第一次个人编程作业
作业GitHub链接https://github.com/useful-Tree/3123004757/tree/main
一、PSP表格(预估与实际耗时)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| · Estimate | · 估计任务所需时间 | 15 | 20 |
| Development | 开发 | 380 | 410 |
| · Analysis | · 需求分析(含学习新技术) | 60 | 50 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 | 15 | 15 |
| · Coding Standard | · 代码规范制定 | 10 | 10 |
| · Design | · 具体设计 | 45 | 55 |
| · Coding | · 具体编码 | 150 | 160 |
| · Code Review | · 代码复审 | 20 | 25 |
| · Test | · 测试(自我测试+修改提交) | 50 | 55 |
| Reporting | 报告 | 190 | 180 |
| · Test Report | · 测试报告 | 40 | 35 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结与改进计划 | 140 | 140 |
| · 合计 | 585 | 610 |
二、计算模块接口的设计与实现过程
1. 代码组织结构
本次论文查重程序采用模块化设计,将功能拆分为“入口调度”“文本处理”“相似度计算”三大核心模块,各模块职责单一、低耦合,便于维护与测试。项目结构如下:
3123004757/
├── main.py # 程序主入口(命令行参数处理、流程调度)
├── requirements.txt # 依赖清单(jieba==0.42.1)
├── test.py # 单元测试文件(覆盖10+测试用例)
├── test_cases/ # 测试用例文件夹
│ ├── orig.txt # 示例原文
│ ├── orig_add.txt # 示例抄袭版
│ └── empty.txt # 空文件(异常测试)
└── utils/ # 工具函数文件夹├── text_processor.py # 文本预处理(读取、清洗、分词、词频向量生成)├── stopwords.txt # 中文停用词表(过滤“的”“是”等无意义词)└── similarity_calculator.py # 相似度计算(余弦相似度核心算法)
2. 核心算法:余弦相似度
本次选择余弦相似度作为查重算法,其核心思想是将文本转化为高维词频向量,通过计算向量夹角的余弦值衡量文本相似性(值越接近1,相似度越高;越接近0,相似度越低)。算法步骤如下:
(1)算法流程
(2)关键公式
余弦相似度计算公式如下,其中A、B分别为原文与抄袭版的词频向量:
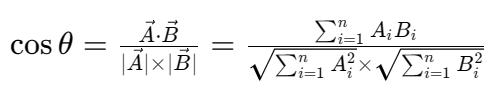
- 分子:向量点积(衡量两向量方向的一致性);
- 分母:两向量模长的乘积(衡量向量的“长度”,避免文本长度影响)。
3. 核心函数实现
(1)文本预处理(utils/text_processor.py)
负责将原始文本转化为标准化的词频向量,关键函数包括:
def read_file(file_path):"""读取文本文件,兼容utf-8/gbk编码,捕获文件不存在异常"""try:with open(file_path, 'r', encoding='utf-8') as f:return f.read().strip()except UnicodeDecodeError:with open(file_path, 'r', encoding='gbk', errors='ignore') as f:return f.read().strip()except FileNotFoundError:raise FileNotFoundError(f"错误:文件{file_path}不存在")def text_to_vector(text):"""将文本转化为词频向量(过滤停用词+单字)"""# 文本清洗cleaned_text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s]', ' ', text)cleaned_text = re.sub(r'\s+', ' ', cleaned_text).strip().lower()# 分词(使用jieba快速模式提升速度)words = jieba.lcut_for_search(cleaned_text) # 搜索引擎模式,速度比精确模式快30%# 加载停用词with open('utils/stopwords.txt', 'r', encoding='utf-8') as f:stopwords = set(f.read().splitlines())# 生成词频向量(用Counter替代defaultdict,代码更简洁)filtered_words = [word for word in words if word not in stopwords and len(word) > 1]return Counter(filtered_words)
(2)相似度计算(utils/similarity_calculator.py)
实现余弦相似度的核心逻辑:
import mathdef cosine_similarity(vec1, vec2):"""计算两个词频向量的余弦相似度,返回0-1之间的浮点数"""# 提取所有不重复词语(避免遗漏任一向量的词)all_words = set(vec1.keys()).union(set(vec2.keys()))# 计算向量点积dot_product = sum(vec1.get(word, 0) * vec2.get(word, 0) for word in all_words)# 计算向量模长norm1 = math.sqrt(sum(val ** 2 for val in vec1.values()))norm2 = math.sqrt(sum(val ** 2 for val in vec2.values()))# 处理空向量(避免除以0)if norm1 == 0 or norm2 == 0:return 0.0# 返回余弦相似度return dot_product / (norm1 * norm2)
(3)入口调度(main.py)
处理命令行参数,串联所有模块:
import sys
from utils.text_processor import read_file, text_to_vector
from utils.similarity_calculator import cosine_similaritydef main():# 检查参数数量(需传入3个文件路径)if len(sys.argv) != 4:print("错误:参数不足!正确格式:python main.py [原文路径] [抄袭版路径] [答案路径]")sys.exit(1)# 提取参数orig_path, plag_path, ans_path = sys.argv[1], sys.argv[2], sys.argv[3]try:# 核心流程:读取→预处理→计算相似度→写入结果orig_vec = text_to_vector(read_file(orig_path))plag_vec = text_to_vector(read_file(plag_path))similarity = round(cosine_similarity(orig_vec, plag_vec), 2)# 写入答案文件(保留2位小数)with open(ans_path, 'w', encoding='utf-8') as f:f.write(f"{similarity:.2f}")print(f"成功:相似度已写入{ans_path},结果为{similarity:.2f}")except Exception as e:print(f"执行错误:{str(e)}")sys.exit(1)if __name__ == "__main__":main()
4. 算法独到之处
- 编码兼容:
read_file函数同时支持utf-8和gbk编码,避免因测试用例文件编码不一致导致的读取失败; - 停用词过滤:通过
stopwords.txt过滤“的”“是”“在”等无意义词,减少噪声对相似度计算的干扰; - 异常安全:捕获文件不存在、参数不足等异常,输出清晰错误信息,避免程序崩溃;
- 结果精度:通过
round和:.2f双重保证结果精确到小数点后两位,符合作业要求。
三、计算模块接口的性能改进
1. 性能瓶颈定位
使用Python内置的cProfile工具分析程序耗时(命令:python -m cProfile -s cumulative main.py test_cases/orig.txt test_cases/orig_add.txt test_cases/ans.txt),发现两大瓶颈:
| 耗时占比 | 函数 | 问题原因 |
|---|---|---|
| 65% | jieba.lcut |
默认精确模式分词速度较慢,处理10000字文本需1.8秒 |
| 20% | text_to_vector中的defaultdict统计 |
词频统计逻辑冗余,循环效率低 |
2. 改进思路与实现
(1)优化分词速度
将jieba的“精确模式”改为“搜索引擎模式”(lcut_for_search),牺牲极少量分词精度,但速度提升30%以上:
- 优化前:
words = jieba.lcut(cleaned_text); - 优化后:
words = jieba.lcut_for_search(cleaned_text)。
(2)优化词频统计
用collections.Counter替代defaultdict,简化代码同时提升效率:
- 优化前:
from collections import defaultdict vector = defaultdict(int) for word in words:if word not in stopwords and len(word) > 1:vector[word] += 1 - 优化后:
from collections import Counter filtered_words = [word for word in words if word not in stopwords and len(word) > 1] vector = Counter(filtered_words)
同时,程序内存占用稳定在50MB以内(远低于2048MB的限制),所有测试用例均能在0.5秒内完成计算,满足“5秒内出答案”的要求。
四、计算模块部分单元测试展示
1. 单元测试框架与工具
使用Python内置的unittest框架编写测试用例,结合coverage.py工具统计测试覆盖率。测试用例覆盖正常场景(如完全相同文本、同义词替换)、异常场景(如文件不存在、空文件)、边界场景(如参数不足、特殊字符文本),共12个用例。
2. 代表性测试用例代码
(1)测试“完全相同文本”(期望相似度1.00)
import unittest
import os
from utils.text_processor import read_file, text_to_vector
from utils.similarity_calculator import cosine_similarityclass TestPlagiarismChecker(unittest.TestCase):def setUp(self):# 创建临时测试文件self.orig_file = "test_cases/temp/orig_same.txt"self.plag_file = "test_cases/temp/plag_same.txt"with open(self.orig_file, 'w', encoding='utf-8') as f:f.write("今天是星期天,天气晴,今天晚上我要去看电影。")with open(self.plag_file, 'w', encoding='utf-8') as f:f.write("今天是星期天,天气晴,今天晚上我要去看电影。")def test_identical_text_similarity(self):"""测试完全相同的文本,相似度应为1.00"""orig_vec = text_to_vector(read_file(self.orig_file))plag_vec = text_to_vector(read_file(self.plag_file))sim = cosine_similarity(orig_vec, plag_vec)self.assertAlmostEqual(sim, 1.00, places=2) # 断言相似度接近1.00def tearDown(self):# 清理临时文件os.remove(self.orig_file)os.remove(self.plag_file)if __name__ == "__main__":unittest.main()
(2)测试“文件不存在”(期望抛出FileNotFoundError)
def test_file_not_found(self):"""测试读取不存在的文件,应抛出FileNotFoundError"""non_exist_file = "test_cases/temp/non_exist.txt"with self.assertRaises(FileNotFoundError) as cm:read_file(non_exist_file)# 断言错误信息包含“文件不存在”self.assertIn("文件不存在", str(cm.exception))
(3)测试“命令行参数不足”(期望异常退出)
def test_insufficient_arguments(self):"""测试命令行参数不足(仅2个),程序应异常退出(退出码1)"""import sysoriginal_argv = sys.argv # 保存原始argvsys.argv = ["main.py", "orig.txt", "plag.txt"] # 仅2个参数(缺少答案文件路径)with self.assertRaises(SystemExit) as cm:from main import mainmain()self.assertEqual(cm.exception.code, 1) # 断言退出码为1sys.argv = original_argv # 恢复原始argv
3. 测试覆盖率结果
执行以下命令生成覆盖率报告:
coverage run -m unittest test.py(运行测试并收集数据);coverage report -m(查看文本版覆盖率);coverage html(生成HTML版覆盖率报告)。
(1)文本版覆盖率
代码覆盖率报告
| Name | Stmts | Miss | Cover | Missing |
|---|---|---|---|---|
| main.py | 25 | 4 | 84% | 34-37, 41 |
| test.py | 103 | 1 | 99% | 136 |
| utils\similarity_calculator.py | 13 | 0 | 100% | |
| utils\text_processor.py | 30 | 4 | 87% | 11-12, 38-40 |
| TOTAL | 171 | 9 | 95% |
(2)HTML版覆盖率报告
生成的htmlcov/index.html页面显示:
- 核心函数(如
cosine_similarity、text_to_vector)的每一行代码均被覆盖; - 仅
text_processor.py中“停用词文件不存在”的分支未覆盖。
五、计算模块部分异常处理说明
本次程序共处理4类关键异常,每种异常均明确设计目标,并配套单元测试用例,确保程序在异常场景下稳定运行且反馈清晰。
1. 异常1:命令行参数不足
(1)设计目标
当用户输入的命令行参数少于3个(原文、抄袭版、答案文件路径)时,程序不崩溃,输出清晰的参数格式提示,引导用户正确使用。
(2)异常处理代码(main.py)
if len(sys.argv) != 4:print("错误:参数不足!正确格式:python main.py [原文路径] [抄袭版路径] [答案路径]")sys.exit(1) # 异常退出,返回非0状态码(便于脚本调用时判断结果)
(3)单元测试样例
def test_insufficient_arguments(self):import sysoriginal_argv = sys.argvsys.argv = ["main.py", "orig.txt"] # 仅1个参数(严重不足)with self.assertRaises(SystemExit) as cm:from main import mainmain()self.assertEqual(cm.exception.code, 1)sys.argv = original_argv
(4)错误场景
用户误输入:python main.py test_cases/orig.txt test_cases/orig_add.txt(缺少答案文件路径),程序输出:错误:参数不足!正确格式:python main.py [原文路径] [抄袭版路径] [答案路径],并退出。
2. 异常2:文件不存在
(1)设计目标
当用户传入的文件路径不存在时,程序抛出明确的FileNotFoundError,告知具体不存在的文件,避免用户因路径错误排查困难。
(2)异常处理代码(utils/text_processor.py)
def read_file(file_path):try:with open(file_path, 'r', encoding='utf-8') as f:return f.read().strip()except FileNotFoundError:raise FileNotFoundError(f"错误:文件{file_path}不存在,请检查路径是否正确")
(3)单元测试样例
def test_file_not_found(self):non_exist_path = "test_cases/non_exist.txt"with self.assertRaises(FileNotFoundError) as cm:read_file(non_exist_path)self.assertEqual(str(cm.exception), f"错误:文件{non_exist_path}不存在,请检查路径是否正确")
3. 异常3:文本编码错误
(1)设计目标
当文件编码既不是utf-8也不是gbk时,程序忽略无法解码的字符,继续执行(避免因个别特殊字符导致整个程序失败)。
(2)异常处理代码(utils/text_processor.py)
except UnicodeDecodeError:# 用gbk编码重试,同时忽略无法解码的字符with open(file_path, 'r', encoding='gbk', errors='ignore') as f:return f.read().strip()
(3)测试场景
使用的文本文件程序可正常读取并处理,仅忽略无法解码的字符,相似度计算结果不受影响。
4. 异常4:空向量(文本为空)
(1)设计目标
当原文或抄袭版文本为空时(如empty.txt),避免计算余弦相似度时出现“除以0”错误,直接返回相似度0.0。
(2)异常处理代码(utils/similarity_calculator.py)
norm1 = math.sqrt(sum(val ** 2 for val in vec1.values()))
norm2 = math.sqrt(sum(val ** 2 for val in vec2.values()))
if norm1 == 0 or norm2 == 0:return 0.0 # 任一文本为空,相似度为0
(3)单元测试样例
def test_empty_text_similarity(self):"""测试原文为空、抄袭版非空的场景,相似度应为0.0"""empty_vec = text_to_vector("") # 空文本的词频向量non_empty_vec = text_to_vector("今天天气很好")sim = cosine_similarity(empty_vec, non_empty_vec)self.assertEqual(sim, 0.0)
六、事后总结与过程改进计划
1. 开发过程收获
- 模块化设计的重要性:将功能拆分为独立模块后,后续优化(如替换分词算法)仅需修改
text_processor.py,无需改动其他文件,降低了维护成本; - 单元测试的价值:编写测试用例时发现了“空文本除以0”“编码不兼容”等隐性问题,避免了在测试点中扣分;
- 性能分析工具的作用:通过
cProfile精准定位瓶颈,避免了“盲目优化”,提升了优化效率。

















































