Spark 以及 spark streaming 核心原理及实践
导语
spark 已经成为广告、报表以及推荐系统等大数据计算场景中首选系统,因效率高,易用以及通用性越来越得到大家的青睐,我自己最近半年在接触spark以及spark streaming之后,对spark技术的使用有一些自己的经验积累以及心得体会,在此分享给大家。
本文依次从spark生态,原理,基本概念,spark streaming原理及实践,还有spark调优以及环境搭建等方面进行介绍,希望对大家有所帮助。
spark 生态及运行原理

Spark 特点
-
运行速度快 => Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
-
适用场景广泛 => 大数据分析统计,实时数据处理,图计算及机器学习
-
易用性 => 编写简单,支持80种以上的高级算子,支持多种语言,数据源丰富,可部署在多种集群中
-
容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
Spark的适用场景
目前大数据处理场景有以下几个类型:
-
复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
-
基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
-
基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
Spark成功案例
目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。这些应用场景的普遍特点是计算量大、效率要求高。
腾讯 / yahoo / 淘宝 / 优酷土豆
spark运行架构
spark基础运行架构如下所示:

spark结合yarn集群背后的运行流程如下所示:

spark 运行流程:
Spark架构采用了分布式计算中的Master-Slave模型。Master是对应集群中的含有Master进程的节点,Slave是集群中含有Worker进程的节点。
-
Master作为整个集群的控制器,负责整个集群的正常运行;
-
Worker相当于计算节点,接收主节点命令与进行状态汇报;
-
Executor负责任务的执行;
-
Client作为用户的客户端负责提交应用;
-
Driver负责控制一个应用的执行。
Spark集群部署后,需要在主节点和从节点分别启动Master进程和Worker进程,对整个集群进行控制。在一个Spark应用的执行过程中,Driver和Worker是两个重要角色。Driver 程序是应用逻辑执行的起点,负责作业的调度,即Task任务的分发,而多个Worker用来管理计算节点和创建Executor并行处理任务。在执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器,同时Executor对相应数据分区的任务进行处理。
-
Excecutor /Task 每个程序自有,不同程序互相隔离,task多线程并行
-
集群对Spark透明,Spark只要能获取相关节点和进程
-
Driver 与Executor保持通信,协作处理
三种集群模式:
1.Standalone 独立集群
2.Mesos, apache mesos
3.Yarn, hadoop yarn
基本概念:
-
Application =>Spark的应用程序,包含一个Driver program和若干Executor
-
SparkContext => Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor
-
Driver Program => 运行Application的main()函数并且创建SparkContext
-
Executor => 是为Application运行在Worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。每个Application都会申请各自的Executor来处理任务
-
Cluster Manager =>在集群上获取资源的外部服务 (例如:Standalone、Mesos、Yarn)
-
Worker Node => 集群中任何可以运行Application代码的节点,运行一个或多个Executor进程
-
Task => 运行在Executor上的工作单元
-
Job => SparkContext提交的具体Action操作,常和Action对应
-
Stage => 每个Job会被拆分很多组task,每组任务被称为Stage,也称TaskSet
-
RDD => 是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类
-
DAGScheduler => 根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler
-
TaskScheduler => 将Taskset提交给Worker node集群运行并返回结果
-
Transformations => 是Spark API的一种类型,Transformation返回值还是一个RDD,所有的Transformation采用的都是懒策略,如果只是将Transformation提交是不会执行计算的
-
Action => 是Spark API的一种类型,Action返回值不是一个RDD,而是一个scala集合;计算只有在Action被提交的时候计算才被触发。
Spark核心概念之RDD

Spark核心概念之Transformations / Actions

Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的。 Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中。
Action是返回值返回给driver或者存储到文件,是RDD到result的变换,Transformation是RDD到RDD的变换。
只有action执行时,rdd才会被计算生成,这是rdd懒惰执行的根本所在。
Spark核心概念之Jobs / Stage
Job => 包含多个task的并行计算,一个action触发一个job
stage => 一个job会被拆为多组task,每组任务称为一个stage,以shuffle进行划分

Spark核心概念之Shuffle
以reduceByKey为例解释shuffle过程。

在没有task的文件分片合并下的shuffle过程如下:(spark.shuffle.consolidateFiles=false)

fetch 来的数据存放到哪里?
刚 fetch 来的 FileSegment 存放在 softBuffer 缓冲区,经过处理后的数据放在内存 + 磁盘上。这里我们主要讨论处理后的数据,可以灵活设置这些数据是“只用内存”还是“内存+磁盘”。如果spark.shuffle.spill = false就只用内存。由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
shuffle之所以需要把中间结果放到磁盘文件中,是因为虽然上一批task结束了,下一批task还需要使用内存。如果全部放在内存中,内存会不够。另外一方面为了容错,防止任务挂掉。
存在问题如下:
-
产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
-
缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 MR 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了cores× R × 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
为了解决上述问题,我们可以使用文件合并的功能。
在进行task的文件分片合并下的shuffle过程如下:(spark.shuffle.consolidateFiles=true)

以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlock i',每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 cores× R。FileConsolidation 功能可以通过spark.shuffle.consolidateFiles=true来开启。
Spark核心概念之Cache
val rdd1 = ... // 读取hdfs数据,加载成RDD
rdd1.cache
val rdd2 = rdd1.map(...)
val rdd3 = rdd1.filter(...)
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
rdd1.unpersist
cache和unpersisit两个操作比较特殊,他们既不是action也不是transformation。cache会将标记需要缓存的rdd,真正缓存是在第一次被相关action调用后才缓存;unpersisit是抹掉该标记,并且立刻释放内存。只有action执行时,rdd1才会开始创建并进行后续的rdd变换计算。
cache其实也是调用的persist持久化函数,只是选择的持久化级别为MEMORY_ONLY。
persist支持的RDD持久化级别如下:

需要注意的问题:
Cache或shuffle场景序列化时, spark序列化不支持protobuf message,需要java 可以serializable的对象。一旦在序列化用到不支持java serializable的对象就会出现上述错误。
Spark只要写磁盘,就会用到序列化。除了shuffle阶段和persist会序列化,其他时候RDD处理都在内存中,不会用到序列化。
Spark Streaming运行原理
spark程序是使用一个spark应用实例一次性对一批历史数据进行处理,spark streaming是将持续不断输入的数据流转换成多个batch分片,使用一批spark应用实例进行处理。

从原理上看,把传统的spark批处理程序变成streaming程序,spark需要构建什么?

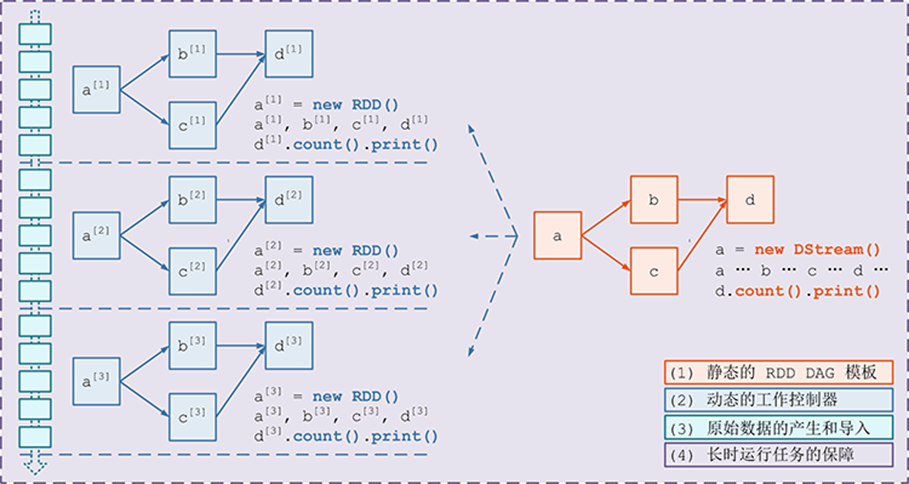
需要构建4个东西:
-
一个静态的 RDD DAG 的模板,来表示处理逻辑;
-
一个动态的工作控制器,将连续的 streaming data 切分数据片段,并按照模板复制出新的 RDD ;
-
DAG 的实例,对数据片段进行处理;
-
Receiver进行原始数据的产生和导入;Receiver将接收到的数据合并为数据块并存到内存或硬盘中,供后续batch RDD进行消费;
-
对长时运行任务的保障,包括输入数据的失效后的重构,处理任务的失败后的重调。
具体streaming的详细原理可以参考广点通出品的源码解析文章:
https://github.com/lw-lin/CoolplaySpark/blob/master/Spark%20Streaming%20%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E7%B3%BB%E5%88%97/0.1%20Spark%20Streaming%20%E5%AE%9E%E7%8E%B0%E6%80%9D%E8%B7%AF%E4%B8%8E%E6%A8%A1%E5%9D%97%E6%A6%82%E8%BF%B0.md#24
对于spark streaming需要注意以下三点:
- 尽量保证每个work节点中的数据不要落盘,以提升执行效率。

- 保证每个batch的数据能够在batch interval时间内处理完毕,以免造成数据堆积。

- 使用steven提供的框架进行数据接收时的预处理,减少不必要数据的存储和传输。从tdbank中接收后转储前进行过滤,而不是在task具体处理时才进行过滤。


Spark 资源调优
内存管理:

Executor的内存主要分为三块:
第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;
第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;
第三块是让RDD持久化时使用,默认占Executor总内存的60%。
每个task以及每个executor占用的内存需要分析一下。每个task处理一个partiiton的数据,分片太少,会造成内存不够。
其他资源配置:

相关文章:

Spark 以及 spark streaming 核心原理及实践
导语 spark 已经成为广告、报表以及推荐系统等大数据计算场景中首选系统,因效率高,易用以及通用性越来越得到大家的青睐,我自己最近半年在接触spark以及spark streaming之后,对spark技术的使用有一些自己的经验积累以及心得体会&…...

数据融合平台是什么?如何搭建数据融合平台?
目录 一、数据融合是什么 1. 定义 2. 作用 二、数据融合平台的功能是什么 1. 数据抽取 2. 数据清洗 3. 数据转换 4. 数据关联 5. 数据存储 三、如何让搭建数据融合平台 1. 需求分析 2. 选择合适的技术和工具 3. 设计平台架构 4. 开发和部署平台 5. 数据迁移和融…...

Linux之线程同步与互斥
目录 一、线程互斥 1.1、进程线程间的互斥相关背景概念 1.2、互斥量mutex 1.2.1、互斥量的接⼝ 1.3、互斥量实现原理探究 1.4、互斥量的封装 二、线程同步 2.1、条件变量 2.2、同步概念与竞态条件 2.3、条件变量函数 2.4、⽣产者消费者模型 2.4.1、为何要使⽤⽣产者…...

uniapp开发小程序,导出文件打开并保存,实现过程downloadFile下载,openDocument打开
uniapp开发小程序,导出文件打开并保存 实现思路 1、调用请求获取到后端接口返回的下载文件的url路径 (注意必须是https的路径,域名需要配置在微信小程序后台的合法域名里面) 2、使用 uni.downloadFile 方法 (下载文件…...

腾讯云COS“私有桶”下,App如何安全获得音频调用流程
流程图 #mermaid-svg-Phy4VCltBRZ90UH8 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Phy4VCltBRZ90UH8 .error-icon{fill:#552222;}#mermaid-svg-Phy4VCltBRZ90UH8 .error-text{fill:#552222;stroke:#552222;}#me…...

简单的 Flask 后端应用
from flask import Flask, request, jsonify, session import os app Flask(__name__) app.secret_key os.urandom(24) users { 123: admin, admin: admin } # 登录接口 app.route(/login, methods[POST]) def login(): data request.get_json() username data.get(usern…...

Android 中 解析 XML 字符串的几种方式
在 Android 开发中,解析 XML 文件有多种方式,每种方式都有其特点和适用场景。常见的 XML 解析方式有 DOM 解析、SAX 解析 和 XmlPullParser 解析。 1、DOM 解析 DOM(Document Object Model)解析是一种基于树结构的解析方式&#…...

git commit
git commit 是版本控制的核心操作之一,用于将暂存区的修改记录为新的版本提交。以下是关键步骤和最佳实践: 基础操作 提交单个文件: bash Copy Code git commit -m “提交信息” 提交多个文件: bash Copy Code …...
)
【新手向】GitHub Desktop 的使用说明(含 GitHub Desktop 和 Git 的功能对比)
GitHub Desktop 是 GitHub 公司推出的一款桌面应用程序,旨在帮助开发人员更轻松地使用 GitHub,以下是其简单的使用说明: 安装与登录 下载 GitHub Desktop |GitHub 桌面 访问GitHub Desktop 官方网站,根据自己的操作系统下载对应的…...
)
Tomcat项目本地部署(Servlet为例)
在Windows上部署 在idea中打开项目 首先我们需要准备一个Servlet项目,我之前的Servlet项目是用eclipse写的,这种情况下如果用idea直接打开的话会出现左侧目录无法显示的情况,这个时候我们就需要用别的方法打开 打开项目管理 如下图&#…...

Linux——linux的基本命令
目录 一、linux的目录结构 二、绝对路径和相对路径 三、文件类型(linux下所有东西都可看作文件) 四、文件的权限 五、文件权限的修改(chmod) 六、linux常用的命令 七、文件查看命令 八、文件编辑命令 九、文件压缩与解压…...

wireshark过滤显示rtmp协议
wireshark中抓包显示的数据报文中,明明可以看到有 rtmp 协议的报文,但是过滤的时候却显示一条都没有 查看选项中的配置,已经没有 RTMP 这个协议了,已经被 RTMPT 替换了,过滤框中输入 rtmpt 过滤即可...

Fiddler抓包工具使用技巧:如何结合Charles和Wireshark提升开发调试效率
在开发过程中,网络调试工具是每个程序员的必备利器,特别是当涉及到Web应用和移动应用的调试时,抓包工具的作用尤为突出。无论是处理复杂的API调用、分析性能瓶颈,还是排查网络通信问题,抓包工具都能够帮助开发者精准地…...

LVS负载均衡群集
这里写目录标题 案例:部署Tomcat案例分析案例概述案例前置知识点Tomcat 简介应用场景 案例环境 案例实施实施准备关闭 firewalld 防火墙在安装Tomcat之前必须先安装JDK 查看JDK是否安装安装配置 TomcatTomcat 的安装和配置步骤如下:解压后生成 apache-tomcat-9.0.8文件夹&#…...
)
【unitrix】 3.5 类型级别的比较系统(cmp.rs)
一、源码 这段代码定义了一个类型级别的比较系统,主要用于在编译时比较类型并得出比较结果。它使用了 Rust 的类型系统和标记特征(trait)来实现这一功能。 use crate::sealed::Sealed; use crate::number::{Z0, P1, N1}; use core::cmp::Ordering;// 比较结果类型…...

防御式编程:防止 XSS 攻击
对用户输入进行编码和过滤是防止 XSS 攻击的关键。以下是改进后的代码示例: from flask import Flask, request, escape from markupsafe import Markup app Flask(__name__) app.route(/comment, methods[POST]) def comment(): user_comment escape(re…...

【Java项目设计】基于Springboot+Vue的OA办公自动化系统
介绍: 基于Springboot为后端,vue为前端的企业综合性OA办公自动化平台,涵盖九大核心模块,全方位解决企业日常办公需求,提升工作效率和管理水平。系统采用模块化设计,功能全面且易于扩展,从基础登…...

WebServer实现:muduo库的主丛Reactor架构
前言 作为服务器,核心自然是高效的处理来自client的多个连接啦,那问题在于,如何高效的处理client的连接呢?这里就介绍两种架构:单Reactor架构和主丛Reactor架构。 单Reactor架构 单Reactor架构的核心为,由一个主线程监…...

每天一个前端小知识 Day 7 - 现代前端工程化与构建工具体系
现代前端工程化与构建工具体系 1. 为什么要工程化?(面试高频问题) 问题痛点: 模块太多、无法组织;代码冗长、性能差;浏览器兼容性差;团队协作混乱,缺少规范与自动化。 工程化目标…...

nginx的下载与安装 mac
1. 下载 方法一:本地下载 链接:https://nginx.org/en/download.html(可直接搜官网) 下载到本地后,上传到linux的某个文件夹中 方法二:直接linux上下载(推荐) wget -c http://ngi…...

[持续集成]
学习目标 能够使用 Git 代码托管平台管理代码能够实现 jenkinspostman 的持续集成能够实现 jenkins代码 的持续集成 持续集成 概念 : 将自己工作成果持续不断地把代码聚集在一起,成员可以每天集成一次或多次相关工具 : git : 代码管理工具,自带本地仓库gitee : 远程代码管理…...
: 使用场景)
Spring Aop @AfterThrowing (异常通知): 使用场景
核心定义 AfterThrowing 是 Spring AOP 中专门用于处理异常场景的**通知(Advice)**类型。它的核心作用是: 仅在目标方法(连接点)的执行过程中抛出异常时,执行一段特定的逻辑。如果目标方法成功执行并正常…...

【赵渝强老师】Kubernetes的安全框架
Kubernetes集群的安全框架主要由以下认证、鉴权和准入控制三个阶段组成。这三个阶段的关系如下图所示。 视频讲解如下 【赵渝强老师】Kubernetes的安全框架 认证(Authentication) 当客户端与Kubernetes集群建立HTTP通信时,首先HTTP请求会进…...

【Python小练习】3D散点图
资产风险收益三维分析 背景 王老师是一名金融工程研究员,需要对多个资产的预期收益、风险(波动率)和与市场的相关性进行综合分析,以便为投资组合优化提供决策依据。 代码实现 import matplotlib.pyplot as plt from mpl_toolk…...

腾讯混元3D制作简单模型教程-2
以下是腾讯混元3D制作简单模型的详细教程,整合最新版本特性(截至2025年6月),操作门槛低且无需专业基础: 🖥 一、在线生成(最快30秒完成) 访问平台 打开 腾讯混元3D创作引擎官网…...

NVIDIA开源Fast-dLLM!解析分块KV缓存与置信度感知并行解码技术
Talk主页:http://qingkeai.online/ 文章原文:https://mp.weixin.qq.com/s/P0PIAMo1GVYH4mdWdIde_Q Fast-dLLM 是NVIDIA联合香港大学、MIT等机构推出的扩散大语言模型推理加速方案。 论文:Fast-dLLM: Training-free Acceleration of Diffusion…...
)
大白话说目标检测中的IOU(Intersection over Union)
很多同学在学习目标检测时都会遇到IoU这个概念,但总觉得理解不透彻。这其实很正常,因为IoU就像个"多面手",在目标检测的各个阶段都要"打工",而且每个阶段的"工作内容"还不太一样。 今天我就让IoU自…...

CentOS 8解决ssh连接github时sign_and_send_pubkey失败问题
我在一台centos8机器上安装git环境以连接到github,首先第一步需配置好ssh环境,因为我已经有一台Ubuntu机器已经配置好ssh环境,所以我ftp Ubuntu机器取得id_rsa id_rsa.pub known_hosts三个文件,然后执行命令: $ git …...

回答 如何通过inode client的SSLVPN登录之后,访问需要通过域名才能打开的服务
需要dns代理 1 配置需求或说明 1.1 适用的产品系列 本案例适用于软件平台为Comware V7系列防火墙:本案例适用于如F5080、F5060、F5030、F5000-M等F5000、F5000-X系列的防火墙。 注:本案例是在F100-C-G2的Version 7.1.064, Release 9510P08版本上进行…...
)
OpenCV实现二值图细化(骨架提取)
对二值图进行细化(骨架提取),也就是把每根线条细化到一个像素的宽度。有两个比较成熟的算法实现此功能,分别是Zhang-Suen算法和Guo-Hall算法。 我们下面使用OpenCVSharp,使用C#实现上述两个算法: private…...

Excel常用公式大全
资源宝整理分享:https://www.httple.net Excel常用公式大全可以帮助用户提高工作效率,掌握常用的Excel公式,让数据处理和计算工作更加便捷高效。了解公式学习方法、用途,不再死记硬背,拒绝漫无目的。 命令用途注释说…...
)
在 Windows 上使用 Docker Desktop 快速搭建本地 Kubernetes 环境(附详细部署教程)
言简意赅的讲解Docker Desktop for Windows搭建Kubernetes解决的痛点 目标读者: 对 Docker Desktop 有一定了解,能在 Windows 上成功安装和使用 Docker Desktop。想要在本地快速搭建一套 Kubernetes 环境进行测试或学习的开发者。 一、准备工作 安装 Doc…...

Python设计模式终极指南:18种模式详解+正反案例对比+框架源码剖析
下面我将全面解析18种Python设计模式,每种模式都包含实际应用场景、优缺点分析、框架引用案例、可运行代码示例以及正反案例对比,帮助您深入理解设计模式的价值。 一、创建型模式(5种) 1. 单例模式(Singleton&#x…...

第1章: 伯努利模型的极大似然估计与贝叶斯估计
伯努利模型的极大似然估计与贝叶斯估计 import numpy as np import matplotlib.pyplot as plt from scipy.stats import beta, bernoulli from scipy.optimize import minimize_scalar# 设置中文字体 plt.rcParams[font.sans-serif] [SimHei] # 使用黑体 plt.rcParams[axes.…...

IPv4编址及IPv4路由基础
一、实验目的 掌握接口 IPv4 地址的配置方法理解 LoopBack 接口的作用与含义理解直连路由的产生原则掌握静态路由的配置方法并理解其生效的条件掌握通过 PING 工具测试网络层连通性掌握并理解特殊静态路由的配置方法与应用场景 二、实验环境 安装有eNSP模拟器的PC一台&#…...

基于Python的机动车辆推荐及预测分析系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...

SpringBoot扩展——发送邮件!
发送邮件 在日常工作和生活中经常会用到电子邮件。例如,当注册一个新账户时,系统会自动给注册邮箱发送一封激活邮件,通过邮件找回密码,自动批量发送活动信息等。邮箱的使用基本包括这几步:先打开浏览器并登录邮箱&…...

啊啊啊啊啊啊啊啊code
前序遍历和中序遍历构建二叉树 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val val; }* TreeNode(int val, TreeNode left, TreeNod…...

不同程度多径效应影响下的无线通信网络电磁信号仿真数据生成程序
生成.mat数据: %创建时间:2025年6月19日 %zhouzhichao %遍历生成不同程度多径效应影响的无线通信网络拓扑推理数据用于测试close all clearsnr 40; n 30;dataset_n 100;for bias 0.1:0.1:0.9nodes_P ones(n,1);Sampling_M 3000;%获取一帧信号及对…...

C语言学习day17-----位运算
目录 1.位运算 1.1基础知识 1.1.1定义 1.1.2用途 1.1.3软件控制硬件 1.2运算符 1.2.1与 & 1.2.2或 | 1.2.3非 ~ 1.2.4异或 ^ 1.2.5左移 << 1.2.6右移 >> 1.2.7代码实现 1.2.8置0 1.2.9置1 1.2.10不借助第三方变量,实现两个数的交换…...

Spring MVC参数绑定终极手册:单多参对象集合JSON文件上传精讲
我们通过浏览器访问不同的路径,就是在发送不同的请求,在发送请求时,可能会带一些参数,本文将介绍了Spring MVC中处理不同请求参数的多种方式 一、传递单个参数 接收单个参数,在Spring MVC中直接用方法中的参数就可以…...
(2)——fllodfill算法)
宽度优先遍历(bfs)(2)——fllodfill算法
欢迎来到博主的专栏:算法解析 博主ID:代码小豪 文章目录 floodfiil算法leetcode733——图像渲染题目解析算法原理题解代码 leetcode130——被围绕的区域题目解析算法原理题解代码 floodfiil算法 floodfill算法,在博主这里看来则是一个区域填…...

嵌入式编译工具链熟悉与游戏移植
一、Linux 系统编译工具链使用与 mininim 源码编译 在 Ubuntu 系统上编译 mininim 开源游戏需要正确配置编译工具链和依赖库。以下是详细的操作步骤和故障解决方法: 1. 环境准备与源码获取 首先需要安装必要的编译工具和依赖库: # 更新系统软件包索引…...
 服务器是一种网络协议)
STUN (Session Traversal Utilities for NAT) 服务器是一种网络协议
STUN (Session Traversal Utilities for NAT) 服务器是一种网络协议,主要用于帮助位于网络地址转换 (NAT) 设备(如路由器)后面的客户端发现自己的公共 IP 地址和端口号。这对于建立点对点 (P2P) 通信至关重要,尤其是在 VoIP&#…...
Transformer结构介绍
[编码器 Encoder] ←→ [解码器 Decoder] 编码器: 输入:源语言序列输出:每个词的上下文表示(embedding) 解码器:输入:目标语言序列编码器输出输出:下一个词的概率分布(目标句子生成)…...

SpringBoot扩展——应用Web Service!
应用Web Service Web Service是一个SOA(面向服务的编程)架构,这种架构不依赖于语言,不依赖于平台,可以在不同的语言之间相互调用,通过Internet实现基于HTTP的网络应用间的交互调用。Web Service是一个可以…...

5G核心网周期性注册更新机制:信令流程与字段解析
一、周期性注册更新的技术背景与流程概述 1.1 注册更新的核心目的 在5G网络中,UE通过周期性注册更新维持与核心网的连接状态,主要作用包括: 状态保活:避免AMF因超时而释放UE上下文(T3512定时器超时前需完成更新);位置更新:通知网络UE的当前位置,确保寻呼可达;能力同…...
)
【LLM学习笔记3】搭建基于chatgpt的问答系统(下)
目录 一、检查结果检查有害内容检查是否符合产品信息 二、搭建一个简单的问答系统三、评估输出1.当存在一个简单的正确答案2.当不存在一个简单的正确答案 一、检查结果 本章将引领你了解如何评估系统生成的输出。在任何场景中,无论是自动化流程还是其他环境&#x…...

算法导论第十九章 并行算法:解锁计算新维度
第十九章 并行算法:解锁计算新维度 “并行计算不是未来,而是现在。” —— David Patterson 在单核性能增长放缓的时代,并行算法成为突破计算极限的关键。本章将带你探索多核处理器、分布式系统和GPU加速的奇妙世界,揭示如何通过协…...

Python 数据分析与可视化 Day 1 - Pandas 数据分析基础入门
🎯 今日目标 理解 Pandas 的作用和核心概念学会创建 Series 和 DataFrame掌握基本数据读取(CSV)与常用查看方法 🧰 1. 什么是 Pandas? Pandas 是基于 NumPy 的强大数据分析库,提供了灵活的表格数据结构 Da…...