LLM大语言模型自动化测试(ROUGE和RAGAS)及优化方案
1. 模型自动化测试
模型的测试中,不同类型的任务评测指标有显著差异,比如:
分类任务:
准确率(Accuracy):正确预测的比例。
精确度(Precision)、召回率(Recall)与F1分数(F1 Score):用于衡量二分类或多分类问题中正类别的识别效果。
文本生成任务:
BLEU (Bilingual Evaluation Understudy) 分数:主要用于机器翻译等自然语言处理任务中,通过比较候选翻译与一个或多个参考翻译之间的n-gram重叠来计算得分。
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 分数:常用于自动摘要评价,它基于n-gram召回率、精确率以及F-measure。
Perplexity (困惑度):用来衡量概率分布模型预测样本的不确定程度;越低越好。
图像识别/目标检测:
Intersection over Union (IoU):两个边界框相交部分面积与并集面积之比。
mAP (mean Average Precision):平均精度均值,广泛应用于物体检测任务中
ROUGE是基于召回率的评估指标,特别适用于 文本摘要、问答生成 和 机器翻译 等任务。其核心思想是通过对生成文本和参考文本的 n-gram 或 子序列 匹配程度进行评估。
ROUGE Scores (Recall Oriented Understudy for Gisting Evaluation)
rouge-n-(r/p/f): 这是基于词级别的n-gram匹配度量,其中n=1,意味着考虑单个词汇的重合情况;n=2,意味着考虑两个词汇组成的短语的重合情况;n=L(long),意味着考虑一个模型输出与测试用例中最长公共子序列的重合情况。
rouge-n-r:召回率(Recall),表示模型输出正确预测出测试用例的比例。
rouge-n-p:精确率(Precision),表示模型输出有多大部分也出现在测试用例中。
rouge-n-f:F1分数,是召回率和精确率的调和平均值,综合考量了两者的表现。
相关文章:ROUGE: A Package for Automatic Evaluation of Summaries (Chin-Yew Lin, 2004)
Rouge-L分数可以评估输出的SQL语句有多少部分是有用的,因此它能大致反映出模型的能力。
from rouge import Rouge
# 生成文本
generated_text = "你需要的sql: SELECT * FROM employees WHERE employee_id NOT IN (SELECT employee_id FROM job_history)。 你可以用这句SQL查找到你要的信息。"
# 参考文本列表
reference_texts = "SELECT * FROM employees WHERE employee_id NOT IN (SELECT employee_id FROM job_history)"
# 计算 ROUGE 指标
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts)
# 打印结果
print("ROUGE-1 p:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 r:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 f:", scores[0]["rouge-1"]["f"])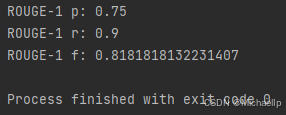
from rouge import Rouge
# 生成文本
generated_text = "SELECT * FROM employees WHERE employee_id NOT IN (SELECT employee_id FROM job_history)"
# 参考文本列表
reference_texts = "SELECT * FROM employees WHERE employee_id NOT IN (SELECT employee_id FROM job_history)"
# 计算 ROUGE 指标
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts)
# 打印结果
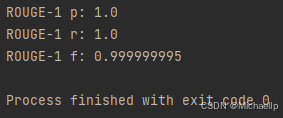
print("ROUGE-1 p:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 r:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 f:", scores[0]["rouge-1"]["f"])
如何根据 Rouge 指标进行优化
1.优化Prompt
提示词工程就是研究如何构建和调整提示词,从而让大语言模型实现各种符合用户预期的任务的过程。利用one-shot和few-shot引导大模型给出正确答案。
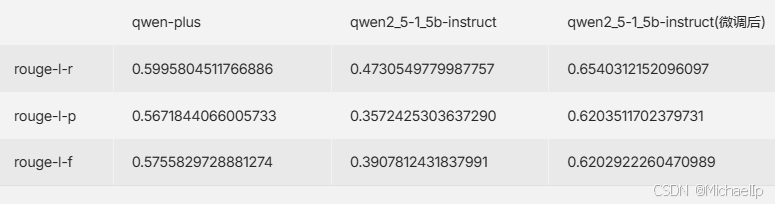
2.微调
qwen2_5-1_5b-instruct 是比 qwen-plus反应更快的模型,当准确率相对较低,当如果针对具体业务微调后,Rouge分数比qwen-plus高,反应还是原来那样快。
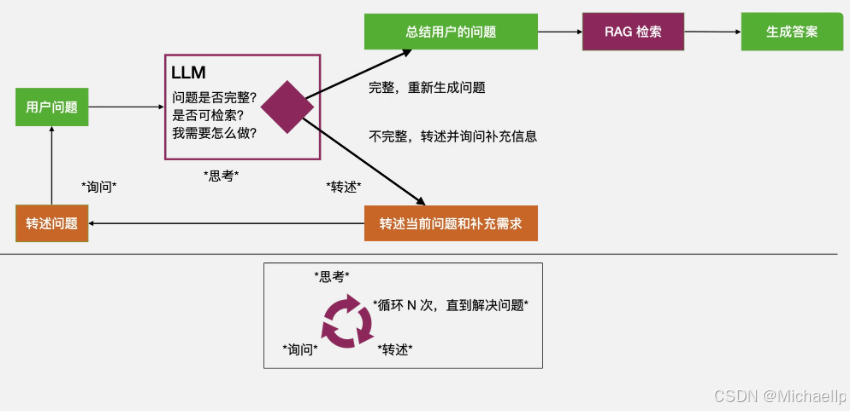
3.Enrich补全需求
一种理想的通过多轮对话补全需求的方案。该设想是通过大模型多次主动与用户沟通,不断收集信息,完善对用户真实意图的理解,补全执行用户需求所需的各项参数。如下图所示。
2. RAG自动化测试
Ragas是现在评估RAG系统的非常标准化的工具。
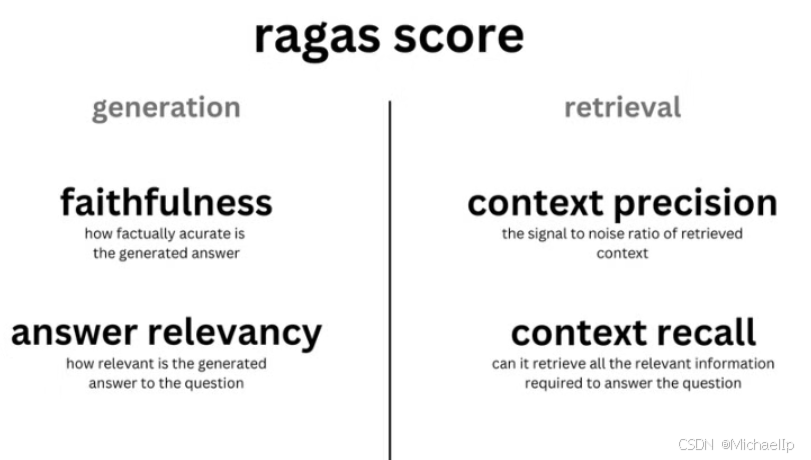
Ragas 默认提供了多项指标,可以用来全链路评测应用的问答质量。比如:
整体回答质量的评估:
Answer Correctness,用于评估 RAG 应用生成答案的准确度。
生成环节的评估:
Answer Relevancy,用于评估 RAG 应用生成的答案是否与问题相关。
Faithfulness,用于评估 RAG 应用生成的答案和检索到的参考资料的事实一致性。
召回阶段的评估:
Context Precision,用于评估 contexts 中与准确答案相关的条目是否排名靠前、占比高(信噪比)。
Context Recall,用于评估有多少相关参考资料被检索到,越高的得分意味着更少的相关参考资料被遗漏。
评估前你需要准备三种数据:
- question,输入给 RAG 应用的问题
- answer,RAG 应用给出的答案
- ground_truth,你预先知道的正确的答案
为了方便演示,我会为你提供“不知道”、“幻觉”、“正确回答”三种回答
安装Ragas
pip install ragas==0.2.6
pip show ragas
了解整体回答 Answer Correctness 的计算过程
Answer correctness 的得分由生成答案(answer)和正确答案(ground truth)的语义相似度和事实准确度计算得出。
1.语义相似度
语义相似度是通过文本向量模型(Text Embedding Model)计算 answer 和 ground truth 的文本向量,然后计算两个文本向量的余弦相似度。
2.事实准确度
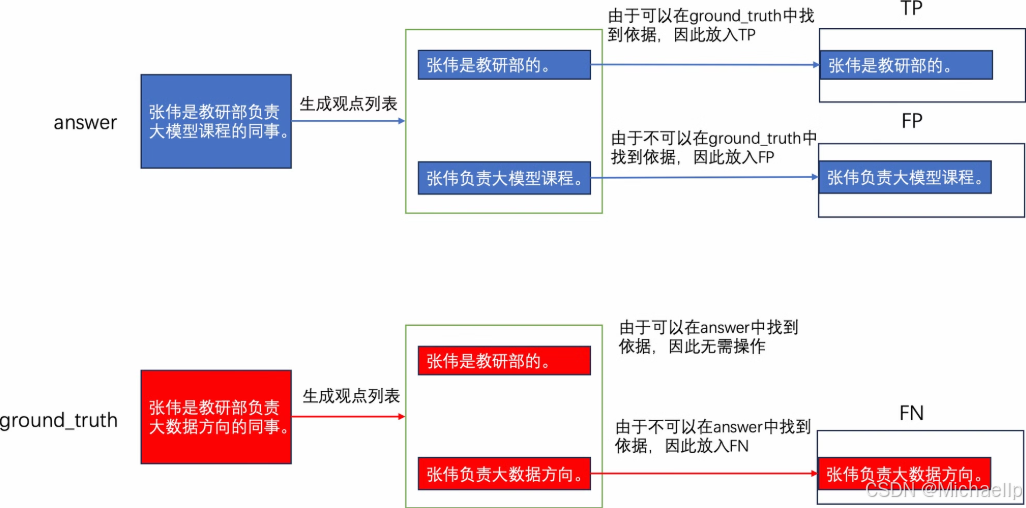
生成观点列表:
用大模型分别提取 answer 和 ground_truth 的观点。
例如:
answer: [“张伟是教研部的”, “张伟负责大模型课程”]
ground_truth: [“张伟是教研部的”, “张伟负责大数据方向”]
匹配观点:
TP (True Positive): answer 和 ground_truth 匹配的观点。
例如: “张伟是教研部的”
FP (False Positive): answer 有但 ground_truth 没有的观点。
例如: “张伟负责大模型课程”
FN (False Negative): ground_truth 有但 answer 没有的观点。
例如: “张伟负责大数据方向”
计算 F1 分数:F1 = TP / (TP + 0.5 * (FP + FN)) 如果 TP > 0,否则 F1 = 0
例如:TP = 1, FP = 1, FN = 1 F1 = 1 / (1 + 0.5 * (1 + 1)) = 0.5
分数汇总
得到语义相似度和事实准确度的分数后,对两者加权求和,即可得到最终的 Answer Correctness 的分数。
Answer Correctness 的得分 = 0.25 * 语义相似度得分 + 0.75 * 事实准确度得分
相关代码
from langchain_community.llms.tongyi import Tongyi
from langchain_community.embeddings import DashScopeEmbeddings
from datasets import Dataset # ragas评估工具及相关指标
from ragas import evaluate
from ragas.metrics import faithfulness,answer_relevancy,context_recall,context_precision,answer_correctnessfrom config.load_key import load_key
load_key()# =============== 准备示例数据 ===============
data_samples = {'question': [ # 测试问题列表'张伟是哪个部门的?','张伟是哪个部门的?','张伟是哪个部门的?'],'answer': [ # 系统生成的不同答案,用于评估答案质量'根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。','张伟是人事部门的','张伟是教研部的'],'ground_truth':[ # 标准答案,用于对比评估'张伟是教研部的成员','张伟是教研部的成员','张伟是教研部的成员'],'contexts' : [['提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ', '绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源'],['李凯 教研部主任 ', '牛顿发现了万有引力'],['牛顿发现了万有引力', '张伟 教研部工程师,他最近在负责课程研发'],]
}# =============== 创建数据集 ===============
# 将字典格式数据转换为Dataset对象,便于评估使用
dataset = Dataset.from_dict(data_samples)# =============== 进行评估 ===============
score = evaluate(dataset = dataset, # 要评估的数据集metrics=[answer_correctness], # 使用answer_correctness指标评估答案的正确性# 使用通义千问plus模型作为评估模型llm=Tongyi(model_name="qwen-plus"),# 使用DashScope的文本向量化模型进行文本编码embeddings=DashScopeEmbeddings(model="text-embedding-v3")
)# 将评估结果转换为pandas数据框并打印
print(score.to_pandas())把上面代码中metrics替换成下面的ragas评估指标
ragas评估指标说明:
- answer_correctness: 评估答案的正确性
- context_recall: 评估上下文的召回率
- context_precision: 评估上下文的精确度
- faithfulness: 评估答案与上下文的一致性
- answer_relevancy: 评估答案与问题的相关性
当metrics=[answer_correctness]
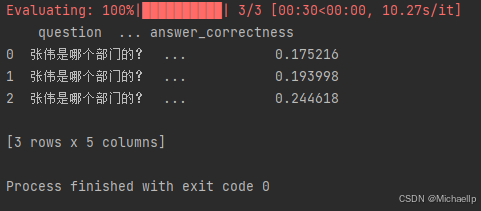
当metrics=[answer_correctness]
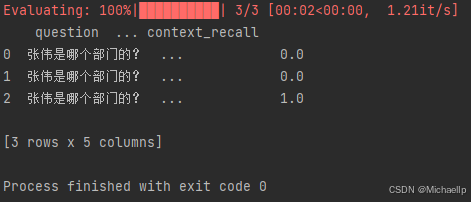
当metrics=[context_precision]
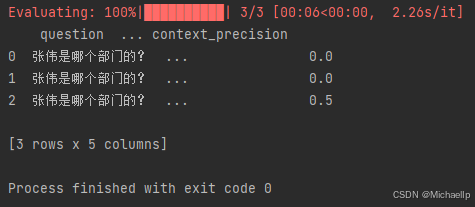
当metrics=[faithfulness]
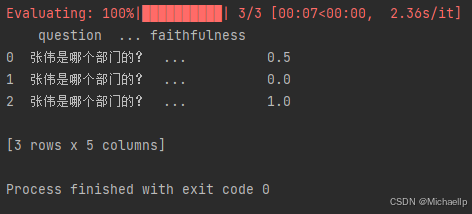
当metrics=[answer_relevancy]
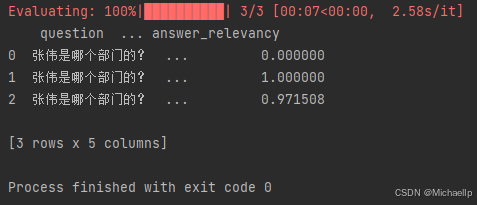
如何根据 Ragas 指标进行优化
做评测的最终目的不是为了拿到分数,而是根据这些分数确定优化的方向。上面代码展示了answer correctness、context recall、context precision三个指标的概念与计算方法,当观察到某几个指标的分数较低时,应该制定相应的优化措施。
Context Recall
context recall指标评测的是RAG应用在检索阶段的表现。如果该指标得分较低,可以尝试从以下方面进行优化:
1.检查知识库:如果你发现某些测试样本缺少相关知识,则需要对知识库进行补充。
2.更换embedding模型
MTEB——海量文本嵌入基准测试(MassiveTextEmbeddingBenchmark),下面是英文和中文Embedding 排行榜(截至 2025/01/01)
https://huggingface.co/spaces/mteb/leaderboard
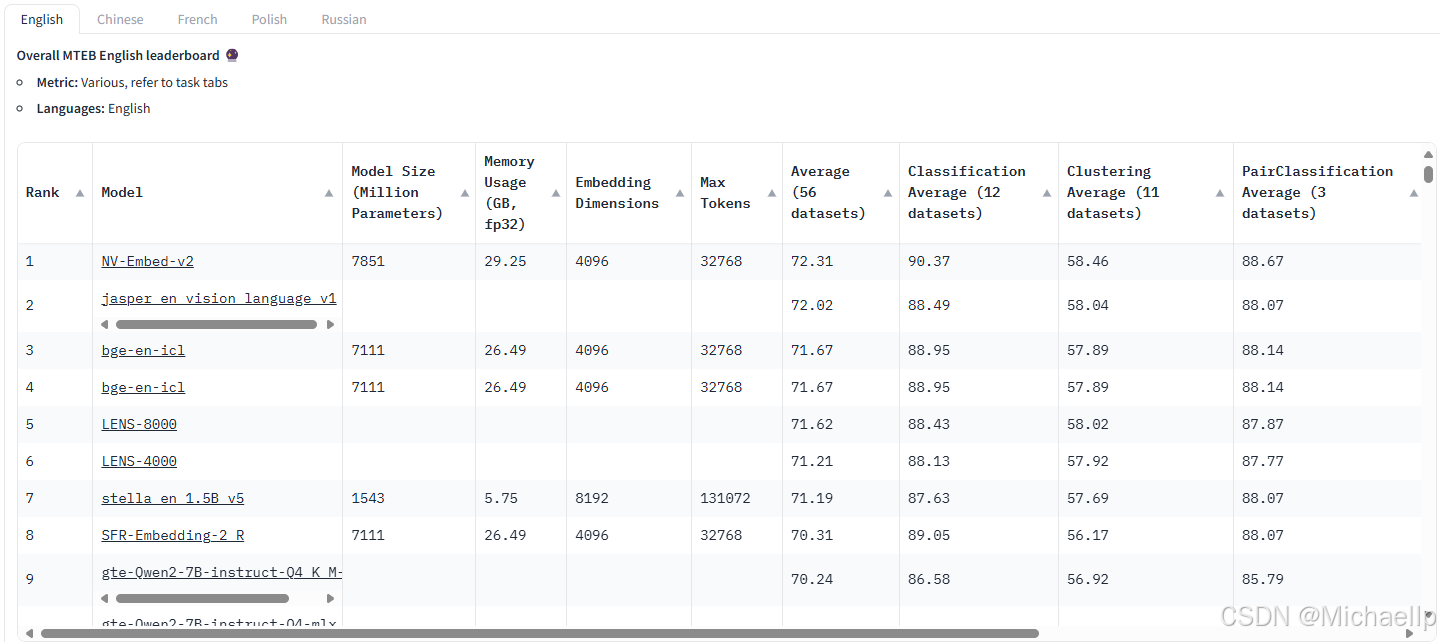
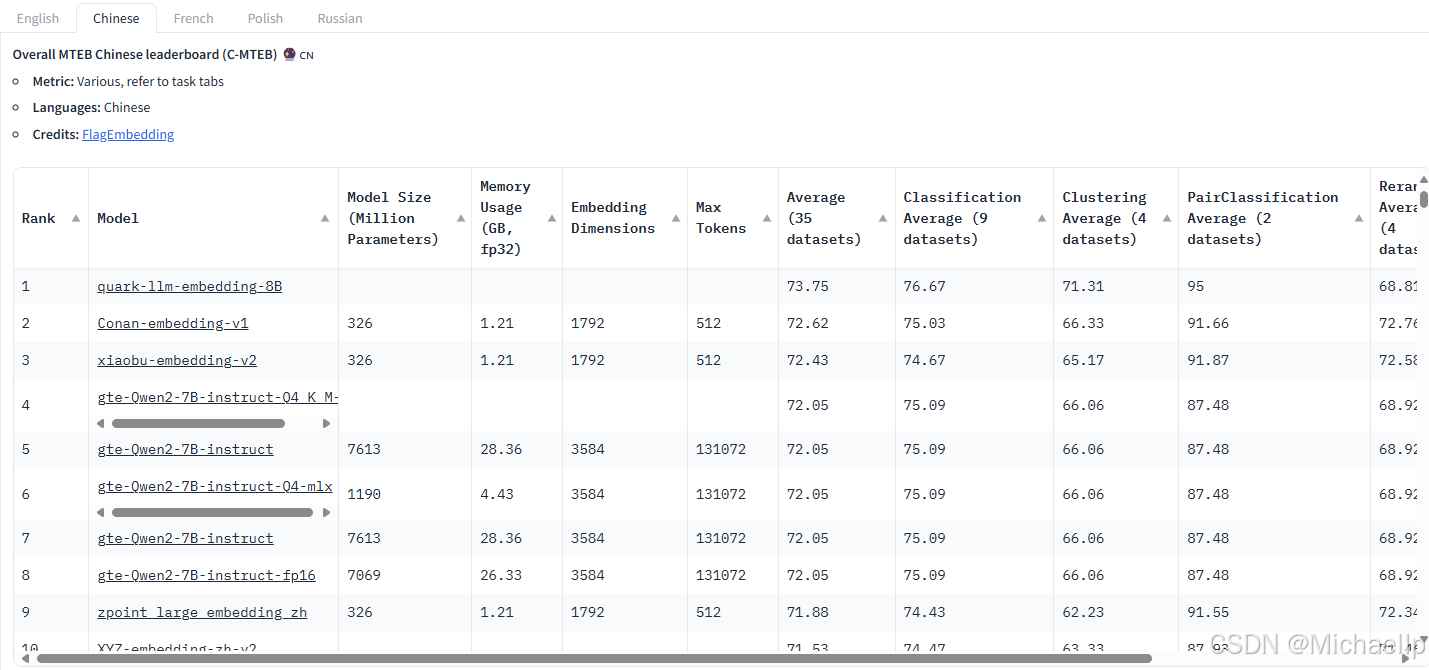
3.query改写

Context Precision
与context recall一样,context precision指标评测的也是RAG应用在检索阶段的表现,但是更注重相关的文本段是否具有靠前的排名。如果该指标得分较低,你可以尝试context recall中的优化措施,并且可以尝试在检索阶段加入rerank(重排序),来提升相关文本段的排名。
Answer Correctness
answer correctness指标评测的是RAG系统整体的综合指标。如果该指标得分较低,而前两项分数较高,说明RAG系统在检索阶段表现良好,但是生成阶段出了问题。你可以尝试前边教程学到的方法,如优化prompt、调整大模型生成的超参数(如temperature)等,你也可以更换性能更加强劲的大模型,甚至对大模型进行微调等方法来提升生成答案的准确度。
相关文章:
及优化方案)
LLM大语言模型自动化测试(ROUGE和RAGAS)及优化方案
1. 模型自动化测试 模型的测试中,不同类型的任务评测指标有显著差异,比如: 分类任务: 准确率(Accuracy):正确预测的比例。 精确度(Precision)、召回率(Recal…...

你已经分清JAVA中JVM、JDK与JRE的作用和关系了吗?
你已经分清JAVA中JVM、JDK与JRE的作用和关系了吗? 一. JVM、JDK与JRE的关系二. JVM、JDK与JRE的作用2.1 什么是JVM?2.2 什么是JDK?2.3 什么是JRE? 前言 点个免费的赞和关注,有错误的地方请指出,看个人主页有…...

实际开发中,常见pdf|word|excel等文件的预览和下载
实际开发中,常见pdf|word|excel等文件的预览和下载 背景相关类型数据之间的转换1、File转Blob2、File转ArrayBuffer3、Blob转ArrayBuffer4、Blob转File5、ArrayBuffer转Blob6、ArrayBuffer转File 根据Blob/File类型生成可预览的Base64地址基于Blob类型的各种文件的下载各种类型…...

Elasticsearch:Lucene 2024 年回顾
作者:来自 Elastic Chris Hegarty 2024 年对于 Apache Lucene 来说又是重要的一年。在本篇博文中,我们将探讨主要亮点。 Apache Lucene 在 2024 年表现出色,发布了许多版本,包括三年来的首次重大更新,其中包含令人兴奋…...

springboot实战纪实-课程介绍
教程介绍 Spring Boot是由Pivotal团队提供的一套开源框架,可以简化spring应用的创建及部署。它提供了丰富的Spring模块化支持,可以帮助开发者更轻松快捷地构建出企业级应用。 Spring Boot通过自动配置功能,降低了复杂性,同时支持…...
?)
什么是TDD测试驱动开发(Test Driven Development)?
什么是测试驱动开发? 软件开发团队通常会编写自动化测试套件来防止回归。这些测试通常是在编写应用程序功能代码之后编写的。我们将采用另一种方法:在实现应用程序代码之前编写测试。这称为测试驱动开发 (TDD)。 为什么要应用 TDD?通过在实…...

学习随记:word2vec的distance程序源码注释、输入输出文件格式说明
word2vec中有5个程序,其中demo-word.sh中涉及两个:word2vec、distance。考虑到distance比较简单,所以我从这个入手,希望通过简单代码理解如何在一个高维数据空间计算距离(查找)。一维数据的查找,…...

CSS 之 position 定位属性详解
CSS系列文章目录 CSS 之 display 布局属性详解 CSS 之 position 定位属性详解一文搞懂flex布局 【弹性盒布局】 文章目录 CSS系列文章目录一、前言二、静态定位:position:static;二、相对定位:position:relative三、绝对定位:pos…...

初学STM32 --- USMART
目录 USMART简介 USMART主要特点: USMART原理 USMART组成: USMART 的实现流程简单概括 USMART扫描函数: USMART系统命令 USMART移植 USMART简介 USMART是一个串口调试组件,可以大大提高代码调试效率! USMART主…...

MySQL叶子节点为啥使用双向链表?不使用单向呢?
文章内容收录到个人网站,方便阅读:http://hardyfish.top/ 文章内容收录到个人网站,方便阅读:http://hardyfish.top/ 文章内容收录到个人网站,方便阅读:http://hardyfish.top/ MySQL 中的 B 树索引&#x…...

4_TypeScript 条件语句 --[深入浅出 TypeScript 测试]
在 TypeScript 中,条件语句用于根据不同的条件执行不同的代码块。这些语句包括 if 语句、else if 语句、else 语句和 switch 语句。通过使用条件语句,你可以编写出能够根据特定逻辑分支的代码,从而实现更加动态和灵活的功能。 1. if 语句 i…...

vue elementUI Plus实现拖拽流程图,不引入插件,纯手写实现。
vue elementUI Plus实现拖拽流程图,不引入插件,纯手写实现。 1.设计思路:2.设计细节3.详细代码实现 1.设计思路: 左侧button列表是要拖拽的组件。中间是拖拽后的流程图。右侧是拖拽后的数据列表。 我们拖动左侧组件放入中间的流…...

图漾相机基础操作
1.客户端概述 1.1 简介 PercipioViewer是图漾基于Percipio Camport SDK开发的一款看图软件,可实时预览相机输出的深度图、彩色图、IR红外图和点云图,并保存对应数据,还支持查看设备基础信息,在线修改gain、曝光等各种调节相机成像的参数功能…...

【阅读笔记】基于FPGA的红外图像二阶牛顿插值算法的实现
图像缩放技术在图像显示、传输、分析等多个领域中扮演着重要角色。随着数字图像处理技术的发展,对图像缩放质量的要求也越来越高。二阶牛顿插值因其在处理图像时能够较好地保持边缘特征和减少细节模糊,成为了图像缩放中的一个研究热点。 一、 二阶牛顿插…...

K210识别技术简介与基础使用方法
目录 一、K210芯片概述 二、K210的硬件配置与开发环境 1. 硬件配置 2. 开发环境 三、K210的识别技术基础 1. 图像识别 2. 语音识别 四、K210识别技术的基础使用方法 1. 图像识别基础使用 2. 语音识别基础使用 五、K210识别技术的应用场景 六、总结与展望 一、K210芯…...

【Android学习】Adapter中使用Context
参考文章 文章目录 1. 通过 Adapter 构造函数传入 Context2. 通过 Parent.context 获取3. 通过 onAttachedToRecyclerView() 方法获取4. 通过 ImageView 获取 context (局限于本例子中)5. 四种方法对比分析6. 作者推荐的方法 需求: Glide加载图片需要用到Context 1…...

LLM大模型RAG内容安全合规检查
1.了解内容安全合规涉及的范围 我们先回顾一下智能答疑机器人的问答流程。问答流程主要包括用户、智能答疑机器人、知识库、大语言模型这四个主体。 涉及内容安全的关键阶段主要有: 输入阶段:用户发起提问。 输出阶段:机器人返回回答。 知识…...

Flink operator实现自动扩缩容
官网文档位置: 1.Autoscaler | Apache Flink Kubernetes Operator 2.Configuration | Apache Flink Kubernetes Operator 1.部署K8S集群 可参照我之前的文章k8s集群搭建 2.Helm安装Flink-Operator helm repo add flink-operator-repo https://downloads.apach…...

数据挖掘——集成学习
数据挖掘——集成学习 集成学习Bagging:有放回采样随机森林 BoostingStacking 集成学习 集成学习(Ensemble learning)方法通过组合多种学习算法来获得比单独使用任何一种算法更好的预测性能。 动机是为了提高但分类器的性能 Bagging&…...

XGBoost 简介:高效机器学习算法的实用指南
1. 什么是 XGBoost? XGBoost,全称 eXtreme Gradient Boosting,是一种基于 梯度提升决策树(GBDT) 的高效实现。相比传统的 GBDT,XGBoost 在速度、内存利用和并行化等方面做了很多优化,因此在大规…...
【NLP高频面题 - Transformer篇】什么是缩放点积注意力,为什么要除以根号d?
什么是缩放点积注意力,为什么要除以根号d? 重要性:★★★ Transformer 自注意力机制也被称为缩放点积注意力机制,这是因为其计算过程是先求查询矩阵与键矩阵的点积,再用 d k \sqrt{d_k} dk 对结果进行缩放。这…...

HTML——56.表单发送
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title>表单发送</title></head><body><!--注意:1.表单接收程序,放在服务器环境中(也就是这里的www文件目录中)2.表单发送地址&#x…...
概览)
C++26 函数契约(Contract)概览
文章目录 1. 什么是契约编程?契约编程的三大核心: 2. C26 契约编程的语法语法示例 3. 契约检查模式3.1. default 模式3.2. audit 模式3.3. axiom 模式检查模式的设置 4. 契约编程与传统 assert 的区别示例对比 5. 契约编程的应用场景6. 注意事项7. 示例: 带契约的矩形面积计算…...

【HTML】Day02
【HTML】Day02 1. 列表标签1.1 无序列表1.2 有序列表1.3 定义列表 2. 表格标签2.1 合并单元格 3. 表单标签3.1 input标签基本使用3.2 上传多个文件 4. 下拉菜单、文本域5. label标签6. 按钮button7. div与span、字符实体字符实体 1. 列表标签 作用:布局内容排列整齐…...

Kafka的rebalance机制
1、什么是 rebalance 机制 重平衡(rebalance)机制规定了如何让消费者组下的所有消费者来分配 topic 中的每一个分区。 2、rebalance 机制的触发条件是什么 (1)消费者组内成员变更 成员增加:当有新的消费者加入到消费…...

Spring Boot - 日志功能深度解析与实践指南
文章目录 概述1. Spring Boot 日志功能概述2. 默认日志框架:LogbackLogback 的核心组件Logback 的配置文件 3. 日志级别及其配置配置日志级别3.1 配置文件3.2 环境变量3.3 命令行参数 4. 日志格式自定义自定义日志格式 5. 日志文件输出6. 日志归档与清理7. 自定义日…...

【React+TypeScript+DeepSeek】穿越时空对话机
引言 在这个数字化的时代,历史学习常常给人一种距离感。教科书中的历史人物似乎永远停留在文字里,我们无法真正理解他们的思想和智慧。如何让这些伟大的历史人物"活"起来?如何让历史学习变得生动有趣?带着这些思考&…...

2025年贵州省职业院校技能大赛信息安全管理与评估赛项规程
贵州省职业院校技能大赛赛项规程 赛项名称: 信息安全管理与评估 英文名称: Information Security Management and Evaluation 赛项组别: 高职组 赛项编号: GZ032 1 2 一、赛项信息 赛项类别 囚每年赛 □隔年赛(□单数年…...

2、蓝牙打印机点灯-GPIO输出控制
1、硬件 1.1、看原理图 初始状态位高电平. 需要驱动PA1输出高低电平控制PA1. 1.2、看手册 a、系统架构图 GPIOA在APB2总线上。 b、RCC使能 GPIOA在第2位。 c、GPIO寄存器配置 端口:PA1 模式:通用推挽输出模式 -- 输出0、1即可 速度:5…...

推荐系统重排:DPP 多样性算法
行列式点过程(DPP)算法:原理、应用及优化 推荐系统【多样性算法】系列文章(置顶) 1.推荐系统重排:MMR 多样性算法 2.推荐系统重排:DPP 多样性算法 引言 行列式点过程(Determinanta…...

【业务场景】sql server从Windows迁移到Linux
目录 1.背景 2.Linux安装sql server 3.服务器不开端口的问题 4.数据库导入导出问题 1.背景 博主在24年年底接手运维了一个政府的老系统,整个应用和数据库单点部署在一台Windows Server服务器上,数据库选型是经典的老项目标配——sql server。随着近…...
请求)
SpringMVC(三)请求
目录 一、RequestMapping注解 1.RequestMapping的属性 实例 1.在这里创建文件,命名为Test: 2.复现-返回一个页面: 创建test界面(随便写点什么): Test文件中编写: 编辑 运行: 3.不返回…...

【HeadFirst系列之HeadFirst设计模式】第1天之HeadFirst设计模式开胃菜
HeadFirst设计模式开胃菜 前言 从今日起,陆续分享《HeadFirst设计模式》的读书笔记,希望能够帮助大家更好的理解设计模式,提高自己的编程能力。 今天要分享的是【HeadFirst设计模式开胃菜】,主要介绍了设计模式的基本概念、设计模…...

Spring线程池优雅关闭
前言 线程池大家一定不陌生,常被用来异步执行一些耗时的任务。但是线程池如何优雅的关闭,却少有人关注。 当 JVM 进程关闭时,你提交到线程池的任务会被如何处理?如何保证任务不丢? ThreadPoolExecutor Java 对线程…...

Spring为什么要用三级缓存解决循环依赖?
1.什么是循环依赖 本文为了方便说明,先设置两个业务层对象,命名为AService和BService。其中Spring是如何把一个Bean对象创建出来的,其生命周期如下: 构造方法–> 不同对象 --> 注入依赖 -->初始化前 --> 初始化后–&…...

【苏德矿高等数学】第4讲:数列极限定义-1
2. 数列极限 数列极限是整个微积分的核心。它的思想贯穿整个微积分之中。 数列极限是最基本的、最核心的、最重要的、最难的。 2.1 数列 【定义】无限排列的一列数 a 1 , a 2 , ⋯ , a n , ⋯ a_1,a_2,\cdots,a_n,\cdots a1,a2,⋯,an,⋯就称为数列,记作 { …...
核心知识)
Go语言的 的并发编程(Concurrency)核心知识
Go语言的并发编程(Concurrency)核心知识 在现代软件开发中,尤其是处理高并发任务时,优秀的并发编程能力显得尤为重要。Go语言(或称Golang)是为并发编程而生的一种编程语言,它通过简洁的语法和强…...

Go语言中的逃逸分析:深入浅出
Go语言中的逃逸分析:深入浅出 在Go语言中,逃逸分析(Escape Analysis)是一个非常重要且强大的编译器优化技术。它帮助编译器决定一个变量是在栈上分配还是在堆上分配,从而影响程序的性能和内存管理。本文将深入探讨Go语…...

flux中的缓存
1. cache,onBackpressureBuffer。都是缓存。cache可以将hot流的数据缓存起来。onBackpressureBuffer也是缓存,但是当下游消费者的处理速度比上游生产者慢时,上游生产的数据会被暂时存储在缓冲区中,防止丢失。 2. Flux.range 默认…...

Vue3中使用 Vue Flow 流程图方法
效果图: 最近项目开发时有一个流程图的功能,需要做流程节点的展示,就搜到了 Vue Flow 这个插件,这个插件总得来说还可以,简单已使用,下边就总结一下使用的方法: Vue Flow官网:https…...

[Effective C++]条款42 typename
本文初发于 “天目中云的小站”,同步转载于此。 条款42 : 了解typename的双重意义 本条款中我们将了解typename的两种使用场景, 对typename的内涵及使用加深认知. template声明式 在template的声明中, template<class T>和template<typename T>都是被允…...
)
MySQL 8 主从同步配置(Master-Slave Replication)
📋 MySQL 8 主从同步配置(Master-Slave Replication) 🔧 目标: 配置 MySQL 8 主从同步,实现 主库(Master) 处理写操作,从库(Slave) 处理读操作,达到 读写分离 和 高可用性 的目的。 🔑 核心步骤: 配置 主库(Master)配置 从库(Slave)启动主从复制验证主从…...
)
STM32第十一课:STM32-基于标准库的42步进电机的简单IO控制(附电机教程,看到即赚到)
一:步进电机简介 步进电机又称为脉冲电机,简而言之,就是一步一步前进的电机。基于最基本的电磁铁原理,它是一种可以自由回转的电磁铁,其动作原理是依靠气隙磁导的变化来产生电磁转矩,步进电机的角位移量与输入的脉冲个数严格成正…...
)
模拟(算法-6)
模拟简介 模拟就是根据题目要求,比着葫芦画瓢,即直接按照题目要求写就行了 考察的是我们的编码能力 步骤: 演草纸上画图模拟(重要) 代码编写 虽然很多时候此类题比较简单,但是也有例外,如本文第…...
)
Clickhouse集群部署(3分片1副本)
Clickhouse集群部署 3台Linux服务器,搭建Clickhouse集群3分片1副本模式 1、安装Java、Clickhouse、Zookeeper dpkg -i clickhouse-client_23.2.6.34_amd64.deb dpkg -i clickhouse-common-static_23.2.6.34_amd64.deb dpkg -i clickhouse-server_23.2.6.34_amd64…...
MySQL 案例)
MySQL(六)MySQL 案例
1. MySQL 案例 1.1. 设计数据库 1、首先根据相关业务需求(主要参考输出输入条件)规划出表的基本结构 2、根据业务规则进行状态字段设计 3、预估相关表的数据量进行容量规划 4、确定主键 5、根据对相关处理语句的分析对数据结构进行相应的变更。 设计表的时…...
)
【网络协议栈】TCP/IP协议栈中重要协议和技术(DNS、ICMP、NAT、代理服务器、以及内网穿透)
每日激励:“请给自己一个鼓励说:Jack我很棒!—Jack” 绪论: 本章是TCP/IP网络协议层的完结篇,本章将主要去补充一些重要的协议和了解一些网络中常见的名词,具体如:DNS、ICMP、NAT、代理服务器…...

NLP中特征提取方法的总结
1. Bag of Words (BOW) 描述:将文本表示为一个词汇表中的词频向量,忽略词的顺序。 优点:实现简单,广泛应用。 缺点:不考虑词序和上下文信息,向量空间维度可能非常大。 应用:文本分类、情感分…...

《HarmonyOS第一课》焕新升级,赋能开发者快速掌握鸿蒙应用开发
随着HarmonyOS NEXT发布,鸿蒙生态日益壮大,广大开发者对于系统化学习平台和课程的需求愈发强烈。近日,华为精心打造的《HarmonyOS第一课》全新上线,集“学、练、考”于一体,凭借多维融合的教学模式与系统课程设置&…...
)
JMeter + Grafana +InfluxDB性能监控 (二)
您可以通过JMeter、Grafana 和 InfluxDB来搭建一个炫酷的基于JMeter测试数据的性能测试监控平台。 下面,笔者详细介绍具体的搭建过程。 安装并配置InfluxDB 您可以从清华大学开源软件镜像站等获得InfluxDB的RPM包,这里笔者下载的是influxdb-1.8.0.x86_…...