📚 读者导航
| 读者类型 | 建议阅读章节 | 预期收获 |
|---|---|---|
| 初学者 | 一、二、六 | 理解基础概念,掌握可视化监控 |
| 中级开发者 | 一至四、六 | 搭建监控体系,进行基础调优 |
| 高级工程师 | 三至八 | 生产环境部署,深度调优策略 |
| 架构师 | 四、七、八 | 容量规划,最佳实践,未来展望 |
🎯 前言
Apache Kafka 作为现代数据架构的核心组件,其监控和调优是确保系统稳定性和高性能的关键。本文采用渐进式学习路径,从基础概念到生产落地,满足不同阶段读者的需求:
- 初学者:通过可视化界面快速理解Kafka监控概念
- 开发者:掌握代码实现和基础调优技巧
- 工程师:深入生产环境配置和性能优化
- 架构师:了解容量规划和最佳实践策略
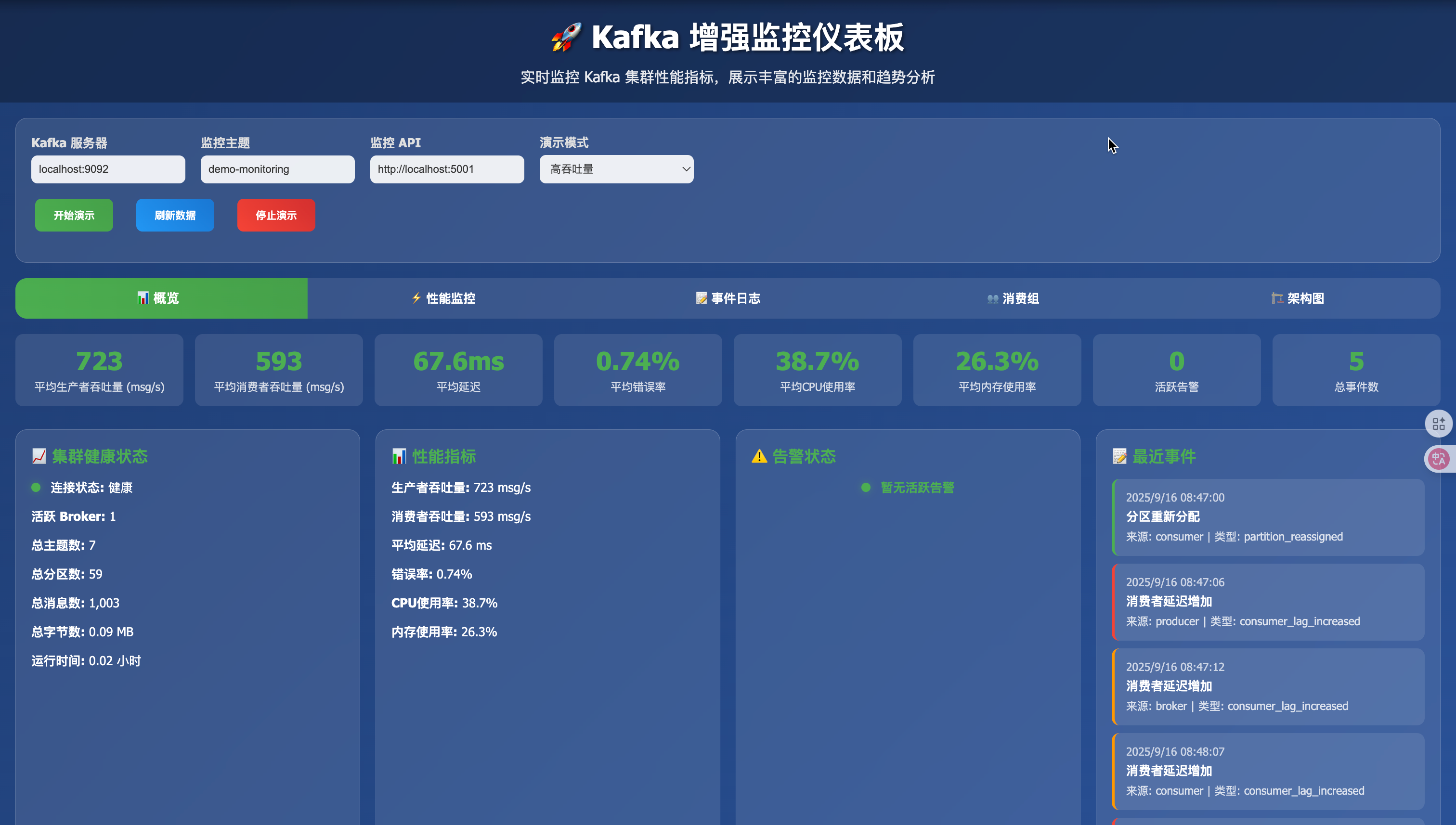
🚀 快速入门:5分钟上手Kafka监控
💡 初学者专享:如果你是新手上路,建议先体验可视化监控,再深入理论学习
第一步:启动演示系统
# 1. 进入项目目录
cd lesson_eight# 2. 一键启动(推荐新手使用)
python quick_start.py# 3. 访问监控面板
# 浏览器打开:http://localhost:5001/dashboard
第二步:观察关键指标
在监控面板中,你会看到以下关键指标:
| 指标 | 位置 | 说明 | 正常范围 |
|---|---|---|---|
| 连接状态 | 集群健康状态 | Kafka是否正常运行 | 绿色✅ |
| 生产者吞吐量 | 生产者性能指标 | 每秒发送消息数 | 根据业务调整 |
| 消费者Lag | 消费者性能指标 | 待处理消息数量 | < 1000条 |
| 延迟 | 实时性能趋势 | 消息处理延迟 | < 100ms |
第三步:理解指标含义
# 用简单的比喻理解指标
def monitor_analogy():"""Kafka监控就像监控一个快递分拣中心:生产者吞吐量 = 每分钟收到的包裹数量消费者吞吐量 = 每分钟分拣完成的包裹数量 Consumer Lag = 等待分拣的包裹数量延迟 = 从收到包裹到分拣完成的时间"""pass
第四步:识别问题
当指标出现异常时:
- 🔴 红色警告:立即处理
- 🟡 黄色警告:需要关注
- 🟢 绿色正常:运行良好
一、Kafka 监控核心概念 🎯
1.1 为什么需要监控?
💡 初学者提示:监控就像汽车的仪表盘,让你实时了解系统状态
在生产环境中,Kafka 集群面临着多重挑战:
🔴 常见问题场景
- 消息堆积:消费者处理速度跟不上生产者速度 → 业务延迟增加
- 延迟波动:网络抖动、GC 停顿导致的延迟突增 → 用户体验下降
- 可靠性问题:副本同步失败、ISR 收缩 → 数据丢失风险
- 资源瓶颈:磁盘 I/O、网络带宽、内存使用 → 系统性能下降
📊 监控的价值
# 监控前:被动发现问题
def reactive_approach():"""被动响应模式"""if user_complaint_received():investigate_issue() # 问题已经影响用户fix_problem()# 监控后:主动预防问题
def proactive_approach():"""主动预防模式"""if lag_threshold_exceeded():scale_consumers() # 提前扩容if disk_usage_high():cleanup_old_data() # 提前清理
⚠️ 关键提醒:没有完善的监控体系,这些问题往往在业务受到影响时才能被发现,为时已晚。
1.2 监控体系架构
🏗️ 架构师视角:理解监控系统的整体设计思路
graph TBsubgraph "Kafka 集群"B1[Broker 1]B2[Broker 2]B3[Broker 3]endsubgraph "监控数据收集层"JMX[JMX Exporter<br/>📊 JVM指标]KEXP[Kafka Exporter<br/>📈 Kafka指标]NEXP[Node Exporter<br/>💻 系统指标]endsubgraph "存储与查询层"PROM[Prometheus<br/>🗄️ 时序数据库]GRAF[Grafana<br/>📊 可视化面板]endsubgraph "告警与通知层"ALERT[AlertManager<br/>🚨 告警管理]NOTIFY[通知渠道<br/>📧 邮件/钉钉/微信]endB1 --> JMXB2 --> JMXB3 --> JMXB1 --> KEXPJMX --> PROMKEXP --> PROMNEXP --> PROMPROM --> GRAFPROM --> ALERTALERT --> NOTIFYstyle B1 fill:#e1f5festyle B2 fill:#e1f5festyle B3 fill:#e1f5festyle PROM fill:#f3e5f5style GRAF fill:#e8f5e8
🔍 各层职责说明
| 层级 | 组件 | 职责 | 适用读者 |
|---|---|---|---|
| 数据收集 | JMX Exporter | 收集JVM性能指标 | 中级+ |
| Kafka Exporter | 收集Kafka特有指标 | 中级+ | |
| Node Exporter | 收集系统资源指标 | 中级+ | |
| 存储查询 | Prometheus | 时序数据存储和查询 | 高级+ |
| Grafana | 数据可视化展示 | 所有 | |
| 告警通知 | AlertManager | 告警规则管理和分发 | 高级+ |
| 通知渠道 | 多渠道告警通知 | 高级+ |
二、关键监控指标详解 📊
🎓 学习路径:初学者重点关注概念理解,开发者关注代码实现,工程师关注阈值配置
2.1 消费滞后(Consumer Lag)
🚨 最重要指标:这是最直观的业务健康指标,直接反映消息处理能力
📖 基础概念
定义:消费滞后 = 分区最新位点 - 消费者已提交位点
# 初学者理解:Lag就像排队等待处理的任务数量
def simple_lag_explanation():"""想象一个餐厅:- 最新位点 = 当前排队的客人总数- 已提交位点 = 已经入座的客人数量 - Lag = 还在排队等待的客人数量"""total_customers = 100 # 最新位点seated_customers = 85 # 已提交位点waiting_customers = 15 # Lag = 100 - 85return waiting_customers
💻 代码实现
# 开发者实现:Lag 计算示例
def calculate_lag(partition_metadata, consumer_group_metadata):"""计算消费组的 Lag"""lags = {}for topic_partition, offset_info in consumer_group_metadata.items():latest_offset = partition_metadata[topic_partition]['high_watermark']committed_offset = offset_info['committed_offset']lag = latest_offset - committed_offsetlags[topic_partition] = lagreturn lags# 高级工程师:实时Lag监控
class LagMonitor:def __init__(self):self.alert_thresholds = {'normal': 1000,'warning': 10000, 'critical': 50000}def check_lag_status(self, lag_value):if lag_value < self.alert_thresholds['normal']:return 'healthy', 'green'elif lag_value < self.alert_thresholds['warning']:return 'warning', 'yellow'else:return 'critical', 'red'
⚙️ 监控阈值建议
| 业务类型 | 正常阈值 | 警告阈值 | 严重阈值 | 说明 |
|---|---|---|---|---|
| 实时交易 | < 100 | 100-1000 | > 1000 | 对延迟敏感 |
| 日志收集 | < 1000 | 1000-10000 | > 10000 | 允许一定延迟 |
| 批处理 | < 10000 | 10000-100000 | > 100000 | 可以容忍较大延迟 |
| 数据同步 | < 5000 | 5000-50000 | > 50000 | 根据业务需求调整 |
2.2 吞吐量指标 🚀
📈 性能核心:吞吐量决定了系统的处理能力上限
📖 基础概念
吞吐量是系统在单位时间内处理的数据量,就像高速公路的车流量。
# 初学者理解:吞吐量就像工厂的生产线效率
def throughput_analogy():"""想象一个汽车工厂:- 生产者吞吐量 = 每分钟生产的汽车数量- 消费者吞吐量 = 每分钟销售的汽车数量- Broker吞吐量 = 每分钟通过工厂的消息数量"""cars_produced_per_minute = 60 # 生产者吞吐量cars_sold_per_minute = 55 # 消费者吞吐量efficiency = cars_sold_per_minute / cars_produced_per_minute # 处理效率return efficiency
🔍 关键指标详解
| 指标类型 | 指标名称 | 单位 | 重要性 | 适用读者 |
|---|---|---|---|---|
| 生产者 | records/sec |
条/秒 | ⭐⭐⭐ | 所有 |
bytes/sec |
字节/秒 | ⭐⭐⭐ | 中级+ | |
| 消费者 | poll records/sec |
条/秒 | ⭐⭐⭐ | 所有 |
fetch requests/sec |
次/秒 | ⭐⭐ | 中级+ | |
| Broker | messages in/sec |
条/秒 | ⭐⭐⭐ | 所有 |
messages out/sec |
条/秒 | ⭐⭐⭐ | 所有 |
💻 代码实现
# 开发者实现:吞吐量监控
class ThroughputMonitor:def __init__(self):self.producer_metrics = {'records_per_sec': 0,'bytes_per_sec': 0,'errors_per_sec': 0}self.consumer_metrics = {'records_per_sec': 0,'fetch_requests_per_sec': 0,'processing_time_ms': 0}def calculate_producer_throughput(self, records_count, bytes_count, time_seconds):"""计算生产者吞吐量"""self.producer_metrics['records_per_sec'] = records_count / time_secondsself.producer_metrics['bytes_per_sec'] = bytes_count / time_secondsreturn self.producer_metricsdef calculate_consumer_throughput(self, records_count, fetch_requests, time_seconds):"""计算消费者吞吐量"""self.consumer_metrics['records_per_sec'] = records_count / time_secondsself.consumer_metrics['fetch_requests_per_sec'] = fetch_requests / time_secondsreturn self.consumer_metrics
⚙️ 性能基准参考
| 场景 | 生产者吞吐量 | 消费者吞吐量 | 说明 |
|---|---|---|---|
| 单机测试 | 10K-50K msg/s | 5K-20K msg/s | 开发环境基准 |
| 小型生产 | 50K-200K msg/s | 20K-100K msg/s | 业务量较小的系统 |
| 中型生产 | 200K-1M msg/s | 100K-500K msg/s | 中等规模业务 |
| 大型生产 | 1M+ msg/s | 500K+ msg/s | 大规模业务系统 |
2.3 延迟指标
端到端延迟:从生产者发送到消费者处理完成的总时间
import time
import jsonclass LatencyTracker:def __init__(self):self.latencies = []def record_produce_latency(self, message):"""记录生产者延迟"""produce_ts = message.get('produce_timestamp', time.time() * 1000)current_ts = time.time() * 1000latency = current_ts - produce_tsself.latencies.append(latency)def get_percentile_latency(self, percentile):"""获取百分位延迟"""if not self.latencies:return 0sorted_latencies = sorted(self.latencies)index = int(len(sorted_latencies) * percentile / 100)return sorted_latencies[index]
2.4 ISR(In-Sync Replicas)监控
ISR 是保证数据可靠性的关键指标:
def check_isr_health(partition_metadata):"""检查 ISR 健康状态"""health_status = {}for topic_partition, metadata in partition_metadata.items():replicas_count = len(metadata['replicas'])isr_count = len(metadata['isr'])health_ratio = isr_count / replicas_count if replicas_count > 0 else 0health_status[topic_partition] = {'replicas': replicas_count,'isr': isr_count,'health_ratio': health_ratio,'status': 'healthy' if health_ratio >= 0.67 else 'warning' if health_ratio >= 0.33 else 'critical'}return health_status
三、监控方案搭建实战
3.1 基于 Prometheus + Grafana 的监控方案
3.1.1 环境准备
# 1. 下载 JMX Exporter
wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.19.0/jmx_prometheus_javaagent-0.19.0.jar# 2. 创建 JMX 配置文件
cat > jmx_kafka.yml << EOF
rules:- pattern: kafka.server<type=BrokerTopicMetrics, name=MessagesInPerSec, topic=(.+)><>Countname: kafka_server_messages_in_per_seclabels:topic: "$1"- pattern: kafka.server<type=BrokerTopicMetrics, name=BytesInPerSec, topic=(.+)><>Countname: kafka_server_bytes_in_per_seclabels:topic: "$1"- pattern: kafka.server<type=ReplicaManager, name=PartitionCount><>Valuename: kafka_server_replica_manager_partition_count
EOF
3.1.2 Kafka 配置修改
# 修改 kafka-server-start.sh
export KAFKA_OPTS="-javaagent:/opt/jmx_prometheus_javaagent.jar=7071:/opt/jmx_kafka.yml"
3.1.3 Docker Compose 部署
version: '3.8'
services:prometheus:image: prom/prometheus:latestports:- "9090:9090"volumes:- ./prometheus.yml:/etc/prometheus/prometheus.ymlcommand:- '--config.file=/etc/prometheus/prometheus.yml'- '--storage.tsdb.path=/prometheus'- '--web.console.libraries=/etc/prometheus/console_libraries'- '--web.console.templates=/etc/prometheus/consoles'grafana:image: grafana/grafana:latestports:- "3000:3000"environment:- GF_SECURITY_ADMIN_PASSWORD=adminvolumes:- grafana-storage:/var/lib/grafanakafka-exporter:image: danielqsj/kafka-exporter:latestports:- "9308:9308"command:- '--kafka.server=kafka:9092'volumes:grafana-storage:
3.2 自定义指标收集
3.2.1 生产者指标收集
from prometheus_client import Counter, Histogram, Gauge, start_http_server
import timeclass ProducerMetrics:def __init__(self, topic_name):self.topic_name = topic_nameself.records_sent_total = Counter('kafka_producer_records_sent_total','Total number of records sent',['topic', 'status'])self.records_sent_bytes = Counter('kafka_producer_records_sent_bytes_total','Total bytes of records sent',['topic'])self.produce_latency = Histogram('kafka_producer_latency_seconds','Producer latency',['topic'],buckets=(0.001, 0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0))self.batch_size = Gauge('kafka_producer_batch_size','Current batch size',['topic'])def record_success(self, record_size_bytes, latency_seconds):self.records_sent_total.labels(topic=self.topic_name, status='success').inc()self.records_sent_bytes.labels(topic=self.topic_name).inc(record_size_bytes)self.produce_latency.labels(topic=self.topic_name).observe(latency_seconds)def record_failure(self, error_type):self.records_sent_total.labels(topic=self.topic_name, status='failure').inc()
3.2.2 消费者指标收集
class ConsumerMetrics:def __init__(self, topic_name, group_id):self.topic_name = topic_nameself.group_id = group_idself.records_consumed_total = Counter('kafka_consumer_records_consumed_total','Total number of records consumed',['topic', 'group_id'])self.consumer_lag = Gauge('kafka_consumer_lag','Consumer lag for partition',['topic', 'group_id', 'partition'])self.consumption_latency = Histogram('kafka_consumer_processing_latency_seconds','Consumer processing latency',['topic', 'group_id'],buckets=(0.001, 0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0, 2.5, 5.0))self.poll_duration = Histogram('kafka_consumer_poll_duration_seconds','Consumer poll duration',['topic', 'group_id'],buckets=(0.001, 0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0))def record_consumption(self, partition, processing_time):self.records_consumed_total.labels(topic=self.topic_name, group_id=self.group_id).inc()self.consumption_latency.labels(topic=self.topic_name,group_id=self.group_id).observe(processing_time)def update_lag(self, partition, lag_value):self.consumer_lag.labels(topic=self.topic_name,group_id=self.group_id,partition=str(partition)).set(lag_value)
四、性能调优实战
4.1 生产者调优
4.1.1 吞吐量优化
def create_high_throughput_producer():"""创建高吞吐量生产者配置"""config = {'bootstrap.servers': 'localhost:9092',# 批量发送优化'batch.size': 256 * 1024, # 256KB 批量大小'linger.ms': 50, # 等待 50ms 聚合批量# 压缩优化'compression.type': 'lz4', # LZ4 压缩,平衡压缩率和 CPU# 异步发送优化'max.in.flight.requests.per.connection': 5,# 可靠性配置'acks': '1', # 平衡性能和可靠性'retries': 3,'retry.backoff.ms': 100,# 缓冲区优化'buffer.memory': 64 * 1024 * 1024, # 64MB 缓冲区'send.buffer.bytes': 128 * 1024, # 128KB 发送缓冲区'receive.buffer.bytes': 64 * 1024, # 64KB 接收缓冲区}return Producer(config)
4.1.2 延迟优化
def create_low_latency_producer():"""创建低延迟生产者配置"""config = {'bootstrap.servers': 'localhost:9092',# 立即发送,不等待批量'batch.size': 1,'linger.ms': 0,# 不使用压缩以减少 CPU 开销'compression.type': 'none',# 减少网络往返'acks': '1','retries': 0, # 不重试以减少延迟# 小缓冲区'buffer.memory': 32 * 1024 * 1024,# 快速失败'request.timeout.ms': 5000,'delivery.timeout.ms': 10000,}return Producer(config)
4.2 消费者调优
4.2.1 吞吐量优化
def create_high_throughput_consumer():"""创建高吞吐量消费者配置"""config = {'bootstrap.servers': 'localhost:9092','group.id': 'high-throughput-group',# 批量拉取优化'fetch.min.bytes': 1024 * 1024, # 1MB 最小拉取'fetch.max.wait.ms': 500, # 最多等待 500ms'max.partition.fetch.bytes': 8 * 1024 * 1024, # 8MB 单分区拉取# 批量处理'max.poll.records': 2000, # 单次拉取 2000 条记录# 心跳和会话优化'session.timeout.ms': 30000,'heartbeat.interval.ms': 10000,# 手动提交控制'enable.auto.commit': False,# 网络优化'fetch.max.bytes': 50 * 1024 * 1024, # 50MB 最大拉取}return Consumer(config)
4.2.2 延迟优化
def create_low_latency_consumer():"""创建低延迟消费者配置"""config = {'bootstrap.servers': 'localhost:9092','group.id': 'low-latency-group',# 立即拉取,不等待批量'fetch.min.bytes': 1,'fetch.max.wait.ms': 0,# 小批量处理'max.poll.records': 100,'max.partition.fetch.bytes': 1024 * 1024, # 1MB# 快速心跳'session.timeout.ms': 10000,'heartbeat.interval.ms': 3000,# 自动提交减少处理开销'enable.auto.commit': True,'auto.commit.interval.ms': 1000,}return Consumer(config)
4.3 Broker 调优
4.3.1 磁盘 I/O 优化
# server.properties 优化配置# 日志段优化
log.segment.bytes=1073741824 # 1GB 段大小
log.segment.ms=604800000 # 7天段滚动
log.retention.hours=168 # 7天保留期# 刷盘优化
log.flush.interval.messages=10000 # 每10000条消息刷盘
log.flush.interval.ms=1000 # 每秒刷盘# 网络线程优化
num.network.threads=8 # 网络线程数 = CPU核心数
num.io.threads=16 # I/O线程数 = 2 * CPU核心数# 副本优化
replica.fetch.max.bytes=1048576 # 1MB 副本拉取
replica.socket.timeout.ms=30000 # 30秒副本超时
replica.lag.time.max.ms=10000 # 10秒副本滞后超时
4.3.2 JVM 优化
# kafka-server-start.sh JVM 参数
export KAFKA_HEAP_OPTS="-Xmx6g -Xms6g"
export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true"
五、完整实战案例
5.1 项目结构
kafka_monitoring_demo/
├── requirements.txt
├── config/
│ ├── producer_config.py
│ └── consumer_config.py
├── metrics/
│ ├── producer_metrics.py
│ ├── consumer_metrics.py
│ └── monitoring_server.py
├── producers/
│ ├── high_throughput_producer.py
│ └── low_latency_producer.py
├── consumers/
│ ├── high_throughput_consumer.py
│ └── low_latency_consumer.py
├── monitoring/
│ ├── lag_monitor.py
│ └── health_checker.py
├── visualization/
│ └── dashboard.html
└── demo_runner.py
5.2 依赖管理
# requirements.txt
confluent-kafka==2.3.0
prometheus-client==0.19.0
flask==3.0.0
kafka-python==2.0.2
psutil==5.9.6
matplotlib==3.8.2
plotly==5.17.0
5.3 监控服务器实现
# metrics/monitoring_server.py
from flask import Flask, jsonify, render_template
from prometheus_client import generate_latest, CONTENT_TYPE_LATEST
import threading
import time
from collections import defaultdict, deque
import jsonapp = Flask(__name__)# 全局指标存储
metrics_store = {'producer': defaultdict(lambda: {'records_sent': 0,'bytes_sent': 0,'errors': 0,'latency_p50': 0,'latency_p95': 0,'latency_p99': 0}),'consumer': defaultdict(lambda: {'records_consumed': 0,'lag': 0,'processing_latency': 0,'errors': 0}),'broker': {'isr_count': 0,'under_replicated_partitions': 0,'active_controllers': 0}
}recent_events = deque(maxlen=1000)@app.route('/metrics')
def metrics():"""Prometheus 指标端点"""return generate_latest(), 200, {'Content-Type': CONTENT_TYPE_LATEST}@app.route('/api/metrics')
def api_metrics():"""REST API 指标端点"""return jsonify({'timestamp': int(time.time() * 1000),'metrics': dict(metrics_store),'recent_events': list(recent_events)})@app.route('/api/health')
def health_check():"""健康检查端点"""health_status = {'status': 'healthy','timestamp': int(time.time() * 1000),'components': {'producer': 'healthy','consumer': 'healthy','broker': 'healthy'}}# 检查关键指标for topic, metrics in metrics_store['consumer'].items():if metrics['lag'] > 10000:health_status['status'] = 'warning'health_status['components']['consumer'] = 'warning'breakreturn jsonify(health_status)@app.route('/dashboard')
def dashboard():"""监控面板"""return render_template('dashboard.html')def update_metrics(metric_type, topic, **kwargs):"""更新指标"""if metric_type in metrics_store and topic in metrics_store[metric_type]:for key, value in kwargs.items():if key in metrics_store[metric_type][topic]:metrics_store[metric_type][topic][key] = valuedef add_event(event_type, message, level='info'):"""添加事件"""event = {'timestamp': int(time.time() * 1000),'type': event_type,'message': message,'level': level}recent_events.append(event)if __name__ == '__main__':app.run(host='0.0.0.0', port=5000, debug=True)
六、可视化面板设计
6.1 实时监控面板
我们的可视化面板将包含以下关键组件:
- 实时指标展示:吞吐量、延迟、Lag
- 历史趋势图:时间序列数据展示
- 告警状态:健康状态和异常告警
- 集群拓扑:Broker 和分区分布
- 性能分析:热点分区、瓶颈分析
6.2 交互式图表
使用 Plotly 创建交互式图表,支持:
- 时间范围选择
- 指标对比
- 钻取分析
- 实时刷新
七、生产环境最佳实践
7.1 监控告警策略
# alerting_rules.yml
groups:- name: kafka_alertsrules:- alert: KafkaConsumerLagHighexpr: kafka_consumer_lag_sum > 10000for: 5mlabels:severity: warningannotations:summary: "Kafka consumer lag is high"description: "Consumer lag is {{ $value }} messages"- alert: KafkaISRShrinkingexpr: kafka_server_replicas_not_in_isr > 0for: 2mlabels:severity: criticalannotations:summary: "Kafka ISR is shrinking"description: "{{ $value }} replicas are not in ISR"- alert: KafkaBrokerDownexpr: up{job="kafka-broker"} == 0for: 1mlabels:severity: criticalannotations:summary: "Kafka broker is down"description: "Broker {{ $labels.instance }} is not responding"
7.2 容量规划
def capacity_planning(peak_throughput, avg_message_size, retention_days):"""容量规划计算"""# 计算所需分区数max_partition_throughput = 10000 # 单分区最大吞吐量required_partitions = peak_throughput / max_partition_throughput# 计算存储需求daily_data_size = peak_throughput * avg_message_size * 86400 # 每日数据量total_storage = daily_data_size * retention_days * 3 # 3副本# 计算网络带宽需求network_bandwidth = peak_throughput * avg_message_size * 8 # bits per secondreturn {'required_partitions': int(required_partitions),'total_storage_gb': total_storage / (1024**3),'network_bandwidth_mbps': network_bandwidth / (1024**2),'recommended_brokers': max(3, int(required_partitions / 10))}
八、总结与展望
8.1 关键要点
- 监控先行:建立完善的监控体系是调优的基础
- 指标驱动:基于关键指标制定调优策略
- 渐进优化:从小处着手,逐步优化
- 持续改进:定期回顾和调整配置
8.2 未来发展方向
- AI 驱动的自动调优:基于历史数据预测和自动调整参数
- 更细粒度的监控:消息级别的延迟跟踪
- 云原生集成:与 Kubernetes 生态深度集成
- 实时决策:基于监控数据的实时流量调度
🎓 学习路径规划
📚 初学者路径(1-2周)
目标:理解基本概念,能够使用监控面板
| 学习内容 | 时间 | 实践任务 | 检验标准 |
|---|---|---|---|
| 快速入门部分 | 1天 | 启动演示系统 | 能够访问监控面板 |
| 核心概念理解 | 2-3天 | 观察指标变化 | 理解Lag、吞吐量含义 |
| 基础指标解读 | 3-4天 | 模拟异常场景 | 能够识别警告状态 |
| 可视化操作 | 2-3天 | 自定义图表 | 能够创建简单仪表板 |
成果展示:能够独立运行监控系统并解释基本指标
🛠️ 开发者路径(2-4周)
目标:掌握代码实现,能够搭建基础监控
| 学习内容 | 时间 | 实践任务 | 检验标准 |
|---|---|---|---|
| 指标收集代码 | 1周 | 实现生产者/消费者监控 | 代码能够正常运行 |
| 监控服务器搭建 | 1周 | 部署Prometheus+Grafana | 系统稳定运行 |
| 告警规则配置 | 3-5天 | 设置关键指标告警 | 告警能够正常触发 |
| 性能调优基础 | 1周 | 调整生产者/消费者参数 | 性能有明显提升 |
成果展示:能够独立搭建完整的监控体系
🏗️ 工程师路径(1-2个月)
目标:深入生产环境,掌握高级调优技巧
| 学习内容 | 时间 | 实践任务 | 检验标准 |
|---|---|---|---|
| 生产环境部署 | 2周 | 多节点集群监控 | 集群稳定运行 |
| 高级调优策略 | 2周 | 针对业务场景优化 | 性能达到预期目标 |
| 容量规划 | 1周 | 制定扩容方案 | 方案通过评审 |
| 故障排查 | 1周 | 模拟故障场景 | 能够快速定位问题 |
成果展示:能够独立设计生产级监控方案
🎯 架构师路径(持续学习)
目标:制定技术战略,指导团队实践
| 学习内容 | 时间 | 实践任务 | 检验标准 |
|---|---|---|---|
| 技术选型决策 | 持续 | 评估新技术方案 | 方案落地成功 |
| 团队能力建设 | 持续 | 培训团队成员 | 团队整体能力提升 |
| 最佳实践总结 | 持续 | 形成标准化文档 | 文档被广泛使用 |
| 前瞻性研究 | 持续 | 跟踪技术发展 | 能够预测技术趋势 |
成果展示:能够引领团队技术发展方向
📋 实践检查清单
✅ 初学者检查清单
✅ 开发者检查清单
✅ 工程师检查清单
✅ 架构师检查清单


🎉 结语
通过本文的渐进式学习路径,无论你是初学者还是资深工程师,都能找到适合自己的学习内容:
- 初学者:从可视化体验开始,逐步建立概念认知
- 开发者:通过代码实践,掌握技术实现细节
- 工程师:深入生产环境,积累实战经验
- 架构师:站在更高维度,思考技术战略
记住,监控和调优是一个持续的过程,需要根据业务变化和系统演进不断调整策略。希望本文能够成为你在Kafka监控路上的得力助手!






教程)
)







)


)

)



)







)





)





 补题)
)


)
