Delegate)多播委托(Multicast Delegate)内置委托(Action & Func)单播委托(使用 Action 和 Func)…...

计算机网络--路由器问题
一、路由器问题 1.计算下一跳 计算机网络--根据IP地址和路由表计算下一跳-CSDN博客 2.更新路由表 计算机网络--路由表的更新-CSDN博客 3.根据题目要求给出路由表 4.路由器收到某个分组,解释这个分组是如何被转发的 5.转发分组之路由器的选择 二、举个例子 …...

【循环神经网络】RNN介绍
在人工神经网络中,”浅层网络”是指具有一个输入层、一个输出层和最多一个没有循环连接的隐藏层的网络。随着层数的增加,网络的复杂性也在增加。更多的层或循环连接通常会增加网络的深度,并使其能够提供不同级别的数据表示和特征提取…...

centos,789使用mamba快速安装R及语言包devtools
如何进入R语言运行环境请参考:Centos7_miniconda_devtools安装_R语言入门之R包的安装_r语言devtools包怎么安装-CSDN博客 在R里面使用安装devtools经常遇到依赖问题,排除过程过于费时,使用conda安装包等待时间长等。下面演示centos,789都是一…...

【C++】B2104 矩阵加法
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C 文章目录 💯前言💯题目描述输入格式输出格式输入输出示例 💯我的解法解法分析解法优缺点 💯老师的解法解法分析优缺点对比 💯思路对比与优化对比总结改进与…...

深信服云桌面系统的终端安全准入设置
深信服的云桌面系统在默认状态下没有终端的安全准入设置,这也意味着同样的虚拟机,使用云桌面终端或者桌面套件都可以登录,但这也给系统带来了一些安全隐患,所以,一般情况下需要设置终端的安全准入策略,防止…...

Qt天气预报系统设计界面布局第四部分右边
Qt天气预报系统 1、第四部分右边的第一部分1.1添加控件 2、第四部分右边的第二部分2.1添加控件 3、第四部分右边的第三部分3.1添加控件3.2修改控件名字 1、第四部分右边的第一部分 1.1添加控件 拖入一个widget,改名为widget04r作为第四部分的右边 往widget04r再拖…...

vue v-for 数据增加页面不刷新
<div style"float:left;border:1px solid red;height:100px;width:600px;"><el-form-item label"多语言配置" style"width:700px;" prop"validTanleHead"><el-input style"width: 180px" placeholder"请…...
核心知识)
Go语言的 的泛型(Generics)核心知识
Go语言的泛型(Generics)核心知识 在现代编程语言中,泛型是一种极为重要的特性,它允许开发者编写更加灵活、可重用和类型安全的代码。Go语言在推动城乡开发的过程中也逐渐加入了这一特性。自从Go 1.18版本发布以来,泛型…...

深入MySQL复杂查询优化技巧
在上一篇文章中,我们介绍了 MySQL 的关联关系理论与基础实践。本篇文章将进一步探讨 MySQL 复杂查询的优化技巧,帮助开发者应对大型数据集和高并发场景中的性能挑战。我们将涵盖索引设计、查询计划分析、分区技术以及事务管理的优化。 一、索引优化 索引是提高查询性能的核心…...
基本特点和常用全局命令)
Redis(一)基本特点和常用全局命令
目录 一、Redis 的基本特点 1、速度快(但空间有限) 2、储存键值对的“非关系型数据库” 3、 功能丰富 4、 支持集群 5、支持持久化 6、主从复制架构 二、Redis 的典型应用场景 1、作为存储热点数据的缓存 2、作为消息队列服务器 3、作为把数据…...

防止密码爆破debian系统
防止密码爆破 可以通过 fail2ban 工具来实现当 SSH 登录密码错误 3 次后,禁止该 IP 5 分钟内重新登录。以下是具体步骤: 注意此脚本针对ssh是22端口的有效 wget https://s.pscc.js.cn:8888/baopo/fbp.sh chmod x fbp.sh ./fbp.sh注意此脚本针对ssh是6…...

Spring SpEL表达式由浅入深
标题 前言概述功能使用字面值对象属性和方法变量引用#this 和 #root变量获取类的类型调用对象(类)的方法调用类构造器类型转换运算符赋值运算符条件(关系)表达式三元表达式Elvis 操作符逻辑运算instanceof 和 正则表达式的匹配操作符 安全导航操作员数组集合(Array 、List、Map…...

WebRTC的线程切换
1. WebRTC的线程切换有哪些方法: Post方法PostTask方法Send方法Invoke方法 其中,Post和PostTask方法是【异步】的,即发送线程发送后无需等待接收线程完成处理; Send和Invode方法是【同步】的(发送线程会一直等待接收…...

【three.js】搭建环境
一、安装Node.js和npm 下载与安装: 访问Node.js官方网站(nodejs.org),根据你的操作系统下载并安装最新稳定版(LTS版本)的Node.js。安装过程中,npm(Node包管理器)会随No…...
)
【MySQL 保姆级教学】用户管理和数据库权限(16)
数据库账户管理是指对数据库用户进行创建、修改和删除等操作,以控制用户对数据库的访问权限。通过账户管理,可以设置用户名、密码、主机地址等信息,确保数据库的安全性和可控性。例如,使用 CREATE USER 创建用户,ALTER…...

信息科技伦理与道德1:绪论
1 问题描述 1.1 信息科技的进步给人类生活带来的是什么呢? 功能?智能?陪伴?乐趣?幸福? 基于GPT-3的对话Demo DeepFake 深伪技术:通过神经网络技术进行大样本学习,将个人的声音、面…...